here::here("code", "_common.R") |>
source()
# Load packages
if (!requireNamespace("pacman")) install.packages("pacman")
pacman::p_load(semTools, lme4, MIIVsem)58 Modellizzazione SEM in Piccoli Campioni
Prerequisiti
Concetti e Competenze Chiave
Preparazione del Notebook
58.1 Introduzione
Questo capitolo si concentra sull’applicazione dei modelli SEM in contesti caratterizzati da campioni di piccole dimensioni e sintetizza l’esposizione di Rosseel (2020) su questo argomento, mentre si avvale di esempi numerici tratti dai principi di Kline (2023).
È risaputo che la maggior parte dei metodi di stima e inferenza in SEM si basa su presupposti asintotici, presupponendo la presenza di campioni casuali di grandi dimensioni. Tuttavia, nei casi di campioni più limitati, come quelli con N < 200, emergono specifiche problematiche: i metodi iterativi possono non convergere, si possono verificare soluzioni non valide a causa dei casi di Heywood o di altri risultati anomali difficili da interpretare, e le stime dei parametri possono risultare fortemente distorte.
Innanzitutto, i modelli strutturali possono diventare molto complessi, coinvolgendo numerose variabili (sia osservate che latenti), rendendo necessaria l’analisi di numerosi parametri e richiedendo un adeguato volume di dati per ottenere stime accurate. Inoltre, il framework statistico alla base della SEM tradizionale si fonda sulla teoria dei grandi campioni, suggerendo che una buona precisione nelle stime dei parametri e nell’inferenza sia garantita solo con campioni di dimensioni considerevoli. Alcuni studi di simulazione hanno addirittura suggerito che dimensioni del campione enormi siano necessarie per risultati affidabili, sebbene tali conclusioni siano rilevanti solo in specifici contesti e abbiano contribuito alla convinzione generalizzata che la SEM sia applicabile solo con campioni di dimensioni considerevoli (ad es. n > 500) o addirittura molto grandi (n > 2000).
Tuttavia, la realtà delle dimensioni ridotte dei campioni è una situazione comune per molte ragioni. In tali casi, molti ricercatori esitano ad utilizzare la SEM e si affidano a metodologie subottimali, come l’analisi di regressione o l’analisi di percorso basate su punteggi sommati. Tuttavia, è importante notare che il bias associato alle dimensioni ridotte del campione può essere ancora più accentuato in tecniche come la regressione multipla o l’analisi di percorso con variabili manifeste, soprattutto in assenza di considerazioni sull’errore di misurazione. Una strategia più efficace potrebbe essere quella di adottare l’approccio della SEM, pur cercando soluzioni per affrontare le sfide poste dalle dimensioni ridotte del campione.
Questo capitolo si propone di esplorare diverse strategie per superare tali sfide nell’utilizzo della SEM con campioni di piccole dimensioni. Sarà organizzato in tre sezioni: innanzitutto, verranno esaminate le problematiche comuni associate alle dimensioni ridotte del campione nella SEM. Successivamente, saranno presentati quattro approcci alternativi di stima che possono essere impiegati quando le dimensioni del campione sono limitate, anziché ricorrere alla SEM tradizionale. Infine, saranno discussi alcuni possibili correttivi per le statistiche di test e gli errori standard nelle situazioni di piccoli campioni. L’efficacia di alcune di queste tecniche sarà illustrata tramite l’analisi di un modello di fattore comune applicato a un campione di dimensioni ridotte.
58.2 Problemi con le Piccole Dimensioni del Campione nella SEM
Consideriamo un modello SEM con almeno 4 indicatori continui per ciascuna variabile latente. Se tutte le variabili osservate sono continue, lo stimatore di default nella maggior parte (se non in tutti) dei pacchetti software SEM è il metodo della massima verosimiglianza. Generalmente, lo stimatore della massima verosimiglianza è una buona scelta perché presenta molte proprietà statistiche desiderabili. Inoltre, l’approccio della massima verosimiglianza può essere adattato per gestire dati mancanti (sotto l’assunzione che i dati siano mancanti casualmente) e sono stati sviluppati errori standard e statistiche di test “robusti” per trattare dati non normali e modelli mal specificati.
Tuttavia, se la dimensione del campione è relativamente piccola (ad esempio, n < 200), possono sorgere diversi problemi. Innanzitutto, il modello potrebbe non convergere, il che significa che l’ottimizzatore (l’algoritmo che cerca di trovare i valori dei parametri del modello che massimizzano la verosimiglianza dei dati) non è riuscito a trovare una soluzione che soddisfi uno o più criteri di convergenza. In rare occasioni, l’ottimizzatore potrebbe semplicemente sbagliare. In questo caso, modificare i criteri di convergenza, passare a un altro algoritmo di ottimizzazione o fornire valori iniziali migliori potrebbe risolvere il problema. Ma se la dimensione del campione è piccola, potrebbe benissimo essere che il set di dati non contenga informazioni sufficienti per trovare una soluzione unica per il modello.
Un secondo problema potrebbe essere che il modello ottenga la convergenza ma produca una soluzione non ammissibile. Ciò significa che alcuni parametri assumono valori inamissibili. L’esempio più comune è una varianza negativa. Un altro esempio è un valore di correlazione che supera 1 (in valore assoluto). È importante rendersi conto che alcuni approcci di stima (sia frequentisti che bayesiani) potrebbero, per progettazione, non produrre mai soluzioni fuori gamma. Sebbene ciò possa sembrare una caratteristica desiderabile, maschera potenziali problemi con il modello o i dati. È importante che gli utenti notino varianze negative (o altri parametri fuori gamma). Le varianze negative sono spesso innocue, ma possono essere un sintomo di una cattiva specificazione strutturale.
Un terzo problema riguarda il fatto che la massima verosimiglianza è una tecnica per grandi campioni. Questo implica che lavorare con piccole dimensioni del campione può portare a stime puntuali distorte, errori standard troppo piccoli, intervalli di confidenza non sufficientemente ampi e p-valori per test di ipotesi non affidabili.
58.3 Soluzioni Possibili per la Stima dei Parametri
In questa sezione, consideriamo brevemente quattro approcci alternativi per stimare i parametri in un contesto SEM con dimensioni di campione piccole. Ci limitiamo ai metodi frequentisti e alle soluzioni disponibili in software gratuiti e open-source.
58.3.1 Stima di Verosimiglianza Penalizzata
I metodi di stima di verosimiglianza penalizzata (o metodi di regolarizzazione) sono stati sviluppati nella letteratura del machine learning statistico e sono particolarmente utili quando la dimensione del campione è piccola rispetto al numero di variabili nel modello. Questi metodi sono simili ai metodi di verosimiglianza ordinari (come la massima verosimiglianza) ma includono un termine di penalità aggiuntivo per controllare la complessità del modello. Il termine di penalità può essere formulato per incorporare conoscenze pregresse sui parametri o per scoraggiare valori dei parametri meno realistici (ad esempio, lontani da zero). Due termini di penalità popolari sono la penalità ridge e la penalità lasso (least absolute shrinkage and selection operator).
