14 La verosimiglianza
Nei capitoli precedenti abbiamo utilizzato le distribuzioni di probabilità come strumenti per descrivere il comportamento delle variabili casuali. Assumendo un modello probabilistico con parametri noti, siamo stati in grado di calcolare la probabilità di osservare determinati valori o configurazioni dei dati.
Nella pratica della ricerca scientifica, tuttavia, il problema che si presenta è spesso di natura opposta. Uno psicologo clinico osserva che 18 pazienti su 25 hanno risposto positivamente a un nuovo trattamento. La domanda non è “qual è la probabilità di osservare 18 successi?” ma piuttosto “quanto è efficace questo trattamento?” — cioè, quali valori del tasso di risposta sono più compatibili con questi dati? I dati vengono osservati per primi, e ciò che si desidera comprendere è quali valori dei parametri del modello siano più plausibili alla luce di quell’evidenza empirica. Questo ribaltamento di prospettiva, che va dal calcolo della probabilità dei dati dato il modello alla valutazione dei parametri dato l’insieme dei dati osservati, costituisce il nucleo dell’inferenza statistica.
La funzione di verosimiglianza nasce precisamente per affrontare questo problema inverso. Essa non assegna probabilità ai parametri, ma misura quanto ciascun possibile valore parametrico renda plausibili i dati osservati, assumendo che il modello probabilistico sia corretto. In altre parole, la verosimiglianza costruisce una mappa della plausibilità parametrica, che permette di confrontare diversi valori dei parametri in base alla loro capacità di spiegare l’evidenza empirica.
In questo capitolo la funzione di verosimiglianza viene introdotta come concetto centrale dell’inferenza bayesiana. Nel capitolo successivo ne analizzeremo le principali proprietà matematiche e mostreremo come, combinata con le credenze a priori, essa conduca in modo naturale alla costruzione della distribuzione a posteriori.
Per seguire questo capitolo è necessario aver letto:
- Capitolo 5
- Capitolo 10 — per il contesto inferenziale
- Capitolo 11
- Capitolo 12 — fondamentale
- Capitolo 13 — fondamentale
Questo capitolo formalizza la funzione di verosimiglianza, uno dei tre pilastri dell’inferenza bayesiana (insieme a prior e posterior).
Conoscenze matematiche richieste:
- Appendice C - per verosimiglianze con dati multipli
Panoramica del capitolo
- Definizione e interpretazione della funzione di verosimiglianza.
- Distinzione tra verosimiglianza e funzione di probabilità.
- Log-verosimiglianza: vantaggi computazionali e analitici.
- Verosimiglianza per dati binomiali e gaussiani.
- Stima di massima verosimiglianza (MLE).
- Verosimiglianza congiunta per osservazioni multiple.
- Rapporto di verosimiglianze per il confronto tra ipotesi.
14.1 Il principio della verosimiglianza
Il principio di verosimiglianza costituisce uno dei fondamenti dell’inferenza statistica. Esso fornisce un criterio sistematico per valutare quanto ciascun possibile valore dei parametri di un modello sia compatibile con i dati osservati. Invece di assegnare probabilità ai parametri, come avviene nell’inferenza bayesiana completa, il principio di verosimiglianza stabilisce come confrontare tra loro diversi valori parametrici sulla base della loro capacità di spiegare l’evidenza empirica.
14.1.1 Definizione formale
Definizione 14.1 (Funzione di verosimiglianza) Sia \(Y\) una variabile casuale (o un vettore di variabili casuali) la cui distribuzione dipende da un parametro incognito \(\theta \in \Theta\). Tale distribuzione è descritta da una funzione di densità di probabilità (nel caso continuo) o da una funzione di massa di probabilità (nel caso discreto), che indichiamo con \(f(y \mid \theta)\).
Una volta osservato un particolare insieme di dati \(y\), la funzione di verosimiglianza è definita come: \[ L(\theta; y) = f(y \mid \theta). \]
In questa definizione è fondamentale distinguere chiaramente il ruolo delle due quantità coinvolte:
- \(y\) è fissato: rappresenta i dati effettivamente osservati;
- \(\theta\) è variabile: rappresenta i possibili valori del parametro incognito \(\theta \in \Theta\).
Di conseguenza, la funzione di verosimiglianza associa a ciascun valore possibile di \(\theta\) un grado di compatibilità con i dati osservati.
Interpretazione. La verosimiglianza non rappresenta la probabilità che un’ipotesi sul parametro \(\theta\) sia vera. Essa misura invece quanto i dati osservati risultino plausibili assumendo che il parametro abbia un determinato valore. Valori di \(\theta\) per i quali i dati risultano più plausibili ricevono un supporto maggiore dalla funzione di verosimiglianza.
Questa distinzione è cruciale: la verosimiglianza confronta ipotesi parametriche, ma non assegna loro probabilità.
14.1.2 Verosimiglianza e funzione di probabilità: due prospettive
Dal punto di vista formale, la funzione di probabilità e la funzione di verosimiglianza hanno la stessa espressione matematica, \(f(y \mid \theta)\). Tuttavia, esse svolgono ruoli concettualmente distinti, a seconda di quale quantità venga considerata variabile e quale venga considerata fissata.
La funzione di probabilità descrive il comportamento dei dati prima che essi siano osservati. Risponde alla domanda: “Se il parametro avesse valore \(\theta\), quali dati potremmo osservare e con quale probabilità?” In questo contesto, \(\theta\) è fisso (un’ipotesi sul modello) e \(y\) è variabile (l’esito incerto).
La funzione di verosimiglianza, invece, entra in gioco dopo l’osservazione dei dati. Risponde alla domanda: “Avendo osservato il dato \(y\), quali valori del parametro \(\theta\) sono più compatibili con questa evidenza?” In questo caso, \(y\) è fisso (l’evidenza empirica) e \(\theta\) è variabile (l’oggetto dell’inferenza).
In altri termini, passare dalla probabilità alla verosimiglianza significa cambiare prospettiva: dall’analisi dei dati possibili all’analisi dei parametri incogniti.
| Caratteristica | Funzione di probabilità | Funzione di verosimiglianza |
|---|---|---|
| Quantità variabile | \(y\) (aleatoria) | \(\theta\) (incognita) |
| Quantità fissata | \(\theta\) (assunto noto) | \(y\) (osservato) |
| Domanda centrale | Quali dati aspettarsi? | Quali valori dei parametri sono più plausibili? |
| Scopo principale | Predizione | Inferenza |
Questa dualità mette in evidenza un punto essenziale: la stessa espressione matematica può assumere significati concettualmente diversi, a seconda dell’obiettivo dell’analisi.
Nell’approccio bayesiano, la funzione di verosimiglianza svolge un ruolo centrale di collegamento tra i dati e i parametri. Essa si combina con la distribuzione a priori per determinare la distribuzione a posteriori: \[ p(\theta \mid y) \propto L(\theta; y), p(\theta). \]
I dati non aggiornano direttamente le credenze sui parametri, ma lo fanno attraverso la verosimiglianza, che quantifica quanto ciascun valore di \(\theta\) sia compatibile con l’evidenza osservata. Nel capitolo successivo analizzeremo in dettaglio le proprietà matematiche di questa funzione e il suo ruolo nel meccanismo di aggiornamento bayesiano.
14.2 La log-verosimiglianza
14.2.1 Definizione e motivazione
In ambito statistico e computazionale è spesso conveniente lavorare non direttamente con la funzione di verosimiglianza, ma con il suo logaritmo naturale, detto log-verosimiglianza. Essa è definita come: \[ \ell(\theta; y) = \log L(\theta; y) = \log f(y \mid \theta). \]
La log-verosimiglianza non introduce nuove informazioni rispetto alla verosimiglianza originale, ma ne riformula l’espressione in una forma più adatta sia all’analisi matematica sia al calcolo numerico. Questa trasformazione è ampiamente utilizzata in pratica, specialmente quando si lavora con campioni di grandi dimensioni o con modelli complessi.
14.2.2 Vantaggi computazionali e analitici
14.2.2.1 Vantaggi computazionali: la stabilità numerica
Quando i dati osservati sono numerosi, la verosimiglianza è spesso espressa come il prodotto di molte probabilità (o densità) individuali. Poiché tali quantità sono generalmente minori di 1, il loro prodotto può diventare estremamente piccolo, fino a risultare numericamente indistinguibile da zero nei calcoli effettuati al computer. Questo fenomeno è noto come underflow numerico.
La log-verosimiglianza risolve questo problema trasformando il prodotto in una somma. Nel caso di osservazioni indipendenti \(y_1, \ldots, y_n\), si ha infatti: \[ \ell(\theta; y_1, \ldots, y_n) = \log L(\theta; y) = \sum_{i=1}^n \log f(y_i \mid \theta). \]
Poiché le somme di numeri reali sono molto più stabili dei prodotti di valori molto piccoli, questa trasformazione garantisce una maggiore affidabilità numerica nei calcoli.
