here::here("code", "_common.R") |>
source()
# Load packages
if (!requireNamespace("pacman")) install.packages("pacman")
pacman::p_load(eRm, mirt, grid, TAM, ggmirt, psychotools)71 Implementazione
In questo capitolo apprenderai come:
- comprendere il ruolo del modello di Rasch nella valutazione dei test psicometrici;
- applicare metodi grafici e statistici per valutare l’adattamento degli item e delle persone;
- interpretare curve caratteristiche e curve di informazione per analizzare le prestazioni di un test;
- stimare e interpretare parametri delle persone e degli item;
- calcolare l’affidabilità condizionale e l’errore standard di misurazione;
- utilizzare strumenti per verificare la validità e l’affidabilità complessiva di un test.
Prerequisiti
- Leggere il capitolo 8, Item Response Theory, del testo Principles of psychological assessment di Petersen (2024).
Preparazione del Notebook
71.1 Introduzione
In questo capitolo esamineremo il tutorial di Debelak et al. (2022).
71.2 Un esempio pratico
Il set di dati data.fims.Aus.Jpn.scored contiene le risposte valutate per un sottoinsieme di item da parte di studenti australiani e giapponesi nello studio “First International Mathematics Study” (FIMS, Husén, 1967).
data(data.fims.Aus.Jpn.scored, package = "TAM")
fims <- data.fims.Aus.Jpn.scoredglimpse(fims)
#> Rows: 6,371
#> Columns: 16
#> $ SEX <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
#> $ M1PTI1 <dbl> 1, 0, 1, 1, 1, 1, 0, 1, 0, 0, 1, 1, 1, 0, 0, 0, 1, 1, 1, 1…
#> $ M1PTI2 <dbl> 0, 1, 0, 1, 1, 1, 0, 1, 0, 1, 1, 1, 0, 1, 0, 0, 1, 1, 1, 1…
#> $ M1PTI3 <dbl> 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1…
#> $ M1PTI6 <dbl> 1, 0, 0, 1, 1, 0, 0, 1, 0, 0, 1, 1, 0, 0, 1, 0, 1, 0, 0, 0…
#> $ M1PTI7 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
#> $ M1PTI11 <dbl> 1, 0, 0, 1, 1, 0, 1, 1, 0, 1, 1, 1, 0, 1, 1, 0, 1, 1, 1, 1…
#> $ M1PTI12 <dbl> 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0…
#> $ M1PTI14 <dbl> 0, 1, 0, 0, 1, 0, 1, 1, 1, 0, 0, 1, 0, 0, 1, 0, 1, 0, 1, 1…
#> $ M1PTI17 <dbl> 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 1, 1, 0, 0, 0…
#> $ M1PTI18 <dbl> 0, 0, 1, 0, 1, 1, 0, 1, 0, 1, 0, 1, 0, 0, 1, 1, 0, 0, 1, 1…
#> $ M1PTI19 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
#> $ M1PTI21 <dbl> 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0…
#> $ M1PTI22 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
#> $ M1PTI23 <dbl> 1, 1, 1, 0, 1, 0, 0, 1, 0, 1, 1, 0, 1, 1, 1, 0, 0, 1, 1, 1…
#> $ country <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…Oltre alle risposte sui 14 item di matematica, il data set contiene anche informazioni sul genere del partecipate e sul paese d’origine.
Esaminiamo le risposte dei primi 400 partecipanti. Con le seguenti istruzioni, per facilitare la manipolazione dei dati, cambiamo il nome delle colonne.
responses <- fims[1:400, 2:15]
colnames(responses) <- gsub("M1PTI", "I", colnames(responses))
glimpse(responses)
#> Rows: 400
#> Columns: 14
#> $ I1 <dbl> 1, 0, 1, 1, 1, 1, 0, 1, 0, 0, 1, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1,…
#> $ I2 <dbl> 0, 1, 0, 1, 1, 1, 0, 1, 0, 1, 1, 1, 0, 1, 0, 0, 1, 1, 1, 1, 1,…
#> $ I3 <dbl> 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1,…
#> $ I6 <dbl> 1, 0, 0, 1, 1, 0, 0, 1, 0, 0, 1, 1, 0, 0, 1, 0, 1, 0, 0, 0, 0,…
#> $ I7 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
#> $ I11 <dbl> 1, 0, 0, 1, 1, 0, 1, 1, 0, 1, 1, 1, 0, 1, 1, 0, 1, 1, 1, 1, 0,…
#> $ I12 <dbl> 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
#> $ I14 <dbl> 0, 1, 0, 0, 1, 0, 1, 1, 1, 0, 0, 1, 0, 0, 1, 0, 1, 0, 1, 1, 0,…
#> $ I17 <dbl> 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 1, 1, 0, 0, 0, 0,…
#> $ I18 <dbl> 0, 0, 1, 0, 1, 1, 0, 1, 0, 1, 0, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0,…
#> $ I19 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
#> $ I21 <dbl> 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0,…
#> $ I22 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1,…
#> $ I23 <dbl> 1, 1, 1, 0, 1, 0, 0, 1, 0, 1, 1, 0, 1, 1, 1, 0, 0, 1, 1, 1, 0,…71.3 Modello di Rasch
Un’analisi IRT può essere paragonata a un’analisi fattoriale. Dopo avere adattato il modello di Rasch ai dati usando mirt(), possiamo usare la funzione summary() per ottenere quella che viene definita “soluzione fattoriale”, che include i carichi fattoriali (F1) e le comunalità (h2). Le comunalità, essendo carichi fattoriali al quadrato, sono interpretate come la varianza spiegata in un item dal tratto latente. Nel caso presente, tutti gli item hanno una relazione sostanziale (saturazioni \(\approx\) .50) con il tratto latente, indicando che il tratto latente è un buon indicatore della varianza osservata in quegli item. Questo suggerisce che il tratto latente è in grado di spiegare una porzione almento moderata della varianza nei punteggi degli item.
mirt_rm <- mirt(responses, 1, itemtype = "Rasch", verbose = FALSE)
summary(mirt_rm)
#> F1 h2
#> I1 0.238
#> I2 0.238
#> I3 0.238
#> I6 0.238
#> I7 0.238
#> I11 0.238
#> I12 0.238
#> I14 0.238
#> I17 0.238
#> I18 0.238
#> I19 0.238
#> I21 0.238
#> I22 0.238
#> I23 0.238
#>
#> SS loadings: 0
#> Proportion Var: 0
#>
#> Factor correlations:
#>
#> F1
#> F1 1Nell’IRT, tuttavia, siamo generalmente più interessati ai parametri di discriminazione e difficoltà. Questi parametri possono essere estratti dall’oggetto creato da mirt() nel seguente modo:
params_rm <- coef(mirt_rm, IRTpars = TRUE, simplify = TRUE)
round(params_rm$items, 2) # g = c = guessing parameter
#> a b g u
#> I1 1 -1.10 0 1
#> I2 1 -1.25 0 1
#> I3 1 -2.04 0 1
#> I6 1 -0.05 0 1
#> I7 1 2.53 0 1
#> I11 1 -1.25 0 1
#> I12 1 0.81 0 1
#> I14 1 -0.50 0 1
#> I17 1 1.33 0 1
#> I18 1 -0.40 0 1
#> I19 1 2.06 0 1
#> I21 1 1.75 0 1
#> I22 1 2.41 0 1
#> I23 1 -1.93 0 1- \(a\) (Discriminazione): Il parametro \(a\) (discriminazione) rappresenta la pendenza delle curve caratteristiche degli item (ICC - Item Characteristic Curves). Una pendenza elevata (valore alto di \(a\)) indica che l’item è molto efficace nel distinguere tra individui con livelli diversi del tratto latente (ad esempio, abilità). Questo significa che piccole variazioni nel tratto latente portano a grandi cambiamenti nella probabilità di rispondere correttamente all’item. Una pendenza bassa (valore basso di \(a\)) suggerisce che l’item non è altrettanto efficace nel discriminare tra livelli diversi del tratto latente. In questo caso, anche ampie variazioni nel tratto latente comportano solo piccoli cambiamenti nella probabilità di risposta corretta. Nel modello di Rasch si assume che tutti gli item abbiano la stessa pendenza (o potere discriminante), e quindi tutti i valori di \(a\) sono fissati allo stesso valore (ovvero 1).
- \(b\) (Difficoltà): Rappresenta il livello di abilità a cui un rispondente ha il 50% di probabilità di rispondere correttamente all’item. Un valore positivo indica un item più difficile (richiede un livello di abilità superiore per rispondere correttamente), mentre un valore negativo indica un item più facile. Ad esempio, I7 ha un valore di difficoltà di 2.53, il che significa che è relativamente difficile, mentre I3, con un valore di -2.04, è relativamente facile.
- \(g\) (Probabilità di Indovinare): In questo modello, la probabilità di indovinare è impostata a zero per tutti gli item, il che è coerente con il modello di Rasch, dove non si considera la possibilità di indovinare correttamente un item per caso.
Adattiamo ora ai dati il modello di Rasch con la funzione eRm::RM()
rm_sum0 <- eRm::RM(responses)summary(rm_sum0)
#>
#> Results of RM estimation:
#>
#> Call: eRm::RM(X = responses)
#>
#> Conditional log-likelihood: -1887
#> Number of iterations: 23
#> Number of parameters: 13
#>
#> Item (Category) Difficulty Parameters (eta): with 0.95 CI:
#> Estimate Std. Error lower CI upper CI
#> I2 -1.420 0.121 -1.658 -1.183
#> I3 -2.210 0.145 -2.494 -1.926
#> I6 -0.215 0.108 -0.426 -0.004
#> I7 2.364 0.170 2.031 2.697
#> I11 -1.420 0.121 -1.658 -1.183
#> I12 0.642 0.113 0.422 0.863
#> I14 -0.663 0.110 -0.879 -0.448
#> I17 1.152 0.122 0.913 1.391
#> I18 -0.565 0.109 -0.778 -0.351
#> I19 1.889 0.146 1.602 2.175
#> I21 1.578 0.134 1.315 1.841
#> I22 2.244 0.163 1.925 2.564
#> I23 -2.103 0.141 -2.379 -1.827
#>
#> Item Easiness Parameters (beta) with 0.95 CI:
#> Estimate Std. Error lower CI upper CI
#> beta I1 1.273 0.118 1.041 1.504
#> beta I2 1.420 0.121 1.183 1.658
#> beta I3 2.210 0.145 1.926 2.494
#> beta I6 0.215 0.108 0.004 0.426
#> beta I7 -2.364 0.170 -2.697 -2.031
#> beta I11 1.420 0.121 1.183 1.658
#> beta I12 -0.642 0.113 -0.863 -0.422
#> beta I14 0.663 0.110 0.448 0.879
#> beta I17 -1.152 0.122 -1.391 -0.913
#> beta I18 0.565 0.109 0.351 0.778
#> beta I19 -1.889 0.146 -2.175 -1.602
#> beta I21 -1.578 0.134 -1.841 -1.315
#> beta I22 -2.244 0.163 -2.564 -1.925
#> beta I23 2.103 0.141 1.827 2.379La funzione RM() impone un vincolo sulle stime dei parametri di difficoltà degli item. Questo vincolo è che la media di questi parametri (beta) sia zero. Questo approccio è noto come “parametrizzazione ancorata” o “centrata”. Il vantaggio di questa parametrizzazione è che posiziona la scala di difficoltà degli item in un punto di riferimento fisso, facilitando il confronto tra diversi set di item o tra diverse applicazioni dello stesso test.
Verifichiamo.
coef(rm_sum0)
#> beta I1 beta I2 beta I3 beta I6 beta I7 beta I11 beta I12 beta I14
#> 1.2726 1.4203 2.2098 0.2153 -2.3639 1.4203 -0.6424 0.6633
#> beta I17 beta I18 beta I19 beta I21 beta I22 beta I23
#> -1.1517 0.5646 -1.8886 -1.5781 -2.2444 2.1029sum(rm_sum0$betapar)
#> [1] 8.882e-16Nella parametrizzazione utilizzata da mirt(), i parametri di difficoltà vengono invece stimati senza un vincolo sulla loro media. Questo può portare a stime dei parametri di difficoltà che differiscono da quelle ottenute tramite RM(). Questa libertà nella stima dei parametri permette una flessibilità maggiore, specialmente in modelli IRT complessi o multidimensionali, ma può rendere più complesso il confronto diretto tra set di item o test differenti.
Dalla soluzione prodotta da eRm::RM() possiamo estrarre le stime sia nei termini della facilità che della difficoltà degli item.
tab <- data.frame(
item_score = colSums(responses),
easiness = coef(rm_sum0),
difficulty = -coef(rm_sum0)
)
tab[order(tab$item_score), ]
#> item_score easiness difficulty
#> I7 40 -2.3639 2.3639
#> I22 44 -2.2444 2.2444
#> I19 58 -1.8886 1.8886
#> I21 73 -1.5781 1.5781
#> I17 98 -1.1517 1.1517
#> I12 134 -0.6424 0.6424
#> I6 204 0.2153 -0.2153
#> I18 233 0.5646 -0.5646
#> I14 241 0.6633 -0.6633
#> I1 287 1.2726 -1.2726
#> I2 297 1.4203 -1.4203
#> I11 297 1.4203 -1.4203
#> I23 336 2.1029 -2.1029
#> I3 341 2.2098 -2.2098In alterativa, possiamo usare il pacchetto TAM. Come nel caso di mirt, anche in questo caso viene usata una procedura di stima di massima verosimiglianza marginale.
tam_rm <- tam.mml(responses)
#> ....................................................
#> Processing Data 2025-03-22 08:06:23.614344
#> * Response Data: 400 Persons and 14 Items
#> * Numerical integration with 21 nodes
#> * Created Design Matrices ( 2025-03-22 08:06:23.615454 )
#> * Calculated Sufficient Statistics ( 2025-03-22 08:06:23.616819 )
#> ....................................................
#> Iteration 1 2025-03-22 08:06:23.617928
#> E Step
#> M Step Intercepts |----
#> Deviance = 5667.9246
#> Maximum item intercept parameter change: 0.3147
#> Maximum item slope parameter change: 0
#> Maximum regression parameter change: 0
#> Maximum variance parameter change: 0.123
#> ....................................................
#> Iteration 2 2025-03-22 08:06:23.618981
#> E Step
#> M Step Intercepts |--
#> Deviance = 5633.0417 | Absolute change: 34.88 | Relative change: 0.006193
#> Maximum item intercept parameter change: 0.003284
#> Maximum item slope parameter change: 0
#> Maximum regression parameter change: 0
#> Maximum variance parameter change: 0.007956
#> ....................................................
#> Iteration 3 2025-03-22 08:06:23.622938
#> E Step
#> M Step Intercepts |--
#> Deviance = 5633.0057 | Absolute change: 0.036 | Relative change: 6.39e-06
#> Maximum item intercept parameter change: 0.002198
#> Maximum item slope parameter change: 0
#> Maximum regression parameter change: 0
#> Maximum variance parameter change: 0.005837
#> ....................................................
#> Iteration 4 2025-03-22 08:06:23.62338
#> E Step
#> M Step Intercepts |--
#> Deviance = 5632.9887 | Absolute change: 0.017 | Relative change: 3.02e-06
#> Maximum item intercept parameter change: 0.00151
#> Maximum item slope parameter change: 0
#> Maximum regression parameter change: 0
#> Maximum variance parameter change: 0.004059
#> ....................................................
#> Iteration 5 2025-03-22 08:06:23.623682
#> E Step
#> M Step Intercepts |--
#> Deviance = 5632.9805 | Absolute change: 0.0081 | Relative change: 1.44e-06
#> Maximum item intercept parameter change: 0.001036
#> Maximum item slope parameter change: 0
#> Maximum regression parameter change: 0
#> Maximum variance parameter change: 0.002812
#> ....................................................
#> Iteration 6 2025-03-22 08:06:23.623967
#> E Step
#> M Step Intercepts |--
#> Deviance = 5632.9767 | Absolute change: 0.0039 | Relative change: 6.8e-07
#> Maximum item intercept parameter change: 0.00071
#> Maximum item slope parameter change: 0
#> Maximum regression parameter change: 0
#> Maximum variance parameter change: 0.001944
#> ....................................................
#> Iteration 7 2025-03-22 08:06:23.624269
#> E Step
#> M Step Intercepts |--
#> Deviance = 5632.9749 | Absolute change: 0.0018 | Relative change: 3.2e-07
#> Maximum item intercept parameter change: 0.000486
#> Maximum item slope parameter change: 0
#> Maximum regression parameter change: 0
#> Maximum variance parameter change: 0.001342
#> ....................................................
#> Iteration 8 2025-03-22 08:06:23.624569
#> E Step
#> M Step Intercepts |--
#> Deviance = 5632.974 | Absolute change: 0.0009 | Relative change: 1.5e-07
#> Maximum item intercept parameter change: 0.000333
#> Maximum item slope parameter change: 0
#> Maximum regression parameter change: 0
#> Maximum variance parameter change: 0.000925
#> ....................................................
#> Iteration 9 2025-03-22 08:06:23.624879
#> E Step
#> M Step Intercepts |--
#> Deviance = 5632.9736 | Absolute change: 0.0004 | Relative change: 7e-08
#> Maximum item intercept parameter change: 0.000228
#> Maximum item slope parameter change: 0
#> Maximum regression parameter change: 0
#> Maximum variance parameter change: 0.000637
#> ....................................................
#> Iteration 10 2025-03-22 08:06:23.625187
#> E Step
#> M Step Intercepts |--
#> Deviance = 5632.9734 | Absolute change: 0.0002 | Relative change: 3e-08
#> Maximum item intercept parameter change: 0.000156
#> Maximum item slope parameter change: 0
#> Maximum regression parameter change: 0
#> Maximum variance parameter change: 0.000439
#> ....................................................
#> Iteration 11 2025-03-22 08:06:23.625501
#> E Step
#> M Step Intercepts |--
#> Deviance = 5632.9733 | Absolute change: 0.0001 | Relative change: 2e-08
#> Maximum item intercept parameter change: 0.000107
#> Maximum item slope parameter change: 0
#> Maximum regression parameter change: 0
#> Maximum variance parameter change: 0.000302
#> ....................................................
#> Iteration 12 2025-03-22 08:06:23.625786
#> E Step
#> M Step Intercepts |-
#> Deviance = 5632.9733 | Absolute change: 0 | Relative change: 1e-08
#> Maximum item intercept parameter change: 0.000073
#> Maximum item slope parameter change: 0
#> Maximum regression parameter change: 0
#> Maximum variance parameter change: 0.000208
#> ....................................................
#> Iteration 13 2025-03-22 08:06:23.626048
#> E Step
#> M Step Intercepts |-
#> Deviance = 5632.9732 | Absolute change: 0 | Relative change: 0
#> Maximum item intercept parameter change: 5e-05
#> Maximum item slope parameter change: 0
#> Maximum regression parameter change: 0
#> Maximum variance parameter change: 0.000143
#> ....................................................
#> Iteration 14 2025-03-22 08:06:23.626315
#> E Step
#> M Step Intercepts |-
#> Deviance = 5632.9732 | Absolute change: 0 | Relative change: 0
#> Maximum item intercept parameter change: 0.000034
#> Maximum item slope parameter change: 0
#> Maximum regression parameter change: 0
#> Maximum variance parameter change: 0.000098
#> ....................................................
#> Item Parameters
#> xsi.index xsi.label est
#> 1 1 I1 -1.1029
#> 2 2 I2 -1.2505
#> 3 3 I3 -2.0422
#> 4 4 I6 -0.0480
#> 5 5 I7 2.5312
#> 6 6 I11 -1.2505
#> 7 7 I12 0.8132
#> 8 8 I14 -0.4952
#> 9 9 I17 1.3263
#> 10 10 I18 -0.3969
#> 11 11 I19 2.0639
#> 12 12 I21 1.7545
#> 13 13 I22 2.4145
#> 14 14 I23 -1.9345
#> ...................................
#> Regression Coefficients
#> [,1]
#> [1,] 0
#>
#> Variance:
#> [,1]
#> [1,] 0.9037
#>
#>
#> EAP Reliability:
#> [1] 0.656
#>
#> -----------------------------
#> Start: 2025-03-22 08:06:23.613484
#> End: 2025-03-22 08:06:23.628764
#> Time difference of 0.01528 secsPossiamo ispezionare le stime dei parametri con
tam_rm$item
#> item N M xsi.item AXsi_.Cat1 B.Cat1.Dim1
#> I1 I1 400 0.7175 -1.10293 -1.10293 1
#> I2 I2 400 0.7425 -1.25048 -1.25048 1
#> I3 I3 400 0.8525 -2.04220 -2.04220 1
#> I6 I6 400 0.5100 -0.04803 -0.04803 1
#> I7 I7 400 0.1000 2.53123 2.53123 1
#> I11 I11 400 0.7425 -1.25048 -1.25048 1
#> I12 I12 400 0.3350 0.81319 0.81319 1
#> I14 I14 400 0.6025 -0.49523 -0.49523 1
#> I17 I17 400 0.2450 1.32632 1.32632 1
#> I18 I18 400 0.5825 -0.39687 -0.39687 1
#> I19 I19 400 0.1450 2.06394 2.06394 1
#> I21 I21 400 0.1825 1.75454 1.75454 1
#> I22 I22 400 0.1100 2.41452 2.41452 1
#> I23 I23 400 0.8400 -1.93454 -1.93454 1Le colonne di questo output possono essere interpretate come segue:
-
itemindica il nome dell’item. -
Nindica il numero di candidati che hanno risposto a ciascun item. In questo caso, tutti i 400 candidati hanno risposto a ogni item. -
Mè la media delle risposte a ciascun item. Nel caso di un item con una media alta ciò significa che a tale item è stata fornita uba risposta corretta da una alta percentuale di candidati. -
xsi.itemper il modello di Rasch è il parametro di difficoltà dell’item. Gli item con valori alti tendono ad essere più difficili. -
AXsi.Cat1ripete la difficoltà dell’item per il modello di Rasch, ma permetterebbe l’inclusione di una matrice di design A, che non abbiamo usato qui. Per i modelli politomici, l’output includerà parametri dell’item per più di una categoria. -
B.Cat1.Dim1è il parametro di discriminazione o pendenza dell’item. Per il modello di Rasch, la pendenza è 1 per ogni item.
Possiamo mostrare solo la difficoltà e l’errore standard con:
tam_rm$xsi
#> xsi se.xsi
#> I1 -1.10293 0.1199
#> I2 -1.25048 0.1231
#> I3 -2.04220 0.1490
#> I6 -0.04803 0.1092
#> I7 2.53123 0.1742
#> I11 -1.25048 0.1231
#> I12 0.81319 0.1149
#> I14 -0.49523 0.1113
#> I17 1.32632 0.1250
#> I18 -0.39687 0.1105
#> I19 2.06394 0.1501
#> I21 1.75454 0.1378
#> I22 2.41452 0.1675
#> I23 -1.93454 0.1445La parametrizzazione classica IRT si ottiene con:
tam_rm$item_irt
#> item alpha beta
#> 1 I1 1 -1.10293
#> 2 I2 1 -1.25048
#> 3 I3 1 -2.04220
#> 4 I6 1 -0.04803
#> 5 I7 1 2.53123
#> 6 I11 1 -1.25048
#> 7 I12 1 0.81319
#> 8 I14 1 -0.49523
#> 9 I17 1 1.32632
#> 10 I18 1 -0.39687
#> 11 I19 1 2.06394
#> 12 I21 1 1.75454
#> 13 I22 1 2.41452
#> 14 I23 1 -1.9345471.4 Valutazione del Test
Il primo approccio per valutare i test consiste nell’utilizzo di metodi grafici. Tra questi, il primo strumento che esaminiamo è la mappa persona-item, utile per verificare se il campione di partecipanti copre l’intera gamma di difficoltà degli item e se, viceversa, gli item coprono l’intero spettro delle abilità del campione.
Il secondo metodo riguarda il confronto tra le Curve Caratteristiche degli Item (ICC) teoriche ed empiriche, che consente di identificare eventuali item con scarsa aderenza al modello.
Infine, il terzo approccio è il test grafico per il Funzionamento Differenziale degli Item (DIF), che offre un metodo visivo per rilevare discrepanze nel comportamento degli item tra gruppi di rispondenti.
71.4.1 Mappa Persona-Item
La Mappa Persona-Item (nota anche come Wright Map o person-item map) è uno strumento grafico utile per valutare quanto efficacemente gli item coprono l’intervallo delle abilità latenti nel campione studiato. Questo strumento consente di rispondere alla domanda: Quanto bene gli item riflettono la gamma delle abilità latenti presenti nel campione?
La costruzione della mappa avviene in due fasi:
- Distribuzione delle abilità latenti: Si rappresenta graficamente la distribuzione delle abilità latenti (\(\theta\)) del campione di persone.
- Difficoltà degli item: Si sovrappone la difficoltà di ciascun item sulla stessa scala di \(\theta\) utilizzata per le abilità.
L’allineamento di queste due rappresentazioni permette di valutare visivamente la corrispondenza tra le abilità del campione e le difficoltà degli item. Idealmente, le difficoltà degli item dovrebbero coprire l’intera gamma delle abilità delle persone, e viceversa. Questa corrispondenza è essenziale per garantire una stima precisa dei parametri degli item e delle abilità dei rispondenti.
La mappa persona-item fornisce quindi una panoramica intuitiva e immediata dell’adeguatezza del test rispetto al campione studiato, evidenziando eventuali gap nella copertura delle abilità o difficoltà non equilibrate.
Per generare una mappa persona-item, è possibile utilizzare la funzione:
itempersonMap(mirt_rm)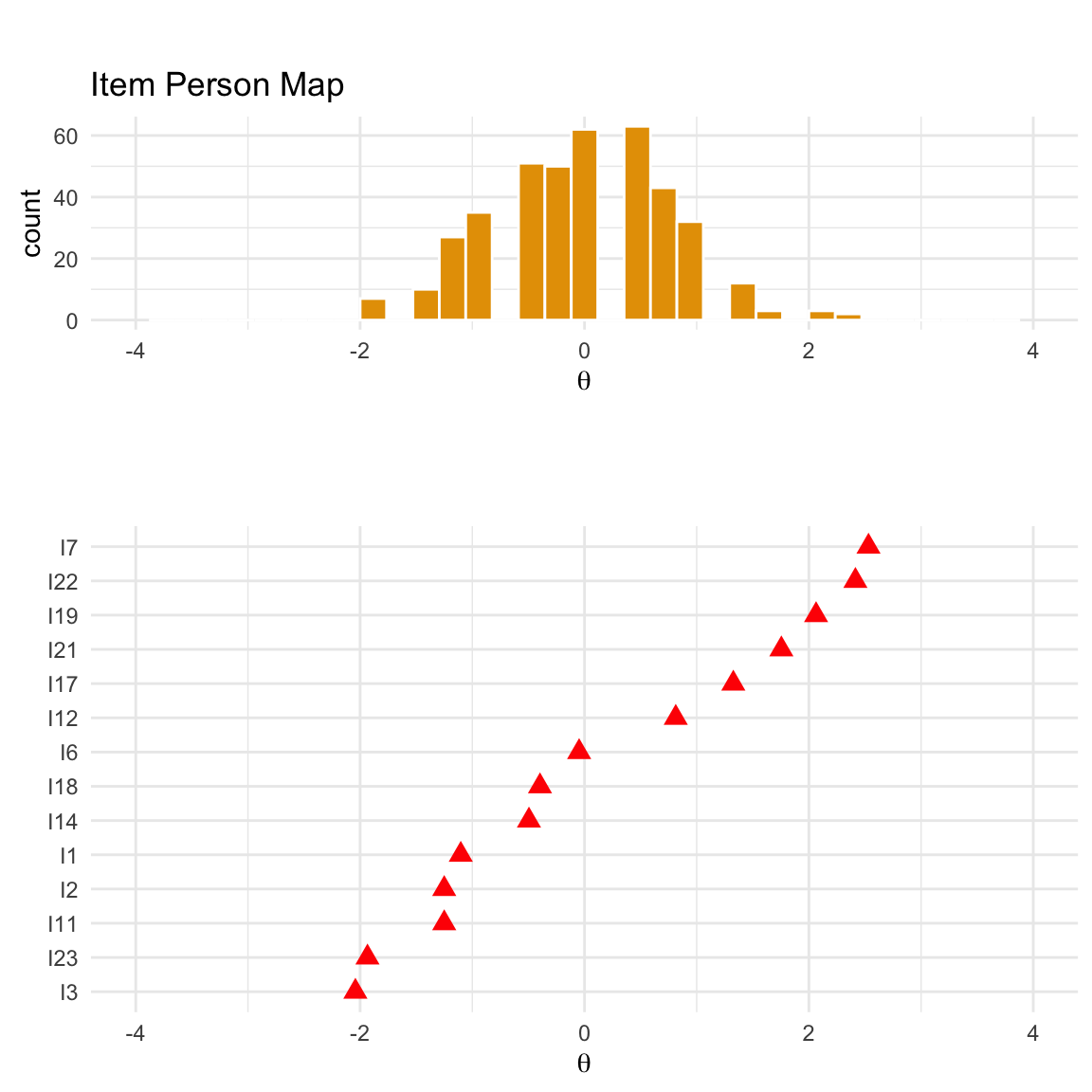
Questa funzione consente di visualizzare facilmente le distribuzioni e di valutare il bilanciamento tra le abilità delle persone e le difficoltà degli item.
