15 Proprietà della verosimiglianza e aggiornamento bayesiano
Introduzione
Nel capitolo precedente abbiamo introdotto la funzione di verosimiglianza come lo strumento che quantifica la compatibilità relativa tra i dati osservati e i possibili valori dei parametri di un modello. Attraverso esempi concreti, abbiamo osservato alcune sue caratteristiche ricorrenti: la verosimiglianza tende a concentrarsi attorno a un valore ben definito, diventa progressivamente più stretta con l’aumentare della dimensione del campione e, per campioni sufficientemente ampi, assume una forma approssimativamente gaussiana.
Queste osservazioni sollevano naturalmente alcune domande di fondo: perché la verosimiglianza si comporta in questo modo? E, soprattutto, in che modo queste proprietà influenzano la costruzione e l’evoluzione della distribuzione a posteriori nell’inferenza bayesiana?
Il presente capitolo affronta queste domande fornendo una lettura teorica unificante dei fenomeni osservati. Mostreremo che il comportamento della verosimiglianza non è accidentale, ma riflette regolarità matematiche profonde che governano il comportamento delle statistiche campionarie e il flusso di informazione dai dati ai parametri. In particolare, vedremo perché la verosimiglianza tende a concentrarsi attorno al valore corretto del parametro e perché la sua informatività cresce al crescere del numero di osservazioni disponibili.
In questa prospettiva, l’aggiornamento bayesiano potrà essere reinterpretato come un processo di integrazione dell’informazione, in cui la verosimiglianza e la distribuzione a priori contribuiscono in modo complementare alla forma finale della distribuzione a posteriori. Questa lettura mette in evidenza come l’evidenza empirica e la conoscenza pregressa non siano in competizione, ma cooperino nella costruzione dell’inferenza.
Infine, discuteremo il ruolo di due risultati fondamentali della teoria della probabilità, ovvero la Legge dei Grandi Numeri e il Teorema del Limite Centrale, che aiutano a comprendere il comportamento asintotico dell’inferenza bayesiana. Senza entrare in dimostrazioni formali, useremo questi teoremi per spiegare perché, al crescere dei dati, la distribuzione a posteriori tende a concentrarsi attorno al valore vero del parametro e perché, in molti contesti, essa può essere ben approssimata da una distribuzione gaussiana, indipendentemente dalla forma iniziale del prior.
Per seguire questo capitolo è necessario aver letto:
- Capitolo 5
- Capitolo 10
- Capitolo 12
- Capitolo 13
- Capitolo 14 — fondamentale
Questo capitolo completa lo studio della verosimiglianza, introducendo score function, informazione di Fisher, coniugazione e fornendo gli strumenti operativi per l’inferenza bayesiana parametrica.
Conoscenze matematiche richieste:
- Appendice F - per derivate e integrali della verosimiglianza
Panoramica del capitolo
- Collegamento tra proprietà della media campionaria e forma della verosimiglianza.
- Precisione come misura di informatività e regola di combinazione delle precisioni.
- Aggiornamento bayesiano nel caso gaussiano: formula esplicita per la distribuzione a posteriori.
- Legge dei Grandi Numeri e convergenza della distribuzione a posteriori.
- Teorema del Limite Centrale e approssimazione normale della distribuzione a posteriori.
- Combinazione di evidenze da studi multipli.
- Limiti dell’inferenza: distinzione tra incertezza campionaria e distorsioni sistematiche.
15.1 Dalla media campionaria alla verosimiglianza
15.1.1 Il problema inferenziale
Consideriamo un problema concreto: stimare la prevalenza \(\theta\) di sintomi depressivi clinicamente rilevanti nella popolazione studentesca universitaria. Poiché non è possibile osservare l’intera popolazione, raccogliamo un campione di \(n\) studenti e registriamo, per ciascuno, la presenza (1) o assenza (0) del sintomo.
Dal punto di vista probabilistico, le osservazioni \(X_1, X_2, \ldots, X_n\) possono essere modellate come variabili casuali indipendenti e identicamente distribuite (i.i.d.) con distribuzione di Bernoulli:
\[ X_i \mid \theta \sim \text{Bernoulli}(\theta). \]
L’informazione contenuta nel campione viene tipicamente riassunta dalla proporzione campionaria
\[ \bar{X} = \frac{1}{n}\sum_{i=1}^n X_i, \] che rappresenta la frazione di studenti nel campione che presentano il sintomo.
Prima di osservare i dati, le nostre conoscenze su \(\theta\) possono essere rappresentate da una distribuzione a priori. Dopo l’osservazione, l’aggiornamento bayesiano avviene tramite la verosimiglianza. Per capire perché la verosimiglianza ha la forma che osserviamo nei grafici, dobbiamo quindi capire come si comporta la media campionaria \(\bar{X}\).
15.1.2 Perché la verosimiglianza è centrata nel punto giusto
Un primo fatto fondamentale è che, in media, la proporzione campionaria coincide con il parametro che vogliamo stimare.
Teorema 15.1 Per osservazioni i.i.d. con \(\mathbb{E}[X_i \mid \theta] = \theta\):
\[ \mathbb{E}[\bar{X} \mid \theta] = \theta. \]
Interpretazione. Se potessimo ripetere l’esperimento molte volte, la media delle proporzioni osservate coinciderebbe con il valore vero di \(\theta\). In altre parole, \(\bar{X}\) non tende sistematicamente a sovrastimare o sottostimare il parametro.
Conseguenza per la verosimiglianza. Poiché la funzione di verosimiglianza riflette quanto i dati sono compatibili con ciascun valore di \(\theta\), questa proprietà spiega perché il picco della verosimiglianza si trovi in corrispondenza della proporzione osservata \(\bar{X}\). La verosimiglianza è quindi centrata correttamente.
\[ \mathbb{E}[\bar{X} \mid \theta] = \mathbb{E}\!\left[\frac{1}{n}\sum_{i=1}^n X_i\right] = \frac{1}{n}\sum_{i=1}^n \mathbb{E}[X_i \mid \theta] = \theta. \]
15.1.3 Perché la verosimiglianza diventa più stretta con più dati
Un secondo fatto cruciale riguarda quanto la proporzione campionaria può fluttuare attorno al suo valore medio.
Teorema 15.2 Per osservazioni i.i.d. con varianza \(\text{Var}(X_i \mid \theta) = \sigma^2\):
\[ \text{Var}(\bar{X} \mid \theta) = \frac{\sigma^2}{n}. \]
Interpretazione. All’aumentare del numero di osservazioni, la variabilità della media campionaria diminuisce. Ogni nuovo dato contribuisce a “stabilizzare” la stima.
Conseguenza per la verosimiglianza. Poiché la verosimiglianza riflette l’incertezza sulla posizione del parametro, questa proprietà spiega perché la funzione di verosimiglianza diventa sempre più concentrata al crescere di \(n\). In termini intuitivi, più dati osserviamo, meno valori di \(\theta\) restano compatibili con l’evidenza.
\[ \text{Var}(\bar{X} \mid \theta) = \frac{1}{n^2}\sum_{i=1}^n \text{Var}(X_i \mid \theta) = \frac{\sigma^2}{n}. \]
15.1.4 Il caso Bernoulliano: quanta incertezza rimane?
Nel caso delle variabili di Bernoulli, la variabilità di ciascuna osservazione dipende dal valore stesso di \(\theta\):
\[ \text{Var}(X_i \mid \theta) = \theta(1-\theta). \]
Di conseguenza, la variabilità della proporzione campionaria è:
\[ \text{Var}(\bar{X} \mid \theta) = \frac{\theta(1-\theta)}{n}. \]
La quantità
\[ \text{SE}(\bar{X}) = \sqrt{\frac{\theta(1-\theta)}{n}} \] è detta errore standard e rappresenta l’ordine di grandezza delle fluttuazioni attese di \(\bar{X}\) attorno al valore vero di \(\theta\).
Questa espressione ha una forma particolarmente informativa:
- l’incertezza è massima quando \(\theta = 0.5\);
- diminuisce rapidamente al crescere di \(n\);
- tende a zero quando \(\theta\) è vicino a 0 o a 1.
