41. Dati non gaussiani e categoriali#
Nel materiale precedente di questa dispensa è stato discusso l’utilizzo dello stimatore di massima verosimiglianza (ML), comunemente adottato nei modelli di Analisi Fattoriale Confermativa (CFA) e Structural Equation Modeling (SEM) presenti nella letteratura di ricerca applicata. Tuttavia, l’uso dello stimatore ML è appropriato esclusivamente per dati multivariati normali, ovvero quando la distribuzione congiunta delle variabili continue è normalmente distribuita. In presenza di dati continui che presentano una forte deviazione dalla normalità, come asimmetria o curtosi elevate, o quando gli indicatori non sono a livello di scala intervallare (per esempio, dati binari, politomici o ordinali), è consigliabile adottare stimatori alternativi al ML.
41.1. Dati non Gaussiani e Stimatori Alternativi#
Nonostante la stima di massima verosimiglianza (ML) rimanga robusta a piccole deviazioni dalla normalità, situazioni di marcata non normalità richiedono l’adozione di stimatori alternativi per preservare l’affidabilità statistica. L’uso del ML in tali condizioni può portare a:
Sovrastima della statistica chi-quadrato (\(\chi^2\)) del modello;
Sottostima degli indici di bontà di adattamento, come il Tucker-Lewis Index (TLI) e il Comparative Fit Index (CFI);
Sottostima degli errori standard delle stime dei parametri.
Questi problemi si accentuano in campioni di dimensioni ridotte. Per mitigare tali effetti, si raccomanda l’uso dei seguenti stimatori:
GLS (Generalized Least Squares):
Uso: Adatto per dati completi senza valori mancanti.
Funzione di Discrepanza: La funzione di discrepanza del GLS misura quanto la matrice di covarianza stimata dal modello (\(\Sigma(\theta)\)) si differenzia dalla matrice di covarianza osservata (\(S\)). La formula \(F_{\text{GLS}}(S, \Sigma(\theta)) = \frac{1}{2} \text{traccia}(S - \Sigma(\theta))^2\) utilizza la traccia (la somma degli elementi sulla diagonale principale della matrice) per quantificare questa differenza.
Interpretazione: Un valore più basso della funzione di discrepanza indica un migliore adattamento del modello ai dati.
WLS (Weighted Least Squares):
Uso: Conosciuto come stimatore Asintoticamente Libero da Distribuzione (ADF), utile per dati complessi.
Funzione di Discrepanza: \(F_{\text{ADF}}(S, \Sigma(\theta)) = \text{vecs}(S - \Sigma(\theta))'W\text{vecs}(S - \Sigma(\theta))\). Qui,
vecs()trasforma la matrice di covarianza in un vettore (prendendo solo la parte inferiore della matrice), eWè una matrice di pesi che dà diversa importanza ai vari elementi nel calcolo della discrepanza.Interpretazione: Un valore più basso indica che il modello si adatta meglio ai dati, tenendo conto della ponderazione specifica di
W.
DWLS (Diagonally Weighted Least Squares):
Uso: Una versione semplificata di WLS.
Funzione di Discrepanza: \(F_{\text{DWLS}}(S, \Sigma(\theta)) = \text{vecs}(S - \Sigma(\theta))'D\text{vecs}(S - \Sigma(\theta))\), dove
Dè una matrice di pesi diagonale.Interpretazione: Simile a WLS, ma semplifica i calcoli usando solo una matrice di pesi diagonale, che considera solo gli elementi sulla diagonale della matrice di covarianza.
ULS (Unweighted Least Squares):
Uso: Considerato un caso speciale di WLS.
Funzione di Discrepanza: \(F_{\text{ULS}}(S, \Sigma(\theta)) = \text{vecs}(S - \Sigma(\theta))'\text{vecs}(S - \Sigma(\theta))\). Qui, si utilizza una matrice di identità come peso, il che significa che tutti gli elementi hanno lo stesso peso nel calcolo della discrepanza.
Interpretazione: Un approccio più diretto rispetto a WLS, che non pondera gli elementi in modo diverso. Un valore più basso indica un migliore adattamento del modello.
In sintesi, questi stimatori vengono utilizzati per valutare quanto bene un modello SEM si adatti ai dati. Differiscono nel modo in cui trattano le discrepanze tra i dati osservati e quelli stimati dal modello, e ciascuno ha specifiche situazioni in cui risulta più appropriato.
41.1.1. ML Robusto: Adattamento in Presenza di Non Normalità#
Oltre ai quattro metodi di stima già menzionati (GLS, WLS, DWLS, ULS), un altro stimatore importante nel contesto del Structural Equation Modeling (SEM) è il ML Robusto (Robust Maximum Likelihood). Il ML Robusto è una variante della stima di massima verosimiglianza tradizionale, progettata per migliorare l’affidabilità statistica quando i dati deviano significativamente dalla normalità. Questo stimatore:
Corregge la Sovrastima di \(\chi^2\): Offre una correzione alla sovrastima della statistica chi-quadrato tipica del ML tradizionale.