La parte superiore della mappa persona-item mostra un istogramma delle stime dei parametri di abilità, mentre la parte inferiore mostra le stime delle difficoltà per ciascun item del test. Per ogni item, la stima della difficoltà è indicata dalla posizione del punto sulla linea tratteggiata corrispondente a quell’item. Ad esempio, la difficoltà stimata per l’item 1 corrisponde alla posizione del punto sulla linea tratteggiata più in alto. La mappa persona-item offre un controllo visivo di coerenza per le stime del nostro modello IRT (Teoria della Risposta all’Item). Le stime delle abilità sono più accurate quando cadono nel mezzo della distribuzione dei parametri degli item e viceversa. Pertanto, idealmente, l’istogramma delle abilità e le stime delle difficoltà dovrebbero essere centrate sullo stesso punto e mostrare un’ampia sovrapposizione. Nel nostro test, sembra essere questo il caso.
In alternativa, possiamo usare la funzione plotPImap() di eRm.
71.4.2 ICC Empiriche
Le Curve Caratteristiche degli Item (ICC) descrivono la relazione teorica tra l’abilità dei partecipanti al test e la probabilità di una risposta corretta che ci aspettiamo sotto il modello di Rasch per una data difficoltà. La ICC attesa per un item può essere tracciata dopo che la sua difficoltà è stata stimata. Oltre alle probabilità attese di una risposta corretta illustrate dall’ICC, possiamo anche tracciare le frequenze relative empiriche di una risposta corretta. Queste frequenze relative empiriche sono indicate nella figura come punti e vengono chiamate ICC empiriche.
Usando eRm possimo generare le ECC empiriche nel modo seguente.
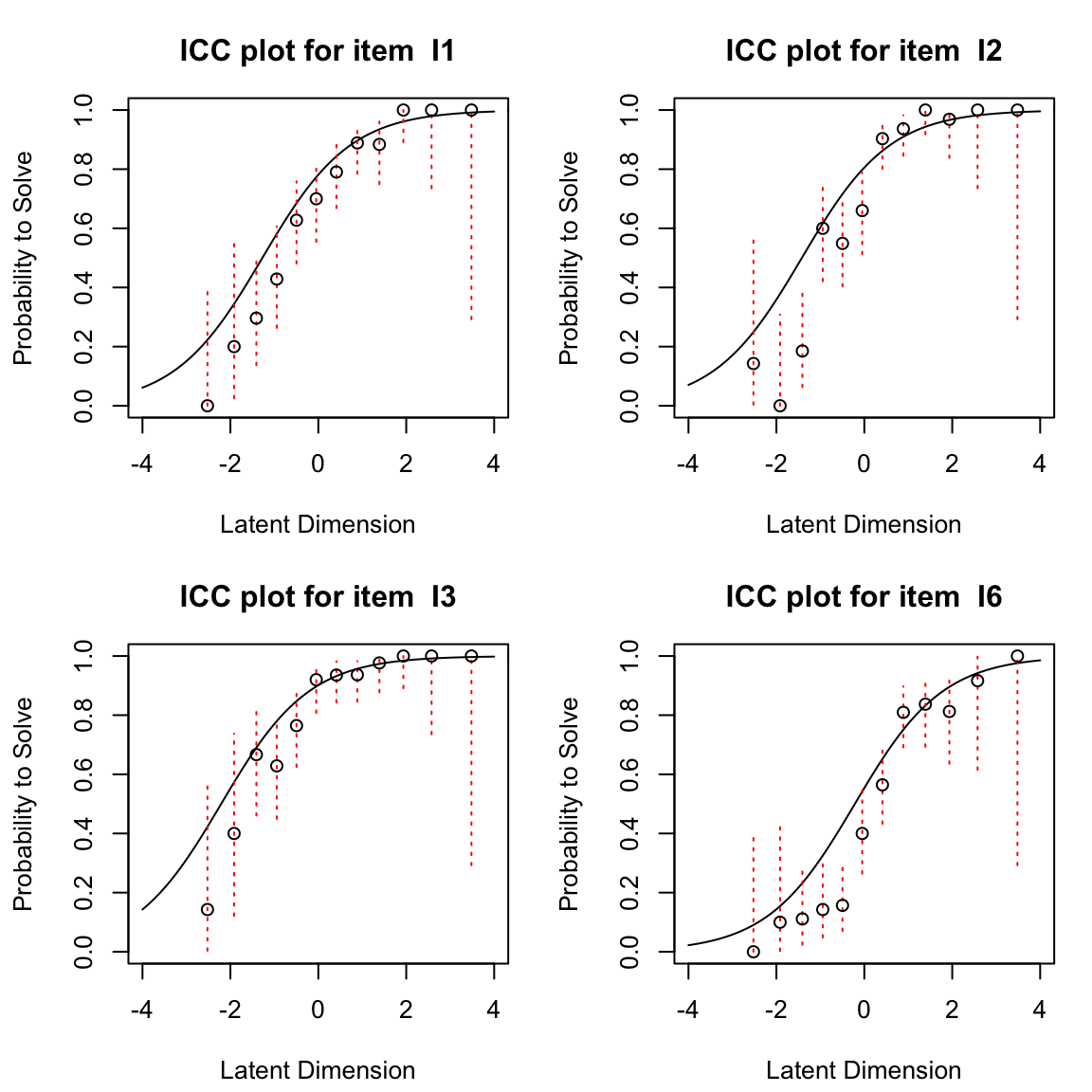
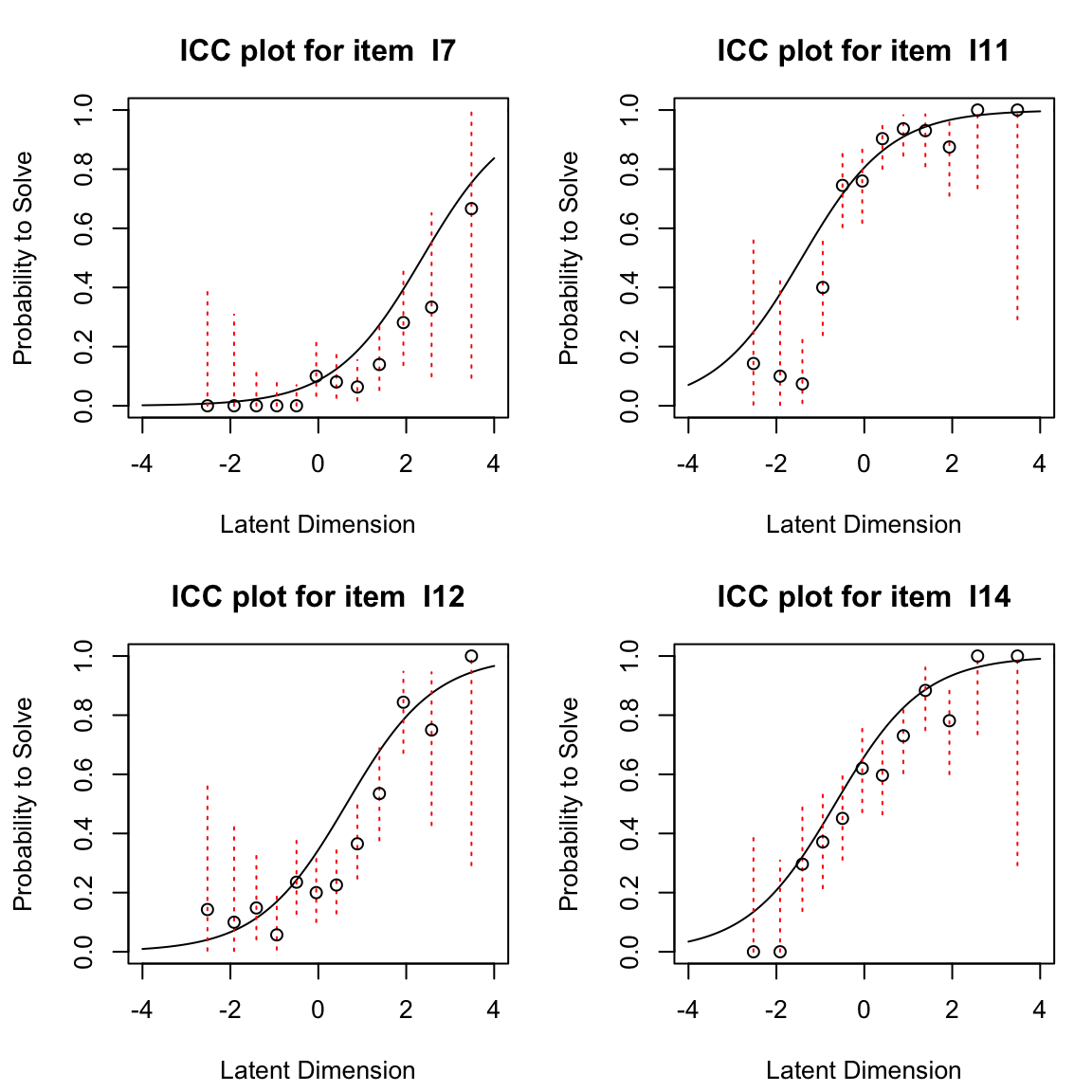
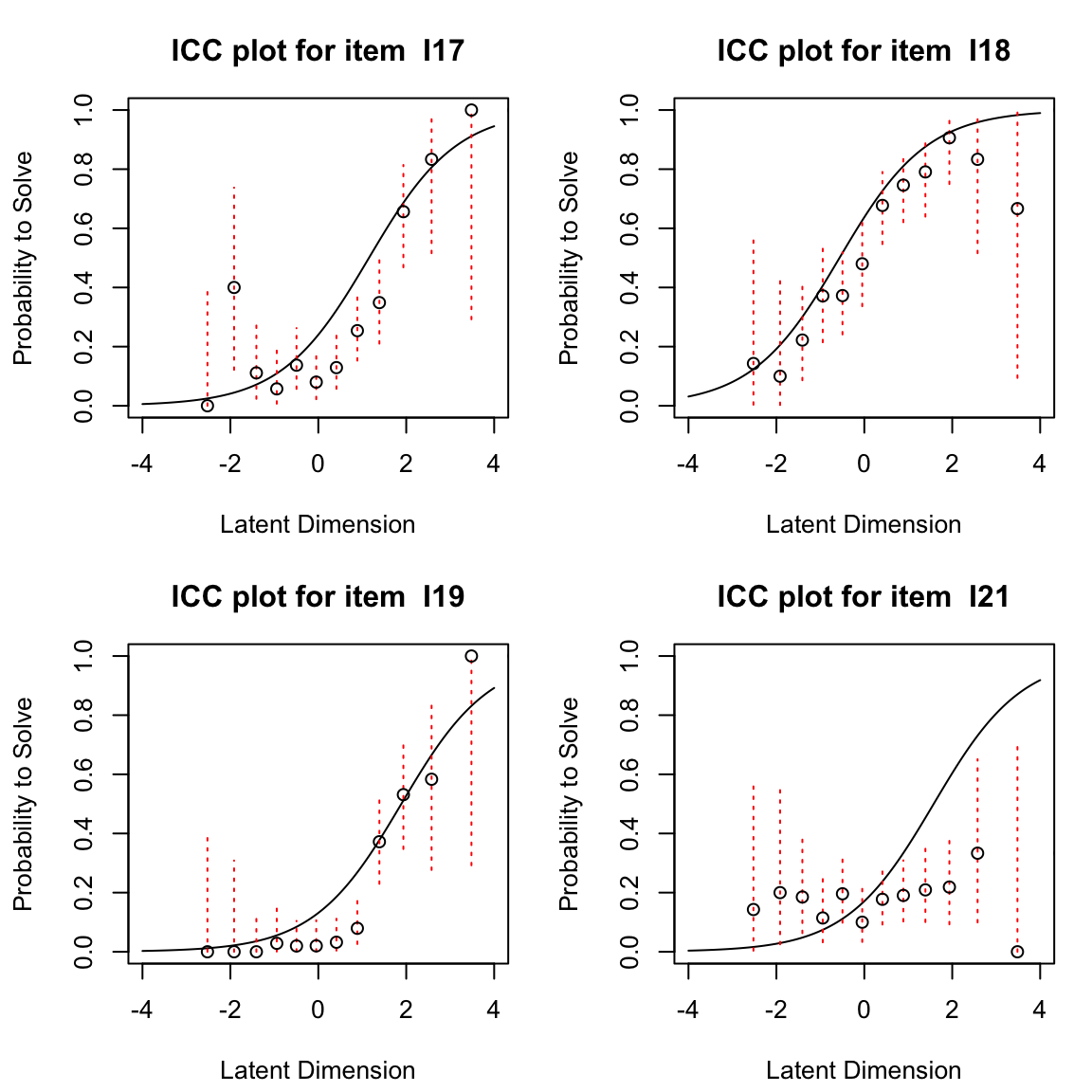
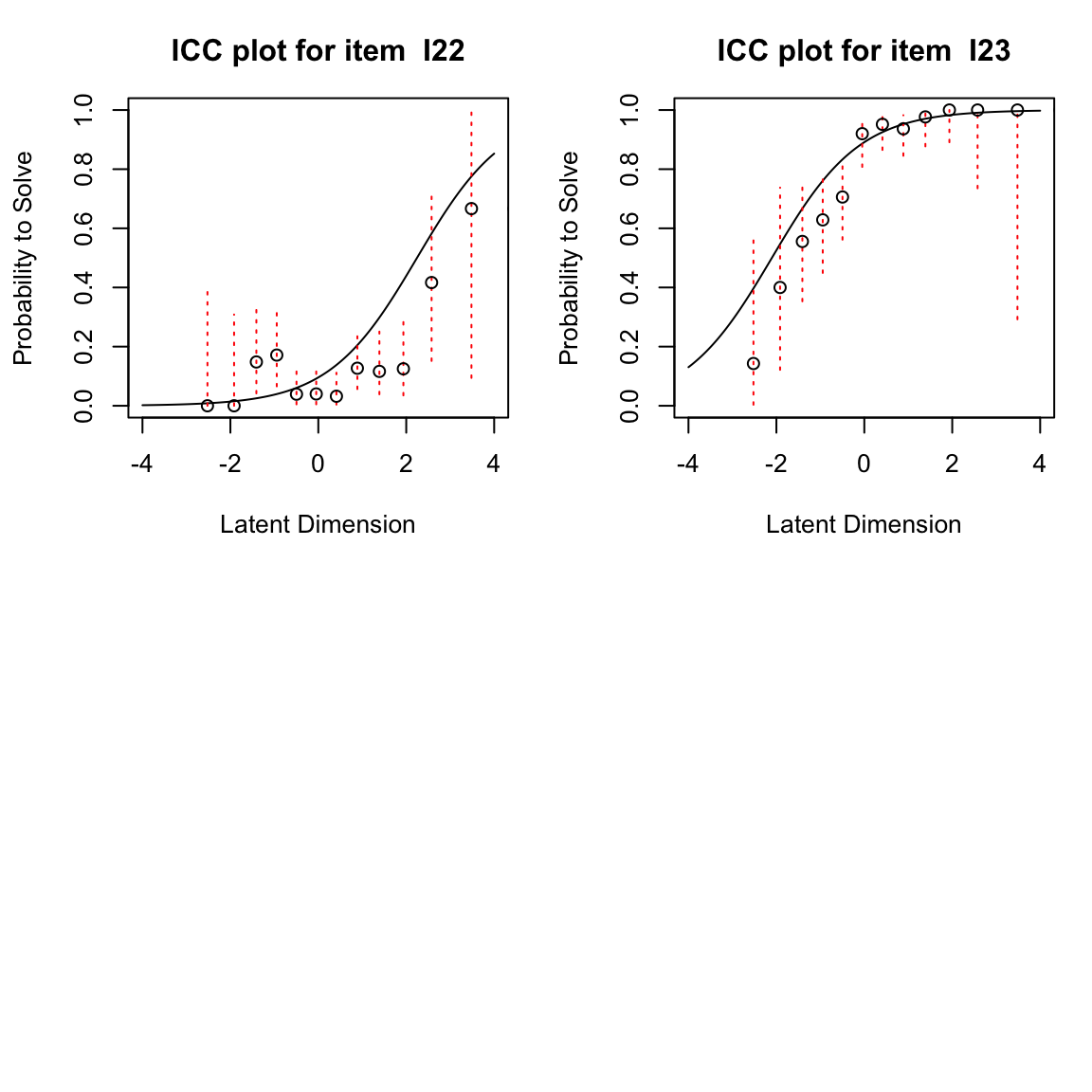
Le ICC empiriche sono rappresentate dai singoli punti, mentre la ICC attesa sotto il modello di Rasch è indicata dalla linea liscia. Dalle figure precedenti, per gli item 12 e 14 notiamo che in generale la forma dell’ICC empirica è molto ben allineata con l’ICC attesa, ma per l’item 12 l’ICC empirica mostra valori sopra zero anche per le abilità più basse a sinistra della dimensione latente. Questo potrebbe indicare una tendenza al tentativo di indovinare (guessing). Per l’item 19, l’ICC empirica appare più ripida dell’ICC attesa sotto il modello di Rasch. Mostra un salto molto più pronunciato tra la prima metà approssimativa dei punti e i punti rimanenti. Per l’item 21, al contrario, l’ICC empirica è molto più piatta rispetto a quella attesa. Confronteremo la nostra impressione visiva con le statistiche di adattamento degli item per questi item di seguito.
È possibile visualizzare le ICC attese di tutti gli item del test in un unico grafico utilizzando la funzione plotjointICC(). Questo grafico ci permette di esaminare come la difficoltà influenzi la probabilità che un candidato risponda correttamente a un item. Ricordiamo che la difficoltà di un item è definita come il livello di abilità in cui una persona ha una probabilità del 50% di rispondere correttamente all’item. Abbiamo aggiunto una linea tratteggiata orizzontale alla probabilità di 0.5 usando il comando segments. Il punto in cui un’ICC interseca questa linea rappresenta la sua difficoltà. Questo ci permette di leggere facilmente le difficoltà relative degli item dal grafico. Spostandosi da sinistra a destra, il primo ICC intersecato dalla linea orizzontale corrisponde all’item meno difficile (in questo caso l’item 3, seguito da vicino dall’item 23, come indicato nell’ordine degli item nella legenda), e l’ultimo ICC intersecato dalla linea orizzontale è per l’item più difficile (in questo caso l’item 7).
Da notare che le ICC attese nella figura sono parallele per definizione. Il modello di Rasch assume che le ICC siano parallele, quindi produrrà sempre ICC teoriche o attese parallele, anche quando gli item hanno in realtà pendenze o tassi di guessing diversi, come abbiamo visto in precedenza per le ICC empiriche.
eRm::plotjointICC(rm_sum0, cex = 0.7)
segments(-2.5, 0.5, 4, 0.5, lty = 2)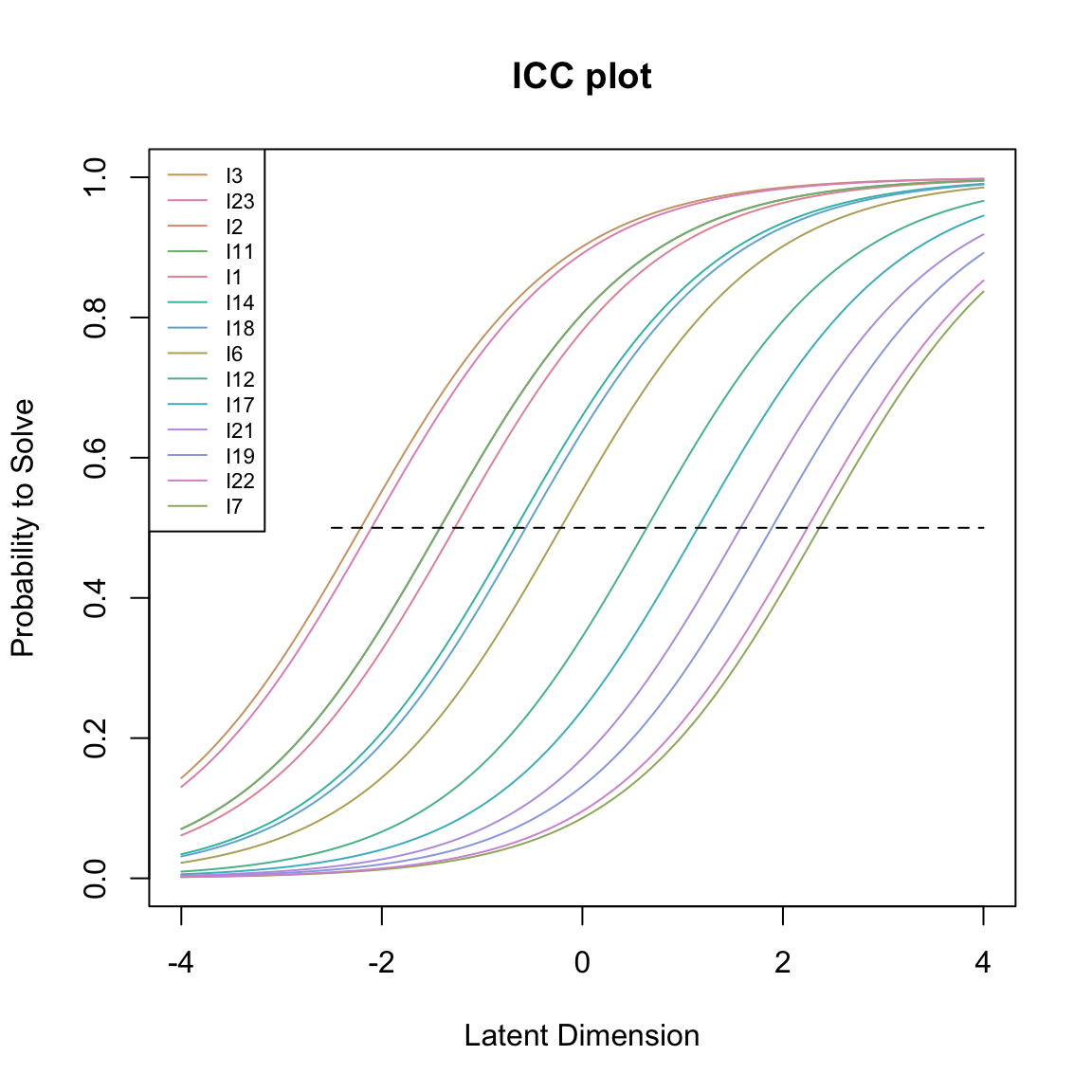
In alternativa, possiamo generare le ICC usando il pacchetto mirt:
mirt_rm <- mirt(responses, 1, "Rasch")
#>
Iteration: 1, Log-Lik: -2816.924, Max-Change: 0.03346
Iteration: 2, Log-Lik: -2816.650, Max-Change: 0.02041
Iteration: 3, Log-Lik: -2816.562, Max-Change: 0.01357
Iteration: 4, Log-Lik: -2816.520, Max-Change: 0.01027
Iteration: 5, Log-Lik: -2816.501, Max-Change: 0.00584
Iteration: 6, Log-Lik: -2816.493, Max-Change: 0.00395
Iteration: 7, Log-Lik: -2816.490, Max-Change: 0.00307
Iteration: 8, Log-Lik: -2816.488, Max-Change: 0.00174
Iteration: 9, Log-Lik: -2816.487, Max-Change: 0.00118
Iteration: 10, Log-Lik: -2816.487, Max-Change: 0.00094
Iteration: 11, Log-Lik: -2816.487, Max-Change: 0.00054
Iteration: 12, Log-Lik: -2816.487, Max-Change: 0.00036
Iteration: 13, Log-Lik: -2816.487, Max-Change: 0.00028
Iteration: 14, Log-Lik: -2816.487, Max-Change: 0.00016
Iteration: 15, Log-Lik: -2816.487, Max-Change: 0.00011
Iteration: 16, Log-Lik: -2816.487, Max-Change: 0.00008
plot(mirt_rm, type = "trace")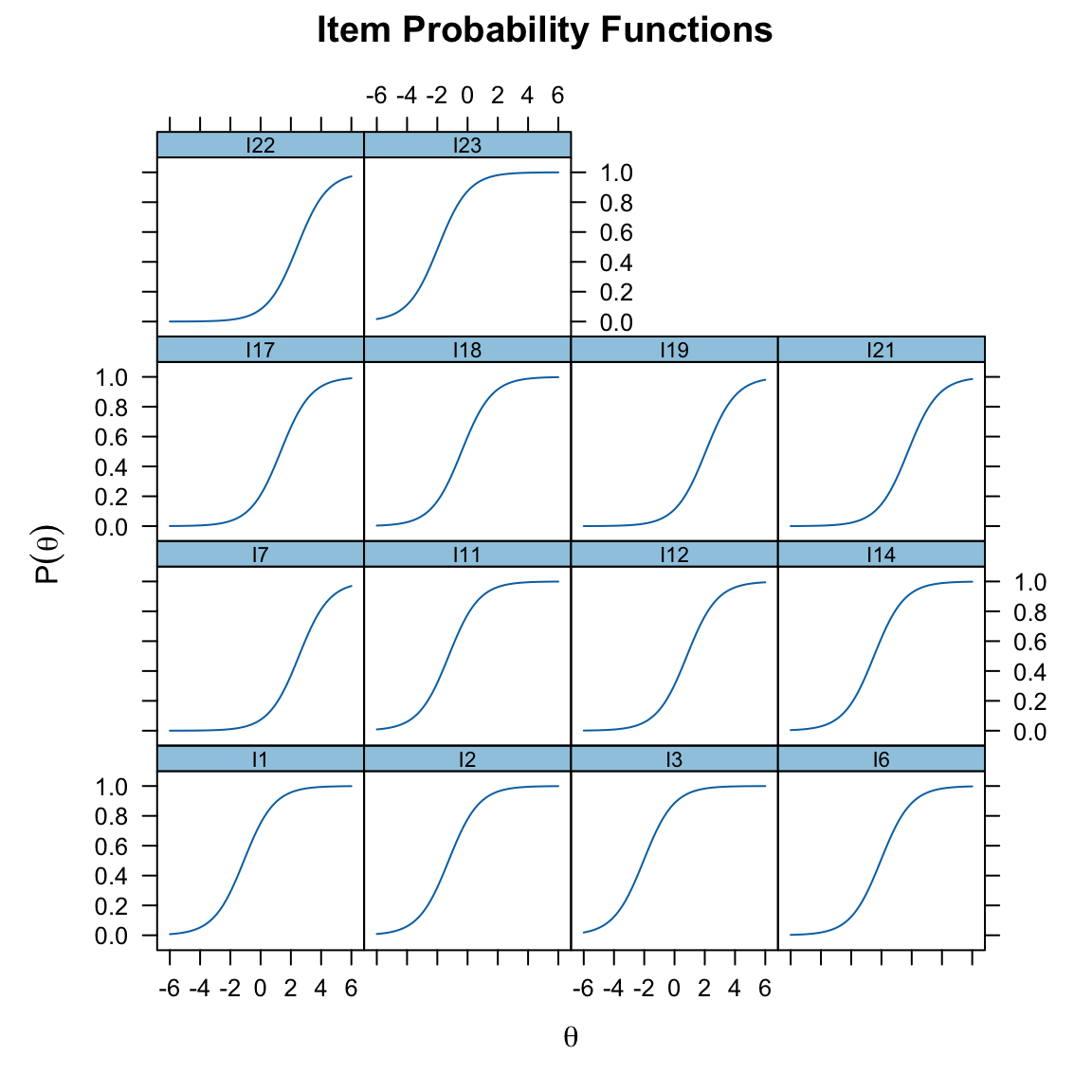
Le curve caratteristiche degli item offrono un quadro dettagliato e visuale di come ciascun item del test si comporta attraverso diversi livelli dell’abilità latente. Per esempio:
-
Visualizzazione della Difficoltà e della Discriminazione:
- Supponiamo di avere un item che mostra una curva con una ripida salita in un punto specifico della scala di abilità. Questo indica che l’item ha una difficoltà concentrata attorno a quel punto e che discrimina efficacemente tra rispondenti con abilità appena al di sotto e al di sopra di quel livello.