# Il prodotto diretto di molte probabilità piccole può collassare a zero (underflow)
n <- 1000
theta <- 0.3
set.seed(42)
dati <- sample(0:1, n, replace = TRUE)
# Verosimiglianza diretta: prodotto rischioso
prod(dbinom(dati, 1, theta)) # Potrebbe risultare 0
#> [1] 0
# Log-verosimiglianza: calcolo stabile
sum(dbinom(dati, 1, theta, log = TRUE)) # Restituisce un valore finito
#> [1] -781Questo esempio mostra come la log-verosimiglianza permetta di lavorare con campioni di grandi dimensioni senza perdere informazione a causa dei limiti della rappresentazione numerica.
14.2.2.2 Vantaggi analitici: una forma più maneggevole
Oltre ai vantaggi computazionali, la log-verosimiglianza presenta anche importanti benefici dal punto di vista analitico.
Semplificazione delle derivate. Poiché il logaritmo trasforma un prodotto in una somma, il calcolo delle derivate della log-verosimiglianza risulta in genere più semplice rispetto a quello delle derivate della verosimiglianza originale. Questo aspetto è particolarmente utile quando si studia il comportamento della funzione al variare dei parametri.
Equivalenza dei massimi. Il logaritmo naturale è una funzione monotona crescente. Di conseguenza, massimizzare la log-verosimiglianza \(\ell(\theta; y)\) è matematicamente equivalente a massimizzare la verosimiglianza \(L(\theta; y)\). I valori del parametro \(\theta\) che rendono massima una funzione rendono massima anche l’altra.
In sintesi, l’uso della log-verosimiglianza offre un duplice vantaggio: da un lato evita problemi numerici legati all’underflow, dall’altro rende più agevole l’analisi matematica della funzione di verosimiglianza. Per questi motivi, la log-verosimiglianza rappresenta lo strumento standard sia nell’inferenza statistica classica sia in quella bayesiana.
14.3 Verosimiglianza per dati binomiali
14.3.1 Un esempio introduttivo: il lancio di una moneta
Consideriamo il problema di stimare la probabilità \(\theta\) che una moneta produca l’esito Testa. Assumiamo che ogni lancio sia indipendente dagli altri e che la probabilità \(\theta\) rimanga costante da un lancio all’altro.
Se in \(n\) lanci osserviamo \(y\) esiti Testa, il numero totale di successi segue una distribuzione binomiale. In questo contesto, la probabilità di osservare esattamente quei dati, dato un valore del parametro \(\theta\), è: \[ P(\text{dati} \mid \theta) = \theta^y (1-\theta)^{n-y}. \]
Se ora fissiamo i dati osservati e consideriamo questa stessa espressione come funzione del parametro \(\theta\), otteniamo la funzione di verosimiglianza: \[ L(\theta; \text{dati}) \propto \theta^y (1-\theta)^{n-y}. \]
Il simbolo \(\propto\) indica che stiamo trascurando eventuali costanti moltiplicative che non dipendono da \(\theta\) e che quindi non influenzano il confronto tra valori diversi del parametro.
L’idea fondamentale è la seguente: la verosimiglianza non chiede quanto siano probabili i dati in generale, ma quali valori di \(\theta\) rendano più plausibili i dati che abbiamo effettivamente osservato.
14.3.2 Esempio: due scenari a confronto
Per comprendere meglio il significato della verosimiglianza, confrontiamo due situazioni semplici.
14.3.2.1 Scenario 1: 1 Testa su 2 lanci
Supponiamo di osservare un esito Testa in due lanci della moneta (\(n = 2\), \(y = 1\)).
Valutiamo la plausibilità di due possibili valori del parametro:
Se \(\theta = 0.5\): \[ L(0.5) = 0.5^1 \cdot 0.5^1 = 0.25. \]
Se \(\theta = 0.4\): \[ L(0.4) = 0.4^1 \cdot 0.6^1 = 0.24. \]
In questo caso, il valore \(\theta = 0.5\) rende i dati leggermente più plausibili rispetto a \(\theta = 0.4\). La differenza è modesta, ma il confronto è già informativo.
14.3.2.2 Scenario 2: 1 Testa su 3 lanci
Consideriamo ora un campione leggermente più grande: un esito Testa osservato in tre lanci (\(n = 3\), \(y = 1\)).
Se \(\theta = 0.5\): \[ L(0.5) = 0.5^1 \cdot 0.5^2 = 0.125. \]
Se \(\theta = 0.4\): \[ L(0.4) = 0.4^1 \cdot 0.6^2 = 0.144. \]
In questo caso, i dati supportano maggiormente il valore \(\theta = 0.4\) rispetto a \(\theta = 0.5\). Osservare una sola Testa su tre lanci è infatti più compatibile con una moneta leggermente sbilanciata verso Croce.
Questo esempio mostra chiaramente che la verosimiglianza dipende dai dati osservati: a parità di numero di successi, un campione più grande può cambiare il grado di supporto assegnato ai diversi valori del parametro.
14.3.3 La verosimiglianza come funzione di \(\theta\)
Possiamo visualizzare la funzione di verosimiglianza calcolandola per tutti i valori possibili di \(\theta \in [0,1]\).
theta_seq <- seq(0, 1, length.out = 200)
# Scenario 1: 2 lanci, 1 testa
lik1 <- theta_seq^1 * (1 - theta_seq)^1
# Scenario 2: 3 lanci, 1 testa
lik2 <- theta_seq^1 * (1 - theta_seq)^2
df <- data.frame(
theta = rep(theta_seq, 2),
likelihood = c(lik1, lik2),
scenario = rep(c("2 lanci (1 testa)", "3 lanci (1 testa)"), each = length(theta_seq))
)
ggplot(df, aes(x = theta, y = likelihood, color = scenario)) +
geom_line(linewidth = 1.2) +
scale_fill_qualitative() +
labs(
x = expression(theta),
y = "Verosimiglianza",
color = "Scenario"
) 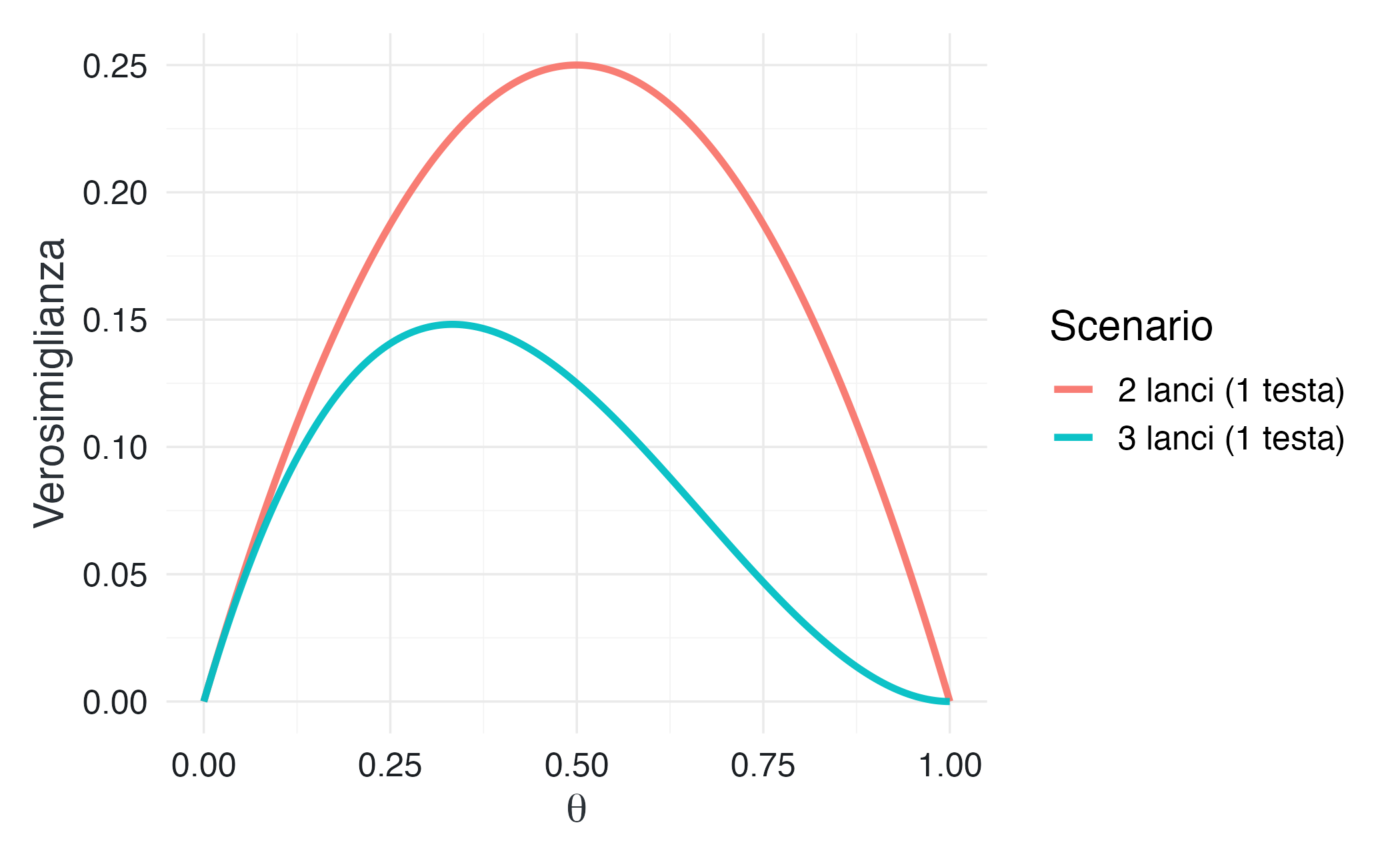
Osservazioni chiave. Il massimo della verosimiglianza coincide con la proporzione campionaria osservata, cioè \(\hat{\theta} = y/n\). Inoltre, all’aumentare della dimensione del campione, la funzione di verosimiglianza tende a concentrarsi sempre di più attorno al suo massimo, diventando più stretta. Questo riflette il fatto che dati più numerosi forniscono un’informazione più precisa sul valore del parametro.
