7 ✏️ Esercizi
7.1 Normazione Basata sulla Regressione: Metodi Avanzati per l’Interpretazione dei Test Psicometrici
La normazione basata sulla regressione rappresenta un metodo statistico avanzato utilizzato per trasformare i punteggi grezzi di un test in punteggi standardizzati, consentendo un confronto equo tra individui di diverse età o caratteristiche demografiche. Questo approccio supera i limiti delle metodologie tradizionali, che tipicamente si basano su fasce di età discrete e tabelle di conversione statiche, introducendo modelli di regressione che descrivono in modo continuo la relazione tra i punteggi grezzi e le variabili predittive, come l’età.
Tale metodologia risulta particolarmente preziosa nell’ambito dei test psicometrici e delle valutazioni cognitive, dove le performance possono variare significativamente in funzione dello sviluppo cognitivo o di altri fattori demografici rilevanti.
7.2 Principio Fondamentale e Vantaggi
Nei test di valutazione cognitiva, come quelli che misurano il ragionamento verbale, l’intelligenza o la memoria, si osserva naturalmente una variazione dei punteggi grezzi in relazione all’età. Ad esempio, un bambino di 7 anni tipicamente ottiene un punteggio inferiore rispetto a un adolescente di 15 anni in molti test cognitivi, senza che questo indichi necessariamente una performance deficitaria, ma piuttosto una normale differenza nello sviluppo cognitivo atteso per quelle fasce d’età.
La normazione basata sulla regressione presenta diversi vantaggi rispetto ai metodi tradizionali:
- Continuità: Evita i “salti” artificiali nei punteggi normativi che possono verificarsi al passaggio tra fasce d’età discrete.
- Precisione: Produce stime più accurate dei punteggi normativi, specialmente per età ai confini delle fasce tradizionali.
- Efficienza statistica: Utilizza in modo più efficiente tutti i dati disponibili nel campione normativo.
- Flessibilità: Può incorporare facilmente più variabili predittive oltre all’età (es. genere, livello di istruzione).
- Adattabilità: Può modellare relazioni non lineari complesse tra età e performance.
7.3 Applicazione della Normazione con il Test IDS-2
7.3.1 Descrizione dello Strumento
Il test IDS-2 (Intelligence and Development Scales, 2a Edizione) è una batteria completa che valuta lo sviluppo cognitivo e le competenze evolutive in soggetti dai 5 ai 20 anni. Questo strumento, ampiamente utilizzato in ambito clinico ed educativo, permette di ottenere un profilo dettagliato delle abilità del soggetto in diverse aree funzionali.
Nell’esempio che segue, analizziamo i dati relativi al Sottotest 14 (Denominare Contrari), che fa parte della scala di Ragionamento Verbale e misura specificamente:
- Competenza lessicale: L’ampiezza e la profondità del vocabolario posseduto
- Flessibilità cognitiva: La capacità di identificare relazioni semantiche opposte
- Velocità di elaborazione semantica: L’efficienza nell’accesso al lessico mentale
7.3.2 Dataset e Preparazione dei Dati
Il dataset IDS2_sample contiene dati di un campione normativo con le seguenti variabili principali:
-
age: Età dei partecipanti (espressa in mesi) -
y14: Punteggio grezzo ottenuto nel sottotest “Denominare Contrari”
# Caricamento dati
IDS2_sample <- read.table(
here::here("data", "IDS2_sample.txt"),
header = TRUE
)
# Anteprima dati
head(IDS2_sample)
#> age y7 y14
#> 1 10.971 17 17
#> 2 11.674 20 19
#> 3 11.444 22 23
#> 4 10.049 14 14
#> 5 14.182 20 19
#> 6 6.554 11 11Per migliorare la stabilità numerica nei calcoli statistici successivi, aggiungiamo una costante infinitesimale ai punteggi per eliminare eventuali valori zero che potrebbero creare problemi in alcune trasformazioni matematiche:
IDS2_sample$y14_a <- IDS2_sample$y14 + 0.00017.4 Modellazione Statistica Avanzata con il BCPE
Il modello Box-Cox Power Exponential (BCPE) rappresenta una scelta particolarmente avanzata per la normazione basata sulla regressione, poiché permette di modellare simultaneamente quattro parametri fondamentali della distribuzione dei punteggi:
- Tendenza centrale (μ): Il valore medio o mediano dei punteggi grezzi in funzione dell’età
- Dispersione (σ): La variabilità dei punteggi attorno alla tendenza centrale
- Asimmetria (ν): Il grado di simmetria/asimmetria nella distribuzione dei punteggi
- Curtosi (τ): La forma delle code della distribuzione (più o meno pesanti rispetto alla distribuzione normale)
L’implementazione del modello utilizza P-splines (spline penalizzate), che garantiscono che la relazione tra punteggio grezzo ed età sia modellata in modo flessibile e adattativo, senza imporre forme funzionali rigide. Questo è particolarmente importante quando la relazione tra età e performance non segue un semplice andamento lineare, come spesso accade nei test cognitivi.
