65. Modelli per Risposte Politomiche#
65.1. Introduzione#
Le opinioni delle persone vengono frequentemente esplorate mediante scale di risposta che variano da “completamente in disaccordo” a “completamente d’accordo”. Questi tipi di dati, noti come dati ordinali, sono molto diffusi in psicologia. Nonostante sia ampiamente riconosciuto che i dati ordinali non siano veri dati metrici, è comune nella ricerca psicologica analizzarli con metodi progettati per dati metrici, che può portare a conclusioni errate (Liddell & Kruschke, 2018).
Le principali problematiche legate all’uso di tali metodi con dati ordinali includono:
Distanza non uniforme tra le categorie: Le categorie di risposta in una scala ordinale potrebbero non avere intervalli equidistanti, una condizione spesso presupposta nei modelli statistici per dati metrici. La percezione della differenza tra “completamente in disaccordo” e “moderatamente in disaccordo” potrebbe essere meno marcata rispetto a quella tra “moderatamente in disaccordo” e “moderatamente d’accordo”.
Distribuzione non normale delle risposte: Le risposte ordinali possono distribuirsi in modo non normale, specialmente se le estremità della scala sono selezionate frequentemente dai partecipanti.
Varianze eterogenee delle variabili latenti: Le varianze delle variabili latenti, che sono alla base delle osservazioni ordinali, possono variare significativamente tra gruppi, condizioni o periodi di tempo. Queste varianze eterogenee non sono facilmente gestibili né identificabili mediante l’approccio metrico tradizionale.
Per affrontare queste sfide, sono stati sviluppati numerosi modelli parametrici per dati ordinali, tra cui il Graded Response Model (GRM).
suppressPackageStartupMessages({
library("tidyverse")
library("mirt")
# devtools::install_github("masurp/ggmirt")
library("ggmirt")
library("psychotools")
library("WrightMap")
library("latex2exp")
library("lavaan")
})
65.2. Modelli Cumulativi e del Graded Response Model (GRM)#
65.2.1. Modelli Cumulativi#
I modelli cumulativi sono usati in psicometria per analizzare dati ordinati, come le risposte alle scale di Likert. Questi modelli presuppongono l’esistenza di una variabile latente continua che influisce sulle risposte osservate categoriche. La variabile latente rappresenta il tratto o l’attitudine non direttamente osservabile che si vuole misurare (ad esempio, l’accordo o disaccordo su una questione).
Immaginiamo una scala Likert a quattro punti:
Completamente in disaccordo
In disaccordo
D’accordo
Completamente d’accordo
La “variabile latente” è un grado di accordo che non vediamo direttamente, ma che possiamo dedurre dalle risposte date. Per modellare questa variabile, usiamo dei punti di taglio o “soglie” che aiutano a dividere i diversi livelli di risposta.
Le soglie sono valori critici che separano le diverse categorie di risposta. Ad esempio:
Soglia 1 separa “Completamente in disaccordo” da “In disaccordo”
Soglia 2 separa “In disaccordo” da “D’accordo”
Soglia 3 separa “D’accordo” da “Completamente d’accordo”
L’affermazione corretta sarebbe: La probabilità di cadere in una specifica categoria dipende dalla posizione relativa dei punti di taglio rispetto al valore della variabile latente. La probabilità che una persona scelga una particolare categoria di risposta si calcola usando la funzione logistica, una forma specifica di funzione di distribuzione cumulativa. Questa funzione stima la probabilità che la risposta di una persona cada in una certa categoria basandosi sul suo livello sulla variabile latente.
Per rendere tutto più chiaro, ecco come si calcolano le probabilità per ogni categoria della scala Likert:
Completamente in disaccordo:
La probabilità è data dalla soglia 1 meno zero (perché non c’è nulla di meno di “completamente in disaccordo”).
Calcolo: \( \frac{1}{1 + e^{\text{soglia 1}}} \)
In disaccordo:
Calcoliamo la differenza tra la soglia 2 e la soglia 1.
Calcolo: \( \frac{1}{1 + e^{\text{soglia 2}}} - \frac{1}{1 + e^{\text{soglia 1}}} \)
D’accordo:
Differenza tra la soglia 3 e la soglia 2.
Calcolo: \( \frac{1}{1 + e^{\text{soglia 3}}} - \frac{1}{1 + e^{\text{soglia 2}}} \)
Completamente d’accordo:
Qui calcoliamo da soglia 3 a infinito.
Calcolo: \( 1 - \frac{1}{1 + e^{\text{soglia 3}}} \)
Questo metodo mostra come i valori di soglia sul continuum latente determinano le probabilità di risposta in ciascuna categoria.
65.3. Graded Response Model (GRM)#
Il Graded Response Model (GRM) rappresenta una specializzazione dei modelli cumulativi, ideata specificamente per analizzare risposte a item che presentano molteplici categorie, come quelle trovate nelle scale di Likert. È estremamente utile per valutare tratti o opinioni che non sono semplicemente “presenti” o “assenti”, ma che variano lungo un continuum.
Nel GRM, ciascun item della scala di misurazione viene analizzato considerando diversi parametri di difficoltà, uno per ciascuna delle categorie di risposta. Questi parametri definiscono le “soglie” che un individuo deve superare per essere classificato in una categoria piuttosto che in un’altra.
Nel GRM, la probabilità che un individuo con una certa abilità latente \( \theta \) selezioni una risposta in una categoria \( k \) o superiore è modellata tramite la funzione logistica:
dove:
\( a \) rappresenta il parametro di discriminazione dell’item, indicando quanto efficacemente l’item può distinguere tra soggetti a diversi livelli di \( \theta \).
\( b_k \) è il parametro di difficoltà associato alla soglia della categoria \( k \), indicando il livello di \( \theta \) necessario per avere il 50% di probabilità di selezionare quella categoria o una superiore.
Le curve logistiche derivanti tracciano graficamente come la probabilità di rispondere in una determinata categoria cresce all’aumentare di \( \theta \), fornendo una visione dettagliata del processo decisionale del rispondente.
Uno dei principali vantaggi del GRM è la sua capacità di fornire dettagliate analisi individuali e di gruppo su come variano le risposte alle domande. Questo può aiutare i ricercatori a comprendere non solo se i rispondenti sono d’accordo o in disaccordo con una dichiarazione, ma anche il grado di certezza o indecisione dietro ogni scelta di risposta.
65.3.1. Esempio#
Immaginiamo di avere un item che misura l’opinione su una politica ambientale su una scala da 1 a 4. Un individuo con un basso valore di \(\theta\) potrebbe avere una probabilità molto alta di scegliere “1 - completamente in disaccordo”. Man mano che il valore di \(\theta\) aumenta, la probabilità di scegliere categorie superiori (2, 3, 4) aumenta in accordo con i parametri di difficoltà e discriminazione stimati dal modello.
In conclusione, il GRM fornisce uno strumento potente per analizzare dati ordinali, consentendo di comprendere meglio come varie soglie di risposta si relazionano a differenti livelli di un tratto latente e come vari individui possono differire nella loro risposta a un dato item.
65.4. Una Applicazione Concreta#
Utilizzeremo i dati di un recente articolo che indaga l‘“effetto dell’elevazione iniziale” (Anvari et al., 2022), e ci concentreremo sui 10 item negativi dalla PANAS. I dati sono disponibili sul sito web OSF.
df.all <- read_csv("https://osf.io/download/6fbr5/")
# if you have issues with the link, please try downloading manually using the same URL as above
# and read the file from your local drive.
# subset items and demographic variables
df <- df.all %>%
select(
starts_with("PANASD2_1"),
starts_with("PANASD2_20"),
age, Sex, Group
) %>%
select(!PANASD2_10_Active) %>%
select(!PANASD2_1_Attentive)
Rows: 1856 Columns: 74
── Column specification ────────────────────────────────────────────────────────────────────────────────────────────────
Delimiter: ","
chr (10): id, RecordedDate.Recruitment, Group, RecordedDate.D2, Anchor.Posit...
dbl (62): Finished.D2, AnxietyD2_OnEdge, AnxietyD2_Uneasy, AnxietyD2_Anxious...
lgl (2): Finished.Recruitment, Finished.D1
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
# Rinomina le colonne del data frame
df <- df %>%
rename(
Distressed = PANASD2_11_Distressed,
Upset = PANASD2_12_Upset,
Hostile = PANASD2_13_Hostile,
Irritable = PANASD2_14_Irritable,
Scared = PANASD2_15_Scared,
Afraid = PANASD2_16_Afraid,
Ashamed = PANASD2_17_Ashamed,
Guilty = PANASD2_18_Guilty,
Nervous = PANASD2_19_Nervous,
Jittery = PANASD2_20_Jittery
)
glimpse(df)
Rows: 1,856
Columns: 13
$ Distressed <dbl> 2, 2, 2, 1, 2, 2, 4, 1, 1, 3, 1, 4, 2, 4, 4, 1, 2, 2, 1, 2,…
$ Upset <dbl> 1, 1, 4, 1, 1, 5, 2, 1, 2, 2, 2, 3, 1, 3, 5, 1, 1, 2, 1, 1,…
$ Hostile <dbl> 1, 1, 2, 1, 1, 3, 1, 1, 1, 4, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2,…
$ Irritable <dbl> 1, 1, 3, 1, 2, 5, 3, 1, 2, 4, 2, 3, 1, 2, 3, 1, 4, 1, 1, 2,…
$ Scared <dbl> 1, 1, 3, 1, 1, 4, 1, 1, 1, 2, 2, 2, 1, 4, 4, 1, 1, 1, 1, 2,…
$ Afraid <dbl> 1, 1, 4, 1, 1, 3, 1, 1, 1, 3, 1, 2, 1, 4, 4, 1, 1, 1, 1, 2,…
$ Ashamed <dbl> 1, 1, 2, 1, 1, 3, 1, 1, 1, 2, 1, 4, 1, 1, 3, 1, 3, 1, 1, 1,…
$ Guilty <dbl> 2, 1, 2, 1, 1, 3, 3, 1, 1, 3, 1, 4, 1, 1, 3, 1, 2, 1, 1, 1,…
$ Nervous <dbl> 1, 1, 2, 1, 2, 4, 4, 1, 1, 4, 2, 4, 2, 1, 5, 1, 2, 1, 1, 2,…
$ Jittery <dbl> 1, 2, 3, 1, 1, 2, 3, 3, 2, 1, 2, 2, 1, 1, 4, 1, 2, 2, 1, 3,…
$ age <dbl> 27, 32, 21, 27, 20, 22, 23, 25, 21, 26, 38, 36, 24, 21, 19,…
$ Sex <chr> "Male", "Male", "Female", "Male", "Male", "Male", "Female",…
$ Group <chr> "Later Start", "Later Start", "Later Start", "Later Start",…
Dato che ci sono solo 5 partecipanti che utilizzano etichette diverse da Femminile/Maschile (troppo pochi per un’analisi statistica robusta), li rimuoveremo per avere un dataset completo per tutte le variabili in questo esempio.
df <- df %>%
filter(Sex %in% c("Female", "Male"))
df_num <- df[, 1:10]
glimpse(df_num)
Rows: 1,851
Columns: 10
$ Distressed <dbl> 2, 2, 2, 1, 2, 2, 4, 1, 1, 3, 1, 4, 2, 4, 4, 1, 2, 2, 1, 2,…
$ Upset <dbl> 1, 1, 4, 1, 1, 5, 2, 1, 2, 2, 2, 3, 1, 3, 5, 1, 1, 2, 1, 1,…
$ Hostile <dbl> 1, 1, 2, 1, 1, 3, 1, 1, 1, 4, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2,…
$ Irritable <dbl> 1, 1, 3, 1, 2, 5, 3, 1, 2, 4, 2, 3, 1, 2, 3, 1, 4, 1, 1, 2,…
$ Scared <dbl> 1, 1, 3, 1, 1, 4, 1, 1, 1, 2, 2, 2, 1, 4, 4, 1, 1, 1, 1, 2,…
$ Afraid <dbl> 1, 1, 4, 1, 1, 3, 1, 1, 1, 3, 1, 2, 1, 4, 4, 1, 1, 1, 1, 2,…
$ Ashamed <dbl> 1, 1, 2, 1, 1, 3, 1, 1, 1, 2, 1, 4, 1, 1, 3, 1, 3, 1, 1, 1,…
$ Guilty <dbl> 2, 1, 2, 1, 1, 3, 3, 1, 1, 3, 1, 4, 1, 1, 3, 1, 2, 1, 1, 1,…
$ Nervous <dbl> 1, 1, 2, 1, 2, 4, 4, 1, 1, 4, 2, 4, 2, 1, 5, 1, 2, 1, 1, 2,…
$ Jittery <dbl> 1, 2, 3, 1, 1, 2, 3, 3, 2, 1, 2, 2, 1, 1, 4, 1, 2, 2, 1, 3,…
Esaminiamo la distribuzione delle risposte in ciascuna categoria, per ciascun item.
