here::here("code", "_common.R") |>
source()
# Load packages
if (!requireNamespace("pacman")) install.packages("pacman")
pacman::p_load(
petersenlab, magrittr, viridis, pROC, ROCR, rms, ResourceSelection,
gridExtra, grid, ggpubr, msir, car, ggrepel, MOTE,
tinytex
)83 Predizione
In questo capitolo imparerai a
- conoscere le problematiche di base della predizione statistica;
- calcolare e interpretare la curva ROC e la statistica AUC.
Prerequisiti
- Leggere il capitolo 9 Prediction del testo di Petersen (2024).
Preparazione del Notebook
83.1 Introduzione
Le predizioni rappresentano un aspetto cruciale in numerosi ambiti. Possono riguardare sia dati categoriali, valutabili attraverso strumenti come matrici di confusione e modelli di regressione logistica, sia dati continui, analizzabili tramite regressioni multiple o modelli più complessi come quelli misti o a equazioni strutturali.
Il capitolo si concentra sulla valutazione delle predizioni in contesti categoriali, approfondendo l’utilizzo della curva ROC e dell’AUC (Area Under the Curve) per misurare la qualità dei modelli predittivi.
83.2 Probabilità di una condizione medica
Un esempio classico, discusso da Petersen (2024), illustra il problema di calcolare la probabilità di avere l’HIV (\(P(HIV \mid Test+)\)) partendo da un risultato positivo a un test diagnostico. Le informazioni di base sono:
- Tasso di base dell’HIV (\(P(HIV)\)): 0.3% (0.003), ovvero la probabilità che una persona nella popolazione generale abbia l’HIV.
- Sensibilità del test (\(P(Test+ \mid HIV)\)): 95% (0.95), ovvero la probabilità che il test sia positivo quando la persona ha l’HIV.
- Specificità del test (\(P(Test- \mid \neg HIV)\)): 99.28% (0.9928), ovvero la probabilità che il test sia negativo quando la persona non ha l’HIV.
Utilizziamo il teorema di Bayes per calcolare \(P(HIV \mid Test+)\):
\[ P(HIV \mid Test+) = \frac{P(Test+ \mid HIV) \cdot P(HIV)}{P(Test+)}, \]
dove il denominatore \(P(Test+)\) rappresenta la probabilità complessiva di un test positivo, somma di:
- Veri positivi: \(P(Test+ \mid HIV) \cdot P(HIV)\),
- Falsi positivi: \(P(Test+ \mid \neg HIV) \cdot P(\neg HIV)\).
Con \(P(Test+ \mid \neg HIV) = 1 - P(Test- \mid \neg HIV) = 1 - 0.9928 = 0.0072\), e \(P(\neg HIV) = 1 - P(HIV) = 0.997\), possiamo calcolare:
\[ P(Test+) = (0.95 \cdot 0.003) + (0.0072 \cdot 0.997) \approx 0.010027. \]
Inserendo i valori nella formula di Bayes:
\[ P(HIV \mid Test+) = \frac{0.95 \cdot 0.003}{0.010027} \approx 0.2844 \quad (28.44\%). \]
Un primo test positivo aumenta quindi la probabilità di avere l’HIV al 28.44%.
Dopo un primo test positivo, la probabilità di avere l’HIV è aumentata al 28.44%. Consideriamo ora l’effetto di un secondo test positivo e calcoliamo la probabilità aggiornata di avere l’HIV.
La probabilità di ottenere un secondo test positivo (\(P(\text{Secondo Test+})\)) si calcola considerando due scenari:
-
La persona ha l’HIV:
- Probabilità: \(P(HIV \mid Test+) = 0.2844\),
- Sensibilità del test: \(P(Test+ \mid HIV) = 0.95\).
-
La persona non ha l’HIV:
- Probabilità: \(P(\neg HIV \mid Test+) = 1 - P(HIV \mid Test+) = 0.7156\),
- Tasso di falsi positivi: \(P(Test+ \mid \neg HIV) = 0.0072\).
La probabilità totale è data da:
\[ P(\text{Secondo Test+}) = P(Test+ \mid HIV) \cdot P(HIV \mid Test+) + P(Test+ \mid \neg HIV) \cdot P(\neg HIV \mid Test+). \]
Sostituendo i valori:
\[ P(\text{Secondo Test+}) = (0.95 \cdot 0.2844) + (0.0072 \cdot 0.7156) \approx 0.2753. \]
Aggiorniamo la probabilità di avere l’HIV dopo un secondo test positivo usando nuovamente il teorema di Bayes:
\[ P(HIV \mid \text{Secondo Test+}) = \frac{P(Test+ \mid HIV) \cdot P(HIV \mid Test+)}{P(\text{Secondo Test+})}. \]
Sostituendo i valori:
\[ P(HIV \mid \text{Secondo Test+}) = \frac{0.95 \cdot 0.2844}{0.2753} \approx 0.981 \quad (98.1\%). \]
L’esempio presentato da Petersen (2024) è rilevante per il problema generale della predizione, in quanto illustra come il ragionamento bayesiano consenta di integrare informazioni iniziali e successive per migliorare la precisione delle stime. In particolare, i risultati evidenziano tre aspetti fondamentali:
Tasso di base come punto di partenza cruciale: La probabilità iniziale (prior) di avere l’HIV, pari allo 0.3%, sottolinea quanto sia importante considerare il contesto epidemiologico e demografico nella fase iniziale della predizione. Questo valore guida l’intero processo di aggiornamento e mostra che una condizione rara richiede prove forti per modificarne la probabilità.
Aggiornamento incrementale delle probabilità: Il passaggio da una probabilità del 28.44% dopo un primo test positivo a una probabilità del 98.1% dopo un secondo test positivo evidenzia la potenza del teorema di Bayes nel combinare evidenze successive. Ogni risultato positivo aggiunge informazioni che riducono l’incertezza iniziale, migliorando progressivamente la qualità della predizione.
Valore aggiunto dei test ripetuti: L’analisi dimostra che l’efficacia diagnostica cresce con l’accumularsi di evidenze. Test ripetuti consentono di discriminare meglio tra casi veri positivi e falsi positivi, fornendo stime più affidabili e utili per decisioni cliniche.
Questi risultati mettono in luce l’importanza del ragionamento bayesiano non solo per valutare la probabilità di una condizione medica, ma anche per affrontare una vasta gamma di problemi di predizione in cui l’incertezza iniziale può essere ridotta integrando dati nuovi. L’approccio evidenzia come sia possibile arrivare a conclusioni robuste anche in contesti caratterizzati da bassi tassi di base e test diagnostici non perfetti.
83.3 Accuratezza delle Predizioni
Dopo l’introduzione sull’uso del teorema di Bayes per la predizione, Petersen (2024) affronta il tema delle predizioni con una tabella 2 × 2. Per spiegare questo caso, Petersen (2024) presenta un esempio adattato da Meehl & Rosen (1955).
Immaginiamo che l’esercito americano utilizzi un test per escludere i candidati con basse probabilità di completare l’addestramento di base. Per analizzare l’accuratezza delle predizioni effettuate, possiamo utilizzare una matrice di confusione, che confronta le predizioni del test con i risultati reali.
| Decisione (Predizione) | Adattamento Effettivo (Scarso) | Adattamento Effettivo (Buono) | Totale Predetto | Rapporto di Selezione (SR) |
|---|---|---|---|---|
| Escludere | TP = 86 (0.043) | FP = 422 (0.211) | 508 | SR = 0.254 |
| Trattenere | FN = 14 (0.007) | TN = 1.478 (0.739) | 1,492 | 1 − SR = 0.746 |
| Totale Effettivo | 100 | 1,900 | N = 2,000 | |
| Tasso di Base (BR) | BR = 0.05 | 1 − BR = 0.95 |
83.3.1 La Matrice di Confusione
La matrice di confusione è uno strumento che mette in relazione le predizioni di un modello con i risultati osservati. Nel caso di una predizione binaria (es. sì/no o positivo/negativo), la matrice è organizzata in quattro categorie:
- Vero Positivo (TP): La predizione corretta che identifica una persona con la caratteristica (es. cattivo adattamento).
- Vero Negativo (TN): La predizione corretta che identifica una persona senza la caratteristica.
- Falso Positivo (FP): L’errore in cui si predice la presenza della caratteristica quando in realtà non è presente.
- Falso Negativo (FN): L’errore in cui si predice l’assenza della caratteristica quando in realtà è presente.
Questi quattro risultati consentono di valutare l’accuratezza di un modello.
83.3.2 Tassi Marginali e Indicatori Chiave
Dalla matrice di confusione possiamo calcolare alcuni tassi e indicatori utili:
Tasso di Base (BR): La probabilità che una persona abbia la caratteristica di interesse. Ad esempio: \[ BR = \frac{FN + TP}{N} = \frac{100}{2000} = 0.05 \] Ciò significa che solo il 5% dei candidati ha un cattivo adattamento.