- Al contrario, una curva più graduale suggerisce che l’item è meno discriminante, con una variazione più ampia nella probabilità di risposta corretta a seconda del livello di abilità.
-
Identificazione di Lacune nella Valutazione:
- Visualizzando le curve di più item, possiamo identificare se ci sono lacune nella copertura dell’abilità latente. Ad esempio, se tutti gli item hanno curve che si concentrano su livelli di abilità bassi, potrebbe esserci una mancanza di item difficili per misurare l’abilità ad alti livelli.
- Inoltre, se le curve degli item si sovrappongono eccessivamente, potrebbe indicare ridondanza tra gli item, suggerendo che alcuni di essi non aggiungono informazioni uniche alla valutazione.
-
Confronto tra Diversi Tipi di Item:
- Per esempio, gli item progettati per misurare concetti di base potrebbero avere curve che mostrano alta probabilità di risposta corretta anche a livelli di abilità bassi.
- Al contrario, item progettati per essere più impegnativi potrebbero mostrare probabilità elevate di risposta corretta solo a livelli di abilità più alti.
71.4.3 Test Grafico
Il test grafico del modello, basato sui principi di Rasch (1960), è un metodo intuitivo per valutare l’invarianza degli item in un test, confrontando i parametri degli item stimati per due gruppi di persone. Affinché il modello di Rasch sia considerato valido, è necessario che le stime dei parametri degli item per i diversi gruppi concordino, fino a una trasformazione lineare. In termini pratici, ciò si traduce nel fatto che, quando visualizzate in un grafico, le stime dei parametri degli item dei due gruppi dovrebbero allinearsi lungo una linea retta.
Per complementare questa analisi, possiamo ricorrere al test del rapporto di verosimiglianza di Andersen (1973), un approccio ben consolidato per verificare l’adeguatezza del modello di Rasch nel rappresentare il comportamento dei partecipanti ai test. Il test di Andersen valuta se le stime dei parametri degli item rimangono consistenti tra diversi gruppi di partecipanti. Se i parametri degli item stimati individualmente per ciascun gruppo differiscono significativamente, ciò indica che il modello di Rasch potrebbe non essere un’adeguata rappresentazione del comportamento osservato nei test.
A differenza del test grafico, il test del rapporto di verosimiglianza confronta il massimo della verosimiglianza condizionata sotto il modello di Rasch con il massimo della verosimiglianza condizionata quando i parametri degli item possono variare tra i gruppi. Questa metodologia offre un’indicazione di quanto efficacemente ciascun modello rappresenti il comportamento dei partecipanti.
Il test del rapporto di verosimiglianza utilizza la statistica di test \(T = −2 \cdot log(LR)\), che ha una distribuzione campionaria approssimativamente \(\chi^2\) per campioni grandi. Valori del rapporto di verosimiglianza inferiori a 1, o valori elevati di T, suggeriscono una violazione del modello di Rasch.
Il test di Andersen è implementato nel pacchetto eRm in R, offrendo uno strumento utile per l’analisi. Tuttavia, è importante notare che un risultato non significativo in questo test non può essere interpretato automaticamente come supporto per il modello di Rasch, specialmente se il modello più generale non descrive adeguatamente i dati. Inoltre, la capacità di rilevare differenze tra i gruppi specificati dipende dall’effettiva diversità dei parametri del modello tra questi gruppi. Sono stati messi a punto approcci più flessibili per rilevare le differenze nei parametri.
lrt_mean_split <- LRtest(rm_sum0, splitcr = "mean")
lrt_mean_split
#>
#> Andersen LR-test:
#> LR-value: 79.71
#> Chi-square df: 13
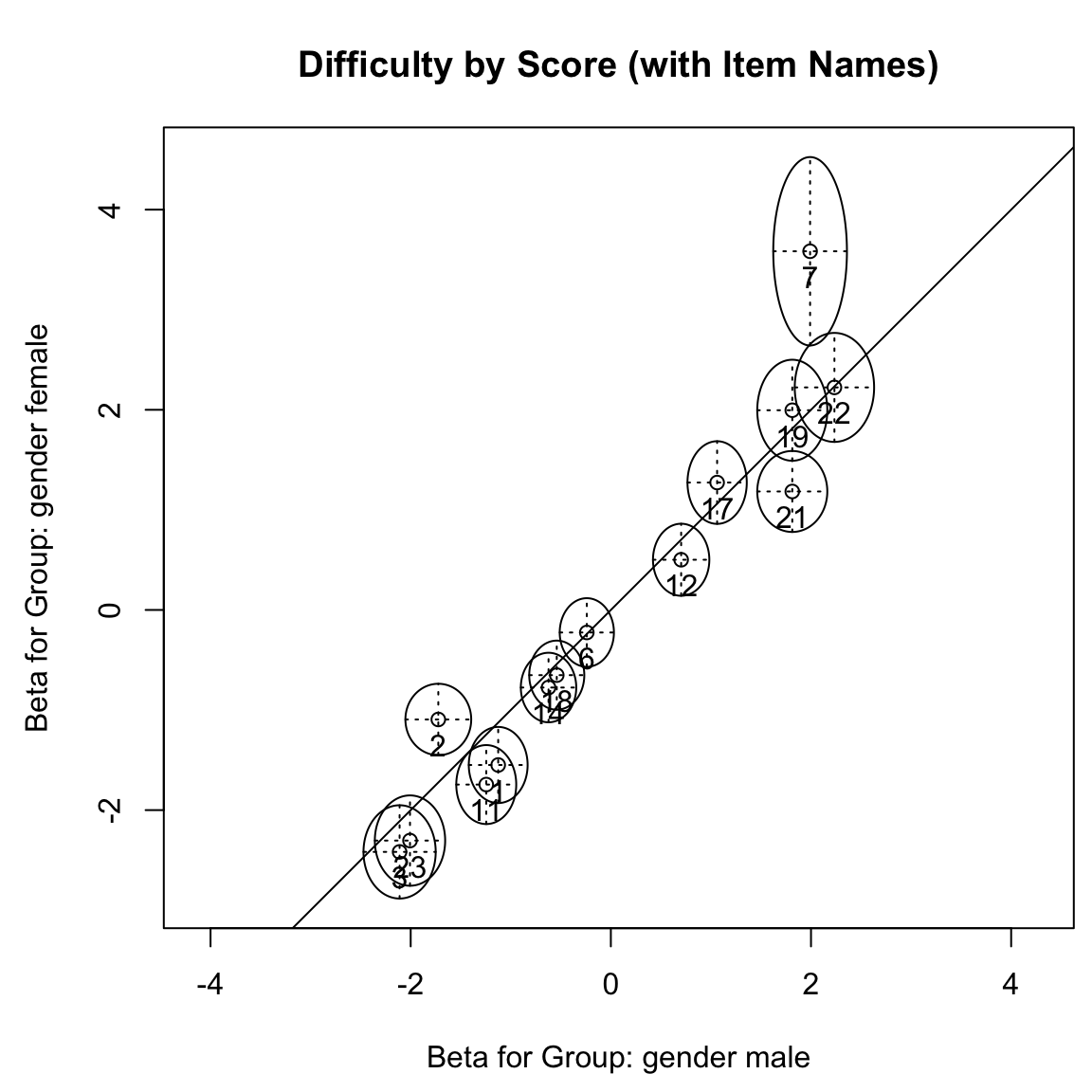
#> p-value: 0L’output di questo test mostra una violazione significativa del modello di Rasch al livello \(\alpha\) = 0.05.
plotGOF(
lrt_mean_split,
tlab = "item", pos = 1,
main = "Difficulty by Score (with Item Names)",
conf = list(gamma = 0.95, col = 1)
)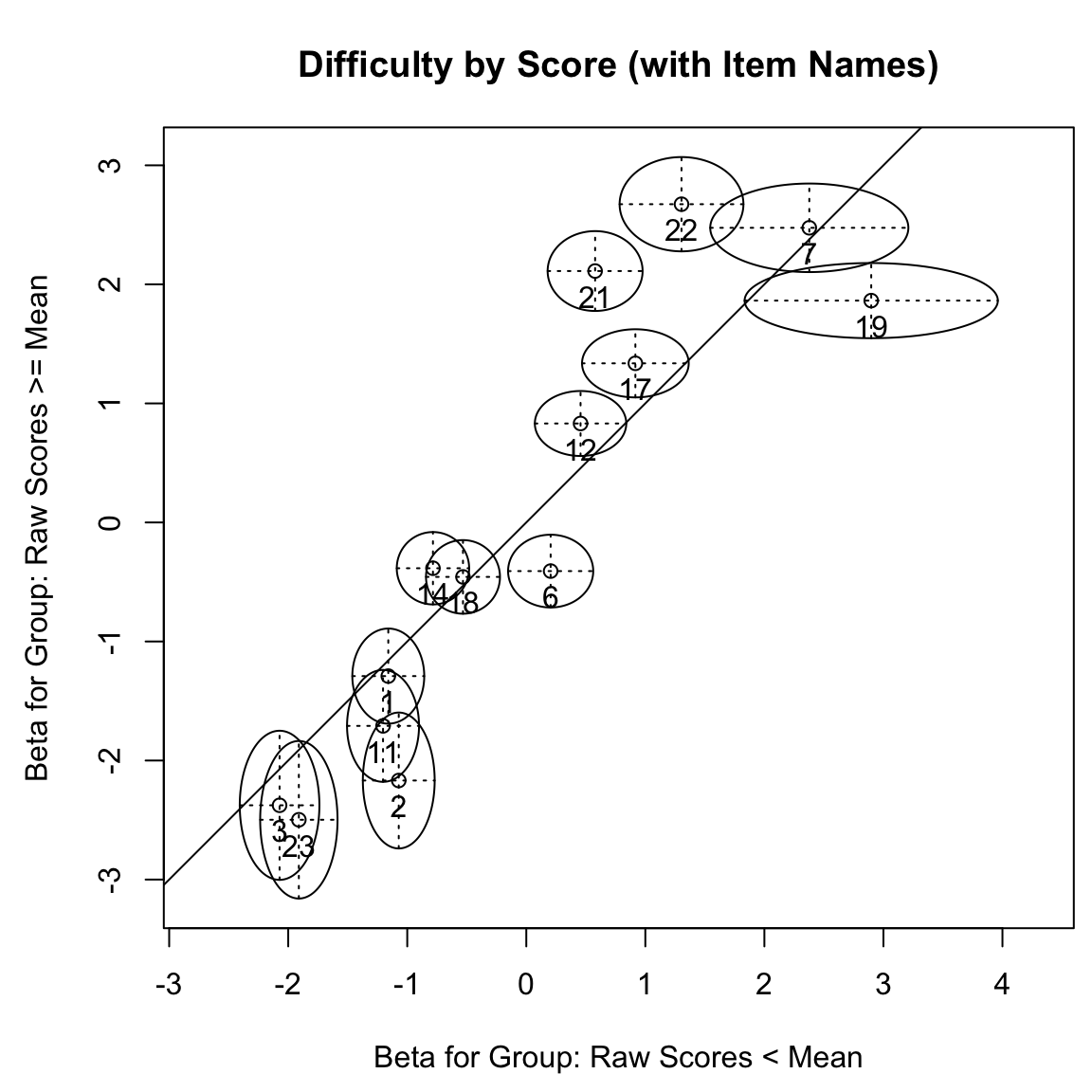
Ora possiamo tracciare le stime delle difficoltà di ciascun gruppo utilizzando la funzione plotGOF() per creare il test grafico. La funzione plotGOF() prende il risultato di LRtest() e traccia le stime dei parametri degli item per i due gruppi. Per facilitare la valutazione visiva, plotGOF() può opzionalmente etichettare gli item e aggiungere ellissi di confidenza.
Per creare il grafico per il test grafico basato sulla divisione media, possiamo procedere in questo modo: ogni piccolo cerchio nella Figura mostra le stime delle difficoltà per un singolo item. La coordinata x di un cerchio indica la sua stima di difficoltà per i partecipanti al test con punteggi sotto la media e la sua coordinata y indica la stima di difficoltà per i partecipanti al test con punteggi sopra la media. La linea y = x è fornita come riferimento, poiché i punti che cadono su questa linea avrebbero la stessa stima in entrambi i gruppi. La distanza tra qualsiasi punto e la linea di riferimento y = x indica quanto le stime differiscono tra i due gruppi. Indica anche la direzione di questa differenza. Gli item sotto la linea sono più difficili per i partecipanti al test con punteggi sotto la media, mentre gli item sopra la linea sono più difficili per i partecipanti al test con punteggi sopra la media.
Gli assi orizzontali e verticali mostrano intervalli di confidenza per le stime per ciascun gruppo di partecipanti al test. La larghezza di ciascun intervallo di confidenza è determinata dall’elemento gamma della lista fornita a conf. L’impostazione predefinita gamma = .95 produce intervalli di confidenza al 95% per ciascun asse dell’ellisse. Quando un’ellisse di confidenza non incrocia la linea di riferimento, l’item rispettivo è diagnosticato come mostrante un significativo DIF.
La figura indica che gli item 2, 6, 21 e 22 differiscono significativamente tra le persone con punteggi sopra e sotto la media, poiché le loro ellissi di confidenza non incrociano la linea di riferimento. Gli item 21 e 22 sono più difficili per le persone con punteggi pari o superiori alla media, mentre gli item 2 e 6 sono più difficili per le persone con punteggi sotto la media. Tali violazioni del modello possono verificarsi quando le ICC osservate differiscono dalle ICC attese sotto il modello di Rasch per i partecipanti al test con abilità basse e alte. Questo può accadere, ad esempio, se è presente il tentativo di indovinare (guessing), o se la pendenza è più ripida o meno ripida di quanto previsto dal modello di Rasch.
Possiamo anche fornire all’argomento splitcr una variabile che divide i partecipanti al test in gruppi. Ad esempio, possiamo testare se i parametri degli item differiscono in base al genere passando un vettore contenente le appartenenze di gruppo come argomento splitcr.
lrt_gender <- LRtest(rm_sum0, splitcr = gender)
lrt_gender
#>
#> Andersen LR-test:
#> LR-value: 32.97
#> Chi-square df: 13
#> p-value: 0.002Come nel test precedente, anche il Test del Rapporto di Verosimiglianza (LRT) per il genere indica una violazione significativa del modello di Rasch al livello α = 0.05.
plotGOF(
lrt_gender,
tlab = "item", pos = 1,
main = "Difficulty by Score (with Item Names)",
conf = list(gamma = 0.95, col = 1)
)
La figura indica che gli item 2, 7 e 21 differiscono tra partecipanti al test femminili e maschili. Gli item 2 e 7 sono più difficili per i partecipanti femminili, mentre l’item 21 è più difficile per i partecipanti maschili.
71.4.4 Test di Wald
Le impostazioni del test del rapporto di verosimiglianza di Andersen (1973) e del test di Wald sono molto simili. Entrambi i test si basano sull’idea che il modello di Rasch sia un modello ragionevole per i dati dei test solo se i parametri degli item stimati non variano sistematicamente tra gruppi di persone. In entrambi i test, consideriamo le stime dei parametri degli item per ciascun gruppo di persone. A differenza del test del rapporto di verosimiglianza, tuttavia, il test di Wald confronta direttamente le stime dei parametri degli item dei gruppi. In sostanza, il test di Wald calcola la differenza tra la stima del primo gruppo della difficoltà dell’item i, β̂(1)i, e quella del secondo gruppo, β̂(2)i. Questa differenza viene divisa per il suo errore standard per tenere conto del fatto che tutte le stime sono soggette a rumore. Questo porta alla statistica di test per l’item i:
\[ T_i = \frac{\hat{\beta}^{(1)}_i - \hat{\beta}^{(2)}_i}{\sqrt{se(\hat{\beta}^{(1)}_i)^2 + se(\hat{\beta}^{(2)}_i)^2}}, \]
dove $ se(^{(1)}_i) $ e $ se(^{(2)}_i) $ indicano rispettivamente gli errori standard di $ ^{(1)}_i $ e $ ^{(2)}_i $.
Per campioni di grandi dimensioni, $ T_i $ approssimativamente segue una distribuzione normale standard sotto l’ipotesi nulla che il vero parametro dell’item sia lo stesso per entrambi i gruppi. Valori estremi di $ T_i $ sono improbabili sotto la distribuzione normale. Quindi, un valore estremo di $ T_i $, con un piccolo valore p, indica che l’item i viola il modello di Rasch.
Eseguiamo il test con R:
Waldtest(rm_sum0, splitcr = "mean")
#>
#> Wald test on item level (z-values):
#>
#> z-statistic p-value
#> beta I1 -0.514 0.607
#> beta I2 -3.328 0.001
#> beta I3 -0.838 0.402
#> beta I6 -2.555 0.011
#> beta I7 0.210 0.834
#> beta I11 -1.773 0.076
#> beta I12 1.562 0.118
#> beta I14 1.821 0.069
#> beta I17 1.550 0.121
#> beta I18 0.333 0.739
#> beta I19 -1.827 0.068
#> beta I21 5.768 0.000
#> beta I22 4.106 0.000
#> beta I23 -1.560 0.119Questi test indicano nuovamente che gli item 2, 6, 21 e 22 differiscono significativamente tra i partecipanti al test con punteggi sopra e sotto la media.
Possiamo anche eseguire il test per la differenza tra maschi e femmine:
Waldtest(rm_sum0, splitcr = gender)
#>
#> Wald test on item level (z-values):
#>
#> z-statistic p-value
#> beta I1 -1.727 0.084
#> beta I2 2.543 0.011
#> beta I3 -1.020 0.308
#> beta I6 0.067 0.946
#> beta I7 3.089 0.002
#> beta I11 -1.978 0.048
#> beta I12 -0.861 0.389
#> beta I14 -0.673 0.501
#> beta I17 0.815 0.415
#> beta I18 -0.493 0.622
#> beta I19 0.583 0.560
#> beta I21 -2.305 0.021
#> beta I22 -0.030 0.976
#> beta I23 -1.019 0.308I risultati qui concordano in gran parte anche con la figura precedente. In linea con il test grafico, il test di Wald indica che gli item 2, 7 e 21 differiscono tra i gruppi.
71.4.5 Ancoraggio
L’ancoraggio è una procedura cruciale quando si confrontano le stime dei parametri degli item tra diversi gruppi, un passo fondamentale in test come il Wald e in metodi grafici. Tale processo necessita di particolare attenzione perché implica la restrizione di alcuni parametri degli item per allineare le scale latenti tra i gruppi. Ad esempio, fissare il parametro del primo item a zero in entrambi i gruppi crea un punto di riferimento comune, ma anche limitazioni.
La scelta degli item di ancoraggio è delicata: fissare un parametro in entrambi i gruppi significa non poter più valutare la differenza per quell’item specifico. La selezione dovrebbe essere guidata da un’attenta analisi dei dati e da considerazioni teoriche. Approcci guidati dai dati sono stati proposti per identificare item invarianti o escludere quelli con DIF, processo noto come purificazione. Tuttavia, occorre cautela: anche metodi ben progettati possono portare a conclusioni errate se gli item di ancoraggio scelti sono inappropriati.
In pratica, spesso si adotta una restrizione in cui la somma dei parametri degli item è zero per tutti i gruppi. Questo approccio, adottato da pacchetti software come eRm e difR in R, si basa sull’assunzione che eventuali DIF si annullino su tutti gli item. Ma se questa assunzione non è valida, o se l’ancoraggio include item con DIF, potremmo incorrere in errori interpretativi.
In sintesi, l’ancoraggio è una strategia potente ma che richiede un’attenta considerazione e un’analisi critica. È fondamentale non solo selezionare gli item di ancoraggio adeguati ma anche interpretare i risultati con una comprensione chiara delle ipotesi e delle potenziali limitazioni del metodo scelto.
resp <- as.matrix(responses)
anchortest(
resp ~ gender,
class = "constant",
select = "MPT"
)
#> Anchor items:
#> respI23, respI3, respI22, respI12
#>
#> Final DIF tests:
#>
#> Simultaneous Tests for General Linear Hypotheses
#>
#> Linear Hypotheses:
#> Estimate Std. Error z value Pr(>|z|)
#> respI1 == 0 0.21972 0.29124 0.75 0.4506
#> respI2 == 0 -0.83344 0.29343 -2.84 0.0045
#> respI3 == 0 0.10283 0.26853 0.38 0.7018
#> respI6 == 0 -0.21887 0.27110 -0.81 0.4195
#> respI7 == 0 -1.79695 0.57084 -3.15 0.0016
#> respI11 == 0 0.29599 0.29835 0.99 0.3212
#> respI12 == 0 -0.00299 0.22722 -0.01 0.9895
#> respI14 == 0 -0.05134 0.27413 -0.19 0.8514
#> respI17 == 0 -0.41504 0.30706 -1.35 0.1765
#> respI18 == 0 -0.09294 0.27284 -0.34 0.7334
#> respI19 == 0 -0.38657 0.36100 -1.07 0.2842
#> respI21 == 0 0.42520 0.32052 1.33 0.1846
#> respI22 == 0 -0.19346 0.30037 -0.64 0.5195
#> (Univariate p values reported)anchortest(
resp ~ gender,
class = "forward",
select = "MTT"
)
#> Anchor items:
#> respI23, respI12, respI18, respI14, respI6, respI1, respI11,
#> respI19, respI17
#>
#> Final DIF tests:
#>
#> Simultaneous Tests for General Linear Hypotheses
#>
#> Linear Hypotheses:
#> Estimate Std. Error z value Pr(>|z|)
#> respI1 == 0 0.2818 0.2362 1.19 0.2328
#> respI2 == 0 -0.7714 0.2660 -2.90 0.0037
#> respI3 == 0 0.1649 0.3229 0.51 0.6097
#> respI6 == 0 -0.1568 0.2157 -0.73 0.4671
#> respI7 == 0 -1.7349 0.5574 -3.11 0.0019
#> respI11 == 0 0.3580 0.2432 1.47 0.1410
#> respI12 == 0 0.0591 0.2262 0.26 0.7940
#> respI14 == 0 0.0107 0.2188 0.05 0.9610
#> respI17 == 0 -0.3530 0.2514 -1.40 0.1603
#> respI18 == 0 -0.0309 0.2175 -0.14 0.8871
#> respI19 == 0 -0.3245 0.3030 -1.07 0.2841
#> respI21 == 0 0.4872 0.2952 1.65 0.0989
#> respI22 == 0 -0.1314 0.3717 -0.35 0.7237
#> (Univariate p values reported)anchortest(
resp ~ gender,
select = "Gini"
)
#> Anchor items:
#> respI23
#>
#> Final DIF tests:
#>
#> Simultaneous Tests for General Linear Hypotheses
#>
#> Linear Hypotheses:
#> Estimate Std. Error z value Pr(>|z|)
#> respI1 == 0 0.12610 0.38737 0.33 0.7448
#> respI2 == 0 -0.92706 0.38904 -2.38 0.0172
#> respI3 == 0 0.00921 0.42718 0.02 0.9828
#> respI6 == 0 -0.31249 0.37656 -0.83 0.4066
#> respI7 == 0 -1.89057 0.63210 -2.99 0.0028
#> respI11 == 0 0.20238 0.39228 0.52 0.6059
#> respI12 == 0 -0.09661 0.38679 -0.25 0.8028
#> respI14 == 0 -0.14496 0.37695 -0.38 0.7006
#> respI17 == 0 -0.50866 0.40738 -1.25 0.2118
#> respI18 == 0 -0.18656 0.37641 -0.50 0.6202
#> respI19 == 0 -0.48019 0.45080 -1.07 0.2868
#> respI21 == 0 0.33158 0.41809 0.79 0.4277
#> respI22 == 0 -0.28708 0.47621 -0.60 0.5466
#> (Univariate p values reported)Gli output di R della funzione anchortest() elencano gli item di ancoraggio selezionati dai rispettivi approcci di selezione dell’ancoraggio, oltre ai risultati del test di Wald basati su questi item di ancoraggio. Tutti e tre gli approcci portano a risultati in cui solo gli item 2 e 7 mostrano DIF per genere, mentre il test grafico e il test di Wald in eRm hanno identificato anche l’item 21 e l’item 11 (al limite) come aventi DIF.
Riesaminando il test grafico nella figura precedente, notiamo che gli item 2 e 7 mostrano DIF nella stessa direzione (sopra la diagonale), mentre gli item 21 e 11 sono orientati nella direzione opposta (sotto la diagonale) e in misura minore.