Per illustrare come funziona questa penalizzazione, immaginate un modello di regressione univariata con un gran numero di predittori. Senza penalizzazione, tutti i coefficienti di regressione sono calcolati nel modo usuale. Tuttavia, il termine di penalità ridge ridurrà tutti i coefficienti verso zero, mentre la penalità lasso ridurrà ulteriormente i piccoli coefficienti fino a zero. In quest’ultimo approccio, sopravvivono solo i predittori “forti” (per i quali c’è un forte supporto nei dati), mentre i predittori “deboli” che possono essere difficilmente distinti dal rumore vengono eliminati. In generale, l’aggiunta di termini di penalità porta a modelli meno complessi, il che è particolarmente vantaggioso se la dimensione del campione è piccola.
Sebbene queste approcci di penalizzazione siano esistiti da alcuni decenni, sono stati applicati solo di recente alla SEM. Due esempi nel software R sono il pacchetto regsem (Jacobucci, Grimm, Brandmaier, Serang e Kievit, 2018) e il pacchetto lslx (Huang e Hu, 2018).
Uno svantaggio di questi metodi di penalizzazione è che l’utente deve indicare quali parametri richiedono la penalizzazione e in che misura. In un’analisi esplorativa, può essere utile e persino vantaggioso penalizzare i parametri verso zero se nel dati non si trova un forte supporto per essi. Tuttavia, la SEM è di solito un approccio confermativo, e l’utente deve assicurarsi che tutti i parametri inizialmente postulati nel modello non vengano rimossi dalla penalizzazione.
58.3.2 Model-implied instrumental variables
Bollen (1996) ha proposto un approccio alternativo di stima per i modelli SEM basato sull’utilizzo di variabili strumentali implicite nel modello in combinazione con il metodo dei minimi quadrati a due stadi (MIIV-2SLS). In questo approccio, il modello viene tradotto in un insieme di equazioni (di regressione). Successivamente, ogni variabile latente in queste equazioni viene sostituita con il suo indicatore principale (solitamente il primo indicatore, dove il carico fattoriale è fissato a uno e l’intercetta a zero) meno il suo termine di errore residuo. Le equazioni risultanti non contengono più variabili latenti ma hanno una struttura dell’errore più complessa. È importante notare che la stima dei minimi quadrati ordinari non è più adatta per risolvere queste equazioni poiché alcuni predittori sono ora correlati con il termine di errore nell’equazione. Qui entrano in gioco le variabili strumentali (anche chiamate strumenti). Per ogni equazione, è necessario trovare un insieme di variabili strumentali. Una variabile strumentale deve essere non correlata con il termine di errore dell’equazione ma fortemente correlata con il predittore problematico. Di solito, le variabili strumentali sono ricercate al di fuori del modello, ma nell’approccio di Bollen, le variabili strumentali sono selezionate tra le variabili osservate che fanno parte del modello. Sono stati sviluppati diversi procedimenti automatizzati per trovare queste variabili strumentali all’interno del modello. Una volta selezionati gli strumenti, è necessaria una procedura di stima per stimare tutti i coefficienti delle equazioni, come il metodo dei minimi quadrati a due stadi (2SLS).
Una motivazione principale per MIIV-2SLS è che è robusto: non si basa sulla normalità ed è meno probabile che diffonda il bias (che può derivare da errate specificazioni strutturali) in una parte del modello ad altre parti del modello. Un’altra caratteristica attraente di MIIV-2SLS è che non è iterativo. Ciò significa che non possono esserci problemi di convergenza e MIIV-2SLS può fornire una soluzione ragionevole per modelli in cui il massimo verosimigliante fallisce nella convergenza.
Sono necessarie ulteriori ricerche per valutare le prestazioni di questo stimatore in contesti in cui la dimensione del campione è (molto) piccola. L’approccio MIIV-2SLS è disponibile nel pacchetto R MIIVsem (Fisher, Bollen, Gates, & Rönkkö, 2017).
58.3.3 Stima a Due Fasi
Nel metodo di stima a due fasi, si effettua una distinzione tra la parte di misurazione e la parte strutturale (di regressione) del modello, e la stima avviene in due passaggi distinti. Nel primo passo, vengono adattati uno per uno tutti i modelli di misurazione. Nel secondo passo, viene adattato il modello completo, inclusa la parte strutturale, ma i parametri dei modelli di misurazione vengono mantenuti fissi ai valori trovati nel primo passo. La principale motivazione per l’approccio a due fasi è quella di separare il modello (o i modelli) di misurazione dalla parte strutturale durante la stima in modo che non possano influenzarsi reciprocamente. Nel tradizionale framework della massima verosimiglianza, invece, tutti i parametri vengono adattati simultaneamente. Di conseguenza, errori nella specificazione del modello strutturale possono influenzare i pesi fattoriali stimati di uno o più modelli di misurazione, e ciò può causare problemi di interpretazione per le variabili latenti.
L’approccio a due fasi è stato recentemente implementato nel pacchetto R lavaan (Rosseel, 2012).
58.3.4 Regressione del Punteggio dei Fattori
L’idea fondamentale della regressione del punteggio dei fattori è quella di sostituire tutte le variabili latenti con i loro punteggi. Questo processo è simile al metodo in due fasi, dove ciascun modello di misurazione viene adattato individualmente. Successivamente, si calcolano i punteggi dei fattori per tutte le variabili latenti nel modo consueto. Una volta che le variabili latenti sono sostituite dai loro punteggi, tutte le variabili diventano osservabili. In un passaggio finale, si stima la parte strutturale del modello. Questa stima può consistere in un’analisi di regressione o in un’analisi dei percorsi. Il termine “regressione del punteggio dei fattori” si riferisce a entrambi gli scenari.
Se usata in modo ingenuo, questa regressione potrebbe portare a un notevole bias nelle stime dei parametri della parte strutturale, anche con campioni di grandi dimensioni. Questo si verifica perché i punteggi dei fattori vengono trattati come se fossero osservati senza errore di misurazione. Esistono però diversi metodi per correggere questo bias. Ad esempio, il metodo di Croon (2002) procede come segue: prima, si calcola la matrice di varianza-covarianza dei punteggi dei fattori. Poi, sulla base delle informazioni dei modelli di misurazione, gli elementi di questa matrice vengono corretti per approssimare le varianze e covarianze implicite dal modello delle variabili latenti. Questa matrice di varianza-covarianza corretta diventa poi l’input per un’analisi di regressione o dei percorsi regolare.
