here::here("code", "_common.R") |>
source()
# Load packages
if (!requireNamespace("pacman")) install.packages("pacman")
pacman::p_load(
grid, latex2exp, mirt, TAM, ggmirt, cmdstanr, posterior,
rstan, tidyr, psych, rsvg, effectsize
)69 Stima
In questo capitolo apprenderai come:
Prerequisiti
- Leggere il capitolo 8, Item Response Theory, del testo Principles of psychological assessment di Petersen (2024).
69.0.1 Introduzione
Per utilizzare il modello di Rasch nella ricerca pratica, è essenziale comprendere come stimare i suoi parametri a partire dai dati osservati. In questa sezione verranno illustrati diversi metodi di stima, ognuno dei quali consente di calcolare sia i parametri degli item che quelli delle persone, differenziandosi però per l’approccio utilizzato.
Alcuni metodi, come la massima verosimiglianza congiunta e l’inferenza bayesiana, stimano simultaneamente i parametri degli item e delle persone. Altri, come la massima verosimiglianza condizionale e la massima verosimiglianza marginale, separano il processo di stima: i parametri degli item vengono stimati per primi, seguiti dalla stima dei parametri delle persone in una fase successiva. Questa distinzione tra approcci permette di scegliere la metodologia più adatta al contesto e alle caratteristiche dei dati analizzati.
69.1 La Funzione di Verosimiglianza
La stima dei parametri nel modello di Rasch si basa sulla funzione di verosimiglianza, che rappresenta la probabilità di osservare i dati disponibili dato un insieme di parametri sconosciuti. Nel contesto del modello, \(U_{pi}\) denota la risposta (corretta o errata) fornita dalla persona \(p\) all’item \(i\), dove una risposta corretta è codificata come 1 e una errata come 0. La probabilità condizionale che una persona con abilità \(\theta_p\) risponda specificamente \(u_{pi}\) all’item \(i\), la cui difficoltà è \(\beta_i\), è definita dalla formula:
\[ \text{Pr}(U_{pi} = u_{pi} | \theta_p, \beta_i) = \frac{\exp\{u_{pi} \cdot (\theta_p - \beta_i)\}}{1 + \exp(\theta_p - \beta_i)}. \]
Questa equazione calcola la probabilità della risposta osservata, basandosi sulla differenza tra l’abilità della persona (\(\theta_p\)) e la difficoltà dell’item (\(\beta_i\)). Se l’abilità \(\theta_p\) supera la difficoltà \(\beta_i\), la probabilità di una risposta corretta (\(u_{pi} = 1\)) è elevata; al contrario, se \(\theta_p\) è inferiore a \(\beta_i\), tale probabilità sarà ridotta.
69.1.1 Verosimiglianza Complessiva per una Persona
La verosimiglianza complessiva per una persona \(p\) rispetto a tutte le sue risposte agli item del test (\(i = 1, \dots, I\)) si ottiene moltiplicando le probabilità condizionali di ciascuna risposta. La funzione di verosimiglianza totale è quindi espressa come:
\[ L_{up}(\theta_p, \beta) = \prod_{i=1}^{I} \frac{\exp\{u_{pi} \cdot (\theta_p - \beta_i)\}}{1 + \exp(\theta_p - \beta_i)}. \]
Riorganizzando per maggiore chiarezza, questa può essere riscritta come:
\[ L_{up}(\theta_p, \beta) = \frac{\exp(r_p \cdot \theta_p - \sum_{i=1}^{I} u_{pi} \cdot \beta_i)}{\prod_{i=1}^{I} [1 + \exp(\theta_p - \beta_i)]}, \tag{1} \]
dove:
- \(r_p = \sum_{i=1}^{I} u_{pi}\) rappresenta il punteggio grezzo della persona \(p\), ovvero il numero totale di risposte corrette.
Questa formulazione sintetizza come la funzione di verosimiglianza dipenda non solo dal parametro di abilità \(\theta_p\) della persona, ma anche dai parametri di difficoltà \(\beta_i\) degli item. La funzione è essenziale per stimare questi parametri e per interpretare la relazione tra abilità e difficoltà nel contesto del test.
69.2 Stima dei Parametri nel Modello di Rasch
L’?eq-rasch-likelihood rappresenta la base comune per tutti i metodi di stima dei parametri nel modello di Rasch. Tuttavia, il metodo scelto per stimare i parametri influenzerà il modo in cui l’abilità delle persone (\(\theta_p\)) e la difficoltà degli item (\(\beta_i\)) vengono calcolate e interpretate:
- Stima simultanea: Alcuni metodi, come la massima verosimiglianza congiunta e l’inferenza bayesiana, stimano simultaneamente \(\theta_p\) e \(\beta_i\).
- Stima separata: Altri metodi, come la massima verosimiglianza condizionale e la massima verosimiglianza marginale, stimano \(\beta_i\) in un primo passaggio, per poi derivare \(\theta_p\).
Ogni approccio introduce assunzioni specifiche che influenzano le proprietà delle stime e la loro applicabilità in diversi contesti.
69.2.1 Stima della Massima Verosimiglianza Congiunta
La stima della massima verosimiglianza congiunta (JML) mira a determinare simultaneamente i parametri delle persone (\(\theta_p\)) e degli item (\(\beta_i\)) che massimizzano la probabilità complessiva dei dati osservati, come descritto nella funzione di verosimiglianza del modello di Rasch. Questo approccio identifica il set di parametri più probabili che potrebbero aver generato il dataset analizzato.
Punti di forza:
- Metodo diretto e intuitivo, che utilizza tutta l’informazione disponibile nei dati osservati.
Limitazioni:
- Stime inconsistenti: Nonostante la semplicità del metodo, JML non garantisce stime consistenti dei parametri degli item, anche con campioni di grandi dimensioni. Questo limita la sua affidabilità, specialmente in contesti che richiedono alta precisione e robustezza nelle stime.
- Bias intrinseco: Le stime delle abilità (\(\theta_p\)) e delle difficoltà (\(\beta_i\)) possono essere influenzate l’una dall’altra, causando errori sistematici.
Implementazione in R:
- JML è implementato nel pacchetto TAM, attraverso la funzione
tam.jml(). Sebbene disponibile, il suo utilizzo è sconsigliato in analisi avanzate o quando la consistenza delle stime è critica.
69.2.2 Stima della Massima Verosimiglianza Condizionale
La stima della massima verosimiglianza condizionale (CML) affronta le limitazioni della JML separando la stima dei parametri degli item da quella delle persone. Questo approccio procede in due fasi:
-
Stima dei parametri degli item:
- La CML utilizza le statistiche sufficienti delle persone (ad esempio, i punteggi grezzi \(r_p = \sum u_{pi}\)) per isolare i parametri degli item. In questa fase, le abilità delle persone (\(\theta_p\)) non sono direttamente considerate, evitando il bias congiunto.
-
Stima dei parametri delle persone:
- Una volta stimati i parametri degli item (\(\beta_i\)), si procede alla stima delle abilità (\(\theta_p\)) basandosi sui dati individuali e sulle difficoltà stimate.
Vantaggi:
- Fornisce stime consistenti dei parametri degli item.
- Evita il problema del bias associato alla stima simultanea di JML.
Limitazioni:
- L’accuratezza dei parametri delle persone dipende dalla precisione delle stime degli item nella prima fase.
Implementazione in R:
- La CML è implementata nel pacchetto eRm tramite la funzione
RM(), che consente di stimare i parametri degli item in modo robusto e separato.
69.2.3 Stima della Massima Verosimiglianza Marginale
La stima della massima verosimiglianza marginale (MML) rappresenta un approccio avanzato che considera le abilità delle persone come una variabile casuale seguendo una distribuzione ipotizzata, tipicamente normale. Questo metodo differisce dalla CML trattando i parametri delle abilità (\(\theta_p\)) come effetti casuali anziché fissi, e li integra nella funzione di verosimiglianza complessiva.
Come funziona:
-
Distribuzione marginale delle abilità:
- La MML assume che le abilità (\(\theta_p\)) siano distribuite nella popolazione secondo una distribuzione nota (ad esempio, una normale standard). Invece di stimare direttamente \(\theta_p\), il metodo stima i parametri degli item (\(\beta_i\)) tenendo conto di questa distribuzione.
-
Scoring individuale:
- Dopo aver stimato i parametri degli item, si calcolano i punteggi individuali (\(\theta_p\)) basandosi sulle risposte e sui parametri stimati.
Vantaggi:
- Produce stime più precise e realistiche dei parametri degli item rispetto alla JML.
- È particolarmente utile quando le abilità nella popolazione seguono una distribuzione continua e ipotizzabile.
Limitazioni:
- La validità delle stime dipende dalla correttezza dell’assunzione sulla distribuzione delle abilità (\(\theta_p\)).
Implementazione in R:
- La MML è supportata dai pacchetti mirt e TAM. Ad esempio:
- Funzioni come
mirt()in mirt permettono stime flessibili con distribuzioni marginali specificabili. - Anche ltm (sebbene non più attivamente sviluppato) offre strumenti per la stima marginale.
- Funzioni come
69.2.4 Confronto tra i Metodi
| Metodo | Caratteristiche principali | Pro | Contro |
|---|---|---|---|
| JML (Massima Verosimiglianza Congiunta) | Stima simultanea di \(\theta_p\) e \(\beta_i\). | Intuitivo e diretto. | Stime inconsistenti; bias congiunto. |
| CML (Massima Verosimiglianza Condizionale) | Stima separata in due fasi: prima \(\beta_i\), poi \(\theta_p\). | Stime consistenti per \(\beta_i\); evita il bias. | Dipende dall’accuratezza delle stime iniziali degli item. |
| MML (Massima Verosimiglianza Marginale) | Integra una distribuzione marginale per \(\theta_p\); tratta \(\theta_p\) come effetti casuali. | Stime realistiche e robuste; considera la distribuzione della popolazione. | Dipende dall’assunzione sulla distribuzione delle abilità. |
In conclusione, ogni metodo presenta vantaggi e svantaggi che lo rendono più o meno adatto a specifici contesti di analisi. La JML è utile per analisi preliminari o semplici, ma è limitata dalla mancanza di consistenza. La CML e la MML offrono stime più robuste e realistiche, con la MML che si distingue per la sua flessibilità nell’incorporare distribuzioni di popolazione.
