here::here("code", "_common.R") |> source()
# Load packages
if (!requireNamespace("pacman")) install.packages("pacman")
pacman::p_load(lavaan, psych, BifactorIndicesCalculator, semPlot)43 Modello bifattoriale
L’obiettivo di questo capitolo è di presentare un’introduzione al modello bifattoriale.
Prerequisiti
Concetti e Competenze Chiave
Preparazione del Notebook
43.1 Introduzione
Numerose misure psicologiche sono progettate per valutare individui su un singolo costrutto. Tuttavia, caratteristiche psicologiche complesse come depressione e ansia spesso si manifestano in modi vari. Di conseguenza, è consigliabile includere item che coprono diverse aree tematiche per assicurare una validità di contenuto adeguata. Pertanto, molte scale di valutazione comunemente usate producono dati che si prestano a interpretazioni valide sia attraverso un modello unidimensionale, con un forte fattore generale, sia tramite un modello multidimensionale, che comprende due o più fattori correlati.
43.2 Struttura Fattoriale
Recenti studi hanno evidenziato che, di fronte a misure che generano dati multidimensionali a causa di una diversificata struttura di contenuto, l’adozione di un modello di misurazione bifattoriale può essere particolarmente efficace per rappresentare la struttura sottostante. Questo modello suggerisce che le correlazioni tra gli item di un test possono essere spiegate attraverso due tipi di fattori: (a) un fattore generale che riflette la varianza condivisa tra tutti gli item, e (b) una serie di fattori di gruppo che catturano la varianza specifica non spiegata dal fattore generale e che è comune tra item simili in termini di contenuto. Generalmente, si ritiene che il fattore generale e i fattori di gruppo siano indipendenti.
Il fattore generale rappresenta il costrutto principale che lo strumento si propone di misurare, mentre i fattori di gruppo individuano costrutti più specifici legati a sottodomini. I modelli bifattoriali sono utilizzati per diverse finalità importanti:
- Analizzare la distribuzione della varianza quando si presume che uno strumento misuri sia varianza generale sia specifica di gruppo.
- Gestire la multidimensionalità in modo che la misura risulti “essenzialmente unidimensionale”, pur presentando dimensioni secondarie.
- Verificare la presenza di un fattore generale sufficientemente robusto da giustificare l’uso di un modello di misurazione unidimensionale.
- Determinare l’adeguatezza di un punteggio complessivo e valutare l’utilità di analizzare le sottoscale specifiche.
Questi approcci permettono una comprensione più profonda e una valutazione più accurata della struttura sottostante dei dati psicologici, offrendo agli specialisti gli strumenti per interpretare con maggiore precisione i risultati dei test psicologici.
43.3 Un esempio pratico
Consideriamo i dati SRS_data forniti dal pacchetto BifactorIndicesCalculator. Il dataset contiene 500 risposte al test SRS-22r sulla qualità della vita legata alla scoliosi, composta da 20 item. La sottoscala “Function” è composta dagli item 5, 9, 12, 15 e 18. La sottoscala “Pain” è composta dagli item 1, 2, 8, 11 e 17. La sottoscala “SelfImage” è composta dagli item 4, 6, 10, 14 e 19. La sottoscala “MentalHealth” è composta dagli item 3, 7, 13, 16 e 20.
Iniziamo esaminando le statistiche descrittive a livello di item e le correlazioni tra gli item.
