9. Fondamenti teorici#
La teoria classica dei test (Classic Test Theory, CTT) è una teoria fondamentale utilizzata in psicometria per valutare e misurare le caratteristiche psicologiche degli individui attraverso l’uso di test e questionari. Secondo questa teoria, il punteggio ottenuto da un individuo in un test è influenzato da due componenti principali: il punteggio vero dell’individuo sulla caratteristica misurata e l’errore casuale di misurazione.
Il punteggio vero rappresenta la misura effettiva della caratteristica che si intende valutare nel soggetto. Tuttavia, a causa di vari fattori come l’errore di misurazione, le distrazioni o l’incertezza dell’individuo durante il test, il punteggio osservato può deviare dal punteggio vero. Questa discrepanza tra il punteggio vero e il punteggio osservato viene definita errore di misurazione.
La teoria classica dei test si focalizza sulla quantificazione della relazione tra il punteggio vero, il punteggio osservato e l’errore di misurazione. Attraverso l’uso di statistiche come la media, la deviazione standard e il coefficiente di affidabilità, questa teoria fornisce una base concettuale per la costruzione dei test, l’interpretazione dei risultati e l’analisi dell’affidabilità del test stesso.
È importante notare che negli ultimi anni sono state sviluppate altre teorie, come la teoria della risposta all’item o la teoria della generalizzabilità (Generalizability Theory), che cercano di superare alcune delle limitazioni della teoria classica dei test. Tuttavia, nonostante queste nuove teorie, la teoria classica dei test continua ad essere ampiamente utilizzata e costituisce ancora una base fondamentale per la valutazione e la misurazione delle caratteristiche psicologiche degli individui.
9.1. La Teoria Classica#
La Teoria Classica dei Test (CTT), inizialmente sviluppata da Spearman [Spe04] e formalizzata successivamente da Lord and Novick [LN68], rappresenta la prima teoria che si occupa della misurazione dei costrutti psicologici attraverso l’utilizzo di test. Uno dei concetti fondamentali all’interno della CTT riguarda l’affidabilità dei punteggi ottenuti dai test. L’affidabilità, in questo contesto, indica la capacità del test di produrre risultati coerenti e stabili in diverse occasioni. Questo concetto può essere compreso attraverso l’equazione fondamentale della CTT:
dove \(X\) rappresenta il punteggio osservato nel test, \(T\) è il punteggio vero (ovvero la rappresentazione della variabile latente di interesse), e \(E\) rappresenta l’errore di misurazione.
Un aspetto di particolare rilevanza all’interno della CTT riguarda la varianza dell’errore. Maggiore è questa varianza, minore sarà la precisione con cui il punteggio vero si riflette nei punteggi osservati. In un contesto ideale, gli errori di misurazione sarebbero tutti nulli, garantendo punteggi esatti per ogni partecipante. Tuttavia, a causa delle inevitabili imperfezioni, si verifica una certa variazione negli errori. La deviazione standard associata a questi errori è chiamata errore standard di misurazione e viene indicata con \(\sigma_E\). Uno degli obiettivi principali della CTT è stimare \(\sigma_E\) al fine di valutare la qualità di una scala psicometrica.
9.2. Le due componenti del punteggio osservato#
L’eq. (9.1) rappresenta il cuore del modello, sottolineando che il punteggio osservato è il risultato dell’addizione del punteggio vero e dell’errore di misurazione.
L’obiettivo principale della CTT è quantificare l’errore di misurazione (rappresentato da \(\sigma_E\)) per valutare l’affidabilità del test e ottenere una stima dell’errore standard di misurazione. L’affidabilità del test riflette la precisione con cui il test può misurare il punteggio vero (Coaley, 2014). Si calcola come il rapporto tra la varianza dei punteggi veri e la varianza dei punteggi osservati. Un’alta affidabilità indica una ridotta incertezza dovuta all’errore di misurazione (\(\sigma_E\)), indicando che il punteggio osservato (\(X\)) fornisce una misura accurata del punteggio vero (\(T\)). Al contrario, una bassa affidabilità indica un elevato errore di misurazione (\(\sigma_E\)) e una significativa discrepanza tra il punteggio osservato e il punteggio vero.
