6 Equating nei Test Psicologici
Prerequisiti
Concetti e Competenze Chiave
- Comprendere il processo di equating e la sua importanza per rendere confrontabili i punteggi di forme diverse di un test.
- Conoscere i principali disegni sperimentali (gruppi equivalenti, gruppi non equivalenti e gruppo unico) e i loro requisiti.
- Distinguere tra metodi lineari (media, lineare) e non lineari (equipercentile) e le loro applicazioni pratiche.
- Essere consapevoli della possibilità di usare item comuni o persone comuni per collegare le scale di punteggio attraverso modelli della teoria della risposta all’item.
Preparazione del Notebook
6.1 Introduzione
L’equating è una procedura statistica utilizzata quando somministrazioni su più occasioni e a diversi gruppi di esaminandi possono portare a una sovraesposizione degli item, compromettendo la sicurezza del test. Per limitare l’esposizione degli item, si possono utilizzare forme alternative del test. Tuttavia, l’uso di forme multiple genera scale di punteggio diverse, che misurano il costrutto di interesse a livelli di difficoltà differenti. L’obiettivo dell’equating è quindi correggere queste differenze di difficoltà tra le forme del test, rendendo le scale di punteggio comparabili.
L’equating è il processo che stabilisce una relazione statistica tra le distribuzioni dei punteggi di diverse forme di un test e, di conseguenza, tra le scale di punteggio associate. Questo permette di rendere confrontabili i punteggi, anche se derivano da forme diverse dello stesso test. Quando le forme del test sono costruite seguendo le stesse specifiche (ad esempio, misurano lo stesso costrutto con uguale affidabilità) e hanno caratteristiche statistiche simili (difficoltà comparabile, distribuzione dei punteggi analoga), questa relazione è definita come funzione di equating. La funzione di equating consente di tradurre i punteggi da una scala all’altra, trattandole come scale parallele secondo la teoria classica dei test.
Se, invece, le forme del test differiscono in aspetti significativi, come la lunghezza o il contenuto, la relazione tra le scale viene definita linking, e non equating. In questo caso, le scale risultano correlate ma non parallele né interscambiabili, poiché non garantiscono piena equivalenza nei punteggi. La relazione tra queste scale è descritta da una funzione di linking.
Per ottenere una funzione di equating valida, devono essere soddisfatti alcuni requisiti fondamentali:
- Le forme del test devono misurare lo stesso costrutto con la stessa affidabilità.
- I risultati dell’equating devono garantire equità, ovvero ogni esaminando dovrebbe ottenere lo stesso risultato indipendentemente dal fatto che gli venga somministrata la forma \(X\) o la forma \(Y\) (Lord, 1980).
- La funzione di equating deve essere simmetrica: se un punteggio è tradotto da una scala all’altra, il processo inverso deve restituire il punteggio originale.
- La funzione deve essere invariabile rispetto alla popolazione degli esaminandi: deve funzionare nello stesso modo per diversi gruppi di persone.
In sintesi, si può dire che l’equating si applica a scale parallele nel senso della teoria classica dei test (stessa media della distribuzione, identica varianza, medesima affidabilità, misurazione dello stesso costrutto, struttura e difficoltà degli item pressoché identiche), mentre il linking si utilizza per scale non parallele, che possono essere comparabili solo in modo parziale (lunghezza differente, contenuti parzialmente diversi, variabilità non perfettamente sovrapponibile, difficoltà degli item non completamente omogenee).
6.2 Progettazione dell’Equating
Le procedure di equating e linking dei punteggi osservati richiedono dati raccolti in diverse somministrazioni del test. Il disegno di equating specifica come le forme del test e i gruppi di esaminandi differiscono tra le somministrazioni. Per semplicità, i disegni di equating possono essere classificati in tre tipi principali: gruppo unico, gruppi equivalenti e gruppi non equivalenti. Le forme del test vengono costruite in base al tipo di gruppo considerato.
6.2.1 Disegno a gruppo unico
In questo disegno, un unico gruppo, campionato dalla popolazione target \(T\), sostiene due forme del test \(X\) e \(Y\). È possibile bilanciare l’ordine di somministrazione (metà del gruppo sostiene \(X\) prima di \(Y\) e l’altra metà viceversa). Eventuali differenze nelle distribuzioni dei punteggi tra \(X\) e \(Y\) vengono attribuite esclusivamente alle forme del test, poiché si assume che l’abilità del gruppo resti costante.
6.2.2 Disegno a gruppi equivalenti
Questo disegno prevede che due campioni casuali della popolazione target \(T\) sostengano rispettivamente \(X\) e \(Y\). Anche in questo caso, si assume che l’abilità dei due gruppi sia costante, e le differenze nei punteggi riflettono le differenze di difficoltà tra le forme del test.
6.2.3 Disegno a gruppi non equivalenti
Quando i gruppi non sono equivalenti, sorgono due problemi:
- La popolazione target deve essere definita indirettamente, utilizzando campioni da due popolazioni di esaminandi, \(P\) e \(Q\).
- Le differenze di abilità tra i gruppi devono essere considerate, poiché possono confondere la stima delle differenze di difficoltà tra le forme del test.
Per affrontare questi problemi, si utilizza un anchor test, \(V\), un test comune somministrato a entrambi i gruppi per controllare o eliminare le differenze di abilità. In alternativa, si possono usare covariate esterne, come i punteggi ottenuti in altri test.
