4. Valutazioni normative e criteriali#
Questo capitolo si propone di introdurre l’utilizzo del software “R”, ponendo l’attenzione sulla differenza tra valutazioni normative e criteriali.
source("../_common.R")
4.1. Punteggi Grezzi e Trasformati#
Nell’ambito dei test psicometrici, il punteggio grezzo costituisce la valutazione più immediata e si basa sulla somma delle risposte categorizzate, come quelle corrette o errate, o vero o falso. Nonostante la sua immediatezza, il punteggio grezzo presenta limitazioni interpretative, poiché non considera fattori contestuali quali il numero totale di domande o il livello di difficoltà di queste.
Per mitigare queste limitazioni, i punteggi grezzi vengono spesso convertiti in formati che permettono un’interpretazione più contestualizzata, quali i punteggi standardizzati o scalati. Queste trasformazioni facilitano l’interpretazione dei risultati ottenuti.
L’interpretazione dei risultati dei test necessita di un riferimento comparativo. A seconda del contesto, può essere utile confrontare le prestazioni con una norma di riferimento o con criteri specifici.
Le interpretazioni basate sulla norma confrontano la performance di un individuo con quella di un gruppo di riferimento o normativo, offrendo una valutazione relativa alla prestazione tipica o “normale”. Un esempio è rappresentato dai test di intelligenza. Al contrario, le interpretazioni basate sul criterio valutano le prestazioni rispetto a un livello di competenza specifico, indipendentemente dalla performance altrui.
Un altro approccio interpretativo è offerto dalla Teoria della Risposta agli Item (IRT), che fornisce un’analisi avanzata delle prestazioni nei test, permettendo un’esplorazione dettagliata delle risposte individuali.
4.2. Interpretazioni Basate sulla Norma (Norm-Referenced)#
Per valutare la performance in un test psicologico, può essere utile confrontarla con quella di un gruppo predefinito. I punteggi grezzi acquisiscono significato quando messi a confronto con le prestazioni di un gruppo normativo. In questo contesto, i punteggi grezzi vengono trasformati in punteggi derivati basati sulle performance di un gruppo normativo specifico.
Un aspetto cruciale in queste interpretazioni è la pertinenza del gruppo di riferimento. È fondamentale che questo gruppo sia rappresentativo degli individui ai quali il test è destinato o con cui il partecipante viene confrontato.
La selezione del campione normativo, chiamato anche campione di standardizzazione, segue il principio del campionamento casuale stratificato proporzionale, assicurando che il campione rifletta proporzionalmente le caratteristiche demografiche nazionali. Tale rappresentatività è vitale per l’interpretazione basata sulla norma, rendendo necessaria l’accurata selezione e descrizione del campione da parte degli sviluppatori del test.
Quando si utilizzano questi test, è cruciale valutare se il campione di standardizzazione è rappresentativo per l’uso previsto e se le caratteristiche demografiche del campione corrispondono a quelle dei soggetti testati. La pertinenza e l’attualità del campione, insieme alla sua dimensione, sono fattori chiave per garantire interpretazioni valide e affidabili.
Una considerazione finale riguardante le interpretazioni basate sulla norma è l’importanza della standardizzazione nella somministrazione. È fondamentale che il campione di riferimento venga sottoposto al test nelle stesse condizioni e secondo le stesse procedure amministrative che saranno utilizzate nella pratica effettiva. Di conseguenza, quando il test viene somministrato in contesti clinici, è cruciale che l’utente del test segua attentamente le procedure amministrative prescritte. Ad esempio, nel caso di test standardizzati, è essenziale leggere le istruzioni testuali esattamente come sono fornite e rispettare rigorosamente i limiti di tempo. Sarebbe irragionevole confrontare la performance dell’esaminando in un test a tempo con quella di un campione di standardizzazione che ha avuto più o meno tempo per completare gli item. Questa necessità di seguire procedure standardizzate si applica a tutti i test standardizzati, sia quelli con interpretazioni basate sulla norma che quelli basati sul criterio.
4.2.1. Punteggi Derivati#
In ambito psicometrico, i punteggi derivati da test possono assumere diverse forme, ciascuna con implicazioni specifiche per l’interpretazione dei dati. Esploreremo le tipologie più comuni:
Punteggi Standardizzati:
Questi punteggi trasformano i punteggi grezzi (ad esempio, il numero di risposte corrette) in misure standardizzate. Ciò permette di ottenere valori invarianti rispetto a variabili come l’età dell’individuo.
Si calcolano stabilendo una media e una deviazione standard specifiche a priori.
Esempi:
z-scores: Misurano la distanza di un punteggio dalla media, espressa in deviazioni standard. Hanno una media di 0 e una deviazione standard di 1.
T-scores: Trasformano i punteggi in valori positivi, con una media di 50 e una deviazione standard di 10.
Punteggi di QI: Tipici delle scale di intelligenza, hanno una media di 100 e una deviazione standard di 15.
Punteggi Standardizzati Normalizzati:
Quando i punteggi originali non seguono una distribuzione normale, si utilizzano trasformazioni non lineari per normalizzarli.
Esempi:
Stanine: Suddividono i punteggi in 9 categorie (da 1 a 9).
Punteggi scalati di Wechsler: Utilizzati nei test di intelligenza di Wechsler.
Equivalenti della Curva Normale (NCE): Esprimono la posizione di un punteggio rispetto alla distribuzione normale.
Ranghi Percentili:
Vanno da 1 a 99 e indicano la posizione relativa di un soggetto rispetto alla popolazione.
Ad esempio, un punteggio al 75° percentile significa che il soggetto ha ottenuto un risultato migliore del 75% della popolazione.
