44. Exploratory Structural Equation Modeling (ESEM)#
L’Exploratory Structural Equation Modeling (ESEM) è un framework analitico che integra i modelli di misurazione dell’Analisi Fattoriale Esplorativa (EFA) con il più strutturato approccio della Confirmatory Factor Analysis (CFA). Questa integrazione permette di godere dei benefici tipici della CFA, come la specificità e la rigore, pur mantenendo la flessibilità dell’EFA, che considera le saturazioni incrociate tra i fattori.
Inoltre, lo sviluppo della rotazione target nell’ESEM facilita la definizione a priori dei principali carichi fattoriali, mentre consente che i carichi incrociati rimangano il più possibile vicini a zero, ma siano stimati in maniera libera. Questa tecnica di rotazione consente di applicare il modello in modo confermativo, basandosi su una struttura fattoriale predefinita, pur adottando una flessibilità tipica dell’EFA.
In questo modo, l’ESEM si presta sia a usi confermativi che esplorativi, combinando i vantaggi di entrambi gli approcci — EFA e CFA — in un unico modello comprensivo.
44.1. Limitazioni della CFA#
Nel modello di misurazione di Confirmatory Factor Analysis (CFA), comunemente adottato nella ricerca psicologica, solitamente sappiamo quali indicatori appartengono a ciascun fattore latente, una struttura denominata “a priori”. Questo approccio è utilizzato per verificare se la struttura fattoriale presunta corrisponde effettivamente ai dati raccolti.
Tuttavia, nonostante la popolarità della CFA, essa presenta delle limitazioni significative. I modelli CFA spesso risultano eccessivamente semplici e restrittivi, presupponendo “fattori puri”, cioè assumento che ciascun item saturi solamente sui suoi fattori latenti predeterminati, con saturazioni incrociate (ovvero, contributi di un item a fattori non primari) vincolate a zero. Questa restrizione può non riflettere adeguatamente la realtà di molte misure psicologiche, dove gli item tendono a riflettere più di un costrutto. Questo approccio può portare a una rappresentazione artificiale delle relazioni tra gli item e i fattori, risultando in statistiche di adattamento del modello sovrastimate e correlazioni tra fattori positivamente distorte. Studi di simulazione hanno mostrato che anche piccole saturazioni incrociate, se ignorate, possono portare ad una distorsione nelle stime dei parametri.
Un altro problema è rappresentato dagli indici di bontà di adattamento utilizzati nei modelli CFA, che sono spesso troppo restrittivi per strumenti psicologici multifattoriali, rendendo quasi impossibile ottenere un “buon” adattamento senza significative modifiche ai modelli. Tuttavia, quando analizzati a livello di item e per affidabilità, i modelli che non mostrano un buon adattamento possono comunque indicare saturazioni ragionevoli e alti livelli di affidabilità.
In risposta a queste sfide, sono stati sviluppati approcci più flessibili e robusti, come l’Exploratory Structural Equation Modeling (ESEM).
44.2. Exploratory Structural Equation Modeling#
L’ESEM combina elementi delle CFA e dell’Exploratory Factor Analysis (EFA) all’interno del tradizionale framework delle Equazioni Strutturali (SEM). Questo approccio rappresenta un compromesso tra la ricerca iterativa di soluzioni fattoriali ottimali, tipica dell’EFA, e la modellazione teorica restrittiva delle CFA.
L’ESEM è essenzialmente un metodo confermativo che permette anche un’esplorazione attraverso l’uso di rotazioni mirate, mantenendo la presenza di caricamenti incrociati, seppur minimizzati. All’interno dell’ESEM, il ricercatore può prevedere a priori una struttura fattoriale, similmente a quanto avviene nelle CFA, ma con una maggiore flessibilità permessa dalla possibilità di modellare saturazioni incrociate.
Nell’ESEM, i fattori generali e specifici devono essere specificati come totalmente indipendenti, e le rotazioni ortogonali sono comuni nei modelli bifattoriali. I metodi di rotazione più usati nell’ESEM includono le rotazioni geomin e target, con rotazioni ortogonali adatte ai modelli più complessi.
Le analisi di simulazione indicano che le correlazioni tra i fattori latenti ottenute con l’ESEM sono generalmente meno distorte e più vicine alle vere associazioni, rendendo i modelli ESEM più coerenti con le teorie sottostanti e le intenzioni degli strumenti psicometrici misurati.