Rapporto di Selezione (SR): La probabilità di essere esclusi dal programma: \[ SR = \frac{TP + FP}{N} = \frac{508}{2000} = 0.254 \] In questo caso, il 25,4% dei candidati è stato escluso.
Percentuale di Accuratezza: Rappresenta la proporzione di predizioni corrette sul totale: \[ \text{Accuratezza} = 100 \times \frac{TP + TN}{N} = 100 \times \frac{86 + 1478}{2000} = 78\% \]
Accuratezza per Caso: Misura la precisione che si otterrebbe effettuando predizioni casuali basate solo sulle probabilità marginali (BR e SR). Per esempio: \[ P(TP) = BR \times SR = 0.05 \times 0.254 = 0.0127 \] \[ P(TN) = (1 − BR) \times (1 − SR) = 0.95 \times 0.746 = 0.7087 \] \[ \text{Accuratezza per Caso} = P(TP) + P(TN) = 0.0127 + 0.7087 = 0.7214 \, (72,14\%) \]
Confrontando il 78% di accuratezza del modello con il 72.14% ottenibile per caso, il modello fornisce un miglioramento del 6%.
83.3.3 L’Importanza del Tasso di Base
Quando il tasso di base è molto basso (come in questo caso, BR = 0.05), l’accuratezza complessiva può essere ingannevole. Se predicessimo che nessuno ha un cattivo adattamento, otterremmo un’accuratezza del 95%, ma il modello non identificherebbe alcun caso di cattivo adattamento.
| Decisione (Predizione) | Adattamento Effettivo (Scarso) | Adattamento Effettivo (Buono) | Totale Predetto |
|---|---|---|---|
| Escludere | TP = 0 | FP = 0 | 0 |
| Trattenere | FN = 100 | TN = 1,900 | 2,000 |
| Totale Effettivo | 100 | 1,900 | N = 2,000 |
In questo caso, l’accuratezza complessiva sarebbe: \[ P(\text{Accuratezza}) = \frac{TP + TN}{N} = \frac{0 + 1900}{2000} = 95\%. \]
Questo esempio evidenzia che un’elevata accuratezza complessiva non garantisce un buon modello, specialmente quando il tasso di base è sbilanciato.
In conclusione, l’analisi di una matrice di confusione richiede attenzione ai tassi di base e agli errori, poiché l’accuratezza globale può essere fuorviante. È essenziale confrontare il valore del modello con ciò che si otterrebbe per caso o con strategie alternative, come basarsi solo sul tasso di base. Inoltre, occorre considerare il peso relativo degli errori (falsi positivi e falsi negativi) in base al contesto applicativo. Questi aspetti saranno discussi nel prossimo paragrafo.
83.3.4 Diversi Tipi di Errori e i loro Costi
In un processo di classificazione, non tutti gli errori hanno lo stesso costo. Esistono due tipi principali di errori: i falsi positivi e i falsi negativi, ciascuno con implicazioni diverse che dipendono dal contesto della predizione.
Spesso, l’accuratezza complessiva può essere aumentata affidandosi semplicemente al tasso di base, ma in molte situazioni può essere preferibile utilizzare uno strumento di screening, anche a costo di una minore accuratezza complessiva, se ciò consente di minimizzare errori specifici che hanno costi elevati. Ad esempio:
Screening medico: Consideriamo uno strumento di screening per l’HIV. I falsi positivi (classificare erroneamente una persona come a rischio) comportano costi come la necessità di test di conferma e, talvolta, ansia temporanea per l’individuo. Tuttavia, un falso negativo (non identificare una persona effettivamente a rischio) ha costi molto più alti, poiché potrebbe portare a un mancato intervento precoce, con conseguenze gravi per la salute. In questo caso, i costi associati ai falsi negativi superano di gran lunga quelli dei falsi positivi, rendendo lo screening preferibile nonostante una diminuzione dell’accuratezza complessiva.
Selezione del personale in situazioni di rischio: La CIA, ad esempio, ha utilizzato strumenti di selezione per identificare potenziali spie durante periodi di guerra. Un falso positivo in questo contesto (considerare erroneamente una persona come una spia) potrebbe risultare nell’esclusione di un candidato innocente. Un falso negativo (assumere una persona che è effettivamente una spia) comporta rischi molto più gravi, rendendo cruciale l’identificazione corretta delle spie, anche a costo di più falsi positivi.
Il modo in cui i costi degli errori vengono valutati dipende fortemente dal contesto. Alcuni potenziali costi dei falsi positivi includono trattamenti medici non necessari o il rischio di incarcerare una persona innocente. Al contrario, i falsi negativi possono portare al rilascio di una persona pericolosa, alla mancata individuazione di una malattia grave, o al mancato riconoscimento di un rischio imminente.
83.3.5 Importanza del Rapporto di Selezione e del Tasso di Base
Il costo degli errori può variare a seconda di come si imposta il rapporto di selezione (cioè, quanto rigorosamente si applica il criterio per accettare o escludere un individuo). La scelta di un rapporto di selezione meno restrittivo o più restrittivo influisce sulla probabilità di incorrere in falsi positivi e falsi negativi e può dipendere dal contesto e dai costi associati agli errori.
- Criterio meno rigido: Se escludere candidati è costoso, ad esempio quando si ha la necessità di assumere molte persone, potrebbe essere più utile un criterio di selezione permissivo, che accetta anche persone con un rischio potenziale.
- Criterio più rigido: In contesti in cui non è necessario accettare molti individui, si può adottare un criterio di selezione più rigido per ridurre i rischi, scartando un numero maggiore di candidati sospetti.
Quando il rapporto di selezione differisce dal tasso di base degli esiti negativi effettivi, inevitabilmente si generano errori:
- Se, ad esempio, il rapporto di selezione prevede di escludere il 25% dei candidati, ma solo il 5% risulta effettivamente “non idoneo,” il risultato sarà un numero elevato di falsi positivi.
- D’altro canto, se si esclude solo l’1% dei candidati mentre il tasso di non idoneità è del 5%, si finirà per includere molti falsi negativi.
83.3.6 Predizioni e Affidabilità in Condizioni di Basso Tasso di Base
Fare predizioni accurate diventa particolarmente complesso quando il tasso di base è basso, come nel caso di eventi rari (ad esempio, il suicidio). In questi casi, il numero di casi positivi reali è molto ridotto, rendendo difficile identificare correttamente i pochi eventi positivi senza generare numerosi falsi positivi o falsi negativi.
Questa difficoltà può essere compresa in relazione alla teoria classica dei test, che definisce l’affidabilità come il rapporto tra la varianza del punteggio vero e la varianza del punteggio osservato. Con un tasso di base molto basso, la varianza del punteggio vero è ridotta, il che abbassa l’affidabilità della misura e rende più complessa una predizione accurata.
83.3.7 Sensibilità, Specificità, PPV e NPV
Come abbiamo visto, la percentuale di accuratezza da sola non è sufficiente per valutare l’efficacia di un modello, poiché è molto influenzata dai tassi di base. Ad esempio, se il tasso di base è basso, potremmo ottenere un’alta percentuale di accuratezza semplicemente affermando che nessuno ha la condizione; se è alto, affermando che tutti ce l’hanno. Perciò, è essenziale considerare altre metriche di accuratezza, come sensibilità (SN), specificità (SP), valore predittivo positivo (PPV) e valore predittivo negativo (NPV).
Queste metriche, che si possono calcolare dalla matrice di confusione, ci aiutano a valutare se il modello è efficace nel rilevare la condizione senza includere erroneamente i casi negativi. Analizziamole in dettaglio:
-
Sensibilità (SN): indica la capacità del test di identificare correttamente i veri positivi, cioè le persone con la condizione. Si calcola come la proporzione di veri positivi (\(\text{TP}\)) rispetto al totale di persone con la condizione (\(\text{TP} + \text{FN}\)):
\[ \frac{\text{TP}}{\text{TP} + \text{FN}} = \frac{86}{86 + 14} = 0.86 \]
-
Specificità (SP): misura la capacità del test di identificare correttamente i veri negativi, ossia le persone senza la condizione. Si calcola come la proporzione di veri negativi (\(\text{TN}\)) rispetto al totale di persone senza la condizione (\(\text{TN} + \text{FP}\)):
\[ \frac{\text{TN}}{\text{TN} + \text{FP}} = \frac{1,478}{1,478 + 422} = 0.78 \]
-
Valore Predittivo Positivo (PPV): indica la probabilità che una persona classificata come positiva abbia effettivamente la condizione. Si calcola come la proporzione di veri positivi (\(\text{TP}\)) sul totale dei positivi stimati (\(\text{TP} + \text{FP}\)):
\[ \frac{\text{TP}}{\text{TP} + \text{FP}} = \frac{86}{86 + 422} = 0.17 \]
-
Valore Predittivo Negativo (NPV): rappresenta la probabilità che una persona classificata come negativa non abbia effettivamente la condizione. Si calcola come la proporzione di veri negativi (\(\text{TN}\)) sul totale dei negativi stimati (\(\text{TN} + \text{FN}\)):
\[ \frac{\text{TN}}{\text{TN} + \text{FN}} = \frac{1,478}{1,478 + 14} = 0.99 \]
Ogni misura è espressa come una proporzione, variando da 0 a 1, dove valori più alti indicano una maggiore accuratezza per ciascun aspetto specifico. Usando queste metriche otteniamo un quadro dettagliato dell’efficacia dello strumento a un determinato cutoff.