4.3. Interpretazioni Basate su Criteri#
L’approccio delle valutazioni basate su criteri specifici è diventato sempre più rilevante nel mondo dell’educazione e della psicometria a partire dagli anni Sessanta. Questo approccio, noto anche come valutazione basata su contenuti, dominio o obiettivi, si concentra sulla misurazione delle competenze individuali rispetto a standard definiti, piuttosto che sul confronto con le prestazioni di un gruppo di riferimento.
Ecco alcune metodologie e applicazioni comuni:
Percentuale di Risposte Corrette:
Questo metodo fornisce un’indicazione diretta delle competenze di uno studente.
Ad esempio, se uno studente risponde correttamente all’85% delle domande di matematica, l’insegnante può valutare le sue abilità in modo specifico.
Test di Padronanza:
Questi test determinano se uno studente ha acquisito una competenza specifica.
Ad esempio, gli esami per la patente di guida valutano se lo studente ha raggiunto il livello di padronanza richiesto.
Valutazioni Basate su Standard:
Queste valutazioni classificano i risultati in categorie di prestazione (ad esempio, base, competente, avanzato).
Spesso, i punteggi vengono correlati a voti letterali basati su una percentuale di correttezza.
I punti di forza delle valutazioni basate su criteri includono:
Comparazione con Standard Predefiniti:
Valutano il raggiungimento di competenze o obiettivi specifici, indipendentemente dalle prestazioni altrui.
Questo approccio evita il bias derivante dal confronto con altri studenti.
Focalizzazione su Competenze Specifiche:
Questi test richiedono una definizione precisa dell’area di conoscenza o abilità valutata.
Sono ideali per valutare aree di contenuto specifiche.
4.3.1. Benefici#
Valutazione Mirata delle Competenze: Fornisce una verifica concreta del conseguimento delle conoscenze e abilità delineate dal programma di studi.
Personalizzazione dell’Insegnamento: Identifica le aree di debolezza, consentendo un approccio didattico più focalizzato e personalizzato.
In conclusione, le valutazioni basate su criteri rappresentano un’alternativa preziosa ai metodi di valutazione tradizionali, specialmente in contesti in cui è fondamentale misurare le competenze individuali. Questo approccio è in crescente adozione in ambiti educativi e formativi, enfatizzando l’importanza dell’acquisizione di conoscenze e abilità mirate.
4.4. Analisi Comparativa tra Valutazioni Normative e Basate su Criteri#
La distinzione tra valutazioni normative (norm-referenced) e basate su criteri (criterion-referenced) è fondamentale per interpretare le prestazioni individuali nei test. Sebbene un test possa teoricamente adottare entrambi gli approcci interpretativi, di solito si orienta verso uno dei due, a seconda dell’obiettivo specifico.
Ecco una panoramica delle differenze:
Valutazioni Normative:
Versatilità: Si applicano a test che valutano una vasta gamma di dimensioni, come attitudini, risultati scolastici, interessi, atteggiamenti e comportamenti.
Ampio Quadro: Ideali per esplorare costrutti generali come l’attitudine generale o l’intelligenza.
Selezione delle Domande: Preferiscono domande di difficoltà intermedia, evitando quelle troppo semplici o complesse.
Valutazioni Basate su Criteri:
Specificità: Associate principalmente a test che mirano a valutare conoscenze o competenze specifiche.
Focalizzazione: Concentrate su abilità e competenze ben definite.
Calibrazione delle Domande: La difficoltà delle domande è tarata in base alle conoscenze o abilità specifiche da valutare.
È importante notare che queste interpretazioni non sono mutuamente esclusive. Alcuni test offrono sia valutazioni normative che basate su criteri, fornendo una visione completa delle prestazioni relative rispetto a un gruppo di riferimento e del livello di competenza in un ambito specifico. Questa dualità interpretativa è preziosa in vari contesti.
4.5. Analisi dei Punteggi secondo la Teoria della Risposta agli Item#
La Teoria della Risposta agli Item (IRT) rappresenta un notevole avanzamento nel campo della psicometria, fornendo strumenti essenziali per valutare con precisione le capacità e i tratti latenti degli individui.
Fondamenti e Principi dell’IRT: L’IRT si basa sull’assunto che ogni persona possieda un livello di un tratto latente, come l’intelligenza, che è indipendente dalle specifiche domande del test o dal metodo di valutazione utilizzato. Attraverso l’applicazione di modelli matematici complessi, l’IRT consente di posizionare ogni individuo su un continuum di tratto latente, offrendo una misurazione delle capacità più precisa rispetto ai tradizionali punteggi grezzi.
Vantaggi dei Punteggi basati sull’IRT: I punteggi derivati dall’IRT presentano significativi vantaggi. Essi sono trattati come punteggi a intervalli costanti, consentendo comparazioni valide tra le performance di soggetti o gruppi diversi. Inoltre, questi punteggi mantengono una deviazione standard uniforme attraverso diverse fasce d’età, rendendoli particolarmente adatti per monitorare l’evoluzione o il progresso delle abilità nel tempo.
Applicazioni Pratiche e Prospettive Future dell’IRT: Una delle applicazioni più innovative dell’IRT è lo sviluppo dei test adattivi computerizzati (CAT), in cui le domande vengono selezionate dinamicamente in base alle risposte precedenti del candidato. Questo metodo consente valutazioni precise ed efficienti delle abilità in tempo reale. Ad esempio, i punteggi IRT, come i W-scores nel Woodcock-Johnson IV, vengono utilizzati per analizzare variazioni nelle capacità cognitive legate ai processi di apprendimento o ai declini cognitivi.