Errore Standard Affidabile: Fornisce stime più accurate degli errori standard, cruciali in presenza di non normalità.
Migliora Indici di Bontà di Adattamento: Offre valutazioni più precise di indici come TLI e CFI.
In conclusione, l’adozione di stimatori come il ML Robusto o il WLS si rivela essenziale per garantire l’integrità delle analisi SEM in presenza di dati non normali, specialmente quando le dimensioni del campione sono limitate o i dati presentano caratteristiche complesse.
Esempio. Esaminiamo qui un esempio discusso da Brown [Bro15] (tabelle 9.5 – 9.7).
d <- readRDS(here::here("data", "brown_table_9_5_data.RDS"))
head(d)
| x1 | x2 | x3 | x4 | x5 | |
|---|---|---|---|---|---|
| <int> | <int> | <int> | <int> | <int> | |
| 1 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 | 0 | 0 |
| 4 | 4 | 2 | 2 | 1 | 1 |
| 5 | 1 | 0 | 1 | 6 | 0 |
| 6 | 0 | 0 | 0 | 0 | 0 |
Le statistiche descrittive di questo campione di dati mostrano valori eccessivi di asimmetria e di curtosi.
psych::describe(d)
| vars | n | mean | sd | median | trimmed | mad | min | max | range | skew | kurtosis | se | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| <int> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | |
| x1 | 1 | 870 | 1.4701149 | 2.172832 | 0 | 1.0086207 | 0 | 0 | 8 | 8 | 1.506406 | 1.252591 | 0.07366591 |
| x2 | 2 | 870 | 0.8229885 | 1.601474 | 0 | 0.4152299 | 0 | 0 | 8 | 8 | 2.398394 | 5.670143 | 0.05429505 |
| x3 | 3 | 870 | 1.2655172 | 2.070024 | 0 | 0.7772989 | 0 | 0 | 8 | 8 | 1.797942 | 2.343203 | 0.07018040 |
| x4 | 4 | 870 | 1.0264368 | 1.928047 | 0 | 0.5359195 | 0 | 0 | 8 | 8 | 2.157445 | 3.977564 | 0.06536693 |
| x5 | 5 | 870 | 0.6068966 | 1.519175 | 0 | 0.1839080 | 0 | 0 | 8 | 8 | 3.103965 | 9.373781 | 0.05150485 |
Definiamo un modello ad un fattore e, seguendo Brown [Bro15], aggiungiamo una correlazione residua tra gli indicatori X1 e X3:
model <- '
f1 =~ x1 + x2 + x3 + x4 + x5
x1 ~~ x3
'
Procediamo alla stima dei parametri utilizzando uno stimatore di ML robusto. La sintassi lavaan è la seguente:
fit <- cfa(model, data = d, mimic = "MPLUS", estimator = "MLM")
Per esaminare la soluzione ottenuta ci focalizziamo sulla statistica \(\chi^2\) – si consideri la soluzione robusta fornita nell’output.
out <- summary(fit)
print(out)
lavaan 0.6.17 ended normally after 28 iterations
Estimator ML
Optimization method NLMINB
Number of model parameters 16
Number of observations 870
Model Test User Model:
Standard Scaled
Test Statistic 25.913 10.356
Degrees of freedom 4 4
P-value (Chi-square) 0.000 0.035
Scaling correction factor 2.502
Satorra-Bentler correction (Mplus variant)
Parameter Estimates:
Standard errors Robust.sem
Information Expected
Information saturated (h1) model Structured
Latent Variables:
Estimate Std.Err z-value P(>|z|)
f1 =~
x1 1.000
x2 0.703 0.062 11.338 0.000
x3 1.068 0.044 24.304 0.000
x4 0.918 0.063 14.638 0.000
x5 0.748 0.055 13.582 0.000
Covariances:
Estimate Std.Err z-value P(>|z|)
.x1 ~~
.x3 0.655 0.143 4.579 0.000
Intercepts:
Estimate Std.Err z-value P(>|z|)
.x1 1.470 0.074 19.968 0.000
.x2 0.823 0.054 15.166 0.000
.x3 1.266 0.070 18.043 0.000
.x4 1.026 0.065 15.712 0.000
.x5 0.607 0.051 11.790 0.000
Variances:
Estimate Std.Err z-value P(>|z|)
.x1 2.040 0.228 8.952 0.000
.x2 1.241 0.124 10.019 0.000
.x3 1.227 0.169 7.255 0.000
.x4 1.458 0.177 8.233 0.000
.x5 0.807 0.100 8.063 0.000
f1 2.675 0.289 9.273 0.000
Per fare un confronto, adattiamo lo stesso modello ai dati usando lo stimatore di ML.