La stima dell’errore standard di misurazione comporta il calcolo della deviazione standard della variabile casuale \(E\) (ossia \(\sigma_E\)), che rappresenta l’errore di misurazione influente sui punteggi veri. Questa stima offre un’indicazione della dispersione dei punteggi osservati attorno ai punteggi veri, causata dall’errore di misurazione.
Nelle prossime sezioni, esploreremo come il concetto chiave di attendibilità nella CTT possa essere collegato al coefficiente di determinazione nel contesto del modello statistico di regressione lineare. Inoltre, vedremo come l’errore standard di misurazione della CTT possa essere associato all’errore standard nella regressione.
9.2.1. Il punteggio vero#
L’eq. (9.1) ci spiega che il punteggio osservato è il risultato della combinazione di due componenti: una componente sistematica (il punteggio vero) e una componente aleatoria (l’errore di misurazione). Ma cosa rappresenta esattamente il punteggio vero? La Teoria Classica dei Test (CTT) attribuisce diverse interpretazioni al concetto di punteggio vero.
Da un punto di vista psicologico, la CTT considera il test come una selezione casuale di domande da un insieme più ampio di domande che riflettono il costrutto da misurare [[Nun94]; [Kli13]]. In questo contesto, il punteggio vero rappresenta il punteggio che un partecipante otterrebbe se rispondesse a tutte le domande dell’insieme completo. L’errore di misurazione riflette quindi quanto le domande selezionate rappresentano l’intero insieme di domande relative al costrutto.
In modo equivalente, il punteggio vero può essere considerato come il punteggio non influenzato da fattori esterni al costrutto, come effetti di apprendimento, fatica, memoria, motivazione, e così via. Poiché è concepito come un processo completamente casuale, la componente aleatoria non introduce alcun bias nella tendenza centrale della misurazione (la media di \(E\) è assunta essere uguale a 0).
Dal punto di vista statistico, il punteggio vero è un punteggio inosservabile che rappresenta il valore atteso di infinite misurazioni del punteggio ottenute:
Combinando le definizioni presentate sopra, Lord and Novick [LN68] concepiscono il punteggio vero come la media dei punteggi che un soggetto otterrebbe se il test venisse somministrato ripetutamente nelle stesse condizioni, senza effetti di apprendimento o fatica.
9.2.2. Somministrazioni ripetute#
Nel modello della Teoria Classica dei Test (CTT) possiamo distinguere due tipi di esperimenti casuali: uno in cui l’unità di osservazione (l’individuo) è considerata come una variabile campionaria, e l’altro in cui il punteggio per un determinato individuo è trattato come una variabile casuale.
Un importante risultato è dato dalla combinazione di questi due esperimenti casuali, dimostrando che i risultati della CTT, sviluppata ipotizzando somministrazioni ripetute immaginarie del test allo stesso individuo nelle stesse condizioni, si estendono al caso di una singola somministrazione del test su un campione di individui [AY01]. Questo risultato ci permette di attribuire un significato empirico alle quantità discusse dalla CTT quando consideriamo la somministrazione del test a una popolazione di individui:
\(\sigma^2_X\) rappresenta la varianza del punteggio osservato nella popolazione,
\(\sigma^2_T\) rappresenta la varianza del punteggio vero nella popolazione,
\(\sigma^2_E\) rappresenta la varianza della componente d’errore nella popolazione.
9.2.3. Le assunzioni sul punteggio ottenuto#
La CTT assume che la media del punteggio osservato \(X\) sia uguale alla media del punteggio vero,
in altri termini, assume che il punteggio osservato fornisca una stima statisticamente corretta dell’abilità latente (punteggio vero).
In pratica, il punteggio osservato non sarà mai uguale all’abilità latente, ma corrisponde solo ad uno dei possibili punteggi che il soggetto può ottenere, subordinatamente alla sua abilità latente. L’errore della misura è la differenza tra il punteggio osservato e il punteggio vero:
In base all’assunzione secondo cui il valore atteso dei punteggi è uguale alla media del valore vero, segue che
ovvero, il valore atteso degli errori è uguale a zero.