# Preparare una lista per memorizzare le tabelle delle frequenze relative
frequencies_list <- list()
# Calcolare le frequenze relative per ciascuna emozione
for (i in names(df_num)) {
# Calcolo della tabella di frequenza
freq_table <- table(df_num[[i]])
# Conversione in frequenze relative
relative_freq_table <- prop.table(freq_table) * 100
# Aggiungere la tabella alla lista con un nome appropriato
frequencies_list[[i]] <- relative_freq_table
}
# Stampare le tabelle delle frequenze relative per ciascuna emozione
frequencies_list
$Distressed
1 2 3 4 5
36.574824 27.336575 18.962723 13.614263 3.511615
$Upset
1 2 3 4 5
50.945435 22.474338 14.262561 8.860076 3.457590
$Hostile
1 2 3 4 5
61.750405 19.989195 11.777418 5.186386 1.296596
$Irritable
1 2 3 4 5
40.572663 25.769854 17.287952 11.993517 4.376013
$Scared
1 2 3 4 5
57.536467 19.989195 12.047542 8.049703 2.377093
$Afraid
1 2 3 4 5
53.916802 19.935170 13.452188 9.562399 3.133441
$Ashamed
1 2 3 4 5
66.018368 17.990276 9.346299 4.592112 2.052944
$Guilty
1 2 3 4 5
64.235548 17.450027 10.210697 5.942734 2.160994
$Nervous
1 2 3 4 5
35.008104 26.039978 17.666126 16.423555 4.862237
$Jittery
1 2 3 4 5
42.895732 26.472177 19.556996 8.806051 2.269044
Adattiamo ai dati il modello uni-fattoriale, per variabili ordinali.
mod_cfa <- "F =~ Distressed + Upset+ Hostile + Irritable + Scared +
Afraid + Ashamed + Guilty + Nervous + Jittery"
my_cfa <- cfa(
mod_cfa,
data = df_num,
std.lv = TRUE,
ordered=c('Distressed', 'Upset', 'Hostile', 'Irritable', 'Scared',
'Afraid', 'Ashamed', 'Guilty', 'Nervous', 'Jittery')
)
Le misure di bontà di adattamento sono buone.
fitMeasures(my_cfa, c(
"chisq", "df", "pvalue",
"rmsea", "srmr", "gfi", "cfi", "tli"
)) %>%
as.data.frame() %>%
t() %>%
as.data.frame() %>%
round(3)
| chisq | df | pvalue | rmsea | srmr | gfi | cfi | tli | |
|---|---|---|---|---|---|---|---|---|
| <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | |
| . | 609.2 | 35 | 0 | 0.094 | 0.059 | 0.992 | 0.988 | 0.985 |
Esaminiamo le saturazioni fattoriali.
out <- parameterEstimates(my_cfa)
out[out$op == "=~", ]
| lhs | op | rhs | est | se | z | pvalue | ci.lower | ci.upper | |
|---|---|---|---|---|---|---|---|---|---|
| <chr> | <chr> | <chr> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | |
| 1 | F | =~ | Distressed | 0.6625537 | 0.015920202 | 41.61717 | 0 | 0.6313506 | 0.6937567 |
| 2 | F | =~ | Upset | 0.8029147 | 0.010980723 | 73.12038 | 0 | 0.7813928 | 0.8244365 |
| 3 | F | =~ | Hostile | 0.6461593 | 0.017707487 | 36.49074 | 0 | 0.6114533 | 0.6808654 |
| 4 | F | =~ | Irritable | 0.7319141 | 0.012891703 | 56.77404 | 0 | 0.7066468 | 0.7571814 |
| 5 | F | =~ | Scared | 0.8808961 | 0.008358931 | 105.38383 | 0 | 0.8645129 | 0.8972794 |
| 6 | F | =~ | Afraid | 0.8792873 | 0.007816413 | 112.49243 | 0 | 0.8639674 | 0.8946072 |
| 7 | F | =~ | Ashamed | 0.7811557 | 0.013513552 | 57.80536 | 0 | 0.7546697 | 0.8076418 |
| 8 | F | =~ | Guilty | 0.7393991 | 0.014947237 | 49.46728 | 0 | 0.7101031 | 0.7686952 |
| 9 | F | =~ | Nervous | 0.7953141 | 0.010096867 | 78.76841 | 0 | 0.7755247 | 0.8151036 |
| 10 | F | =~ | Jittery | 0.6423809 | 0.015861305 | 40.49988 | 0 | 0.6112933 | 0.6734685 |
Ora adattiamo ai dati il Graded Response Model:
mirt_grm <- mirt(df_num, 1, itemtype = "graded", verbose = FALSE)
Esaminiamo la soluzione fattoriale.
summary(mirt_grm)
F1 h2
Distressed 0.698 0.488
Upset 0.816 0.666
Hostile 0.656 0.430
Irritable 0.722 0.521
Scared 0.880 0.774
Afraid 0.878 0.771
Ashamed 0.773 0.598
Guilty 0.727 0.528
Nervous 0.821 0.674
Jittery 0.662 0.438
SS loadings: 5.888
Proportion Var: 0.589
Factor correlations:
F1
F1 1
Ci possiamo ora chiedere in che misura i risultati IRT differiscano da quelli ottenuti con una CFA. Per rispondere possiamo semplicemente estrarre i punteggi fattoriali da entrambi i modelli e calcolare la correlazione.
cor.test(predict(my_cfa), fscores(mirt_grm))
Pearson's product-moment correlation
data: predict(my_cfa) and fscores(mirt_grm)
t = 601.09, df = 1849, p-value < 2.2e-16
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
0.9972080 0.9976729
sample estimates:
cor
0.997451
Come si può vedere, le due soluzioni sono quasi equivalenti. Questo è un bel esempio di come due approcci molto diversi portino a una stima quasi identica del tratto latente.
65.5. Parametri IRT nel Graded Response Model (GRM)#
Il Graded Response Model (GRM) impiega specifici parametri per analizzare le risposte a questionari con più categorie di risposta. Ogni item nel GRM è caratterizzato da un singolo parametro di discriminazione che misura la capacità dell’item di distinguere tra soggetti con diversi livelli del tratto latente. Questo parametro indica quanto efficacemente un item può differenziare tra individui che variano nel tratto che si intende misurare.
In aggiunta, il GRM definisce per ogni item diversi parametri di difficoltà, noti anche come soglie, che corrispondono a ciascuna transizione tra le categorie di risposta. Questi parametri di difficoltà rappresentano il livello di tratto latente necessario affinché un individuo abbia una probabilità del 50% di rispondere in una determinata categoria o in una superiore.
Per chiarire ulteriormente, consideriamo un individuo con un livello di tratto latente \( \theta \) superiore a una specifica soglia \( b_k \) del modello. In questo caso, la probabilità che l’individuo scelga la categoria di risposta successiva o una superiore sarà maggiore del 50%. Ciò deriva dalla natura della funzione logistica usata nel GRM, la quale stabilisce che se il tratto latente \( \theta \) di un individuo supera il valore della soglia \( b_k \), allora la probabilità di selezionare quella categoria o una successiva supera il 50%.
coef(mirt_grm, IRT = TRUE, simplify = TRUE)$items %>%
round(2) %>%
as.data.frame()
| a | b1 | b2 | b3 | b4 | |
|---|---|---|---|---|---|
| <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | |
| Distressed | 1.66 | -0.46 | 0.55 | 1.37 | 2.62 |
| Upset | 2.41 | 0.05 | 0.79 | 1.44 | 2.24 |
| Hostile | 1.48 | 0.47 | 1.39 | 2.36 | 3.60 |
| Irritable | 1.78 | -0.32 | 0.60 | 1.37 | 2.40 |
| Scared | 3.15 | 0.24 | 0.87 | 1.42 | 2.23 |
| Afraid | 3.12 | 0.13 | 0.76 | 1.31 | 2.10 |
| Ashamed | 2.08 | 0.54 | 1.29 | 1.94 | 2.68 |
| Guilty | 1.80 | 0.50 | 1.23 | 1.92 | 2.83 |
| Nervous | 2.45 | -0.46 | 0.37 | 1.00 | 2.03 |
| Jittery | 1.50 | -0.25 | 0.78 | 1.86 | 3.13 |
65.6. Curve di risposta alle categorie#
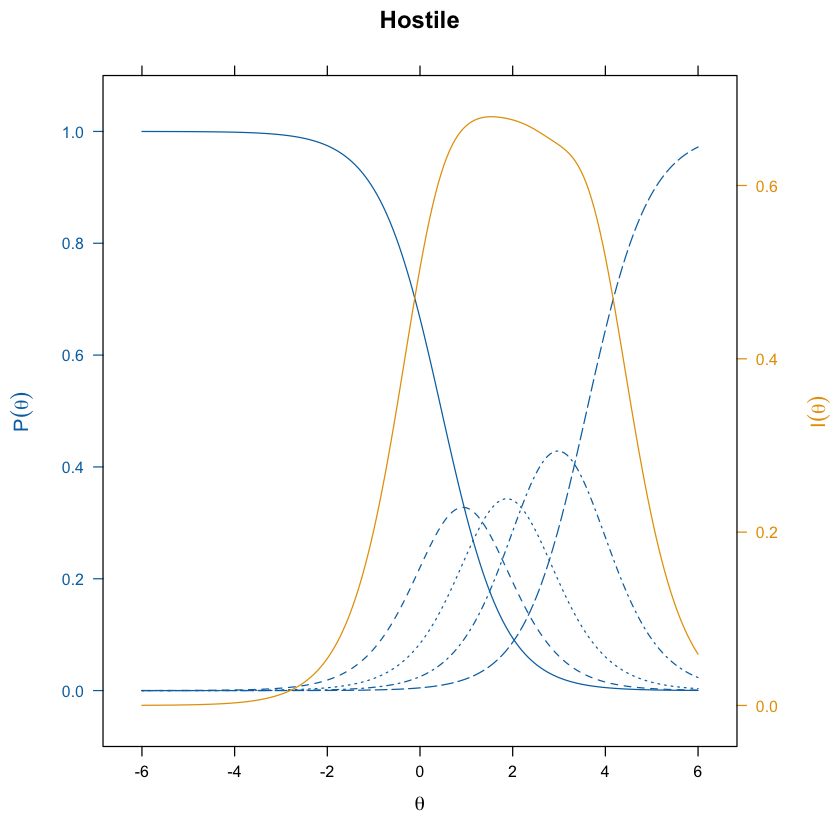
Spesso è di interesse esaminare le probabilità di risposta a categorie specifiche sulla scala di valutazione di un item. Le curve di risposta alle categorie (CRC) sono strumenti grafici essenziali per analizzare come le probabilità di risposta a diverse categorie di un item cambiano in relazione al tratto latente di un individuo. Queste curve offrono una rappresentazione visiva dettagliata e intuitiva della relazione tra il livello di un tratto latente e la probabilità di scegliere specifiche categorie di risposta in un questionario.
Ogni curva in un grafico CRC rappresenta la probabilità che un rispondente con un determinato livello di tratto latente scelga una particolare categoria di risposta.
Per costruire una CRC, si considerano sia il oarametro di discriminazione (a) sia i parametri di difficoltà o soglie (\( b_k \)).