fit2 <- cfa(model, data = d)
Notiamo come il valore della statistica \(\chi^2\) ora ottenuto sia molto maggiore di quello trovato in precedenza.
out <- summary(fit2)
print(out)
lavaan 0.6.17 ended normally after 28 iterations
Estimator ML
Optimization method NLMINB
Number of model parameters 11
Number of observations 870
Model Test User Model:
Test statistic 25.913
Degrees of freedom 4
P-value (Chi-square) 0.000
Parameter Estimates:
Standard errors Standard
Information Expected
Information saturated (h1) model Structured
Latent Variables:
Estimate Std.Err z-value P(>|z|)
f1 =~
x1 1.000
x2 0.703 0.035 20.133 0.000
x3 1.068 0.034 31.730 0.000
x4 0.918 0.042 21.775 0.000
x5 0.748 0.033 22.416 0.000
Covariances:
Estimate Std.Err z-value P(>|z|)
.x1 ~~
.x3 0.655 0.091 7.213 0.000
Variances:
Estimate Std.Err z-value P(>|z|)
.x1 2.040 0.128 15.897 0.000
.x2 1.241 0.070 17.671 0.000
.x3 1.227 0.095 12.942 0.000
.x4 1.458 0.090 16.135 0.000
.x5 0.807 0.053 15.119 0.000
f1 2.675 0.220 12.154 0.000
41.1.2. Dati Categoriali#
Nella discussione precedente, abbiamo esaminato il modello CFA presupponendo che i dati fossero continui e normalmente distribuiti in maniera multivariata. Tuttavia, abbiamo anche trattato la stima robusta per dati non normalmente distribuiti. Ora, è fondamentale riconoscere che molti dei dati utilizzati nelle analisi fattoriali confermative (CFA) o SEM provengono da questionari e scale di tipo Likert, che producono dati categoriali, inclusi formati binari, ordinali e nominali. Questi dati sono di natura ordinale e non sono continui.
L’uso del metodo di massima verosimiglianza (ML) ordinario non è raccomandato quando si analizzano dati con almeno un indicatore categoriale. Trattare tali variabili come se fossero continue può portare a varie conseguenze indesiderate, tra cui:
Stime Attenuate delle Relazioni: Le relazioni tra gli indicatori possono risultare attenuate, specialmente se influenzate da effetti di pavimento o soffitto.
Emergenza di “Pseudo-Fattori”: La possibilità di identificare falsi fattori, che non rappresentano veri costrutti ma sono piuttosto artefatti del metodo statistico utilizzato.
Distorsione degli Indici di Bontà di Adattamento e delle Stime degli Errori Standard: Questi indici, che valutano la qualità dell’adattamento del modello, possono essere distorti, così come le stime degli errori standard.
Stime Errate dei Parametri: I parametri del modello potrebbero essere stimati in modo inaccurato.
Per mitigare questi problemi, esistono stimatori specifici per i dati categoriali, tra cui:
WLS (Weighted Least Squares): Adatto per dati categoriali, considera il peso specifico di ciascuna osservazione.
WLSMV (Weighted Least Squares Mean and Variance Adjusted): Una versione modificata di WLS che si adatta meglio alle peculiarità dei dati categoriali.
ULS (Unweighted Least Squares): Questo stimatore non prevede ponderazioni e può essere utile per dati categoriali senza presupporre pesi specifici.
Nelle sezioni seguenti, approfondiremo l’approccio CFA per dati categoriali, evidenziando le specificità e le migliori pratiche per gestire questo tipo di dati nelle analisi CFA. Questo ci permetterà di effettuare inferenze più accurate, preservando l’integrità e la validità delle conclusioni derivanti dalle analisi.
41.1.3. Un esempio concreto#
Nell’esempio discusso da Brown [Bro15], i ricercatori desiderano verificare un modello uni-fattoriale di dipendenza da alcol in un campione di 750 pazienti ambulatoriali. Gli indicatori di alcolismo sono item binari che riflettono la presenza/assenza di sei criteri diagnostici per l’alcolismo (0 = criterio non soddisfatto, 1 = criterio soddisfatto). I dati sono i seguenti:
d1 <- readRDS(here::here("data", "brown_table_9_9_data.RDS"))
head(d1)
| y1 | y2 | y3 | y4 | y5 | y6 | |
|---|---|---|---|---|---|---|
| <int> | <int> | <int> | <int> | <int> | <int> | |
| 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 2 | 1 | 1 | 1 | 1 | 1 | 1 |
| 3 | 1 | 1 | 1 | 1 | 1 | 0 |
| 4 | 1 | 1 | 1 | 1 | 1 | 1 |
| 5 | 0 | 0 | 0 | 0 | 0 | 0 |
| 6 | 1 | 1 | 0 | 1 | 1 | 1 |
È possibile evidenziare la natura ordinale dei dati esaminando le tabelle bivariate che mostrano la frequenza di combinazioni specifiche tra due variabili.