6.3 Funzioni di Equating
Le procedure di equating utilizzano funzioni matematiche per mappare i punteggi di una forma del test su una scala comune. Queste funzioni possono essere classificate come lineari (ad esempio, identità, media e regressione lineare) o non lineari (ad esempio, equipercentile). Ogni tipo di funzione si basa su assunzioni specifiche riguardo le differenze di difficoltà tra le forme del test.
6.3.1 Funzione di identità
La funzione di identità si applica quando le forme del test hanno la stessa scala. In questo caso, i punteggi non vengono modificati, e la relazione tra \(X\) e \(Y\) è semplicemente:
\[ id_Y(x) = x. \]
6.3.2 Funzione della media
Nell’equating basato sulla media, si assume che la forma \(X\) differisca dalla forma \(Y\) per un valore costante lungo l’intera scala dei punteggi. Ad esempio, se la forma \(X\) è più facile di 2 punti rispetto alla forma \(Y\) per gli esaminandi con punteggi alti, si assume che sia ugualmente più facile di 2 punti anche per quelli con punteggi bassi. Sebbene questa ipotesi di differenza costante possa risultare troppo restrittiva in molte situazioni di testing, l’equating basato sulla media è utile per illustrare alcuni concetti fondamentali dell’equating.
La funzione basata sulla media calcola le differenze di difficoltà tra le due forme utilizzando la differenza tra le medie dei punteggi, \(\mu_Y - \mu_X\). La funzione è espressa come:
\[ mean_Y(x) = x + (\mu_Y - \mu_X). \]
6.3.3 Funzione Lineare
A differenza della funzione basata sulla media, che assume una differenza costante tra due forme del test, l’equating lineare consente che le differenze di difficoltà tra le forme \(X\) e \(Y\) varino lungo la scala dei punteggi. Ad esempio, l’equating lineare permette che la forma \(X\) sia più difficile della forma \(Y\) per esaminandi con punteggi bassi, ma meno difficile per esaminandi con punteggi alti.
Nell’equating lineare, i punteggi che si trovano a una distanza standardizzata equivalente (in unità di deviazione standard) dalle rispettive medie vengono resi uguali. In questo modo, l’equating lineare tiene conto sia delle differenze nei valori medi, sia delle differenze nelle unità di scala (deviazioni standard) delle due forme. Definendo \(\sigma_X\) e \(\sigma_Y\) come le deviazioni standard dei punteggi nelle forme \(X\) e \(Y\), l’equazione di conversione lineare si basa sull’uguaglianza degli z-score tra le due forme, espressa come:
\[ \frac{x - \mu_X}{\sigma_X} = \frac{y - \mu_Y}{\sigma_Y}. \]
Risolvendo questa equazione per \(y\), si ottiene la funzione di equating lineare:
\[ lin_Y(x) = \frac{\sigma_Y}{\sigma_X}x + \left(\mu_Y - \frac{\sigma_Y}{\sigma_X}\mu_X\right), \]
dove il coefficiente angolare (\(\text{slope}\)) è dato da \(\frac{\sigma_Y}{\sigma_X}\) e l’intercetta (\(\text{intercept}\)) è \(\mu_Y - \frac{\sigma_Y}{\sigma_X}\mu_X\).
Se le deviazioni standard delle due forme (\(\sigma_X\) e \(\sigma_Y\)) fossero uguali, la funzione lineare si ridurrebbe alla funzione basata sulla media. Questo dimostra che la funzione lineare generalizza quella basata sulla media, includendo la possibilità di differenze nella dispersione dei punteggi tra le forme.
6.3.4 Equipercentile Equating
L’equating equipercentile è una tecnica avanzata utilizzata nei casi in cui le differenze tra le forme di un test non possono essere descritte da una relazione lineare. A differenza dell’equating lineare, che assume una variazione proporzionale lungo tutta la scala dei punteggi, l’equipercentile permette di modellare differenze complesse utilizzando una curva che descrive le variazioni di difficoltà tra le forme.
Ad esempio, con l’equipercentile, la forma \(X\) potrebbe risultare più difficile della forma \(Y\) per i punteggi estremamente alti e bassi, ma meno difficile per i punteggi intermedi. Questa flessibilità rende il metodo equipercentile più generale rispetto a quello lineare.
La funzione di equating è definita come equipepercentile quando la distribuzione dei punteggi della forma \(X\), convertita sulla scala della forma \(Y\), risulta identica alla distribuzione dei punteggi della forma \(Y\) nella popolazione. In altre parole, i punteggi di \(X\) vengono mappati sui punteggi di \(Y\) in modo che i ranghi percentili corrispondano tra le due forme.
Il processo di sviluppo della funzione equipercentile consiste nell’identificare, per ciascun punteggio di \(X\), il punteggio di \(Y\) che ha lo stesso rango percentile. Questo metodo garantisce che la relazione tra le due scale tenga conto delle differenze lungo l’intera distribuzione, offrendo una maggiore precisione nei casi in cui i punteggi non si distribuiscono in modo simile tra le due forme del test.
6.4 Equating dei Test basato sulla CTT
Nelle sezioni successive, applicheremo i metodi di equating basati sulla Classical Test Theory (CTT) descritti in precedenza. Come esempio, analizzeremo il caso di un disegno a gruppi equivalenti utilizzando i dati forniti dal set ACTmath, disponibile nel pacchetto equate. Questi dati derivano da due somministrazioni del test di matematica ACT (Kolen e Brennan, 2014). Il dataset è organizzato in un data frame con tre colonne: la prima rappresenta la scala dei punteggi (da 0 a 40 punti), mentre la seconda e la terza colonna riportano il numero di esaminandi delle forme \(X\) e \(Y\) che hanno ottenuto ciascun punteggio.