Considerando questi risultati nel loro insieme, si può concludere che potrebbe essere presente un DIF non bilanciato e che la diagonale usata nella Figura 6.4 non è ideale per valutare gli item. Per illustrare ciò, tracciamo manualmente una linea di riferimento alternativa attraverso la posizione dell’item 23, che è stato selezionato come item di ancoraggio (primario) dai tre approcci presentati in psychotools, utilizzando il comando abline.
plotGOF(
lrt_gender,
tlab = "item", pos = 1,
main = "Difficulty by Gender (with Item Names)",
conf = list(gamma = 0.95, col = 1)
)
abline(-0.3, 1, lty=2)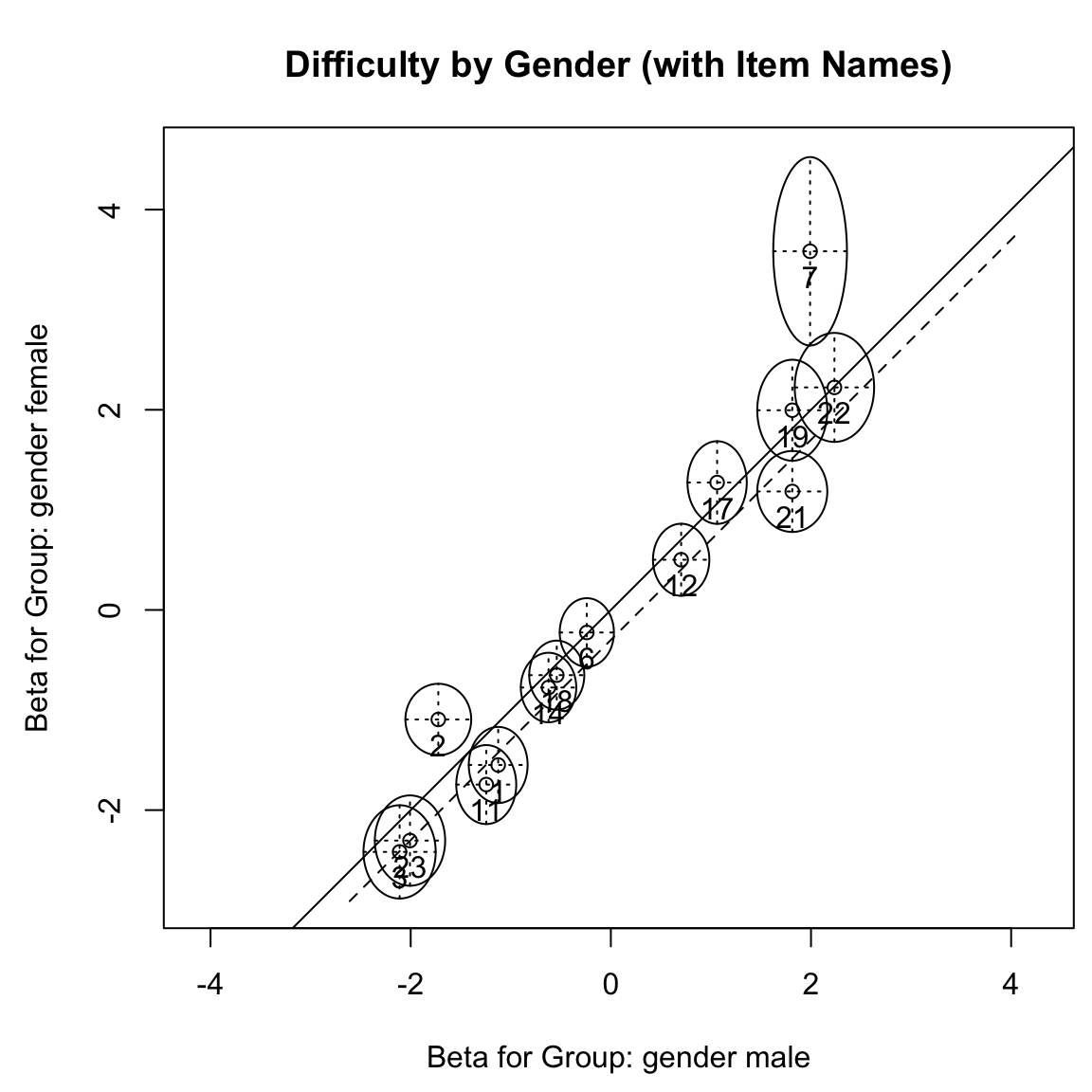
Come si può vedere nella figura risultante, basandoci sulla linea di riferimento alternativa, non troviamo più DIF negli item 11 e 21, ma gli item 2 e 7 mostrano ancora più chiaramente un DIF.
Per questo set di dati, la stessa conclusione viene raggiunta in eRm quando si utilizza la funzione stepwiseIt(), che esegue diversi test di Wald e ad ogni passo esclude l’item singolo con la statistica di test più grande.
stepwiseIt(rm_sum0, criterion = list("Waldtest", gender))
#> Eliminated item - Step 1: I7
#> Eliminated item - Step 2: I2
#>
#> Results for stepwise item elimination:
#> Number of steps: 2
#> Criterion: Waldtest
#>
#> z-statistic p-value
#> Step 1: I7 3.089 0.002
#> Step 2: I2 3.059 0.002Utilizzando questo metodo, dopo l’esclusione degli item 7 e 2, che presentavano il DIF più marcato, non si rilevano più differenze significative nei test degli item rimanenti. Per visualizzare meglio questo processo, immaginiamo la figura precedente: inizialmente, la linea di riferimento corrisponde alla diagonale solida. Tuttavia, dopo aver eliminato l’item 7, questa linea si sposta verso quella tratteggiata nel secondo passaggio e, rimuovendo poi l’item 2, si allinea o si avvicina molto alla linea tratteggiata nel terzo passaggio. Di conseguenza, gli item restanti non mostrano più un DIF significativo.
In sintesi, mentre i test grafici e di Wald basati sulla restrizione della somma zero possono risultare ingannevoli in presenza di un DIF non bilanciato, l’impiego di metodi di ancoraggio avanzati e l’approccio di eliminazione graduale degli item possono offrire una visione più accurata e dettagliata della situazione.
71.4.6 Rimozione di item
Se questa analisi facesse parte della costruzione di un test reale, gli item che mostrano DIF (o altre anomalie nelle analisi successive) dovrebbero essere attentamente esaminati da esperti di contenuto per decidere se modificarli o rimuoverli dal test. Nella discussione seguente, tuttavia, non rimuoveremo gli item perché desideriamo mantenere il set di dati completo. Tuttavia, se si desiderasse rimuovere alcuni item (ovvero colonne) dal set di dati, ciò potrebbe essere fatto con i seguenti comandi.
Dopo aver rimosso degli item, l’intero processo dovrebbe ricominciare da capo, rifacendo il modello di Rasch e indagando sugli item rimanenti.
71.4.7 Test di Martin-Löf
Nella sezione precedente, abbiamo visto che il test del rapporto di verosimiglianza di Andersen (1973) verifica l’ipotesi che i parametri degli item siano invarianti per vari gruppi di persone. Una ipotesi correlata riguarda l’invarianza dei parametri delle persone per diversi gruppi di item.
Qui, la domanda fondamentale è se diversi gruppi di item misurino tratti latenti differenti. Ciò rappresenterebbe una violazione del modello di Rasch, il quale implica un singolo tratto latente alla base di tutti gli item. Se questo tipo di violazione del modello viene rilevato, un modello IRT multidimensionale potrebbe essere più appropriato.
Un metodo comune per valutare la dimensionalità in generale è l’analisi fattoriale esplorativa. Qui invece descriveremo il test di Martin-Löf che affronta l’ipotesi alternativa secondo cui gruppi di item misurano tratti latenti differenti ed è disponibile nel pacchetto eRm. Come il test del rapporto di verosimiglianza di Andersen, questo test si basa sul confronto di due verosimiglianze condizionate. La prima verosimiglianza condizionata Lu(r,β) è quella del modello di Rasch. La seconda verosimiglianza condizionata Lu(r1, r2, β) è nuovamente quella di un modello più generale che ora permette diversi parametri di persona per specifici gruppi di item. I gruppi di item devono essere definiti prima dell’analisi, il che può essere fatto in base alle loro difficoltà (cioè, testiamo item facili contro difficili) o in base a diverse dimensioni latenti che si sospetta siano misurate dai gruppi di item (cioè, il gruppo di item 1 è sospettato di misurare una dimensione latente diversa rispetto al gruppo di item 2). Se la seconda verosimiglianza è maggiore, ciò indica una violazione del modello di Rasch (analogamente al test del rapporto di verosimiglianza di Andersen).
Il test di Martin-Löf è spesso descritto come un test per la unidimensionalità. Certi tipi di multidimensionalità possono anche manifestarsi come DIF. Per questa ragione, i test che mirano a rilevare il DIF, possono anche essere sensibili a certe violazioni della unidimensionalità.
mloef_median <- MLoef(rm_sum0, splitcr = "median")
mloef_median
#>
#> Martin-Loef-Test (split criterion: median)
#> LR-value: 67.083
#> Chi-square df: 48
#> p-value: 0.036Otteniamo un valore p inferiore a 0.05. Ciò indica che le stime dei parametri delle persone ottenute dagli item facili e difficili differiscono in modo significativo, ovvero, una violazione del modello di Rasch.
71.5 Item e Person Fit
71.5.1 Tests e Statistiche di Bontà di Adattamento
In questa sezione esaminiamo una varietà di metodi per valutare l’adattamento dei dati di risposta agli item e al modello di Rasch. Alcuni di questi metodi sono test statistici formali, mentre altri sono statistiche descrittive per le quali sono stati suggeriti nella letteratura dei limiti critici empirici. Vedremo anche che esistono approcci per valutare l’adattamento a livello dell’intero test psicologico, così come approcci focalizzati sulla valutazione dell’adattamento di singoli item o individui.
71.5.2 Test di Bontà di Adattamento χ2 e G2
Nella valutazione del modello di Rasch, esaminiamo due classi principali di test di bontà di adattamento: il test χ2 e il test G2, entrambi noti nell’analisi delle tabelle di contingenza. A differenza dei test del rapporto di verosimiglianza o dei test di Martin-Löf, il test χ2 non confronta l’adattamento relativo di due modelli. Piuttosto, esso valuta quanto accuratamente i modelli di risposta previsti dal modello di Rasch corrispondano ai modelli di risposta osservati. Questo avviene attraverso il confronto tra il numero di partecipanti che mostrano ciascun modello di risposta osservato e il numero previsto dal modello di Rasch.
Il principio dei test di bontà di adattamento χ2 per il modello di Rasch è basato sull’analisi di tutti i possibili modelli di risposta (combinazioni di 0 e 1 per risposte errate e corrette). Definiamo Ou come il numero osservato di partecipanti con il modello di risposta u e Eu come il numero previsto sotto il modello di Rasch. La statistica del test χ2 è data da:
\[ T = \sum_{u} \frac{(O_u - E_u)^2}{E_u} \]
In questa formula, le differenze tra osservazioni e previsioni sono elevate al quadrato e poi ponderate inversamente rispetto alla frequenza attesa. In campioni di grandi dimensioni, T segue approssimativamente una distribuzione χ2, se il modello di Rasch è appropriato. Valori alti di T indicano una cattiva adattazione del modello.
Tuttavia, il test χ2 richiede che ogni modello di risposta abbia una frequenza attesa sufficientemente alta, una condizione spesso non soddisfatta in test con molti item. In questi casi, il test χ2 non segue una distribuzione χ2 sotto l’ipotesi nulla, rendendolo poco pratico. Una soluzione potrebbe essere quella di raggruppare i modelli di risposta per aumentare le frequenze attese.
Parallelamente, la statistica del rapporto di verosimiglianza G2, anch’essa derivante dall’analisi dei dati categoriali, è calcolata come:
\[ G^2 = 2 \sum_{u} O_u \log \left( \frac{O_u}{E_u} \right) \]
G2 confronta le frequenze osservate con quelle attese, anziché le verosimiglianze di due modelli. Se le frequenze attese sono vicine a quelle osservate, il rapporto \(\frac{O_u}{E_u}\) si avvicina a 1, rendendo il logaritmo naturale \(\log\left(\frac{O_u}{E_u}\right)\) vicino a 0 e la statistica G2 tende a 0, indicando un buon adattamento. Anche G2 segue una distribuzione χ2 se il modello di Rasch è appropriato. Tuttavia, proprio come per il test χ2, G2 è praticabile solo con grandi frequenze attese, limitandone l’uso effettivo. Nonostante ciò, G2 è importante da comprendere poiché molte altre statistiche di test si basano su di esso.
71.5.3 Statistica M2
La statistica M2, sviluppata da Maydeu-Olivares e Joe (2006), affronta il problema dei modelli di risposta rari che possono complicare i test χ2. Invece di confrontare le frequenze di interi modelli di risposta, la statistica M2 utilizza le informazioni provenienti dagli item individuali e dalle coppie di item. Specificatamente, confronta: 1. Le frequenze attese e osservate delle risposte corrette agli item individuali. 2. Le frequenze attese e osservate delle risposte corrette a entrambi gli item in una coppia di item.
Per esempio, con due item, confronterebbe le frequenze osservate e attese per una risposta corretta al primo item, al secondo item e ad entrambi gli item insieme. Questo approccio è simile all’analisi delle tabelle di frequenza per le coppie di item. La statistica M2, come il test di bontà di adattamento χ2, implica un cattivo adattamento tra i dati e il modello di Rasch se produce un valore elevato o, equivalentemente, un valore p piccolo. Senza violazione del modello, la statistica M2 segue approssimativamente una distribuzione χ2 con gradi di libertà calcolati come $ k - d $, dove $ k $ è il numero di frequenze confrontate e $ d $ è il numero di parametri liberi del modello.
71.5.4 Errore Quadratico Medio di Approssimazione (RMSEA)
Il RMSEA deriva dalla statistica M2. Utilizza i gradi di libertà (nuovamente $ k - d $) e la dimensione del campione $ P $ per calcolare il valore RMSEA. La formula per il RMSEA è:
\[ \text{RMSEA} = \sqrt{\frac{M2 - df}{P \cdot df}} \]
Valori di RMSEA vicini a 0 generalmente indicano un buon adattamento del modello ai dati. Sebbene non esistano linee guida universalmente accettate per interpretare il RMSEA, un valore intorno a 0,05 è spesso considerato indicativo di un buon adattamento del modello.
71.5.5 Residuo Quadratico Medio Standardizzato (SRMSR)
SRMSR è un’altra statistica di adattamento complessivo che confronta le correlazioni o le covarianze osservate tra tutte le coppie di item con quelle previste sotto il modello di Rasch (o un altro modello della teoria della risposta agli item). Valori vicini a 0 suggeriscono un buon adattamento del modello. Maydeu-Olivares (2013) raccomanda l’uso di un valore di soglia di 0.05 per SRMSR, simile al RMSEA.
Nel complesso, queste statistiche (M2, RMSEA e SRMSR) sono utili per valutare l’adattamento di un modello, come il modello di Rasch, a un dato insieme di dati di risposta agli item. Forniscono diverse prospettive attraverso le quali la congruenza tra i dati e il modello teorico può essere valutata, ognuna con il suo focus unico e metodo di calcolo.
fit_rasch <- mirt(responses, 1, itemtype = "Rasch", verbose = FALSE)
fit_rasch
#>
#> Call:
#> mirt(data = responses, model = 1, itemtype = "Rasch", verbose = FALSE)
#>
#> Full-information item factor analysis with 1 factor(s).
#> Converged within 0.0001 tolerance after 16 EM iterations.
#> mirt version: 1.44.0
#> M-step optimizer: nlminb
#> EM acceleration: Ramsay
#> Number of rectangular quadrature: 61
#> Latent density type: Gaussian
#>
#> Log-likelihood = -2816
#> Estimated parameters: 15
#> AIC = 5663
#> BIC = 5723; SABIC = 5675
#> G2 (16368) = 1319, p = 1
#> RMSEA = 0, CFI = NaN, TLI = NaNM2(fit_rasch)
#> M2 df p RMSEA RMSEA_5 RMSEA_95 SRMSR TLI CFI
#> stats 277.6 90 0 0.07227 0.06262 0.08192 0.09414 0.7495 0.7522La statistica M2 è alta e significativa, indicando che ci sono differenze preoccupanti tra il modello e i dati. Questo è ulteriormente supportato da un RMSEA troppo alto e da un CFA e TLI lontani da 1.
Ricordiamo il significato degli indici RMSEA, CFA e TLI.
RMSEA (Root Mean Square Error of Approximation): - Il RMSEA è una misura di adattamento che valuta quanto bene un modello si adatta ai dati a livello di popolazione. - Un valore basso di RMSEA indica un buon adattamento, suggerendo che il modello approssima bene la realtà. - Generalmente, un RMSEA inferiore a 0.05 o 0.06 è considerato indicativo di un ottimo adattamento del modello.
CFA (Comparative Fit Index): - Il CFA è un indice relativo di bontà di adattamento che confronta il modello specificato con un modello nullo o di base. - Valori più vicini a 1 indicano un adattamento migliore. Un CFA superiore a 0.90 o 0.95 è spesso considerato indicativo di un buon adattamento.
TLI (Tucker-Lewis Index): - Simile al CFA, il TLI è un altro indice relativo di adattamento che tiene conto della complessità del modello. - Anche per il TLI, valori più vicini a 1 indicano un adattamento migliore. Valori superiori a 0.90 o 0.95 sono generalmente considerati buoni.
71.6 Valutare l’Adattamento degli Item
Tuttavia, nell’IRT, ci interessiamo maggiormente agli indici di adattamento degli item e delle persone. L’IRT ci consente di valutare quanto bene ogni item si adatti al modello e se i pattern di risposta individuali sono allineati con il modello.
Iniziamo con l’addattamento agli item. Sono stati proposti diversi indici per valutare l’adattamento degli item e possiamo utilizzare la funzione itemfit() per ottenere una varietà di questi indici. Di default, riceviamo l’S_X2 di Orlando e Thissen (2000) con i corrispondenti gradi di libertà (dfs), RMSEA e valori p. Questo test dovrebbe risultare non significativo per indicare un buon adattamento dell’item. Come vediamo qui sotto, diversi item mostra un cattivo adattamento.
itemfit(fit_rasch)
#> item S_X2 df.S_X2 RMSEA.S_X2 p.S_X2
#> 1 I1 4.150 7 0.000 0.762
#> 2 I2 19.334 7 0.066 0.007
#> 3 I3 5.528 7 0.000 0.596
#> 4 I6 14.086 8 0.044 0.080
#> 5 I7 8.977 7 0.027 0.254
#> 6 I11 23.364 7 0.077 0.001
#> 7 I12 17.673 7 0.062 0.014
#> 8 I14 9.790 7 0.032 0.201
#> 9 I17 35.134 7 0.100 0.000
#> 10 I18 3.697 7 0.000 0.814
#> 11 I19 20.932 7 0.071 0.004
#> 12 I21 86.542 7 0.169 0.000
#> 13 I22 73.458 7 0.154 0.000
#> 14 I23 7.612 7 0.015 0.36871.6.1 Statistiche di Infit e Outfit
Nella sezione precedente abbiamo discusso i test χ2 e M2, basati sul confronto tra le frequenze osservate e quelle attese secondo il modello di Rasch. Le statistiche di adattamento presentate di seguito si basano su un approccio simile, utilizzando i residui di Rasch. Questi sono le differenze tra le risposte osservate (vale a dire, le risposte 0 o 1 per gli item dicotomici) e i loro valori attesi (cioè, le probabilità predette di una risposta corretta secondo il modello di Rasch). Tipicamente, questi valori attesi vengono calcolati in base alle stime dei parametri degli item e delle persone.
Generalmente, quando c’è un buon adattamento tra i dati e il modello, si può prevedere che i residui siano piccoli. Pertanto, è naturale che i residui di Rasch possano essere utilizzati per valutare l’adattamento del modello di Rasch. Vedremo che nell’analisi di Rasch non solo i casi in cui i residui sono più grandi del previsto possono essere motivo di preoccupazione, ma anche quelli in cui i residui sono più piccoli del previsto.
Un approccio comune per verificare l’adattamento di singoli item usando i residui di Rasch consiste nel calcolare le statistiche di infit e outfit. Descriveremo i passaggi per calcolare queste statistiche prima di affrontarne l’interpretazione. Ci concentreremo sul caso in cui queste statistiche vengono calcolate per singoli item.
71.6.1.1 Outfit
La funzione principale della statistica di outfit è quella di quantificare in che misura le risposte dei partecipanti si allontanano dalle previsioni del modello. Questo indice si calcola attraverso diversi passaggi, che mirano a stabilire la misura in cui le risposte individuali si discostano dalle aspettative teoriche.
1. Definizione dei Residui di Rasch: Inizialmente, per ogni partecipante e per ciascun item del test, si calcola il residuo di Rasch. Un residuo è essenzialmente la differenza tra la risposta osservata di un individuo a un determinato item e la risposta prevista da quel partecipante per lo stesso item. La risposta prevista è calcolata sulla base della probabilità, fornita dal modello di Rasch, che il partecipante risponda correttamente all’item. Ad esempio, se il modello prevede che un partecipante abbia il 40% di probabilità di rispondere correttamente a un item e il partecipante risponde effettivamente correttamente, il residuo corrispondente sarà $ 1 - 0.40 = 0.60 $.
2. Standardizzazione dei Residui di Rasch: Successivamente, questi residui vengono standardizzati. La standardizzazione implica l’adeguamento dei residui in modo che abbiano una media di zero e una varianza di uno. Ciò permette di confrontare i residui in maniera uniforme, indipendentemente dalle caratteristiche specifiche degli item o dei partecipanti.
3. Calcolo dello Z-Score: Per ciascun residuo, si calcola lo z-score standardizzato, $ Z_{si} $, utilizzando la formula:
\[ Z_{si} = \frac{X_{si} - E(X_{si})}{\sqrt{Var(X_{si})}}, \]
dove $ Z_{si} $ rappresenta lo z-score del residuo per il partecipante $ s $ all’item $ i $, $ X_{si} $ è la risposta osservata, $ E(X_{si}) $ è la risposta attesa (basata sulla probabilità di una risposta corretta secondo il modello di Rasch), e $ Var(X_{si}) $ è la varianza della risposta attesa.
4. Calcolo della Statistica di Outfit: Per calcolare la statistica di outfit mean square (MSQ) per un specifico item, si seguono questi passaggi: - Si elevano al quadrato gli z-score standardizzati di ogni partecipante per l’item in questione. - Si sommano tutti questi valori quadrati. - Si divide la somma ottenuta per il numero totale dei partecipanti.
La formula risultante per la statistica di outfit MSQ per l’item $ i $ è la seguente:
\[ \text{Outfit MSQ}_i = \frac{\sum_{p=1}^{P} Z_{pi}^2}{P}. \]
Questa procedura fornisce una misura dell’adattamento delle risposte degli individui all’item specifico, rispetto alle previsioni del modello di Rasch. Un valore di MSQ significativamente alto o basso può indicare potenziali discrepanze tra le risposte osservate e quelle previste, suggerendo la necessità di ulteriori analisi o revisioni del modello o degli item del test.
Secondo Wright e Masters (1990), questa statistica ha un valore atteso di 1 sotto il modello di Rasch. Valori superiori a 1 indicano residui di Rasch più grandi del previsto secondo il modello di Rasch, e quindi una possibile violazione del modello. Tali item vengono anche detti mostrare un underfit. Valori inferiori a 1 indicano che i residui sono inferiori al previsto. Ciò è considerato indicare un overfit delle risposte al modello di Rasch. In questo contesto, overfit significa che la deviazione tra i valori attesi e i dati empirici è minore del previsto.
Possiamo inoltre ottenere una statistica di mean square pesata e standardizzata per ciascun item, tipicamente denotata da ti. Siano \(\sqrt[3]{\text{MSQ}_i}\) e sd(MSQ_i) il cubo radice e la deviazione standard attesa di Outfit MSQ_i, rispettivamente. Allora la statistica standardizzata ti è
\[ \text{Outfit ti} = \left( \sqrt[3]{\text{MSQ}_i} - 1 \right) \left( \frac{3}{\text{sd(MSQ}_i)} \right) + \left( \frac{\text{sd(MSQ}_i)}{3} \right). \]
Questa statistica standardizzata ti è spesso presentata nei risultati del software in aggiunta alla statistica MSQ.
Item che mostrano underfit e overfit possono anche essere identificati approssimativamente usando le loro ICC empiriche, come abbiamo già visto in precedenza. Gli item che mostrano underfit hanno ICC empiriche più piatte di quelle previste sotto il modello di Rasch. Gli item che mostrano overfit hanno ICC empiriche più ripide del previsto.
71.6.1.2 Infit
L’indice di infit è un altro indice critico nel modello di Rasch. A differenza dell’outfit, che è più influenzato da risposte casuali o outlier, l’infit è più sensibile alle risposte che sono incoerenti con il pattern generale del modello. L’infit è calcolato come una media ponderata dei residui standardizzati, dove i pesi sono inversamente proporzionali alla varianza degli item. Questo rende l’infit particolarmente utile per identificare problemi di adattamento del modello legati alla consistenza interna delle risposte.
La statistica di infit MSQ, come quella di outfit, serve a valutare l’adattamento delle risposte individuali rispetto alle aspettative teoriche del modello. Tuttavia, la statistica di infit differisce dall’outfit per il modo in cui tratta i residui.
1. Ponderazione dei Residui di Rasch: Nella statistica di infit, i residui di Rasch delle risposte individuali vengono ponderati in base alla loro varianza attesa sotto il modello di Rasch. Ciò significa che i residui con varianze minori (che tendono a verificarsi quando c’è una grande distanza tra le abilità dei rispondenti e la difficoltà degli item) hanno un impatto relativamente minore sulla statistica di infit rispetto a quelli con varianze maggiori.
2. Riduzione dell’Impatto degli Outlier: Questo approccio di ponderazione rende la statistica di infit meno sensibile agli outlier rispetto all’outfit. In altre parole, mentre la statistica di outfit è influenzata in maniera più uniforme da tutte le deviazioni dalle aspettative del modello, l’infit dà maggiore peso alle deviazioni che sono meno estreme o più prevedibili data la struttura del modello.
3. Formula per la Statistica di Infit MSQ: La formula per calcolare l’Infit MSQ per un dato item $ i $ è la seguente:
\[ \text{Infit MSQ}_i = \frac{\sum_{p=1}^{P} W_{pi} Z_{pi}^2}{\sum_{p=1}^{P} W_{pi}}, \]
dove: - $ Z_{pi} $ rappresenta il residuo di Rasch standardizzato per il rispondente $ p $ all’item $ i $. - $ W_{pi} $ è la varianza attesa del residuo $ Z_{pi} $ sotto il modello di Rasch. - $ P $ è il numero totale dei rispondenti.
4. Standardizzazione della Statistica Infit: Come per l’outfit, è anche possibile calcolare una versione standardizzata dell’Infit MSQ per ogni item. Questa versione standardizzata, nota come statistica Infit t, consente di confrontare più facilmente l’adattamento degli item in diverse situazioni o in diversi test, normalizzando i valori su una scala comune.
In sintesi, la statistica di infit MSQ offre un modo ponderato per valutare l’adattamento delle risposte ai singoli item in un test basato sul modello di Rasch, tenendo conto della varianza attesa delle risposte. Questo la rende particolarmente utile per identificare i casi in cui le risposte si discostano dalle previsioni del modello in modi meno estremi o più in linea con la struttura del modello stesso.
71.6.1.3 Soglie
Per entrambi i valori MSQ e t delle statistiche di infit e outfit, sono stati proposti vari valori di soglia. Bond e Fox (2007) e Engelhard (2013) menzionano valori di soglia di -2 e 2 per le statistiche t, mentre Paek e Cole (2020) suggeriscono -3 e 3. Analogamente, Bond e Fox (2007) danno 0.75 e 1.3 come valori di soglia per le statistiche MSQ, mentre DeMars (2010) menziona 0.6 e 1.5 come possibili alternative. Desjardins e Bulut (2018), d’altra parte, si oppongono all’uso di valori di soglia specifici per queste statistiche.
