74. Invarianza Fattoriale Longitudinale#
L’obiettivo di questo capitolo è esaminare come è possibile estendere i modelli SEM per adattarli alle particolarità dei dati longitudinali. Per semplificare, cominciamo concentrandoci su due misurazioni temporali consecutive.
74.1. L’Invarianza delle Misure nel Tempo#
74.1.1. Introduzione#
Quando si confrontano gli stessi costrutti nel tempo, è fondamentale assicurarsi che le misurazioni siano invarianti a livello fattoriale. Le tecniche di Modelli di Equazioni Strutturali (SEM) permettono di testare questa ipotesi, che è cruciale per qualsiasi analisi longitudinale.
74.1.2. Concetto di Invarianza di Misurazione#
L’invarianza di misurazione si riferisce alla capacità di uno strumento di misurazione di rilevare lo stesso costrutto nella stessa unità di misura in diverse occasioni. Questo garantisce che i punteggi ottenuti siano comparabili nel tempo. Ad esempio, se usi una bilancia per misurare il peso, devi assicurarti che sia tarata allo stesso modo in ogni misurazione. Senza questa invarianza, i punteggi non sarebbero quantitativamente comparabili.
Tuttavia, garantire l’invarianza di misurazione è più complesso con strumenti psicologici rispetto a quelli fisici. Non possiamo calibrare strumenti psicologici come facciamo con dispositivi fisici. In questi casi, si assume l’invarianza (non ideale) o si testa utilizzando modelli formali che permettono di valutare se lo strumento mantiene la stessa metrica nel tempo.
74.1.3. Equazioni Fondamentali della SEM per Modelli Longitudinali#
74.1.4. Equazione Fondamentale per i Punteggi degli Indicatori#
L’equazione fondamentale per i punteggi degli indicatori in un modello di equazioni strutturali (SEM) è:
Per comprendere meglio questa equazione, analizziamo ogni componente e poi vediamo un esempio concreto.
74.1.4.1. Componenti dell’Equazione#
\( y_{io} \): Punteggi degli indicatori.
Questi sono i valori osservati per un indicatore specifico (ad esempio, un item di un questionario) per l’individuo \( i \) al tempo \( o \).
\( o \): Occasione di misurazione.
Rappresenta i diversi momenti in cui vengono effettuate le misurazioni (ad esempio, T1, T2, T3).
\( i \): Deviazione individuale dai valori previsti (varianza residua).
Indica la differenza tra il punteggio osservato dell’indicatore per un individuo e il valore previsto dal modello.
\( \tau_{o} \): Medie degli indicatori.
È il valore medio atteso per l’indicatore in ogni occasione di misurazione. In altre parole, è l’intercetta della retta di regressione che rappresenta il valore atteso dell’indicatore quando il costrutto latente è zero.
\( \eta_{o} \): Punteggi del costrutto latente.
Rappresenta il valore del costrutto latente per l’individuo \( i \) al tempo \( o \). È la variabile che si intende misurare (ad esempio, la depressione, la soddisfazione lavorativa).
\( \Lambda_{o} \): Carichi fattoriali.
Questa è la matrice dei carichi fattoriali che mostra la relazione tra gli indicatori e il costrutto latente. Indica quanto ogni indicatore rappresenti il costrutto latente.
\( \Theta_{o} \): Varianze residue.
È la matrice delle varianze residue o degli errori unici degli indicatori. Indica quanto dell’errore non è spiegato dal costrutto latente.
74.1.4.2. Esempio Concreto#
Supponiamo di voler misurare il livello di ansia in un gruppo di persone utilizzando un questionario con tre domande (indicatori) in due momenti diversi (T1 e T2).
Indicatori (y): Risposte alle domande del questionario.
Costrutto latente (\(\eta\)): Livello di ansia.
Carichi fattoriali (\(\Lambda\)): Quanto ogni domanda del questionario riflette il livello di ansia.
Intercette (\(\tau\)): Il punteggio medio delle risposte alle domande quando l’ansia è zero.
Varianze residue (\(\Theta\)): Errori specifici delle risposte alle domande che non sono spiegati dall’ansia.
Per il momento T1, l’equazione per la prima domanda del questionario per un individuo specifico può essere scritta come:
Supponiamo che:
\(\tau_{T1} = 2\): Il punteggio medio atteso per la prima domanda quando l’ansia è zero è 2.
\(\Lambda_{T1} = 0.8\): La prima domanda riflette l’ansia con un carico fattoriale di 0.8.
\(\eta_{iT1} = 3\): Il livello di ansia per l’individuo \( i \) al tempo T1 è 3.
\(\Theta_{1iT1} = 0.5\): L’errore residuo specifico per la risposta alla prima domanda è 0.5.
Sostituendo questi valori nell’equazione, otteniamo:
Calcolando il valore:
Quindi, il punteggio osservato per la prima domanda del questionario per l’individuo \( i \) al tempo T1 è 4.9.
Questo processo viene ripetuto per ogni domanda e per ogni momento di misurazione, permettendo di modellare come i punteggi degli indicatori riflettano il costrutto latente di ansia nel tempo, tenendo conto degli errori specifici di ogni indicatore.