Nelle CRC:
L’asse orizzontale rappresenta il tratto latente (\( \theta \)), che varia da basso a alto.
L’asse verticale rappresenta la probabilità, che varia da 0 a 1, di scegliere una specifica categoria.
Le curve per le categorie più estreme (ad esempio, la prima e l’ultima categoria in un questionario a più categorie) tendono ad avere una forma a S. Questo perché, per queste categorie, le probabilità di risposta aumentano da zero a un massimo e poi si stabilizzano. Per la prima categoria, la curva aumenta all’inizio e poi si appiattisce man mano che il tratto latente aumenta oltre la prima soglia. Per l’ultima categoria, la curva rimane bassa fino a quando il tratto non supera l’ultima soglia e poi sale verso l’1.
Le curve per le categorie intermedie spesso assumono una forma campaniforme. Questo accade perché la probabilità di selezionare una categoria intermedia inizia a crescere solo dopo aver superato la soglia inferiore, raggiunge un picco quando il tratto latente si avvicina alla soglia successiva, e poi decresce nuovamente man mano che il tratto continua ad aumentare. Questo picco riflette il punto in cui un rispondente con un tratto specifico è più propenso a scegliere quella categoria piuttosto che le categorie adiacenti.
Le CRC sono particolarmente utili per:
Valutare l’adeguatezza degli item: Identificare se gli item discriminano efficacemente a diversi livelli del tratto e se le soglie sono posizionate appropriatamente.
Ottimizzare i questionari: Selezionare o modificare gli item in modo che coprano adeguatamente l’intero spettro del tratto latente.
Analizzare le risposte: Comprendere meglio come varie subpopolazioni rispondano agli item, basandosi sulle loro caratteristiche latenti.
tracePlot(mirt_grm) +
labs(color = "Answer Options")
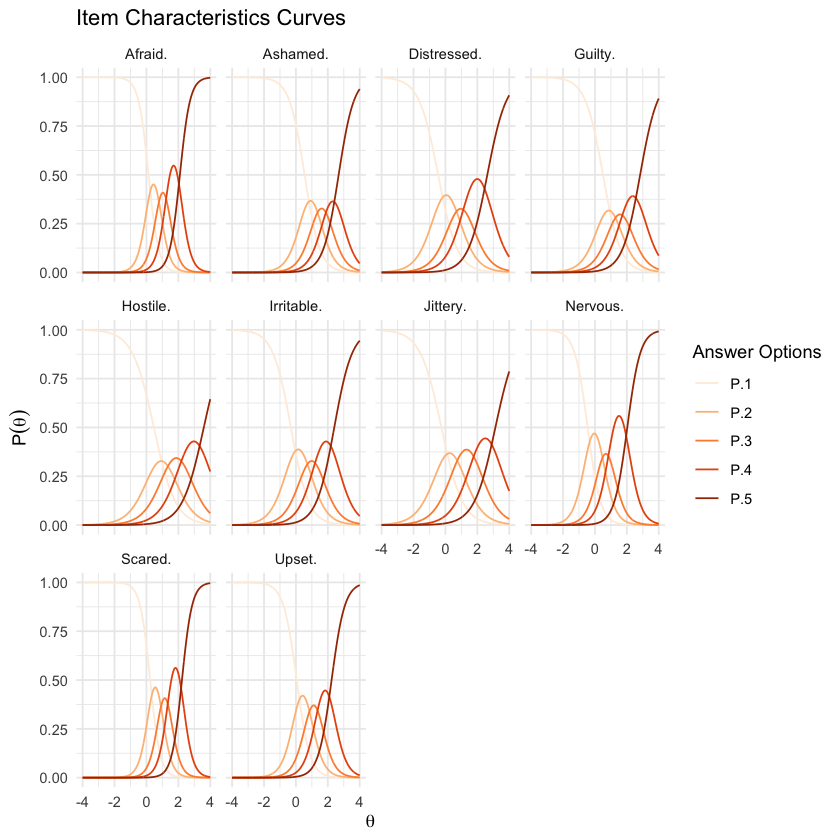
Queste curve hanno una chiara relazione con \(\theta\): Man mano che \(\theta\) aumenta, la probabilità di approvare una categoria aumenta e poi diminuisce mentre le risposte passano alla categoria successiva più alta. Di nuovo, vediamo chiaramente che tutte le opzioni di risposta dell’item coprono un’ampia gamma del tratto latente.
Possiamo anche usare una sintassi alternativa.
update(itemplot(mirt_grm, 1, type = "trace"), main = colnames(df_num)[1])
update(itemplot(mirt_grm, 2, type = "trace"), main = colnames(df_num)[2])
update(itemplot(mirt_grm, 3, type = "trace"), main = colnames(df_num)[3])
update(itemplot(mirt_grm, 4, type = "trace"), main = colnames(df_num)[4])
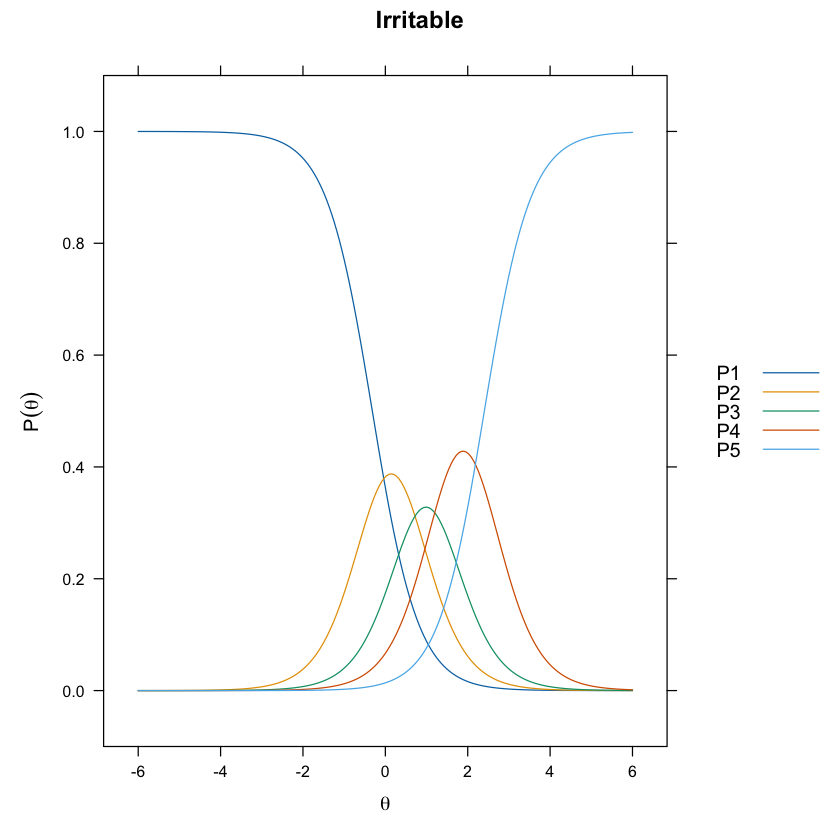
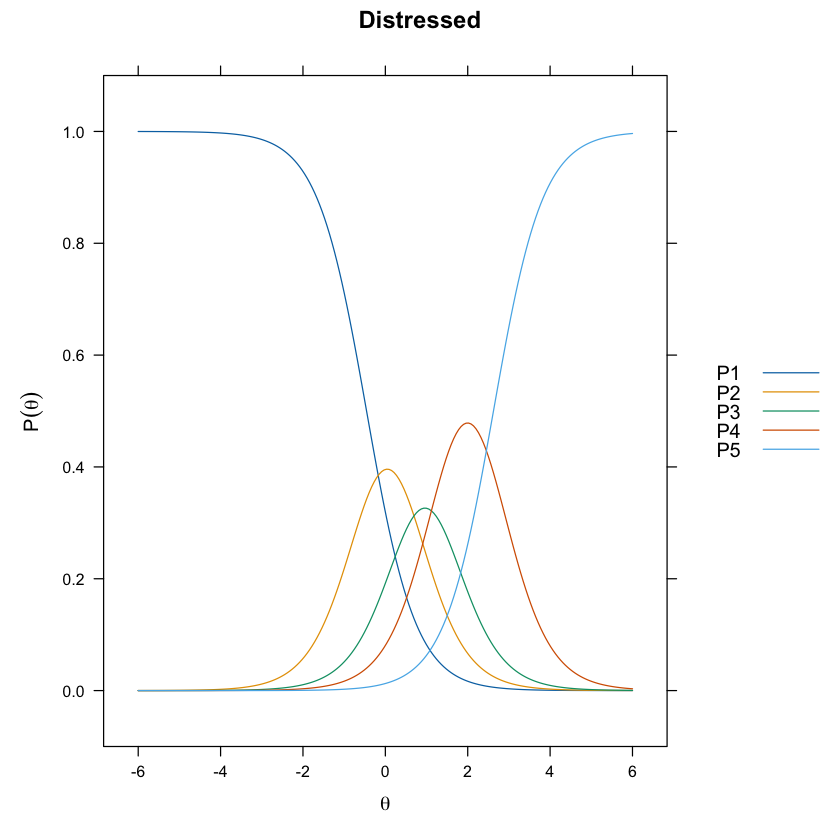
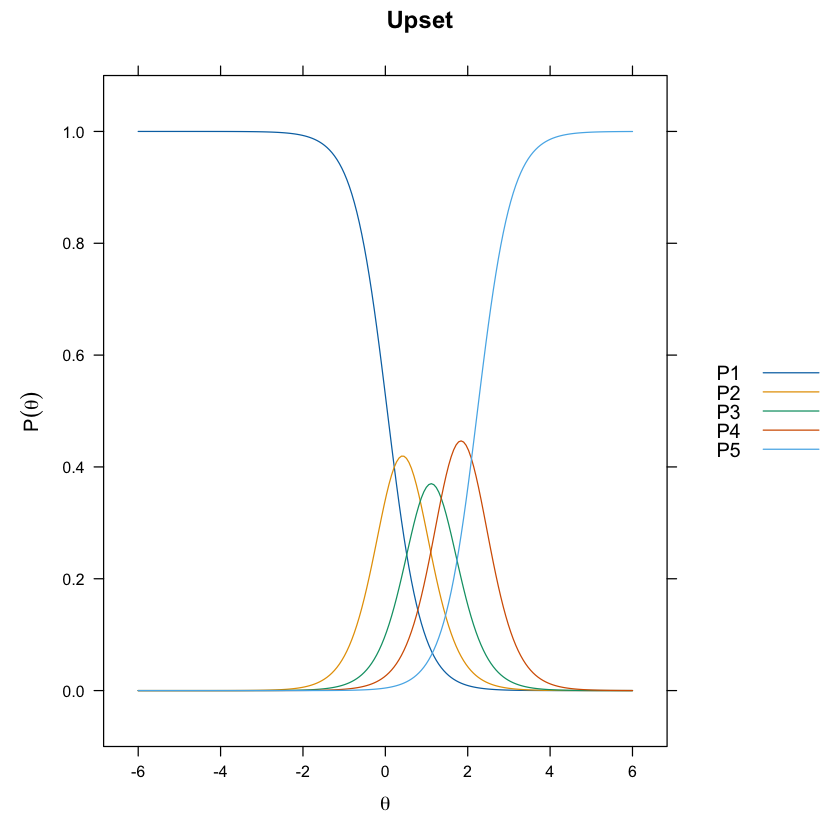
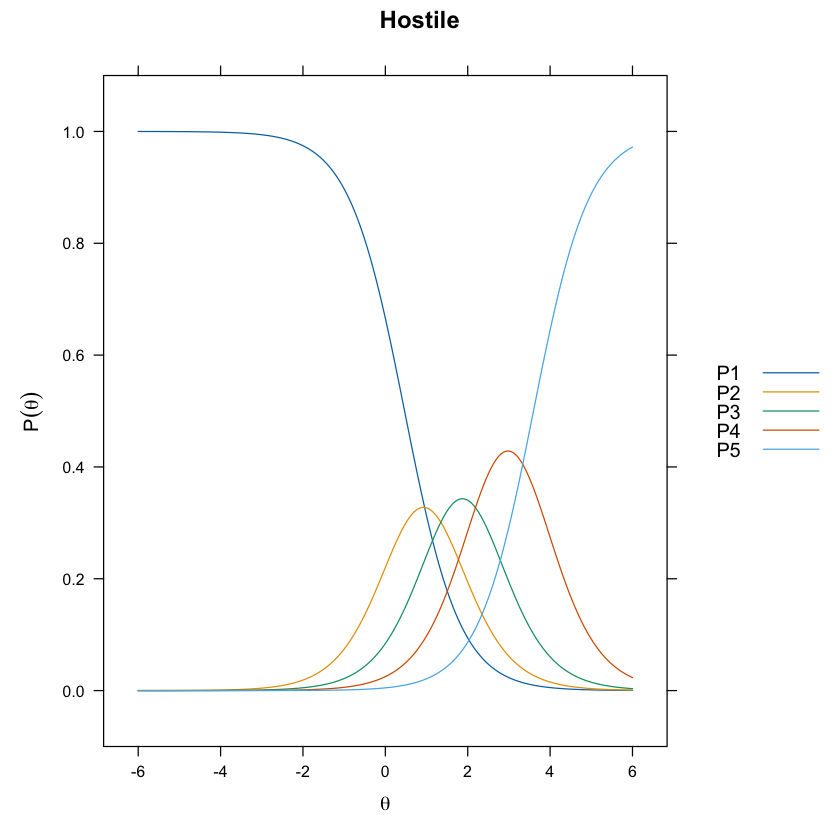
La stessa informazione dei grafici precedenti può essere fornita esaminando le funzioni cumulative.