Per dare un contenuto concreto alle affermazioni precedenti, consideriamo la seguente simulazione svolta in \(\textsf{R}\). In tale simulazione il punteggio vero \(T\) e l’errore \(E\) sono creati in modo tale da soddisfare i vincoli della CTT: \(T\) e \(E\) sono variabili casuali gaussiane tra loro incorrelate. Nella simulazione generiamo 100 coppie di valori \(X\) e \(T\) con i seguenti parametri: \(T \sim \mathcal{N}(\mu_T = 12, \sigma^2_T = 6)\), \(E \sim \mathcal{N}(\mu_E = 0, \sigma^2_T = 3)\):
set.seed(8394)
n <- 100
Sigma <- matrix(c(6, 0, 0, 3), byrow = TRUE, ncol = 2)
mu <- c(12, 0)
dat <- mvrnorm(n, mu, Sigma, empirical = TRUE)
T <- dat[, 1]
E <- dat[, 2]
Le istruzioni precedenti (empirical = TRUE) creano un campione di valori nei quali le medie e la matrice di covarianze assumono esattamente i valori richiesti. Possiamo dunque immaginare tale insieme di dati come la “popolazione”.
Secondo la CTT, il punteggio osservato è \(X = T + E\). Simuliamo dunque il punteggio osservato \(X\) come:
X <- T + E
Le prime 6 osservazioni così ottenute sono:
tibble(X, T, E) |> head()
| X | T | E |
|---|---|---|
| <dbl> | <dbl> | <dbl> |
| 15.698623 | 16.765359 | -1.0667358 |
| 13.657503 | 12.248096 | 1.4094073 |
| 6.731979 | 7.852136 | -1.1201563 |
| 14.621813 | 14.233699 | 0.3881133 |
| 10.606647 | 10.187035 | 0.4196115 |
| 12.370288 | 13.329971 | -0.9596831 |
Un diagramma di dispersione è fornito nella figura seguente:
tibble(X, T) |>
ggplot(aes(T, X)) +
geom_point(position = position_jitter(w = .3, h = .3)) +
geom_abline(col = "blue")
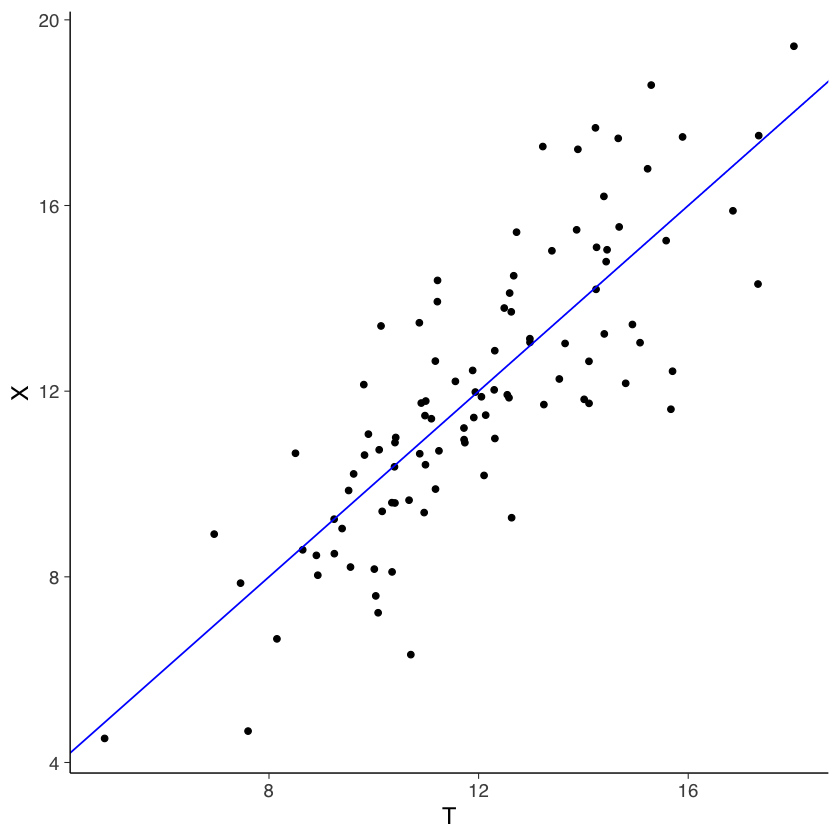
Secondo la CTT, il valore atteso di \(T\) è uguale al valore atteso di \(X\). Verifichiamo questa assunzione nei nostri dati
mean(T) == mean(X)
L’errore deve avere media zero:
mean(E)
Le varianze dei punteggi veri, dei punteggi osservati e degli errori sono rispettivamente uguali a:
c(var(T), var(X), var(E))
- 6
- 9
- 3
9.3. L’errore standard della misurazione \(\sigma_E\)#
La radice quadrata della varianza degli errori di misurazione, ovvero la deviazione standard degli errori, \(\sigma_E\), è la quantità fondamentale della CTT ed è chiamata errore standard della misurazione. La stima dell’errore standard della misurazione costituisce uno degli obiettivi più importanti della CTT.