Quando un modello ESEM include solo una parte di misurazione, viene definito come “analisi fattoriale esplorativa” o EFA. Se il modello include anche una parte strutturale, come regressioni tra variabili latenti, è classificato come “modello di equazioni strutturali esplorativo” o ESEM.
44.3. Otto Misure di Personalità#
In questo esempio pratico analizzeremo nuovamente i dati di Brown [Bro15], ovvero otto misure di personalità raccolte su un campione di 250 pazienti che hanno concluso un programma di psicoterapia. Utilizzeremo un’analisi EFA mediante la funzione efa() di lavaan.
Gli item sono i seguenti:
anxiety (N1),
hostility (N2),
depression (N3),
self-consciousness (N4),
warmth (E1),
gregariousness (E2),
assertiveness (E3),
positive emotions (E4).
varnames <- c("N1", "N2", "N3", "N4", "E1", "E2", "E3", "E4")
sds <- "5.7 5.6 6.4 5.7 6.0 6.2 5.7 5.6"
cors <- "
1.000
0.767 1.000
0.731 0.709 1.000
0.778 0.738 0.762 1.000
-0.351 -0.302 -0.356 -0.318 1.000
-0.316 -0.280 -0.300 -0.267 0.675 1.000
-0.296 -0.289 -0.297 -0.296 0.634 0.651 1.000
-0.282 -0.254 -0.292 -0.245 0.534 0.593 0.566 1.000"
psychot_cor_mat <- getCov(cors, names = varnames)
n <- 250
Definiamo un modello ad un solo fattore comune.
# 1-factor model
f1 <- '
efa("efa")*f1 =~ N1 + N2 + N3 + N4 + E1 + E2 + E3 + E4
'
Definiamo un modello con due fattori comuni.
# 2-factor model
f2 <- '
efa("efa")*f1 +
efa("efa")*f2 =~ N1 + N2 + N3 + N4 + E1 + E2 + E3 + E4
'
Adattiamo ai dati il modello ad un fattore comune.
efa_f1 <-cfa(
model = f1,
sample.cov = psychot_cor_mat,
sample.nobs = 250,
rotation = "oblimin"
)
Esaminiamo la soluzione ottenuta.
semPlot::semPaths(efa_f1,
what = "col", whatLabels = "std", style = "mx",
layout = "tree2", nCharNodes = 7,
shapeMan = "rectangle", sizeMan = 8, sizeMan2 = 5
)
summary(
efa_f1,
fit.measures = TRUE,
standardized = TRUE,
rsquare = TRUE
) |>
print()
lavaan 0.6.17 ended normally after 2 iterations
Estimator ML
Optimization method NLMINB
Number of model parameters 16
Rotation method OBLIMIN OBLIQUE
Oblimin gamma 0
Rotation algorithm (rstarts) GPA (30)
Standardized metric TRUE
Row weights None
Number of observations 250
Model Test User Model:
Test statistic 375.327
Degrees of freedom 20
P-value (Chi-square) 0.000
Model Test Baseline Model:
Test statistic 1253.791
Degrees of freedom 28
P-value 0.000
User Model versus Baseline Model:
Comparative Fit Index (CFI) 0.710
Tucker-Lewis Index (TLI) 0.594
Loglikelihood and Information Criteria:
Loglikelihood user model (H0) -2394.637
Loglikelihood unrestricted model (H1) -2206.974
Akaike (AIC) 4821.275
Bayesian (BIC) 4877.618
Sample-size adjusted Bayesian (SABIC) 4826.897
Root Mean Square Error of Approximation:
RMSEA 0.267
90 Percent confidence interval - lower 0.243
90 Percent confidence interval - upper 0.291
P-value H_0: RMSEA <= 0.050 0.000
P-value H_0: RMSEA >= 0.080 1.000
Standardized Root Mean Square Residual:
SRMR 0.187
Parameter Estimates:
Standard errors Standard
Information Expected
Information saturated (h1) model Structured
Latent Variables:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
f1 =~ efa
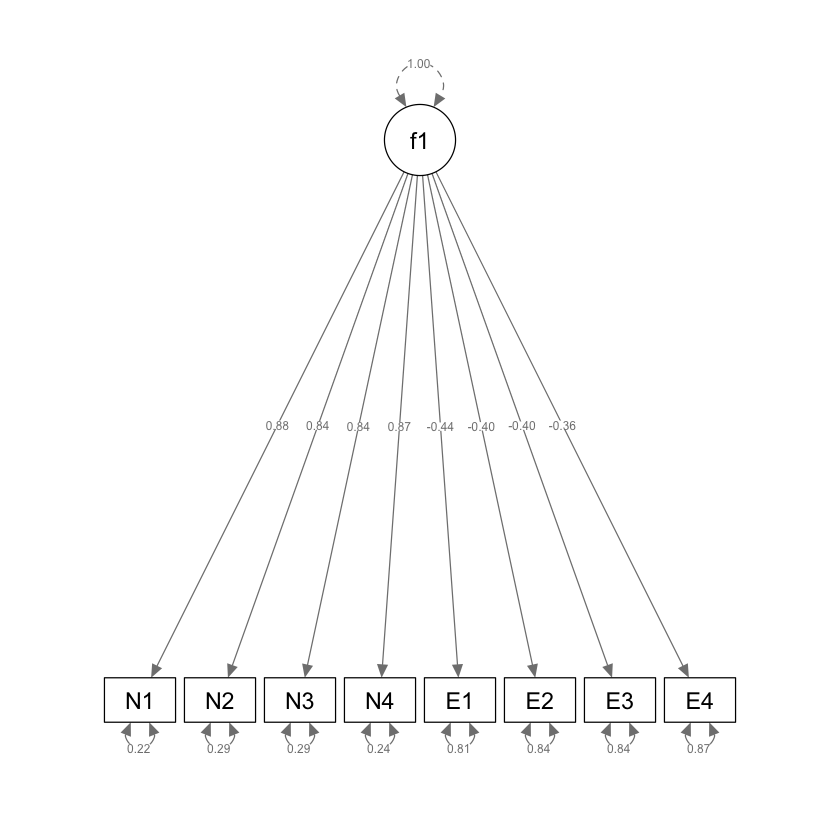
N1 0.879 0.051 17.333 0.000 0.879 0.880
N2 0.841 0.052 16.154 0.000 0.841 0.842
N3 0.841 0.052 16.175 0.000 0.841 0.843
N4 0.870 0.051 17.065 0.000 0.870 0.872
E1 -0.438 0.062 -7.041 0.000 -0.438 -0.439
E2 -0.398 0.063 -6.327 0.000 -0.398 -0.398
E3 -0.398 0.063 -6.342 0.000 -0.398 -0.399
E4 -0.364 0.063 -5.746 0.000 -0.364 -0.364
Variances:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
.N1 0.224 0.028 7.915 0.000 0.224 0.225
.N2 0.289 0.033 8.880 0.000 0.289 0.290
.N3 0.288 0.032 8.866 0.000 0.288 0.289
.N4 0.239 0.029 8.174 0.000 0.239 0.240
.E1 0.804 0.073 10.963 0.000 0.804 0.807
.E2 0.838 0.076 11.008 0.000 0.838 0.841
.E3 0.837 0.076 11.007 0.000 0.837 0.841
.E4 0.864 0.078 11.041 0.000 0.864 0.867
f1 1.000 1.000 1.000
R-Square:
Estimate
N1 0.775
N2 0.710
N3 0.711
N4 0.760
E1 0.193
E2 0.159
E3 0.159
E4 0.133
standardizedSolution(efa_f1)
| lhs | op | rhs | est.std | se | z | pvalue | ci.lower | ci.upper |
|---|---|---|---|---|---|---|---|---|
| <chr> | <chr> | <chr> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> |
| f1 | =~ | N1 | 0.8803717 | 0.01821233 | 48.339322 | 0.000000e+00 | 0.8446762 | 0.9160673 |
| f1 | =~ | N2 | 0.8424369 | 0.02179745 | 38.648409 | 0.000000e+00 | 0.7997147 | 0.8851591 |
| f1 | =~ | N3 | 0.8431190 | 0.02173170 | 38.796733 | 0.000000e+00 | 0.8005257 | 0.8857124 |
| f1 | =~ | N4 | 0.8719792 | 0.01898826 | 45.922019 | 0.000000e+00 | 0.8347629 | 0.9091955 |
| f1 | =~ | E1 | -0.4389273 | 0.05368053 | -8.176656 | 2.220446e-16 | -0.5441392 | -0.3337153 |
| f1 | =~ | E2 | -0.3983268 | 0.05581495 | -7.136560 | 9.570122e-13 | -0.5077221 | -0.2889315 |
| f1 | =~ | E3 | -0.3991904 | 0.05577170 | -7.157580 | 8.211209e-13 | -0.5085009 | -0.2898799 |
| f1 | =~ | E4 | -0.3644271 | 0.05743899 | -6.344595 | 2.230112e-10 | -0.4770055 | -0.2518488 |