xtabs(~ y1 + y2, d1)
y2
y1 0 1
0 103 65
1 156 426
xtabs(~ y3 + y4, d1)
y4
y3 0 1
0 41 39
1 119 551
xtabs(~ y5 + y6, d1)
y6
y5 0 1
0 95 168
1 60 427
Nelle tabelle precedenti, si osserva una maggiore frequenza di casi in cui entrambe le variabili assumono il valore 1, rispetto ai casi in cui entrambe sono 0 o in cui una è 1 e l’altra è 0. Questo suggerisce l’esistenza di una relazione ordinale tra le coppie di variabili nel dataset.
41.1.4. Il Modello Basato sulle Soglie per Risposte Categoriali Ordinate#
Il modello basato sulle soglie per risposte categoriali ordinate si basa sull’idea che ogni risposta di una variabile categoriale possa essere vista come il risultato di una variabile continua non osservata, che è normalmente distribuita. Questa variabile nascosta, chiamata variabile latente, rappresenta la tendenza di una persona a rispondere in un determinato modo. Le risposte che vediamo, classificate in categorie, sono in realtà approssimazioni di questa variabile latente.
Immaginiamo di utilizzare un questionario dove le risposte sono su una scala Likert a 7 punti. Questo crea una variabile categoriale con sette categorie ordinate. Se denotiamo con I un particolare item del questionario e con I* la sua corrispondente variabile latente non osservabile, possiamo descrivere il loro legame attraverso le seguenti equazioni, che mappano la variabile latente alle risposte osservabili:
In queste equazioni, \( t_i \) (con i da 1 a 6) rappresenta le soglie che dividono l’intero spettro della variabile latente in sette categorie. Le soglie sono disposte in modo che \( -\infty < t_1 < t_2 < t_3 < t_4 < t_5 < t_6 < \infty \). È importante notare che il numero di soglie è sempre uno in meno rispetto al numero di categorie, un po’ come il numero di variabili dummy usate nell’analisi di regressione per codificare una variabile categoriale.
Questo processo di categorizzazione può essere visualizzato come segue: si immagini una curva normale che rappresenta la distribuzione della variabile latente I*. Le sei linee verticali nella figura rappresentano le soglie \( t_1 \) a \( t_6 \). Le risposte possibili vanno da I = 1 a I = 7, e la categoria specifica (I) dipende dall’intervallo, definito dalle soglie, in cui il valore di I* si trova.
# Definire le soglie
thresholds <- c(-3, -2, -1, 0, 1, 2, 3)
# Creare un dataframe per la curva normale
x_values <- seq(-4, 4, length.out = 300)
y_values <- dnorm(x_values)
curve_data <- data.frame(x = x_values, y = y_values)
# Creare il plot
ggplot(curve_data, aes(x = x, y = y)) +
geom_line() +
geom_vline(xintercept = thresholds, col = "red") +
scale_y_continuous(breaks = NULL) +
scale_x_continuous(breaks = thresholds, labels = c("t1", "t2", "t3", "t4", "t5", "t6", "t7")) +
labs(
title = "Categorization of Latent Continuous Variable to Categorical Variable",
x = "Latent Continuous Variable I*",
y = ""
) +
theme_minimal()
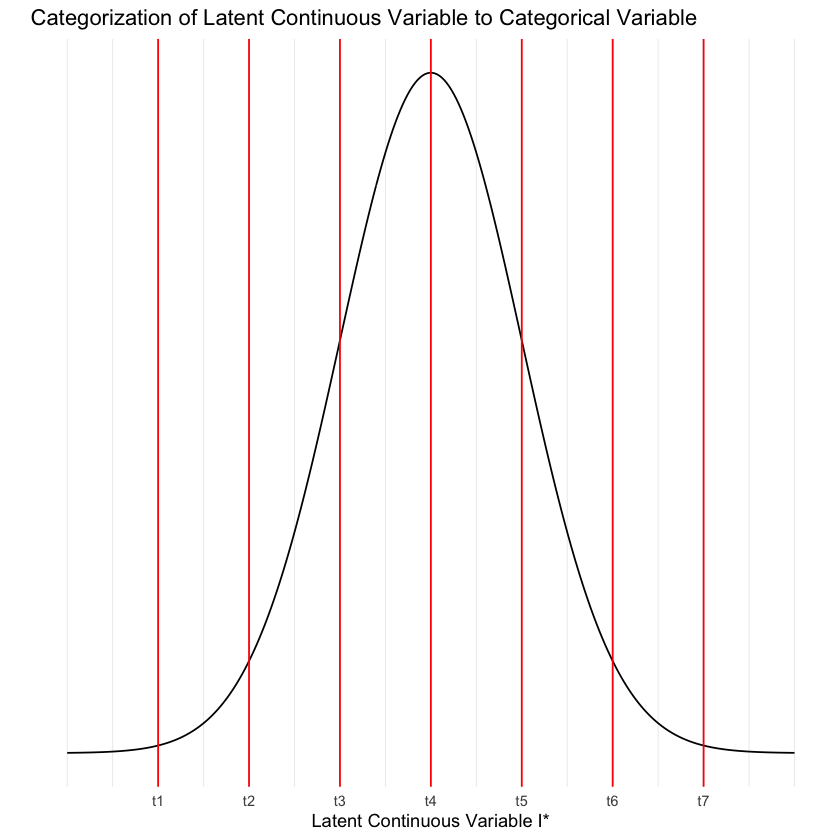
La conversione della variabile latente \( I^* \) in dati su una scala Likert comporta inevitabilmente degli errori di misurazione e campionamento. Come evidenziato da O’Brien (1985), questo processo di categorizzazione introduce due tipi principali di errore:
Errore di categorizzazione: Questo errore deriva dalla segmentazione di una scala continua in una scala categoriale, dove la variabile latente viene divisa in categorie distinte.
