here::here("code", "_common.R") |>
source()
# Load packages
if (!requireNamespace("pacman")) install.packages("pacman")
pacman::p_load(
lavaan, lavaanExtra, lavaanPlot, lavaan, psych, mvnormalTest, semPlot,
DiagrammeRsvg, rsvg, effectsize
)43 Confronto tra modelli
In questo capitolo imparerai a:
Prerequisiti
- Leggere il capitolo Structural Equation Modeling del testo di Petersen (2024).
Preparazione del Notebook
43.1 Introduzione
I ricercatori spesso confrontano modelli alternativi di equazioni strutturali che includono le stesse variabili e sono adattati agli stessi dati. Il contesto più frequente si verifica quando un singolo modello iniziale viene testato attraverso una serie di passaggi. Ad ogni passaggio, il modello iniziale viene ridefinito aggiungendo uno o più parametri liberi, il che generalmente migliora l’adattamento, oppure eliminando (fissando a zero) uno o più parametri liberi, il che generalmente peggiora l’adattamento. Una coppia di modelli alternativi così specificata viene definita “modelli nidificati”, poiché il modello più semplice dei due, o modello vincolato, è un sottoinsieme proprio del modello più complesso, o modello non vincolato. Un contesto diverso si verifica quando ci sono due o più modelli iniziali tali che (1) ogni modello si basa su una teoria diversa e (2) i modelli alternativi non sono nidificati nella loro relazione l’uno con l’altro. In entrambi i contesti, la scelta tra modelli concorrenti dovrebbe essere guidata tanto da basi concettuali quanto da considerazioni statistiche.
43.2 Confrontare Modelli nel SEM
Nel contesto dei Modelli di Equazioni Strutturali (SEM), un aspetto critico è il confronto tra diversi modelli per determinare quale sia il più adeguato. Questo confronto si presenta frequentemente nella forma di analisi di modelli nidificati. In tale contesto, si confronta un modello considerato “pieno” o “meno restrittivo” con un altro modello che è “ridotto” o “più restrittivo”.
Il modello pieno include un insieme più ampio di parametri e ipotesi, offrendo una rappresentazione più complessa delle relazioni tra le variabili. Al contrario, il modello ridotto è una versione più semplificata, con meno parametri e ipotesi, risultando in una struttura più contenuta e potenzialmente più parsimoniosa.
Questo tipo di confronto è cruciale per valutare l’adeguatezza dei modelli SEM, permettendo ai ricercatori di decidere se la complessità aggiuntiva del modello pieno sia giustificata rispetto al modello ridotto in termini di adattamento ai dati e coerenza con la teoria sottostante.
43.3 Analisi dei Modelli Nidificati
Nell’ambito dei Modelli di Equazioni Strutturali (SEM), i modelli nidificati occupano un ruolo centrale. Due modelli sono definiti come nidificati quando soddisfano specifici criteri gerarchici, delineati come segue:
-
Formazione del Modello Vincolato:
- Si crea un modello vincolato applicando una o più restrizioni a un modello non vincolato esistente. Questo processo aumenta i gradi di libertà del modello vincolato (C) rispetto a quelli del modello non vincolato (U), risultando in \(\text{df}_C > \text{df}_U\).
-
Differenze nei Gradi di Libertà:
- La differenza \(\text{df}_C - \text{df}_U\) rappresenta il numero di restrizioni imposte al modello non vincolato per creare il modello vincolato, che equivale alla variazione nel numero di parametri liberi tra i due modelli.
-
Parametri Liberi e Vincolati:
- I parametri liberi nel modello vincolato costituiscono un sottoinsieme di quelli presenti nel modello non vincolato. Allo stesso modo, i parametri fissi nel modello non vincolato formano un sottoinsieme di quelli nel modello vincolato.
-
Confronto dei Valori di Chi-Quadro:
- Tra i due modelli, il valore di \(\chi^2\) è minore o uguale nel modello non vincolato rispetto a quello nel modello vincolato, ovvero \(\chi^2_U \leq \chi^2_C\). Questo implica che le distribuzioni di probabilità possibili nel modello vincolato sono comprese anche nel modello non vincolato, che può tuttavia suggerire ulteriori distribuzioni non coerenti con il modello vincolato.
Questo tipo di relazione gerarchica, conosciuta come annidamento dei parametri, permette di valutare l’impatto di specifiche restrizioni o aggiunte di parametri. Ad esempio, un parametro libero in un modello non vincolato può essere fissato a zero, eliminando di conseguenza l’effetto corrispondente nel modello vincolato, oppure può essere sottoposto a un vincolo specificato dal ricercatore, riducendo così il numero di parametri liberi ma mantenendo l’effetto nel modello vincolato.
Consideriamo, per esempio, un modello di percorso non vincolato U con effetti diretti: \(X \rightarrow Y_1 \rightarrow Y_2\) e \(X \rightarrow Y_2\). Ridefinendo il percorso \(X \rightarrow Y_2 = 0\), eliminiamo questa connessione dal modello U, generando così il modello vincolato C1, nidificato sotto U. Un’alternativa potrebbe essere imporre un vincolo di uguaglianza tra \(X\rightarrow Y_2\) e \(Y_1 \rightarrow Y_2\), indicando che gli effetti diretti non standardizzati di \(X\) e \(Y_1\) su \(Y_2\) sono identici. Questo produce un modello vincolato, C2, con un parametro libero in meno rispetto a U ma che include tutti i percorsi di U.
Nelle prossime sezioni, esamineremo come testare le ipotesi inerenti a questi modelli nidificati e come valutare la loro adeguatezza nel contesto SEM.
43.4 Strategie di Costruzione e Potatura nei Modelli SEM
43.4.1 Costruzione Progressiva del Modello
La costruzione di modelli SEM inizia tipicamente con un modello iniziale semplice e vincolato, che riflette le ipotesi fondamentali basate su teorie sostanziali. Questo approccio, detto anche ricerca in avanti, implica l’aggiunta progressiva di parametri liberi che rappresentano ipotesi precedentemente escluse, in base alla loro importanza. Sebbene questo processo possa generalmente migliorare l’adattamento del modello (riduzione di chiML), un adattamento migliore non è necessariamente indicativo di una maggiore correttezza del modello. La costruzione del modello può teoricamente proseguire fino a quando non si raggiunge un modello perfettamente adatto ai dati (dfM = 0), ma è essenziale valutare la validità teorica e la parsimonia del modello in ogni passaggio.
43.4.2 Potatura Retrograda del Modello
In contrasto, la potatura del modello, o ricerca all’indietro, inizia con un modello più complesso e non vincolato. In questa fase, il ricercatore semplifica il modello eliminando parametri liberi (fissandoli a zero) o imponendo vincoli di stima. Questo processo richiede di dare priorità alle ipotesi in ordine inverso di importanza. Il modello iniziale dovrebbe essere congruente con i dati, altrimenti non ha senso restringerlo ulteriormente. Tipicamente, come si procede con la potatura, l’adattamento complessivo del modello ai dati tende a peggiorare (aumento di chiML). Il criterio per arrestare la potatura si basa sull’adattamento del modello: si ferma quando ulteriori restrizioni peggiorerebbero significativamente l’adattamento ai dati.
43.4.3 Obiettivi e Considerazioni
L’obiettivo sia nella costruzione che nella potatura di modelli è identificare un modello con una struttura di covarianza (e, se presente, anche di media) correttamente specificata e teoricamente giustificata. Idealmente, entrambi gli approcci dovrebbero convergere verso lo stesso modello ottimale, benché ciò non sia garantito. È importante evitare il rischio di formulare ipotesi post hoc (HARKing), presentando modelli scoperti in modo esplorativo come se fossero stati ipotizzati a priori. Una soluzione a questo problema è la preregistrazione del piano di analisi.
43.4.4 Punti di Forza Relativi
- Costruzione del Modello: Partire da un modello più semplice può essere vantaggioso, soprattutto per i neofiti del SEM, poiché facilita l’identificazione statistica e riduce il rischio di errori nella specificazione del modello.
- Potatura del Modello: Questo approccio può essere particolarmente efficace per i modelli di misurazione, dove le variabili osservate sono usate come indicatori di un numero limitato di fattori comuni. Un modello di misurazione correttamente specificato inizialmente può rendere la potatura più efficace rispetto alla costruzione.