4.6. Quali tipi di punteggi usare?#
4.7. La Selezione del Punteggio Appropriato per la Valutazione#
Determinare il tipo di punteggio più adeguato per un test è essenziale per ottenere informazioni specifiche e pertinenti dalla valutazione. Le diverse categorie di punteggi forniscono risposte a domande distinte riguardo alle prestazioni degli esaminandi:
Punteggi Grezzi:
Rappresentano la quantità totale di risposte corrette accumulate da un individuo.
Offrono una visione immediata del livello di prestazione e permettono di stabilire un ordine tra i partecipanti.
Sono utili per identificare rapidamente il posizionamento relativo di un individuo all’interno di un gruppo.
Punteggi Norm-Referenced Standard:
Forniscono un confronto diretto tra le prestazioni di un individuo e quelle di un gruppo normativo.
Consentono di interpretare la prestazione su una scala relativa, facilitando la comprensione del rendimento in termini di posizione all’interno di una popolazione di riferimento.
Punteggi Criterion-Referenced:
Indicano se un individuo ha raggiunto un determinato standard di competenza.
Sono particolarmente indicati per valutare il conseguimento di obiettivi specifici o competenze chiave.
Punteggi Basati sull’IRT (Inclusi i Punteggi Rasch):
Offrono una misurazione su scala a intervalli costanti, riflettendo la posizione di un individuo su un continuum di un tratto latente.
Sono ideali per tracciare il progresso nel tempo o confrontare le prestazioni attraverso diverse valutazioni di un medesimo tratto.
Ad esempio, nel caso di Giovanni, che ha beneficiato di un programma di supporto alla lettura:
Punteggi Norm-Referenced: Fornirebbero insight su come le capacità di lettura di Giovanni si confrontano con quelle dei suoi coetanei dopo l’intervento.
Punteggi Rasch o IRT: Consentirebbero di valutare l’evoluzione precisa delle competenze di lettura di Giovanni, misurando il progresso a partire dal suo livello iniziale.
Punteggi Grezzi: Darebbero indicazioni sul miglioramento assoluto, sebbene privi della capacità di riflettere le variazioni in termini di difficoltà degli item o di altri fattori.
Punteggi Criterion-Referenced: Stabilirebbero se Giovanni ha raggiunto specifici obiettivi di competenza in lettura definiti a priori.
In contesti educativi, l’uso di punteggi norm-referenced standardizzati per età può essere preferibile per determinare se uno studente sta progredendo adeguatamente rispetto ai suoi pari. In contesti clinici, come nella gestione della depressione, i punteggi criterion-referenced possono offrire una valutazione mirata del raggiungimento di soglie di miglioramento clinico significativo.
In conclusione, la scelta del tipo di punteggio da utilizzare è guidata dal contesto di valutazione e dall’obiettivo specifico della misurazione. Diverse tipologie di punteggi illuminano aspetti distinti delle prestazioni, rendendoli più o meno adatti a seconda delle esigenze informative della valutazione.
4.8. Significato e Applicazione delle Norme e dei Punteggi Standardizzati#
Per chiarire questi concetti, esaminiamo i dati della Tabella 2.1 di Bandalos [Ban18]. Con degli esempi numerici, analizzeremo vari tipi di punteggi normativi, tra cui:
Punteggi Percentili: Che indicano la posizione relativa di un individuo all’interno del gruppo normativo.
Punteggi Standardizzati e Normalizzati: Che trasformano i punteggi grezzi in una scala standard per facilitare il confronto tra diversi individui o gruppi.
Stanini: Un metodo di punteggio che divide i punteggi in intervalli standardizzati.
Equivalenti alla Curva Normale: Che adattano i punteggi a una distribuzione normale.
Nei capitoli successivi esamineremo come calcolare i punteggi basati sulla teoria IRT.
Iniziamo a leggere i dati.
raw_score <- c(
26, 25, 33, 31, 26, 34, 29, 36, 25, 29, 28, 32, 25,
30, 27, 31, 30, 30, 35, 30, 27, 26, 34, 32, 26, 34,
30, 28, 28, 31, 30, 27, 26, 29, 29, 33, 27, 35, 26,
27, 28, 29, 28, 27, 34, 36, 26, 26, 34, 30, 34, 27
)
4.8.1. Distribuzione di frequenze#
freq <- table(raw_score) # frequency
cumfreq <- cumsum(freq) # cumulative frequency
perc <- prop.table(freq) * 100 # percentage
cumperc <- cumsum(perc) # cumulative percentage
pr <- (cumperc - 0.5 * perc) # percentile rank
cbind(freq, cumfreq, perc, cumperc, pr)
| freq | cumfreq | perc | cumperc | pr | |
|---|---|---|---|---|---|
| 25 | 3 | 3 | 5.769231 | 5.769231 | 2.884615 |
| 26 | 8 | 11 | 15.384615 | 21.153846 | 13.461538 |
| 27 | 7 | 18 | 13.461538 | 34.615385 | 27.884615 |
| 28 | 5 | 23 | 9.615385 | 44.230769 | 39.423077 |
| 29 | 5 | 28 | 9.615385 | 53.846154 | 49.038462 |
| 30 | 7 | 35 | 13.461538 | 67.307692 | 60.576923 |
| 31 | 3 | 38 | 5.769231 | 73.076923 | 70.192308 |
| 32 | 2 | 40 | 3.846154 | 76.923077 | 75.000000 |
| 33 | 2 | 42 | 3.846154 | 80.769231 | 78.846154 |
| 34 | 6 | 48 | 11.538462 | 92.307692 | 86.538462 |
| 35 | 2 | 50 | 3.846154 | 96.153846 | 94.230769 |
| 36 | 2 | 52 | 3.846154 | 100.000000 | 98.076923 |
4.8.2. Punteggi Percentili#
I punteggi percentili sono un modo efficace per interpretare e confrontare i punteggi di un individuo con quelli di un campione normativo. Un punteggio percentile indica la posizione relativa di un individuo all’interno di un gruppo normativo. Più specificamente, un punteggio percentile mostra la percentuale di persone nel campione normativo che ha ottenuto un punteggio uguale o inferiore a quello dell’individuo in questione.