| N1 | ~~ | N1 | 0.2249456 | 0.03206479 | 7.015345 | 2.293721e-12 | 0.1620998 | 0.2877914 |
| N2 | ~~ | N2 | 0.2903001 | 0.03672516 | 7.904666 | 2.664535e-15 | 0.2183201 | 0.3622801 |
| N3 | ~~ | N3 | 0.2891503 | 0.03664399 | 7.890797 | 3.108624e-15 | 0.2173294 | 0.3609712 |
| N4 | ~~ | N4 | 0.2396523 | 0.03311262 | 7.237491 | 4.569678e-13 | 0.1747527 | 0.3045518 |
| E1 | ~~ | E1 | 0.8073429 | 0.04708357 | 17.147019 | 0.000000e+00 | 0.7150608 | 0.8996250 |
| E2 | ~~ | E2 | 0.8413358 | 0.04442120 | 18.939962 | 0.000000e+00 | 0.7542718 | 0.9283997 |
| E3 | ~~ | E3 | 0.8406470 | 0.04448315 | 18.898100 | 0.000000e+00 | 0.7534617 | 0.9278324 |
| E4 | ~~ | E4 | 0.8671929 | 0.04181755 | 20.737533 | 0.000000e+00 | 0.7852320 | 0.9491538 |
| f1 | ~~ | f1 | 1.0000000 | 0.00000000 | NA | NA | 1.0000000 | 1.0000000 |
lavaan::residuals(efa_f1, type = "cor") |>
print()
$type
[1] "cor.bollen"
$cov
N1 N2 N3 N4 E1 E2 E3 E4
N1 0.000
N2 0.025 0.000
N3 -0.011 -0.001 0.000
N4 0.010 0.003 0.027 0.000
E1 0.035 0.068 0.014 0.065 0.000
E2 0.035 0.056 0.036 0.080 0.500 0.000
E3 0.055 0.047 0.040 0.052 0.459 0.492 0.000
E4 0.039 0.053 0.015 0.073 0.374 0.448 0.421 0.000
Adattiamo ai dati il modello a due fattori comuni.
efa_f2 <- cfa(
model = f2,
sample.cov = psychot_cor_mat,
sample.nobs = 250,
rotation = "oblimin"
)
Esaminiamo la soluzione ottenuta.
semPlot::semPaths(efa_f2,
what = "col", whatLabels = "std", style = "mx",
layout = "tree2", nCharNodes = 7,
shapeMan = "rectangle", sizeMan = 8, sizeMan2 = 5
)
summary(
efa_f2,
fit.measures = TRUE,
standardized = TRUE,
rsquare = TRUE
) |>
print()
lavaan 0.6.17 ended normally after 1 iteration
Estimator ML
Optimization method NLMINB
Number of model parameters 23
Rotation method OBLIMIN OBLIQUE
Oblimin gamma 0
Rotation algorithm (rstarts) GPA (30)
Standardized metric TRUE
Row weights None
Number of observations 250
Model Test User Model:
Test statistic 9.811
Degrees of freedom 13
P-value (Chi-square) 0.709
Model Test Baseline Model:
Test statistic 1253.791
Degrees of freedom 28
P-value 0.000
User Model versus Baseline Model:
Comparative Fit Index (CFI) 1.000
Tucker-Lewis Index (TLI) 1.006
Loglikelihood and Information Criteria:
Loglikelihood user model (H0) -2211.879
Loglikelihood unrestricted model (H1) -2206.974
Akaike (AIC) 4469.758
Bayesian (BIC) 4550.752
Sample-size adjusted Bayesian (SABIC) 4477.840
Root Mean Square Error of Approximation:
RMSEA 0.000
90 Percent confidence interval - lower 0.000
90 Percent confidence interval - upper 0.048