In entrambi i casi, è cruciale basare le decisioni su solide basi teoriche oltre che su considerazioni statistiche, per assicurare che il modello finale sia non solo adatto ai dati ma anche coerente con il quadro teorico sottostante.
43.5 Strategie di Ridefinizione dei Modelli SEM: Approcci Teorici ed Empirici
43.5.1 Approccio Teorico nella Ridefinizione dei Modelli
Nel processo di costruzione o potatura dei Modelli di Equazioni Strutturali (SEM), l’approccio teorico gioca un ruolo fondamentale. Qui, le modifiche al modello sono guidate da ipotesi teoriche predefinite e specifiche. Ad esempio, considerando un modello di percorso non vincolato U con le relazioni \(X \rightarrow Y_1 \rightarrow Y_2\) e \(X \rightarrow Y_2\), un ricercatore potrebbe ipotizzare che l’effetto di X su Y2 sia esclusivamente indiretto attraverso Y1. Questa ipotesi può essere testata vincolando il coefficiente di \(X \rightarrow Y_2\) a zero. Se l’adattamento del modello così modificato non è significativamente inferiore rispetto al modello non vincolato, l’ipotesi di un effetto indiretto viene supportata, a patto che la direzionalità delle relazioni sia corretta.
Questo approccio enfatizza che le modifiche al modello dovrebbero essere effettuate sulla base di solide basi teoriche e concettuali, piuttosto che su criteri puramente statistici, come evidenziato da Jöreskog (1969): “La decisione di smettere di aggiungere parametri non può basarsi solo su una base statistica; ciò dipende in gran parte dall’interpretazione dei dati da parte del ricercatore, basata su considerazioni teoriche e concettuali sostanziali.”
43.5.2 Approccio Empirico nella Ridefinizione dei Modelli
Al contrario, l’approccio empirico nella costruzione o potatura dei modelli SEM si basa su criteri statistici. In questo scenario, i parametri liberi vengono aggiunti o eliminati a seconda della loro significatività statistica o di altri indicatori empirici. Per esempio, se i percorsi sono eliminati solo perché i loro coefficienti non sono statisticamente significativi, la ridefinizione del modello è guidata da considerazioni puramente empiriche. Questo approccio è analogo alla tecnica di eliminazione all’indietro nella regressione multipla, dove il software sceglie quali predittori rimuovere in base a criteri di significatività statistica.
43.5.3 Implicazioni per l’Interpretazione dei Modelli
La scelta tra un approccio teorico o empirico nella ridefinizione dei modelli SEM ha implicazioni significative per come interpretiamo i risultati. Un modello modificato in base a criteri teorici forti offre una maggiore fiducia nella validità delle sue conclusioni, mentre un modello costruito o potato basandosi principalmente su criteri empirici può essere soggetto a errori di Tipo I o II e può non essere replicabile in campioni diversi.
È fondamentale che i ricercatori si avvicinino alla costruzione e alla potatura dei modelli SEM con un equilibrio tra intuizioni teoriche e risultati empirici, per assicurare che i modelli finali siano non solo statisticamente validi ma anche teoricamente giustificati e interpretativamente significativi.
43.6 Test della Differenza Chi-Quadro nel SEM
43.6.1 Principi Fondamentali
Il test della differenza Chi-Quadro (chiD) è una tecnica statistica essenziale nel contesto dei Modelli di Equazioni Strutturali (SEM) per valutare l’effetto delle modifiche ai parametri sui modelli. Questo test viene utilizzato sia nella potatura (restrizione dei parametri) che nella costruzione (aggiunta di parametri) dei modelli. Il valore chiD rappresenta la differenza tra i valori di chi-quadro (chi-quadro massima verosimiglianza, chiML) di due modelli nidificati. I gradi di libertà associati, dfD, sono determinati dalla differenza nei gradi di libertà dei due modelli (\(\text{df}_C - \text{df}_U\)).
43.6.2 Applicazione del Test
Per applicare il test della differenza chi-quadro, si seguono questi passaggi:
- Definizione dei Modelli: Identificare il modello pieno (con tutti i parametri ritenuti rilevanti) e il modello ridotto (una versione semplificata del modello pieno con alcune restrizioni).
- Stima dei Modelli: Utilizzare metodi di massima verosimiglianza per stimare entrambi i modelli.
- Calcolo del Rapporto di Verosimiglianze: Calcolare la differenza tra i logaritmi delle funzioni di verosimiglianza dei due modelli (\(D = -2(\ln(L_r) - \ln(L_f))\)).
- Test Statistico: Utilizzare la distribuzione chi-quadrato per determinare il p-value. Un p-value basso indica che il modello ridotto non si adatta ai dati così come il modello pieno.
43.6.3 Interpretazione dei Risultati
Un valore piccolo di chiD suggerisce che non c’è una differenza significativa nell’adattamento tra i due modelli, mentre un valore grande indica una differenza significativa. In termini di potatura, un grande chiD implica che il modello è stato eccessivamente vincolato. Nella costruzione, un grande chiD supporta la conservazione del parametro libero aggiunto. Tuttavia, prima di trarre conclusioni definitive, è cruciale considerare l’adattamento complessivo del modello, sia a livello globale che locale.
43.6.4 Considerazioni nella Stima ML Robusta
Nel caso di stima ML robusta, la differenza tra i chi-quadri scalati non può essere interpretata come un test dell’ipotesi di adattamento uguale a causa delle distribuzioni non centrali in condizioni di non normalità. Sono disponibili metodi specifici per calcolare una statistica di differenza chi-quadro scalata che segue approssimativamente le distribuzioni chi-quadro.
43.6.5 Implicazioni Teoriche ed Empiriche
La decisione di modificare un modello basandosi su un approccio teorico o empirico ha implicazioni significative. Ad esempio, l’eliminazione di percorsi non significativi su base puramente statistica può portare a conclusioni errate se non supportate da una solida base teorica. Inoltre, è importante essere consapevoli dei rischi associati alla capitalizzazione sul caso, come errori di Tipo I e II, e del pericolo di seguire “sentieri che si biforcano” nelle decisioni analitiche, che possono rendere i risultati specifici del campione e difficili da replicare. Per mitigare questi rischi, è consigliabile basare le modifiche del modello più su orientamenti teorici che sui risultati dei test di significatività.
43.7 Test della Differenza Chi-Quadro Scalato
Il metodo di Satorra e Bentler (2001) permette di calcolare manualmente una statistica di differenza chi-quadro scalata quando si confrontano due modelli gerarchici nella stima ML robusta. Si presume che il modello 1 sia più vincolato rispetto al modello 2 (cioè, dfM1 > dfM2), i chi-quadri non scalati siano chiML e i chi-quadri scalati siano chiSB. La statistica di test Satorra-Bentler è definita come segue:
- Calcolare la Statistica di Differenza Chi-Quadro non Scalata e i suoi Gradi di Libertà:
- chiD = chiML1 - chiML2 e dfD = dfM1 - dfM2.
- Recuperare il Fattore di Correzione di Scala, c, per Ogni Modello:
- c1 = chiML1 / chiSB1 e c2 = chiML2 / chiSB2.
- Calcolare la Statistica di Differenza Chi-Quadro Scalata, chiSD:
- chiSD = chiD / ((c1 / dfM1 - c2 / dfM2) / dfD).
- La probabilità per chiSD (dfD) in una distribuzione chi-quadro centrale rappresenta il p-value per il test di differenza chi-quadro scalato.
In campioni piccoli o quando il modello più vincolato è molto errato, il denominatore di chiSD può essere < 0, invalidando il test. Questo test è implementato nella funzione lavTestLRT() in lavaan (Rosseel et al., 2023).