update(itemplot(mirt_grm, 1, type = "threshold"), main = colnames(df_num)[1])
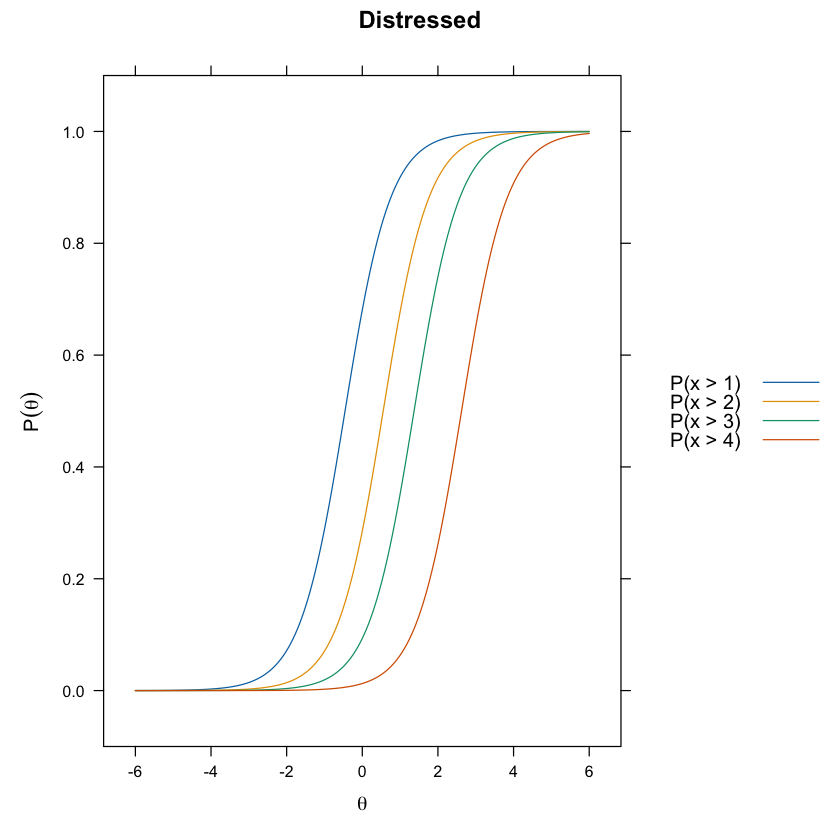
update(itemplot(mirt_grm, 2, type = "threshold"), main = colnames(df_num)[2])
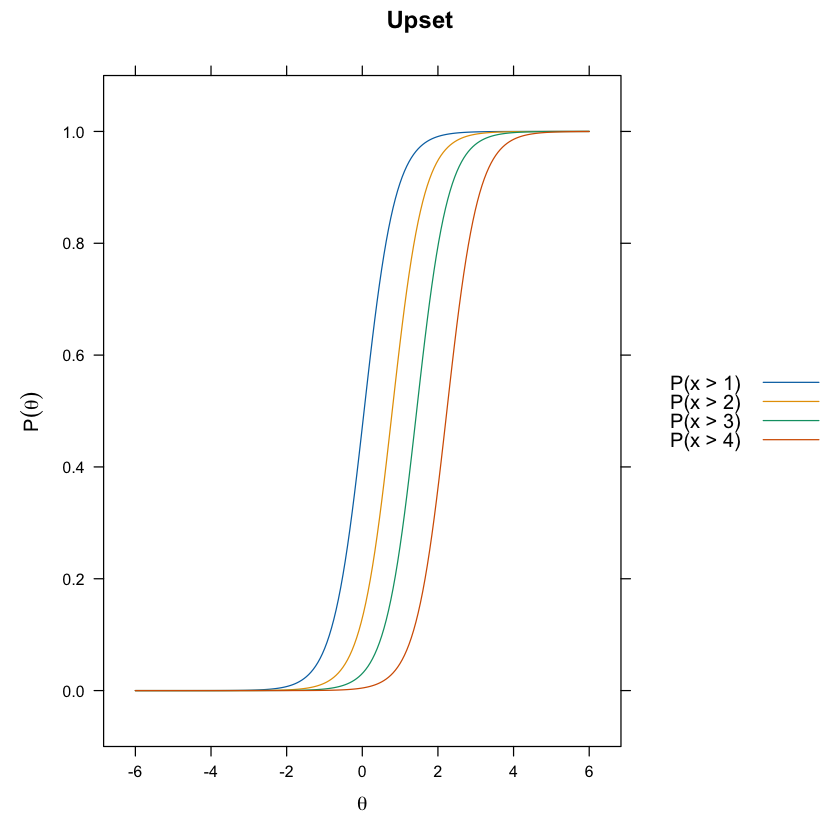
update(itemplot(mirt_grm, 3, type = "threshold"), main = colnames(df_num)[3])
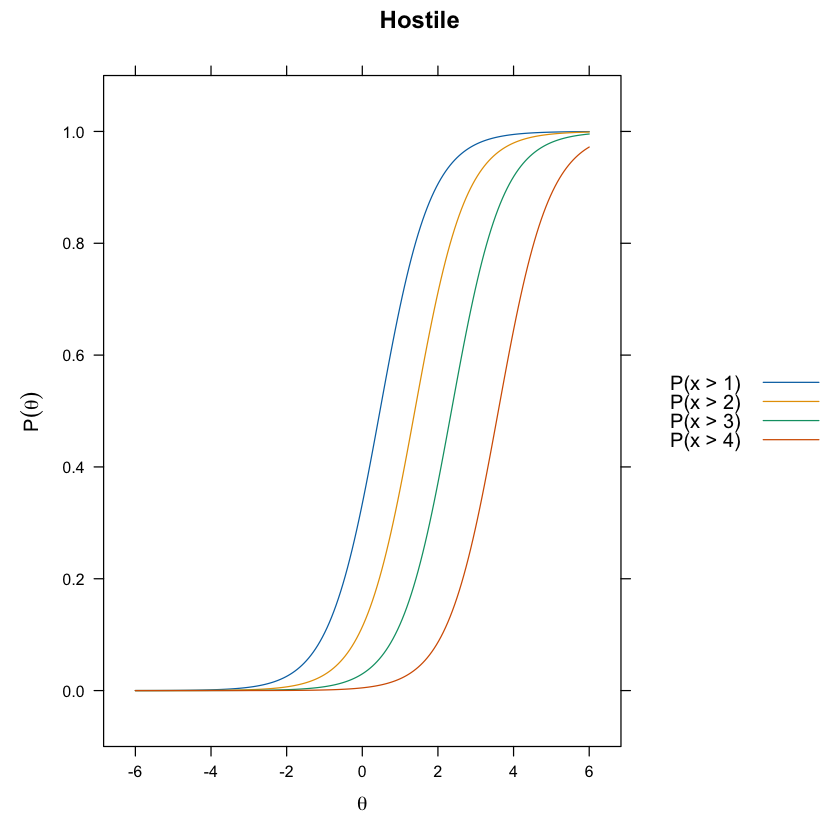
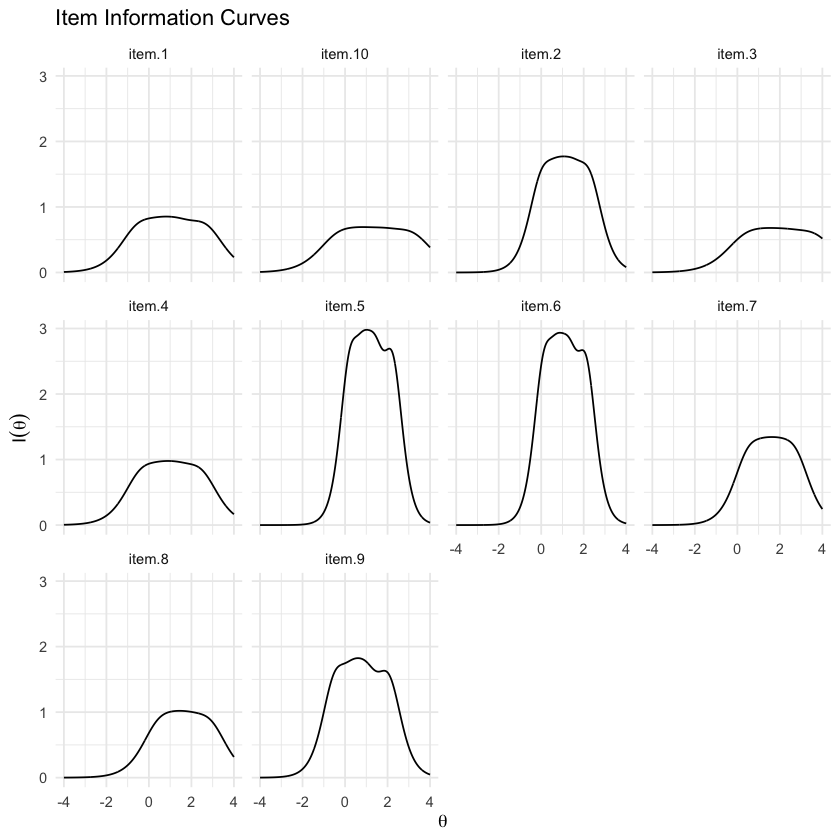
65.7. Curve di Informazione degli Item (IIC)#
Il concetto di “informazione” in contesti statistici, specialmente nella Teoria della Risposta all’Item (IRT), riguarda la capacità di un item di fornire stime precise di un tratto latente, comunemente indicato con \( \theta \). L’informazione a livello di item, visualizzata tramite le Curve di Informazione degli Item (IIC), quantifica l’efficacia con cui ogni item contribuisce alla precisione della stima del tratto latente; quindi, più elevato è il livello di informazione offerto da un item, più accurata sarà la stima di \( \theta \).
Le IIC permettono di osservare visivamente dove e quanto ciascun item contribuisce alla precisione della stima del tratto. Un item con un’alta informazione sarà più sensibile a specifici livelli di \( \theta \), offrendo stime più precise in quel range. Questo è particolarmente utile in test adattivi computerizzati, dove la selezione degli item si basa sulla loro capacità di misurare efficacemente il tratto all’attuale stima di \( \theta \) del rispondente.
Nell’esempio, gli item 2, 5, 6 e 9 mostrano elevati livelli di informazione nei loro grafici IIC. Questo indica che sono particolarmente efficaci nella misurazione di specifici intervalli del tratto latente. Questa efficacia è ulteriormente confermata dai loro elevati carichi fattoriali, suggerendo che questi item sono molto discriminanti per i livelli di \( \theta \) corrispondenti.
