83. Modello LCS univariato#
I Latent Change Score Models (LCSM; McArdle, 2001, 2009; McArdle & Hamagami, 2001) rappresentano un’evoluzione nell’analisi dei dati longitudinali. Per comprendere la differenza tra i modelli LGM e LCSM, è utile considerare come ciascuno di essi modelli il cambiamento nel tempo.
83.1. Modelli LGM (Latent Growth Models)#
I modelli LGM sono utilizzati per descrivere le traiettorie di crescita di una variabile nel tempo. In un LGM, la variabile latente rappresentante il cambiamento è modellata direttamente attraverso diverse misurazioni temporali. Questi modelli cercano di catturare il pattern di crescita o declino di una variabile (come l’abilità cognitiva o un sintomo clinico) nel tempo. Un LGM si focalizza sull’intero percorso della variabile, analizzando come la traiettoria generale cambia in risposta a vari fattori.
83.2. Modelli LCSM (Latent Change Score Models)#
I modelli LCSM, invece, si concentrano sul cambiamento specifico tra due momenti temporali consecutivi. Questi modelli sono particolarmente utili quando l’interesse è capire come e perché una variabile cambia da un momento all’altro. Diversamente dai LGM, che guardano alla traiettoria generale, i LCSM esaminano il cambiamento incrementale, offrendo una comprensione più dettagliata delle dinamiche del cambiamento. I LCSM analizzano come i cambiamenti in una variabile (ad esempio, l’abilità cognitiva) tra due momenti temporali siano associati a fattori esterni o ad altre variabili misurate.
83.3. Vantaggi dei Modelli LCSM#
I modelli LCSM offrono un’analisi più dettagliata del cambiamento, consentendo di isolare il cambiamento intra-individuale dalla variabilità inter-individuale. Questo approccio permette una comprensione più precisa delle dinamiche del cambiamento e di come variabili esterne influenzino il cambiamento da un momento all’altro.
83.4. Struttura del Capitolo#
In questo capitolo, inizieremo con l’esame dei modelli LCSM univariati. Successivamente, considereremo il caso bivariato, estendendo l’analisi a situazioni in cui due variabili cambiano nel tempo e influenzano reciprocamente i loro cambiamenti.
source("../_common.R")
suppressPackageStartupMessages({
library("DT")
library("kableExtra")
library("lme4")
library("lcsm")
library("tidyr")
library("stringr")
library("reshape2")
})
83.5. Analisi di una Misura Unica in Due Momenti Temporali#
Iniziamo con il caso più semplice di una singola variabile misurata in due diversi momenti nel tempo. Immaginiamo, ad esempio, un ricercatore che studia un qualche aspetto psicologico, misurando una determinata variabile su un gruppo di soggetti in due periodi distinti, identificati come Tempo 1 (T1) e Tempo 2 (T2). L’approccio convenzionale per analizzare se i punteggi di un gruppo di individui variano tra T1 e T2 è quello di utilizzare il test t di Student per dati appaiati. Questo test, ampiamente utilizzato per confrontare le medie di due misurazioni correlate (come i punteggi di uno stesso gruppo di individui in due momenti diversi), permette di stabilire se ci sia stata una variazione “statisticamente significativa” nei punteggi medi del gruppo di soggetti tra i due momenti considerati. Il modello Latent Change Score (LCS) offre una prospettiva più avanzata e dettagliata rispetto al test t di Student tradizionale. Il modello LCS permette non solo di valutare se ci sia stata una variazione nei punteggi medi, ma anche di esaminare la natura di questa variazione su base individuale. Mentre il test t tradizionale si concentra sul cambiamento a livello di gruppo, il modello LCS ci consente di indagare come e perché ogni singolo individuo nel campione possa aver sperimentato un cambiamento tra T1 e T2.
Utilizziamo lo script fornito da Kievit et al. [KBZ+18] per simulare i dati che corrispondono alla situazione descritta sopra.
ULCS_simulate <- '
##### The following lines specify the core assumptions of the LCS
##### and should not generally be modified
COG_T2 ~ 1*COG_T1 # Fixed regression of COG_T2 on COG_T1
dCOG1 =~ 1*COG_T2 # Fixed regression of dCOG1 on COG_T2
COG_T2 ~ 0*1 # This line constrains the intercept of COG_T2 to 0
COG_T2 ~~ 0*COG_T2 # This fixes the variance of the COG_T2 to 0
###### The following five parameters will be estimated in the model.
###### Values can be modified manually to examine the effect on the model
dCOG1 ~ 4*1 # This fixes the intercept of the change score to 10
COG_T1 ~ 10*1 # This fixes the intercept of COG_T1 to 50
dCOG1 ~~ 5*dCOG1 # This fixes the variance of the change scores to 5.
COG_T1 ~~ 8*COG_T1 # This fixes the variance of the COG_T1 to 8.
dCOG1 ~ -0.1*COG_T1 # This fixes the self-feedback parameter to -0.1.
'
set.seed(42)
samplesize <- 100
simdatULCS <- simulateData(ULCS_simulate, sample.nobs = samplesize, meanstructure = TRUE)
head(simdatULCS)
| COG_T2 | COG_T1 | |
|---|---|---|
| <dbl> | <dbl> | |
| 1 | 9.673594 | 5.047393 |
| 2 | 15.824384 | 10.192440 |
| 3 | 10.870739 | 10.273960 |
| 4 | 12.686939 | 6.160675 |
| 5 | 11.054693 | 9.764821 |
| 6 | 13.444989 | 10.145172 |
print(colMeans(simdatULCS)) # sanity check the means
COG_T2 COG_T1
12.81156 10.02172
Interpretiamo i valori precedenti come le medie calcolate sulla base dei risultati di 100 soggetti dei punteggi di un ipotetico test cognitivo nei momenti T1 e T2.
Da un punto di vista matematico, modelliamo i punteggi di un individuo \(i\) sul costrutto di interesse COG al tempo \(t\) come risultato di una componente autoregressiva più un residuo. Assegnando un peso di regressione di 1 per COG_T2 rispetto a COG_T1, l’equazione autoregressiva diventa:
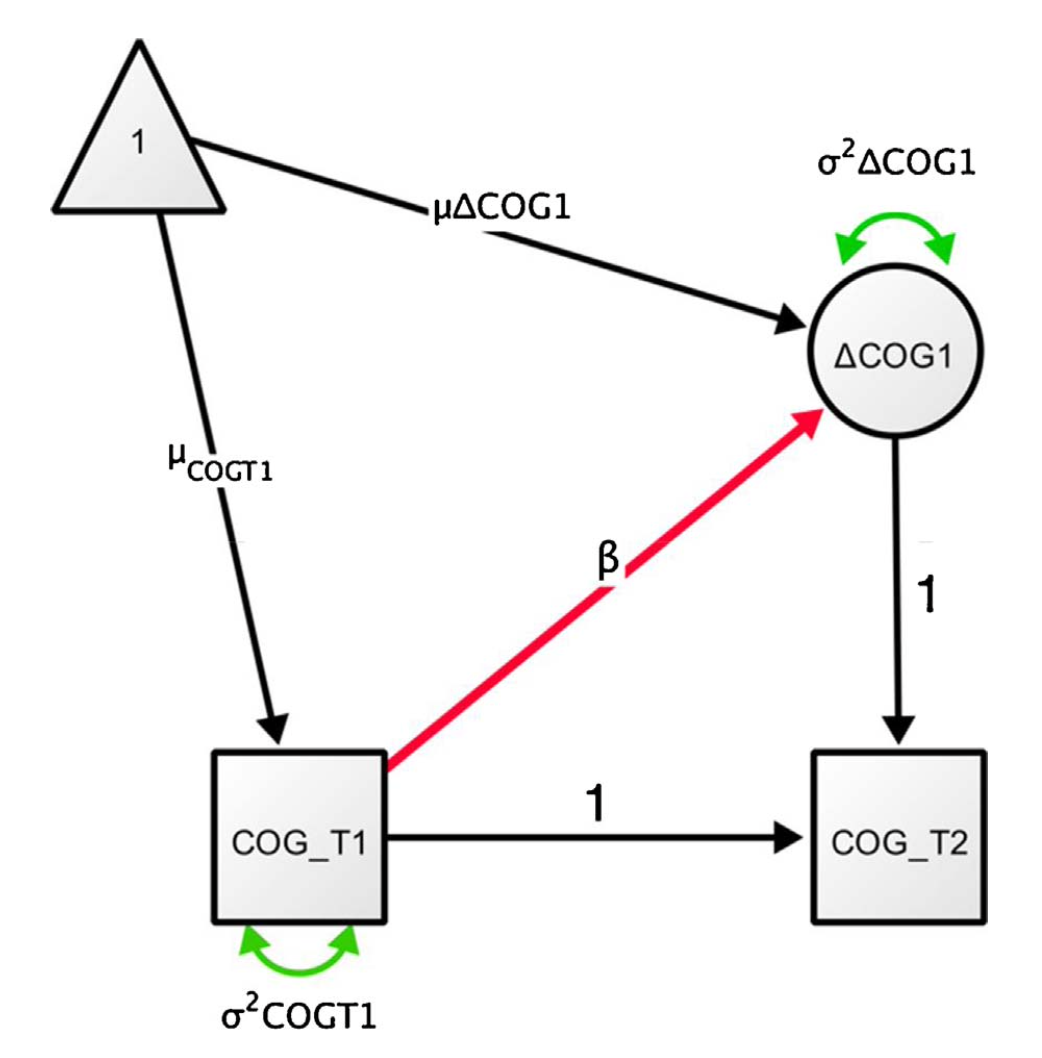
Fig. 83.1 Diagramma di percorso semplificato di un LCSM univariato. La variabile COG viene misurata in due momenti (COG_T1 e COG_T2). Il cambiamento (ΔCOG1) tra i due momenti viene modellato come una variabile latente. (La figura è tratta da Kievit et al. [KBZ+18].)#
Questa formulazione indica che il punteggio di COG al tempo 2 (COG_{i,t2}) è uguale al punteggio al tempo 1 (COG_{i,t1}) più un cambiamento latente (\(\Delta COG_{i,1}\)).