43.7.1 Esempio
Consideriamo nuovamente i dati discussi da Brown (2015) relativi al modello di misurazione per la depressione maggiore così come è definita nel DSM-IV. Ignoriamo qui le differenze di genere. Leggiamo i dati in \(\mathsf{R}\):
Consideriamo il seguente modello:
model_mdd <- "
MDD =~ mdd1 + mdd2 + mdd3 + mdd4 + mdd5 + mdd6 + mdd7 + mdd8 + mdd9
"Adattiamo il modello ai dati.
fit_mdd <- cfa(
model_mdd,
data = d_mdd
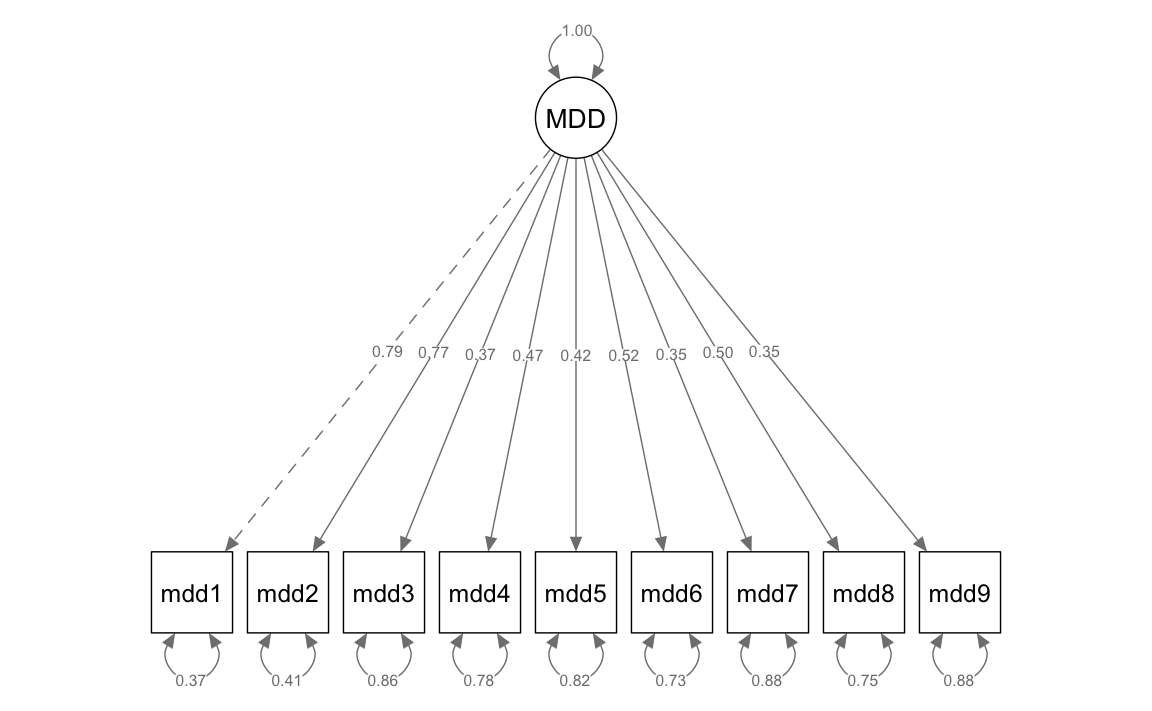
)semPaths(fit_mdd,
whatLabels = "std",
sizeMan = 8,
edge.label.cex = 0.7,
style = "mx",
nCharNodes = 0, nCharEdges = 0
)
fitMeasures(fit_mdd)
#> npar fmin chisq
#> 18.000 0.074 110.272
#> df pvalue baseline.chisq
#> 27.000 0.000 1297.618
#> baseline.df baseline.pvalue cfi
#> 36.000 0.000 0.934
#> tli nnfi rfi
#> 0.912 0.912 0.887
#> nfi pnfi ifi
#> 0.915 0.686 0.934
#> rni logl unrestricted.logl
#> 0.934 -13747.192 -13692.056
#> aic bic ntotal
#> 27530.385 27613.546 750.000
#> bic2 rmsea rmsea.ci.lower
#> 27556.389 0.064 0.052
#> rmsea.ci.upper rmsea.ci.level rmsea.pvalue
#> 0.077 0.900 0.029
#> rmsea.close.h0 rmsea.notclose.pvalue rmsea.notclose.h0
#> 0.050 0.019 0.080
#> rmr rmr_nomean srmr
#> 0.191 0.191 0.044
#> srmr_bentler srmr_bentler_nomean crmr
#> 0.044 0.044 0.050
#> crmr_nomean srmr_mplus srmr_mplus_nomean
#> 0.050 0.044 0.044
#> cn_05 cn_01 gfi
#> 273.824 320.411 0.964
#> agfi pgfi mfi
#> 0.940 0.578 0.946
#> ecvi
#> 0.195Gli indici Comparative Fit Index (CFI) = 0.934 e Tucker-Lewis Index (TLI) = 0.912 sono superiori a 0.9, dunque sono almeno sufficienti per gli standard correnti. L’indice RMSEA = 0.064 è appena superiore alla soglia di 0.06. L’indice SRMR = 0.044 è inferiore alla soglia 0.05. Dunque, complessivamente, il modello sembra adeguato.
Adattiamo ora il modello con la modifica proposta da {cite:t}brown2015confirmatory, ovvero
model2_mdd <- "
MDD =~ mdd1 + mdd2 + mdd3 + mdd4 + mdd5 + mdd6 + mdd7 + mdd8 + mdd9
mdd1 ~~ mdd2
"
fit2_mdd <- cfa(
model2_mdd,
data = d_mdd
)Eseguiamo il test del rapporto di verosimiglianze:
lavTestLRT(fit_mdd, fit2_mdd)
#>
#> Chi-Squared Difference Test
#>
#> Df AIC BIC Chisq Chisq diff RMSEA Df diff Pr(>Chisq)
#> fit2_mdd 26 27490 27577 67.6
#> fit_mdd 27 27530 27614 110.3 42.7 0.236 1 6.3e-11Il test indica che il modello alternativo si adatta meglio ai dati del modello originale.
Esaminiamo gli indici di bontà di adattamento.
effectsize::interpret(fit2_mdd)
#> Name Value Threshold Interpretation
#> 1 GFI 0.97807 0.95 satisfactory
#> 2 AGFI 0.96205 0.90 satisfactory
#> 3 NFI 0.94794 0.90 satisfactory
#> 4 NNFI 0.95439 0.90 satisfactory
#> 5 CFI 0.96706 0.90 satisfactory
#> 6 RMSEA 0.04617 0.05 satisfactory
#> 7 SRMR 0.03675 0.08 satisfactory
#> 8 RFI 0.92791 0.90 satisfactory
#> 9 PNFI 0.68462 0.50 satisfactory
#> 10 IFI 0.96732 0.90 satisfactoryGli indici Comparative Fit Index (CFI) = 0.967 e Tucker-Lewis Index (TLI) = 0.954 sono superiori a 0.95. L’indice RMSEA = 0.046. L’indice SRMR = 0.037.
Il “costo” che si paga per questo miglioramento dell’adattamento è che indici di adattamento così buoni, probabilmente, non si replicheranno in un altro campione di dati, a meno che venga introdotto un qualche altro aggiustamento che, sicuramente, sarà diverso da quello usato nel campione corrente. Personalmente, non avrei introdotto il “miglioramento” proposto da {cite:t}brown2015confirmatory in quanto, anche senza un tale aggiustamento post-hoc, il modello produce un adattamento accettabile.
43.8 Confronto di Modelli Non Annidati
Proseguendo, analizzeremo l’adattamento di due modelli distinti, entrambi costituiti dalle stesse variabili e applicati agli stessi dati. Tuttavia, a differenza di quanto precedentemente delineato, questi modelli non sono collegati gerarchicamente, ma si configurano come modelli non annidati. Questa situazione si presenta comunemente quando i ricercatori mettono a confronto modelli basati su teorie divergenti. È possibile effettuare un confronto informale dei valori del chi-quadrato derivanti da modelli non annidati, ma la loro differenza non va interpretata come una statistica di test valida. In altre parole, i test di differenza del chi-quadrato, sia in forma scalata che non, non sono appropriati in questo contesto. La ragione risiede nel fatto che la differenza tra le statistiche di test di modelli non annidati non segue una distribuzione chi-quadrato centrale. Sebbene siano stati compiuti sforzi per elaborare test di significatività adatti al confronto di modelli non annidati, questi metodi non hanno trovato un ampio utilizzo e spesso portano a complicazioni interpretative (Levy & Hancock, 2007).
