7. ✏️ Esercizi#
7.1. Ottimizzazione dello scoring dei dati di questionari ordinali#
Precedentemente, nell’Esercizio sulla scala Likert, abbiamo effettuato lo scoring del questionario Strengths and Difficulties Questionnaire (SDQ) utilizzando l’approccio chiamato “Likert scaling”, in cui le categorie di risposta “non vero”, “un po’ vero” e “certamente vero” sono state assegnate ai numeri interi consecutivi 0-1-2. Oltre a riflettere il presunto grado crescente di accordo in queste opzioni di risposta, l’assegnazione dei numeri interi era arbitraria, poiché non c’era una particolare ragione per cui abbiamo assegnato 0-1-2 anziché, ad esempio, 1-2-3. Un tale modo arbitrario di valutare le risposte degli item è chiamato anche “measurement by fiat”. In questo tutorial, cercheremo di trovare punteggi “ottimali” per le risposte ordinate al SDQ. “Ottimale” significa che i punteggi che assegniamo alle risposte non sono solo dei punteggi qualsiasi, ma sono i “migliori” tra tutti gli altri possibili punteggi in base a qualche criterio statistico.
Esistono molti modi per “ottimizzare” i punteggi degli item; qui, massimizzeremo il rapporto tra la varianza del punteggio totale e la somma delle varianze dei punteggi degli item. In psicometria, il soddisfacimento di questo criterio porta alla massimizzazione della somma delle correlazioni degli item (e quindi della “coerenza interna” del punteggio del test misurata dall’alpha di Cronbach).
source("../_common.R")
library("aspect")
Importiamo nuovamente i dati del Strengths and Difficulties Questionnaire (SDQ).
load("../data/data_sdq/SDQ.RData")
glimpse(SDQ)
Rows: 228
Columns: 51
$ Gender <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
$ consid <dbl> 1, 2, 2, 2, 0, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2…
$ restles <dbl> 2, 0, 0, 0, 1, 0, 2, 1, 2, 0, 1, 1, 0, 1, 0, 2, 0, 1, 1, 1, 0…
$ somatic <dbl> 2, 2, 0, 0, 2, 1, 0, 0, 1, 0, 0, 2, 0, 0, 1, 2, 1, 1, 1, 1, 1…
$ shares <dbl> 1, 1, 2, 2, 0, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 1, 2, 1, 2, 2…
$ tantrum <dbl> 0, 0, 0, 0, 1, 0, 2, 0, 2, 0, 0, 1, 0, 1, 1, 2, 0, 1, 1, 1, 0…
$ loner <dbl> 0, 0, 0, 0, 0, 0, 0, 2, 2, 0, 0, 1, 0, 0, 0, 1, 0, 0, 2, 2, 0…
$ obeys <dbl> 2, 2, 2, 2, 0, 2, 2, 2, 2, 2, 1, 1, 2, 2, 1, 2, 2, 2, 1, 2, 2…