L’analisi delle IIC non solo identifica quali item sono più informativi ma anche a quali livelli di \( \theta \) ciascun item è ottimale. Questo consente ai ricercatori e agli sviluppatori di test di:
Selezionare item adatti per diverse fasce di abilità: Assicurando che il test sia equilibrato e fornisca misurazioni precise attraverso l’intero spettro del tratto latente.
Rimodellare e raffinare gli item: Gli item che forniscono poca informazione possono essere modificati o sostituiti per migliorare l’efficacia generale del test.
Bilanciare la difficoltà degli item: Distribuire adeguatamente gli item in modo che il test possa misurare efficacemente sia i bassi che gli alti livelli di \( \theta \).
In sintesi, le Curve di Informazione degli Item sono strumenti importanti per comprendere e ottimizzare la capacità di un questionario di misurare con precisione e affidabilità il tratto latente. Offrono una base solida per decisioni informate riguardo la selezione degli item e la costruzione di test, garantendo che ogni componente del questionario contribuisca in modo significativo alla valutazione del tratto di interesse.
itemInfoPlot(mirt_grm, facet = TRUE)
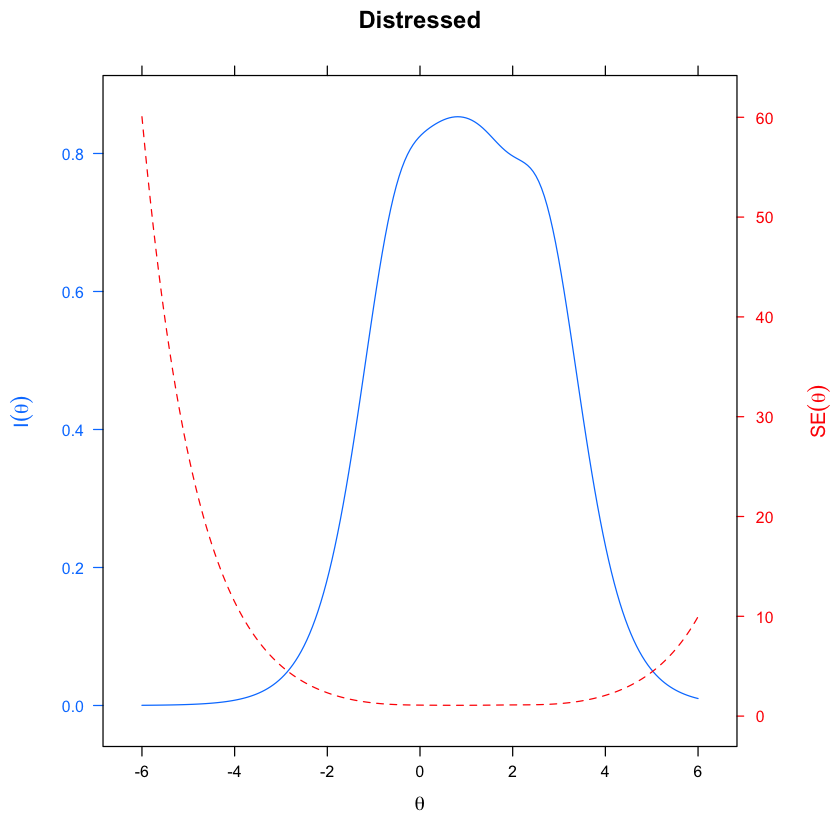
La curva di informazione di un item, insieme alla rappresentazione dell’errore standard (SE), può essere generata con l’istruzione seguente:
update(itemplot(mirt_grm, 1, type = "infoSE"), main = colnames(df_num)[1])
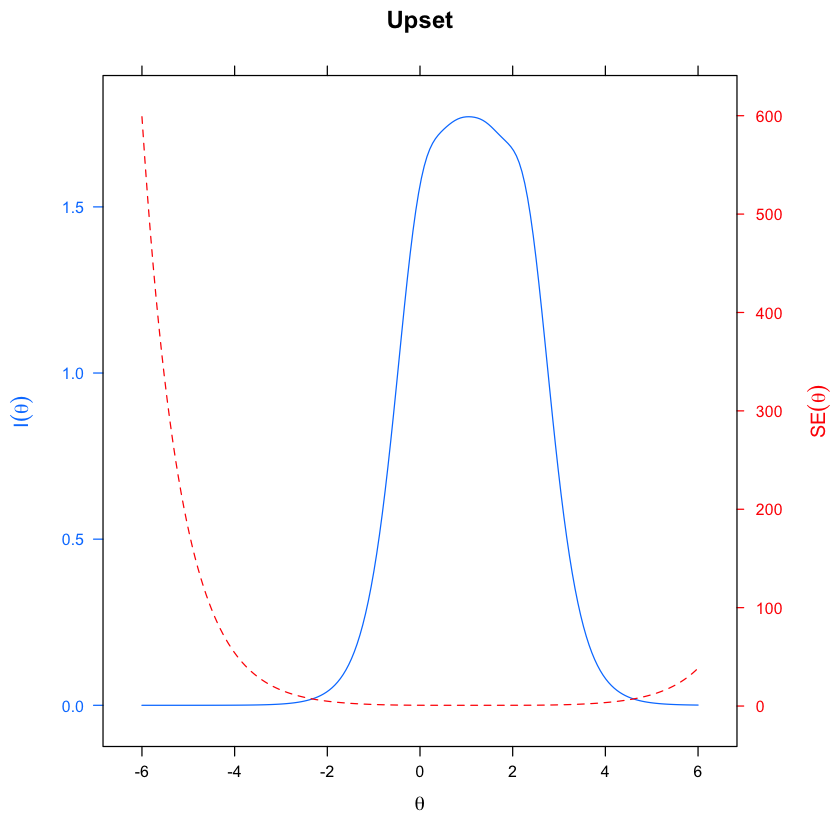
update(itemplot(mirt_grm, 2, type = "infoSE"), main = colnames(df_num)[2])
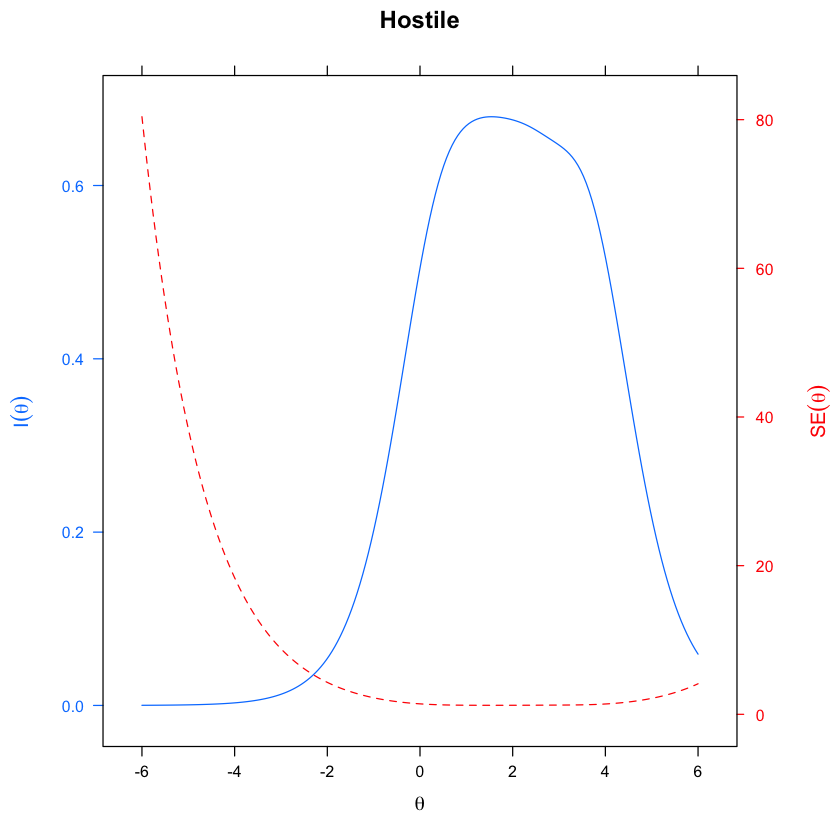
update(itemplot(mirt_grm, 3, type = "infoSE"), main = colnames(df_num)[3])
La curva di informazione dell’item insieme alle curve di risposta alle categorie può essere rappresentata mediante l’istruzione seguente.
update(itemplot(mirt_grm, 1, type = "infotrace"), main = colnames(df_num)[1])
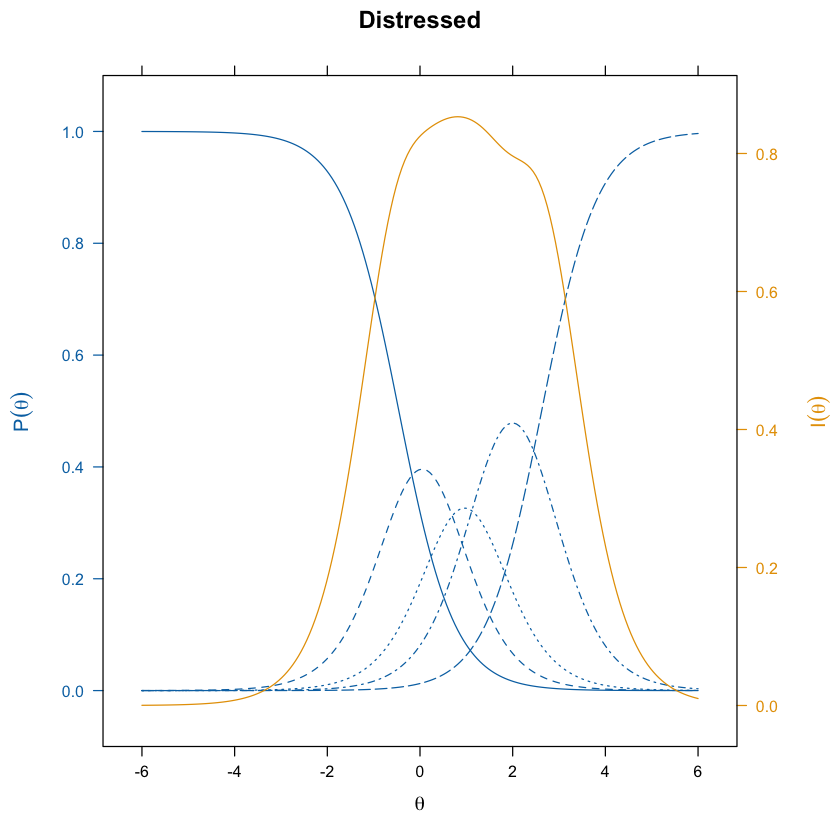
update(itemplot(mirt_grm, 2, type = "infotrace"), main = colnames(df_num)[2])
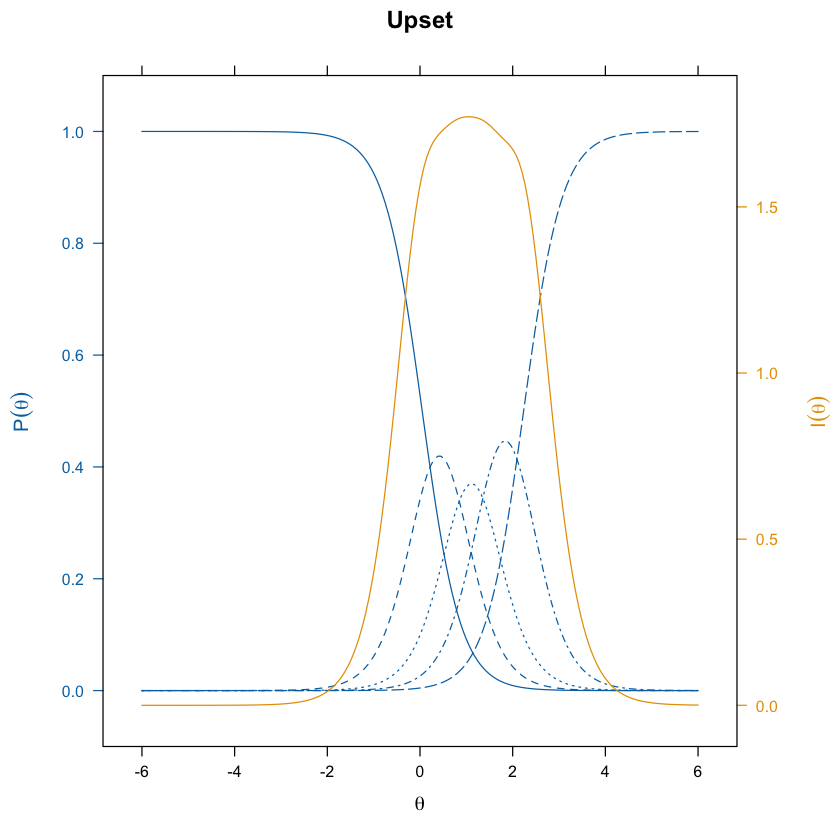
update(itemplot(mirt_grm, 3, type = "infotrace"), main = colnames(df_num)[3])
65.8. Curva di Informazione del Test#
La Curva di Informazione del Test (Test Information Curve, TIC) illustra come un test nel suo insieme misura un tratto latente specifico.