Nel disegno a gruppi equivalenti, un campione casuale di esaminandi sostiene la forma \(X\), mentre un secondo campione casuale sostiene la forma \(Y\). Poiché entrambi i campioni sono estratti in modo casuale dalla stessa popolazione, eventuali differenze nella distribuzione dei punteggi sono attribuite esclusivamente alle differenze di difficoltà tra le due forme del test. La randomizzazione garantisce, infatti, che i due gruppi siano equivalenti in termini di abilità valutata.
Procediamo ora all’estrazione dei dati per le forme \(X\) e \(Y\), ottenendo le rispettive distribuzioni di frequenza.
form_x <- as.freqtab(ACTmath[, 1:2])
form_y <- as.freqtab(ACTmath[, c(1, 3)])head(form_x)
#> total count
#> 1 0 0
#> 2 1 1
#> 3 2 1
#> 4 3 3
#> 5 4 9
#> 6 5 18head(form_y)
#> total count
#> 1 0 0
#> 2 1 1
#> 3 2 3
#> 4 3 13
#> 5 4 42
#> 6 5 59Esaminiamo le statistiche descrittive.
Esaminiamo le distribuzioni dei punteggi. Il metodo di equating basato sulla CTT richiede che le due forme del test abbiano la stessa distribuzione.
plot(x = form_x, main = "Bar plot of the test scores on form X")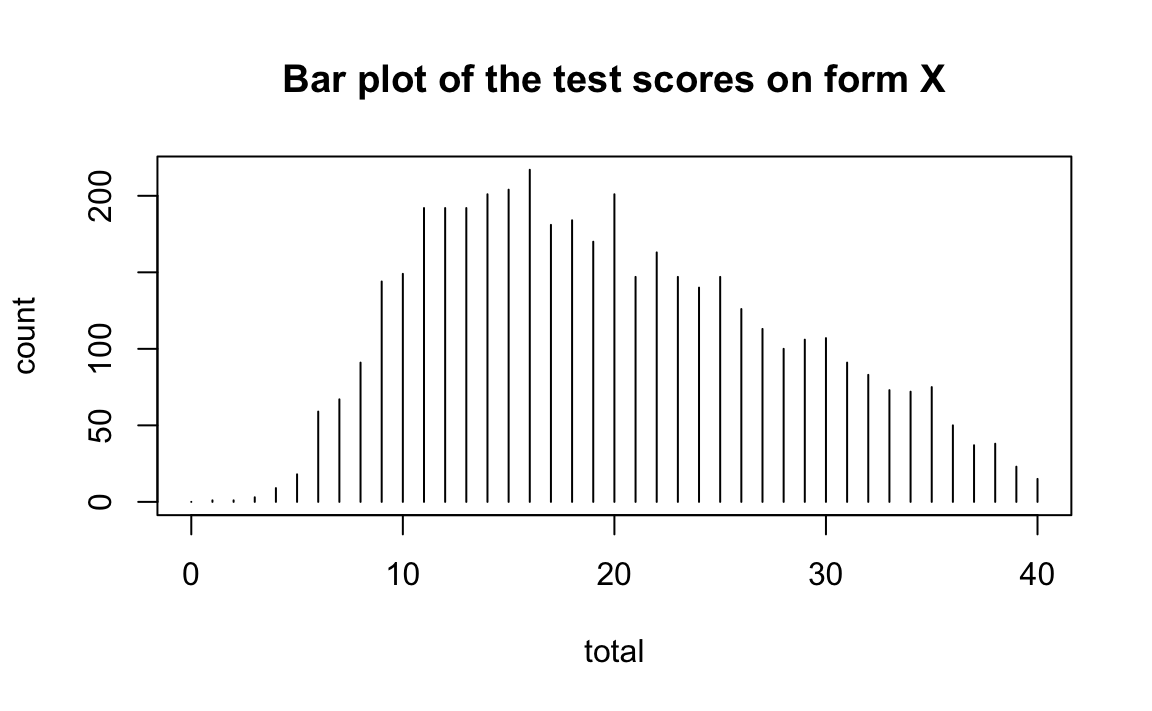
plot(x = form_y, main = "Bar plot of the test scores on form Y")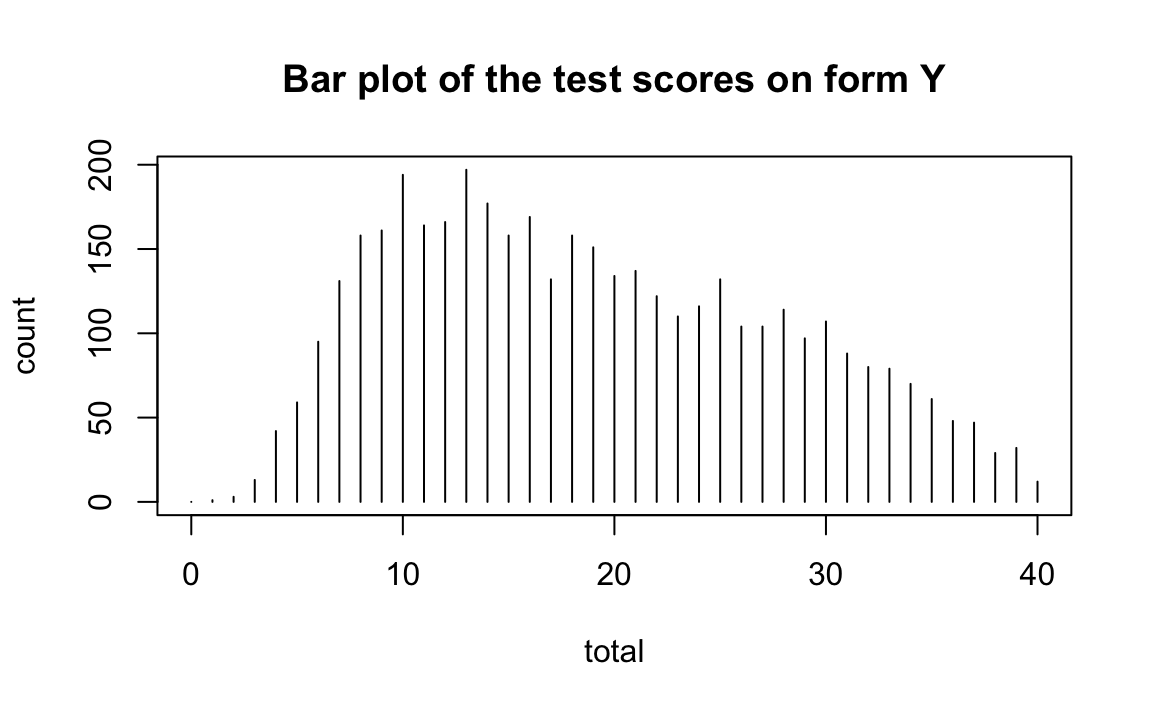
6.5 Metodi di Equating Lineare
I metodi di equating lineare comprendono diverse funzioni: identità (ossia, nessun equating), media, lineare semplice e nonlineare.
6.5.1 Equating Basato sulla Media
Questo metodo corregge i punteggi della nuova forma (X) utilizzando la differenza tra le medie delle due forme (X e Y) come costante fissa. In altre parole, il punteggio sulla scala di X viene traslato di un valore pari alla differenza delle medie, per compensare eventuali discrepanze di difficoltà tra le due forme.
Trasformiamo i punteggi X con il metodo di equating basato sulla media usando la funzione equate().
mean_yx <- equate(form_x, form_y, type = "mean")
