here::here("code", "_common.R") |>
source()
# Load packages
if (!requireNamespace("pacman")) install.packages("pacman")
pacman::p_load(combinat, gtools)
# Riapplica il tema per sicurezza
apply_visual_theme()3 Equiprobabilità e calcolo combinatorio
Introduzione
Qual è la probabilità di ottenere “testa” nel lancio di una moneta? La risposta che viene spontanea, “1/2”, sembra ovvia, quasi banale. Eppure, dietro a questa apparente semplicità si nasconde una questione epistemologica profonda che merita di essere esaminata con attenzione.
La formula che abbiamo imparato a scuola,
\[ \text{Probabilità} = \frac{\text{casi favorevoli}}{\text{casi possibili}}, \] viene spesso presentata come la definizione di probabilità. Ma è davvero così? E soprattutto: quando possiamo legittimamente utilizzarla?
Il problema nascosto nella formula “ovvia”
Fermiamoci un momento a riflettere. Perché diciamo che la probabilità di testa è 1/2? La risposta immediata è: “Perché ci sono due esiti possibili e uno solo è favorevole.” Ma questa risposta presuppone qualcosa di cruciale che non viene detto esplicitamente: che i due esiti siano ugualmente plausibili.
E perché dovrebbero esserlo? Non per una legge di natura. Una moneta truccata ha comunque due facce, ma non assegneremmo 1/2 a ciascuna. L’equiprobabilità non è una proprietà della moneta, ma delle nostre credenze sulla moneta, basate su ciò che sappiamo (o non sappiamo) di essa.
Questa osservazione, apparentemente pedante, ha conseguenze profonde. Ciò significa che la formula classica non definisce la probabilità in generale, ma vale solo in un contesto ben preciso: quello delle condizioni di equiprobabilità, in cui tutti gli esiti sono considerati a priori ugualmente plausibili.
Perché questo è importante per la psicologia
Lo psicologo potrebbe chiedersi: “Perché preoccuparsi di queste sottigliezze filosofiche?” La risposta è che nella ricerca psicologica l’equiprobabilità è quasi sempre violata e ignorare questo fatto porta a errori sistematici.
Consideriamo alcuni esempi:
Test psicometrici: gli item di un questionario non sono tutti ugualmente difficili. Assumere che ogni risposta sia equiprobabile significa ignorare completamente la struttura del test.
Risposte ai questionari: le persone non scelgono le opzioni di risposta in modo casuale. Fenomeni come l’acquiescenza (tendenza a rispondere “sì”) o la desiderabilità sociale rendono alcune risposte più probabili di altre.
Variabilità individuale: in quasi ogni fenomeno psicologico, le persone differiscono sistematicamente. Un trattamento non ha la stessa probabilità di successo per tutti i pazienti.
In tutti questi casi, applicare meccanicamente la formula “casi favorevoli su casi possibili” produce risultati fuorvianti. La formula presuppone una simmetria che semplicemente non esiste.
Il percorso del capitolo
In questo capitolo faremo tre cose:
Capiremo quando l’equiprobabilità è giustificata e cosa significa esattamente assumerla. Capiremo che non si tratta di una proprietà del mondo, ma di una scelta inferenziale basata sullo stato delle nostre informazioni.
Impareremo le tecniche combinatorie (permutazioni, disposizioni e combinazioni) come strumenti per contare le configurazioni equiprobabili, riconoscendo che la combinatoria è un’ancella dell’equiprobabilità e non il suo fondamento.
Introdurremo la distribuzione Beta come generalizzazione continua che ci permette di rappresentare credenze non uniformi, aprendo la strada a modelli più realistici per i fenomeni psicologici.
ConsiglioPrerequisiti
Per seguire questo capitolo è necessario aver letto:
Conoscenze matematiche richieste:
- Appendice D - per operazioni su eventi
- Appendice E - fondamentale per permutazioni, disposizioni e combinazioni
Competenze pratiche:
- familiarità di base con R per eseguire le simulazioni Monte Carlo presentate nel capitolo
Panoramica del capitolo
- Il principio di indifferenza e la simmetria epistemica.
- Formula classica come caso speciale bayesiano.
- Tecniche di calcolo combinatorio: permutazioni, disposizioni, combinazioni.
- Quando l’equiprobabilità NON si applica.
- La distribuzione Beta come generalizzazione continua.
- Applicazioni psicologiche.
AttenzionePreparazione del Notebook
3.1 Il principio di indifferenza
Partiamo dalla domanda fondamentale: quando è legittimo assumere che tutti gli esiti siano ugualmente probabili?
La risposta, secondo la prospettiva bayesiana, non riguarda le proprietà fisiche degli oggetti, ma lo stato delle nostre conoscenze. Il principio che giustifica l’equiprobabilità è chiamato principio di indifferenza.
Definizione 3.1 (Principio di indifferenza) Se non abbiamo ragioni per distinguere tra \(n\) possibilità mutualmente esclusive ed esaustive, è razionalmente coerente assegnare a ciascuna la stessa credenza, pari a \(1/n\).
3.1.1 L’equiprobabilità come simmetria dell’ignoranza
Questa definizione merita una lettura attenta. Non dice che gli esiti sono equiprobabili. Dice che è razionale trattarli come tali quando non abbiamo informazioni che ci permettano di distinguerli.
In questa prospettiva, l’equiprobabilità non è una proprietà del mondo, ma una proprietà della nostra relazione epistemica con esso. Riflette la simmetria della nostra ignoranza: se non conosciamo nulla che favorisca un esito rispetto a un altro, non abbiamo basi razionali per assegnare probabilità diverse.
Questa è una distinzione cruciale che separa l’interpretazione bayesiana da quella frequentista:
ImportanteDue modi di pensare all’equiprobabilità
Prospettiva frequentista
«Il dado è equo, quindi ogni faccia ha probabilità 1/6.»
Qui l’equiprobabilità è una proprietà fisica del dado, qualcosa che esiste indipendentemente da chi osserva.
Prospettiva bayesiana
«Non dispongo di informazioni che favoriscano una faccia rispetto alle altre, quindi assegno a ciascuna una probabilità di 1/6.»
In questo caso, l’equiprobabilità è una proprietà dello stato informativo dell’osservatore, non del dado in sé.
La differenza può sembrare sottile, ma ha conseguenze importanti. Secondo la prospettiva bayesiana, se domani scoprissi che il dado è leggermente sbilanciato, non direi: “Mi ero sbagliato sulla natura del dado”, ma piuttosto: “Le mie informazioni sono cambiate, quindi cambiano anche le mie assegnazioni probabilistiche”. L’equiprobabilità iniziale non era un errore, ma la scelta razionale, date le informazioni disponibili in quel momento.
3.1.2 Condizioni di applicabilità
Il principio di indifferenza è potente ma non automatico. Non possiamo invocarlo ogni volta che ci fa comodo. La sua applicazione richiede che siano soddisfatte alcune condizioni:
Simmetria fisica rilevante Il sistema deve essere costruito o configurato in modo che non ci siano differenze rilevanti tra gli esiti. Un dado regolare, una moneta bilanciata o un’urna con palline indistinguibili soddisfano questa condizione.
Ignoranza genuina Non devono essere disponibili informazioni empiriche, teoriche o contestuali che permettano di distinguere razionalmente tra gli esiti. Se so che il mio avversario bara, non posso più assumere equiprobabilità.
Assenza di struttura rilevante Il processo che genera gli esiti non deve presentare pattern, dipendenze o vincoli che rendano alcuni risultati più probabili di altri.