describe(SRS_data)| vars | n | mean | sd | median | trimmed | mad | min | max | range | skew | kurtosis | se | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| <int> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | |
| SRS_1 | 1 | 500 | 3.69 | 1.065 | 4 | 3.78 | 1.48 | 1 | 5 | 4 | -0.5509 | -0.4413 | 0.0476 |
| SRS_2 | 2 | 500 | 3.81 | 1.030 | 4 | 3.92 | 1.48 | 1 | 5 | 4 | -0.7148 | -0.0679 | 0.0460 |
| SRS_3 | 3 | 500 | 3.90 | 1.090 | 4 | 4.04 | 1.48 | 1 | 5 | 4 | -0.8323 | -0.0397 | 0.0487 |
| SRS_4 | 4 | 500 | 3.23 | 1.280 | 3 | 3.29 | 1.48 | 1 | 5 | 4 | -0.1059 | -1.0236 | 0.0572 |
| SRS_5 | 5 | 500 | 4.20 | 0.894 | 4 | 4.30 | 1.48 | 2 | 5 | 3 | -0.7453 | -0.5385 | 0.0400 |
| SRS_6 | 6 | 500 | 3.91 | 0.872 | 4 | 3.95 | 1.48 | 1 | 5 | 4 | -0.3767 | -0.3859 | 0.0390 |
| SRS_7 | 7 | 500 | 4.24 | 1.011 | 5 | 4.40 | 0.00 | 1 | 5 | 4 | -1.2842 | 1.0807 | 0.0452 |
| SRS_8 | 8 | 500 | 3.80 | 1.132 | 4 | 3.91 | 1.48 | 1 | 5 | 4 | -0.5140 | -0.6993 | 0.0506 |
| SRS_9 | 9 | 500 | 4.41 | 1.004 | 5 | 4.63 | 0.00 | 1 | 5 | 4 | -1.7706 | 2.4517 | 0.0449 |
| SRS_10 | 10 | 500 | 3.70 | 0.855 | 4 | 3.71 | 1.48 | 1 | 5 | 4 | -0.2302 | -0.2097 | 0.0382 |
| SRS_11 | 11 | 500 | 4.50 | 0.839 | 5 | 4.69 | 0.00 | 1 | 5 | 4 | -2.0302 | 4.0862 | 0.0375 |
| SRS_12 | 12 | 500 | 4.26 | 1.028 | 5 | 4.44 | 0.00 | 1 | 5 | 4 | -1.3462 | 1.1192 | 0.0460 |
| SRS_13 | 13 | 500 | 3.85 | 0.927 | 4 | 3.94 | 1.48 | 1 | 5 | 4 | -0.6457 | 0.0497 | 0.0414 |
| SRS_14 | 14 | 500 | 4.72 | 0.676 | 5 | 4.89 | 0.00 | 1 | 5 | 4 | -2.8155 | 8.2069 | 0.0303 |
| SRS_15 | 15 | 500 | 4.81 | 0.629 | 5 | 4.99 | 0.00 | 1 | 5 | 4 | -4.1179 | 18.0401 | 0.0281 |
| SRS_16 | 16 | 500 | 4.24 | 0.960 | 5 | 4.40 | 0.00 | 1 | 5 | 4 | -1.2300 | 0.9875 | 0.0429 |
| SRS_17 | 17 | 500 | 4.74 | 0.860 | 5 | 4.99 | 0.00 | 1 | 5 | 4 | -3.4840 | 11.2987 | 0.0385 |
| SRS_18 | 18 | 500 | 2.92 | 0.923 | 3 | 2.92 | 0.00 | 1 | 5 | 4 | 0.0515 | 0.8364 | 0.0413 |
