source("../../code/_common.R")2 ✏ Esercizi
Prerequisiti
Concetti e Competenze Chiave
Preparazione del Notebook
2.1 Manipolazione di dati a livello di scala Likert
In questo tutorial, ripreso da Brown (2023), esamineremo i dati di un questionario ordinale. In particolare, esamineremo il Strengths and Difficulties Questionnaire (SDQ), ovvero un breve questionario di screening comportamentale progettato per valutare i comportamenti di bambini e adolescenti tra i 3 e i 16 anni. Il SDQ è disponibile in diverse versioni per soddisfare le esigenze di ricercatori, clinici ed educatori. Per maggiori informazioni, è possibile consultare il sito ufficiale http://www.sdqinfo.org/, dove è possibile scaricare il questionario, insieme alle chiavi di scoring e alle norme pubblicate dal distributore del test.
Il questionario include 25 item suddivisi in 5 scale (o dimensioni) che misurano specifici aspetti comportamentali. Ogni scala comprende 5 item:
-
Sintomi Emotivi: somatizzazione, preoccupazioni, infelicità, attaccamento, paura
-
Problemi di Condotta: capricci, ubbidienza*, litigi, bugie, furti
-
Iperattività: irrequietezza, agitazione, distrazione, riflessione, attenzione
-
Problemi con i Pari: solitudine, amicizia, popolarità, vittimismo, miglior amico più grande
- Comportamento Prosociale: considerazione, condivisione, empatia, gentilezza, aiuto agli altri
Ogni item viene valutato dai partecipanti utilizzando le seguenti opzioni di risposta:
-
0 = “Non vero”
-
1 = “Parzialmente vero”
- 2 = “Assolutamente vero”
Alcuni item nel SDQ rappresentano comportamenti che devono essere invertiti rispetto alla scala di appartenenza, ossia item a punteggio invertito. Questo significa che punteggi alti sulla scala corrispondono a punteggi bassi per questi specifici item. Ad esempio, l’item “Di solito faccio ciò che mi viene detto” (variabile “obeys”) è un item a punteggio invertito per la scala “Problemi di Condotta”.
Nel SDQ sono presenti 5 item di questo tipo, contrassegnati con un asterisco (*) nella tabella. Questi item devono essere codificati invertendo i punteggi (ad esempio, da 0 a 2 e viceversa) prima di calcolare il punteggio complessivo della scala.
In questo studio, i partecipanti sono studenti di prima media (Year 7) provenienti dalla stessa scuola, per un totale di 228 ragazzi. Si tratta di un campione della comunità scolastica, quindi non ci si aspetta che molti dei partecipanti superino le soglie cliniche indicate dal test.
Il questionario SDQ è stato somministrato due volte:
- La prima somministrazione è avvenuta all’inizio della scuola secondaria, quando i ragazzi erano nel Year 7.
- La seconda somministrazione è avvenuta un anno dopo, quando i partecipanti erano nel Year 8.
Questa progettazione longitudinale consente di analizzare eventuali cambiamenti nei punteggi SDQ durante il passaggio tra il primo e il secondo anno di scuola secondaria.
2.2 Emotional Symptoms scale
Iniziamo ad esaminare la scala Emotional Symptoms. Questa scala non contiene item reverse. Importiamo i dati in R.