$ worries <dbl> 1, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 2, 0, 1, 2, 0, 1, 1, 2, 1, 0…
$ caring <dbl> 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 1, 2, 2, 1, 2…
$ fidgety <dbl> 0, 0, 0, 0, 0, 0, 2, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0…
$ friend <dbl> 2, 2, 2, 2, 0, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2…
$ fights <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ unhappy <dbl> 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 2, 1, 0…
$ popular <dbl> 2, 2, 2, 1, 1, 2, 2, 2, 2, 2, 2, 2, 1, 1, 1, 2, 1, 2, 1, 1, 2…
$ distrac <dbl> 0, 1, 0, 0, 1, 0, 2, 0, 0, 0, 0, 1, 0, 0, 1, 2, 0, 0, 1, 0, 0…
$ clingy <dbl> 1, 1, 0, 1, 1, 1, 2, 0, 0, 0, 0, 1, 0, 2, 2, 1, 2, 0, 2, 2, 0…
$ kind <dbl> 1, 2, 2, 2, 1, 2, 2, 2, 2, 1, 1, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2…
$ lies <dbl> 0, 0, 0, 0, 2, 0, 1, 0, 2, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0…
$ bullied <dbl> 0, 0, 0, 0, 2, 0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 1, 1, 0…
$ helpout <dbl> 2, 1, 2, 2, 0, 2, 2, 2, 1, 2, 1, 2, 2, 1, 2, 2, 1, 2, 1, 2, 2…
$ reflect <dbl> 1, 1, 2, 2, 0, 2, 2, 2, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 1, 1, 2…
$ steals <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0…
$ oldbest <dbl> 1, 0, 2, 1, 0, 1, 1, 1, 0, 0, 0, 1, 0, 0, 1, 1, 0, 0, 2, 1, 1…
$ afraid <dbl> 0, 0, 1, 1, 0, 0, 0, 0, 0, 1, 0, 2, 2, 0, 1, 1, 1, 0, 1, 1, 0…
$ attends <dbl> 2, 2, 1, 2, 0, 2, 2, 2, 2, 2, 1, 1, 2, 1, 2, 2, 1, 1, 1, 1, 2…
$ consid2 <dbl> 1, 2, 2, 2, NA, 2, 2, 2, 2, 2, NA, 1, NA, 2, 2, NA, 1, 2, 2, …
$ restles2 <dbl> 0, 1, 2, 1, NA, 0, 1, 1, 0, 0, NA, 2, NA, 0, 1, NA, 1, 1, 2, …
$ somatic2 <dbl> 0, 1, 1, 0, NA, 0, 0, 0, 0, 0, NA, 2, NA, 0, 1, NA, 0, 1, 2, …
$ shares2 <dbl> 1, 2, 2, 1, NA, 2, 1, 2, 2, 2, NA, 2, NA, 2, 2, NA, 1, 2, 1, …
$ tantrum2 <dbl> 0, 1, 2, 0, NA, 0, 2, 0, 0, 0, NA, 2, NA, 0, 1, NA, 1, 0, 2, …
$ loner2 <dbl> 0, 0, 1, 0, NA, 0, 0, 0, 0, 0, NA, 1, NA, 1, 0, NA, 0, 0, 1, …
$ obeys2 <dbl> 2, 1, 2, 1, NA, 2, 2, 2, 2, 1, NA, 1, NA, 2, 1, NA, 1, 2, 1, …
$ worries2 <dbl> 0, 0, 1, 0, NA, NA, 1, 0, 0, 0, NA, 1, NA, 1, 2, NA, 0, 0, 2,…
$ caring2 <dbl> 2, 2, 1, 2, NA, 2, 2, 2, 2, 2, NA, 2, NA, 2, 2, NA, 1, 2, 2, …
