9 Covarianza e correlazione
Introduzione
Un ricercatore sta analizzando i dati di uno studio sulla relazione tra ansia e prestazione cognitiva negli studenti universitari. I risultati preliminari mostrano che, in media, livelli più alti di ansia si associano a punteggi più bassi nei test di memoria di lavoro. Ma quanto è robusta questa associazione? È clinicamente o teoricamente rilevante? E come possiamo comunicare questo risultato in modo che sia confrontabile con altri studi, condotti su popolazioni diverse e con strumenti di misura differenti?
Queste domande richiedono strumenti che vadano oltre la descrizione di tendenze generali. La covarianza quantifica la tendenza di due variabili a variare insieme in modo sistematico, mentre la correlazione standardizza tale misura su una scala universale, permettendo confronti trasversali. Insieme, questi indici costituiscono il vocabolario essenziale per descrivere e comunicare relazioni tra variabili in psicologia.
Dal punto di vista bayesiano, covarianza e correlazione possono essere interpretate come riassunti quantitativi della struttura delle nostre credenze, così come codificata nella distribuzione congiunta. Quando affermiamo che due variabili sono correlate negativamente con \(\rho = -0.40\), stiamo esprimendo una proprietà specifica di come crediamo che queste variabili si comportino congiuntamente, un’informazione che può derivare da dati osservati, da conoscenze teoriche pregresse, o da una combinazione delle due.
Prima di introdurre formalmente questi concetti, estenderemo brevemente il framework delle distribuzioni congiunte al caso di variabili continue, mostrando come le stesse idee si applichino quando le variabili assumono valori su scale numeriche continue.
Per seguire questo capitolo è necessario aver letto:
- Capitolo 6 — per il concetto di variabili casuali multiple.
- Capitolo 7 — per densità congiunte.
- Capitolo 8 — fondamentale per valore atteso e varianza.
Questo capitolo estende al caso bivariato i concetti di valore atteso e varianza, introducendo misure di dipendenza lineare tra variabili.
Conoscenze matematiche richieste:
- Appendice C - per calcoli con distribuzioni discrete congiunte.
- Appendice F - per densità congiunte continue.
Competenze pratiche:
- Familiarità con R e visualizzazione di distribuzioni bivariate
Panoramica del capitolo
- Estensione al caso continuo: dalle tabelle alle densità congiunte.
- Covarianza come misura della co-variazione lineare.
- Correlazione come versione standardizzata della covarianza.
- Proprietà matematiche e loro significato pratico.
- Il concetto di incorrelazione e la sua relazione con l’indipendenza.
- Applicazioni nell’inferenza bayesiana e nella ricerca psicologica.
9.1 Dalle tabelle discrete alle densità continue
Nel Capitolo 2 abbiamo utilizzato tabelle congiunte 2×2 per rappresentare in modo coerente le nostre credenze su coppie di variabili binarie. Gli stessi principi si estendono senza difficoltà anche a situazioni più complesse: tabelle con un numero maggiore di categorie quando le variabili assumono più livelli discreti e densità congiunte quando le variabili sono continue.
9.1.1 Tabelle con più categorie
Consideriamo un esempio tratto dalla letteratura psicologica: la relazione tra ansia e prestazione cognitiva negli studenti universitari. Numerosi studi suggeriscono una relazione negativa tra questi fattori (Eysenck et al., 2007). Supponiamo di codificare l’ansia in tre livelli (bassa, media, alta) e la prestazione in tre livelli (insufficiente, sufficiente, buona).
Una possibile distribuzione congiunta che rappresenta le nostre credenze, informate dalla letteratura, potrebbe essere la seguente:
| Ansia Bassa | Ansia Media | Ansia Alta | Marginale | |
|---|---|---|---|---|
| Insufficiente | 0.05 | 0.10 | 0.15 | 0.30 |
| Sufficiente | 0.15 | 0.20 | 0.10 | 0.45 |
| Buona | 0.10 | 0.10 | 0.05 | 0.25 |
| Marginale | 0.30 | 0.40 | 0.30 | 1.00 |
Ogni cella rappresenta il nostro grado di credenza in una specifica configurazione. Ad esempio, assegniamo una probabilità pari a 0.20 alla combinazione “prestazione sufficiente e ansia media”, mentre attribuiamo solo 0.05 alla configurazione “buona prestazione e ansia alta”, riflettendo l’idea di una relazione negativa tra ansia e prestazione.
I principi di costruzione e interpretazione sono gli stessi visti per le tabelle 2×2: le distribuzioni marginali si ottengono sommando lungo le righe o le colonne, le distribuzioni condizionate si ricavano dividendo per la marginale appropriata e la coerenza è garantita dalla non negatività delle celle e dalla somma totale pari a uno.
9.1.2 Il caso continuo: densità congiunte
Quando le variabili assumono valori continui, come i punteggi su scale psicometriche standardizzate, i tempi di reazione o le misure fisiologiche, la distribuzione congiunta non può più essere rappresentata da una tabella finita, ma viene descritta mediante una densità congiunta \(f(x,y)\).
L’interpretazione rimane invariata: la densità indica quanto riteniamo plausibile una determinata regione dello spazio delle configurazioni possibili.
Definizione 9.1 Una densità congiunta \(f(x,y)\) assegna a ogni configurazione \((x,y)\) un valore che rappresenta la concentrazione della credenza in quella regione. Per essere coerente, deve soddisfare:
Non negatività: \(f(x,y) \geq 0\) per ogni \((x,y)\);
Normalizzazione: \[ \int_{-\infty}^{+\infty} \int_{-\infty}^{+\infty} f(x,y)\,dx\,dy = 1. \]
Come nel caso discreto, la densità congiunta contiene tutte le informazioni sulle relazioni tra le variabili. Le densità marginali si ottengono integrando rispetto a una delle variabili:
\[ f_X(x) = \int_{-\infty}^{+\infty} f(x,y)\,dy, \qquad f_Y(y) = \int_{-\infty}^{+\infty} f(x,y)\,dx. \]
Le densità condizionate si ottengono dividendo la densità congiunta per la marginale appropriata:
\[ f_{X \mid Y}(x \mid y) = \frac{f(x,y)}{f_Y(y)}. \]
9.1.3 Regole di somma e prodotto per le densità congiunte
Le regole di somma e prodotto che abbiamo introdotto per le tabelle discrete si applicano senza modifiche concettuali anche nel caso continuo, sostituendo le somme con gli integrali.
Regola di somma (marginalizzazione) La densità marginale di una variabile si ottiene integrando la densità congiunta rispetto all’altra: \[ f_Y(y) = \int_{-\infty}^{+\infty} f_{X,Y}(x,y)\,dx, \qquad f_X(x) = \int_{-\infty}^{+\infty} f_{X,Y}(x,y)\,dy. \]
-
Regola di prodotto La densità congiunta può essere scomposta come prodotto di una marginale e di una condizionata:
\[ f_{X,Y}(x,y) = f_{Y \mid X}(y \mid x) f_X(x) = f_{X \mid Y}(x \mid y) f_Y(y). \]
Queste relazioni mostrano che conoscere la distribuzione congiunta equivale a conoscere tutte le distribuzioni marginali e condizionate, e viceversa. La distribuzione congiunta rimane quindi l’elemento fondamentale per descrivere le relazioni tra le variabili.
9.1.4 Visualizzazione di una distribuzione congiunta continua
Per rendere più concreto il concetto di densità congiunta, consideriamo nuovamente la relazione tra ansia e prestazione cognitiva, questa volta modellata come una distribuzione continua. Possiamo visualizzare la densità come una mappa termica in cui i colori più caldi indicano le configurazioni a cui attribuiamo una maggiore probabilità.