load("../../data/data_sdq/SDQ.RData")
glimpse(SDQ)
#> Rows: 228
#> Columns: 51
#> $ Gender <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …
#> $ consid <dbl> 1, 2, 2, 2, 0, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, …
#> $ restles <dbl> 2, 0, 0, 0, 1, 0, 2, 1, 2, 0, 1, 1, 0, 1, 0, 2, 0, 1, 1, …
#> $ somatic <dbl> 2, 2, 0, 0, 2, 1, 0, 0, 1, 0, 0, 2, 0, 0, 1, 2, 1, 1, 1, …
#> $ shares <dbl> 1, 1, 2, 2, 0, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 1, 2, 1, …
#> $ tantrum <dbl> 0, 0, 0, 0, 1, 0, 2, 0, 2, 0, 0, 1, 0, 1, 1, 2, 0, 1, 1, …
#> $ loner <dbl> 0, 0, 0, 0, 0, 0, 0, 2, 2, 0, 0, 1, 0, 0, 0, 1, 0, 0, 2, …
#> $ obeys <dbl> 2, 2, 2, 2, 0, 2, 2, 2, 2, 2, 1, 1, 2, 2, 1, 2, 2, 2, 1, …
#> $ worries <dbl> 1, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 2, 0, 1, 2, 0, 1, 1, 2, …
#> $ caring <dbl> 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 1, 2, 2, …
#> $ fidgety <dbl> 0, 0, 0, 0, 0, 0, 2, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0, …
#> $ friend <dbl> 2, 2, 2, 2, 0, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 1, …
#> $ fights <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
#> $ unhappy <dbl> 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 2, …
#> $ popular <dbl> 2, 2, 2, 1, 1, 2, 2, 2, 2, 2, 2, 2, 1, 1, 1, 2, 1, 2, 1, …
#> $ distrac <dbl> 0, 1, 0, 0, 1, 0, 2, 0, 0, 0, 0, 1, 0, 0, 1, 2, 0, 0, 1, …
#> $ clingy <dbl> 1, 1, 0, 1, 1, 1, 2, 0, 0, 0, 0, 1, 0, 2, 2, 1, 2, 0, 2, …
#> $ kind <dbl> 1, 2, 2, 2, 1, 2, 2, 2, 2, 1, 1, 2, 2, 2, 2, 2, 1, 2, 2, …
#> $ lies <dbl> 0, 0, 0, 0, 2, 0, 1, 0, 2, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, …
#> $ bullied <dbl> 0, 0, 0, 0, 2, 0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 1, …
#> $ helpout <dbl> 2, 1, 2, 2, 0, 2, 2, 2, 1, 2, 1, 2, 2, 1, 2, 2, 1, 2, 1, …
#> $ reflect <dbl> 1, 1, 2, 2, 0, 2, 2, 2, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 1, …
#> $ steals <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, …
#> $ oldbest <dbl> 1, 0, 2, 1, 0, 1, 1, 1, 0, 0, 0, 1, 0, 0, 1, 1, 0, 0, 2, …
#> $ afraid <dbl> 0, 0, 1, 1, 0, 0, 0, 0, 0, 1, 0, 2, 2, 0, 1, 1, 1, 0, 1, …
#> $ attends <dbl> 2, 2, 1, 2, 0, 2, 2, 2, 2, 2, 1, 1, 2, 1, 2, 2, 1, 1, 1, …
#> $ consid2 <dbl> 1, 2, 2, 2, NA, 2, 2, 2, 2, 2, NA, 1, NA, 2, 2, NA, 1, 2,…
#> $ restles2 <dbl> 0, 1, 2, 1, NA, 0, 1, 1, 0, 0, NA, 2, NA, 0, 1, NA, 1, 1,…
#> $ somatic2 <dbl> 0, 1, 1, 0, NA, 0, 0, 0, 0, 0, NA, 2, NA, 0, 1, NA, 0, 1,…
#> $ shares2 <dbl> 1, 2, 2, 1, NA, 2, 1, 2, 2, 2, NA, 2, NA, 2, 2, NA, 1, 2,…
#> $ tantrum2 <dbl> 0, 1, 2, 0, NA, 0, 2, 0, 0, 0, NA, 2, NA, 0, 1, NA, 1, 0,…
#> $ loner2 <dbl> 0, 0, 1, 0, NA, 0, 0, 0, 0, 0, NA, 1, NA, 1, 0, NA, 0, 0,…
#> $ obeys2 <dbl> 2, 1, 2, 1, NA, 2, 2, 2, 2, 1, NA, 1, NA, 2, 1, NA, 1, 2,…
#> $ worries2 <dbl> 0, 0, 1, 0, NA, NA, 1, 0, 0, 0, NA, 1, NA, 1, 2, NA, 0, 0…
#> $ caring2 <dbl> 2, 2, 1, 2, NA, 2, 2, 2, 2, 2, NA, 2, NA, 2, 2, NA, 1, 2,…
#> $ fidgety2 <dbl> 0, 1, 0, 0, NA, 0, 1, 0, 0, 0, NA, 2, NA, 0, 0, NA, 1, 0,…
#> $ friend2 <dbl> 2, 2, 1, 2, NA, 2, 2, 2, 2, 2, NA, 2, NA, 1, 2, NA, 2, 2,…
