63. Oltre il Modello di Rasch#
Nell’ambito dei modelli IRT, il modello di Rasch impone i vincoli più restrittivi. Tali vincoli possono essere rilassati progressivamente definendo quelli che vengono chiamati modelli 1PL, 2PL e 3Pl.
source("../_common.R")
suppressPackageStartupMessages({
library("eRm")
library("mirt")
library("grid")
library("TAM")
# devtools::install_github("masurp/ggmirt")
library("ggmirt")
library("psychotools")
library("latex2exp")
})
Il set di dati data.fims.Aus.Jpn.scored contiene le risposte valutate fornite da studenti australiani e giapponesi per un sottoinsieme di item nello studio “First International Mathematics Study” (FIMS, Husén, 1967). Ogni item rappresenta un problema matematico, e i valori 1 indicano una risposta corretta, mentre i valori 0 indicano una risposta incorretta.
Ad esempio:
QUESTION 1 (FIMS1) 43.0 - 17.6 is equal to ______ (Ans: 25.4)
QUESTION 2 (FIMS2)
How many seven-man teams can you make out of 7 nine-man teams? A. 7 B. 8 C. 9 D. 16 E. 63 (Ans: C)
QUESTION 10 (FIMS18)
There are 227 boys in a school. Every boy in the school belongs to either the music club or the sports club, and some boys belong to both clubs. The music club has 120 members, and 36 of these are also members of the sports club. What is the total membership of the sports club? _______________ (Ans: 143)
data(data.fims.Aus.Jpn.scored, package = "TAM")
fims <- data.fims.Aus.Jpn.scored
dim(fims)
- 6371
- 16
Nelle analisi successive ci limiteremo alle risposte dei primi 400 partecipanti. Per facilitare la manipolazione dei dati, cambiamo il nome delle colonne.
responses <- fims[1:400, 2:15]
colnames(responses) <- gsub("M1PTI", "I", colnames(responses))
glimpse(responses)
Rows: 400
Columns: 14
$ I1 <dbl> 1, 0, 1, 1, 1, 1, 0, 1, 0, 0, 1, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1, 1, …
$ I2 <dbl> 0, 1, 0, 1, 1, 1, 0, 1, 0, 1, 1, 1, 0, 1, 0, 0, 1, 1, 1, 1, 1, 1, …
$ I3 <dbl> 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, …
$ I6 <dbl> 1, 0, 0, 1, 1, 0, 0, 1, 0, 0, 1, 1, 0, 0, 1, 0, 1, 0, 0, 0, 0, 1, …
$ I7 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ I11 <dbl> 1, 0, 0, 1, 1, 0, 1, 1, 0, 1, 1, 1, 0, 1, 1, 0, 1, 1, 1, 1, 0, 1, …
$ I12 <dbl> 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ I14 <dbl> 0, 1, 0, 0, 1, 0, 1, 1, 1, 0, 0, 1, 0, 0, 1, 0, 1, 0, 1, 1, 0, 1, …
$ I17 <dbl> 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, …
$ I18 <dbl> 0, 0, 1, 0, 1, 1, 0, 1, 0, 1, 0, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, …
$ I19 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ I21 <dbl> 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, …
$ I22 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, …
$ I23 <dbl> 1, 1, 1, 0, 1, 0, 0, 1, 0, 1, 1, 0, 1, 1, 1, 0, 0, 1, 1, 1, 0, 1, …
63.1. Modello ad Un Parametro#
Il modello ad un parametro è formulato nel modo seguente:
dove \(\alpha\) rappresenta la pendenza delle ICC. L’assenza di un pedice significa che \(\alpha\) non varia tra gli item.
Nel contesto del modello IRT (Teoria della Risposta all’Item) a un parametro, il parametro \(\alpha\) è collegato alla pendenza della Funzione di Risposta all’Item (IRF). Esso riflette quanto bene un item è in grado di discriminare tra individui situati in punti diversi lungo il continuum. Di conseguenza, \(\alpha\) è noto come il parametro di discriminazione dell’item.
Per facilitare la comprensione, supponiamo di avere tre item con diversi valori di \(\alpha\), tutti posizionati a \(0.0\) (cioè, \(\delta_1 = \delta_2 = \delta_3 = 0\)). I nostri tre parametri di discriminazione sono \(0\), \(1\) e \(2\). Inoltre, abbiamo un rispondente A situato a \(-1\) (\(\theta_A = -1\)) e un altro rispondente B situato a \(1\) (cioè, \(\theta_B = 1\)). Per l’item con \(\alpha = 0.0\), la nostra IRF e la linea di regressione logit sono orizzontali. Di conseguenza, la probabilità prevista di una risposta di tipo 1 per entrambi i rispondenti è \(0.5\):
In questo caso, l’item non fornisce alcuna informazione utile per differenziare tra i due rispondenti. Questa mancanza di potere discriminatorio è una funzione diretta di \(\alpha = 0.0\).
Al contrario, con il secondo item (\(\alpha = 1\)) abbiamo previsioni diverse per i nostri rispondenti:
Per il rispondente A la probabilità \(p_2 = 0.2689\) e per il rispondente B \(p_2 = 0.7311\). Pertanto, il parametro \(\alpha\) di questo item ci permette di distinguere tra i due rispondenti.
Sviluppando ulteriormente questa idea, troviamo che il terzo item (\(\alpha = 2.0\)) avrebbe l’ICC (e la linea di regressione logit) più ripida dei tre item. Questa ripidità si riflette in una maggiore differenza nelle probabilità previste per i nostri rispondenti rispetto ai due item precedenti:
Ovvero, per questo item il rispondente A ha una probabilità \(p_3 = 0.1192\) e per il rispondente B \(p_3 = 0.8808\). In breve, l’entità della differenza in queste probabilità previste è una funzione diretta del parametro \(\alpha\) dell’item. Pertanto, gli item con \(\alpha\) maggiori (cioè con linee di regressione logit e IRF più ripide) discriminano meglio tra i rispondenti situati in punti diversi del continuum rispetto agli item con \(\alpha\) minori.
In sintesi, maggiore è il valore di \(\alpha\), più ripida sarà la curva ICC e maggiore sarà la discriminazione tra individui con diversi livelli di abilità \(\theta\).
63.1.1. Modello di Rasch e Modello 1PL#
Per riassumere, sia il modello 1PL che il modello di Rasch richiedono che gli item abbiano un parametro \(\alpha\) costante, ma permettono che gli item differiscano nelle loro posizioni. Nel modello di Rasch, questo parametro costante è fissato a \(1.0\), mentre nel modello 1PL, \(\alpha\) non deve necessariamente essere uguale a \(1.0\). Matematicamente, i modelli 1PL e Rasch sono equivalenti e i valori di un modello possono essere trasformati nell’altro attraverso una riscalatura appropriata.