Il cambiamento latente può essere definito come:
In questo contesto, all’interno dei modelli SEM, si introduce un fattore latente \(\Delta COG1\), che rappresenta il cambiamento tra il tempo 1 e il tempo 2. Questo fattore latente è identificato al tempo 2 con un carico fattoriale fissato a 1, catturando così il cambiamento osservato.
È poi possibile aggiungere un parametro di regressione \(\beta\) al modello, per indagare se il grado di cambiamento dipenda dai punteggi al tempo 1:
Con questo modello, possiamo rispondere a tre domande fondamentali. La prima riguarda l’esistenza di un cambiamento medio degno di nota da T1 a T2, misurato dalla media del fattore di cambiamento latente, \(\mu_{\Delta COG1}\). Questo approccio può essere considerato equivalente a un test t di Student per dati appaiati sotto determinate condizioni. Oltre a questo, il modello permette di stimare la varianza del fattore di cambiamento, \(\sigma^2_{\Delta COG1}\), che riflette quanto gli individui differiscono nel cambiamento nel tempo. Infine, si può specificare un parametro autoregressivo o una covarianza \(\beta\), che quantifica la dipendenza del cambiamento dai punteggi iniziali.
In breve, il modello LCS offre un approccio solido per esaminare i cambiamenti nel tempo in un costrutto latente. Non solo fornisce una stima del cambiamento medio nel tempo, ma anche una valutazione della variazione individuale in questo cambiamento. Inoltre, consente di valutare l’effetto dei punteggi iniziali sul cambiamento nel tempo del costrutto latente.
Il precedente modello LCS può essere formulato nella sintassi di lavaan nel modo seguente.
ULCS <- '
COG_T2 ~ 1*COG_T1 # Fixed regression of COG_T2 on COG_T1
dCOG1 =~ 1*COG_T2 # Fixed loading of dCOG1 on COG_T2
COG_T2 ~ 0*1 # This line constrains the intercept of COG_T2 to 0
COG_T2 ~~ 0*COG_T2 # This fixes the variance of the COG_T2 to 0
dCOG1 ~ 1 # This estimates the intercept of the change scores
COG_T1 ~ 1 # This estimates the intercept of COG_T1
dCOG1 ~~ dCOG1 # This estimates the variance of the change scores
COG_T1 ~~ COG_T1 # This estimates the variance of COG_T1
dCOG1 ~ COG_T1 # This estimates the self-feedback parameter
'
Adattiamo ai dati simulati il modello LCS specificato sopra.
fitULCS <- lavaan(ULCS, data=simdatULCS, estimator='mlr', fixed.x=FALSE, missing='fiml')
Esaminiamo la soluzione.
summary(fitULCS, fit.measures = TRUE, standardized = TRUE, rsquare = TRUE) |>
print()
lavaan 0.6.17 ended normally after 37 iterations
Estimator ML
Optimization method NLMINB
Number of model parameters 5
Number of observations 100
Number of missing patterns 1
Model Test User Model:
Standard Scaled
Test Statistic 0.000 0.000
Degrees of freedom 0 0
Model Test Baseline Model:
Test statistic 105.669 85.223
Degrees of freedom 1 1
P-value 0.000 0.000
Scaling correction factor 1.240
User Model versus Baseline Model:
Comparative Fit Index (CFI) 1.000 1.000
Tucker-Lewis Index (TLI) 1.000 1.000
Robust Comparative Fit Index (CFI) 1.000
Robust Tucker-Lewis Index (TLI) 1.000
Loglikelihood and Information Criteria:
Loglikelihood user model (H0) -461.157 -461.157
Loglikelihood unrestricted model (H1) -461.157 -461.157
Akaike (AIC) 932.314 932.314
Bayesian (BIC) 945.339 945.339
Sample-size adjusted Bayesian (SABIC) 929.548 929.548
Root Mean Square Error of Approximation:
RMSEA 0.000 NA
90 Percent confidence interval - lower 0.000 NA
90 Percent confidence interval - upper 0.000 NA
P-value H_0: RMSEA <= 0.050 NA NA
P-value H_0: RMSEA >= 0.080 NA NA
Robust RMSEA 0.000
90 Percent confidence interval - lower 0.000
90 Percent confidence interval - upper 0.000
P-value H_0: Robust RMSEA <= 0.050 NA
P-value H_0: Robust RMSEA >= 0.080 NA
Standardized Root Mean Square Residual:
SRMR 0.000 0.000
Parameter Estimates:
Standard errors Sandwich
Information bread Observed
Observed information based on Hessian
Latent Variables:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
dCOG1 =~
COG_T2 1.000 2.038 0.590
Regressions:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
COG_T2 ~
COG_T1 1.000 1.000 0.839
dCOG1 ~
COG_T1 -0.038 0.064 -0.582 0.560 -0.018 -0.053
Intercepts:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
.COG_T2 0.000 0.000 0.000
.dCOG1 3.166 0.648 4.886 0.000 1.554 1.554
COG_T1 10.022 0.290 34.604 0.000 10.022 3.460
Variances:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
.COG_T2 0.000 0.000 0.000
.dCOG1 4.140 0.733 5.645 0.000 0.997 0.997
COG_T1 8.387 1.305 6.426 0.000 8.387 1.000
R-Square:
Estimate
COG_T2 1.000
dCOG1 0.003
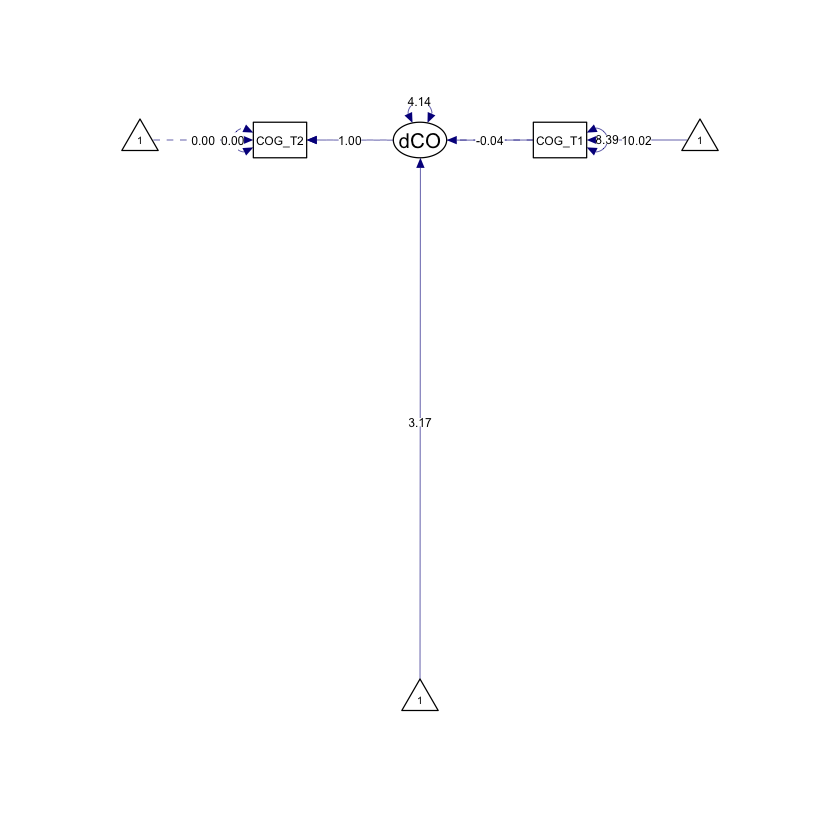
Il cambiamento nel punteggio latente tra i momenti T1 e T2 è stimato essere uguale a 3.166 (SE = 0.648). Questo valore può essere messo in relazione alla differenza tra le medie dei punteggi in due momenti temporali che viene calcolata da un test t di Student per dati appaiati. Si noti però che, mentre nel caso del test t la differenza riguarda i punteggi osservati, nei modelli LSC essa descrive la variazione tra i punteggi latenti nei momenti T1 e T2.