La parola chiave qui è giudizio. L’equiprobabilità non si applica in modo meccanico, ma richiede una valutazione esplicita del contesto e delle assunzioni implicite. L’indifferenza non è mai “data”; è sempre assunta e, in quanto tale, deve poter essere giustificata.
AvvisoIl paradosso di Bertrand: quando l’indifferenza fallisce
L’applicazione ingenua del principio di indifferenza può condurre a contraddizioni, come mostra il celebre paradosso di Bertrand.
Supponiamo che una fabbrica produca cubi con lato compreso tra 0 e 1 metro. Qual è la probabilità che un cubo selezionato a caso abbia un lato maggiore di 0.5 m?
Risposta 1: se assumiamo equiprobabilità rispetto alla lunghezza del lato, otteniamo \(P(\text{lato} > 0.5) = 0.5\).
Risposta 2: se assumiamo equiprobabilità rispetto al volume, il calcolo cambia completamente (il volume varia come il cubo del lato).
Quale risposta è corretta? Entrambe e nessuna. Il paradosso non segnala un fallimento della teoria, ma un’ambiguità nella formulazione del problema. La domanda “Qual è la probabilità?” non ha senso finché non specifichiamo rispetto a quale variabile stiamo assumendo l’indifferenza.
Dal punto di vista bayesiano, ciò significa che il principio di indifferenza richiede sempre di specificare lo spazio delle possibilità che riteniamo epistemicamente appropriato. Non esiste un’applicazione “automatica”: ogni assunzione di equiprobabilità è una scelta di modellazione che deve essere argomentata.
3.1.3 Un principio umile
Il principio di indifferenza è spesso frainteso come una regola che ci dice cosa è probabile. In realtà è molto più modesto: ci dice cosa è razionale credere quando non sappiamo nulla.
In un certo senso, è il punto di partenza dell’ignoranza razionale. Non pretende di descrivere il mondo, ma di fornire una base coerente da cui partire quando le informazioni sono assenti. Non appena si acquisiscono informazioni rilevanti, l’equiprobabilità cede il passo a distribuzioni più informate.
Questa umiltà epistemica è fondamentale. L’equiprobabilità non è la regola, ma il caso limite dell’assenza di regole.
3.2 La formula classica come caso speciale
Una volta compreso il principio di indifferenza, possiamo finalmente dare una collocazione precisa alla formula classica della probabilità. Non si tratta di una definizione fondamentale, ma di un teorema derivato che vale sotto condizioni specifiche.
Teorema 3.1 (Formula classica della probabilità) Sia \(\Omega = \{\omega_1, \ldots, \omega_n\}\) uno spazio campionario finito in cui, per simmetria epistemica, tutti gli esiti sono ritenuti equiprobabili:
\[ P(\omega_i) = \frac{1}{n} \quad \text{per ogni } i. \]
Allora, per qualsiasi evento \(A \subseteq \Omega\),
\[ P(A) = \frac{|A|}{|\Omega|} = \frac{\text{casi favorevoli}}{\text{casi possibili}}. \]
Dimostrazione
Per l’assioma di additività, la probabilità di un evento \(A\) è data dalla somma delle probabilità degli esiti elementari che lo compongono:
\[ P(A) = \sum_{\omega_i \in A} P(\omega_i). \]
Poiché ciascun esito ha probabilità \(1/n\) e l’evento \(A\) contiene \(|A|\) elementi:
\[ P(A) = |A| \cdot \frac{1}{n} = \frac{|A|}{|\Omega|}. \]
3.2.1 La formula classica è una conseguenza, non un punto di partenza
Questa derivazione chiarisce un punto spesso oscurato nelle presentazioni introduttive: la formula “casi favorevoli su casi possibili” non definisce che cosa sia una probabilità. È una conseguenza degli assiomi di coerenza che abbiamo visto nel capitolo precedente e vale solo quando l’ipotesi di equiprobabilità è giustificata.
Le condizioni necessarie sono:
- spazio campionario finito e ben definito;
- assunzione giustificata di equiprobabilità;
- rispetto degli assiomi di coerenza.
Se una di queste condizioni viene meno, la formula perde di validità. Non è “sbagliata” in senso assoluto, semplicemente non si applica.
3.2.2 Implicazioni per l’uso della combinatoria
Questa comprensione ha una conseguenza pratica importante: il calcolo combinatorio (permutazioni, disposizioni, combinazioni) è uno strumento operativo, non un fondamento teorico della probabilità.
La combinatoria ci aiuta a contare le configurazioni possibili. Tale conteggio ha un senso probabilistico solo se le configurazioni contate sono equiprobabili. Se non lo sono, contare non serve a nulla, o peggio, fornisce risposte fuorvianti.
In altre parole: prima verifichiamo se l’equiprobabilità è giustificata, poi usiamo la combinatoria per contare. Non il contrario.
3.3 Tecniche di calcolo combinatorio
Assumendo che l’equiprobabilità sia stata verificata e giustificata, il calcolo combinatorio fornisce gli strumenti per elencare sistematicamente tutte le possibili configurazioni. La scelta della tecnica appropriata dipende da due domande:
- L’ordine conta? La sequenza ABC è diversa da CBA?
- Selezioniamo tutti gli elementi o solo alcuni?
3.3.1 Principio della somma
Quando uno spazio delle possibilità si suddivide in categorie mutuamente esclusive, il numero totale di configurazioni è la somma dei casi in ciascuna categoria:
\[ n_{\text{totale}} = n_1 + n_2 + \dots + n_k. \]
NotaEsempio clinico
Un paziente può accedere a:
- 8 protocolli cognitivi,
- 6 protocolli comportamentali,
- 10 protocolli integrati.
Se non abbiamo informazioni che favoriscano un tipo di protocollo rispetto agli altri, le opzioni equiprobabili sono:
\[ 8 + 6 + 10 = 24, \] con probabilità \(1/24\) per ciascun protocollo specifico.
Nota: questa equiprobabilità presuppone che non ci siano indicazioni cliniche che rendano alcuni protocolli più appropriati di altri per questo specifico paziente. Se tali indicazioni esistono, l’equiprobabilità non è più giustificata.
3.3.2 Principio del prodotto
Quando una configurazione è il risultato di scelte sequenziali indipendenti, il numero totale di possibilità si ottiene moltiplicando:
\[ n_{\text{totale}} = n_1 \times n_2 \times \dots \times n_k. \]
NotaEsempio: disegno sperimentale
Nella progettazione di uno studio:
- 3 metodi di valutazione,
- 4 frequenze di misurazione,
- 2 durate di follow-up,
producono:
\[ 3 \times 4 \times 2 = 24 \] disegni possibili. Se non abbiamo ragioni teoriche per preferire un disegno a un altro, ciascuno ha una probabilità \(1/24\) di essere “quello giusto” per il nostro scopo.
Nota: nella pratica, quasi sempre abbiamo delle ragioni per preferire alcuni disegni, come considerazioni sulla fattibilità, sul costo e sulla validità. L’equiprobabilità è raramente la descrizione corretta della nostra incertezza riguardo alla scelta del disegno.
3.3.3 Permutazioni: tutti gli ordinamenti di \(n\) elementi
Le permutazioni contano i modi di ordinare \(n\) oggetti distinti quando l’ordine è rilevante:
\[ P_n = n! = n \times (n-1) \times \cdots \times 1. \tag{3.1}\]
L’intuizione è semplice: il primo elemento può essere scelto in \(n\) modi, il secondo in \(n-1\), e così via.