15.1.5 Visualizzazione: come la verosimiglianza cambia con \(n\)
# Proporzione osservata fissa
p_obs <- 0.6
# Diverse dimensioni campionarie
n_values <- c(10, 50, 200)
# Griglia di valori per theta
theta_grid <- seq(0.01, 0.99, length.out = 500)
# Calcolo delle verosimiglianze
likelihood_data <- do.call(rbind, lapply(n_values, function(n) {
y <- round(p_obs * n) # numero di successi
lik <- dbinom(y, size = n, prob = theta_grid)
# Normalizziamo per confronto visivo
lik_norm <- lik / max(lik)
data.frame(
theta = theta_grid,
likelihood = lik_norm,
n = factor(paste0("n = ", n), levels = paste0("n = ", n_values))
)
}))
ggplot(likelihood_data, aes(x = theta, y = likelihood, color = n)) +
geom_line(linewidth = 1.2) +
geom_vline(xintercept = p_obs, linetype = "dashed") +
scale_fill_qualitative()
labs(
x = expression(theta),
y = "Verosimiglianza (normalizzata)",
color = "Dimensione\ncampionaria"
)
#> <ggplot2::labels> List of 3
#> $ x : expression(theta)
#> $ y : chr "Verosimiglianza (normalizzata)"
#> $ colour: chr "Dimensione\ncampionaria"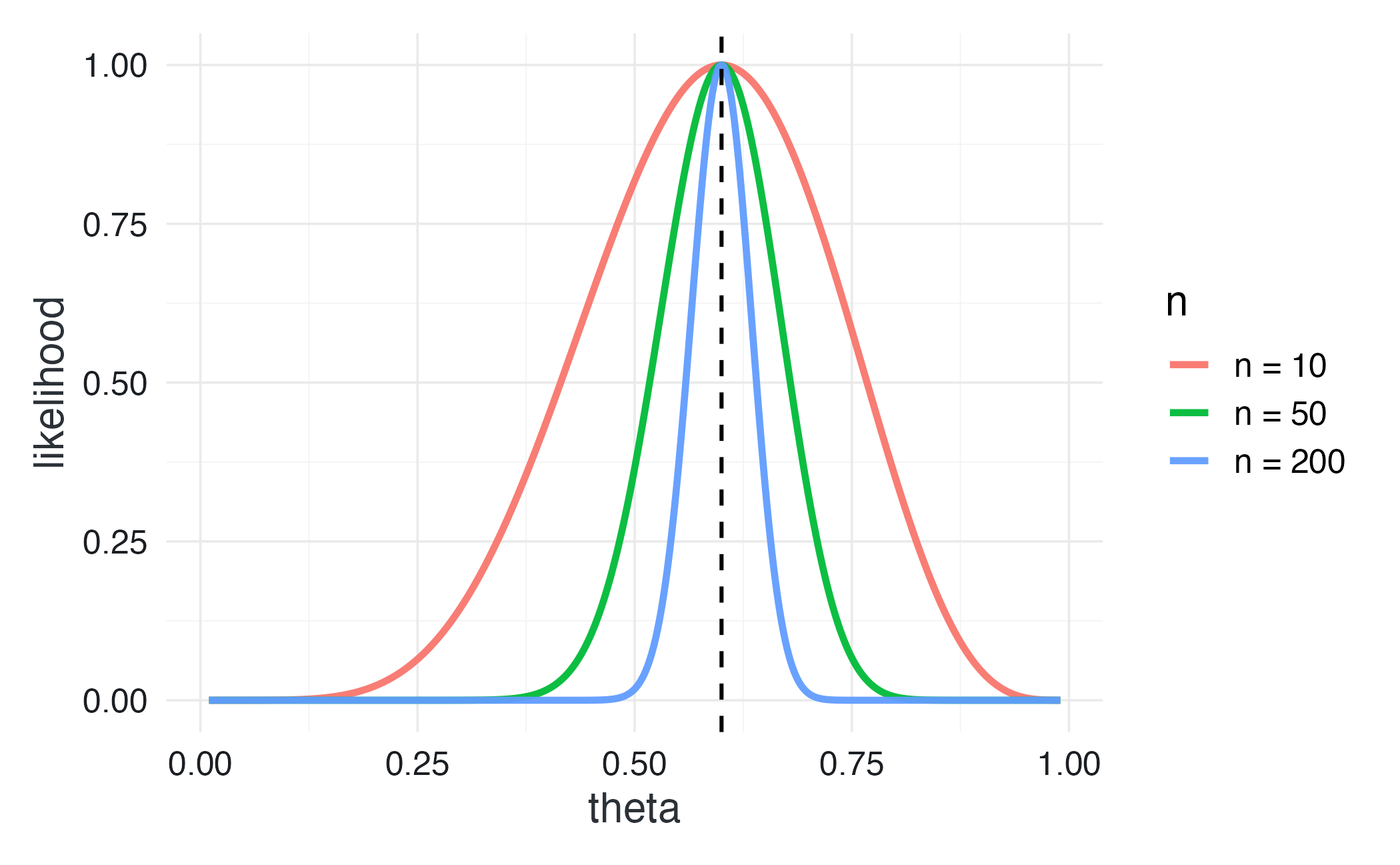
Lettura del grafico. A parità di proporzione osservata (\(\bar{X} = 0.6\)), campioni più grandi producono funzioni di verosimiglianza sempre più strette. Questo illustra visivamente il principio chiave di questa sezione:
la forma della verosimiglianza riflette direttamente la variabilità della media campionaria.
15.2 Precisione e informatività
15.2.1 Perché parlare di precisione?
Nell’inferenza bayesiana è spesso più utile ragionare in termini di precisione piuttosto che di varianza. La precisione è definita come l’inverso della varianza:
\[ \tau = \frac{1}{\sigma^2}. \]
Questa scelta non è puramente convenzionale. La precisione fornisce infatti una misura diretta di quanta informazione è contenuta in una distribuzione:
- una varianza grande indica molta incertezza e quindi bassa precisione;
- una varianza piccola indica poca incertezza e quindi alta precisione.
In altre parole, la precisione quantifica quanto “strettamente” una distribuzione è concentrata attorno ai valori più plausibili del parametro.
15.2.2 La precisione della media campionaria
Nel capitolo precedente abbiamo visto che la varianza della media campionaria decresce con il numero di osservazioni:
\[ \text{Var}(\bar{X} \mid \theta) = \frac{\sigma^2}{n}. \]
Passando alla precisione otteniamo:
\[ \text{Precisione}(\bar{X} \mid \theta) = \frac{1}{\text{Var}(\bar{X} \mid \theta)} = \frac{n}{\sigma^2}. \]
Osservazione chiave. La precisione cresce in modo lineare con la dimensione campionaria \(n\). Questo significa che:
- ogni nuova osservazione aggiunge la stessa quantità di informazione;
- l’informazione totale fornita dai dati è la somma delle informazioni contenute nelle singole osservazioni.
Questa proprietà è fondamentale, perché anticipa uno dei meccanismi centrali dell’aggiornamento bayesiano:
le informazioni si combinano in modo additivo quando sono espresse in termini di precisione.
15.2.3 Errore standard e informatività dei dati
L’errore standard
\[ \text{SE} = \frac{\sigma}{\sqrt{n}} \] fornisce una misura immediata dell’incertezza associata alla media campionaria come stima del parametro.
Dal punto di vista bayesiano:
- un errore standard piccolo indica che i dati sono molto informativi: la verosimiglianza è stretta e concentrata;
- un errore standard grande indica che i dati sono poco informativi: la verosimiglianza è ampia e diffusa.
La precisione e l’errore standard descrivono quindi lo stesso fenomeno da due prospettive complementari:
- l’errore standard misura l’incertezza residua;
- la precisione misura l’informazione accumulata.
15.2.4 Visualizzazione: come informazione e incertezza cambiano con \(n\)
n_seq <- 1:200
sigma <- 1 # varianza unitaria per semplicità
precision_data <- data.frame(
n = n_seq,
se = sigma / sqrt(n_seq),
precision = n_seq / sigma^2
)
p1 <- ggplot(precision_data, aes(x = n, y = se)) +
geom_line(linewidth = 1.2) +
scale_fill_qualitative() +
labs(
x = "Dimensione campionaria (n)",
y = "Errore standard",
title = "Errore standard\ndecresce come 1/√n"
)
p2 <- ggplot(precision_data, aes(x = n, y = precision)) +
geom_line(linewidth = 1.2) +
scale_fill_qualitative() +
labs(
x = "Dimensione campionaria (n)",
y = "Precisione",
title = "Precisione cresce\nlinearmente con n"
)
p1 + p2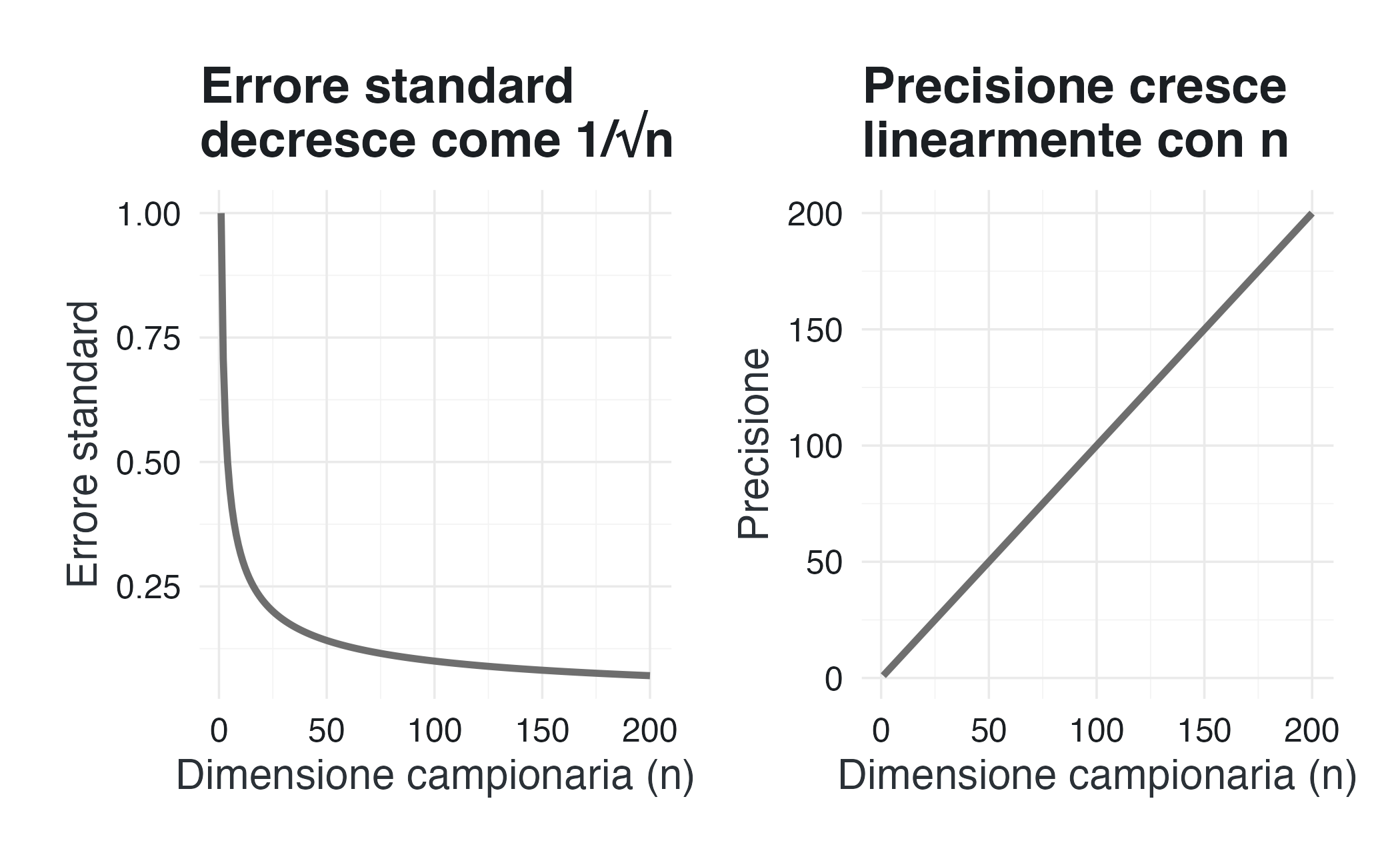
Lettura dei grafici. Il primo grafico mostra che l’errore standard decresce lentamente, come \(1/\sqrt{n}\): raddoppiare il campione non dimezza l’incertezza. Il secondo grafico mostra invece che la precisione cresce linearmente con \(n\): ogni osservazione aggiunge la stessa quantità di informazione.