Esercizio 69.1 Consideriamo ora la procedura di stima del livello di abilità \(\theta\) di un individuo nel modello di Rasch attraverso l’uso della massima verosimiglianza marginale. La procedura per stimare la posizione di un individuo, dato un particolare pattern di risposte, può essere formulata con i seguenti passaggi.
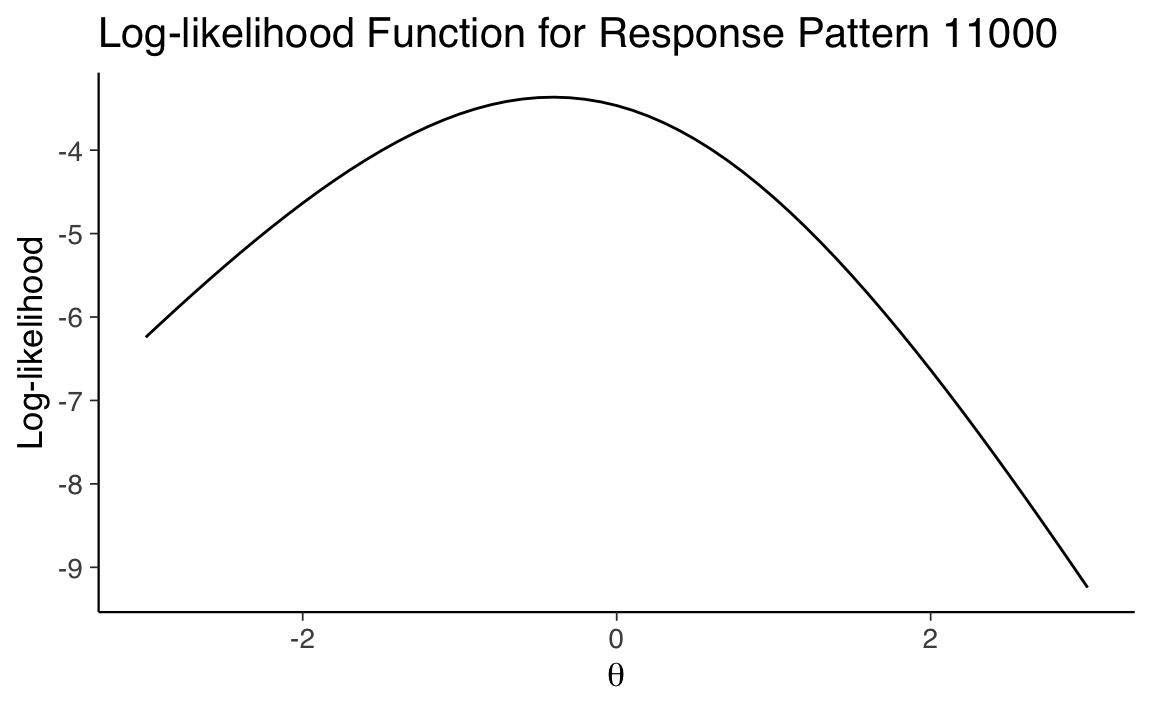
Consideriamo un determinato pattern di risposta. Per esempio, il pattern “11000” indica che un particolare individuo ha fornito due risposte corrette seguite da tre errate a cinque item, con un totale di \(X = 2\) risposte corrette.
Calcoliamo le probabilità per ogni risposta. Utilizziamo l’Equazione 67.1 per calcolare la probabilità di ciascuna risposta nel pattern, in base a un dato livello di abilità \(\theta\).
Determiniamo la probabilità del pattern di risposta. Questo passaggio si basa sull’assunzione di indipendenza condizionale (ovvero, per un dato \(\theta\), le risposte sono indipendenti l’una dall’altra). Questa assunzione ci permette di applicare la regola di moltiplicazione per eventi indipendenti alle probabilità degli item per ottenere la probabilità complessiva del pattern di risposta per un dato \(\theta\).
Ripetiamo i calcoli per diversi valori di \(\theta\). Ripetiamo i passaggi 1 e 2 per una serie di valori di \(\theta\). Nel nostro esempio, il range di \(\theta\) va da \(-3\) a \(3\).
Determiniamo il valore di \(\theta\) con la massima verosimiglianza. L’ultimo passaggio consiste nel determinare quale valore di \(\theta\) tra quelli calcolati nel passaggio 3 abbia la più alta verosimiglianza di produrre il pattern “11000”. Per fare questo scegliamo il valore \(\theta\) per cui la verosimiglianza è massima.
Di seguito, esaminiamo uno script in R che implementa questa procedura.
# Definiamo il pattern di risposta
response_pattern <- c(1, 1, 0, 0, 0)
# Range di valori di theta da esplorare
theta_values <- seq(-3, 3, by = 0.01)
# Funzione per calcolare la probabilità di un singolo pattern di risposta
calculate_probability <- function(theta, pattern) {
correct_probs <- exp(theta) / (1 + exp(theta))
item_probs <- ifelse(pattern == 1, correct_probs, 1 - correct_probs)
prod(item_probs)
}
# Per semplicità, assumiamo che il parametro di difficoltà (beta) sia zero per tutti gli item.
# Calcoliamo le probabilità per ogni valore di theta. Usiamo sapply per applicare
# la funzione calculate_probability a ciascun valore di theta nel range specificato.
probabilities <- sapply(theta_values, calculate_probability, pattern = response_pattern)
# Identifichiamo il valore di theta con la massima verosimiglianza
best_theta <- theta_values[which.max(probabilities)]
print(paste("Valore di theta calcolato con la massima verosimiglianza:", best_theta))
#> [1] "Valore di theta calcolato con la massima verosimiglianza: -0.41"Questo script calcola la probabilità di ottenere il pattern di risposta “11000” per cinque item per un dato intervallo di valori di \(\theta\) e identifica il valore di \(\theta\) che massimizza questa probabilità. Si noti che il modello di Rasch prevede che tutti gli item abbiano la stessa discriminazione, quindi non è necessario specificare un parametro di discriminazione per ogni item. Abbiamo assunto inoltre che la difficoltà di tutti gli item sia uguale a zero.
La verosimiglianza di un pattern di risposta di un singolo rispondente a diversi item può essere rappresentata simbolicamente nel modo seguente. Se consideriamo \(x\) come il pattern di risposta di un rispondente (ad esempio, \(x = 11000\) indica che il rispondente ha risposto correttamente ai primi due item e ha dato risposte sbagliate agli ultimi tre), la verosimiglianza del vettore di risposta \(x_i\) della persona \(i\) è espressa come:
\[ \begin{equation} L(x_i) = \prod_{j=1}^{L} p_{ij}, \end{equation} \]
dove \(p_{ij} = p(x_{ij} = 1 \mid \theta_i, \alpha_j, \delta_j)\) rappresenta la probabilità che la persona \(i\), con un livello di abilità \(\theta_i\), risponda correttamente all’item \(j\). In questa formula, \(\alpha_j\) è il parametro di discriminazione dell’item \(j\) e \(\delta_j\) è il suo parametro di difficoltà. Il parametro \(\alpha_j\) indica quanto bene l’item \(j\) è in grado di discriminare tra rispondenti di diversi livelli di abilità, mentre \(\delta_j\) rappresenta il livello di abilità per cui la probabilità di una risposta corretta è del 50%. Il prodotto è calcolato su tutti gli \(L\) item a cui il rispondente ha risposto, e il simbolo \(\prod\) rappresenta il prodotto di tutte queste probabilità individuali.
Il calcolo diretto della verosimiglianza può diventare problematico all’aumentare del numero di item, poiché il prodotto di molteplici probabilità può risultare in valori molto piccoli, difficili da gestire con precisione in calcoli numerici. Pertanto, è spesso più pratico lavorare con la trasformazione logaritmica naturale della verosimiglianza, ovvero \(\log_e(L(x_i))\) o \(\ln(L(x_i))\). Questa trasformazione converte il prodotto in una somma, come segue:
\[ \begin{equation} \ln L(x_i) = \sum_{j=1}^{L} \ln(p_{ij}). \end{equation} \]
L’uso del logaritmo naturale trasforma quindi la verosimiglianza in una somma di logaritmi, semplificando il calcolo e riducendo i problemi di rappresentazione numerica nei calcoli complessi.
# Definizione del pattern di risposta
response_pattern <- c(1, 1, 0, 0, 0)
# Range di valori di theta da esplorare
theta_values <- seq(-3, 3, by = 0.1)
# Calcolo della log-verosimiglianza per ogni valore di theta
log_likelihoods <- numeric(length(theta_values))
for (i in seq_along(theta_values)) {
theta <- theta_values[i]
log_item_probs <- numeric(length(response_pattern))
# Calcolo delle probabilità logaritmiche individuali per ogni item nel pattern
for (j in seq_along(response_pattern)) {
prob_correct <- exp(theta) / (1 + exp(theta))
prob <- ifelse(response_pattern[j] == 1, prob_correct, 1 - prob_correct)
log_item_probs[j] <- log(prob)
}
# Calcolo della log-verosimiglianza
log_likelihoods[i] <- sum(log_item_probs)
}
# Creazione di un dataframe per il plotting
plot_data <- data.frame(theta = theta_values, log_likelihood = log_likelihoods)
# Rappresentazione grafica della log-verosimiglianza
ggplot(plot_data, aes(x = theta, y = log_likelihood)) +
geom_line() +
labs(
x = expression(theta), y = "Log-likelihood",
title = "Log-likelihood Function for Response Pattern 11000"
) 
69.3 Errore Standard della Stima e Informazione dell’Item
Nel modello di Rasch, l’Errore Standard della Stima (EES) è un indicatore chiave che quantifica l’incertezza associata alla stima del livello di abilità di un individuo (\(\theta\)). L’EES è fondamentale perché fornisce una misura della precisione con cui la stima di \(\theta\) riflette l’abilità reale del rispondente. Un EES più basso indica una stima più precisa, mentre un EES più alto segnala una maggiore incertezza.