NotaEsempio: ordine di presentazione degli stimoli
In un esperimento sulla memoria, 5 parole vengono presentate in ordine casuale. Quanti ordinamenti sono possibili?
\[ 5! = 120. \]
Se la randomizzazione è davvero casuale (equiprobabilità degli ordinamenti), ogni sequenza specifica ha probabilità \(1/120 \approx 0.008\).
parole <- c("Tavolo", "Fiore", "Automobile", "Stella", "Libro")
n_perm <- factorial(length(parole))
cat("Parole:", paste(parole, collapse = ", "), "\n")
#> Parole: Tavolo, Fiore, Automobile, Stella, Libro
cat("Ordini possibili:", n_perm, "\n")
#> Ordini possibili: 120
cat("P(ordine specifico):", round(1/n_perm, 5), "\n\n")
#> P(ordine specifico): 0.00833
# Esempi di sequenze
set.seed(123)
cat("Sequenze casuali:\n")
#> Sequenze casuali:
for(i in 1:3) {
cat(" ", paste(sample(parole), collapse = " → "), "\n")
}
#> Automobile → Fiore → Libro → Stella → Tavolo
#> Automobile → Tavolo → Fiore → Libro → Stella
#> Fiore → Automobile → Tavolo → Stella → LibroNota psicologica: l’equiprobabilità degli ordinamenti è ciò che la randomizzazione produce per disegno. Tuttavia, gli effetti psicologici degli ordinamenti non sono equiprobabili: alcuni ordinamenti possono produrre più interferenza di altri, alcuni possono facilitare la memoria. La randomizzazione garantisce l’equiprobabilità nella selezione, non negli effetti.
3.3.4 Disposizioni: \(k\) elementi ordinati da \(n\)
Le disposizioni contano i modi di scegliere e ordinare \(k\) oggetti distinti da un insieme di \(n\) elementi:
\[ D_{n,k} = \frac{n!}{(n-k)!} = n \times (n-1) \times \cdots \times (n-k+1). \tag{3.2}\]
NotaEsempio: assegnazione di ruoli in terapia di gruppo
Con 8 partecipanti e 3 ruoli distinti (facilitatore, osservatore, timekeeper):
\[ D_{8,3} = \frac{8!}{5!} = 8 \times 7 \times 6 = 336. \]
In assenza di informazioni sulle competenze individuali, ogni assegnazione ha una probabilità di \(1/336 \approx 0.003\).
n <- 8 # partecipanti
k <- 3 # ruoli
n_disp <- factorial(n) / factorial(n - k)
cat("Partecipanti:", n, "\n")
#> Partecipanti: 8
cat("Ruoli da assegnare:", k, "\n")
#> Ruoli da assegnare: 3
cat("Assegnazioni possibili:", n_disp, "\n")
#> Assegnazioni possibili: 336
cat("P(assegnazione specifica):", round(1/n_disp, 5))
#> P(assegnazione specifica): 0.00298Nota clinica: nella pratica, raramente si assegnano ruoli ignorando le caratteristiche delle persone. Un facilitatore efficace richiede competenze specifiche. L’equiprobabilità descrive l’assegnazione casuale pura, non la decisione clinica informata.
3.3.5 Combinazioni: \(k\) elementi non ordinati da \(n\)
Le combinazioni contano i sottoinsiemi di \(k\) elementi scelti da \(n\), quando l’ordine non è rilevante:
\[ C_{n,k} = \binom{n}{k} = \frac{n!}{k!(n-k)!}. \tag{3.3}\]
La formula si ottiene dividendo le disposizioni per \(k!\), che elimina i conteggi multipli degli stessi elementi in ordini diversi.
NotaEsempio: formazione di coppie terapeutiche
Con 12 volontari per il peer counseling, le coppie possibili sono:
\[ \binom{12}{2} = \frac{12!}{2! \cdot 10!} = \frac{12 \times 11}{2} = 66. \]
Se non disponiamo di informazioni sulla compatibilità, ogni coppia ha una probabilità di \(1/66 \approx 0.015\).
Nota: l’equiprobabilità delle coppie è un’assunzione molto forte. Nella realtà, alcune coppie funzionano meglio di altre per ragioni di personalità, di esperienza o semplicemente per “chimica” interpersonale. Un modello più realistico dovrebbe assegnare probabilità diverse a coppie diverse in base a predittori di compatibilità.
ConsiglioRiepilogo: quale tecnica usare?
| Tecnica | Ordine conta? | Formula | Esempio psicologico |
|---|---|---|---|
| Permutazioni | Sì (tutti gli elementi) | \(n!\) | Ordine di \(n\) stimoli |
| Disposizioni | Sì (solo \(k\) elementi) | \(\frac{n!}{(n-k)!}\) | Assegnazione di ruoli |
| Combinazioni | No | \(\binom{n}{k}\) | Formazione di gruppi |
ImportanteIl punto fondamentale da non dimenticare
Ogni formula combinatoria presuppone che tutte le configurazioni elencate siano equiprobabili.
Se disponiamo di informazioni che distinguono alcune configurazioni, come ordini che causano interferenza, ruoli assegnati in base alle competenze o coppie incompatibili, il modello uniforme non è più appropriato. La combinatoria ci dice quante configurazioni esistono, non quali siano più probabili.
3.4 Quando l’equiprobabilità non si applica
Finora abbiamo trattato l’equiprobabilità come se fosse la norma. È il momento di ribaltare la prospettiva: nella ricerca psicologica, l’equiprobabilità è l’eccezione, non la regola.
3.4.1 La variabilità è la norma, non l’anomalia
Quasi ogni fenomeno psicologico presenta una variabilità sistematica. Gli item di un test hanno difficoltà diverse. Le persone hanno abilità diverse. I trattamenti funzionano in modo diverso per pazienti diversi. Le risposte ai questionari sono influenzate dagli stili individuali.
Questa variabilità non è “rumore” da eliminare, ma spesso è la sostanza stessa di ciò che studiamo. Ignorarla assumendo equiprobabilità significa perdere l’essenza del fenomeno.
3.4.2 Esempio: difficoltà degli item nei test
Consideriamo un test psicometrico con 5 item di difficoltà diversa:
# Item con diversi livelli di difficoltà (probabilità di risposta corretta)
item_difficolta <- c(0.9, 0.7, 0.5, 0.3, 0.1)
cat("Probabilità di risposta corretta per item:\n")
#> Probabilità di risposta corretta per item:
for(i in seq_along(item_difficolta)) {
cat(" Item", i, ":", item_difficolta[i], "\n")
}
#> Item 1 : 0.9
#> Item 2 : 0.7
#> Item 3 : 0.5
#> Item 4 : 0.3
#> Item 5 : 0.1
# Simulazione: 1000 rispondenti completano il test
set.seed(123)
risposte <- replicate(1000, rbinom(5, 1, item_difficolta))
cat("\nProporzioni osservate (simulate):", round(rowMeans(risposte), 2))
#>
#> Proporzioni osservate (simulate): 0.89 0.71 0.48 0.29 0.1Le proporzioni osservate riflettono fedelmente le probabilità sottostanti, che sono molto diverse tra loro. Assumere equiprobabilità (\(P = 0.5\) per ogni item) produrrebbe:
- una sottostima della performance sugli item facili (0.9 e 0.7);
- una sovrastima della performance sugli item difficili (0.3 e 0.1).
L’errore non è solo quantitativo. È concettuale: si ignorerebbe una proprietà fondamentale degli item, ovvero la loro difficoltà, che è esattamente ciò che il test è progettato per sfruttare.
3.4.3 La lezione più ampia
Questo esempio illustra un principio generale: l’equiprobabilità è un’ipotesi da verificare, non da assumere per default.