Simile al metodo in due fasi, la regressione del punteggio dei fattori (combinata con la correzione di Croon) può essere un’alternativa utile per modelli piuttosto grandi in combinazione con una dimensione campionaria relativamente piccola. Inoltre, è possibile adattare i modelli di misurazione utilizzando un stimatore non iterativo, evitando problemi di convergenza. Tuttavia, la correzione di Croon può produrre una matrice di varianza-covarianza (per le variabili appartenenti alla parte strutturale) che non è definita positiva, specialmente se l’errore di misurazione è sostanziale. Pertanto, la correzione di Croon non è esente da problemi di stima. In questo caso, l’unica soluzione potrebbe essere quella di creare un punteggio somma per ogni variabile latente e stimare un modello in cui ogni variabile latente ha un unico indicatore (il punteggio somma) con la sua affidabilità fissata a un valore realistico fornito dall’utente.
58.3.5 Discussione
Tutti i metodi descritti in questa sezione hanno vantaggi e svantaggi. L’approccio della verosimiglianza penalizzata è forse l’unico metodo specificamente progettato per gestire campioni (molto) piccoli. Gli altri tre metodi utilizzano un approccio di “divide et impera”; scompongono il modello completo in parti più piccole e stimano i parametri di ciascuna parte in successione. Oltre a ridurre la complessità e a essere meno vulnerabili a problemi di convergenza, gli ultimi tre metodi hanno il vantaggio di essere efficaci nel localizzare le parti problematiche all’interno di un modello ampio.
58.4 Inferenze per Modelli SEM in Piccoli Campioni
Molti autori hanno documentato che quando la dimensione del campione è piccola, il test del chi-quadrato porta ad un inflezione degli errori di Tipo I anche nelle circostanze ideali (cioè, modello correttamente specificato, dati normali). Allo stesso modo, gli errori standard sono spesso attenuati (troppo piccoli) e gli intervalli di confidenza non sono sufficientemente ampi.
Nelle due sottosezioni successive, {cite:t}rosseel2020small discute brevemente alcuni tentativi per affrontare questi problemi di inferenza su campioni piccoli nella modellizzazione SEM.
58.4.1 Migliorare la statistica test del chi-quadrato
Sono state suggerite diverse correzioni per migliorare le prestazioni della statistica del test del chi-quadrato, come la correzione di Bartlett. I risultati di studi di simulazione su questo tema, però, non sono coerenti e, secondo {cite:t}rosseel2020small, per valutare i modelli quando la dimensione del campione è piccola, potrebbe essere opportuno abbandonare del tutto il test del chi-quadrato e esplorare approcci alternativi.
Un approccio è quello di considerare gli intervalli di confidenza e i test di aderenza basati sull’indice SRMR (standardized root mean square residuals; Maydeu-Olivares, Shi, & Rosseel, 2018). Questi test sembrano funzionare bene anche quando n = 100 (la dimensione del campione più piccola considerata in Maydeu-Olivares et al., 2018) e il modello non è troppo grande. Questi test sono stati implementati come parte della funzione lavResiduals() del pacchetto lavaan.
58.4.2 Una migliore stima degli Errori Standard e degli Intervalli di Confidenza
In generale, è ben noto che se si utilizza la teoria dei grandi campioni per costruire espressioni analitiche al fine di calcolare gli errori standard, questi possono avere prestazioni scadenti in campioni di piccole dimensioni.
Quando le assunzioni alla base degli errori standard analitici non sono soddisfatte, spesso si suggerisce di utilizzare un approccio di resampling. Un metodo popolare è il bootstrap (Efron & Tibshirani, 1993): viene generato un campione bootstrap (o campione di replica) e si stima un nuovo set di parametri per questo campione bootstrap. Questo processo viene ripetuto un gran numero di volte (ad esempio, 1.000), e la deviazione standard di un parametro su tutti i campioni bootstrap replicati viene utilizzata come stima dell’errore standard per quel parametro. Purtroppo, nonostante molti altri vantaggi, sembra che il bootstrap non sia una soluzione affidabile quando la dimensione del campione è (molto) piccola (Yung & Bentler, 1996).
In alternativa, sono state sviluppate correzioni per dimensioni di campione piccole sugli errori standard (robusti) e sono state recentemente adattate al contesto SEM. Tuttavia, questa tecnologia non è ancora disponibile nei software SEM.
58.4.3 Strategie Alternative
Oltre ai metodi precedenti suggeriti da {cite:t}rosseel2020small, altre strategie possibili sono stati indicate da {cite:t}kline2023principles.
Selezione di Indicatori con Elevate Caratteristiche Psicometriche: {cite:t}
kline2023principlesconsiglia di utilizzare indicatori che mostrino eccellenti proprietà psicometriche, idealmente con carichi standardizzati superiori a .70 per gli indicatori continui. Questa pratica riduce il rischio di incorrere in casi di Heywood.Applicazione di Restrizioni di Uguaglianza sui Carichi Non Standardizzati: Imponendo vincoli di uguaglianza sulle saturazioni degli indicatori relativi allo stesso fattore si possono evitare soluzioni inammissibili. Questo approccio è particolarmente valido quando gli indicatori sono sulla stessa scala. Un’alternativa valida consiste nel fissare le saturazioni degli indicatori dello stesso fattore a valori costanti non nulli, che riflettano le variazioni nelle loro deviazioni standard.
SEM Basato su Compositi per Modelli Complessi in Campioni Piccoli: Questo approccio implica l’utilizzo di metodi basati su compositi, che sono combinazioni lineari di variabili osservate. In pratica, le variabili osservate vengono combinate in modi specifici per formare indicatori composti che rappresentano i costrutti latenti nel modello. Questi indicatori composti vengono quindi utilizzati per stimare i parametri del modello SEM. L’obiettivo è ottenere risultati per modelli complessi che richiederebbero campioni molto più ampi con il tradizionale approccio SEM. Tuttavia, è importante notare che i risultati del SEM basato su compositi possono essere soggetti a distorsioni anche nei campioni di piccole dimensioni.
Parceling: Questa strategia coinvolge la creazione di “parcel” o aggregati di due o più indicatori a livello di item attraverso la media dei singoli item. In altre parole, gli indicatori originali sono raggruppati in insiemi più piccoli e i loro valori sono combinati per creare nuovi indicatori aggregati. Questi nuovi indicatori vengono quindi utilizzati per rappresentare i costrutti latenti nel modello SEM. Sebbene il parceling possa ridurre la varianza dell’errore e migliorare la stabilità dei modelli, è importante considerare le sue limitazioni, tra cui la possibile perdita di informazioni e la sensibilità alle scelte fatte durante il processo di parceling. I risultati ottenuti con il parceling possono variare notevolmente in base alle decisioni prese dal ricercatore durante l’analisi.
