12 Distribuzioni di variabili casuali discrete
Introduzione
Come discusso nel Capitolo 11, le distribuzioni di probabilità sono strumenti epistemici che permettono di rappresentare formalmente l’incertezza. In questo capitolo ci concentreremo sulle distribuzioni discrete, utilizzate per modellare fenomeni con esiti numerabili, come conteggi, scelte categoriali ed eventi binari.
Nel framework bayesiano, le distribuzioni discrete svolgono tre ruoli strettamente interconnessi. In qualità di verosimiglianza, descrivono il modo in cui i dati osservati vengono generati in funzione di un determinato valore del parametro. Come distribuzioni a priori e a posteriori, rappresentano le nostre credenze sui parametri prima e dopo l’osservazione dei dati. Infine, come distribuzioni predittive, esprimono le nostre aspettative riguardo alle osservazioni future, integrando l’incertezza sui parametri con la struttura del modello.
In questa prospettiva, i parametri delle distribuzioni, come \(p\) nella distribuzione binomiale o \(\lambda\) nella distribuzione di Poisson, non sono valori da “scoprire”, ma quantità su cui siamo più o meno incerti. L’inferenza bayesiana permette di descrivere questa incertezza e di aggiornarla in modo coerente sulla base dei dati osservati.
Una nota importante: quando presentiamo le distribuzioni discrete come Bernoulli, Binomiale e Poisson, lavoriamo inizialmente con la verosimiglianza condizionale \(P(\text{dati}|\theta)\), dove \(\theta\) (es. \(p\) o \(\lambda\)) è condizionato su un valore specifico. Questo non significa che \(\theta\) sia “noto” o “fisso” in senso ontologico, ma solo che stiamo calcolando la probabilità dei dati per un dato valore del parametro. In seguito vedremo come integrare l’incertezza su \(\theta\) attraverso le distribuzioni predittive, dove \(\theta\) viene marginalizzato anziché condizionato.
Per seguire questo capitolo è necessario aver letto:
- Capitolo 6
- Capitolo 7
- Capitolo 8
- Capitolo 11 — fondamentale
Questo capitolo studia in dettaglio le distribuzioni discrete (Bernoulli, Binomiale, Poisson) essenziali per modellare conteggi, eventi binari e fenomeni psicologici discreti.
Conoscenze matematiche richieste:
- Appendice E - per coefficienti binomiali
12.1 Funzioni R per le distribuzioni
Per ogni distribuzione, R fornisce quattro funzioni con prefissi standardizzati:
# Esempio con binomiale: n=10 prove, p=0.6 probabilità di successo
# d = densità (massa di probabilità)
dbinom(7, size = 10, prob = 0.6) # P(X = 7)
#> [1] 0.215
# p = probabilità cumulativa
pbinom(7, size = 10, prob = 0.6) # P(X ≤ 7)
#> [1] 0.833
# q = quantile
qbinom(0.95, size = 10, prob = 0.6) # 95° percentile
#> [1] 8
# r = generazione casuale
rbinom(5, size = 10, prob = 0.6) # 5 simulazioni
#> [1] 8 6 7 7 5Nell’inferenza bayesiana, la funzione d viene utilizzata per calcolare la verosimiglianza, mentre la funzione r permette di simulare dalla distribuzione predittiva.
12.2 Distribuzione uniforme discreta
12.2.1 Definizione
Definizione 12.1 Una variabile casuale \(X\) ha distribuzione uniforme discreta su \({1,\ldots,N}\) se a ciascun valore possibile viene assegnata la stessa probabilità:
\[ X \sim \text{Uniforme-Discreta}(N), \qquad P(X = x) = \frac{1}{N} \quad \text{per } x \in {1,\ldots,N}. \]
Proprietà: \[ \mathbb{E}(X) = \frac{N+1}{2}, \qquad \mathbb{V}(X) = \frac{N^2 - 1}{12}. \]
12.2.1.1 Interpretazione epistemica
La distribuzione uniforme discreta implementa il principio di indifferenza: quando non vi sono informazioni che discriminino tra le alternative, tutte le possibilità sono trattate come equiprobabili. La distribuzione uniforme riflette uno stato informativo simmetrico rispetto agli esiti, non una caratteristica oggettiva del sistema osservato.
12.2.2 Ruolo nell’inferenza bayesiana
Nel paradigma bayesiano, la distribuzione uniforme discreta svolge un ruolo fondamentale come distribuzione a priori non informativa su spazi parametrici finiti. Quando ci troviamo di fronte a un insieme di \(K\) ipotesi o modelli alternativi, e non disponiamo di alcuna informazione preliminare che favorisca specifiche alternative, la scelta più neutrale consiste nell’attribuire a ciascuna ipotesi la medesima probabilità iniziale:
\[ P(M_k) = \frac{1}{K}, \qquad k = 1, \ldots, K. \]
Questa assegnazione formalizza esplicitamente l’indifferenza epistemica tra le opzioni disponibili, assicurando che l’evidenza empirica derivante dai dati sia l’unico fattore a guidare l’aggiornamento delle credenze attraverso il teorema di Bayes.