Il modello viene implementato utilizzando la libreria gamlss in R:
BCPE_mod_sp <- gamlss(
y14_a ~ pbm(age, method = "GAIC", k = log(nrow(IDS2_sample)), inter = 5, mono = "up"),
sigma.formula = ~ pb(age, method = "GAIC", k = log(nrow(IDS2_sample)), inter = 5),
nu.formula = ~1,
tau.formula = ~1,
family = BCPE,
data = IDS2_sample,
method = RS(1000)
)
#> GAMLSS-RS iteration 1: Global Deviance = 8348
#> GAMLSS-RS iteration 2: Global Deviance = 8346
#> GAMLSS-RS iteration 3: Global Deviance = 8346
#> GAMLSS-RS iteration 4: Global Deviance = 8346
#> GAMLSS-RS iteration 5: Global Deviance = 8346
#> GAMLSS-RS iteration 6: Global Deviance = 83467.4.1 Elementi Chiave del Modello
-
pbm(age, ..., mono = "up"): Utilizza P-splines monotone crescenti per modellare la tendenza centrale, riflettendo l’aspettativa che le prestazioni cognitive mediamente aumentino con l’età. -
pb(age, ...): Utilizza P-splines standard (non monotone) per modellare la dispersione, permettendo variazioni nella variabilità dei punteggi durante lo sviluppo. -
method = "GAIC", k = log(nrow(IDS2_sample)): Utilizza il criterio GAIC (Generalized Akaike Information Criterion) per selezionare automaticamente il grado ottimale di smoothing nelle splines. -
inter = 5: Specifica il numero di intervalli per le splines, bilanciando flessibilità e parsimonia. -
nu.formula = ~1, tau.formula = ~1: Modella asimmetria e curtosi come costanti indipendenti dall’età, semplificando il modello.
7.5 Visualizzazione e Interpretazione delle Curve Centili
La funzione centiles.fan di gamlss consente di visualizzare graficamente la distribuzione dei punteggi normati in funzione dell’età, fornendo un potente strumento per l’interpretazione dei risultati:
centiles.fan(
BCPE_mod_sp,
xvar = IDS2_sample$age,
points = TRUE,
colors = "gray",
col = "black",