Quando la rifiutiamo, non stiamo “complicando” il modello. Riconosciamo che il mondo è più ricco di quanto l’equiprobabilità possa rappresentare. Per fortuna, esistono strumenti che ci permettono di esprimere questa ricchezza, come la distribuzione Beta che vedremo ora.
3.5 La distribuzione Beta: dal discreto al continuo
Finora abbiamo ragionato su spazi finiti, ovvero un numero limitato di esiti ciascuno con la propria probabilità. Ma in molti contesti di ricerca psicologica non ci limitiamo a contare gli eventi, bensì dobbiamo stimare dei parametri sconosciuti che possono assumere qualsiasi valore in un intervallo continuo.
Qual è la probabilità che un paziente risponda a un trattamento? Non si tratta di un esito discreto tra un numero finito di possibilità, ma di un valore \(\theta\) che può assumere qualsiasi valore compreso tra 0 e 1.
La distribuzione Beta è lo strumento che ci permette di rappresentare le nostre credenze sui parametri di questo tipo.
3.5.1 Intuizione: la Beta come “memoria di esperienze”
Prima di vedere le formule, cerchiamo di capire l’intuizione alla base. La distribuzione \(\text{Beta}(\alpha, \beta)\) può essere pensata come la sintesi di esperienze passate codificate sotto forma di “conteggi virtuali”:
- \(\alpha - 1\) = numero di “successi” osservati (o immaginati);
- \(\beta - 1\) = numero di “insuccessi” osservati (o immaginati).
Questa interpretazione rende la Beta sorprendentemente intuitiva:
Beta(1, 1): nessuna esperienza pregressa. Ogni valore di \(\theta\) è ugualmente plausibile. È l’analogo continuo dell’equiprobabilità.
Beta(5, 5): è come se avessimo osservato 4 successi e 4 insuccessi. Credenza centrata sui valori medi, con incertezza moderata.
Beta(20, 10): come se avessimo osservato 19 successi e 9 insuccessi. Aspettativa di valori elevati (~0.67), con maggiore certezza.
Beta(2, 8): come se avessimo osservato 1 successo e 7 insuccessi. Aspettativa di valori bassi (~0.20).
NotaVisualizzazione: forme della distribuzione Beta
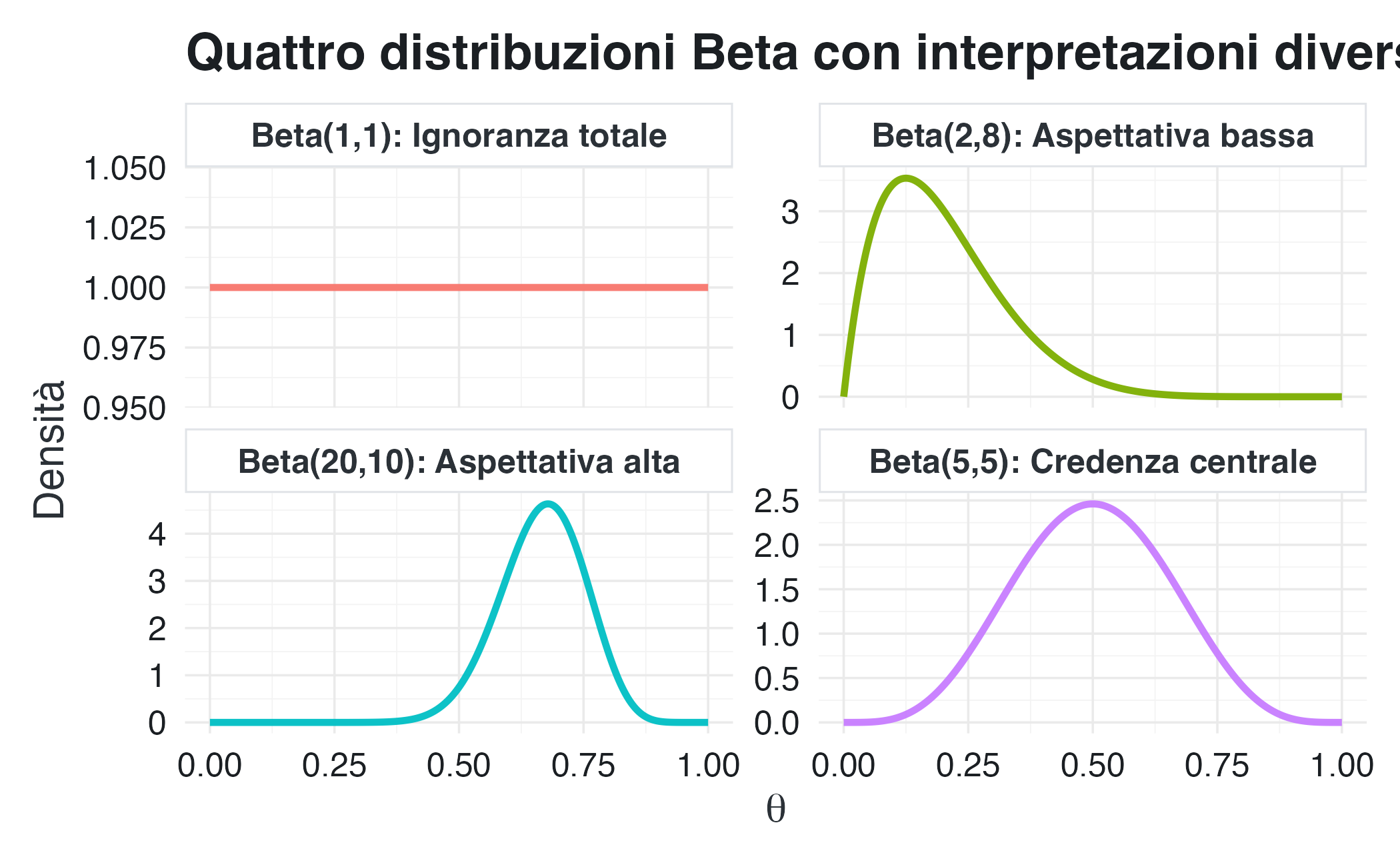
Ogni grafico mostra una diversa distribuzione Beta. La forma cambia drammaticamente in base ai parametri, consentendo di rappresentare credenze molto diverse, dalla completa ignoranza alla forte convinzione, dalla simmetria all’asimmetria marcata.
3.5.2 Due parametri, due significati
La distribuzione Beta ha due parametri, \(\alpha\) e \(\beta\), che controllano due aspetti distinti delle nostre credenze:
ConsiglioInterpretazione dei parametri
-
Posizione (dove pensiamo che si trovi \(\theta\)):
\[\mathbb{E}[\theta] = \frac{\alpha}{\alpha + \beta}\]Se \(\alpha > \beta\), la media è maggiore di 0.5; se \(\alpha < \beta\), è minore di 0.5.
-
Forza della convinzione (quanto siamo sicuri):
la somma \(\alpha + \beta\) controlla la concentrazione della distribuzione.Valori elevati → distribuzione stretta (siamo sicuri);
Valori bassi → distribuzione diffusa (siamo incerti).
Questa separazione è cruciale: possiamo esprimere credenze diverse sia su dove pensiamo che si trovi il parametro, sia su quanto siamo sicuri di questa valutazione.