Infine, quando nel campione sono presenti sia esiti Testa sia esiti Croce, i valori estremi del parametro (con \(\theta\) molto vicino a 0 o a 1) risultano fortemente incompatibili con i dati e ricevono un supporto empirico praticamente nullo.
14.3.4 Verosimiglianza binomiale completa
Consideriamo ora un esperimento più realistico, con \(n = 30\) lanci e \(y = 23\) esiti Testa. Il numero totale di successi è modellato mediante una distribuzione binomiale. In questo caso, la funzione di verosimiglianza completa è: \[ L(\theta; y, n) = \binom{n}{y} \theta^y (1-\theta)^{n-y} = \binom{30}{23} \theta^{23} (1-\theta)^7. \]
In questo esempio manteniamo la costante combinatoria \(\binom{30}{23}\), poiché stiamo lavorando con l’espressione completa della verosimiglianza. Sebbene tale costante non influenzi il valore del parametro che massimizza la funzione, essa è rilevante quando si confrontano verosimiglianze su scala assoluta.
n <- 30
y <- 23
theta <- seq(0, 1, length.out = 1000)
likelihood <- dbinom(y, size = n, prob = theta)
ggplot(data.frame(theta, likelihood), aes(x = theta, y = likelihood)) +
geom_line(linewidth = 1.2) +
geom_vline(xintercept = y/n, linetype = "dashed") +
scale_fill_qualitative() +
labs(
x = expression(theta),
y = "Verosimiglianza"
) 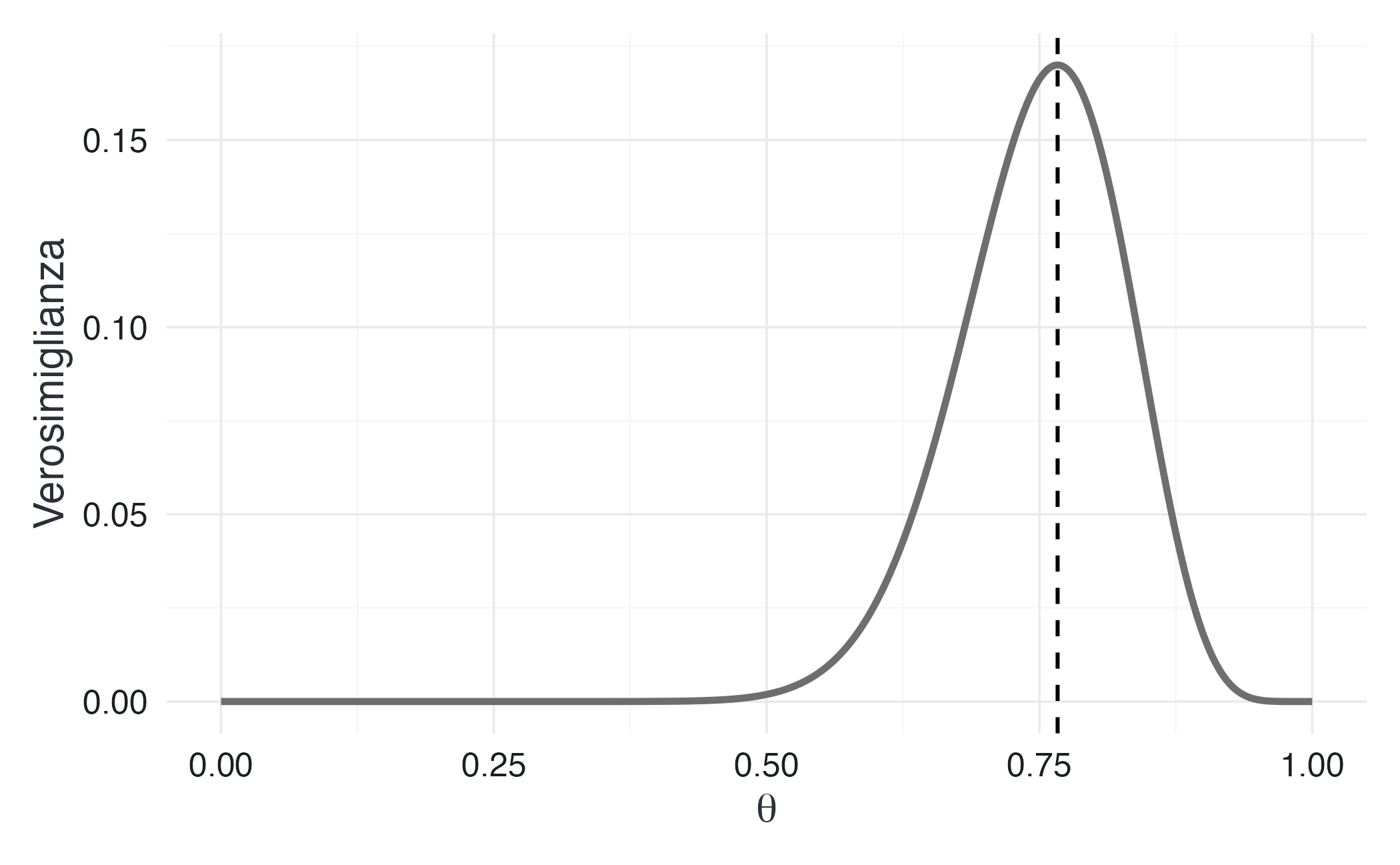
L’analisi grafica mostra un picco ben definito in corrispondenza di \(\theta \approx 0.77\), che coincide con la proporzione campionaria \(\hat{\theta} = 23/30\). Questo valore rappresenta la stima di massima verosimiglianza del parametro.
La forma relativamente concentrata della curva indica che il campione fornisce un’informazione piuttosto precisa su \(\theta\). Al contrario, i valori estremi del parametro risultano fortemente incompatibili con i dati osservati e sono quindi supportati in misura trascurabile dalla verosimiglianza.
14.4 La massima verosimiglianza come criterio frequentista
La funzione di verosimiglianza è uno strumento centrale dell’inferenza statistica. Nel paradigma frequentista, essa viene spesso utilizzata per ottenere una stima puntuale del parametro, detta stima di massima verosimiglianza (MLE).
È importante sottolineare fin da subito che questo non è lo scopo della verosimiglianza nell’approccio bayesiano.
L’inferenza bayesiana non mira a individuare un singolo valore “migliore” del parametro, ma a descrivere l’intera distribuzione dei valori plausibili di \(\theta\) alla luce dei dati osservati.
Tuttavia, comprendere il criterio di massima verosimiglianza è utile per due motivi:
- aiuta a chiarire il significato operativo della funzione di verosimiglianza;
- fornisce un punto di confronto con l’approccio bayesiano, che verrà sviluppato nei capitoli successivi.
14.4.1 Il principio (in un’ottica frequentista)
Nel paradigma frequentista, la stima di massima verosimiglianza è definita come il valore del parametro che massimizza la funzione di verosimiglianza:
\[ \hat{\theta}_{\text{MLE}} = \arg\max_{\theta} L(\theta; y). \]
Questo criterio seleziona il valore di \(\theta\) che rende i dati osservati più compatibili, in termini di verosimiglianza, rispetto a ogni altra ipotesi parametrica.
