57. Affidabilità longitudinale#
Nel capitolo L’affidabilità tra giudici abbiamo illustrato come calcolare l’affidabilità delle misure di un disegno longitudinale usando il framework della teoria della generalizzabilità. Questo capitolo affronta lo stesso problema usano i modelli di equazioni strutturali.
suppressPackageStartupMessages({
library("tidyverse")
library("here")
library("psych")
library("rio")
library("semTools")
library("lme4") # for multilevel models
library("tidyr") # for data management
})
# https://quantdev.ssri.psu.edu/sites/qdev/files/BL_CH7_2019_0602.html
Grazie ai progressi tecnologici, i metodi di raccolta dati longitudinali intensivi si sono sviluppati notevolmente. Tali dati possono ora essere raccolti in maniera meno invasiva, riducendo gli ostacoli per i partecipanti. Tradizionalmente, i dati longitudinali si caratterizzavano per un numero limitato di misurazioni ripetute con ampi intervalli temporali. Le nuove tecniche di raccolta dati, ad esempio tramite applicazioni per smartphone o tablet, hanno portato a dati con un maggior numero di occasioni di misurazione, vicine tra loro temporalmente. Questi dati longitudinali intensivi permettono di investigare la dinamica di processi variabili, come i cambiamenti quotidiani di vari stati psicologici.
I dati raccolti con misure quotidiane presentano una struttura annidata, in quanto più occasioni di misurazione sono raggruppate all’interno della stessa persona. Attualmente, due tecniche sono comunemente impiegate per analizzare l’affidabilità con dati annidati: la teoria della generalizzabilità e l’approccio fattoriale. La teoria della generalizzabilità scompone la varianza totale in elementi di tempo, item e persona, valutando così l’affidabilità del cambiamento nel tempo a livello individuale. Nonostante i suoi vantaggi, questo approccio si basa su assunzioni che potrebbero non essere sempre verificate dai dati.
L’approccio fattoriale è più flessibile e permette di modellare le associazioni degli item con il punteggio vero e le varianze degli errori. In particolare, l’analisi fattoriale confermativa multilivello (MCFA) viene utilizzata per ottenere elementi di varianza al fine di determinare l’affidabilità specifica per il tempo (a livello intra-individuale) e per la persona (a livello inter-individuale).
L’articolo di van Alphen et al. [vAJJidW+22] descrive come sia possibile valutare l’affidabilità con dati longitudinali intensivi quotidiani. Nel loro tutorial, gli autori utilizzano dati empirici raccolti tramite una misura dello stress lavorativo quotidiano per insegnanti di scuola secondaria. Inoltre, van Alphen et al. [vAJJidW+22] confrontano gli indici di affidabilità derivati dal metodo MCFA con quelli ottenuti tramite la teoria della generalizzabilità.
57.1. Affidabilità nei Modelli Fattoriali a Livello Singolo#
L’analisi fattoriale confermativa (CFA) è diventata lo standard per determinare la dimensionalità e l’affidabilità dei punteggi in psicologia. L’affidabilità, in dati con un singolo livello, può essere valutata mediante diversi indici. A differenza del coefficiente di consistenza interna \(\alpha\), l’indice \(\omega\) non assume che i diversi carichi fattoriali degli item contribuiscano equamente al costrutto latente.
I valori di \(\omega\) variano da zero a uno, dove valori vicini a uno indicano una migliore affidabilità della scala. Il valore effettivo di \(\omega\) può essere interpretato come la proporzione di varianza nei punteggi della scala spiegata dalla variabile latente comune a tutti gli indicatori.
L’affidabilità composita \(\omega\), per un costrutto misurato con \(p\) item, è definita come:
dove \(i\) indica l’item, \(\lambda\) rappresenta un carico fattoriale, \(\Phi\) rappresenta la varianza del fattore, e \(\theta\) rappresenta la varianza residua dell’item.
van Alphen et al. [vAJJidW+22] propongono il seguente esempio. Consideriamo un modello unifattoriale in cui la varianza del fattore sia fissata a 1 per l’identificazione del modello, con saturazioni su tre indicatori pari a 0.7, 0.8 e 0.9. Le specificità saranno dunque 0.51, 0.36 e 0.19. Possiamo determinare l’affidabilità \(\omega\) della scala inserendo questi valori nell’equazione precedente, il che produce un’affidabilità di .84.