mean_yx
#>
#> Mean Equating: form_x to form_y
#>
#> Design: equivalent groups
#>
#> Summary Statistics:
#> mean sd skew kurt min max n
#> x 19.85 8.21 0.38 2.30 1.00 40.00 4329
#> y 18.98 8.94 0.35 2.15 1.00 40.00 4152
#> yx 18.98 8.21 0.38 2.30 0.13 39.13 4329
#>
#> Coefficients:
#> intercept slope cx cy sx sy
#> -0.8726 1.0000 20.0000 20.0000 40.0000 40.0000Possiamo anche consultare la tabella di concordanza per verificare come i punteggi della forma \(X\) siano cambiati dopo essere stati equiparati alla forma \(Y\). La tabella di concordanza indica che un esaminando che ha ottenuto un punteggio di 1 sulla forma \(X\) si aspetterebbe di ottenere un punteggio di 1-0.873 sulla forma \(Y\). In pratica, si tratta di una semplice trasformazione: il punteggio della forma \(X\) viene incrementato di -0.873.
head(mean_yx$concordance)
#> scale yx
#> 1 0 -0.8726
#> 2 1 0.1274
#> 3 2 1.1274
#> 4 3 2.1274
#> 5 4 3.1274
#> 6 5 4.1274Possiamo unire la tabella di concordanza alla forma \(X\) in modo da visualizzare insieme sia i punteggi originali che quelli equiparati per ogni esaminando.
# Save the concordance table
form_yx <- mean_yx$concordance
# Rename the first column to total
colnames(form_yx)[1] <- "total"
# Merge the concordance table to form x
data_xy <- merge(form_x, form_yx)
head(data_xy)
#> total count yx
#> 1 0 0 -0.8726
#> 2 1 1 0.1274
#> 3 2 1 1.1274
#> 4 3 3 2.1274
#> 5 4 9 3.1274
#> 6 5 18 4.1274Sia form_x che form_xy sono tabelle di contingenza.
form_yx |> head()
#> total yx
#> 1 0 -0.8726
#> 2 1 0.1274
#> 3 2 1.1274
#> 4 3 2.1274
#> 5 4 3.1274
#> 6 5 4.1274form_x |> head()
#> total count
#> 1 0 0
#> 2 1 1
#> 3 2 1
#> 4 3 3
#> 5 4 9
#> 6 5 18Per ottenere i dati grezzi, prima le trasformiamo in un oggetto data.frame.
form_x_df <- form_x |> as.data.frame()
form_yx_df <- form_yx |> as.data.frame()Poi ricostruiamo i dati grezzi.