Per esemplificare il concetto, consideriamo il calcolo di un quantile di ordine 0.74. Questo significa che stiamo cercando il valore al di sotto del quale si trova il 74% dei punteggi nel campione normativo. In altre parole, un individuo con un punteggio corrispondente a questo quantile ha superato il 74% delle persone nel gruppo normativo.
Il calcolo dei punteggi percentili può essere effettuato attraverso l’analisi statistica dei dati di un campione rappresentativo. Questi dati vengono ordinati in modo crescente, e si identifica il punteggio che corrisponde al percentile desiderato. Nel caso del quantile 0.74, si cerca il punteggio che si trova alla posizione che corrisponde al 74% della lunghezza totale dell’elenco ordinato dei punteggi.
# P74
quantile(raw_score, .74)
# Use a different type (see https://en.wikipedia.org/wiki/Quantile#Estimating_quantiles_from_a_sample)
quantile(raw_score, .74, type = 6)
I punteggi percentili sono particolarmente utili perché offrono una comprensione intuitiva della posizione di un individuo rispetto agli altri. Tuttavia, è importante notare che essi rappresentano una scala ordinale e, pertanto, le differenze tra i punteggi percentili non sono necessariamente uniformi o proporzionali attraverso l’intera gamma di punteggi.
In conclusione, i punteggi percentili sono uno strumento fondamentale nella valutazione psicologica e educativa, poiché forniscono un modo diretto e facilmente interpretabile per valutare le prestazioni di un individuo in confronto a un campione normativo.
4.8.3. Punteggi Standardizzati#
I punteggi standardizzati rappresentano una trasformazione essenziale nel campo della psicometria, che consente di convertire i punteggi grezzi ottenuti in un test in una scala unificata. Questa trasformazione permette di confrontare i risultati di individui o gruppi in maniera equa e coerente, superando le variazioni di scala o di difficoltà tra diversi test.
4.8.3.1. Principi Fondamentali dei Punteggi Standardizzati#
Media e Deviazione Standard Predefinite: I punteggi standardizzati sono calcolati in modo tale da avere una media e una deviazione standard specifiche, stabilite in anticipo. Per esempio, spesso si utilizza una media di 100 e una deviazione standard di 15 (come nei test di intelligenza) o una media di 0 e una deviazione standard di 1 (come negli z-score).
Risultati Confrontabili: Attraverso questa standardizzazione, i punteggi diventano direttamente confrontabili. Un punteggio standardizzato rispetto a una media di 100 e una deviazione standard di 15, ad esempio, permette di valutare rapidamente se un punteggio è al di sopra, al di sotto o vicino alla media del campione normativo.
4.8.3.2. Come Funziona la Trasformazione#
Il processo di standardizzazione implica la sottrazione della media del campione normativo dal punteggio grezzo di un individuo, seguita dalla divisione del risultato per la deviazione standard del campione normativo. In termini matematici, se \( X \) è un punteggio grezzo, \( \mu \) è la media del campione normativo e \( \sigma \) è la deviazione standard del campione normativo, allora il punteggio standardizzato \( Z \) è calcolato come:
4.8.3.3. Utilità dei Punteggi Standardizzati#
Comparabilità: Rendono i punteggi ottenuti da test diversi o da campioni diversi direttamente comparabili.
Interpretazione Facilitata: Forniscono un modo semplice per interpretare i punteggi individuali in termini di posizione relativa rispetto alla media del campione normativo.
Adattabilità: Sono utili in una varietà di contesti, da test educativi a valutazioni cliniche.
In conclusione, i punteggi standardizzati sono uno strumento cruciale nella psicometria e nella valutazione educativa. Trasformando i punteggi grezzi in una scala comune con media e deviazione standard specifiche, facilitano il confronto e l’interpretazione dei risultati dei test, rendendo più accessibile l’analisi e la valutazione delle prestazioni individuali e di gruppo.
Nel caso dell’esempio, i calcoli si svolgono in R nel modo seguente:
z_score <- (raw_score - mean(raw_score)) / sd(raw_score)
c(mean = mean(z_score), sd = sd(z_score))
- mean
- -4.93712309283053e-16
- sd
- 1
4.8.3.4. Punteggi T#
I punteggi T sono una forma specifica di punteggi standardizzati, utilizzati frequentemente nella psicometria per rendere più accessibili e interpretabili i risultati dei test. A differenza dei punteggi z, che tipicamente hanno una media di 0 e una deviazione standard di 1, i punteggi T sono trasformati in modo da avere una media fissata a 50 e una deviazione standard di 10.
4.8.3.5. Caratteristiche Principali dei Punteggi T#
Media e Deviazione Standard: La media fissata a 50 e la deviazione standard di 10 sono scelte per offrire una scala più intuitiva e di facile lettura rispetto agli z-score. Questa trasformazione sposta la scala degli z-score in una gamma numericamente più familiare e più semplice da interpretare per la maggior parte delle persone.
Calcolo dei Punteggi T: Il calcolo dei punteggi T avviene trasformando prima i punteggi grezzi in z-score e poi convertendo questi z-score nella scala dei punteggi T. Matematicamente, se \( Z \) è lo z-score, il punteggio T corrispondente \( T \) è calcolato come:
\[ T = 50 + 10 \times Z. \]Questa formula adatta lo z-score in una scala che inizia da 50 e si allarga in entrambe le direzioni con incrementi standard di 10 per ogni deviazione standard.