t.test(x = simdatULCS$COG_T1, y = simdatULCS$COG_T2)
Welch Two Sample t-test
data: simdatULCS$COG_T1 and simdatULCS$COG_T2
t = -6.1614, df = 192.21, p-value = 4.142e-09
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-3.682920 -1.896764
sample estimates:
mean of x mean of y
10.02172 12.81156
Il coefficiente 4.140 (SE = 0.733) stima la varianza con la quale gli individui differiscono nel cambiamento che manifestano nel tempo. Infine, il coefficiente -0.038 (SE = 0.064) stima la componente autoregressiva dal tempo T1 al tempo T2.
Mediante semPaths possiamo generare il seguente diagramma di percorso.
fitULCS |>
semPaths(
style = "ram",
whatLabels = "par", edge.label.cex = .6,
label.prop = 0.9, edge.label.color = "black", rotation = 4,
equalizeManifests = FALSE, optimizeLatRes = TRUE,
node.width = 1.5,
edge.width = 0.5, shapeMan = "rectangle", shapeLat = "ellipse",
shapeInt = "triangle", sizeMan = 4, sizeInt = 2, sizeLat = 4,
curve = 2, unCol = "#070b8c"
)
83.6. Indicatori multipli in due rilevazioni temporali#
Quello esaminato sopra era il caso più semplice di un modello LCS. Più comune è il caso in cui vengono esaminati indicatori multipli in due diversi momenti del tempo. Anche in questo caso, iniziamo simulando i dati per la situazione descritta mediante lo script fornito da Kievit et al. [KBZ+18].
#Simulate data for a Univariate Latent Change Score model.
MILCS_simulate <- '
#### The following two lines specify the measurement model for multiple indicators (X1-X3)
#### measured on two occasions (T1-T2)
COG_T1=~.8*T1X1+.9*T1X2+.7*T1X3 # This specifies the measurement model for COG_T1
COG_T2=~.8*T2X1+.9*T2X2+.7*T2X3 # This specifies the measurement model for COG_T2
##### The following lines specify the core assumptions of the LCS
##### and should not generally be modified
COG_T2 ~ 1*COG_T1 # Fixed regression of COG_T2 on COG_T1
dCOG1 =~ 1*COG_T2 # Fixed regression of dCOG1 on COG_T2
COG_T2 ~ 0*1 # This line constrains the intercept of COG_T2 to 0
COG_T2 ~~ 0*COG_T2 # This fixes the variance of the COG_T2 to 0
T1X1~0*1 # This fixes the intercept of X1 to 0
T1X2~1*1 # This fixes the intercept of X2 to 1
T1X3~.5*1 # This fixes the intercept of X3 to 0.5
T2X1~0*1 # This fixes the intercept of X1 to 0
T2X2~1*1 # This fixes the intercept of X2 to 1
T2X3~.5*1 # This fixes the intercept of X3 to 0.5
###### The following five parameters will be estimated in the model.
###### Values can be modified manually to examine the effect on the model
dCOG1 ~ 10*1 # This fixes the intercept of the change score to 10
COG_T1 ~ 50*1 # This fixes the intercept of COG_T1 to 50.
dCOG1 ~~ 5*dCOG1 # This fixes the variance of the change scores to 5.
COG_T1 ~~ 8*COG_T1 # This fixes the variance of the COG_T1 to 8.
dCOG1 ~ -0.1*COG_T1 # This fixes the self-feedback parameter to -0.1.
'
Simuliamo i dati.
set.seed(123)
samplesize <- 100
simdatMILCS <- simulateData(MILCS_simulate, sample.nobs = samplesize, meanstructure = TRUE)
Queste sono le medie delle tre variabili nei due momenti temporali.
print(colMeans(simdatMILCS))
T1X1 T1X2 T1X3 T2X1 T2X2 T2X3
39.66328 45.74262 35.16919 43.92156 50.35134 38.76447
Esaminiamo come variano i punteggi dei tre indicatori nei due momenti del tempo.
id <- factor(1:samplesize)
plotdattemp <- data.frame(
c(simdatMILCS$T1X1, simdatMILCS$T1X2, simdatMILCS$T1X3),
c(simdatMILCS$T2X1, simdatMILCS$T2X2, simdatMILCS$T2X3),
as.factor(c(id, id, id)),
c(
rep("X1", times = samplesize),
rep("X2", times = samplesize),
rep("X3", times = samplesize)
)
)
colnames(plotdattemp) <- c("COG_T1", "COG_T2", "id", "Indicator")
plotdat <- melt(plotdattemp, by = "id")
ggplot(plotdat, aes(variable, value, group = id, col = Indicator)) +
geom_point(size = 3, alpha = .7) +
geom_line(alpha = .7) +
ggtitle("Multiple indicator Latent Change Score model") +
ylab("Cognitive scores") +
xlab("Time points") +
facet_grid(~Indicator)
Using id, Indicator as id variables
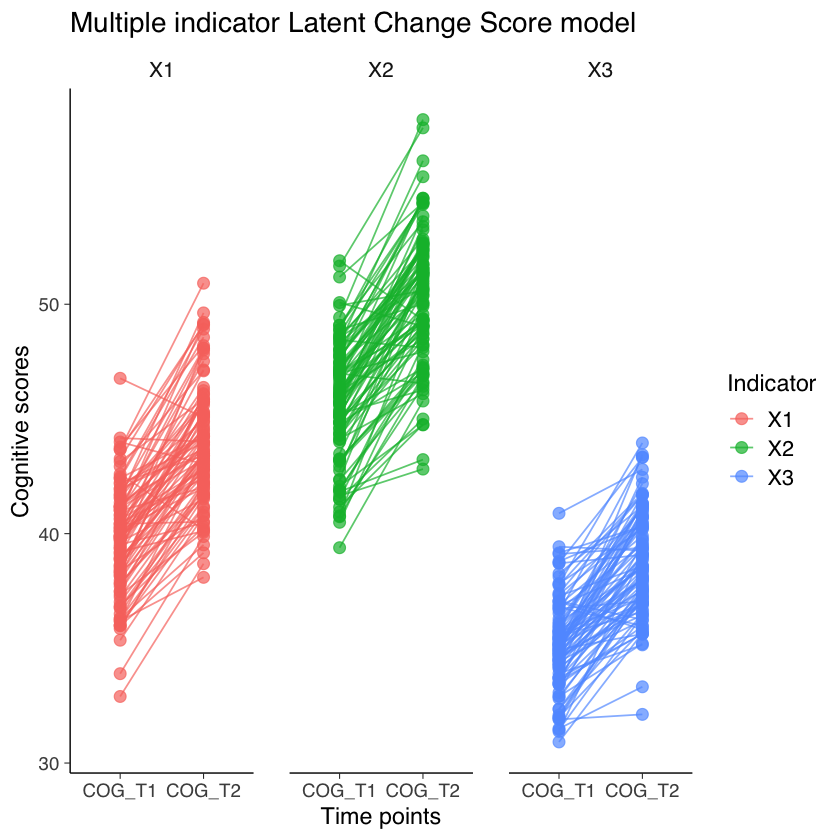
Definiamo il modello LCS per indicatori multipli e due momenti temporali mediante il codice fornito da Kievit et al. [KBZ+18].