I dati trasformati X sono semplicemente una tralazione lineare dei dati originari.
plot(raw_data_x, raw_data_yx, type = 'l')
6.5.2 Equating Lineare
Questo metodo corregge i punteggi della nuova forma (\(X\)) utilizzando sia la differenza delle medie che quella delle deviazioni standard tra le due forme (\(X\) e \(Y\)), applicando un’equazione lineare.
linear_yx <- equate(form_x, form_y, type = "linear")
linear_yx
#>
#> Linear Equating: form_x to form_y
#>
#> Design: equivalent groups
#>
#> Summary Statistics:
#> mean sd skew kurt min max n
#> x 19.85 8.21 0.38 2.30 1.00 40.00 4329
#> y 18.98 8.94 0.35 2.15 1.00 40.00 4152
#> yx 18.98 8.94 0.38 2.30 -1.54 40.91 4329
#>
#> Coefficients:
#> intercept slope cx cy sx sy
#> -2.632 1.089 20.000 20.000 40.000 40.000plot(linear_yx)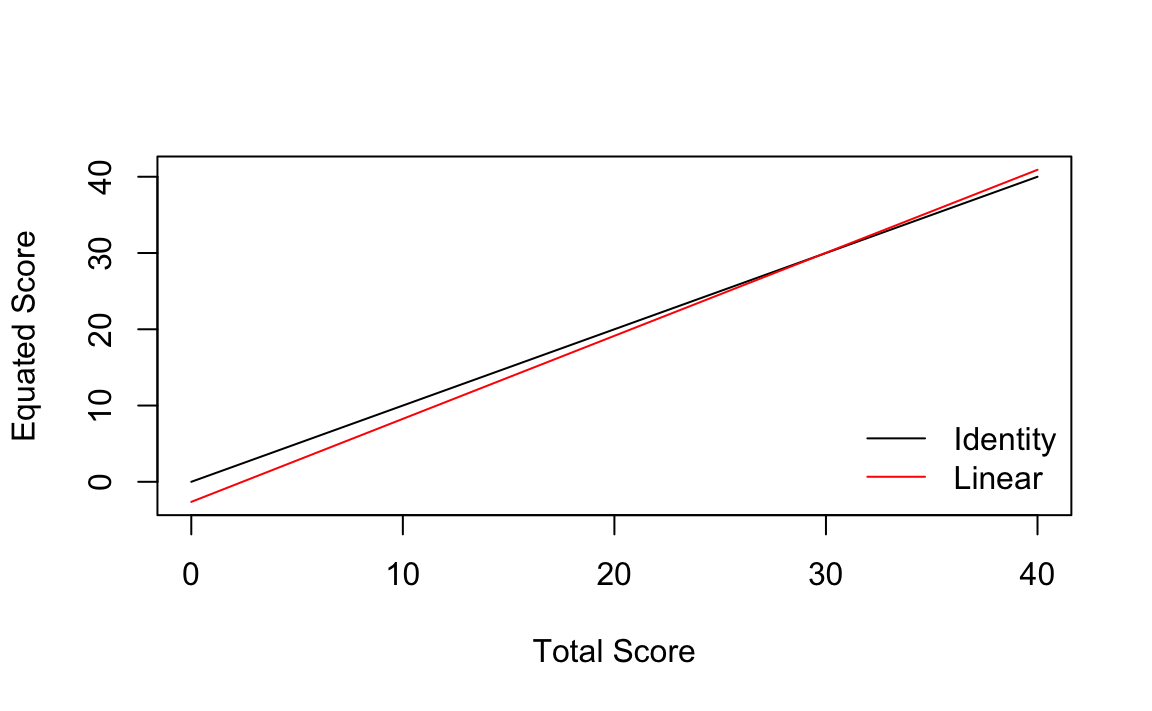
Possiamo anche eseguire un bootstrap per il processo di equating e creare un grafico degli errori standard:
linear_yx_boot <- equate(form_x, form_y, type = "linear", boot = TRUE, reps = 5)
plot(linear_yx_boot, out = "se")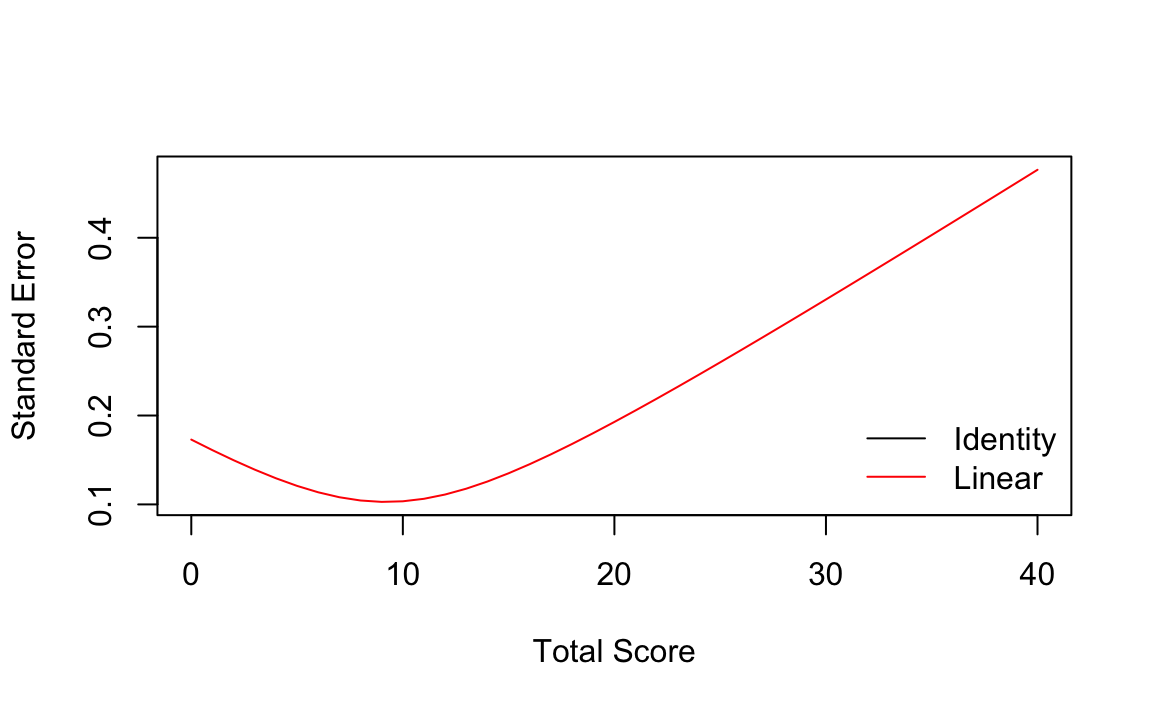
6.5.3 Equating Non Lineare
I metodi di equating non lineare includono l’equipercentile, l’arco circolare e le funzioni composte.