74.1.4.3. Equazione per le Medie Previste#
\( E() \): operatore di aspettativa
\( \mu_{y} \): medie degli indicatori
\( \alpha \): medie dei costrutti latenti
74.1.4.4. Matrice delle Varianze e Covarianze Implicite dal Modello#
\( \Sigma \): varianze e covarianze implicite dal modello
\( \Psi \): varianze e covarianze tra i costrutti
\( \Lambda' \): trasposta della matrice \( \Lambda \)
74.1.5. Interpretazione delle Equazioni#
Nelle equazioni, la “o” indica le diverse occasioni di misurazione. Se una matrice ha il pedice “o”, significa che le stime sono uniche per ciascuna occasione (liberamente stimate). Se il pedice “o” non è presente, le stime sono vincolate ad essere uguali attraverso le diverse occasioni.
74.1.6. Invarianza Fattoriale Longitudinale#
Meredith (1964, 1993) ha analizzato le condizioni per mantenere l’invarianza fattoriale nei modelli statistici. L’invarianza è garantita quando le influenze esterne modificano solo i punteggi veri degli indicatori, senza alterare le specificità degli stessi. Ciò significa che le influenze dovrebbero cambiare solo le informazioni legate al costrutto di base, non quelle peculiari a ciascun indicatore. Se gli elementi unici degli indicatori sono influenzati, le relazioni tra gli indicatori possono essere compromesse, impedendo l’invarianza fattoriale.
Meredith dimostra che l’invarianza fattoriale si preserva se le influenze esterne alterano solo la varianza del punteggio vero degli indicatori, lasciando inalterate le varianze specifiche. In contesti di ricerca longitudinale, fattori come età, esperienza, contesto e scelte personali possono influenzare le misure nel tempo. L’invarianza si preserva se queste influenze modificano solo i punteggi veri e non significativamente i fattori unici.
74.1.7. Livelli di Invarianza Fattoriale#
La letteratura categorizza diversi livelli di invarianza:
Invarianza Configurale: La struttura dei fattori è invariata.
Invarianza Debole (Metrica): I carichi fattoriali sono invariati.
Invarianza Forte (Scalare): Sia i carichi fattoriali sia le intercette sono invariati.
74.1.8. Applicazione nei Modelli Longitudinali#
Per i modelli longitudinali, l’invarianza si applica agli indicatori e ai costrutti misurati in più occasioni. I costrutti valutati in un unico momento non influenzano l’analisi dell’invarianza, essendo indipendenti e stimati liberamente.
Le equazioni specificate e i livelli di invarianza fattoriale permettono di testare e valutare la costanza o i cambiamenti di un costrutto latente nel tempo.
74.1.9. Invarianza Configurale (Livello 0)#
L’invarianza configurale rappresenta il livello base di invarianza, dove si assume che la struttura dei fattori e i loro indicatori rimangano invariati nel tempo o tra gruppi. Non ci sono restrizioni sui parametri, quindi le intercette, i carichi fattoriali, le varianze e le covarianze dei residui possono variare. Le equazioni chiave sono:
\( y_{o} = \tau_{o} + \Lambda_{o} \eta_{o} + \Theta_{o} \)
\( E(y_{o}) = \mu_{yo} = \tau_{o} + \Lambda_{o} \alpha_{o} \)
\( \Sigma_{o} = \Lambda_{o} \Psi_{o} \Lambda_{o}' + \Theta_{o} \)
In questo livello, l’invarianza configurale richiede che lo schema complessivo dei carichi fattoriali sia lo stesso in ogni momento temporale, anche se i valori specifici di questi carichi possono variare. Questo livello è qualitativo e viene utilizzato come base per confrontare modelli con vincoli più restrittivi.
74.1.10. Invarianza Fattoriale Debole (Metrica) (Livello 1)#
Al livello di invarianza debole, i carichi fattoriali (\(\Lambda\)) sono costanti nel tempo o tra gruppi, il che implica che la relazione tra i costrutti latenti e gli indicatori rimane stabile. Le equazioni sono:
\( y_{o} = \tau_{o} + \Lambda \eta_{o} + \Theta_{o} \)
\( E(y_{o}) = \mu_{yo} = \tau_{o} + \Lambda \alpha_{o} \)
\( \Sigma_{o} = \Lambda \Psi_{o} \Lambda' + \Theta_{o} \)
In questo livello, le intercette (\(\tau_{o}\)) e le varianze dei residui (\(\Theta_{o}\)) possono ancora variare. L’importanza delle intercette qui non è centrale, poiché l’enfasi è sulla costanza dei carichi fattoriali.
74.1.11. Invarianza Fattoriale Forte (Scalare) (Livello 2)#
L’invarianza forte, o scalare, richiede che non solo i carichi fattoriali (\(\Lambda\)), ma anche le intercette (\(\tau\)) degli indicatori siano uguali nel tempo o tra gruppi. Le equazioni per questo livello sono:
\( y_{o} = \tau + \Lambda \eta_{o} + \Theta_{o} \)
\( E(y_{o}) = \mu_{yo} = \tau + \Lambda \alpha_{o} \)
\( \Sigma_{o} = \Lambda \Psi_{o} \Lambda' + \Theta_{o} \)
L’uguaglianza delle intercette è cruciale qui perché assicura che qualsiasi differenza osservata nei punteggi medi degli indicatori non sia dovuta a differenze nelle intercette, ma piuttosto a variazioni nei costrutti latenti (\(\eta_{o}\)).