58.4.3.1 Parceling
Approfondiamo brevemente la strategia del parceling. Il parceling è una strategia che comporta la suddivisione di un set di item in gruppi più piccoli, o “parcel”, per semplificare i modelli e migliorare la loro stima e adattamento.
Un esempio, citato in {cite:t}kline2023principles, illustra come il parceling possa essere utilizzato in una CFA per ridurre il numero di indicatori e semplificare il modello. {cite:t}kline2023principles considera un questionario di 120 item diviso in tre gruppi distinti di 40 item ciascuno, ognuno mirato a misurare un dominio specifico di un costrutto. In un campione di 150 partecipanti, un’analisi fattoriale confermativa (CFA) con tre fattori e 40 indicatori per fattore, con 120 indicatori totali, può presentare sfide notevoli nella stima del modello a causa della ridotta dimensione del campione. Per affrontare questi problemi, il ricercatore può suddividere ogni gruppo di 40 item in 4 gruppi minori (o “parcel”) di 10 item ciascuno, sommando i punteggi all’interno di ogni “parcel”. Questi punteggi aggregati sostituiscono poi gli item singoli come indicatori in un modello CFA a 3 fattori che avrà quindi solo 12 indicatori in totale (4 indicatori parcellizzati per fattore). Se gli indicatori parcellizzati hanno una distribuzione normale, per la stima si può ricorrere al metodo dei minimi quadrati (ML); altrimenti, si può utilizzare un estimatore ML robusto.
Questo metodo è particolarmente utile in situazioni dove si hanno molti item e campioni di dimensioni ridotte, e offre diversi benefici, tra cui:
Maggiore Affidabilità: Il parceling può aumentare l’affidabilità di una scala psicometrica, poiché gli item aggregati tendono ad avere maggior coerenza interna rispetto agli item singoli.
Rapporto Varianza Comune/Varianza Unica: Utilizzando il parceling, si può ottenere un rapporto più favorevole tra la varianza comune (quella spiegata dai fattori comuni) e la varianza unica (quella non spiegata).
Minore Probabilità di Violazioni Distribuzionali: La pratica del parceling riduce la probabilità che le assunzioni distribuzionali siano violate, il che è importante per l’applicazione di certe tecniche statistiche.
Nonostante i suoi benefici, il parceling ha anche limitazioni. La metodologia utilizzata per formare i parcel può influenzare i risultati. Inoltre, il parceling non è consigliabile quando gli item all’interno di un parcel non sono unidimensionali, poiché ciò può distorcere i risultati. È fondamentale verificare l’unidimensionalità prima di procedere con il parceling.
In studi con campioni di piccole dimensioni, il parceling ha dimostrato diversi vantaggi, come mostrato nello studio di simulazione di Orçan e Yanyun (2016). Questi includono una riduzione della complessità del modello, tassi di errore di Tipo I più ragionevoli e tassi di errore di Tipo I più bassi quando si utilizza il metodo di stima della massima verosimiglianza con errori standard robusti (MLR) a livello di parcel.
In conclusione, il parceling è una tecnica utile che può migliorare l’affidabilità e la validità dei modelli psicometrici, specialmente in presenza di grandi set di item e campioni di piccole dimensioni. Tuttavia, è essenziale valutare attentamente la sua applicabilità e procedere con cautela, specialmente per quanto riguarda l’unidimensionalità dei parcel.
58.5 SEM in un Piccolo Campione
{cite:t}kline2023principles discute uno studio in cui è stato applicato un modello CFA a due fattori ad un campione di 103 donne, le quali hanno compilato questionari su esperienze di origine familiare e adattamento coniugale {cite:p}sabatelli2003family.
# input the correlations in lower diagnonal form
sabatelliLower.cor <- "
1.000
.740 1.000
.265 .422 1.000
.305 .401 .791 1.000
.315 .351 .662 .587 1.000 "
# name the variables and convert to full correlation matrix
sabatelli.cor <- lavaan::getCov(sabatelliLower.cor, names = c(
"problems", "intimacy", "father", "mother", "both"
)
)
# add the standard deviations and convert to covariances
sabatelli.cov <- lavaan::cor2cov(sabatelli.cor, sds = c(
32.936, 22.749, 13.390, 13.679, 14.382
)
)Il modello proposto dagli autori è specificato di seguito:
sabatelli_model <- "
# common factors
# loading for intimacy constrained to equal .691
Marital =~ problems + intimacy
FOE =~ father + mother + both
"In riferimento al modello specificato sopra, la soluzione fornita da lavaan risulta inammissibile a causa di un caso di Heywood, evidenziato da una varianza d’errore negativa per la variabile “intimità”.
original <- lavaan::sem(sabatelli_model,
sample.cov = sabatelli.cov,
sample.nobs = 103
)lavaan::summary(original,
fit.measures = TRUE, standardized = TRUE,
rsquare = TRUE
) |> print()lavaan 0.6.17 ended normally after 141 iterations
Estimator ML
Optimization method NLMINB
Number of model parameters 11
Number of observations 103
Model Test User Model:
Test statistic 4.688
Degrees of freedom 4
P-value (Chi-square) 0.321
Model Test Baseline Model:
Test statistic 271.302
Degrees of freedom 10
P-value 0.000
User Model versus Baseline Model:
Comparative Fit Index (CFI) 0.997
Tucker-Lewis Index (TLI) 0.993
Loglikelihood and Information Criteria:
Loglikelihood user model (H0) -2087.964
Loglikelihood unrestricted model (H1) -2085.620
Akaike (AIC) 4197.928
Bayesian (BIC) 4226.910
Sample-size adjusted Bayesian (SABIC) 4192.163
Root Mean Square Error of Approximation:
RMSEA 0.041
90 Percent confidence interval - lower 0.000
90 Percent confidence interval - upper 0.159
P-value H_0: RMSEA <= 0.050 0.448
P-value H_0: RMSEA >= 0.080 0.387
Standardized Root Mean Square Residual:
SRMR 0.028
Parameter Estimates:
Standard errors Standard
Information Expected
Information saturated (h1) model Structured
Latent Variables:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
Marital =~
problems 1.000 23.362 0.713
intimacy 1.006 0.221 4.547 0.000 23.503 1.038
FOE =~
father 1.000 12.488 0.937
mother 0.919 0.089 10.320 0.000 11.480 0.843
both 0.808 0.098 8.206 0.000 10.088 0.705
Covariances:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
Marital ~~
FOE 129.409 44.216 2.927 0.003 0.444 0.444
Variances:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
.problems 528.472 130.514 4.049 0.000 528.472 0.492
.intimacy -39.892 109.200 -0.365 0.715 -39.892 -0.078
.father 21.613 10.983 1.968 0.049 21.613 0.122
.mother 53.509 11.710 4.570 0.000 53.509 0.289
.both 103.075 16.168 6.375 0.000 103.075 0.503
Marital 545.776 169.103 3.227 0.001 1.000 1.000
FOE 155.939 26.732 5.833 0.000 1.000 1.000
R-Square:
Estimate
problems 0.508
intimacy NA
father 0.878
mother 0.711
both 0.497
Per ovviare ad un tale problema, in una nuova analisi del modello di adattamento coniugale è stato applicato un vincolo specifico ai carichi non standardizzati degli indicatori. A causa delle differenze sostanziali nelle metriche tra le due variabili, ovvero “intimacy” (con una deviazione standard di 22.749) e “problems” (con una deviazione standard di 32.936), sono state fissate le seguenti saturazioni fattoriali: il carico per la variabile “problemi” è stato fissato a 1, mentre il carico per la variabile “intimità” è stato fissato a 0.691. Questi valori sono stati calcolati in modo da riflettere proporzionalmente la differenza nelle deviazioni standard tra le due variabili.