MILCS <- '
COG_T1 =~ 1*T1X1+T1X2+T1X3 # This specifies the measurement model for COG_T1
COG_T2 =~ 1*T2X1+equal("COG_T1=~T1X2")*T2X2+equal("COG_T1=~T1X3")*T2X3 # This specifies the measurement model for COG_T2 with the equality constrained factor loadings
COG_T2 ~ 1*COG_T1 # Fixed regression of COG_T2 on COG_T1
dCOG1 =~ 1*COG_T2 # Fixed regression of dCOG1 on COG_T2
COG_T2 ~ 0*1 # This line constrains the intercept of COG_T2 to 0
COG_T2 ~~ 0*COG_T2 # This fixes the variance of the COG_T2 to 0
dCOG1 ~ 1 # This estimates the intercept of the change score
COG_T1 ~ 1 # This estimates the intercept of COG_T1
dCOG1 ~~ dCOG1 # This estimates the variance of the change scores
COG_T1 ~~ COG_T1 # This estimates the variance of the COG_T1
dCOG1~COG_T1 # This estimates the self-feedback parameter
T1X1~~T2X1 # This allows residual covariance on indicator X1 across T1 and T2
T1X2~~T2X2 # This allows residual covariance on indicator X2 across T1 and T2
T1X3~~T2X3 # This allows residual covariance on indicator X3 across T1 and T2
T1X1~~T1X1 # This allows residual variance on indicator X1
T1X2~~T1X2 # This allows residual variance on indicator X2
T1X3~~T1X3 # This allows residual variance on indicator X3
T2X1~~equal("T1X1~~T1X1")*T2X1 # This allows residual variance on indicator X1 at T2
T2X2~~equal("T1X2~~T1X2")*T2X2 # This allows residual variance on indicator X2 at T2
T2X3~~equal("T1X3~~T1X3")*T2X3 # This allows residual variance on indicator X3 at T2
T1X1~0*1 # This constrains the intercept of X1 to 0 at T1
T1X2~1 # This estimates the intercept of X2 at T1
T1X3~1 # This estimates the intercept of X3 at T1
T2X1~0*1 # This constrains the intercept of X1 to 0 at T2
T2X2~equal("T1X2~1")*1 # This estimates the intercept of X2 at T2
T2X3~equal("T1X3~1")*1 # This estimates the intercept of X3 at T2
'
Il modello “MILCS” rappresenta un’estensione del caso precedente, che riguardava un singolo indicatore in due momenti temporali. Nel modello MILCS, COG_T1 e COG_T2 sono variabili latenti identificate da più indicatori (T1X1, T1X2, T1X3 per COG_T1 e T2X1, T2X2, T2X3 per COG_T2). Questo offre una comprensione più ricca di ogni misurazione cognitiva, catturando diverse sfaccettature o aspetti in ciascun momento temporale.
Vengono introdotti vari vincoli per l’identificazione del modello.
Vincoli di Regressione e delle Intercette: Come nel modello precedente, la regressione di COG_T2 su COG_T1 è fissata e l’intercetta di COG_T2 è vincolata a 0, così come la varianza di COG_T2.
Vincoli di Carico Fattoriale Uguale: Un aspetto nuovo di MILCS è l’uso di vincoli di eguaglianza sulle saturazioni fattoriali degli indicatori corrispondenti di COG_T1 e COG_T2 (ad es.,
equal("COG_T1=~T1X2")*T2X2). Questo assicura che gli indicatori misurino lo stesso costrutto in modo consistente attraverso i due tempi.Covarianza Residua e Varianza degli Indicatori: Il modello permette covarianze residue tra gli stessi indicatori attraverso i tempi (es. T1X1~~T2X1) e stima la varianza residua per ogni indicatore in entrambi i momenti temporali.
Stima degli Intercette degli Indicatori: Vengono fissati vincoli sulle intercette degli indicatori. Il vincolo
T1X1~0*1fissa l’intercetta dell’indicatore T1X1 a 0. Questo significa che, per l’indicatore T1X1, il punto di partenza o il valore di base è impostato a zero. Questo fornisce un punto di riferimento standardizzato per l’analisi degli indicatori all’interno del modello. Al contrario, le intercette per altri indicatori come T1X2 sono stimate liberamente, permettendo al modello di adattarsi meglio ai dati.
Il modello consente di interpretare il cambiamento non solo in termini di un’unica misurazione globale, ma attraverso varie dimensioni, fornendo insight più dettagliati sulle dinamiche del cambiamento cognitivo. Il diagramma di percorso per il modello MILCS è fornito nella figura seguente.
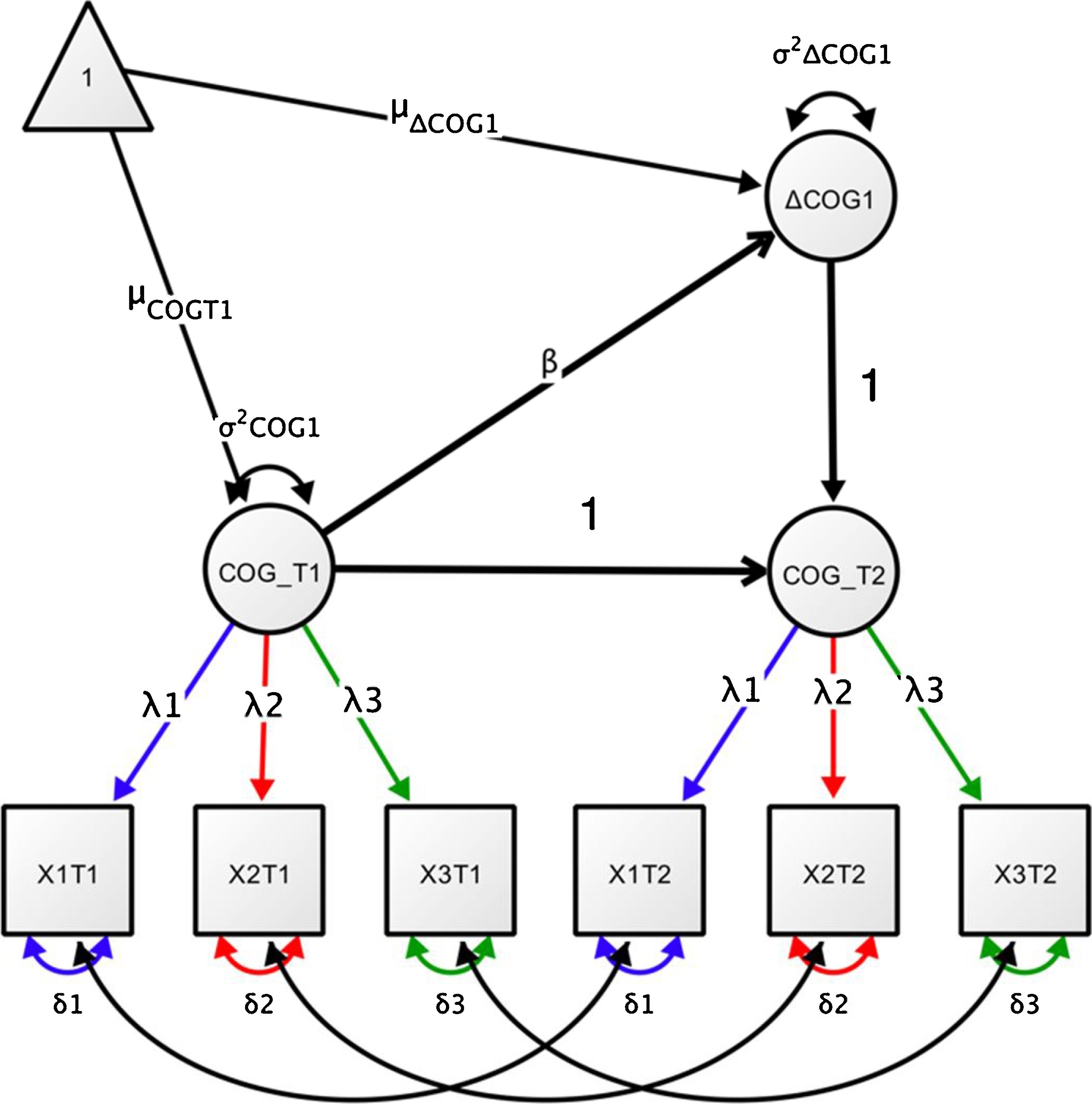
Fig. 83.2 Diagramma di percorso di un LCSM univariato con indicatori multipli. Il costrutto latente di interesse (COG) viene misurato in due momenti temporali (COG_T1 e COG_T2), ciascuno utilizzando tre indicatori (X1, X2, X3). Si assume l’invarianza della misurazione e gli errori residui correlati nel tempo. (La figura è tratta da Kievit et al. [KBZ+18].)#
Adattiamo il modello ai dati.