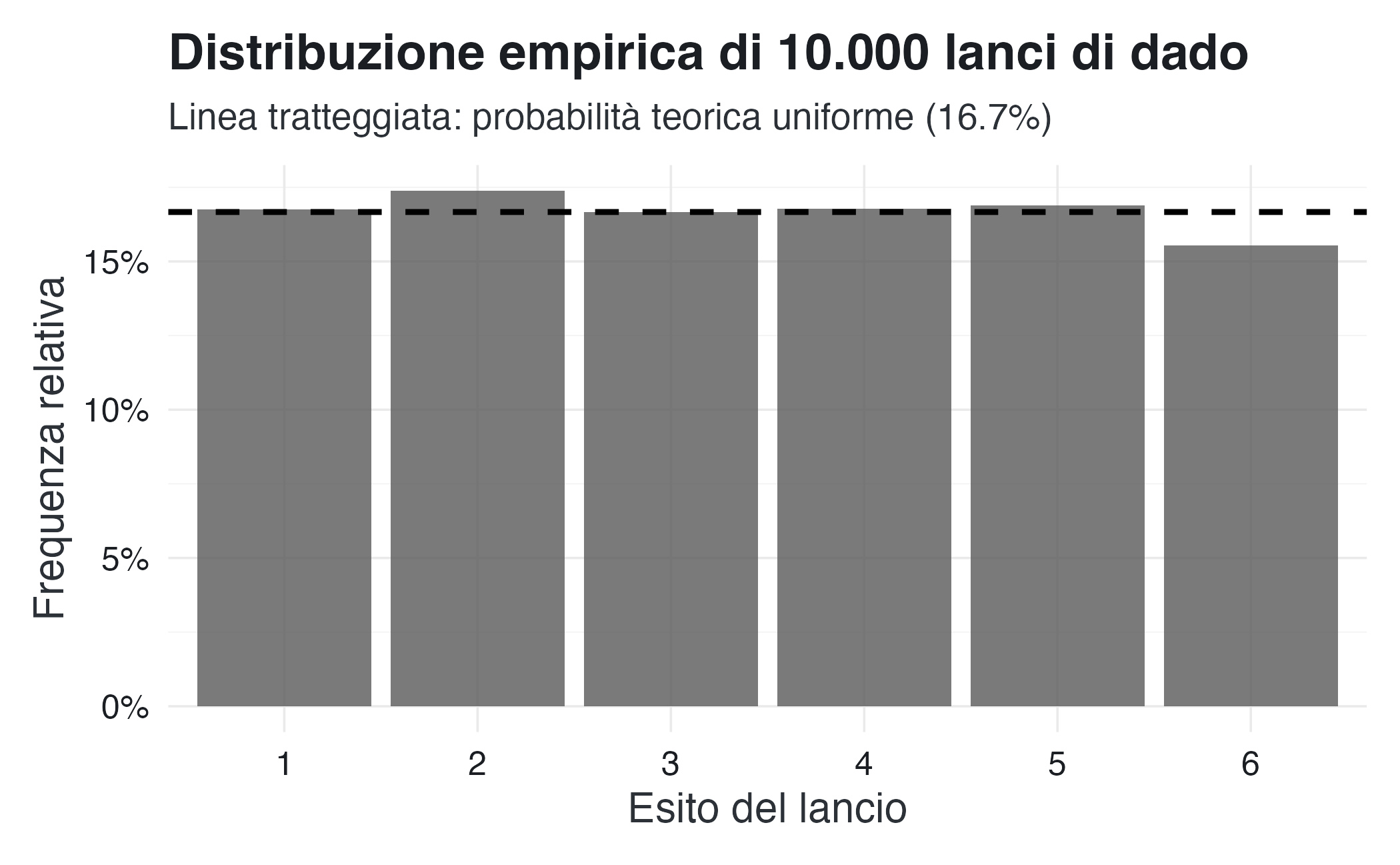
Il lancio di un dado a sei facce rappresenta l’esempio paradigmatico di distribuzione uniforme discreta. Nell’ipotesi di perfetta simmetria del dado, ogni esito \(\{1, 2, 3, 4, 5, 6\}\) ha probabilità pari a \(1/6\).
# Confronto tra valori teorici ed empirici
media_teorica <- (N + 1) / 2
varianza_teorica <- (N^2 - 1) / 12
cat("Confronto statistico:\n")
#> Confronto statistico:
cat(" • Media:\n")
#> • Media:
cat(" Teorica:", media_teorica, "\n")
#> Teorica: 3.5
cat(" Empirica:", round(mean(lanci), 4), "\n\n")
#> Empirica: 3.46
cat(" • Varianza:\n")
#> • Varianza:
cat(" Teorica:", round(varianza_teorica, 4), "\n")
#> Teorica: 2.92
cat(" Empirica:", round(var(lanci), 4))
#> Empirica: 2.87# Visualizzazione della distribuzione empirica
ggplot(data.frame(Esito = lanci), aes(x = factor(Esito))) +
geom_bar(aes(y = ..prop.., group = 1), alpha = 0.8) +
geom_hline(yintercept = 1/N, linetype = "dashed", linewidth = 1) +
scale_y_continuous(labels = scales::percent_format()) +
scale_fill_qualitative() +
labs(
title = "Distribuzione empirica di 10.000 lanci di dado",
subtitle = paste("Linea tratteggiata: probabilità teorica uniforme (",
round(100/N, 1), "%)", sep = ""),
x = "Esito del lancio",
y = "Frequenza relativa"
) 
12.3 Distribuzione di Bernoulli
12.3.1 Definizione
Definizione 12.2 Una variabile casuale \(X\) segue una distribuzione di Bernoulli se può assumere solo due valori possibili, convenzionalmente codificati come 1 (“successo”) e 0 (“insuccesso”). La probabilità di successo è indicata con \(p\), mentre la probabilità di insuccesso è \(1 - p\):
\[ X \sim \text{Bernoulli}(p), \qquad P(X = x) = p^x (1-p)^{1-x}, \quad x \in {0,1}. \]
Proprietà: \[ \mathbb{E}(X) = p, \qquad \mathbb{V}(X) = p(1-p). \]
La distribuzione di Bernoulli rappresenta il modello probabilistico più semplice per descrivere fenomeni aleatori dicotomici, nei quali ogni osservazione corrisponde a un singolo esito binario.
12.3.1.1 Interpretazione epistemica
Il parametro \(p\) rappresenta la probabilità associata all’esito etichettato come “successo”. Dal punto di vista epistemico, (p) può essere interpretato come il grado di credenza o l’informazione disponibile circa il verificarsi di tale esito, prima dell’osservazione dei dati.
In ambito psicologico e sperimentale, la distribuzione di Bernoulli è frequentemente utilizzata per modellare eventi come risposte corrette/errate, presenza/assenza di un comportamento, decisioni sì/no o superamento/fallimento di una prova. In tutti questi casi, l’incertezza riguarda un singolo evento e non una sequenza di prove.
12.3.2 Ruolo nell’inferenza bayesiana
La distribuzione di Bernoulli costituisce il modello di base per l’analisi di dati binari ed è un elemento fondamentale nell’inferenza bayesiana. In particolare, essa descrive il meccanismo generativo di ciascuna osservazione individuale, mentre l’aggregazione di più prove indipendenti conduce naturalmente alla distribuzione binomiale, trattata nel paragrafo successivo.
Nell’approccio bayesiano, il parametro \(p\) è considerato una variabile casuale e viene tipicamente modellato mediante una distribuzione Beta, che funge da prior coniugato. Questa scelta consente di aggiornare le credenze su \(p\) in modo analitico, combinando informazione a priori e dati osservati in maniera coerente e trasparente.