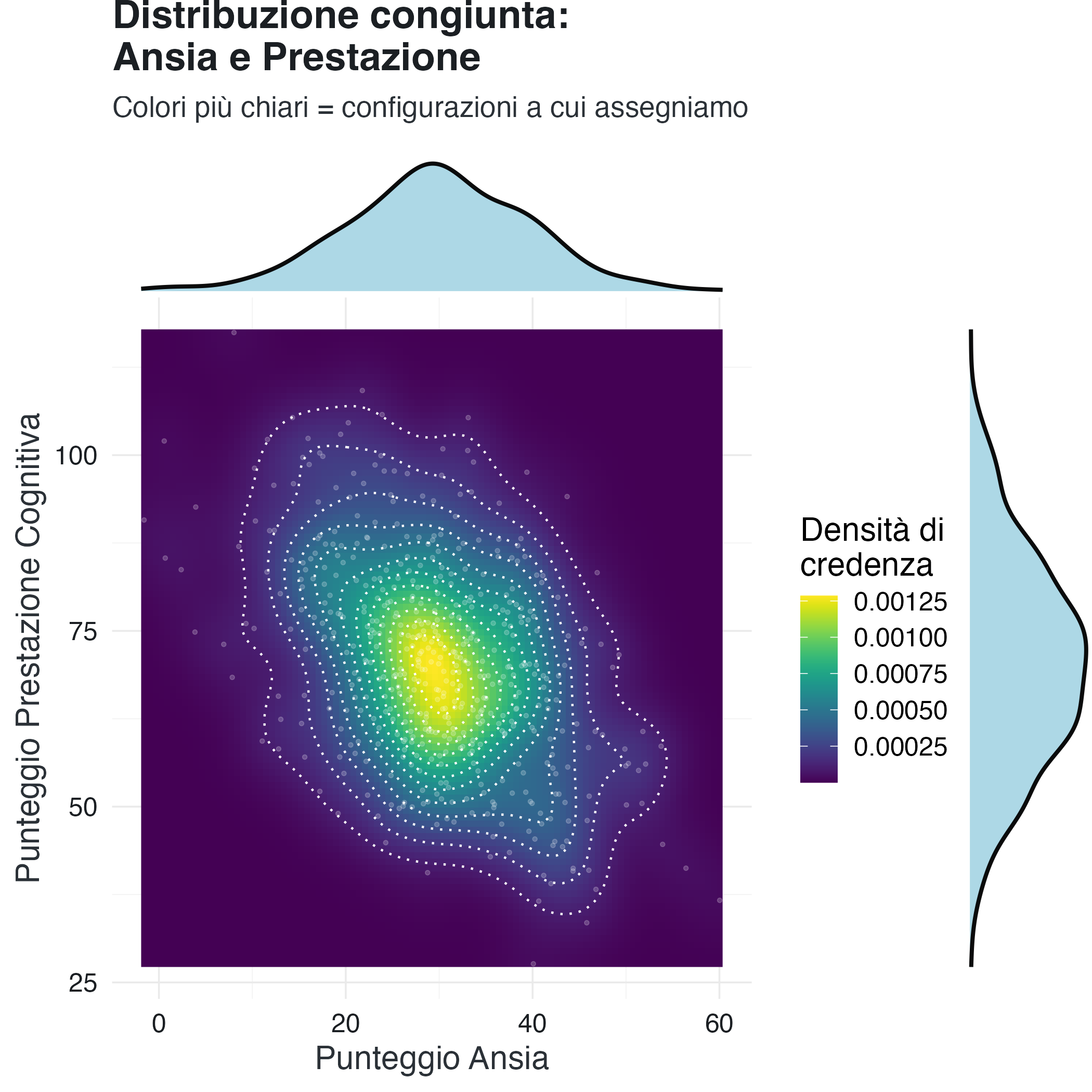
La visualizzazione rivela diversi aspetti della struttura delle nostre credenze. La regione più chiara, situata nella parte centro-sinistra in alto, rappresenta le configurazioni a cui attribuiamo la massima credibilità: bassa ansia associata a buona prestazione. Le regioni più scure, verso l’angolo in alto a destra, indicano configurazioni meno plausibili: alta ansia con buona prestazione. L’orientamento ellittico della distribuzione, inclinato verso il basso da sinistra a destra, riflette la correlazione negativa che abbiamo incorporato nelle nostre credenze sulla base della letteratura.
I grafici ai margini mostrano le densità marginali, ottenute proiettando la distribuzione congiunta su ciascun asse. Queste rappresentano le nostre credenze su ciascuna variabile singolarmente, quando non sono condizionate dall’altra.
La distribuzione congiunta contiene tutta l’informazione sulle relazioni tra le variabili. Tuttavia, comunicare e interpretare un’intera distribuzione può risultare complesso.
La covarianza e la correlazione sono riassunti numerici che:
- catturano l’aspetto lineare della relazione;
- condensano l’informazione in un singolo numero;
- comportano una perdita di informazione: dipendenze non lineari possono esistere anche in presenza di correlazione nulla.
Questi indici sono strumenti utili ma parziali: la distribuzione congiunta resta la fonte primaria dell’informazione.
9.2 Covarianza: misura della co-variazione lineare
9.2.1 La domanda fondamentale: le variabili si muovono insieme?
Prima di introdurre la formula matematica, consideriamo l’intuizione sottostante. Quando diciamo che due variabili “co-variano”, intendiamo che tendono a muoversi insieme in modo sistematico:
- Quando l’ansia è sopra la sua media, la prestazione tende a essere sotto la sua media?
- Quando il supporto sociale è elevato, il benessere tende a essere elevato?
- Quando lo stress aumenta, i sintomi depressivi aumentano?
La covarianza formalizza questa intuizione, quantificando la tendenza delle variabili a deviare dalle rispettive medie nella stessa direzione (covarianza positiva) o in direzioni opposte (covarianza negativa).
9.2.2 Definizione formale
Definizione 9.2 La covarianza tra due variabili casuali \(X\) e \(Y\) è definita come:
\[ \text{Cov}(X, Y) = \mathbb{E}\left[(X - \mathbb{E}[X])(Y - \mathbb{E}[Y])\right]. \]
Nel caso di variabili discrete con distribuzione congiunta \(p(x,y)\), questa definizione assume la forma:
\[ \text{Cov}(X, Y) = \sum_{x}\sum_{y}(x - \mu_X)(y - \mu_Y)\,p(x, y), \]
dove \(\mu_X = \mathbb{E}[X]\) e \(\mu_Y = \mathbb{E}[Y]\) sono i valori attesi delle due variabili.
L’interpretazione della covarianza emerge direttamente dalla struttura del prodotto \((X - \mu_X)(Y - \mu_Y)\):
- quando entrambe le variabili sono sopra le rispettive medie, il prodotto è positivo (+)(+) = (+);
- quando entrambe sono sotto le rispettive medie, il prodotto è ancora positivo (−)(−) = (+);
- quando una è sopra e l’altra sotto, il prodotto è negativo (+)(−) = (−).
La covarianza è la media di questi prodotti, ponderata secondo la distribuzione congiunta:
- una covarianza positiva indica che le variabili tendono a muoversi nella stessa direzione;
- una covarianza negativa indica che tendono a muoversi in direzioni opposte;
- una covarianza nulla segnala l’assenza di una tendenza lineare sistematica.