fitMILCS <- lavaan(MILCS, data=simdatMILCS, estimator='mlr', fixed.x=FALSE, missing='fiml')
Esaminiamo la soluzione.
summary(fitMILCS, fit.measures = TRUE, standardized = TRUE, rsquare = TRUE) |>
print()
lavaan 0.6.17 ended normally after 65 iterations
Estimator ML
Optimization method NLMINB
Number of model parameters 22
Number of equality constraints 7
Number of observations 100
Number of missing patterns 1
Model Test User Model:
Standard Scaled
Test Statistic 12.687 12.026
Degrees of freedom 12 12
P-value (Chi-square) 0.392 0.444
Scaling correction factor 1.055
Yuan-Bentler correction (Mplus variant)
Model Test Baseline Model:
Test statistic 615.947 602.011
Degrees of freedom 15 15
P-value 0.000 0.000
Scaling correction factor 1.023
User Model versus Baseline Model:
Comparative Fit Index (CFI) 0.999 1.000
Tucker-Lewis Index (TLI) 0.999 1.000
Robust Comparative Fit Index (CFI) 1.000
Robust Tucker-Lewis Index (TLI) 1.001
Loglikelihood and Information Criteria:
Loglikelihood user model (H0) -1087.543 -1087.543
Scaling correction factor 0.658
for the MLR correction
Loglikelihood unrestricted model (H1) -1081.200 -1081.200
Scaling correction factor 1.005
for the MLR correction
Akaike (AIC) 2205.086 2205.086
Bayesian (BIC) 2244.164 2244.164
Sample-size adjusted Bayesian (SABIC) 2196.790 2196.790
Root Mean Square Error of Approximation:
RMSEA 0.024 0.005
90 Percent confidence interval - lower 0.000 0.000
90 Percent confidence interval - upper 0.106 0.100
P-value H_0: RMSEA <= 0.050 0.608 0.661
P-value H_0: RMSEA >= 0.080 0.171 0.134
Robust RMSEA 0.000
90 Percent confidence interval - lower 0.000
90 Percent confidence interval - upper 0.104
P-value H_0: Robust RMSEA <= 0.050 0.673
P-value H_0: Robust RMSEA >= 0.080 0.143
Standardized Root Mean Square Residual:
SRMR 0.038 0.038
Parameter Estimates:
Standard errors Sandwich
Information bread Observed
Observed information based on Hessian
Latent Variables:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
COG_T1 =~
1.000 2.179 0.919
(.p2.) 1.106 0.033 33.436 0.000 2.409 0.933
(.p3.) 0.817 0.029 27.789 0.000 1.780 0.865
COG_T2 =~
1.000 2.498 0.936
(COG_T1=~T1X2) 1.106 0.033 33.436 0.000 2.762 0.948
(COG_T1=~T1X3) 0.817 0.029 27.789 0.000 2.040 0.892
dCOG1 =~
1.000 0.692 0.692
Regressions:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
COG_T2 ~
COG_T1 1.000 0.872 0.872
dCOG1 ~
COG_T1 -0.158 0.105 -1.500 0.134 -0.199 -0.199
Covariances:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
.T1X1 ~~
.T2X1 -0.033 0.140 -0.237 0.813 -0.033 -0.038
.T1X2 ~~
.T2X2 -0.117 0.136 -0.857 0.392 -0.117 -0.136
.T1X3 ~~
.T2X3 -0.006 0.123 -0.052 0.959 -0.006 -0.006
Intercepts:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
.COG_T2 0.000 0.000 0.000
.dCOG1 10.511 4.119 2.552 0.011 6.077 6.077
COG_T1 39.667 0.232 170.663 0.000 18.208 18.208
.T1X1 0.000 0.000 0.000
.T1X2 (.26.) 1.842 1.384 1.331 0.183 1.842 0.714
.T1X3 (.27.) 2.828 1.238 2.284 0.022 2.828 1.374
.T2X1 0.000 0.000 0.000
.T2X2 (T1X2) 1.842 1.384 1.331 0.183 1.842 0.632
.T2X3 (T1X3) 2.828 1.238 2.284 0.022 2.828 1.236
Variances:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
.COG_T2 0.000 0.000 0.000
.dCOG1 2.873 0.444 6.471 0.000 0.960 0.960
COG_T1 4.746 0.742 6.397 0.000 1.000 1.000
.T1X1 (.19.) 0.875 0.129 6.806 0.000 0.875 0.156
.T1X2 (.20.) 0.856 0.139 6.143 0.000 0.856 0.129
.T1X3 (.21.) 1.068 0.128 8.356 0.000 1.068 0.252
.T2X1 (T1X1) 0.875 0.129 6.806 0.000 0.875 0.123
.T2X2 (T1X2) 0.856 0.139 6.143 0.000 0.856 0.101
.T2X3 (T1X3) 1.068 0.128 8.356 0.000 1.068 0.204
R-Square:
Estimate
COG_T2 1.000
dCOG1 0.040
T1X1 0.844
T1X2 0.871
T1X3 0.748
T2X1 0.877
T2X2 0.899
T2X3 0.796
L’intercetta di dCOG1, che è 7.885 con un errore standard di 3.207, rappresenta il valore medio stimato del cambiamento latente (dCOG1) nel campione. Questo numero indica la media generale del cambiamento osservato, considerando tutti gli individui nel campione.
La varianza di dCOG1, che è 3.230 con un errore standard di 0.675, descrive la varianza nel cambiamento del costrutto tra gli individui nel tempo. Questo valore indica quanto gli individui differiscono nel loro cambiamento, riflettendo l’eterogeneità del cambiamento nel campione.
Il coefficiente di -0.100 con un errore standard di 0.079 nella regressione di dCOG1 su COG_T1 rappresenta il parametro autoregressivo, che indica l’effetto della misura iniziale (COG_T1) sul cambiamento (dCOG1). Un valore negativo suggerisce che valori più alti di COG_T1 sono associati a una riduzione nel cambiamento (dCOG1), ma poiché il valore p (0.206) non è significativo, non possiamo confermare con sicurezza questa relazione nel modello.
I valori di CFI e TLI molto vicini o uguali a 1, RMSEA e SRMR molto bassi, e un p-value elevato per il test di chi-quadrato indicano un buon adattamento del modello ai dati. Questi risultati suggeriscono che il modello specificato si adatta bene ai dati osservati.