Questa differenza di comportamento spiega perché, nell’inferenza bayesiana, la precisione sia spesso il linguaggio più naturale per descrivere il contributo dei dati.
15.3 L’aggiornamento bayesiano come combinazione di precisioni
15.3.1 L’idea chiave
Nel caso gaussiano, l’aggiornamento bayesiano può essere compreso in modo sorprendentemente semplice: la stima a posteriori è una media ponderata tra ciò che credevamo prima e ciò che ci dicono i dati, dove i pesi sono dati dalle rispettive precisioni.
Questa sezione rende esplicita questa idea nel contesto più semplice possibile, ma anche uno dei più istruttivi.
15.3.2 Il caso gaussiano: prior e dati
Supponiamo di avere una credenza iniziale sul parametro \(\theta\), rappresentata da una distribuzione a priori gaussiana:
\[ \theta \sim \mathcal{N}(\mu_0, \sigma_0^2). \]
Questa distribuzione riassume ciò che sappiamo (o crediamo di sapere) prima di osservare nuovi dati:
- \(\mu_0\) è il valore più plausibile secondo le nostre conoscenze pregresse;
- \(\sigma_0^2\) quantifica l’incertezza associata a tale credenza.
Ora raccogliamo un campione di \(n\) osservazioni indipendenti:
\[ X_1, \ldots, X_n \sim \mathcal{N}(\theta, \sigma^2), \] dove la varianza \(\sigma^2\) è nota. Come visto nelle sezioni precedenti, tutta l’informazione rilevante contenuta nel campione è riassunta dalla media campionaria \(\bar{X}\).
15.3.3 La verosimiglianza come distribuzione informativa
Considerata come funzione del parametro \(\theta\), la verosimiglianza associata ai dati è proporzionale a una distribuzione normale:
\[ L(\theta; \bar{x}) \propto \exp \!\left(-\frac{n(\bar{x}-\theta)^2}{2\sigma^2}\right). \]
Questa funzione:
- è centrata sulla media osservata \(\bar{x}\);
- ha varianza \(\sigma^2/n\);
- diventa più stretta al crescere del numero di osservazioni.
In termini di precisione, l’informazione fornita dai dati è pari a:
\[ \tau_{\text{dati}} = \frac{n}{\sigma^2}. \]
15.3.4 La distribuzione a posteriori
Il teorema di Bayes stabilisce che la distribuzione a posteriori è proporzionale al prodotto tra prior e verosimiglianza:
\[ p(\theta \mid \bar{x}) \propto p(\theta)\, L(\theta; \bar{x}). \]
Nel caso gaussiano, questo prodotto genera ancora una distribuzione normale:
\[ \theta \mid \bar{x} \sim \mathcal{N}(\mu_{\text{post}}, \sigma_{\text{post}}^2). \]
Teorema 15.3 (Aggiornamento bayesiano gaussiano (forma esplicita)) La media a posteriori è una media ponderata tra prior e dati:
\[ \mu_{\text{post}} = \frac{\tau_0 \mu_0 + \tau_{\text{dati}} \bar{x}} {\tau_0 + \tau_{\text{dati}}}, \] dove:
- \(\tau_0 = 1/\sigma_0^2\) è la precisione del prior;
- \(\tau_{\text{dati}} = n/\sigma^2\) è la precisione dei dati.
La precisione a posteriori è la somma delle precisioni:
\[ \tau_{\text{post}} = \tau_0 + \tau_{\text{dati}}. \]
15.3.5 Come leggere queste formule
Queste espressioni matematiche traducono in modo preciso la logica dell’aggiornamento bayesiano:
Media ponderata La stima a posteriori si colloca tra \(\mu_0\) e \(\bar{x}\), più vicina alla fonte di informazione più precisa.
Somma delle informazioni Le precisioni si sommano: l’incertezza diminuisce ogni volta che incorporiamo nuova informazione.
Dominanza dei dati Quando il campione è grande, \(\tau_{\text{dati}}\) domina e la posterior è centrata vicino a \(\bar{x}\).
Dominanza del prior Quando i dati sono pochi o molto rumorosi, il prior ha un peso maggiore.
In breve:
Bayes aggiorna credenze facendo una media, ma una media “intelligente”, pesata dall’informazione disponibile.
15.3.6 Esempio numerico
L’esempio seguente mostra visivamente come prior e dati contribuiscano alla distribuzione a posteriori in proporzione alle loro precisioni.
# Parametri del prior
mu_0 <- 100
sigma_0 <- 15
tau_0 <- 1 / sigma_0^2
# Parametri dei dati
n <- 25
x_bar <- 115
sigma <- 20 # deviazione standard nota
tau_data <- n / sigma^2
# Calcolo della posterior
tau_post <- tau_0 + tau_data
sigma_post <- sqrt(1 / tau_post)
mu_post <- (tau_0 * mu_0 + tau_data * x_bar) / tau_post
# Griglia di valori
theta_grid <- seq(60, 150, length.out = 500)
# Calcolo delle distribuzioni
prior_density <- dnorm(theta_grid, mu_0, sigma_0)
likelihood <- dnorm(theta_grid, x_bar, sigma / sqrt(n))
posterior_density <- dnorm(theta_grid, mu_post, sigma_post)
# Normalizzazione per visualizzazione
likelihood_norm <- likelihood * max(prior_density) / max(likelihood)
plot_data <- data.frame(
theta = rep(theta_grid, 3),
density = c(prior_density, likelihood_norm, posterior_density),
type = factor(rep(c("Prior", "Verosimiglianza", "Posterior"), each = length(theta_grid)),
levels = c("Prior", "Verosimiglianza", "Posterior"))
)
ggplot(plot_data, aes(x = theta, y = density, color = type, linetype = type)) +
geom_line(linewidth = 1.2) +
scale_fill_qualitative() +
scale_linetype_manual(values = c("solid", "dashed", "solid")) +
labs(
x = expression(theta),
y = "Densità",
color = "",
linetype = ""
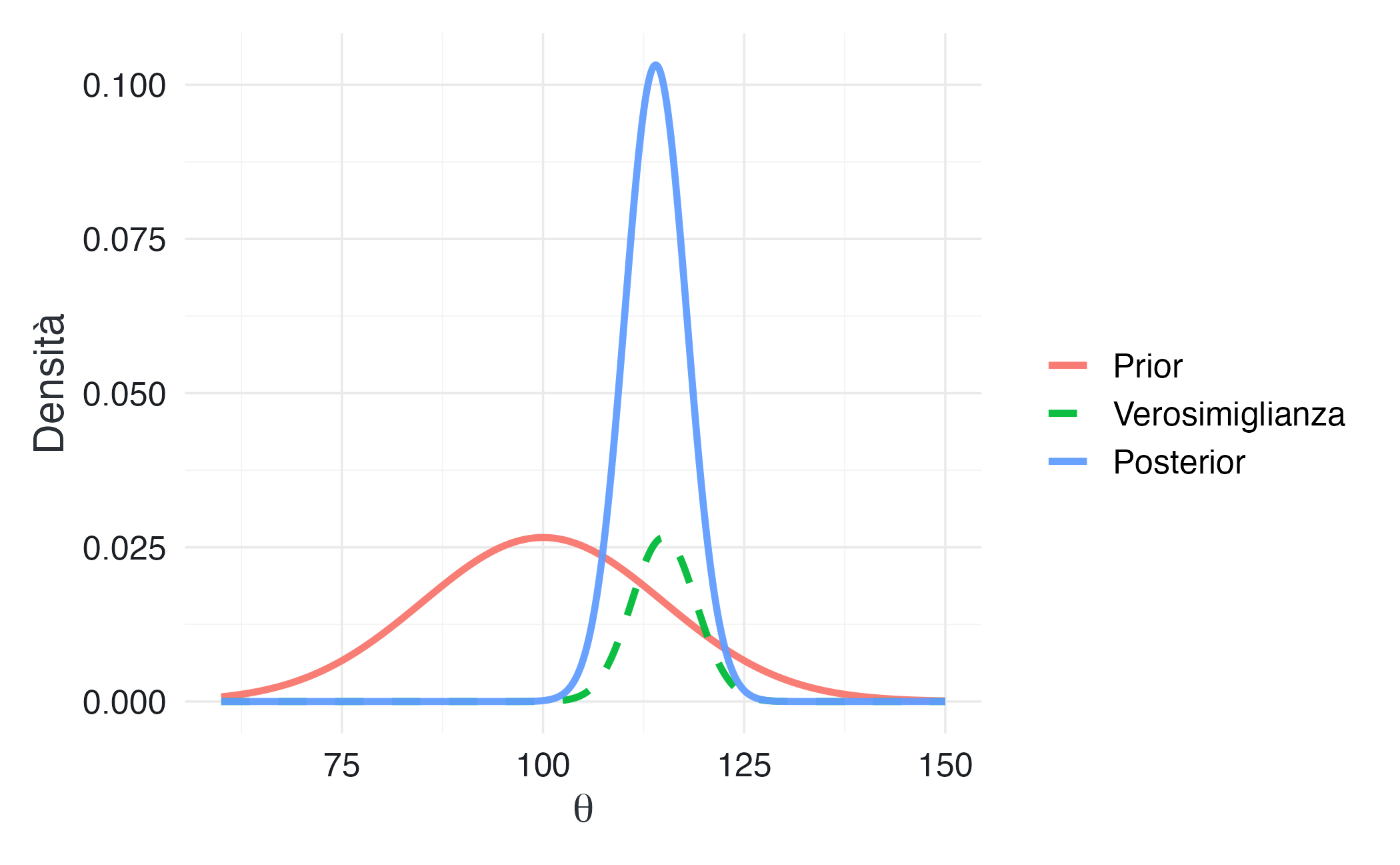
) 
# Stampa dei risultati
cat("Prior: N(", mu_0, ", ", sigma_0, "²)\n", sep = "")
#> Prior: N(100, 15²)
cat("Dati: n =", n, ", media campionaria =", x_bar, "\n")
#> Dati: n = 25 , media campionaria = 115
cat("Precisione prior:", round(tau_0, 6), "\n")
#> Precisione prior: 0.00444
cat("Precisione dati:", round(tau_data, 6), "\n")
#> Precisione dati: 0.0625
cat("Precisione posterior:", round(tau_post, 6), "\n")
#> Precisione posterior: 0.0669
cat("\nMedia posterior:", round(mu_post, 2), "\n")
#>
#> Media posterior: 114
cat("Deviazione standard posterior:", round(sigma_post, 2), "\n")
#> Deviazione standard posterior: 3.86In questo esempio, la precisione dei dati (\(\tau_{\text{dati}} = 0.062\)) è circa 14.1 volte maggiore della precisione del prior (\(\tau_0 = 0.004\)). Di conseguenza, la media a posteriori (114) è molto più vicina alla media campionaria (115) che alla media a priori (100).