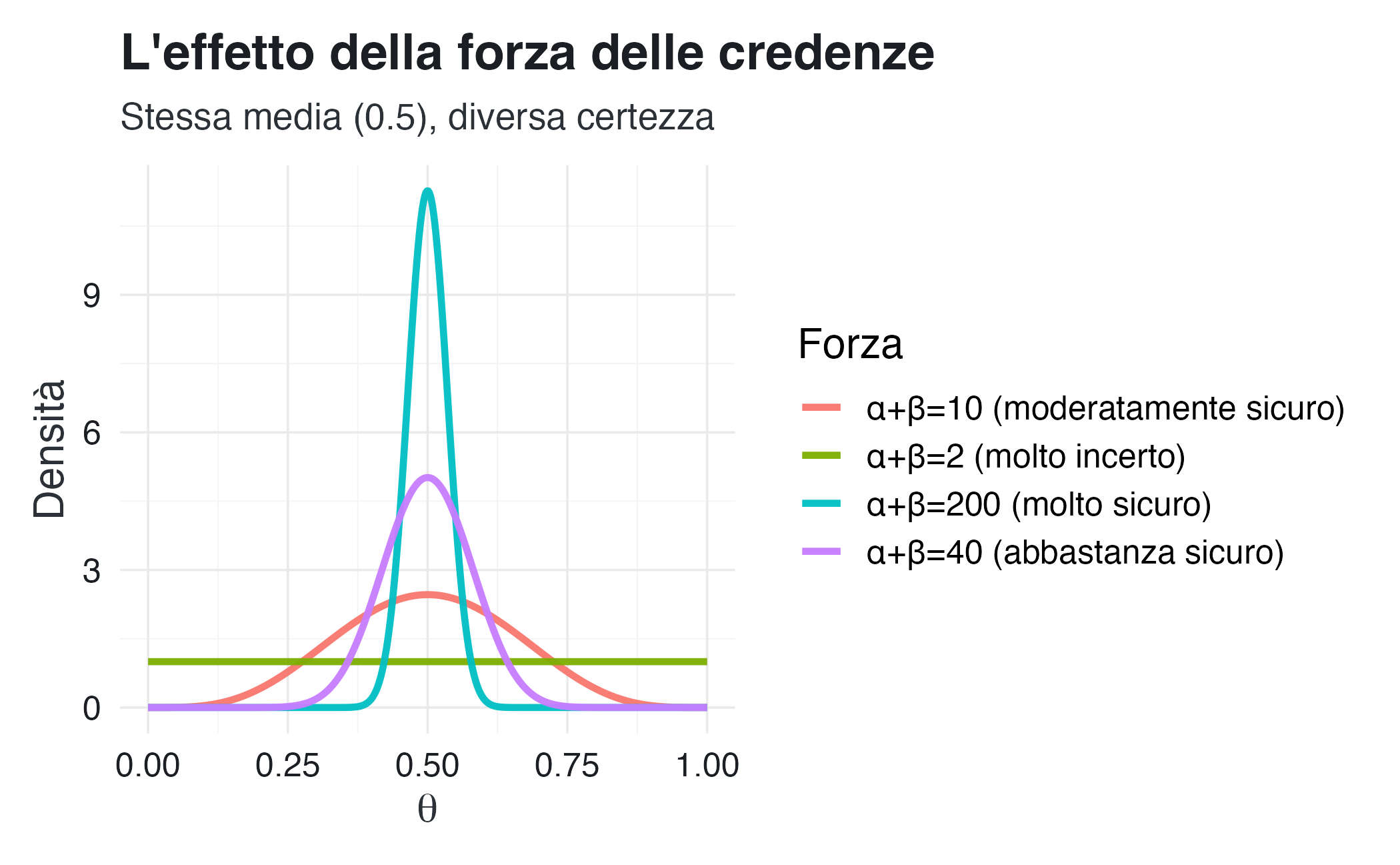
3.5.3 Definizione formale
Definizione 3.2 Una variabile casuale \(\theta \sim \text{Beta}(\alpha, \beta)\) ha densità:
\[ f(\theta; \alpha, \beta) = \frac{\Gamma(\alpha + \beta)}{\Gamma(\alpha)\Gamma(\beta)} \theta^{\alpha-1}(1-\theta)^{\beta-1}, \quad \theta \in [0,1]. \]
Proprietà principali
- Media: \(\mathbb{E}[\theta] = \frac{\alpha}{\alpha+\beta}\)
- Varianza: \(\frac{\alpha\beta}{(\alpha+\beta)^2(\alpha+\beta+1)}\)
- Moda: \(\frac{\alpha-1}{\alpha+\beta-2}\) per \(\alpha,\beta>1\)
Casi notevoli
- Beta(1,1): distribuzione uniforme su [0,1]—massima ignoranza
- Beta(0.5,0.5): prior di Jeffreys—ignoranza “non informativa” in senso tecnico
3.5.4 Beta(1,1): l’equiprobabilità continua
Il caso Beta(1,1) merita un’attenzione particolare. Questa distribuzione è semplicemente la distribuzione uniforme sull’intervallo [0,1]: ogni valore è ugualmente plausibile.
Rappresenta l’analogo continuo del principio di indifferenza. Se nel caso discreto affermavamo che “tutti gli esiti sono ugualmente probabili”, nel caso continuo possiamo dire che “tutti i valori del parametro sono ugualmente plausibili”.
Questo crea un ponte concettuale importante:
\[ \text{Equiprobabilità discreta} \longleftrightarrow \text{Uniformità continua (Beta(1,1))} \]
Ma proprio come l’equiprobabilità discreta è spesso inappropriata, anche la Beta(1,1) è spesso una scelta troppo “ignorante”. Se abbiamo qualche informazione sul parametro, e quasi sempre l’abbiamo, possiamo codificarla in una distribuzione Beta più informativa.
3.6 Aggiornamento bayesiano: il modello Beta-Binomiale
La distribuzione Beta non è solo uno strumento per rappresentare le credenze a priori. Possiede una proprietà matematica straordinaria: quando osserviamo dati binomiali (successi e insuccessi), la forma della distribuzione si aggiorna in modo semplice e interpretabile.
3.6.1 La regola dell’aggiornamento
Se partiamo da una credenza \(\text{Beta}(\alpha, \beta)\) e osserviamo \(k\) successi su \(n\) prove, la nuova credenza (posteriore) è:
\[ \theta \sim \text{Beta}(\alpha, \beta) \;\xrightarrow{\text{osserviamo } k \text{ su } n}\; \theta \mid k \sim \text{Beta}(\alpha + k, \beta + n - k). \]
Questa proprietà, chiamata coniugazione Beta-Binomiale, rende l’aggiornamento bayesiano estremamente intuitivo: i successi osservati si “aggiungono” ad \(\alpha\), mentre gli insuccessi si “aggiungono” a \(\beta\).
3.6.2 Interpretazione: combinare conoscenza precedente e nuovi dati
L’aggiornamento ha un’interpretazione semplice in termini di “conteggi virtuali”:
- prima dell’osservazione: abbiamo \(\alpha - 1\) successi virtuali e \(\beta - 1\) insuccessi virtuali;
- dopo l’osservazione: si aggiungono \(k\) successi reali e \(n-k\) insuccessi reali;
- risultato: \((\alpha - 1 + k)\) successi totali, \((\beta - 1 + n - k)\) insuccessi totali.
I dati “si sommano” alla conoscenza precedente. Più dati raccogliamo, più la distribuzione si concentra e la nostra certezza aumenta.
NotaEsempio: test a scelta multipla
Uno studente risponde a 20 domande con quattro opzioni di risposta ciascuna. Adottiamo un prior Beta(1,3), che riflette l’ipotesi iniziale di risposte casuali (media = 1/4 = 0.25).