Consideriamo un test diagnostico con sensibilità pari a 0.85, ossia con probabilità \(p = 0.85\) di fornire un risultato positivo quando la condizione è presente. Ogni singolo esito del test può essere modellato come una variabile di Bernoulli.
cat("Valore teorico:", p_sens)
#> Valore teorico: 0.85La simulazione mostra che, su un numero elevato di osservazioni, la proporzione campionaria di esiti positivi si avvicina al valore del parametro \(p\). Tuttavia, per campioni più piccoli, tale proporzione può variare sensibilmente, riflettendo l’incertezza intrinseca associata alle singole osservazioni binarie.
12.4 Distribuzione binomiale
12.4.1 Dalla Bernoulli alla binomiale
La distribuzione binomiale nasce come estensione naturale della distribuzione di Bernoulli al caso di più osservazioni indipendenti. Comprenderne la costruzione passo per passo aiuta a chiarire il significato della sua formula e delle sue componenti.
Supponiamo di osservare \(n\) prove indipendenti, ciascuna caratterizzata da due soli esiti possibili:
- successo \(1\), con probabilità \(p\);
- insuccesso \(0\), con probabilità \(1 - p\).
L’obiettivo è descrivere la probabilità di osservare un determinato numero totale di successi al termine delle \(n\) prove.
12.4.2 Passo 1 — Probabilità di una sequenza specifica
Consideriamo una sequenza ordinata di \(n\) esiti che contenga esattamente \(k\) successi e \(n-k\) insuccessi. Poiché le prove sono indipendenti, la probabilità di osservare quella specifica sequenza è data dal prodotto delle probabilità dei singoli esiti:
\[ p^k (1-p)^{n-k}. \] Questa probabilità è identica per qualsiasi sequenza che presenti \(k\) successi, indipendentemente dall’ordine in cui essi compaiono.
12.4.3 Passo 2 — Conteggio delle sequenze possibili
Nella maggior parte delle applicazioni non interessa l’ordine degli esiti, ma solo quanti successi si verificano complessivamente. È quindi necessario contare quante sequenze distinte di lunghezza \(n\) contengono esattamente \(k\) successi.
Questo numero è fornito dal coefficiente binomiale:
\[ \binom{n}{k}, \] che rappresenta il numero di modi in cui è possibile scegliere \(k\) posizioni di successo tra le \(n\) prove disponibili.
12.4.4 Passo 3 — Probabilità di \(k\) successi
Le sequenze che contengono \(k\) successi sono:
- tutte equiprobabili;
- mutuamente esclusive.
La probabilità di osservare esattamente \(k\) successi è quindi ottenuta sommando le probabilità di tutte queste sequenze:
\[ P(X = k) = \binom{n}{k} p^k (1-p)^{n-k}. \]
Questa espressione costituisce la funzione di massa di probabilità della distribuzione binomiale.
La distribuzione binomiale nasce dalla combinazione di due componenti fondamentali:
Componente probabilistica \(p^k (1-p)^{n-k}\): probabilità associata a una specifica configurazione di successi e insuccessi.
Componente combinatoria \(\binom{n}{k}\): numero di configurazioni distinte che producono lo stesso numero totale di successi.
La probabilità binomiale è il prodotto di questi due fattori.
12.4.5 Definizione
Definizione 12.3 Una variabile casuale \(X\) che rappresenta il numero di successi osservati in \(n\) prove indipendenti di Bernoulli, ciascuna con probabilità di successo \(p\), segue una distribuzione binomiale:
\[ X \sim \mathrm{Binomiale}(n, p), \qquad P(X = k) = \binom{n}{k} p^k (1-p)^{n-k}, \quad k = 0,1,\dots,n. \]
Momenti principali: \[ \mathbb{E}(X) = np, \qquad \mathbb{V}(X) = np(1-p). \]
12.4.5.1 Interpretazione epistemica
La distribuzione binomiale rappresenta le nostre credenze sul numero di successi quando:
- il numero di prove \(n\) è noto;
- il parametro \(p\) esprime l’incertezza sulla probabilità di successo di ciascuna singola prova.
Il coefficiente binomiale riflette il fatto che molti pattern distinti di esiti possono condurre allo stesso conteggio complessivo di successi.
12.4.6 Ruolo nell’inferenza bayesiana
La distribuzione binomiale costituisce la verosimiglianza fondamentale per dati binari aggregati. Osservati \(y\) successi su \(n\) prove, la verosimiglianza per il parametro \(p\) è:
\[ L(p \mid y,n) \propto p^y (1-p)^{n-y}. \]
Assumendo una prior beta:
\[ p \sim \mathrm{Beta}(\alpha,\beta), \] la distribuzione a posteriori risulta ancora una beta:
\[ p \mid y \sim \mathrm{Beta}(\alpha + y,\; \beta + n - y). \]
Questa relazione di coniugazione rende l’aggiornamento delle credenze particolarmente semplice: i dati osservati si traducono in un incremento diretto degli pseudo-conteggi associati alla prior.