# analysis with constrained loadings for indicators of marital adjustment
# model df = 5
# standard deviations for both indicators
# of the marital factor are listed next
# intimacy, sd = 22.749
# problems, sd = 32.936
# ratio = 22.749/32.936 = .691
# specify model with constrained loadings for problems, intimacy
proportional.model <- "
# common factors
# loading for intimacy constrained to equal .691
Marital =~ 1*problems + .691*intimacy
FOE =~ father + mother + both
"proportional <- lavaan::sem(proportional.model,
sample.cov = sabatelli.cov,
sample.nobs = 103
)semPlot::semPaths(proportional,
what = "col", whatLabels = "par", style = "mx",
layout = "tree2", nCharNodes = 7,
shapeMan = "rectangle", sizeMan = 8, sizeMan2 = 5
)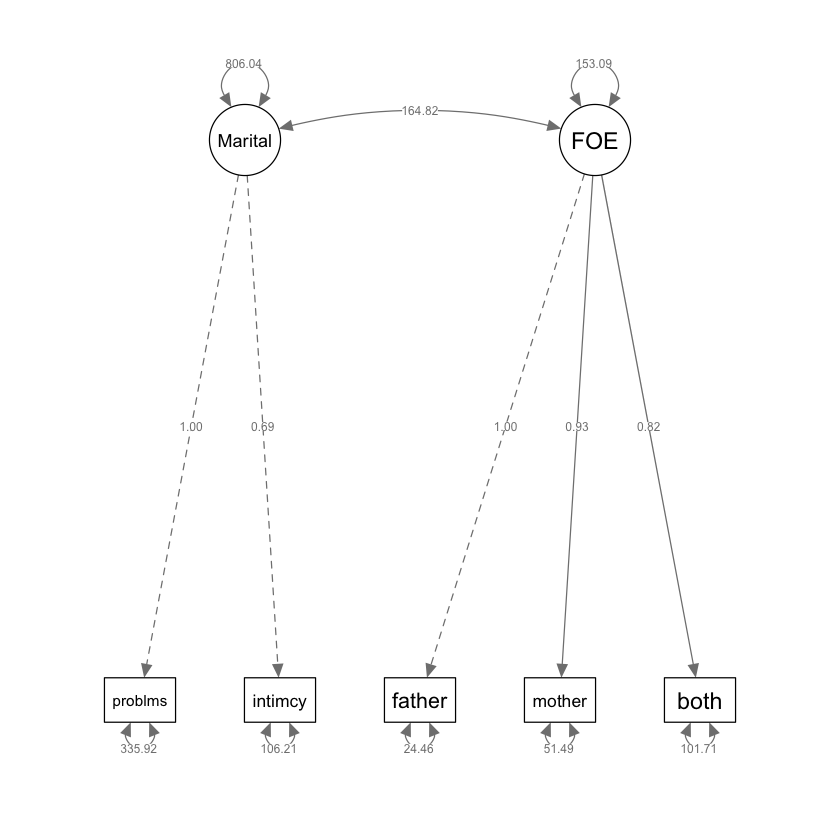
lavaan::summary(proportional,
fit.measures = TRUE, standardized = TRUE,
rsquare = TRUE
) |> print()lavaan 0.6.17 ended normally after 110 iterations
Estimator ML
Optimization method NLMINB
Number of model parameters 10
Number of observations 103
Model Test User Model:
Test statistic 8.449
Degrees of freedom 5
P-value (Chi-square) 0.133
Model Test Baseline Model:
Test statistic 271.302
Degrees of freedom 10
P-value 0.000
User Model versus Baseline Model:
Comparative Fit Index (CFI) 0.987
Tucker-Lewis Index (TLI) 0.974
Loglikelihood and Information Criteria:
Loglikelihood user model (H0) -2089.845
Loglikelihood unrestricted model (H1) -2085.620
Akaike (AIC) 4199.690
Bayesian (BIC) 4226.037
Sample-size adjusted Bayesian (SABIC) 4194.449
Root Mean Square Error of Approximation:
RMSEA 0.082
90 Percent confidence interval - lower 0.000
90 Percent confidence interval - upper 0.174
P-value H_0: RMSEA <= 0.050 0.242
P-value H_0: RMSEA >= 0.080 0.584
Standardized Root Mean Square Residual:
SRMR 0.045
Parameter Estimates:
Standard errors Standard
Information Expected
Information saturated (h1) model Structured
Latent Variables:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
Marital =~
problems 1.000 28.391 0.840
intimacy 0.691 19.618 0.885
FOE =~
father 1.000 12.373 0.929
mother 0.935 0.091 10.279 0.000 11.568 0.850
both 0.821 0.100 8.235 0.000 10.155 0.710
Covariances:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
Marital ~~
FOE 164.822 42.788 3.852 0.000 0.469 0.469
Variances:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
.problems 335.923 80.080 4.195 0.000 335.923 0.294
.intimacy 106.214 34.373 3.090 0.002 106.214 0.216
.father 24.457 11.060 2.211 0.027 24.457 0.138
.mother 51.489 11.730 4.389 0.000 51.489 0.278
.both 101.712 16.070 6.329 0.000 101.712 0.497
Marital 806.040 132.946 6.063 0.000 1.000 1.000
FOE 153.095 26.669 5.741 0.000 1.000 1.000
R-Square:
Estimate
problems 0.706
intimacy 0.784
father 0.862
mother 0.722
both 0.503
fitMeasures(proportional, c("chisq", "df", "cfi", "tli", "rmsea", "srmr")) |>
print()chisq df cfi tli rmsea srmr