Per derivare lo stimatore di massima verosimiglianza nel caso di una prova bernoulliana ripetuta, è opportuno lavorare con la log-verosimiglianza. Dati \(n\) lanci indipendenti con \(y\) successi (Testa), si ha:
\[ \ell(\theta) = \log L(\theta; y) = y \log \theta + (n-y) \log(1-\theta). \]
Per trovare il massimo, calcoliamo la derivata prima rispetto a \(\theta\) e la poniamo uguale a zero:
\[ \frac{d\ell}{d\theta} = \frac{y}{\theta} - \frac{n-y}{1-\theta} = 0. \]
Risolvendo l’equazione per \(\theta\) si ottiene:
\[ \frac{y}{\theta} = \frac{n-y}{1-\theta} \quad \Rightarrow \quad y(1-\theta) = (n-y)\theta \quad \Rightarrow \quad y - y\theta = n\theta - y\theta \quad \Rightarrow \quad y = n\theta. \]
Pertanto, lo stimatore di massima verosimiglianza è:
\[ \hat{\theta}_{\text{MLE}} = \frac{y}{n}. \] Questo risultato mostra che, nel modello binomiale, la stima di massima verosimiglianza coincide con la proporzione campionaria.
14.4.2 La verosimiglianza su una griglia di valori
Un modo particolarmente intuitivo per studiare la funzione di verosimiglianza consiste nel valutarla su una griglia di possibili valori del parametro \(\theta\).
Questo approccio non è specifico della stima di massima verosimiglianza: al contrario, esso sarà centrale nell’inferenza bayesiana, dove la distribuzione a posteriori verrà ottenuta combinando, punto per punto, la verosimiglianza con una distribuzione a priori.
Osservando i valori della verosimiglianza sulla griglia, è possibile individuare il punto in cui essa raggiunge il massimo.
mle_grid <- theta_grid[which.max(likelihood)]
mle_grid
#> [1] 0.767Questo valore coincide con la stima di massima verosimiglianza, ma qui l’aspetto rilevante è un altro: la verosimiglianza è una funzione definita su tutto lo spazio dei parametri. Nel capitolo successivo, questa stessa griglia verrà utilizzata per costruire direttamente la distribuzione a posteriori, combinando la verosimiglianza con una distribuzione a priori.
14.4.3 Verosimiglianza e inferenza bayesiana
Nell’approccio bayesiano, la funzione di verosimiglianza non viene utilizzata per selezionare un singolo valore del parametro. Il suo ruolo è invece quello di modellare come i dati aggiornano le credenze su tutti i valori possibili di \(\theta\).
Solo in un caso particolare — quando la distribuzione a priori è uniforme — il valore che massimizza la verosimiglianza coincide con la moda della distribuzione a posteriori. In questo caso, la stima di massima verosimiglianza coincide con la stima Maximum A Posteriori (MAP).
Al di fuori di questo caso specifico, l’inferenza bayesiana produce una distribuzione a posteriori la cui forma dipende congiuntamente dalla verosimiglianza e dalla distribuzione a priori, e non può essere riassunta in modo adeguato da una singola stima puntuale.
14.5 Verosimiglianza congiunta
Il concetto di verosimiglianza si estende in modo naturale al caso di osservazioni multiple, dando origine alla verosimiglianza congiunta. Questo strumento consente di combinare in modo coerente l’informazione proveniente da un intero campione di dati, fornendo una valutazione globale della plausibilità di un parametro alla luce di tutta l’evidenza disponibile.
14.5.1 Dalle osservazioni singole al campione
Sia \(y_1, y_2, \ldots, y_n\) un campione di osservazioni indipendenti provenienti da una distribuzione che dipende da un parametro incognito \(\theta\). In questo caso, la verosimiglianza complessiva è data dal prodotto delle verosimiglianze associate alle singole osservazioni: \[ L(\theta; y_1, \ldots, y_n) = \prod_{i=1}^n f(y_i \mid \theta). \]
Questa forma riflette direttamente l’assunzione di indipendenza: ogni osservazione contribuisce in modo moltiplicativo alla plausibilità complessiva del parametro.
Passando alla rappresentazione logaritmica, il prodotto si trasforma in una somma: \[ \ell(\theta; y_1, \ldots, y_n) = \sum_{i=1}^n \log f(y_i \mid \theta). \]
Questa proprietà non è solo computazionalmente conveniente, ma evidenzia anche un aspetto concettuale importante: ogni osservazione aggiunge un contributo informativo alla valutazione complessiva di \(\theta\).
14.5.2 Esempio: osservazioni Bernoulliane
Nel caso di \(n\) lanci indipendenti di una moneta, in cui ogni esito \(y_i\) vale 1 per Testa e 0 per Croce, la verosimiglianza congiunta assume la forma: \[ L(\theta; y_1, \ldots, y_n) = \prod_{i=1}^n \theta^{y_i}(1-\theta)^{1-y_i} = \theta^{\sum_{i=1}^n y_i}(1-\theta)^{n-\sum_{i=1}^n y_i}. \]
Un aspetto cruciale di questa espressione è che essa dipende dai dati solo attraverso il numero totale di successi \[ S_n = \sum_{i=1}^n y_i. \]
Questa quantità costituisce una statistica sufficiente per il parametro \(\theta\): una volta noto \(S_n\), l’intera sequenza delle osservazioni individuali non fornisce ulteriore informazione rilevante ai fini dell’inferenza su \(\theta\).
Da un punto di vista pratico, ciò significa che non è necessario conoscere l’ordine o la disposizione specifica degli esiti Testa e Croce: è sufficiente conoscere il numero totale di successi osservati. Questo fatto anticipa un principio centrale dell’inferenza bayesiana: l’aggiornamento delle credenze dipende dai dati solo attraverso le informazioni statisticamente rilevanti.
14.5.3 Combinazione di studi indipendenti
La verosimiglianza congiunta fornisce anche un meccanismo naturale per integrare evidenze provenienti da studi diversi. Supponiamo di disporre di quattro studi indipendenti che indagano lo stesso parametro sottostante \(\theta\), come la probabilità di successo in una prova Bernoulliana. Assumendo che tutti gli studi condividano lo stesso valore di \(\theta\), la log-verosimiglianza complessiva è data dalla somma delle log-verosimiglianze associate a ciascuno studio: \[ \ell(\theta) = \sum_{i=1}^{4} \left[ y_i \log(\theta) + (n_i - y_i)\log(1-\theta) \right]. \]
Consideriamo i seguenti dati:
- studio 1: 23 successi su 30 prove;
- studio 2: 20 successi su 28 prove;
- studio 3: 29 successi su 40 prove;
- studio 4: 29 successi su 36 prove.
Sviluppando esplicitamente la somma otteniamo: \[ \begin{aligned} \ell(\theta) ={}& 23\log(\theta) + 7\log(1-\theta) \;+ \\ &20\log(\theta) + 8\log(1-\theta) \;+ \\ &29\log(\theta) + 11\log(1-\theta) \;+ \\ &29\log(\theta) + 7\log(1-\theta). \end{aligned} \]
Questa espressione mostra in modo trasparente come ciascuno studio contribuisca additivamente all’evidenza complessiva sul parametro \(\theta\).