Errore di trasformazione: Questo errore emerge quando le categorie hanno larghezze disuguali, influenzando la fedeltà della rappresentazione delle misure originali della variabile latente.
Di conseguenza, è fondamentale che le soglie siano stimate contemporaneamente agli altri parametri nel modello di equazioni strutturali per garantire che tali errori siano minimizzati e che l’analisi rifletta accuratamente la realtà sottostante.
41.1.5. Modellazione di Variabili Categoriali nei Modelli CFA#
Nell’ambito dei modelli CFA, le variabili categoriali ordinate vengono spesso modellate collegandole a una variabile latente sottostante, denominata \( I^* \). Questa variabile latente rappresenta una sorta di “propensione nascosta” che influisce sulle risposte osservate nelle variabili categoriali.
Per esemplificare, consideriamo il seguente modello che esprime la variabile latente \( I^* \) attraverso una serie di predittori (x1, x2, …, xp), ognuno dei quali contribuisce all’esito con un effetto quantificato dai coefficienti \( \beta_1, \beta_2, ..., \beta_P \):
In questa equazione:
\( I^*_i \) indica la propensione latente per l’osservatore \( i \).
\( \beta_0 \) è un termine costante che agisce come intercetta.
\( \beta_1, \dots, \beta_P \) sono i coefficienti che misurano l’impatto di ciascun predittore sulla propensione latente.
\( e_i \) è il termine di errore che rappresenta le variazioni non spiegate dai predittori.
Quando la variabile categoriale \( I \) funge da indicatore di un fattore latente \( \xi \) in un modello fattoriale confermativo, la formulazione dell’equazione si semplifica a:
In questa configurazione, \( \beta_1 \) rappresenta il carico fattoriale, indicando quanto fortemente il fattore latente \( \xi \) influisce sulla variabile latente \( I^* \). Questo schema è analogo a quello usato per modellare indicatori di misurazione continui nei modelli SEM.
Questo approccio riflette l’idea che le risposte categoriali osservabili possono essere considerate come manifestazioni esterne di una propensione interna latente. Per la stima di tali modelli, il metodo dei minimi quadrati ponderati (WLS) è generalmente appropriato. Tuttavia, è importante tenere presente che la modellazione di risposte categoriali ordinate può richiedere considerazioni aggiuntive per gestire adeguatamente la loro natura ordinale, dettagli che verranno approfonditi nelle sezioni seguenti.
41.1.6. Adattamento del Modello con lmer#
Specifichiamo il modello nel modo seguente:
model1 <- '
etoh =~ y1 + y2 + y3 + y4 + y5 + y6
'
Nell’analizzare dati ottenuti da scale ordinali, il software lavaan impiega un metodo specializzato per gestire la natura particolare dei dati categoriali. Questo approccio utilizza lo stimatore WLSMV (Weighted Least Squares Mean and Variance Adjusted). La stima dei parametri avviene tramite il metodo dei minimi quadrati ponderati diagonalmente (DWLS), che si concentra sulle componenti diagonali della matrice di peso. Questa specificità rende lo stimatore WLSMV particolarmente adatto per analizzare dati non normali.
Una caratteristica importante dello stimatore WLSMV è la sua capacità di calcolare errori standard robusti. Questi sono determinati attraverso un metodo che mantiene l’affidabilità delle stime anche quando i dati non soddisfano le tradizionali assunzioni di normalità. Inoltre, le statistiche di test prodotte da WLSMV sono adeguatamente corrette per tenere conto delle variazioni nella media e nella varianza dei dati. Questo tipo di correzione è cruciale per garantire l’accuratezza e la validità delle statistiche di test, specialmente quando la distribuzione dei dati devia dalla normalità.
