66. Analisi della Scala di Mokken#
L’analisi delle scale di Mokken (MSA), intitolata in onore del matematico e scienziato politico olandese Robert J. Mokken, rappresenta un insieme di metodologie impiegate nell’ambito della Teoria Non Parametrica della Risposta agli Item (NIRT). Questa teoria si basa sull’idea che i costrutti psicologici siano entità latenti, cioè non direttamente osservabili, che emergono tramite le risposte fornite ai test. Le risposte degli individui agli item del test rivelano la loro posizione lungo un continuum latente, evidenziando il livello al quale possiedono il costrutto studiato.
A differenza dei modelli parametrici della Teoria della Risposta agli Item (IRT), come il modello di Rasch e i modelli a uno, due e tre parametri (1PL, 2PL, 3PL), i modelli MSA sono non parametrici e si caratterizzano per assunzioni meno stringenti. Questi modelli possono essere applicati a item sia dicotomici sia politomici, offrendo strumenti analitici per valutare quanto accuratamente gli item di un test rappresentano la variabile latente di interesse.
66.1. Scaling di Guttman#
La MSA trova le sue radici nello scaling di Guttman, sviluppato nel 1950 da Louis Guttman. Questo metodo, originariamente concepito per item dicotomici, mira a estrarre una singola dimensione dai dati, posizionando sia le persone che gli item su questa dimensione tramite valori numerici. Ad esempio, consideriamo cinque item di un test psicologico e cinque rispondenti ipotetici, A, B, C, D ed E, che rispondono a questi item. Le risposte vengono rappresentate in una tabella dove 1 indica una risposta corretta e 0 una errata.
Items |
Esaminati |
1 |
2 |
3 |
4 |
5 |
|---|---|---|---|---|---|---|
A |
1 |
1 |
1 |
1 |
1 |
|
B |
1 |
1 |
1 |
1 |
0 |
|
C |
1 |
1 |
1 |
0 |
0 |
|
D |
1 |
1 |
0 |
0 |
0 |
|
E |
1 |
0 |
0 |
0 |
0 |
In questa tabella, che rappresenta una scala di Guttman, gli item sono ordinati dal più facile al più difficile, e i rispondenti dall’abilità maggiore a quella minore. Si presume che un rispondente che ha risposto correttamente ad un item di difficoltà superiore abbia risposto correttamente anche a tutti gli item di difficoltà inferiore. Le deviazioni da questo modello sono considerate “errori di Guttman”.
La scala di Guttman, basandosi su un principio deterministico, non riesce sempre a catturare pienamente la complessità dei dati reali. Tuttavia, offre una rappresentazione chiara della relazione cumulativa o gerarchica tra gli item di un test e le abilità dei rispondenti. Questo modello suggerisce che, se una persona dimostra una competenza specifica, si presume che possieda anche tutte le competenze di base correlate.
Tuttavia, quando emergono eccezioni a questa regola, ossia risposte corrette a item difficili ma errate a quelli più semplici, si potrebbe dedurre che il test richieda competenze multiple e non unicamente riconducibili a una dimensione unica. Questo fenomeno mette in luce la complessità e la multidimensionalità delle competenze umane.
In conclusione, la MSA si adatta particolarmente a contesti dove i processi di risposta non sono completamente chiari (come quando la prestazione dipende da una struttura multidimensionale di abilità), consentendo di verificare se le risposte dei partecipanti rispettino i requisiti del modello e di ordinare persone e item su una scala ordinale, basandosi sui punteggi totali grezzi.
66.2. Analisi della Scala di Mokken#
La MSA si colloca all’interno del paradigma dello scaling di Guttman, ma transita dal modello deterministico classico di Guttman a un approccio probabilistico. Il modello di Guttman si basa sul principio di perfetta transitività, secondo cui, in presenza di una sequenza di item ordinati per difficoltà, un rispondente che riesce a rispondere correttamente a un item difficoltoso dovrebbe anche rispondere correttamente agli item più semplici. Tuttavia, questo modello deterministico cumulativo spesso non riflette la realtà dei dati empirici, influenzati dalla complessità delle abilità umane e da altre variabili. Di conseguenza, sono stati adottati modelli probabilistici, come la MSA e il modello di Rasch, che permettono una certa varianza nelle risposte.
La MSA, evoluzione probabilistica dello scaling di Guttman, consente un certo grado di violazioni di questo modello, risultando meno restrittiva e più aderente ai dati empirici. Questo modello facilita l’analisi dell’unidimensionalità e la misurazione di variabili latenti su una scala unidimensionale, specialmente utile con un numero limitato di item.
A differenza di metodi come l’analisi fattoriale e l’analisi di affidabilità, la scala di Guttman e, per estensione, la MSA, sono ottimizzate per l’analisi di item con significative differenze di difficoltà. La MSA si articola in due modelli IRT non parametrici principali: il Modello di Omogeneità Monotona (MHM) e il Modello di Monotonicità Doppia (DMM).
Modello di Omogeneità Monotona (MHM) Il MHM, il primo modello della MSA, si fonda su tre presupposti fondamentali: unidimensionalità, monotonicità e indipendenza locale. Queste assunzioni sono vitali per il suo funzionamento. Se valide, consentono di posizionare gli individui su una scala unidimensionale ordinale, con un ordinamento costante attraverso tutti gli item. In presenza di un insieme omogeneo di item, l’ordinamento degli individui rimane invariato per ogni sottoinsieme di item. Il MHM fornisce una base robusta per l’analisi delle risposte agli item, soprattutto in contesti dove la monotonicità è cruciale.