# Dati dei quattro studi
studi <- data.frame(
successi = c(23, 20, 29, 29),
prove = c(30, 28, 40, 36)
)
# Log-verosimiglianza congiunta
log_lik_congiunta <- function(theta) {
sum(studi$successi * log(theta) +
(studi$prove - studi$successi) * log(1 - theta))
}
theta_seq <- seq(0.5, 0.9, length.out = 200)
log_lik_vals <- sapply(theta_seq, log_lik_congiunta)
ggplot(data.frame(theta = theta_seq, log_lik = log_lik_vals),
aes(x = theta, y = log_lik)) +
geom_line(linewidth = 1.2) +
scale_fill_qualitative() +
labs(
x = expression(theta),
y = "Log-verosimiglianza congiunta",
title = "Profilo di verosimiglianza\nper i quattro studi combinati"
) 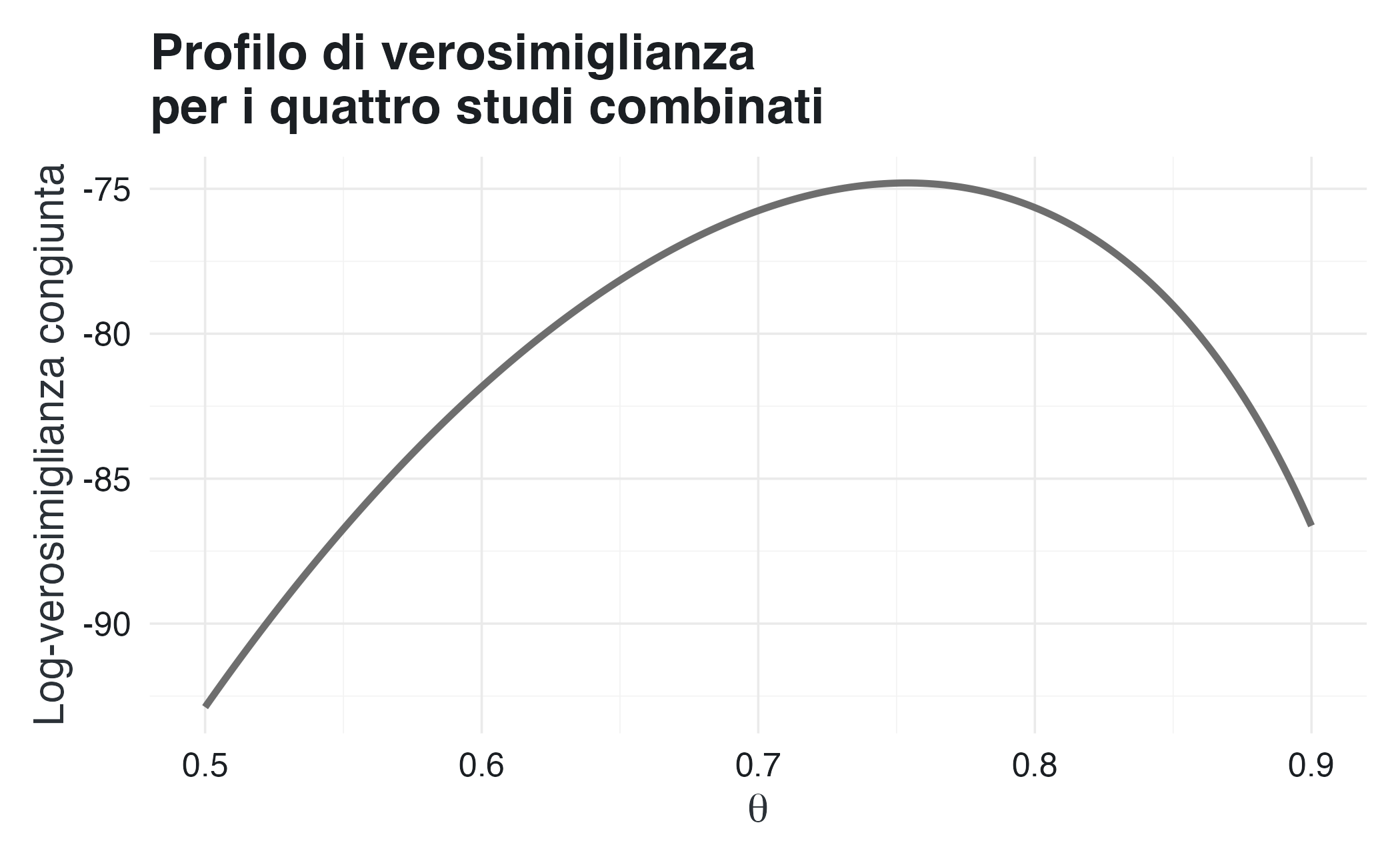
Il profilo risultante mostra come l’informazione proveniente dai diversi studi si combini in modo coerente, producendo una funzione di verosimiglianza più concentrata rispetto a quella che si otterrebbe analizzando ciascuno studio separatamente.
Nel paradigma frequentista, il massimo di questa funzione di verosimiglianza congiunta fornisce una stima puntuale del parametro \(\theta\) basata su tutti gli studi considerati insieme. Nel caso binomiale, tale valore coincide con la proporzione complessiva di successi: \[ \hat{\theta} = \frac{\sum_i y_i}{\sum_i n_i}. \]
Questa osservazione, tuttavia, non esaurisce il ruolo della verosimiglianza. Nell’approccio bayesiano, l’intera funzione di verosimiglianza, e non solo il suo massimo, verrà combinata con una distribuzione a priori per ottenere la distribuzione a posteriori.
14.6 Verosimiglianza gaussiana
La distribuzione gaussiana (o Normale) occupa un ruolo centrale in statistica. Essa fornisce un modello efficace per molte variabili continue di interesse psicologico e scientifico, come il quoziente intellettivo (QI), i tempi di reazione e numerose misure psicofisiologiche.
In questa sezione utilizzeremo la distribuzione gaussiana per illustrare come la verosimiglianza si comporta nel caso di dati continui e per preparare il terreno all’aggiornamento bayesiano nel modello normale–normale, che verrà discusso nel manuale.
14.6.1 Caso di una singola osservazione
Supponiamo che una variabile casuale segua una distribuzione Normale con media incognita \(\mu\) e deviazione standard nota \(\sigma\). Dopo aver osservato un singolo valore \(y\), la funzione di verosimiglianza per \(\mu\) è data da:
\[ L(\mu; y) = \frac{1}{\sigma\sqrt{2\pi}} \exp!\left(-\frac{(y-\mu)^2}{2\sigma^2}\right). \]
È fondamentale ricordare il cambio di prospettiva:
- il valore osservato \(y\) è fissato;
- la quantità che varia è il parametro \(\mu\).
Vista come funzione di \(\mu\), la verosimiglianza ha la forma di una curva a campana centrata esattamente sul valore osservato \(y\). Questo riflette un principio intuitivo: i valori di \(\mu\) più vicini all’osservazione rendono i dati più plausibili.
y_obs <- 114
sigma <- 15
mu_grid <- seq(70, 160, length.out = 500)
likelihood <- dnorm(y_obs, mean = mu_grid, sd = sigma)
ggplot(data.frame(mu = mu_grid, lik = likelihood),
aes(x = mu, y = lik)) +
geom_line(linewidth = 1.2) +
geom_vline(xintercept = y_obs, linetype = "dashed") +
scale_fill_qualitative() +
labs(
x = expression(mu),
y = "Verosimiglianza"
) 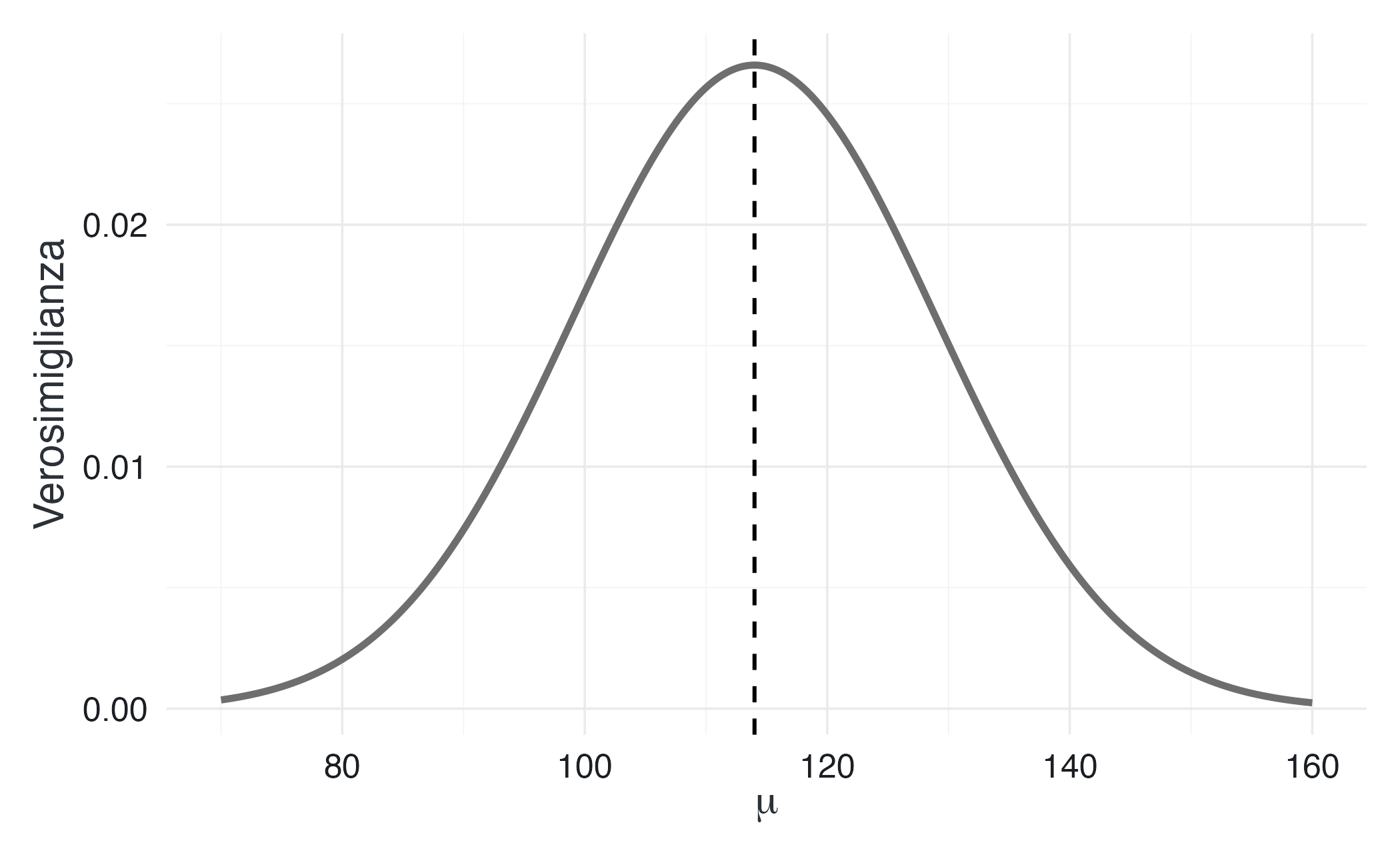
Questo primo caso mostra già un punto chiave: una singola osservazione fornisce informazione su \(\mu\), ma in modo ancora molto impreciso.