Nella IRT, ogni item di un test fornisce una certa quantità di informazione a seconda del livello del tratto latente (\(\theta\)) del rispondente. La Curva di Informazione del Test è ottenuta sommando le informazioni di tutti gli item del test per ciascun valore di \(\theta\). Questo processo crea una funzione che mostra quanto bene il test nel suo complesso è in grado di misurare il tratto latente su diversi livelli.
La TIC è quindi una funzione di informazione della scala, che riassume la capacità complessiva del test di fornire informazioni statistiche su \(\theta\). Mostra l’efficacia del test in termini di precisione e affidabilità delle stime di \(\theta\) a vari livelli.
La TIC non solo mostra dove il test è più informativo ma permette anche di calcolare gli errori standard condizionali dei punteggi stimati:
Errori Standard (SE): Gli errori standard dei punteggi stimati su \(\theta\) sono inversamente proporzionali alla radice quadrata dell’informazione fornita dal test a quel livello di \(\theta\). In pratica, ciò significa che maggiore è l’informazione che il test fornisce per un dato livello di \(\theta\), minore è l’incertezza (o l’errore standard) associata alla stima di \(\theta\) a quel livello.
La Curva di Informazione del Test è uno strumento essenziale nella IRT, permettendo ai ricercatori e psicometrici di valutare la precisione complessiva di un test e di identificare a quali livelli di \(\theta\) il test è più efficace. Questo può guidare miglioramenti nel design del test e assicurare che il test sia ben calibrato per misurare accuratamente il tratto latente di interesse.
testInfoPlot(mirt_grm, adj_factor = .5)
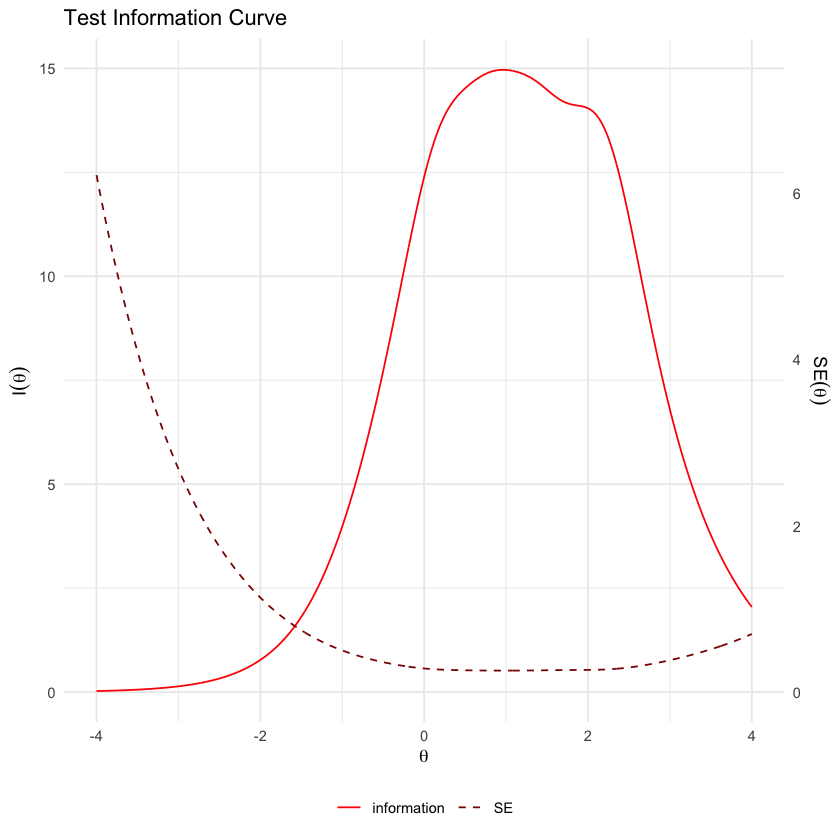
In maniera equivalente possiamo usare la seguente sintassi.
plot(mirt_grm,
type = "infoSE", theta_lim = c(-6, 6),
main = "Test Information Function and Conditional Standard Error"
)
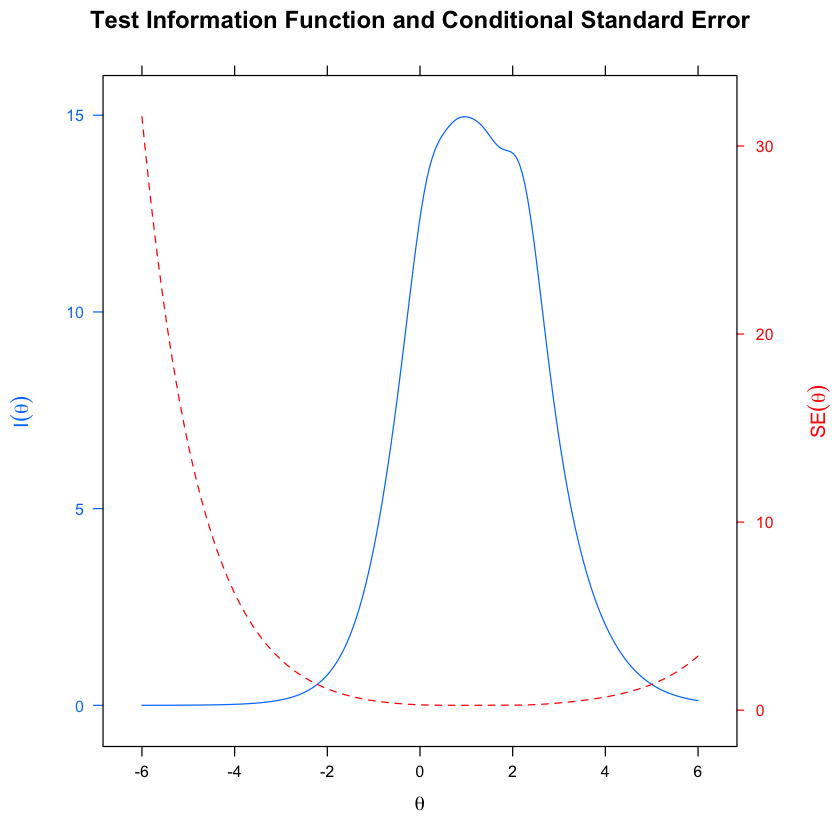
La relazione tra le informazioni sulla scala e gli errori standard condizionati è illustrata sopra. La linea blu continua rappresenta la funzione delle informazioni sulla scala. Complessivamente, la scala ha fornito il maggior numero di informazioni nell’intervallo da -4 a +4. La linea rossa fornisce un riferimento visivo su come la precisione dell’indice varia attraverso theta, con valori più piccoli che corrispondono a una migliore precisione dell’indice. Poiché gli errori standard condizionati riflettono matematicamente la curva delle informazioni sulla scala, la precisione stimata del punteggio è stata migliore nell’intervallo di theta da -2 a +4.
65.8.1. Affidabilità Condizionale nell’IRT#
La Teoria della Risposta all’Item (IRT) offre un approccio sofisticato e dettagliato per valutare l’affidabilità di un test, che si distingue significativamente da quello della teoria classica dei test (CTT). Mentre la CTT, utilizzando il coefficiente di alpha di Cronbach o omega, fornisce una stima dell’affidabilità come un valore unico per tutto il test, l’IRT permette una valutazione dell’affidabilità che varia in base al livello del tratto latente (\(\theta\)). Questo concetto è noto come “affidabilità condizionale”.
Nella CTT i coefficienti di affidabilità (Alpha di Cronbach, Omega) assumono che l’affidabilità sia una proprietà stabile del test, indipendentemente dal livello di abilità dei rispondenti.
Nell’IRT:
L’affidabilità di un test nell’IRT non è considerata una caratteristica uniforme del test ma varia a seconda del livello del tratto latente del rispondente. Questo significa che un test può essere più affidabile per misurare tratti ad alti o bassi livelli di \(\theta\) rispetto a livelli intermedi.
L’affidabilità condizionale in un punto specifico del tratto latente è calcolata come \( R(\theta) = 1 - \frac{1}{I(\theta)} \), dove \( I(\theta) \) è l’informazione del test a quel livello di \(\theta\). L’informazione del test, che è inversamente proporzionale all’errore standard della stima di \(\theta\), riflette la precisione con cui il tratto è misurato. Maggiore è l’informazione, maggiore è l’affidabilità e minore l’errore di misura.
L’uso dell’affidabilità condizionale permette una comprensione più precisa e differenziata dell’efficacia di un test. Ad esempio:
Ottimizzazione dei Test: Sapendo che un test è più affidabile per certi livelli di \(\theta\), gli sviluppatori possono cercare di migliorare la precisione del test in aree dove l’affidabilità è più bassa.
Interpretazione Differenziata: Gli utenti del test possono interpretare i risultati con maggiore cautela in quelle regioni del tratto latente dove l’affidabilità è più bassa, prendendo decisioni più informate sui risultati del test.
In sintesi, l’IRT fornisce un quadro più dinamico e dettagliato dell’affidabilità rispetto alla CTT.
plot(mirt_grm,
type = "rxx", theta_lim = c(-6, 6),
main = "Conditional Reliabilty Curve"
)
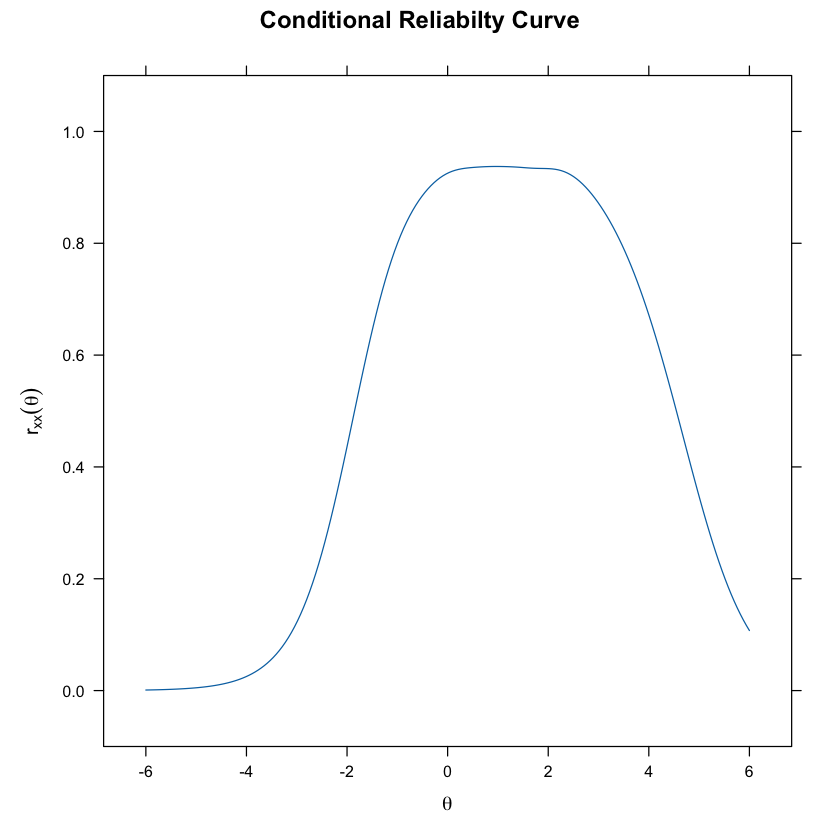
Per i dati in discussione, vediamo che le stime dei punteggi sono più affidabili nell’intervallo di theta da -2 a +5.