Possiamo calcolare le statistiche infit e oputfit degli item usando il pacchetto eRm:
rm_sum0 <- RM(responses)
eRm::itemfit(person.parameter(rm_sum0))
#>
#> Itemfit Statistics:
#> Chisq df p-value Outfit MSQ Infit MSQ Outfit t Infit t Discrim
#> I1 325.4 397 0.996 0.818 0.904 -1.750 -1.666 0.418
#> I2 273.8 397 1.000 0.688 0.809 -2.928 -3.271 0.520
#> I3 289.2 397 1.000 0.727 0.869 -1.574 -1.505 0.371
#> I6 333.6 397 0.991 0.838 0.860 -2.317 -3.257 0.505
#> I7 272.9 397 1.000 0.686 0.838 -1.328 -1.423 0.279
#> I11 332.5 397 0.992 0.836 0.816 -1.432 -3.143 0.473
#> I12 458.7 397 0.018 1.152 0.972 1.538 -0.538 0.321
#> I14 395.8 397 0.508 0.994 1.023 -0.043 0.492 0.320
#> I17 524.1 397 0.000 1.317 0.936 2.290 -1.031 0.280
#> I18 432.9 397 0.104 1.088 1.019 1.121 0.424 0.314
#> I19 226.7 397 1.000 0.569 0.750 -2.579 -2.999 0.453
#> I21 906.0 397 0.000 2.276 1.246 5.846 2.986 -0.108
#> I22 728.0 397 0.000 1.829 0.985 2.918 -0.105 0.059
#> I23 275.9 397 1.000 0.693 0.852 -1.918 -1.812 0.412In alternativa, è possibile usare la funzione mirt del pacchetto mirt:
mirt_rm <- mirt(responses, 1, "Rasch")
#>
Iteration: 1, Log-Lik: -2816.924, Max-Change: 0.03346
Iteration: 2, Log-Lik: -2816.650, Max-Change: 0.02041
Iteration: 3, Log-Lik: -2816.562, Max-Change: 0.01357
Iteration: 4, Log-Lik: -2816.520, Max-Change: 0.01027
Iteration: 5, Log-Lik: -2816.501, Max-Change: 0.00584
Iteration: 6, Log-Lik: -2816.493, Max-Change: 0.00395
Iteration: 7, Log-Lik: -2816.490, Max-Change: 0.00307
Iteration: 8, Log-Lik: -2816.488, Max-Change: 0.00174
Iteration: 9, Log-Lik: -2816.487, Max-Change: 0.00118
Iteration: 10, Log-Lik: -2816.487, Max-Change: 0.00094
Iteration: 11, Log-Lik: -2816.487, Max-Change: 0.00054
Iteration: 12, Log-Lik: -2816.487, Max-Change: 0.00036
Iteration: 13, Log-Lik: -2816.487, Max-Change: 0.00028
Iteration: 14, Log-Lik: -2816.487, Max-Change: 0.00016
Iteration: 15, Log-Lik: -2816.487, Max-Change: 0.00011
Iteration: 16, Log-Lik: -2816.487, Max-Change: 0.00008
mirt::itemfit(mirt_rm, fit_stats = "infit", method = "ML")
#> item outfit z.outfit infit z.infit
#> 1 I1 0.814 -1.683 0.904 -1.665
#> 2 I2 0.685 -2.793 0.809 -3.271
#> 3 I3 0.724 -1.510 0.870 -1.493
#> 4 I6 0.834 -2.272 0.860 -3.258
#> 5 I7 0.682 -1.357 0.831 -1.504
#> 6 I11 0.832 -1.381 0.816 -3.143
#> 7 I12 1.148 1.484 0.971 -0.554
#> 8 I14 0.990 -0.086 1.023 0.494
#> 9 I17 1.315 2.276 0.935 -1.040
#> 10 I18 1.083 1.011 1.019 0.426
#> 11 I19 0.569 -2.585 0.748 -3.014
#> 12 I21 2.279 5.852 1.244 2.960
#> 13 I22 1.823 2.911 0.978 -0.165
#> 14 I23 0.690 -1.831 0.853 -1.804La tabella risultante inizia con le statistiche del test di adattamento χ2 approssimativo, i suoi gradi di libertà e i valori di p risultanti. Se il modello di Rasch è valido, la statistica di test risultante può essere approssimativamente descritta da una distribuzione χ2, il che porta ai valori di p presentati.
Le colonne seguenti presentano le statistiche MSQ e t di infit e outfit. Per le statistiche MSQ di infit e outfit, valori vicini a 1 indicano un buon adattamento del modello, mentre per le statistiche t di infit e outfit, valori vicini a 0 indicano un buon adattamento. Valori più alti indicano che le risposte sono più casuali di quanto previsto dal modello di Rasch, segnalando un sottoadattamento (underfit); valori più bassi indicano che le risposte sono meno casuali del previsto, segnalando un sovradattamento (overfit).
Seguendo una delle linee guida proposte, esamineremo ulteriormente quegli item i cui valori t di infit o outfit sono inferiori a -2 o superiori a 2 (ma esistono linee guida alternative). Troviamo che per gli item 2, 6, 11 e 19, almeno un valore t è inferiore a -2, indicando un sovradattamento. Per l’item 19 ciò è supportato dal fatto che la ICC empirica ha una pendenza più ripida rispetto alla ICC attesa.
Per gli item 17, 21 e 22, invece, almeno un valore t per le statistiche di infit e outfit è superiore a 2, indicando un sottoadattamento. Questo è nuovamente in linea con l’esame delle ICC, dove abbiamo riscontrato che la ICC empirica per l’item 21 ha una pendenza inferiore rispetto alla ICC attesa.
itemfitPlot(mirt_rm)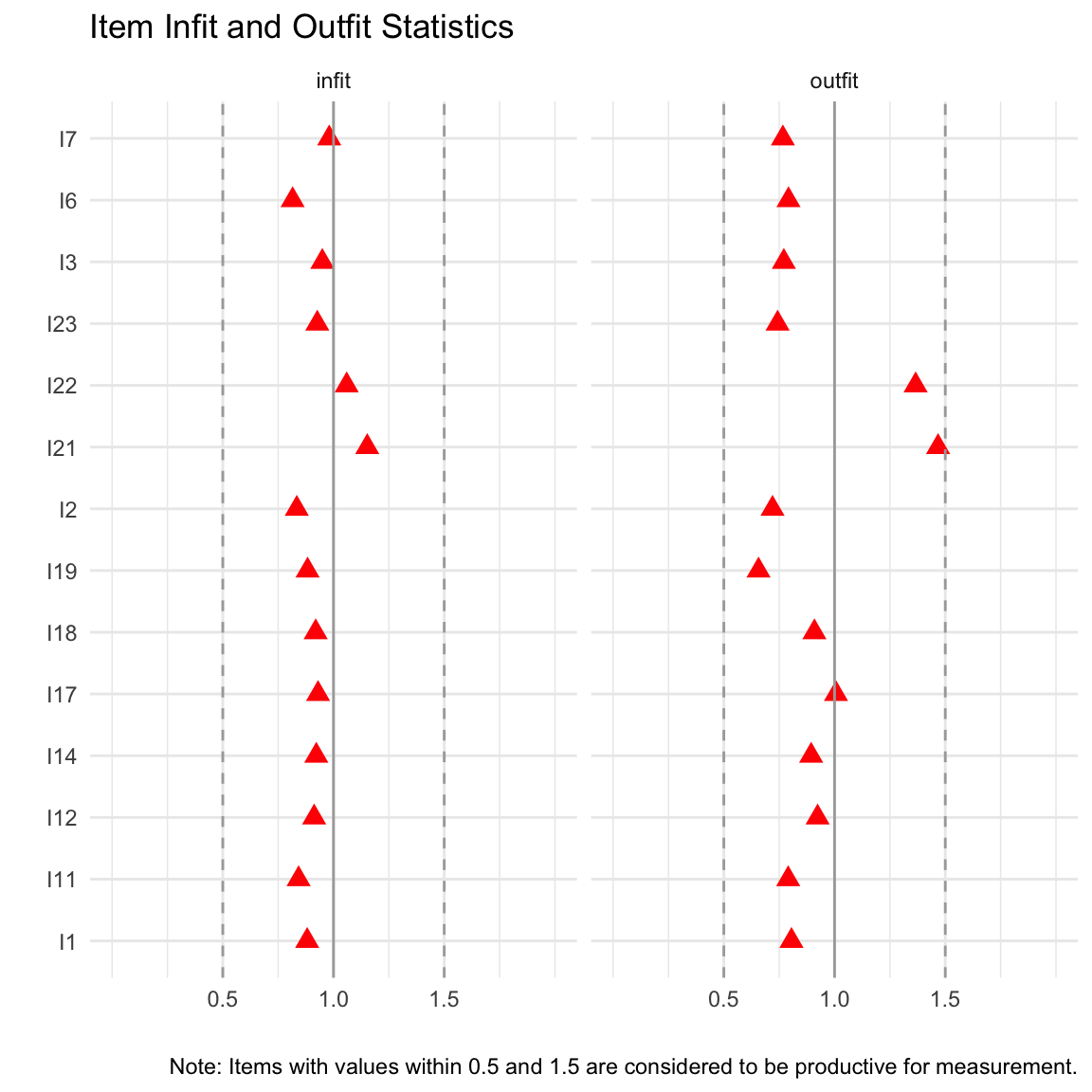
71.6.2 Valutare l’Adattamento delle Persone
Possiamo generare le stesse misure di adattamento per ogni persona per valutare quanto bene i pattern di risposta di ciascuno si allineano con il modello. Ragioniamo in questo modo: se una persona con un alto valore di \(\theta\) (cioè alta abilità latente) non risponde correttamente a un item facile, questa persona non si adatta bene al modello. Al contrario, se una persona con bassa abilità risponde correttamente a una domanda molto difficile, anche questo non è conforme al modello. Nella pratica, è probabile che ci saranno alcune persone che non si adattano bene al modello. Tuttavia, finché il numero di rispondenti non conformi è basso, la situazione è accettabile. Di solito, ci concentriamo nuovamente sulle statistiche di infit e outfit. Se meno del 5% dei rispondenti presenta valori di infit e outfit superiori o inferiori a 1.96 e -1.96, possiamo considerare il modello adeguato.
Stimiamo gli indici infit e outfit delle persone usando eRm:
eRm::personfit(person.parameter(rm_sum0))
#>
#> Personfit Statistics:
#> Chisq df p-value Outfit MSQ Infit MSQ Outfit t Infit t
#> 1 13.191 13 0.433 0.942 1.080 0.07 0.35
#> 2 7.004 13 0.902 0.500 0.744 -0.44 -0.85
#> 3 7.564 13 0.871 0.540 0.799 -0.37 -0.62
#> 4 13.651 13 0.399 0.975 1.112 0.14 0.44
#> 5 4.024 13 0.991 0.287 0.354 -1.81 -2.20
#> 6 22.049 13 0.055 1.575 1.304 0.96 1.01
#> 7 22.823 13 0.044 1.630 1.623 1.02 1.83
#> 8 12.937 13 0.453 0.924 0.746 0.00 -0.66
#> 9 71.924 13 0.000 5.137 1.376 2.32 1.11
#> 10 22.507 13 0.048 1.608 1.065 1.12 0.30
#> 11 8.244 13 0.827 0.589 0.786 -0.83 -0.52
#> 12 17.925 13 0.160 1.280 0.916 0.67 -0.10
#> 13 5.629 13 0.959 0.402 0.667 -0.33 -1.01
#> 14 18.081 13 0.154 1.291 0.950 0.62 -0.07
#> 15 9.427 13 0.740 0.673 0.890 -0.50 -0.24
#> 16 49.152 13 0.000 3.511 1.562 1.53 1.20
#> 17 16.140 13 0.242 1.153 1.094 0.46 0.37
#> 18 7.400 13 0.880 0.529 0.785 -0.39 -0.68
#> 19 4.698 13 0.981 0.336 0.424 -1.70 -1.96
#> 20 4.698 13 0.981 0.336 0.424 -1.70 -1.96
#> 21 45.736 13 0.000 3.267 1.221 1.99 0.79
#> 22 5.441 13 0.964 0.389 0.501 -1.49 -1.60
#> 23 6.693 13 0.917 0.478 0.812 -0.21 -0.49
#> 24 9.043 13 0.770 0.646 0.957 -0.19 -0.05
#> 25 11.936 13 0.533 0.853 1.032 -0.01 0.21
#> 26 8.349 13 0.820 0.596 0.851 -0.49 -0.42
#> 27 28.139 13 0.009 2.010 1.853 1.40 2.35
#> 28 7.921 13 0.849 0.566 0.731 -0.84 -0.66
#> 29 65.841 13 0.000 4.703 1.677 1.83 1.38
#> 30 8.297 13 0.824 0.593 0.752 -0.70 -0.71
#> 31 6.582 13 0.922 0.470 0.660 -0.78 -1.18
#> 32 11.044 13 0.607 0.789 1.055 -0.12 0.28
#> 33 10.084 13 0.687 0.720 0.908 -0.39 -0.18
#> 34 13.555 13 0.406 0.968 1.375 0.25 1.23
#> 35 23.622 13 0.035 1.687 1.170 1.23 0.60
#> 36 10.893 13 0.620 0.778 0.863 -0.33 -0.28
#> 37 6.064 13 0.944 0.433 0.585 -1.15 -1.38
#> 38 28.190 13 0.009 2.014 1.700 1.77 1.73
#> 39 13.747 13 0.392 0.982 1.271 0.36 0.85
#> 40 34.164 13 0.001 2.440 1.211 1.50 0.76
#> 41 71.924 13 0.000 5.137 1.376 2.32 1.11
#> 42 10.846 13 0.624 0.775 0.840 -0.31 -0.32
#> 43 4.024 13 0.991 0.287 0.354 -1.81 -2.20
#> 44 6.981 13 0.903 0.499 0.661 -1.04 -0.90
#> 45 68.333 13 0.000 4.881 1.024 2.24 0.18
#> 46 15.795 13 0.260 1.128 1.141 0.41 0.55
#> 47 21.711 13 0.060 1.551 1.756 0.86 1.83
#> 48 13.778 13 0.390 0.984 1.094 0.25 0.37
#> 49 15.991 13 0.250 1.142 1.334 0.60 0.81
#> 50 10.989 13 0.612 0.785 1.008 -0.24 0.13
#> 51 12.656 13 0.475 0.904 1.053 -0.04 0.27
#> 52 4.166 13 0.989 0.298 0.804 0.40 0.00
#> 53 7.533 13 0.873 0.538 0.972 -0.17 0.04
#> 54 5.025 13 0.975 0.359 0.491 -1.08 -1.99
#> 55 11.323 13 0.584 0.809 1.061 -0.08 0.30
#> 56 42.848 13 0.000 3.061 1.148 1.39 0.46
#> 57 30.248 13 0.004 2.161 1.909 1.95 2.13
#> 58 17.432 13 0.180 1.245 1.137 0.57 0.47
#> 59 5.671 13 0.957 0.405 0.521 -1.43 -1.51
#> 60 4.093 13 0.990 0.292 0.390 -1.43 -2.02
#> 61 16.035 13 0.247 1.145 1.125 0.43 0.44
#> 62 18.197 13 0.150 1.300 1.095 0.65 0.37
#> 63 19.944 13 0.097 1.425 1.438 0.90 1.15
#> 64 37.689 13 0.000 2.692 2.222 1.74 2.65
#> 65 24.532 13 0.027 1.752 1.618 1.21 1.51
#> 66 12.174 13 0.513 0.870 0.973 0.09 0.04
#> 67 19.625 13 0.105 1.402 1.199 0.84 0.68
#> 68 12.566 13 0.482 0.898 0.877 -0.05 -0.24
#> 69 18.670 13 0.134 1.334 1.365 0.74 1.10
#> 70 7.604 13 0.868 0.543 0.755 -0.60 -0.78
#> 71 9.725 13 0.716 0.695 0.926 -0.50 -0.08
#> 72 5.025 13 0.975 0.359 0.491 -1.08 -1.99
#> 73 7.079 13 0.898 0.506 0.637 -1.02 -0.98
#> 74 7.604 13 0.868 0.543 0.755 -0.60 -0.78
#> 75 4.219 13 0.989 0.301 0.456 -0.98 -1.79
#> 76 5.671 13 0.957 0.405 0.521 -1.43 -1.51
#> 77 9.064 13 0.768 0.647 0.829 -0.38 -0.50
#> 78 8.268 13 0.826 0.591 0.796 -0.58 -0.46
#> 79 11.044 13 0.607 0.789 1.055 -0.12 0.28
#> 80 5.828 13 0.952 0.416 0.549 -1.31 -1.31
#> 81 10.485 13 0.654 0.749 0.917 -0.24 -0.10
#> 82 10.894 13 0.620 0.778 1.038 -0.04 0.22
#> 83 10.090 13 0.687 0.721 0.868 -0.30 -0.24
#> 84 6.768 13 0.914 0.483 0.619 -1.09 -1.05
#> 85 4.024 13 0.991 0.287 0.354 -1.81 -2.20
#> 86 6.471 13 0.927 0.462 0.649 -0.80 -1.22
#> 87 8.129 13 0.835 0.581 0.875 -0.36 -0.24
#> 88 12.393 13 0.496 0.885 0.903 -0.06 -0.14
#> 89 5.671 13 0.957 0.405 0.521 -1.43 -1.51
#> 90 5.123 13 0.972 0.366 0.513 -1.18 -1.46
#> 91 5.358 13 0.966 0.383 0.507 -1.32 -1.73
#> 92 4.093 13 0.990 0.292 0.390 -1.43 -2.02
#> 93 6.582 13 0.922 0.470 0.660 -0.78 -1.18
#> 94 12.089 13 0.520 0.864 0.995 -0.08 0.09
#> 95 5.629 13 0.959 0.402 0.667 -0.33 -1.01
#> 96 24.693 13 0.025 1.764 1.076 1.33 0.34
#> 97 15.117 13 0.300 1.080 1.025 0.32 0.19
#> 98 9.836 13 0.707 0.703 0.918 -0.43 -0.15
#> 99 10.893 13 0.620 0.778 0.863 -0.33 -0.28
#> 100 7.268 13 0.888 0.519 0.764 -0.41 -0.76
#> 101 8.268 13 0.826 0.591 0.796 -0.58 -0.46
#> 102 13.275 13 0.427 0.948 0.998 0.06 0.11
#> 103 20.669 13 0.080 1.476 1.181 0.98 0.58
#> 104 24.874 13 0.024 1.777 1.370 1.40 1.00
#> 105 6.582 13 0.922 0.470 0.660 -0.78 -1.18
#> 106 5.025 13 0.975 0.359 0.491 -1.08 -1.99
#> 107 5.159 13 0.972 0.368 0.485 -1.37 -1.84
#> 108 22.383 13 0.050 1.599 1.205 1.16 0.64
#> 109 4.024 13 0.991 0.287 0.354 -1.81 -2.20
#> 110 4.698 13 0.981 0.336 0.424 -1.70 -1.96
#> 111 5.025 13 0.975 0.359 0.491 -1.08 -1.99
#> 112 6.942 13 0.905 0.496 0.675 -0.81 -0.85
#> 113 5.358 13 0.966 0.383 0.507 -1.32 -1.73
#> 114 9.883 13 0.703 0.706 0.844 -0.51 -0.34
#> 115 18.178 13 0.151 1.298 1.534 0.63 1.62
#> 116 4.347 13 0.987 0.310 0.634 -0.11 -0.77
#> 117 10.403 13 0.661 0.743 1.095 -0.05 0.41
#> 118 26.269 13 0.016 1.876 1.226 1.46 0.75
#> 119 5.828 13 0.952 0.416 0.549 -1.31 -1.31
#> 120 40.540 13 0.000 2.896 1.718 1.51 1.87
#> 121 5.441 13 0.964 0.389 0.501 -1.49 -1.60
#> 122 28.230 13 0.008 2.016 1.666 1.41 1.93
#> 123 5.638 13 0.958 0.403 0.735 -0.38 -0.69
#> 124 5.671 13 0.957 0.405 0.521 -1.43 -1.51
#> 125 38.771 13 0.000 2.769 1.219 1.46 0.72
#> 126 45.617 13 0.000 3.258 1.202 1.98 0.73
#> 127 102.531 13 0.000 7.324 1.711 2.35 1.44
#> 128 40.524 13 0.000 2.895 1.439 1.51 1.26
#> 129 7.301 13 0.886 0.521 0.779 -0.40 -0.70
#> 130 26.975 13 0.013 1.927 1.304 1.52 0.95
#> 131 8.842 13 0.785 0.632 0.892 -0.42 -0.27
#> 132 9.427 13 0.740 0.673 0.890 -0.50 -0.24
#> 133 27.405 13 0.011 1.957 1.442 1.35 1.38
#> 134 19.833 13 0.099 1.417 1.647 0.72 1.92
#> 135 25.521 13 0.020 1.823 1.546 1.22 1.64
#> 136 11.116 13 0.601 0.794 1.081 -0.15 0.33
#> 137 17.812 13 0.165 1.272 1.014 0.67 0.16
#> 138 16.064 13 0.246 1.147 1.220 0.45 0.67
#> 139 5.739 13 0.955 0.410 0.644 -0.70 -1.01
#> 140 5.123 13 0.972 0.366 0.513 -1.18 -1.46
#> 141 7.079 13 0.898 0.506 0.637 -1.02 -0.98
#> 142 11.503 13 0.569 0.822 1.160 0.06 0.61
#> 143 10.950 13 0.615 0.782 0.932 -0.18 -0.06
#> 144 6.064 13 0.944 0.433 0.585 -1.15 -1.38
#> 145 4.917 13 0.977 0.351 0.633 -0.47 -1.06
#> 146 5.284 13 0.968 0.377 0.630 -0.37 -1.16
#> 147 24.053 13 0.031 1.718 1.470 1.37 1.26
#> 148 15.117 13 0.300 1.080 1.025 0.32 0.19
#> 149 5.441 13 0.964 0.389 0.501 -1.49 -1.60
#> 150 5.159 13 0.972 0.368 0.485 -1.37 -1.84
#> 151 11.637 13 0.558 0.831 0.940 -0.20 -0.05
#> 152 8.673 13 0.797 0.619 0.812 -0.44 -0.56
#> 153 6.263 13 0.936 0.447 0.628 -0.83 -1.32
#> 154 15.001 13 0.307 1.071 1.263 0.31 0.77
#> 155 17.014 13 0.199 1.215 1.418 0.55 1.23
#> 156 7.268 13 0.888 0.519 0.764 -0.41 -0.76
#> 157 12.366 13 0.498 0.883 1.136 -0.04 0.50
#> 158 8.924 13 0.779 0.637 0.938 -0.21 -0.11
#> 159 9.201 13 0.758 0.657 0.810 -0.59 -0.41
#> 160 5.441 13 0.964 0.389 0.501 -1.49 -1.60
#> 161 27.205 13 0.012 1.943 1.221 1.16 0.79
#> 162 5.123 13 0.972 0.366 0.513 -1.18 -1.46
#> 163 58.610 13 0.000 4.186 1.621 2.44 1.86
#> 164 10.699 13 0.636 0.764 0.896 -0.16 -0.26
#> 165 41.122 13 0.000 2.937 1.378 1.53 1.12
#> 166 5.159 13 0.972 0.368 0.485 -1.37 -1.84
#> 167 58.082 13 0.000 4.149 1.313 1.56 0.62
#> 168 17.858 13 0.163 1.276 1.502 0.60 1.54
#> 169 146.257 13 0.000 10.447 1.338 2.27 0.65
#> 170 21.252 13 0.068 1.518 1.420 1.00 1.24
#> 171 26.862 13 0.013 1.919 1.962 1.31 2.59
#> 172 4.219 13 0.989 0.301 0.456 -0.98 -1.79
#> 173 9.220 13 0.756 0.659 1.019 0.02 0.17
#> 174 7.856 13 0.853 0.561 0.817 -0.10 -0.47
#> 175 11.453 13 0.573 0.818 0.834 -0.21 -0.34
#> 176 7.466 13 0.877 0.533 0.799 -0.13 -0.53
#> 177 4.219 13 0.989 0.301 0.456 -0.98 -1.79
#> 178 10.699 13 0.636 0.764 0.896 -0.16 -0.26
#> 179 20.347 13 0.087 1.453 1.320 0.91 0.99
#> 180 123.641 13 0.000 8.832 2.158 3.23 2.72
#> 181 8.282 13 0.825 0.592 1.068 0.61 0.35
#> 182 8.856 13 0.784 0.633 0.808 -0.41 -0.58
#> 183 48.852 13 0.000 3.489 1.539 2.10 1.65
#> 184 4.093 13 0.990 0.292 0.390 -1.43 -2.02
#> 185 10.976 13 0.613 0.784 1.153 0.01 0.59
#> 186 4.219 13 0.989 0.301 0.456 -0.98 -1.79
#> 187 6.768 13 0.914 0.483 0.619 -1.09 -1.05
#> 188 46.013 13 0.000 3.287 1.243 2.00 0.86
#> 189 36.359 13 0.001 2.597 1.751 1.60 2.16
#> 190 20.042 13 0.094 1.432 1.448 0.88 1.30
#> 191 5.159 13 0.972 0.368 0.485 -1.37 -1.84
#> 192 58.333 13 0.000 4.167 1.599 2.43 1.80
#> 193 7.144 13 0.895 0.510 0.663 -0.92 -1.06
#> 194 5.671 13 0.957 0.405 0.521 -1.43 -1.51
#> 195 11.730 13 0.550 0.838 0.857 -0.16 -0.27
#> 196 13.872 13 0.383 0.991 0.924 0.14 -0.10
#> 197 9.064 13 0.768 0.647 0.829 -0.38 -0.50
#> 198 4.281 13 0.988 0.306 0.544 -0.56 -1.41
#> 199 5.739 13 0.955 0.410 0.644 -0.70 -1.01
#> 200 10.577 13 0.646 0.755 0.746 -0.35 -0.61
#> 201 17.316 13 0.185 1.237 1.268 0.60 0.78
#> 202 6.263 13 0.936 0.447 0.628 -0.83 -1.32
#> 203 9.807 13 0.710 0.700 0.767 -0.43 -0.66
#> 204 6.263 13 0.936 0.447 0.628 -0.83 -1.32
#> 205 10.485 13 0.654 0.749 0.917 -0.24 -0.10
#> 206 9.169 13 0.760 0.655 1.086 -0.01 0.35
#> 207 16.656 13 0.215 1.190 1.409 0.52 1.13
#> 208 11.758 13 0.548 0.840 0.980 -0.07 0.07
#> 209 5.828 13 0.952 0.416 0.549 -1.31 -1.31
#> 210 14.935 13 0.311 1.067 1.217 0.35 0.68
#> 211 5.348 13 0.967 0.382 0.570 -0.68 -1.62
#> 212 5.441 13 0.964 0.389 0.501 -1.49 -1.60
#> 213 5.671 13 0.957 0.405 0.521 -1.43 -1.51
#> 214 5.123 13 0.972 0.366 0.513 -1.18 -1.46
#> 215 5.638 13 0.958 0.403 0.735 -0.38 -0.69
#> 216 6.768 13 0.914 0.483 0.619 -1.09 -1.05