9.2.3 Formula computazionale
La covarianza può essere calcolata in modo equivalente mediante la formula:
\[ \text{Cov}(X, Y) = \mathbb{E}[XY] - \mathbb{E}[X]\mathbb{E}[Y]. \]
Questa espressione ha un’interpretazione illuminante: confronta il valore atteso del prodotto \(XY\) sotto la distribuzione congiunta effettiva con il valore che si otterrebbe se le variabili fossero indipendenti (nel qual caso \(\mathbb{E}[XY] = \mathbb{E}[X]\mathbb{E}[Y]\)). La differenza misura quanto la distribuzione congiunta si discosti dall’indipendenza in termini di co-variazione lineare.
Partiamo dalla definizione:
\[ \text{Cov}(X, Y) = \mathbb{E}\bigl[(X - \mathbb{E}[X])(Y - \mathbb{E}[Y])\bigr]. \]
Espandiamo il prodotto:
\[ = \mathbb{E}\bigl[XY - X\mathbb{E}[Y] - \mathbb{E}[X]Y + \mathbb{E}[X]\mathbb{E}[Y]\bigr]. \]
Per la linearità del valore atteso e poiché \(\mathbb{E}[X]\) e \(\mathbb{E}[Y]\) sono costanti:
\[ \begin{aligned} &= \mathbb{E}[XY] - \mathbb{E}[X\mathbb{E}[Y]] - \mathbb{E}[\mathbb{E}[X]Y] + \mathbb{E}[\mathbb{E}[X]\mathbb{E}[Y]] \\ &= \mathbb{E}[XY] - \mathbb{E}[Y]\mathbb{E}[X] - \mathbb{E}[X]\mathbb{E}[Y] + \mathbb{E}[X]\mathbb{E}[Y]. \end{aligned} \]
Semplificando:
\[ \text{Cov}(X, Y) = \mathbb{E}[XY] - \mathbb{E}[X]\mathbb{E}[Y]. \]
9.2.4 Relazione con la varianza
La covarianza generalizza il concetto di varianza. In particolare, la varianza di una variabile è la covarianza della variabile con se stessa:
\[ \mathbb{V}(X) = \text{Cov}(X, X) = \mathbb{E}\left[(X - \mathbb{E}[X])^2\right]. \]
Mentre la varianza misura quanto una singola variabile si discosta dal proprio valore atteso, la covarianza misura quanto le deviazioni di due variabili tendano a muoversi insieme.
9.2.5 Ponte applicativo: cosa ci dice la covarianza nella pratica clinica
Quando calcoliamo la covarianza tra ansia e prestazione e otteniamo un valore negativo, formalizziamo l’osservazione clinica secondo cui “i pazienti più ansiosi tendono a ottenere prestazioni peggiori”. Tuttavia, la covarianza grezza presenta un limite importante: il suo valore numerico dipende dalle unità di misura utilizzate. Se misurassimo l’ansia su una scala da 0 a 100 invece che da 0 a 10, la covarianza cambierebbe di un fattore 10, anche se la relazione tra le variabili rimane invariata.
Questo ci porta alla necessità di utilizzare la correlazione.
Applichiamo ora questi concetti alla tabella congiunta ansia–prestazione introdotta in precedenza. Utilizziamo la seguente codifica numerica: prestazione \(X \in \{0,1,2\}\) (insufficiente, sufficiente, buona) e ansia \(Y \in \{0,1,2\}\) (bassa, media, alta).
# Tabella congiunta
tab_joint <- matrix(
c(0.05, 0.10, 0.15,
0.15, 0.20, 0.10,
0.10, 0.10, 0.05),
nrow = 3, byrow = TRUE,
dimnames = list(
Prestazione = c("Insufficiente (0)", "Sufficiente (1)", "Buona (2)"),
Ansia = c("Bassa (0)", "Media (1)", "Alta (2)")
)
)
cat("Distribuzione congiunta:\n")
#> Distribuzione congiunta:
print(tab_joint)
#> Ansia
#> Prestazione Bassa (0) Media (1) Alta (2)
#> Insufficiente (0) 0.05 0.1 0.15
#> Sufficiente (1) 0.15 0.2 0.10
#> Buona (2) 0.10 0.1 0.05Il primo passo consiste nel calcolare i valori attesi dalle distribuzioni marginali:
# Valori delle variabili
val_prest <- 0:2
val_ansia <- 0:2
# Distribuzioni marginali
marg_prest <- rowSums(tab_joint)
marg_ansia <- colSums(tab_joint)
# Valori attesi
E_X <- sum(val_prest * marg_prest)
E_Y <- sum(val_ansia * marg_ansia)
cat("\nDistribuzioni marginali:\n")
#>
#> Distribuzioni marginali:
cat("P(Prestazione):", marg_prest, "\n")
#> P(Prestazione): 0.3 0.45 0.25
cat("P(Ansia):", marg_ansia, "\n")
#> P(Ansia): 0.3 0.4 0.3
cat("\nValori attesi:\n")
#>
#> Valori attesi:
cat("E[Prestazione] =", round(E_X, 3), "\n")
#> E[Prestazione] = 0.95
cat("E[Ansia] =", round(E_Y, 3), "\n")
#> E[Ansia] = 1Ora calcoliamo \(\mathbb{E}[XY]\) sommando il prodotto \(xy\) pesato dalla probabilità congiunta \(p(x,y)\):
Infine, applichiamo la formula computazionale:
Questa covarianza negativa riflette la struttura delle nostre credenze: abbiamo assegnato una probabilità maggiore alle configurazioni in cui un’alta ansia si accompagna a una bassa prestazione, generando una co-variazione negativa sistematica.
9.3 Correlazione: covarianza standardizzata
9.3.1 Il problema delle unità di misura
La covarianza presenta un limite pratico rilevante: il suo valore numerico dipende dalle unità di misura delle variabili. Se misurassimo l’ansia su una scala da 0 a 100 anziché da 0 a 2, la covarianza cambierebbe di un fattore costante, anche se la struttura della relazione rimanesse invariata.
Questo rende impossibile rispondere a domande come: “La relazione tra ansia e prestazione nel mio studio è più forte o più debole di quella trovata in altri studi?”. La correlazione risolve questo problema standardizzando la covarianza.
Definizione 9.3 Il coefficiente di correlazione (o correlazione di Pearson) tra due variabili casuali \(X\) e \(Y\) è definito come:
\[ \rho(X,Y) = \frac{\text{Cov}(X,Y)}{\sqrt{\mathbb{V}(X)\,\mathbb{V}(Y)}} = \frac{\text{Cov}(X,Y)}{\sigma_X \sigma_Y}, \]
dove \(\sigma_X\) e \(\sigma_Y\) sono le deviazioni standard di \(X\) e \(Y\).
La correlazione può essere interpretata come la covarianza tra le versioni standardizzate delle variabili. Dividendo il valore della covarianza per il prodotto delle deviazioni standard, si ottiene un indice adimensionale che misura la forza della relazione lineare su una scala universale.
9.3.2 Proprietà fondamentali
Il coefficiente di correlazione possiede proprietà che ne facilitano l’interpretazione:
Limitatezza: vale sempre \(-1 \leq \rho(X,Y) \leq 1\).
Invarianza rispetto a trasformazioni lineari: se \(a > 0\) e \(b > 0\), allora \[ \rho(aX + c,\, bY + d) = \rho(X,Y). \] Cambiare scala o origine delle misure non altera la correlazione.
-
Valori estremi:
- \(\rho = +1\): relazione lineare perfetta positiva (\(Y = a + bX\) con \(b > 0\));
- \(\rho = -1\): relazione lineare perfetta negativa (\(Y = a + bX\) con \(b < 0\));
- \(\rho = 0\): assenza di relazione lineare (ma possibili dipendenze non lineari!).