| SRS_19 | 19 | 500 | 3.60 | 1.107 | 4 | 3.69 | 1.48 | 1 | 5 | 4 | -0.5442 | -0.2818 | 0.0495 |
| SRS_20 | 20 | 500 | 3.99 | 0.900 | 4 | 4.09 | 1.48 | 1 | 5 | 4 | -0.8992 | 0.7480 | 0.0402 |
round(cor(SRS_data, use = "pairwise.complete.obs"), 2)| SRS_1 | SRS_2 | SRS_3 | SRS_4 | SRS_5 | SRS_6 | SRS_7 | SRS_8 | SRS_9 | SRS_10 | SRS_11 | SRS_12 | SRS_13 | SRS_14 | SRS_15 | SRS_16 | SRS_17 | SRS_18 | SRS_19 | SRS_20 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SRS_1 | 1.00 | 0.88 | 0.43 | 0.36 | 0.36 | 0.39 | 0.34 | 0.70 | 0.31 | 0.37 | 0.46 | 0.59 | 0.37 | 0.36 | 0.19 | 0.40 | 0.38 | 0.30 | 0.27 | 0.33 |
| SRS_2 | 0.88 | 1.00 | 0.40 | 0.38 | 0.35 | 0.42 | 0.35 | 0.70 | 0.34 | 0.40 | 0.49 | 0.58 | 0.35 | 0.38 | 0.20 | 0.37 | 0.39 | 0.29 | 0.31 | 0.32 |
| SRS_3 | 0.43 | 0.40 | 1.00 | 0.32 | 0.33 | 0.39 | 0.50 | 0.46 | 0.30 | 0.32 | 0.24 | 0.46 | 0.55 | 0.34 | 0.19 | 0.55 | 0.25 | 0.25 | 0.28 | 0.41 |
| SRS_4 | 0.36 | 0.38 | 0.32 | 1.00 | 0.23 | 0.43 | 0.32 | 0.33 | 0.19 | 0.43 | 0.20 | 0.30 | 0.30 | 0.20 | 0.23 | 0.32 | 0.10 | 0.21 | 0.54 | 0.32 |
| SRS_5 | 0.36 | 0.35 | 0.33 | 0.23 | 1.00 | 0.33 | 0.39 | 0.33 | 0.47 | 0.34 | 0.23 | 0.52 | 0.31 | 0.29 | 0.20 | 0.42 | 0.28 | 0.31 | 0.25 | 0.40 |
| SRS_6 | 0.39 | 0.42 | 0.39 | 0.43 | 0.33 | 1.00 | 0.48 | 0.37 | 0.25 | 0.64 | 0.28 | 0.37 | 0.41 | 0.38 | 0.22 | 0.47 | 0.22 | 0.31 | 0.62 | 0.41 |
| SRS_7 | 0.34 | 0.35 | 0.50 | 0.32 | 0.39 | 0.48 | 1.00 | 0.40 | 0.24 | 0.37 | 0.22 | 0.42 | 0.53 | 0.44 | 0.23 | 0.78 | 0.19 | 0.39 | 0.39 | 0.56 |
| SRS_8 | 0.70 | 0.70 | 0.46 | 0.33 | 0.33 | 0.37 | 0.40 | 1.00 | 0.30 | 0.37 | 0.36 | 0.52 | 0.40 | 0.28 | 0.14 | 0.42 | 0.31 | 0.32 | 0.28 | 0.34 |
| SRS_9 | 0.31 | 0.34 | 0.30 | 0.19 | 0.47 | 0.25 | 0.24 | 0.30 | 1.00 | 0.36 | 0.26 | 0.49 | 0.32 | 0.29 | 0.22 | 0.32 | 0.35 | 0.27 | 0.20 | 0.31 |
| SRS_10 | 0.37 | 0.40 | 0.32 | 0.43 | 0.34 | 0.64 | 0.37 | 0.37 | 0.36 | 1.00 | 0.26 | 0.37 | 0.30 | 0.34 | 0.22 | 0.39 | 0.19 | 0.28 | 0.54 | 0.35 |