74.1.12. Invarianza Fattoriale Rigorosa (Livello 3)#
L’invarianza fattoriale rigorosa aggiunge il vincolo che anche le varianze dei residui (\(\Theta\)) degli indicatori siano costanti nel tempo o tra gruppi. Le equazioni sono:
\( y_{o} = \tau + \Lambda \eta_{o} + \Theta \)
\( E(y_{o}) = \mu_{yo} = \tau + \Lambda \alpha_{o} \)
\( \Sigma_{o} = \Lambda \Psi_{o} \Lambda' + \Theta \)
Questo livello è molto restrittivo, in quanto presuppone
che non solo i carichi fattoriali e le intercette, ma anche le varianze residue degli indicatori siano costanti. In pratica, questo significa che l’errore unico di ciascun indicatore non cambia nel tempo, il che è una condizione molto rigorosa e spesso non realistica.
74.1.13. Ruolo delle Intercette#
Le intercette (\(\tau\)) rappresentano i punti in cui la linea di regressione tra i costrutti latenti e i loro indicatori incontra l’asse delle ordinate. In altre parole, indicano il valore atteso degli indicatori quando il valore del costrutto latente è zero. L’uguaglianza delle intercette è importante nei livelli di invarianza forte e rigorosa, poiché garantisce che le differenze nei punteggi medi degli indicatori riflettano differenze nei costrutti latenti piuttosto che variazioni sistematiche non attribuibili a questi costrutti.
74.1.14. Conclusione#
Mentre l’invarianza configurale stabilisce la base qualitativa della struttura del modello, i livelli successivi introducono vincoli più restrittivi che richiedono la costanza dei carichi fattoriali, delle intercette e delle varianze residue. L’invarianza rigorosa rappresenta la condizione più stringente, assicurando che qualsiasi variazione osservata sia dovuta a cambiamenti reali nei costrutti latenti piuttosto che a distorsioni sistematiche o errori di misurazione.
74.2. La Variazione Temporale di Positive Affect#
Esaminiamo un’applicazione concreta utilizzando nuovamente i dati relativi alla misurazione di Positive Affect (Glad, Cheerful, Happy) mediante tre indicatori in due momenti del tempo (Little [Lit23]).
dat <- read.table(
file = "../data/grade7and8.long.823.dat",
col.names = c(
"PAT1P1", "PAT1P2", "PAT1P3", "NAT1P1", "NAT1P2", "NAT1P3",
"PAT2P1", "PAT2P2", "PAT2P3", "NAT2P1", "NAT2P2", "NAT2P3",
"PAT3P1", "PAT3P2", "PAT3P3", "NAT3P1", "NAT3P2", "NAT3P3",
"grade", "female", "black", "hispanic", "other"
)
)
glimpse(dat)
Rows: 823
Columns: 23
$ PAT1P1 <dbl> 1.50000, 2.98116, 3.50000, 3.00000, 3.00000, 3.00000, 3.00000…
$ PAT1P2 <dbl> 1.50000, 2.98284, 4.00000, 3.50000, 2.50000, 2.50000, 2.50000…
$ PAT1P3 <dbl> 2.00000, 2.98883, 4.00000, 2.50000, 3.00000, 3.00000, 4.00000…
$ NAT1P1 <dbl> 2.50000, 1.56218, 1.50000, 1.50000, 1.00000, 1.50000, 1.00000…
$ NAT1P2 <dbl> 3.50000, 1.45688, 1.00000, 2.00000, 1.00000, 2.50000, 1.00000…
$ NAT1P3 <dbl> 3.00000, 1.65477, 1.00000, 1.50000, 1.00000, 2.50000, 1.00000…
$ PAT2P1 <dbl> 4.00000, 4.00000, 4.00000, 2.95942, 3.17170, 2.00000, 3.00000…
$ PAT2P2 <dbl> 4.00000, 4.00000, 2.50000, 2.99083, 2.87806, 2.00000, 3.00000…
$ PAT2P3 <dbl> 4.00000, 4.00000, 4.00000, 3.06670, 3.11031, 3.00000, 4.00000…
$ NAT2P1 <dbl> 2.00000, 1.00000, 1.00000, 1.65159, 1.65777, 2.00000, 1.00000…
$ NAT2P2 <dbl> 1.00000, 1.00000, 1.00000, 1.42599, 1.44804, 2.00000, 1.00000…
$ NAT2P3 <dbl> 2.00000, 1.00000, 1.00000, 1.67184, 1.56296, 2.00000, 1.00000…