Nel caso presente, abbiamo:
sqrt(var(E))
Ricordiamo che la deviazione standard indica quanto i dati di una distribuzione si discostano dalla media di quella distribuzione. È simile allo scarto tipico, ovvero la distanza media tra i valori della distribuzione e la loro media. Possiamo dunque utilizzare questa proprietà per descrivere il modo in cui la CTT interpreta la quantità \(\sigma_E\): l’errore standard della misurazione \(\sigma_E\) ci dice qual è, approssimativamente, la quantità attesa di variazione del punteggio osservato, se il test venisse somministrato ripetute volte al medesimo rispondente sotto le stesse condizioni (ovvero, in assenza di effetti di apprendimento o di fatica).
9.4. Assiomi della Teoria Classica#
La CTT assume che gli errori siano delle variabili casuali incorrelate tra loro
e incorrelate con il punteggio vero,
le quali seguono una distribuzione gaussiana con media zero e deviazione standard pari a \(\sigma_E\):
La quantità \(\sigma_E\) è appunto l’errore standard della misurazione. Sulla base di tali assunzioni la CTT deriva la formula dell’attendibilità di un test. Si noti che le assunzioni della CTT hanno una corrispondenza puntuale con le assunzioni su cui si basa il modello di regressione lineare.
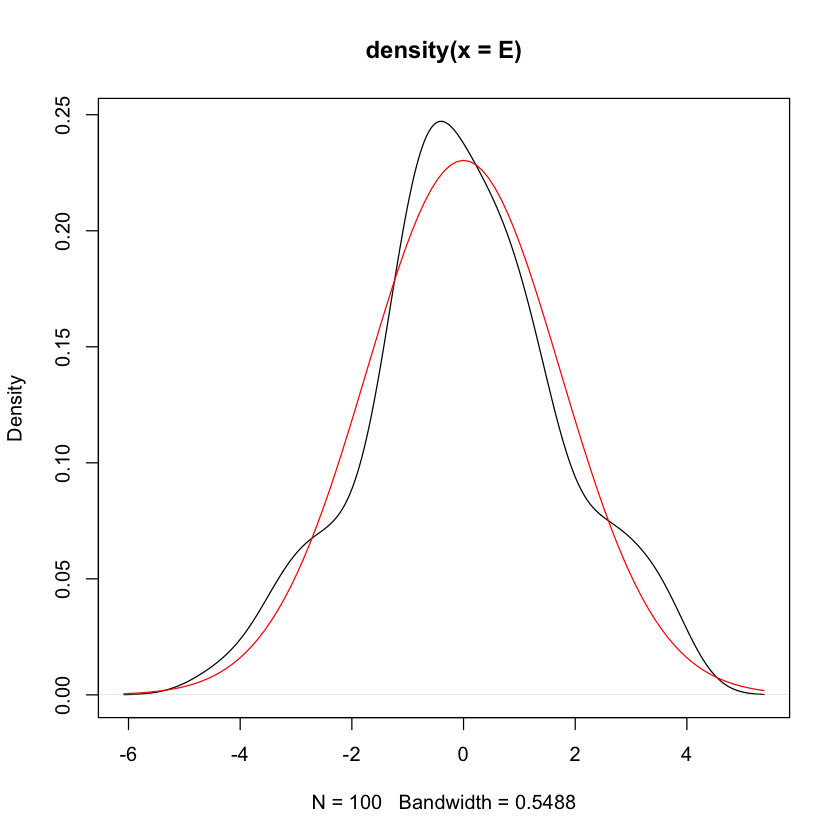
Verifichiamo le assunzioni per i dati dell’esempio.