| SRS_11 | 0.46 | 0.49 | 0.24 | 0.20 | 0.23 | 0.28 | 0.22 | 0.36 | 0.26 | 0.26 | 1.00 | 0.42 | 0.19 | 0.33 | 0.20 | 0.23 | 0.39 | 0.18 | 0.24 | 0.19 |
| SRS_12 | 0.59 | 0.58 | 0.46 | 0.30 | 0.52 | 0.37 | 0.42 | 0.52 | 0.49 | 0.37 | 0.42 | 1.00 | 0.43 | 0.46 | 0.23 | 0.46 | 0.44 | 0.33 | 0.32 | 0.43 |
| SRS_13 | 0.37 | 0.35 | 0.55 | 0.30 | 0.31 | 0.41 | 0.53 | 0.40 | 0.32 | 0.30 | 0.19 | 0.43 | 1.00 | 0.35 | 0.17 | 0.57 | 0.21 | 0.30 | 0.35 | 0.60 |
| SRS_14 | 0.36 | 0.38 | 0.34 | 0.20 | 0.29 | 0.38 | 0.44 | 0.28 | 0.29 | 0.34 | 0.33 | 0.46 | 0.35 | 1.00 | 0.33 | 0.46 | 0.38 | 0.30 | 0.32 | 0.34 |
| SRS_15 | 0.19 | 0.20 | 0.19 | 0.23 | 0.20 | 0.22 | 0.23 | 0.14 | 0.22 | 0.22 | 0.20 | 0.23 | 0.17 | 0.33 | 1.00 | 0.27 | 0.20 | 0.17 | 0.29 | 0.24 |
| SRS_16 | 0.40 | 0.37 | 0.55 | 0.32 | 0.42 | 0.47 | 0.78 | 0.42 | 0.32 | 0.39 | 0.23 | 0.46 | 0.57 | 0.46 | 0.27 | 1.00 | 0.19 | 0.38 | 0.36 | 0.59 |
| SRS_17 | 0.38 | 0.39 | 0.25 | 0.10 | 0.28 | 0.22 | 0.19 | 0.31 | 0.35 | 0.19 | 0.39 | 0.44 | 0.21 | 0.38 | 0.20 | 0.19 | 1.00 | 0.25 | 0.15 | 0.16 |
| SRS_18 | 0.30 | 0.29 | 0.25 | 0.21 | 0.31 | 0.31 | 0.39 | 0.32 | 0.27 | 0.28 | 0.18 | 0.33 | 0.30 | 0.30 | 0.17 | 0.38 | 0.25 | 1.00 | 0.25 | 0.31 |
| SRS_19 | 0.27 | 0.31 | 0.28 | 0.54 | 0.25 | 0.62 | 0.39 | 0.28 | 0.20 | 0.54 | 0.24 | 0.32 | 0.35 | 0.32 | 0.29 | 0.36 | 0.15 | 0.25 | 1.00 | 0.41 |
| SRS_20 | 0.33 | 0.32 | 0.41 | 0.32 | 0.40 | 0.41 | 0.56 | 0.34 | 0.31 | 0.35 | 0.19 | 0.43 | 0.60 | 0.34 | 0.24 | 0.59 | 0.16 | 0.31 | 0.41 | 1.00 |
SRS_UnidimensionalModel <-
"
SRS =~ SRS_1 + SRS_2 + SRS_3 + SRS_4 + SRS_5 +
SRS_6 + SRS_7 + SRS_8 + SRS_9 + SRS_10 +
SRS_11 + SRS_12 + SRS_13 + SRS_14 + SRS_15 +
SRS_16 + SRS_17 + SRS_18 + SRS_19 + SRS_20
"
SRS_Unidimensional <- lavaan::cfa(SRS_UnidimensionalModel,
SRS_data,
ordered = paste0("SRS_", 1:20),
orthogonal = TRUE
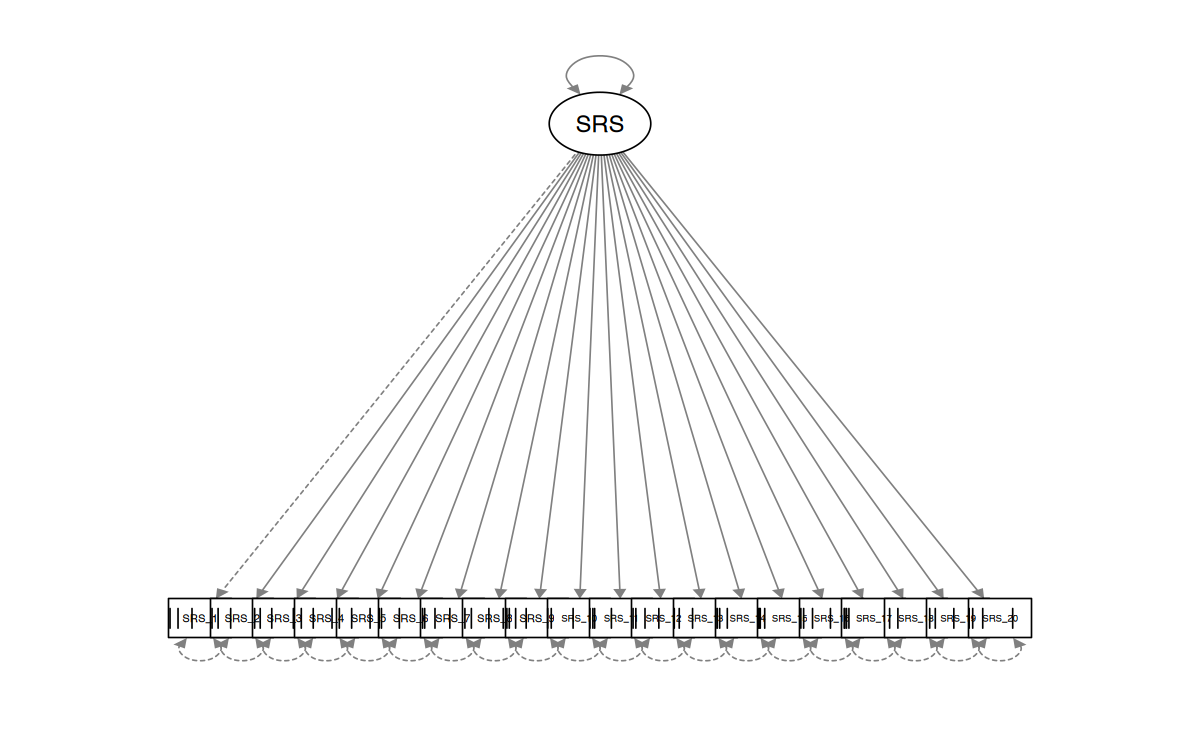
)semPaths(
SRS_Unidimensional,
intercepts = FALSE
)
Esaminiamo la bontà di adattamento.