$ PAT3P1 <dbl> 4.00000, 4.00000, 4.00000, 4.00000, 2.67109, 3.00000, 2.50000…
$ PAT3P2 <dbl> 4.00000, 4.00000, 4.00000, 3.50000, 2.85851, 2.00000, 2.00000…
$ PAT3P3 <dbl> 4.00000, 4.00000, 3.48114, 3.50000, 3.28099, 2.50000, 3.50000…
$ NAT3P1 <dbl> 1.00000, 1.00000, 1.18056, 1.00000, 1.19869, 2.00000, 1.00000…
$ NAT3P2 <dbl> 1.00000, 1.00000, 1.00000, 1.50000, 1.00000, 2.00000, 1.00000…
$ NAT3P3 <dbl> 2.50000, 1.00000, 1.62051, 1.00000, 1.00000, 3.00000, 1.00000…
$ grade <int> 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7…
$ female <int> 2, 1, 2, 1, 1, 1, 2, 1, 1, 1, 2, 1, 1, 1, 2, 1, 2, 2, 2, 1, 1…
$ black <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0…
$ hispanic <int> 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0…
$ other <int> 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0…
Per questi dati, abbiamo visto che il modello di invarianza configurale (livello 0) viene espresso nel modo seguente:
mod_0 <- "
# Definizione dei fattori latenti al tempo T1
Fattore_T1 =~ NA*PAT1P1 + PAT1P2 + PAT1P3
# Definizione dei fattori latenti al tempo T2
Fattore_T2 =~ NA*PAT2P1 + PAT2P2 + PAT2P3
# Varianza dei fattori latenti
Fattore_T1 ~~ 1*Fattore_T1
Fattore_T2 ~~ 1*Fattore_T2
# Covarianza tra i fattori latenti
Fattore_T1 ~~ Fattore_T2
# Definizione degli errori di misurazione per gli indicatori al tempo T1
PAT1P1 ~~ PAT1P1
PAT1P2 ~~ PAT1P2
PAT1P3 ~~ PAT1P3
# Definizione degli errori di misurazione per gli indicatori al tempo T2
PAT2P1 ~~ PAT2P1
PAT2P2 ~~ PAT2P2
PAT2P3 ~~ PAT2P3
# Covarianze tra i residui degli item tra T1 e T2
PAT1P1 ~~ PAT2P1
PAT1P2 ~~ PAT2P2
PAT1P3 ~~ PAT2P3
# Opzionale: Specifica delle medie degli indicatori (intercette)
PAT1P1 ~ 1
PAT1P2 ~ 1
PAT1P3 ~ 1
PAT2P1 ~ 1
PAT2P2 ~ 1
PAT2P3 ~ 1
"
Adattiamo il modello configurale ai dati.
fit_0 <- lavaan::sem(mod_0, data = dat, meanstructure = TRUE)
Definiamo il modello di invarianza fattoriale debole (Metrica) (Livello 1) e lo adattiamo ai dati. Per trasformare il modello configuralmente invariante (mod_0) in un modello che implementi l’invarianza debole (metrica) di livello 1, è necessario imporre l’uguaglianza dei carichi fattoriali tra i due momenti temporali. In pratica, ciò significa che i carichi fattoriali dei corrispondenti indicatori nei diversi momenti temporali (T1 e T2) devono essere uguali.
mod_1 <- "
# Definizione dei fattori latenti al tempo T1 con carichi fattoriali uguali a T2
Fattore_T1 =~ a1*PAT1P1 + a2*PAT1P2 + a3*PAT1P3
# Definizione dei fattori latenti al tempo T2 con carichi fattoriali uguali a T1
Fattore_T2 =~ a1*PAT2P1 + a2*PAT2P2 + a3*PAT2P3
# Varianza dei fattori latenti
Fattore_T1 ~~ 1*Fattore_T1
Fattore_T2 ~~ 1*Fattore_T2
# Covarianza tra i fattori latenti
Fattore_T1 ~~ Fattore_T2
# Definizione degli errori di misurazione per gli indicatori al tempo T1
PAT1P1 ~~ PAT1P1
PAT1P2 ~~ PAT1P2
PAT1P3 ~~ PAT1P3
# Definizione degli errori di misurazione per gli indicatori al tempo T2
PAT2P1 ~~ PAT2P1
PAT2P2 ~~ PAT2P2
PAT2P3 ~~ PAT2P3
# Covarianze tra i residui degli item tra T1 e T2
PAT1P1 ~~ PAT2P1
PAT1P2 ~~ PAT2P2
PAT1P3 ~~ PAT2P3
# Opzionale: Specifica delle medie degli indicatori (intercette)
PAT1P1 ~ 1
PAT1P2 ~ 1
PAT1P3 ~ 1
PAT2P1 ~ 1
PAT2P2 ~ 1
PAT2P3 ~ 1
"
fit_1 <- lavaan::sem(mod_1, data = dat, meanstructure = TRUE)
Verifichiamo.