9.3.3 Ponte applicativo: perché usiamo la correlazione negli articoli scientifici
La correlazione si è affermata come il linguaggio comune per comunicare l’intensità delle associazioni in psicologia e nelle scienze del comportamento per motivi ben precisi.
Comparabilità: un coefficiente \(\rho = -0.40\) tra ansia e prestazione ha lo stesso significato numerico indipendentemente dalle scale specifiche utilizzate (es., GAD-7 vs. BAI, o diversi test di memoria di lavoro). Questo permette confronti diretti e meta-analitici tra studi condotti con strumenti e campioni differenti.
Interpretabilità intuitiva: il quadrato del coefficiente di correlazione, \(\rho^2\), rappresenta la proporzione di varianza condivisa tra le due variabili. Ad esempio, con \(\rho = -0.40\), il 16% della variabilità osservata nella prestazione è “spiegata” (in senso statistico) dalla variabilità nei punteggi di ansia, e viceversa.
Sintesi per la meta-analisi: essendo una misura standardizzata e priva di unità di misura, la correlazione può essere facilmente aggregata e mediata tra una moltitudine di studi, permettendo di ottenere una stima più precisa e robusta dell’associazione “vera” a livello di popolazione, al netto delle singole peculiarità metodologiche.
# Calcolo delle varianze
Var_X <- sum(val_prest^2 * marg_prest) - E_X^2
Var_Y <- sum(val_ansia^2 * marg_ansia) - E_Y^2
# Correlazione
rho_XY <- Cov_XY / sqrt(Var_X * Var_Y)
cat("Varianze:\n")
#> Varianze:
cat("Var(X) =", round(Var_X, 4), "\n")
#> Var(X) = 0.547
cat("Var(Y) =", round(Var_Y, 4), "\n")
#> Var(Y) = 0.6
cat("\nDeviazioni standard:\n")
#>
#> Deviazioni standard:
cat("σ_X =", round(sqrt(Var_X), 4), "\n")
#> σ_X = 0.74
cat("σ_Y =", round(sqrt(Var_Y), 4), "\n")
#> σ_Y = 0.775
cat("\nCorrelazione:\n")
#>
#> Correlazione:
cat("ρ(X,Y) =", round(rho_XY, 3), "\n")
#> ρ(X,Y) = -0.262Il valore \(\rho(X,Y) \approx -0.26\) indica una relazione lineare negativa di entità moderata. Questa interpretazione può essere articolata su tre livelli:
- la direzione negativa conferma che livelli elevati di ansia tendono a essere associati a prestazioni più basse;
- l’intensità moderata (circa 0.26 in valore assoluto) segnala che la relazione non è deterministica, ma che permane una considerevole variabilità non spiegata;
- la varianza condivisa è \(\rho^2 = 0.068\), ovvero circa il 7% della variabilità di una variabile è associato alla variabilità dell’altra.
9.3.4 Linee guida interpretative e contesto psicologico
Le convenzioni suggerite da Cohen (1988) forniscono un punto di riferimento generale per interpretare l’entità di una correlazione:
- \(|\rho| < 0.3\): correlazione modesta (“small”);
- \(0.3 \leq |\rho| < 0.5\): correlazione moderata (“medium”);
- \(|\rho| \geq 0.5\): correlazione sostanziale (“large”).
Tuttavia, queste soglie devono essere sempre valutate alla luce del contesto specifico della ricerca psicologica. L’impatto pratico di una correlazione dipende fortemente dal dominio di studio. Di seguito alcuni riferimenti tipici:
| Contesto psicometrico/sperimentale | Correlazione tipica | Interpretazione |
|---|---|---|
| Affidabilità test-retest | 0.70 – 0.90 | Valore necessario per scale considerate affidabili |
| Validità convergente | 0.40 – 0.70 | Scale che misurano costrutti simili dovrebbero correlare in questo intervallo |
| Validità discriminante | < 0.30 | Scale che misurano costrutti distinti dovrebbero correlare debolmente |
| Predittori comportamentali | 0.20 – 0.40 | Intervallo tipico in psicologia sociale e della personalità |
| Effetti pre-post interventi clinici | 0.50 – 0.80 | Riflette un cambiamento clinicamente significativo |
Una correlazione di \(|\rho| = 0.26\) tra ansia e prestazione cognitiva, benché classificabile come “modesta” secondo Cohen, può avere una rilevanza pratica non trascurabile. Se la relazione ha una componente causale, anche una riduzione modesta dell’ansia potrebbe portare a un miglioramento tangibile delle prestazioni in una frazione rilevante della popolazione studentesca.
9.4 Proprietà matematiche della covarianza
Le proprietà matematiche della covarianza non sono soltanto risultati formali, ma hanno conseguenze pratiche rilevanti per l’analisi dei dati psicologici.
Teorema 9.1 (Proprietà della covarianza) Siano \(X\), \(Y\) e \(Z\) variabili casuali e \(a\), \(b\), \(c\) costanti reali. Allora valgono le seguenti proprietà:
Simmetria \[ \text{Cov}(X, Y) = \text{Cov}(Y, X). \]
Covarianza con una costante \[ \text{Cov}(c, X) = 0. \]
Linearità rispetto a moltiplicazione per costanti \[ \text{Cov}(aX, bY) = ab \cdot \text{Cov}(X, Y). \]
Additività rispetto alla somma \[ \text{Cov}(X + Y, Z) = \text{Cov}(X, Z) + \text{Cov}(Y, Z). \]
Varianza della somma \[ \mathbb{V}(X + Y) = \mathbb{V}(X) + \mathbb{V}(Y) + 2\,\text{Cov}(X, Y). \]
La proprietà della varianza di una somma merita particolare attenzione, poiché chiarisce come l’incertezza si propaga quando più componenti contribuiscono a un’unica quantità:
- se la covarianza è positiva, le fluttuazioni delle variabili tendono ad andare nella stessa direzione, amplificando la variabilità complessiva;
- se la covarianza è negativa, le fluttuazioni tendono a compensarsi reciprocamente, riducendo la variabilità totale;
- se la covarianza è nulla (ovvero le variabili sono incorrelate), la varianza della somma è semplicemente la somma delle varianze individuali.
9.4.1 Ponte applicativo: affidabilità delle scale composite
Questa proprietà spiega il motivo per cui le scale psicometriche composte da più item tendono a essere più affidabili (cioè meno influenzate dal rumore casuale) dei singoli item presi isolatamente. Quando gli item misurano lo stesso costrutto latente, tendono a essere positivamente correlati tra loro. Nella formula della varianza del punteggio totale, le covarianze positive tra item si sommano, amplificando la componente di varianza comune, ovvero il “segnale” attribuibile al costrutto sottostante, mentre l’errore di misura casuale tende a non correlare e a non accumularsi nella stessa misura. Il risultato è un punteggio totale più stabile e meno soggetto a fluttuazioni casuali rispetto a qualsiasi item individuale.
Il benessere psicologico viene spesso concettualizzato come un costrutto multidimensionale. Consideriamo due componenti correlate:
- benessere emotivo (\(\sigma_e = 0.4\));
- benessere sociale (\(\sigma_s = 0.3\));
- correlazione tra le componenti: \(\rho = 0.6\).