69.3.1 Calcolo dell’EES
L’EES è determinato dall’informazione totale dell’item a un dato livello di abilità \(\theta\), indicata con \(I(\theta)\). L’EES è definito come l’inverso della radice quadrata di \(I(\theta)\):
\[ \text{EES}(\theta) = \frac{1}{\sqrt{I(\theta)}}, \]
dove \(I(\theta)\) rappresenta l’informazione totale accumulata dagli item del test a quel livello di abilità.
69.3.2 Informazione dell’Item
L’informazione dell’item misura il contributo di ciascun item alla precisione della stima di \(\theta\). Per un dato livello di abilità, l’informazione fornita da un singolo item dipende dalla probabilità che il rispondente dia una risposta corretta (\(p_{ij}\)) e dalla probabilità di una risposta errata (\(1 - p_{ij}\)). La formula per calcolare l’informazione totale degli item è:
\[ I(\theta) = \sum_{j=1}^{L} p_{ij}(1 - p_{ij}), \]
dove:
- \(L\) è il numero totale di item del test.
- \(p_{ij}\) è la probabilità che una persona con abilità \(\theta\) risponda correttamente all’item \(j\).
L’informazione fornita da un singolo item raggiunge il suo massimo quando la difficoltà dell’item (\(\delta_j\)) è uguale al livello di abilità del rispondente (\(\theta\)). In questa condizione, l’item discrimina al meglio tra rispondenti con livelli di abilità leggermente superiori o inferiori a \(\delta_j\).
69.3.3 Relazione tra Informazione e Precisione
- Massima informazione, minima incertezza: Quando \(I(\theta)\) è alta, l’EES (\(\text{EES}(\theta)\)) è basso, indicando una stima precisa.
- Bassa informazione, alta incertezza: Quando \(I(\theta)\) è bassa, l’EES è alto, segnalando una maggiore incertezza nella stima di \(\theta\).
Questa relazione evidenzia l’importanza di progettare test con item che siano informativi per il range di abilità di interesse.
69.3.4 Curva di Informazione dell’Item
L’informazione dell’item varia a seconda del livello di abilità del rispondente. Per visualizzare questa relazione, si traccia la curva di informazione dell’item, che rappresenta l’informazione fornita da un singolo item in funzione di \(\theta\). Alcune caratteristiche della curva:
- Ha una forma a campana.
- Raggiunge il picco quando \(\theta = \delta_j\), ossia quando l’abilità del rispondente corrisponde alla difficoltà dell’item.
- Larghezza e altezza della curva dipendono dalla discriminazione dell’item (nel modello Rasch, fissata a 1).
La somma delle curve di informazione dei singoli item produce la curva di informazione totale del test, che mostra la precisione complessiva del test a diversi livelli di abilità.
69.3.5 Applicazioni pratiche
Progettazione del test: La conoscenza dell’informazione degli item aiuta a creare test che siano più informativi per specifici livelli di abilità, riducendo l’EES per i range di interesse.
-
Interpretazione dei risultati: L’EES permette di stimare intervalli di confidenza per \(\theta\), fornendo una misura della precisione della stima:
\[ \text{Intervallo di confidenza per } \theta = \theta \pm 1.96 \cdot \text{EES}(\theta). \]
L’analisi dell’informazione dell’item e del test è quindi essenziale per garantire che le misurazioni ottenute siano affidabili e utili per l’interpretazione e il confronto delle abilità.
Esercizio 69.2 Utilizzando il modello di Rasch, possiamo calcolare le probabilità di risposta corretta per diversi valori di abilità e, di conseguenza, la Funzione Informativa dell’Item (Item Information Function, IIF):
# Definizione di un range di abilità
theta <- seq(-4, 4, by = 0.1)
# Definizione di un parametro di difficoltà dell'item
beta <- 0
# Calcolo delle probabilità di risposta corretta per ciascun valore di abilità usando la funzione logistica
prob_correct <- exp(theta - beta) / (1 + exp(theta - beta))
# Calcolo dell'informazione dell'item
item_info <- prob_correct * (1 - prob_correct)
# Creazione della prima grafica (ICC)
plot(theta, prob_correct,
type = "l", col = "blue", lwd = 2,
xlab = "Abilita' theta", ylab = "Probabilita' di Risposta Corretta",
main = "Curva Caratteristica dell'Item (ICC) e Informazione dell'Item"
)
# Aggiunta di un secondo asse y per l'informazione
par(new = TRUE)
plot(theta, item_info,
type = "l", col = "red", lwd = 2,
xlab = "", ylab = "", axes = FALSE, ann = FALSE
)
# Aggiungere l'asse y di destra per l'informazione
axis(side = 4, at = pretty(range(item_info)))
mtext("Informazione", side = 4, line = 3)
# Aggiunta della legenda
legend("topright",
legend = c("ICC", "Informazione"),
col = c("blue", "red"), lty = 1, cex = 0.8
)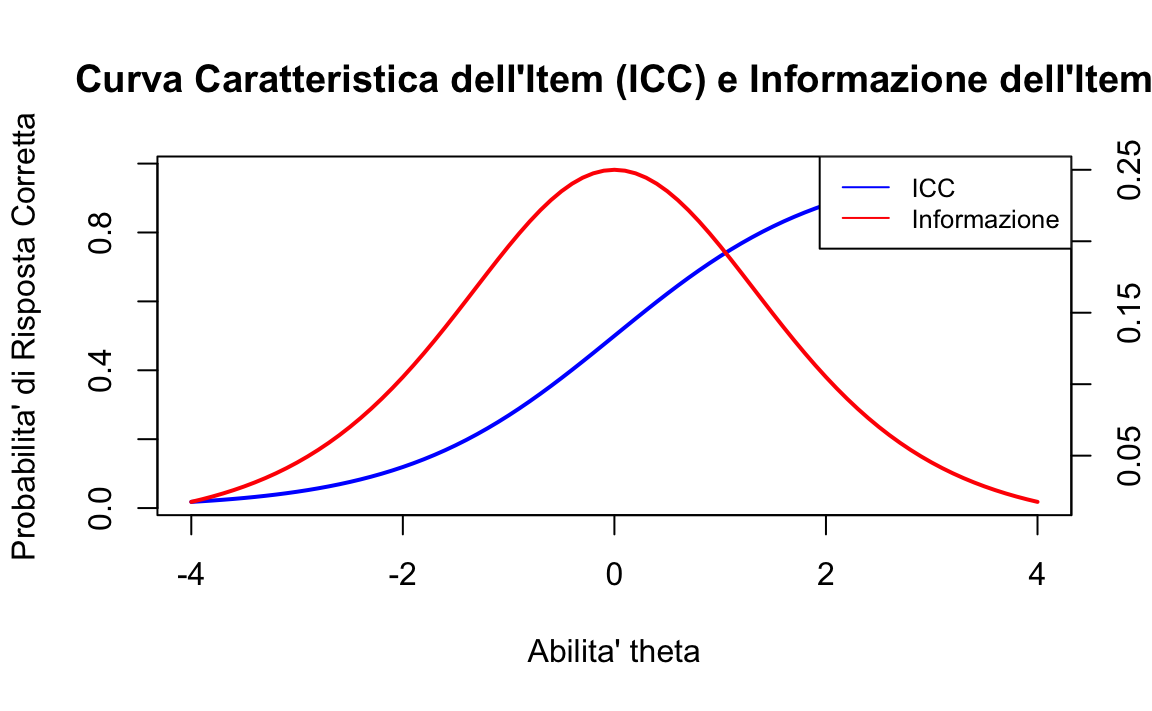
Questa rappresentazione grafica in R mostra come l’informazione vari in funzione del livello di abilità. In generale, l’informazione è massima quando l’abilità dell’esaminando è vicina alla difficoltà dell’item e diminuisce man mano che ci si allontana da questo punto.
Il concetto di informazione in IRT è fondamentale sia per la costruzione del test sia per la sua interpretazione. Indica quanto efficacemente ciascun item misura l’abilità a vari livelli e aiuta a determinare quali item sono più informativi per la stima dell’abilità degli esaminandi. Inoltre, fornisce indicazioni sulla precisione con cui l’abilità degli esaminandi può essere stimata a vari punti lungo la scala di abilità.