$ fidgety2 <dbl> 0, 1, 0, 0, NA, 0, 1, 0, 0, 0, NA, 2, NA, 0, 0, NA, 1, 0, 2, …
$ friend2 <dbl> 2, 2, 1, 2, NA, 2, 2, 2, 2, 2, NA, 2, NA, 1, 2, NA, 2, 2, 2, …
$ fights2 <dbl> 0, 0, 0, 0, NA, 0, 0, 0, 0, 0, NA, 2, NA, 0, 0, NA, 0, 0, 0, …
$ unhappy2 <dbl> 0, 0, 1, 0, NA, 0, 0, 0, 0, 0, NA, 1, NA, 0, 0, NA, 0, 0, 1, …
$ popular2 <dbl> 2, 1, 1, 2, NA, 2, 1, 2, 2, 2, NA, 2, NA, 2, 2, NA, 1, 2, 1, …
$ distrac2 <dbl> 0, 0, 0, 2, NA, 0, 2, 1, 0, 0, NA, 1, NA, 0, 1, NA, 1, 0, 2, …
$ clingy2 <dbl> 1, 1, 1, 0, NA, 1, 1, 1, 0, 0, NA, 1, NA, 0, 0, NA, 2, 0, 2, …
$ kind2 <dbl> 2, 2, 2, 2, NA, 2, 2, 2, 2, 2, NA, 2, NA, 2, 2, NA, 1, 2, 2, …
$ lies2 <dbl> 1, 0, 0, 0, NA, 0, 1, 0, 1, 0, NA, 1, NA, 0, 0, NA, 1, 0, 0, …
$ bullied2 <dbl> 0, 0, 0, 0, NA, 0, 2, 0, 0, 0, NA, 0, NA, 0, 0, NA, 0, 0, 0, …
$ helpout2 <dbl> 1, 1, 1, 2, NA, 2, 2, 1, 2, 1, NA, 2, NA, 2, 1, NA, 0, 2, 1, …
$ reflect2 <dbl> 1, 1, 2, 1, NA, 2, 1, 2, 1, 2, NA, 1, NA, 2, 1, NA, 1, 2, 1, …
$ steals2 <dbl> 0, 0, 0, 0, NA, 0, 0, 0, 0, 0, NA, 2, NA, 0, 0, NA, 0, 0, 0, …
$ oldbest2 <dbl> 0, 0, 1, 0, NA, 1, 0, 1, 1, 0, NA, 1, NA, 0, 0, NA, 0, 0, 1, …
$ afraid2 <dbl> 0, 1, 0, 0, NA, 0, 0, 0, 0, 0, NA, 2, NA, 0, 0, NA, 0, 0, 2, …
$ attends2 <dbl> 1, 1, 2, 0, NA, 2, 2, 2, 2, 1, NA, 1, NA, 2, 2, NA, 1, 1, 0, …
Per analizzare solo gli item che misurano i Sintomi Emotivi, è conveniente creare un nuovo data frame.
items_emotion <- c("somatic", "worries", "unhappy", "clingy", "afraid")
sdq_emo <- SDQ[, items_emotion]
sdq_emo |>
head()
| somatic | worries | unhappy | clingy | afraid |
|---|---|---|---|---|
| <dbl> | <dbl> | <dbl> | <dbl> | <dbl> |
| 2 | 1 | 0 | 1 | 0 |
| 2 | 0 | 0 | 1 | 0 |
| 0 | 0 | 0 | 0 | 1 |
| 0 | 0 | 0 | 1 | 1 |
| 2 | 1 | 0 | 1 | 0 |
| 1 | 0 | 0 | 1 | 0 |
Affrontiamo il problema dei dati mancanti come discusso in precedenza.
sdq_emo <- sdq_emo %>%
mutate_at(vars(somatic:afraid), ~ ifelse(is.na(.), mean(., na.rm = TRUE), .))
Eliminiamo i valori decimali.
sdq_emo <- round(sdq_emo)
emotional_symptoms <- c("somatic", "worries", "unhappy", "clingy", "afraid")
result <- lapply(emotional_symptoms, function(x) sort(unique(sdq_emo[[x]])))
result |> print()
[[1]]
[1] 0 1 2
[[2]]
[1] 0 1 2
[[3]]
[1] 0 1 2
[[4]]
[1] 0 1 2
[[5]]
[1] 0 1 2
Trasformiamo il data frame in una matrice.