# Dati osservati: 23 successi su 30 prove
n <- 30
y <- 23
# Prior: Beta(2, 2) - moderatamente informativa, centrata su 0.5
alpha_prior <- 2
beta_prior <- 2
# Posterior: Beta(25, 9)
alpha_post <- alpha_prior + y
beta_post <- beta_prior + (n - y)
# Visualizzazione
p_seq <- seq(0, 1, length.out = 1000)
df <- data.frame(
p = rep(p_seq, 2),
densita = c(dbeta(p_seq, alpha_prior, beta_prior),
dbeta(p_seq, alpha_post, beta_post)),
tipo = rep(c("Prior Beta(2,2)", "Posterior Beta(25,9)"), each = length(p_seq))
)
ggplot(df, aes(x = p, y = densita, color = tipo)) +
geom_line(linewidth = 1.2) +
scale_fill_qualitative() +
labs(
title = "Aggiornamento Bayesiano: Beta-Binomiale",
subtitle = "23 successi su 30 prove",
x = "p", y = "Densità"
) 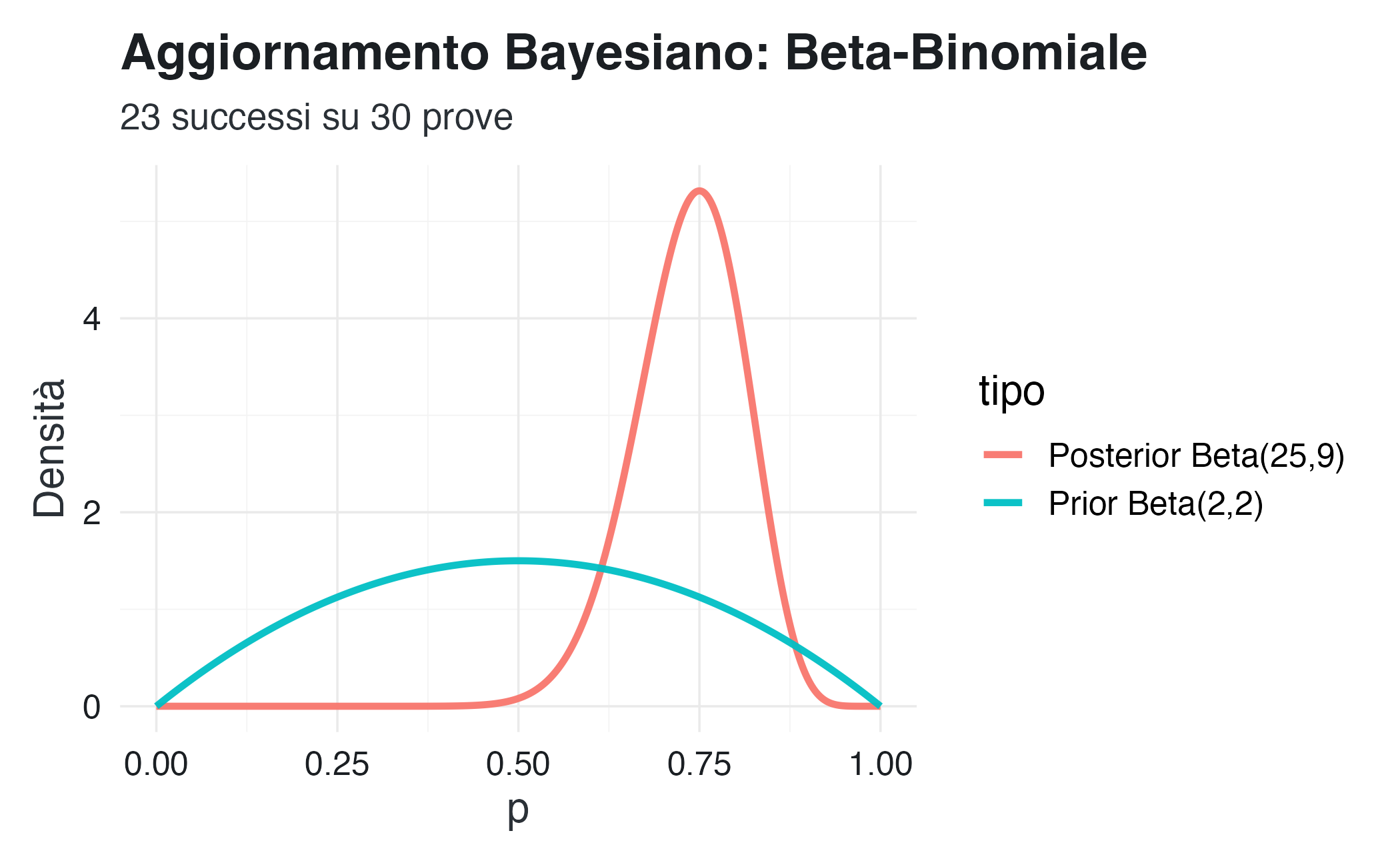
La distribuzione a posteriori si concentra attorno a \(p \approx 0.74\), mostrando una notevole riduzione dell’incertezza rispetto alla prior. Ciò riflette l’aggiornamento coerente delle credenze alla luce dei 23 successi osservati.
12.5 Distribuzione di Poisson
12.5.1 Quando ha senso usare la distribuzione di Poisson
La distribuzione di Poisson viene utilizzata per modellare il numero di eventi che si verificano in un intervallo di tempo o di spazio, quando sono soddisfatte le seguenti condizioni:
- gli eventi sono rari rispetto all’ampiezza dell’intervallo considerato;
- gli eventi si verificano indipendentemente l’uno dall’altro;
- la probabilità che due o più eventi avvengano simultaneamente è trascurabile.
Esempi tipici in psicologia includono il numero di attacchi di panico in un mese, il numero di errori in un compito di attenzione sostenuta (es. CPT), il numero di comportamenti autolesionistici in una settimana, o il numero di risvegli notturni in pazienti con disturbi del sonno.
12.5.2 Definizione
Definizione 12.4 Una variabile casuale \(Y\) segue una distribuzione di Poisson con parametro \(\lambda > 0\) se la probabilità di osservare \(y\) eventi è:
\[ Y \sim \text{Poisson}(\lambda), \qquad P(Y = y) = \frac{\lambda^y e^{-\lambda}}{y!}, \quad y = 0, 1, 2, \ldots \]
Proprietà caratteristica: \[ \mathbb{E}(Y) = \mathbb{V}(Y) = \lambda. \]
12.5.2.1 Interpretazione epistemica
Il parametro \(\lambda\) rappresenta il tasso medio atteso di occorrenza degli eventi nell’intervallo considerato. Ad esempio, affermare che \(\lambda = 0.7\) significa ritenere che, in media, ci si aspetti meno di un evento per intervallo, pur ammettendo che possano verificarsi anche eventi multipli.
La proprietà \(\mathbb{E}(Y) = \mathbb{V}(Y)\) prende il nome di equidispersione e costituisce un’assunzione forte del modello. Nei dati psicologici e comportamentali è tuttavia frequente osservare sovradispersione, ossia una varianza maggiore della media. In tali situazioni, la distribuzione di Poisson può risultare inadeguata e vengono spesso preferiti modelli più flessibili, come la distribuzione binomiale negativa.
La distribuzione di Poisson non modella se un evento si verifica, ma quante volte si verifica in un dato intervallo, assumendo eventi rari e indipendenti nel tempo o nello spazio.
12.5.3 Ruolo nell’inferenza bayesiana
Nel framework bayesiano, la distribuzione di Poisson svolge il ruolo di verosimiglianza per dati di conteggio. Il parametro \(\lambda\) è trattato come una quantità incerta, su cui esprimere una distribuzione a priori.
La distribuzione coniugata per \(\lambda\) è la distribuzione Gamma, che consente un aggiornamento analiticamente semplice delle credenze.
Coniugazione Gamma–Poisson. Se \[ \lambda \sim \text{Gamma}(\alpha, \beta), \] e osserviamo conteggi indipendenti \(y_1, \ldots, y_n\), allora la distribuzione a posteriori è:
\[ \lambda \mid \mathbf{y} \sim \text{Gamma}\left(\alpha + \sum_{i=1}^n y_i,\; \beta + n\right). \]
L’aggiornamento è intuitivo:
- il numero totale di eventi osservati aggiorna il parametro di forma;
- il numero di intervalli osservati aggiorna il parametro di scala (o tasso).