P-value H_0: RMSEA <= 0.050 0.957
P-value H_0: RMSEA >= 0.080 0.001
Standardized Root Mean Square Residual:
SRMR 0.010
Parameter Estimates:
Standard errors Standard
Information Expected
Information saturated (h1) model Structured
Latent Variables:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
f1 =~ efa
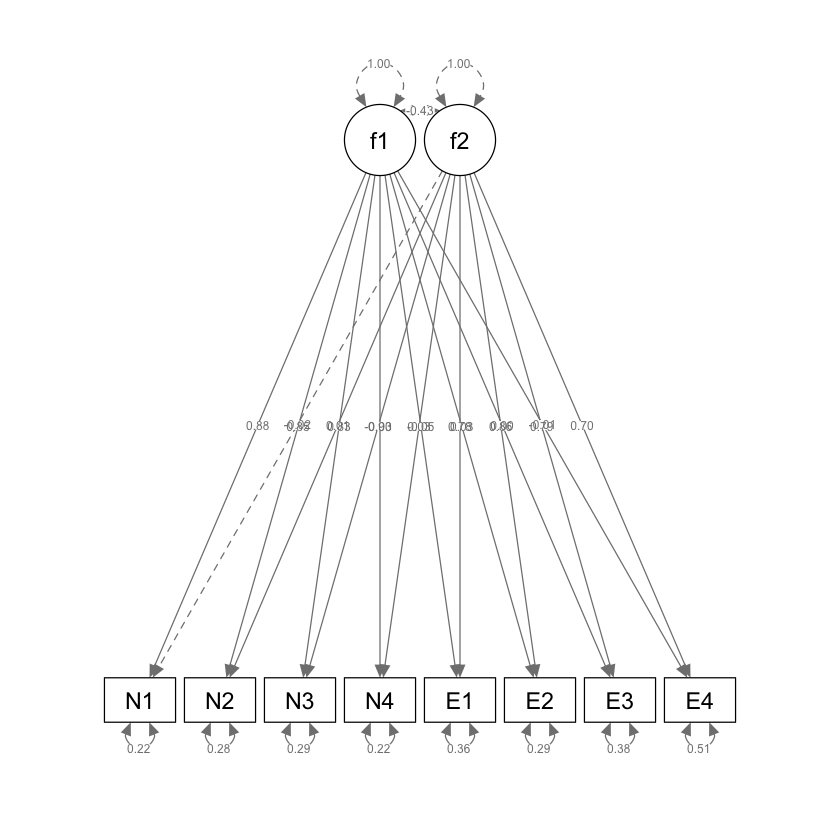
N1 0.874 0.053 16.592 0.000 0.874 0.876
N2 0.851 0.055 15.551 0.000 0.851 0.853
N3 0.826 0.054 15.179 0.000 0.826 0.828
N4 0.896 0.053 16.802 0.000 0.896 0.898
E1 -0.046 0.040 -1.138 0.255 -0.046 -0.046
E2 0.035 0.034 1.030 0.303 0.035 0.035
E3 0.000 0.040 0.010 0.992 0.000 0.000
E4 -0.006 0.049 -0.131 0.896 -0.006 -0.006
f2 =~ efa
N1 -0.017 0.032 -0.539 0.590 -0.017 -0.017
N2 0.011 0.035 0.322 0.748 0.011 0.011
N3 -0.035 0.036 -0.949 0.343 -0.035 -0.035
N4 0.031 0.031 0.994 0.320 0.031 0.031
E1 0.776 0.059 13.125 0.000 0.776 0.778
E2 0.854 0.058 14.677 0.000 0.854 0.855
E3 0.785 0.060 13.106 0.000 0.785 0.787
E4 0.695 0.063 10.955 0.000 0.695 0.697
Covariances:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
f1 ~~
f2 -0.432 0.059 -7.345 0.000 -0.432 -0.432
Variances:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
.N1 0.218 0.028 7.790 0.000 0.218 0.219
.N2 0.279 0.032 8.693 0.000 0.279 0.280
.N3 0.287 0.032 8.907 0.000 0.287 0.289
.N4 0.216 0.029 7.578 0.000 0.216 0.217
.E1 0.361 0.044 8.226 0.000 0.361 0.362
.E2 0.292 0.043 6.787 0.000 0.292 0.293
.E3 0.379 0.046 8.315 0.000 0.379 0.381
.E4 0.509 0.053 9.554 0.000 0.509 0.511
f1 1.000 1.000 1.000
f2 1.000 1.000 1.000
R-Square:
Estimate
N1 0.781
N2 0.720
N3 0.711
N4 0.783
E1 0.638
E2 0.707
E3 0.619
E4 0.489
standardizedSolution(efa_f2)
| lhs | op | rhs | est.std | se | z | pvalue | ci.lower | ci.upper |
|---|---|---|---|---|---|---|---|---|
| <chr> | <chr> | <chr> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> |
| f1 | =~ | N1 | 0.8761395232 | 0.02407374 | 36.39399384 | 0.000000e+00 | 0.82895586 | 0.92332319 |
| f1 | =~ | N2 | 0.8531678270 | 0.02702386 | 31.57091115 | 0.000000e+00 | 0.80020204 | 0.90613362 |
| f1 | =~ | N3 | 0.8279481145 | 0.02867524 | 28.87327885 | 0.000000e+00 | 0.77174568 | 0.88415055 |
| f1 | =~ | N4 | 0.8978425346 | 0.02300070 | 39.03544436 | 0.000000e+00 | 0.85276199 | 0.94292308 |
| f1 | =~ | E1 | -0.0459319488 | 0.04188336 | -1.09666348 | 2.727885e-01 | -0.12802182 | 0.03615792 |
| f1 | =~ | E2 | 0.0348802799 | 0.03211345 | 1.08615802 | 2.774091e-01 | -0.02806092 | 0.09782148 |