14.6.2 Caso di un campione gaussiano
Consideriamo ora un campione di \(n\) osservazioni indipendenti e identicamente distribuite (i.i.d.)
\[ y_1, \ldots, y_n \sim \mathcal{N}(\mu, \sigma^2), \] dove la varianza \(\sigma^2\) è nota.
In questo caso, la verosimiglianza congiunta è il prodotto delle densità individuali:
\[ L(\mu; y_1, \ldots, y_n) = \prod_{i=1}^n \frac{1}{\sqrt{2\pi\sigma^2}} \exp!\left[-\frac{(y_i-\mu)^2}{2\sigma^2}\right]. \]
Per analizzare questa funzione in modo più semplice, consideriamo la log-verosimiglianza:
$$ () = -(2^2)
- _{i=1}^n (y_i-)^2. $$
Questa espressione mette in evidenza un fatto cruciale: tutta l’informazione sui dati rilevante per \(\mu\) è contenuta nella somma dei quadrati degli scarti rispetto a \(\mu\).
Nel paradigma frequentista, massimizzare la log-verosimiglianza equivale a minimizzare tale somma, e conduce a un risultato ben noto:
\[ \hat{\mu}_{\text{MLE}} = \frac{1}{n}\sum_{i=1}^n y_i = \bar{y}. \]
Anche in questo caso, sottolineiamo che il valore della MLE non è l’obiettivo principale in un’ottica bayesiana: ciò che conta è la forma completa della funzione di verosimiglianza.
set.seed(42)
y <- c(26, 35, 30, 25, 44, 30, 33, 43, 22, 43, 24, 19, 39, 31, 25,
28, 35, 30, 26, 31, 41, 36, 26, 35, 33, 28, 27, 34, 27, 22)
sigma <- 6.5
log_lik <- function(mu) {
sum(dnorm(y, mean = mu, sd = sigma, log = TRUE))
}
mu_grid <- seq(25, 40, length.out = 200)
ll_vals <- sapply(mu_grid, log_lik)
ggplot(data.frame(mu = mu_grid, ll = ll_vals),
aes(x = mu, y = ll)) +
geom_line(linewidth = 1.2) +
geom_vline(xintercept = mean(y), linetype = "dashed") +
scale_fill_qualitative() +
labs(
x = expression(mu),
y = "Log-verosimiglianza"
) 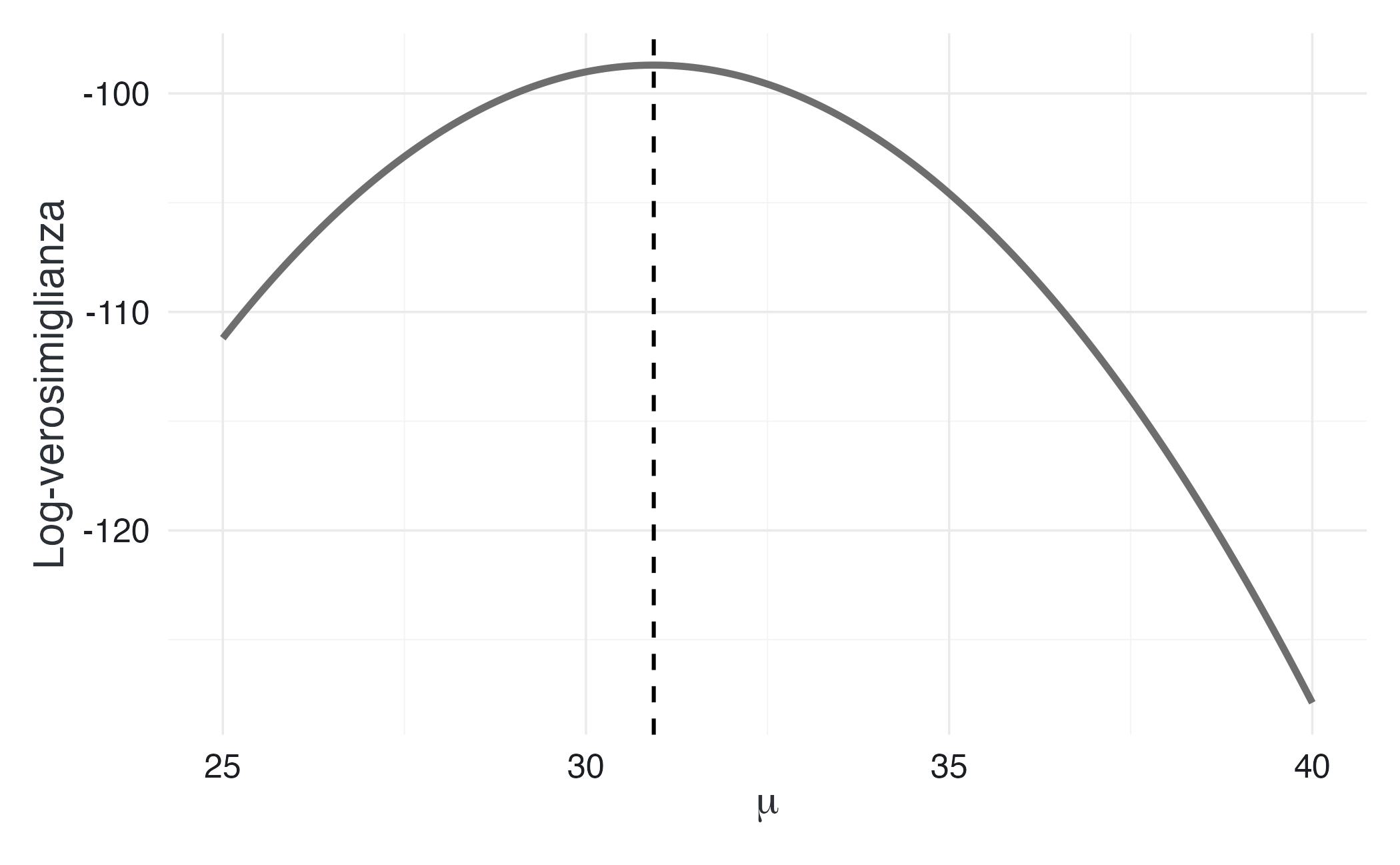
Nel caso gaussiano, la log-verosimiglianza è una funzione quadratica di \(\mu\), cioè una parabola con concavità verso il basso. Il suo vertice si trova in corrispondenza della media campionaria \(\bar{y}\).
Poiché la verosimiglianza è l’esponenziale della log-verosimiglianza, essa assume la forma di una curva a campana centrata su \(\bar{y}\). La larghezza di questa campana dipende da due fattori:
- la variabilità delle osservazioni (\(\sigma^2\));
- il numero di dati raccolti (\(n\)).
In particolare, la verosimiglianza per \(\mu\) è una distribuzione gaussiana con varianza \(\sigma^2/n\). Questo risultato è cruciale: nel modello normale–normale, la quantità \(\sigma^2/n\) determina direttamente quanto i dati rendono la distribuzione a posteriori più o meno concentrata.
14.7 Confrontare ipotesi tramite la verosimiglianza
La funzione di verosimiglianza consente non solo di valutare singoli valori di un parametro, ma anche di confrontare direttamente ipotesi alternative. In particolare, è possibile confrontare quanto meglio una ipotesi spiega i dati rispetto a un’altra, utilizzando il rapporto delle loro verosimiglianze.
Questo tipo di confronto verrà sviluppato in modo sistematico nell’inferenza bayesiana attraverso il fattore di Bayes. Per chi fosse interessato a un’anticipazione di questa idea, il box seguente presenta il concetto di rapporto di verosimiglianze.
Confronto tra due ipotesi puntuali
Dato un modello e due ipotesi alternative sui parametri, \(\theta_0\) e \(\theta_1\), il rapporto di verosimiglianze è definito come:
\[ \Lambda = \frac{L(\theta_1 ; \text{dati})}{L(\theta_0 ; \text{dati})}. \]
Si tratta, quindi, di un confronto diretto tra le verosimiglianze: il numeratore indica quanto i dati sono plausibili assumendo \(\theta_1\), mentre il denominatore indica quanto lo sono assumendo \(\theta_0\). Il rapporto di verosimiglianze non è la probabilità che \(H_1\) sia vera: misura solo quante volte i dati sono più compatibili con \(H_1\) rispetto a \(H_0\).