Questo significa che l’84% della varianza totale nei punteggi della scala è spiegata dal fattore comune.
57.2. Affidabilità nei Modelli Fattoriali Multilivello#
Nella ricerca psicologica, i dati spesso presentano una struttura annidata, dove le unità di livello inferiore sono considerate annidate in unità di livello superiore. Ad esempio, gli studenti possono essere annidati nelle classi, o i pazienti negli ospedali. Con misure giornaliere degli individui su diversi giorni, le occasioni di misurazione sono annidate negli individui. Allo stesso modo, i dati empirici utilizzati nell’esempio presentato qui, sono raccolti dagli stessi insegnanti durante 15 occasioni di misurazione. Queste occasioni sono annidate all’interno di ciascun insegnante. L’analisi fattoriale multilivello consente modelli diversi per varianze e covarianze delle differenze intra-individuali e inter-individuali (Muthén, 1994). Nell’esempio discusso, van Alphen et al. [vAJJidW+22] si concentrano su strutture con due livelli, costituiti da occasioni (Livello 1, o il livello interno) all’interno di individui (Livello 2, o il livello esterno).
La Fig.Un modello configurale multilivello con i carichi fattoriali, varianze residuali e varianza del fattoriali dell’esempio discusso da van2022determining. (Figura tratta da van2022determining). fornisce una rappresentazione grafica di un modello fattoriale multilivello. In tale analisi fattoriale confermativa (CFA) a due livelli, i punteggi degli item sono decomposti in componenti (latenti) a livello interno ed esterno. La parte a livello esterno modella la struttura di covarianza a livello inter-individuale, spiegando le differenze tra gli individui. L’interpretazione di questa parte del modello è paragonabile a una CFA ad un singolo livello. La parte a livello interno modella la struttura di covarianza a livello delle occasioni di misurazione, spiegando le differenze all’interno degli individui tra i diversi punti temporali. In questo esempio, il livello dell’occasione è rappresentativo delle caratteristiche di stato degli individui, perché mostra i cambiamenti giornalieri delle condizioni degli individui. Il livello inter-individuale, quindi, si riferisce alle caratteristiche di tratto degli individui, poiché tali misure sono un aggregato delle misure giornaliere e rappresentano una misura più stabile (cioè, a lungo termine), simile a una misura della personalità.