Una soluzione più pragmatica è rappresentata dalla famiglia degli indici di adattamento predittivo, conosciuti anche come criteri teorico-informativi. Questi indici non sono test di significatività, poiché le loro distribuzioni di probabilità variano ampiamente a seconda del tipo di modello e dei dati considerati e, pertanto, rimangono generalmente ignote. Piuttosto, essi riflettono sia la qualità dell’adattamento del modello sia la sua complessità, bilanciando questi due aspetti. Ciò implica l’applicazione di una penalità per la complessità del modello, che consente di regolare l’adattamento in funzione del numero di parametri liberi. Per esempio, nel caso di due modelli non annidati che mostrano un adattamento simile agli stessi dati, verrà privilegiato il modello meno complesso, in quanto considerato più probabile nella generalizzazione su campioni replicati. In questo scenario, il valore del criterio informativo sarà inferiore per il modello più semplice, dato che una penalità maggiore per la complessità viene applicata all’adattamento del modello più complesso. Di conseguenza, il modello con il criterio informativo più basso è da preferire. In questo capitolo, dopo aver introdotto un problema di ricerca, esploreremo due indici di adattamento predittivo ampiamente usati (AIC e BIC).
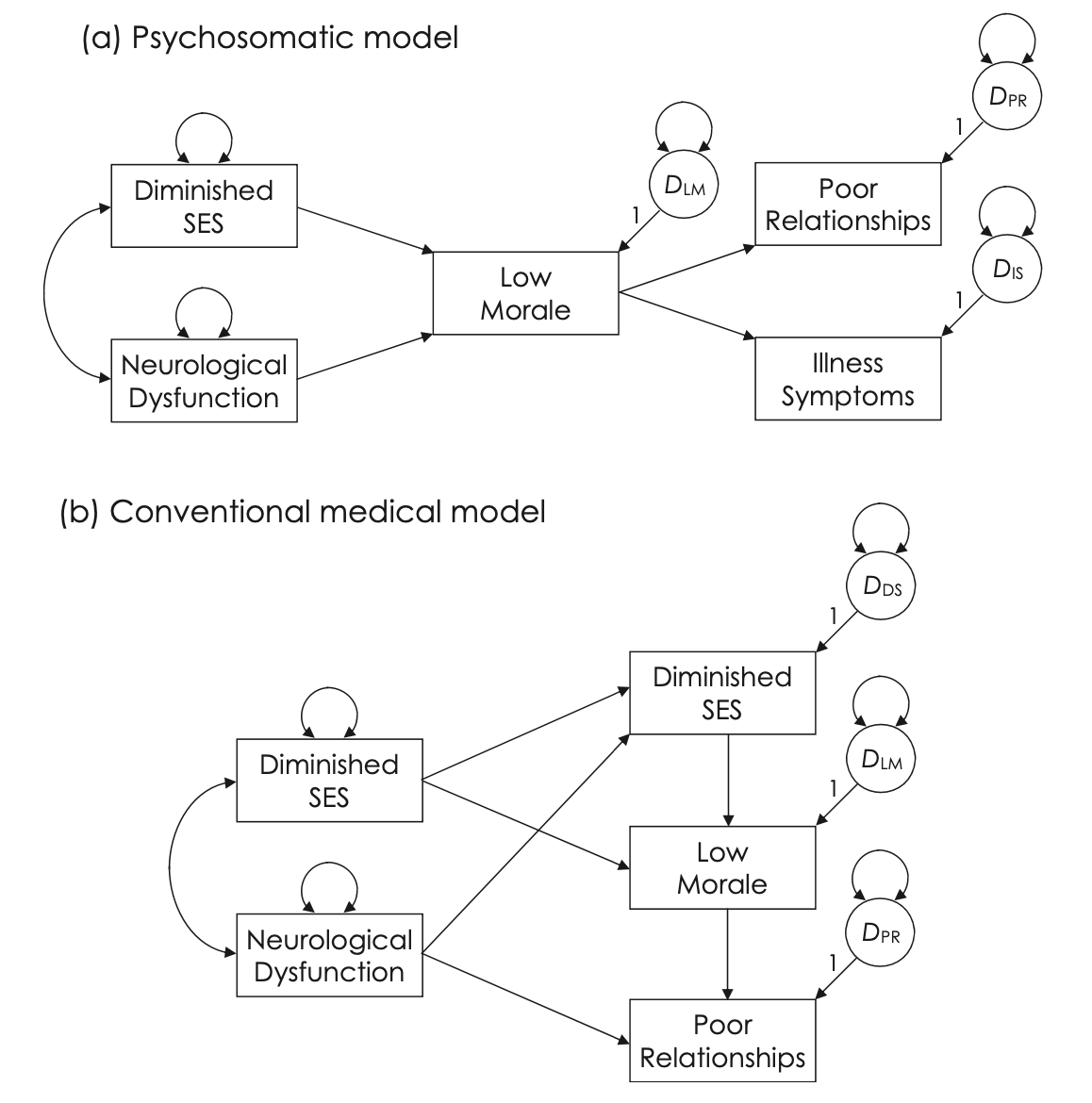
Nella figura sono presentati due modelli di percorso che descrivono il recupero dei pazienti dopo un intervento chirurgico cardiaco (Romney et al., 1992) – si veda Kline (2023), cap. 11. Il modello psicosomatico rappresenta le ipotesi che il morale del paziente trasmetta gli effetti della disfunzione neurologica e dello stato socioeconomico ridotto (SES) su sintomi della malattia e scarse relazioni sociali. Il modello medico rappresenta un diverso schema di relazioni causali tra le stesse variabili. In particolare, sia i sintomi della malattia sia la disfunzione neurologica sono specificati come variabili esogene con effetti diretti sul SES ridotto, basso morale e scarse relazioni. Tra queste tre variabili endogene, si ipotizza che il SES ridotto influenzi indirettamente le scarse relazioni attraverso il suo impatto precedente sul basso morale. Ci sono ulteriori effetti indiretti nel modello medico convenzionale dalle variabili esogene a quelle endogene. I due modelli nella figura non sono annidati, quindi il test della differenza del chi-quadro non può essere utilizzato per confrontarli direttamente. È dunque necessario seguire un altro approccio.
43.9 AIC e BIC
Uno degli indici di adattamento predittivo più noti basato sulla stima di massima verosimiglianza (ML) è il Criterio di Informazione di Akaike (AIC), che prende il nome dallo statistico Hirotugu Akaike. La formula per l’AIC di Akaike (1974, p. 719) è:
\[ \text{AIC} = -2 \ln L_0 + 2q \]
dove \(L_0\) è la funzione di verosimiglianza massimizzata nella stima ML per il modello del ricercatore e \(q\) è il numero di parametri liberi del modello. Si noti che la penalità per la complessità nell’equazione precedente, \(2q\), diventa relativamente più piccola all’aumentare della dimensione del campione (Mulaik, 2009b).
Un diverso indice teorico-informativo che tiene direttamente conto della dimensione del campione è il Criterio di Informazione Bayesiano (BIC) (Raftery, 1993; Schwarz, 1978). La formula è
\[ \text{BIC} = -2 \ln L_0 + q \ln N \]
Confrontato con l’AIC, il BIC impone una penalità relativa maggiore per la complessità del modello.
Supponiamo che il numero di parametri stimati liberamente sia \(q = 10\) e che \(N = 300\). La penalità AIC equivale a \(2(10)\), ovvero 20.000 (Equazione 11.4), ma la penalità BIC per lo stesso modello è \(10 (\ln 300)\), ovvero 50.038, più del doppio rispetto all’AIC. I valori relativi delle penalità BIC aumentano più lentamente all’aumentare della dimensione del campione; in altre parole, la sua penalità è asintotica su campioni sempre più grandi (Mulaik, 2009b).
In sostanza, sia l’AIC che il BIC sono strumenti per bilanciare l’adattamento del modello con la sua complessità, ma differiscono nel modo in cui valutano e penalizzano questa complessità, soprattutto in relazione alla dimensione del campione.