pch = 16,
ylab = "Punteggio grezzo",
xlab = "Età in mesi"
)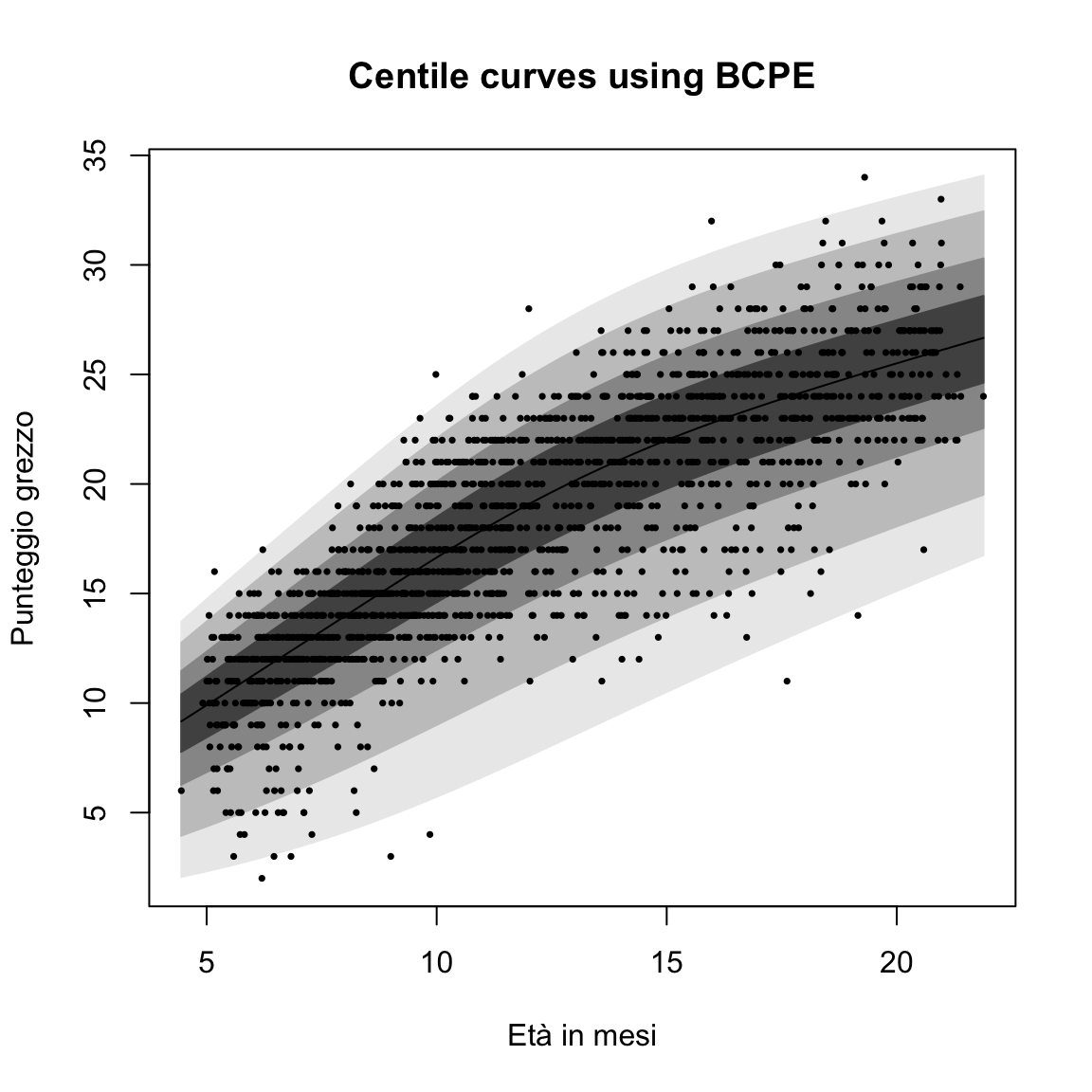
7.5.1 Interpretazione delle Curve Centili
Le curve centili rappresentano visivamente la distribuzione condizionata dei punteggi a ogni età:
- 50° percentile (curva mediana): Rappresenta il valore mediano previsto per una data età. Un bambino che ottiene un punteggio su questa curva ha una performance esattamente nella media rispetto ai suoi coetanei.
- 10°-90° percentile: Delimita l’intervallo in cui ricade l’80% centrale dei punteggi. Punteggi all’interno di questo intervallo sono considerati nella norma.
- 2°-98° percentile: Delimita una fascia di valori più ampia che include il 96% dei soggetti. Punteggi al di fuori di questo intervallo meritano particolare attenzione.
- <2° o >98° percentile: Valori estremamente bassi o alti che possono indicare significative deviazioni dalla norma e giustificare approfondimenti diagnostici.
7.6 Calcolo dei Punteggi Normati Individuali
Per determinare il punteggio normato di un individuo, dobbiamo stabilire la sua posizione relativa rispetto alla distribuzione condizionata dei punteggi per la sua specifica età. Questo processo avviene in due fasi principali:
7.6.1 1. Calcolo del Percentile Individuale
Prima calcoliamo il percentile corrispondente al punteggio grezzo dell’individuo, data la sua età:
CDF_sample <- pBCPE(
IDS2_sample$y14_a,
mu = BCPE_mod_sp$mu.fv,
sigma = BCPE_mod_sp$sigma.fv,
nu = BCPE_mod_sp$nu.fv,
tau = BCPE_mod_sp$tau.fv,
lower.tail = TRUE
)In questo passaggio, pBCPE calcola la funzione di distribuzione cumulativa del modello BCPE, restituendo la probabilità che un soggetto con una data età ottenga un punteggio inferiore o uguale al punteggio osservato. Questo valore rappresenta il percentile del soggetto nella distribuzione.