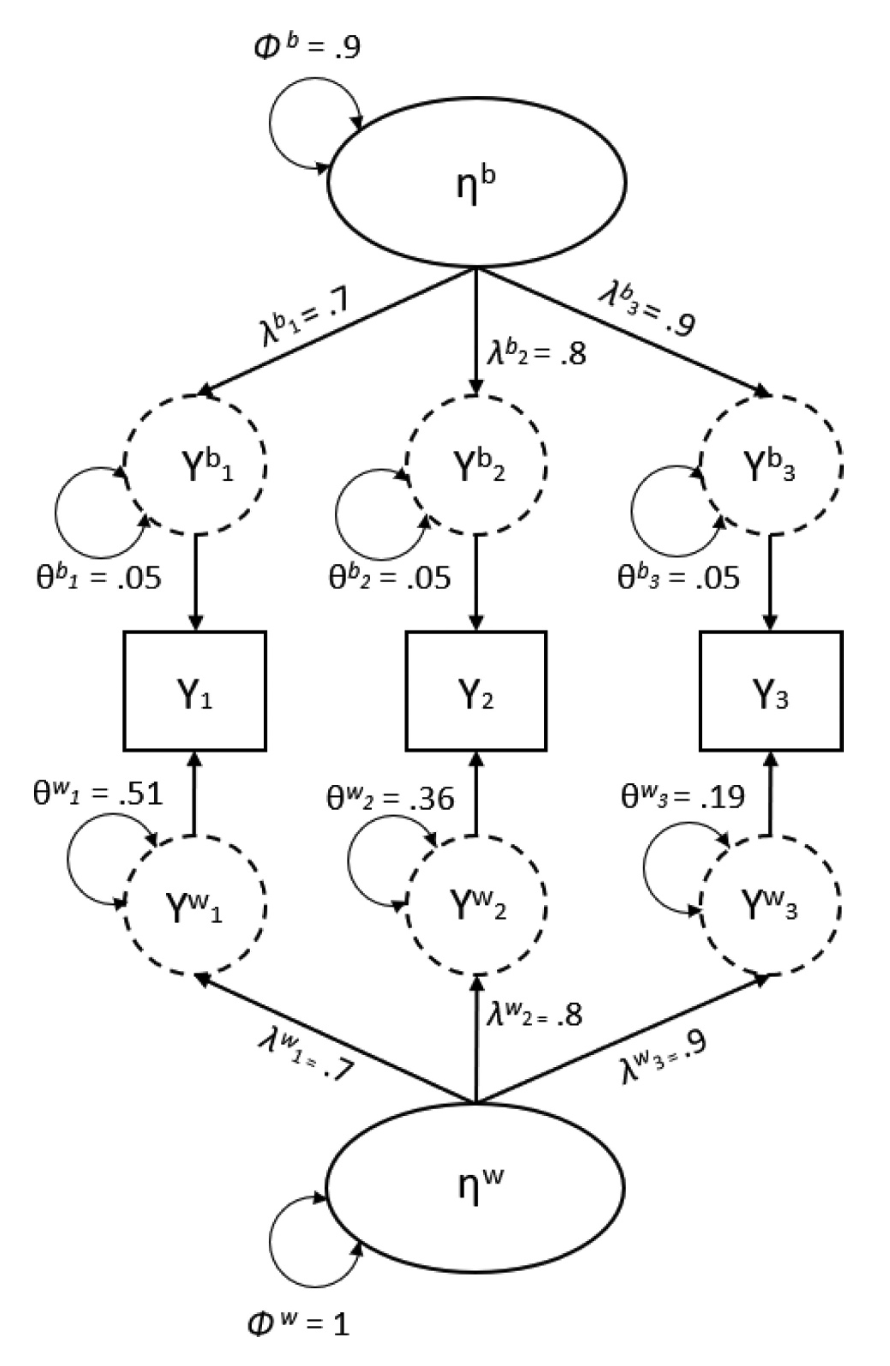
Fig. 57.1 Un modello configurale multilivello con i carichi fattoriali, varianze residuali e varianza del fattoriali dell’esempio discusso da van Alphen et al. [vAJJidW+22]. (Figura tratta da van Alphen et al. [vAJJidW+22]).#
Geldhof et al. (2014) hanno esteso il metodo esistente per determinare ω a modelli a due livelli, risultando in indici di affidabilità a livello interno (ωw) e a livello esterno (ωb). Questo approccio è stato è stato poi sviluppato da Lai (2021).
57.3. Calcolo dell’Affidabilità della Scala con Dati Giornalieri#
van Alphen et al. [vAJJidW+22] considerano un dataset che include misure longitudinali intensive giornaliere sullo stress degli insegnanti. In questo contesto, il fattore comune a livello esterno può essere interpretato come la componente stabile del fattore stress, mentre il fattore comune a livello interno rappresenta la parte variabile nel tempo del fattore stress. Quando ci si concentra sulle componenti a livello interno ed esterno dello stesso fattore, il modello fattoriale multilivello è conosciuto come modello configurale (Stapleton et al., 2016).
Nel modello fattoriale configurale multilivello, i fattori a livello interno ed esterno riflettono le componenti interne ed esterne della stessa variabile latente. Di conseguenza, la struttura fattoriale è la stessa per entrambi i livelli e i carichi fattoriali sono uguali tra i livelli (Asparouhov & Muthen, 2012). Lai (2021) ha fornito equazioni per calcolare stime di affidabilità a livello interno (ωw) ed esterno (ωb), specificamente per questi modelli configurali. van Alphen et al. [vAJJidW+22] forniscono un esempio di calcolo per entrambi questi indici di affidabilità.
La seguente equazione viene utilizzata per determinare l’affidabilità a livello interno in un modello configurale:
dove il pedice \(w\) si riferisce al livello interno. Si noti che i carichi fattoriali (\(\lambda\)) non hanno un pedice specifico di livello perché sono vincolati ad essere uguali tra i livelli.
Confrontando questa equazione omega al livello interno (2) con l’equazione utilizzata per determinare l’affidabilità utilizzando una CFA ad un livello singolo, si vede che la varianza fattoriale a livello interno (\(\Phi_w\)) viene utilizzata al posto della varianza totale (\(\Phi\)). In questo contesto multilivello, \(\theta_w\) rappresenta la varianza residua solo al livello interno.