fit.subset <- c(
"chisq.scaled", "df", "pvalue.scaled",
"rmsea.scaled", "rmsea.pvalue.scale",
"rmsea.ci.lower.scaled", "rmsea.ci.upper.scaled",
"cfi", "tli", "srmr"
)fitmeasures(SRS_Unidimensional, fit.subset) |> print() chisq.scaled df pvalue.scaled
2087.431 170.000 0.000
rmsea.scaled rmsea.ci.lower.scaled rmsea.ci.upper.scaled
0.150 0.145 0.156
cfi tli srmr
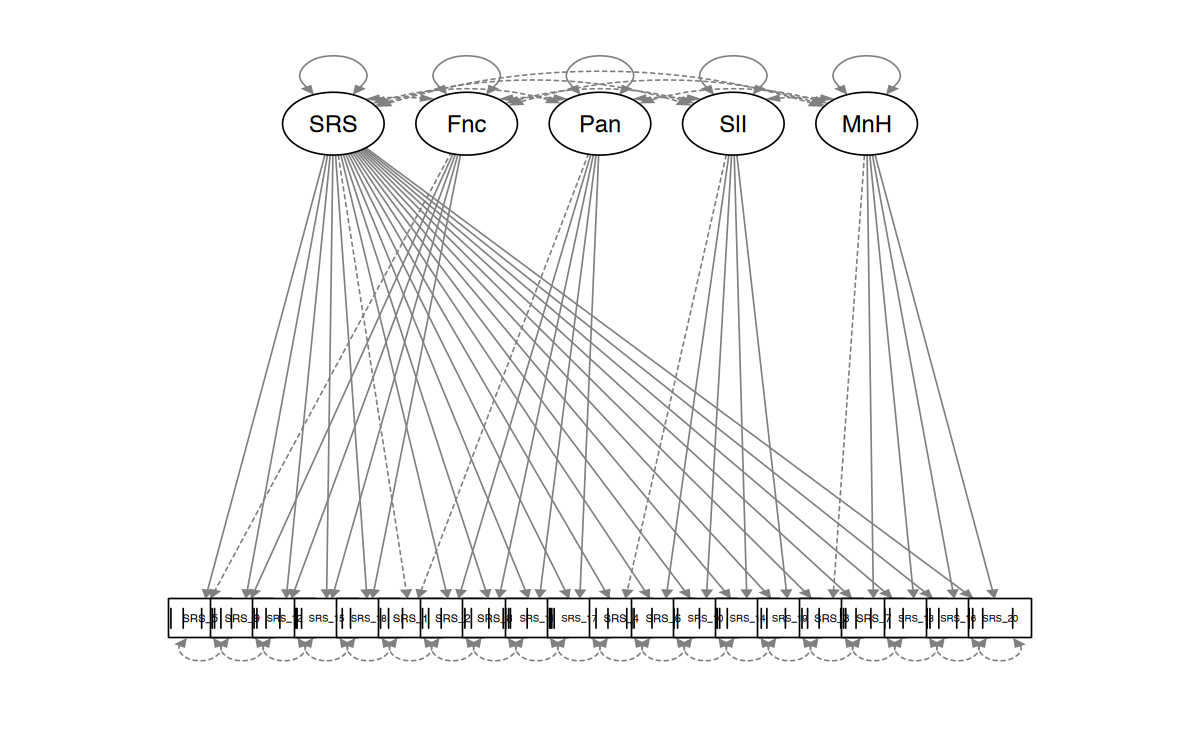
0.961 0.956 0.119 SRS_BifactorModel <-
"
SRS =~ SRS_1 + SRS_2 + SRS_3 + SRS_4 + SRS_5 +
SRS_6 + SRS_7 + SRS_8 + SRS_9 + SRS_10 +
SRS_11 + SRS_12 + SRS_13 + SRS_14 + SRS_15 +
SRS_16 + SRS_17 + SRS_18 + SRS_19 + SRS_20
Function =~ SRS_5 + SRS_9 + SRS_12 + SRS_15 + SRS_18
Pain =~ SRS_1 + SRS_2 + SRS_8 + SRS_11 + SRS_17
SelfImage =~ SRS_4 + SRS_6 + SRS_10 + SRS_14 + SRS_19
MentalHealth =~ SRS_3 + SRS_7 + SRS_13 + SRS_16 + SRS_20
"
SRS_bifactor <- lavaan::cfa(SRS_BifactorModel,
SRS_data,
ordered = paste0("SRS_", 1:20),
orthogonal = TRUE
)semPaths(
SRS_bifactor,
intercepts = FALSE
)
Esaminiamo la bontà di adattamento.
fitmeasures(SRS_bifactor, fit.subset) |> print() chisq.scaled df pvalue.scaled
468.648 150.000 0.000
rmsea.scaled rmsea.ci.lower.scaled rmsea.ci.upper.scaled
0.065 0.059 0.072
cfi tli srmr
0.997 0.996 0.055 Confrontiamo i due modelli.
lavTestLRT(SRS_Unidimensional, SRS_bifactor) |> print()
Scaled Chi-Squared Difference Test (method = "satorra.2000")
lavaan->lavTestLRT():
lavaan NOTE: The "Chisq" column contains standard test statistics, not
the robust test that should be reported per model. A robust difference
test is a function of two standard (not robust) statistics.