Utilizzando lo script fornito da Kline (2023), iniziamo a importare i dati in R:
# input the correlations in lower diagnonal form
romneyLower.cor <- "
1.00
.53 1.00
.15 .18 1.00
.52 .29 -.05 1.00
.30 .34 .23 .09 1.00 "
# name the variables and convert to full correlation matrix
romney.cor <- lavaan::getCov(romneyLower.cor, names = c(
"morale", "symptoms",
"dysfunction", "relations", "ses"
))Esaminiamo le matrici di correlazioni e covarianze:
# display the correlations
romney.cor
#> morale symptoms dysfunction relations ses
#> morale 1.00 0.53 0.15 0.52 0.30
#> symptoms 0.53 1.00 0.18 0.29 0.34
#> dysfunction 0.15 0.18 1.00 -0.05 0.23
#> relations 0.52 0.29 -0.05 1.00 0.09
#> ses 0.30 0.34 0.23 0.09 1.00# add the standard deviations and convert to covariances
romney.cov <- lavaan::cor2cov(romney.cor, sds = c(
3.75, 17.00, 19.50,
3.50, 24.70
))
# display the covariances
romney.cov
#> morale symptoms dysfunction relations ses
#> morale 14.062 33.79 10.969 6.825 27.79
#> symptoms 33.788 289.00 59.670 17.255 142.77
#> dysfunction 10.969 59.67 380.250 -3.413 110.78
#> relations 6.825 17.25 -3.413 12.250 7.78
#> ses 27.787 142.77 110.779 7.780 610.09Specifichiamo il modello psicosomatico.
somatic.model <- "
# regressions
morale ~ ses + dysfunction
relations ~ morale
symptoms ~ morale
# without the zero constraint listed next,
# lavaan automatically specifies correlated
# disturbances for symptoms and relations,
# but their disturbances are independent in
# figure 11.1
symptoms ~~ 0*relations
# unanalyzed association between ses and dysfunction
# automatically specified
"Specifichiamo il modello medico convenzionale.
medical.model <- "
# regressions
ses ~ symptoms + dysfunction
morale ~ symptoms + ses
relations ~ dysfunction + morale
# unanalyzed association between symptoms and dysfunction
# automatically specified
"Adattiamo ai dati il modello psicosomatico.
somatic <- lavaan::sem(somatic.model,
sample.cov = romney.cov,
sample.nobs = 469, fixed.x = FALSE, sample.cov.rescale = FALSE
)semPaths(somatic,
whatLabels = "std",
sizeMan = 10,
edge.label.cex = 1.0,
style = "mx",
nCharNodes = 0, nCharEdges = 0
)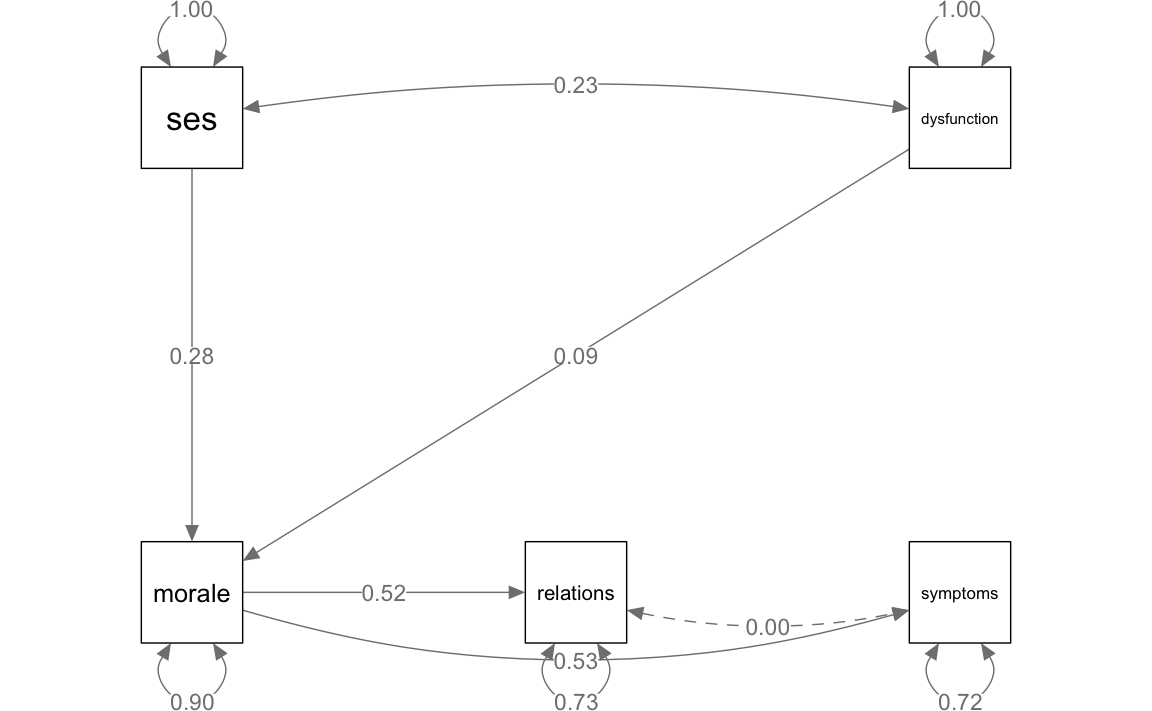
lavaan::summary(somatic, fit.measures = TRUE, rsquare = TRUE)
#> lavaan 0.6-19 ended normally after 1 iteration
#>
#> Estimator ML
#> Optimization method NLMINB
#> Number of model parameters 10
#>
#> Number of observations 469
#>
#> Model Test User Model:
#>
#> Test statistic 40.488
#> Degrees of freedom 5
#> P-value (Chi-square) 0.000
#>
#> Model Test Baseline Model:
#>
#> Test statistic 390.816
#> Degrees of freedom 9
#> P-value 0.000
#>
#> User Model versus Baseline Model:
#>
#> Comparative Fit Index (CFI) 0.907
#> Tucker-Lewis Index (TLI) 0.833
#>
#> Loglikelihood and Information Criteria:
#>
#> Loglikelihood user model (H0) -8572.844
#> Loglikelihood unrestricted model (H1) -8552.599
#>
#> Akaike (AIC) 17165.687
#> Bayesian (BIC) 17207.193
#> Sample-size adjusted Bayesian (SABIC) 17175.455
#>
#> Root Mean Square Error of Approximation:
#>
#> RMSEA 0.123
#> 90 Percent confidence interval - lower 0.090
#> 90 Percent confidence interval - upper 0.159
#> P-value H_0: RMSEA <= 0.050 0.000
#> P-value H_0: RMSEA >= 0.080 0.982
#>
#> Standardized Root Mean Square Residual:
#>
#> SRMR 0.065
#>
#> Parameter Estimates:
#>
#> Standard errors Standard
#> Information Expected
#> Information saturated (h1) model Structured
#>
#> Regressions:
#> Estimate Std.Err z-value P(>|z|)
#> morale ~
#> ses 0.043 0.007 6.217 0.000
#> dysfunction 0.016 0.009 1.897 0.058
#> relations ~
#> morale 0.485 0.037 13.184 0.000
#> symptoms ~
#> morale 2.403 0.178 13.535 0.000
#>
#> Covariances:
#> Estimate Std.Err z-value P(>|z|)
#> .relations ~~
#> .symptoms 0.000
#> ses ~~
#> dysfunction 110.779 22.821 4.854 0.000
#>
#> Variances:
#> Estimate Std.Err z-value P(>|z|)
#> .morale 12.699 0.829 15.313 0.000
#> .relations 8.938 0.584 15.313 0.000
#> .symptoms 207.820 13.571 15.313 0.000
#> ses 610.090 39.840 15.313 0.000
#> dysfunction 380.250 24.831 15.313 0.000
#>
#> R-Square:
#> Estimate
#> morale 0.097
#> relations 0.270
#> symptoms 0.281Ora approfondiamo l’analisi dei residui. Nel contesto di un modello SEM, i residui sono derivati dalle differenze tra la matrice di correlazioni (o covarianze) osservata e quella prevista dal modello. Queste differenze sono elaborate attraverso specifiche funzioni per generare i residui. Utilizzando il pacchetto lavaan in R, possiamo accedere a tre principali tipi di residui: standardized.mplus, normalized, e cor.bollen.
Residui Standardizzati (Standardized.mplus): Questo tipo di residuo è una versione standardizzata dei residui. I residui standardizzati sono ottenuti calcolando la differenza tra i valori osservati e quelli previsti dal modello, e dividendo questa differenza per uno stimatore della deviazione standard del residuo. Questo processo trasforma i residui in una scala in cui hanno una varianza approssimativamente uguale. I residui standardizzati sono utili per identificare punti dati che il modello non riesce a spiegare bene. In
lavaan,type = "standardized.mplus"si riferisce a una particolare forma di standardizzazione dei residui, simile a quella utilizzata nel software Mplus.Residui Normalizzati (Normalized): I residui normalizzati sono un altro tipo di residui standardizzati. Sono calcolati come i residui standardizzati ma poi vengono normalizzati. La normalizzazione qui significa che i residui vengono ulteriormente trasformati in modo che la loro distribuzione si avvicini a una distribuzione normale. Questo è utile per verificare se i residui seguono una distribuzione normale, il che è un’assunzione comune in molti modelli statistici, inclusi quelli SEM.