4.8.3.6. Utilizzo dei Punteggi T#
Facilità di Interpretazione: I punteggi T sono particolarmente utili quando si desidera presentare i risultati dei test in un formato che sia immediatamente comprensibile, senza la necessità di ulteriori calcoli o trasformazioni.
Comparabilità: Consentono di confrontare i risultati di test diversi in modo più diretto, grazie alla loro scala standardizzata.
Ampio Utilizzo: Sono ampiamente usati in vari ambiti della valutazione psicologica, inclusi l’educazione, la ricerca e la pratica clinica.
In sintesi, i punteggi T offrono un modo efficace e standardizzato per interpretare i risultati dei test, rendendo i dati più accessibili e immediatamente comprensibili. La loro trasformazione da z-score a una scala con media 50 e deviazione standard 10 facilita la comprensione e la comparazione dei punteggi tra diversi test e diversi individui.
Svolgendo i calcoli in R otteniamo
T_score <- z_score * 10 + 50
c(mean = mean(T_score), sd = sd(T_score))
- mean
- 50
- sd
- 10
4.8.4. Punteggi Stanini#
I punteggi Stanini rappresentano un metodo standardizzato per categorizzare i risultati dei test in psicometria, utilizzando una scala di nove intervalli. Ogni intervallo è definito da un cut-off di 10 punti, rendendo questo sistema particolarmente intuitivo e facile da interpretare. La scala Stanini è progettata per fornire una visione chiara e semplificata della posizione relativa di un individuo all’interno di un gruppo normativo.
4.8.4.1. Caratteristiche dei Punteggi Stanini#
Intervalli di Scala: La scala Stanini è divisa in nove intervalli, con ogni intervallo corrispondente a un punteggio specifico. Ad esempio, un punteggio Stanini di 1 indica i punteggi più bassi, mentre un punteggio di 9 rappresenta i punteggi più alti.
Facilità di Interpretazione: I punteggi Stanini offrono un modo semplice e diretto per comprendere i risultati dei test, permettendo una rapida valutazione del livello relativo di prestazione di un individuo rispetto alla popolazione di riferimento.
4.8.4.2. Calcolo dei Punteggi Stanini#
Per calcolare i punteggi Stanini, è necessario seguire alcuni passaggi:
Determinare Media e Deviazione Standard: Inizialmente, si calcolano la media e la deviazione standard dei dati del campione normativo.
Applicare la Formula dei Punteggi Stanini: Per ogni punteggio grezzo, si applica la seguente formula per calcolare il punteggio Stanini corrispondente:
\[ \text{Stanine} = \left( \frac{\text{Punteggio Grezzo} - \text{Media}}{\text{Deviazione Standard}} \right) \times 2 + 5. \]Questa formula trasforma il punteggio grezzo in un valore sulla scala Stanini.
Arrotondare al Numero Intero Più Vicino: Infine, si arrotonda il risultato al numero intero più vicino per ottenere il punteggio Stanini finale.
4.8.4.3. Applicazioni dei Punteggi Stanini#
Semplificazione dell’Analisi: I punteggi Stanini sono particolarmente utili in contesti educativi e di ricerca, dove è necessario semplificare l’analisi e la comunicazione dei risultati.
Valutazione Rapida: Forniscono agli insegnanti, ai clinici e ai ricercatori uno strumento rapido per valutare il posizionamento di un individuo rispetto ai coetanei o alla popolazione di riferimento.
In sintesi, i punteggi Stanini offrono un metodo efficace e semplificato per interpretare i risultati dei test psicometrici. La loro struttura a intervalli permette una categorizzazione chiara dei punteggi, rendendo più agevole la comprensione e la comparazione delle prestazioni relative degli individui.
Per l’esempio presente abbiamo:
mean_score <- mean(raw_score)
sd_score <- sd(raw_score)
stanine_scores <- round((raw_score - mean_score) / sd_score * 2 + 5)
print(stanine_scores)
[1] 3 2 7 6 3 8 5 9 2 5 4 7 2 5 3 6 5 5 8 5 3 3 8 7 3 8 5 4 4 6 5 3 3 5 5 7 3 8
[39] 3 3 4 5 4 3 8 9 3 3 8 5 8 3
È importante ricordare che la trasformazione in punti z non cambia la forma della distribuzione.
plot(density(raw_score))

plot(density(z_score))

plot(density(T_score))

plot(density(stanine_scores))

4.8.5. Equivalenti alla Curva Normale (NCE)#
Gli Equivalenti alla Curva Normale, noti come NCE (dall’inglese “Normal Curve Equivalents”), sono un tipo di punteggio standardizzato utilizzato in ambito psicometrico. Questi punteggi vengono calcolati per trasformare i punteggi grezzi ottenuti in un test in una scala che rifletta una distribuzione approssimativamente normale. L’obiettivo principale dei punteggi NCE è quello di rendere i punteggi di diverse misure o test direttamente confrontabili, mantenendo una distribuzione che si allinea strettamente con una curva normale standard.
4.8.5.1. Caratteristiche dei Punteggi NCE#
Distribuzione Normalizzata: I punteggi NCE sono progettati per aderire a una distribuzione normale. Ciò significa che, a differenza di altri tipi di punteggi, i NCE si allineano più da vicino con le caratteristiche di una curva di distribuzione gaussiana, con la maggior parte dei punteggi concentrati intorno alla media e una distribuzione simmetrica verso gli estremi.
Facilità di Comparazione: Grazie alla loro standardizzazione, i punteggi NCE consentono un confronto diretto e significativo tra le prestazioni in diversi test o misure. Questo è particolarmente utile in contesti educativi e clinici dove è necessario interpretare e confrontare i risultati di diversi test.