In questo caso, il nostro strumento mostra:
- Alta sensibilità (0.86): è efficace nel rilevare chi ha la condizione.
- Bassa specificità (0.78): classifica erroneamente come positivi molti casi che non hanno la condizione.
- Basso PPV (0.17): la maggior parte dei casi classificati come positivi sono in realtà negativi, indicando una frequenza elevata di falsi positivi.
- Alto NPV (0.99): quasi tutti i casi classificati come negativi non hanno la condizione.
Quindi, pur avendo una buona capacità di rilevare i positivi (alta sensibilità), il modello è meno efficace nel limitare i falsi positivi (basso PPV). Questo potrebbe essere accettabile se l’obiettivo è identificare tutti i potenziali casi positivi, anche a costo di includere molti falsi positivi, ma potrebbe non essere ideale se il costo degli errori di falsa positività è elevato.
83.4 Stime di Accuratezza e Cutoff
Sensibilità, specificità, PPV e NPV variano in base al cutoff (ovvero, la soglia) per la classificazione. Consideriamo il seguente esempio. Degli alieni visitano la Terra e sviluppano un test per determinare se una bacca è commestibile o non commestibile.
sampleSize <- 1000
edibleScores <- rnorm(sampleSize, 50, 15)
inedibleScores <- rnorm(sampleSize, 100, 15)
edibleData <- data.frame(score = c(edibleScores, inedibleScores), type = c(rep("edible", sampleSize), rep("inedible", sampleSize)))
cutoff <- 75
hist_edible <- density(edibleScores, from = 0, to = 150) %$%
data.frame(x = x, y = y) %>%
mutate(area = x >= cutoff)
hist_edible$type[hist_edible$area == TRUE] <- "edible_FP"
hist_edible$type[hist_edible$area == FALSE] <- "edible_TN"
hist_inedible <- density(inedibleScores, from = 0, to = 150) %$%
data.frame(x = x, y = y) %>%
mutate(area = x < cutoff)
hist_inedible$type[hist_inedible$area == TRUE] <- "inedible_FN"
hist_inedible$type[hist_inedible$area == FALSE] <- "inedible_TP"
density_data <- bind_rows(hist_edible, hist_inedible)
density_data$type <- factor(density_data$type, levels = c("edible_TN", "inedible_TP", "edible_FP", "inedible_FN"))La figura successiva mostra le distribuzioni dei punteggi in base al tipo di bacca. Si può notare come ci sono due distribuzioni distinte, ma con una certa sovrapposizione. Pertanto, qualsiasi cutoff selezionato comporterà almeno alcune classificazioni errate. L’entità della sovrapposizione delle distribuzioni riflette la quantità di errore di misurazione dello strumento rispetto alla caratteristica di interesse.
ggplot(data = edibleData, aes(x = score, ymin = 0, fill = type)) +
geom_density(alpha = .5) +
scale_fill_manual(
name = "Tipo di Bacca", values = c(viridis(2)[1], viridis(2)[2])
) +
scale_y_continuous(name = "Frequenza") 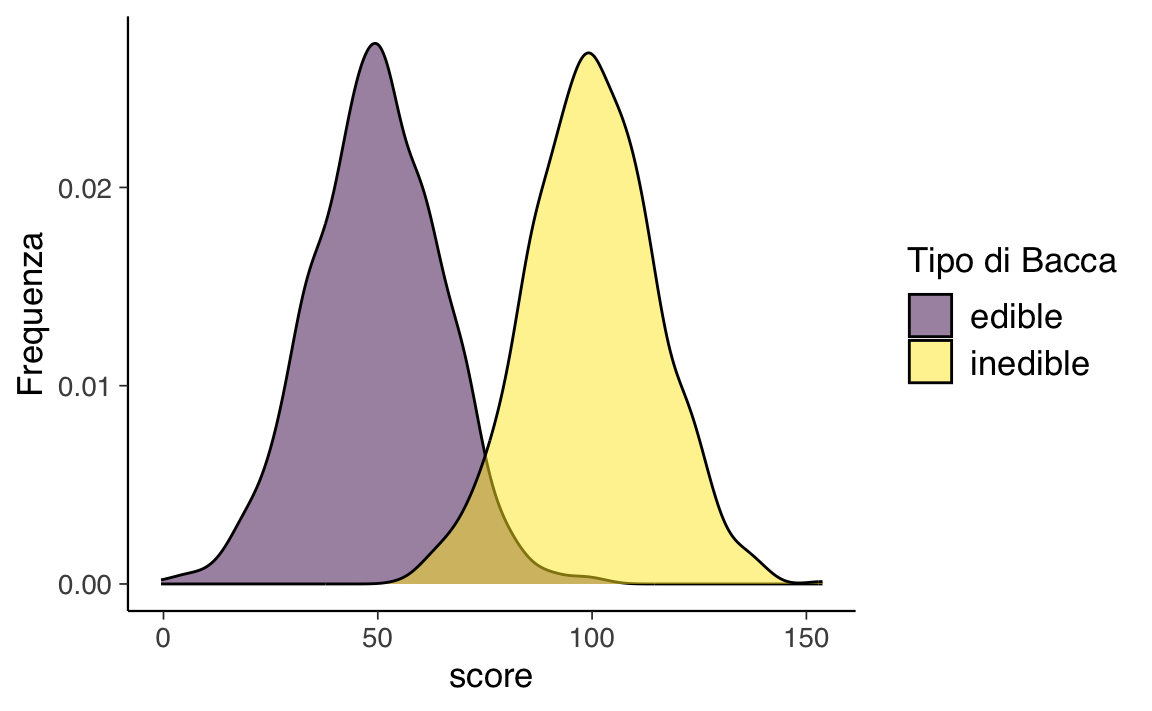
La figura successiva mostra le distribuzioni dei punteggi in base al tipo di bacca con un cutoff. La linea rossa indica il cutoff: il livello al di sopra del quale le bacche vengono classificate come non commestibili. Ci sono errori su entrambi i lati del cutoff. Sotto il cutoff, ci sono dei falsi negativi (blu): bacche non commestibili erroneamente classificate come commestibili. Sopra il cutoff, ci sono dei falsi positivi (verde): bacche commestibili erroneamente classificate come non commestibili. I costi dei falsi negativi potrebbero includere malattia o morte derivanti dal consumo di bacche non commestibili, mentre i costi dei falsi positivi potrebbero includere maggiore tempo per trovare cibo, insufficienza di cibo e fame.