#> $ fights2 <dbl> 0, 0, 0, 0, NA, 0, 0, 0, 0, 0, NA, 2, NA, 0, 0, NA, 0, 0,…
#> $ unhappy2 <dbl> 0, 0, 1, 0, NA, 0, 0, 0, 0, 0, NA, 1, NA, 0, 0, NA, 0, 0,…
#> $ popular2 <dbl> 2, 1, 1, 2, NA, 2, 1, 2, 2, 2, NA, 2, NA, 2, 2, NA, 1, 2,…
#> $ distrac2 <dbl> 0, 0, 0, 2, NA, 0, 2, 1, 0, 0, NA, 1, NA, 0, 1, NA, 1, 0,…
#> $ clingy2 <dbl> 1, 1, 1, 0, NA, 1, 1, 1, 0, 0, NA, 1, NA, 0, 0, NA, 2, 0,…
#> $ kind2 <dbl> 2, 2, 2, 2, NA, 2, 2, 2, 2, 2, NA, 2, NA, 2, 2, NA, 1, 2,…
#> $ lies2 <dbl> 1, 0, 0, 0, NA, 0, 1, 0, 1, 0, NA, 1, NA, 0, 0, NA, 1, 0,…
#> $ bullied2 <dbl> 0, 0, 0, 0, NA, 0, 2, 0, 0, 0, NA, 0, NA, 0, 0, NA, 0, 0,…
#> $ helpout2 <dbl> 1, 1, 1, 2, NA, 2, 2, 1, 2, 1, NA, 2, NA, 2, 1, NA, 0, 2,…
#> $ reflect2 <dbl> 1, 1, 2, 1, NA, 2, 1, 2, 1, 2, NA, 1, NA, 2, 1, NA, 1, 2,…
#> $ steals2 <dbl> 0, 0, 0, 0, NA, 0, 0, 0, 0, 0, NA, 2, NA, 0, 0, NA, 0, 0,…
#> $ oldbest2 <dbl> 0, 0, 1, 0, NA, 1, 0, 1, 1, 0, NA, 1, NA, 0, 0, NA, 0, 0,…
#> $ afraid2 <dbl> 0, 1, 0, 0, NA, 0, 0, 0, 0, 0, NA, 2, NA, 0, 0, NA, 0, 0,…
#> $ attends2 <dbl> 1, 1, 2, 0, NA, 2, 2, 2, 2, 1, NA, 1, NA, 2, 2, NA, 1, 1,…Selezioniamo solo gli item della Emotional Symptoms scale al tempo 1.
items_emotion <- c("somatic", "worries", "unhappy", "clingy", "afraid")
sdq_emo <- SDQ[, items_emotion]
sdq_emo |>
head()
#> # A tibble: 6 × 5
#> somatic worries unhappy clingy afraid
#> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 2 1 0 1 0
#> 2 2 0 0 1 0
#> 3 0 0 0 0 1
#> 4 0 0 0 1 1
#> 5 2 1 0 1 0
#> 6 1 0 0 1 0Calcoliamo il punteggio della scala.
rowSums(sdq_emo)
#> [1] 4 3 1 2 4 2 4 0 1 1 0 8 2 3 7 4 5 2 8 6 1 4 9
#> [24] 4 5 9 0 3 3 1 0 2 6 3 9 4 4 0 7 1 3 6 4 5 4 1
#> [47] 4 1 0 5 1 2 2 4 4 4 6 1 8 3 2 2 4 1 1 0 2 2 7
#> [70] 5 0 NA NA 1 1 7 4 1 8 3 5 0 5 4 0 1 1 5 3 6 1 3
#> [93] 2 6 6 0 2 4 5 3 3 1 1 7 2 3 5 5 NA 0 4 0 4 1 1
#> [116] 1 1 0 2 7 0 3 8 4 6 NA 2 4 7 1 0 0 1 0 4 3 0 10
#> [139] 5 2 1 6 1 2 1 0 1 NA 4 4 2 4 7 5 6 1 0 5 3 1 3
#> [162] 3 6 4 2 3 1 0 3 3 0 3 0 0 0 2 2 2 0 1 5 3 3 1
#> [185] 4 3 1 6 2 4 2 NA 0 2 5 5 0 2 2 3 4 0 2 4 2 2 1
#> [208] 3 2 0 1 0 0 8 1 1 2 1 2 2 4 0 0 1 2 2 1 6Notiamo che ci sono diversi punteggi mancanti, denotati da NA. Un primo metodo per affrontare i dati mancanti è semplicemente quello di ignorarli:
rowSums(sdq_emo, na.rm = TRUE)
#> [1] 4 3 1 2 4 2 4 0 1 1 0 8 2 3 7 4 5 2 8 6 1 4 9
#> [24] 4 5 9 0 3 3 1 0 2 6 3 9 4 4 0 7 1 3 6 4 5 4 1
#> [47] 4 1 0 5 1 2 2 4 4 4 6 1 8 3 2 2 4 1 1 0 2 2 7
#> [70] 5 0 2 7 1 1 7 4 1 8 3 5 0 5 4 0 1 1 5 3 6 1 3
#> [93] 2 6 6 0 2 4 5 3 3 1 1 7 2 3 5 5 4 0 4 0 4 1 1
#> [116] 1 1 0 2 7 0 3 8 4 6 0 2 4 7 1 0 0 1 0 4 3 0 10
#> [139] 5 2 1 6 1 2 1 0 1 4 4 4 2 4 7 5 6 1 0 5 3 1 3
#> [162] 3 6 4 2 3 1 0 3 3 0 3 0 0 0 2 2 2 0 1 5 3 3 1
#> [185] 4 3 1 6 2 4 2 4 0 2 5 5 0 2 2 3 4 0 2 4 2 2 1
#> [208] 3 2 0 1 0 0 8 1 1 2 1 2 2 4 0 0 1 2 2 1 6Tuttavia, questa non è una buona idea. Anche per il fatto che, in questo modo non verrà calcolato il punteggio totale di 7 partecipanti. Possiamo identificare le colonne in cui ci sono dei valori mancanti usando summary().