Correlazione dei Residui secondo Bollen (Cor.bollen): Questo tipo di residuo si riferisce alla correlazione tra i residui di due variabili diverse nel modello. Il metodo
cor.bollencalcola la correlazione tra i residui dopo che il modello è stato adattato ai dati. Questo tipo di analisi è utile per rilevare se ci sono correlazioni non modellate tra le variabili che potrebbero influenzare la validità del modello.
lavaan::residuals(somatic, type = "standardized.mplus")
#> $type
#> [1] "standardized.mplus"
#>
#> $cov
#> morale reltns symptm ses dysfnc
#> morale 0.000
#> relations 0.000 0.000
#> symptoms 0.000 0.427 0.000
#> ses 0.000 -1.776 4.542 0.000
#> dysfunction 0.000 -3.291 2.549 0.000 0.000lavaan::residuals(somatic, type = "normalized")
#> $type
#> [1] "normalized"
#>
#> $cov
#> morale reltns symptm ses dysfnc
#> morale 0.000
#> relations 0.000 0.000
#> symptoms 0.000 0.300 0.000
#> ses 0.000 -1.424 3.711 0.000
#> dysfunction 0.000 -2.769 2.142 0.000 0.000lavaan::residuals(somatic, type = "cor.bollen")
#> $type
#> [1] "cor.bollen"
#>
#> $cov
#> morale reltns symptm ses dysfnc
#> morale 0.000
#> relations 0.000 0.000
#> symptoms 0.000 0.014 0.000
#> ses 0.000 -0.066 0.181 0.000
#> dysfunction 0.000 -0.128 0.100 0.000 0.000Adattiamo ai dati il modello medico convenzionale.
medical <- lavaan::sem(medical.model,
sample.cov = romney.cov,
sample.nobs = 469, fixed.x = FALSE, sample.cov.rescale = FALSE
)semPaths(medical,
whatLabels = "std",
sizeMan = 10,
edge.label.cex = 1.15,
style = "mx",
nCharNodes = 0, nCharEdges = 0
)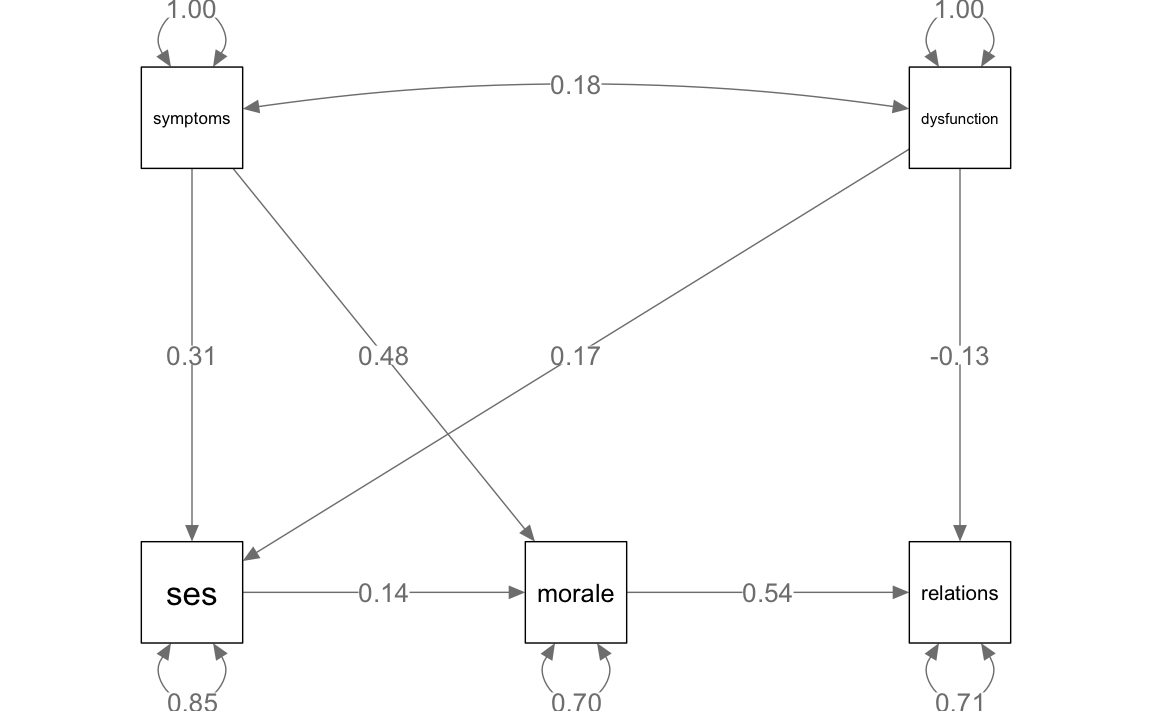
lavaan::summary(medical, fit.measures = TRUE, rsquare = TRUE)
#> lavaan 0.6-19 ended normally after 1 iteration
#>
#> Estimator ML
#> Optimization method NLMINB
#> Number of model parameters 12
#>
#> Number of observations 469
#>
#> Model Test User Model:
#>
#> Test statistic 3.245
#> Degrees of freedom 3
#> P-value (Chi-square) 0.355
#>
#> Model Test Baseline Model:
#>
#> Test statistic 400.859
#> Degrees of freedom 9
#> P-value 0.000
#>
#> User Model versus Baseline Model:
#>
#> Comparative Fit Index (CFI) 0.999
#> Tucker-Lewis Index (TLI) 0.998
#>
#> Loglikelihood and Information Criteria:
#>
#> Loglikelihood user model (H0) -8554.222
#> Loglikelihood unrestricted model (H1) -8552.599
#>
#> Akaike (AIC) 17132.444
#> Bayesian (BIC) 17182.251
#> Sample-size adjusted Bayesian (SABIC) 17144.166
#>
#> Root Mean Square Error of Approximation:
#>
#> RMSEA 0.013
#> 90 Percent confidence interval - lower 0.000
#> 90 Percent confidence interval - upper 0.080
#> P-value H_0: RMSEA <= 0.050 0.742
#> P-value H_0: RMSEA >= 0.080 0.050
#>
#> Standardized Root Mean Square Residual:
#>
#> SRMR 0.016
#>
#> Parameter Estimates:
#>
#> Standard errors Standard
#> Information Expected
#> Information saturated (h1) model Structured
#>
#> Regressions:
#> Estimate Std.Err z-value P(>|z|)
#> ses ~
#> symptoms 0.448 0.063 7.110 0.000
#> dysfunction 0.221 0.055 4.019 0.000
#> morale ~
#> symptoms 0.107 0.009 11.756 0.000
#> ses 0.021 0.006 3.291 0.001
#> relations ~
#> dysfunction -0.024 0.007 -3.335 0.001
#> morale 0.504 0.037 13.745 0.000
#>
#> Covariances:
#> Estimate Std.Err z-value P(>|z|)
#> symptoms ~~
#> dysfunction 59.670 15.553 3.836 0.000
#>
#> Variances:
#> Estimate Std.Err z-value P(>|z|)
#> .ses 521.598 34.062 15.313 0.000
#> .morale 9.884 0.645 15.313 0.000
#> .relations 8.732 0.570 15.313 0.000
#> symptoms 289.000 18.872 15.313 0.000
#> dysfunction 380.250 24.831 15.313 0.000
#>
#> R-Square:
#> Estimate
#> ses 0.145
#> morale 0.297
#> relations 0.290lavaan::residuals(medical, type = "standardized.mplus")
#> $type
#> [1] "standardized.mplus"
#>
#> $cov
#> ses morale reltns symptm dysfnc
#> ses 0.000
#> morale 0.000 0.000
#> relations -1.161 -1.818 NA
#> symptoms 0.000 0.000 0.833 0.000
#> dysfunction 0.000 0.842 0.862 0.000 0.000lavaan::residuals(medical, type = "normalized")
#> $type
#> [1] "normalized"
#>
#> $cov
#> ses morale reltns symptm dysfnc
#> ses 0.000
#> morale 0.000 0.000
#> relations -0.901 -0.080 -0.069
#> symptoms 0.000 0.000 0.573 0.000
#> dysfunction 0.000 0.680 0.370 0.000 0.000lavaan::residuals(medical, type = "cor.bollen")
#> $type
#> [1] "cor.bollen"
#>
#> $cov
#> ses morale reltns symptm dysfnc
#> ses 0.000
#> morale 0.000 0.000
#> relations -0.041 -0.003 0.000
#> symptoms 0.000 0.000 0.028 0.000
#> dysfunction 0.000 0.032 0.017 0.000 0.000In conclusione, i valori i valori degli indici di adattamento predittivo per i due modelli alternativi di Romney et al. (1992) sono stati generati seguendo le istruzioni precedentemente descritte. Non sorprende che l’adattamento globale del modello medico convenzionale, più complesso (con $ dfM = 3 $), sia migliore rispetto a quello del modello psicosomatico, più semplice (con $ dfM = 5 $). Nonostante il modello medico convenzionale sia più complesso e quindi soggetto a una penalità maggiore per il minor numero di gradi di libertà, i valori ottenuti sia nell’AIC che nel BIC sono inferiori rispetto a quelli del modello psicosomatico. Questo indica che il vantaggio in termini di adattamento del modello medico convenzionale è sufficiente a superare la penalità per la sua maggiore complessità. In base a queste analisi, il modello medico convenzionale è considerato più adatto rispetto al modello psicosomatico, come evidenziato dai valori più bassi nei criteri AIC e BIC.