Il punteggio complessivo è una combinazione ponderata: \[ \text{Benessere} = 0.6 \cdot E + 0.4 \cdot S \]
# Definizione dei parametri
sigma_emotivo <- 0.4
sigma_sociale <- 0.3
rho <- 0.6
w_emotivo <- 0.6
w_sociale <- 0.4
# Covarianza tra le componenti
Cov_ES <- rho * sigma_emotivo * sigma_sociale
# Calcolo della varianza del punteggio composito
Var_benessere <- w_emotivo^2 * sigma_emotivo^2 +
w_sociale^2 * sigma_sociale^2 +
2 * w_emotivo * w_sociale * Cov_ES
sigma_benessere <- sqrt(Var_benessere)
cat("Componenti della varianza:\n")
#> Componenti della varianza:
cat("- Contributo emotivo: ", round(w_emotivo^2 * sigma_emotivo^2, 4), "\n")
#> - Contributo emotivo: 0.0576
cat("- Contributo sociale: ", round(w_sociale^2 * sigma_sociale^2, 4), "\n")
#> - Contributo sociale: 0.0144
cat("- Contributo covarianza: ", round(2 * w_emotivo * w_sociale * Cov_ES, 4), "\n")
#> - Contributo covarianza: 0.0346
cat("\nVarianza totale:", round(Var_benessere, 4), "\n")
#>
#> Varianza totale: 0.107
cat("Deviazione standard:", round(sigma_benessere, 3), "\n")
#> Deviazione standard: 0.326Il termine di covarianza contribuisce significativamente alla varianza totale. Questo riflette il fatto che le due componenti tendono a variare insieme: quando il benessere emotivo è alto, anche quello sociale tende a essere alto, amplificando la variabilità complessiva del costrutto.
9.5 Incorrelazione e indipendenza
9.5.1 Definizione di incorrelazione
Due variabili casuali \(X\) e \(Y\) si dicono incorrelate quando la loro covarianza è nulla:
\[ \text{Cov}(X, Y) = 0 \quad \Leftrightarrow \quad \rho(X, Y) = 0. \]
L’incorrelazione indica l’assenza di una tendenza lineare sistematica alla co-variazione. Sapere che \(X\) è sopra la sua media non ci dice nulla sulla direzione in cui \(Y\) tenderà a discostarsi dalla propria media.
9.5.2 La distinzione cruciale: incorrelazione non implica indipendenza
Una delle trappole concettuali più importanti in statistica riguarda la relazione tra incorrelazione e indipendenza.
L’indipendenza implica l’incorrelazione Se \(X\) e \(Y\) sono indipendenti, allora necessariamente \(\text{Cov}(X,Y) = 0\).
L’incorrelazione NON implica l’indipendenza Possono esistere variabili con \(\text{Cov}(X,Y) = 0\) che sono fortemente dipendenti in modo non lineare.
Questa asimmetria nasce dal fatto che la correlazione cattura esclusivamente la componente lineare della relazione. Le relazioni non lineari possono essere molto intense, ma produrre comunque una covarianza nulla.
9.5.3 Un esempio psicologico: la legge di Yerkes-Dodson
Un esempio classico di relazione non lineare in psicologia è la legge di Yerkes-Dodson, che descrive il legame tra arousal (attivazione fisiologica) e prestazione. Tale relazione ha una forma a U rovesciata: la prestazione migliora all’aumentare dell’arousal fino a un punto ottimale, dopodiché declina se l’arousal diventa eccessivo.
set.seed(42)
n <- 500
# Simuliamo arousal distribuito uniformemente
arousal <- runif(n, 0, 10)
# La prestazione segue una parabola invertita con rumore
# Massimo a arousal = 5
prestazione <- -0.4 * (arousal - 5)^2 + 10 + rnorm(n, 0, 1)
# Calcoliamo la correlazione
r_lineare <- cor(arousal, prestazione)
# Grafico
df_yd <- data.frame(arousal = arousal, prestazione = prestazione)
ggplot(df_yd, aes(x = arousal, y = prestazione)) +
geom_point(alpha = 0.4, size = 1.5) +
geom_smooth(method = "lm", se = FALSE, color = "red",
linetype = "dashed", linewidth = 1) +
geom_smooth(method = "loess", se = FALSE, color = "blue", linewidth = 1.2) +
annotate("text", x = 8, y = 12,
label = paste0("r = ", round(r_lineare, 3)),
size = 4, color = "red") +
labs(
title = "Legge di Yerkes-Dodson: arousal e prestazione",
subtitle = "Linea blu: relazione vera (curvilinea) | Linea rossa: regressione lineare",
x = "Livello di arousal",
y = "Prestazione"
)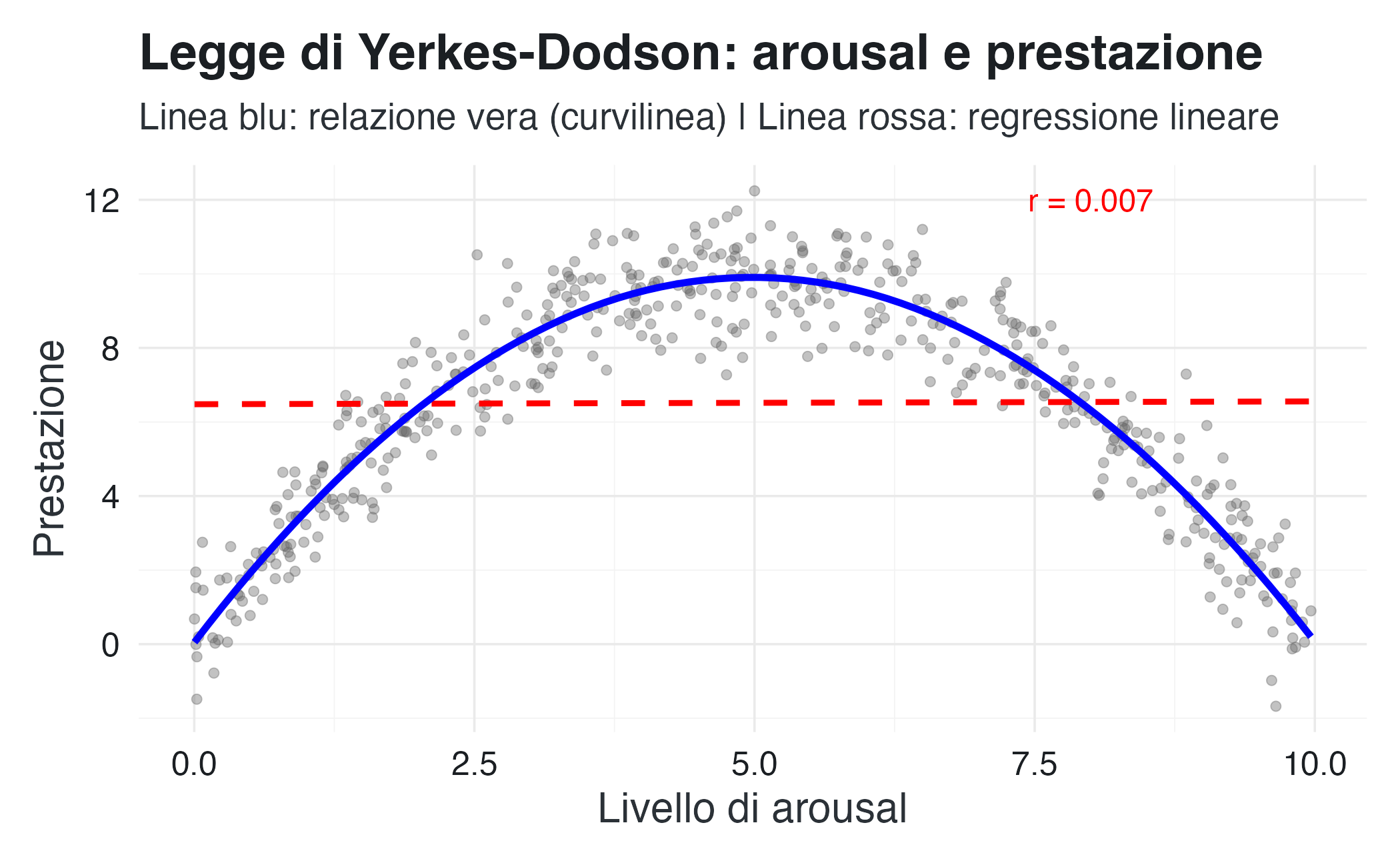
Interpretazione clinica: un terapeuta che valutasse soltanto la correlazione lineare tra ansia (una forma di arousal) e prestazione potrebbe concludere erroneamente che “non vi sia alcuna relazione”. In realtà, la relazione è forte ma curvilinea: sia livelli troppo bassi che troppo alti di ansia compromettono la prestazione. Questa intuizione ha implicazioni dirette per l’intervento: l’obiettivo non è eliminare l’ansia, ma modularla per raggiungere un livello ottimale.