summary(sdq_emo)
#> somatic worries unhappy clingy
#> Min. :0.000 Min. :0.000 Min. :0.000 Min. :0.000
#> 1st Qu.:0.000 1st Qu.:0.000 1st Qu.:0.000 1st Qu.:0.000
#> Median :0.000 Median :0.000 Median :0.000 Median :1.000
#> Mean :0.611 Mean :0.621 Mean :0.317 Mean :0.842
#> 3rd Qu.:1.000 3rd Qu.:1.000 3rd Qu.:1.000 3rd Qu.:1.000
#> Max. :2.000 Max. :2.000 Max. :2.000 Max. :2.000
#> NA's :2 NA's :1 NA's :1
#> afraid
#> Min. :0.00
#> 1st Qu.:0.00
#> Median :0.00
#> Mean :0.48
#> 3rd Qu.:1.00
#> Max. :2.00
#> NA's :3Un approccio semplice per gestire il problema dei dati mancanti è l’imputazione, che consiste nel sostituire i valori mancanti con stime plausibili basate sulle informazioni disponibili nel dataset. Il metodo più elementare di imputazione prevede la sostituzione del valore mancante con la media della colonna corrispondente. Questo approccio è facile da implementare e può essere utile come soluzione preliminare, ma potrebbe non catturare correttamente la variabilità e le relazioni tra le variabili.
Questa istruzione utilizza la funzione mutate_at del pacchetto dplyr per applicare una trasformazione a colonne specifiche (da somatic a afraid). All’interno della funzione di trasformazione, essa controlla se ogni valore è mancante (NA). Se lo è, lo sostituisce con la media della colonna usando mean(., na.rm = TRUE), che calcola la media escludendo eventuali valori mancanti.
Possiamo ora calcolare il punteggio della scala per ciascun partecipante.
SDQ$s_emotion <- rowSums(sdq_emo) |> round()
SDQ$s_emotion
#> [1] 4 3 1 2 4 2 4 0 1 1 0 8 2 3 7 4 5 2 8 6 1 4 9
#> [24] 4 5 9 0 3 3 1 0 2 6 3 9 4 4 0 7 1 3 6 4 5 4 1
#> [47] 4 1 0 5 1 2 2 4 4 4 6 1 8 3 2 2 4 1 1 0 2 2 7
#> [70] 5 0 2 8 1 1 7 4 1 8 3 5 0 5 4 0 1 1 5 3 6 1 3
#> [93] 2 6 6 0 2 4 5 3 3 1 1 7 2 3 5 5 5 0 4 0 4 1 1
#> [116] 1 1 0 2 7 0 3 8 4 6 0 2 4 7 1 0 0 1 0 4 3 0 10
#> [139] 5 2 1 6 1 2 1 0 1 4 4 4 2 4 7 5 6 1 0 5 3 1 3
#> [162] 3 6 4 2 3 1 0 3 3 0 3 0 0 0 2 2 2 0 1 5 3 3 1
#> [185] 4 3 1 6 2 4 2 5 0 2 5 5 0 2 2 3 4 0 2 4 2 2 1
#> [208] 3 2 0 1 0 0 8 1 1 2 1 2 2 4 0 0 1 2 2 1 6Un istogramma si ottiene nel modo seguente.