8.449 5.000 0.987 0.974 0.082 0.045 lavaan::parameterEstimates(proportional) |> print() lhs op rhs est se z pvalue ci.lower ci.upper
1 Marital =~ problems 1.000 0.000 NA NA 1.000 1.000
2 Marital =~ intimacy 0.691 0.000 NA NA 0.691 0.691
3 FOE =~ father 1.000 0.000 NA NA 1.000 1.000
4 FOE =~ mother 0.935 0.091 10.279 0.000 0.757 1.113
5 FOE =~ both 0.821 0.100 8.235 0.000 0.625 1.016
6 problems ~~ problems 335.923 80.080 4.195 0.000 178.970 492.877
7 intimacy ~~ intimacy 106.214 34.373 3.090 0.002 38.843 173.584
8 father ~~ father 24.457 11.060 2.211 0.027 2.779 46.134
9 mother ~~ mother 51.489 11.730 4.389 0.000 28.498 74.481
10 both ~~ both 101.712 16.070 6.329 0.000 70.216 133.208
11 Marital ~~ Marital 806.040 132.946 6.063 0.000 545.471 1066.608
12 FOE ~~ FOE 153.095 26.669 5.741 0.000 100.825 205.365
13 Marital ~~ FOE 164.822 42.788 3.852 0.000 80.959 248.684lavaan::standardizedSolution(proportional) |> print() lhs op rhs est.std se z pvalue ci.lower ci.upper
1 Marital =~ problems 0.840 0.036 23.439 0.000 0.770 0.910
2 Marital =~ intimacy 0.885 0.037 24.040 0.000 0.813 0.957
3 FOE =~ father 0.929 0.035 26.779 0.000 0.861 0.997
4 FOE =~ mother 0.850 0.040 21.126 0.000 0.771 0.929
5 FOE =~ both 0.710 0.055 12.800 0.000 0.601 0.818
6 problems ~~ problems 0.294 0.060 4.884 0.000 0.176 0.412
7 intimacy ~~ intimacy 0.216 0.065 3.317 0.001 0.088 0.344
8 father ~~ father 0.138 0.064 2.139 0.032 0.012 0.264
9 mother ~~ mother 0.278 0.068 4.065 0.000 0.144 0.412
10 both ~~ both 0.497 0.079 6.313 0.000 0.342 0.651
11 Marital ~~ Marital 1.000 0.000 NA NA 1.000 1.000
12 FOE ~~ FOE 1.000 0.000 NA NA 1.000 1.000
13 Marital ~~ FOE 0.469 0.091 5.177 0.000 0.292 0.647Nonostante gli indici di bontà di adattamento siano eccellenti, la potenza di questa analisi statistica risulta estremamente limitata. Per valutare questa limitazione, è possibile utilizzare la funzione semTools::findRMSEAsamplesize(). Questa funzione calcola la dimensione del campione necessaria per rilevare una differenza significativa tra RMSEA_0 e RMSEA_A, considerando un modello con df gradi di libertà.
Per esempio, se desideriamo distinguere tra RMSEA_0=0.05 e RMSEA_A=0.10 utilizzando il modello attuale con 5 gradi di libertà, la funzione ci indica che sono necessarie 561 osservazioni per ottenere una potenza statistica di 0.8:
semTools::findRMSEAsamplesize(0.05, .10, 5, .80, .05, 1)
561
Per creare un grafico che rappresenti la potenza statistica per rilevare la differenza tra RMSEA_0=0.05 e RMSEA_A=0.10 (utilizzati qui come esempio) al variare della dimensione del campione, è possibile seguire la seguente procedura:
semTools::plotRMSEApower(rmsea0 = .05, rmseaA = .10, df = 5, 50, 1000)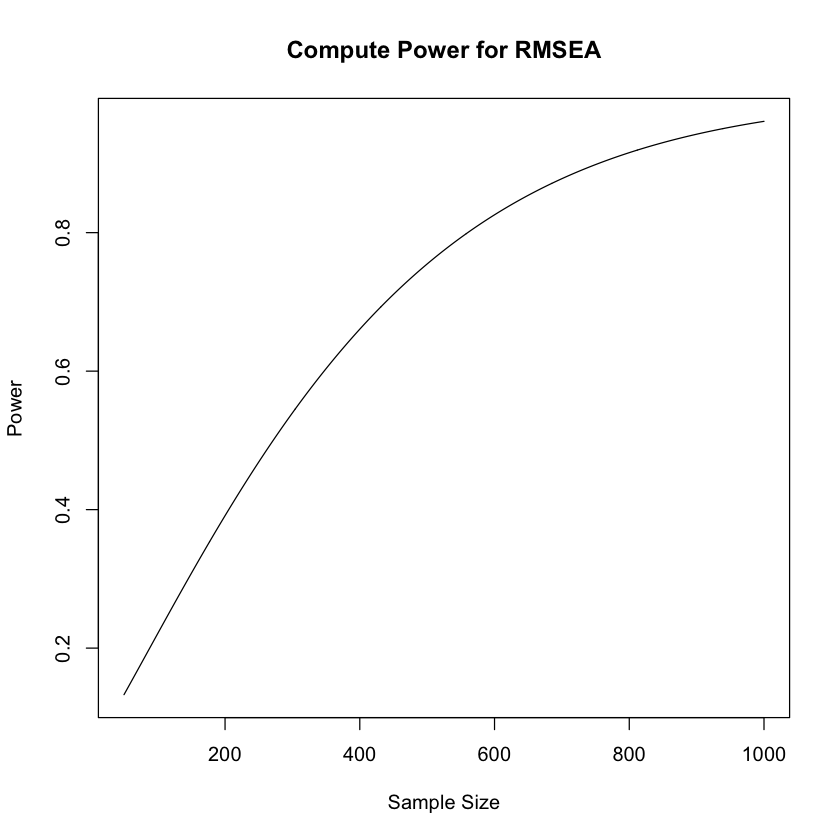
Questa analisi di potenza indica che la dimensione del campione utilizzato (\(n\) = 103) è del tutto inadeguata.