| f1 | =~ | E3 | 0.0004048221 | 0.04030477 | 0.01004402 | 9.919862e-01 | -0.07859108 | 0.07940073 |
| f1 | =~ | E4 | -0.0064182980 | 0.04931573 | -0.13014707 | 8.964501e-01 | -0.10307536 | 0.09023876 |
| f2 | =~ | N1 | -0.0170399299 | 0.03201090 | -0.53231646 | 5.945068e-01 | -0.07978014 | 0.04570028 |
| f2 | =~ | N2 | 0.0113498402 | 0.03500517 | 0.32423325 | 7.457615e-01 | -0.05725903 | 0.07995871 |
| f2 | =~ | N3 | -0.0346710680 | 0.03754544 | -0.92344282 | 3.557765e-01 | -0.10825878 | 0.03891664 |
| f2 | =~ | N4 | 0.0308917397 | 0.02998259 | 1.03032261 | 3.028586e-01 | -0.02787306 | 0.08965654 |
| f2 | =~ | E1 | 0.7778646427 | 0.03799550 | 20.47254878 | 0.000000e+00 | 0.70339484 | 0.85233445 |
| f2 | =~ | E2 | 0.8553962991 | 0.03237211 | 26.42386727 | 0.000000e+00 | 0.79194813 | 0.91884447 |
| f2 | =~ | E3 | 0.7870607946 | 0.03768569 | 20.88486912 | 0.000000e+00 | 0.71319819 | 0.86092340 |
| f2 | =~ | E4 | 0.6965219261 | 0.04556084 | 15.28773160 | 0.000000e+00 | 0.60722432 | 0.78581954 |
| N1 | ~~ | N1 | 0.2191956687 | 0.03170768 | 6.91301577 | 4.744649e-12 | 0.15704976 | 0.28134157 |
| N2 | ~~ | N2 | 0.2803386887 | 0.03624154 | 7.73528689 | 1.021405e-14 | 0.20930658 | 0.35137080 |
| N3 | ~~ | N3 | 0.2885084763 | 0.03644206 | 7.91690962 | 2.442491e-15 | 0.21708336 | 0.35993360 |
| N4 | ~~ | N4 | 0.2168781811 | 0.03209316 | 6.75776865 | 1.401324e-11 | 0.15397673 | 0.27977963 |
| E1 | ~~ | E1 | 0.3619601932 | 0.04713705 | 7.67888939 | 1.598721e-14 | 0.26957327 | 0.45434711 |
| E2 | ~~ | E2 | 0.2928483379 | 0.04628174 | 6.32751356 | 2.491432e-10 | 0.20213779 | 0.38355888 |
| E3 | ~~ | E3 | 0.3808103127 | 0.04868397 | 7.82208813 | 5.107026e-15 | 0.28539148 | 0.47622914 |
| E4 | ~~ | E4 | 0.5109551463 | 0.05301682 | 9.63760518 | 0.000000e+00 | 0.40704410 | 0.61486620 |
| f1 | ~~ | f1 | 1.0000000000 | 0.00000000 | NA | NA | 1.00000000 | 1.00000000 |
| f2 | ~~ | f2 | 1.0000000000 | 0.00000000 | NA | NA | 1.00000000 | 1.00000000 |
| f1 | ~~ | f2 | -0.4318172849 | 0.05799109 | -7.44626950 | 9.592327e-14 | -0.54547773 | -0.31815684 |
Anche se abbiamo introdotto finora soltanto la misura di bontà di adattamento del chi-quadrato, aggiungiamo qui il calcolo di altre misure di bontà di adattamento che discuteremo in seguito.
fit_measures_robust <- c(
"chisq", "df", "pvalue", "cfi", "rmsea", "srmr"
)
Confrontiamo le misure di bontà di adattamento del modello che ipotizza un solo fattore comune e il modello che ipotizza la presenza di due fattori comuni.