parameterEstimates(fit_1) |> print()
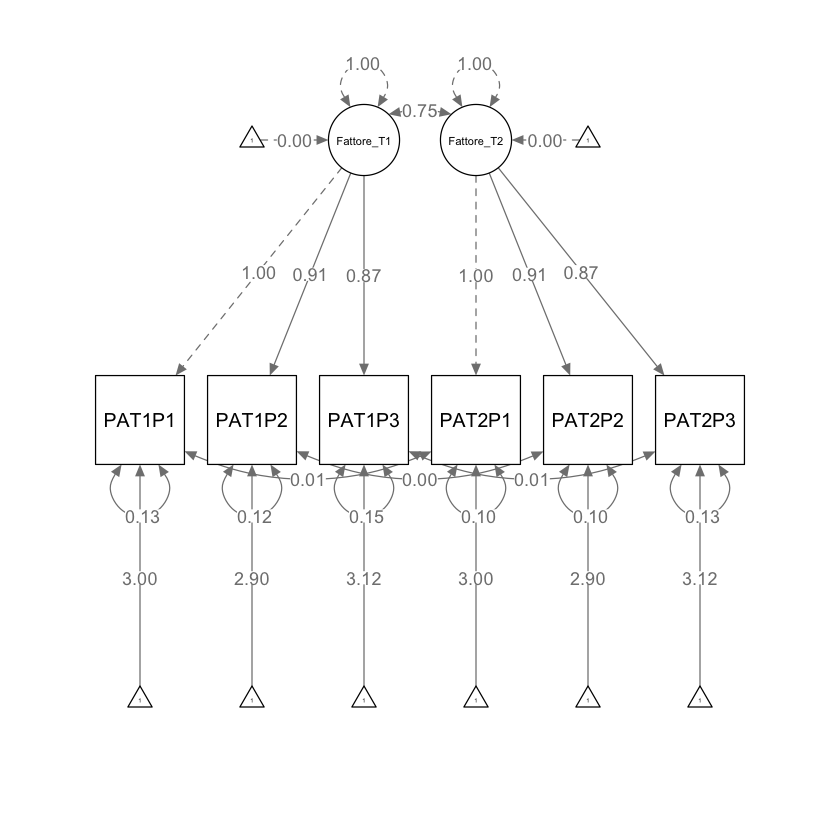
lhs op rhs label est se z pvalue ci.lower ci.upper
1 Fattore_T1 =~ PAT1P1 a1 1.000 0.000 NA NA 1.000 1.000
2 Fattore_T1 =~ PAT1P2 a2 0.909 0.012 76.344 0.000 0.885 0.932
3 Fattore_T1 =~ PAT1P3 a3 0.868 0.012 70.562 0.000 0.844 0.892
4 Fattore_T2 =~ PAT2P1 a1 1.000 0.000 NA NA 1.000 1.000
5 Fattore_T2 =~ PAT2P2 a2 0.909 0.012 76.344 0.000 0.885 0.932
6 Fattore_T2 =~ PAT2P3 a3 0.868 0.012 70.562 0.000 0.844 0.892
7 Fattore_T1 ~~ Fattore_T1 1.000 0.000 NA NA 1.000 1.000
8 Fattore_T2 ~~ Fattore_T2 1.000 0.000 NA NA 1.000 1.000
9 Fattore_T1 ~~ Fattore_T2 0.746 0.015 50.642 0.000 0.717 0.775
10 PAT1P1 ~~ PAT1P1 0.127 0.011 12.027 0.000 0.107 0.148
11 PAT1P2 ~~ PAT1P2 0.124 0.009 13.192 0.000 0.106 0.143
12 PAT1P3 ~~ PAT1P3 0.150 0.010 15.039 0.000 0.130 0.169
13 PAT2P1 ~~ PAT2P1 0.096 0.009 11.271 0.000 0.080 0.113
14 PAT2P2 ~~ PAT2P2 0.103 0.008 13.167 0.000 0.088 0.119
15 PAT2P3 ~~ PAT2P3 0.127 0.008 15.168 0.000 0.110 0.143
16 PAT1P1 ~~ PAT2P1 0.015 0.007 2.216 0.027 0.002 0.028
17 PAT1P2 ~~ PAT2P2 0.005 0.006 0.795 0.427 -0.007 0.017
18 PAT1P3 ~~ PAT2P3 0.011 0.006 1.693 0.090 -0.002 0.023
19 PAT1P1 ~1 2.992 0.037 80.841 0.000 2.919 3.064
20 PAT1P2 ~1 2.896 0.034 85.230 0.000 2.829 2.962
21 PAT1P3 ~1 3.112 0.033 93.930 0.000 3.047 3.177
22 PAT2P1 ~1 3.002 0.036 82.243 0.000 2.930 3.073
23 PAT2P2 ~1 2.909 0.034 86.592 0.000 2.843 2.975
24 PAT2P3 ~1 3.127 0.033 95.593 0.000 3.063 3.191
25 Fattore_T1 ~1 0.000 0.000 NA NA 0.000 0.000
26 Fattore_T2 ~1 0.000 0.000 NA NA 0.000 0.000
semPaths(fit_1,
whatLabels = "est",
sizeMan = 10,
edge.label.cex = 0.9,
style = "ram",
nCharNodes = 0, nCharEdges = 0
)

Definiamo il modello di invarianza fattoriale forte (scalare) (Livello 2). Per trasformare il modello in modo da implementare l’invarianza forte, dobbiamo imporre l’uguaglianza sia dei carichi fattoriali sia delle intercette degli indicatori nei diversi momenti temporali. Questo significa che oltre ai carichi fattoriali, anche le intercette (o medie) degli indicatori devono essere uguali tra i due momenti del tempo (T1 e T2).