Modello di Monotonicità Doppia (DMM) Il DMM estende il MHM includendo un ulteriore vincolo: le Funzioni di Risposta agli Item (IRF) non devono intersecarsi. Questo modello esamina la relazione tra la difficoltà degli item e il livello di abilità dei rispondenti. La validità dell’Invariance of Item Ordering (IIO) indica che l’ordinamento degli item per difficoltà è uniforme a tutti i livelli di abilità. La violazione dell’IIO può suggerire un fenomeno di Differential Item Functioning (DIF), mettendo in dubbio l’invarianza della misurazione e suggerendo che l’ordine degli item potrebbe variare tra sottogruppi di rispondenti con abilità simili.
In conclusione, la MSA rappresenta un’evoluzione metodologica significativa rispetto allo scaling di Guttman, offrendo un approccio meno restrittivo e più adatto all’analisi dei dati empirici. Fornisce un quadro analitico efficace per l’indagine dettagliata delle risposte agli item e delle abilità dei rispondenti in contesti psicologici e educativi.
66.3. Confronto tra il Modello di Rasch e l’Analisi della Scala di Mokken#
Il Modello di Rasch (RM) assume che la probabilità di risposta corretta a un item sia determinata dall’abilità della persona (θ) e dalla difficoltà dell’item (δ). La relazione tra la probabilità di una risposta corretta e θ è descritta da una funzione logistica, con IRFs parallele e dalla stessa pendenza. Questo modello è definito parametrico poiché utilizza una funzione parametrica specifica, la funzione logistica, per stabilire tale relazione.
Il Modello di Rasch prevede che i punteggi grezzi totali siano sufficienti per stimare i parametri delle persone e degli item. È considerato il modello più restrittivo rispetto al Modello di Monotonicità Omogenea (MHM) e al Modello di Monotonicità Doppia (DMM) per le sue assunzioni aggiuntive.
D’altra parte, l’Analisi della Scala di Mokken (MSA) appartiene alla categoria dei modelli non parametrici della IRT (NIRT), che non prevedono una funzione specifica per le IRFs. In questi modelli, il punteggio grezzo totale fornisce un ordine basato sulla variabile latente θ, poiché θ non è direttamente stimato. Questo approccio è meno restrittivo rispetto ai modelli parametrici e consente una maggiore flessibilità nell’analisi dei dati.
Il MHM, il modello meno restrittivo tra i tre, si basa su tre assunzioni fondamentali: unidimensionalità, monotonicità e indipendenza locale. Questo modello permette di ordinare gli individui su una scala unidimensionale ordinale, mantenendo costante questo ordinamento attraverso tutti gli item. Il DMM, invece, aggiunge l’assunzione di IRF non intersecanti al MHM, producendo scale ordinali separate per persone e item.
Un punto critico è che, mentre il Modello di Rasch crea una scala metrica comune per persone e item, consentendo misurazioni indipendenti da persone e item, il DMM genera scale ordinali distinte. Inoltre, i modelli NIRT, come la MSA, non richiedono la conformità degli item a una funzione logistica specifica, evitando così la necessità di scartare gli item che non seguono tale funzione, una limitazione dei modelli PIRT (Parametric Item Response Theory).
In sintesi, mentre il Modello di Rasch offre un approccio più restrittivo ma preciso, basato su assunzioni specifiche e una scala metrica comune, la MSA offre una maggiore flessibilità e applicabilità a un’ampia gamma di dati, pur producendo scale ordinali distinte per persone e item. Questa differenza chiave tra i due approcci sottolinea l’importanza di scegliere il modello più adatto in base agli obiettivi specifici e alla natura dei dati in esame.
66.4. Confronto tra la Teoria Classica dei Test e l’Analisi delle Scale di Mokken#
Esaminiamo le somiglianze e le differenze tra la Teoria Classica dei Test (CTT) e l’Analisi delle Scale di Mokken (MSA).
La CTT si fonda su alcune assunzioni chiave:
I punteggi osservati sono la somma di punteggi veri e errori di misura, con l’assunzione che gli errori abbiano media zero in prove ripetute.
Non esiste correlazione tra i punteggi di errore e i punteggi veri.
I punteggi veri in un test sono indipendenti dai punteggi di errore in un altro test.
Gli errori di misura in due test somministrati agli stessi soggetti sono indipendenti.
Nella CTT, i punteggi totali sono visti come indicatori della posizione degli individui su un continuum di tratti latenti. La proporzione di risposte corrette a un item, definita come “valore p”, indica la difficoltà dell’item. La CTT valuta anche la discriminazione degli item, ovvero la loro capacità di distinguere tra soggetti con differenti livelli del tratto, attraverso la correlazione tra le risposte corrette a singoli item e il punteggi totale del test. Un altro aspetto fondamentale della CTT è l’enfasi sulla affidabilità, considerata come la correlazione tra i punteggi osservati in forme parallele del test.
Passando al confronto con l’Analisi delle Scale di Mokken, notiamo alcune similarità nei metodi per calcolare la difficoltà degli item e le abilità dei partecipanti. Ad esempio, il coefficiente di scalabilità di un singolo item (Hi) in MSA può essere paragonato alla correlazione tra le risposte corrette ai singoli item e il punteggio totale del test in CTT. Analogamente, il coefficiente di scalabilità tra coppie di item (Hij) in MSA è simile alla correlazione tra coppie di item in CTT. Il coefficiente di scalabilità complessivo (H) in MSA è comparabile agli indici di discriminazione media degli item in CTT.
Tuttavia, una differenza importante tra MSA e CTT risiede nella capacità di MSA di testare direttamente e empiricamente le sue assunzioni, come l’indipendenza locale, l’unidimensionalità e la monotonicità. Per esempio, un coefficiente di scalabilità negativo in MSA potrebbe sollevare dubbi sugli assunti del Modello di Omogeneità Monotona (MHM). Questa capacità di verifica empirica conferisce alla MSA un valore aggiunto in termini di robustezza e trasparenza.