Osserviamo 7 risposte corrette. La posterior diventa:
\[ \text{Beta}(1 + 7, 3 + 13) = \text{Beta}(8, 16). \]
La media posteriore è \(8/24 \approx 0.33\), un valore più alto del prior (0.25), ma non di molto. Lo studente sembra ottenere risultati leggermente migliori rispetto al caso, ma i dati non sono sufficienti per esserne certi.
theta <- seq(0, 1, length.out = 500)
prior <- dbeta(theta, 1, 3)
posterior <- dbeta(theta, 8, 16)
df <- data.frame(
theta = rep(theta, 2),
Densita = c(prior, posterior),
Tipo = rep(c("Prior Beta(1,3)", "Posterior Beta(8,16)"), each = 500)
)
ggplot(df, aes(x = theta, y = Densita, color = Tipo)) +
geom_line(linewidth = 1.3) +
geom_vline(xintercept = c(0.25, 0.33), linetype = "dashed", alpha = 0.5) +
scale_fill_qualitative() +
labs(title = "Aggiornamento bayesiano: prima e dopo 20 risposte",
x = expression(theta ~ "(probabilità di risposta corretta)"),
y = "Densità") 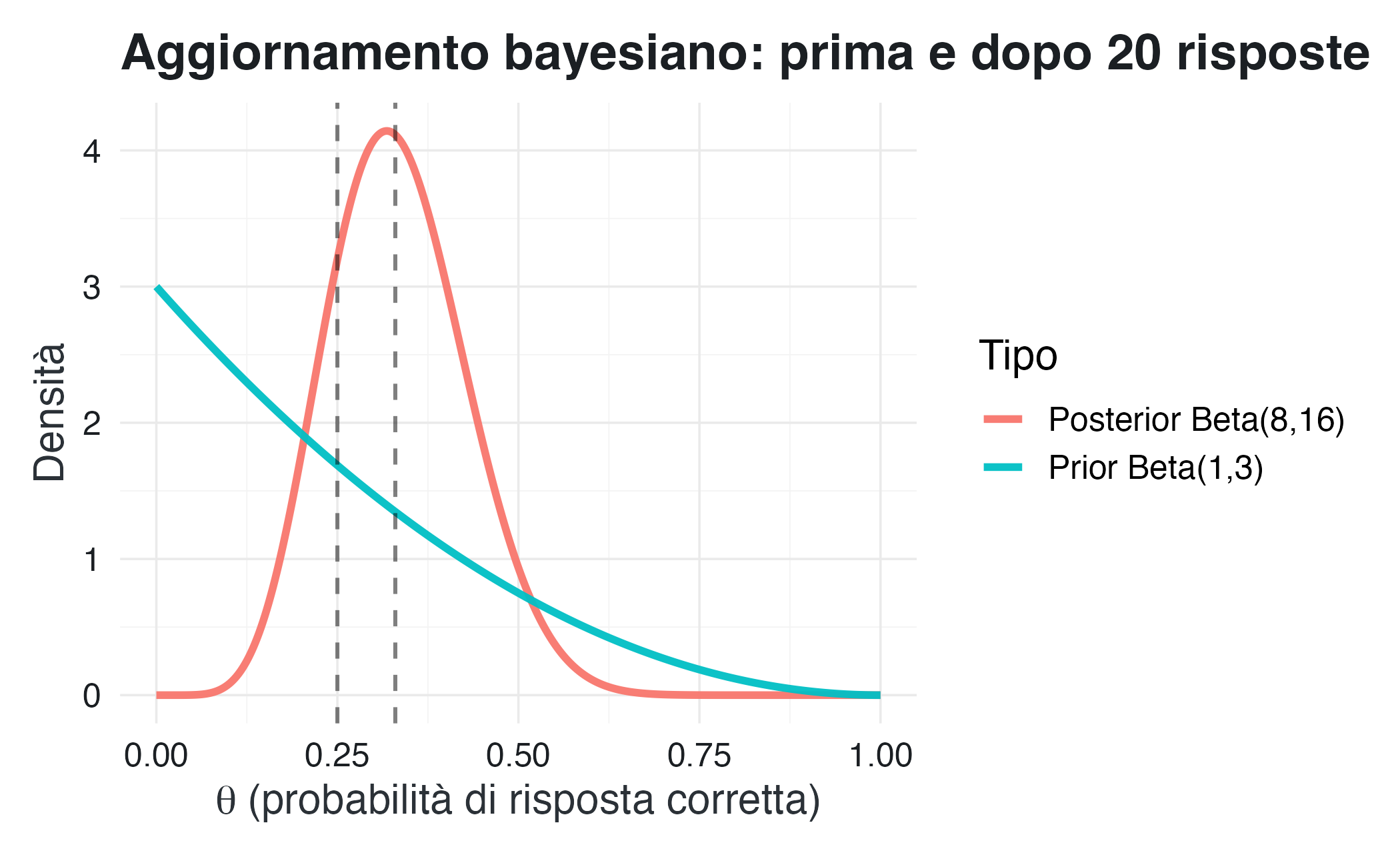
Intervallo di credibilità
alpha_post <- 8
beta_post <- 16
ci <- qbeta(c(0.025, 0.975), alpha_post, beta_post)
cat("Media posteriore:", round(alpha_post/(alpha_post + beta_post), 3), "\n")
#> Media posteriore: 0.333
cat("Intervallo di credibilità 95%: [", round(ci[1], 2), ",", round(ci[2], 2), "]")
#> Intervallo di credibilità 95%: [ 0.16 , 0.53 ]L’intervallo [0.18, 0.52] esprime la nostra incertezza residua: siamo ragionevolmente sicuri che la probabilità vera si trovi in questo intervallo, ma l’intervallo è ancora piuttosto ampio.
3.6.3 Nota sull’interpretazione degli intervalli
Gli intervalli di credibilità bayesiani hanno un’interpretazione diretta e intuitiva che spesso manca agli intervalli di confidenza frequentisti:
Intervallo di credibilità (95%): “C’è il 95% di probabilità che il valore vero del parametro sia compreso in questo intervallo, date le informazioni a nostra disposizione.”
Intervallo di confidenza (95%): “Se ripetessimo l’esperimento infinite volte, il 95% degli intervalli così calcolati conterrebbe il vero parametro.”
La prima interpretazione è quella che le persone pensano di fare quando usano gli intervalli di confidenza. La seconda è quella che stanno effettivamente stanno facendo nel framework frequentista. L’approccio bayesiano permette di fare ciò che è naturale pensare.
3.6.4 Aggiornamento sequenziale: la conoscenza si accumula
Una conseguenza pratica importante del modello Beta-Binomiale è che consente di aggiornare le credenze man mano che si osservano nuovi dati, senza dover ricalcolare tutto da capo.