Df AIC BIC Chisq Chisq diff Df diff Pr(>Chisq)
SRS_bifactor 150 309
SRS_Unidimensional 170 1965 1007 20 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Consideriamo ora gli indici specifici per un modello bifattoriale.
bifactorIndices(SRS_bifactor, UniLambda = SRS_Unidimensional) |> print()$ModelLevelIndices
ECV.SRS PUC Omega.SRS OmegaH.SRS ARPB
0.673 0.789 0.942 0.834 0.121
$FactorLevelIndices
ECV_SS ECV_SG ECV_GS Omega OmegaH H FD
SRS 0.673 0.6728 0.673 0.942 0.8338 0.943 0.952
Function 0.197 0.0415 0.803 0.799 0.0912 0.403 0.710
Pain 0.412 0.1115 0.588 0.882 0.3427 0.696 0.921
SelfImage 0.328 0.0818 0.672 0.850 0.2025 0.591 0.830
MentalHealth 0.342 0.0923 0.658 0.892 0.2930 0.615 0.854
$ItemLevelIndices
IECV RelParBias
SRS_1 0.510 0.3534
SRS_2 0.498 0.3675
SRS_3 0.798 0.0366
SRS_4 0.612 0.0522
SRS_5 0.635 0.0226
SRS_6 0.637 0.0881
SRS_7 0.632 0.1789
SRS_8 0.682 0.1034
SRS_9 0.588 0.0192
SRS_10 0.649 0.0642
SRS_11 0.633 0.1217
SRS_12 0.938 0.1001
SRS_13 0.624 0.1179
SRS_14 0.999 0.0990
SRS_15 1.000 0.1011
SRS_16 0.601 0.1898
SRS_17 0.750 0.0392
SRS_18 0.999 0.0933
SRS_19 0.458 0.1664
SRS_20 0.691 0.1048
I ModelLevelIndices possono essere spiegati nel modo seguente:
ECV.SRS: Questo indica la proporzione di varianza spiegata dal fattore generale nel modello bifattoriale. ECV sta per “Explained Common Variance” (Varianza Comune Spiegata). Un valore più alto indica che una maggiore parte della varianza totale nei dati è spiegata dal fattore generale.
PUC: Questo è l’acronimo di “Percentage of Uniqueness in Common” (Percentuale di Unicità nel Comune). Indica quanto della varianza unica (cioè quella non spiegata dal fattore generale) è presente nei fattori di gruppo. Un valore basso indica che i fattori di gruppo spiegano una maggiore parte della varianza unica nei dati.
Omega.SRS: Questo indice rappresenta il coefficiente di affidabilità del fattore generale del modello bifattoriale. Indica quanto sia affidabile il fattore generale nel catturare la varianza comune tra tutti gli item del test. Un valore più alto indica maggiore affidabilità.
OmegaH.SRS: Questo indice rappresenta il coefficiente di affidabilità dei fattori di gruppo nel modello bifattoriale. Indica quanto sia affidabile l’insieme dei fattori di gruppo nel catturare la varianza condivisa tra gli item del gruppo specifico. Anche qui, un valore più alto indica maggiore affidabilità.
ARPB: Questo sta per “Average Reproducibility of Parameter Estimates” (Riproducibilità Media delle Stime dei Parametri). Rappresenta la riproducibilità media delle stime dei parametri del modello bifattoriale. In sostanza, valuta quanto le stime dei parametri del modello sono affidabili e riproducibili.
La sezione dell’output FactorLevelIndices riguarda gli indici a livello di fattore del modello bifattoriale.
ECV_SS, ECV_SG, ECV_GS: Questi rappresentano rispettivamente la proporzione di varianza spiegata dal Fattore Generale (GG), dal Fattore Specifico (SS) e dall’Interazione tra Fattore Generale e Fattore Specifico (GS) per ciascun fattore. Indicano quanto ciascun tipo di varianza contribuisce alla spiegazione della varianza totale nell’insieme dei dati del fattore.
Omega: Questo indice rappresenta il coefficiente di affidabilità dell’estratto del Fattore Generale per ciascun fattore. Indica quanto sia affidabile il Fattore Generale nel catturare la varianza comune tra gli item di quel particolare fattore. Un valore più alto indica maggiore affidabilità.