In conclusione, sebbene la CTT offra un framework solido per comprendere e interpretare i punteggi dei test, l’MSA propone un approccio più flessibile e verificabile, estremamente utile per analizzare la struttura dei dati di test e per valutare la validità delle scale di misura.
66.5. Modelli di Analisi delle Scale di Mokken#
L’Analisi delle Scale di Mokken (MSA) adotta due modelli non parametrici distinti per l’elaborazione delle scale nella Teoria della Risposta agli Item (IRT). Questi modelli non parametrici sono caratterizzati da assunzioni meno restrittive rispetto ad altri modelli IRT e si focalizzano principalmente sull’analisi dettagliata dell’adattamento del modello e sulla esplorazione dei dati.
66.5.1. Modello di Omogeneità Monotona di Mokken#
Introdotta da Mokken nel 1971, l’omogeneità monotona è uno dei due modelli fondamentali nell’ambito dei modelli non parametrici IRT, l’altro essendo il modello di doppia monotonicità.
66.5.1.1. Caratteristiche del Modello di Omogeneità Monotona#
Questo modello si basa sull’assunzione di omogeneità monotona, che stabilisce che se un individuo ha una probabilità maggiore o uguale di rispondere correttamente a un item rispetto a un altro, questa condizione deve valere per tutti gli item del set. In termini pratici, ciò significa che se l’individuo A ha maggiori probabilità di risposta corretta rispetto all’individuo B su un certo item, lo stesso deve valere per tutti gli altri item della scala, riflettendo l’idea che gli item possono essere ordinati in una scala unidimensionale dove un singolo tratto latente o abilità determina una risposta consistente.
66.5.1.2. Presupposti del modello:#
Unidimensionalità: Tutti gli item misurano un unico attributo, rappresentato da una variabile latente \( h \).
Monotonicità: Con l’aumentare di \( h \), aumenta anche la probabilità di ottenere un punteggio almeno pari a \( x_j \) per ogni item \( j \), riflettendo un incremento monotono del tratto misurato.
Indipendenza locale: Gli item correlati al medesimo attributo presentano una correlazione positiva nei punteggi variando \( h \). Tuttavia, rimuovendo questa fonte di variazione, gli item risultano statisticamente indipendenti, dimostrando la validità dell’unidimensionalità della scala.
66.5.1.3. Vantaggi del modello#
Il modello di omogeneità monotona è particolarmente flessibile in quanto non necessita di una specifica forma funzionale per descrivere la relazione tra la probabilità di risposta e il tratto latente, rendendolo ideale per studi dove la distribuzione del tratto latente è sconosciuta o difficile da specificare.
66.5.1.4. Verifica dell’omogeneità monotona#
L’omogeneità monotona viene verificata utilizzando coefficienti di scalabilità, come il coefficiente \( H \) di Mokken, che quantifica la forza della relazione monotona tra gli item e il tratto latente. Valori più elevati di \( H \) indicano una maggiore omogeneità e una migliore qualità della scala nel rappresentare il tratto latente, essenziali per assicurare la validità delle misurazioni.
66.5.2. Modello di Doppia Monotonicità di Mokken#
Il modello di doppia monotonicità estende l’omogeneità monotona aggiungendo requisiti più stringenti sulla monotonicità delle funzioni di risposta degli item (IRF).
66.5.2.1. Caratteristiche Principali#
Questo modello richiede che la probabilità di rispondere correttamente a un item, o di scegliere una risposta più alta in un item graduato, non solo aumenti monotonamente con il tratto latente, ma che tale incremento sia sempre crescente per ogni item lungo il continuum del tratto. Ciò assicura una coerenza nell’ordinamento dei soggetti e nella relazione tra il tratto latente e la probabilità di risposta per ogni item.
66.5.2.2. Implementazione e Verifica#
Per garantire un ordinamento equo degli item per rispondenti di diverse abilità, è essenziale dimostrare l’invarianza dell’ordinamento degli item, mantenendolo costante indipendentemente dal livello di abilità dei rispondenti. Questa invarianza si realizza attraverso IRF non intersecanti, garantendo che l’ordinamento degli item rimanga costante per ogni valore del tratto latente \( h \).
66.6. L’Affidabilità nei Test Psicometrici#
L’affidabilità di un test psicometrico indica il grado in cui i risultati del test sono consistenti e privi di errori di misurazione. Tradizionalmente, si valuta l’affidabilità esaminando la stabilità dei punteggi tra diverse somministrazioni del test, che possono avvenire in momenti differenti o attraverso versioni parallele del test. In teoria, se i punteggi veri degli esaminandi non cambiano, ci si aspetterebbe una correlazione perfetta tra i punteggi ottenuti nelle diverse somministrazioni. Qualsiasi variazione rispetto a questa correlazione ideale viene attribuita all’errore di misurazione.
Tuttavia, misurare l’affidabilità attraverso somministrazioni ripetute o forme parallele del test presenta delle sfide, inclusa la difficoltà di creare test paralleli veramente comparabili e l’influenza di fattori esterni come la memoria o l’effetto pratica. Di conseguenza, l’affidabilità è frequentemente stimata mediante tecniche che necessitano una sola somministrazione del test.
L’alfa di Cronbach è uno dei metodi più diffusi per stimare l’affidabilità, nonostante le sue note limitazioni. Per esempio, presume che tutti gli item del test siano equamente correlati, una condizione che non sempre si verifica nella pratica. Rispondendo a queste limitazioni, Mokken ha introdotto nel 1971 un coefficiente di affidabilità alternativo, noto come ρ (rho) o statistica MS, che si basa sulla presunzione della validità della doppia monotonicità, una condizione piuttosto esigente.