Per migliorare il nostro giudizio sull’adattamento del modello consideriamo l’analisi dei residui.
lavaan::residuals(proportional, type = "standardized.mplus") |> print()$type
[1] "standardized.mplus"
$cov
prblms intmcy father mother both
problems NA
intimacy NA 0.918
father -3.994 1.039 0.002
mother -0.871 1.049 0.328 0.000
both 0.407 0.930 0.352 -2.776 NA
lavaan::lavResiduals(proportional, type = "cor.bollen", summary = TRUE) |> print()$type
[1] "cor.bollen"
$cov
prblms intmcy father mother both
problems 0.000
intimacy -0.004 0.000
father -0.101 0.036 0.000
mother -0.030 0.048 0.002 0.000
both 0.035 0.056 0.003 -0.016 0.000
$cov.z
prblms intmcy father mother both
problems 0.000
intimacy -2.524 0.000
father -2.386 1.245 0.000
mother -0.586 1.134 0.881 0.000
both 0.523 0.936 0.507 -1.143 0.000
$summary
cov
crmr 0.044
crmr.se 0.015
crmr.exactfit.z 0.504
crmr.exactfit.pvalue 0.307
ucrmr 0.023
ucrmr.se 0.029
ucrmr.ci.lower -0.024
ucrmr.cilupper 0.071
ucrmr.closefit.h0.value 0.050
ucrmr.closefit.z -0.928
ucrmr.closefit.pvalue 0.823
Questi sono risultati relativamente scarsi per un modello così piccolo. Il computer non è stato in grado di calcolare tutti i residui standardizzati possibili, il che non è sorprendente in un campione così ridotto.
58.5.1 Stimatore MIIV-2SLS
Una seconda analisi viene condotta utilizzando lo stimatore MIIV-2SLS. Il pacchetto MIIVsem non calcola statistiche globali di bontà di adattamento. Al contrario, calcola il test di Sargan per ciascun indicatore previsto dal modello. Le statistiche del test di Sargan approssimano distribuzioni chi-quadro centrali con gradi di libertà equivalenti al numero di item meno uno, quindi df = 2. L’ipotesi nulla è che ogni insieme di strumenti multipli sia incorrelato con il termine di errore per l’equazione. Il mancato rifiuto dell’ipotesi nulla per il test di Sargan suggerisce una buona corrispondenza del modello con i dati.
MIIVsem::miivs(sabatelli_model)Model Equation Information
LHS RHS MIIVs
intimacy problems father, mother, both
mother father problems, intimacy, both
both father problems, intimacy, mother
sabatelli <- MIIVsem::miive(sabatelli_model,
sample.cov = sabatelli.cov,
sample.nobs = 103, var.cov = TRUE
)
lavaan::summary(sabatelli, rsquare = TRUE) |> print()MIIVsem (0.5.8) results
Number of observations 103
Number of equations 3
Estimator MIIV-2SLS
Standard Errors standard
Missing listwise
Parameter Estimates:
STRUCTURAL COEFFICIENTS:
Estimate Std.Err z-value P(>|z|) Sargan df P(Chi)
FOE =~
father 1.000
mother 0.899 0.089 10.149 0.000 1.763 2 0.414
both 0.787 0.099 7.935 0.000 3.590 2 0.166
Marital =~
problems 1.000
intimacy 0.805 0.155 5.195 0.000 4.980 2 0.083
INTERCEPTS:
Estimate Std.Err z-value P(>|z|)
both 0.000
father 0.000
intimacy 0.000
mother 0.000
problems 0.000
VARIANCES:
Estimate Std.Err z-value P(>|z|)
FOE 158.501
Marital 702.393
both 103.301
father 20.856
intimacy 50.871
mother 54.195
problems 422.427
COVARIANCES:
Estimate Std.Err z-value P(>|z|)
Marital ~~
FOE 157.495
R-SQUARE:
Estimate
problems 0.624
intimacy 0.900
father 0.884
mother 0.703
both 0.487
NULLSi noti che le stime standardizzate non sono calcolate nella versione del pacchetto MIIVsem utilizzata in questa analisi. I valori non standardizzati delle saturazioni fattoriali sono simili a quelli ottenuti in precedenza.
Il pacchetto MIIVsem non fornisce né le correlazioni previste dal modello per gli indicatori né i residui di correlazione. Per ottenere i residui di correlazione per l’estimatore 2SLS, è possibile utilizzare il pacchetto lavaan per specificare nuovamente il modello precedentemente adattato, ma con l’importante modifica di fissare tutti i parametri non standardizzati in modo che siano identici alle loro controparti 2SLS. Successivamente, è possibile adattare nuovamente il modello con questi parametri fissati alla matrice di covarianza. La matrice di correlazione prevista in questa analisi si basa sulle stime dei parametri 2SLS, consentendo così di ottenere i residui di correlazione desiderati.
sabatelliFixed.model <- "
# common factors
Marital =~ 1.0*problems + .805*intimacy
FOE =~ 1.0*father + .899*mother + .787*both
# factor variances, covariances
FOE ~~ 158.501*FOE
Marital ~~ 157.495*FOE
Marital ~~ 702.393*Marital
# indicator error variances
father ~~ 20.856*father
mother ~~ 54.195*mother
both ~~ 103.301*both
problems ~~ 422.427*problems
intimacy ~~ 50.781*intimacy
"sabatelliFixed <- lavaan::sem(sabatelliFixed.model,
sample.cov = sabatelli.cov,
sample.nobs = 103
)# standardized parameter "estimates" listed
# next are fixed to nonzero constants, and
# standard errors are undefined
lavaan::parameterEstimates(sabatelliFixed)| lhs | op | rhs | est | se | z | pvalue | ci.lower | ci.upper |
|---|---|---|---|---|---|---|---|---|
| <chr> | <chr> | <chr> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> |
| Marital | =~ | problems | 1.000 | 0 | NA | NA | 1.000 | 1.000 |
| Marital | =~ | intimacy | 0.805 | 0 | NA | NA | 0.805 | 0.805 |
| FOE | =~ | father | 1.000 | 0 | NA | NA | 1.000 | 1.000 |
| FOE | =~ | mother | 0.899 | 0 | NA | NA | 0.899 | 0.899 |
| FOE | =~ | both | 0.787 | 0 | NA | NA | 0.787 | 0.787 |
| FOE | ~~ | FOE | 158.501 | 0 | NA | NA | 158.501 | 158.501 |
| Marital | ~~ | FOE | 157.495 | 0 | NA | NA | 157.495 | 157.495 |
| Marital | ~~ | Marital | 702.393 | 0 | NA | NA | 702.393 | 702.393 |
| father | ~~ | father | 20.856 | 0 | NA | NA | 20.856 | 20.856 |
| mother | ~~ | mother | 54.195 | 0 | NA | NA | 54.195 | 54.195 |
| both | ~~ | both | 103.301 | 0 | NA | NA | 103.301 | 103.301 |
| problems | ~~ | problems | 422.427 | 0 | NA | NA | 422.427 | 422.427 |
| intimacy | ~~ | intimacy | 50.781 | 0 | NA | NA | 50.781 | 50.781 |
lavaan::residuals(sabatelliFixed, type = "standardized.mplus") |> print()$type
[1] "standardized.mplus"
$cov
prblms intmcy father mother both
problems -0.338
intimacy -0.180 0.092
father -0.938 0.016 -0.073
mother -0.120 0.293 0.043 0.116
both 0.491 0.412 0.067 0.100 0.118
lavaan::residuals(sabatelliFixed, type = "cor.bollen") |> print()$type
[1] "cor.bollen"
$cov
prblms intmcy father mother both
problems 0.000
intimacy -0.010 0.000
father -0.086 0.001 0.000
mother -0.008 0.026 0.003 0.000
both 0.055 0.038 0.006 0.002 0.000
Si noti che nessuno dei residui di correlazione assoluti basati sui risultati 2SLS supera lo 0.10, compreso il residuo per la coppia di indicatori “problems” e “father”. In termini di adattamento locale, dunque, in questo esempio i risultati dello stimatore 2SLS sono da preferire rispetto a quelli dello stimatore ML.