mod_2 <- "
# Definizione dei fattori latenti al tempo T1 con carichi fattoriali e intercette uguali a T2
Fattore_T1 =~ a1*PAT1P1 + a2*PAT1P2 + a3*PAT1P3
PAT1P1 ~ b1*1
PAT1P2 ~ b2*1
PAT1P3 ~ b3*1
# Definizione dei fattori latenti al tempo T2 con carichi fattoriali e intercette uguali a T1
Fattore_T2 =~ a1*PAT2P1 + a2*PAT2P2 + a3*PAT2P3
PAT2P1 ~ b1*1
PAT2P2 ~ b2*1
PAT2P3 ~ b3*1
# Varianza dei fattori latenti
Fattore_T1 ~~ 1*Fattore_T1
Fattore_T2 ~~ 1*Fattore_T2
# Covarianza tra i fattori latenti
Fattore_T1 ~~ Fattore_T2
# Definizione degli errori di misurazione per gli indicatori al tempo T1
PAT1P1 ~~ PAT1P1
PAT1P2 ~~ PAT1P2
PAT1P3 ~~ PAT1P3
# Definizione degli errori di misurazione per gli indicatori al tempo T2
PAT2P1 ~~ PAT2P1
PAT2P2 ~~ PAT2P2
PAT2P3 ~~ PAT2P3
# Covarianze tra i residui degli item tra T1 e T2
PAT1P1 ~~ PAT2P1
PAT1P2 ~~ PAT2P2
PAT1P3 ~~ PAT2P3
"
Adattiamo il modello di invarianza fattoriale forte ai dati.
fit_2 <- lavaan::sem(mod_2, data = dat, meanstructure = TRUE)
Verifichiamo se i vincoli richiesti siano stati effetivamente implementati.
parameterEstimates(fit_2) |> print()
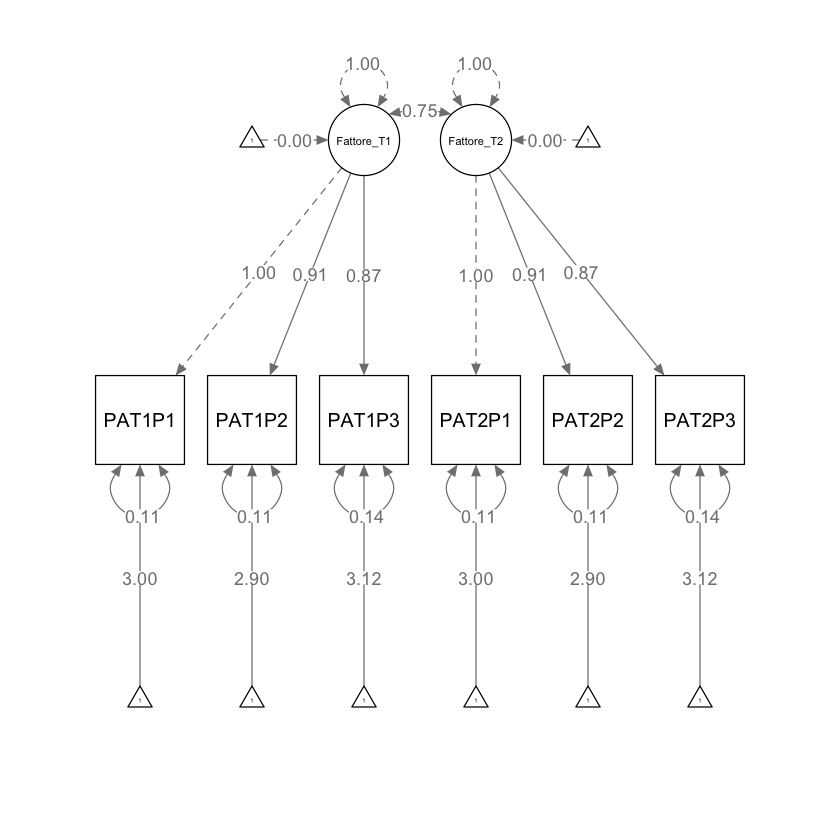
lhs op rhs label est se z pvalue ci.lower ci.upper
1 Fattore_T1 =~ PAT1P1 a1 1.000 0.000 NA NA 1.000 1.000
2 Fattore_T1 =~ PAT1P2 a2 0.909 0.012 76.346 0.000 0.885 0.932
3 Fattore_T1 =~ PAT1P3 a3 0.868 0.012 70.565 0.000 0.844 0.892
4 PAT1P1 ~1 b1 2.997 0.034 88.886 0.000 2.931 3.063
5 PAT1P2 ~1 b2 2.902 0.031 94.305 0.000 2.842 2.963
6 PAT1P3 ~1 b3 3.120 0.030 104.590 0.000 3.061 3.178
7 Fattore_T2 =~ PAT2P1 a1 1.000 0.000 NA NA 1.000 1.000
8 Fattore_T2 =~ PAT2P2 a2 0.909 0.012 76.346 0.000 0.885 0.932
9 Fattore_T2 =~ PAT2P3 a3 0.868 0.012 70.565 0.000 0.844 0.892
10 PAT2P1 ~1 b1 2.997 0.034 88.886 0.000 2.931 3.063
11 PAT2P2 ~1 b2 2.902 0.031 94.305 0.000 2.842 2.963
12 PAT2P3 ~1 b3 3.120 0.030 104.590 0.000 3.061 3.178
13 Fattore_T1 ~~ Fattore_T1 1.000 0.000 NA NA 1.000 1.000
14 Fattore_T2 ~~ Fattore_T2 1.000 0.000 NA NA 1.000 1.000
15 Fattore_T1 ~~ Fattore_T2 0.746 0.015 50.620 0.000 0.717 0.775
16 PAT1P1 ~~ PAT1P1 0.127 0.011 12.027 0.000 0.107 0.148
17 PAT1P2 ~~ PAT1P2 0.124 0.009 13.192 0.000 0.106 0.143
18 PAT1P3 ~~ PAT1P3 0.150 0.010 15.039 0.000 0.130 0.169
19 PAT2P1 ~~ PAT2P1 0.096 0.009 11.271 0.000 0.080 0.113
20 PAT2P2 ~~ PAT2P2 0.103 0.008 13.166 0.000 0.088 0.119
21 PAT2P3 ~~ PAT2P3 0.127 0.008 15.168 0.000 0.110 0.143
22 PAT1P1 ~~ PAT2P1 0.015 0.007 2.216 0.027 0.002 0.028
23 PAT1P2 ~~ PAT2P2 0.005 0.006 0.794 0.427 -0.007 0.017
24 PAT1P3 ~~ PAT2P3 0.011 0.006 1.692 0.091 -0.002 0.023
25 Fattore_T1 ~1 0.000 0.000 NA NA 0.000 0.000
26 Fattore_T2 ~1 0.000 0.000 NA NA 0.000 0.000
semPaths(fit_2,
whatLabels = "est",
sizeMan = 10,
edge.label.cex = 0.9,
style = "ram",
nCharNodes = 0, nCharEdges = 0
)
Concludendo, procediamo ora a definire il modello di invarianza fattoriale rigorosa (Livello 3) nei modelli SEM longitudinali. Per ottenere l’invarianza fattoriale rigorosa, oltre a mantenere l’uguaglianza dei carichi fattoriali e delle intercette degli indicatori, come nel modello di invarianza forte, è altresì essenziale stabilire l’uguaglianza delle varianze degli errori degli indicatori tra i diversi punti temporali considerati.