NotaEsempio: apprendimento progressivo
Osserviamo uno studente che risponde a 20 domande una alla volta. Come cambiano le nostre credenze?
set.seed(42)
theta_vero <- 0.4 # La "vera" abilità dello studente
n_domande <- 20
risposte <- rbinom(n_domande, 1, theta_vero)
alpha <- 1; beta <- 3 # Prior
theta_grid <- seq(0, 1, length.out = 200)
df_evol <- data.frame()
for(i in c(0, 5, 10, 20)) {
if(i == 0) {
dens <- dbeta(theta_grid, alpha, beta)
label <- "Prior (n=0)"
} else {
a <- 1 + sum(risposte[1:i])
b <- 3 + i - sum(risposte[1:i])
dens <- dbeta(theta_grid, a, b)
label <- paste0("n = ", i)
}
df_evol <- rbind(df_evol, data.frame(
theta = theta_grid, Densita = dens, n = label
))
}
ggplot(df_evol, aes(x = theta, y = Densita, color = n)) +
geom_line(linewidth = 1.2) +
geom_vline(xintercept = theta_vero, linetype = "dashed") +
annotate("text", x = theta_vero + 0.05, y = max(df_evol$Densita) * 0.9,
label = expression(theta~"vero"), hjust = 0) +
scale_fill_qualitative() +
labs(title = "Come cambiano le credenze con l'accumularsi dei dati",
x = expression(theta), y = "Densità", color = "Osservazioni") 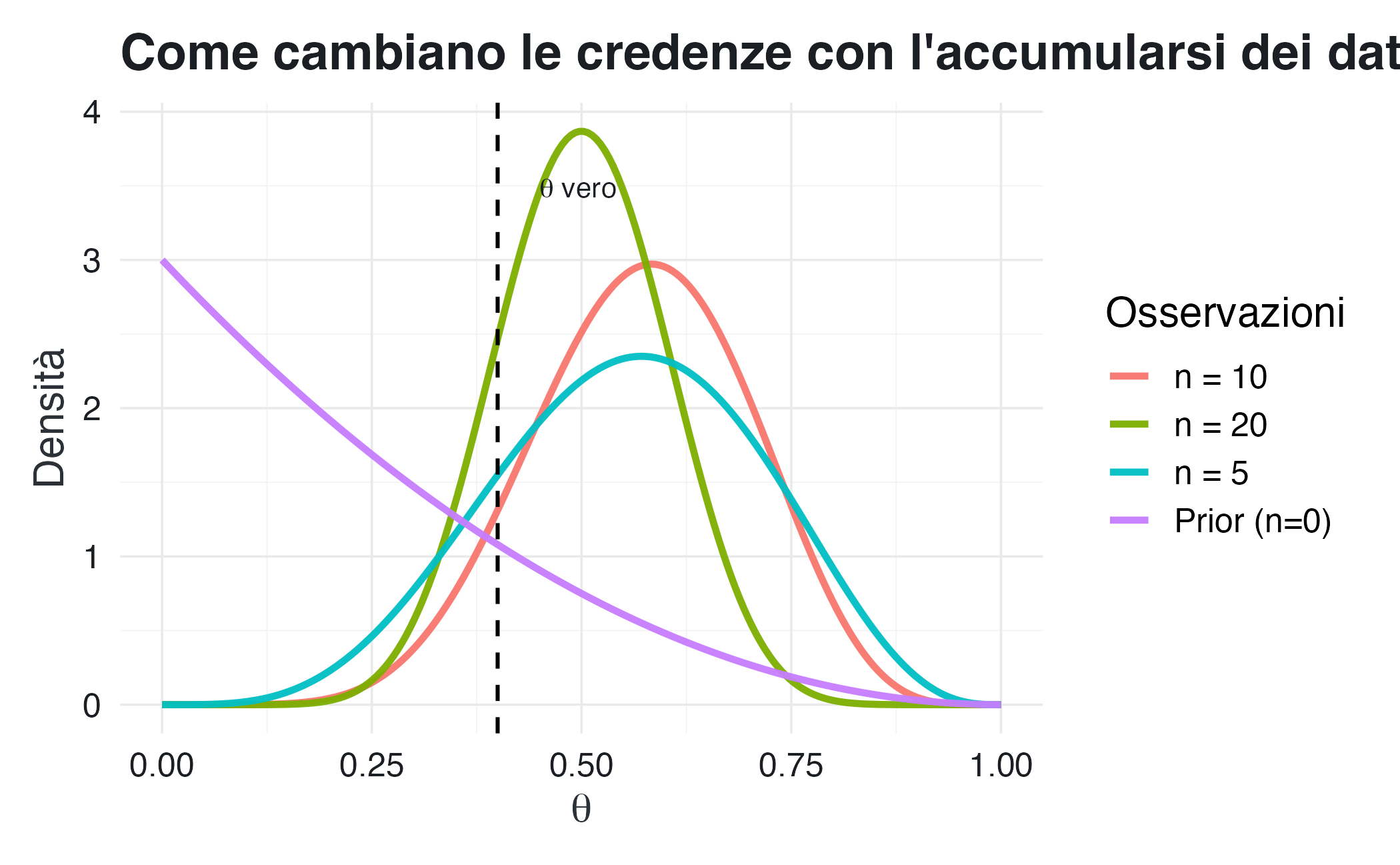
Interpretazione: partendo da un prior diffuso e centrato su valori bassi, la distribuzione si sposta gradualmente verso il valore vero (\(\theta = 0.4\)) e si restringe, riflettendo una crescente certezza. Questo è l’apprendimento bayesiano in azione: la conoscenza si accumula e l’incertezza diminuisce.
3.7 Applicazioni psicologiche
Gli strumenti che abbiamo sviluppato, come il principio di indifferenza, la combinatoria e la distribuzione Beta, non sono esercizi astratti. Trovano infatti applicazione diretta in contesti psicologici concreti.
3.7.1 Item Response Theory (IRT): oltre l’equiprobabilità degli item
Nella psicologia dell’apprendimento, la teoria della risposta agli item (IRT) formalizza ciò che ogni insegnante sa intuitivamente: la probabilità di rispondere correttamente a una domanda dipende sia dallo studente che dalla domanda stessa.
Il modello base della IRT esprime questa dipendenza:
\[ P(\text{corretto} \mid \theta, b) = \frac{1}{1 + e^{-(\theta - b)}}, \] dove:
- \(\theta\) è l’abilità dello studente (un parametro continuo);
- \(b\) è la difficoltà dell’item (un altro parametro).
Questa formulazione rifiuta esplicitamente il presupposto dell’equiprobabilità, riconoscendo che gli item presentano livelli di difficoltà intrinseci diversi e che la probabilità di risposta corretta per lo stesso item varia in base alle abilità degli individui. L’Item Response Theory incarna questo principio, sostituendo l’assunzione di equiprobabilità con un modello che mira a catturare la struttura latente e differenziata del fenomeno psicometrico.
3.7.2 Bias di risposta nei questionari
Quando un partecipante risponde a un questionario, non sceglie le opzioni “a caso”. Ci sono dei fenomeni sistematici che influenzano le risposte:
- Acquiescenza: tendenza a rispondere “sì” o “d’accordo” indipendentemente dal contenuto;
- Desiderabilità sociale: tendenza a dare risposte socialmente accettabili;
- Effetti di posizione: preferenza per le opzioni centrali o estreme.
Questi bias significano che le opzioni di risposta non sono equiprobabili. Un modello adeguato deve esplicitare queste tendenze e distinguere la variabilità dovuta al costrutto misurato da quella dovuta allo stile di risposta.
3.7.3 Efficacia degli interventi: variabilità individuale
Quando si valuta l’efficacia di un trattamento, l’equiprobabilità è particolarmente inappropriata. Non tutti i pazienti rispondono allo stesso modo: alcuni migliorano, altri no e altri ancora peggiorano.
L’approccio bayesiano permette di:
- iniziare con prior informativi basati su studi precedenti o meta-analisi;
- aggiornare progressivamente man mano che i dati si accumulano;
- rappresentare esplicitamente la variabilità interindividuale;
- quantificare l’incertezza in modo interpretabile.
Questo approccio produce stime che riconoscono la complessità del fenomeno, invece di nasconderla sotto l’ipotesi di uniformità.
Riflessioni conclusive
Siamo partiti da una domanda apparentemente ingenua: “Quando possiamo dire che gli esiti sono ‘ugualmente probabili’?” e abbiamo scoperto che la risposta ci porta al cuore dell’epistemologia della probabilità.
Il messaggio fondamentale
L’equiprobabilità non è un fatto del mondo. Si tratta di una scelta inferenziale che riflette uno stato particolare di conoscenza: quello in cui non abbiamo ragioni per distinguere tra le varie possibilità. Rappresenta il punto di partenza dell’ignoranza razionale, non la descrizione di come funziona la realtà.