43.10 Indici di Modifica e Statistiche Correlate nel SEM
Nell’elaborazione di modelli SEM (Structural Equation Modeling), esiste la possibilità di implementare modifiche attraverso processi automatizzati. Questi interventi, di carattere esplorativo, si basano sull’aggiunta o sulla rimozione di parametri seguendo criteri empirici, come la significatività statistica di un indice di modifica (MI) o di un test di punteggio. Gli indici di modifica, in particolare, sono calcolati per quei parametri che nel modello sono stati inizialmente vincolati e servono a stimare quanto il chi-quadrato del modello di massima verosimiglianza (chiML) si ridurrebbe se un dato parametro vincolato venisse liberato.
Il meccanismo di modifica automatica opera liberando, ad ogni iterazione, il parametro vincolato che presenta il valore di MI più alto. Questo processo continua finché non si raggiunge un MI che è statisticamente significativo secondo i criteri stabiliti dal ricercatore. È cruciale, tuttavia, riconoscere che l’uso di questa metodologia, specialmente in campioni di piccole dimensioni, può portare alla formulazione di modelli che si basano eccessivamente sul caso. Di conseguenza, questi modelli potrebbero risultare poco robusti e difficilmente replicabili in studi successivi. L’automazione nel processo di ottimizzazione dei modelli SEM richiede dunque un’attenta valutazione del contesto e della dimensione del campione per garantire l’affidabilità e la validità dei risultati ottenuti.
Un altro strumento di uso frequente nei SEM è il test di Wald, basato sulla statistica W. Questo test è progettato per valutare l’impatto che avrebbe la fissazione a zero di un parametro precedentemente stimato liberamente nel modello. In termini più tecnici, il test di Wald stima l’incremento che si verificherebbe nel chi-quadrato del modello di massima verosimiglianza (chiML) se tale parametro fosse “potato”, ovvero escluso dal modello.
Similmente ai processi di modifica automatica, l’efficacia del test di Wald può essere influenzata dalla casualità. Un aspetto cruciale da considerare è la sensibilità di questi test alla dimensione del campione. Infatti, anche piccole modifiche nella bontà di adattamento del modello possono assumere una significatività statistica notevole in campioni di ampie dimensioni.
Di conseguenza, quando si valutano gli indici di modifica come il MI (Modifica Index), è essenziale che il ricercatore non si limiti a considerarne la sola significatività statistica. È importante anche valutare l’entità del cambiamento che si verificherebbe nel coefficiente del parametro se fosse liberato. Se il cambiamento previsto è minimo, la significatività statistica dell’indice di modifica potrebbe essere più indicativa della dimensione del campione che non della sostanziale rilevanza dell’effetto analizzato. Questa considerazione sottolinea l’importanza di un approccio olistico e critico nell’interpretazione dei risultati dei test diagnostici in SEM, specialmente in contesti dove la dimensione del campione può influenzare significativamente i risultati.
fit_mdd <- cfa(
model_mdd,
data = d_mdd
)Calcoliamo gli indici di modifica.
modification_indices <- lavInspect(fit_mdd, "mi")
modification_indices
#> lhs op rhs mi epc sepc.lv sepc.all sepc.nox
#> 20 mdd1 ~~ mdd2 46.877 0.732 0.732 0.560 0.560
#> 21 mdd1 ~~ mdd3 4.996 -0.211 -0.211 -0.108 -0.108
#> 22 mdd1 ~~ mdd4 4.625 -0.215 -0.215 -0.108 -0.108
#> 23 mdd1 ~~ mdd5 7.797 -0.266 -0.266 -0.137 -0.137
#> 24 mdd1 ~~ mdd6 6.434 -0.236 -0.236 -0.132 -0.132
#> 25 mdd1 ~~ mdd7 0.293 0.053 0.053 0.026 0.026
#> 26 mdd1 ~~ mdd8 5.046 -0.219 -0.219 -0.116 -0.116
#> 27 mdd1 ~~ mdd9 5.385 0.187 0.187 0.111 0.111
#> 28 mdd2 ~~ mdd3 1.435 -0.138 -0.138 -0.055 -0.055
#> 29 mdd2 ~~ mdd4 10.931 -0.402 -0.402 -0.158 -0.158
#> 30 mdd2 ~~ mdd5 5.835 -0.281 -0.281 -0.113 -0.113
#> 31 mdd2 ~~ mdd6 2.235 -0.169 -0.169 -0.074 -0.074
#> 32 mdd2 ~~ mdd7 0.394 -0.076 -0.076 -0.029 -0.029
#> 33 mdd2 ~~ mdd8 0.027 -0.019 -0.019 -0.008 -0.008
#> 34 mdd2 ~~ mdd9 2.070 -0.142 -0.142 -0.066 -0.066
#> 35 mdd3 ~~ mdd4 16.199 0.591 0.591 0.155 0.155
#> 36 mdd3 ~~ mdd5 3.298 0.258 0.258 0.069 0.069
#> 37 mdd3 ~~ mdd6 6.361 0.337 0.337 0.098 0.098
#> 38 mdd3 ~~ mdd7 0.499 -0.106 -0.106 -0.027 -0.027
#> 39 mdd3 ~~ mdd8 0.014 -0.017 -0.017 -0.005 -0.005
#> 40 mdd3 ~~ mdd9 2.860 -0.208 -0.208 -0.064 -0.064
#> 41 mdd4 ~~ mdd5 12.198 0.509 0.509 0.136 0.136
#> 42 mdd4 ~~ mdd6 17.435 0.573 0.573 0.165 0.165
#> 43 mdd4 ~~ mdd7 1.272 -0.174 -0.174 -0.043 -0.043
#> 44 mdd4 ~~ mdd8 0.975 0.143 0.143 0.039 0.039
#> 45 mdd4 ~~ mdd9 1.879 -0.173 -0.173 -0.053 -0.053
#> 46 mdd5 ~~ mdd6 7.502 0.364 0.364 0.107 0.107
#> 47 mdd5 ~~ mdd7 0.096 0.046 0.046 0.012 0.012
#> 48 mdd5 ~~ mdd8 4.217 0.288 0.288 0.080 0.080
#> 49 mdd5 ~~ mdd9 0.544 -0.090 -0.090 -0.028 -0.028
#> 50 mdd6 ~~ mdd7 2.046 -0.201 -0.201 -0.055 -0.055
#> 51 mdd6 ~~ mdd8 0.877 0.124 0.124 0.037 0.037
#> 52 mdd6 ~~ mdd9 2.479 -0.180 -0.180 -0.061 -0.061
#> 53 mdd7 ~~ mdd8 0.188 0.064 0.064 0.017 0.017
#> 54 mdd7 ~~ mdd9 13.527 0.474 0.474 0.139 0.139
#> 55 mdd8 ~~ mdd9 0.322 0.069 0.069 0.022 0.022Nel modello che stiamo analizzando, l’indice di modifica (MI) più elevato si riferisce alla possibile modifica del parametro che governa la correlazione tra i residui degli indicatori mm1 e mm2. Nel modello model_mdd questa correlazione residua è impostata a zero, indicando l’assenza di una correlazione diretta tra questi residui. Tuttavia, l’indice di modifica suggerisce che se permettessimo a questa correlazione di essere stimata liberamente dal modello (anziché tenerla fissa a zero), si verificherebbe un miglioramento dell’adattamento del modello ai dati osservati. Questa osservazione è in linea con il modello alternativo che è stato proposto per questi dati proposto da Brown (2015).