58.6 Considerazioni Conclusive
In questo capitolo abbiamo discusso diversi problemi nel contesto della SEM quando le dimensioni del campione sono ridotte e vengono utilizzati metodi di stima standard (massima verosimiglianza), come la mancata convergenza, le soluzioni non ammissibili, il bias, le statistiche di test poco performanti e gli intervalli di confidenza e gli errori standard inaccurati. Come possibili soluzioni per ottenere stime puntuali migliori, {cite:t}rosseel2020small presenta quattro approcci alternativi alla stima: la stima della verosimiglianza penalizzata, le variabili strumentali derivanti dal modello, la stima a due fasi e la regressione dei punteggi fattoriali. Solo il primo metodo è stato specificamente progettato per gestire campioni ridotti. Gli altri approcci sono stati sviluppati con altre preoccupazioni in mente, ma potrebbero essere alternative valide per la stima quando le dimensioni del campione sono ridotte.
Per quanto riguarda l’inferenza, {cite:t}rosseel2020small discute vari tentativi per migliorare le prestazioni della statistica del chi-quadro per valutare l’adattamento globale in presenza di campioni ridotti. Per quanto riguarda gli errori standard, sottolinea che il bootstrapping potrebbe non essere la soluzione che stiamo cercando. Per ottenere errori standard (e intervalli di confidenza) migliori nel contesto di campioni ridotti, {cite:t}rosseel2020small ritiene che sia necessario aspettare fino a quando nuove tecnologie saranno disponibili. Altri suggerimenti sono stati forniti da {cite:t}kline2023principles. La tecnica del “parceling” è stata presentata in relazione alla discussione fornita da {cite:t}rioux2020item.
Informazioni sull’Ambiente di Sviluppo
sessionInfo()R version 4.4.1 (2024-06-14)
Platform: aarch64-apple-darwin20
Running under: macOS 15.0
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.4-arm64/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.4-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.0
locale:
[1] C
time zone: Europe/Rome
tzcode source: internal
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] MIIVsem_0.5.8 lme4_1.1-35.5 Matrix_1.7-0 ggokabeito_0.1.0
[5] viridis_0.6.5 viridisLite_0.4.2 ggpubr_0.6.0 ggExtra_0.10.1
[9] gridExtra_2.3 patchwork_1.3.0 bayesplot_1.11.1 semTools_0.5-6
[13] semPlot_1.1.6 lavaan_0.6-18 psych_2.4.6.26 scales_1.3.0
[17] markdown_1.13 knitr_1.48 lubridate_1.9.3 forcats_1.0.0
[21] stringr_1.5.1 dplyr_1.1.4 purrr_1.0.2 readr_2.1.5
[25] tidyr_1.3.1 tibble_3.2.1 ggplot2_3.5.1 tidyverse_2.0.0
[29] here_1.0.1
loaded via a namespace (and not attached):
[1] rstudioapi_0.16.0 jsonlite_1.8.9 magrittr_2.0.3
[4] TH.data_1.1-2 estimability_1.5.1 farver_2.1.2
[7] nloptr_2.1.1 rmarkdown_2.28 vctrs_0.6.5
[10] minqa_1.2.8 base64enc_0.1-3 rstatix_0.7.2
[13] htmltools_0.5.8.1 broom_1.0.6 Formula_1.2-5
[16] htmlwidgets_1.6.4 plyr_1.8.9 sandwich_3.1-1
[19] emmeans_1.10.4 zoo_1.8-12 uuid_1.2-1
[22] igraph_2.0.3 mime_0.12 lifecycle_1.0.4
[25] pkgconfig_2.0.3 R6_2.5.1 fastmap_1.2.0
[28] shiny_1.9.1 digest_0.6.37 OpenMx_2.21.12
[31] fdrtool_1.2.18 colorspace_2.1-1 rprojroot_2.0.4
[34] Hmisc_5.1-3 fansi_1.0.6 timechange_0.3.0
[37] abind_1.4-8 compiler_4.4.1 withr_3.0.1
[40] glasso_1.11 htmlTable_2.4.3 backports_1.5.0
[43] carData_3.0-5 ggsignif_0.6.4 MASS_7.3-61
[46] corpcor_1.6.10 gtools_3.9.5 tools_4.4.1
[49] pbivnorm_0.6.0 foreign_0.8-87 zip_2.3.1
[52] httpuv_1.6.15 nnet_7.3-19 glue_1.7.0
[55] quadprog_1.5-8 promises_1.3.0 nlme_3.1-166
[58] lisrelToR_0.3 grid_4.4.1 pbdZMQ_0.3-13
[61] checkmate_2.3.2 cluster_2.1.6 reshape2_1.4.4
[64] generics_0.1.3 gtable_0.3.5 tzdb_0.4.0
[67] data.table_1.16.0 hms_1.1.3 car_3.1-2
[70] utf8_1.2.4 sem_3.1-16 pillar_1.9.0
[73] IRdisplay_1.1 rockchalk_1.8.157 later_1.3.2
[76] splines_4.4.1 lattice_0.22-6 survival_3.7-0
[79] kutils_1.73 tidyselect_1.2.1 miniUI_0.1.1.1
[82] pbapply_1.7-2 stats4_4.4.1 xfun_0.47
[85] qgraph_1.9.8 arm_1.14-4 stringi_1.8.4
[88] pacman_0.5.1 boot_1.3-31 evaluate_1.0.0
[91] codetools_0.2-20 mi_1.1 cli_3.6.3
[94] RcppParallel_5.1.9 IRkernel_1.3.2 rpart_4.1.23
[97] xtable_1.8-4 repr_1.1.7 munsell_0.5.1
[100] Rcpp_1.0.13 coda_0.19-4.1 png_0.1-8
[103] XML_3.99-0.17 parallel_4.4.1 jpeg_0.1-10
[106] mvtnorm_1.3-1 openxlsx_4.2.7.1 crayon_1.5.3
[109] rlang_1.1.4 multcomp_1.4-26 mnormt_2.1.1