Tuttavia, per alcuni, il modello di Rasch rappresenta una prospettiva filosofica diversa da quella incarnata nel modello 1PL. Il modello 1PL si concentra sull’adattare i dati nel miglior modo possibile, data la struttura del modello. Al contrario, il modello di Rasch viene utilizzato per costruire la variabile di interesse (cfr. Andrich, 1988; Wilson, 2005; Wright, 1984; Wright & Masters, 1982; Wright & Stone, 1979). In breve, questa prospettiva sostiene che il modello di Rasch sia lo standard secondo il quale si può creare uno strumento per misurare una variabile. Questa visione è analoga a ciò che avviene nelle scienze fisiche. Ad esempio, consideriamo la misurazione del tempo. La misurazione del tempo implica un processo ripetitivo che segna incrementi uguali (cioè, unità) della variabile latente del tempo. Per misurare il tempo, dobbiamo definire la nostra unità (ad esempio, un periodo standard di oscillazione). Con il modello di Rasch, l’unità è definita come il logit, ossia la distanza sul nostro continuum che porta a un aumento del rapporto di successo di un fattore uguale alla costante trascendentale \(e\). Pertanto, analogamente alla misurazione del tempo, le nostre misurazioni con un modello a un parametro si basano sull’uso (ripetitivo) di un’unità che rimane costante nella nostra metrica.
Per semplicità, nel seguito utilizzeremo il termine generale modello 1PL per riferirci sia alla situazione in cui \(\alpha = 1.0\) (cioè, il modello di Rasch) sia alla situazione in cui \(\alpha\) è uguale a qualche altra costante. Tuttavia, quando usiamo il termine modello di Rasch, ci riferiamo soltanto alla situazione in cui \(\alpha = 1.0\).
mirt_rm <- mirt(responses, 1, "Rasch")
Iteration: 1, Log-Lik: -2816.924, Max-Change: 0.03346
Iteration: 2, Log-Lik: -2816.650, Max-Change: 0.02041
Iteration: 3, Log-Lik: -2816.562, Max-Change: 0.01357
Iteration: 4, Log-Lik: -2816.520, Max-Change: 0.01027
Iteration: 5, Log-Lik: -2816.501, Max-Change: 0.00584
Iteration: 6, Log-Lik: -2816.493, Max-Change: 0.00395
Iteration: 7, Log-Lik: -2816.490, Max-Change: 0.00307
Iteration: 8, Log-Lik: -2816.488, Max-Change: 0.00174
Iteration: 9, Log-Lik: -2816.487, Max-Change: 0.00118
Iteration: 10, Log-Lik: -2816.487, Max-Change: 0.00094
Iteration: 11, Log-Lik: -2816.487, Max-Change: 0.00054
Iteration: 12, Log-Lik: -2816.487, Max-Change: 0.00036
Iteration: 13, Log-Lik: -2816.487, Max-Change: 0.00028
Iteration: 14, Log-Lik: -2816.487, Max-Change: 0.00016
Iteration: 15, Log-Lik: -2816.487, Max-Change: 0.00011
Iteration: 16, Log-Lik: -2816.487, Max-Change: 0.00008
63.1.2. Discriminazione#
La formula generale per una curva caratteristica dell’item (ICC) in un modello 1PL è:
dove:
\( P(\theta) \) è la probabilità di una risposta corretta.
\( \theta \) è l’abilità del rispondente.
\( a \) è il parametro di discriminazione dell’item, fisso per tutti gli item.
\( b \) è il parametro di difficoltà dell’item.
Nel modello di Rasch, il parametro di discriminazione \(a\) viene fissato a 1 per tutti gli item, per cui otteniamo
Il concetto di “discriminazione” nel contesto dei modelli di risposta all’item (IRT) si riferisce alla capacità di un item di distinguere tra individui con abilità leggermente superiore e quelli con abilità leggermente inferiore rispetto alla difficoltà dell’item stesso. Questa capacità discriminante è caratterizzata dalla pendenza della curva caratteristica dell’item (ICC) “nel mezzo”, ovvero per livelli di abilità vicini alla difficoltà dell’item, con discriminazioni più elevate che corrispondono a pendenze più ripide.
# Definizione della funzione sigmoide per rappresentare le ICC
sigmoid <- function(x, beta) {
1 / (1 + exp(-beta * (x - 0)))
}
# Creazione di una sequenza di livelli di abilità
abilities <- seq(-2, 2, length.out = 100)
# Calcolo delle probabilità per due item con diversi valori di discriminazione
# Per l'item di sinistra (discriminazione inferiore, beta=1)
probabilities_left <- sigmoid(abilities, beta = 1)
# Per l'item di destra (discriminazione superiore, beta=2)
probabilities_right <- sigmoid(abilities, beta = 2)
# Creazione del dataframe per ggplot
data <- data.frame(
Ability = rep(abilities, 2),
Probability = c(probabilities_left, probabilities_right),
Item = rep(c("Lower Discrimination (beta=1)", "Higher Discrimination (beta=2)"), each = 100)
)
# Creazione del grafico
ggplot(data, aes(x = Ability, y = Probability, color = Item)) +
geom_line() +
scale_color_manual(values = c("blue", "orange")) +
geom_point(
data = data.frame(
Ability = c(-0.5, 0.5, -0.5, 0.5),
Probability = c(sigmoid(-0.5, 1), sigmoid(0.5, 1), sigmoid(-0.5, 2), sigmoid(0.5, 2)),
Item = c("Lower Discrimination (beta=1)", "Lower Discrimination (beta=1)", "Higher Discrimination (beta=2)", "Higher Discrimination (beta=2)")
),
aes(x = Ability, y = Probability, color = Item)
) +
ggtitle("Item Characteristic Curves (ICCs) for Different Discriminations") +
xlab("Ability (theta)") +
ylab("Probability of Correct Response")
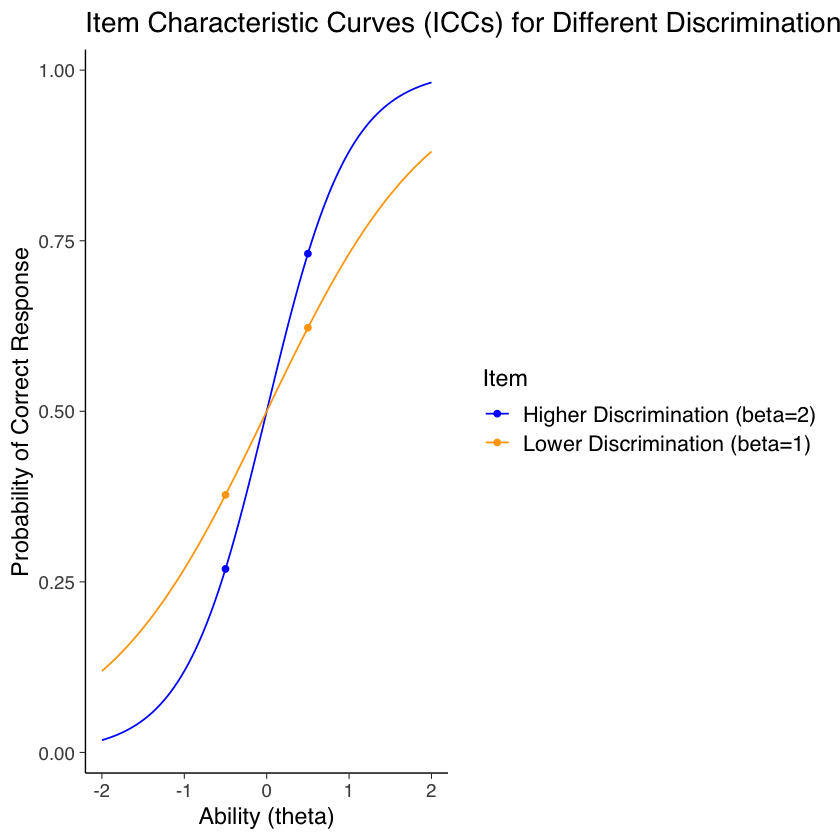
Consideriamo due diverse Curve Caratteristiche dell’Item (ICC) per item con difficoltà zero.