In conclusione, lavaan offre un approccio avanzato per la modellazione di dati categoriali utilizzando lo stimatore WLSMV, che è ottimizzato per rispondere alle esigenze specifiche di questi tipi di dati. Questo si traduce in stime più precise e statistiche di test affidabili, rendendo lavaan uno strumento molto appropriato per l’analisi di dati categoriali complessi.
fit1 <- cfa(
model1,
data = d1,
ordered = names(d1),
estimator = "WLSMVS",
mimic = "mplus"
)
Esaminiamo la soluzione ottenuta:
out = summary(fit1, fit.measures = TRUE)
print(out)
lavaan 0.6.17 ended normally after 16 iterations
Estimator DWLS
Optimization method NLMINB
Number of model parameters 12
Number of observations 750
Model Test User Model:
Standard Scaled
Test Statistic 5.651 9.540
Degrees of freedom 9 9
P-value (Chi-square) 0.774 0.389
Scaling correction factor 0.592
mean and variance adjusted correction (WLSMV)
Model Test Baseline Model:
Test statistic 1155.845 694.433
Degrees of freedom 15 9
P-value 0.000 0.000
Scaling correction factor 1.664
User Model versus Baseline Model:
Comparative Fit Index (CFI) 1.000 0.999
Tucker-Lewis Index (TLI) 1.005 0.999
Root Mean Square Error of Approximation:
RMSEA 0.000 0.009
90 Percent confidence interval - lower 0.000 0.000
90 Percent confidence interval - upper 0.028 0.051
P-value H_0: RMSEA <= 0.050 0.999 0.944
P-value H_0: RMSEA >= 0.080 0.000 0.000
Standardized Root Mean Square Residual:
SRMR 0.031 0.031
Parameter Estimates:
Parameterization Delta
Standard errors Robust.sem
Information Expected
Information saturated (h1) model Unstructured
Latent Variables:
Estimate Std.Err z-value P(>|z|)
etoh =~
y1 1.000
y2 0.822 0.072 11.392 0.000
y3 0.653 0.092 7.097 0.000
y4 1.031 0.075 13.703 0.000
y5 1.002 0.072 13.861 0.000
y6 0.759 0.076 10.011 0.000
Thresholds:
Estimate Std.Err z-value P(>|z|)
y1|t1 -0.759 0.051 -14.890 0.000
y2|t1 -0.398 0.047 -8.437 0.000
y3|t1 -1.244 0.061 -20.278 0.000
y4|t1 -0.795 0.051 -15.436 0.000
y5|t1 -0.384 0.047 -8.148 0.000
y6|t1 -0.818 0.052 -15.775 0.000
Variances:
Estimate Std.Err z-value P(>|z|)
.y1 0.399
.y2 0.594
.y3 0.744
.y4 0.361
.y5 0.397
.y6 0.653
etoh 0.601 0.063 9.596 0.000
Si presti particolare attenzione alla seguente porzione dell’output:
Estimate Std.Err z-value P(>|z|)
y1|t1 -0.759 0.051 -14.890 0.000
y2|t1 -0.398 0.047 -8.437 0.000
y3|t1 -1.244 0.061 -20.278 0.000
y4|t1 -0.795 0.051 -15.436 0.000
y5|t1 -0.384 0.047 -8.148 0.000
y6|t1 -0.818 0.052 -15.775 0.000
In questa porzione dell’output di lavaan sono presentati i risultati per le “soglie” (thresholds) relative alle variabili categoriali ordinate utilizzate nel modello SEM. Ecco una spiegazione dettagliata:
Thresholds (Soglie):
Ogni soglia rappresenta un punto di cutoff lungo la variabile continua latente (indicata in precedenza come I*), che determina le categorie della variabile categoriale osservata.
Nell’output,
y1|t1,y2|t1, ecc., rappresentano soglie per le variabili rispettive (y1, y2, …, y6). Il termine “t1” si riferisce alla prima soglia per ciascuna di queste variabili.
Estimate (Stima):
Questi valori indicano la posizione della soglia sulla scala della variabile continua latente. Per esempio, la soglia per y1 è a -0.759. Questo significa che la divisione tra le prime due categorie di y1 si verifica a -0.759 sulla scala della variabile latente.
Std.Err (Errore Standard):
L’errore standard della stima di ogni soglia. Ad esempio, per y1, l’errore standard è 0.051. Questo offre un’idea della variabilità o incertezza nella stima della soglia.
z-value:
Il valore z indica il rapporto tra la stima della soglia e il suo errore standard. Un valore z elevato suggerisce che la stima della soglia è significativamente diversa da zero (ovvero, la soglia è ben definita). Per esempio, per y1, il valore z è -14.890, che è statisticamente significativo.