7.6.2 2. Conversione in Punteggi Z
Successivamente, convertiamo i percentili in punteggi Z utilizzando l’inversa della distribuzione normale standard:
IDS2_sample$z_score <- qnorm(CDF_sample)Il punteggio Z (o punteggio standard) rappresenta la distanza del punteggio individuale dalla media della popolazione di riferimento (per quella specifica età), espressa in unità di deviazione standard. L’interpretazione dei punteggi Z è la seguente:
- Z = 0: Performance esattamente nella media
- Z = +1: Performance superiore di una deviazione standard rispetto alla media
- Z = -1: Performance inferiore di una deviazione standard rispetto alla media
- Z ≥ +2: Performance significativamente superiore alla media (circa top 2.5%)
- Z ≤ -2: Performance significativamente inferiore alla media (circa bottom 2.5%)
7.6.3 Esempio Concreto
Per illustrare il processo con un esempio concreto:
- Supponiamo che un bambino di 96 mesi (8 anni) ottenga un punteggio grezzo di 12 nel sottotest “Denominare Contrari”
- Dalle curve centili, determiniamo che per questa età il punteggio mediano atteso è circa 11
- Applicando il modello BCPE, calcoliamo che questo punteggio corrisponde al 65° percentile
- Convertendo in punteggio Z, otteniamo Z = 0.39
- Interpretiamo: il bambino ha una performance leggermente sopra la media rispetto ai coetanei, ma ben all’interno del range normale
7.7 Rappresentazione Grafica della Relazione tra Punteggi Grezzi e Normati
Per comprendere meglio la relazione tra i punteggi grezzi originali e i punteggi Z derivati, possiamo visualizzare questa relazione graficamente:
plot(IDS2_sample$y14, IDS2_sample$z_score,
xlab = "Punteggio Grezzo",
ylab = "Punteggio Normato (Z-score)",
main = "Relazione tra Punteggi Grezzi e Punteggi Normati",
pch = 16, col = "blue")
# Aggiungere una linea di tendenza
abline(lm(z_score ~ y14, data = IDS2_sample), col = "red", lwd = 2)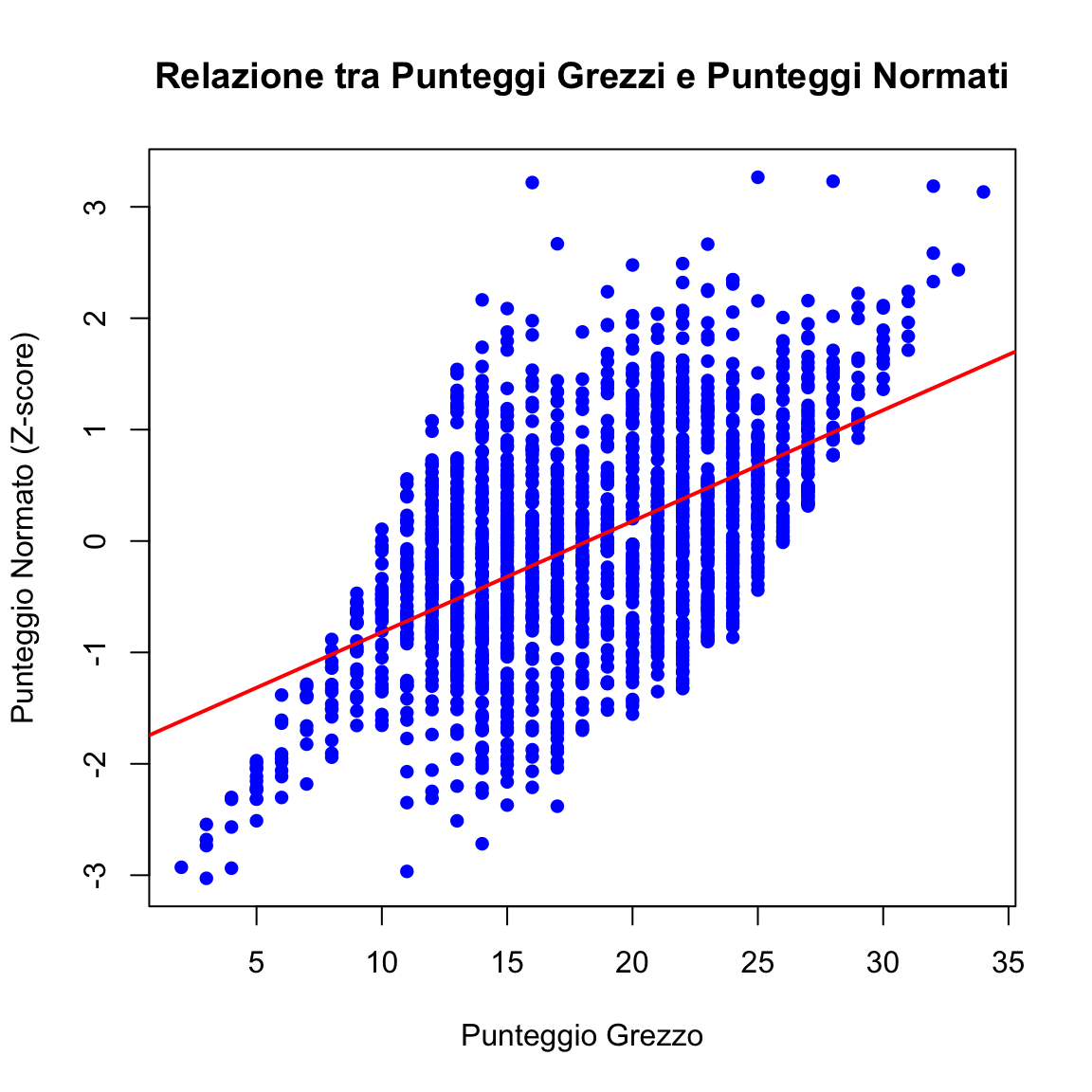
Questa visualizzazione mostra chiaramente che:
- La relazione tra punteggi grezzi e Z-score non è perfettamente lineare
- Lo stesso punteggio grezzo può corrispondere a diversi Z-score a seconda dell’età del soggetto
- La dispersione attorno alla linea di tendenza illustra l’effetto della correzione per età
7.8 Estensioni e Considerazioni Avanzate
Il modello BCPE presentato può essere ulteriormente esteso per incorporare altre variabili predittive rilevanti oltre all’età, come:
- Genere: Se esistono differenze sistematiche tra maschi e femmine
- Livello di istruzione: Per tenere conto del background educativo
- Background socioeconomico: Per controlli demografici più completi
- Bilinguismo: Per considerare l’influenza di specifiche caratteristiche linguistiche
Inoltre, è possibile implementare modelli ancora più flessibili utilizzando:
- Reti neurali: Per catturare relazioni non parametriche complesse
- Modelli bayesiani: Per incorporare conoscenze a priori e quantificare l’incertezza nelle stime
- Analisi longitudinali: Per tracciare lo sviluppo individuale nel tempo
7.9 Conclusione
La normazione basata sulla regressione, specialmente quando implementata attraverso modelli avanzati come il BCPE con P-splines, offre un approccio statisticamente robusto e clinicamente rilevante per l’interpretazione dei test psicometrici. Rispetto ai metodi tradizionali basati su tabelle normative discrete, questo approccio garantisce:
- Maggiore precisione: Stime più accurate dei valori normativi a tutte le età
- Continuità: Eliminazione degli artefatti ai confini delle fasce d’età
- Flessibilità: Capacità di modellare relazioni complesse e non lineari tra età e performance
- Efficienza statistica: Utilizzo ottimale dei dati disponibili nel campione normativo
L’implementazione di questi metodi avanzati di normazione permette ai clinici e ai ricercatori di ottenere valutazioni più precise e affidabili, migliorando sia l’accuratezza diagnostica che l’utilità dei test psicometrici nella pratica professionale e nella ricerca.