Un esempio classico di applicazione della distribuzione di Poisson è il dataset di von Bortkiewicz sui decessi causati da calci di cavallo nell’esercito prussiano, spesso citato come prototipo di processo con eventi rari e indipendenti.
# Dati storici
decessi <- 0:4
freq_oss <- c(109, 65, 22, 3, 1)
n_tot <- sum(freq_oss)
# Stima del tasso medio
lambda_mle <- sum(decessi * freq_oss) / n_tot
data.frame(
Decessi = decessi,
Frequenza_osservata = round(freq_oss / n_tot, 4),
Prob_Poisson = round(dpois(decessi, lambda = lambda_mle), 4)
)
#> Decessi Frequenza_osservata Prob_Poisson
#> 1 0 0.545 0.5434
#> 2 1 0.325 0.3314
#> 3 2 0.110 0.1011
#> 4 3 0.015 0.0206
#> 5 4 0.005 0.0031L’elevata corrispondenza tra le frequenze osservate e le probabilità teoriche suggerisce che il processo generativo sia compatibile con le assunzioni della distribuzione di Poisson.
12.5.4 Aggiornamento bayesiano del tasso
# Prior debolmente informativa
alpha_prior <- 0.5
beta_prior <- 1
# Totale eventi osservati
y_tot <- sum(decessi * freq_oss)
# Posterior
alpha_post <- alpha_prior + y_tot
beta_post <- beta_prior + n_tot
# Stima a posteriori
lambda_post <- alpha_post / beta_post
IC_95 <- qgamma(c(0.025, 0.975), alpha_post, beta_post)La distribuzione a posteriori fornisce una stima coerente del tasso di occorrenza e quantifica in modo esplicito l’incertezza residua sul parametro \(\lambda\).
Avvertenza per il lettore
Questa sezione introduce un concetto che verrà sviluppato in modo sistematico nei capitoli successivi. La sua comprensione completa richiede familiarità con:
- la distribuzione Beta (trattata nel prossimo capitolo),
- l’integrazione per marginalizzazione,
- le distribuzioni predittive e i modelli gerarchici.
È del tutto legittimo saltare questa sezione e tornarci dopo aver studiato le distribuzioni continue. È inclusa come anticipazione concettuale per il lettore curioso, ma non è necessaria per proseguire.
Da verosimiglianza condizionale a distribuzione predittiva
Quando modelliamo \(Y \sim \text{Binomiale}(n, p)\), lavoriamo tipicamente con la verosimiglianza condizionale:
\[ P(Y = k \mid p) = \binom{n}{k} p^k (1-p)^{n-k} \]
Questa formula ci dice: “Qual è la probabilità di osservare \(k\) successi, dato un valore specifico del parametro \(p\)?” Qui \(p\) è condizionato: stiamo calcolando la verosimiglianza per un particolare valore di \(p\), non perché \(p\) sia “noto” o “oggettivamente fisso”, ma perché questa è la struttura della verosimiglianza.
Tuttavia, nell’approccio bayesiano, \(p\) è una quantità incerta su cui abbiamo una distribuzione di credenza. Quando vogliamo fare previsioni sui dati futuri senza fissare un valore specifico di \(p\), dobbiamo integrare la nostra incertezza su \(p\) attraverso la sua distribuzione a priori.
Dalla condizionalità alla marginalizzazione
Se rappresentiamo la nostra incertezza su \(p\) con una distribuzione Beta:
\[ p \sim \text{Beta}(\alpha, \beta) \] e vogliamo calcolare la probabilità di osservare \(k\) successi integrando su tutti i possibili valori di \(p\), dobbiamo calcolare la distribuzione predittiva a priori:
\[ P(Y = k) = \int_0^1 P(Y = k \mid p) \cdot P(p) \, dp = \int_0^1 \binom{n}{k} p^k (1-p)^{n-k} \cdot \frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta)} p^{\alpha-1}(1-p)^{\beta-1} \, dp \]
Questo integrale, sebbene tecnicamente complesso, produce una forma chiusa nota come distribuzione beta-binomiale:
\[ Y \sim \text{BetaBinomiale}(n, \alpha, \beta) \] con funzione di massa:
\[ P(Y = k) = \binom{n}{k} \frac{B(k + \alpha, n - k + \beta)}{B(\alpha, \beta)} \] dove \(B(\cdot, \cdot)\) è la funzione beta.
Interpretazione epistemica
La transizione da binomiale a beta-binomiale riflette un cambiamento di prospettiva:
-
Verosimiglianza condizionale \(P(Y \mid p)\): “Quant’è probabile osservare \(k\) successi condizionando su un valore specifico \(p\)?”
- Risposta: distribuzione Binomiale
- \(p\) è trattato come parametro condizionato
-
Distribuzione predittiva \(P(Y)\): “Quant’è probabile osservare \(k\) successi prima di sapere quale sia il valore di \(p\)?”
- Risposta: distribuzione Beta-Binomiale
- \(p\) è marginalizzato (integrato via) per riflettere l’incertezza
Entrambe sono perfettamente coerenti con l’approccio bayesiano: nella prima condizioniamo su \(p\) per strutturare la verosimiglianza, nella seconda marginalizziamo su \(p\) per fare previsioni che tengano conto dell’incertezza sul parametro.