Inserendo i nostri valori esemplificativi della Fig.Un modello configurale multilivello con i carichi fattoriali, varianze residuali e varianza del fattoriali dell’esempio discusso da van2022determining. (Figura tratta da van2022determining). nell’Equazione precedente si ottiene un’affidabilità a livello interno di 0.84. Ciò significa che il fattore comune a livello interno spiega l’84% della varianza totale nei punteggi di deviazione della scala a livello interno:
Con il pedice \(b\) che si riferisce al livello esterno, l’equazione per l’affidabilità a livello esterno in un modello configurale diventa quindi:
dove \(n\) è il numero di misurazioni. In questa equazione, la varianza dell’errore di campionamento delle medie osservate a livello di persona viene aggiunta al denominatore aggiungendo \(\Phi_w/n\) e \(\Sigma \theta_w/n\). Nel nostro esempio, useremo \(n = 15\). Nel contesto di misure longitudinali, ciò significa che i dati sono stati raccolti in 15 occasioni. Inserendo i valori esemplificativi di van Alphen et al. [vAJJidW+22], l’affidabilità a livello esterno è 0.90, indicando che il fattore comune a livello esterno spiega il 90% della varianza totale nelle medie osservate a livello di persona dei punteggi della scala:
Queste equazioni forniscono un metodo per valutare l’affidabilità delle componenti a livello interno ed esterno di una scala in studi longitudinali intensivi, consentendo ai ricercatori di distinguere tra variazioni stabili e temporanee all’interno dei dati.
57.4. Confronto con la Teoria della Generalizzabilità#
van Alphen et al. [vAJJidW+22] hanno anche derivato le componenti di varianza per il calcolo del punteggio di affidabilità a livello interno e a livello esterno utilizzando la teoria della generalizzabilità. Per questi dati, van Alphen et al. [vAJJidW+22] trovano che la stima dell’affidabilità a livello interno è .87, molto simile alla stima ottenuta con l’approccio CFA multilivello. Tuttavia, la stima a livello esterno ottenuta con il metodo della generalizzabilità è 0.99, che è .11 più alta rispetto all’approccio analitico fattoriale. Questa differenza potrebbe essere causata dalle assunzioni più rigide fatte dal metodo della teoria della generalizzabilità. Tuttavia, van Alphen et al. [vAJJidW+22] notano che questi risultati sono specifici al dataset utilizzato e sarebbe necessario uno studio di simulazione per valutare, in generale, quali sono le differenze sistematiche tra le stime di affidabilità ottenute con i due diversi metodi.
Qui sotto viene presentato il metodo SEM per il calcolo dell’affidabilità inter- e intra-persona usando gli script R forniti da van Alphen et al. [vAJJidW+22].
van_alphen <- read.table("../data/data_van_alphen.dat", na.strings = "9999")
colnames(van_alphen) <- c("day", "school", "ID", "str1", "str2", "str3", "str4")
van_alphen |> head()
| day | school | ID | str1 | str2 | str3 | str4 | |
|---|---|---|---|---|---|---|---|
| <int> | <int> | <int> | <int> | <int> | <int> | <int> | |
| 1 | 1 | 1 | 1 | 26 | NA | 24 | 78 |
| 2 | 1 | 1 | 30 | NA | 24 | 24 | 50 |
| 3 | 1 | 1 | 55 | NA | 36 | 70 | 72 |
| 4 | 1 | 1 | 92 | NA | 37 | 34 | 41 |
| 5 | 1 | 2 | 20 | 24 | NA | 24 | 36 |
| 6 | 1 | 2 | 22 | 12 | NA | 18 | 39 |
van_alphen |> tail()
| day | school | ID | str1 | str2 | str3 | str4 | |
|---|---|---|---|---|---|---|---|
| <int> | <int> | <int> | <int> | <int> | <int> | <int> | |
| 1264 | 15 | 6 | 62 | NA | 66 | 57 | 61 |
| 1265 | 15 | 6 | 87 | NA | 42 | 59 | 83 |
| 1266 | 15 | 6 | 115 | 53 | NA | 53 | 45 |
| 1267 | 15 | 6 | 118 | NA | 16 | 32 | 16 |
| 1268 | 15 | 6 | 123 | 23 | 22 | 23 | NA |