Interpretazione
- \(\Lambda > 1\): i dati risultano più plausibili assumendo \(\theta_1\) rispetto a \(\theta_0\); quindi l’evidenza relativa favorisce \(\theta_1\);
- \(\Lambda < 1\): i dati risultano più plausibili assumendo \(\theta_0\); quindi l’evidenza relativa favorisce \(\theta_0\);
- \(\Lambda \approx 1\): le due ipotesi hanno un potere esplicativo simile; quindi i dati non permettono di discriminare in modo netto tra loro.
La distanza dall’unità indica quanto un’ipotesi renda i dati più (o meno) plausibili rispetto all’altra. In questo modo, il rapporto di verosimiglianze fornisce una misura continua e graduata della forza dell’evidenza empirica, evitando valutazioni dicotomiche e mettendo in primo piano il contributo informativo dei dati.
Esempio: moneta equilibrata vs. sbilanciata
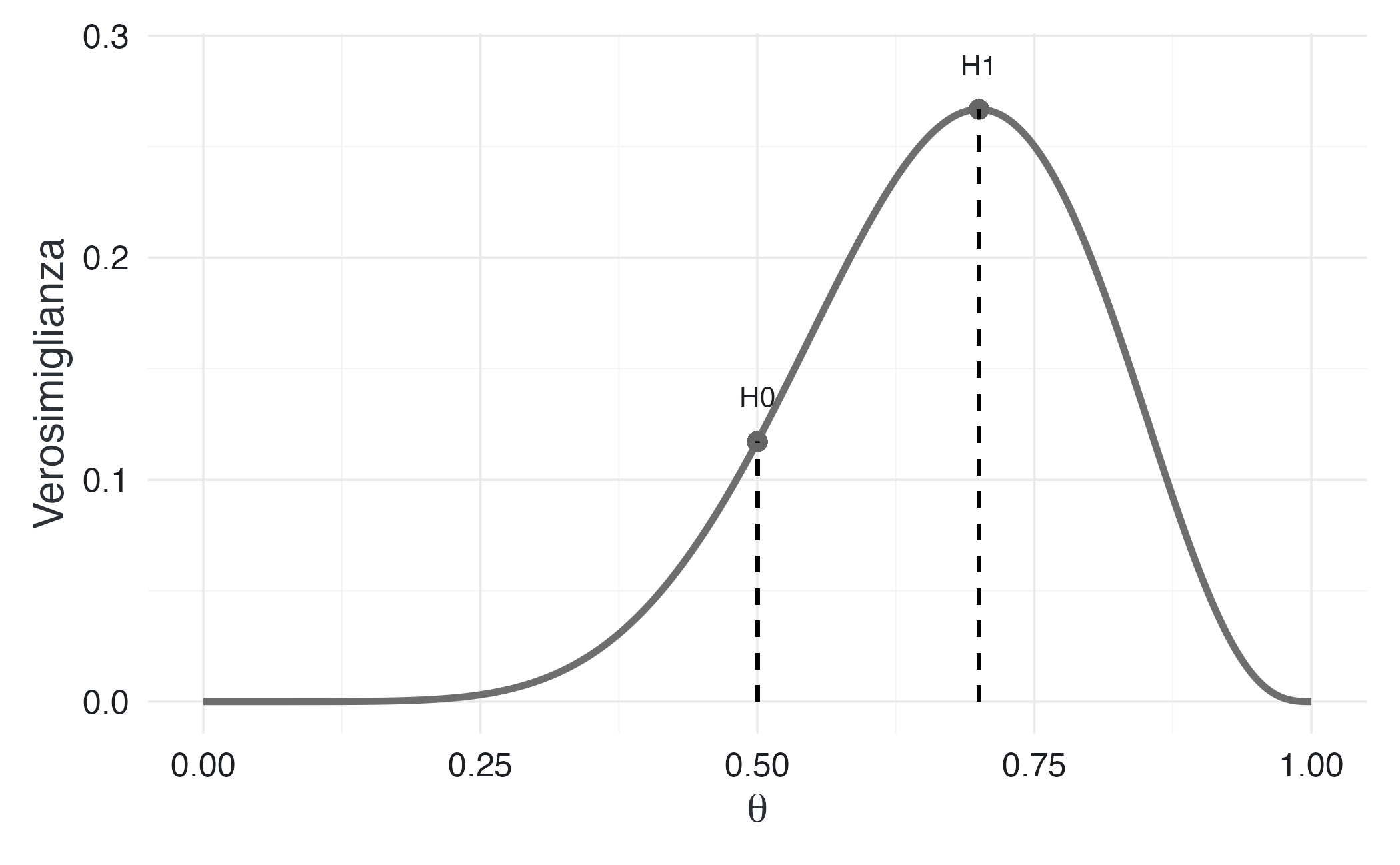
Supponiamo di osservare \(x = 7\) successi su \(n = 10\) lanci. Confrontiamo due modelli:
- \(H_0\): moneta equilibrata (\(\theta_0 = 0.5\));
- \(H_1\): moneta sbilanciata (\(\theta_1 = 0.7\)).
Il rapporto di circa 2.3 indica che i dati sono circa 2.3 volte più probabili sotto \(H_1\) rispetto a \(H_0\). È un’evidenza moderata a favore della moneta sbilanciata.
theta_seq <- seq(0, 1, length.out = 500)
lik_vals <- dbinom(y, n, prob = theta_seq)
ggplot(data.frame(theta = theta_seq, lik = lik_vals), aes(x = theta, y = lik)) +
geom_line(linewidth = 1.2) +
geom_point(aes(x = 0.5, y = L_H0), size = 3) +
geom_point(aes(x = 0.7, y = L_H1), size = 3) +
geom_segment(aes(x = 0.5, xend = 0.5, y = 0, yend = L_H0),
linetype = "dashed") +
geom_segment(aes(x = 0.7, xend = 0.7, y = 0, yend = L_H1),
linetype = "dashed") +
annotate("text", x = 0.5, y = L_H0 + 0.02, label = "H0") +
annotate("text", x = 0.7, y = L_H1 + 0.02, label = "H1") +
scale_fill_qualitative() +
labs(
x = expression(theta),
y = "Verosimiglianza"
) 
Connessione con l’inferenza bayesiana
Nel caso di ipotesi puntuali e priori uniformi sui modelli, il rapporto di verosimiglianze coincide con il fattore di Bayes, che rappresenta uno strumento centrale del confronto tra modelli in ambito bayesiano.
Nel manuale, il fattore di Bayes verrà introdotto come estensione naturale di questo principio, integrando la verosimiglianza con le credenze a priori.
Questo box è incluso per completezza: l’AIC è un criterio molto usato in ambito frequentista, ma non è lo strumento standard in un corso bayesiano.
Il Criterio di Informazione di Akaike (AIC) fornisce una soluzione semplice per il problema della selezione dei modelli.
Il problema dell’overfitting
Quando si confrontano modelli, quelli più complessi (con un maggior numero di parametri) tendono ad adattarsi meglio ai dati. Tuttavia, questo vantaggio può riflettere solo una maggiore flessibilità e non una reale capacità esplicativa. Questo fenomeno è noto come “sovradattamento” (overfitting) e richiede quindi criteri che penalizzino opportunamente la complessità.
Definizione dell’AIC
Il Criterio di Informazione di Akaike (AIC) fornisce una misura per confrontare modelli statistici, conciliando la bontà di adattamento ai dati con la loro complessità:
\[ \text{AIC} = 2k - 2\log(\hat{L}), \] dove \(k\) è il numero di parametri stimati del modello e \(\hat{L}\) rappresenta il valore massimo della funzione di verosimiglianza per quel modello.
La formula unisce due principi fondamentali dell’inferenza statistica. Il termine \(-2\log(\hat{L})\) misura la mancanza di adattamento (lack of fit): valori minori indicano una maggiore compatibilità del modello con i dati. Il termine \(2k\) opera invece come una penalità per la complessità, penalizzando i modelli con un numero elevato di parametri e promuovendo la parsimonia. In sostanza, l’AIC rappresenta un compromesso tra capacità esplicativa e semplicità, premiando i modelli che descrivono bene i dati utilizzando un numero minore di parametri.
Interpretazione: nel confronto tra modelli, viene preferito il modello con il valore AIC più basso. La penalità \(2k\) garantisce che un adattamento ai dati leggermente migliore, ma ottenuto aggiungendo molti parametri, non venga considerato un reale miglioramento del modello, promuovendo il principio di parsimonia.