Per illustrare il punto in modo ancora più estremo, consideriamo una relazione quadratica perfetta:
\[ Y = X^2, \quad \text{con } X \sim \text{Uniforme}(-2, 2) \]
set.seed(42)
n <- 1000
X <- runif(n, -2, 2)
Y <- X^2 + rnorm(n, 0, 0.3)
cat("Coefficiente di correlazione lineare di Pearson:\n")
#> Coefficiente di correlazione lineare di Pearson:
cat(" r(X, Y) =", round(cor(X, Y), 3), "\n\n")
#> r(X, Y) = -0.013
cat("Nonostante r ≈ 0, Y è COMPLETAMENTE determinato da X!\n")
#> Nonostante r ≈ 0, Y è COMPLETAMENTE determinato da X!
cat("La correlazione cattura solo la componente lineare della relazione.\n")
#> La correlazione cattura solo la componente lineare della relazione.ggplot(data.frame(X = X, Y = Y), aes(x = X, y = Y)) +
geom_point(alpha = 0.4, size = 1.5) +
geom_smooth(method = "lm", se = FALSE, color = "red", linetype = "dashed") +
stat_function(fun = function(x) x^2, color = "blue", linewidth = 1) +
labs(
title = "Relazione quadratica Y = X² + ε",
subtitle = "La correlazione lineare è zero, ma la dipendenza è perfetta",
x = "X",
y = "Y"
) 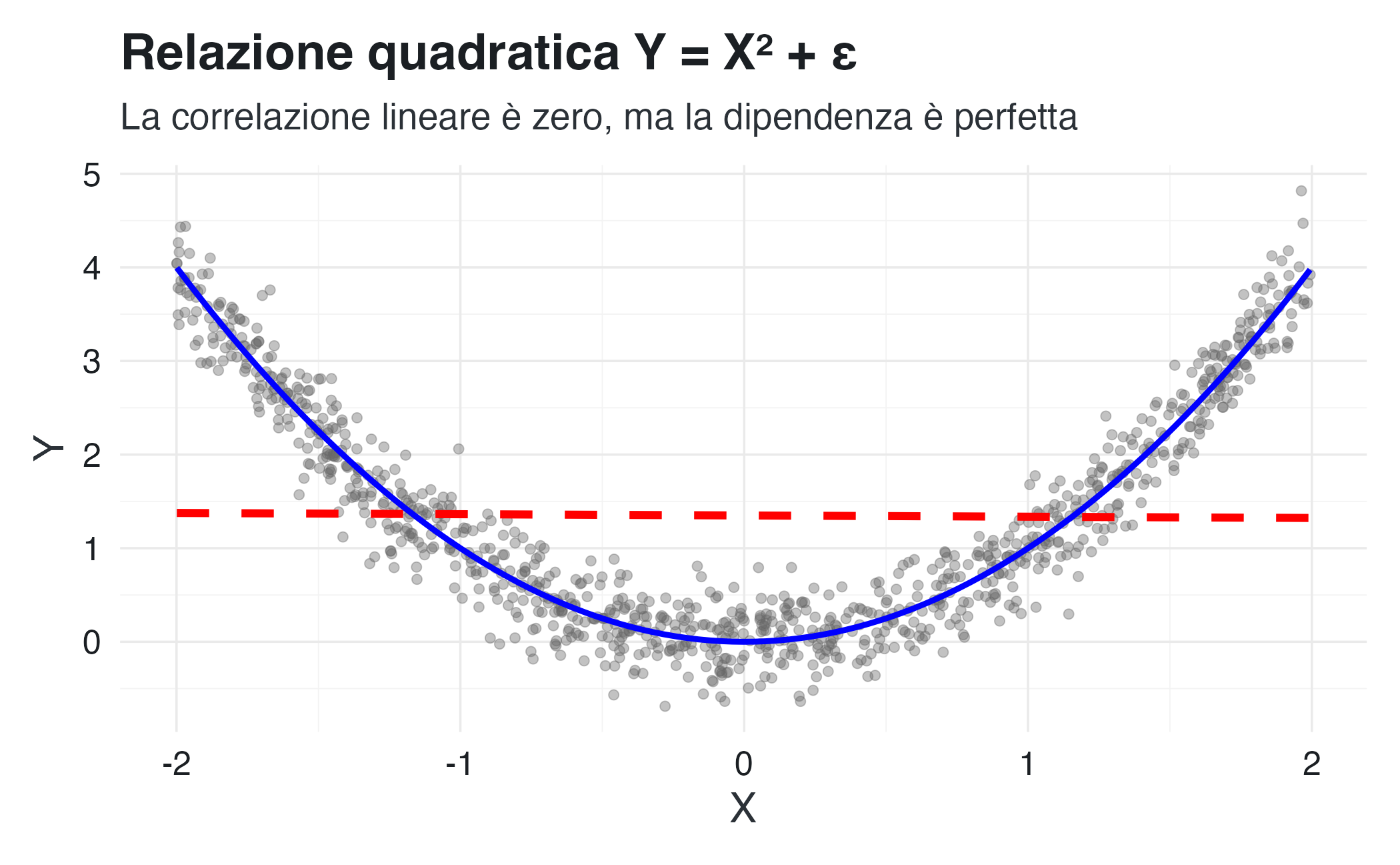
La correlazione è nulla perché la relazione è simmetrica rispetto a zero: per \(X > 0\) la relazione è positiva, per \(X < 0\) è negativa, e le due tendenze si compensano esattamente nel calcolo della covarianza lineare.
9.5.4 Implicazioni pratiche per la ricerca
La lezione operativa è cruciale: un coefficiente di correlazione pari a zero non autorizza di per sé a concludere che non esista alcuna associazione tra due variabili. Prima di affermare l’assenza di relazione, è necessario:
- visualizzare sempre i dati con uno scatterplot, esaminando possibili pattern curvilinei o a cluster;
- considerare relazioni non lineari teoricamente plausibili nel dominio di ricerca (come l’esempio di Yerkes-Dodson);
- utilizzare misure complementari quando appropriato, come la correlazione di Spearman per rilevare relazioni monotone, o modelli di regressione flessibili.
La correlazione è uno strumento potente, ma la sua interpretazione è limitata alla componente lineare della dipendenza. Confondere “assenza di correlazione lineare” con “assenza di relazione” è un errore metodologico comune che può portare a conclusioni errate.