15.4 La Legge dei Grandi Numeri e la convergenza bayesiana
Tra i risultati fondamentali della teoria della probabilità, la Legge dei Grandi Numeri (LGN) descrive come l’informazione fornita dai dati si stabilizzi progressivamente all’aumentare del numero di osservazioni. Nella sua interpretazione più intuitiva, essa afferma che, ripetendo molte volte lo stesso esperimento nelle medesime condizioni, la frequenza relativa di un evento tende ad avvicinarsi alla sua probabilità teorica.
In termini più formali, se \(X_1, \dots, X_n\) sono variabili casuali indipendenti e identicamente distribuite con valore atteso \(\mu\), la media campionaria
\[ \bar X_n = \frac{1}{n}\sum_{i=1}^{n} X_i \] tende, al crescere di \(n\), a concentrarsi attorno al valore costante \(\mu\).
Questo non significa che la media campionaria smetta di fluttuare, ma che deviazioni ampie dal valore vero diventano sempre meno probabili: le oscillazioni persistono, ma si fanno progressivamente più piccole e trascurabili rispetto a \(\mu\).
15.4.1 Conseguenze per la verosimiglianza
La Legge dei Grandi Numeri ha un impatto diretto sul comportamento della funzione di verosimiglianza. Nei modelli in cui il massimo della verosimiglianza coincide con una statistica campionaria — come la media nel caso gaussiano — tale massimo converge al valore vero del parametro.
Di conseguenza, all’aumentare della quantità di dati, la funzione di verosimiglianza:
- si concentra sempre più attorno al valore corretto del parametro;
- assegna un supporto sempre minore ai valori alternativi;
- restringe progressivamente l’insieme dei parametri plausibili.
L’incertezza non viene eliminata, ma localizzata: le ipotesi sbagliate non scompaiono, diventano semplicemente sempre meno credibili alla luce dell’evidenza accumulata.
15.4.2 Conseguenze per l’inferenza bayesiana: la consistenza
Questo comportamento della verosimiglianza si riflette direttamente nell’aggiornamento bayesiano delle credenze e conduce al principio di consistenza bayesiana.
Teorema 15.4 (Consistenza bayesiana) Se la distribuzione a priori assegna probabilità positiva a ogni intorno del valore vero \(\theta_0\), allora, al crescere della dimensione campionaria (\(n \to \infty\)), la distribuzione a posteriori si concentra sempre più attorno a \(\theta_0\).
In termini intuitivi, questo risultato afferma che l’inferenza bayesiana è un procedimento auto-correttivo. Le credenze iniziali possono essere imprecise, deboli o persino fortemente divergenti tra loro; tuttavia, purché non escludano a priori il valore vero del parametro, l’accumulo dell’evidenza empirica le costringe progressivamente a convergere verso la stessa conclusione.
Con l’aumentare dei dati:
- l’influenza del prior si attenua;
- l’informazione fornita dai dati diventa dominante;
- la distribuzione a posteriori diventa una rappresentazione sempre più concentrata e accurata del parametro che governa il fenomeno osservato.
15.4.3 Simulazione: convergenza con prior diversi
set.seed(42)
theta_true <- 0.45
n_values <- c(10, 50, 200, 1000)
# Prior diversi
priors <- list(
A = c(2, 8), # Prior pessimista (media = 0.2)
B = c(8, 2), # Prior ottimista (media = 0.8)
C = c(1, 1) # Prior uniforme (media = 0.5)
)
# Funzione per calcolare la posterior Beta
compute_posterior <- function(prior_params, n, theta_true) {
y <- rbinom(1, n, theta_true)
c(prior_params[1] + y, prior_params[2] + n - y)
}
# Generazione dei dati per il plot
set.seed(42)
theta_grid <- seq(0.01, 0.99, length.out = 300)
all_data <- do.call(rbind, lapply(n_values, function(n) {
do.call(rbind, lapply(names(priors), function(name) {
post <- compute_posterior(priors[[name]], n, theta_true)
data.frame(
theta = theta_grid,
density = dbeta(theta_grid, post[1], post[2]),
researcher = name,
n = n
)
}))
}))
all_data$n_label <- factor(paste("n =", all_data$n),
levels = paste("n =", n_values))
all_data$researcher <- factor(all_data$researcher,
labels = c("Prior pessimista (β = 0.2)",
"Prior ottimista (β = 0.8)",
"Prior uniforme"))
ggplot(all_data, aes(x = theta, y = density, color = researcher)) +
geom_line(linewidth = 1) +
geom_vline(xintercept = theta_true, linetype = "dashed",
linewidth = 0.8) +
facet_wrap(~ n_label, scales = "free_y", ncol = 2) +
scale_fill_qualitative() +
labs(
x = expression(theta),
y = "Densità a posteriori",
color = "Ricercatore"
) +
theme(legend.position = "bottom")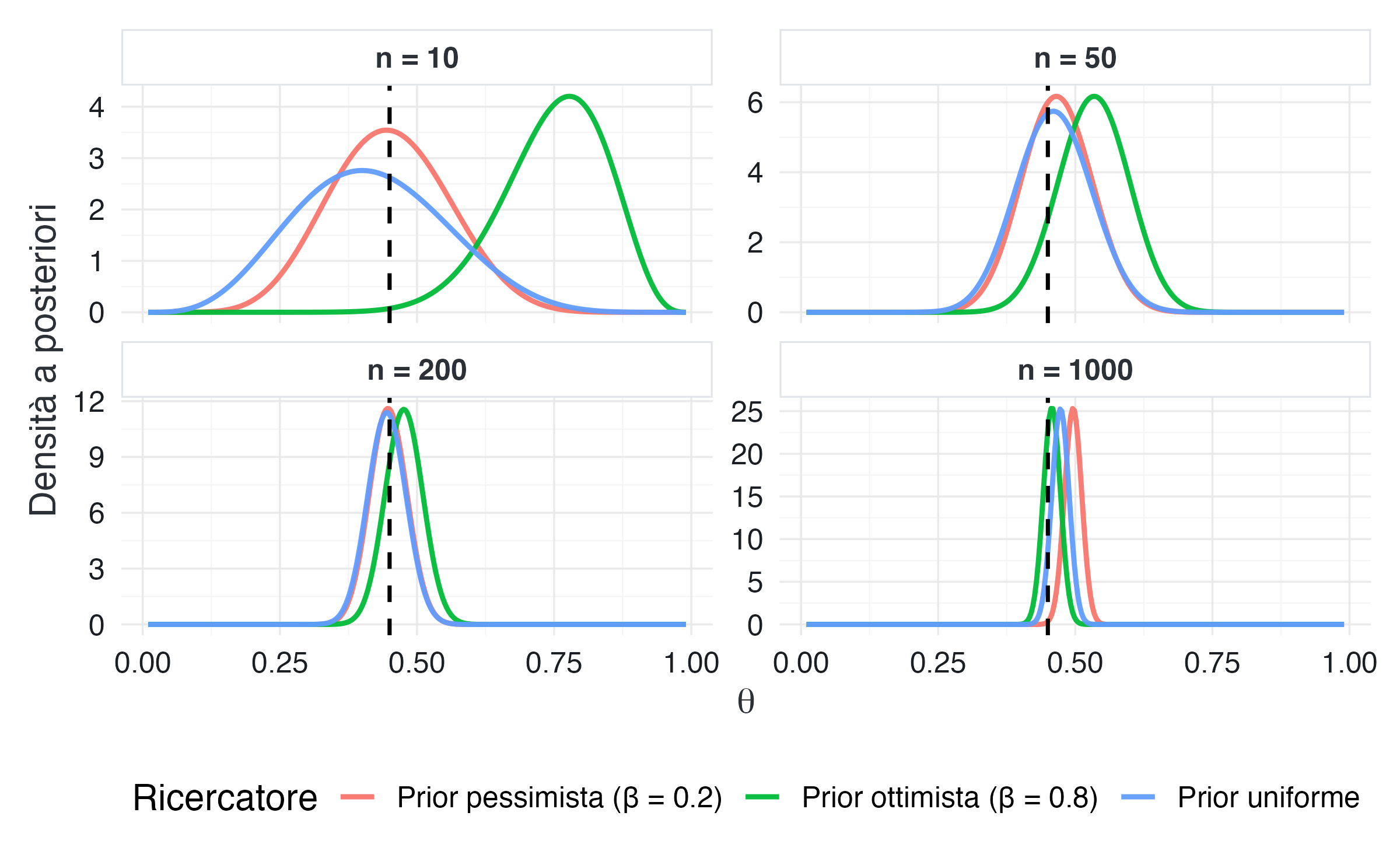
Lettura del grafico. Quando il campione è molto piccolo (\(n = 10\)), le distribuzioni a posteriori riflettono ancora fortemente le diverse credenze iniziali dei ricercatori. Con \(n = 50\), inizia a emergere un avvicinamento sistematico. A partire da \(n = 200\), le posteriori risultano sostanzialmente sovrapposte, e con \(n = 1000\) sono praticamente indistinguibili, tutte fortemente concentrate attorno al valore vero \(\theta_0\).