Simulazione in R
In R, la distribuzione beta-binomiale è disponibile tramite il pacchetto extraDistr:
# Simulazione: confronto tra binomiale (p fisso) e beta-binomiale (p incerto)
set.seed(42)
n <- 20 # numero di prove
# Scenario 1: Binomiale con p fissato a 0.3
# (come se sapessimo con certezza che p = 0.3)
p_fisso <- 0.3
y_bin <- rbinom(n = 10000, size = n, prob = p_fisso)
# Scenario 2: Beta-binomiale con p ~ Beta(3, 7)
# (rappresenta incertezza su p, con E[p] ≈ 0.3 ma varianza positiva)
alpha <- 3
beta <- 7
y_bb <- rbbinom(n = 10000, size = n, alpha = alpha, beta = beta)Confrontiamo le distribuzioni:
# Preparazione dati per visualizzazione
df_comparison <- data.frame(
k = 0:n,
Binomiale = dbinom(0:n, size = n, prob = p_fisso),
BetaBinomiale = dbbinom(0:n, size = n, alpha = alpha, beta = beta)
) |>
pivot_longer(cols = c(Binomiale, BetaBinomiale),
names_to = "Modello",
values_to = "Probabilità")
# Visualizzazione
ggplot(df_comparison, aes(x = k, y = Probabilità, fill = Modello)) +
geom_col(position = "dodge", alpha = 0.8) +
scale_fill_qualitative() +
labs(
title = "Confronto: Binomiale vs Beta-Binomiale",
subtitle = bquote("Binomiale:" ~ p == 0.3 ~ "(fisso)" ~ "|" ~
"Beta-Binomiale:" ~ p %~% Beta(3,7) ~ "(incerto)"),
x = "Numero di successi (k)",
y = "Probabilità P(Y = k)"
) +
theme(legend.position = "top")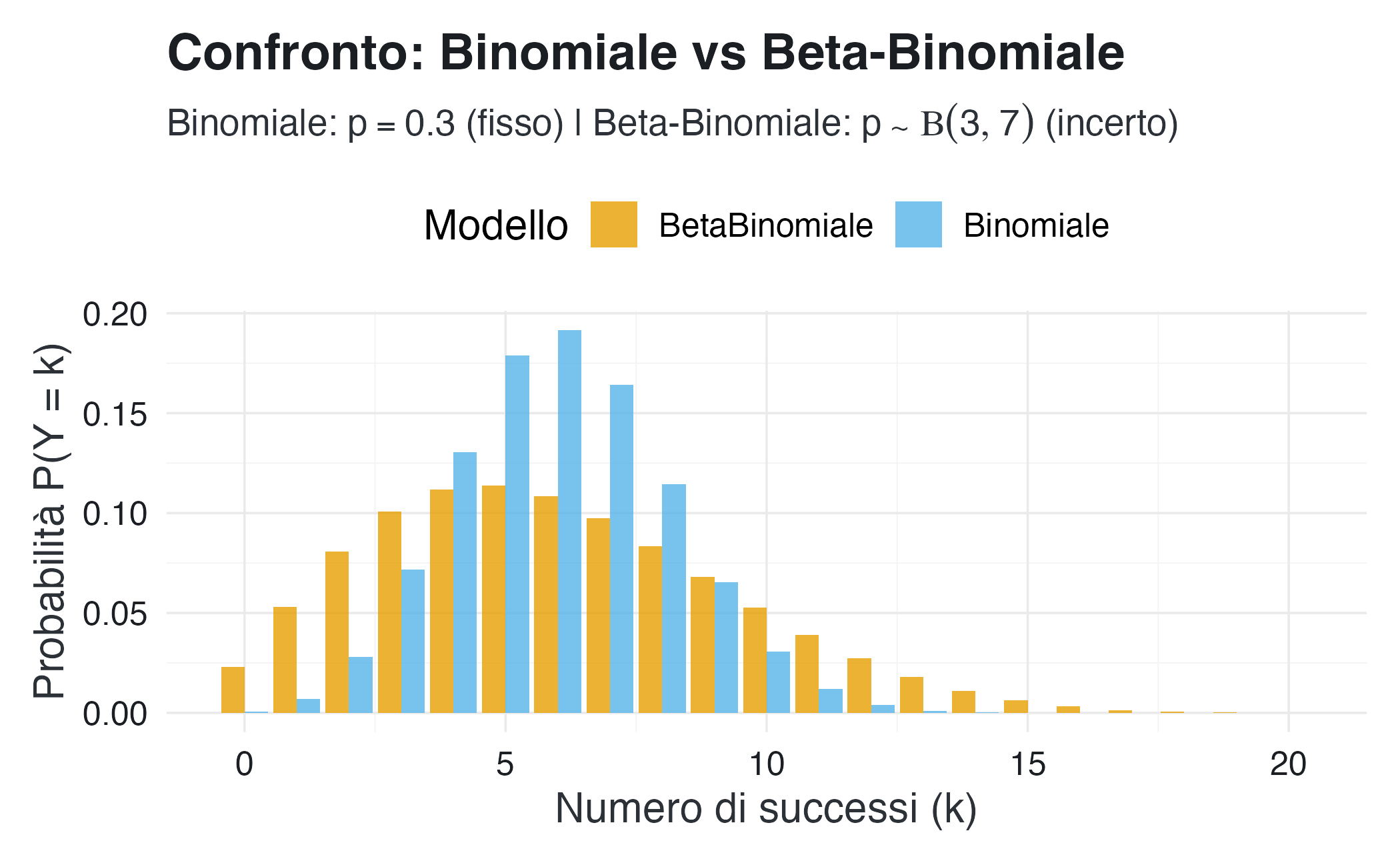
Osservazione chiave: la beta-binomiale presenta code più pesanti e una distribuzione più dispersa rispetto alla binomiale. Questo riflette l’ulteriore fonte di incertezza: non solo la variabilità campionaria (binomiale), ma anche l’incertezza sul valore del parametro \(p\) stesso.
La sovradispersione come firma dell’incertezza parametrica
Confrontiamo le varianze empiriche:
Interpretazione: la beta-binomiale anticipa una maggiore dispersione, poiché integra due fonti di incertezza:
- Variabilità campionaria: la fluttuazione casuale nel numero di successi (presente in entrambi i modelli).
- Incertezza parametrica: il fatto che non sappiamo esattamente quale sia il valore di \(p\) (presente solo nella beta-binomiale).
Questa “varianza extra” rispetto alla binomiale standard è detta sovradispersione ed è una caratteristica distintiva delle distribuzioni predittive.
Dove riapparirà nel manuale
La distribuzione beta-binomiale, e più in generale il concetto di distribuzione predittiva, ricomparirà in tre contesti fondamentali:
Distribuzioni predittive bayesiane, quando si vogliono prevedere nuove osservazioni integrando l’incertezza a posteriori sui parametri dopo aver osservato dati.
Sovradispersione nei dati empirici, quando la variabilità osservata eccede quella prevista dalla binomiale standard, segnalando che è necessario modellare l’eterogeneità tra unità di osservazione.
Modelli gerarchici, quando ogni unità (persona, gruppo, item) possiede il proprio parametro \(p_i\), estratto da una distribuzione comune \(\text{Beta}(\alpha, \beta)\).
Messaggio da portare con sé
La distribuzione beta-binomiale non introduce un nuovo tipo di fenomeno, ma un nuovo livello di rappresentazione dell’incertezza: quello relativo al parametro stesso. Passa dalla domanda “Cosa succede dato \(p\)?” alla domanda “Cosa succede quando non so esattamente quale sia \(p\)?”