cor(E, T)
plot(density(E))
curve(dnorm(x, mean(E), sd(E)), add = TRUE, col = "red")
9.5. Misure parallele, \(\tau\)-equivalenti, essenzialmente \(\tau\)-equivalenti e congenetiche#
Nell’ambito della CTT, le misure della stessa entità (che possono essere item, sottoscale o test) possono essere classificate in base al loro livello di similarità. In questa sezione, verranno definiti quattro livelli di similarità: misure parallele, \(\tau\)-equivalenti, essenzialmente \(\tau\)-equivalenti e congeneriche. È importante notare che questi livelli sono gerarchici nel senso che il livello più alto (misure parallele) richiede la maggiore similarità, mentre i livelli inferiori nella gerarchia consentono una minore similarità nelle proprietà del test. Ad esempio, le misure parallele devono avere varianze di vero punteggio uguali, mentre le misure congenetiche non richiedono questa condizione.
Un modo utile per comprendere questi livelli è riflettere sulle relazioni tra i punteggi veri di coppie di misure [Kom97]. Nella CTT, la relazione tra i punteggi veri su due misure (\(t_i\) e \(t_j\)) è espressa come:
Se il termine \(b_{ij}\) non è zero, le due misure hanno quote di punteggio vero differenti. Se il termine \(a_{ij}\) non è zero, le medie del punteggio vero delle misure sono diverse. I termini \(a_{ij}\) e \(b_{ij}\) sono sottoscritti per entrambe le misure (\(i\) e \(j\)), indicando che queste costanti possono variare tra le coppie di misure (anche se possono essere uguali tra tutte le coppie di misure).
9.5.1. Misure parallele#
Le misure parallele rappresentano il tipo di similarità più forte tra le misure. Per le misure parallele, \(a_{ij}\) = 0 e \(b_{ij}\) = 1 per tutte le coppie di misure. Ciò implica che i punteggi veri di tutte le misure sono esattamente uguali. Di conseguenza, le varianze dei punteggi veri delle misure saranno anch’esse uguali. Le misure parallele presentano anche varianze di errore uguali. Queste proprietà (medie dei punteggi veri uguali, varianze dei punteggi veri uguali e varianze di errore uguali) implicano che le misure parallele avranno anche medie dei punteggi osservati uguali e varianze dei punteggi osservati uguali. Inoltre, i punteggi osservati avranno correlazioni uguali tra loro. Quest’ultima proprietà deriva dal fatto che i punteggi osservati sulle misure parallele sono perfettamente correlati linearmente. Le misure parallele, quindi, catturano un costrutto comune e misurano tale costrutto con la stessa precisione.
Simuliamo i punteggi di due test paralleli in R.
set.seed(2237) # setting the seed ensure reproducibility
num_person <- 1000 # number of respondents
# True scores for Test 1
t1 <- rnorm(num_person, mean = 20, sd = 5)
# Error scores for Test 1
e1 <- rnorm(num_person, mean = 0, sd = 2)
# Observed scores for Test 1
x1 <- t1 + e1
# True scores for Test 2
t2 <- t1 # parallel tests have equal true scores
# Error scores for Test 2
e2 <- rnorm(num_person, mean = 0, sd = 2)
# Observed scores for Test 2
x2 <- t2 + e2
# Merge into a data frame
test_df <- data.frame(x1, x2)
# Get means and variances
mv <- datasummary(x1 + x2 ~ Mean + Var,
data = test_df,
output = "data.frame"
)
mv
| Mean | Var | |
|---|---|---|
| <chr> | <chr> | <chr> |
| x1 | 20.41 | 29.20 |
| x2 | 20.31 | 30.27 |
cor(test_df$x1, test_df$x2)
Nel caso di due test paralleli, le medie e le varianze dei punteggi osservati sono (teoricamente) uguali; la correlazione descrive l’affidabilità del test.