# collect them for each model
rbind(
fitmeasures(efa_f1, fit_measures_robust),
fitmeasures(efa_f2, fit_measures_robust)
) %>%
# wrangle
data.frame() %>%
mutate(
chisq = round(chisq, digits = 0),
df = as.integer(df),
pvalue = ifelse(pvalue == 0, "< .001", pvalue)
) %>%
mutate_at(vars(cfi:srmr), ~ round(., digits = 3))
| chisq | df | pvalue | cfi | rmsea | srmr |
|---|---|---|---|---|---|
| <dbl> | <int> | <chr> | <dbl> | <dbl> | <dbl> |
| 375 | 20 | < .001 | 0.71 | 0.267 | 0.187 |
| 10 | 13 | 0.709310449320098 | 1.00 | 0.000 | 0.010 |
lavaan::residuals(efa_f2, type = "cor") |>
print()
$type
[1] "cor.bollen"
$cov
N1 N2 N3 N4 E1 E2 E3 E4
N1 0.000
N2 0.018 0.000
N3 -0.014 -0.006 0.000
N4 -0.003 -0.013 0.017 0.000
E1 -0.003 0.015 -0.012 0.000 0.000
E2 -0.009 -0.004 0.006 0.007 0.006 0.000
E3 0.015 -0.008 0.011 -0.016 0.006 -0.010 0.000
E4 -0.001 0.000 -0.013 0.009 -0.024 0.006 0.016 0.000
L’evidenza empirica supporta la superiorità del modello a due fattori rispetto a quello ad un solo fattore comune. In particolare, l’analisi fattoriale esplorativa svolta mediante la funzione efa() evidenzia la capacità del modello a due fattori di fornire una descrizione adeguata della struttura dei dati e di distinguere in modo sensato tra i due fattori ipotizzati.
44.4. Considerazioni Conclusive#
L’Exploratory Structural Equation Modeling (ESEM) rappresenta un ponte significativo tra i modelli di misurazione tradizionali dell’Exploratory Factor Analysis (EFA) e il più esteso quadro del Confirmatory Factor Analysis/Structural Equation Modeling (CFA/SEM). Grazie a questo, l’ESEM combina i benefici dell’EFA con quelli del CFA/SEM, fornendo un approccio più flessibile e inclusivo nell’analisi dei dati. Tale integrazione ha segnato un progresso notevole nella ricerca statistica, evidenziando l’importanza dell’EFA che precedentemente era sottovalutata.
L’ESEM e il quadro bifattoriale-ESEM, in particolare, offrono una rappresentazione più fedele e precisa della multidimensionalità dei costrutti psicometrici, che è spesso presente nelle misurazioni. Questo approccio riconosce e gestisce meglio la natura multidimensionale dei costrutti, a differenza dell’approccio tradizionale del CFA, che tende a sovrastimare le correlazioni tra i fattori quando non considera adeguatamente la loro natura gerarchica e interconnessa (Asparouhov et al., 2015; Morin et al., 2020).
Nonostante questi vantaggi, l’ESEM presenta alcune limitazioni che devono essere considerate:
Complessità Computazionale: L’ESEM può essere più complesso e richiedere maggiori risorse computazionali rispetto agli approcci tradizionali, soprattutto quando si gestiscono grandi set di dati o modelli con molti fattori.
Interpretazione dei Risultati: A causa della sua flessibilità, l’ESEM può produrre risultati che sono più difficili da interpretare. Ad esempio, la sovrapposizione tra i fattori può complicare l’interpretazione dei costrutti.
Rischio di Overfitting: La maggiore flessibilità dell’ESEM può anche portare a un rischio maggiore di overfitting, specialmente in campioni più piccoli o con modelli eccessivamente complessi.
Necessità di Esperienza e Conoscenza: Per utilizzare efficacemente l’ESEM, è richiesta una comprensione approfondita della teoria sottostante e delle tecniche statistiche, che può essere una barriera per alcuni ricercatori.
Nonostante queste limitazioni, ci si aspetta che ulteriori sviluppi e applicazioni dell’ESEM portino a soluzioni più integrate e a un consenso più ampio sulle migliori pratiche nell’uso di questo potente strumento statistico.