mod_3 <- "
# Definizione dei fattori latenti al tempo T1 con carichi fattoriali e intercette uguali a T2
Fattore_T1 =~ a1*PAT1P1 + a2*PAT1P2 + a3*PAT1P3
PAT1P1 ~ b1*1
PAT1P2 ~ b2*1
PAT1P3 ~ b3*1
# Definizione dei fattori latenti al tempo T2 con carichi fattoriali e intercette uguali a T1
Fattore_T2 =~ a1*PAT2P1 + a2*PAT2P2 + a3*PAT2P3
PAT2P1 ~ b1*1
PAT2P2 ~ b2*1
PAT2P3 ~ b3*1
# Varianza dei fattori latenti
Fattore_T1 ~~ 1*Fattore_T1
Fattore_T2 ~~ 1*Fattore_T2
# Covarianza tra i fattori latenti
Fattore_T1 ~~ Fattore_T2
# Definizione delle varianze degli errori di misurazione per gli indicatori, uguali tra T1 e T2
PAT1P1 ~~ d1*PAT1P1
PAT1P2 ~~ d2*PAT1P2
PAT1P3 ~~ d3*PAT1P3
PAT2P1 ~~ d1*PAT2P1
PAT2P2 ~~ d2*PAT2P2
PAT2P3 ~~ d3*PAT2P3
"
Adattiamo il modello di invarianza fattoriale rigorosa ai dati.
fit_3 <- lavaan::sem(mod_3, data = dat, meanstructure = TRUE)
Verifichiamo se i vincoli richiesti siano stati effetivamente implementati.
parameterEstimates(fit_3) |> print()
lhs op rhs label est se z pvalue ci.lower ci.upper
1 Fattore_T1 =~ PAT1P1 a1 1.000 0.000 NA NA 1.000 1.000
2 Fattore_T1 =~ PAT1P2 a2 0.911 0.012 78.398 0 0.888 0.934
3 Fattore_T1 =~ PAT1P3 a3 0.873 0.012 73.112 0 0.850 0.896
4 PAT1P1 ~1 b1 2.997 0.034 89.109 0 2.931 3.063
5 PAT1P2 ~1 b2 2.902 0.031 94.029 0 2.842 2.963
6 PAT1P3 ~1 b3 3.120 0.030 104.337 0 3.061 3.178
7 Fattore_T2 =~ PAT2P1 a1 1.000 0.000 NA NA 1.000 1.000
8 Fattore_T2 =~ PAT2P2 a2 0.911 0.012 78.398 0 0.888 0.934
9 Fattore_T2 =~ PAT2P3 a3 0.873 0.012 73.112 0 0.850 0.896
10 PAT2P1 ~1 b1 2.997 0.034 89.109 0 2.931 3.063
11 PAT2P2 ~1 b2 2.902 0.031 94.029 0 2.842 2.963
12 PAT2P3 ~1 b3 3.120 0.030 104.337 0 3.061 3.178
13 Fattore_T1 ~~ Fattore_T1 1.000 0.000 NA NA 1.000 1.000
14 Fattore_T2 ~~ Fattore_T2 1.000 0.000 NA NA 1.000 1.000
15 Fattore_T1 ~~ Fattore_T2 0.751 0.015 51.209 0 0.722 0.779
16 PAT1P1 ~~ PAT1P1 d1 0.111 0.007 16.473 0 0.098 0.124
17 PAT1P2 ~~ PAT1P2 d2 0.115 0.006 18.682 0 0.103 0.127
18 PAT1P3 ~~ PAT1P3 d3 0.138 0.006 21.215 0 0.125 0.150
19 PAT2P1 ~~ PAT2P1 d1 0.111 0.007 16.473 0 0.098 0.124
20 PAT2P2 ~~ PAT2P2 d2 0.115 0.006 18.682 0 0.103 0.127
21 PAT2P3 ~~ PAT2P3 d3 0.138 0.006 21.215 0 0.125 0.150
22 Fattore_T1 ~1 0.000 0.000 NA NA 0.000 0.000
23 Fattore_T2 ~1 0.000 0.000 NA NA 0.000 0.000
semPaths(fit_3,
whatLabels = "est",
sizeMan = 10,
edge.label.cex = 0.9,
style = "ram",
nCharNodes = 0, nCharEdges = 0
)
Indici di fit per il livello 0:
fitMeasures(fit_0, c("chisq", "df", "cfi", "tli", "rmsea", "srmr")) |> print()
chisq df cfi tli rmsea srmr
6.065 5.000 1.000 0.999 0.016 0.010
Indici di fit per il livello 1:
fitMeasures(fit_1, c("chisq", "df", "cfi", "tli", "rmsea", "srmr")) |> print()
chisq df cfi tli rmsea srmr
218.564 9.000 0.944 0.907 0.168 0.645
Indici di fit per il livello 2:
fitMeasures(fit_2, c("chisq", "df", "cfi", "tli", "rmsea", "srmr")) |> print()
chisq df cfi tli rmsea srmr
218.892 12.000 0.945 0.931 0.145 0.645
Indici di fit per il livello 3:
fitMeasures(fit_3, c("chisq", "df", "cfi", "tli", "rmsea", "srmr")) |> print()
chisq df cfi tli rmsea srmr
249.876 18.000 0.938 0.949 0.125 0.651
Eseguiamo ora il confronto tra modelli usando il test del rapporto tra verosimiglianze. Il test LRT confronta coppie di modelli per valutare se l’aggiunta di vincoli (come l’uguaglianza dei carichi o delle intercette) peggiora significativamente l’adattamento del modello ai dati.