M <- sdq_emo |> as.matrix()
M
| somatic | worries | unhappy | clingy | afraid |
|---|---|---|---|---|
| 2 | 1 | 0 | 1 | 0 |
| 2 | 0 | 0 | 1 | 0 |
| 0 | 0 | 0 | 0 | 1 |
| 0 | 0 | 0 | 1 | 1 |
| 2 | 1 | 0 | 1 | 0 |
| 1 | 0 | 0 | 1 | 0 |
| 0 | 1 | 1 | 2 | 0 |
| 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 1 |
| 0 | 0 | 0 | 0 | 0 |
| 2 | 2 | 1 | 1 | 2 |
| 0 | 0 | 0 | 0 | 2 |
| 0 | 1 | 0 | 2 | 0 |
| 1 | 2 | 1 | 2 | 1 |
| 2 | 0 | 0 | 1 | 1 |
| 1 | 1 | 0 | 2 | 1 |
| 1 | 1 | 0 | 0 | 0 |
| 1 | 2 | 2 | 2 | 1 |
| 1 | 1 | 1 | 2 | 1 |
| 1 | 0 | 0 | 0 | 0 |
| 2 | 1 | 0 | 0 | 1 |
| 2 | 2 | 2 | 1 | 2 |
| 0 | 1 | 1 | 1 | 1 |
| 1 | 2 | 0 | 0 | 2 |
| 2 | 2 | 2 | 2 | 1 |
| 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 2 | 0 |
| 1 | 0 | 1 | 1 | 0 |
| 0 | 0 | 0 | 1 | 0 |
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| 1 | 0 | 0 | 1 | 0 |
| 1 | 0 | 0 | 1 | 1 |
| 1 | 1 | 0 | 1 | 1 |
| 0 | 0 | 0 | 0 | 0 |
| 0 | 2 | 0 | 0 | 0 |
| 1 | 1 | 1 | 0 | 1 |
| 1 | 0 | 0 | 1 | 0 |
| 1 | 0 | 0 | 1 | 0 |
| 0 | 0 | 0 | 1 | 0 |
| 1 | 0 | 0 | 2 | 0 |
| 0 | 1 | 0 | 1 | 0 |
| 0 | 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 |
| 1 | 2 | 1 | 2 | 2 |
| 0 | 1 | 0 | 0 | 0 |
| 0 | 0 | 0 | 1 | 0 |
| 0 | 0 | 0 | 1 | 1 |
| 1 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 2 | 0 |
| 1 | 0 | 0 | 0 | 1 |
| 1 | 0 | 1 | 1 | 1 |
| 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 1 |
| 0 | 1 | 0 | 1 | 0 |
| 0 | 1 | 0 | 0 | 0 |
| 2 | 1 | 1 | 1 | 1 |
Implementiamo lo scaling ottimale con la funzione corAspect().
opt <- corAspect(M, aspect = "aspectSum", level = "ordinal")
Esaminiamo il risultato ottenuto.
attributes(opt)
- $names
-
- 'loss'
- 'catscores'
- 'cormat'
- 'eigencor'
- 'indmat'
- 'scoremat'
- 'data'
- 'burtmat'
- 'niter'
- 'call'
- $class
- 'aspect'
opt$scoremat
| somatic | worries | unhappy | clingy | afraid | |
|---|---|---|---|---|---|
| 1 | 1.9720960 | 0.4454555 | -0.6009399 | 0.2369782 | -0.7685934 |
| 2 | 1.9720960 | -0.8540365 | -0.6009399 | 0.2369782 | -0.7685934 |
| 3 | -0.9013969 | -0.8540365 | -0.6009399 | -1.1988603 | 1.0085914 |