Per superare alcune delle difficoltà legate alla statistica ρ, Van der Ark, Van der Palm e Sijtsma nel 2011 hanno proposto il Coefficiente di Affidabilità delle Classi Latenti (LCRC). Questo indicatore, che necessita solo della condizione di indipendenza locale tra gli item, è un estimatore non distorto dell’affidabilità dei punteggi dei test. La condizione meno restrittiva rende il LCRC un’opzione più flessibile e praticabile in vari contesti di test, rispetto al coefficiente ρ.
La selezione del metodo più adeguato per stimare l’affidabilità di un test dipende dalle caratteristiche specifiche del test stesso e dalle esigenze di misurazione. Sebbene l’alfa di Cronbach sia ancora ampiamente utilizzato e riconosciuto come uno standard, alternative come la statistica ρ di Mokken e il LCRC offrono strumenti supplementari che possono risultare più appropriati in situazioni dove le assunzioni dell’alfa di Cronbach non sono rispettate o nei contesti in cui si impiegano modelli non parametrici, come quelli dell’Analisi delle Scale di Mokken.
Queste alternative permettono agli sviluppatori di test di adattare meglio le metodologie di valutazione dell’affidabilità alle specifiche caratteristiche del test e alle necessità di misurazione, contribuendo così a una più accurata interpretazione dei risultati del test.
66.7. Coefficienti di Scalabilità nelle Scale Mokken#
I coefficienti di scalabilità nelle Scale di Mokken, designati come \( H \), \( H_i \) e \( H_{ij} \), sono elementi chiave nell’Analisi delle Scale di Mokken (MSA). Questi coefficienti sono utilizzati per valutare la qualità della misurazione, quantificando quanto coerentemente e ordinatamente gli item e i punteggi totali si distribuiscono lungo un continuum latente. Essi riflettono quanto bene gli item si organizzano in una gerarchia e quanto i punteggi degli item siano ordinati consistentemente.
Coefficienti di Scalabilità Singoli (\( H_i \)): Questi valutano la qualità di ciascun item individualmente. Un valore elevato di \( H_i \) indica che l’item è particolarmente efficace nel discriminare tra rispondenti con diversi livelli del tratto latente e contribuisce all’ordinamento dei rispondenti lungo il continuum. Valori superiori a 0.30 sono generalmente considerati accettabili, indicando una buona capacità di discriminazione.
Coefficienti di Scalabilità per Coppie di Item (\( H_{ij} \)): Questi coefficienti esaminano la coerenza tra coppie di item nella scala. Valori positivi indicano che la coppia di item è coerente con il modello di omogeneità monotona. Al contrario, valori negativi possono suggerire la presenza di multidimensionalità o di non monotonicità, mettendo in luce potenziali problemi nell’omogeneità o unidimensionalità della scala.
Coefficienti di Scalabilità per l’Intero Test (\( H \)): Questo indice misura la qualità complessiva del test, rivelando in che misura la struttura dei dati si avvicina a un modello di Guttman perfetto. Valori di \( H \) tra 0.30 e 0.40 indicano una scala debole, valori tra 0.40 e 0.50 indicano una scala moderata, mentre valori superiori a 0.50 denotano una scala forte.
Questi coefficienti derivano dall’analisi del rapporto tra gli errori di Guttman osservati e quelli teoricamente previsti. Un coefficiente \( H \) vicino all’unità suggerisce una perfetta aderenza al modello di Guttman, indicando un errore minimo, mentre valori vicini a zero indicano una sostanziale presenza di errori di Guttman.
Oltre a valutare la precisione dell’ordinamento dei rispondenti e la qualità degli item, i coefficienti di scalabilità offrono indicazioni sulla validità di costrutto di una scala. Anche se una scala mostra una forte capacità discriminante (indicata da valori elevati di \( H_i \) e \( H \)), potrebbe carentare in termini di validità di costrutto se gli item non coprono adeguatamente l’intero spettro del costrutto target. Analogamente, valori elevati di \( H_{ij} \) tra specifiche coppie di item possono suggerire una potenziale ridondanza.
66.8. Analisi degli Errori Standard nei Coefficienti di Scalabilità delle Scale Mokken#
Gli errori standard (SE) sono misure dell’incertezza associata alle stime dei coefficienti di scalabilità nelle scale di Mokken. Un errore standard alto rispetto al valore del coefficiente stesso indica maggiore incertezza nella stima. Ad esempio, un errore standard di 0.08 per un coefficiente \( H_i \) di 0.30 suggerisce che il valore effettivo del coefficiente nella popolazione potrebbe discostarsi notevolmente da 0.30. Questo elevato livello di incertezza mette in discussione l’affidabilità della scalabilità degli item, indicando che il coefficiente potrebbe non essere un indicatore stabile delle proprietà di scalabilità degli item nella scala di Mokken.
La grandezza dell’errore standard è influenzata principalmente da due fattori:
Dimensione del campione: Maggiore è il campione, generalmente minore è l’errore standard. Questo è dovuto al fatto che stime basate su campioni più grandi tendono ad essere più vicine ai veri valori della popolazione.
Asimmetria delle distribuzioni dei punteggi degli item: Distribuzioni più asimmetriche possono aumentare l’errore standard, poiché complicano la stima precisa dei coefficienti di scalabilità.
Gli intervalli di confidenza (CI) al 95% per i coefficienti di scalabilità possono essere calcolati utilizzando la formula:
Nonostante gli item con bassi coefficienti di scalabilità siano spesso considerati candidati per l’eliminazione, come suggerito da Mokken (1971), Crișan e colleghi (2020) avvertono contro la rimozione acritica di tali item. Essi sostengono che la decisione di escludere item dalle scale dovrebbe essere presa con cautela, valutando non solo le considerazioni psicometriche ma anche la rilevanza teorica e il contenuto degli item. Eliminare item può infatti ridurre la copertura del costrutto misurato e la validità dei criteri, anche se può sembrare migliorare l’affidabilità o la validità predittiva della scala.