Questa simulazione fornisce un’illustrazione concreta del principio di consistenza bayesiana: a sufficienza di dati, ricercatori con prior molto diversi arrivano alle stesse conclusioni.
15.5 Il Teorema del Limite Centrale e l’approssimazione normale
15.5.1 Perché la normalità emerge
Nel capitolo precedente abbiamo visto che, all’aumentare del numero di osservazioni, la verosimiglianza tende a concentrarsi attorno a un valore ben definito del parametro. Un ulteriore passo consiste nel capire perché questa concentrazione assume spesso una forma gaussiana, anche quando i dati non provengono da una popolazione normale.
La risposta a questa domanda è fornita dal Teorema del Limite Centrale (TLC), uno dei risultati più importanti della teoria della probabilità.
15.5.2 L’idea del Teorema del Limite Centrale
In forma intuitiva, il TLC afferma che, quando si calcola la media di molte osservazioni indipendenti, il risultato tende a comportarsi come una variabile normale. Questo accade indipendentemente dalla forma della distribuzione originale, purché la varianza sia finita.
In altri termini:
- i singoli dati possono essere asimmetrici, discreti o irregolari;
- ma le medie campionarie tendono a seguire una distribuzione gaussiana.
Teorema 15.5 (Teorema del Limite Centrale (forma intuitiva)) Per osservazioni i.i.d. con media \(\mu\) e varianza \(\sigma^2 < \infty\), la distribuzione della media campionaria \(\bar X_n\) può essere approssimata, per \(n\) sufficientemente grande, da una distribuzione normale:
\[ \bar{X}_n \;\dot\sim\; \mathcal{N}\!\left(\mu, \frac{\sigma^2}{n}\right). \]
Questa proprietà spiega perché le distribuzioni gaussiane compaiano così frequentemente in statistica: non perché la natura sia normale, ma perché facciamo medie.
15.5.3 Conseguenze per la verosimiglianza
Poiché in molti modelli la verosimiglianza dipende dalla media campionaria (o da statistiche che si comportano in modo analogo), il TLC implica che, per campioni sufficientemente grandi, la verosimiglianza assuma una forma approssimativamente normale rispetto al parametro:
\[ L(\theta \mid \bar{x}) \;\approx\; \mathcal{N}\!\left(\bar{x}, \frac{\sigma^2}{n}\right), \] interpretata come funzione di \(\theta\).
È importante sottolineare che questa normalità non deriva dalla distribuzione delle singole osservazioni, ma dal loro comportamento aggregato. Anche partendo da popolazioni fortemente non gaussiane, la verosimiglianza tende ad assumere una struttura a campana man mano che il numero di dati cresce.
15.5.4 Conseguenze per l’inferenza bayesiana
Se la verosimiglianza è approssimativamente normale e il prior non è patologico, anche la distribuzione a posteriori eredita questa forma. Questo fatto è formalizzato da un risultato noto come teorema di Bernstein–von Mises.
Teorema 15.6 (Teorema di Bernstein–von Mises (interpretazione)) Sotto condizioni di regolarità e per campioni sufficientemente grandi, la distribuzione a posteriori può essere approssimata da una distribuzione normale centrata sul valore stimato del parametro, con una dispersione che riflette la quantità di informazione contenuta nei dati.
Interpretazione intuitiva. Quando i dati sono numerosi:
- il ruolo del prior diventa marginale;
- la posterior è dominata dalla verosimiglianza;
- la forma della posterior è ben approssimata da una gaussiana, anche se il prior e il modello iniziale non lo erano.
Questo risultato spiega perché, in molti contesti applicativi, l’inferenza bayesiana produca risultati simili a quelli frequentisti per grandi campioni, pur mantenendo un’interpretazione probabilistica distinta.
15.5.5 Visualizzazione: il TLC in una popolazione non normale
set.seed(42)
# Popolazione: distribuzione uniforme (non gaussiana)
population <- runif(1e6, min = 0, max = 1)
# Funzione per simulare distribuzioni campionarie
simulate_sampling_dist <- function(pop, sample_size, n_samples = 1e5) {
replicate(n_samples, mean(sample(pop, sample_size, replace = TRUE)))
}
# Diverse dimensioni campionarie
sample_sizes <- c(1, 5, 30)
sampling_data <- do.call(rbind, lapply(sample_sizes, function(n) {
means <- simulate_sampling_dist(population, n)
data.frame(
mean = means,
n = factor(paste("n =", n), levels = paste("n =", sample_sizes))
)
}))
ggplot(sampling_data, aes(x = mean)) +
geom_histogram(aes(y = after_stat(density)), bins = 40,
alpha = 0.7) +
stat_function(fun = dnorm,
args = list(mean = 0.5, sd = sqrt(1/12) / sqrt(30)),
data = subset(sampling_data, n == "n = 30"),
linewidth = 1.2) +
facet_wrap(~ n, scales = "free_y") +
scale_fill_qualitative() +
labs(
x = "Media campionaria",
y = "Densità"
) 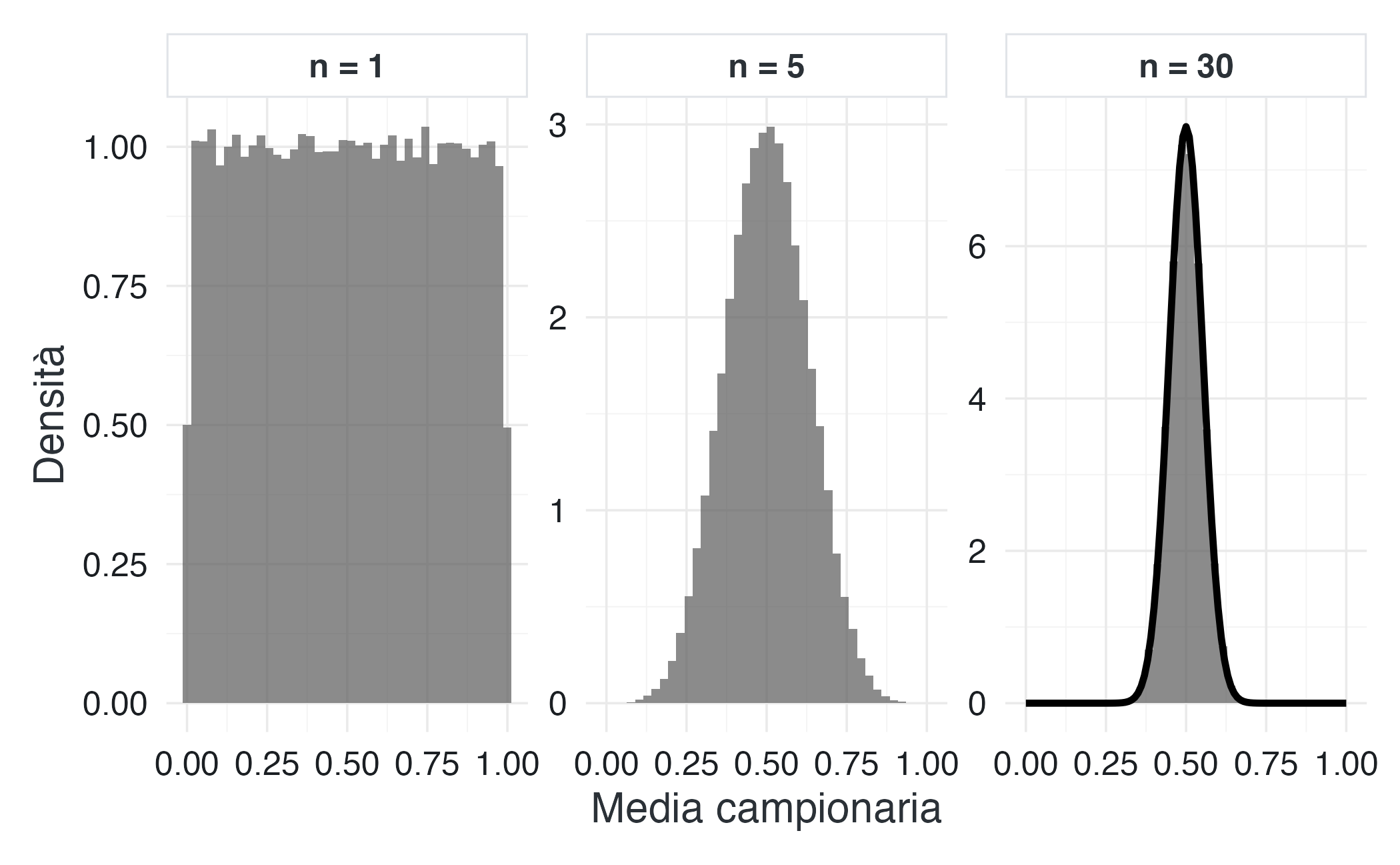
Lettura del grafico. Con \(n = 1\), la distribuzione delle medie coincide con la distribuzione originale. Già con \(n = 5\), inizia a emergere una forma a campana. Con \(n = 30\), la distribuzione delle medie è praticamente indistinguibile da una normale.