9.6 Covarianza nell’inferenza bayesiana
Nell’inferenza bayesiana, la covarianza non svolge soltanto un ruolo descrittivo, ma diventa parte integrante della rappresentazione delle nostre credenze sui parametri del modello.
9.6.1 Covarianza a priori
Prima di osservare i dati, possiamo specificare una distribuzione a priori sui parametri che includa una struttura di covarianza. Questa scelta riflette le nostre assunzioni teoriche sulle relazioni tra i parametri.
# Prior multivariata normale per due parametri
mu_prior <- c(0, 0)
Sigma_prior <- matrix(c(1, 0.7, 0.7, 1), nrow = 2)
# Simuliamo dalla prior
set.seed(123)
samples_prior <- mvrnorm(1000, mu_prior, Sigma_prior)
cat("Matrice di covarianza a priori:\n")
#> Matrice di covarianza a priori:
print(Sigma_prior)
#> [,1] [,2]
#> [1,] 1.0 0.7
#> [2,] 0.7 1.0
cat("\nCorrelazione a priori tra parametri:", 0.7, "\n")
#>
#> Correlazione a priori tra parametri: 0.7
# Visualizzazione
ggplot(as.data.frame(samples_prior), aes(x = V1, y = V2)) +
geom_point(alpha = 0.4) +
labs(
title = "Prior multivariata con correlazione 0.7",
subtitle = "Credenze iniziali sulla relazione tra parametri",
x = expression(theta[1]),
y = expression(theta[2])
) 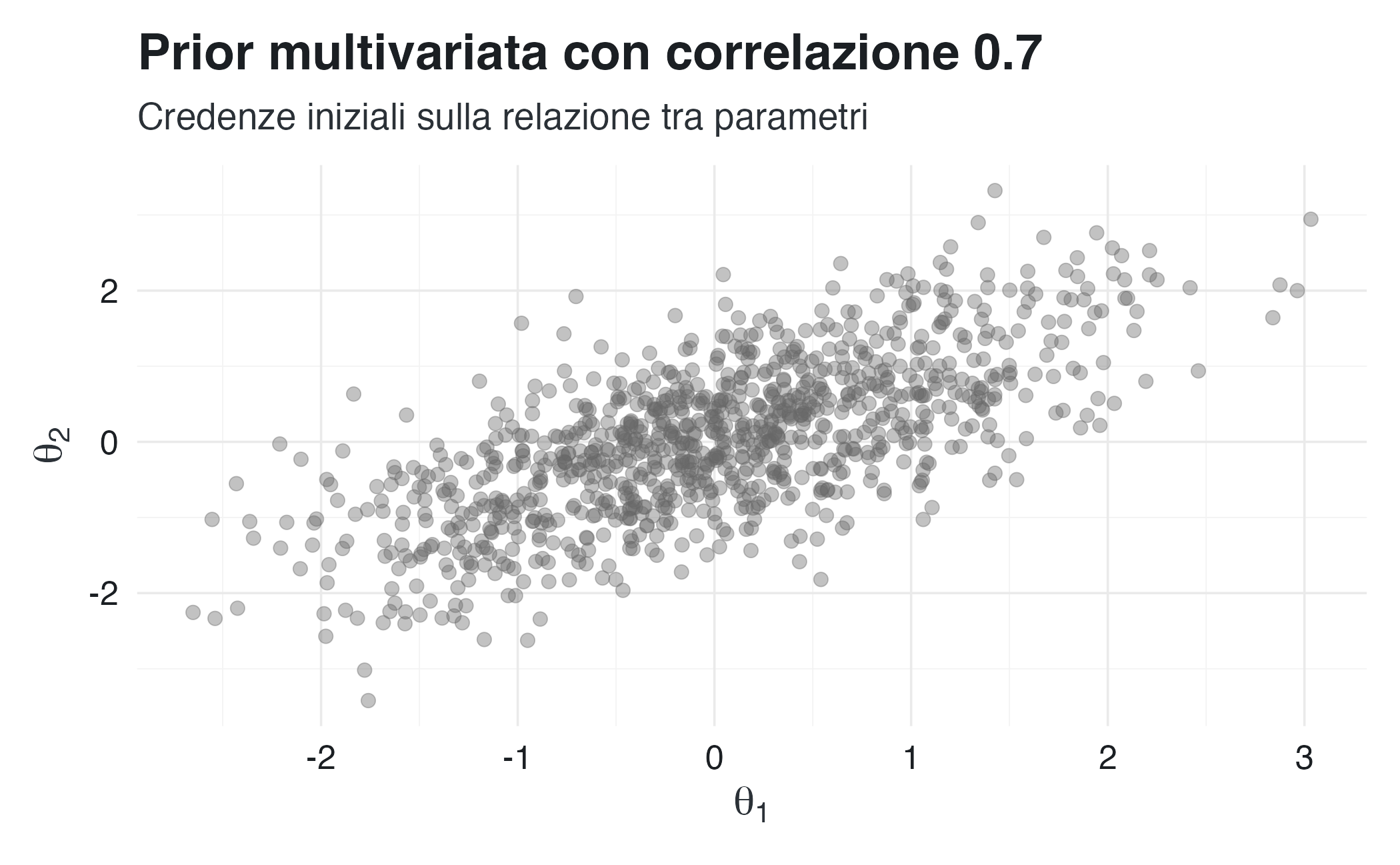
Specificare una correlazione positiva nella prior equivale ad affermare che riteniamo plausibile una variazione congiunta dei due parametri: valori elevati di uno tendono ad accompagnarsi a valori elevati dell’altro.
9.6.2 Covarianza a posteriori
Dopo l’osservazione dei dati, la distribuzione a posteriori presenta una propria struttura di covarianza che rappresenta lo stato aggiornato delle nostre credenze. La covarianza a posteriori riflette l’interazione tra l’informazione a priori e l’evidenza empirica.
9.6.3 Ponte applicativo: interpretare l’incertezza congiunta sui parametri
In un modello di regressione, la covarianza a posteriori tra i parametri, per esempio tra l’intercetta (\(\beta_0\)) e la pendenza (\(\beta_1\)), rivela come le incertezze sui singoli parametri sono correlate tra loro. Una covarianza negativa (comune quando il predittore non è centrato sullo zero) indica che una sovrastima dell’intercetta tende ad associarsi a una sottostima della pendenza, e viceversa. Questa informazione è essenziale per:
- costruire intervalli di credibilità congiunti, che descrivono regioni plausibili per le coppie di valori dei parametri, piuttosto che limitarsi a considerare i parametri singolarmente;
- propagare correttamente l’incertezza nelle previsioni, poiché gli errori nei parametri non sono indipendenti;
- valutare l’identificabilità del modello, in quanto una covarianza molto elevata in valore assoluto può segnalare collinearità o problemi di stima.
Riflessioni conclusive
La covarianza e la correlazione sono strumenti fondamentali per quantificare la relazione lineare tra due variabili casuali. Come abbiamo visto, questi indici emergono naturalmente dalla distribuzione congiunta e ne forniscono una sintesi numerica utile, ma inevitabilmente parziale.
Per lo psicologo clinico e il ricercatore, questi concetti hanno un’utilità pratica immediata:
- nella validazione degli strumenti: le correlazioni misurano la validità convergente e discriminante tra scale;
- nello studio delle differenze individuali: quantificano l’intensità delle associazioni tra tratti di personalità, stati emotivi e comportamenti;
- nella pratica clinica: informano sulle aspettative di comorbidità, aiutando a prevedere la probabilità congiunta di sintomi;
- nella modellazione statistica: la matrice di covarianza è il cuore della regressione multipla, dell’analisi fattoriale e dei modelli a equazioni strutturali.