66.9. Procedura di Selezione Automatica degli Item nelle Scale di Mokken#
La Procedura di Selezione Automatica degli Item (AISP) è un approccio utilizzato nell’Analisi delle Scale di Mokken (MSA) per identificare e selezionare item da un insieme più vasto, basandosi sulle assunzioni del Modello di Mokken (MHM). Questo metodo è particolarmente efficace per verificare l’unidimensionalità di una scala e individuare gli item che non aderiscono ai criteri di scalabilità stabiliti.
66.9.1. Criteri principali per la selezione degli item nella scala di Mokken:#
Covarianza individuale (\(H_i\)): Ogni item deve presentare una covarianza che supera un valore soglia prestabilito, comunemente fissato a \(c = 0.30\).
Covarianza reciproca (\(H_{ij}\)): La covarianza tra ogni coppia di item deve essere positiva, indicando che gli item sono consistenti tra loro rispetto al tratto latente misurato.
Il processo di costruzione di una scala inizia con la selezione dei due item che mostrano la \(H_{ij}\) più alta. Successivamente, si aggiungono item che soddisfano i criteri descritti. Gli item che non rispettano questi criteri vengono scartati o riservati per la costruzione di una possibile seconda scala.
L’AISP si distingue dall’analisi fattoriale esplorativa in quanto, a differenza di quest’ultima, non garantisce necessariamente il ritrovamento di una soluzione. Ad esempio, l’AISP potrebbe concludersi senza identificare una scala valida se tutti i valori di \(H_{ij}\) sono inferiori a 0.30, sottolineando l’importanza di non dipendere esclusivamente dai risultati automatici del software, ma di integrare un’analisi critica che tenga conto del contesto teorico e del contenuto degli item.
Sebbene l’AISP sia uno strumento prezioso per la costruzione delle scale di Mokken, ricerche di simulazione hanno indicato che può essere meno efficace rispetto ad altri metodi non parametrici nel determinare la vera dimensionalità dei dati, soprattutto quando le dimensioni sono correlate o gli item saturano su più dimensioni. Di conseguenza, è essenziale che i ricercatori applichino l’AISP con discernimento, esaminando attentamente vari valori di soglia \(c\) per assicurare un’interpretazione accurata della struttura dei dati.
66.10. Principio di Monotonicità nelle Scale di Mokken#
La monotonicità è un concetto cruciale nelle scale di Mokken che stabilisce come la posizione di un individuo su una variabile latente (un tratto o caratteristica non direttamente osservabile) influenzi la probabilità di rispondere correttamente a un item. Questo principio sostiene che, man mano che un individuo ascende su questa variabile latente, la sua probabilità di fornire una risposta corretta dovrebbe aumentare o, quantomeno, non diminuire. Tale concetto è applicabile sia agli item dicotomici (con due possibili risposte) sia a quelli politomici (con risposte multiple).
66.10.1. Valutazione della Monotonicità#
Uno dei metodi principali per valutare la monotonicità è attraverso l’analisi dei restscore gruppi. Il “restscore” è il punteggio totale ottenuto da una persona in un test, escludendo il punteggio dell’item specifico in esame. Ad esempio, in un test composto da 10 item, il restscore di un individuo, se si sta analizzando l’item numero 10, sarà la somma dei punteggi ottenuti negli altri 9 item.
I gruppi di restscore vengono categorizzati dal punteggio minimo al massimo possibile, escludendo l’item sotto analisi. Nei grafici, si confronta la percentuale di risposte corrette all’item in questione per ogni gruppo di restscore. Idealmente, dovremmo osservare un incremento o almeno una stabilità nella percentuale di risposte corrette all’aumentare del restscore. Se i gruppi di restscore sono numericamente limitati, compromettendo l’affidabilità delle stime, può essere utile unire gruppi adiacenti per ottenere dimensioni di campione maggiori e stime più accurate.
Il restscore agisce come un indicatore approssimativo della posizione di un individuo sulla variabile latente \( \theta \). Se la monotonicità è confermata, ci si aspetta che la percentuale di risposte corrette cresca o rimanga costante al crescere del restscore, indicando che gli individui con un restscore più elevato hanno maggiori probabilità di rispondere correttamente rispetto a coloro con un restscore inferiore.
Per illustrare il principio del restscore esaminiamo l’esempio seguente. Simuliamo i dati di 5 item. Calcoliamo il restscore per l’item 5.