Esercizio 69.3 Per dimostrare come calcolare la TIF in \(\mathsf{R}\), possiamo estendere l’esempio precedente includendo più item e sommando le loro informazioni:
# Definizione di parametri di difficoltà per diversi item
beta_items <- c(-1, 0, 1) # Esempio di tre item con difficoltà diverse
# Calcolo dell'informazione per ogni item e somma per ottenere la TIF
test_info <- rep(0, length(theta))
for (beta in beta_items) {
prob_correct <- exp(theta - beta) / (1 + exp(theta - beta))
item_info <- prob_correct * (1 - prob_correct)
test_info <- test_info + item_info
}
# Creazione del grafico della TIF
plot(theta, test_info,
type = "l", col = "blue", lwd = 2,
xlab = "Abilità theta", ylab = "Informazione del Test",
main = "Funzione di Informazione del Test (TIF)"
)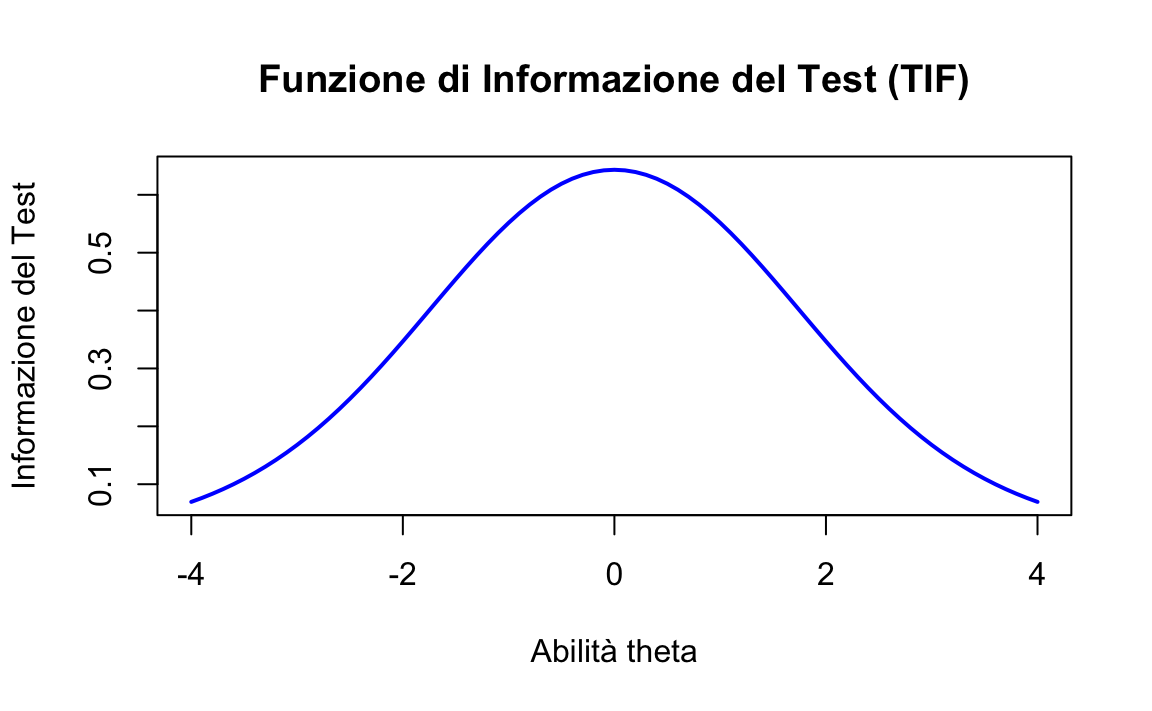
In questo esempio, calcoliamo e sommiamo le informazioni di tre item con diverse difficoltà per visualizzare la TIF di un test ipotetico. La TIF mostra in modo chiaro come il test nel suo insieme stima l’abilità degli esaminandi a vari livelli, fornendo così indicazioni preziose sulla costruzione e sull’utilizzo ottimale del test in diversi contesti.
69.4 Stima dell’Abilità
Nel contesto dell’IRT, la stima dell’abilità di un esaminando (\(\theta\)) viene effettuata utilizzando metodi iterativi, come la massima verosimiglianza, che sfruttano i dati del test e i parametri degli item. Questo processo consente di stimare il livello di abilità in modo personalizzato, tenendo conto del pattern di risposte specifico di ciascun esaminando.
69.4.1 Procedura di Stima dell’Abilità
-
Punto di partenza:
- La stima inizia con un’ipotesi iniziale o un valore a priori per l’abilità dell’esaminando. Questo valore può essere scelto in base a considerazioni teoriche (ad esempio, \(\theta = 0\), corrispondente alla media presunta dell’abilità) o determinato da informazioni preliminari.
-
Utilizzo dei parametri degli item:
- I parametri noti degli item (ad esempio, difficoltà (_i) e discriminazione (a_i)) vengono utilizzati per calcolare la probabilità che l’esaminando risponda correttamente a ciascun item in base al livello di abilità iniziale ipotizzato. Questa probabilità è calcolata attraverso la funzione di risposta dell’item (IRF).
-
Iterazione per aggiustare la stima:
- Il livello di abilità viene aggiornato iterativamente. L’obiettivo di ogni iterazione è migliorare la corrispondenza tra le probabilità previste di risposta corretta (basate sul livello di abilità stimato) e il pattern effettivo di risposte fornite dall’esaminando.
- Questo processo continua fino a quando le modifiche alla stima di \(\theta\) diventano trascurabili, indicando che è stato raggiunto un punto di convergenza. Il risultato finale è una stima stabile e affidabile dell’abilità.
-
Stima personalizzata:
- Il processo viene ripetuto per ciascun esaminando, assicurando che ogni stima di \(\theta\) sia basata esclusivamente sulle sue risposte.
69.4.2 Metodi alternativi di stima
-
Stima simultanea:
- In alternativa alla stima iterativa individuale, esistono approcci che stimano simultaneamente i livelli di abilità di tutti gli esaminandi. Questi metodi sono particolarmente utili in presenza di un ampio campione, ottimizzando il processo di calcolo.
-
Stima Bayesiana:
- La stima bayesiana combina i dati del test con una distribuzione a priori sull’abilità (\(\theta\)) per ottenere una stima posteriore. Questo approccio è particolarmente utile quando il numero di item è limitato o le risposte sono incomplete.
69.4.3 Importanza della Stima dell’Abilità
La stima dell’abilità in IRT è fondamentale per due motivi principali:
-
Valutazione personalizzata:
- Permette di misurare l’abilità di ciascun esaminando in maniera individualizzata, considerando le interazioni specifiche tra il rispondente e gli item. Questa personalizzazione rende la stima più accurata rispetto ai punteggi grezzi, che non tengono conto delle caratteristiche degli item.
-
Analisi mirate:
- Poiché la stima dell’abilità è direttamente legata ai parametri degli item, consente di condurre analisi dettagliate sull’efficacia del test (ad esempio, quali item sono più informativi per specifici livelli di abilità) e sulle caratteristiche dei rispondenti.
In conclusione, la stima dell’abilità in IRT è un processo iterativo che utilizza i parametri degli item e il pattern di risposte individuali per fornire stime accurate e personalizzate del livello di abilità di ciascun esaminando. Grazie alla sua precisione, questa metodologia rappresenta una componente essenziale dell’IRT, sia per la valutazione degli esaminandi sia per l’ottimizzazione dei test.
69.5 Stima Bayesiana
La stima bayesiana sta diventando un metodo sempre più popolare per stimare i parametri del modello di Rasch. Come la stima della massima verosimiglianza congiunta, la stima bayesiana stima simultaneamente sia i parametri delle persone che quelli degli item. Tuttavia, mentre la stima della massima verosimiglianza congiunta trova i valori di \(\theta\) e \(\beta\) massimizzando la verosimiglianza congiunta, la stima bayesiana utilizza la regola di Bayes per trovare la densità a posteriori, \(f(\theta,\beta \mid u)\).
Nel modello di Rasch, la regola di Bayes afferma che:
\[ f(\theta,\beta \mid u) = \frac{\text{Pr}(u \mid \theta,\beta)f(\theta,\beta)}{\text{Pr}(u)}. \]
Il primo termine nel numeratore, \(\text{Pr}(u \mid \theta, \beta)\), è la verosimiglianza congiunta. Il secondo è la distribuzione a priori congiunta per \(\theta\) e \(\beta\). Il denominatore è la probabilità media dei dati osservati rispetto alla distribuzione a priori congiunta.
A differenza della stima della massima verosimiglianza, che si concentra sulla massimizzazione della verosimiglianza, la stima bayesiana integra le informazioni a priori con i dati osservati. La regola di Bayes combina la verosimiglianza dei dati osservati (la probabilità di osservare i dati dati i parametri) con la distribuzione a priori (le nostre credenze sui parametri prima di osservare i dati) per produrre una distribuzione a posteriori (le nostre credenze aggiornate sui parametri dopo aver osservato i dati). La densità a posteriori \(f(\theta,\beta \mid u)\) ci fornisce una stima completa dei parametri, considerando sia i dati osservati sia le informazioni a priori.
In pratica, la stima bayesiana fornisce un approccio flessibile e informativo alla stima dei parametri nel modello di Rasch, consentendo l’integrazione di conoscenze pregresse e osservazioni attuali.