Questo esempio mostra in modo visivo il messaggio centrale del TLC:
la normalità non è una proprietà dei dati, ma delle medie dei dati.
15.6 Combinazione di evidenze da studi multipli
15.6.1 L’idea di base
Uno dei punti di forza dell’approccio bayesiano è la possibilità di integrare in modo coerente evidenze provenienti da fonti diverse. Questo principio è alla base della meta-analisi bayesiana, che combina i risultati di studi indipendenti per ottenere stime più precise e robuste. Quando più studi indipendenti indagano lo stesso parametro \(\theta\), ciascuno di essi può essere visto come una fonte di informazione parziale, caratterizzata da una stima centrale e da un certo grado di incertezza.
Il principio fondamentale è semplice:
le informazioni si combinano sommando le loro precisioni.
15.6.2 Il principio della somma delle precisioni
Supponiamo che ciascuno studio \(i\) fornisca:
- una stima \(\bar{x}_i\) del parametro \(\theta\);
- una misura della sua incertezza, espressa tramite la precisione \(\tau_i\) (l’inverso della varianza).
La stima combinata risulta essere una media ponderata:
\[ \bar{x}_{\text{comb}} = \frac{\sum_i \tau_i \bar{x}_i}{\sum_i \tau_i}, \] dove i pesi riflettono l’affidabilità relativa degli studi.
Allo stesso tempo, la precisione complessiva è semplicemente:
\[ \tau_{\text{comb}} = \sum_i \tau_i. \]
Queste formule riflettono esattamente la logica dell’aggiornamento bayesiano: ogni nuova fonte di informazione contribuisce in proporzione alla propria precisione, riducendo l’incertezza complessiva.
15.6.3 Esempio: sintesi di due studi
Consideriamo due studi indipendenti che stimano la prevalenza di un sintomo:
# Parametri degli studi
studi <- data.frame(
studio = c("A", "B"),
n = c(50, 200),
proporzione = c(0.42, 0.38),
se = c(0.07, 0.035)
)
studi$precisione <- 1 / studi$se^2
precisione_totale <- sum(studi$precisione)
media_combinata <- sum(studi$precisione * studi$proporzione) / precisione_totale
se_combinato <- sqrt(1 / precisione_totale)#> Stima combinata: 0.388
#> Errore standard combinato: 0.0313
#> Precisioni:
#> - Studio A: 204
#> - Studio B: 816
#> - Totale: 1020Risultato chiave. La stima combinata ha un errore standard (0.031) inferiore a quello di entrambi gli studi presi singolarmente. Questo accade perché la precisione totale (1020.4) è la somma delle precisioni individuali: l’incertezza si riduce man mano che integriamo più evidenza affidabile.1
15.6.4 Visualizzazione: perché uno studio pesa più dell’altro
theta_grid <- seq(0.2, 0.6, length.out = 500)
meta_data <- data.frame(
theta = rep(theta_grid, 3),
density = c(
dnorm(theta_grid, studi$proporzione[1], studi$se[1]),
dnorm(theta_grid, studi$proporzione[2], studi$se[2]),
dnorm(theta_grid, media_combinata, se_combinato)
),
studio = factor(rep(c("Studio A (n=50)", "Studio B (n=200)", "Combinato"),
each = length(theta_grid)),
levels = c("Studio A (n=50)", "Studio B (n=200)", "Combinato"))
)
ggplot(meta_data, aes(x = theta, y = density, color = studio, linetype = studio)) +
geom_line(linewidth = 1.2) +
scale_fill_qualitative() +
scale_linetype_manual(values = c("dashed", "dashed", "solid")) +
labs(
x = expression(theta),
y = "Densità",
color = "",
linetype = ""
) 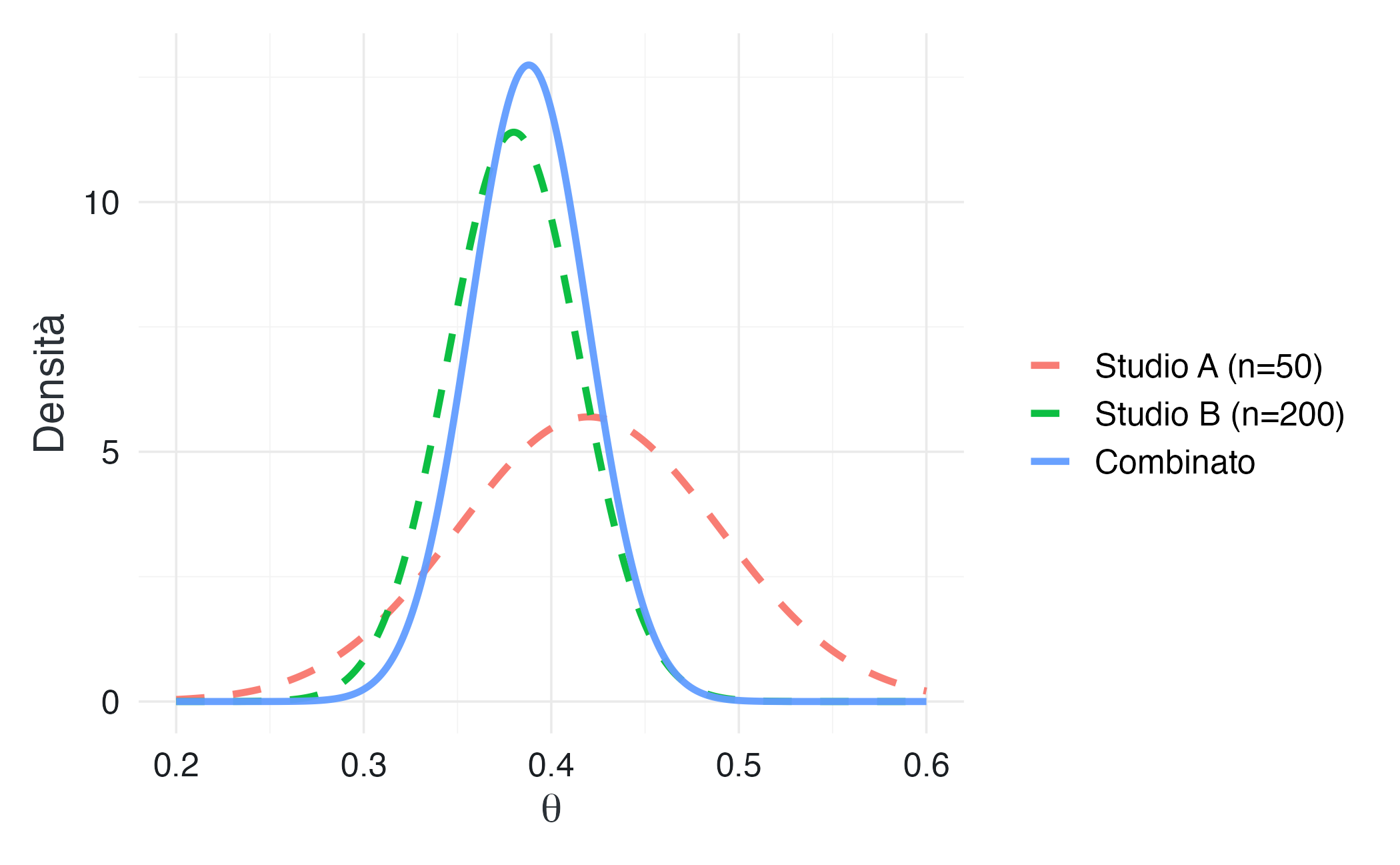
Lettura del grafico. Lo studio B, avendo una dimensione campionaria maggiore, presenta una distribuzione più stretta e quindi una precisione più elevata. Di conseguenza, la stima combinata (linea verde) risulta più vicina allo studio B che allo studio A. L’intervallo risultante è inoltre più stretto di entrambi, riflettendo la maggiore informazione complessiva.
La stima combinata (0.388) è più vicina al valore riportato dallo studio B (0.38) perché questo studio fornisce un’informazione più precisa. In un’ottica bayesiana, le evidenze non si contano, si pesano: fonti più affidabili contribuiscono di più alla conclusione finale.
Questo principio — che formalizza il modo ottimale di integrare informazioni incerte — ha ispirato numerose ricerche nelle scienze cognitive e percettive, dove ci si è chiesti se il sistema umano integri i segnali sensoriali in modo coerente con l’inferenza bayesiana (Domini & Caudek, 2011).
15.7 Limiti dell’inferenza: precisione vs. accuratezza
15.7.1 Cosa misura davvero l’errore standard
Le quantità studiate in questo capitolo, come la concentrazione della verosimiglianza, il restringimento della distribuzione a posteriori e la riduzione dell’errore standard, descrivono una sola dimensione dell’inferenza statistica: la precisione, cioè quanto una stima è influenzata dalla variabilità campionaria.
Un errore standard piccolo indica che, se ripetessimo lo studio molte volte nelle stesse condizioni, otterremmo risultati molto simili. Tuttavia, questa stabilità non garantisce che la stima sia vicina al valore vero del parametro.