# Caricare le librerie necessarie
library(dplyr)
library(ggplot2)
# Generare un set di dati per 10 rispondenti con 4 item
set.seed(42) # Per la riproducibilità
data <- as.data.frame(matrix(sample(0:1, 40, replace = TRUE, prob = c(0.5, 0.5)), nrow = 10))
# Nominare le colonne come Item1, Item2, ..., Item4
names(data) <- paste("Item", 1:4, sep = "")
# Calcolare il restscore escludendo l'Item 5 (che verrà calcolato basandosi sul restscore)
data$Restscore <- rowSums(data)
# Generare l'Item 5 basandosi sul restscore per assicurare la monotonicità
data$Item5 <- ifelse(data$Restscore <= 1, 0,
ifelse(data$Restscore <= 2, sample(c(0, 1), 1, prob = c(0.7, 0.3)), 1)
)
# Analizzare la monotonicità
# Raggruppare per restscore e calcolare la media di Item5
monotonicity_analysis <- data %>%
group_by(Restscore) %>%
summarise(
Percentuale_Risposte_Corrette = mean(Item5),
Conteggio_Rispondenti = n()
)
# Creare un grafico per visualizzare la relazione
ggplot(monotonicity_analysis, aes(x = Restscore, y = Percentuale_Risposte_Corrette)) +
geom_line(group = 1, color = "blue") +
geom_point(size = 3, color = "red") +
labs(
title = "Analisi della Monotonicità per Item 5",
x = "Restscore",
y = "Percentuale di Risposte Corrette"
) +
theme_minimal()
# Visualizzare i dati
print(monotonicity_analysis)
Attaching package: ‘dplyr’
The following objects are masked from ‘package:stats’:
filter, lag
The following objects are masked from ‘package:base’:
intersect, setdiff, setequal, union
# A tibble: 4 × 3
Restscore Percentuale_Risposte_Corrette Conteggio_Rispondenti
<dbl> <dbl> <int>
1 0 0 2
2 1 0 3
3 2 0 3
4 3 1 2
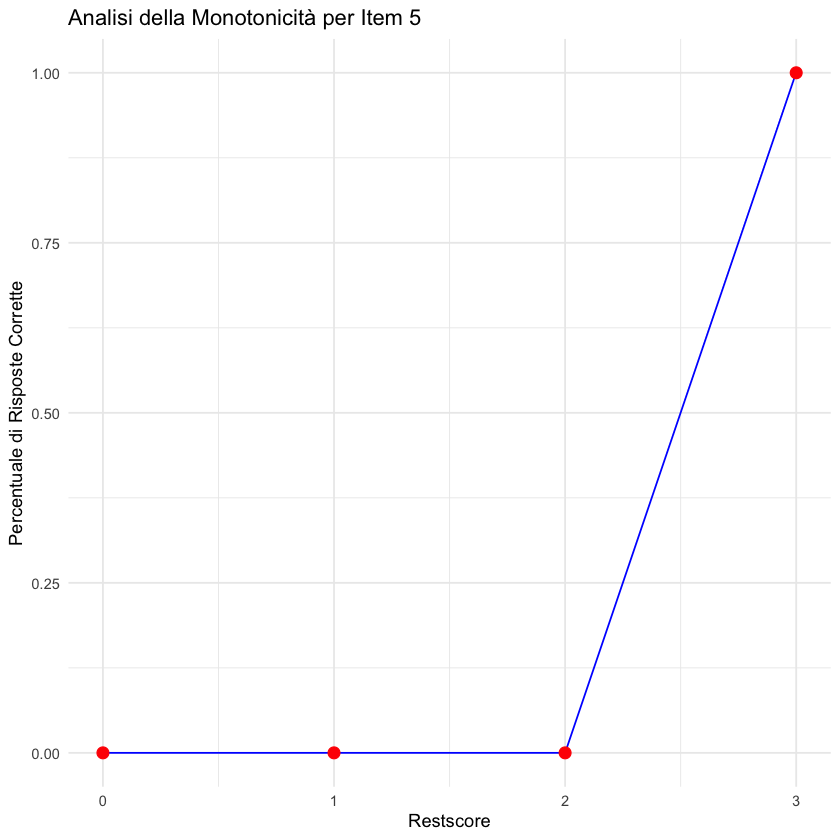
Il restscore è un punteggio complessivo ottenuto da un rispondente su tutti gli item di un test, escludendo l’item specifico che stiamo analizzando. Fornisce una misura approssimativa di dove si colloca quel rispondente sulla scala della variabile latente, che è la caratteristica o il tratto che il test intende misurare.
Asse X (Restscore): L’asse orizzontale del grafico rappresenta il restscore. I valori aumentano da sinistra a destra, indicando che il punteggio complessivo ottenuto dagli individui sugli altri item aumenta.
Asse Y (Percentuale di Risposte Corrette): L’asse verticale mostra la percentuale di risposte corrette all’item specifico che stiamo analizzando. Questo valore varia da 0 a 1, dove 0 indica nessuna risposta corretta e 1 indica che tutti i rispondenti con quel particolare restscore hanno risposto correttamente all’item.
Monotonicità: Il principio di monotonicità afferma che man mano che un individuo si colloca a livelli superiori della variabile latente (qui rappresentata dal restscore), la sua probabilità di rispondere correttamente a un item dovrebbe aumentare o almeno rimanere invariata.
Visualizzazione della Monotonicità: Nel grafico, ci aspettiamo di vedere una linea che sale o rimane costante all’aumentare del restscore. Se la linea sale, ciò indica che, come previsto, gli individui con un restscore più alto tendono a rispondere correttamente all’item più frequentemente rispetto a quelli con un restscore più basso. Questo conferma che l’item analizzato si comporta in modo monotonico rispetto alla variabile latente misurata dal test.
Anomalie: Se la linea scendesse in qualsiasi punto, ciò indicherebbe una violazione del principio di monotonicità, suggerendo che l’item potrebbe non essere appropriato per misurare il tratto in modo coeso con gli altri item del test.
In sintesi, il grafico fornisce un modo visuale e diretto per verificare se l’item specifico rispetta il principio di monotonicità rispetto alla variabile latente.
L’analisi delle IRF è fondamentale per esplorare come varia la performance degli item lungo il continuum della variabile latente. A differenza della Teoria della Risposta agli Item (IRT) parametrica, che si concentra sulla stima dei parametri specifici degli item, l’IRT non parametrico (NIRT) adottato nelle scale di Mokken utilizza metodi grafici per analizzare il funzionamento degli item a vari livelli del tratto latente.