In questa funzione, sigmoid <- function(x, beta) { 1 / (1 + exp(-beta * (x - 0))) }``, il parametro beta` rappresenta la discriminazione dell’item, mentre la difficoltà dell’item è implicitamente fissata a zero (b = 0). Questa funzione, quindi, non modella direttamente variazioni nella difficoltà dell’item, ma solo nella discriminazione.
Le ICC sono calcolate per due item con diversi livelli di discriminazione, rappresentati come “Lower Discrimination (beta=1)” e “Higher Discrimination (beta=2)” nel grafico. Le probabilità che persone con abilità di −0.5 e +0.5 risolvano correttamente l’item sono rispettivamente approssimativamente 0.38 e 0.62 per l’item con discriminazione inferiore (beta=1, rappresentato con la curva blu)
sigmoid <- function(x, beta) {
1 / (1 + exp(-beta * (x - 0)))
}
sigmoid(-0.5, 1)
sigmoid(0.5, 1)
e 0.27 e 0.73 per l’item con discriminazione superiore (beta=2, rappresentato con la curva arancione)
sigmoid(-0.5, 2)
sigmoid(0.5, 2)
Ciò indica che due persone con una differenza di 1 nella loro abilità mostrano una differenza di 0.24 nella loro probabilità di risolvere correttamente l’item con discriminazione inferiore (curva blu) e una differenza di 0.46 per l’item con discriminazione superiore (curva arancione).
La pendenza al centro dell’ICC, dove la curva è quasi lineare, può essere approssimata da questa differenza sull’asse y divisa per la differenza sull’asse x, risultando in circa 0.24 per l’item con discriminazione inferiore e 0.46 per quello con discriminazione superiore. In termini più semplici, la pendenza è una misura di quanto rapidamente la probabilità di una risposta corretta aumenta (o diminuisce) in relazione a un cambiamento nell’abilità dell’individuo. Una pendenza più ripida, come quella dell’item con discriminazione superiore (curva arancione), indica una maggiore discriminazione, cioè l’item è più efficace nel distinguere tra persone con livelli di abilità leggermente differenti.
Nel Modello di Rasch, si assume che tutti gli item abbiano la stessa discriminazione, con una pendenza di 1. Questo è evidente dalla formula del modello, dove l’unico parametro per ciascun item \(i\) è la sua difficoltà \(\beta_i\), senza parametri aggiuntivi per modellare la discriminazione. Tuttavia, questo approccio è spesso considerato troppo rigido dal punto di vista della modellazione, poiché molti test reali contengono item con discriminazioni disuguali. In contrasto, il modello logistico a due parametri (2PL) di Birnbaum incorpora un parametro di pendenza, permettendo a ciascun item di avere una discriminazione diversa.
In sintesi, la discriminazione in un test psicometrico è un concetto chiave che descrive quanto efficacemente un item può differenziare tra rispondenti con abilità simili ma non identiche. Maggiore è la discriminazione, più efficacemente l’item può identificare le differenze sottili nelle abilità dei rispondenti.
63.2. Modello IRT a due parametri#
Il modello 2PL, noto come “Modello IRT a due parametri”, prevede che le curve caratteristiche degli item non siano tra loro parallele. Questo modello utilizza due parametri per descrivere le curve caratteristiche di ciascun item: il parametro di difficoltà \(\delta_i\) e il parametro di discriminazione \(\alpha_i\). Il parametro \(\alpha_i\) consente alle curve caratteristiche di avere pendenze diverse e riflette la capacità discriminante dell’item rispetto alla variabile latente. Le curve caratteristiche nel modello 2PL hanno la seguente forma:
Adattiamo il modello 2PL ai dati.
mirt_2pl <- mirt(responses, 1, "2PL")
Iteration: 1, Log-Lik: -2818.855, Max-Change: 0.66304
Iteration: 2, Log-Lik: -2772.597, Max-Change: 0.26013
Iteration: 3, Log-Lik: -2762.517, Max-Change: 0.12884
Iteration: 4, Log-Lik: -2760.353, Max-Change: 0.06587
Iteration: 5, Log-Lik: -2759.824, Max-Change: 0.03961
Iteration: 6, Log-Lik: -2759.675, Max-Change: 0.02169
Iteration: 7, Log-Lik: -2759.622, Max-Change: 0.01040
Iteration: 8, Log-Lik: -2759.609, Max-Change: 0.00642
Iteration: 9, Log-Lik: -2759.605, Max-Change: 0.00396
Iteration: 10, Log-Lik: -2759.602, Max-Change: 0.00160
Iteration: 11, Log-Lik: -2759.602, Max-Change: 0.00089
Iteration: 12, Log-Lik: -2759.602, Max-Change: 0.00064
Iteration: 13, Log-Lik: -2759.601, Max-Change: 0.00020
Iteration: 14, Log-Lik: -2759.601, Max-Change: 0.00009
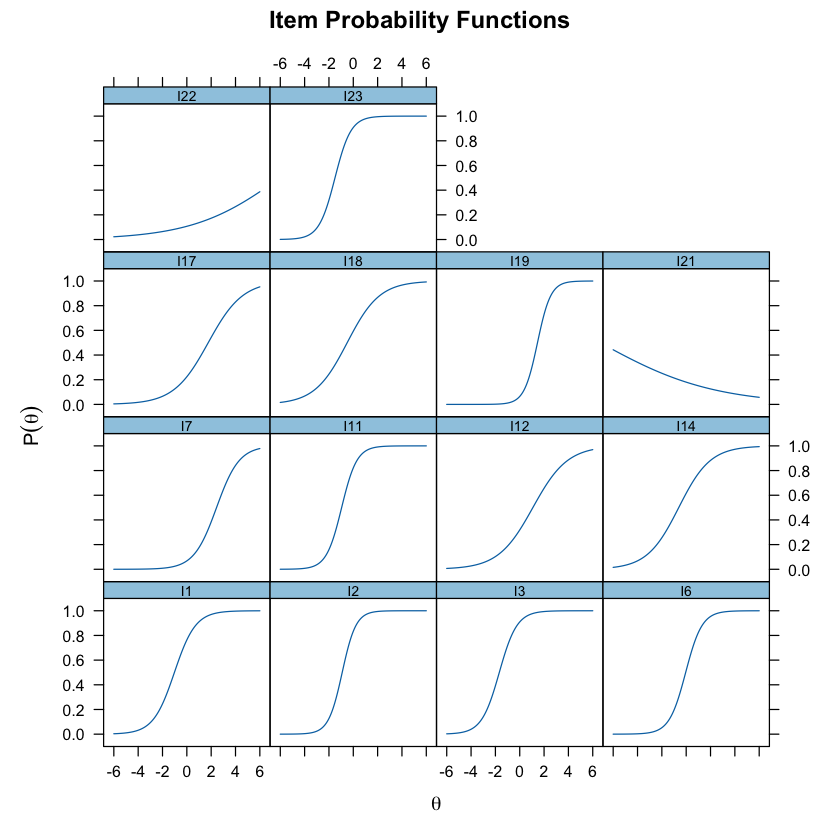
Esaminiamo le curve caratteristiche degli item.