ggplot(data = density_data, aes(x = x, ymin = 0, ymax = y, fill = type)) +
geom_ribbon(alpha = 1) +
scale_fill_manual(
name = "Tipo di Bacca",
values = c(viridis(4)[4], viridis(4)[1], viridis(4)[3], viridis(4)[2]),
breaks = c("edible_TN", "inedible_TP", "edible_FP", "inedible_FN"),
labels = c(
"Commestibile: TN", "Non Commestibile: TP",
"Commestibile: FP", "Non Commestibile: FN")
) +
geom_line(aes(y = y)) +
geom_vline(xintercept = cutoff, color = "red", linewidth = 2) +
scale_x_continuous(name = "Punteggio") +
scale_y_continuous(name = "Frequenza") 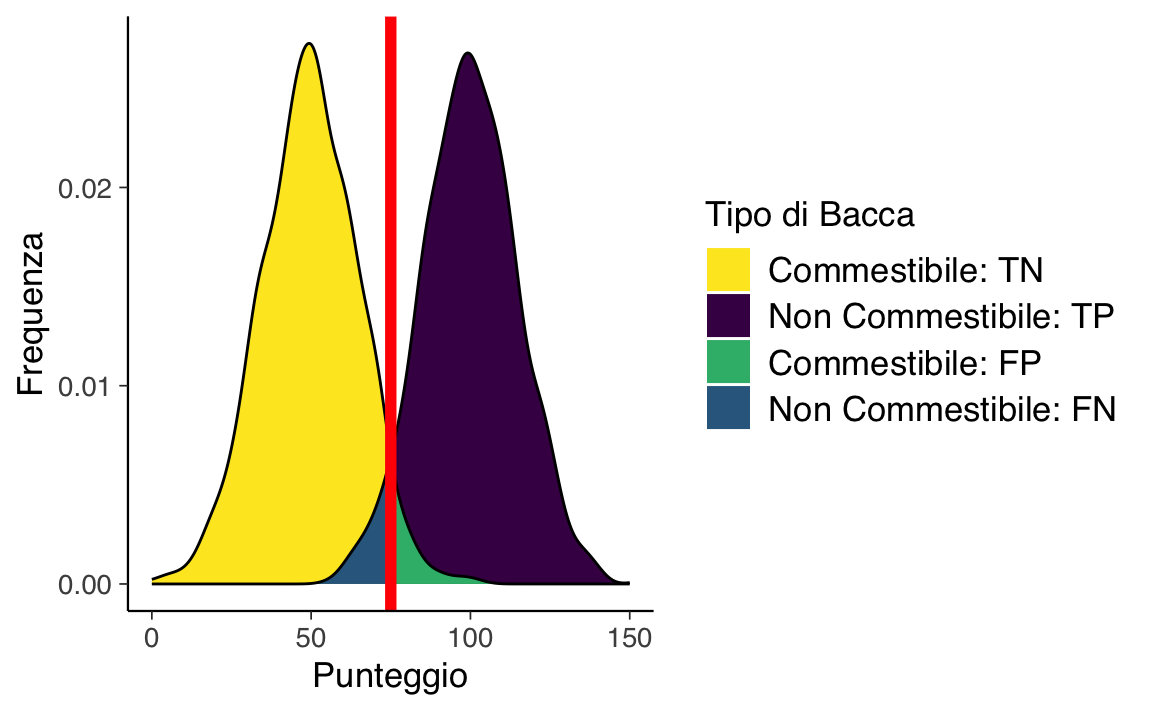
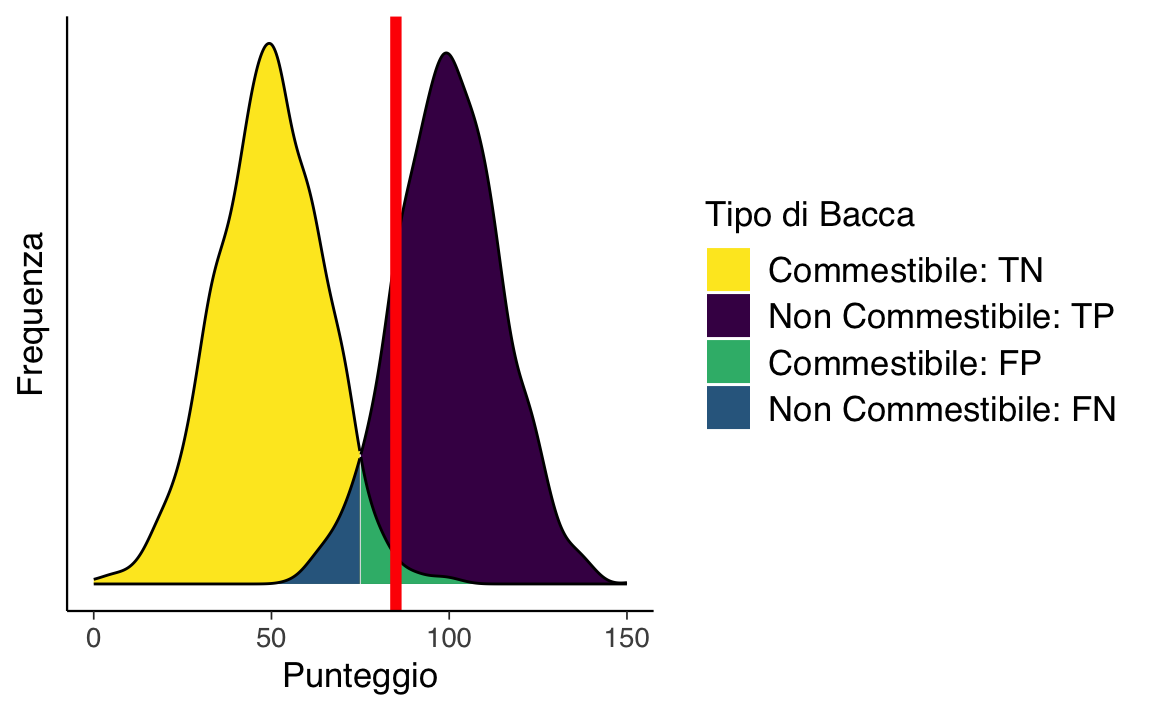
A seconda dei nostri obiettivi di valutazione, potremmo voler usare un diverso rapporto di selezione modificando il cutoff. La Figura mostra le distribuzioni dei punteggi quando si aumenta il cutoff. Ora ci sono più falsi negativi (blu) e meno falsi positivi (verde). Se alziamo il cutoff per essere più conservativi, il numero di falsi negativi aumenta, mentre il numero di falsi positivi diminuisce. Di conseguenza, aumentando il cutoff, la sensibilità e il valore predittivo negativo (NPV) diminuiscono, mentre la specificità e il valore predittivo positivo (PPV) aumentano. Un cutoff più alto potrebbe essere ottimale se i costi dei falsi positivi sono considerati superiori a quelli dei falsi negativi. Ad esempio, se gli alieni non possono rischiare di mangiare bacche non commestibili perché sono fatali, e ci sono abbastanza bacche commestibili per nutrire la colonia aliena.
# Raise the cutoff
cutoff <- 85
ggplot(data = density_data, aes(x = x, ymin = 0, ymax = y, fill = type)) +
geom_ribbon(alpha = 1) +
scale_fill_manual(
name = "Tipo di Bacca",
values = c(viridis(4)[4], viridis(4)[1], viridis(4)[3], viridis(4)[2]),
breaks = c("edible_TN", "inedible_TP", "edible_FP", "inedible_FN"),
labels = c(
"Commestibile: TN", "Non Commestibile: TP",
"Commestibile: FP", "Non Commestibile: FN")
) +
geom_line(aes(y = y)) +
geom_vline(xintercept = cutoff, color = "red", linewidth = 2) +
scale_x_continuous(name = "Punteggio") +
scale_y_continuous(name = "Frequenza") +
theme(
axis.text.y = element_blank(),
axis.ticks.y = element_blank()
)
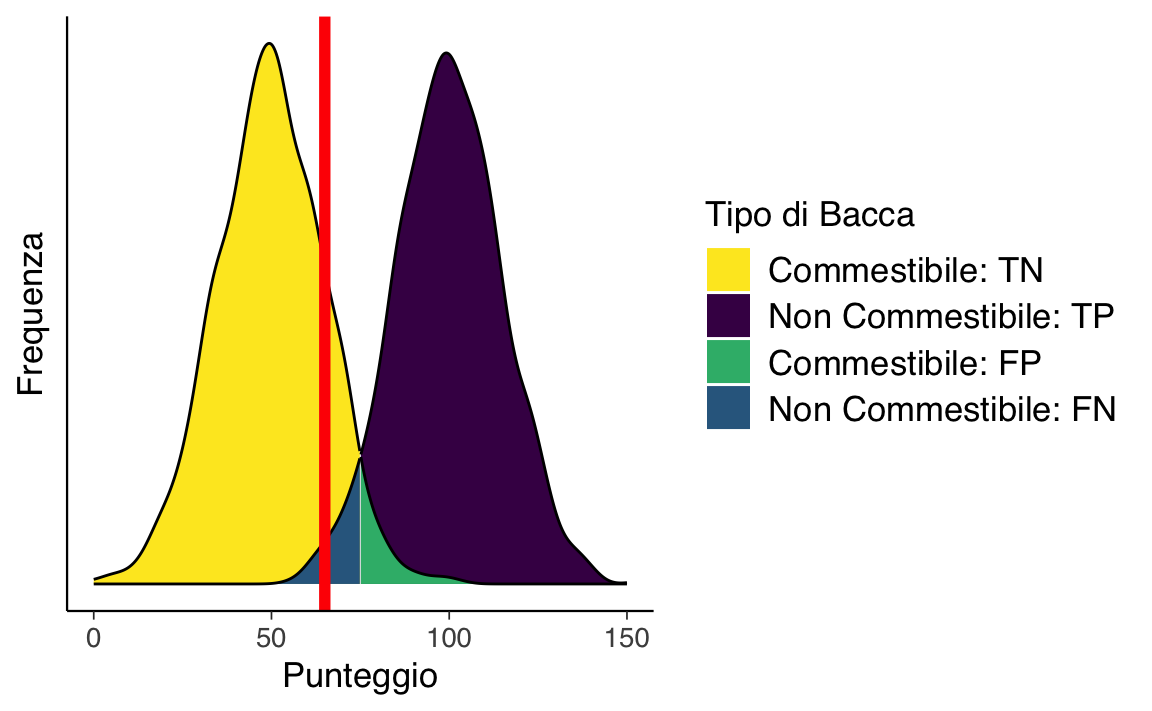
In alternativa, possiamo abbassare il cutoff per essere più liberali. La Figura seguente mostra le distribuzioni dei punteggi quando abbassiamo il cutoff. Ora ci sono meno falsi negativi (blu) e più falsi positivi (verde). Abbassando il cutoff, la sensibilità e il NPV aumentano, mentre la specificità e il PPV diminuiscono. Un cutoff più basso potrebbe essere ottimale se i costi dei falsi negativi sono considerati superiori a quelli dei falsi positivi. Ad esempio, se gli alieni non possono rischiare di perdere bacche commestibili perché sono scarse, e mangiare bacche non commestibili comporta solo disagi temporanei.