9.5.2. Misure \(\tau\)-equivalenti#
Le misure \(\tau\)-equivalenti, talvolta chiamate misure con equivalenza dei punteggi veri, presentano una forma di similarità leggermente più debole rispetto alle misure parallele. Come le misure parallele, le misure \(\tau\)-equivalenti hanno \(a_{ij}\) = 0 e \(b_{ij}\) = 1 per tutte le coppie di misure; ciò significa che hanno varianze dei punteggi veri uguali. Tuttavia, le misure \(\tau\)-equivalenti non sono obbligate ad avere varianze di errore uguali. È importante notare che la \(\tau\)-equivalenza non richiede necessariamente varianze di errore diverse, ma semplicemente consente la possibilità di varianze di errore diverse. La \(\tau\)-equivalenza, quindi, rilassa il vincolo che le varianze di errore debbano essere uguali. Pertanto, sebbene le misure \(\tau\)-equivalenti debbano avere varianze dei punteggi veri uguali, possono o meno avere varianze di punteggio osservato uguali. Le misure \(\tau\)-equivalenti presentano anche covarianze dei punteggi veri (e dei punteggi osservati) uguali tra loro.
Simuliamo due misure \(\tau\)-equivalenti.
set.seed(2237) # setting the seed ensure reproducibility
num_person <- 1000 # number of respondents
# True scores for Test 1
t1 <- rnorm(num_person, mean = 20, sd = 5)
# Error scores for Test 1
e1 <- rnorm(num_person, mean = 0, sd = 2)
# Observed scores for Test 1
x1 <- t1 + e1
# True scores for Test 2
t2 <- t1 # parallel tests have equal true scores
# Error scores for Test 2
e2 <- rnorm(num_person, mean = 0, sd = 2)
# Observed scores for Test 2
x2 <- t2 + e2
Se conosciamo i punteggi veri, le stime dell’affidabilità di x1 e x2 sono:
# Reliability for x1
var(t1) / var(x1)
# Reliability for x2
var(t2) / var(x2)
# Merge into a data frame
test_df <- data.frame(x1, x2)
# Get means and variances
mv <- datasummary(x1 + x2 ~ Mean + Var,
data = test_df,
output = "data.frame"
)
mv
| Mean | Var | |
|---|---|---|
| <chr> | <chr> | <chr> |
| x1 | 20.41 | 29.20 |
| x2 | 20.31 | 30.27 |
cor(test_df$x1, test_df$x2)
In conclusione, nel caso di due test \(\tau\)-equivalenti, le medie e le varianze dei punteggi osservati sono (teoricamente) uguali. Anche in questo caso, la correlazione descrive l’affidabilità del test.
9.5.3. Misure essenzialmente \(\tau\)-equivalenti#
Le misure essenzialmente \(\tau\)-equivalenti sono una forma leggermente più debole di \(\tau\)-equivalenza in cui \(a_{ij} \neq 0\) ma \(b_{ij} = 1\). Ciò significa che i punteggi veri delle misure essenzialmente \(\tau\)-equivalenti possono differire per una costante additiva. Ad esempio, in una coppia di misure essentially \(\tau\)-equivalenti, un punteggio vero potrebbe essere 2 in più dell’altro. Sebbene la \(\tau\)-equivalenza essenziale ammetta differenze costanti tra i punteggi veri, ciò non è obbligatorio. Alcuni elementi di un insieme \(\tau\)-equivalente possono avere medie di punteggio vero che differiscono per una costante e altri no. È importante notare che se due punteggi veri differiscono per una costante, sarebbero comunque perfettamente correlati linearmente. E sebbene tali punteggi veri possano avere medie diverse, non avrebbero varianze diverse. Pertanto, le loro varianze di punteggio vero sarebbero uguali, anche se le varianze di punteggio osservato potrebbero essere diverse poiché le misure essenzialmente \(\tau\)-equivalenti possono avere varianze di errore diverse. I punteggi veri delle misure essenzialmente \(\tau\)-equivalenti sono perfettamente correlati linearmente, quindi queste misure avrebbero covarianze di punteggio vero uguali tra loro. Tuttavia, né i punteggi \(\tau\)-equivalenti né quelli essenazialmente \(\tau\)-equivalenti avranno correlazioni uguali. Questo perché possono avere varianze di punteggio osservato e deviazioni standard diverse.