Un avvertimento cruciale emerso nel capitolo è che la covarianza e la correlazione catturano soltanto la componente lineare della relazione. L’esempio della legge di Yerkes-Dodson mostra come associazioni psicologicamente significative possano rimanere nascoste a questi indici. Per un’analisi solida, l’esplorazione numerica sempre essere affiancata da un’attenta visualizzazione dei dati.
Nel prosieguo del manuale incontreremo spesso distribuzioni multivariate, in particolare la distribuzione normale multivariata, in cui l’intera struttura di dipendenza lineare è codificata nella matrice di covarianza. La padronanza dei concetti qui sviluppati è un prerequisito indispensabile per poter utilizzare tali modelli in modo critico e informato.
Punti chiave da ricordare
Concetti essenziali di questo capitolo:
-
Dalle tabelle discrete alle densità congiunte
- Estensione naturale al caso continuo: \(f(x,y)\) è la densità congiunta.
- Regole di somma e prodotto si applicano sostituendo somme con integrali.
- La distribuzione congiunta contiene tutta l’informazione sulle relazioni.
-
Covarianza come misura della co-variazione lineare
- \(\text{Cov}(X,Y) = \mathbb{E}[(X-\mu_X)(Y-\mu_Y)]\) quantifica la tendenza a variare insieme:
- positiva: valori alti insieme, bassi insieme;
- negativa: valori alti con bassi;
- nulla: assenza di relazione lineare sistematica.
-
Formula computazionale della covarianza
- \(\text{Cov}(X,Y) = \mathbb{E}[XY] - \mathbb{E}[X]\mathbb{E}[Y]\).
- Confronta il prodotto osservato con quello atteso sotto indipendenza.
-
Correlazione come standardizzazione
- \(\rho(X,Y) = \frac{\text{Cov}(X,Y)}{\sigma_X \sigma_Y}\).
- Sempre \(-1 \leq \rho \leq 1\) (adimensionale).
- Permette confronti tra studi e scale diverse.
-
Incorrelazione ≠ indipendenza
- Indipendenza \(\Rightarrow\) incorrelazione (sempre).
- Incorrelazione \(\not\Rightarrow\) indipendenza (relazioni non lineari!).
- Esempio: legge di Yerkes-Dodson (arousal-prestazione).
-
Varianza della somma
- \(\text{Var}(X+Y) = \text{Var}(X) + \text{Var}(Y) + 2\text{Cov}(X,Y)\).
- Spiega perché scale composite sono più affidabili.
Formule da ricordare:
\[ \text{Cov}(X,Y) = \mathbb{E}[XY] - \mathbb{E}[X]\mathbb{E}[Y] \]
\[ \rho(X,Y) = \frac{\text{Cov}(X,Y)}{\sigma_X \sigma_Y} \]
\[ \text{Var}(X + Y) = \text{Var}(X) + \text{Var}(Y) + 2\text{Cov}(X,Y) \]
Linee guida interpretative (Cohen): - \(|\rho| < 0.3\): modesta; - \(0.3 \leq |\rho| < 0.5\): moderata; - \(|\rho| \geq 0.5\): sostanziale.
Per il prossimo capitolo:
nel Capitolo 10 passeremo all’inferenza statistica, presentando la distribuzione campionaria, l’errore standard e il teorema del limite centrale. Questi concetti rappresentano il ponte concettuale tra la probabilità, che descrive fenomeni aleatori, e la statistica inferenziale di stampo bayesiano, che aggiorna le nostre credenze alla luce dei dati osservati.
sessionInfo()
#> R version 4.5.2 (2025-10-31)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Tahoe 26.2
#>
#> Matrix products: default
#> BLAS: /System/Library/Frameworks/Accelerate.framework/Versions/A/Frameworks/vecLib.framework/Versions/A/libBLAS.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
#>
#> locale:
#> [1] C.UTF-8/UTF-8/C.UTF-8/C/C.UTF-8/C.UTF-8
#>
#> time zone: Europe/Rome
#> tzcode source: internal
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] ggExtra_0.11.0 viridis_0.6.5 viridisLite_0.4.2
#> [4] MASS_7.3-65 ragg_1.5.0 tinytable_0.15.2
#> [7] withr_3.0.2 systemfonts_1.3.1 patchwork_1.3.2
#> [10] ggdist_3.3.3 tidybayes_3.0.7 bayesplot_1.15.0
#> [13] ggplot2_4.0.1 reliabilitydiag_0.2.1 priorsense_1.2.0
#> [16] posterior_1.6.1 loo_2.9.0 rstan_2.32.7
#> [19] StanHeaders_2.32.10 brms_2.23.0 Rcpp_1.1.1
#> [22] sessioninfo_1.2.3 conflicted_1.2.0 janitor_2.2.1
#> [25] matrixStats_1.5.0 modelr_0.1.11 tibble_3.3.1
#> [28] dplyr_1.1.4 tidyr_1.3.2 rio_1.2.4
#> [31] here_1.0.2
#>
#> loaded via a namespace (and not attached):
#> [1] gridExtra_2.3 inline_0.3.21 sandwich_3.1-1
#> [4] rlang_1.1.7 magrittr_2.0.4 multcomp_1.4-29
#> [7] snakecase_0.11.1 otel_0.2.0 compiler_4.5.2
#> [10] mgcv_1.9-4 vctrs_0.6.5 stringr_1.6.0
#> [13] pkgconfig_2.0.3 arrayhelpers_1.1-0 fastmap_1.2.0
#> [16] backports_1.5.0 labeling_0.4.3 promises_1.5.0
#> [19] rmarkdown_2.30 purrr_1.2.1 xfun_0.55
#> [22] cachem_1.1.0 jsonlite_2.0.0 later_1.4.5
#> [25] broom_1.0.11 parallel_4.5.2 R6_2.6.1
#> [28] stringi_1.8.7 RColorBrewer_1.1-3 lubridate_1.9.4
#> [31] estimability_1.5.1 knitr_1.51 zoo_1.8-15
#> [34] httpuv_1.6.16 Matrix_1.7-4 splines_4.5.2
#> [37] timechange_0.3.0 tidyselect_1.2.1 abind_1.4-8
#> [40] yaml_2.3.12 miniUI_0.1.2 codetools_0.2-20
#> [43] curl_7.0.0 pkgbuild_1.4.8 lattice_0.22-7
#> [46] shiny_1.12.1 bridgesampling_1.2-1 S7_0.2.1
#> [49] coda_0.19-4.1 evaluate_1.0.5 survival_3.8-3
#> [52] isoband_0.3.0 RcppParallel_5.1.11-1 pillar_1.11.1
#> [55] tensorA_0.36.2.1 checkmate_2.3.3 stats4_4.5.2
#> [58] distributional_0.6.0 generics_0.1.4 rprojroot_2.1.1
#> [61] rstantools_2.6.0 scales_1.4.0 xtable_1.8-4
#> [64] glue_1.8.0 emmeans_2.0.1 tools_4.5.2
#> [67] mvtnorm_1.3-3 grid_4.5.2 QuickJSR_1.8.1
#> [70] colorspace_2.1-2 nlme_3.1-168 cli_3.6.5
#> [73] textshaping_1.0.4 svUnit_1.0.8 Brobdingnag_1.2-9
#> [76] V8_8.0.1 gtable_0.3.6 digest_0.6.39
#> [79] TH.data_1.1-5 htmlwidgets_1.6.4 farver_2.1.2
#> [82] memoise_2.0.1 htmltools_0.5.9 lifecycle_1.0.5
#> [85] mime_0.13