# Lower the cutoff
cutoff <- 65
ggplot(data = density_data, aes(x = x, ymin = 0, ymax = y, fill = type)) +
geom_ribbon(alpha = 1) +
scale_fill_manual(
name = "Tipo di Bacca",
values = c(viridis(4)[4], viridis(4)[1], viridis(4)[3], viridis(4)[2]),
breaks = c("edible_TN", "inedible_TP", "edible_FP", "inedible_FN"),
labels = c(
"Commestibile: TN", "Non Commestibile: TP",
"Commestibile: FP", "Non Commestibile: FN")
) +
geom_line(aes(y = y)) +
geom_vline(xintercept = cutoff, color = "red", linewidth = 2) +
scale_x_continuous(name = "Punteggio") +
scale_y_continuous(name = "Frequenza") +
theme(
axis.text.y = element_blank(),
axis.ticks.y = element_blank()
)
In sintesi, sensibilità e specificità variano in base al cutoff utilizzato per la classificazione. Se aumentiamo il cutoff, la specificità e il PPV aumentano, mentre la sensibilità e il NPV diminuiscono. Se abbassiamo il cutoff, la sensibilità e il NPV aumentano, mentre la specificità e il PPV diminuiscono. Pertanto, il cutoff ottimale dipende dai costi associati ai falsi negativi e ai falsi positivi. Se i falsi negativi sono più costosi, dovremmo impostare un cutoff basso; se i falsi positivi sono più costosi, dovremmo impostare un cutoff alto.
83.5 Teoria della Detezione del Segnale
La Teoria della Detezione del Segnale (Signal Detection Theory, SDT) è un approccio probabilistico che descrive la capacità di rilevare uno stimolo target (segnale) in un contesto di stimoli non target (rumore). Sviluppata durante la Seconda Guerra Mondiale per ottimizzare le prestazioni di radar e sonar, questa teoria distingue tra due aspetti fondamentali: sensibilità e bias.
Sensibilità
La sensibilità quantifica l’abilità di discriminare tra segnale e rumore, indipendentemente dalle tendenze decisionali. È una misura della qualità del sistema di rilevamento.Bias
Il bias riflette la tendenza dell’osservatore a rispondere in modo conservativo o liberale, cioè a sovrastimare o sottostimare la presenza del segnale, influenzando la soglia decisionale.
Originariamente impiegata per la selezione e l’addestramento degli operatori radar, la SDT ha trovato applicazioni in numerosi settori moderni. In medicina, ad esempio, viene utilizzata per valutare la capacità di diagnosticare patologie come tumori o infezioni. In psicologia, la SDT ha contribuito a studiare processi percettivi e decisionali, come la percezione sociale, evidenziando differenze sistematiche nella sensibilità e nel bias tra individui o gruppi.
83.5.1 Metriche Principali
La SDT introduce metriche specifiche per quantificare sensibilità e bias:
-
\(d'\): misura la sensibilità, rappresentando la separazione statistica tra distribuzioni di segnale e rumore.
- \(\beta\), \(c\), \(b\): diverse misure del bias decisionale, che descrivono l’inclinazione del soggetto verso risposte più conservative o liberali.
83.6 Curva ROC e AUC
La curva ROC (Receiver Operating Characteristic) è uno strumento essenziale per l’analisi delle prestazioni di modelli di classificazione binaria, particolarmente utile per visualizzare il compromesso tra sensibilità e specificità. Questa curva è strettamente connessa alla Signal Detection Theory (SDT), che fornisce una base teorica per comprendere i processi decisionali sotto incertezza.
Mentre la SDT descrive i principi fondamentali del processo decisionale, la curva ROC rappresenta un’applicazione pratica che consente di analizzare come la variazione della soglia decisionale influenzi le prestazioni del modello. Questa analisi è particolarmente utile per identificare soglie che ottimizzino il bilanciamento tra errori di classificazione (falsi positivi e falsi negativi).
83.6.1 Definizione e Significato
La curva ROC visualizza il compromesso tra sensibilità (True Positive Rate, TPR) e 1-specificità (False Positive Rate, FPR) al variare della soglia decisionale. Ogni punto della curva rappresenta una combinazione specifica di questi due indicatori.
- Sensibilità (TPR): proporzione di casi positivi correttamente classificati rispetto al totale dei veri positivi.
- 1-Specificità (FPR): proporzione di falsi positivi rispetto al totale dei veri negativi.
83.6.1.1 Costruzione della Curva ROC
- Calcolo di TPR e FPR: Si definiscono diverse soglie per il modello e, per ciascuna, si calcolano i valori di sensibilità e 1-specificità.
- Grafico bidimensionale: La sensibilità è rappresentata sull’asse y, mentre 1-specificità è riportata sull’asse x.
- Interpretazione: Una curva che si avvicina all’angolo superiore sinistro indica prestazioni elevate, con alta sensibilità e specificità. Una curva vicina alla diagonale principale rappresenta invece un modello privo di capacità discriminativa.
83.6.2 Area Sotto la Curva (AUC)
L’Area Under the Curve (AUC) è una misura aggregata della capacità del modello di distinguere tra classi. È definita come l’area sotto la curva ROC e può assumere valori compresi tra 0.5 (discriminazione casuale) e 1 (classificazione perfetta).
83.6.2.1 Interpretazione dei Valori di AUC
- AUC = 1: Il modello distingue perfettamente tra classi positive e negative.
- 0.9 ≤ AUC < 1: Prestazioni eccellenti.
- 0.75 ≤ AUC < 0.9: Buone prestazioni.
- 0.5 ≤ AUC < 0.75: Prestazioni moderate.
- AUC = 0.5: Nessuna capacità discriminativa (classificazione casuale).
83.6.3 Limiti della Curva ROC e dell’AUC
Sebbene la curva ROC e l’AUC siano strumenti utili, presentano alcune limitazioni che devono essere considerate per una corretta interpretazione.
83.6.3.1 Problema dei Base Rate
I base rate rappresentano la prevalenza di ciascuna classe nella popolazione. In dataset sbilanciati, l’AUC può essere fuorviante, poiché misura le prestazioni globali senza distinguere tra le difficoltà nella classificazione delle diverse classi.
Ad esempio, un modello potrebbe ottenere un AUC elevato classificando correttamente quasi tutti i casi della classe più frequente, trascurando però le prestazioni sulla classe meno rappresentata. Questo problema è particolarmente rilevante in applicazioni critiche, come la diagnosi di malattie rare, dove l’accuratezza della classe minoritaria è cruciale.
83.6.4 La Base Rate Fallacy e i Limiti dell’AUC
La Base Rate Fallacy si manifesta quando i tassi di prevalenza di un evento (i cosiddetti base rate) vengono ignorati nell’interpretazione delle probabilità o nella valutazione delle prestazioni di un modello. Questo errore è particolarmente rilevante nei contesti in cui una delle due classi è molto meno frequente dell’altra.
Ad esempio, consideriamo un test diagnostico con un’accuratezza del 90% per una malattia rara che colpisce solo l’1% della popolazione. Anche se il test sembra altamente affidabile, il numero di falsi positivi potrebbe essere molto elevato rispetto ai veri positivi, a causa della bassa prevalenza della malattia. Di conseguenza, il valore predittivo positivo (probabilità che un individuo con test positivo sia realmente malato) sarebbe molto basso, rendendo il test di scarsa utilità pratica nonostante un AUC apparentemente elevato.