69.5.1 Implementazione
Esaminiamo un’applicazione della stima Bayesiana usando il linguaggio probabilistico Stan. Il modello di Rasch è implementato nel file rasch_model.stan utilizzando le distribuzioni a priori specificate da Debelak et al. (2022).
stan_file <- "../../code/rasch_model.stan"
mod <- cmdstan_model(stan_file)
mod$print()
#> data {
#> int<lower=1> num_person;
#> int<lower=1> num_item;
#> array[num_person, num_item] int<lower=0, upper=1> U;
#> }
#> parameters {
#> vector[num_person] theta;
#> vector[num_item] beta;
#> real mu_beta;
#> real<lower=0> sigma2_theta;
#> real<lower=0> sigma2_beta;
#> }
#> transformed parameters {
#> array[num_person, num_item] real<lower=0, upper=1> prob_solve;
#> for (p in 1:num_person)
#> for (i in 1:num_item)
#> prob_solve[p, i] = inv_logit(theta[p] - beta[i]);
#> }
#> model {
#> for (p in 1:num_person)
#> for (i in 1:num_item)
#> U[p, i] ~ bernoulli(prob_solve[p, i]);
#> theta ~ normal(0, sqrt(sigma2_theta));
#> beta ~ normal(mu_beta, sqrt(sigma2_beta));
#> sigma2_theta ~ inv_chi_square(0.5);
#> sigma2_beta ~ inv_chi_square(0.5);
#> }Nella presente implementazione bayesiana del modello di Rasch, le sezioni “transformed parameters” e “model” hanno un ruolo centrale nel definire come i dati vengono processati e come il modello viene applicato. Vediamo dettagliatamente ciascuna sezione:
69.5.1.1 Sezione Transformed Parameters
Nella sezione transformed parameters, viene definita la trasformazione dei parametri di base (i parametri theta per le abilità delle persone e beta per la difficoltà degli item) in una probabilità di risposta corretta per ogni coppia persona-item. Qui viene usata la funzione logistica inversa per convertire la differenza tra l’abilità della persona e la difficoltà dell’item in una probabilità:
transformed parameters {
array[num_person, num_item] real<lower=0, upper=1> prob_solve;
for (p in 1:num_person)
for (i in 1:num_item)
prob_solve[p, i] = inv_logit(theta[p] - beta[i]);
}Questa trasformazione serve a mappare la differenza tra l’abilità della persona (theta[p]) e la difficoltà dell’item (beta[i]) in un intervallo di probabilità tra 0 e 1. La funzione inv_logit è comunemente usata per questo scopo, essendo la funzione logistica inversa.
69.5.1.2 Sezione Model
Nella sezione model, vengono definite le distribuzioni di probabilità per i dati osservati e i parametri del modello, che sono essenziali per la stima bayesiana. Questa parte del codice descrive come i dati sono generati, supponendo il modello di Rasch:
model {
for (p in 1:num_person)
for (i in 1:num_item)
U[p, i] ~ bernoulli(prob_solve[p, i]);
theta ~ normal(0, sqrt(sigma2_theta));
beta ~ normal(mu_beta, sqrt(sigma2_beta));
sigma2_theta ~ inv_chi_square(0.5);
sigma2_beta ~ inv_chi_square(0.5);
}-
U[p, i] ~ bernoulli(prob_solve[p, i]): ogni rispostaU[p, i], che indica se la personapha risposto correttamente all’itemi, segue una distribuzione di Bernoulli dove la probabilità di successo è data daprob_solve[p, i]. Questa è la vera verosimiglianza del modello, che collega i dati osservati alle probabilità calcolate tramite il modello logistico. -
theta ~ normal(0, sqrt(sigma2_theta))ebeta ~ normal(mu_beta, sqrt(sigma2_beta)): le distribuzioni a priori per i parametrithetaebetasono normali. Questo significa che, in assenza di dati, si assume che queste variabili si distribuiscano normalmente con una media di 0 perthetaemu_betaperbeta, e una deviazione standard derivata dai parametri di varianzasigma2_thetaesigma2_beta. -
sigma2_theta ~ inv_chi_square(0.5)esigma2_beta ~ inv_chi_square(0.5): le varianzesigma2_thetaesigma2_betahanno distribuzioni a priori che seguono una distribuzione chi quadrato inversa con parametro di forma 0.5. Questa è una scelta comune per imporre una distribuzione non informativa (vaga) sui parametri di scala.
In conclusione, la sezione transformed parameters calcola le probabilità di risposta corretta basate sui parametri di abilità e difficoltà, mentre la sezione model specifica come questi parametri e le risposte osservate interagiscono secondo il modello di Rasch, definendo così la struttura della verosimiglianza e delle priorità nel contesto bayesiano.
Compiliamo il modello usando CmdStan:
mod$compile()Definiamo i dati nel formato appropriato per Stan:
data(data.fims.Aus.Jpn.scored, package = "TAM")
people <- 1:400
responses <- data.fims.Aus.Jpn.scored[people, 2:15]
responses <- as.matrix(sapply(responses, as.integer))
colnames(responses) <- gsub("M1PTI", "I", colnames(responses))
stan_data <- list(
num_person = nrow(responses),
num_item = ncol(responses),
U = responses
)Eseguiamo il campionamento MCMC per ottenere la distribuzione a posteriori dei parametri.
fit <- mod$sample(
data = stan_data,
chains = 4, # Number of MCMC chains
parallel_chains = 2, # Number of chains to run in parallel
iter_warmup = 2000, # Number of warmup iterations per chain
iter_sampling = 2000, # Number of sampling iterations per chain
seed = 1234 # Set a seed for reproducibility
)
#> Running MCMC with 4 chains, at most 2 in parallel...
#>
#> Chain 1 Iteration: 1 / 4000 [ 0%] (Warmup)
#> Chain 2 Iteration: 1 / 4000 [ 0%] (Warmup)
#> Chain 1 Iteration: 100 / 4000 [ 2%] (Warmup)
#> Chain 2 Iteration: 100 / 4000 [ 2%] (Warmup)
#> Chain 1 Iteration: 200 / 4000 [ 5%] (Warmup)
#> Chain 2 Iteration: 200 / 4000 [ 5%] (Warmup)
#> Chain 1 Iteration: 300 / 4000 [ 7%] (Warmup)
#> Chain 2 Iteration: 300 / 4000 [ 7%] (Warmup)
#> Chain 1 Iteration: 400 / 4000 [ 10%] (Warmup)
#> Chain 2 Iteration: 400 / 4000 [ 10%] (Warmup)
#> Chain 1 Iteration: 500 / 4000 [ 12%] (Warmup)
#> Chain 2 Iteration: 500 / 4000 [ 12%] (Warmup)
#> Chain 1 Iteration: 600 / 4000 [ 15%] (Warmup)
#> Chain 2 Iteration: 600 / 4000 [ 15%] (Warmup)
#> Chain 1 Iteration: 700 / 4000 [ 17%] (Warmup)
#> Chain 2 Iteration: 700 / 4000 [ 17%] (Warmup)
#> Chain 1 Iteration: 800 / 4000 [ 20%] (Warmup)
#> Chain 2 Iteration: 800 / 4000 [ 20%] (Warmup)
#> Chain 1 Iteration: 900 / 4000 [ 22%] (Warmup)
#> Chain 2 Iteration: 900 / 4000 [ 22%] (Warmup)
#> Chain 1 Iteration: 1000 / 4000 [ 25%] (Warmup)
#> Chain 2 Iteration: 1000 / 4000 [ 25%] (Warmup)
#> Chain 1 Iteration: 1100 / 4000 [ 27%] (Warmup)
#> Chain 2 Iteration: 1100 / 4000 [ 27%] (Warmup)
#> Chain 1 Iteration: 1200 / 4000 [ 30%] (Warmup)
#> Chain 2 Iteration: 1200 / 4000 [ 30%] (Warmup)
#> Chain 1 Iteration: 1300 / 4000 [ 32%] (Warmup)
#> Chain 2 Iteration: 1300 / 4000 [ 32%] (Warmup)
#> Chain 1 Iteration: 1400 / 4000 [ 35%] (Warmup)
#> Chain 2 Iteration: 1400 / 4000 [ 35%] (Warmup)
#> Chain 1 Iteration: 1500 / 4000 [ 37%] (Warmup)
#> Chain 2 Iteration: 1500 / 4000 [ 37%] (Warmup)
#> Chain 1 Iteration: 1600 / 4000 [ 40%] (Warmup)
#> Chain 2 Iteration: 1600 / 4000 [ 40%] (Warmup)
#> Chain 1 Iteration: 1700 / 4000 [ 42%] (Warmup)
#> Chain 2 Iteration: 1700 / 4000 [ 42%] (Warmup)
#> Chain 1 Iteration: 1800 / 4000 [ 45%] (Warmup)
#> Chain 2 Iteration: 1800 / 4000 [ 45%] (Warmup)
#> Chain 1 Iteration: 1900 / 4000 [ 47%] (Warmup)
#> Chain 2 Iteration: 1900 / 4000 [ 47%] (Warmup)
#> Chain 1 Iteration: 2000 / 4000 [ 50%] (Warmup)
#> Chain 1 Iteration: 2001 / 4000 [ 50%] (Sampling)
#> Chain 2 Iteration: 2000 / 4000 [ 50%] (Warmup)
#> Chain 2 Iteration: 2001 / 4000 [ 50%] (Sampling)
#> Chain 1 Iteration: 2100 / 4000 [ 52%] (Sampling)
#> Chain 2 Iteration: 2100 / 4000 [ 52%] (Sampling)
#> Chain 1 Iteration: 2200 / 4000 [ 55%] (Sampling)
#> Chain 2 Iteration: 2200 / 4000 [ 55%] (Sampling)
#> Chain 1 Iteration: 2300 / 4000 [ 57%] (Sampling)
#> Chain 2 Iteration: 2300 / 4000 [ 57%] (Sampling)
#> Chain 1 Iteration: 2400 / 4000 [ 60%] (Sampling)
#> Chain 2 Iteration: 2400 / 4000 [ 60%] (Sampling)
#> Chain 1 Iteration: 2500 / 4000 [ 62%] (Sampling)
#> Chain 2 Iteration: 2500 / 4000 [ 62%] (Sampling)
#> Chain 1 Iteration: 2600 / 4000 [ 65%] (Sampling)
#> Chain 2 Iteration: 2600 / 4000 [ 65%] (Sampling)
#> Chain 1 Iteration: 2700 / 4000 [ 67%] (Sampling)
#> Chain 2 Iteration: 2700 / 4000 [ 67%] (Sampling)
#> Chain 1 Iteration: 2800 / 4000 [ 70%] (Sampling)
#> Chain 2 Iteration: 2800 / 4000 [ 70%] (Sampling)
#> Chain 1 Iteration: 2900 / 4000 [ 72%] (Sampling)
#> Chain 2 Iteration: 2900 / 4000 [ 72%] (Sampling)
#> Chain 1 Iteration: 3000 / 4000 [ 75%] (Sampling)
#> Chain 2 Iteration: 3000 / 4000 [ 75%] (Sampling)
#> Chain 1 Iteration: 3100 / 4000 [ 77%] (Sampling)
#> Chain 2 Iteration: 3100 / 4000 [ 77%] (Sampling)
#> Chain 1 Iteration: 3200 / 4000 [ 80%] (Sampling)
#> Chain 2 Iteration: 3200 / 4000 [ 80%] (Sampling)
#> Chain 1 Iteration: 3300 / 4000 [ 82%] (Sampling)
#> Chain 2 Iteration: 3300 / 4000 [ 82%] (Sampling)
#> Chain 1 Iteration: 3400 / 4000 [ 85%] (Sampling)
#> Chain 2 Iteration: 3400 / 4000 [ 85%] (Sampling)
#> Chain 1 Iteration: 3500 / 4000 [ 87%] (Sampling)
#> Chain 2 Iteration: 3500 / 4000 [ 87%] (Sampling)
#> Chain 1 Iteration: 3600 / 4000 [ 90%] (Sampling)
#> Chain 2 Iteration: 3600 / 4000 [ 90%] (Sampling)
#> Chain 1 Iteration: 3700 / 4000 [ 92%] (Sampling)
#> Chain 2 Iteration: 3700 / 4000 [ 92%] (Sampling)
#> Chain 1 Iteration: 3800 / 4000 [ 95%] (Sampling)
#> Chain 2 Iteration: 3800 / 4000 [ 95%] (Sampling)
#> Chain 1 Iteration: 3900 / 4000 [ 97%] (Sampling)
#> Chain 2 Iteration: 3900 / 4000 [ 97%] (Sampling)
#> Chain 1 Iteration: 4000 / 4000 [100%] (Sampling)
#> Chain 1 finished in 14.5 seconds.