Non è necessario padroneggiare ora i dettagli matematici: essi verranno ripresi e chiariti in modo sistematico nel capitolo dedicato alle distribuzioni continue (Capitolo 13) e nei capitoli dedicati alle distribuzioni predittive e ai modelli gerarchici del sito utet-companion.
Per il momento, è sufficiente:
- riconoscere che la beta-binomiale esiste;
- comprenderne il ruolo concettuale: marginalizzare l’incertezza sul parametro;
- ricordare che produce sovradispersione rispetto alla binomiale condizionale.
Questi concetti diventeranno centrali quando affronteremo l’inferenza bayesiana completa.
Riflessioni conclusive
Le distribuzioni discrete esaminate in questo capitolo costituiscono strumenti epistemici fondamentali per rappresentare e aggiornare le credenze relative a fenomeni caratterizzati da esiti numerabili. Ciascuna distribuzione incorpora assunzioni specifiche sul processo di generazione dei dati: la distribuzione uniforme discreta formalizza uno stato di indifferenza epistemica rispetto a un insieme finito di alternative; la distribuzione di Bernoulli modella eventi binari elementari; la distribuzione binomiale descrive il numero di successi in una serie di prove indipendenti con probabilità costante; la distribuzione di Poisson rappresenta il verificarsi di eventi rari governati da un tasso medio costante; la distribuzione beta-binomiale, infine, estende il modello binomiale descrivendo la distribuzione dei conteggi quando vi è incertezza sul parametro sottostante.
In questa prospettiva bayesiana, i parametri di tali modelli non sono semplici quantità fisse da “stimare”, ma grandezze incerte su cui formuliamo distribuzioni di credenza. L’eleganza formale del framework bayesiano emerge in modo particolarmente chiaro attraverso le relazioni di coniugazione: la distribuzione beta fornisce una rappresentazione naturale delle credenze sul parametro \(p\) della distribuzione di Bernoulli e di quella binomiale, mentre la distribuzione gamma svolge un ruolo analogo per il parametro \(\lambda\) della distribuzione di Poisson. Queste relazioni consentono aggiornamenti coerenti e, in molti casi, analiticamente trattabili delle credenze alla luce dei dati osservati.
Nel capitolo successivo ci occuperemo delle distribuzioni continue, come la distribuzione beta, la distribuzione gamma, la distribuzione normale e altre ancora. Queste distribuzioni svolgeranno un duplice ruolo: da un lato, fungeranno da modelli per le variabili continue osservabili; dall’altro, costituiranno distribuzioni a priori naturali per i parametri dei modelli discreti introdotti in questo capitolo. In questo modo, completeremo progressivamente il vocabolario probabilistico essenziale per sviluppare e comprendere l’inferenza bayesiana in contesti sempre più generali.
Guida rapida: quale distribuzione usare?
| Distribuzione | Dominio | Quando usarla | Prior tipici | Esempio psicologico |
|---|---|---|---|---|
| Uniforme discreta | {1,…,N} | Scelta casuale tra N alternative equiprobabili | — | Randomizzazione tra 4 condizioni sperimentali |
| Bernoulli | {0,1} | Singolo esito binario (successo/fallimento) | Beta(1,1) o Beta(α,β) | Risposta corretta a un item del test |
| Binomiale | {0,…,n} | Numero di successi su n prove indipendenti | Beta(α,β) | 18 risposte corrette su 25 domande |
| Poisson | {0,1,2,…} | Conteggio di eventi rari in tempo/spazio fisso | Gamma(α,β) | 3 attacchi di panico in un mese |
| Beta-Binomiale | {0,…,n} | Binomiale con p incerto (sovradispersione) | Beta(α,β) su p | Successi quando ogni soggetto ha un p diverso |
Come scelgo la distribuzione giusta?
Segui questo albero decisionale per identificare la distribuzione appropriata:
flowchart TD
A[Che tipo di dato hai?] --> B{Binario0/1}
A --> C{Conteggiointero ≥ 0}
A --> D{Categorico1,2,...,K}
B --> B1[Singola osservazione?]
B1 -->|Sì| B2[Bernoullies: risposta corretta]
B1 -->|No, n prove| B3[Binomialees: k su n corrette]
C --> C1{Eventi rariin tempo/spaziofisso?}
C1 -->|Sì| C2[Poissones: attacchi di panico/mese]
C1 -->|No, n fissato| C3[Binomialees: sintomi presenti su checklist]
D --> D1{Tutti ugualmenteprobabili?}
D1 -->|Sì| D2[Uniforme discretaes: dado equo]
D1 -->|No| D3[Categorica/Multinomialecapitolo futuro]
style B2 fill:#e1f5e1
style B3 fill:#e1f5e1
style C2 fill:#fff4e1
style C3 fill:#e1f5e1
style D2 fill:#f0f0f0flowchart TD
A[Che tipo di dato hai?] --> B{Binario0/1}
A --> C{Conteggiointero ≥ 0}
A --> D{Categorico1,2,...,K}
B --> B1[Singola osservazione?]
B1 -->|Sì| B2[Bernoullies: risposta corretta]
B1 -->|No, n prove| B3[Binomialees: k su n corrette]
C --> C1{Eventi rariin tempo/spaziofisso?}
C1 -->|Sì| C2[Poissones: attacchi di panico/mese]
C1 -->|No, n fissato| C3[Binomialees: sintomi presenti su checklist]
D --> D1{Tutti ugualmenteprobabili?}
D1 -->|Sì| D2[Uniforme discretaes: dado equo]
D1 -->|No| D3[Categorica/Multinomialecapitolo futuro]
style B2 fill:#e1f5e1
style B3 fill:#e1f5e1
style C2 fill:#fff4e1
style C3 fill:#e1f5e1
style D2 fill:#f0f0f0
Punti chiave da ricordare
Concetti essenziali di questo capitolo:
-
Distribuzione di Bernoulli
- Modella singolo evento binario: successo (1) o fallimento (0)
- \(P(X=1) = \theta\), \(P(X=0) = 1-\theta\)
- \(\mathbb{E}[X] = \theta\), \(\text{Var}(X) = \theta(1-\theta)\)
- Base per tutti i modelli binari in psicologia
-
Distribuzione Binomiale
- Conteggio di successi in \(n\) prove Bernoulli indipendenti
- \(P(X=k) = \binom{n}{k}\theta^k(1-\theta)^{n-k}\)
- \(\mathbb{E}[X] = n\theta\), \(\text{Var}(X) = n\theta(1-\theta)\)
- Usata per: risposte corrette in test, prevalenze, adesione a trattamenti
-
Distribuzione di Poisson
- Conteggio di eventi rari in intervallo fisso
- \(P(X=k) = \frac{\lambda^k e^{-\lambda}}{k!}\), \(k = 0,1,2,\ldots\)
- \(\mathbb{E}[X] = \lambda\), \(\text{Var}(X) = \lambda\) (equidispersione!)