83.6.4.1 Limiti dell’AUC
Pur essendo una misura aggregata utile per valutare le prestazioni complessive di un modello, l’AUC presenta alcune importanti limitazioni:
Insensibilità ai Base Rate
L’AUC non tiene conto della distribuzione delle classi, il che può portare a valutazioni fuorvianti in presenza di classi sbilanciate. Un modello potrebbe ottenere un AUC elevato classificando correttamente quasi tutti i casi della classe dominante, ignorando però quelli della classe meno rappresentata.Mancanza di Dettagli sulle Soglie
Essendo una misura aggregata, l’AUC non fornisce informazioni sulle prestazioni del modello a una soglia decisionale specifica. Questo può rappresentare un limite pratico quando è necessario scegliere un cutoff ottimale per massimizzare le prestazioni in un determinato contesto applicativo.Trattamento Simmetrico degli Errori
L’AUC considera falsi positivi e falsi negativi come equivalenti. Tuttavia, in molti contesti reali (ad esempio, in ambito medico), questi errori hanno conseguenze molto diverse, e il loro bilanciamento può essere cruciale.Sovrastima delle Prestazioni in Dataset Sbilanciati
Nei dataset con classi fortemente sbilanciate, l’AUC può mascherare le difficoltà del modello nel trattare correttamente la classe meno rappresentata, portando a una sopravvalutazione delle sue prestazioni globali.
In sintesi, sebbene la curva ROC e l’AUC siano strumenti fondamentali per l’analisi delle prestazioni dei modelli di classificazione, devono essere utilizzati con consapevolezza dei loro limiti. In contesti caratterizzati da base rate sbilanciati, è importante integrare queste metriche con altre, come i valori predittivi positivo e negativo, o analisi mirate delle soglie decisionali.
Una valutazione completa delle prestazioni di un modello richiede di considerare il contesto applicativo, i costi relativi degli errori di classificazione e le implicazioni pratiche delle decisioni prese sulla base dei risultati del modello. Solo così è possibile ottimizzare il processo decisionale e garantire l’utilità del modello nelle applicazioni reali.
83.6.5 Esempio in R
In questo esempio, utilizziamo un dataset simulato che rappresenta i punteggi ottenuti da un questionario psicologico sullo stress percepito e la loro associazione con l’appartenenza a due gruppi: basso stress e alto stress.
Creiamo un dataset con 200 partecipanti, suddivisi equamente tra i due gruppi:
# Generazione del dataset simulato
set.seed(123)
n <- 200
# Creazione di variabili
group <- factor(
rep(c("Basso", "Alto"), each = n / 2),
levels = c("Basso", "Alto")
)
stress_score <- c(
rnorm(n / 2, mean = 50, sd = 10), # Gruppo basso stress
rnorm(n / 2, mean = 70, sd = 10) # Gruppo alto stress
)
# Creazione del dataframe
data_stress <- data.frame(
group = group,
stress_score = stress_score
)
# Visualizzazione delle prime righe
head(data_stress)
#> group stress_score
#> 1 Basso 44.40
#> 2 Basso 47.70
#> 3 Basso 65.59
#> 4 Basso 50.71
#> 5 Basso 51.29
#> 6 Basso 67.15Il dataset contiene:
-
group: Gruppo di appartenenza (Basso o Alto stress percepito). -
stress_score: Punteggio del questionario sullo stress percepito (variabile continua).
83.6.5.1 Generazione della Curva ROC
Utilizziamo la curva ROC per valutare la capacità del questionario di distinguere tra i due gruppi.
# Generazione della curva ROC
rocCurve <- roc(data_stress$group, data_stress$stress_score)Visualizziamo il grafico della curva ROC e calcoliamo l’AUC:
# Visualizzazione della curva ROC
plot(rocCurve, legacy.axes = TRUE, print.auc = TRUE)83.6.5.2 Calcolo di Punti sulla Curva ROC per Soglie Specifiche
Fissiamo una serie di soglie per classificare i partecipanti in base al punteggio di stress percepito. Classifichiamo i partecipanti come “Alto stress” se il loro punteggio è superiore o uguale alla soglia, altrimenti come “Basso stress”.
# Definiamo diverse soglie
thresholds <- seq(0, 100, by = 5)
# Funzione per calcolare sensibilità e specificità
calc_metrics <- function(threshold, data) {
# Predizione basata sulla soglia
predicted <- factor(
ifelse(data$stress_score <= threshold, "Alto", "Basso"),
levels = c("Alto", "Basso")
)
# Gruppo osservato
actual <- factor(data$group, levels = c("Alto", "Basso"))
# Matrice di confusione
conf_matrix <- table(Predicted = predicted, Actual = actual)
# Estrarre metriche dalla matrice di confusione
TP <- conf_matrix["Alto", "Alto"]
FP <- conf_matrix["Alto", "Basso"]
TN <- conf_matrix["Basso", "Basso"]
FN <- conf_matrix["Basso", "Alto"]
# Calcolo di sensibilità e specificità
sensitivity <- TP / (TP + FN)
specificity <- TN / (TN + FP)
# Restituzione dei risultati
return(list(
threshold = threshold,
sensitivity = sensitivity,
specificity = specificity,
fpr = 1 - specificity
))
}
# Calcolo metriche per ogni soglia
results <- lapply(thresholds, function(t) calc_metrics(t, data_stress))
# Estrazione dei valori per il plotting
fpr_values <- sapply(results, function(x) x$fpr)
sens_values <- sapply(results, function(x) x$sensitivity)
# Invertire y per calcolare i punti richiesti
points_inverted <- list(x = fpr_values, y = 1 - sens_values)
# Visualizzazione della curva ROC
plot(rocCurve, legacy.axes = TRUE, print.auc = TRUE)
# Plot dei punti con colori appropriati
points(points_inverted$x, points_inverted$y, col = "green", pch = 19, cex = 0.8)
# Aggiunta di etichette per soglie selezionate
selected_thresholds <- seq(0, 100, by = 20)
for (threshold in selected_thresholds) {
idx <- which(thresholds == threshold)
if (length(idx) > 0) {
text(
points_inverted$x[idx],
points_inverted$y[idx],
labels = threshold,
pos = 3,
cex = 0.7
)
}
}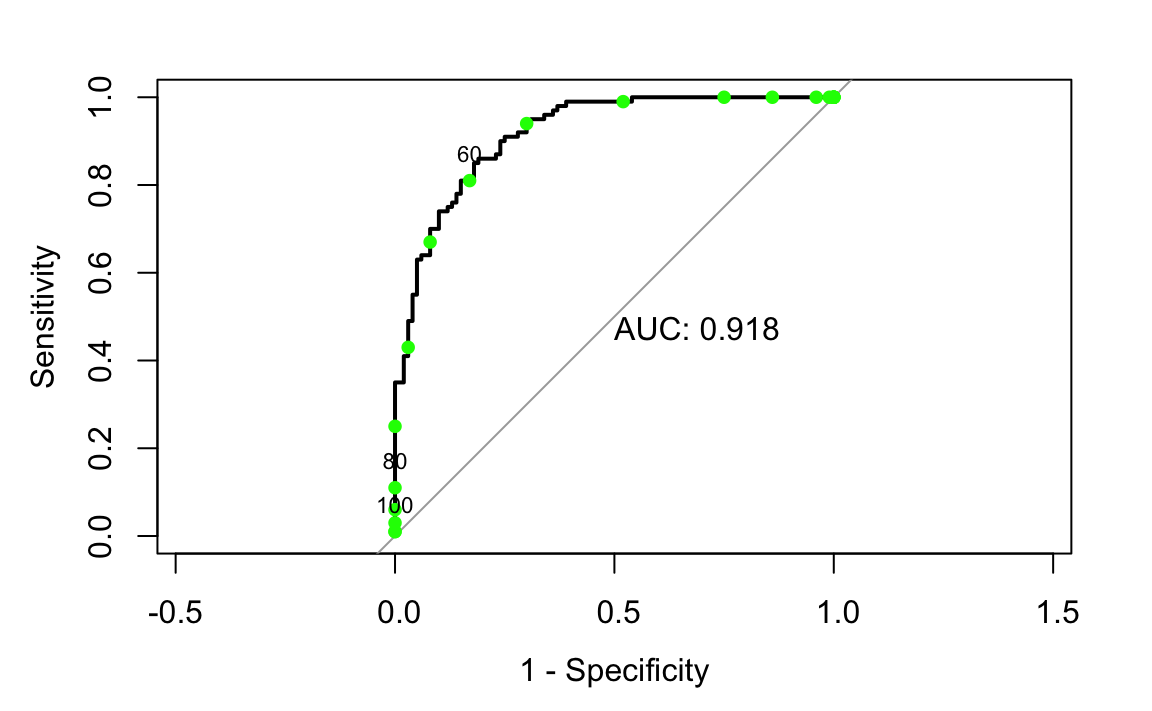
La curva ROC permette di valutare l’abilità di un modello di distinguere tra due gruppi (ad esempio, “Basso stress” e “Alto stress”). Ogni punto sulla curva ROC corrisponde a una soglia specifica utilizzata per classificare i partecipanti. Per calcolare questi punti, seguiamo i seguenti passaggi:
1. Definizione delle Soglie. Le soglie sono valori specifici del punteggio continuo (stress_score) che separano i gruppi. Per ogni soglia:
- I partecipanti con punteggio ≥ soglia vengono classificati come “Alto stress”.