4.8.5.2. Calcolo e Utilizzo dei Punteggi NCE#
Il calcolo dei punteggi NCE si basa sulla trasformazione dei punteggi grezzi in modo che si adattino a una distribuzione normalizzata. Questo processo implica l’uso di formule matematiche che riallineano i dati grezzi su una scala standard, considerando la media e la deviazione standard del campione normativo.
Una volta calcolati, i punteggi NCE offrono una visione chiara e immediata delle prestazioni relative di un individuo o di un gruppo, rispetto a un campione normativo. Questo tipo di punteggio è particolarmente utile quando i punteggi grezzi provengono da distribuzioni che non seguono una curva normale, consentendo così un’interpretazione più accurata e standardizzata dei risultati.
4.8.5.3. Applicazioni Pratiche dei Punteggi NCE#
I punteggi NCE trovano impiego in una varietà di contesti, tra cui:
Valutazioni Educative: In ambito scolastico, per confrontare le prestazioni degli studenti in test diversi.
Ricerca Psicologica: Per analizzare e confrontare i risultati di diversi studi o misure psicometriche.
Pratica Clinica: Nella valutazione di clienti o pazienti utilizzando diversi strumenti diagnostici.
In conclusione, i punteggi Equivalenti alla Curva Normale rappresentano uno strumento psicometrico potente per standardizzare e confrontare efficacemente i risultati di diversi test o misure, assicurando che questi siano interpretati all’interno di un quadro coerente e comparabile.
Per i dati dell’esempio abbiamo:
# Using normal quantile
qnorm_pr <- qnorm(pr / 100)
# Convert raw scores
normalized_zscore <- as.vector(qnorm_pr[as.character(raw_score)])
In alternativa, è possibile usare la trasformazione di Box-Cox, che è una tecnica parametrica che cerca di correggere le asimmetrie e trasformare i dati in una forma che approssima una distribuzione normale. È efficace per i dati positivi. La trasformazione è definita come segue:
dove \(x\) è il valore originale e \(\lambda\) è il parametro di trasformazione che viene spesso trovato attraverso la massimizzazione della verosimiglianza.
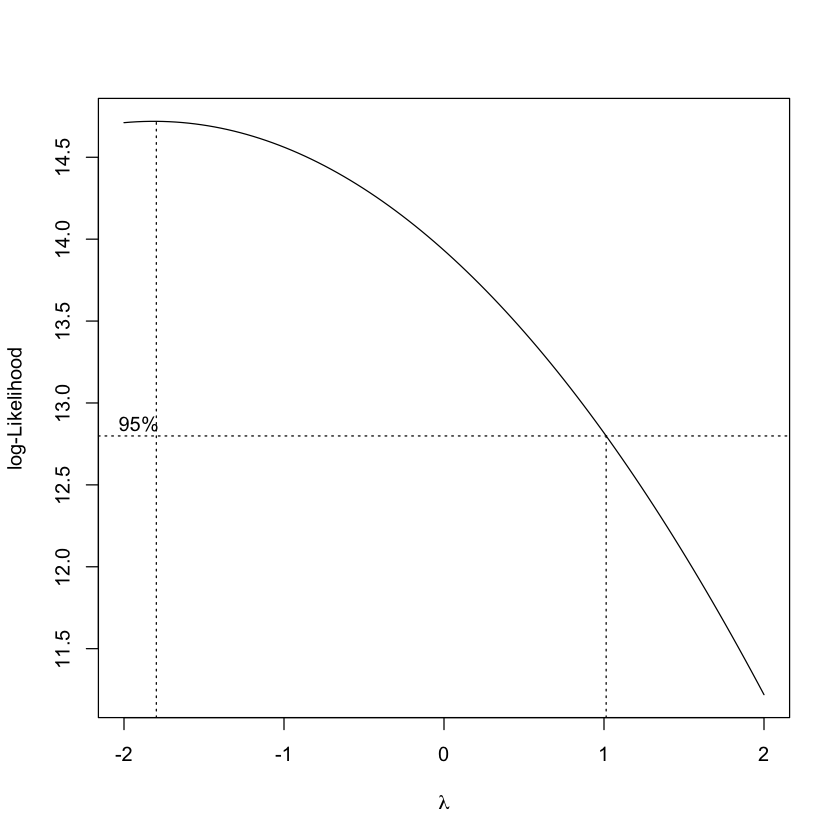
Supponiamo di voler utilizzare la trasformazione di Box-Cox sul nostro set di dati. La procedura è la seguente. Questo codice utilizza la funzione boxcox dal pacchetto MASS per trovare il valore di \(\lambda\) che massimizza la log-verosimiglianza della trasformazione di Box-Cox applicata ai dati. Poi, utilizza questo \(\lambda\) per trasformare i dati.