SDQ |>
ggplot(aes(x = s_emotion)) +
geom_histogram(bins = 10)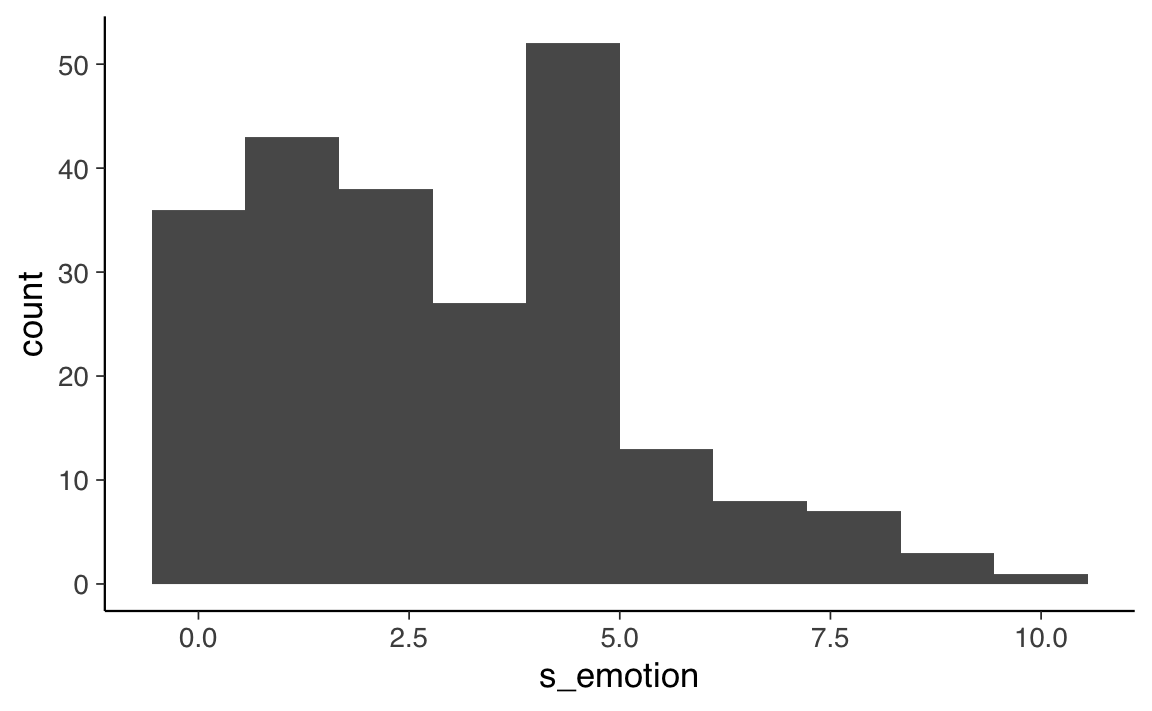
hist(SDQ$s_emotion)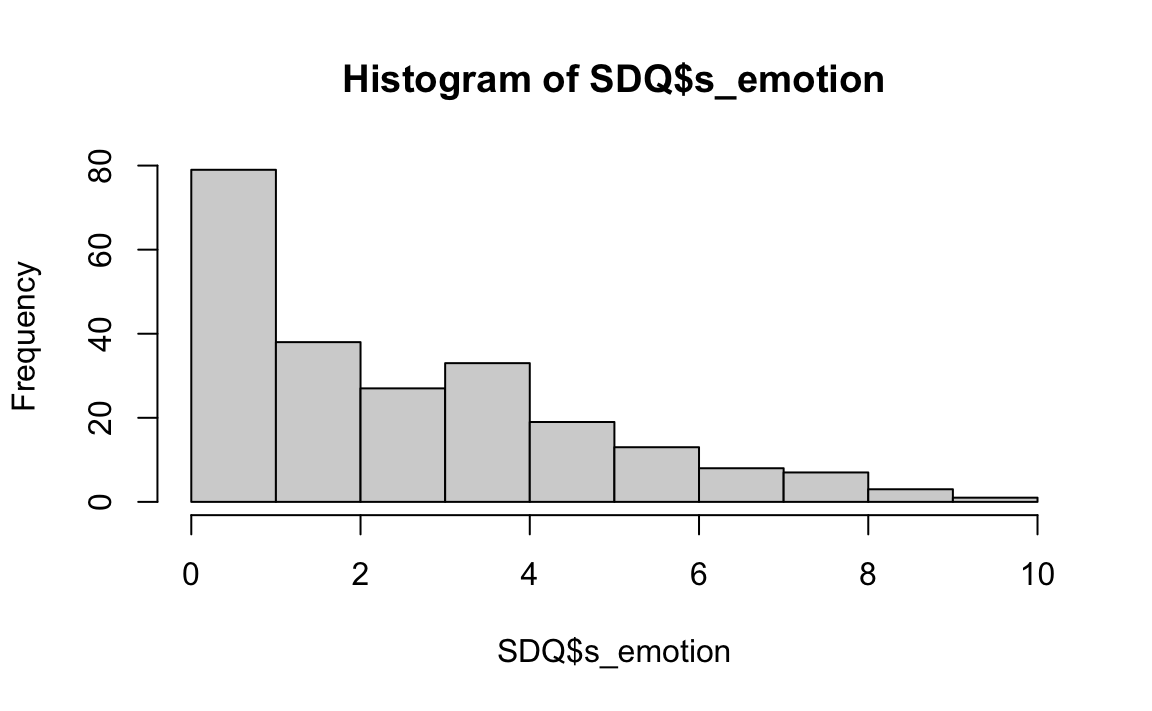
Più utile è un KDE plot.