plot(mirt_2pl, type = "trace")
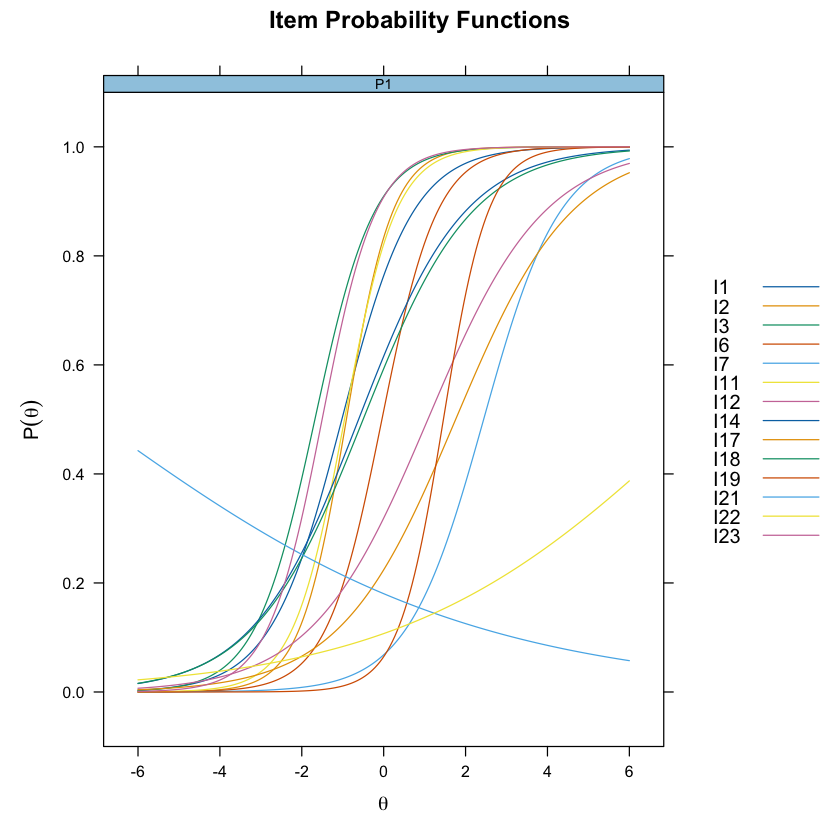
plot(mirt_2pl, type = "trace", facet_items = FALSE)
Possiamo visualizzare le stime dei parametri degli item per il 2PL utilizzando la funzione coef().
coef(mirt_2pl, IRTpars = TRUE, simplify = TRUE)
- $items
A matrix: 14 × 4 of type dbl a b g u I1 1.1474247 -1.02151843 0 1 I2 1.7687105 -0.91065318 0 1 I3 1.3724569 -1.67979991 0 1 I6 1.4786119 -0.04254241 0 1 I7 1.0714345 2.44143950 0 1 I11 1.5944811 -0.95699944 0 1 I12 0.7033227 1.07888714 0 1 I14 0.7707027 -0.61243178 0 1 I17 0.7066769 1.75774430 0 1 I18 0.7498268 -0.50187180 0 1 I19 1.8311083 1.45897744 0 1 I21 -0.2139602 -7.07607206 0 1 I22 0.2769275 7.65692247 0 1 I23 1.5212898 -1.50340795 0 1 - $means
- F1: 0
- $cov
A matrix: 1 × 1 of type dbl F1 F1 1
Effettuiamo un confronto tra il modello di Rash e il modello 2PL.
anova(mirt_rm, mirt_2pl)
| AIC | SABIC | HQ | BIC | logLik | X2 | df | p | |
|---|---|---|---|---|---|---|---|---|
| <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | |
| mirt_rm | 5662.973 | 5675.249 | 5686.683 | 5722.845 | -2816.487 | NA | NA | NA |
| mirt_2pl | 5575.203 | 5598.118 | 5619.462 | 5686.964 | -2759.601 | 113.7703 | 13 | 0 |
Questo indica che il 2PL fornisce un adattamento significativamente migliore rispetto al modello di Rasch, suggerendo che gli item non hanno tutti la stessa pendenza.
63.3. Modello IRT a tre parametri#
Per considerare l’eventuale tendenza dei rispondenti a indovinare, i modelli IRT introducono un ulteriore parametro, denotato con \(\gamma_i\). Il modello a tre parametri (3PL) assume la seguente forma:
Il parametro \(\gamma_i\) ha l’effetto di introdurre un asintoto orizzontale maggiore di zero per valori di \(\theta_v\) tendenti a \(-\infty\). In altre parole, per item con \(\gamma_i = 0.25\), la probabilità di risposta corretta dovuta al caso è almeno pari a 0.25, anche per i livelli di abilità latente più bassi.