OmegaH: Questo indice rappresenta il coefficiente di affidabilità dell’estratto del Fattore Specifico per ciascun fattore. Indica quanto sia affidabile l’insieme dei Fattori Specifici nel catturare la varianza condivisa tra gli item del gruppo specifico. Anche qui, un valore più alto indica maggiore affidabilità.
H: Questo indice rappresenta la quota della varianza unica spiegata dal Fattore Generale per ciascun fattore. Indica quanto della varianza unica è spiegata dal Fattore Generale piuttosto che da fattori specifici.
FD: Questo indice rappresenta la distorsione fattoriale, che è una misura di quanto i dati si adattino bene al modello bifattoriale. Valori vicini a 1 indicano un buon adattamento.
Infine, l’output ItemLevelIndices riguarda gli indici a livello di item in un modello bifattoriale.
IECV: Questo indica la proporzione di varianza spiegata dal Fattore Generale per ciascun item. IECV sta per “Item Explained Common Variance” (Varianza Comune Spiegata dell’Item). Indica quanto della varianza totale dell’item può essere spiegata dal Fattore Generale del modello bifattoriale. Valori più alti indicano che il Fattore Generale contribuisce maggiormente a spiegare le variazioni osservate nell’item.
RelParBias: Questo rappresenta il bias relativo dei parametri dell’item. Indica quanto i parametri dell’item sono influenzati dalla presenza del Fattore Generale e dai fattori specifici nel modello. Valori più alti indicano una maggiore influenza dei fattori specifici rispetto al Fattore Generale nell’item.
Per i dati dell’esempio considerato, di seguito è riportata un’interpretazione succinta dei risultati chiave per ciascun gruppo principale di risultati:
43.3.1 Model-Level Indices
- ECV.SRS (Explained Common Variance): Il 67.28% della varianza osservata è spiegata dal modello.
- PUC (Percentage of Uncontaminated Correlations): Il 78.95% delle correlazioni tra gli item è “puro”, cioè non contaminato da altri fattori oltre al fattore generale.
- Omega.SRS: La consistenza interna complessiva del test è molto alta (0.942), indicando una buona affidabilità.
- OmegaH.SRS: Il 83.38% della varianza totale standardizzata è attribuibile al fattore generale, confermando che è un fattore dominante nel modello.
- ARPB (Average Relative Parameter Bias): Un bias relativo medio basso (0.121) suggerisce che le stime dei parametri sono relativamente poco distorte.
43.3.2 Factor-Level Indices
- ECV (Explained Common Variance) per i fattori specifici:
- Funzione: 19.73% della varianza è spiegata dal fattore specifico “Funzione”, con l’80.27% attribuibile al fattore generale.
- Dolore (Pain): 41.24% della varianza è spiegata dal fattore specifico “Dolore”.
- Autopercezione (SelfImage): 32.80% della varianza è spiegata dal fattore specifico “Autopercezione”.
- Salute Mentale (MentalHealth): 34.24% della varianza è spiegata dal fattore specifico “Salute Mentale”.
- Omega e OmegaH per ogni fattore specifico: Le misure Omega indicano la consistenza interna per ciascun sottogruppo di item, mentre OmegaH indica la proporzione della varianza attribuibile ai fattori specifici rispetto al fattore generale.
43.3.3 Item-Level Indices
- IECV (Item Explained Common Variance): Valori come 0.937 per SRS_12 e quasi 1 per SRS_14, SRS_15 e SRS_18 indicano che questi item sono molto influenzati dal fattore generale.
- RelParBias (Relative Parameter Bias): La maggior parte degli item mostra un bias relativo basso, suggerendo che gli effetti dei fattori specifici su questi item sono correttamente rappresentati senza grande distorsione.
In sintesi, il modello bifattoriale sembra adattarsi bene ai dati, con un forte fattore generale che domina la struttura del test, supportato da alcuni fattori specifici che spiegano porzioni significative della varianza in diverse aree tematiche. Gli item individuati con alti valori di IECV sono particolarmente rappresentativi del fattore generale.
43.4 Commenti e considerazioni conclusive
In questo capitolo, abbiamo esplorato diversi indici derivati dall’analisi con un modello bifattoriale, ognuno dei quali rivela aspetti specifici delle proprietà psicometriche di uno strumento di misura. Questi indici sono di grande utilità per gli sviluppatori e i valutatori di scale, oltre a essere strumenti preziosi per i ricercatori e i professionisti che le impiegano nella pratica clinica e nella ricerca. Inoltre, contribuiscono allo sviluppo e alla comprensione dei costrutti psicologici che tali strumenti intendono misurare.