È anche possibile calcolare una singola stima di affidabilità IRT. L’affidabilità marginale per la scala nel suo complesso è di 0.87.
marginal_rxx(mirt_grm)
65.9. Curva caratteristica della scala#
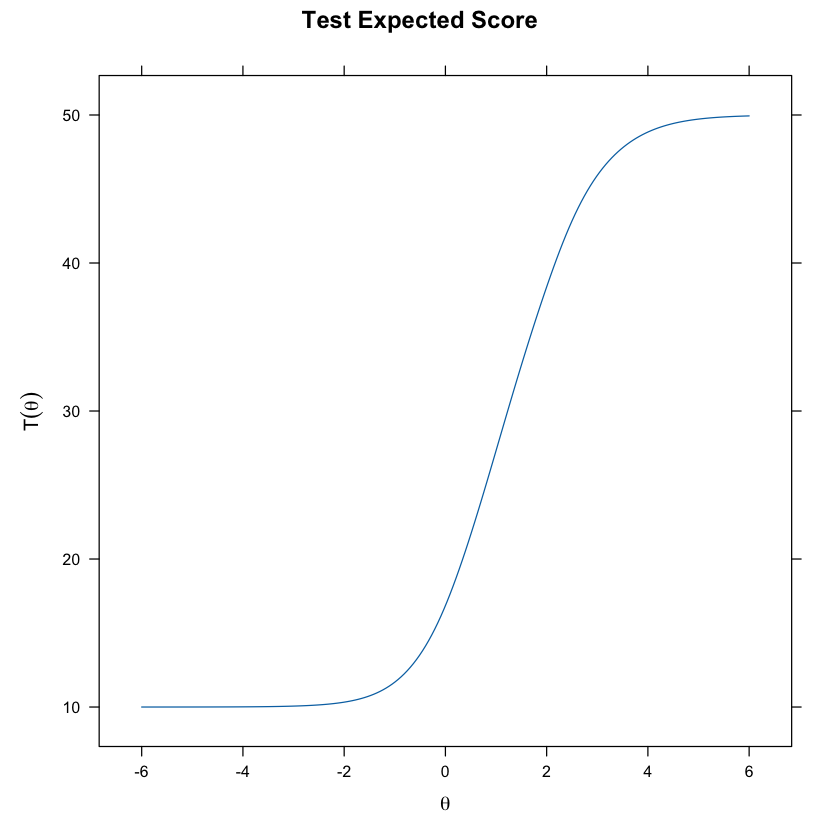
La Curva Caratteristica della Scala (Scale Characteristic Curve, SCC) permette di tradurre le stime dei punteggi latenti (θ) in punteggi su una scala più comprensibile e direttamente applicabile. Questo processo è particolarmente utile per rendere i risultati di un modello IRT più accessibili e interpretativamente validi in contesti pratici.
Nell’IRT, i punteggi \(\theta\) rappresentano la stima del tratto latente di una persona. Questi punteggi sono analoghi ai punteggi del fattore nella Analisi dei Fattori Confermativi (CFA) e vengono spesso espressi in una scala z, che è una scala normale standard con una media di 0 e una deviazione standard di 1.
Nell’IRT, i punteggi \(\theta\) possono essere stimati tramite il metodo EAP, che utilizza la probabilità a posteriori del tratto latente dato un insieme di risposte per produrre una stima ponderata del tratto.
Una volta ottenuti i punteggi \(\theta\), l’interesse si sposta spesso su come questi possono essere trasformati per riflettere una metrica più familiare o utilizzata praticamente.
La Funzione Caratteristica della Scala (SCC) è una funzione matematica che trasforma i punteggi \(\theta\) stimati in punteggi sulla scala originale del test o questionario. Questa funzione tiene conto della distribuzione dei punteggi \(\theta\) e di come questi si correlano con i punteggi osservati, fornendo una stima del punteggio “vero” atteso su una scala originale che può essere più intuitiva per interpretare i risultati.
La trasformazione dei punteggi \(\theta\) in punteggi sulla scala originale è cruciale per facilitare l’interpretazione dei risultati. La SCC permette ai risultati di essere presentati in una forma direttamente comparabile con altre metriche standard utilizzate nel campo di applicazione.
plot(mirt_grm,
type = "score", theta_lim = c(-6, 6),
main = "Test Expected Score"
)
65.10. Statistiche di Infit e Outfit#
Consideriamo la bontà di adattamento con le statistiche di infit e outfit.
mirt::itemfit(mirt_grm, fit_stats = "infit", method = "ML")
| item | outfit | z.outfit | infit | z.infit |
|---|---|---|---|---|
| <chr> | <dbl> | <dbl> | <dbl> | <dbl> |
| Distressed | 1.0212414 | 0.4769906 | 1.0009891 | 0.03963688 |
| Upset | 0.7724958 | -2.5666950 | 0.9023095 | -2.34278922 |
| Hostile | 1.0357427 | 0.4962970 | 0.9889173 | -0.23379715 |
| Irritable | 0.8752693 | -2.4796215 | 0.9427137 | -1.56167437 |
| Scared | 0.6369161 | -2.1127647 | 0.8363244 | -3.68553433 |
| Afraid | 0.6484001 | -2.4269880 | 0.8130223 | -4.40485340 |
| Ashamed | 0.8098411 | -1.4938081 | 0.9348448 | -1.30253073 |
| Guilty | 0.8538007 | -1.4995277 | 0.9419180 | -1.26399205 |
| Nervous | 0.7637294 | -4.4562351 | 0.8775752 | -3.33051668 |
| Jittery | 0.9522237 | -1.0023827 | 0.9724985 | -0.73765061 |
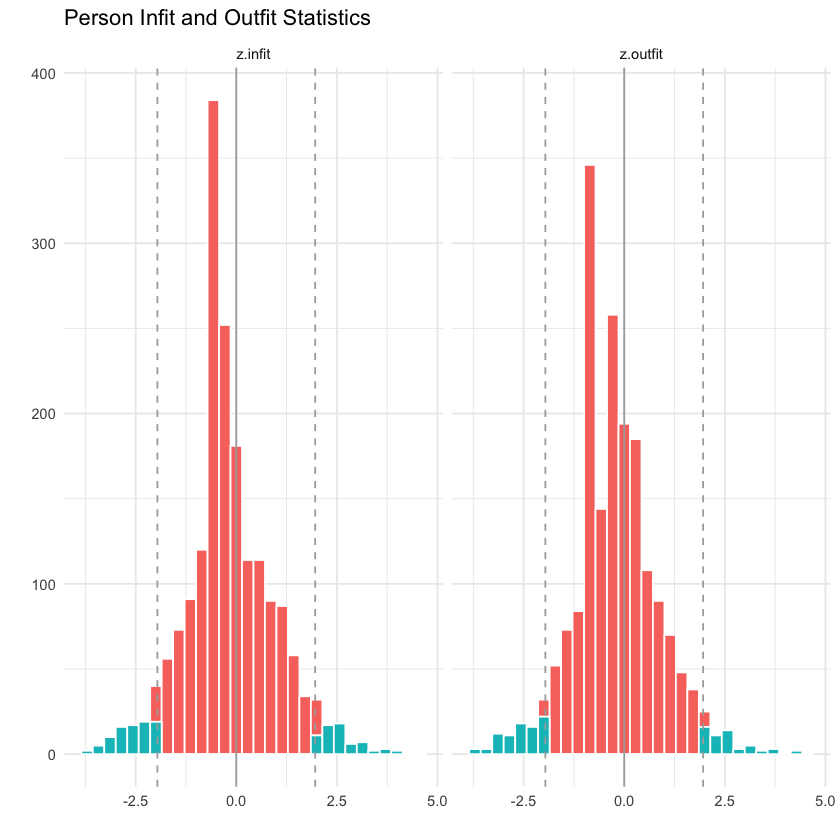
Adattamento dei rispondenti.
personfitPlot(mirt_grm)
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
65.11. Abilità#
Le stime delle abilità dei partecipanti si ottengono nel modo seguente:
# Calcola le stime delle abilità utilizzando il metodo EAPsum
abilita_partecipanti <- fscores(mirt_grm, method = "EAP", full.scores = TRUE)
# Visualizza le stime delle abilità
head(abilita_partecipanti)
| F1 |
|---|
| -0.7733695 |
| -0.8326588 |
| 1.0148012 |
| -1.5150601 |
| -0.5076489 |
| 1.4867209 |
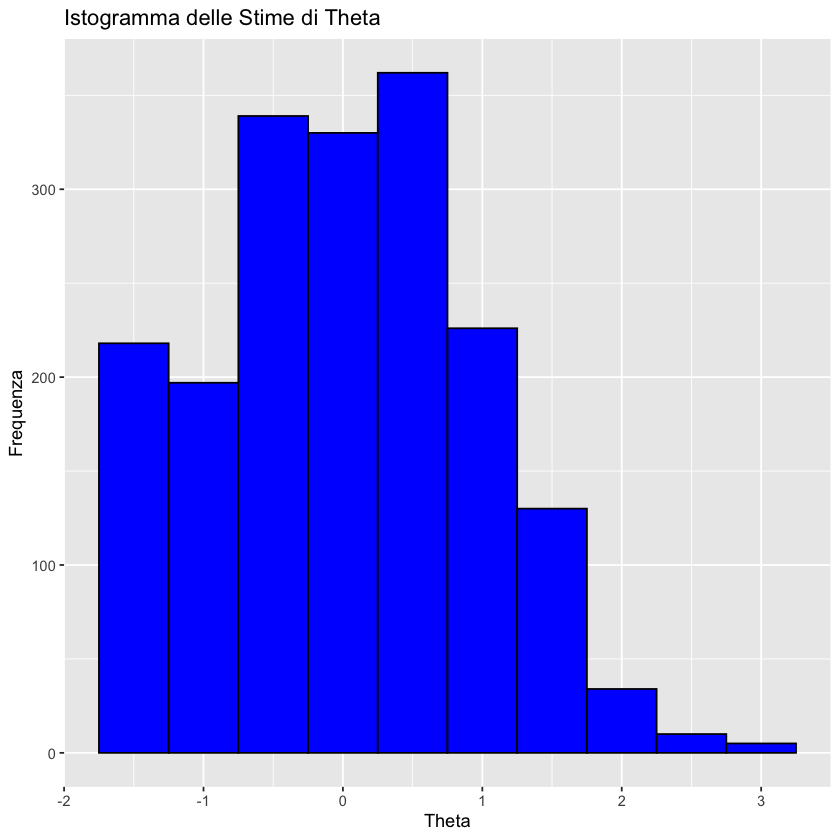
ggplot(data.frame(abilita_partecipanti), aes(x = abilita_partecipanti)) +
geom_histogram(binwidth = 0.5, fill = "blue", color = "black") +
labs(title = "Istogramma delle Stime di Theta", x = "Theta", y = "Frequenza")
Verifichiamo creando un diagramma a dispersione con l’abilità \(\theta\) stimata dal modello GRM in ascissa e il punteggio totale del test in ordinata.