#> 217 5.775 13 0.954 0.413 0.860 -0.01 -0.18
#> 218 12.704 13 0.471 0.907 0.921 -0.01 -0.09
#> 219 5.920 13 0.949 0.423 0.747 -0.34 -0.65
#> 220 4.698 13 0.981 0.336 0.424 -1.70 -1.96
#> 221 27.073 13 0.012 1.934 1.200 1.15 0.73
#> 222 7.441 13 0.878 0.532 0.713 -0.86 -0.86
#> 223 5.629 13 0.959 0.402 0.667 -0.33 -1.01
#> 224 4.219 13 0.989 0.301 0.456 -0.98 -1.79
#> 225 9.128 13 0.763 0.652 0.859 -0.44 -0.27
#> 226 14.019 13 0.372 1.001 1.074 0.17 0.32
#> 227 10.950 13 0.615 0.782 0.932 -0.18 -0.06
#> 228 13.778 13 0.390 0.984 1.094 0.25 0.37
#> 229 5.671 13 0.957 0.405 0.521 -1.43 -1.51
#> 230 8.261 13 0.826 0.590 0.741 -0.77 -0.63
#> 231 6.768 13 0.914 0.483 0.619 -1.09 -1.05
#> 232 10.663 13 0.639 0.762 0.843 -0.37 -0.34
#> 233 62.458 13 0.000 4.461 2.648 3.13 3.89
#> 234 8.736 13 0.793 0.624 0.755 -0.50 -0.59
#> 235 7.856 13 0.853 0.561 0.817 -0.10 -0.47
#> 236 7.921 13 0.849 0.566 0.731 -0.84 -0.66
#> 237 7.921 13 0.849 0.566 0.731 -0.84 -0.66
#> 238 4.374 13 0.987 0.312 0.865 0.40 0.07
#> 239 18.149 13 0.152 1.296 1.223 0.92 0.53
#> 240 33.118 13 0.002 2.366 1.889 1.72 2.43
#> 241 4.024 13 0.991 0.287 0.354 -1.81 -2.20
#> 242 8.795 13 0.788 0.628 0.782 -0.71 -0.54
#> 243 7.441 13 0.878 0.532 0.713 -0.86 -0.86
#> 244 8.232 13 0.828 0.588 0.749 -0.78 -0.60
#> 245 5.629 13 0.959 0.402 0.667 -0.33 -1.01
#> 246 4.219 13 0.989 0.301 0.456 -0.98 -1.79
#> 247 22.642 13 0.046 1.617 0.967 1.00 -0.01
#> 248 16.010 13 0.249 1.144 1.334 0.44 0.96
#> 249 4.024 13 0.991 0.287 0.354 -1.81 -2.20
#> 250 18.843 13 0.128 1.346 1.182 0.65 0.62
#> 251 4.347 13 0.987 0.310 0.634 -0.11 -0.77
#> 252 9.201 13 0.758 0.657 0.810 -0.59 -0.41
#> 253 6.471 13 0.927 0.462 0.649 -0.80 -1.22
#> 254 9.300 13 0.750 0.664 0.822 -0.62 -0.41
#> 255 5.671 13 0.957 0.405 0.521 -1.43 -1.51
#> 256 18.159 13 0.152 1.297 1.362 0.70 0.99
#> 257 12.841 13 0.460 0.917 1.162 0.07 0.53
#> 258 5.358 13 0.966 0.383 0.507 -1.32 -1.73
#> 259 6.914 13 0.907 0.494 0.910 0.11 -0.05
#> 260 7.500 13 0.875 0.536 0.710 -0.98 -0.78
#> 261 6.981 13 0.903 0.499 0.661 -1.04 -0.90
#> 262 4.024 13 0.991 0.287 0.354 -1.81 -2.20
#> 263 7.784 13 0.857 0.556 1.094 0.58 0.37
#> 264 8.736 13 0.793 0.624 0.755 -0.50 -0.59
#> 265 9.302 13 0.750 0.664 1.038 -0.21 0.23
#> 266 8.484 13 0.811 0.606 0.901 -0.26 -0.24
#> 267 4.219 13 0.989 0.301 0.456 -0.98 -1.79
#> 268 20.660 13 0.080 1.476 1.214 0.84 0.76
#> 269 6.471 13 0.927 0.462 0.649 -0.80 -1.22
#> 270 8.367 13 0.819 0.598 0.829 -0.27 -0.51
#> 271 23.034 13 0.041 1.645 1.150 0.95 0.52
#> 272 8.666 13 0.798 0.619 0.756 -0.51 -0.58
#> 273 7.851 13 0.853 0.561 0.740 -0.78 -0.76
#> 274 19.063 13 0.121 1.362 1.210 0.66 0.70
#> 275 8.232 13 0.828 0.588 0.749 -0.78 -0.60
#> 276 14.978 13 0.309 1.070 1.236 0.31 0.78
#> 277 12.381 13 0.497 0.884 1.034 -0.08 0.21
#> 278 4.917 13 0.977 0.351 0.633 -0.47 -1.06
#> 279 5.123 13 0.972 0.366 0.513 -1.18 -1.46
#> 280 11.266 13 0.589 0.805 1.035 0.00 0.22
#> 281 30.642 13 0.004 2.189 1.642 1.39 1.61
#> 282 16.130 13 0.242 1.152 1.025 0.45 0.19
#> 283 10.799 13 0.628 0.771 1.136 -0.01 0.54
#> 284 5.441 13 0.964 0.389 0.501 -1.49 -1.60
#> 285 17.337 13 0.184 1.238 1.623 0.57 1.67
#> 286 5.894 13 0.950 0.421 0.769 -0.35 -0.58
#> 287 32.260 13 0.002 2.304 1.363 1.77 0.99
#> 288 23.818 13 0.033 1.701 1.277 1.00 0.82
#> 289 4.024 13 0.991 0.287 0.354 -1.81 -2.20
#> 290 9.693 13 0.719 0.692 0.728 -0.50 -0.67
#> 291 11.568 13 0.563 0.826 0.991 -0.21 0.09
#> 292 15.005 13 0.307 1.072 1.001 0.32 0.13
#> 293 12.043 13 0.524 0.860 0.736 -0.14 -0.69
#> 294 8.465 13 0.812 0.605 0.790 -0.47 -0.64
#> 296 5.739 13 0.955 0.410 0.644 -0.70 -1.01
#> 297 15.671 13 0.267 1.119 1.279 0.41 0.83
#> 298 7.784 13 0.857 0.556 1.094 0.58 0.37
#> 299 15.524 13 0.276 1.109 1.298 0.38 0.85
#> 300 32.032 13 0.002 2.288 1.795 2.03 1.84
#> 301 5.025 13 0.975 0.359 0.491 -1.08 -1.99
#> 302 5.358 13 0.966 0.383 0.507 -1.32 -1.73
#> 303 10.577 13 0.646 0.755 0.746 -0.35 -0.61
#> 304 12.076 13 0.521 0.863 0.975 -0.08 0.03
#> 305 14.767 13 0.322 1.055 0.934 0.27 -0.07
#> 306 18.873 13 0.127 1.348 1.290 0.78 0.83
#> 308 14.151 13 0.363 1.011 1.091 0.28 0.37
#> 309 5.739 13 0.955 0.410 0.644 -0.70 -1.01
#> 310 18.159 13 0.152 1.297 1.087 0.72 0.36
#> 311 5.348 13 0.967 0.382 0.570 -0.68 -1.62
#> 312 16.035 13 0.247 1.145 1.125 0.43 0.44
#> 313 23.034 13 0.041 1.645 1.150 0.95 0.52
#> 314 6.942 13 0.905 0.496 0.675 -0.81 -0.85
#> 315 11.315 13 0.584 0.808 1.024 -0.23 0.19
#> 316 7.471 13 0.876 0.534 0.633 -0.99 -1.06
#> 317 24.891 13 0.024 1.778 1.098 1.34 0.40
#> 318 18.175 13 0.151 1.298 0.811 0.70 -0.41
#> 319 6.024 13 0.945 0.430 0.903 0.01 -0.08
#> 320 13.667 13 0.398 0.976 1.072 0.11 0.32
#> 321 7.500 13 0.875 0.536 0.710 -0.98 -0.78
#> 322 8.736 13 0.793 0.624 0.755 -0.50 -0.59
#> 323 13.747 13 0.392 0.982 1.201 0.18 0.63
#> 324 28.435 13 0.008 2.031 1.448 1.03 1.04
#> 325 6.896 13 0.907 0.493 0.768 -0.53 -0.58
#> 326 15.660 13 0.268 1.119 1.228 0.39 0.69
#> 327 8.736 13 0.793 0.624 0.755 -0.50 -0.59
#> 328 4.024 13 0.991 0.287 0.354 -1.81 -2.20
#> 329 9.693 13 0.719 0.692 0.728 -0.50 -0.67
#> 330 5.441 13 0.964 0.389 0.501 -1.49 -1.60
#> 331 4.093 13 0.990 0.292 0.390 -1.43 -2.02
#> 332 7.441 13 0.878 0.532 0.713 -0.86 -0.86
#> 333 5.123 13 0.972 0.366 0.513 -1.18 -1.46
#> 334 8.049 13 0.840 0.575 0.762 -0.74 -0.68
#> 335 31.383 13 0.003 2.242 1.672 1.97 1.61
#> 336 4.698 13 0.981 0.336 0.424 -1.70 -1.96
#> 337 10.034 13 0.691 0.717 0.928 -0.13 -0.08
#> 338 11.779 13 0.546 0.841 1.183 0.09 0.68
#> 339 11.266 13 0.589 0.805 1.035 0.00 0.22
#> 340 30.471 13 0.004 2.176 1.461 1.65 1.20
#> 341 4.093 13 0.990 0.292 0.390 -1.43 -2.02
#> 342 17.006 13 0.199 1.215 1.125 0.54 0.45
#> 343 5.123 13 0.972 0.366 0.513 -1.18 -1.46
#> 344 12.126 13 0.517 0.866 0.920 -0.10 -0.09
#> 345 12.257 13 0.507 0.876 0.905 0.10 -0.15
#> 346 12.937 13 0.453 0.924 0.746 0.00 -0.66
#> 347 21.895 13 0.057 1.564 1.668 0.81 1.67
#> 348 13.515 13 0.409 0.965 0.934 0.10 -0.05
#> 349 5.739 13 0.955 0.410 0.644 -0.70 -1.01
#> 350 12.704 13 0.471 0.907 0.921 -0.01 -0.09
#> 351 23.700 13 0.034 1.693 1.714 1.14 1.69
#> 352 7.471 13 0.876 0.534 0.633 -0.99 -1.06
#> 353 26.390 13 0.015 1.885 1.588 1.60 1.51
#> 354 15.315 13 0.288 1.094 1.203 0.35 0.69
#> 355 4.024 13 0.991 0.287 0.354 -1.81 -2.20
#> 356 7.144 13 0.895 0.510 0.663 -0.92 -1.06
#> 357 13.627 13 0.401 0.973 1.200 0.11 0.64
#> 358 5.441 13 0.964 0.389 0.501 -1.49 -1.60
#> 359 18.068 13 0.155 1.291 1.289 0.62 0.97
#> 360 11.936 13 0.533 0.853 1.032 -0.01 0.21
#> 361 8.297 13 0.824 0.593 0.752 -0.70 -0.71
#> 362 21.689 13 0.060 1.549 1.504 1.09 1.28
#> 363 8.673 13 0.797 0.619 0.812 -0.44 -0.56
#> 364 8.349 13 0.820 0.596 0.851 -0.49 -0.42
#> 365 17.601 13 0.173 1.257 1.041 0.65 0.23
#> 366 20.608 13 0.081 1.472 1.003 0.97 0.13
#> 367 8.282 13 0.825 0.592 1.068 0.61 0.35
#> 368 4.567 13 0.984 0.326 0.848 0.42 0.06
#> 369 63.802 13 0.000 4.557 1.160 1.79 0.49
#> 370 38.911 13 0.000 2.779 1.507 1.46 1.42
#> 371 20.974 13 0.073 1.498 1.488 0.91 1.25
#> 372 31.487 13 0.003 2.249 1.150 1.62 0.57
#> 373 5.159 13 0.972 0.368 0.485 -1.37 -1.84
#> 374 7.466 13 0.877 0.533 0.799 -0.13 -0.53
#> 375 26.269 13 0.016 1.876 1.226 1.46 0.75
#> 376 7.268 13 0.888 0.519 0.764 -0.41 -0.76
#> 377 8.747 13 0.792 0.625 0.921 -0.23 -0.17
#> 378 6.389 13 0.931 0.456 0.873 0.07 -0.14
#> 379 19.958 13 0.096 1.426 1.151 0.79 0.58
#> 380 11.666 13 0.555 0.833 1.198 0.21 0.66
#> 381 9.056 13 0.769 0.647 0.959 -0.19 -0.04
#> 382 6.735 13 0.915 0.481 0.635 -1.01 -1.17
#> 383 5.671 13 0.957 0.405 0.521 -1.43 -1.51
#> 384 46.623 13 0.000 3.330 1.814 1.70 2.07
#> 385 27.073 13 0.012 1.934 1.200 1.15 0.73
#> 386 9.883 13 0.703 0.706 0.844 -0.51 -0.34
#> 387 9.512 13 0.733 0.679 0.828 -0.53 -0.36
#> 388 20.986 13 0.073 1.499 1.349 1.05 1.00
#> 389 8.214 13 0.829 0.587 0.737 -0.59 -0.64
#> 390 5.671 13 0.957 0.405 0.521 -1.43 -1.51
#> 391 7.400 13 0.880 0.529 0.785 -0.39 -0.68
#> 392 4.024 13 0.991 0.287 0.354 -1.81 -2.20
#> 393 9.024 13 0.771 0.645 0.802 -0.67 -0.47
#> 394 8.232 13 0.828 0.588 0.749 -0.78 -0.60
#> 395 19.666 13 0.104 1.405 1.465 0.90 1.25
#> 396 8.664 13 0.798 0.619 0.865 -0.24 -0.38
#> 397 5.358 13 0.966 0.383 0.507 -1.32 -1.73
#> 398 4.698 13 0.981 0.336 0.424 -1.70 -1.96
#> 399 14.347 13 0.350 1.025 1.217 0.26 0.77
#> 400 5.284 13 0.968 0.377 0.630 -0.37 -1.16Come per le statistiche di infit e outfit per i singoli item, individui con valori di t superiori a 2 mostrano un comportamento di risposta più casuale rispetto a quanto previsto dal modello di Rasch. Questo può indicare, ad esempio, comportamenti di risposta basati su supposizioni o scarsa attenzione. I modelli di risposta che portano a valori di t inferiori a -2 indicano un comportamento di risposta più deterministico rispetto a quello atteso. In questo esempio, le persone identificate con il numero 5 e 43 mostrano questo comportamento.
Otteniamo le stime infit e outfit per le persone con mirt:
head(personfit(mirt_rm))
#> outfit z.outfit infit z.infit Zh
#> 1 0.9312 0.04185 1.0903 0.3722 -0.1422
#> 2 0.5103 -0.64959 0.7279 -0.8983 0.8888
#> 3 0.5477 -0.56604 0.7821 -0.6818 0.7512
#> 4 0.9963 0.16858 1.1111 0.4302 -0.2316
#> 5 0.2893 -1.88739 0.3522 -2.2386 1.6538
#> 6 1.4647 0.88480 1.3150 1.0096 -1.0020personfit(mirt_rm) %>%
summarize(
infit.outside = prop.table(table(z.infit > 1.96 | z.infit < -1.96)),
outfit.outside = prop.table(table(z.outfit > 1.96 | z.outfit < -1.96))
) # lower row = non-fitting people
#> infit.outside outfit.outside
#> 1 0.9175 0.98
#> 2 0.0825 0.02personfitPlot(mirt_rm)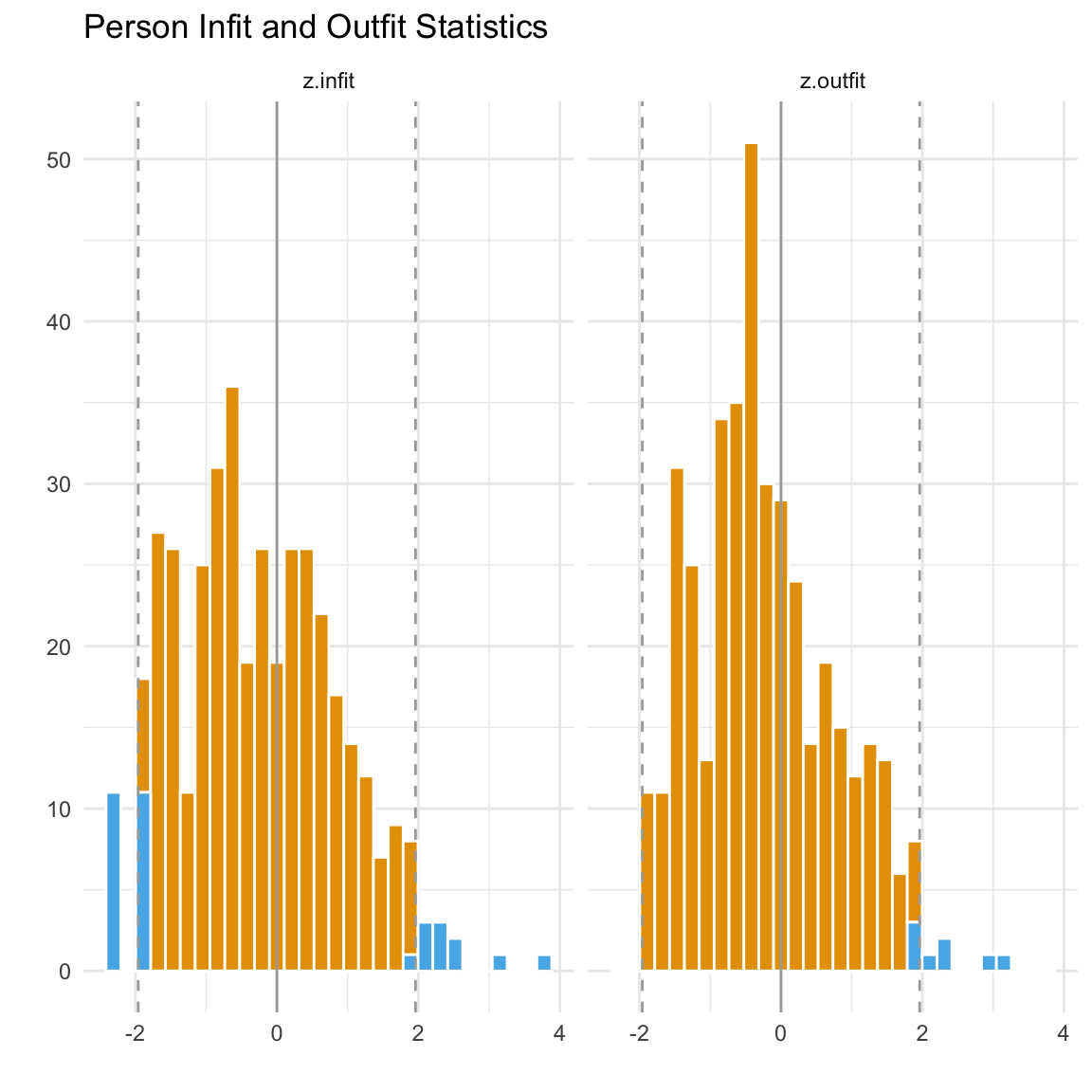
In conclusione, nel caso dei dati in esame, meno del 5% dei rispondenti mostra valori di outfit che eccedono la soglia di 1.96 o che sono inferiori a -1.96. Invece, l’8% dei rispondenti mostra valori di infit che eccedono la soglia di 1.96 o che sono inferiori a -1.96. Questi risultati suggeriscono che il modello di Rasch non è del tutto coerente con i dati esaminati.
71.7 Curva di Informazione dell’Item
Un altro modo per valutare la qualità di ciascun item è tramite la creazione delle cosiddette curve di informazione degli item. L’informazione è un concetto statistico che si riferisce alla capacità di un item di stimare con precisione i punteggi su theta. L’informazione a livello di item chiarisce quanto bene ogni item contribuisca alla precisione nella stima dei punteggi, con livelli più elevati di informazione che portano a stime dei punteggi più accurate.
Per esempio:
- Un item con un’elevata informazione sarà molto utile per discriminare tra rispondenti con diversi livelli di abilità latente attorno a un certo punto della scala di theta. Questo significa che l’item fornisce dati affidabili e significativi sulla capacità o conoscenza che si sta misurando.
- Al contrario, un item con bassa informazione non aggiunge molto alla precisione della stima del punteggio. Questo potrebbe accadere se l’item è troppo facile o troppo difficile per la maggior parte dei rispondenti, o se non è strettamente correlato al tratto latente che si sta cercando di misurare.
La posizione delle Curve Caratteristiche degli Item (ICC) determina le regioni sul tratto latente dove ciascun item fornisce il massimo di informazione. Questo viene illustrato tramite il grafico dell’informazione dell’item.
plotINFO(rm_sum0, type = "item", legpos = FALSE)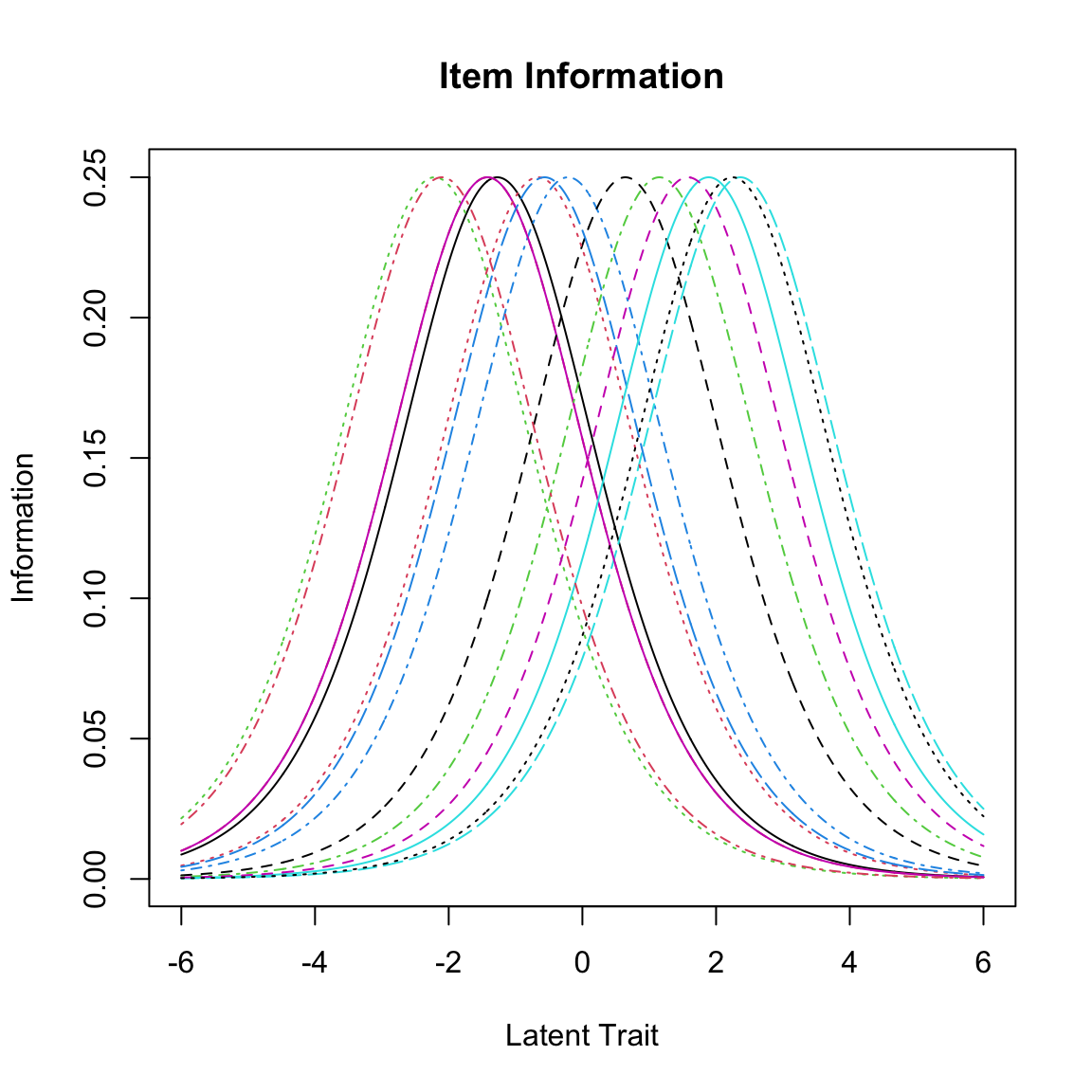
Qui vediamo che alcuni item forniscono maggiori informazioni sui livelli più bassi di \(\theta\), altri a livelli medi di \(\theta\) e altri ancora ai livelli alti di \(\theta\).
71.7.1 Informazione del Test
Il concetto di “informazione” può essere applicato anche all’intera scala del test. La Test Information Curve (TIC) è una rappresentazione grafica che mostra quanta informazione un test fornisce a diversi livelli di abilità latente (\(\theta\)). L’informazione è una misura della precisione con cui il test stima l’abilità di un individuo
In questo caso, osserviamo che la scala è molto efficace nel stimare i punteggi di theta tra -2 e 3, ma presenta una minore precisione nella stima dei punteggi di theta agli estremi. In altre parole, il test fornisce stime accurate per una vasta gamma di abilità medie e leggermente superiori alla media, ma diventa meno affidabile per valutare abilità molto basse o molto elevate.
Questa osservazione ha importanti implicazioni pratiche:
- Valutazione Ottimale per la Maggior Parte dei Rispondenti: La scala è particolarmente adatta per valutare rispondenti il cui livello di abilità si trova all’interno dell’intervallo in cui il test è più informativo (-2 a 4).
- Limiti nella Valutazione degli Estremi: Per rispondenti con abilità molto al di sotto di -2 o molto al di sopra di 4, il test potrebbe non fornire stime di abilità così precise. Questo significa che per questi individui, il test potrebbe non essere in grado di discriminare efficacemente tra diversi livelli di abilità.
Le curve di informazione del test aiutano a identificare dove il test è più efficace e dove potrebbe aver bisogno di miglioramenti o aggiustamenti, come l’aggiunta di item più difficili o più facili per estendere la sua precisione ai livelli estremi di abilità. Questa analisi consente di ottimizzare il test per una valutazione più accurata su tutta la gamma di abilità latente che si intende misurare.
Il grafico dell’informazione del test può essere generato utilizzando eRm::plotINFO:
eRm::plotINFO(rm_sum0, type = "test")
Oppure possiamo usare l’output di mirt:
plot(mirt_rm, type = "info")
71.8 Errore Standard di Misurazione del Test
Il Test Standard Error of Measurement (SEM) è una misura della precisione con cui un test stima il livello di abilità latente (\(\theta\)) per una persona. In altre parole, rappresenta l’incertezza associata alla stima di \(\theta\). Il grafico prodotto da plot(raschModel, type = "SE") mostra come il SEM varia in funzione del livello di abilità latente (\(\theta\)).
- Il SEM è una stima dell’errore standard nella misurazione di \(\theta\).
- È inversamente proporzionale alla quantità di informazione fornita dal test a un dato livello di \(\theta\):
\[ SEM(\theta) = \frac{1}{\sqrt{\text{Informazione}(\theta)}} \]
- Il SEM è espresso nella stessa scala di \(\theta\).
- Un valore più basso del SEM implica una stima più precisa di \(\theta\).
- Il SEM non è costante: varia in base al livello di \(\theta\), riflettendo il fatto che il test è più informativo per alcune abilità rispetto ad altre.
plot(mirt_rm, type = "SE")
Nel modello Rasch, il SEM dipende dalla distribuzione dei parametri di difficoltà (\(b\)) degli item:
- Il SEM minimo si verifica intorno ai valori di \(\theta\) che corrispondono ai parametri di difficoltà (\(b\)) degli item.
- Un SEM alto si verifica a valori di \(\theta\) lontani dal range dei parametri di difficoltà (\(b\)), poiché il test non discrimina bene a quei livelli di abilità.
In conclusione, il grafico del SEM ci aiuta a identificare i punti di forza e di debolezza del test in termini di precisione della stima di \(\theta\). Il SEM ci permette di capire in quali range di \(\theta\) il test fornisce stime più affidabili.