#> Chain 3 Iteration: 1 / 4000 [ 0%] (Warmup)
#> Chain 2 Iteration: 4000 / 4000 [100%] (Sampling)
#> Chain 2 finished in 14.7 seconds.
#> Chain 4 Iteration: 1 / 4000 [ 0%] (Warmup)
#> Chain 3 Iteration: 100 / 4000 [ 2%] (Warmup)
#> Chain 3 Iteration: 200 / 4000 [ 5%] (Warmup)
#> Chain 4 Iteration: 100 / 4000 [ 2%] (Warmup)
#> Chain 3 Iteration: 300 / 4000 [ 7%] (Warmup)
#> Chain 4 Iteration: 200 / 4000 [ 5%] (Warmup)
#> Chain 3 Iteration: 400 / 4000 [ 10%] (Warmup)
#> Chain 4 Iteration: 300 / 4000 [ 7%] (Warmup)
#> Chain 4 Iteration: 400 / 4000 [ 10%] (Warmup)
#> Chain 3 Iteration: 500 / 4000 [ 12%] (Warmup)
#> Chain 3 Iteration: 600 / 4000 [ 15%] (Warmup)
#> Chain 4 Iteration: 500 / 4000 [ 12%] (Warmup)
#> Chain 3 Iteration: 700 / 4000 [ 17%] (Warmup)
#> Chain 4 Iteration: 600 / 4000 [ 15%] (Warmup)
#> Chain 3 Iteration: 800 / 4000 [ 20%] (Warmup)
#> Chain 4 Iteration: 700 / 4000 [ 17%] (Warmup)
#> Chain 3 Iteration: 900 / 4000 [ 22%] (Warmup)
#> Chain 4 Iteration: 800 / 4000 [ 20%] (Warmup)
#> Chain 3 Iteration: 1000 / 4000 [ 25%] (Warmup)
#> Chain 4 Iteration: 900 / 4000 [ 22%] (Warmup)
#> Chain 3 Iteration: 1100 / 4000 [ 27%] (Warmup)
#> Chain 4 Iteration: 1000 / 4000 [ 25%] (Warmup)
#> Chain 3 Iteration: 1200 / 4000 [ 30%] (Warmup)
#> Chain 4 Iteration: 1100 / 4000 [ 27%] (Warmup)
#> Chain 3 Iteration: 1300 / 4000 [ 32%] (Warmup)
#> Chain 4 Iteration: 1200 / 4000 [ 30%] (Warmup)
#> Chain 3 Iteration: 1400 / 4000 [ 35%] (Warmup)
#> Chain 4 Iteration: 1300 / 4000 [ 32%] (Warmup)
#> Chain 3 Iteration: 1500 / 4000 [ 37%] (Warmup)
#> Chain 4 Iteration: 1400 / 4000 [ 35%] (Warmup)
#> Chain 3 Iteration: 1600 / 4000 [ 40%] (Warmup)
#> Chain 4 Iteration: 1500 / 4000 [ 37%] (Warmup)
#> Chain 3 Iteration: 1700 / 4000 [ 42%] (Warmup)
#> Chain 4 Iteration: 1600 / 4000 [ 40%] (Warmup)
#> Chain 3 Iteration: 1800 / 4000 [ 45%] (Warmup)
#> Chain 4 Iteration: 1700 / 4000 [ 42%] (Warmup)
#> Chain 3 Iteration: 1900 / 4000 [ 47%] (Warmup)
#> Chain 4 Iteration: 1800 / 4000 [ 45%] (Warmup)
#> Chain 3 Iteration: 2000 / 4000 [ 50%] (Warmup)
#> Chain 3 Iteration: 2001 / 4000 [ 50%] (Sampling)
#> Chain 4 Iteration: 1900 / 4000 [ 47%] (Warmup)
#> Chain 3 Iteration: 2100 / 4000 [ 52%] (Sampling)
#> Chain 4 Iteration: 2000 / 4000 [ 50%] (Warmup)
#> Chain 4 Iteration: 2001 / 4000 [ 50%] (Sampling)
#> Chain 3 Iteration: 2200 / 4000 [ 55%] (Sampling)
#> Chain 4 Iteration: 2100 / 4000 [ 52%] (Sampling)
#> Chain 4 Iteration: 2200 / 4000 [ 55%] (Sampling)
#> Chain 3 Iteration: 2300 / 4000 [ 57%] (Sampling)
#> Chain 4 Iteration: 2300 / 4000 [ 57%] (Sampling)
#> Chain 3 Iteration: 2400 / 4000 [ 60%] (Sampling)
#> Chain 3 Iteration: 2500 / 4000 [ 62%] (Sampling)
#> Chain 4 Iteration: 2400 / 4000 [ 60%] (Sampling)
#> Chain 3 Iteration: 2600 / 4000 [ 65%] (Sampling)
#> Chain 4 Iteration: 2500 / 4000 [ 62%] (Sampling)
#> Chain 3 Iteration: 2700 / 4000 [ 67%] (Sampling)
#> Chain 4 Iteration: 2600 / 4000 [ 65%] (Sampling)
#> Chain 4 Iteration: 2700 / 4000 [ 67%] (Sampling)
#> Chain 3 Iteration: 2800 / 4000 [ 70%] (Sampling)
#> Chain 4 Iteration: 2800 / 4000 [ 70%] (Sampling)
#> Chain 3 Iteration: 2900 / 4000 [ 72%] (Sampling)
#> Chain 4 Iteration: 2900 / 4000 [ 72%] (Sampling)
#> Chain 3 Iteration: 3000 / 4000 [ 75%] (Sampling)
#> Chain 4 Iteration: 3000 / 4000 [ 75%] (Sampling)
#> Chain 3 Iteration: 3100 / 4000 [ 77%] (Sampling)
#> Chain 4 Iteration: 3100 / 4000 [ 77%] (Sampling)
#> Chain 3 Iteration: 3200 / 4000 [ 80%] (Sampling)
#> Chain 3 Iteration: 3300 / 4000 [ 82%] (Sampling)
#> Chain 4 Iteration: 3200 / 4000 [ 80%] (Sampling)
#> Chain 3 Iteration: 3400 / 4000 [ 85%] (Sampling)
#> Chain 4 Iteration: 3300 / 4000 [ 82%] (Sampling)
#> Chain 4 Iteration: 3400 / 4000 [ 85%] (Sampling)
#> Chain 3 Iteration: 3500 / 4000 [ 87%] (Sampling)
#> Chain 4 Iteration: 3500 / 4000 [ 87%] (Sampling)
#> Chain 3 Iteration: 3600 / 4000 [ 90%] (Sampling)
#> Chain 4 Iteration: 3600 / 4000 [ 90%] (Sampling)
#> Chain 3 Iteration: 3700 / 4000 [ 92%] (Sampling)
#> Chain 3 Iteration: 3800 / 4000 [ 95%] (Sampling)
#> Chain 4 Iteration: 3700 / 4000 [ 92%] (Sampling)
#> Chain 3 Iteration: 3900 / 4000 [ 97%] (Sampling)
#> Chain 4 Iteration: 3800 / 4000 [ 95%] (Sampling)
#> Chain 4 Iteration: 3900 / 4000 [ 97%] (Sampling)
#> Chain 3 Iteration: 4000 / 4000 [100%] (Sampling)
#> Chain 3 finished in 14.9 seconds.
#> Chain 4 Iteration: 4000 / 4000 [100%] (Sampling)
#> Chain 4 finished in 15.0 seconds.
#>
#> All 4 chains finished successfully.
#> Mean chain execution time: 14.8 seconds.