In altre parole:
una stima può essere molto precisa, ma comunque sbagliata.
L’inferenza bayesiana, come qualunque procedura statistica, non può correggere distorsioni sistematiche introdotte prima dell’analisi, durante la progettazione dello studio, la raccolta dei dati o la misurazione dei costrutti.
15.7.2 Fonti comuni di distorsione sistematica
Nella ricerca applicata, in particolare in ambito psicologico e sociale, sono frequenti meccanismi che producono errori sistematici (bias). Anche un’analisi statisticamente impeccabile può portare a conclusioni fuorvianti se questi problemi non vengono affrontati a monte.
Distorsione da selezione Si verifica quando il campione osservato non è rappresentativo della popolazione di interesse. Reclutamento opportunistico, autoselezione o bassi tassi di risposta possono produrre stime che descrivono bene il campione, ma non la popolazione.
Distorsione da desiderabilità sociale In presenza di temi sensibili, i partecipanti possono fornire risposte socialmente accettabili piuttosto che veritiere. In questi casi, le osservazioni non riflettono il costrutto psicologico di interesse, compromettendo la validità delle inferenze.
Errori di misurazione Strumenti poco affidabili o non validati possono introdurre rumore o distorsioni sistematiche. Anche grandi campioni non compensano misure che catturano il fenomeno sbagliato o in modo instabile.
15.7.3 Il paradosso della falsa precisione
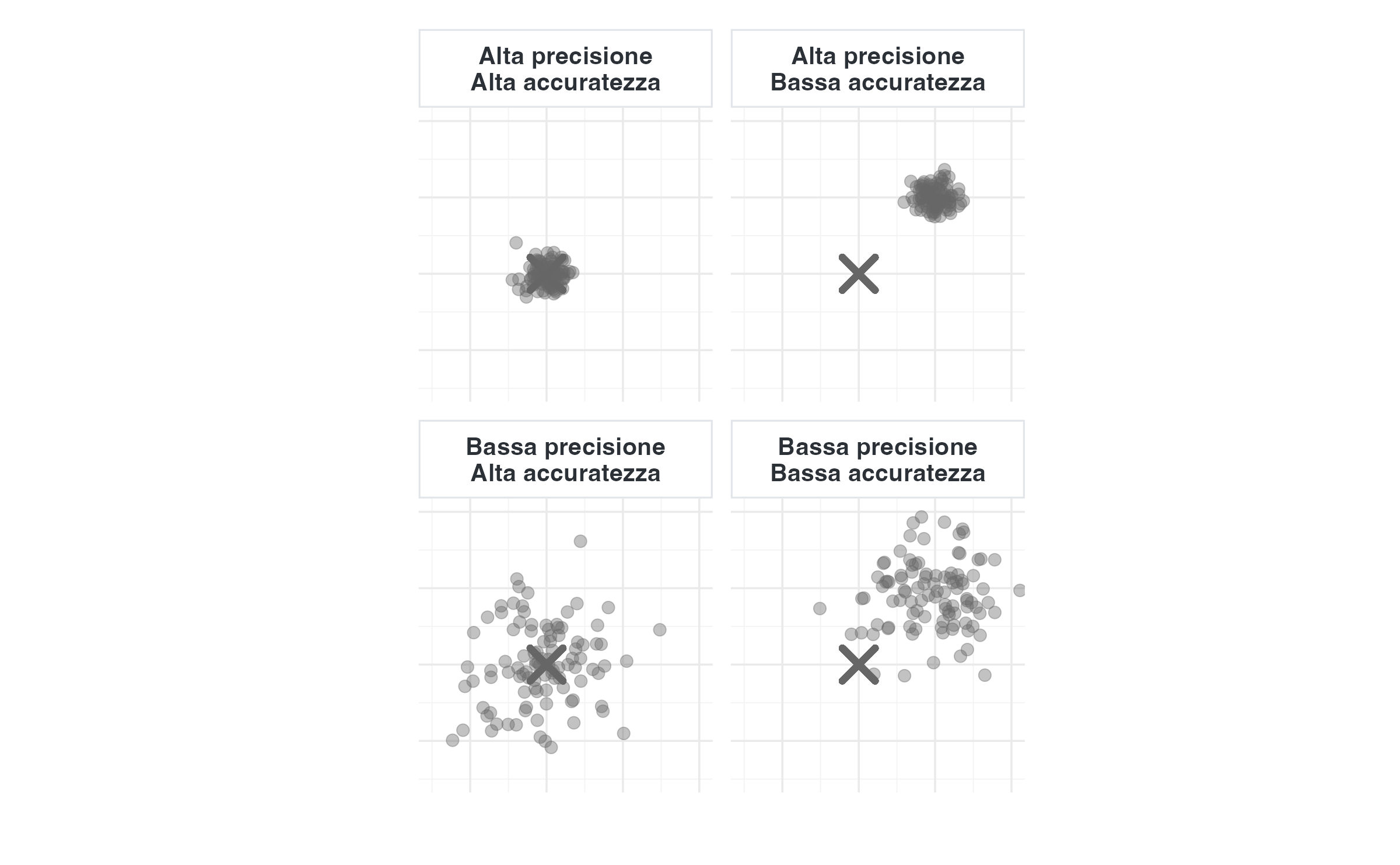
La situazione più insidiosa si verifica quando un’elevata precisione si accompagna a una bassa accuratezza. In questo caso, l’analisi produce intervalli di credibilità molto stretti — che suggeriscono grande certezza — attorno a valori che sono invece sistematicamente distorti.
Un campione numericamente grande ma affetto da bias può essere più pericoloso di un campione piccolo ma corretto: consolida conclusioni errate con un’apparenza di rigore e affidabilità scientifica.
15.7.4 Come mitigare questi limiti
La consapevolezza dei limiti dell’inferenza statistica suggerisce alcune buone pratiche fondamentali.
Progettazione metodologica rigorosa La prevenzione dei bias avviene principalmente prima dell’analisi dei dati: campionamento appropriato, randomizzazione, protocolli standardizzati e strumenti validati sono insostituibili.
Analisi di sensibilità L’approccio bayesiano permette di esplorare esplicitamente l’impatto di ipotesi alternative e di valutare quanto le conclusioni dipendano da assunzioni potenzialmente discutibili.
Trasparenza epistemica È essenziale comunicare chiaramente che gli intervalli di credibilità quantificano solo l’incertezza campionaria. La valutazione critica della qualità dei dati e del disegno di ricerca resta una responsabilità centrale del ricercatore.
Riflessioni conclusive
Questo capitolo ha messo in luce il legame profondo tra il comportamento delle statistiche campionarie e il meccanismo dell’aggiornamento bayesiano. Le proprietà matematiche della media campionaria non sono semplici risultati tecnici, ma costituiscono il fondamento che spiega perché la verosimiglianza e la distribuzione a posteriori assumono le forme osservate.
In particolare, il fatto che la media campionaria sia centrata sul valore del parametro di interesse e che la sua variabilità diminuisca con l’aumentare del numero di osservazioni determina la forma della funzione di verosimiglianza: essa è centrata sul valore osservato e diventa progressivamente più concentrata man mano che l’evidenza empirica cresce. Queste stesse proprietà governano il modo in cui la distribuzione a posteriori risponde ai dati.
Nel caso gaussiano, l’aggiornamento bayesiano assume una forma particolarmente trasparente: la precisione a posteriori è la somma delle precisioni del prior e dei dati, mentre la media a posteriori è una media ponderata delle due fonti di informazione. Grazie al Teorema del Limite Centrale, questo schema si estende in modo approssimato a una vasta classe di modelli, giustificando l’uso dell’approssimazione normale per campioni sufficientemente ampi.
La Legge dei Grandi Numeri garantisce la consistenza dell’inferenza bayesiana: quando l’evidenza empirica diventa abbondante, la distribuzione a posteriori si concentra attorno al valore vero del parametro, indipendentemente dalla distribuzione a priori adottata, purché essa non lo escluda a priori. Questo risultato conferisce una solida robustezza epistemica al metodo bayesiano: nel lungo periodo, i dati prevalgono sulle convinzioni iniziali.
Il Teorema del Limite Centrale spiega inoltre perché la forma normale emerga così frequentemente nella distribuzione a posteriori per grandi campioni, fornendo il fondamento teorico di molte approssimazioni pratiche utilizzate nell’inferenza statistica.
È tuttavia essenziale riconoscere i limiti intrinseci di questi risultati. Tutte le proprietà discusse riguardano esclusivamente l’incertezza dovuta al campionamento casuale. Esse non possono correggere né compensare distorsioni sistematiche legate al disegno di ricerca, alla selezione del campione o agli strumenti di misura. La precisione statistica, quindi, non deve mai essere confusa con la validità scientifica delle conclusioni.
Nei capitoli successivi del manuale principale, questi principi teorici verranno utilizzati in modo operativo nella costruzione, stima e interpretazione di modelli bayesiani applicati alla ricerca psicologica. Il ruolo di questo companion è fornire le basi concettuali necessarie per comprendere perché tali modelli funzionano e in quali condizioni le loro inferenze possono essere considerate affidabili.
Punti chiave da ricordare
Concetti essenziali di questo capitolo:
-
Score function (funzione punteggio)
- \(S(\theta) = \frac{\partial}{\partial\theta}\ell(\theta) = \frac{\partial}{\partial\theta}\log L(\theta)\)
- Pendenza della log-verosimiglianza
- \(S(\hat{\theta}_{\text{MLE}}) = 0\) (condizione del primo ordine per massimo)
- Intuitivamente: “direzione di maggiore crescita della verosimiglianza”
-
Informazione di Fisher
- \(I(\theta) = -\mathbb{E}\left[\frac{\partial^2}{\partial\theta^2}\ell(\theta)\right] = \mathbb{E}[S(\theta)^2]\)
- Quantifica “quanta informazione sul parametro fornisce un’osservazione”
- Curvatura della log-verosimiglianza al punto vero
- \(I_n(\theta) = n \cdot I(\theta)\) per \(n\) osservazioni i.i.d. (informazione si accumula!)