- I partecipanti con punteggio < soglia vengono classificati come “Basso stress”.
2. Sensibilità e Specificità. Per ogni soglia, calcoliamo due metriche fondamentali:
- Sensibilità (True Positive Rate, TPR): proporzione di partecipanti del gruppo “Alto stress” classificati correttamente.
- Specificità: proporzione di partecipanti del gruppo “Basso stress” classificati correttamente. La False Positive Rate (FPR) è complementare alla specificità: \(\text{FPR} = 1 - \text{Specificità}\).
3. Logica della Funzione calc_metrics. La funzione prende una soglia e il dataset come input. I passaggi principali sono:
- Classificazione: per ogni partecipante, confrontiamo il punteggio con la soglia per assegnare la classe predetta.
-
Matrice di Confusione: costruiamo una tabella che confronta le classificazioni predette con quelle osservate per calcolare i seguenti valori:
- TP (True Positives): numero di “Alto stress” predetti correttamente.
- FP (False Positives): numero di “Basso stress” classificati erroneamente come “Alto stress”.
- TN (True Negatives): numero di “Basso stress” classificati correttamente.
- FN (False Negatives): numero di “Alto stress” classificati erroneamente come “Basso stress”.
- Metriche: calcoliamo sensibilità, specificità e FPR.
4. Calcolo e Visualizzazione dei Punti.
- Per ciascuna soglia nella sequenza definita (
seq(0, 100, by = 5)), la funzione calcola le metriche. - I valori di FPR (asse \(x\)) e sensibilità (asse \(y\)) vengono estratti per costruire i punti ROC.
- La curva ROC viene tracciata utilizzando la funzione
roc, mentre i punti calcolati manualmente vengono aggiunti al grafico per confrontarli.
Questa parte del codice calcola e traccia i punti ROC per ogni soglia:
# Calcolo delle metriche per ogni soglia
results <- lapply(thresholds, function(t) calc_metrics(t, data_stress))
# Estrazione di FPR e sensibilità per il plotting
fpr_values <- sapply(results, function(x) x$fpr)
sens_values <- sapply(results, function(x) x$sensitivity)
# Visualizzazione dei punti ROC sul grafico
points(fpr_values, 1 - sens_values, col = "green", pch = 19, cex = 0.8)
# Aggiunta di etichette alle soglie selezionate
selected_thresholds <- seq(0, 100, by = 20)
for (threshold in selected_thresholds) {
idx <- which(thresholds == threshold)
if (length(idx) > 0) {
text(
fpr_values[idx],
1 - sens_values[idx],
labels = threshold,
pos = 3,
cex = 0.7
)
}
}- Inversione di \(y\): per allineare i punti calcolati alla curva ROC, si usa \(1 - \text{Sensibilità}\) sull’asse \(y\). Questo perché la curva ROC calcola direttamente la sensibilità, mentre i punti manuali la confrontano come \(1 - \text{Specificità}\) sull’asse \(x\).
- Punti e Etichette: i punti calcolati vengono evidenziati in verde e annotati con i valori delle soglie.
In sintesi, il grafico finale mostra la curva ROC completa generata automaticamente e i punti calcolati manualmente. Le etichette sulle soglie forniscono informazioni su come il comportamento del modello varia al variare della soglia. Questo approccio permette di comprendere i concetti dietro la costruzione della curva ROC e come ogni soglia influenzi le metriche di classificazione.
Per una rappresentazione più fluida, applichiamo una lisciatura:
# Curva ROC lisciata
plot(
roc(data_stress$group, data_stress$stress_score, smooth = TRUE),
legacy.axes = TRUE, print.auc = TRUE
)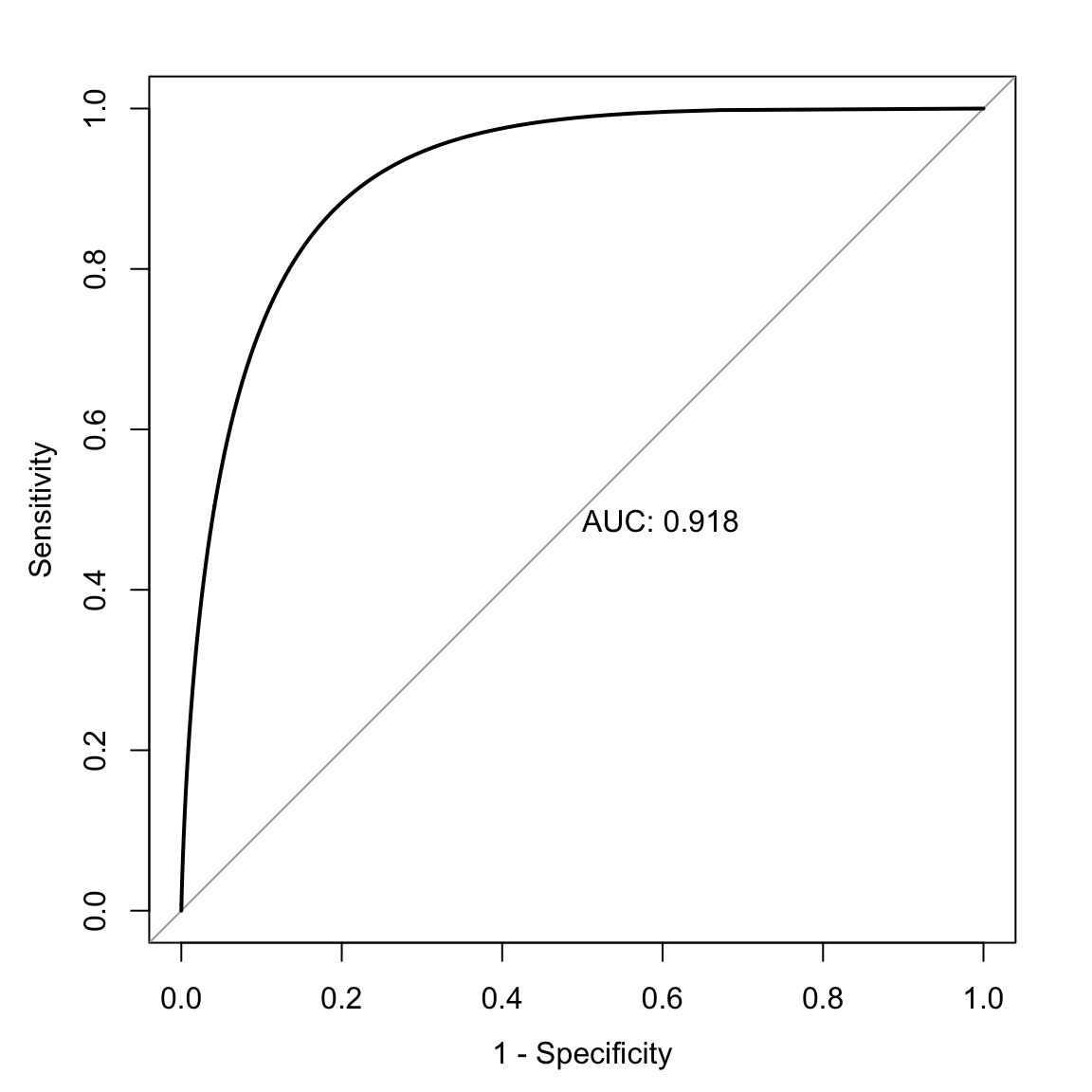
Nel nostro esempio, il valore di AUC ≈ 0.92 indica che il questionario sullo stress percepito ha un’ottima capacità di distinguere tra i due gruppi, essendo molto vicino al valore massimo di 1. Questo risultato evidenzia che il questionario possiede una combinazione di elevata sensibilità e specificità, rendendolo uno strumento efficace per discriminare tra persone con basso e alto stress percepito.
In sintesi, l’analisi dimostra che:
- il questionario è un valido strumento diagnostico;
- l’approccio ROC è utile per valutare l’efficacia di un test psicologico nella distinzione tra gruppi con caratteristiche diverse, come livelli di stress, depressione o ansia.
Questo esempio illustra l’applicazione pratica della curva ROC nel contesto psicologico, sottolineando il suo valore nell’analisi dell’accuratezza di strumenti diagnostici e questionari.
83.7 Riflessioni Conclusive
L’analisi delle prestazioni dei modelli predittivi è un aspetto centrale in numerosi ambiti applicativi, dalla psicologia fino all’intelligenza artificiale. Questo capitolo ha esplorato strumenti e concetti fondamentali per valutare l’accuratezza e l’affidabilità di modelli di classificazione, sottolineando come ciascuno di essi possa contribuire a migliorare la qualità delle decisioni in condizioni di incertezza.