mirt_3pl <- mirt(responses, 1, "3PL")
Iteration: 1, Log-Lik: -2907.091, Max-Change: 3.31584
Iteration: 2, Log-Lik: -2772.694, Max-Change: 1.28437
Iteration: 3, Log-Lik: -2752.349, Max-Change: 0.91384
Iteration: 4, Log-Lik: -2745.974, Max-Change: 0.69216
Iteration: 5, Log-Lik: -2743.438, Max-Change: 0.50378
Iteration: 6, Log-Lik: -2742.271, Max-Change: 0.68486
Iteration: 7, Log-Lik: -2741.541, Max-Change: 0.59761
Iteration: 8, Log-Lik: -2740.785, Max-Change: 0.74759
Iteration: 9, Log-Lik: -2740.617, Max-Change: 1.85539
Iteration: 10, Log-Lik: -2740.417, Max-Change: 0.60454
Iteration: 11, Log-Lik: -2740.374, Max-Change: 3.18943
Iteration: 12, Log-Lik: -2740.327, Max-Change: 0.52006
Iteration: 13, Log-Lik: -2740.324, Max-Change: 0.51847
Iteration: 14, Log-Lik: -2740.301, Max-Change: 0.49143
Iteration: 15, Log-Lik: -2740.282, Max-Change: 0.48597
Iteration: 16, Log-Lik: -2740.213, Max-Change: 0.01722
Iteration: 17, Log-Lik: -2740.211, Max-Change: 0.00752
Iteration: 18, Log-Lik: -2740.210, Max-Change: 0.00116
Iteration: 19, Log-Lik: -2740.210, Max-Change: 0.00410
Iteration: 20, Log-Lik: -2740.210, Max-Change: 0.00015
Iteration: 21, Log-Lik: -2740.210, Max-Change: 0.00074
Iteration: 22, Log-Lik: -2740.210, Max-Change: 0.00017
Iteration: 23, Log-Lik: -2740.210, Max-Change: 0.00069
Iteration: 24, Log-Lik: -2740.210, Max-Change: 0.00064
Iteration: 25, Log-Lik: -2740.210, Max-Change: 0.00024
Iteration: 26, Log-Lik: -2740.210, Max-Change: 0.00057
Iteration: 27, Log-Lik: -2740.210, Max-Change: 0.00018
Iteration: 28, Log-Lik: -2740.210, Max-Change: 0.00015
Iteration: 29, Log-Lik: -2740.210, Max-Change: 0.00053
Iteration: 30, Log-Lik: -2740.210, Max-Change: 0.00056
Iteration: 31, Log-Lik: -2740.210, Max-Change: 0.00025
Iteration: 32, Log-Lik: -2740.210, Max-Change: 0.00048
Iteration: 33, Log-Lik: -2740.210, Max-Change: 0.00019
Iteration: 34, Log-Lik: -2740.210, Max-Change: 0.00015
Iteration: 35, Log-Lik: -2740.210, Max-Change: 0.00045
Iteration: 36, Log-Lik: -2740.210, Max-Change: 0.00011
Iteration: 37, Log-Lik: -2740.210, Max-Change: 0.00046
Iteration: 38, Log-Lik: -2740.210, Max-Change: 0.00023
Iteration: 39, Log-Lik: -2740.210, Max-Change: 0.00041
Iteration: 40, Log-Lik: -2740.210, Max-Change: 0.00030
Iteration: 41, Log-Lik: -2740.210, Max-Change: 0.00009
Esaminiamo le curve caratteristiche degli item.
plot(mirt_3pl, type = "trace", facet_items = FALSE)
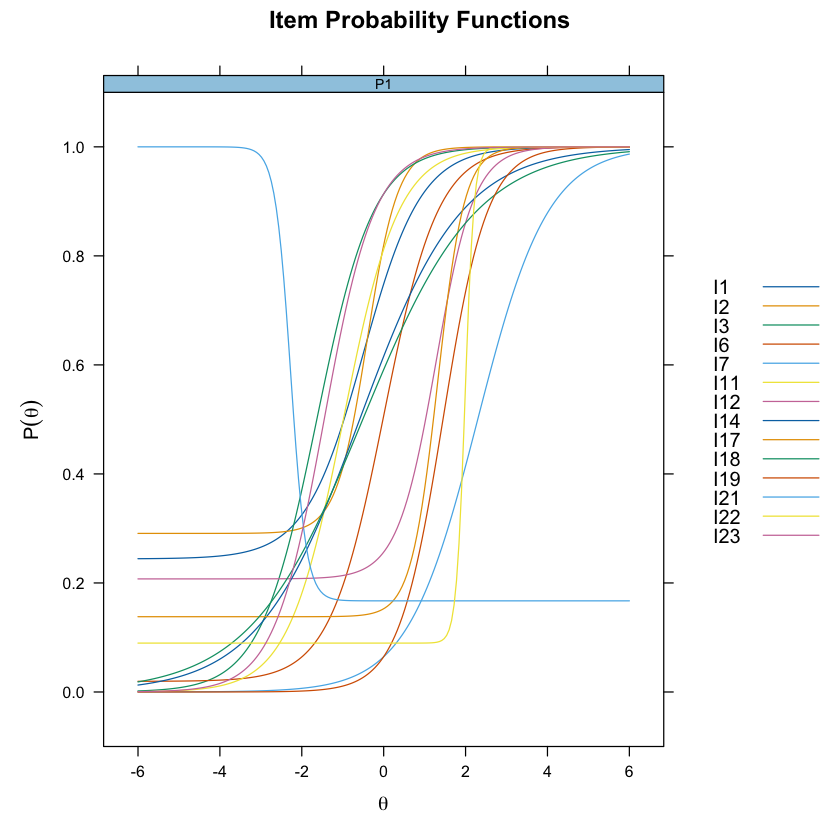
Un elemento chiave del modello 3PL è che l’asintoto inferiore, rappresentato dal parametro \(\gamma_i\), assume un valore maggiore di zero. Questo implica che la probabilità di una risposta corretta, rappresentata da \(\gamma_i\), risulta essere superiore a 0.5 per valori relativamente bassi di abilità latente. In altre parole, gli item con \(\gamma_i > 0\) forniscono una probabilità di risposta corretta più alta anche per rispondenti con livelli di abilità latente relativamente bassi.
Ciò comporta che tali item risultano essere più facili per i rispondenti con abilità latente inferiore, in confronto agli item con \(\gamma_i = 0\). Questa caratteristica dei modelli 3PL permette di includere il tasso di guessing nella probabilità di risposta corretta e offre una maggiore flessibilità nella modellazione del comportamento degli item rispetto al modello a due parametri (2PL), nel quale l’asintoto inferiore è pari a zero.
A negative slope indicates that, all else being equal, a person with a higher value on the latent trait is less likely to give a positive response than a person with a lower value. What a negative slope estimate means for test construction depends on context. For achievement tests, a negative slope indicates that a test item is not behaving like it should. For other psychological tests, such as personality or attitude scales, nega- tive slopes may be intended for some of the items. In this setting, test designers routinely use negatively worded items. A negatively worded version of “I like long walks on the beach”, for example, might be “I do not like long walks on the beach”. A person agreeing with the first would ideally disagree with the second3, so we could legitimately get a negative slope when the version we use is in the opposite direction to the rest of the items.