6.5.3.1 Equating Equipercentile
L’equipercentile funziona suddividendo i punteggi delle forme \(X\) e \(Y\) in percentili. Successivamente, i percentili della forma \(X\) vengono abbinati ai percentili della forma \(Y\).
Ad esempio, possiamo applicare l’equipercentile con il seguente comando:
equi_yx <- equate(form_x, form_y, type = "equipercentile")Ora possiamo verificare come i punteggi di \(X\) siano stati corretti in base ai ranghi percentili delle forme \(X\) e \(Y\). Il grafico seguente mostra che le maggiori discrepanze tra queste due funzioni si trovano alle estremità della distribuzione:
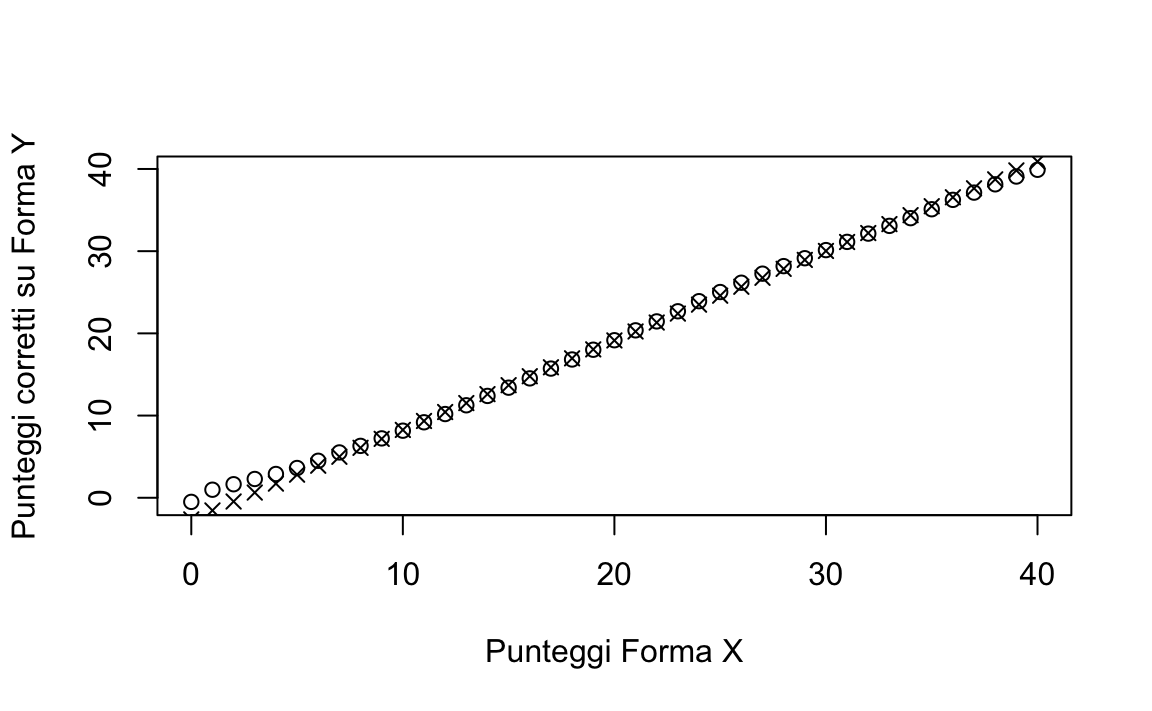
6.5.3.2 Smoothing Loglineare
Possiamo anche aggiungere uno smoothing loglineare al processo e confrontarlo con il metodo equipercentile standard. La linea curva indica l’equipercentile con smussamento loglineare, mentre la linea dritta (con un punto di rottura) rappresenta l’equipercentile standard.
Questo confronto consente di osservare come il processo di smussamento renda la relazione tra le due forme più fluida e meno sensibile alle variazioni estreme.