Generiamo il diagramma di percorso usando semPaths().
fitMILCS |>
semPaths(
style = "ram",
whatLabels = "par", edge.label.cex = .6,
label.prop = 0.9, edge.label.color = "black", rotation = 1,
equalizeManifests = FALSE, optimizeLatRes = TRUE,
node.width = 1.5,
edge.width = 0.5, shapeMan = "rectangle", shapeLat = "ellipse",
shapeInt = "triangle", sizeMan = 4, sizeInt = 2, sizeLat = 4,
curve = 2, unCol = "#070b8c"
)
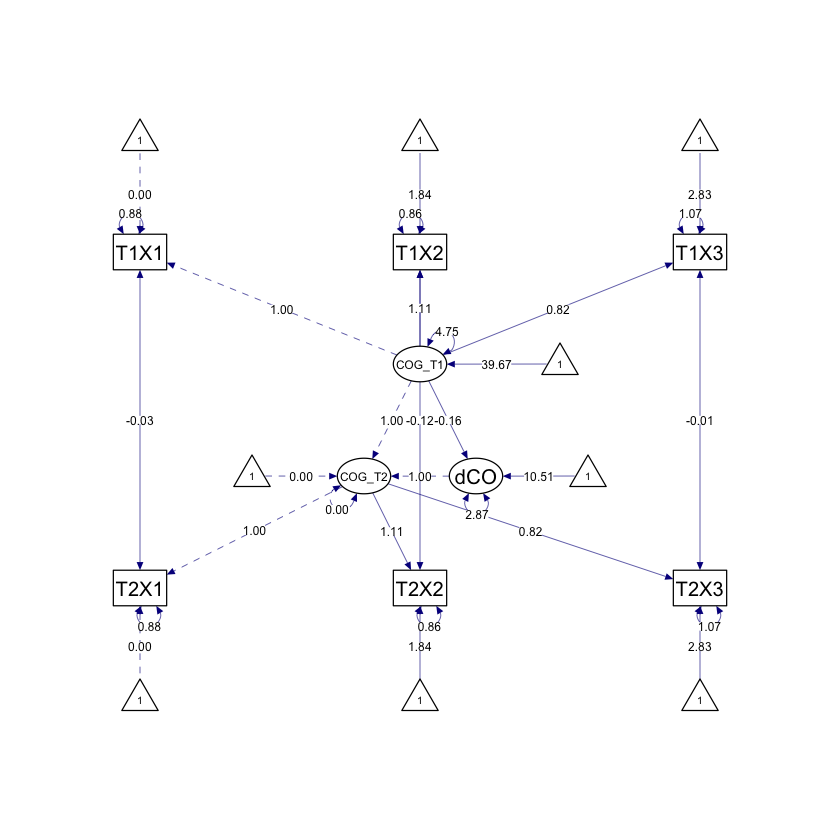
Questo modello è simile al modello univariato LCS per quanto riguarda le domande chiave a cui può rispondere (tasso di cambiamento \(\mu_{\Delta COG1}\), varianza nel cambiamento \(\sigma^2_{\Delta COG1}\), e la relazione tra COG1 e \(\Delta COG1\) catturata da \(\beta\)), ma include i vantaggi della rimozione degli errori di misurazione e dell’istituzione dell’invarianza della misurazione nel tempo e, se necessario, tra gruppi diversi, migliorando così la qualità delle inferenze.
83.7. Modello LCS Bivariato#
I modelli LCS sono stati sviluppati principalmente per studiare le associazioni sequenziali nel tempo tra due o più processi che cambiano nel tempo. In altre parole, le equazioni di cambiamento latente possono essere estese per includere effetti derivanti da variabili aggiuntive per modellare congiuntamente processi multipli di sviluppo (McArdle, 2001; McArdle & Hamagami, 2001). Considereremo qui un modello LCS bivariato con parametri di accoppiamento cambiamento-cambiamento ritardati. Il seguente path diagram è fornito da Wiedemann et al. [WTKovsirE22].
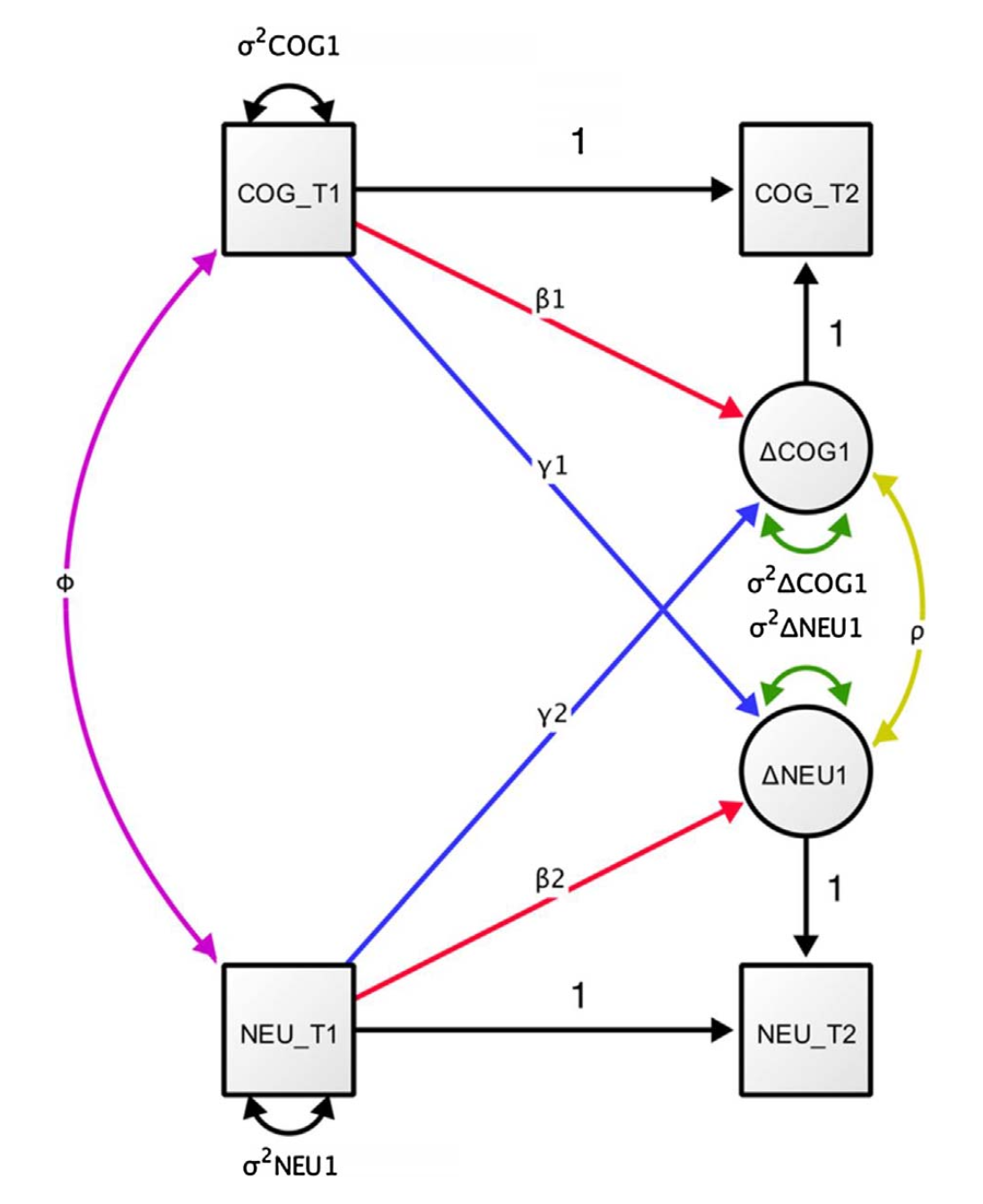
Fig. 83.3 Diagramma di percorso semplificato per un modello LCS bivariato. (la figura è tratta da Kievit et al. [KBZ+18].)#
Come in precedenza per il caso del modello univariato, il modello LCSM bivariato include, per ciascuna di due variabili misurate nel tempo, un fattore di cambiamento costante (alpha_constant), un fattore di cambiamento proporzionale (beta) e l’autoregressione dei punteggi di cambiamento (phi). L’aspetto nuovo riguarda i parametri di “accoppiamento”. Per i modelli LCSM bivariati, tali parametri modellano le interazioni tra le variabili \(X\) e \(Y\). I test su tali parametri consentono di affrontare la seguente domanda della ricerca: le variazioni della variabile Y al momento (t) sono determinate dalle variazioni della variabile X al momento precedente (t-1)? E viceversa. Oppure tutte e due le condizioni insieme. I test statistici sui parametri di accoppiamento consentono di rispondere alle domande precedenti.