Possiamo visualizzare le stime dei parametri degli item per il 3PL utilizzando la funzione coef().
coef(mirt_3pl, IRTpars = TRUE, simplify = TRUE)
- $items
A matrix: 14 × 4 of type dbl a b g u I1 1.4097712 -0.49321069 2.441664e-01 1 I2 2.6665125 -0.40357732 2.909004e-01 1 I3 1.4449658 -1.63252646 1.224781e-04 1 I6 1.5135421 0.00860713 1.949812e-02 1 I7 1.1634394 2.29703116 1.177019e-05 1 I11 1.4873719 -0.98362215 1.450244e-05 1 I12 2.1309230 1.27506046 2.074352e-01 1 I14 0.8047002 -0.58574323 6.144279e-05 1 I17 3.0758348 1.31997827 1.380818e-01 1 I18 0.7239776 -0.51031734 4.102312e-05 1 I19 1.8437010 1.44860652 3.537302e-06 1 I21 -5.2635778 -2.27061550 1.671759e-01 1 I22 9.1791591 1.98999438 8.967797e-02 1 I23 1.6252401 -1.45226821 4.396566e-05 1 - $means
- F1: 0
- $cov
A matrix: 1 × 1 of type dbl F1 F1 1
Effettuiamo il confronto tra i modelli 2PL e 3PL.
anova(mirt_2pl, mirt_3pl)
| AIC | SABIC | HQ | BIC | logLik | X2 | df | p | |
|---|---|---|---|---|---|---|---|---|
| <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | |
| mirt_2pl | 5575.203 | 5598.118 | 5619.462 | 5686.964 | -2759.601 | NA | NA | NA |
| mirt_3pl | 5564.419 | 5598.792 | 5630.808 | 5732.061 | -2740.210 | 38.78358 | 14 | 0.0003938891 |
Il modello 2PL deriva dal modello 3PL impostando un tipo specifico di parametro, ovvero il parametro di guessing, a un valore di 0. Il parametro di guessing nel modello 3PL rappresenta la probabilità che un candidato indovini correttamente un item, anche se non possiede la competenza richiesta per rispondere. Poiché il parametro di guessing può assumere valori tra 0 e 1, ciò significa che il modello ristretto nella nostra analisi, che è il modello 2PL, deriva dal modello più generale impostando un parametro a un valore ai limiti del suo spazio parametrico. In questo scenario, il classico test del rapporto di verosimiglianza può portare a risultati inaccurati.
Pertanto, per interpretare il confronto tra i due modelli utilizziamo solo gli indici di informazione per confrontare il modello 2PL e il modello 3PL. Mentre l’AIC indica una preferenza per il modello 3PL (forse a causa del guessing presente in alcuni item), il BIC mostra una lieve preferenza per il modello 2PL più semplice, poiché penalizza maggiormente l’uso di un maggior numero di parametri nel modello.
63.4. Interpretazione dei parametri#
In un certo senso, l’analisi IRT può essere paragonata all’analisi fattoriale nella Teoria Classica dei Test (CTT). Utilizzando la funzione summary(), otteniamo quella che è nota come soluzione fattoriale, che include i carichi fattoriali (F1) e le comunalità (h2). Queste ultime, essendo i carichi fattoriali al quadrato, vengono interpretate come la varianza spiegata dall’attributo latente in ciascun item. Nella maggior parte dei casi, quasi tutti gli item mostrano una relazione sostanziale (carichi > 0.50) con il tratto latente.
# Factor solution
summary(mirt_3pl)
F1 h2
I1 0.638 0.407
I2 0.843 0.711
I3 0.647 0.419
I6 0.665 0.442
I7 0.564 0.318
I11 0.658 0.433
I12 0.781 0.611
I14 0.427 0.183
I17 0.875 0.766
I18 0.391 0.153
I19 0.735 0.540
I21 -0.951 0.905
I22 0.983 0.967
I23 0.691 0.477
SS loadings: 7.33
Proportion Var: 0.524
Factor correlations:
F1
F1 1
Nell’IRT, tuttavia, siamo solitamente più interessati ai parametri effettivi dell’IRT come discusso sopra (discriminazione, difficoltà e probabilità di indovinare). Tali parametri possono essere estratti come segue:
params3PL <- coef(mirt_3pl, IRTpars = TRUE, simplify = TRUE)
round(params3PL$items, 2) # g = c = guessing parameter
| a | b | g | u | |
|---|---|---|---|---|
| I1 | 1.41 | -0.49 | 0.24 | 1 |
| I2 | 2.67 | -0.40 | 0.29 | 1 |
| I3 | 1.44 | -1.63 | 0.00 | 1 |
| I6 | 1.51 | 0.01 | 0.02 | 1 |
| I7 | 1.16 | 2.30 | 0.00 | 1 |
| I11 | 1.49 | -0.98 | 0.00 | 1 |
| I12 | 2.13 | 1.28 | 0.21 | 1 |
| I14 | 0.80 | -0.59 | 0.00 | 1 |
| I17 | 3.08 | 1.32 | 0.14 | 1 |
| I18 | 0.72 | -0.51 | 0.00 | 1 |
| I19 | 1.84 | 1.45 | 0.00 | 1 |
| I21 | -5.26 | -2.27 | 0.17 | 1 |
| I22 | 9.18 | 1.99 | 0.09 | 1 |
| I23 | 1.63 | -1.45 | 0.00 | 1 |
I valori dei parametri di pendenza (parametri a) variano da 0.80 a 9.18. Il parametro a è una misura di quanto bene un item differenzia individui con diversi livelli di abilità \(\theta\). Valori più grandi, o pendenze più ripide, sono migliori per differenziare i rispondenti. La pendenza può anche essere interpretata come un indicatore della forza della relazione tra un item e un tratto latente, con valori di pendenza più alti che corrispondono a relazioni più forti.
Anche i parametri di difficoltà (parametro b) sono elencati per ciascun item. I parametri di difficoltà sono interpretati come il valore di \(\theta\) che corrisponde a una probabilità del 50% di rispondere correttamente a (o al di sopra di tale posizione) un item. Nel caso presente, i parametri di difficoltà mostrano che gli item coprono un’ampia gamma del tratto latente.
63.5. Invarianza di Gruppo dei Parametri degli Item nella IRT#
Una caratteristica rilevante della teoria della IRT è l’invarianza dei parametri degli item rispetto al livello di abilità degli esaminandi che rispondono agli item. Ciò significa che i parametri degli item sono ciò che si definisce “invarianti di gruppo”. Questo aspetto della teoria può essere spiegato come segue.