Uno dei temi chiave affrontati riguarda l’importanza di metriche come sensibilità, specificità, valore predittivo positivo (PPV) e valore predittivo negativo (NPV), che offrono una descrizione dettagliata delle prestazioni di un modello in relazione ai suoi errori (falsi positivi e falsi negativi). Queste metriche, derivate dalla matrice di confusione, non solo consentono di misurare l’accuratezza complessiva, ma permettono anche di adattare l’interpretazione del modello alle esigenze specifiche del contesto applicativo:
- Sensibilità e specificità descrivono rispettivamente la capacità del modello di rilevare correttamente i positivi e di escludere correttamente i negativi.
- PPV e NPV forniscono informazioni sulla probabilità che una predizione del modello corrisponda alla realtà, tenendo conto della prevalenza delle classi (tasso di base).
La matrice di confusione rappresenta una base analitica essenziale, da cui derivare tassi marginali e indicatori chiave. Tuttavia, è stato evidenziato come l’accuratezza globale possa risultare fuorviante in presenza di tassi di base sbilanciati, poiché essa può essere dominata dalla classe più frequente. Per questo motivo, l’interpretazione delle prestazioni di un modello richiede sempre un’analisi approfondita, che includa sia gli errori commessi che i costi associati a tali errori.
La curva ROC (Receiver Operating Characteristic) e l’AUC (Area Under the Curve) costituiscono strumenti avanzati per analizzare le prestazioni dei modelli predittivi, offrendo un quadro completo della capacità discriminativa del modello al variare delle soglie decisionali. L’AUC, in particolare, sintetizza in un singolo valore la qualità del modello, rendendo possibile il confronto tra diversi approcci anche in presenza di tassi di base molto diversi. Tuttavia, è stato sottolineato come il valore aggregato dell’AUC debba essere interpretato con cautela, in quanto non fornisce informazioni dettagliate sulle prestazioni a soglie specifiche.
Un altro tema affrontato riguarda il teorema di Bayes, applicato a contesti diagnostici per aggiornare la probabilità di una condizione sulla base di nuove evidenze. Questo approccio ha evidenziato l’importanza di integrare informazioni iniziali (priori) con nuove osservazioni (dati) per ridurre l’incertezza e migliorare la precisione delle stime. L’esempio del test diagnostico per l’HIV ha illustrato come l’aggiornamento progressivo delle probabilità consenta di ottenere stime più affidabili anche in contesti caratterizzati da bassi tassi di base e test diagnostici imperfetti.
Infine, sono state discusse le implicazioni pratiche legate alla scelta delle soglie decisionali, al bilanciamento tra diversi tipi di errori e alla gestione delle distribuzioni sbilanciate. In particolare, è stato evidenziato come la selezione del cutoff ottimale debba essere guidata non solo dalle prestazioni globali del modello, ma anche dai costi associati agli errori di classificazione in un dato contesto.
In sintesi, questo capitolo ha fornito una panoramica delle principali metodologie per la valutazione delle predizioni, combinando strumenti tradizionali come la matrice di confusione e il teorema di Bayes con approcci avanzati come la curva ROC e l’AUC. Questi strumenti, utilizzati in modo complementare, consentono di affrontare con rigore e flessibilità le sfide della classificazione, guidando verso decisioni informate e ottimizzate in base alle esigenze specifiche di ciascun contesto applicativo.
Informazioni sull’Ambiente di Sviluppo
sessionInfo()
#> R version 4.4.2 (2024-10-31)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Sequoia 15.3.2
#>
#> Matrix products: default
#> BLAS: /Library/Frameworks/R.framework/Versions/4.4-arm64/Resources/lib/libRblas.0.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.4-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.0
#>
#> locale:
#> [1] C/UTF-8/C/C/C/C
#>
#> time zone: Europe/Rome
#> tzcode source: internal
#>
#> attached base packages:
#> [1] grid stats graphics grDevices utils datasets methods
#> [8] base
#>
#> other attached packages:
#> [1] tinytex_0.56 MOTE_1.0.2 ggrepel_0.9.6
#> [4] car_3.1-3 carData_3.0-5 msir_1.3.3
#> [7] ResourceSelection_0.3-6 rms_7.0-0 Hmisc_5.2-3
#> [10] ROCR_1.0-11 pROC_1.18.5 magrittr_2.0.3
#> [13] petersenlab_1.1.0 ggokabeito_0.1.0 see_0.11.0
#> [16] MASS_7.3-65 viridis_0.6.5 viridisLite_0.4.2
#> [19] ggpubr_0.6.0 ggExtra_0.10.1 gridExtra_2.3
#> [22] patchwork_1.3.0 bayesplot_1.11.1 semTools_0.5-6
#> [25] semPlot_1.1.6 lavaan_0.6-19 psych_2.4.12
#> [28] scales_1.3.0 markdown_1.13 knitr_1.50
#> [31] lubridate_1.9.4 forcats_1.0.0 stringr_1.5.1
#> [34] dplyr_1.1.4 purrr_1.0.4 readr_2.1.5
#> [37] tidyr_1.3.1 tibble_3.2.1 ggplot2_3.5.1
#> [40] tidyverse_2.0.0 here_1.0.1
#>
#> loaded via a namespace (and not attached):
#> [1] splines_4.4.2 later_1.4.1 polspline_1.1.25
#> [4] XML_3.99-0.18 rpart_4.1.24 lifecycle_1.0.4
#> [7] Rdpack_2.6.3 rstatix_0.7.2 rprojroot_2.0.4
#> [10] lattice_0.22-6 rockchalk_1.8.157 backports_1.5.0
#> [13] openxlsx_4.2.8 rmarkdown_2.29 yaml_2.3.10
#> [16] httpuv_1.6.15 qgraph_1.9.8 zip_2.3.2
#> [19] pbapply_1.7-2 DBI_1.2.3 minqa_1.2.8
#> [22] RColorBrewer_1.1-3 multcomp_1.4-28 abind_1.4-8
#> [25] quadprog_1.5-8 nnet_7.3-20 TH.data_1.1-3
#> [28] sandwich_3.1-1 arm_1.14-4 MatrixModels_0.5-3
#> [31] codetools_0.2-20 tidyselect_1.2.1 farver_2.1.2
#> [34] lme4_1.1-36 stats4_4.4.2 base64enc_0.1-3
#> [37] jsonlite_1.9.1 Formula_1.2-5 survival_3.8-3
#> [40] emmeans_1.10.7 tools_4.4.2 Rcpp_1.0.14
#> [43] glue_1.8.0 mnormt_2.1.1 xfun_0.51
#> [46] mgcv_1.9-1 withr_3.0.2 fastmap_1.2.0
#> [49] mitools_2.4 boot_1.3-31 SparseM_1.84-2
#> [52] digest_0.6.37 mi_1.1 timechange_0.3.0
#> [55] R6_2.6.1 mime_0.13 estimability_1.5.1
#> [58] colorspace_2.1-1 mix_1.0-13 gtools_3.9.5
#> [61] jpeg_0.1-10 generics_0.1.3 data.table_1.17.0
#> [64] corpcor_1.6.10 htmlwidgets_1.6.4 pkgconfig_2.0.3
#> [67] sem_3.1-16 gtable_0.3.6 htmltools_0.5.8.1
#> [70] png_0.1-8 reformulas_0.4.0 rstudioapi_0.17.1
#> [73] tzdb_0.5.0 reshape2_1.4.4 coda_0.19-4.1
#> [76] checkmate_2.3.2 nlme_3.1-167 nloptr_2.2.1
#> [79] zoo_1.8-13 parallel_4.4.2 miniUI_0.1.1.1
#> [82] foreign_0.8-88 pillar_1.10.1 reshape_0.8.9
#> [85] vctrs_0.6.5 promises_1.3.2 OpenMx_2.21.13
#> [88] xtable_1.8-4 cluster_2.1.8.1 htmlTable_2.4.3
#> [91] evaluate_1.0.3 pbivnorm_0.6.0 ez_4.4-0
#> [94] mvtnorm_1.3-3 cli_3.6.4 kutils_1.73
#> [97] compiler_4.4.2 rlang_1.1.5 ggsignif_0.6.4
#> [100] labeling_0.4.3 fdrtool_1.2.18 mclust_6.1.1
#> [103] plyr_1.8.9 stringi_1.8.4 munsell_0.5.1
#> [106] MBESS_4.9.3 lisrelToR_0.3 pacman_0.5.1
#> [109] quantreg_6.1 Matrix_1.7-3 hms_1.1.3
#> [112] glasso_1.11 shiny_1.10.0 rbibutils_2.3
#> [115] igraph_2.1.4 broom_1.0.7 RcppParallel_5.1.10