#> Total execution time: 29.9 seconds.Esaminiamo le tracce per due parametri.
fit_draws <- fit$draws() # extract the posterior draws
mcmc_trace(fit_draws, pars = c("beta[1]"))
mcmc_trace(fit_draws, pars = c("theta[1]"))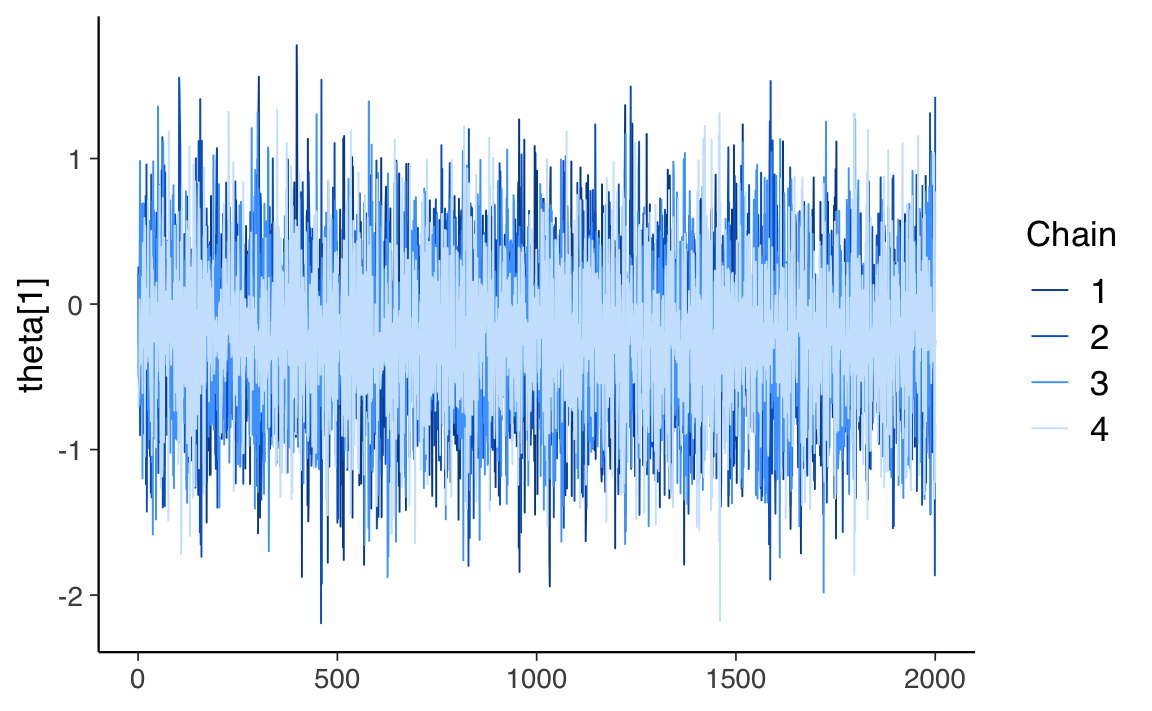
Focalizziamoci sulla stima dei parametri degli item.
parameters <- c(
"beta[1]", "beta[2]", "beta[3]", "beta[4]", "beta[5]",
"beta[6]", "beta[7]", "beta[8]", "beta[9]","beta[10]",
"beta[11]", "beta[12]", "beta[13]", "beta[14]"
)Esaminiamo la statistica rhat.
rhats <- rhat(fit_draws, pars = parameters)
mcmc_rhat(rhats)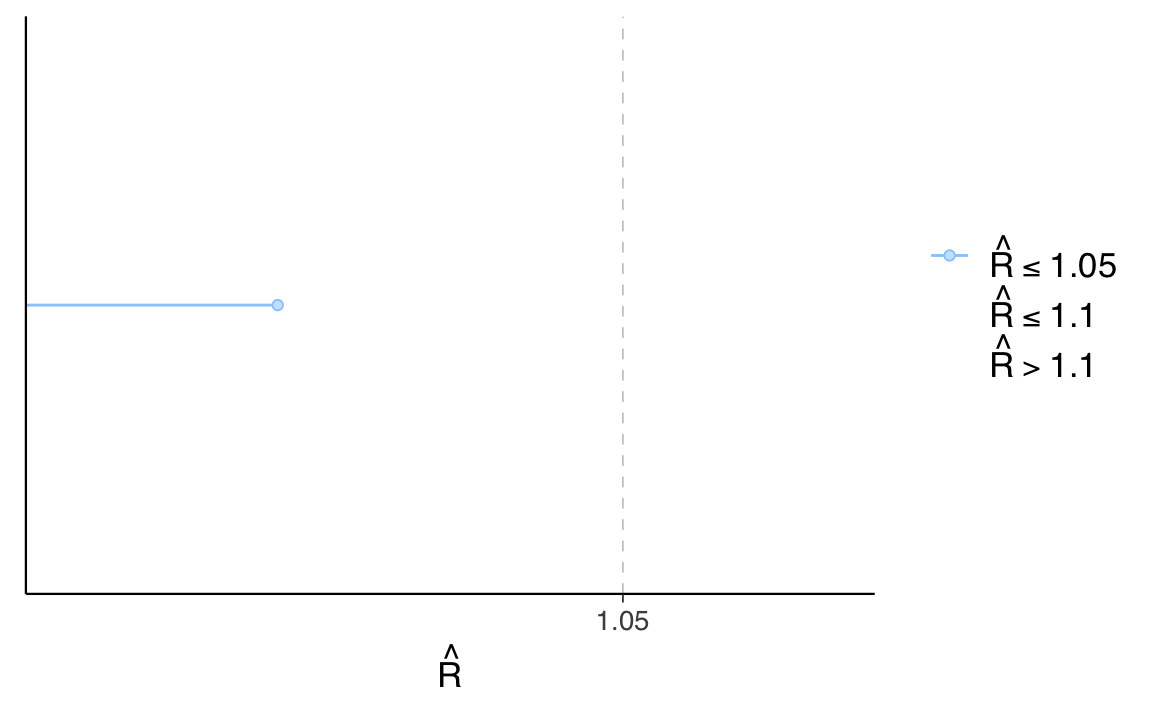
Esaminiamo l’effect ratio:
eff_ratio <- neff_ratio(fit, pars = parameters)
eff_ratio
#> beta[1] beta[2] beta[3] beta[4] beta[5] beta[6] beta[7] beta[8]
#> 1.132 1.189 1.162 1.098 1.357 1.160 1.176 1.082
#> beta[9] beta[10] beta[11] beta[12] beta[13] beta[14]
#> 1.301 1.208 1.263 1.235 1.392 1.306mcmc_neff(eff_ratio)
Esaminiamo l’autocorrelazione.
mcmc_acf(fit_draws, pars = parameters)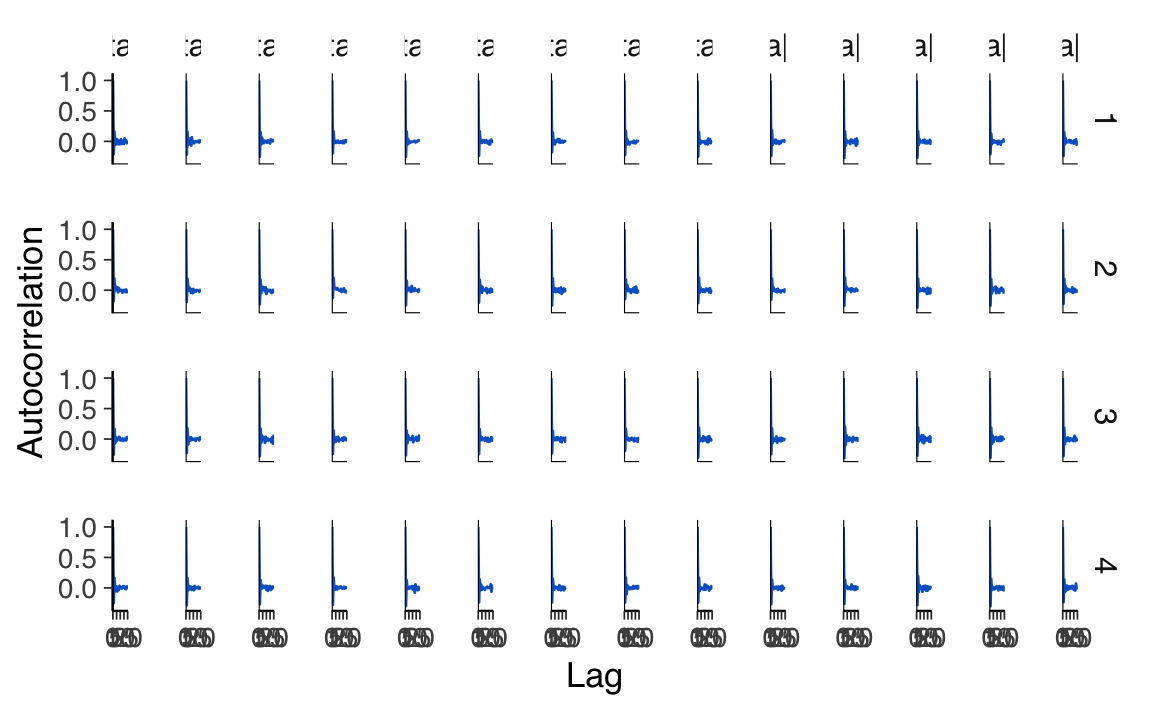
Otteniamo le statistiche riassuntive delle distribuzioni a posteriori dei parametri degli item.
fit$summary(
variables = parameters,
posterior::default_summary_measures(),
extra_quantiles = ~ posterior::quantile2(., probs = c(.0275, .975))
)
#> # A tibble: 14 × 9
#> variable mean median sd mad q5 q95 q2.75 q97.5
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 beta[1] -1.10 -1.10 0.129 0.126 -1.31 -0.892 -1.35 -0.849
#> 2 beta[2] -1.24 -1.24 0.130 0.130 -1.46 -1.03 -1.50 -0.997
#> 3 beta[3] -2.03 -2.02 0.158 0.156 -2.30 -1.77 -2.34 -1.73
#> 4 beta[4] -0.0478 -0.0489 0.120 0.121 -0.241 0.149 -0.274 0.191
#> 5 beta[5] 2.51 2.51 0.183 0.185 2.22 2.82 2.18 2.88
#> 6 beta[6] -1.24 -1.24 0.132 0.131 -1.46 -1.03 -1.50 -0.989
#> 7 beta[7] 0.811 0.810 0.124 0.124 0.610 1.01 0.576 1.05
#> 8 beta[8] -0.493 -0.493 0.120 0.119 -0.688 -0.294 -0.723 -0.263
#> 9 beta[9] 1.32 1.32 0.135 0.138 1.11 1.55 1.07 1.58
#> 10 beta[10] -0.395 -0.395 0.120 0.121 -0.592 -0.196 -0.622 -0.158
#> 11 beta[11] 2.05 2.05 0.158 0.159 1.80 2.31 1.75 2.37
#> 12 beta[12] 1.75 1.74 0.148 0.146 1.50 1.99 1.47 2.04
#> 13 beta[13] 2.40 2.39 0.172 0.172 2.12 2.69 2.07 2.74
#> 14 beta[14] -1.92 -1.92 0.152 0.148 -2.18 -1.67 -2.22 -1.63I risultati ottenuti replicano quelli riportati da Debelak et al. (2022).