Immaginiamo due gruppi di esaminandi, entrambi estratti dalla stessa popolazione. Il primo gruppo presenta punteggi di abilità variabili da -3 a -1, con una media di -2, mentre il secondo gruppo ha punteggi che vanno da +1 a +3, con una media di +2. Si calcola la proporzione osservata di risposte corrette a un determinato item, per ogni livello di abilità, in entrambi i gruppi. Utilizzando la procedura di stima a massima verosimiglianza, si adatta una curva caratteristica dell’item ai dati, ottenendo stime dei parametri dell’item, ad esempio, b = 0.39 e a = 1.27. La curva caratteristica dell’item definita da queste stime viene poi tracciata per l’intervallo di abilità del primo gruppo.
groupinv <- function(mdl, t1l, t1u, t2l, t2u) {
if (missing(t1l)) t1l <- -3
if (missing(t1u)) t1u <- -1
if (missing(t2l)) t2l <- 1
if (missing(t2u)) t2u <- 3
theta <- seq(-3, 3, .1875)
f <- rep(21, length(theta))
wb <- round(runif(1, -3, 3), 2)
wa <- round(runif(1, 0.2, 2.8), 2)
wc <- round(runif(1, 0, .35), 2)
if (mdl == 1 | mdl == 2) {
wc <- 0
}
if (mdl == 1) {
wa <- 1
}
for (g in 1:length(theta)) {
P <- wc + (1 - wc) / (1 + exp(-wa * (theta - wb)))
}
p <- rbinom(length(theta), f, P) / f
lowerg1 <- 0
for (g in 1:length(theta)) {
if (theta[g] <= t1l) {
lowerg1 <- lowerg1 + 1
}
}
upperg1 <- 0
for (g in 1:length(theta)) {
if (theta[g] <= t1u) {
upperg1 <- upperg1 + 1
}
}
theta1 <- theta[lowerg1:upperg1]
p1 <- p[lowerg1:upperg1]
lowerg2 <- 0
for (g in 1:length(theta)) {
if (theta[g] <= t2l) {
lowerg2 <- lowerg2 + 1
}
}
upperg2 <- 0
for (g in 1:length(theta)) {
if (theta[g] <= t2u) {
upperg2 <- upperg2 + 1
}
}
theta2 <- theta[lowerg2:upperg2]
p2 <- p[lowerg2:upperg2]
theta12 <- c(theta1, theta2)
p12 <- c(p1, p2)
par(lab = c(7, 5, 3))
plot(theta12, p12,
xlim = c(-3, 3), ylim = c(0, 1),
xlab = "Ability", ylab = "Probability of Correct Response"
)
if (mdl == 1) {
maintext <- paste("Pooled Groups", "\n", "b=", wb)
}
if (mdl == 2) {
maintext <- paste("Pooled Groups", "\n", "a=", wa, "b=", wb)
}
if (mdl == 3) {
maintext <- paste(
"Pooled Groups", "\n",
"a=", wa, "b=", wb, "c=", wc
)
}
par(new = "T")
plot(theta, P,
xlim = c(-3, 3), ylim = c(0, 1), type = "l",
xlab = "", ylab = "", main = maintext
)
}
set.seed(1)
groupinv(1, -3, -1, 1, 3)
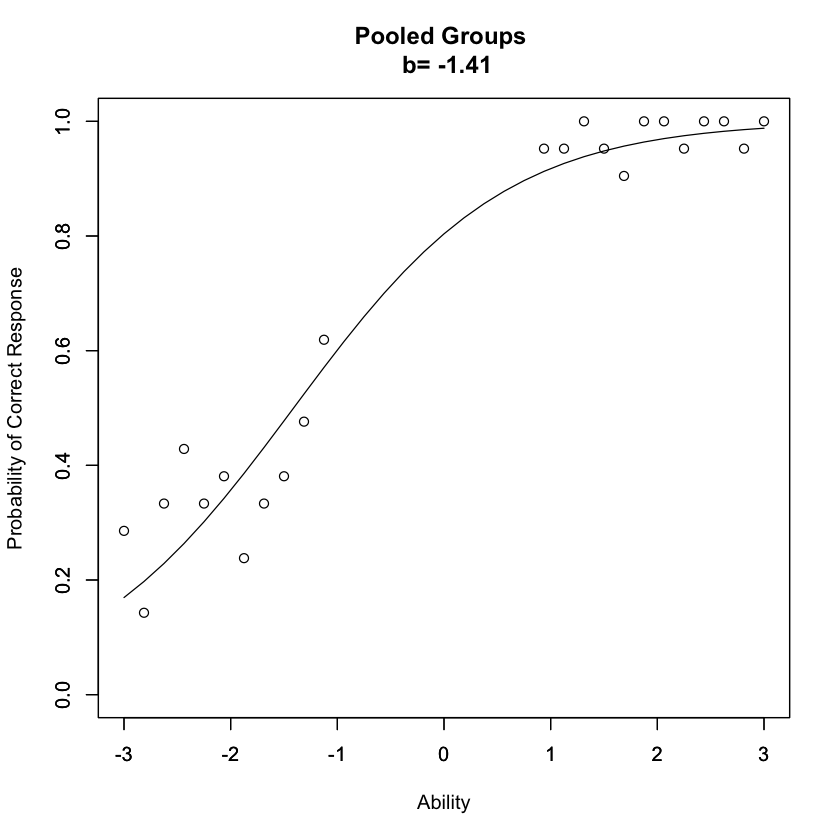
Il punto fondamentale è che gli stessi valori dei parametri a e b si otterrebbero applicando il modello IRT esclusivamente ai dati del primo o del secondo gruppo. Di conseguenza, i parametri dell’item sono invarianti di gruppo. Questa invarianza è una caratteristica potente della teoria della risposta all’item, indicando che i valori dei parametri dell’item sono una proprietà dell’item stesso, non del gruppo che ha risposto all’item. Questo si contrappone alla teoria classica dei test, dove la difficoltà di un item è determinata dalla proporzione complessiva di risposte corrette da parte di un gruppo di esaminandi.
Sebbene i parametri degli item - definiti come attributi intrinseci degli item indipendentemente dalle popolazioni di esaminandi - siano teoricamente invarianti tra gruppi diversi estratti dalla medesima popolazione, le stime ottenute di tali parametri attraverso procedure di massima verosimiglianza possono differire a causa della variabilità campionaria.
In termini statistici, la stima dei parametri degli item per un dato campione è uno stimatore dei parametri reali della popolazione, ma è soggetta a errore campionario. L’errore campionario è direttamente proporzionale alla dimensione del campione e alla varianza dei dati all’interno del campione. Pertanto, benché i valori reali dei parametri degli item siano costanti tra i gruppi estratti dalla stessa popolazione, le stime campionarie di questi parametri mostreranno una distribuzione attorno al vero valore popolazionale, con una variabilità che riflette l’errore campionario.
Inoltre, è fondamentale che l’item venga utilizzato per misurare lo stesso tratto latente in entrambi i gruppi. I parametri di un item non mantengono l’invarianza di gruppo se utilizzati fuori contesto, ovvero per misurare un tratto latente diverso, con esaminandi da una popolazione non adeguata, o se i due gruppi provengono da popolazioni diverse.
L’invarianza di gruppo dei parametri degli item illustra anche una caratteristica fondamentale della curva caratteristica dell’item. Come affermato nei capitoli precedenti, questa curva rappresenta la relazione tra la probabilità di risposta corretta all’item e la scala di abilità. Il principio di invarianza riflette questo, poiché i parametri dell’item sono indipendenti dalla distribuzione degli esaminandi sulla scala di abilità. Da un punto di vista pratico, ciò significa che i parametri dell’intera curva caratteristica dell’item possono essere stimati da qualsiasi segmento della curva.