# True scores for Test 3
t3 <- 5 + t1 # essentially tau-equivalent tests
# Error scores for Test 3 (larger error SDs)
e3 <- rnorm(num_person, mean = 0, sd = 4)
# Observed scores for Test 2
x3 <- t3 + e3
# Merge into a data frame
test_df2 <- data.frame(x1, x3)
# Get means and variances
mv <- datasummary(x1 + x3 ~ Mean + Var,
data = test_df2,
output = "data.frame"
)
mv
| Mean | Var | |
|---|---|---|
| <chr> | <chr> | <chr> |
| x1 | 20.41 | 29.20 |
| x3 | 25.41 | 41.50 |
Se conosciamo i punteggi veri, la stima dell’affidabilità di x3 è:
# Reliability for x3
var(t3) / var(x3)
In conclusione, nel caso di test essenzialmente \(\tau\)-equivalenti, le medie e le varianze dei punteggi osservati sono diverse; la correlazione non è uguale all’affidabilità.
9.6. Misure congeneriche#
Infine, per le misure congeneriche, si ha \(a_{ij} \neq 0\) e \(b_{ij} \neq 1\). Le misure congeneriche non sono soggette a nessuna delle restrizioni precedenti. Non è richiesto che abbiano varianze di errore, varianze di punteggio vero, varianze di punteggio osservato, covarianze di punteggio osservato, correlazioni di punteggio osservato o medie uguali tra di loro. Le misure congeneriche hanno quindi le ipotesi meno restrittive e, di conseguenza, possono differire maggiormente tra loro rispetto alle altre tipologie.
# True scores for Test 4
t4 <- 2 + 0.8 * t1
# Error scores for Test 4 (larger error SDs)
e4 <- rnorm(num_person, mean = 0, sd = 3)
# Observed scores for Test 2
x4 <- t4 + e4
# Merge into a data frame
test_df3 <- data.frame(x1, x4)
# Get means and variances
mv <- datasummary(x1 + x4 ~ Mean + Var,
data = test_df3,
output = "data.frame"
)
mv
| Mean | Var | |
|---|---|---|
| <chr> | <chr> | <chr> |
| x1 | 20.41 | 29.20 |
| x4 | 18.27 | 24.23 |
Se conosciamo i punteggi veri, la stima dell’affidabilità di x4 è:
# Reliability for x4
var(t4) / var(x4)
Nel caso di test congenerici, le medie e le varianze dei punteggi osservati sono diverse; la correlazione non è uguale all’affidabilità. Per distinguere test congenerici dai test essenzialmente \(\tau\)-equivalenti sono necessari più di due test.
9.7. Considerazioni conclusive#
In conclusione, il presente capitolo ha fornito una panoramica dei concetti fondamentali della CTT e ha introdotto quattro tipologie di misure. Le misure parallele sono caratterizzate da una forte somiglianza tra i punteggi veri di tutte le misure, mentre le misure \(\tau\)-equivalenti mostrano un’equivalenza nelle varianze dei punteggi veri. Le misure essenzialmente \(\tau\)-equivalenti, invece, consentono una certa variabilità nei punteggi veri, mentre le misure congeneriche presentano la minore restrizione tra le quattro tipologie, consentendo differenze sia nelle medie che nelle varianze dei punteggi veri. Comprendere queste differenze tra i tipi di misure è essenziale per valutare l’affidabilità e la validità di un test, nonché per interpretare correttamente i risultati ottenuti. Nelle prossime sezioni del corso, approfondiremo ulteriormente questi concetti e affronteremo l’applicazione pratica della CTT nello sviluppo e nella valutazione dei test psicometrici. Per un’approfondimento più dettagliato su questi temi, si consiglia di consultare McDonald [McD13] e Lord and Novick [LN68].