69.6 Grandezza del Campione
La stima dei parametri degli item basata su un campione osservato di risposte è spesso definita come la calibrazione degli item. Generalmente, un campione di calibrazione più ampio consente una stima più accurata dei parametri degli item, sebbene altri fattori influenzino anch’essi l’accuratezza della stima. Ad esempio, la difficoltà di un item può essere stimata con maggiore precisione se l’item non è né troppo facile né troppo difficile per il campione di partecipanti al test. Pertanto, i fattori che influenzano l’accuratezza della stima includono l’allineamento e la forma delle distribuzioni dei parametri degli item e delle persone, il numero di item e la tecnica di stima utilizzata.
Diverse pubblicazioni hanno affrontato la questione della dimensione del campione tipicamente necessaria per lavorare con il modello di Rasch e come questa sia influenzata da questi e altri fattori. Ad esempio, De Ayala (2009) fornisce la linea guida generale che un campione di calibrazione dovrebbe contenere almeno diverse centinaia di rispondenti e cita, tra le altre referenze, un articolo precedente di Wright (1977) che afferma che un campione di calibrazione di 500 sarebbe più che adeguato. De Ayala (2009) suggerisce anche che 250 o più rispondenti sono necessari per adattare un modello di Partial Credit. Poiché il modello di Partial Credit è una generalizzazione del modello di Rasch con più parametri degli item, ciò implica che la dimensione del campione suggerita di 250 dovrebbe essere sufficiente anche per adattare un modello di Rasch. Studi più recenti hanno indagato l’applicazione del modello di Rasch con dimensioni del campione di soli 100 rispondenti (ad esempio, Steinfeld & Robitzsch, 2021; Suárez-Falcón & Glas, 2003). Tali linee guida non devono essere interpretate come regole fisse, ma solo come indicazioni generali in quanto una dimensione del campione adeguata dipende dalle condizioni e dagli obiettivi dell’analisi.
Un metodo più elaborato per determinare la dimensione del campione necessaria è l’analisi della potenza statistica. Qui, l’accuratezza della stima desiderata o il rischio di falsi positivi e falsi negativi devono essere formalizzati prima dell’analisi. La dimensione del campione necessaria viene quindi determinata in base a queste considerazioni.
69.7 Session Info
sessionInfo()
#> R version 4.4.2 (2024-10-31)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Sequoia 15.3.2
#>
#> Matrix products: default
#> BLAS: /Library/Frameworks/R.framework/Versions/4.4-arm64/Resources/lib/libRblas.0.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.4-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.0
#>
#> locale:
#> [1] C/UTF-8/C/C/C/C
#>
#> time zone: Europe/Rome
#> tzcode source: internal
#>
#> attached base packages:
#> [1] stats4 grid stats graphics grDevices utils datasets
#> [8] methods base
#>
#> other attached packages:
#> [1] effectsize_1.0.0 rsvg_2.6.1 rstan_2.32.7
#> [4] StanHeaders_2.32.10 posterior_1.6.1 cmdstanr_0.8.1
#> [7] ggmirt_0.1.0 TAM_4.2-21 CDM_8.2-6
#> [10] mvtnorm_1.3-3 mirt_1.44.0 lattice_0.22-6
#> [13] latex2exp_0.9.6 ggokabeito_0.1.0 see_0.11.0
#> [16] MASS_7.3-65 viridis_0.6.5 viridisLite_0.4.2
#> [19] ggpubr_0.6.0 ggExtra_0.10.1 gridExtra_2.3
#> [22] patchwork_1.3.0 bayesplot_1.11.1 semTools_0.5-6
#> [25] semPlot_1.1.6 lavaan_0.6-19 psych_2.4.12
#> [28] scales_1.3.0 markdown_1.13 knitr_1.50
#> [31] lubridate_1.9.4 forcats_1.0.0 stringr_1.5.1
#> [34] dplyr_1.1.4 purrr_1.0.4 readr_2.1.5
#> [37] tidyr_1.3.1 tibble_3.2.1 ggplot2_3.5.1
#> [40] tidyverse_2.0.0 here_1.0.1
#>
#> loaded via a namespace (and not attached):
#> [1] splines_4.4.2 later_1.4.1 R.oo_1.27.0
#> [4] datawizard_1.0.1 XML_3.99-0.18 rpart_4.1.24
#> [7] lifecycle_1.0.4 Rdpack_2.6.3 rstatix_0.7.2
#> [10] rprojroot_2.0.4 processx_3.8.6 globals_0.16.3
#> [13] insight_1.1.0 rockchalk_1.8.157 backports_1.5.0
#> [16] magrittr_2.0.3 openxlsx_4.2.8 Hmisc_5.2-3
#> [19] rmarkdown_2.29 yaml_2.3.10 httpuv_1.6.15
#> [22] qgraph_1.9.8 zip_2.3.2 pkgbuild_1.4.6
#> [25] sessioninfo_1.2.3 pbapply_1.7-2 minqa_1.2.8
#> [28] multcomp_1.4-28 abind_1.4-8 audio_0.1-11
#> [31] quadprog_1.5-8 R.utils_2.13.0 tensorA_0.36.2.1
#> [34] nnet_7.3-20 TH.data_1.1-3 sandwich_3.1-1
#> [37] inline_0.3.21 listenv_0.9.1 testthat_3.2.3
#> [40] vegan_2.6-10 arm_1.14-4 parallelly_1.42.0
#> [43] permute_0.9-7 codetools_0.2-20 tidyselect_1.2.1
#> [46] farver_2.1.2 lme4_1.1-36 matrixStats_1.5.0
#> [49] base64enc_0.1-3 jsonlite_1.9.1 polycor_0.8-1
#> [52] progressr_0.15.1 Formula_1.2-5 survival_3.8-3
#> [55] emmeans_1.10.7 tools_4.4.2 Rcpp_1.0.14
#> [58] glue_1.8.0 mnormt_2.1.1 admisc_0.37
#> [61] xfun_0.51 mgcv_1.9-1 distributional_0.5.0
#> [64] loo_2.8.0 withr_3.0.2 beepr_2.0
#> [67] fastmap_1.2.0 boot_1.3-31 digest_0.6.37
#> [70] mi_1.1 timechange_0.3.0 R6_2.6.1
#> [73] mime_0.13 estimability_1.5.1 colorspace_2.1-1
#> [76] gtools_3.9.5 jpeg_0.1-10 R.methodsS3_1.8.2
#> [79] utf8_1.2.4 generics_0.1.3 data.table_1.17.0
#> [82] corpcor_1.6.10 SimDesign_2.19.1 htmlwidgets_1.6.4
#> [85] parameters_0.24.2 pkgconfig_2.0.3 sem_3.1-16
#> [88] gtable_0.3.6 brio_1.1.5 htmltools_0.5.8.1
#> [91] carData_3.0-5 png_0.1-8 reformulas_0.4.0
#> [94] rstudioapi_0.17.1 tzdb_0.5.0 reshape2_1.4.4
#> [97] curl_6.2.1 coda_0.19-4.1 checkmate_2.3.2
#> [100] nlme_3.1-167 nloptr_2.2.1 zoo_1.8-13
#> [103] parallel_4.4.2 miniUI_0.1.1.1 foreign_0.8-88
#> [106] pillar_1.10.1 vctrs_0.6.5 promises_1.3.2
#> [109] car_3.1-3 OpenMx_2.21.13 xtable_1.8-4
#> [112] Deriv_4.1.6 cluster_2.1.8.1 dcurver_0.9.2
#> [115] GPArotation_2024.3-1 htmlTable_2.4.3 evaluate_1.0.3
#> [118] pbivnorm_0.6.0 cli_3.6.4 kutils_1.73
#> [121] compiler_4.4.2 rlang_1.1.5 future.apply_1.11.3
#> [124] ggsignif_0.6.4 labeling_0.4.3 fdrtool_1.2.18
#> [127] ps_1.9.0 plyr_1.8.9 stringi_1.8.4
#> [130] QuickJSR_1.6.0 munsell_0.5.1 lisrelToR_0.3
#> [133] bayestestR_0.15.2 V8_6.0.2 pacman_0.5.1
#> [136] Matrix_1.7-3 hms_1.1.3 glasso_1.11
#> [139] future_1.34.0 shiny_1.10.0 rbibutils_2.3
#> [142] igraph_2.1.4 broom_1.0.7 RcppParallel_5.1.10