Un’ulteriore estensione del modello LCS include l’aggiunta di una seconda area di interesse (o terza, quarta, ecc.). Per semplificare la notazione e la rappresentazione grafica, torneremo ad utilizzare solo punteggi osservati, ma tutte le estensioni possono e, dove possibile, dovrebbero essere modellate utilizzando fattori latenti (indicatori multipli). Supponiamo che il secondo dominio sia una misura neurale di interesse (ad esempio, il volume della materia grigia in una regione di interesse), misurata nello stesso numero di occasioni della variabile cognitiva (o delle variabili cognitive). Questo consente di indagare un concetto importante noto come accoppiamento cross-dominio (cross-domain coupling) Diagramma di percorso semplificato per un modello LCS bivariato. (la figura è tratta da kievit2018developmental.), che rende conto della misura in cui il cambiamento in un dominio (ad esempio, ΔCOG) è funzione del livello di partenza nell’altro (cioè NEUT1). Ad esempio, possiamo quantificare in che misura i cambiamenti cognitivi tra T1 e T2 sono funzione della struttura cerebrale (γ2) e della cognizione (β1) al tempo T1 come segue:
Le implicazioni per testare teorie nella neuroscienza cognitiva dello sviluppo dovrebbero essere immediatamente evidenti: i parametri dinamici, mostrati in rosso e blu nella Figura 4, catturano il grado in cui i cambiamenti nei processi cognitivi sono funzione delle condizioni iniziali delle misure cerebrali, e viceversa. I test di rapporto di verosimiglianza su questi parametri dinamici (misure cerebrali che influenzano i tassi di cambiamento nella cognizione, o abilità cognitive che influenzano i cambiamenti neurali) forniscono dunque prove a favore o contro i modelli che rappresentano tali influenze causali uni- o bidirezionali.
Come è chiaro dalla Diagramma di percorso semplificato per un modello LCS bivariato. (la figura è tratta da kievit2018developmental.), il modello bivariato LCS può catturare almeno quattro diverse relazioni cervello-comportamento di interesse.
Primo, abbiamo la covarianza cervello-comportamento alla baseline (mostrata in viola), il focus principale nella neuroscienza cognitiva (tradizionale) dello sviluppo.
Secondo, abbiamo l’accoppiamento cognizione-cervello (mostrato in blu, etichettato γ1), dove i punteggi a T1 nella cognizione predicono la velocità o il grado di cambiamento nella struttura cerebrale. Ad esempio, il grado di pratica del pianoforte nell’infanzia potrebbe influenzare la struttura della materia bianca (ΔNEU1) e prevedere un sostanziale parametro di accoppiamento cognizione-cervello γ1 (Bengtsson et al., 2005).
Terzo, abbiamo la struttura cerebrale che predice la velocità o il grado di cambiamento cognitivo (mostrato in blu, etichettato γ2). Ad esempio, McArdle et al. (2004) hanno dimostrato che la dimensione dei ventricoli in una popolazione più anziana prediceva il tasso di declino della memoria in un intervallo di 7 anni.
Infine, abbiamo una stima del cambiamento correlato (mostrato in giallo), che riflette il grado in cui i cambiamenti nel cervello e nel comportamento si verificano contemporaneamente, tenendo conto dei percorsi di accoppiamento. Ad esempio, Gorbach et al. (2016) hanno osservato un cambiamento correlato tra l’atrofia ippocampale e il declino della memoria episodica negli adulti più anziani. In generale, il cambiamento correlato può riflettere una terza variabile sottostante che influenza entrambi i domini.
Il modello bivariato LCS fornisce un quadro analitico potente per testare un’ampia gamma di ipotesi in modo rigoroso e fondato in molti ambiti della ricerca, tra cui quello della neuroscienza cognitiva dello sviluppo discusso qui nell’esempio di X.
Per chiarire il modello bivariato LCS nel caso semplice descritto sopra, simuliamo i dati come descritto da Kievit et al. [KBZ+18].
# Simulate data for a bivariate Latent Change Score model.
BLCS_simulate <- "
##### The following four parameters capture the core assumptions of the LCS and should not generally be modified
COG_T2 ~ 1*COG_T1 # This parameter regresses COG_T2 perfectly on COG_T1
dCOG1 =~ 1*COG_T2 # This defines the latent change score factor as measured perfectly by scores on COG_T2
COG_T2 ~ 0*1 # This line constrains the intercept of COG_T2 to 0
COG_T2 ~~ 0*COG_T2 # This fixes the variance of the COG_T2 to 0
###### The following five parameters will be estimated in the model. Their values can be modified manually to examine the effect on the raw data and model fit
dCOG1 ~ 10*1 # This fixes the intercept of the change score to 10 (i.e. people gain 10 points on average).
COG_T1 ~ 50*1 # This fixes the intercept of COG_T1 to 50.
dCOG1 ~~ 5*dCOG1 # This fixes the variance of the change scores to 5. This parameter can be changed manually to examine the effects.
COG_T1 ~~ 8*COG_T1 # This fixes the variance of the COG_T1 to 8. This parameter can be changed manually to examine the effects.
dCOG1~-0.1*COG_T1 # This fixes the self-feedback parameter to -0.2. This parameter can be changed manually to examine the effects.
############
NEU_T2 ~ 1*NEU_T1 # This parameter regresses NEU_T2 perfectly on NEU_T1
dNEU1 =~ 1*NEU_T2 # This defines the latent change score factor as measured perfectly by scores on NEU_T2
NEU_T2 ~ 0*1 # This line constrains the intercept of NEU_T2 to 0
NEU_T2 ~~ 0*NEU_T2 # This fixes the variance of the NEU_T1 to 0
###### The following five parameters will be estimated in the model. Their values can be modified manually to examine the effect on the raw data and model fit
dNEU1 ~ 10*1 # This fixes the intercept of the change score to 10 (i.e. people gain 10 points on average).
NEU_T1 ~ 50*1 # This fixes the intercept of NEU_T1 to 50.
dNEU1 ~~ 5*dNEU1 # This fixes the variance of the change scores to 5. This parameter can be changed manually to examine the effects.
NEU_T1 ~~ 8*NEU_T1 # This fixes the variance of the NEU_T1 to 8. This parameter can be changed manually to examine the effects.
dNEU1~-0.1*NEU_T1 # This fixes the self-feedback parameter to -0.1. This parameter can be changed manually to examine the effects.
dNEU1~0.4*COG_T1 # This fixes the coupling (.2) parameter for dNEU. These parameter can be changed manually to examine the effects.
dCOG1~0.3*NEU_T1 # This fixes the coupling (.3) parameter for dCOG. These parameter can be changed manually to examine the effects.
NEU_T1~~5*COG_T1 # This fixes the covariance in scores at T1 to 5
dCOG1~~.2*dNEU1 # This fixes the covariance in change scores to .2
"
# Fix sample size
samplesize <- 500
# Simulate data
set.seed(1234)
simdatBLCS <- simulateData(BLCS_simulate, sample.nobs = samplesize, meanstructure = T) # Simulate data
colMeans(simdatBLCS) # sanity check the means
- COG_T2
- 69.912269516965
- NEU_T2
- 75.0622797639907
- COG_T1
- 49.9284168290873
- NEU_T1
- 50.0730816737093
# theme_set(theme_grey(base_size = 18)) # increase text size
id <- factor(1:samplesize)
plotdattemp <- data.frame(c(simdatBLCS$COG_T1, simdatBLCS$NEU_T1), c(simdatBLCS$COG_T2, simdatBLCS$NEU_T2), as.factor(c(id, id)), c(rep("COG", times = samplesize), rep("NEU", times = samplesize)))
colnames(plotdattemp) <- c("T1", "T2", "id", "Domain")
plotdat <- melt(plotdattemp, by = "id")
ggplot(plotdat, aes(variable, value, group = id, col = Domain)) +
geom_point(size = 3, alpha = .7) +
geom_line(alpha = .7) +
ggtitle("Bivariate Latent Change Score model") +
ylab("Scores") +
xlab("Time points") +
facet_grid(~Domain)
Using id, Domain as id variables
Definiamo il modello LCS bivariato.