Per gli item politomici, la valutazione della monotonicità avviene sia globalmente che per ogni categoria di risposta interna. I coefficienti di scalabilità, come \( H_i \) e \( H_{ij} \), sono impiegati per misurare la monotonicità. Se il Modello di Omogeneità Monotona (MHM) è soddisfatto, le covarianze tra tutte le coppie di item (\( H_{ij} \)) devono essere non negative. Tuttavia, covarianze \( H_{ij} \) non negative da sole non sono sufficienti per garantire funzioni di risposta consistentemente non decrescenti né confermano un adattamento completo al MHM. Generalmente, item con valori di \( H_i \) superiori a 0.30 sono considerati di buona qualità per la scala.
In conclusione, il principio di monotonicità è vitale per assicurare che le scale di Mokken siano valide e affidabili. L’analisi dei restscore e delle IRF fornisce strumenti necessari per verificare questa proprietà fondamentale, garantendo che la scala misuri efficacemente e accuratamente il tratto latente desiderato.
66.11. Il Concetto di Ordinamento Invariante degli Item nei Contesti di Valutazione#
Nell’ambito della psicometria, definire correttamente la difficoltà degli item di un test è fondamentale. L’Ordinamento Invariante degli Item (IIO) si focalizza sulla consistenza dell’ordine di difficoltà degli item attraverso vari sottogruppi di persone. Questo principio garantisce che i confronti basati sui punteggi totali tra i gruppi siano legittimi e che le differenze osservate nei punteggi riflettano distinzioni reali nelle capacità o nelle caratteristiche misurate. Ad esempio, in test psicologici come quelli che valutano la depressione o l’ansia, l’IIO suggerisce che una persona con un punteggio totale più elevato dovrebbe esibire tutti i sintomi di una persona con punteggio inferiore, più ulteriori sintomi che riflettono una maggiore severità.
L’IIO è cruciale per mantenere una progressione logica e valida degli item in un test, da quelli più facili a quelli più difficili, assicurando che tale scala sia applicabile universalmente ai partecipanti. Se un item è percepito come facile per tutti i partecipanti, e uno difficile rappresenta una sfida per tutti, l’ordinamento degli item è detto invariante.
Una violazione dell’IIO può indicare discrepanze nella percezione della difficoltà degli item tra diversi gruppi, il che può evidenziare una funzione differenziale degli item (DIF) o un bias di misurazione. Questo rende problematico ordinare gli item basandosi unicamente sulla loro difficoltà apparente.
Per verificare l’IIO, si impiegano diverse tecniche analitiche. Per esempio, il metodo dei gruppi di restscore analizza se l’ordine di difficoltà degli item rimane costante tra i gruppi formati in base ai punteggi totali escludendo l’item in questione.
66.12. Dimensione del Campione nelle Scale di Mokken#
Nell’ambito della psicometria, la determinazione della dimensione minima del campione necessaria per test statistici affidabili è un’area di interesse consolidata. Tuttavia, quando si tratta dell’Analisi delle Scale di Mokken (MSA), questo tema rimane relativamente inesplorato, e pochi studi hanno indagato specificamente su questo aspetto. È essenziale condurre ulteriori ricerche in questo campo per prevenire problemi come la capitalizzazione sul caso, ossia il rischio di identificare erroneamente scale di Mokken a causa di campioni troppo piccoli, o l’uso inefficiente di risorse in caso di campioni eccessivamente grandi.
Questo fenomeno si verifica quando un’analisi identifica una scala di Mokken che non esiste realmente, un errore spesso attribuibile a dimensioni del campione insufficienti. Al contrario, può anche capitare che una scala effettivamente esistente non venga riconosciuta a causa della stessa limitazione.
Uno studio di Straat et al. (2014) ha esplorato le dimensioni minime del campione necessarie per l’Automated Item Selection Procedure (AISP) e l’algoritmo genetico (GA) nella MSA. I ricercatori hanno analizzato l’impatto di vari fattori come la lunghezza del test, i valori dei coefficienti di scalabilità (Hi) degli item e le correlazioni tra le dimensioni delle scale. Hanno scoperto che i valori di Hi sono particolarmente determinanti: con valori più alti di Hi, sono necessarie dimensioni del campione minori per classificare correttamente gli item. La lunghezza del test ha mostrato un impatto minore, mentre le correlazioni tra le dimensioni hanno avuto un effetto variabile a seconda dei livelli di Hi. Per esempio, con un Hi di .22, erano necessari campioni tra 750 e 1000 persone per ottenere risultati mediocri, e fino a 2500 per risultati eccellenti. Con un Hi di .42, bastavano 50 persone per risultati mediocri e 250 per risultati eccellenti.
Un altro studio, condotto da Watson et al. (2018), ha investigato l’impatto della dimensione del campione sui coefficienti di scalabilità utilizzando dati reali. Hanno estratto campioni di varie dimensioni da un gruppo più ampio e hanno utilizzato il metodo del bootstrapping per analizzare gli effetti. I risultati hanno mostrato che, sebbene i valori medi di Hi rimanessero costanti, campioni più piccoli tendevano a produrre intervalli di confidenza più ampi, indicando una maggiore incertezza nelle stime.
Questi studi sottolineano l’importanza di selezionare con attenzione la dimensione del campione nell’analisi delle Scale di Mokken. Mentre i valori medi di scalabilità possono rimanere stabili, la precisione delle stime e la fiducia nelle conclusioni sulla qualità degli item sono fortemente influenzate dalla dimensione del campione. Una dimensione adeguata del campione è cruciale per garantire l’affidabilità e la validità dei risultati, soprattutto quando si operano in condizioni di risorse limitate.
66.13. Il Ruolo della MSA nella Validazione dei Test Psicometrici#
L’Analisi delle Scale di Mokken (MSA) è un metodo utile per la validazione dei test psicometrici, centrato sul modello di omogeneità monotona. La validità di questo modello si afferma quando sono soddisfatte le condizioni di unidimensionalità, monotonicità, e indipendenza locale. In particolare, se i coefficienti di scalabilità H, Hi e Hij sono positivi e significativamente maggiori di zero — idealmente superiori a 0.30 — si può concludere che i dati aderiscono efficacemente a una struttura di Guttman, indicando la presenza di un costrutto unidimensionale.