43.5 Session Info
sessionInfo()R version 4.4.2 (2024-10-31)
Platform: aarch64-apple-darwin20
Running under: macOS Sequoia 15.1.1
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.4-arm64/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.4-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.0
locale:
[1] C
time zone: Europe/Rome
tzcode source: internal
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] BifactorIndicesCalculator_0.2.2 MASS_7.3-61
[3] viridis_0.6.5 viridisLite_0.4.2
[5] ggpubr_0.6.0 ggExtra_0.10.1
[7] gridExtra_2.3 patchwork_1.3.0
[9] bayesplot_1.11.1 semTools_0.5-6
[11] semPlot_1.1.6 lavaan_0.6-19
[13] psych_2.4.6.26 scales_1.3.0
[15] markdown_1.13 knitr_1.49
[17] lubridate_1.9.3 forcats_1.0.0
[19] stringr_1.5.1 dplyr_1.1.4
[21] purrr_1.0.2 readr_2.1.5
[23] tidyr_1.3.1 tibble_3.2.1
[25] ggplot2_3.5.1 tidyverse_2.0.0
[27] here_1.0.1
loaded via a namespace (and not attached):
[1] rstudioapi_0.17.1 jsonlite_1.8.9 magrittr_2.0.3
[4] TH.data_1.1-2 estimability_1.5.1 farver_2.1.2
[7] nloptr_2.1.1 rmarkdown_2.29 vctrs_0.6.5
[10] Cairo_1.6-2 minqa_1.2.8 base64enc_0.1-3
[13] rstatix_0.7.2 htmltools_0.5.8.1 broom_1.0.7
[16] Formula_1.2-5 htmlwidgets_1.6.4 plyr_1.8.9
[19] sandwich_3.1-1 emmeans_1.10.5 zoo_1.8-12
[22] uuid_1.2-1 igraph_2.1.1 mime_0.12
[25] lifecycle_1.0.4 pkgconfig_2.0.3 Matrix_1.7-1
[28] R6_2.5.1 fastmap_1.2.0 shiny_1.9.1
[31] digest_0.6.37 OpenMx_2.21.13 fdrtool_1.2.18
[34] colorspace_2.1-1 rprojroot_2.0.4 Hmisc_5.2-0
[37] fansi_1.0.6 timechange_0.3.0 abind_1.4-8
[40] compiler_4.4.2 withr_3.0.2 glasso_1.11
[43] htmlTable_2.4.3 backports_1.5.0 carData_3.0-5
[46] ggsignif_0.6.4 corpcor_1.6.10 gtools_3.9.5
[49] tools_4.4.2 pbivnorm_0.6.0 foreign_0.8-87
[52] zip_2.3.1 httpuv_1.6.15 nnet_7.3-19
[55] glue_1.8.0 quadprog_1.5-8 promises_1.3.0
[58] nlme_3.1-166 lisrelToR_0.3 grid_4.4.2
[61] pbdZMQ_0.3-13 checkmate_2.3.2 cluster_2.1.6
[64] reshape2_1.4.4 generics_0.1.3 gtable_0.3.6
[67] tzdb_0.4.0 data.table_1.16.2 hms_1.1.3
[70] car_3.1-3 utf8_1.2.4 sem_3.1-16
[73] pillar_1.9.0 IRdisplay_1.1 rockchalk_1.8.157
[76] later_1.3.2 splines_4.4.2 cherryblossom_0.1.0
[79] lattice_0.22-6 survival_3.7-0 kutils_1.73
[82] tidyselect_1.2.1 miniUI_0.1.1.1 pbapply_1.7-2
[85] airports_0.1.0 stats4_4.4.2 xfun_0.49
[88] qgraph_1.9.8 arm_1.14-4 stringi_1.8.4
[91] pacman_0.5.1 boot_1.3-31 evaluate_1.0.1
[94] codetools_0.2-20 mi_1.1 cli_3.6.3
[97] RcppParallel_5.1.9 IRkernel_1.3.2 rpart_4.1.23
[100] xtable_1.8-4 repr_1.1.7 munsell_0.5.1
[103] Rcpp_1.0.13-1 coda_0.19-4.1 png_0.1-8
[106] XML_3.99-0.17 parallel_4.4.2 usdata_0.3.1
[109] jpeg_0.1-10 lme4_1.1-35.5 mvtnorm_1.3-2
[112] openxlsx_4.2.7.1 crayon_1.5.3 openintro_2.5.0
[115] rlang_1.1.4 multcomp_1.4-26 mnormt_2.1.1