| 4 | -0.9013969 | -0.8540365 | -0.6009399 | 0.2369782 | 1.0085914 |
| 5 | 1.9720960 | 0.4454555 | -0.6009399 | 0.2369782 | -0.7685934 |
| 6 | 0.5862099 | -0.8540365 | -0.6009399 | 0.2369782 | -0.7685934 |
| 7 | -0.9013969 | 0.4454555 | 1.3931034 | 1.6170823 | -0.7685934 |
| 8 | -0.9013969 | -0.8540365 | -0.6009399 | -1.1988603 | -0.7685934 |
| 9 | 0.5862099 | -0.8540365 | -0.6009399 | -1.1988603 | -0.7685934 |
| 10 | -0.9013969 | -0.8540365 | -0.6009399 | -1.1988603 | 1.0085914 |
| 11 | -0.9013969 | -0.8540365 | -0.6009399 | -1.1988603 | -0.7685934 |
| 12 | 1.9720960 | 2.0964116 | 1.3931034 | 0.2369782 | 1.9509426 |
| 13 | -0.9013969 | -0.8540365 | -0.6009399 | -1.1988603 | 1.9509426 |
| 14 | -0.9013969 | 0.4454555 | -0.6009399 | 1.6170823 | -0.7685934 |
| 15 | 0.5862099 | 2.0964116 | 1.3931034 | 1.6170823 | 1.0085914 |
| 16 | 1.9720960 | -0.8540365 | -0.6009399 | 0.2369782 | 1.0085914 |
| 17 | 0.5862099 | 0.4454555 | -0.6009399 | 1.6170823 | 1.0085914 |
| 18 | 0.5862099 | 0.4454555 | -0.6009399 | -1.1988603 | -0.7685934 |
| 19 | 0.5862099 | 2.0964116 | 2.6586118 | 1.6170823 | 1.0085914 |
| 20 | 0.5862099 | 0.4454555 | 1.3931034 | 1.6170823 | 1.0085914 |
| 21 | 0.5862099 | -0.8540365 | -0.6009399 | -1.1988603 | -0.7685934 |
| 22 | 1.9720960 | 0.4454555 | -0.6009399 | -1.1988603 | 1.0085914 |
| 23 | 1.9720960 | 2.0964116 | 2.6586118 | 0.2369782 | 1.9509426 |
| 24 | -0.9013969 | 0.4454555 | 1.3931034 | 0.2369782 | 1.0085914 |
| 25 | 0.5862099 | 2.0964116 | -0.6009399 | -1.1988603 | 1.9509426 |
| 26 | 1.9720960 | 2.0964116 | 2.6586118 | 1.6170823 | 1.0085914 |
| 27 | -0.9013969 | -0.8540365 | -0.6009399 | -1.1988603 | -0.7685934 |
| 28 | 0.5862099 | -0.8540365 | -0.6009399 | 1.6170823 | -0.7685934 |
| 29 | 0.5862099 | -0.8540365 | 1.3931034 | 0.2369782 | -0.7685934 |
| 30 | -0.9013969 | -0.8540365 | -0.6009399 | 0.2369782 | -0.7685934 |
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| 199 | 0.5862099 | -0.8540365 | -0.6009399 | 0.2369782 | -0.7685934 |
| 200 | 0.5862099 | -0.8540365 | -0.6009399 | 0.2369782 | 1.0085914 |
| 201 | 0.5862099 | 0.4454555 | -0.6009399 | 0.2369782 | 1.0085914 |