library(MASS) # Per la funzione boxcox
# Dati di esempio
set.seed(123) # Per rendere l'esempio riproducibile
data <- raw_score
# Trova il miglior lambda per la trasformazione di Box-Cox
bc <- boxcox(data ~ 1, lambda = seq(-2, 2, by = 0.1))
# Calcola la trasformazione di Box-Cox con il lambda ottimale
lambda_opt <- bc$x[which.max(bc$y)]
data_transformed <- (data^lambda_opt - 1) / lambda_opt
Attaching package: ‘MASS’
The following object is masked from ‘package:patchwork’:
area
The following object is masked from ‘package:dplyr’:
select
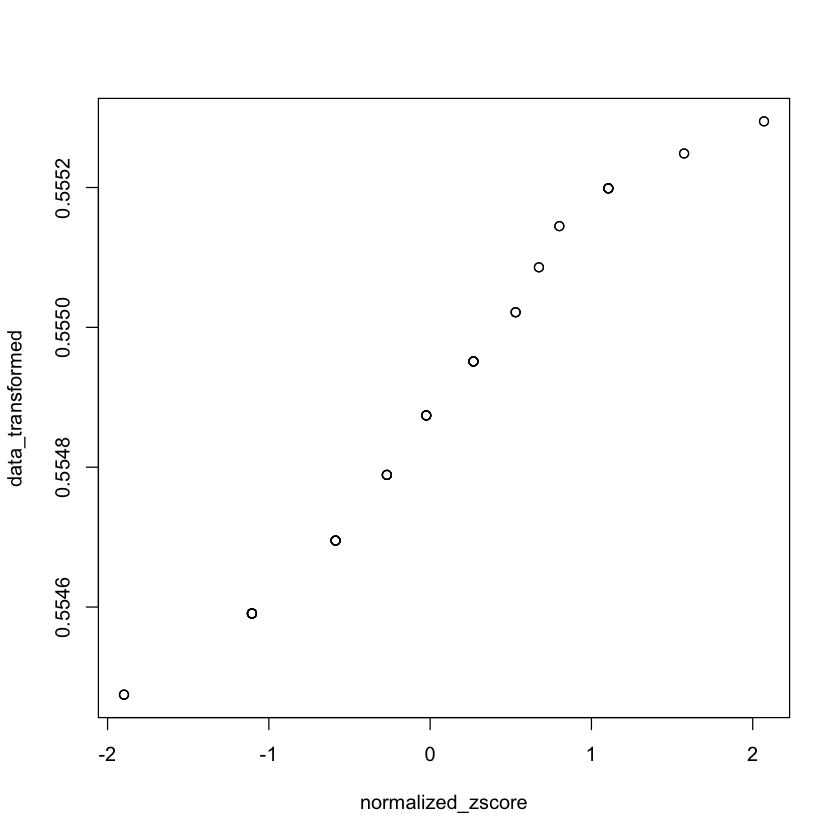
Avendo trovato i dati trasformati con la procedura Box-Cox, li confrontiamo con gli Equivalenti alla Curva Normale (NCE) calcolati con la procedura usuale.
plot(normalized_zscore, data_transformed)
plot(density(normalized_zscore)) # the shape will be closer to normal

plot(density((data_transformed - mean(data_transformed)) / sd(data_transformed)))

Si osservi che i dati NCE presentano una distribuzione più simile a una curva a forma campanulare rispetto ai dati grezzi.
# Perform the Lilliefors (Kolmogorov-Smirnov) normality test
library(nortest)
lillie.test(normalized_zscore)
Lilliefors (Kolmogorov-Smirnov) normality test
data: normalized_zscore
D = 0.085801, p-value = 0.4426
lillie.test(data_transformed)
Lilliefors (Kolmogorov-Smirnov) normality test
data: data_transformed
D = 0.12456, p-value = 0.04274
4.9. Riflessioni Finali sui Metodi di Trasformazione dei Punteggi#
La trasformazione dei punteggi grezzi in formati più interpretabili è una pratica cruciale in psicometria. Due sono i principali approcci utilizzati per attribuire significato ai punteggi di un test: il riferimento normativo e il riferimento criteriale.
4.9.1. Riferimento Normativo#
Nel riferimento normativo, si confronta il punteggio di un individuo con quello medio del gruppo normativo, ovvero gli altri soggetti che hanno svolto lo stesso test. Ci sono diversi tipi di punteggi normati, ciascuno con i suoi specifici vantaggi e limitazioni:
Punteggi Percentili: Questi punteggi sono intuitivi e offrono un’indicazione immediata della posizione relativa di un individuo all’interno di un gruppo. Tuttavia, sono una scala ordinale e non si prestano bene a calcoli matematici più complessi.
Punteggi Standardizzati: Gli z-score e i T-scores rientrano in questa categoria. Sono scalari a intervallo, quindi adatti a operazioni matematiche. Mantengono la forma distributiva originale dei punteggi grezzi, rendendo più agevole la loro elaborazione statistica.
4.9.2. Riferimento Criteriale#
Al contrario del riferimento normativo, il riferimento criteriale confronta i punteggi di un individuo con uno standard prestabilito o un criterio specifico, piuttosto che con i punteggi di altri individui.
4.9.3. Trasformazioni per la Normalizzazione#
Per ottenere una distribuzione dei punteggi più vicina alla curva normale, si possono utilizzare trasformazioni come gli stanini o gli NCE (Normal Curve Equivalents). Questi metodi di normalizzazione aiutano a standardizzare la distribuzione dei punteggi, facilitando così l’interpretazione e l’analisi dei dati psicometrici.
In conclusione, la scelta del metodo di trasformazione dei punteggi dipende dagli obiettivi specifici della valutazione e dall’interpretazione desiderata. La comprensione di queste diverse tecniche è essenziale per una corretta interpretazione dei risultati dei test e per l’analisi psicometrica più generale.
4.10. Considerazioni Conclusive#
Questo capitolo fornisce una panoramica sui diversi tipi di punteggi dei test e il loro significato. Iniziamo notando che i punteggi grezzi, sebbene facili da calcolare, di solito forniscono poche informazioni utili sul rendimento di un esaminando in un test. Di conseguenza, di solito trasformiamo i punteggi grezzi in punteggi derivati, che possono essere di riferimento normativo o al criterio. I punteggi di riferimento normativo confrontano il rendimento di un esaminando con quello di altre persone nel campione di standardizzazione, mentre quelli al criterio confrontano il rendimento con un livello di competenza specificato. È importante valutare l’adeguatezza del campione di standardizzazione quando si utilizzano punteggi di riferimento normativo.