equismooth_yx <- equate(form_x, form_y, type = "equipercentile", smooth = "loglin", degree = 3)
# Compare equating functions
plot(equi_yx, equismooth_yx, addident = FALSE)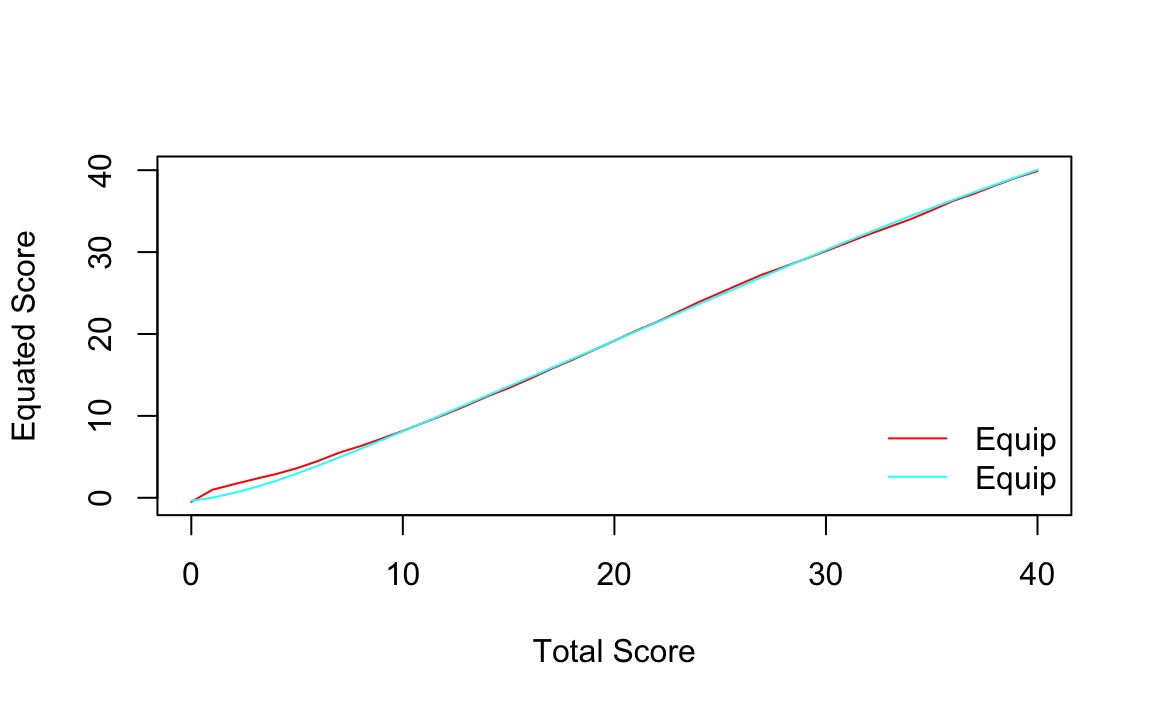
In questo caso, lo smoothing non ha praticamente effetto.
6.6 Gruppi Non Equivalenti
In un disegno a gruppi non equivalenti, non si può assumere che la popolazione di esaminandi che sostiene le diverse forme del test provenga dalla stessa popolazione. Pertanto, è necessario tenere conto delle potenziali differenze nelle loro abilità relative al costrutto misurato. Quando si utilizza un disegno a gruppi non equivalenti, è indispensabile specificare un metodo di equating adeguato.
Generalmente, questi metodi stabiliscono una relazione tra i punteggi totali della forma \(X\) e della forma \(Y\) attraverso i punteggi ottenuti su un insieme comune di item presenti in entrambe le forme (noti come anchor items) e la creazione di una popolazione sintetica ponderata. Per maggiori informazioni su questi metodi, si rimanda ad Albano (2016).
I metodi di equating disponibili nel pacchetto equate per i gruppi non equivalenti includono:
- Tucker
- Nominal
- Levine true score
- Braun/Holland
- Frequency
- Chained
Per un approfondimento, si rimanda al manuale del pacchetto equate.
6.7 Equating Basato sulla Teoria della Risposta all’Item
L’equating basato sulla Item Response Theory (IRT) rappresenta un approccio avanzato per confrontare e rendere comparabili punteggi di diverse forme di un test. Questo metodo sfrutta la capacità della IRT di modellare la relazione tra le risposte degli esaminandi e le caratteristiche degli item. I metodi IRT di equating si dividono in due categorie principali:
- Equating attraverso item comuni
- Equating attraverso persone comuni
In entrambi i casi, gli item comuni o le persone comuni fungono da ponte tra le due forme del test, consentendo di stabilire una scala comune per il confronto dei punteggi.
6.7.1 Equating Attraverso Item Comuni
L’equating basato su item comuni utilizza item identici inclusi in entrambe le forme del test. Questi item condivisi, detti item ancorati (anchor items), permettono di calibrare le due forme su una scala comune. Le applicazioni tipiche includono:
Equating tramite costanti di equating
In questo approccio, si utilizzano costanti per collegare i parametri degli item delle due forme. Queste costanti sono derivate dagli item comuni, che aiutano a compensare le differenze tra le due forme del test.Equating tramite curve caratteristiche del test
Le curve caratteristiche del test (TCC, Test Characteristic Curves) rappresentano la relazione tra i punteggi latenti (\(\theta\)) e i punteggi osservati. Con questo metodo, si utilizzano le TCC delle due forme per stabilire una corrispondenza tra i punteggi.Equating tramite calibrazione simultanea
La calibrazione simultanea prevede di stimare i parametri degli item di entrambe le forme del test in un’unica analisi. Gli item comuni agiscono come vincoli per collegare le due forme sulla stessa scala.
6.7.2 Vantaggi dell’Equating IRT
- Consente di correggere le differenze tra le forme del test basandosi su parametri specifici degli item (difficoltà, discriminazione, probabilità di indovinare).
- Non richiede che le distribuzioni delle abilità degli esaminandi siano identiche per le due forme, rendendolo particolarmente utile per disegni a gruppi non equivalenti.
- Può gestire forme di test con numero di item diverso o contenuti solo parzialmente sovrapposti.