| 202 | -0.9013969 | -0.8540365 | -0.6009399 | -1.1988603 | -0.7685934 |
| 203 | -0.9013969 | 2.0964116 | -0.6009399 | -1.1988603 | -0.7685934 |
| 204 | 0.5862099 | 0.4454555 | 1.3931034 | -1.1988603 | 1.0085914 |
| 205 | 0.5862099 | -0.8540365 | -0.6009399 | 0.2369782 | -0.7685934 |
| 206 | 0.5862099 | -0.8540365 | -0.6009399 | 0.2369782 | -0.7685934 |
| 207 | -0.9013969 | -0.8540365 | -0.6009399 | 0.2369782 | -0.7685934 |
| 208 | 0.5862099 | -0.8540365 | -0.6009399 | 1.6170823 | -0.7685934 |
| 209 | -0.9013969 | 0.4454555 | -0.6009399 | 0.2369782 | -0.7685934 |
| 210 | -0.9013969 | -0.8540365 | -0.6009399 | -1.1988603 | -0.7685934 |
| 211 | -0.9013969 | 0.4454555 | -0.6009399 | -1.1988603 | -0.7685934 |
| 212 | -0.9013969 | -0.8540365 | -0.6009399 | -1.1988603 | -0.7685934 |
| 213 | -0.9013969 | -0.8540365 | -0.6009399 | -1.1988603 | -0.7685934 |
| 214 | 0.5862099 | 2.0964116 | 1.3931034 | 1.6170823 | 1.9509426 |
| 215 | -0.9013969 | 0.4454555 | -0.6009399 | -1.1988603 | -0.7685934 |
| 216 | -0.9013969 | -0.8540365 | -0.6009399 | 0.2369782 | -0.7685934 |
| 217 | -0.9013969 | -0.8540365 | -0.6009399 | 0.2369782 | 1.0085914 |
| 218 | 0.5862099 | -0.8540365 | -0.6009399 | -1.1988603 | -0.7685934 |
| 219 | -0.9013969 | -0.8540365 | -0.6009399 | 1.6170823 | -0.7685934 |
| 220 | 0.5862099 | -0.8540365 | -0.6009399 | -1.1988603 | 1.0085914 |
| 221 | 0.5862099 | -0.8540365 | 1.3931034 | 0.2369782 | 1.0085914 |
| 222 | -0.9013969 | -0.8540365 | -0.6009399 | -1.1988603 | -0.7685934 |
| 223 | -0.9013969 | -0.8540365 | -0.6009399 | -1.1988603 | -0.7685934 |
| 224 | -0.9013969 | 0.4454555 | -0.6009399 | -1.1988603 | -0.7685934 |
| 225 | 0.5862099 | -0.8540365 | -0.6009399 | -1.1988603 | 1.0085914 |
| 226 | -0.9013969 | 0.4454555 | -0.6009399 | 0.2369782 | -0.7685934 |
| 227 | -0.9013969 | 0.4454555 | -0.6009399 | -1.1988603 | -0.7685934 |
| 228 | 1.9720960 | 0.4454555 | 1.3931034 | 0.2369782 | 1.0085914 |
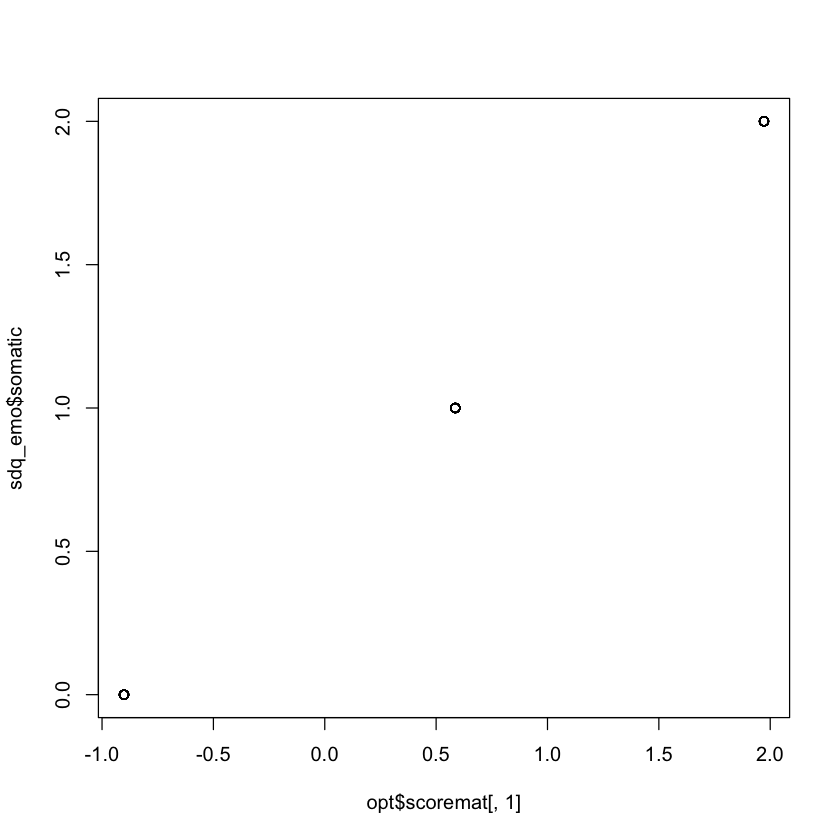
Esaminiamo la relazione tra lo scoring basato sul metodo Likert con lo scoring ottimale.