La conformità al modello di omogeneità monotona implica che la relazione tra la variabile latente \( \theta \) e la probabilità di risposta corretta sia non decrescente. Questa caratteristica corrisponde al criterio di validità che aspetta che variazioni nella variabile latente si riflettano in maniera coerente nelle risposte agli item.
Un elemento avanzato della MSA è il modello di doppia monotonicità, che incorpora l’assunzione dell’Ordinamento Invariante degli Item (IIO). Questo principio sostiene che le Funzioni di Risposta all’Item (IRF) non debbano intersecarsi, aumentando così l’interpretabilità dei punteggi dei test. Anche se una violazione dell’IIO non invalida necessariamente un test, il suo rispetto garantisce una maggiore precisione e riduce il rischio di bias dovuto a funzione differenziale dell’item (DIF), simile a quanto accade nei modelli IRT parametrici.
La MSA dimostra di essere uno strumento prezioso nella validazione di test in contesti psicologici. Confermare il modello di omogeneità monotona attraverso i coefficienti di scalabilità fornisce prove concrete che i test misurano con precisione il costrutto unidimensionale previsto. Questo è essenziale per assicurare che i punteggi dei test riflettano accuratamente le caratteristiche o le capacità misurate.
L’integrazione dell’Ordinamento Invariante degli Item nel modello di doppia monotonicità introduce un ulteriore livello di rigore. Assicurando che le IRF degli item non si intersechino, si migliora notevolmente la capacità di un test di misurare il costrutto in modo equo per tutti i partecipanti, indipendentemente dalle loro caratteristiche individuali.
66.14. Critiche e Difese dell’Analisi delle Scale Mokken#
L’Analisi delle Scale Mokken (MSA) ha affrontato varie critiche sin dagli anni ‘80, soprattutto per quanto riguarda la limitata applicabilità del coefficiente di scalabilità H. Questo parametro è stato ritenuto dipendente dalle specificità del campione e degli item, rendendolo inadatto come misura universale di adattamento del modello. Altre critiche hanno preso di mira il coefficiente di scalabilità degli item Hi, sostenendo che favorisca la selezione di item con Funzioni di Risposta all’Item (IRF) particolarmente ripide e spaziate, escludendo così item validi che potrebbero ridurre la varianza e l’affidabilità complessiva del test. Si è inoltre messa in discussione la capacità della MSA di supportare un ordinamento libero degli item basato sul rango latente, portando alcuni a considerare l’adozione del modello di Rasch come alternativa più robusta.
In difesa della MSA, i suoi sostenitori hanno contrattaccato affermando che le critiche derivano spesso da una lettura selettiva e da una mancata comprensione della natura dei modelli non parametrici. Essi hanno chiarito che i coefficienti H e Hi sono specificamente progettati per misurare l’omogeneità monotona, e non dovrebbero essere confusi con indicatori di doppia monotonia. Hanno anche evidenziato che la dipendenza di H dalla varianza del campione riflette le assunzioni intrinseche del modello, contestualizzando correttamente la sua applicabilità.
Questo dibattito sottolinea l’importanza di comprendere e valutare i metodi statistici come la MSA all’interno del loro specifico contesto di applicazione, considerando le loro potenzialità e limitazioni. La discussione continua a stimolare una riflessione critica sulla selezione e sull’uso di strumenti statistici appropriati nella ricerca psicometrica e educativa.
66.15. Considerazioni Finali#
In questo capitolo, abbiamo affrontato una questione cruciale nella misurazione psicologica: l’efficacia dei punteggi totali grezzi nel classificare gli esaminandi. Tradizionalmente, questi punteggi sono impiegati per ordinare i soggetti su un continuum, dalla maggiore alla minore competenza, ansietà, o depressione. Sebbene sia generalmente riconosciuto che i punteggi grezzi rappresentino una scala ordinale, molti ricercatori li trattano come se appartenessero a una scala ad intervalli. Questo approccio implica che i punteggi grezzi possano stabilire soltanto l’ordine tra i rispondenti, ma non quantificare le distanze tra le loro performance.
Un punto cruciale sollevato in questo capitolo è che i punteggi totali grezzi potrebbero non rappresentare nemmeno una scala ordinale adeguata. Ciò significa che tali punteggi potrebbero non essere sufficientemente affidabili per ordinare correttamente gli esaminandi. Affinché i punteggi grezzi siano considerati effettivamente ordinali, i pattern di risposta degli esaminandi devono conformarsi al Modello di Omogeneità Monotona (MHM). Contrariamente alla teoria classica dei test, che presume che i punteggi totali siano ordinali senza ulteriori verifiche, il MHM, un approccio della Teoria della Risposta agli Item (IRT) non parametrica, ci consente di testare questa assunzione. Lo stesso approccio si applica agli item: l’adattamento al Modello di Doppia Monotonicità (DMM) permette di ordinare gli item in base alla percentuale di risposte corrette, o valore p.
In questo contesto, abbiamo esplorato l’Analisi delle Scale Mokken, un insieme di procedure utilizzate per testare l’adattamento dei dati al MHM e al DMM. Queste analisi forniscono strumenti essenziali per valutare l’affidabilità e la validità dei punteggi totali grezzi impiegati in vari contesti psicologici. L’approfondimento di questi metodi rafforza la nostra comprensione e fiducia nell’uso dei punteggi grezzi, garantendo che essi riflettano accuratamente le caratteristiche psicologiche che intendono misurare.