SDQ |>
ggplot(aes(x = s_emotion)) +
geom_density()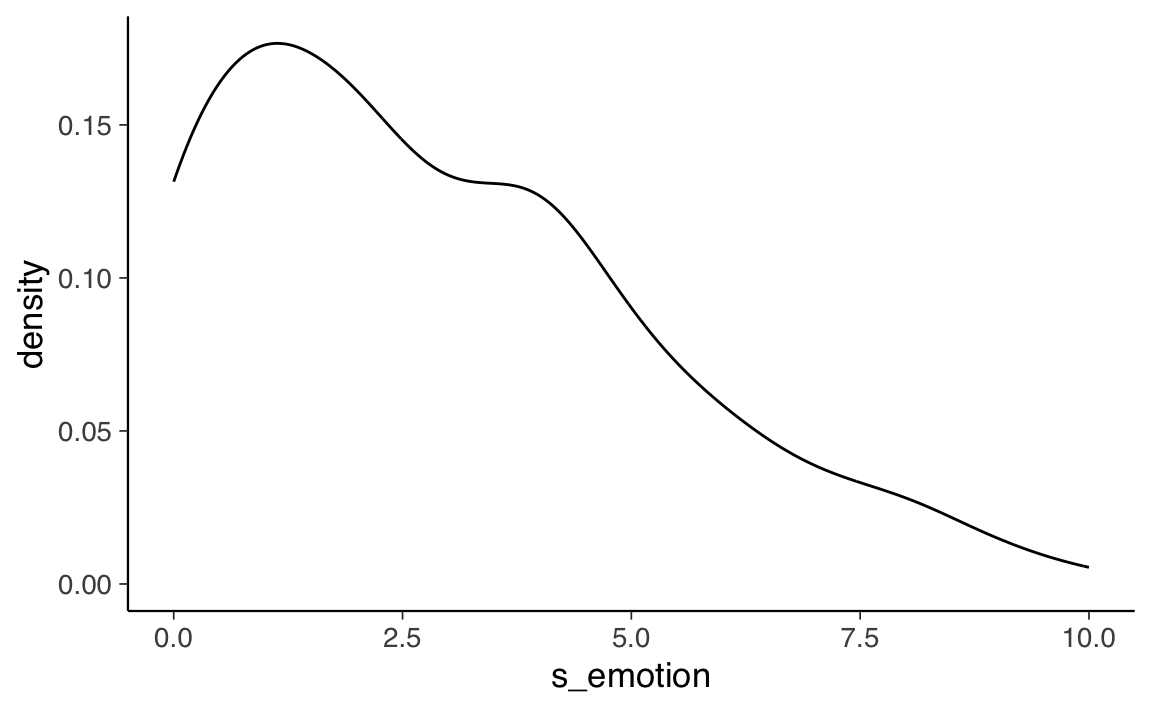
Possiamo ottenere le statistiche descrittive della scala usando la funzione describe del pacchetto psych.
describe(SDQ$s_emotion)
#> vars n mean sd median trimmed mad min max range skew kurtosis se
#> X1 1 228 2.87 2.31 2 2.65 2.97 0 10 10 0.72 -0.14 0.15Come si può vedere, la mediana (il punteggio al di sotto del quale si trova la metà del campione) di s_emotion è 2, mentre la media è più alta e pari a 2.87. Questo perché la distribuione dei punteggi è asimmetrica positiva; in questo caso, la mediana è più rappresentativa della tendenza centrale. Queste statistiche sono coerenti con la nostra osservazione dell’istogramma, che mostra un forte floor effect.
Di seguito sono riportati i valori di soglia per i casi “Normali”, “Borderline” e “Anormali” per i Sintomi Emotivi forniti dal publisher del test (vedi https://sdqinfo.org/). Questi sono i punteggi che distinguono i casi probabilmente borderline e anormali dai casi “normali”.
Normale: 0-5
Borderline: 6
Anormale: 7-10table(SDQ$s_emotion <= 5)
#>
#> FALSE TRUE
#> 32 196In questo campione, dunque, l’85% dei partecipanti è classificato nell’intervallo Normale.
In maniera equivalente otteniamo i valori dei partecipanti “borderline”:
e dei partecipanti “non-normali”:
2.3 Item reverse
In un secondo esempio consideriamo la codifica delle risposte degli item SDQ che misurano i Problemi di Condotta. Alcuni item sono stati codificati usando una codifica inversa. Prima di calcolare il punteggio totale è dunque necessario invertire il punteggio degli item a codifica inversa.
items_conduct <- c("tantrum", "obeys", "fights", "lies", "steals")Per i Problemi di Condotta, abbiamo solo un item reverse, obeys.
tantrum obeys* fights lies stealsPer invertire il codice di questo item, useremo una funzione dedicata del pacchetto psych, reverse.code(). Questa funzione ha la forma generale reverse.code(keys, items,…). L’argomento keys è un vettore di valori 1 o -1, dove -1 implica l’inversione dell’item. L’argomento items sono i nomi delle variabili che vogliamo valutare.