Per interpretazioni basate sui punteggi di riferimento normativo, è utile conoscere la distribuzione normale e i punteggi standard di riferimento. Questi ultimi hanno una media predefinita e una deviazione standard. Esistono anche punteggi normalizzati quando i punteggi non seguono una distribuzione normale. Altri tipi di punteggi di riferimento normativo includono il rango percentile e i punteggi basati su età o livello di scolarità. Tuttavia, questi ultimi sono da evitare, se possibile, a favore di punteggi standard e ranghi percentile.
I punteggi al criterio confrontano il rendimento con un livello specifico di competenza. Sono utili per valutare abilità in domini specifici, ma richiedono una chiara definizione del dominio. A volte, un test può produrre entrambi i tipi di punteggi. Forniamo anche una panoramica dei punteggi basati sulla teoria della risposta agli item (IRT), che sono utili per misurare i cambiamenti nel tempo.
In conclusione, i diversi tipi di punteggi dei test forniscono informazioni per rispondere a diverse domande e devono essere scelti in base alle esigenze specifiche dell’analisi dei dati del test.
4.11. Esercizi#
Bandalos, capitolo 2, E1, E2, E5, E6, E7, E8, E9, E12
4.12. Session Info#
sessionInfo()
R version 4.3.3 (2024-02-29)
Platform: x86_64-apple-darwin20 (64-bit)
Running under: macOS Sonoma 14.3.1
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.3-x86_64/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.3-x86_64/Resources/lib/libRlapack.dylib; LAPACK version 3.11.0
locale:
[1] en_US.UTF-8/UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
time zone: Europe/Rome
tzcode source: internal
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] nortest_1.0-4 MASS_7.3-60.0.1 ggokabeito_0.1.0 viridis_0.6.5
[5] viridisLite_0.4.2 ggpubr_0.6.0 ggExtra_0.10.1 bayesplot_1.11.1
[9] gridExtra_2.3 patchwork_1.2.0 semTools_0.5-6.920 semPlot_1.1.6
[13] lavaan_0.6-17 psych_2.4.1 scales_1.3.0 markdown_1.12
[17] knitr_1.45 lubridate_1.9.3 forcats_1.0.0 stringr_1.5.1
[21] dplyr_1.1.4 purrr_1.0.2 readr_2.1.5 tidyr_1.3.1
[25] tibble_3.2.1 ggplot2_3.5.0 tidyverse_2.0.0 here_1.0.1
loaded via a namespace (and not attached):
[1] rstudioapi_0.15.0 jsonlite_1.8.8 magrittr_2.0.3
[4] TH.data_1.1-2 estimability_1.5 nloptr_2.0.3
[7] rmarkdown_2.26 vctrs_0.6.5 minqa_1.2.6
[10] base64enc_0.1-3 rstatix_0.7.2 htmltools_0.5.7
[13] broom_1.0.5 Formula_1.2-5 htmlwidgets_1.6.4
[16] plyr_1.8.9 sandwich_3.1-0 emmeans_1.10.0
[19] zoo_1.8-12 uuid_1.2-0 igraph_2.0.2
[22] mime_0.12 lifecycle_1.0.4 pkgconfig_2.0.3
[25] Matrix_1.6-5 R6_2.5.1 fastmap_1.1.1
[28] shiny_1.8.0 digest_0.6.34 OpenMx_2.21.11
[31] fdrtool_1.2.17 colorspace_2.1-0 rprojroot_2.0.4
[34] Hmisc_5.1-1 fansi_1.0.6 timechange_0.3.0
[37] abind_1.4-5 compiler_4.3.3 withr_3.0.0
[40] glasso_1.11 htmlTable_2.4.2 backports_1.4.1
[43] carData_3.0-5 ggsignif_0.6.4 corpcor_1.6.10
[46] gtools_3.9.5 tools_4.3.3 pbivnorm_0.6.0
[49] foreign_0.8-86 zip_2.3.1 httpuv_1.6.14
[52] nnet_7.3-19 glue_1.7.0 quadprog_1.5-8
[55] nlme_3.1-164 promises_1.2.1 lisrelToR_0.3
[58] grid_4.3.3 pbdZMQ_0.3-11 checkmate_2.3.1
[61] cluster_2.1.6 reshape2_1.4.4 generics_0.1.3
[64] gtable_0.3.4 tzdb_0.4.0 data.table_1.15.2
[67] hms_1.1.3 car_3.1-2 utf8_1.2.4
[70] sem_3.1-15 pillar_1.9.0 IRdisplay_1.1
[73] rockchalk_1.8.157 later_1.3.2 splines_4.3.3
[76] lattice_0.22-5 survival_3.5-8 kutils_1.73
[79] tidyselect_1.2.0 miniUI_0.1.1.1 pbapply_1.7-2
[82] stats4_4.3.3 xfun_0.42 qgraph_1.9.8
[85] arm_1.13-1 stringi_1.8.3 boot_1.3-29
[88] evaluate_0.23 codetools_0.2-19 mi_1.1
[91] cli_3.6.2 RcppParallel_5.1.7 IRkernel_1.3.2
[94] rpart_4.1.23 xtable_1.8-4 repr_1.1.6
[97] munsell_0.5.0 Rcpp_1.0.12 coda_0.19-4.1
[100] png_0.1-8 XML_3.99-0.16.1 parallel_4.3.3
[103] ellipsis_0.3.2 jpeg_0.1-10 lme4_1.1-35.1
[106] mvtnorm_1.2-4 openxlsx_4.2.5.2 crayon_1.5.2
[109] rlang_1.1.3 multcomp_1.4-25 mnormt_2.1.1