| 1269 | 15 | 6 | 143 | 64 | 64 | 65 | NA |
## Step 5: calculating reliability indices
model5 <- "
level: 1
stress =~ L1*str1 + L2*str2 + L3*str3 + L4*str4
stress ~~ 1*stress
str1 ~~ tw1*str1
str2 ~~ tw2*str2
str3 ~~ tw3*str3
str4 ~~ tw4*str4
level: 2
stress =~ L1*str1 + L2*str2 + L3*str3 + L4*str4
stress ~~ fb*stress
str1 ~~ tb1*str1
str2 ~~ tb2*str2
str3 ~~ tb3*str3
str4 ~~ tb4*str4
# means
str1 + str2 + str3 + str4 ~ 1
# reliability calculations
lambda := L1 + L2 + L3 + L4
thetaw := tw1 + tw2 + tw3 + tw4
thetab := tb1 + tb2 + tb3 + tb4
omega_w := lambda^2 / (lambda^2 + thetaw)
omega_b := (lambda^2 * fb) / (lambda^2 * (1 / 15 + fb) + thetab + thetaw / 15)
"
fit.step5 <- lavaan(
model = model5,
data = van_alphen,
cluster = "ID",
auto.var = TRUE,
missing = "fiml"
)
Show code cell output
Warning message in lav_data_full(data = data, group = group, cluster = cluster, :
“lavaan WARNING:
Level-1 variable “str1” has no variance within some clusters. The
cluster ids with zero within variance are: 124 19 47 66 88 138 94”
Warning message in lav_data_full(data = data, group = group, cluster = cluster, :
“lavaan WARNING:
Level-1 variable “str2” has no variance within some clusters. The
cluster ids with zero within variance are: 124 83 90 19 47 66 27
51 61 106 9 53 93 94 111”
Warning message in lav_data_full(data = data, group = group, cluster = cluster, :
“lavaan WARNING:
Level-1 variable “str3” has no variance within some clusters. The
cluster ids with zero within variance are: 124 19 47 66 94”
Warning message in lav_data_full(data = data, group = group, cluster = cluster, :
“lavaan WARNING:
Level-1 variable “str4” has no variance within some clusters. The
cluster ids with zero within variance are: 19 47 136 94 147 135”
Warning message in lav_data_full(data = data, group = group, cluster = cluster, :
“lavaan WARNING: some cases are empty and will be ignored:
48 98 189 199 348 577 660 793 948 950 959 1001 1025 1207”
Warning message in lavaan(model = model5, data = van_alphen, cluster = "ID", auto.var = TRUE, :
“lavaan WARNING:
the optimizer warns that a solution has NOT been found!”
Warning message in lavaan(model = model5, data = van_alphen, cluster = "ID", auto.var = TRUE, :
“lavaan WARNING: estimation of the baseline model failed.”
summary(fit.step5) |> print()
lavaan 0.6.17 did NOT end normally after 76 iterations
** WARNING ** Estimates below are most likely unreliable
Estimator ML
Optimization method NLMINB
Number of model parameters 21
Number of equality constraints 4
Used Total
Number of observations 1255 1269
Number of clusters [ID] 151
Number of missing patterns -- level 1 3
Parameter Estimates:
Standard errors Standard
Information Observed
Observed information based on Hessian
Level 1 [within]:
Latent Variables:
Estimate Std.Err z-value P(>|z|)
stress =~
str1 (L1) 29.030 NA
str2 (L2) 24.422 NA
str3 (L3) 27.818 NA
str4 (L4) 27.313 NA
Variances:
Estimate Std.Err z-value P(>|z|)
stress 1.000
.str1 (tw1) 110.457 NA
.str2 (tw2) 153.138 NA
.str3 (tw3) 161.843 NA
.str4 (tw4) 175.477 NA
Level 2 [ID]:
Latent Variables:
Estimate Std.Err z-value P(>|z|)
stress =~
str1 (L1) 29.030 NA
str2 (L2) 24.422 NA
str3 (L3) 27.818 NA
str4 (L4) 27.313 NA
Intercepts:
Estimate Std.Err z-value P(>|z|)
.str1 4.967 NA
.str2 3.200 NA
.str3 7.269 NA
.str4 7.205 NA
Variances:
Estimate Std.Err z-value P(>|z|)
stress (fb) 1.720 NA
.str1 (tb1) 34.629 NA
.str2 (tb2) 63.201 NA
.str3 (tb3) 32.098 NA
.str4 (tb4) 54.698 NA
Defined Parameters:
Estimate Std.Err z-value P(>|z|)
lambda 108.583
thetaw 600.915
thetab 184.626
omega_w 0.952
omega_b 0.953