# Fit the Bivariate Latent Change Score model to simulated data
BLCS <- "
COG_T2 ~ 1*COG_T1 # This parameter regresses COG_T2 perfectly on COG_T1
dCOG1 =~ 1*COG_T2 # This defines the latent change score factor as measured perfectly by scores on COG_T2
dCOG1 ~ 1 # This estimates the intercept of the change score
COG_T1 ~ 1 # This estimates the intercept of COG_T1
COG_T2 ~ 0*1 # This constrains the intercept of COG_T2 to 0
NEU_T2 ~ 1*NEU_T1 # This parameter regresses NEU_T2 perfectly on NEU_T1
dNEU1 =~ 1*NEU_T2 # This defines the latent change score factor as measured perfectly by scores on NEU_T2
NEU_T2 ~ 0*1 # This line constrains the intercept of NEU_T2 to 0
NEU_T2 ~~ 0*NEU_T2 # This fixes the variance of the NEU_T1 to 0
dCOG1 ~~ dCOG1 # This estimates the variance of the change scores
COG_T1 ~~ COG_T1 # This estimates the variance of the COG_T1
COG_T2 ~~ 0*COG_T2 # This fixes the variance of the COG_T2 to 0
dNEU1 ~ 1 # This estimates the intercept of the change score
NEU_T1 ~ 1 # This estimates the intercept of NEU_T1
dNEU1 ~~ dNEU1 # This estimates the variance of the change scores
NEU_T1 ~~ NEU_T1 # This estimates the variance of NEU_T1
dNEU1~COG_T1+NEU_T1 # This estimates the COG to NEU coupling parameter and the COG to COG self-feedback
dCOG1~NEU_T1+COG_T1 # This estimates the NEU to COG coupling parameter and the NEU to NEU self-feedback
COG_T1 ~~ NEU_T1 # This estimates the COG_T1 NEU_T1 covariance
dCOG1~~dNEU1 # This estimates the dCOG and dNEU covariance
"
Adattiamo il modello ai dati simulati.
fitBLCS <- lavaan(BLCS, data = simdatBLCS, estimator = "mlr", fixed.x = FALSE, missing = "fiml")
Esaminiamo la soluzione ottenuta.
summary(fitBLCS, fit.measures = TRUE, standardized = TRUE, rsquare = TRUE) |>
print()
lavaan 0.6.17 ended normally after 111 iterations
Estimator ML
Optimization method NLMINB
Number of model parameters 14
Number of observations 500
Number of missing patterns 1
Model Test User Model:
Standard Scaled
Test Statistic 0.000 0.000
Degrees of freedom 0 0
Model Test Baseline Model:
Test statistic 1514.404 1521.338
Degrees of freedom 6 6
P-value 0.000 0.000
Scaling correction factor 0.995
User Model versus Baseline Model:
Comparative Fit Index (CFI) 1.000 1.000
Tucker-Lewis Index (TLI) 1.000 1.000
Robust Comparative Fit Index (CFI) 1.000
Robust Tucker-Lewis Index (TLI) 1.000
Loglikelihood and Information Criteria:
Loglikelihood user model (H0) -4527.601 -4527.601
Loglikelihood unrestricted model (H1) -4527.601 -4527.601
Akaike (AIC) 9083.202 9083.202
Bayesian (BIC) 9142.207 9142.207
Sample-size adjusted Bayesian (SABIC) 9097.770 9097.770
Root Mean Square Error of Approximation:
RMSEA 0.000 NA
90 Percent confidence interval - lower 0.000 NA
90 Percent confidence interval - upper 0.000 NA
P-value H_0: RMSEA <= 0.050 NA NA
P-value H_0: RMSEA >= 0.080 NA NA
Robust RMSEA 0.000
90 Percent confidence interval - lower 0.000
90 Percent confidence interval - upper 0.000
P-value H_0: Robust RMSEA <= 0.050 NA
P-value H_0: Robust RMSEA >= 0.080 NA
Standardized Root Mean Square Residual:
SRMR 0.000 0.000
Parameter Estimates:
Standard errors Sandwich
Information bread Observed
Observed information based on Hessian
Latent Variables:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
dCOG1 =~
COG_T2 1.000 2.242 0.592
dNEU1 =~
NEU_T2 1.000 2.490 0.584
Regressions:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
COG_T2 ~
COG_T1 1.000 1.000 0.761
NEU_T2 ~
NEU_T1 1.000 1.000 0.673
dNEU1 ~
COG_T1 0.436 0.047 9.348 0.000 0.175 0.504
NEU_T1 -0.064 0.047 -1.376 0.169 -0.026 -0.074
dCOG1 ~
NEU_T1 0.238 0.048 5.009 0.000 0.106 0.305
COG_T1 -0.099 0.045 -2.216 0.027 -0.044 -0.127
Covariances:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
COG_T1 ~~
NEU_T1 5.526 0.460 12.019 0.000 5.526 0.668
.dCOG1 ~~
.dNEU1 0.655 0.212 3.090 0.002 0.136 0.136
Intercepts:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
.dCOG1 12.971 1.849 7.015 0.000 5.786 5.786
COG_T1 49.928 0.129 387.666 0.000 49.928 17.337
.COG_T2 0.000 0.000 0.000
.NEU_T2 0.000 0.000 0.000
.dNEU1 6.443 1.829 3.522 0.000 2.587 2.587
NEU_T1 50.073 0.128 390.016 0.000 50.073 17.442
Variances:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
.NEU_T2 0.000 0.000 0.000
.dCOG1 4.737 0.307 15.452 0.000 0.942 0.942
COG_T1 8.294 0.534 15.520 0.000 8.294 1.000
.COG_T2 0.000 0.000 0.000
.dNEU1 4.901 0.338 14.518 0.000 0.790 0.790
NEU_T1 8.242 0.494 16.680 0.000 8.242 1.000
R-Square:
Estimate
NEU_T2 1.000
dCOG1 0.058
COG_T2 1.000
dNEU1 0.210
Possiamo rispondere alle quattro domande di interesse precedentemente menzionate riguardanti le relazioni cervello-comportamento nel modo seguente:
Covarianza Cervello-Comportamento alla Baseline: Nel modello, la covarianza tra COG_T1 (cognizione) e NEU_T1 (struttura cerebrale) al tempo T1 è stimata a 5.552, con un errore standard di 0.479. Questo valore significativo (P<0.000) indica una relazione forte e significativa tra la cognizione e la struttura cerebrale al momento di baseline.
Accoppiamento Cognizione-Cervello: Il parametro γ1, che riflette come i punteggi cognitivi a T1 influenzano la struttura cerebrale, è stimato a 0.274 per NEU_T1 influenzando dCOG1, con un errore standard di 0.044 e un P-value di 0.000. Ciò suggerisce una relazione significativa, dove le variazioni iniziali nella cognizione hanno un impatto sul cambiamento successivo nella struttura cerebrale.
Struttura Cerebrale Predittiva del Cambiamento Cognitivo: Il parametro γ2, che mostra come la struttura cerebrale a T1 influisce sul cambiamento cognitivo, è rappresentato dalla stima di 0.392 per COG_T1 che influisce su dNEU1, con un errore standard di 0.047 e un P-value di 0.000. Questo suggerisce che la struttura cerebrale iniziale ha un impatto significativo sul tasso di cambiamento cognitivo.
Stima del Cambiamento Correlato: La covarianza tra i cambiamenti in cognizione e struttura cerebrale (dCOG1 e dNEU1) è stimata a 0.618, con un errore standard di 0.210 e un P-value di 0.003. Questo indica che c’è una correlazione significativa tra i cambiamenti nel cervello e nel comportamento che va oltre gli effetti diretti misurati.
In sintesi, il modello BLCS fornisce una comprensione dettagliata delle relazioni dinamiche tra cognizione e struttura cerebrale, mostrando sia le correlazioni di base sia i modi in cui questi due domini influenzano reciprocamente i rispettivi cambiamenti nel tempo.