sessionInfo()
#> R version 4.4.2 (2024-10-31)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Sequoia 15.3.2
#>
#> Matrix products: default
#> BLAS: /Library/Frameworks/R.framework/Versions/4.4-arm64/Resources/lib/libRblas.0.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.4-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.0
#>
#> locale:
#> [1] C/UTF-8/C/C/C/C
#>
#> time zone: Europe/Rome
#> tzcode source: internal
#>
#> attached base packages:
#> [1] parallel splines stats graphics grDevices utils datasets
#> [8] methods base
#>
#> other attached packages:
#> [1] gamlss.add_5.1-13 rpart_4.1.24 nnet_7.3-20 mgcv_1.9-1
#> [5] gamlss_5.4-22 nlme_3.1-167 gamlss.dist_6.1-1 gamlss.data_6.0-6
#> [9] rio_1.2.3 ggokabeito_0.1.0 see_0.11.0 MASS_7.3-65
#> [13] viridis_0.6.5 viridisLite_0.4.2 ggpubr_0.6.0 ggExtra_0.10.1
#> [17] gridExtra_2.3 patchwork_1.3.0 bayesplot_1.11.1 semTools_0.5-6
#> [21] semPlot_1.1.6 lavaan_0.6-19 psych_2.4.12 scales_1.3.0
#> [25] markdown_1.13 knitr_1.50 lubridate_1.9.4 forcats_1.0.0
#> [29] stringr_1.5.1 dplyr_1.1.4 purrr_1.0.4 readr_2.1.5
#> [33] tidyr_1.3.1 tibble_3.2.1 ggplot2_3.5.1 tidyverse_2.0.0
#> [37] here_1.0.1
#>
#> loaded via a namespace (and not attached):
#> [1] rstudioapi_0.17.1 jsonlite_1.9.1 magrittr_2.0.3
#> [4] TH.data_1.1-3 estimability_1.5.1 farver_2.1.2
#> [7] nloptr_2.2.1 rmarkdown_2.29 vctrs_0.6.5
#> [10] minqa_1.2.8 base64enc_0.1-3 rstatix_0.7.2
#> [13] htmltools_0.5.8.1 broom_1.0.7 Formula_1.2-5
#> [16] htmlwidgets_1.6.4 plyr_1.8.9 sandwich_3.1-1
#> [19] emmeans_1.10.7 zoo_1.8-13 igraph_2.1.4
#> [22] mime_0.13 lifecycle_1.0.4 pkgconfig_2.0.3
#> [25] Matrix_1.7-3 R6_2.6.1 fastmap_1.2.0
#> [28] rbibutils_2.3 shiny_1.10.0 digest_0.6.37
#> [31] OpenMx_2.21.13 fdrtool_1.2.18 colorspace_2.1-1
#> [34] rprojroot_2.0.4 Hmisc_5.2-3 timechange_0.3.0
#> [37] abind_1.4-8 compiler_4.4.2 withr_3.0.2
#> [40] glasso_1.11 htmlTable_2.4.3 backports_1.5.0
#> [43] carData_3.0-5 ggsignif_0.6.4 corpcor_1.6.10
#> [46] gtools_3.9.5 tools_4.4.2 pbivnorm_0.6.0
#> [49] foreign_0.8-88 zip_2.3.2 httpuv_1.6.15
#> [52] glue_1.8.0 quadprog_1.5-8 promises_1.3.2
#> [55] lisrelToR_0.3 grid_4.4.2 checkmate_2.3.2
#> [58] cluster_2.1.8.1 reshape2_1.4.4 generics_0.1.3
#> [61] gtable_0.3.6 tzdb_0.5.0 data.table_1.17.0
#> [64] hms_1.1.3 car_3.1-3 sem_3.1-16
#> [67] pillar_1.10.1 rockchalk_1.8.157 later_1.4.1
#> [70] lattice_0.22-6 survival_3.8-3 kutils_1.73
#> [73] tidyselect_1.2.1 miniUI_0.1.1.1 pbapply_1.7-2
#> [76] reformulas_0.4.0 stats4_4.4.2 xfun_0.51
#> [79] qgraph_1.9.8 arm_1.14-4 stringi_1.8.4
#> [82] pacman_0.5.1 boot_1.3-31 evaluate_1.0.3
#> [85] codetools_0.2-20 mi_1.1 cli_3.6.4
#> [88] RcppParallel_5.1.10 xtable_1.8-4 Rdpack_2.6.3
#> [91] munsell_0.5.1 Rcpp_1.0.14 coda_0.19-4.1
#> [94] png_0.1-8 XML_3.99-0.18 jpeg_0.1-10
#> [97] lme4_1.1-36 mvtnorm_1.3-3 openxlsx_4.2.8
#> [100] rlang_1.1.5 multcomp_1.4-28 mnormt_2.1.1