P(>|z|):
Il p-value associato al valore z. Un p-value basso (ad esempio, 0.000) indica che la stima della soglia è statisticamente significativa. Questo significa che possiamo essere abbastanza sicuri che la posizione della soglia sulla variabile latente sia accurata e non dovuta al caso.
In sintesi, queste soglie consentono di trasformare la variabile latente continua in una variabile categoriale osservata nel modello. La stima di queste soglie e la loro significatività statistica sono cruciali per comprendere come la variabile latente si traduce nelle categorie osservate.
Confrontiamo ora la soluzione ottenuta con lo stimatore WLSMVS con quella ottenuta mediante lo stimatore ML.
fit2 <- cfa(
model1,
data = d1
)
out <- summary(fit2, fit.measures = TRUE)
print(out)
lavaan 0.6.17 ended normally after 35 iterations
Estimator ML
Optimization method NLMINB
Number of model parameters 12
Number of observations 750
Model Test User Model:
Test statistic 14.182
Degrees of freedom 9
P-value (Chi-square) 0.116
Model Test Baseline Model:
Test statistic 614.305
Degrees of freedom 15
P-value 0.000
User Model versus Baseline Model:
Comparative Fit Index (CFI) 0.991
Tucker-Lewis Index (TLI) 0.986
Loglikelihood and Information Criteria:
Loglikelihood user model (H0) -2087.600
Loglikelihood unrestricted model (H1) -2080.508
Akaike (AIC) 4199.199
Bayesian (BIC) 4254.640
Sample-size adjusted Bayesian (SABIC) 4216.535
Root Mean Square Error of Approximation:
RMSEA 0.028
90 Percent confidence interval - lower 0.000
90 Percent confidence interval - upper 0.054
P-value H_0: RMSEA <= 0.050 0.914
P-value H_0: RMSEA >= 0.080 0.000
Standardized Root Mean Square Residual:
SRMR 0.021
Parameter Estimates:
Standard errors Standard
Information Expected
Information saturated (h1) model Structured
Latent Variables:
Estimate Std.Err z-value P(>|z|)
etoh =~
y1 1.000
y2 0.934 0.093 10.057 0.000
y3 0.390 0.055 7.038 0.000
y4 1.008 0.087 11.541 0.000
y5 1.158 0.101 11.468 0.000
y6 0.700 0.077 9.142 0.000
Variances:
Estimate Std.Err z-value P(>|z|)
.y1 0.109 0.007 14.692 0.000
.y2 0.169 0.010 16.781 0.000
.y3 0.085 0.005 18.483 0.000
.y4 0.102 0.007 14.285 0.000
.y5 0.140 0.010 14.506 0.000
.y6 0.132 0.008 17.514 0.000
etoh 0.065 0.009 7.664 0.000
Si noti che la soluzione ottenuta mediante lo stimatore WLSMVS produce indici di bontà di adattamento migliori e errori standard dei parametri più piccoli.
41.2. Considerazioni Conclusive#
In questo capitolo, abbiamo esplorato la modellazione CFA con dati non normalmente distribuiti. È essenziale riconoscere che, nella pratica analitica, incontrare dati non normalmente distribuiti dovrebbe essere considerato normale. Di conseguenza, si raccomanda l’utilizzo della massima verosimiglianza robusta (ML robusta) ogni volta che sorgono dubbi sulla normalità dei dati.
Ci sono alcune considerazioni importanti da tenere presente:
Stabilità delle stime di parametro: Anche se le versioni robuste di ML forniscono errori standard robusti e statistiche di test adattate, le stime dei parametri ottenute rimangono quelle della stima ML originale.
Robustezza limitata: Gli aggiustamenti robusti compensano la violazione della normalità, ma non coprono la presenza di valori anomali, che richiedono un’analisi separata.
Limitazioni degli aggiustamenti: Gli aggiustamenti robusti non trattano violazioni delle specifiche del modello, che è un altro argomento di discussione nella letteratura CFA e SEM.
Abbiamo anche discusso l’uso dello stimatore WLSMV per dati categoriali, evidenziando come esso fornisca una stima dell’errore standard più precisa rispetto all’MLE standard e all’MLE robusta.
Va notato che WLSMV è un metodo generale per dati categoriali nella CFA, ampiamente implementato in software come MPlus. In lavaan, l’uso di WLSMV può essere attivato semplicemente con lavaan(..., estimator = "WLSMV"), equivalente a lavaan(..., estimator = "DWLS", se = "robust.sem", test = "scaled.shifted").