SDQ[, items_conduct] |> head()
#> # A tibble: 6 × 5
#> tantrum obeys fights lies steals
#> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 0 2 0 0 0
#> 2 0 2 0 0 0
#> 3 0 2 0 0 0
#> 4 0 2 0 0 0
#> 5 1 0 0 2 0
#> 6 0 2 0 0 0Anche in questo caso ci sono dei dati mancanti.
summary(R_conduct)
#> tantrum obeys- fights lies
#> Min. :0.000 Min. :0.000 Min. :0.000 Min. :0.000
#> 1st Qu.:0.000 1st Qu.:0.000 1st Qu.:0.000 1st Qu.:0.000
#> Median :0.000 Median :1.000 Median :0.000 Median :0.000
#> Mean :0.571 Mean :0.579 Mean :0.193 Mean :0.544
#> 3rd Qu.:1.000 3rd Qu.:1.000 3rd Qu.:0.000 3rd Qu.:1.000
#> Max. :2.000 Max. :2.000 Max. :2.000 Max. :2.000
#> NA's :2 NA's :2
#> steals
#> Min. :0.000
#> 1st Qu.:0.000
#> Median :0.000
#> Mean :0.185
#> 3rd Qu.:0.000
#> Max. :2.000
#> NA's :1Usiamo la stessa procedura descritta in precedenza:
Calcoliamo ora il punteggio totale.
SDQ$s_conduct <- rowMeans(R_conduct)SDQ |>
ggplot(aes(x = s_conduct)) +
geom_histogram(bins = 10)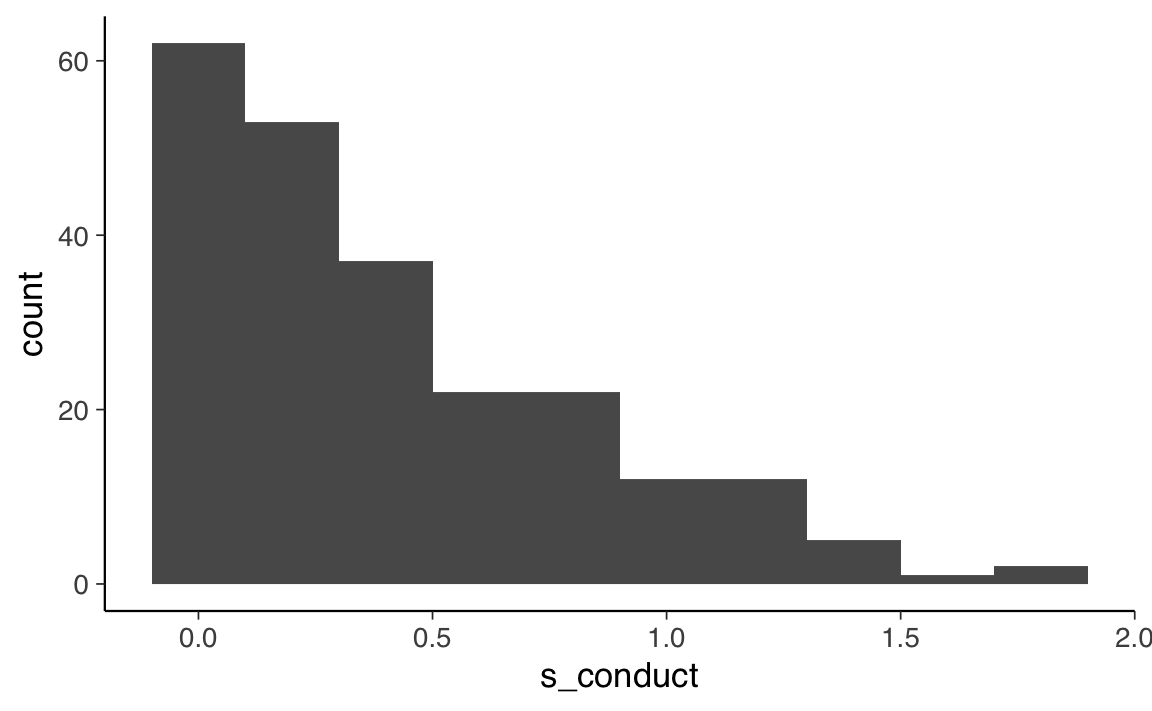
2.4 Session Info
sessionInfo()
#> R version 4.4.2 (2024-10-31)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Sequoia 15.3.2
#>
#> Matrix products: default
#> BLAS: /Library/Frameworks/R.framework/Versions/4.4-arm64/Resources/lib/libRblas.0.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.4-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.0
#>
#> locale:
#> [1] C/UTF-8/C/C/C/C
#>
#> time zone: Europe/Rome
#> tzcode source: internal
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] ggokabeito_0.1.0 see_0.11.0 MASS_7.3-65 viridis_0.6.5
#> [5] viridisLite_0.4.2 ggpubr_0.6.0 ggExtra_0.10.1 gridExtra_2.3
#> [9] patchwork_1.3.0 bayesplot_1.11.1 semTools_0.5-6 semPlot_1.1.6
#> [13] lavaan_0.6-19 psych_2.4.12 scales_1.3.0 markdown_1.13
#> [17] knitr_1.50 lubridate_1.9.4 forcats_1.0.0 stringr_1.5.1
#> [21] dplyr_1.1.4 purrr_1.0.4 readr_2.1.5 tidyr_1.3.1
#> [25] tibble_3.2.1 ggplot2_3.5.1 tidyverse_2.0.0 here_1.0.1
#>