La funzione testInfoPlot() fornisce il grafico del SEM insieme alla curva di informazione del test:
testInfoPlot(mirt_rm, adj_factor = 2)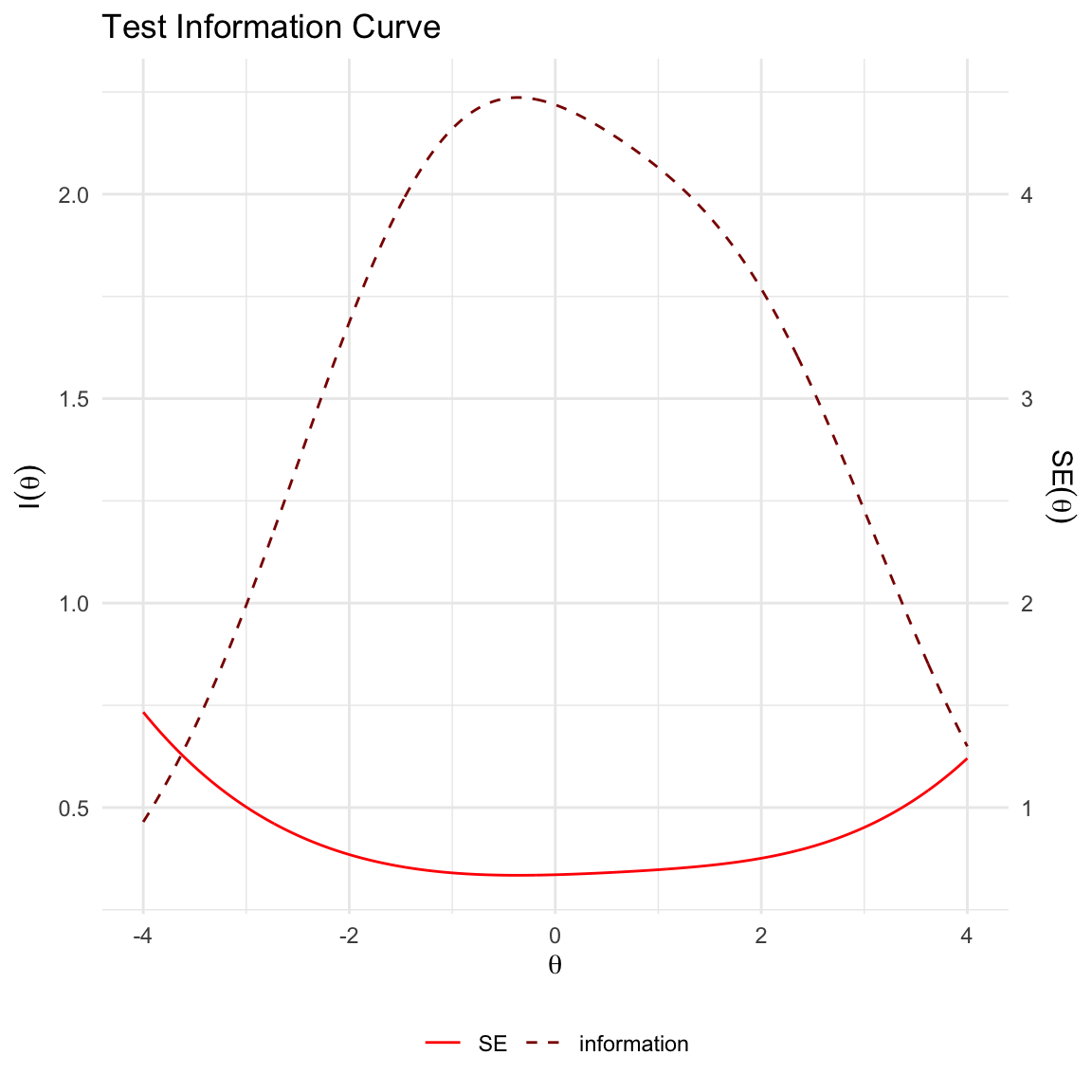
L’informazione del test è maggiore attorno allo zero e, di conseguenza, gli errori standard aumentano allontanandosi dallo zero.
71.9 Stima dei Parametri delle Persone
La stima dei parametri delle persone ottenuta con il metodo di massima verosimiglianza si ottiene nel modo seguente:
theta <- eRm::person.parameter(rm_sum0)
theta
#>
#> Person Parameters:
#>
#> Raw Score Estimate Std.Error
#> 1 -3.39916 1.0848
#> 2 -2.52178 0.8318
#> 3 -1.91598 0.7365
#> 4 -1.40926 0.6924
#> 5 -0.94518 0.6731
#> 6 -0.49650 0.6685
#> 7 -0.04741 0.6730
#> 8 0.41178 0.6831
#> 9 0.88780 0.6977
#> 10 1.38917 0.7203
#> 11 1.93510 0.7620
#> 12 2.57656 0.8513
#> 13 3.48324 1.0968
#> 14 4.45486 NADa notare che questa tabella non mostra una stima per ogni persona. La stima dell’abilità di una persona dipende unicamente dal numero di item a cui ha risposto correttamente. Questo significa che dobbiamo calcolare una stima dell’abilità per ogni possibile punteggio totale (indicato come “punteggi grezzi” nella tabella) e possiamo assegnare tale stima a ciascuna persona che ottiene quel punteggio. Ad esempio, stimiamo che l’abilità di una persona che risponde correttamente a dieci item sia circa 1.39.
Vediamo che le stime dell’abilità aumentano con il punteggio grezzo. Questo ha senso, poiché un candidato ha maggiori probabilità di rispondere correttamente a un item se la sua abilità supera la difficoltà di quell’item. Più item vengono risposti correttamente, più è probabile che l’abilità del candidato sia elevata. Inoltre, vediamo che l’errore standard aumenta con la distanza da zero, come era prevedibile dalla mappa persona-item o dalle curve di informazione degli item e del test, dove abbiamo visto che la maggior parte degli item si trova intorno allo zero.
La mancanza di un errore standard per i candidati che rispondono correttamente a tutti i 14 item potrebbe lasciarci perplessi. La ragione di tale mancanza è che non esiste una stima di massima verosimiglianza per questo punteggio perfetto. Per gestire questo, la funzione person.parameter() utilizza un metodo chiamato interpolazione spline per produrre una stima dell’abilità, ma la procedura non fornisce stime dell’errore. Lo stesso sarebbe vero per i candidati che risolvono correttamente 0 item, ma in questo campione non si è verificato un punteggio di zero.
Possiamo ottenere informazioni sulle stime dell’abilità dei singoli candidati utilizzando la funzione summary(), cioè,
summary(theta)
#>
#> Estimation of Ability Parameters
#>
#> Collapsed log-likelihood: -76.28
#> Number of iterations: 10
#> Number of parameters: 13
#>
#> ML estimated ability parameters (without spline interpolated values):
#> Estimate Std. Err. 2.5 % 97.5 %
#> theta 1 -0.49650 0.6685 -1.80668 0.8137
#> theta 2 -1.40926 0.6924 -2.76632 -0.0522
#> theta 3 -1.40926 0.6924 -2.76632 -0.0522
#> theta 4 -0.49650 0.6685 -1.80668 0.8137
#> theta 5 0.41178 0.6831 -0.92699 1.7506
#> theta 6 -0.94518 0.6731 -2.26446 0.3741
#> theta 7 -0.94518 0.6731 -2.26446 0.3741
#> theta 8 -0.04741 0.6730 -1.36640 1.2716
#> theta 9 -1.91598 0.7365 -3.35958 -0.4724
#> theta 10 -0.49650 0.6685 -1.80668 0.8137
#> theta 11 -0.04741 0.6730 -1.36640 1.2716
#> theta 12 0.41178 0.6831 -0.92699 1.7506
#> theta 13 -1.91598 0.7365 -3.35958 -0.4724
#> theta 14 -0.94518 0.6731 -2.26446 0.3741
#> theta 15 -0.49650 0.6685 -1.80668 0.8137
#> theta 16 -2.52178 0.8318 -4.15206 -0.8915
#> theta 17 -0.04741 0.6730 -1.36640 1.2716
#> theta 18 -1.40926 0.6924 -2.76632 -0.0522
#> theta 19 -0.04741 0.6730 -1.36640 1.2716
#> theta 20 -0.04741 0.6730 -1.36640 1.2716
#> theta 21 -1.40926 0.6924 -2.76632 -0.0522
#> theta 22 -0.04741 0.6730 -1.36640 1.2716
#> theta 23 -1.91598 0.7365 -3.35958 -0.4724
#> theta 24 -1.40926 0.6924 -2.76632 -0.0522
#> theta 25 -0.94518 0.6731 -2.26446 0.3741
#> theta 26 -0.94518 0.6731 -2.26446 0.3741
#> theta 27 -0.94518 0.6731 -2.26446 0.3741
#> theta 28 0.41178 0.6831 -0.92699 1.7506
#> theta 29 -2.52178 0.8318 -4.15206 -0.8915
#> theta 30 -0.49650 0.6685 -1.80668 0.8137
#> theta 31 -0.94518 0.6731 -2.26446 0.3741
#> theta 32 -0.94518 0.6731 -2.26446 0.3741
#> theta 33 -0.49650 0.6685 -1.80668 0.8137
#> theta 34 -1.40926 0.6924 -2.76632 -0.0522
#> theta 35 -0.49650 0.6685 -1.80668 0.8137
#> theta 36 -0.04741 0.6730 -1.36640 1.2716
#> theta 37 -0.49650 0.6685 -1.80668 0.8137
#> theta 38 -0.04741 0.6730 -1.36640 1.2716
#> theta 39 -1.91598 0.7365 -3.35958 -0.4724
#> theta 40 -1.40926 0.6924 -2.76632 -0.0522
#> theta 41 -1.91598 0.7365 -3.35958 -0.4724
#> theta 42 0.41178 0.6831 -0.92699 1.7506
#> theta 43 0.41178 0.6831 -0.92699 1.7506
#> theta 44 0.41178 0.6831 -0.92699 1.7506
#> theta 45 -1.91598 0.7365 -3.35958 -0.4724
#> theta 46 -0.94518 0.6731 -2.26446 0.3741
#> theta 47 1.38917 0.7203 -0.02261 2.8010
#> theta 48 1.38917 0.7203 -0.02261 2.8010
#> theta 49 -2.52178 0.8318 -4.15206 -0.8915
#> theta 50 -0.49650 0.6685 -1.80668 0.8137
#> theta 51 -0.04741 0.6730 -1.36640 1.2716
#> theta 52 -3.39916 1.0848 -5.52537 -1.2730
#> theta 53 1.93510 0.7620 0.44155 3.4287
#> theta 54 -0.94518 0.6731 -2.26446 0.3741
#> theta 55 -0.94518 0.6731 -2.26446 0.3741
#> theta 56 -2.52178 0.8318 -4.15206 -0.8915
#> theta 57 -0.04741 0.6730 -1.36640 1.2716
#> theta 58 0.88780 0.6977 -0.47964 2.2552
#> theta 59 -0.04741 0.6730 -1.36640 1.2716
#> theta 60 0.88780 0.6977 -0.47964 2.2552
#> theta 61 0.88780 0.6977 -0.47964 2.2552
#> theta 62 0.88780 0.6977 -0.47964 2.2552
#> theta 63 0.41178 0.6831 -0.92699 1.7506
#> theta 64 1.38917 0.7203 -0.02261 2.8010
#> theta 65 0.88780 0.6977 -0.47964 2.2552
#> theta 66 1.38917 0.7203 -0.02261 2.8010
#> theta 67 -0.49650 0.6685 -1.80668 0.8137
#> theta 68 -0.04741 0.6730 -1.36640 1.2716
#> theta 69 -0.49650 0.6685 -1.80668 0.8137
#> theta 70 -0.94518 0.6731 -2.26446 0.3741
#> theta 71 0.41178 0.6831 -0.92699 1.7506
#> theta 72 -0.94518 0.6731 -2.26446 0.3741
#> theta 73 0.41178 0.6831 -0.92699 1.7506
#> theta 74 -0.94518 0.6731 -2.26446 0.3741
#> theta 75 1.38917 0.7203 -0.02261 2.8010
#> theta 76 -0.04741 0.6730 -1.36640 1.2716
#> theta 77 -0.94518 0.6731 -2.26446 0.3741
#> theta 78 0.88780 0.6977 -0.47964 2.2552
#> theta 79 -0.94518 0.6731 -2.26446 0.3741
#> theta 80 0.41178 0.6831 -0.92699 1.7506
#> theta 81 0.88780 0.6977 -0.47964 2.2552
#> theta 82 1.38917 0.7203 -0.02261 2.8010
#> theta 83 0.88780 0.6977 -0.47964 2.2552
#> theta 84 0.41178 0.6831 -0.92699 1.7506
#> theta 85 0.41178 0.6831 -0.92699 1.7506
#> theta 86 -0.94518 0.6731 -2.26446 0.3741
#> theta 87 1.38917 0.7203 -0.02261 2.8010
#> theta 88 0.41178 0.6831 -0.92699 1.7506
#> theta 89 -0.04741 0.6730 -1.36640 1.2716
#> theta 90 0.88780 0.6977 -0.47964 2.2552
#> theta 91 -0.49650 0.6685 -1.80668 0.8137
#> theta 92 0.88780 0.6977 -0.47964 2.2552
#> theta 93 -0.94518 0.6731 -2.26446 0.3741
#> theta 94 -0.49650 0.6685 -1.80668 0.8137
#> theta 95 -1.91598 0.7365 -3.35958 -0.4724
#> theta 96 -0.49650 0.6685 -1.80668 0.8137
#> theta 97 -0.49650 0.6685 -1.80668 0.8137
#> theta 98 -0.49650 0.6685 -1.80668 0.8137
#> theta 99 -0.04741 0.6730 -1.36640 1.2716
#> theta 100 -1.40926 0.6924 -2.76632 -0.0522
#> theta 101 0.88780 0.6977 -0.47964 2.2552
#> theta 102 -0.04741 0.6730 -1.36640 1.2716
#> theta 103 0.41178 0.6831 -0.92699 1.7506
#> theta 104 0.41178 0.6831 -0.92699 1.7506
#> theta 105 -0.94518 0.6731 -2.26446 0.3741
#> theta 106 -0.94518 0.6731 -2.26446 0.3741
#> theta 107 -0.49650 0.6685 -1.80668 0.8137
#> theta 108 0.41178 0.6831 -0.92699 1.7506
#> theta 109 0.41178 0.6831 -0.92699 1.7506
#> theta 110 -0.04741 0.6730 -1.36640 1.2716
#> theta 111 -0.94518 0.6731 -2.26446 0.3741
#> theta 112 0.88780 0.6977 -0.47964 2.2552
#> theta 113 -0.49650 0.6685 -1.80668 0.8137
#> theta 114 -0.04741 0.6730 -1.36640 1.2716
#> theta 115 -0.94518 0.6731 -2.26446 0.3741
#> theta 116 -2.52178 0.8318 -4.15206 -0.8915
#> theta 117 -1.40926 0.6924 -2.76632 -0.0522
#> theta 118 -0.49650 0.6685 -1.80668 0.8137
#> theta 119 0.41178 0.6831 -0.92699 1.7506
#> theta 120 -1.91598 0.7365 -3.35958 -0.4724
#> theta 121 -0.04741 0.6730 -1.36640 1.2716
#> theta 122 -0.94518 0.6731 -2.26446 0.3741
#> theta 123 1.93510 0.7620 0.44155 3.4287
#> theta 124 -0.04741 0.6730 -1.36640 1.2716
#> theta 125 -1.91598 0.7365 -3.35958 -0.4724
#> theta 126 -1.40926 0.6924 -2.76632 -0.0522
#> theta 127 -2.52178 0.8318 -4.15206 -0.8915
#> theta 128 -1.91598 0.7365 -3.35958 -0.4724
#> theta 129 -1.40926 0.6924 -2.76632 -0.0522
#> theta 130 -0.49650 0.6685 -1.80668 0.8137
#> theta 131 -0.94518 0.6731 -2.26446 0.3741
#> theta 132 -0.49650 0.6685 -1.80668 0.8137
#> theta 133 -0.94518 0.6731 -2.26446 0.3741
#> theta 134 -1.40926 0.6924 -2.76632 -0.0522
#> theta 135 -0.94518 0.6731 -2.26446 0.3741
#> theta 136 0.88780 0.6977 -0.47964 2.2552
#> theta 137 -0.04741 0.6730 -1.36640 1.2716
#> theta 138 0.41178 0.6831 -0.92699 1.7506
#> theta 139 1.38917 0.7203 -0.02261 2.8010
#> theta 140 0.88780 0.6977 -0.47964 2.2552
#> theta 141 0.41178 0.6831 -0.92699 1.7506
#> theta 142 -1.40926 0.6924 -2.76632 -0.0522
#> theta 143 0.88780 0.6977 -0.47964 2.2552
#> theta 144 -0.49650 0.6685 -1.80668 0.8137
#> theta 145 1.93510 0.7620 0.44155 3.4287
#> theta 146 -1.91598 0.7365 -3.35958 -0.4724
#> theta 147 -0.04741 0.6730 -1.36640 1.2716
#> theta 148 -0.49650 0.6685 -1.80668 0.8137
#> theta 149 -0.04741 0.6730 -1.36640 1.2716
#> theta 150 -0.49650 0.6685 -1.80668 0.8137
#> theta 151 -0.04741 0.6730 -1.36640 1.2716
#> theta 152 -0.94518 0.6731 -2.26446 0.3741
#> theta 153 -0.94518 0.6731 -2.26446 0.3741
#> theta 154 0.41178 0.6831 -0.92699 1.7506
#> theta 155 -0.49650 0.6685 -1.80668 0.8137
#> theta 156 -1.40926 0.6924 -2.76632 -0.0522
#> theta 157 -0.49650 0.6685 -1.80668 0.8137
#> theta 158 -1.40926 0.6924 -2.76632 -0.0522
#> theta 159 0.41178 0.6831 -0.92699 1.7506
#> theta 160 -0.04741 0.6730 -1.36640 1.2716
#> theta 161 -1.40926 0.6924 -2.76632 -0.0522
#> theta 162 0.88780 0.6977 -0.47964 2.2552
#> theta 163 -1.40926 0.6924 -2.76632 -0.0522
#> theta 164 -0.94518 0.6731 -2.26446 0.3741
#> theta 165 -1.91598 0.7365 -3.35958 -0.4724
#> theta 166 -0.49650 0.6685 -1.80668 0.8137
#> theta 167 -3.39916 1.0848 -5.52537 -1.2730
#> theta 168 -0.94518 0.6731 -2.26446 0.3741
#> theta 169 -3.39916 1.0848 -5.52537 -1.2730
#> theta 170 -0.49650 0.6685 -1.80668 0.8137
#> theta 171 -0.94518 0.6731 -2.26446 0.3741
#> theta 172 1.38917 0.7203 -0.02261 2.8010
#> theta 173 -1.91598 0.7365 -3.35958 -0.4724
#> theta 174 -1.91598 0.7365 -3.35958 -0.4724
#> theta 175 0.41178 0.6831 -0.92699 1.7506
#> theta 176 -1.91598 0.7365 -3.35958 -0.4724
#> theta 177 1.38917 0.7203 -0.02261 2.8010
#> theta 178 -0.94518 0.6731 -2.26446 0.3741
#> theta 179 -0.49650 0.6685 -1.80668 0.8137
#> theta 180 -1.91598 0.7365 -3.35958 -0.4724
#> theta 181 -3.39916 1.0848 -5.52537 -1.2730
#> theta 182 -0.94518 0.6731 -2.26446 0.3741
#> theta 183 -1.40926 0.6924 -2.76632 -0.0522
#> theta 184 0.88780 0.6977 -0.47964 2.2552
#> theta 185 -1.40926 0.6924 -2.76632 -0.0522
#> theta 186 1.38917 0.7203 -0.02261 2.8010
#> theta 187 0.41178 0.6831 -0.92699 1.7506
#> theta 188 -1.40926 0.6924 -2.76632 -0.0522
#> theta 189 -1.40926 0.6924 -2.76632 -0.0522
#> theta 190 -0.49650 0.6685 -1.80668 0.8137
#> theta 191 -0.49650 0.6685 -1.80668 0.8137
#> theta 192 -1.40926 0.6924 -2.76632 -0.0522
#> theta 193 -0.49650 0.6685 -1.80668 0.8137
#> theta 194 -0.04741 0.6730 -1.36640 1.2716
#> theta 195 0.41178 0.6831 -0.92699 1.7506
#> theta 196 -0.04741 0.6730 -1.36640 1.2716
#> theta 197 -0.94518 0.6731 -2.26446 0.3741
#> theta 198 1.93510 0.7620 0.44155 3.4287
#> theta 199 1.38917 0.7203 -0.02261 2.8010
#> theta 200 0.41178 0.6831 -0.92699 1.7506
#> theta 201 0.41178 0.6831 -0.92699 1.7506
#> theta 202 -0.94518 0.6731 -2.26446 0.3741
#> theta 203 -0.49650 0.6685 -1.80668 0.8137
#> theta 204 -0.94518 0.6731 -2.26446 0.3741
#> theta 205 0.88780 0.6977 -0.47964 2.2552
#> theta 206 1.93510 0.7620 0.44155 3.4287
#> theta 207 1.93510 0.7620 0.44155 3.4287
#> theta 208 0.88780 0.6977 -0.47964 2.2552
#> theta 209 0.41178 0.6831 -0.92699 1.7506
#> theta 210 1.38917 0.7203 -0.02261 2.8010
#> theta 211 -1.40926 0.6924 -2.76632 -0.0522
#> theta 212 -0.04741 0.6730 -1.36640 1.2716
#> theta 213 -0.04741 0.6730 -1.36640 1.2716
#> theta 214 0.88780 0.6977 -0.47964 2.2552
#> theta 215 1.93510 0.7620 0.44155 3.4287
#> theta 216 0.41178 0.6831 -0.92699 1.7506
#> theta 217 2.57656 0.8513 0.90805 4.2451
#> theta 218 0.41178 0.6831 -0.92699 1.7506
#> theta 219 1.93510 0.7620 0.44155 3.4287
#> theta 220 -0.04741 0.6730 -1.36640 1.2716
#> theta 221 -1.40926 0.6924 -2.76632 -0.0522
#> theta 222 -0.49650 0.6685 -1.80668 0.8137
#> theta 223 -1.91598 0.7365 -3.35958 -0.4724
#> theta 224 1.38917 0.7203 -0.02261 2.8010
#> theta 225 0.88780 0.6977 -0.47964 2.2552
#> theta 226 -0.04741 0.6730 -1.36640 1.2716
#> theta 227 0.88780 0.6977 -0.47964 2.2552
#> theta 228 1.38917 0.7203 -0.02261 2.8010
#> theta 229 -0.04741 0.6730 -1.36640 1.2716
#> theta 230 0.41178 0.6831 -0.92699 1.7506
#> theta 231 0.41178 0.6831 -0.92699 1.7506
#> theta 232 -0.04741 0.6730 -1.36640 1.2716
#> theta 233 -0.94518 0.6731 -2.26446 0.3741
#> theta 234 0.88780 0.6977 -0.47964 2.2552
#> theta 235 -1.91598 0.7365 -3.35958 -0.4724
#> theta 236 0.41178 0.6831 -0.92699 1.7506
#> theta 237 0.41178 0.6831 -0.92699 1.7506
#> theta 238 3.48324 1.0968 1.33357 5.6329
#> theta 239 -3.39916 1.0848 -5.52537 -1.2730
#> theta 240 -0.94518 0.6731 -2.26446 0.3741
#> theta 241 0.41178 0.6831 -0.92699 1.7506
#> theta 242 -0.04741 0.6730 -1.36640 1.2716
#> theta 243 -0.49650 0.6685 -1.80668 0.8137
#> theta 244 0.41178 0.6831 -0.92699 1.7506
#> theta 245 -1.91598 0.7365 -3.35958 -0.4724
#> theta 246 1.38917 0.7203 -0.02261 2.8010
#> theta 247 -0.94518 0.6731 -2.26446 0.3741
#> theta 248 -0.04741 0.6730 -1.36640 1.2716
#> theta 249 0.41178 0.6831 -0.92699 1.7506
#> theta 250 -1.91598 0.7365 -3.35958 -0.4724
#> theta 251 -2.52178 0.8318 -4.15206 -0.8915
#> theta 252 0.41178 0.6831 -0.92699 1.7506
#> theta 253 -0.94518 0.6731 -2.26446 0.3741
#> theta 254 -0.04741 0.6730 -1.36640 1.2716
#> theta 255 -0.04741 0.6730 -1.36640 1.2716
#> theta 256 0.41178 0.6831 -0.92699 1.7506
#> theta 257 0.88780 0.6977 -0.47964 2.2552
#> theta 258 -0.49650 0.6685 -1.80668 0.8137
#> theta 259 -2.52178 0.8318 -4.15206 -0.8915
#> theta 260 -0.04741 0.6730 -1.36640 1.2716
#> theta 261 0.41178 0.6831 -0.92699 1.7506
#> theta 262 0.41178 0.6831 -0.92699 1.7506
#> theta 263 3.48324 1.0968 1.33357 5.6329
#> theta 264 0.88780 0.6977 -0.47964 2.2552
#> theta 265 1.38917 0.7203 -0.02261 2.8010
#> theta 266 -1.40926 0.6924 -2.76632 -0.0522
#> theta 267 1.38917 0.7203 -0.02261 2.8010
#> theta 268 -0.94518 0.6731 -2.26446 0.3741
#> theta 269 -0.94518 0.6731 -2.26446 0.3741
#> theta 270 -1.40926 0.6924 -2.76632 -0.0522
#> theta 271 1.38917 0.7203 -0.02261 2.8010
#> theta 272 0.88780 0.6977 -0.47964 2.2552
#> theta 273 -0.49650 0.6685 -1.80668 0.8137
#> theta 274 -1.91598 0.7365 -3.35958 -0.4724
#> theta 275 0.41178 0.6831 -0.92699 1.7506
#> theta 276 -0.49650 0.6685 -1.80668 0.8137
#> theta 277 -0.04741 0.6730 -1.36640 1.2716
#> theta 278 1.93510 0.7620 0.44155 3.4287
#> theta 279 0.88780 0.6977 -0.47964 2.2552
#> theta 280 1.38917 0.7203 -0.02261 2.8010
#> theta 281 1.38917 0.7203 -0.02261 2.8010
#> theta 282 0.41178 0.6831 -0.92699 1.7506
#> theta 283 -1.40926 0.6924 -2.76632 -0.0522
#> theta 284 -0.04741 0.6730 -1.36640 1.2716
#> theta 285 -1.91598 0.7365 -3.35958 -0.4724
#> theta 286 1.93510 0.7620 0.44155 3.4287
#> theta 287 0.88780 0.6977 -0.47964 2.2552
#> theta 288 1.38917 0.7203 -0.02261 2.8010
#> theta 289 0.41178 0.6831 -0.92699 1.7506
#> theta 290 0.41178 0.6831 -0.92699 1.7506
#> theta 291 -0.04741 0.6730 -1.36640 1.2716
#> theta 292 0.88780 0.6977 -0.47964 2.2552
#> theta 293 -0.04741 0.6730 -1.36640 1.2716
#> theta 294 -0.94518 0.6731 -2.26446 0.3741
#> theta 296 1.38917 0.7203 -0.02261 2.8010
#> theta 297 1.38917 0.7203 -0.02261 2.8010
#> theta 298 3.48324 1.0968 1.33357 5.6329
#> theta 299 0.88780 0.6977 -0.47964 2.2552
#> theta 300 0.41178 0.6831 -0.92699 1.7506
#> theta 301 -0.94518 0.6731 -2.26446 0.3741
#> theta 302 -0.49650 0.6685 -1.80668 0.8137
#> theta 303 0.41178 0.6831 -0.92699 1.7506
#> theta 304 -0.49650 0.6685 -1.80668 0.8137
#> theta 305 -0.04741 0.6730 -1.36640 1.2716
#> theta 306 0.41178 0.6831 -0.92699 1.7506
#> theta 308 1.38917 0.7203 -0.02261 2.8010
#> theta 309 1.38917 0.7203 -0.02261 2.8010
#> theta 310 -0.04741 0.6730 -1.36640 1.2716
#> theta 311 -1.40926 0.6924 -2.76632 -0.0522
#> theta 312 0.88780 0.6977 -0.47964 2.2552
#> theta 313 1.38917 0.7203 -0.02261 2.8010
#> theta 314 0.88780 0.6977 -0.47964 2.2552
#> theta 315 0.41178 0.6831 -0.92699 1.7506
#> theta 316 -0.04741 0.6730 -1.36640 1.2716
#> theta 317 -0.49650 0.6685 -1.80668 0.8137
#> theta 318 0.41178 0.6831 -0.92699 1.7506
#> theta 319 2.57656 0.8513 0.90805 4.2451
#> theta 320 -0.04741 0.6730 -1.36640 1.2716
#> theta 321 -0.04741 0.6730 -1.36640 1.2716
#> theta 322 0.88780 0.6977 -0.47964 2.2552
#> theta 323 0.88780 0.6977 -0.47964 2.2552
#> theta 324 2.57656 0.8513 0.90805 4.2451
#> theta 325 1.38917 0.7203 -0.02261 2.8010
#> theta 326 0.41178 0.6831 -0.92699 1.7506
#> theta 327 0.88780 0.6977 -0.47964 2.2552
#> theta 328 0.41178 0.6831 -0.92699 1.7506
#> theta 329 0.41178 0.6831 -0.92699 1.7506
#> theta 330 -0.04741 0.6730 -1.36640 1.2716
#> theta 331 0.88780 0.6977 -0.47964 2.2552
#> theta 332 -0.49650 0.6685 -1.80668 0.8137
#> theta 333 0.88780 0.6977 -0.47964 2.2552
#> theta 334 -0.49650 0.6685 -1.80668 0.8137
#> theta 335 0.41178 0.6831 -0.92699 1.7506
#> theta 336 -0.04741 0.6730 -1.36640 1.2716
#> theta 337 1.38917 0.7203 -0.02261 2.8010
#> theta 338 -1.40926 0.6924 -2.76632 -0.0522
#> theta 339 1.38917 0.7203 -0.02261 2.8010
#> theta 340 0.88780 0.6977 -0.47964 2.2552
#> theta 341 0.88780 0.6977 -0.47964 2.2552
#> theta 342 1.93510 0.7620 0.44155 3.4287
#> theta 343 0.88780 0.6977 -0.47964 2.2552
#> theta 344 0.41178 0.6831 -0.92699 1.7506
#> theta 345 1.38917 0.7203 -0.02261 2.8010
#> theta 346 -0.04741 0.6730 -1.36640 1.2716
#> theta 347 1.93510 0.7620 0.44155 3.4287
#> theta 348 0.41178 0.6831 -0.92699 1.7506
#> theta 349 1.38917 0.7203 -0.02261 2.8010
#> theta 350 0.41178 0.6831 -0.92699 1.7506
#> theta 351 0.88780 0.6977 -0.47964 2.2552
#> theta 352 -0.04741 0.6730 -1.36640 1.2716
#> theta 353 -0.04741 0.6730 -1.36640 1.2716
#> theta 354 -0.49650 0.6685 -1.80668 0.8137
#> theta 355 0.41178 0.6831 -0.92699 1.7506
#> theta 356 -0.49650 0.6685 -1.80668 0.8137
#> theta 357 -0.04741 0.6730 -1.36640 1.2716
#> theta 358 -0.04741 0.6730 -1.36640 1.2716
#> theta 359 -0.94518 0.6731 -2.26446 0.3741
#> theta 360 -0.94518 0.6731 -2.26446 0.3741
#> theta 361 -0.49650 0.6685 -1.80668 0.8137
#> theta 362 0.41178 0.6831 -0.92699 1.7506
#> theta 363 -0.94518 0.6731 -2.26446 0.3741
#> theta 364 -0.94518 0.6731 -2.26446 0.3741
#> theta 365 -0.04741 0.6730 -1.36640 1.2716
#> theta 366 0.41178 0.6831 -0.92699 1.7506
#> theta 367 -3.39916 1.0848 -5.52537 -1.2730
#> theta 368 -3.39916 1.0848 -5.52537 -1.2730
#> theta 369 -2.52178 0.8318 -4.15206 -0.8915
#> theta 370 -1.91598 0.7365 -3.35958 -0.4724
#> theta 371 0.88780 0.6977 -0.47964 2.2552
#> theta 372 -0.94518 0.6731 -2.26446 0.3741
#> theta 373 -0.49650 0.6685 -1.80668 0.8137
#> theta 374 -1.91598 0.7365 -3.35958 -0.4724
#> theta 375 -0.49650 0.6685 -1.80668 0.8137
#> theta 376 -1.40926 0.6924 -2.76632 -0.0522
#> theta 377 -1.40926 0.6924 -2.76632 -0.0522
#> theta 378 -2.52178 0.8318 -4.15206 -0.8915
#> theta 379 -0.94518 0.6731 -2.26446 0.3741
#> theta 380 -1.91598 0.7365 -3.35958 -0.4724
#> theta 381 -1.40926 0.6924 -2.76632 -0.0522
#> theta 382 -0.49650 0.6685 -1.80668 0.8137
#> theta 383 -0.04741 0.6730 -1.36640 1.2716
#> theta 384 -1.91598 0.7365 -3.35958 -0.4724
#> theta 385 -1.40926 0.6924 -2.76632 -0.0522
#> theta 386 -0.04741 0.6730 -1.36640 1.2716
#> theta 387 0.41178 0.6831 -0.92699 1.7506
#> theta 388 -0.04741 0.6730 -1.36640 1.2716
#> theta 389 0.88780 0.6977 -0.47964 2.2552
#> theta 390 -0.04741 0.6730 -1.36640 1.2716
#> theta 391 -1.40926 0.6924 -2.76632 -0.0522
#> theta 392 0.41178 0.6831 -0.92699 1.7506
#> theta 393 -0.04741 0.6730 -1.36640 1.2716
#> theta 394 0.41178 0.6831 -0.92699 1.7506
#> theta 395 -0.04741 0.6730 -1.36640 1.2716
#> theta 396 -1.40926 0.6924 -2.76632 -0.0522
#> theta 397 -0.49650 0.6685 -1.80668 0.8137
#> theta 398 -0.04741 0.6730 -1.36640 1.2716
#> theta 399 -0.94518 0.6731 -2.26446 0.3741
#> theta 400 -1.91598 0.7365 -3.35958 -0.4724L’output – che qui abbiamo di nuovo troncato per risparmiare spazio – contiene stime ed errori standard, insieme ai limiti inferiori (2.5%) e superiori (97.5%) degli intervalli di confidenza al 95%, per tutti i candidati che hanno risposto correttamente fino a 13 item. I candidati che hanno risposto correttamente a tutti i 14 item (o a nessun item) sono omessi da questo output. Possiamo anche notare che alcuni candidati, ad esempio il secondo e il terzo, ricevono esattamente la stessa stima di abilità ed errore standard. Questo è dovuto al fatto che hanno lavorato sullo stesso set di item e hanno ottenuto lo stesso punteggio totale. In alternativa, possiamo utilizzare il comando coef(theta) per ottenere solo la stima dell’abilità per ciascun candidato.