La formula “casi favorevoli su casi possibili” è una conseguenza di questa assunzione, non una legge universale. Il calcolo combinatorio è uno strumento per contare configurazioni equiprobabili, ma non ci dice nulla su quali configurazioni siano equiprobabili.
Verso modelli più ricchi
Nella ricerca psicologica, l’equiprobabilità è quasi sempre violata. Gli item differiscono per difficoltà, le persone differiscono per abilità e i trattamenti funzionano in modo diverso per pazienti diversi. Questa variabilità non è un fastidio da eliminare: è spesso la sostanza stessa di ciò che studiamo.
La distribuzione Beta ci offre un primo strumento per andare oltre l’equiprobabilità, consentendo di rappresentare credenze con forme e intensità diverse. L’aggiornamento bayesiano ci mostra come queste credenze possano evolversi in modo coerente quando acquisiamo nuove informazioni.
Guardando avanti
Questo capitolo ha stabilito che l’equiprobabilità è un caso speciale, non la norma. Ma come aggiorniamo le nostre credenze quando riceviamo informazioni parziali? Come rappresentiamo la dipendenza tra eventi?
Queste domande ci portano al tema del prossimo capitolo: la probabilità condizionata e il teorema di Bayes, che formalizzano il processo di apprendimento dall’esperienza e costituiscono il cuore dell’inferenza bayesiana.
Punti chiave da ricordare
Importante
Concetti essenziali di questo capitolo:
-
Principio di indifferenza
- L’equiprobabilità riflette simmetria epistemica, non una proprietà fisica del mondo.
- Assegniamo \(P(\omega_i) = 1/n\) solo quando non abbiamo ragioni per preferire un esito.
- Richiede giudizio esplicito sul contesto (simmetria fisica, ignoranza genuina, assenza di struttura).
-
Formula classica come caso speciale
- \(P(A) = |A|/|\Omega|\) è una conseguenza degli assiomi quando vale l’equiprobabilità.
- Non è una definizione universale, ma un’applicazione condizionata.
- Il calcolo combinatorio è strumento operativo, non fondamento teorico.
-
Distribuzione Beta come generalizzazione continua
- Beta(1,1) = massima ignoranza (analogo continuo dell’equiprobabilità).
- I parametri \((\alpha, \beta)\) codificano posizione e forza delle credenze.
- L’aggiornamento: \(\text{Beta}(\alpha, \beta) \to \text{Beta}(\alpha+k, \beta+n-k)\).
-
Limiti dell’equiprobabilità in psicologia
- IRT: probabilità dipende da abilità individuale e difficoltà item.
- Bias di risposta: acquiescenza e desiderabilità sociale violano l’uniformità.
- Variabilità interindividuale richiede modelli flessibili.
Formule da ricordare:
\[ P(A) = \frac{|A|}{|\Omega|} \quad \text{(solo con equiprobabilità)} \]
\[ \text{Beta}(\alpha, \beta) \xrightarrow{\text{dati } k, n} \text{Beta}(\alpha + k, \beta + n - k) \]
Tecniche combinatorie:
| Tecnica | Formula | Quando usarla |
|---|---|---|
| Permutazioni | \(n!\) | Ordine conta, tutti gli elementi |
| Disposizioni | \(\frac{n!}{(n-k)!}\) | Ordine conta, \(k\) elementi |
| Combinazioni | \(\binom{n}{k}\) | Ordine non conta |
Per il prossimo capitolo:
Nel Capitolo 4 vedremo come la probabilità condizionata rappresenti l’aggiornamento bayesiano delle credenze quando riceviamo nuova informazione.
NotaInformazioni sull’ambiente di sviluppo
sessionInfo()
#> R version 4.5.2 (2025-10-31)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Tahoe 26.2
#>
#> Matrix products: default
#> BLAS: /System/Library/Frameworks/Accelerate.framework/Versions/A/Frameworks/vecLib.framework/Versions/A/libBLAS.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
#>
#> locale:
#> [1] C.UTF-8/UTF-8/C.UTF-8/C/C.UTF-8/C.UTF-8
#>
#> time zone: Europe/Rome
#> tzcode source: internal
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] gtools_3.9.5 combinat_0.0-8 ragg_1.5.0
#> [4] tinytable_0.15.2 withr_3.0.2 systemfonts_1.3.1
#> [7] patchwork_1.3.2 ggdist_3.3.3 tidybayes_3.0.7
#> [10] bayesplot_1.15.0 ggplot2_4.0.1 reliabilitydiag_0.2.1
#> [13] priorsense_1.2.0 posterior_1.6.1 loo_2.9.0
#> [16] rstan_2.32.7 StanHeaders_2.32.10 brms_2.23.0
#> [19] Rcpp_1.1.1 sessioninfo_1.2.3 conflicted_1.2.0
#> [22] janitor_2.2.1 matrixStats_1.5.0 modelr_0.1.11
#> [25] tibble_3.3.1 dplyr_1.1.4 tidyr_1.3.2
#> [28] rio_1.2.4 here_1.0.2
#>
#> loaded via a namespace (and not attached):
#> [1] gridExtra_2.3 inline_0.3.21 sandwich_3.1-1
#> [4] rlang_1.1.7 magrittr_2.0.4 multcomp_1.4-29
#> [7] snakecase_0.11.1 otel_0.2.0 compiler_4.5.2
#> [10] vctrs_0.6.5 stringr_1.6.0 pkgconfig_2.0.3
#> [13] arrayhelpers_1.1-0 fastmap_1.2.0 backports_1.5.0
#> [16] labeling_0.4.3 rmarkdown_2.30 purrr_1.2.1
#> [19] xfun_0.55 cachem_1.1.0 jsonlite_2.0.0
#> [22] broom_1.0.11 parallel_4.5.2 R6_2.6.1
#> [25] stringi_1.8.7 RColorBrewer_1.1-3 lubridate_1.9.4
#> [28] estimability_1.5.1 knitr_1.51 zoo_1.8-15
#> [31] pacman_0.5.1 Matrix_1.7-4 splines_4.5.2
#> [34] timechange_0.3.0 tidyselect_1.2.1 abind_1.4-8
#> [37] yaml_2.3.12 codetools_0.2-20 curl_7.0.0
#> [40] pkgbuild_1.4.8 lattice_0.22-7 bridgesampling_1.2-1
#> [43] S7_0.2.1 coda_0.19-4.1 evaluate_1.0.5
#> [46] survival_3.8-3 RcppParallel_5.1.11-1 pillar_1.11.1
#> [49] tensorA_0.36.2.1 checkmate_2.3.3 stats4_4.5.2
#> [52] distributional_0.6.0 generics_0.1.4 rprojroot_2.1.1
#> [55] rstantools_2.6.0 scales_1.4.0 xtable_1.8-4
#> [58] glue_1.8.0 emmeans_2.0.1 tools_4.5.2
#> [61] mvtnorm_1.3-3 grid_4.5.2 QuickJSR_1.8.1
#> [64] colorspace_2.1-2 nlme_3.1-168 cli_3.6.5
#> [67] textshaping_1.0.4 svUnit_1.0.8 Brobdingnag_1.2-9
#> [70] V8_8.0.1 gtable_0.3.6 digest_0.6.39
#> [73] TH.data_1.1-5 htmlwidgets_1.6.4 farver_2.1.2
#> [76] memoise_2.0.1 htmltools_0.5.9 lifecycle_1.0.5
#> [79] MASS_7.3-65