Incorporare una correlazione residua tra mm1 e mm2 significa riconoscere che, oltre alla variazione spiegata dalle variabili latenti comuni, esiste una relazione unica tra questi due indicatori che non è catturata dal modello. Tale relazione potrebbe essere dovuta a fattori specifici relativi a questi indicatori o a una misurazione comune non prevista dal modello originale.
È importante sottolineare che ogni modifica al modello basata sugli indici di modifica dovrebbe essere attentamente valutata per assicurarsi che sia supportata sia da giustificazioni teoriche che empiriche. Aggiungere correlazioni residue può migliorare l’adattamento del modello, ma dovrebbe essere fatto con cautela per evitare di creare un modello eccessivamente complesso che potrebbe non essere generalizzabile al di fuori del campione di dati specifico utilizzato.
43.11 Riflessioni Conclusive
Nel campo dei modelli SEM, è pratica comune selezionare il modello più appropriato da un insieme di alternative, tutte calibrate sugli stessi dati. È frequente il confronto tra modelli gerarchicamente collegati, in cui il modello più restrittivo è incluso, o annidato, in quello meno restrittivo. In queste situazioni, il test di differenza del chi-quadrato viene impiegato per valutare se i modelli hanno un adattamento equivalente. Utilizzare questo test e le statistiche diagnostiche correlate, come gli indici di modifica, richiede un approccio guidato dalla teoria, non solo da criteri empirici. Un eccessivo affidamento su criteri puramente empirici, come la significatività statistica, può portare a una dipendenza eccessiva dal caso.
Per confrontare modelli non annidati, il test di differenza del chi-quadrato non è idoneo, ma si possono adottare gli indici di adattamento predittivo, basati sulla teoria dell’informazione, per la loro valutazione. Quando si decide di mantenere un modello, è cruciale prendere in considerazione anche altri modelli alternativi potenzialmente equivalenti. È importante fornire motivazioni solide su perché il modello selezionato dal ricercatore sia da preferire rispetto a queste alternative equivalenti.
Questo approccio consente una comprensione più profonda e una scelta più informata del modello, assicurando che la selezione sia fondata su basi teoriche solide e non solamente su risultati statistici.
43.12 Session Info
sessionInfo()
#> R version 4.4.2 (2024-10-31)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Sequoia 15.3.2
#>
#> Matrix products: default
#> BLAS: /Library/Frameworks/R.framework/Versions/4.4-arm64/Resources/lib/libRblas.0.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.4-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.0
#>
#> locale:
#> [1] C/UTF-8/C/C/C/C
#>
#> time zone: Europe/Rome
#> tzcode source: internal
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] effectsize_1.0.0 rsvg_2.6.1 DiagrammeRsvg_0.1
#> [4] mvnormalTest_1.0.0 lavaanPlot_0.8.1 lavaanExtra_0.2.1
#> [7] ggokabeito_0.1.0 see_0.11.0 MASS_7.3-65
#> [10] viridis_0.6.5 viridisLite_0.4.2 ggpubr_0.6.0
#> [13] ggExtra_0.10.1 gridExtra_2.3 patchwork_1.3.0
#> [16] bayesplot_1.11.1 semTools_0.5-6 semPlot_1.1.6
#> [19] lavaan_0.6-19 psych_2.4.12 scales_1.3.0
#> [22] markdown_1.13 knitr_1.50 lubridate_1.9.4
#> [25] forcats_1.0.0 stringr_1.5.1 dplyr_1.1.4
#> [28] purrr_1.0.4 readr_2.1.5 tidyr_1.3.1
#> [31] tibble_3.2.1 ggplot2_3.5.1 tidyverse_2.0.0
#> [34] here_1.0.1
#>
#> loaded via a namespace (and not attached):
#> [1] splines_4.4.2 later_1.4.1 datawizard_1.0.1
#> [4] XML_3.99-0.18 rpart_4.1.24 lifecycle_1.0.4
#> [7] Rdpack_2.6.3 rstatix_0.7.2 rprojroot_2.0.4
#> [10] lattice_0.22-6 insight_1.1.0 rockchalk_1.8.157
#> [13] backports_1.5.0 magrittr_2.0.3 openxlsx_4.2.8
#> [16] Hmisc_5.2-3 rmarkdown_2.29 httpuv_1.6.15
#> [19] qgraph_1.9.8 zip_2.3.2 pbapply_1.7-2
#> [22] minqa_1.2.8 RColorBrewer_1.1-3 ADGofTest_0.3
#> [25] multcomp_1.4-28 abind_1.4-8 quadprog_1.5-8
#> [28] pspline_1.0-21 nnet_7.3-20 TH.data_1.1-3
#> [31] sandwich_3.1-1 moments_0.14.1 nortest_1.0-4
#> [34] arm_1.14-4 performance_0.13.0 codetools_0.2-20
#> [37] tidyselect_1.2.1 farver_2.1.2 lme4_1.1-36
#> [40] stats4_4.4.2 base64enc_0.1-3 jsonlite_1.9.1
#> [43] Formula_1.2-5 survival_3.8-3 emmeans_1.10.7
#> [46] tools_4.4.2 Rcpp_1.0.14 glue_1.8.0
#> [49] mnormt_2.1.1 xfun_0.51 withr_3.0.2
#> [52] numDeriv_2016.8-1.1 fastmap_1.2.0 boot_1.3-31
#> [55] digest_0.6.37 mi_1.1 timechange_0.3.0
#> [58] R6_2.6.1 mime_0.13 estimability_1.5.1
#> [61] colorspace_2.1-1 gtools_3.9.5 jpeg_0.1-10
#> [64] copula_1.1-6 DiagrammeR_1.0.11 generics_0.1.3
#> [67] data.table_1.17.0 corpcor_1.6.10 htmlwidgets_1.6.4
#> [70] parameters_0.24.2 pkgconfig_2.0.3 sem_3.1-16
#> [73] gtable_0.3.6 pcaPP_2.0-5 htmltools_0.5.8.1
#> [76] carData_3.0-5 png_0.1-8 reformulas_0.4.0
#> [79] rstudioapi_0.17.1 tzdb_0.5.0 reshape2_1.4.4
#> [82] coda_0.19-4.1 visNetwork_2.1.2 checkmate_2.3.2
#> [85] nlme_3.1-167 curl_6.2.1 nloptr_2.2.1
#> [88] zoo_1.8-13 parallel_4.4.2 miniUI_0.1.1.1
#> [91] foreign_0.8-88 pillar_1.10.1 grid_4.4.2
#> [94] vctrs_0.6.5 promises_1.3.2 car_3.1-3
#> [97] OpenMx_2.21.13 xtable_1.8-4 cluster_2.1.8.1
#> [100] htmlTable_2.4.3 evaluate_1.0.3 pbivnorm_0.6.0
#> [103] mvtnorm_1.3-3 cli_3.6.4 kutils_1.73
#> [106] compiler_4.4.2 rlang_1.1.5 ggsignif_0.6.4
#> [109] fdrtool_1.2.18 plyr_1.8.9 stringi_1.8.4
#> [112] munsell_0.5.1 gsl_2.1-8 lisrelToR_0.3
#> [115] bayestestR_0.15.2 pacman_0.5.1 V8_6.0.2
#> [118] Matrix_1.7-3 hms_1.1.3 stabledist_0.7-2
#> [121] glasso_1.11 shiny_1.10.0 rbibutils_2.3
#> [124] igraph_2.1.4 broom_1.0.7 RcppParallel_5.1.10