- Usata per: numero sintomi, comportamenti rari, crisi panic
-
Proprietà chiave delle distribuzioni discrete
- Dominio: valori numerabili (interi)
- Somma di PMF = 1
- Facilmente visualizzabili con diagrammi a barre
- Simulabili facilmente in R
-
Applicazioni in psicologia
- Bernoulli: diagnosi binaria (disturbo presente/assente)
- Binomiale: accuratezza in test cognitivi, risposte “sì/no” in questionari
- Poisson: eventi psicopatologici infrequenti, conteggio sintomi DSM
Formule da ricordare:
Bernoulli(\(\theta\)): \[ P(X=x) = \theta^x(1-\theta)^{1-x}, \quad x \in \{0,1\} \]
Binomiale(\(n, \theta\)): \[ P(X=k) = \binom{n}{k}\theta^k(1-\theta)^{n-k}, \quad k = 0,1,\ldots,n \] \[ \mathbb{E}[X] = n\theta, \quad \text{Var}(X) = n\theta(1-\theta) \]
Poisson(\(\lambda\)): \[ P(X=k) = \frac{\lambda^k e^{-\lambda}}{k!}, \quad k = 0,1,2,\ldots \] \[ \mathbb{E}[X] = \lambda, \quad \text{Var}(X) = \lambda \]
Proprietà critiche:
- Binomiale è somma di \(n\) Bernoulli i.i.d.
- Poisson è limite di Binomiale per \(n \to \infty\), \(p \to 0\), \(np = \lambda\)
- Poisson ha equidispersione (media = varianza)
- Varianza Binomiale massima quando \(\theta = 0.5\)
Per il prossimo capitolo:
Nel Capitolo 13 studieremo le distribuzioni continue (Beta, Normale, Gamma, Esponenziale), fondamentali per modellare proporzioni, misure psicometriche, tempi di reazione e parametri continui nei modelli bayesiani.
Esercizi
Per ciascuna distribuzione (uniforme, Bernoulli, binomiale, Poisson):
- Scegli parametri appropriati e visualizza la funzione di massa.
- Simula 1000 osservazioni e confronta media/varianza empirica con quella teorica.
- Calcola \(P(X \leq x)\) per qualche valore significativo.
sessionInfo()
#> R version 4.5.2 (2025-10-31)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Tahoe 26.2
#>
#> Matrix products: default
#> BLAS: /System/Library/Frameworks/Accelerate.framework/Versions/A/Frameworks/vecLib.framework/Versions/A/libBLAS.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
#>
#> locale:
#> [1] C.UTF-8/UTF-8/C.UTF-8/C/C.UTF-8/C.UTF-8
#>
#> time zone: Europe/Rome
#> tzcode source: internal
#>
#> attached base packages:
#> [1] splines stats4 stats graphics grDevices utils datasets
#> [8] methods base
#>
#> other attached packages:
#> [1] extraDistr_1.10.0.1 VGAM_1.1-14 reshape2_1.4.5
#> [4] ragg_1.5.0 tinytable_0.15.2 withr_3.0.2
#> [7] systemfonts_1.3.1 patchwork_1.3.2 ggdist_3.3.3
#> [10] tidybayes_3.0.7 bayesplot_1.15.0 ggplot2_4.0.1
#> [13] reliabilitydiag_0.2.1 priorsense_1.2.0 posterior_1.6.1
#> [16] loo_2.9.0 rstan_2.32.7 StanHeaders_2.32.10
#> [19] brms_2.23.0 Rcpp_1.1.1 sessioninfo_1.2.3
#> [22] conflicted_1.2.0 janitor_2.2.1 matrixStats_1.5.0
#> [25] modelr_0.1.11 tibble_3.3.1 dplyr_1.1.4
#> [28] tidyr_1.3.2 rio_1.2.4 here_1.0.2
#>
#> loaded via a namespace (and not attached):
#> [1] gridExtra_2.3 inline_0.3.21 sandwich_3.1-1
#> [4] rlang_1.1.7 magrittr_2.0.4 multcomp_1.4-29
#> [7] snakecase_0.11.1 otel_0.2.0 compiler_4.5.2
#> [10] vctrs_0.6.5 stringr_1.6.0 pkgconfig_2.0.3
#> [13] arrayhelpers_1.1-0 fastmap_1.2.0 backports_1.5.0
#> [16] labeling_0.4.3 rmarkdown_2.30 purrr_1.2.1
#> [19] xfun_0.55 cachem_1.1.0 jsonlite_2.0.0
#> [22] broom_1.0.11 parallel_4.5.2 R6_2.6.1
#> [25] stringi_1.8.7 RColorBrewer_1.1-3 lubridate_1.9.4
#> [28] estimability_1.5.1 knitr_1.51 zoo_1.8-15
#> [31] Matrix_1.7-4 timechange_0.3.0 tidyselect_1.2.1
#> [34] abind_1.4-8 yaml_2.3.12 codetools_0.2-20
#> [37] curl_7.0.0 pkgbuild_1.4.8 lattice_0.22-7
#> [40] plyr_1.8.9 bridgesampling_1.2-1 S7_0.2.1
#> [43] coda_0.19-4.1 evaluate_1.0.5 survival_3.8-3
#> [46] RcppParallel_5.1.11-1 pillar_1.11.1 tensorA_0.36.2.1
#> [49] checkmate_2.3.3 distributional_0.6.0 generics_0.1.4
#> [52] rprojroot_2.1.1 rstantools_2.6.0 scales_1.4.0
#> [55] xtable_1.8-4 glue_1.8.0 emmeans_2.0.1
#> [58] tools_4.5.2 mvtnorm_1.3-3 grid_4.5.2
#> [61] QuickJSR_1.8.1 colorspace_2.1-2 nlme_3.1-168
#> [64] cli_3.6.5 textshaping_1.0.4 svUnit_1.0.8
#> [67] Brobdingnag_1.2-9 V8_8.0.1 gtable_0.3.6
#> [70] digest_0.6.39 TH.data_1.1-5 htmlwidgets_1.6.4
#> [73] farver_2.1.2 memoise_2.0.1 htmltools_0.5.9
#> [76] lifecycle_1.0.5 MASS_7.3-65