L’utilizzo dell’IRT garantisce una maggiore precisione rispetto ai metodi tradizionali, soprattutto in presenza di forme di test complesse. Le funzionalità necessarie per implementare questi metodi sono disponibili nel pacchetto R equateIRT, che offre strumenti avanzati per l’equating basato sulla teoria della risposta all’item. Per ulteriori approfondimenti, si consiglia di consultare la documentazione del pacchetto.
6.8 Riflessioni Conclusive
In questo capitolo abbiamo esplorato i metodi di equating basati sulla Classical Test Theory (CTT) e abbiamo fornito alcuni accenni sui metodi basati sulla Item Response Theory (IRT). Abbiamo analizzato come l’equating consenta di confrontare i punteggi di diverse forme di un test, garantendo equità e comparabilità anche in presenza di differenze di difficoltà tra le forme. In conclusione, la capacità di confrontare e convertire punteggi tra diverse forme di test non è solo un esercizio statistico, ma un elemento fondamentale per assicurare l’equità e la validità dei processi valutativi.
6.9 Session Info
sessionInfo()
#> R version 4.4.2 (2024-10-31)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Sequoia 15.3.2
#>
#> Matrix products: default
#> BLAS: /Library/Frameworks/R.framework/Versions/4.4-arm64/Resources/lib/libRblas.0.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.4-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.0
#>
#> locale:
#> [1] C/UTF-8/C/C/C/C
#>
#> time zone: Europe/Rome
#> tzcode source: internal
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] equate_2.0.8 ggokabeito_0.1.0 see_0.11.0 MASS_7.3-65
#> [5] viridis_0.6.5 viridisLite_0.4.2 ggpubr_0.6.0 ggExtra_0.10.1
#> [9] gridExtra_2.3 patchwork_1.3.0 bayesplot_1.11.1 semTools_0.5-6
#> [13] semPlot_1.1.6 lavaan_0.6-19 psych_2.4.12 scales_1.3.0
#> [17] markdown_1.13 knitr_1.50 lubridate_1.9.4 forcats_1.0.0
#> [21] stringr_1.5.1 dplyr_1.1.4 purrr_1.0.4 readr_2.1.5
#> [25] tidyr_1.3.1 tibble_3.2.1 ggplot2_3.5.1 tidyverse_2.0.0
#> [29] here_1.0.1
#>
#> loaded via a namespace (and not attached):
#> [1] rstudioapi_0.17.1 jsonlite_1.9.1 magrittr_2.0.3
#> [4] TH.data_1.1-3 estimability_1.5.1 farver_2.1.2
#> [7] nloptr_2.2.1 rmarkdown_2.29 vctrs_0.6.5
#> [10] minqa_1.2.8 base64enc_0.1-3 rstatix_0.7.2
#> [13] htmltools_0.5.8.1 broom_1.0.7 Formula_1.2-5
#> [16] htmlwidgets_1.6.4 plyr_1.8.9 sandwich_3.1-1
#> [19] emmeans_1.10.7 zoo_1.8-13 igraph_2.1.4
#> [22] mime_0.13 lifecycle_1.0.4 pkgconfig_2.0.3
#> [25] Matrix_1.7-3 R6_2.6.1 fastmap_1.2.0
#> [28] rbibutils_2.3 shiny_1.10.0 digest_0.6.37
#> [31] OpenMx_2.21.13 fdrtool_1.2.18 colorspace_2.1-1
#> [34] rprojroot_2.0.4 Hmisc_5.2-3 timechange_0.3.0
#> [37] abind_1.4-8 compiler_4.4.2 withr_3.0.2
#> [40] glasso_1.11 htmlTable_2.4.3 backports_1.5.0
#> [43] carData_3.0-5 ggsignif_0.6.4 corpcor_1.6.10
#> [46] gtools_3.9.5 tools_4.4.2 pbivnorm_0.6.0
#> [49] foreign_0.8-88 zip_2.3.2 httpuv_1.6.15
#> [52] nnet_7.3-20 glue_1.8.0 quadprog_1.5-8
#> [55] nlme_3.1-167 promises_1.3.2 lisrelToR_0.3
#> [58] grid_4.4.2 checkmate_2.3.2 cluster_2.1.8.1
#> [61] reshape2_1.4.4 generics_0.1.3 gtable_0.3.6
#> [64] tzdb_0.5.0 data.table_1.17.0 hms_1.1.3
#> [67] car_3.1-3 sem_3.1-16 pillar_1.10.1
#> [70] rockchalk_1.8.157 later_1.4.1 splines_4.4.2
#> [73] lattice_0.22-6 survival_3.8-3 kutils_1.73
#> [76] tidyselect_1.2.1 miniUI_0.1.1.1 pbapply_1.7-2
#> [79] reformulas_0.4.0 stats4_4.4.2 xfun_0.51
#> [82] qgraph_1.9.8 arm_1.14-4 stringi_1.8.4
#> [85] yaml_2.3.10 pacman_0.5.1 boot_1.3-31
#> [88] evaluate_1.0.3 codetools_0.2-20 mi_1.1
#> [91] cli_3.6.4 RcppParallel_5.1.10 rpart_4.1.24
#> [94] xtable_1.8-4 Rdpack_2.6.3 munsell_0.5.1
#> [97] Rcpp_1.0.14 coda_0.19-4.1 png_0.1-8
#> [100] XML_3.99-0.18 parallel_4.4.2 jpeg_0.1-10
#> [103] lme4_1.1-36 mvtnorm_1.3-3 openxlsx_4.2.8
#> [106] rlang_1.1.5 multcomp_1.4-28 mnormt_2.1.1