plot(opt$scoremat[, 1], sdq_emo$somatic)
plot(opt$scoremat[, 5], sdq_emo$afraid)
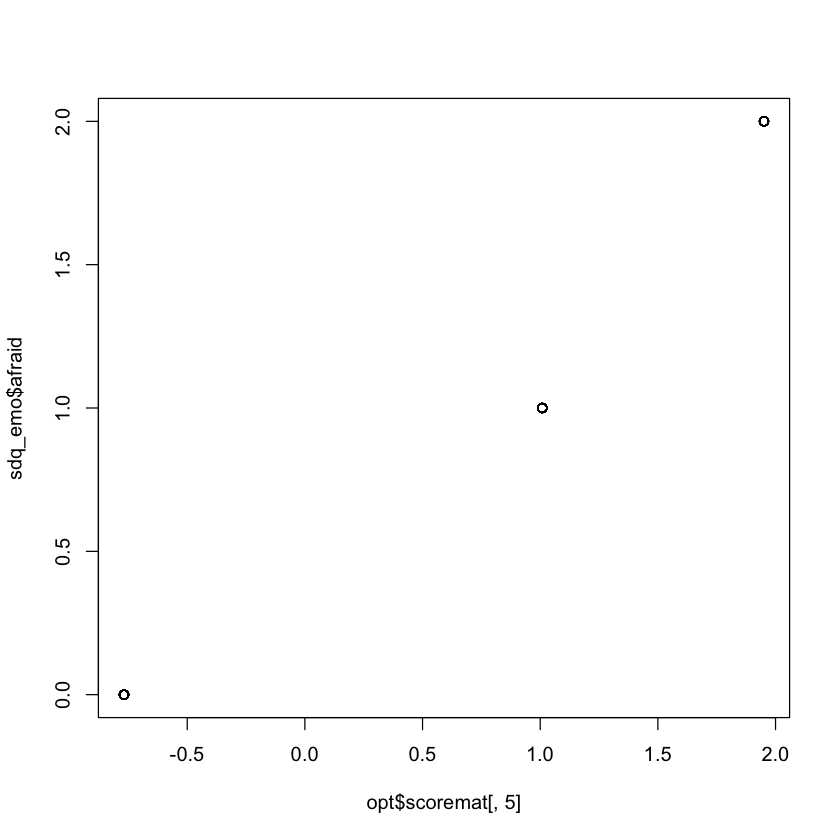
Guardando ai grafici ottenuti, si può notare che 1) i punteggi per le categorie successive aumentano quasi linearmente; 2) le categorie sono approssimativamente equidistanti. Concludiamo che per la valutazione degli item ordinali nella scala dei Sintomi Emotivi del SDQ, la scala Likert è appropriata, e non si può ottenere molto di più dall’ottimizzazione della scala rispetto alla semplice scala Likert di base.