-
Normalità asintotica della MLE
- Per \(n\) grande: \(\hat{\theta}_{\text{MLE}} \approx \mathcal{N}\left(\theta_{\text{vero}}, \frac{1}{I_n(\theta)}\right)\)
- La verosimiglianza diventa approssimativamente normale attorno alla MLE
- Permette approssimazioni gaussiane della posterior (approssimazione di Laplace)
-
Prior coniugati
- Prior e verosimiglianza “coniugati” → posterior della stessa famiglia del prior
- Beta-Binomiale: \(\text{Beta}(\alpha,\beta) + \text{Bin}(n,\theta) \to \text{Beta}(\alpha+k, \beta+n-k)\)
- Normale-Normale: prior Normale + dati Normali → posterior Normale
- Gamma-Poisson: prior Gamma + dati Poisson → posterior Gamma
- Enormemente semplifica i calcoli (forma chiusa!)
-
Interpretazione parametri coniugati
- Beta(\(\alpha, \beta\)): \(\alpha-1\) successi pregressi, \(\beta-1\) fallimenti pregressi
- Gamma(\(\alpha, \beta\)): \(\alpha\) eventi osservati in tempo \(\beta\)
- Parametri prior = “dimensione campionaria equivalente” delle credenze iniziali
-
Aggiornamento sequenziale
- Posterior(oggi) diventa prior(domani)
- Con coniugazione: aggiornare parametri sequenzialmente = aggiornare con tutti i dati insieme
- Proprietà di coerenza temporale: l’ordine dei dati non conta
-
Regola della precisione
- Precisione posteriore = Precisione prior + Precisione likelihood
- \(\tau_{\text{post}} = \tau_{\text{prior}} + \tau_{\text{data}}\)
- Per prior deboli: \(\tau_{\text{post}} \approx \tau_{\text{data}}\) (posterior dominata dai dati)
-
Quando la coniugazione non è disponibile
- Approssimazioni: normale asintotica, approssimazione di Laplace
- Metodi computazionali: MCMC, variational inference
- Prior non coniugati permettono maggiore flessibilità ma richiedono calcolo numerico
Formule da ricordare:
Score function: \[ S(\theta) = \frac{\partial}{\partial\theta}\log L(\theta), \quad S(\hat{\theta}_{\text{MLE}}) = 0 \]
Informazione di Fisher: \[ I(\theta) = -\mathbb{E}\left[\frac{\partial^2}{\partial\theta^2}\log L(\theta)\right] = \mathbb{E}[S(\theta)^2] \]
Informazione per \(n\) osservazioni i.i.d.: \[ I_n(\theta) = n \cdot I(\theta) \]
Normalità asintotica MLE: \[ \hat{\theta}_{\text{MLE}} \xrightarrow{d} \mathcal{N}\left(\theta, \frac{1}{I_n(\theta)}\right) \]
Aggiornamento Beta-Binomiale: \[ \text{Beta}(\alpha, \beta) \xrightarrow{k/n} \text{Beta}(\alpha+k, \beta+n-k) \]
Aggiornamento Normale-Normale (media): \[ \mathcal{N}(\mu_0, \sigma_0^2) \xrightarrow{\bar{x}, n} \mathcal{N}\left(\frac{\tau_0\mu_0 + n\tau\bar{x}}{\tau_0 + n\tau}, \frac{1}{\tau_0 + n\tau}\right) \] dove \(\tau = 1/\sigma^2\) è la precisione.
Aggiornamento Gamma-Poisson: \[ \text{Gamma}(\alpha, \beta) \xrightarrow{\sum x_i, n} \text{Gamma}(\alpha + \sum x_i, \beta + n) \]
Coppie coniugate principali:
| Verosimiglianza | Prior coniugato | Posterior | Parametro |
|---|---|---|---|
| Binomiale | Beta | Beta | Proporzione \(\theta\) |
| Normale (var nota) | Normale | Normale | Media \(\mu\) |
| Normale (media nota) | Gamma | Gamma | Precisione \(\tau\) |
| Poisson | Gamma | Gamma | Rate \(\lambda\) |
| Esponenziale | Gamma | Gamma | Rate \(\lambda\) |
Proprietà critiche:
- Informazione di Fisher cresce linearmente con \(n\)
- Coniugazione preserva la famiglia parametrica
- Prior deboli → posterior dominata dai dati
- Prior informativi → sintesi ponderata
- Aggiornamento sequenziale = aggiornamento batch (con coniugazione)
Conclusione del modulo:
Questo capitolo conclude il modulo di richiamo della teoria della probabilità. Abbiamo costruito un percorso completo: dall’interpretazione bayesiana della probabilità agli assiomi di coerenza, dalle variabili casuali alle distribuzioni parametriche, dalla verosimiglianza all’aggiornamento bayesiano. Questi fondamenti costituiscono la base concettuale e operativa per l’inferenza bayesiana presentata nel manuale principale Inferenza bayesiana in psicologia: Ragionare con l’incertezza.
Per il manuale principale:
Il manuale UTET approfondisce: modelli gerarchici, confronto di modelli, inferenza decisionale, metodi computazionali (MCMC, HMC, Stan), regressione bayesiana, modelli di mistura, analisi di mediazione e moderazione, e applicazioni psicologiche avanzate.
sessionInfo()
#> R version 4.5.2 (2025-10-31)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Tahoe 26.2
#>
#> Matrix products: default
#> BLAS: /System/Library/Frameworks/Accelerate.framework/Versions/A/Frameworks/vecLib.framework/Versions/A/libBLAS.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
#>
#> locale:
#> [1] C.UTF-8/UTF-8/C.UTF-8/C/C.UTF-8/C.UTF-8
#>
#> time zone: Europe/Rome
#> tzcode source: internal
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] ragg_1.5.0 tinytable_0.15.2 withr_3.0.2
#> [4] systemfonts_1.3.1 patchwork_1.3.2 ggdist_3.3.3
#> [7] tidybayes_3.0.7 bayesplot_1.15.0 ggplot2_4.0.1
#> [10] reliabilitydiag_0.2.1 priorsense_1.2.0 posterior_1.6.1
#> [13] loo_2.9.0 rstan_2.32.7 StanHeaders_2.32.10
#> [16] brms_2.23.0 Rcpp_1.1.1 sessioninfo_1.2.3
#> [19] conflicted_1.2.0 janitor_2.2.1 matrixStats_1.5.0
#> [22] modelr_0.1.11 tibble_3.3.1 dplyr_1.1.4
#> [25] tidyr_1.3.2 rio_1.2.4 here_1.0.2
#>
#> loaded via a namespace (and not attached):
#> [1] svUnit_1.0.8 tidyselect_1.2.1 farver_2.1.2
#> [4] S7_0.2.1 fastmap_1.2.0 TH.data_1.1-5
#> [7] tensorA_0.36.2.1 digest_0.6.39 timechange_0.3.0
#> [10] estimability_1.5.1 lifecycle_1.0.5 survival_3.8-3
#> [13] magrittr_2.0.4 compiler_4.5.2 rlang_1.1.7
#> [16] tools_4.5.2 yaml_2.3.12 knitr_1.51
#> [19] labeling_0.4.3 bridgesampling_1.2-1 htmlwidgets_1.6.4
#> [22] curl_7.0.0 pkgbuild_1.4.8 RColorBrewer_1.1-3
#> [25] abind_1.4-8 multcomp_1.4-29 purrr_1.2.1
#> [28] grid_4.5.2 stats4_4.5.2 colorspace_2.1-2
#> [31] xtable_1.8-4 inline_0.3.21 emmeans_2.0.1
#> [34] scales_1.4.0 MASS_7.3-65 cli_3.6.5
#> [37] mvtnorm_1.3-3 rmarkdown_2.30 generics_0.1.4
#> [40] otel_0.2.0 RcppParallel_5.1.11-1 cachem_1.1.0
#> [43] stringr_1.6.0 splines_4.5.2 parallel_4.5.2
#> [46] vctrs_0.6.5 V8_8.0.1 Matrix_1.7-4
#> [49] sandwich_3.1-1 jsonlite_2.0.0 arrayhelpers_1.1-0
#> [52] glue_1.8.0 codetools_0.2-20 distributional_0.6.0
#> [55] lubridate_1.9.4 stringi_1.8.7 gtable_0.3.6
#> [58] QuickJSR_1.8.1 pillar_1.11.1 htmltools_0.5.9
#> [61] Brobdingnag_1.2-9 R6_2.6.1 textshaping_1.0.4
#> [64] rprojroot_2.1.1 evaluate_1.0.5 lattice_0.22-7
#> [67] backports_1.5.0 memoise_2.0.1 broom_1.0.11
#> [70] snakecase_0.11.1 rstantools_2.6.0 gridExtra_2.3
#> [73] coda_0.19-4.1 nlme_3.1-168 checkmate_2.3.3
#> [76] xfun_0.55 zoo_1.8-15 pkgconfig_2.0.3Bibliografia
Questo principio, che formalizza il modo ottimale di combinare informazioni incerte, ha ispirato e motivato una vasta quantità di ricerche empiriche nel campo delle Scienze della Visione. In particolare, ci si è chiesti se il sistema visivo umano si comporti come un “osservatore ideale”, ovvero se integri le informazioni in modo statisticamente ottimale e coerente con l’integrazione bayesiana. Questa domanda ha motivato molti studi condotti per comprendere come un individuo integri segnali visivi che possono essere parzialmente discordanti, come ad esempio quelli provenienti dalla stereopsi e dalla parallasse di movimento (Domini & Caudek, 2011).↩︎