9.8. Session Info#
sessionInfo()
R version 4.3.3 (2024-02-29)
Platform: x86_64-apple-darwin20 (64-bit)
Running under: macOS Sonoma 14.3.1
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.3-x86_64/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.3-x86_64/Resources/lib/libRlapack.dylib; LAPACK version 3.11.0
locale:
[1] en_US.UTF-8/UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
time zone: Europe/Rome
tzcode source: internal
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] MASS_7.3-60.0.1 modelsummary_1.4.5 ggokabeito_0.1.0 viridis_0.6.5
[5] viridisLite_0.4.2 ggpubr_0.6.0 ggExtra_0.10.1 bayesplot_1.11.1
[9] gridExtra_2.3 patchwork_1.2.0 semTools_0.5-6.920 semPlot_1.1.6
[13] lavaan_0.6-17 psych_2.4.1 scales_1.3.0 markdown_1.12
[17] knitr_1.45 lubridate_1.9.3 forcats_1.0.0 stringr_1.5.1
[21] dplyr_1.1.4 purrr_1.0.2 readr_2.1.5 tidyr_1.3.1
[25] tibble_3.2.1 ggplot2_3.5.0 tidyverse_2.0.0 here_1.0.1
loaded via a namespace (and not attached):
[1] rstudioapi_0.15.0 jsonlite_1.8.8 magrittr_2.0.3
[4] TH.data_1.1-2 estimability_1.5 farver_2.1.1
[7] nloptr_2.0.3 rmarkdown_2.26 vctrs_0.6.5
[10] minqa_1.2.6 base64enc_0.1-3 rstatix_0.7.2
[13] htmltools_0.5.7 broom_1.0.5 Formula_1.2-5
[16] htmlwidgets_1.6.4 plyr_1.8.9 sandwich_3.1-0
[19] emmeans_1.10.0 zoo_1.8-12 uuid_1.2-0
[22] igraph_2.0.2 mime_0.12 lifecycle_1.0.4
[25] pkgconfig_2.0.3 Matrix_1.6-5 R6_2.5.1
[28] fastmap_1.1.1 shiny_1.8.0 digest_0.6.34
[31] OpenMx_2.21.11 fdrtool_1.2.17 colorspace_2.1-0
[34] rprojroot_2.0.4 Hmisc_5.1-1 labeling_0.4.3
[37] fansi_1.0.6 timechange_0.3.0 abind_1.4-5
[40] compiler_4.3.3 withr_3.0.0 glasso_1.11
[43] htmlTable_2.4.2 backports_1.4.1 carData_3.0-5
[46] ggsignif_0.6.4 corpcor_1.6.10 gtools_3.9.5
[49] tools_4.3.3 pbivnorm_0.6.0 foreign_0.8-86
[52] zip_2.3.1 httpuv_1.6.14 nnet_7.3-19
[55] glue_1.7.0 quadprog_1.5-8 nlme_3.1-164
[58] promises_1.2.1 lisrelToR_0.3 grid_4.3.3
[61] pbdZMQ_0.3-11 checkmate_2.3.1 cluster_2.1.6
[64] reshape2_1.4.4 generics_0.1.3 gtable_0.3.4
[67] tzdb_0.4.0 data.table_1.15.2 hms_1.1.3
[70] car_3.1-2 utf8_1.2.4 tables_0.9.17
[73] sem_3.1-15 pillar_1.9.0 IRdisplay_1.1
[76] rockchalk_1.8.157 later_1.3.2 splines_4.3.3
[79] lattice_0.22-5 survival_3.5-8 kutils_1.73
[82] tidyselect_1.2.0 miniUI_0.1.1.1 pbapply_1.7-2
[85] stats4_4.3.3 xfun_0.42 qgraph_1.9.8
[88] arm_1.13-1 stringi_1.8.3 boot_1.3-29
[91] evaluate_0.23 codetools_0.2-19 mi_1.1
[94] cli_3.6.2 RcppParallel_5.1.7 IRkernel_1.3.2
[97] rpart_4.1.23 xtable_1.8-4 repr_1.1.6
[100] munsell_0.5.0 Rcpp_1.0.12 coda_0.19-4.1
[103] png_0.1-8 XML_3.99-0.16.1 parallel_4.3.3
[106] ellipsis_0.3.2 jpeg_0.1-10 lme4_1.1-35.1
[109] mvtnorm_1.2-4 insight_0.19.8 openxlsx_4.2.5.2
[112] crayon_1.5.2 rlang_1.1.3 multcomp_1.4-25
[115] mnormt_2.1.1