fit_0: Modello di base (configurale). fit_1: Modello con invarianza debole (metrica). fit_2: Modello con invarianza forte (scalare). fit_3: Modello con invarianza rigorosa.
lavTestLRT(fit_0, fit_1, fit_2, fit_3) |> print()
Chi-Squared Difference Test
Df AIC BIC Chisq Chisq diff RMSEA Df diff Pr(>Chisq)
fit_0 5 7427.8 7531.4 6.0645
fit_1 9 7632.3 7717.1 218.5642 212.500 0.251665 4 < 2.2e-16 ***
fit_2 12 7626.6 7697.3 218.8920 0.328 0.000000 3 0.9547
fit_3 18 7645.6 7688.0 249.8762 30.984 0.071131 6 2.553e-05 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Passando dal modello fit_0 al modello fit_1, si osserva un peggioramento significativo dell’adattamento del modello (p-value < 0.05), indicando che l’ipotesi di invarianza debole non è sostenuta dai dati. Ciò implica che, per questi dati, l’unica forma di invarianza supportata è quella configurale. La validità del modello configurale è ulteriormente confermata dagli indici di adattamento, che risultano appropriati per questo livello di invarianza ma non per i livelli successivi di invarianza metrica, scalare e rigorosa.
Nella pratica, ciò si traduce nel fatto che in base ai dati a disposizione, non possiamo affermare con sicurezza che stiamo misurando lo stesso costrutto nelle due diverse occasioni di misurazione. Di conseguenza, effettuare un confronto diretto delle medie dei punteggi ottenuti nelle due rilevazioni temporali non sarebbe giustificato. I risultati evidenziano che, sebbene ci sia un’equivalenza configurale tra i due momenti, ovvero una somiglianza qualitativa nella struttura di base del modello, non vi è una somiglianza sufficiente in termini quantitativi per consentire confronti validi. Ciò suggerisce che potrebbero essere stati misurati costrutti diversi nei due momenti temporali, o almeno costrutti che non mantengono una sufficiente costanza nelle loro relazioni quantitative nel tempo.
74.3. Considerazioni Conclusive#
In questo capitolo, abbiamo esplorato il modello di analisi fattoriale confermativa (CFA) longitudinale nella sua forma più semplice, cioè quando viene utilizzato per valutare la misurazione di un costrutto in due punti temporali distinti. Il modello CFA longitudinale svolge un ruolo fondamentale nell’assicurare la coerenza e l’affidabilità delle misurazioni nel corso del tempo. Uno degli aspetti chiave trattati è stato l’concetto di invarianza fattoriale, il quale riveste un ruolo cruciale nel garantire che i costrutti esaminati siano misurati in maniera uniforme e comparabile tra le diverse occasioni di misurazione. L’importanza dell’invarianza fattoriale non può essere enfatizzata abbastanza, poiché assicura che le variazioni osservate nei costrutti nel tempo siano effettivamente attribuibili a veri cambiamenti nei fenomeni studiati, piuttosto che a variazioni nelle modalità di misurazione o a potenziali fattori di confondimento.
Oltre a consentire l’analisi dell’invarianza, il modello di analisi fattoriale confermativa longitudinale offre anche la possibilità di testare ipotesi specifiche e di fornire dettagliate informazioni descrittive riguardo ai cambiamenti dei costrutti nel corso del tempo. Questa analisi può comprenderne, per esempio, l’esplorazione delle tendenze di sviluppo di particolari tratti o comportamenti, la valutazione degli effetti di interventi nel corso del tempo o l’analisi delle relazioni tra variabili in momenti temporali differenti.