Possiamo anche stimare l’abilità dei candidati utilizzando la funzione mirt::fscores(). Per i modelli unidimensionali, gli argomenti più importanti di fscores() sono object e method. L’argomento object accetta il risultato della funzione mirt(). L’argomento method indica quale metodo utilizzare per stimare i parametri della persona. Per impostazione predefinita, method="EAP", il che indica che il parametro della persona dovrebbe essere stimato utilizzando il metodo expected a posteriori (EAP). Possiamo calcolare le stime EAP per il modello di Rasch e stampare le sue prime sei voci inserendo:
theta_eap <- fscores(mirt_rm)
head(theta_eap)
#> F1
#> [1,] -0.2177
#> [2,] -0.8276
#> [3,] -0.8276
#> [4,] -0.2177
#> [5,] 0.3914
#> [6,] -0.5213Per impostazione predefinita mirt mostra solo le stime puntuali, ma è possibile aggiungere gli errori standard tramite l’opzione full.scores.SE = TRUE alla funzione fscores(). Gli errori standard dovrebbero essere esaminati prima di interpretare o riportare le stime dei parametri della persona.
La funzione fscores() fornisce anche stimatori di massima verosimiglianza (ML), massimo a posteriori (MAP) e likelihood ponderata (WLE). Ora confrontiamo i quattro tipi di stime dei parametri della persona fornite da mirt. Gli stimatori ML, MAP e WLE possono essere calcolati inserendo
theta_ml <- fscores(mirt_rm, method = "ML", max_theta = 30)
theta_map <- fscores(mirt_rm, method = "MAP")
theta_wle <- fscores(mirt_rm, method = "WLE")
71.10 Affidabilità Condizionale
Il concetto di affidabilità varia tra la CTT e la IRT. Nell’IRT, possiamo calcolare l’affidabilità condizionale, ossia l’affidabilità della scala a diversi livelli di theta.
- Nella CTT, l’affidabilità è solitamente considerata come una proprietà fissa del test, indipendentemente dal livello di abilità dei rispondenti. Si misura spesso attraverso il coefficiente alfa di Cronbach o metodi simili.
- Nell’IRT, invece, l’affidabilità è vista come una proprietà variabile che dipende dal livello di theta del rispondente. A diversi livelli di theta, la precisione con cui il test misura l’abilità può variare significativamente.
L’affidabilità condizionale fornisce una misura più specifica e dettagliata di quanto affidabilmente un test misura l’abilità a diversi livelli di \(\theta\).
conRelPlot(mirt_rm)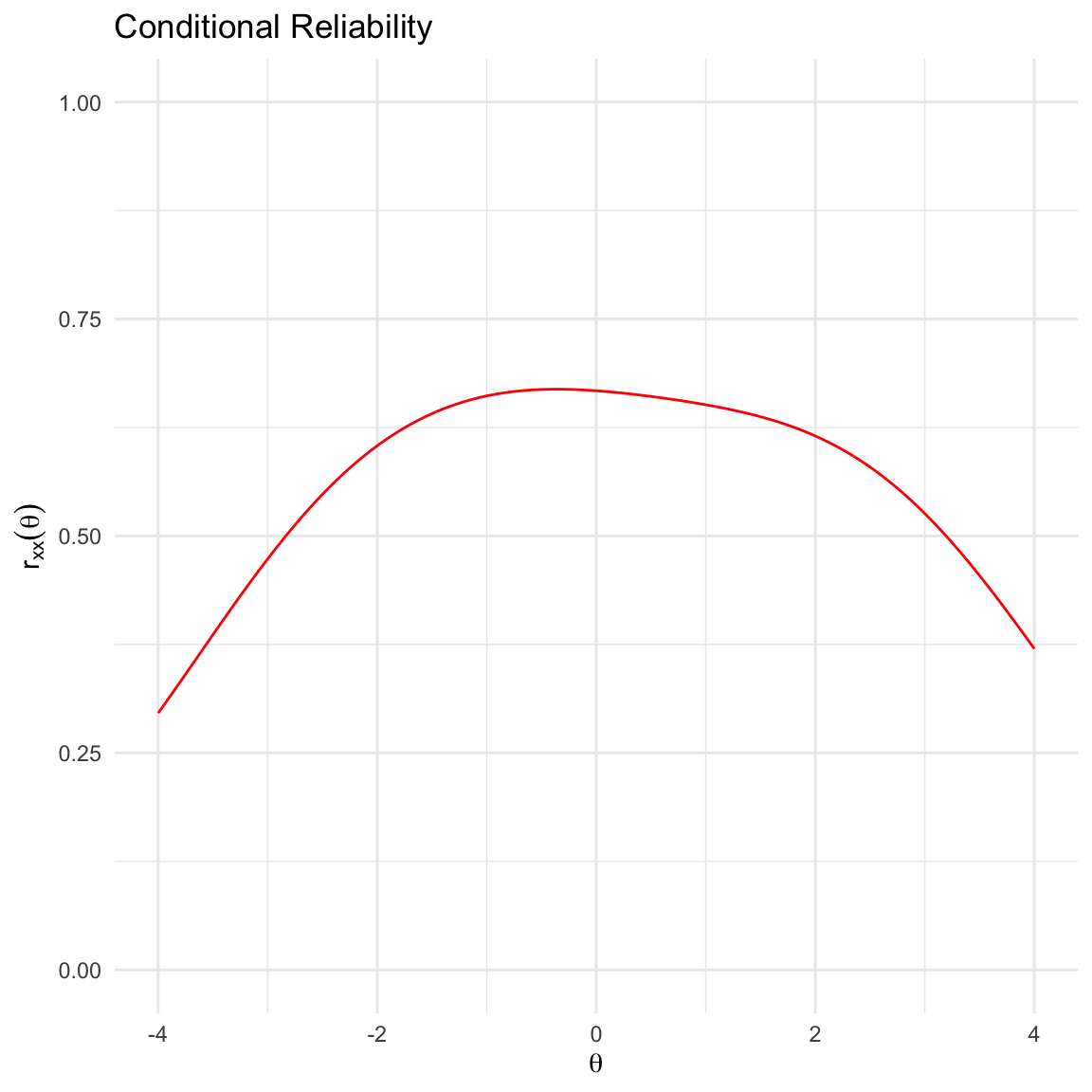
plot(mirt_rm, type = "rxx")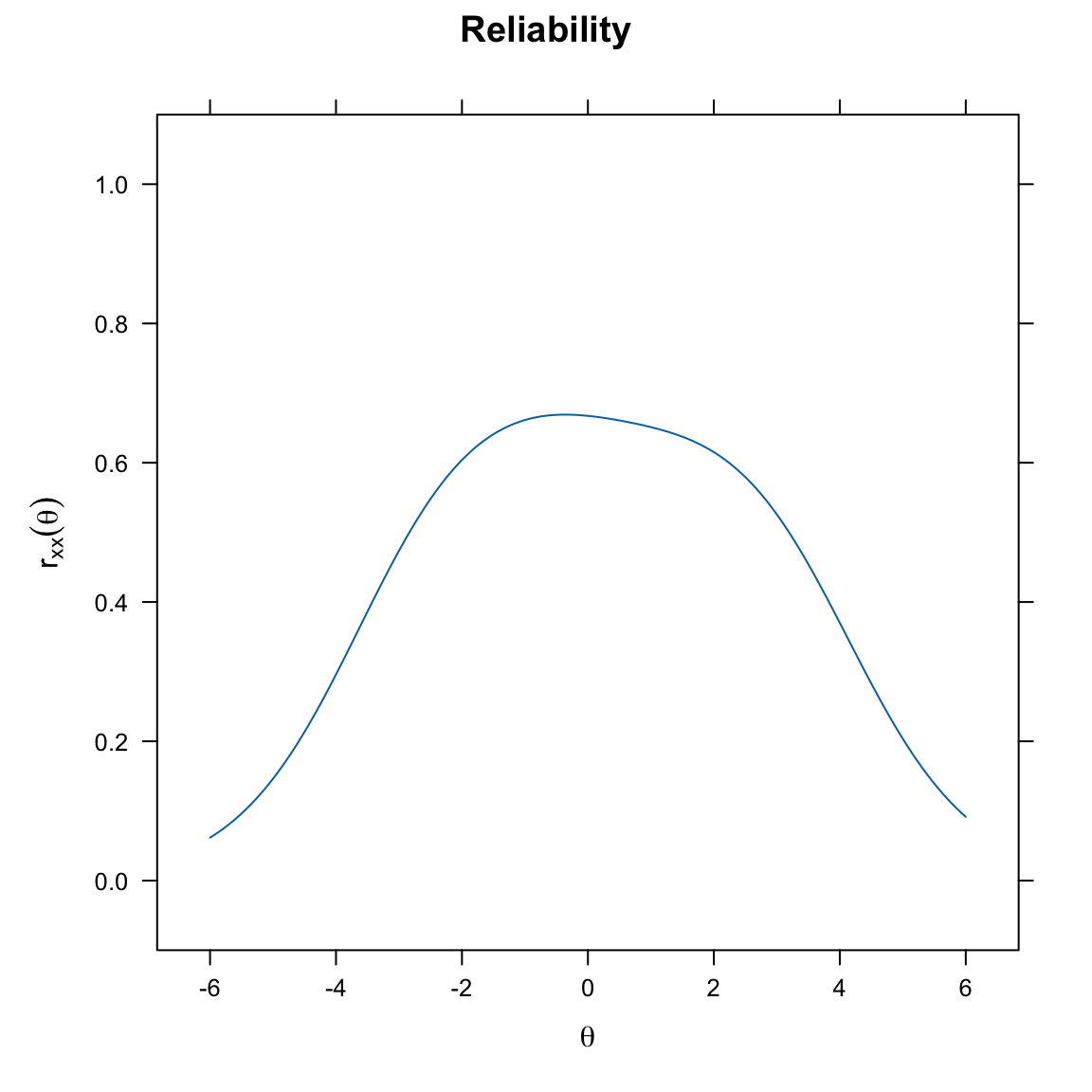
Nel caso presente,
- a livelli medi di \(\theta\): Il test mostra una buona affidabilità, indicando che è in grado di distinguere con precisione tra rispondenti con abilità medie.
- agli estremi di \(\theta\): Il test mostra un’affidabilità più bassa, suggerendo che non è altrettanto efficace nel distinguere tra livelli di abilità molto alti o molto bassi.
In sostanza, l’affidabilità condizionale nell’IRT ci fornisce una comprensione più dettagliata di dove il test funziona bene e dove potrebbe richiedere miglioramenti per valutare con precisione l’abilità su tutta la gamma di theta.
È comunque possibile calcolare un singolo valore di attendibilità:
marginal_rxx(mirt_rm)
#> [1] 0.6982
Il valore riportato (\(r_{xx} = 0.698\)) indica che circa il 70% della varianza osservata nei punteggi stimati è attribuibile al punteggio vero (\(\theta\)), mentre il restante 30% è dovuto all’errore di misura. Questo valore suggerisce che il test stima l’abilità latente \(\theta\) con una precisione accettabile.
71.11 Curva Caratteristica del Test
Una proprietà aggiuntiva di un modello IRT è che il punteggio complessivo delle risposte corrette (la somma dei punteggi per le risposte corrette) risulta essere una stima efficace del tratto latente sottostante. Un grafico della cosiddetta curva caratteristica della scala (scale characteristic curve) permette di valutare visivamente questo aspetto tracciando la relazione tra theta e il punteggio di risposte corrette.
- Questo tipo di grafico mostra come il punteggio totale delle risposte corrette si correla con il livello di abilità latente (theta) stimato dal modello IRT.
- Ad esempio, se la curva mostra che punteggi più alti di risposte corrette corrispondono sistematicamente a livelli più alti di theta e viceversa, ciò indica che il punteggio totale è un buon indicatore del tratto latente.
- Al contrario, se la curva non mostra una relazione chiara o lineare tra punteggio totale e theta, ciò potrebbe suggerire che il punteggio totale non cattura completamente la complessità o le sfumature del tratto latente.
In sintesi, la curva caratteristica della scala fornisce una rappresentazione visiva di come il punteggio totale di risposte corrette rifletta l’abilità latente misurata dal test, offrendo una visione utile per valutare l’efficacia del punteggio totale come indicatore del tratto latente in questione.
scaleCharPlot(mirt_rm)
plot(mirt_rm, type = "score")
Questa curva di solito assume la forma di una S, poiché la relazione è più forte nel range medio di theta e meno precisa agli estremi (come già visto nella curva di informazione del test).
Possiamo ovviamente testare anche questo con una semplice correlazione. Per prima cosa, estraiamo il punteggio latente IRT utilizzando la funzione fscores(). Quindi lo correliamo con il punteggio di risposte corrette.
score <- fscores(mirt_rm)
sumscore <- rowSums(responses)
cor.test(score, sumscore)
#>
#> Pearson's product-moment correlation
#>
#> data: score and sumscore
#> t = 1097, df = 398, p-value <2e-16
#> alternative hypothesis: true correlation is not equal to 0
#> 95 percent confidence interval:
#> 0.9998 0.9999
#> sample estimates:
#> cor
#> 0.9998Nel caso presente, la correlazione è quasi perfetta.
71.12 Riflessioni Conclusive
Tradizionalmente, il punteggio totale ottenuto in un test psicologico è stato considerato come la misura più efficace dell’abilità o della predisposizione di una persona rispetto a un certo tratto di personalità. Tuttavia, la dipendenza del punteggio totale dalla difficoltà degli item presenta limitazioni significative. Ad esempio, due persone possono ottenere lo stesso punteggio totale rispondendo in modo diverso a item di varia difficoltà, il che non riflette accuratamente le loro abilità reali.
Nella Teoria Classica dei Test (CTT), l’enfasi è posta sul punteggio totale, ma questa prospettiva ignora le variazioni nella difficoltà degli item e assume che gli errori di misurazione si annullino reciprocamente attraverso la procedura di sommazione. Tuttavia, la CTT è limitata dalla sua assunzione di varianze di errore uniformi per tutti i rispondenti, dall’aspettativa di errori di misurazione nulli e dalla focalizzazione esclusiva sui punteggi totali, senza considerare l’adattamento di item e persone.
Al contrario, la Teoria della Risposta all’Item (IRT) cambia il focus dai punteggi totali alle risposte a ciascun item, sfruttando le caratteristiche degli item. L’IRT descrive come attributi come abilità, atteggiamento o personalità, insieme alle caratteristiche degli item, influenzino la probabilità di fornire una risposta. Il Modello di Rasch, una forma semplice di IRT per risposte binarie, stabilisce una relazione diretta tra la probabilità di una risposta corretta e il livello di abilità del rispondente.
La stima dell’abilità in IRT non dipende dagli specifici item somministrati, permettendo di confrontare i risultati tra gruppi diversi con lo stesso set di item. Inoltre, la qualità degli item è valutata indipendentemente dal campione di rispondenti, rendendo le proprietà degli item costanti tra diversi gruppi con varie abilità.
L’IRT supera i limiti della CTT stimando congiuntamente le proprietà degli item e il livello di abilità dei rispondenti. Le caratteristiche degli item diventano indipendenti dal campione di individui utilizzato per costruire il test, permettendo la creazione di insiemi di item equivalenti per misurare abilità latenti. Questo approccio offre maggiore precisione e affidabilità nelle misurazioni, assicurando la comparabilità tra diversi gruppi di individui. In conclusione, l’IRT rappresenta un metodo statistico avanzato e versatile per una valutazione più accurata e affidabile di tratti e abilità in contesti psicometrici.
71.13 Session Info
sessionInfo()
#> R version 4.4.2 (2024-10-31)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Sequoia 15.3.2
#>
#> Matrix products: default
#> BLAS: /Library/Frameworks/R.framework/Versions/4.4-arm64/Resources/lib/libRblas.0.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.4-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.0
#>
#> locale:
#> [1] C/UTF-8/C/C/C/C
#>
#> time zone: Europe/Rome
#> tzcode source: internal
#>
#> attached base packages:
#> [1] grid stats4 stats graphics grDevices utils datasets
#> [8] methods base
#>
#> other attached packages:
#> [1] psychotools_0.7-4 ggmirt_0.1.0 TAM_4.2-21 CDM_8.2-6
#> [5] mvtnorm_1.3-3 mirt_1.44.0 lattice_0.22-6 eRm_1.0-6
#> [9] ggokabeito_0.1.0 see_0.11.0 MASS_7.3-65 viridis_0.6.5
#> [13] viridisLite_0.4.2 ggpubr_0.6.0 ggExtra_0.10.1 gridExtra_2.3
#> [17] patchwork_1.3.0 bayesplot_1.11.1 semTools_0.5-6 semPlot_1.1.6
#> [21] lavaan_0.6-19 psych_2.4.12 scales_1.3.0 markdown_1.13
#> [25] knitr_1.50 lubridate_1.9.4 forcats_1.0.0 stringr_1.5.1
#> [29] dplyr_1.1.4 purrr_1.0.4 readr_2.1.5 tidyr_1.3.1
#> [33] tibble_3.2.1 ggplot2_3.5.1 tidyverse_2.0.0 here_1.0.1
#>
#> loaded via a namespace (and not attached):
#> [1] splines_4.4.2 later_1.4.1 R.oo_1.27.0
#> [4] XML_3.99-0.18 rpart_4.1.24 lifecycle_1.0.4
#> [7] Rdpack_2.6.3 rstatix_0.7.2 rprojroot_2.0.4
#> [10] globals_0.16.3 rockchalk_1.8.157 backports_1.5.0
#> [13] magrittr_2.0.3 openxlsx_4.2.8 Hmisc_5.2-3
#> [16] rmarkdown_2.29 yaml_2.3.10 httpuv_1.6.15
#> [19] qgraph_1.9.8 zip_2.3.2 sessioninfo_1.2.3
#> [22] cowplot_1.1.3 pbapply_1.7-2 minqa_1.2.8
#> [25] multcomp_1.4-28 abind_1.4-8 audio_0.1-11
#> [28] quadprog_1.5-8 R.utils_2.13.0 nnet_7.3-20
#> [31] TH.data_1.1-3 sandwich_3.1-1 listenv_0.9.1
#> [34] testthat_3.2.3 vegan_2.6-10 arm_1.14-4
#> [37] parallelly_1.42.0 permute_0.9-7 codetools_0.2-20
#> [40] tidyselect_1.2.1 farver_2.1.2 lme4_1.1-36
#> [43] base64enc_0.1-3 jsonlite_1.9.1 polycor_0.8-1
#> [46] progressr_0.15.1 Formula_1.2-5 survival_3.8-3
#> [49] emmeans_1.10.7 tools_4.4.2 Rcpp_1.0.14
#> [52] glue_1.8.0 mnormt_2.1.1 admisc_0.37
#> [55] xfun_0.51 mgcv_1.9-1 withr_3.0.2
#> [58] beepr_2.0 fastmap_1.2.0 boot_1.3-31
#> [61] digest_0.6.37 mi_1.1 timechange_0.3.0
#> [64] R6_2.6.1 mime_0.13 estimability_1.5.1
#> [67] colorspace_2.1-1 gtools_3.9.5 jpeg_0.1-10
#> [70] R.methodsS3_1.8.2 generics_0.1.3 data.table_1.17.0
#> [73] corpcor_1.6.10 SimDesign_2.19.1 htmlwidgets_1.6.4
#> [76] pkgconfig_2.0.3 sem_3.1-16 gtable_0.3.6
#> [79] brio_1.1.5 htmltools_0.5.8.1 carData_3.0-5
#> [82] png_0.1-8 reformulas_0.4.0 rstudioapi_0.17.1
#> [85] tzdb_0.5.0 reshape2_1.4.4 coda_0.19-4.1
#> [88] checkmate_2.3.2 nlme_3.1-167 nloptr_2.2.1
#> [91] zoo_1.8-13 parallel_4.4.2 miniUI_0.1.1.1
#> [94] foreign_0.8-88 pillar_1.10.1 vctrs_0.6.5
#> [97] promises_1.3.2 car_3.1-3 OpenMx_2.21.13
#> [100] xtable_1.8-4 Deriv_4.1.6 cluster_2.1.8.1
#> [103] dcurver_0.9.2 GPArotation_2024.3-1 htmlTable_2.4.3
#> [106] evaluate_1.0.3 pbivnorm_0.6.0 cli_3.6.4
#> [109] kutils_1.73 compiler_4.4.2 rlang_1.1.5
#> [112] future.apply_1.11.3 ggsignif_0.6.4 labeling_0.4.3
#> [115] fdrtool_1.2.18 plyr_1.8.9 stringi_1.8.4
#> [118] munsell_0.5.1 lisrelToR_0.3 pacman_0.5.1
#> [121] Matrix_1.7-3 hms_1.1.3 glasso_1.11
#> [124] future_1.34.0 shiny_1.10.0 rbibutils_2.3
#> [127] igraph_2.1.4 broom_1.0.7 RcppParallel_5.1.10