7.2. Session Info#
sessionInfo()
R version 4.3.3 (2024-02-29)
Platform: x86_64-apple-darwin20 (64-bit)
Running under: macOS Sonoma 14.3.1
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.3-x86_64/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.3-x86_64/Resources/lib/libRlapack.dylib; LAPACK version 3.11.0
locale:
[1] en_US.UTF-8/UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
time zone: Europe/Rome
tzcode source: internal
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] aspect_1.0-6 ggokabeito_0.1.0 viridis_0.6.5 viridisLite_0.4.2
[5] ggpubr_0.6.0 ggExtra_0.10.1 bayesplot_1.11.1 gridExtra_2.3
[9] patchwork_1.2.0 semTools_0.5-6.920 semPlot_1.1.6 lavaan_0.6-17
[13] psych_2.4.1 scales_1.3.0 markdown_1.12 knitr_1.45
[17] lubridate_1.9.3 forcats_1.0.0 stringr_1.5.1 dplyr_1.1.4
[21] purrr_1.0.2 readr_2.1.5 tidyr_1.3.1 tibble_3.2.1
[25] ggplot2_3.5.0 tidyverse_2.0.0 here_1.0.1
loaded via a namespace (and not attached):
[1] rstudioapi_0.15.0 jsonlite_1.8.8 magrittr_2.0.3
[4] TH.data_1.1-2 estimability_1.5 nloptr_2.0.3
[7] rmarkdown_2.26 vctrs_0.6.5 minqa_1.2.6
[10] base64enc_0.1-3 rstatix_0.7.2 htmltools_0.5.7
[13] broom_1.0.5 Formula_1.2-5 htmlwidgets_1.6.4
[16] plyr_1.8.9 sandwich_3.1-0 emmeans_1.10.0
[19] zoo_1.8-12 uuid_1.2-0 igraph_2.0.2
[22] mime_0.12 lifecycle_1.0.4 pkgconfig_2.0.3
[25] Matrix_1.6-5 R6_2.5.1 fastmap_1.1.1
[28] shiny_1.8.0 digest_0.6.34 OpenMx_2.21.11
[31] fdrtool_1.2.17 colorspace_2.1-0 rprojroot_2.0.4
[34] Hmisc_5.1-1 fansi_1.0.6 timechange_0.3.0
[37] abind_1.4-5 compiler_4.3.3 withr_3.0.0
[40] glasso_1.11 htmlTable_2.4.2 backports_1.4.1
[43] carData_3.0-5 ggsignif_0.6.4 MASS_7.3-60.0.1
[46] corpcor_1.6.10 gtools_3.9.5 tools_4.3.3
[49] pbivnorm_0.6.0 foreign_0.8-86 zip_2.3.1
[52] httpuv_1.6.14 nnet_7.3-19 glue_1.7.0
[55] quadprog_1.5-8 nlme_3.1-164 promises_1.2.1
[58] lisrelToR_0.3 grid_4.3.3 pbdZMQ_0.3-11
[61] checkmate_2.3.1 cluster_2.1.6 reshape2_1.4.4
[64] generics_0.1.3 gtable_0.3.4 tzdb_0.4.0
[67] data.table_1.15.2 hms_1.1.3 car_3.1-2
[70] utf8_1.2.4 sem_3.1-15 pillar_1.9.0
[73] IRdisplay_1.1 rockchalk_1.8.157 later_1.3.2
[76] splines_4.3.3 lattice_0.22-5 survival_3.5-8
[79] kutils_1.73 tidyselect_1.2.0 miniUI_0.1.1.1
[82] pbapply_1.7-2 stats4_4.3.3 xfun_0.42
[85] qgraph_1.9.8 arm_1.13-1 stringi_1.8.3
[88] boot_1.3-29 evaluate_0.23 codetools_0.2-19
[91] mi_1.1 cli_3.6.2 RcppParallel_5.1.7
[94] IRkernel_1.3.2 rpart_4.1.23 xtable_1.8-4
[97] repr_1.1.6 munsell_0.5.0 Rcpp_1.0.12
[100] coda_0.19-4.1 png_0.1-8 XML_3.99-0.16.1
[103] parallel_4.3.3 ellipsis_0.3.2 jpeg_0.1-10
[106] lme4_1.1-35.1 mvtnorm_1.2-4 openxlsx_4.2.5.2
[109] crayon_1.5.2 rlang_1.1.3 multcomp_1.4-25
[112] mnormt_2.1.1