44.5. Session Info#
sessionInfo()
R version 4.3.3 (2024-02-29)
Platform: x86_64-apple-darwin20 (64-bit)
Running under: macOS Sonoma 14.3.1
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.3-x86_64/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.3-x86_64/Resources/lib/libRlapack.dylib; LAPACK version 3.11.0
locale:
[1] en_US.UTF-8/UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
time zone: Europe/Rome
tzcode source: internal
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] ggokabeito_0.1.0 viridis_0.6.5 viridisLite_0.4.2 ggpubr_0.6.0
[5] ggExtra_0.10.1 bayesplot_1.11.1 gridExtra_2.3 patchwork_1.2.0
[9] semTools_0.5-6.920 semPlot_1.1.6 lavaan_0.6-17 psych_2.4.1
[13] scales_1.3.0 markdown_1.12 knitr_1.45 lubridate_1.9.3
[17] forcats_1.0.0 stringr_1.5.1 dplyr_1.1.4 purrr_1.0.2
[21] readr_2.1.5 tidyr_1.3.1 tibble_3.2.1 ggplot2_3.5.0
[25] tidyverse_2.0.0 here_1.0.1
loaded via a namespace (and not attached):
[1] rstudioapi_0.15.0 jsonlite_1.8.8 magrittr_2.0.3
[4] TH.data_1.1-2 estimability_1.5 nloptr_2.0.3
[7] rmarkdown_2.26 vctrs_0.6.5 minqa_1.2.6
[10] base64enc_0.1-3 rstatix_0.7.2 htmltools_0.5.7
[13] broom_1.0.5 Formula_1.2-5 htmlwidgets_1.6.4
[16] plyr_1.8.9 sandwich_3.1-0 emmeans_1.10.0
[19] zoo_1.8-12 uuid_1.2-0 igraph_2.0.2
[22] mime_0.12 lifecycle_1.0.4 pkgconfig_2.0.3
[25] Matrix_1.6-5 R6_2.5.1 fastmap_1.1.1
[28] shiny_1.8.0 numDeriv_2016.8-1.1 digest_0.6.34
[31] OpenMx_2.21.11 fdrtool_1.2.17 colorspace_2.1-0
[34] rprojroot_2.0.4 Hmisc_5.1-1 fansi_1.0.6
[37] timechange_0.3.0 abind_1.4-5 compiler_4.3.3
[40] withr_3.0.0 glasso_1.11 htmlTable_2.4.2
[43] backports_1.4.1 carData_3.0-5 ggsignif_0.6.4
[46] MASS_7.3-60.0.1 corpcor_1.6.10 gtools_3.9.5
[49] tools_4.3.3 pbivnorm_0.6.0 foreign_0.8-86
[52] zip_2.3.1 httpuv_1.6.14 nnet_7.3-19
[55] glue_1.7.0 quadprog_1.5-8 nlme_3.1-164
[58] promises_1.2.1 lisrelToR_0.3 grid_4.3.3
[61] pbdZMQ_0.3-11 checkmate_2.3.1 cluster_2.1.6
[64] reshape2_1.4.4 generics_0.1.3 gtable_0.3.4
[67] tzdb_0.4.0 data.table_1.15.2 hms_1.1.3
[70] car_3.1-2 utf8_1.2.4 sem_3.1-15
[73] pillar_1.9.0 IRdisplay_1.1 rockchalk_1.8.157
[76] later_1.3.2 splines_4.3.3 lattice_0.22-5
[79] survival_3.5-8 kutils_1.73 tidyselect_1.2.0
[82] miniUI_0.1.1.1 pbapply_1.7-2 stats4_4.3.3
[85] xfun_0.42 qgraph_1.9.8 arm_1.13-1
[88] stringi_1.8.3 boot_1.3-29 evaluate_0.23
[91] codetools_0.2-19 mi_1.1 cli_3.6.2
[94] RcppParallel_5.1.7 IRkernel_1.3.2 rpart_4.1.23
[97] xtable_1.8-4 repr_1.1.6 munsell_0.5.0
[100] Rcpp_1.0.12 coda_0.19-4.1 png_0.1-8
[103] XML_3.99-0.16.1 parallel_4.3.3 ellipsis_0.3.2
[106] jpeg_0.1-10 lme4_1.1-35.1 mvtnorm_1.2-4
[109] openxlsx_4.2.5.2 crayon_1.5.2 rlang_1.1.3
[112] multcomp_1.4-25 mnormt_2.1.1