Facciamo un esempio e consideriamo la statistica DIF per il primo item del test, in funzione del genere.
dd <- data.frame(responses, gender = as.factor(fims$SEX[1:400]))
levels(dd$gender) <- c("male", "female")
dif_model <- multipleGroup(
data = dd[, 1:14],
model = 1,
itemtype = "3PL",
group = dd$gender,
invariance = c(colnames(dd)[-c(1)], "free_means", "free_var"),
verbose = FALSE
)
dif_test <- DIF(
MGmodel = dif_model,
which.par = c("a1", "d", "g"),
items2test = c(1), # Testa il DIF solo per l'item 2
p.adjust = "BH" # Adjust per multiple testing usando Benjamini-Hochberg
)
dif_test
| groups | converged | AIC | SABIC | HQ | BIC | X2 | df | p | adj_p | |
|---|---|---|---|---|---|---|---|---|---|---|
| <chr> | <lgl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | |
| I1 | male,female | TRUE | 0.4668205 | 2.922015 | 5.208836 | 12.44121 | 5.53318 | 3 | 0.1366675 | 0.1366675 |
L’ipotesi nulla non può essere rigettata. Dunque, per questo item non ci sono evidenze di Differential Item Functioning (DIF).
63.6. Considerazioni Conclusive#
Il pacchetto mirt (Chalmers, 2021) offre funzionalità per l’adattamento di una varietà di modelli IRT, inclusi i modelli Rasch, 2PL e 3PL, nonché diversi modelli per risposte politomiche utilizzando la massima verosimiglianza marginale. In questo capitolo, abbiamo esplorato come sia possibile confrontare i modelli 1PL, 2PL e 3PL, che sono stati adattati ai dati usando mirt, attraverso il test del rapporto di verosimiglianza e gli indici di informazione.
63.7. Session Info#
sessionInfo()
R version 4.3.3 (2024-02-29)
Platform: x86_64-apple-darwin20 (64-bit)
Running under: macOS Sonoma 14.4.1
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.3-x86_64/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.3-x86_64/Resources/lib/libRlapack.dylib; LAPACK version 3.11.0
locale:
[1] en_US.UTF-8/UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
time zone: Europe/Rome
tzcode source: internal
attached base packages:
[1] grid stats4 stats graphics grDevices utils datasets
[8] methods base
other attached packages:
[1] latex2exp_0.9.6 psychotools_0.7-3 ggmirt_0.1.0 TAM_4.2-21
[5] CDM_8.2-6 mvtnorm_1.2-4 mirt_1.41 lattice_0.22-6
[9] eRm_1.0-6 ggokabeito_0.1.0 viridis_0.6.5 viridisLite_0.4.2
[13] ggpubr_0.6.0 ggExtra_0.10.1 bayesplot_1.11.1 gridExtra_2.3
[17] patchwork_1.2.0 semTools_0.5-6.920 semPlot_1.1.6 lavaan_0.6-17
[21] psych_2.4.3 scales_1.3.0 markdown_1.12 knitr_1.45
[25] lubridate_1.9.3 forcats_1.0.0 stringr_1.5.1 dplyr_1.1.4
[29] purrr_1.0.2 readr_2.1.5 tidyr_1.3.1 tibble_3.2.1
[33] ggplot2_3.5.1 tidyverse_2.0.0 here_1.0.1
loaded via a namespace (and not attached):
[1] rstudioapi_0.16.0 jsonlite_1.8.8 magrittr_2.0.3
[4] TH.data_1.1-2 estimability_1.5 farver_2.1.1
[7] nloptr_2.0.3 rmarkdown_2.26 vctrs_0.6.5
[10] minqa_1.2.6 base64enc_0.1-3 rstatix_0.7.2
[13] htmltools_0.5.8.1 broom_1.0.5 Formula_1.2-5
[16] dcurver_0.9.2 htmlwidgets_1.6.4 plyr_1.8.9
[19] sandwich_3.1-0 emmeans_1.10.0 zoo_1.8-12
[22] uuid_1.2-0 admisc_0.35 igraph_2.0.3
[25] mime_0.12 lifecycle_1.0.4 pkgconfig_2.0.3
[28] Matrix_1.6-5 R6_2.5.1 fastmap_1.1.1
[31] shiny_1.8.1.1 digest_0.6.35 OpenMx_2.21.11
[34] fdrtool_1.2.17 colorspace_2.1-0 rprojroot_2.0.4
[37] Hmisc_5.1-2 vegan_2.6-4 labeling_0.4.3
[40] fansi_1.0.6 timechange_0.3.0 mgcv_1.9-1
[43] abind_1.4-5 compiler_4.3.3 withr_3.0.0
[46] glasso_1.11 htmlTable_2.4.2 backports_1.4.1
[49] carData_3.0-5 ggsignif_0.6.4 MASS_7.3-60.0.1
[52] GPArotation_2024.3-1 corpcor_1.6.10 permute_0.9-7
[55] gtools_3.9.5 tools_4.3.3 pbivnorm_0.6.0
[58] foreign_0.8-86 zip_2.3.1 httpuv_1.6.15
[61] nnet_7.3-19 glue_1.7.0 quadprog_1.5-8
[64] nlme_3.1-164 promises_1.3.0 lisrelToR_0.3
[67] pbdZMQ_0.3-11 checkmate_2.3.1 cluster_2.1.6
[70] reshape2_1.4.4 generics_0.1.3 gtable_0.3.5
[73] tzdb_0.4.0 data.table_1.15.4 hms_1.1.3
[76] Deriv_4.1.3 car_3.1-2 utf8_1.2.4
[79] sem_3.1-15 pillar_1.9.0 IRdisplay_1.1
[82] rockchalk_1.8.157 later_1.3.2 splines_4.3.3
[85] survival_3.5-8 kutils_1.73 tidyselect_1.2.1
[88] miniUI_0.1.1.1 pbapply_1.7-2 xfun_0.43
[91] qgraph_1.9.8 arm_1.13-1 stringi_1.8.3
[94] boot_1.3-30 evaluate_0.23 codetools_0.2-19
[97] mi_1.1 cli_3.6.2 RcppParallel_5.1.7
[100] IRkernel_1.3.2 rpart_4.1.23 xtable_1.8-4
[103] repr_1.1.6 munsell_0.5.1 Rcpp_1.0.12
[106] polycor_0.8-1 coda_0.19-4.1 png_0.1-8
[109] XML_3.99-0.16.1 parallel_4.3.3 jpeg_0.1-10
[112] lme4_1.1-35.3 openxlsx_4.2.5.2 crayon_1.5.2
[115] rlang_1.1.3 multcomp_1.4-25 mnormt_2.1.1