Oltre al WLSMV, lavaan offre anche lo stimatore sperimentale di massima verosimiglianza marginale (MML), che, pur essendo preciso, può essere lento e più suscettibile a problemi di convergenza a causa della complessità dell’integrazione numerica. Un altro stimatore è l’ADF (estimator = “WLS”), che non assume specifiche distributive sui dati, ma richiede una dimensione campionaria molto grande (N > 5000) per considerare affidabili le stime dei parametri, gli errori standard e le statistiche di test.
41.3. Session Info#
sessionInfo()
R version 4.3.3 (2024-02-29)
Platform: x86_64-apple-darwin20 (64-bit)
Running under: macOS Sonoma 14.3.1
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.3-x86_64/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.3-x86_64/Resources/lib/libRlapack.dylib; LAPACK version 3.11.0
locale:
[1] en_US.UTF-8/UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
time zone: Europe/Rome
tzcode source: internal
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] ggokabeito_0.1.0 viridis_0.6.5 viridisLite_0.4.2 ggpubr_0.6.0
[5] ggExtra_0.10.1 bayesplot_1.11.1 gridExtra_2.3 patchwork_1.2.0
[9] semTools_0.5-6.920 semPlot_1.1.6 lavaan_0.6-17 psych_2.4.1
[13] scales_1.3.0 markdown_1.12 knitr_1.45 lubridate_1.9.3
[17] forcats_1.0.0 stringr_1.5.1 dplyr_1.1.4 purrr_1.0.2
[21] readr_2.1.5 tidyr_1.3.1 tibble_3.2.1 ggplot2_3.5.0
[25] tidyverse_2.0.0 here_1.0.1
loaded via a namespace (and not attached):
[1] rstudioapi_0.15.0 jsonlite_1.8.8 magrittr_2.0.3
[4] TH.data_1.1-2 estimability_1.5 farver_2.1.1
[7] nloptr_2.0.3 rmarkdown_2.26 vctrs_0.6.5
[10] minqa_1.2.6 base64enc_0.1-3 rstatix_0.7.2
[13] htmltools_0.5.7 broom_1.0.5 Formula_1.2-5
[16] htmlwidgets_1.6.4 plyr_1.8.9 sandwich_3.1-0
[19] emmeans_1.10.0 zoo_1.8-12 uuid_1.2-0
[22] igraph_2.0.2 mime_0.12 lifecycle_1.0.4
[25] pkgconfig_2.0.3 Matrix_1.6-5 R6_2.5.1
[28] fastmap_1.1.1 shiny_1.8.0 digest_0.6.34
[31] OpenMx_2.21.11 fdrtool_1.2.17 colorspace_2.1-0
[34] rprojroot_2.0.4 Hmisc_5.1-1 fansi_1.0.6
[37] timechange_0.3.0 abind_1.4-5 compiler_4.3.3
[40] withr_3.0.0 glasso_1.11 htmlTable_2.4.2
[43] backports_1.4.1 carData_3.0-5 ggsignif_0.6.4
[46] MASS_7.3-60.0.1 corpcor_1.6.10 gtools_3.9.5
[49] tools_4.3.3 pbivnorm_0.6.0 foreign_0.8-86
[52] zip_2.3.1 httpuv_1.6.14 nnet_7.3-19
[55] glue_1.7.0 quadprog_1.5-8 nlme_3.1-164
[58] promises_1.2.1 lisrelToR_0.3 grid_4.3.3
[61] pbdZMQ_0.3-11 checkmate_2.3.1 cluster_2.1.6
[64] reshape2_1.4.4 generics_0.1.3 gtable_0.3.4
[67] tzdb_0.4.0 data.table_1.15.2 hms_1.1.3
[70] car_3.1-2 utf8_1.2.4 sem_3.1-15
[73] pillar_1.9.0 IRdisplay_1.1 rockchalk_1.8.157
[76] later_1.3.2 splines_4.3.3 lattice_0.22-5
[79] survival_3.5-8 kutils_1.73 tidyselect_1.2.0
[82] miniUI_0.1.1.1 pbapply_1.7-2 stats4_4.3.3
[85] xfun_0.42 qgraph_1.9.8 arm_1.13-1
[88] stringi_1.8.3 boot_1.3-29 evaluate_0.23
[91] codetools_0.2-19 mi_1.1 cli_3.6.2
[94] RcppParallel_5.1.7 IRkernel_1.3.2 rpart_4.1.23
[97] xtable_1.8-4 repr_1.1.6 munsell_0.5.0
[100] Rcpp_1.0.12 coda_0.19-4.1 png_0.1-8
[103] XML_3.99-0.16.1 parallel_4.3.3 ellipsis_0.3.2
[106] jpeg_0.1-10 lme4_1.1-35.1 mvtnorm_1.2-4
[109] openxlsx_4.2.5.2 crayon_1.5.2 rlang_1.1.3
[112] multcomp_1.4-25 mnormt_2.1.1