plot(abilita_partecipanti, rowSums(df_num))
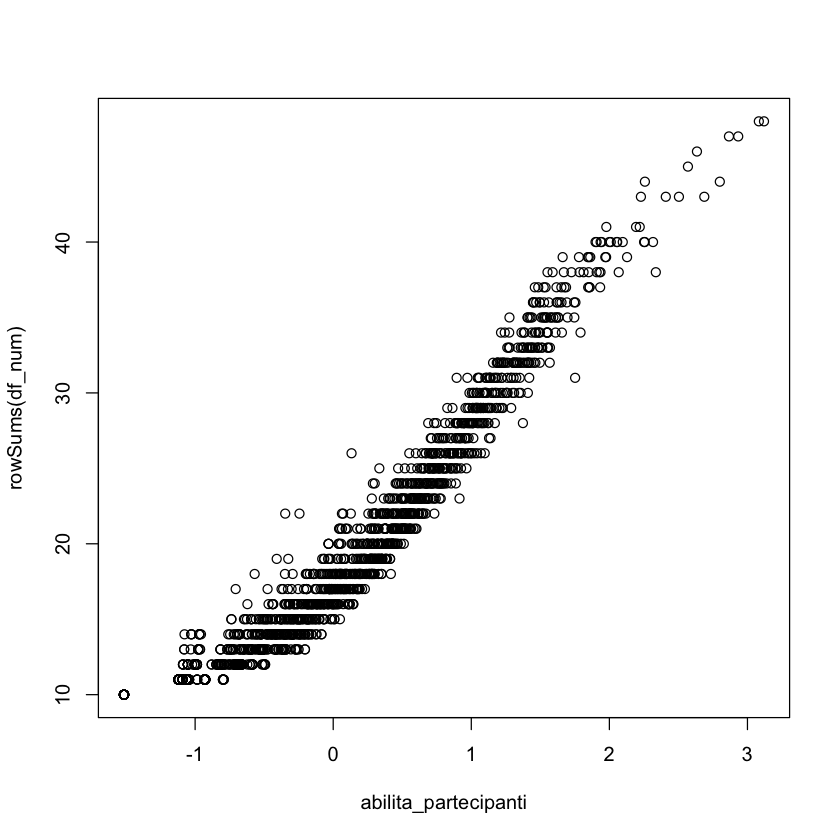
Anche se le correlazione tra i due punteggi è molto alta
print(cor(abilita_partecipanti, rowSums(df_num)))
[,1]
F1 0.9576308
il grafico mostra come questa relazione non è lineare.
65.12. Modello Sequenziale#
Il Modello Sequenziale (Sequential Model), sviluppato da Tutz nel 1990 e ulteriormente elaborato nel 1997, è un approccio innovativo nella teoria della risposta all’item (IRT) per analizzare dati di test con risposte ordinate, in particolare quando le risposte possono essere considerate come il risultato di un processo decisionale sequenziale.
Il Modello Sequenziale si basa sull’idea che le risposte a un item siano il risultato di una serie di decisioni. Invece di scegliere direttamente tra diverse categorie di risposta, si presume che i rispondenti passino attraverso una sequenza di passaggi decisionali, con ogni passaggio che porta a una scelta tra due alternative.
Il modello considera la risposta a un item come una serie di decisioni binarie (sì/no). Ad esempio, in un test a scelta multipla, un rispondente potrebbe prima decidere se una risposta è corretta o errata, e poi, se errata, scegliere tra le opzioni rimanenti.
Ogni passaggio decisionale nella sequenza è modellato separatamente. Questo permette una comprensione più dettagliata di come i rispondenti arrivino alla loro scelta finale.
Il modello è particolarmente utile per item complessi dove la risposta finale è il risultato di una serie di considerazioni o giudizi.
Immaginiamo un questionario per la valutazione di un corso. I partecipanti potrebbero prima decidere se il corso è stato generale positivo o negativo (primo stadio decisionale). Se positivo, potrebbero poi decidere se è stato “buono” o “eccellente” (secondo stadio). Se negativo, la scelta potrebbe essere tra “insufficiente” e “mediocre”.
In sintesi, il Modello Sequenziale di Tutz offre una prospettiva unica sull’analisi di risposte ordinate, enfatizzando il processo decisionale a più stadi che sta dietro la selezione di una risposta.
65.13. Modello a Crediti Parziali#
Il modello a crediti parziali (PCM) è particolarmente utile per valutare risposte a domande che non seguono un ordine prestabilito e che richiedono una valutazione basata sui gradi di successo raggiunti. In questo modello, ciascun item permette di ottenere un punteggio variabile a seconda della completezza o della correttezza della risposta fornita. A differenza di altri modelli, nel PCM le soglie non sono stabilite tra categorie di risposta sequenziali, ma piuttosto tra i diversi livelli di punteggio che possono essere assegnati all’interno dello stesso item. Il modello quindi calcola una soglia specifica necessaria per avanzare da un livello di punteggio al successivo.
65.14. Modello a Crediti Parziali Generalizzato#
Il Modello a Crediti Parziali Generalizzato (Generalized Partial Credit Model, GPCM) è una versione estesa e più versatile del Modello a Crediti Parziali (Partial Credit Model, PCM). Ogni item in un test può avere un numero diverso di categorie di risposta. Questa caratteristica lo rende particolarmente adatto per test che includono item con formati di risposta variabili.
Il GPCM permette che ogni item abbia le proprie soglie specifiche. Questo significa che la transizione da una categoria di risposta all’altra può avere significati diversi per item differenti.
Una caratteristica distintiva del GPCM è che permette a ciascun item di avere il proprio parametro di discriminazione. Questo parametro misura quanto efficacemente un item distingue tra rispondenti con livelli diversi di abilità.
Il GPCM è particolarmente utile in contesti di test dove gli item variano significativamente in termini di formato, difficoltà e capacità di discriminazione. Ad esempio, alcune domande potrebbero essere più efficaci nell’identificare studenti con abilità elevate, mentre altre potrebbero essere migliori nel differenziare tra studenti con abilità più basse.
In sintesi, il Generalized Partial Credit Model fornisce una struttura flessibile e adattabile che può essere calibrata per adattarsi alle specifiche caratteristiche di ciascun item in un test.
65.15. Confronto tra modelli#
Consideriamo il modello a crediti parziali vincolando i coefficienti angolari a 1 e stimando liberamente i parametri di varianza.
mirt_pcm <- mirt(df_num, 1, itemtype = "Rasch", verbose = FALSE)
Esaminiamo il modello a crediti parziali generalizzato.
mirt_gpcm <- mirt(df_num, 1, itemtype = "gpcm", verbose = FALSE)
Confronto PCM vs GPCM.
res_01 <- anova(mirt_pcm, mirt_gpcm) %>% as.data.frame() %>% round(3)
res_01
| AIC | SABIC | HQ | BIC | logLik | X2 | df | p | |
|---|---|---|---|---|---|---|---|---|
| <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | |
| mirt_pcm | 39783.17 | 39879.38 | 39866.65 | 40009.63 | -19850.59 | NA | NA | NA |
| mirt_gpcm | 39497.72 | 39615.04 | 39599.52 | 39773.89 | -19698.86 | 303.454 | 9 | 0 |
Confronto GPCM vs GRM.
res_02 <- anova(mirt_gpcm, mirt_grm) %>%
as.data.frame() %>%
round(3)
res_02
| AIC | SABIC | HQ | BIC | logLik | X2 | df | p | |
|---|---|---|---|---|---|---|---|---|
| <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | |
| mirt_gpcm | 39497.72 | 39615.04 | 39599.52 | 39773.89 | -19698.86 | NA | NA | NA |
| mirt_grm | 39166.40 | 39283.73 | 39268.20 | 39442.57 | -19533.20 | 331.317 | 0 | NaN |
65.16. Dimensione del Campione#
Nel contesto della teoria della risposta all’item (IRT) per dati politomici, la questione della grandezza del campione è fondamentale per garantire l’accuratezza e l’affidabilità delle stime dei parametri del modello. De Ayala (2009) ha fornito una panoramica delle ricerche riguardanti i requisiti di dimensione del campione per i modelli IRT, sia dicotomici che politomici, e ha offerto alcune linee guida utili.
Numero di Categorie di Risposta: Nei modelli politomici, il numero di categorie di risposta per item influisce significativamente sulla precisione della stima. Maggiore è il numero di categorie, maggiore sarà il numero complessivo di parametri dell’item da stimare.
Distribuzione dei Parametri di Item e Persone: Come nei modelli dicotomici, la forma e l’allineamento delle distribuzioni dei parametri di item e persone sono importanti. Una distribuzione ben bilanciata può contribuire a una stima più accurata.
De Ayala propone alcune regole empiriche per le dimensioni minime del campione nei modelli politomici:
Modello a Crediti Parziali e Modello a Scala di Valutazione: Per questi modelli, è suggerita una dimensione minima del campione di circa 250 rispondenti. Questo è particolarmente pertinente per test che comprendono, ad esempio, 25 item con 5 categorie di risposta ciascuno.
Modello di Risposta Graduata: Per il GRM, è raccomandata una dimensione del campione di circa 500 rispondenti, soprattutto quando si lavora con un numero elevato di item e categorie di risposta.
Problemi nella convergenza dell’algoritmo di stima e la presenza di errori standard elevati possono essere segnali che la dimensione del campione utilizzato non è sufficiente per una stima affidabile dei parametri del modello.
In sintesi, la scelta della grandezza del campione nei modelli IRT politomici deve considerare diversi fattori, inclusi il numero di item, il numero di categorie di risposta per item e il rapporto tra il numero di rispondenti e il numero di parametri dell’item da stimare. Seguendo le linee guida suggerite, i ricercatori possono assicurarsi di avere un campione di dimensioni adeguate per ottenere stime affidabili dei parametri del modello.
65.17. Session Info#
sessionInfo()
R version 4.3.3 (2024-02-29)
Platform: x86_64-apple-darwin20 (64-bit)
Running under: macOS Sonoma 14.4.1
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.3-x86_64/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.3-x86_64/Resources/lib/libRlapack.dylib; LAPACK version 3.11.0
locale:
[1] en_US.UTF-8/UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
time zone: Europe/Rome
tzcode source: internal
attached base packages:
[1] stats4 stats graphics grDevices utils datasets methods
[8] base
other attached packages:
[1] lavaan_0.6-17 latex2exp_0.9.6 WrightMap_1.3 psychotools_0.7-3
[5] ggmirt_0.1.0 mirt_1.41 lattice_0.22-6 lubridate_1.9.3
[9] forcats_1.0.0 stringr_1.5.1 dplyr_1.1.4 purrr_1.0.2
[13] readr_2.1.5 tidyr_1.3.1 tibble_3.2.1 ggplot2_3.5.1
[17] tidyverse_2.0.0
loaded via a namespace (and not attached):
[1] gtable_0.3.5 latticeExtra_0.6-30 tzdb_0.4.0
[4] quadprog_1.5-8 vctrs_0.6.5 tools_4.3.3
[7] generics_0.1.3 curl_5.2.1 parallel_4.3.3
[10] fansi_1.0.6 cluster_2.1.6 pkgconfig_2.0.3
[13] Matrix_1.6-5 RColorBrewer_1.1-3 uuid_1.2-0
[16] lifecycle_1.0.4 deldir_2.0-4 farver_2.1.1
[19] compiler_4.3.3 GPArotation_2024.3-1 munsell_0.5.1
[22] mnormt_2.1.1 repr_1.1.6 permute_0.9-7
[25] dcurver_0.9.2 htmltools_0.5.8.1 pillar_1.9.0
[28] crayon_1.5.2 MASS_7.3-60.0.1 vegan_2.6-4
[31] nlme_3.1-164 Deriv_4.1.3 tidyselect_1.2.1
[34] digest_0.6.35 stringi_1.8.3 labeling_0.4.3
[37] splines_4.3.3 fastmap_1.1.1 grid_4.3.3
[40] colorspace_2.1-0 cli_3.6.2 magrittr_2.0.3
[43] base64enc_0.1-3 utf8_1.2.4 IRdisplay_1.1
[46] pbivnorm_0.6.0 withr_3.0.0 scales_1.3.0
[49] bit64_4.0.5 IRkernel_1.3.2 timechange_0.3.0
[52] jpeg_0.1-10 interp_1.1-6 bit_4.0.5
[55] gridExtra_2.3 pbdZMQ_0.3-11 png_0.1-8
[58] hms_1.1.3 pbapply_1.7-2 evaluate_0.23
[61] mgcv_1.9-1 rlang_1.1.3 Rcpp_1.0.12
[64] glue_1.7.0 vroom_1.6.5 jsonlite_1.8.8
[67] R6_2.5.1