#> loaded via a namespace (and not attached):
#> [1] rstudioapi_0.17.1 jsonlite_1.9.1 magrittr_2.0.3
#> [4] TH.data_1.1-3 estimability_1.5.1 farver_2.1.2
#> [7] nloptr_2.2.1 rmarkdown_2.29 vctrs_0.6.5
#> [10] minqa_1.2.8 base64enc_0.1-3 rstatix_0.7.2
#> [13] htmltools_0.5.8.1 broom_1.0.7 Formula_1.2-5
#> [16] htmlwidgets_1.6.4 plyr_1.8.9 sandwich_3.1-1
#> [19] emmeans_1.10.7 zoo_1.8-13 igraph_2.1.4
#> [22] mime_0.13 lifecycle_1.0.4 pkgconfig_2.0.3
#> [25] Matrix_1.7-3 R6_2.6.1 fastmap_1.2.0
#> [28] rbibutils_2.3 shiny_1.10.0 digest_0.6.37
#> [31] OpenMx_2.21.13 fdrtool_1.2.18 colorspace_2.1-1
#> [34] rprojroot_2.0.4 Hmisc_5.2-3 labeling_0.4.3
#> [37] timechange_0.3.0 abind_1.4-8 compiler_4.4.2
#> [40] withr_3.0.2 glasso_1.11 htmlTable_2.4.3
#> [43] backports_1.5.0 carData_3.0-5 ggsignif_0.6.4
#> [46] corpcor_1.6.10 gtools_3.9.5 tools_4.4.2
#> [49] pbivnorm_0.6.0 foreign_0.8-88 zip_2.3.2
#> [52] httpuv_1.6.15 nnet_7.3-20 glue_1.8.0
#> [55] quadprog_1.5-8 nlme_3.1-167 promises_1.3.2
#> [58] lisrelToR_0.3 grid_4.4.2 checkmate_2.3.2
#> [61] cluster_2.1.8.1 reshape2_1.4.4 generics_0.1.3
#> [64] gtable_0.3.6 tzdb_0.5.0 data.table_1.17.0
#> [67] hms_1.1.3 car_3.1-3 sem_3.1-16
#> [70] pillar_1.10.1 rockchalk_1.8.157 later_1.4.1
#> [73] splines_4.4.2 lattice_0.22-6 survival_3.8-3
#> [76] kutils_1.73 tidyselect_1.2.1 miniUI_0.1.1.1
#> [79] pbapply_1.7-2 reformulas_0.4.0 stats4_4.4.2
#> [82] xfun_0.51 qgraph_1.9.8 arm_1.14-4
#> [85] stringi_1.8.4 yaml_2.3.10 pacman_0.5.1
#> [88] boot_1.3-31 evaluate_1.0.3 codetools_0.2-20
#> [91] mi_1.1 cli_3.6.4 RcppParallel_5.1.10
#> [94] rpart_4.1.24 xtable_1.8-4 Rdpack_2.6.3
#> [97] munsell_0.5.1 Rcpp_1.0.14 coda_0.19-4.1
#> [100] png_0.1-8 XML_3.99-0.18 parallel_4.4.2
#> [103] jpeg_0.1-10 lme4_1.1-36 mvtnorm_1.3-3
#> [106] openxlsx_4.2.8 rlang_1.1.5 multcomp_1.4-28
#> [109] mnormt_2.1.1
Brown, A. (2023). Psychometrics in Exercises using R and RStudio: Textbook and Data Resource. https://bookdown.org/annabrown/psychometricsR