Esempio: effetto del contenuto emotivo sulla memoria
Supponiamo di voler valutare l’effetto del contenuto emotivo delle immagini sulla memoria visiva. In un esperimento controllato, 30 partecipanti per condizione hanno mostrato i seguenti risultati:
# Dati sperimentali
successi_neutro <- 14
successi_emozione <- 22
n <- 30Il modello nullo ipotizza che il contenuto emotivo non influenzi la memoria, postulando una probabilità comune per entrambe le condizioni:
Il modello alternativo consente probabilità differenziate, riconoscendo il possibile effetto dell’emozione:
La valutazione mediante AIC bilancia adattamento e complessità:
Una differenza AIC negativa indica che il modello alternativo è preferibile nonostante abbia un parametro in più. L’evidenza suggerisce che il modello che assegna probabilità distinte ai due gruppi descrive meglio i dati osservati.
Nota finale importante. L’AIC è uno strumento di selezione dei modelli tipico dell’inferenza frequentista. Nell’approccio bayesiano, il confronto tra modelli si basa invece sulla probabilità marginale dei dati e sul fattore di Bayes, che tengono conto dell’intera distribuzione a posteriori dei parametri.
Questo confronto verrà discusso nel manuale.
Riflessioni conclusive
La funzione di verosimiglianza è il concetto centrale che collega i dati ai parametri nell’inferenza statistica. Per ogni possibile valore del parametro, essa quantifica quanto i dati osservati siano compatibili con quel valore, fornendo una mappa di plausibilità costruita esclusivamente a partire dall’evidenza empirica.
In questo capitolo abbiamo esplorato le caratteristiche fondamentali della verosimiglianza. Abbiamo visto che essa inverte la prospettiva propria della funzione di probabilità: invece di chiederci quali dati potremmo osservare assumendo un certo valore del parametro, ci chiediamo quali valori del parametro siano più o meno compatibili con i dati effettivamente osservati. Abbiamo inoltre evidenziato i vantaggi computazionali e analitici della log-verosimiglianza, che trasforma prodotti potenzialmente instabili in somme numericamente e concettualmente più maneggevoli.
Abbiamo incontrato la stima di massima verosimiglianza (MLE) come uno dei possibili utilizzi della funzione di verosimiglianza nel paradigma frequentista. Nei modelli semplici, come quello binomiale e quello normale, la MLE coincide con statistiche campionarie intuitive, quali la proporzione e la media del campione. Tuttavia, è importante sottolineare che la MLE non esaurisce il ruolo della verosimiglianza: ciò che conta, in particolare nell’ottica bayesiana, è la forma completa della funzione di verosimiglianza e il modo in cui essa distribuisce il supporto empirico sui diversi valori del parametro.
Abbiamo inoltre visto come la verosimiglianza congiunta consenta di combinare in modo coerente informazioni provenienti da osservazioni multiple o da studi indipendenti, e come il rapporto di verosimiglianza permetta di esprimere l’evidenza relativa a favore di ipotesi alternative. In tutti questi casi, la verosimiglianza emerge come uno strumento cumulativo, che integra l’informazione contenuta nei dati senza introdurre, di per sé, alcuna assunzione sulle credenze a priori.
Nel prossimo capitolo approfondiremo le proprietà matematiche della funzione di verosimiglianza e mostreremo come essa si combini con la distribuzione a priori per generare la distribuzione a posteriori. In particolare, analizzeremo perché la verosimiglianza tende a concentrarsi attorno al valore “vero” del parametro al crescere della quantità di dati, come la sua precisione aumenti con l’ampiezza del campione e come questa informazione si integri con quella contenuta nella distribuzione a priori. Infine, discuteremo il ruolo della legge dei grandi numeri e del teorema del limite centrale nel chiarire il meccanismo dell’aggiornamento bayesiano.
Punti chiave da ricordare
Concetti essenziali di questo capitolo:
-
Verosimiglianza come funzione del parametro
- \(L(\theta \mid D) = p(D \mid \theta)\) è la PMF/PDF dei dati vista come funzione di \(\theta\)
- Cambio di prospettiva: dati fissi, parametro variabile
- Non è una distribuzione su \(\theta\) (non integra a 1!)
- Quantifica “quanto i dati supportano ciascun valore di \(\theta\)”
-
Principio di verosimiglianza
- Tutta l’informazione inferenziale nei dati è contenuta nella verosimiglianza
- Se \(L(\theta \mid D_1) \propto L(\theta \mid D_2)\), i due dataset forniscono la stessa evidenza su \(\theta\)
- Fondamentale nell’approccio bayesiano
-
Log-verosimiglianza
- \(\ell(\theta) = \log L(\theta \mid D)\) trasforma prodotti in somme
- Stessa forma della verosimiglianza (monotona crescente)
- Facilita i calcoli, specialmente con dati multipli
- Numericamente più stabile (evita underflow)
-
Verosimiglianza per dati i.i.d.
- Se \(D = \{x_1, \ldots, x_n\}\) i.i.d., allora \(L(\theta) = \prod_{i=1}^n p(x_i \mid \theta)\)
- Log-verosimiglianza: \(\ell(\theta) = \sum_{i=1}^n \log p(x_i \mid \theta)\)
- Semplifica enormemente i calcoli
-
Massima verosimiglianza (MLE)
- \(\hat{\theta}_{\text{MLE}} = \arg\max_\theta L(\theta \mid D)\)
- Stima che “massimizza la compatibilità con i dati osservati”
- Importante ma non bayesiano (ignora il prior!)
- Spesso coincide con media posteriori per prior uniformi
-
Verosimiglianza relativa
- \(R(\theta) = \frac{L(\theta)}{L(\hat{\theta}_{\text{MLE}})}\) normalizza rispetto al massimo
- Sempre \(0 \leq R(\theta) \leq 1\)
- Facilita interpretazione: “quanto meno supportato è \(\theta\) rispetto alla MLE?”
-
Ruolo nel teorema di Bayes
- \(p(\theta \mid D) \propto L(\theta \mid D) \cdot p(\theta)\)
- Verosimiglianza “ribilancia” il prior alla luce dei dati
- Verosimiglianza piatta → posterior = prior (dati non informativi)
- Verosimiglianza concentrata → posterior dominata dai dati
-
Proprietà della verosimiglianza
- Non è una probabilità (può essere > 1 per variabili continue)
- Non si normalizza (non integra a 1)
- Scala arbitraria: solo i rapporti tra valori contano
- Forma dipende dal modello scelto
Formule da ricordare:
Definizione: \[ L(\theta \mid D) = p(D \mid \theta) = \begin{cases} \prod_{i=1}^n p(x_i \mid \theta) & \text{(i.i.d. discreto)} \\ \prod_{i=1}^n f(x_i \mid \theta) & \text{(i.i.d. continuo)} \end{cases} \]
Log-verosimiglianza: \[ \ell(\theta) = \log L(\theta \mid D) = \sum_{i=1}^n \log p(x_i \mid \theta) \]
Teorema di Bayes con verosimiglianza: \[ p(\theta \mid D) = \frac{L(\theta \mid D) \cdot p(\theta)}{\int L(\theta' \mid D) \cdot p(\theta') \, d\theta'} \]
Forma proporzionale: \[ p(\theta \mid D) \propto L(\theta \mid D) \cdot p(\theta) \]
Esempi di verosimiglianze:
- Bernoulli: \(L(\theta) = \theta^k(1-\theta)^{n-k}\) per \(k\) successi su \(n\)
- Normale (varianza nota): \(L(\mu) \propto \exp\left(-\frac{1}{2\sigma^2}\sum(x_i-\mu)^2\right)\)
- Poisson: \(L(\lambda) = \frac{\lambda^{\sum x_i} e^{-n\lambda}}{\prod x_i!}\)
Proprietà critiche:
- La verosimiglianza non dipende dal prior (solo dai dati e dal modello)
- MLE ignora il prior → non è stima bayesiana
- Con prior uniforme, moda posteriore = MLE
- Log-verosimiglianza facilita derivazioni e calcoli numerici
Per il prossimo capitolo:
Nel Capitolo 15 approfondiremo le proprietà della verosimiglianza, studiando score function, informazione di Fisher, normalità asintotica, e il ruolo della verosimiglianza nell’aggiornamento bayesiano. Vedremo anche come le verosimiglianze si combinano con prior coniugati per produrre posterior di forma chiusa.
sessionInfo()
#> R version 4.5.2 (2025-10-31)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Tahoe 26.2
#>
#> Matrix products: default
#> BLAS: /System/Library/Frameworks/Accelerate.framework/Versions/A/Frameworks/vecLib.framework/Versions/A/libBLAS.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
#>
#> locale:
#> [1] C.UTF-8/UTF-8/C.UTF-8/C/C.UTF-8/C.UTF-8
#>
#> time zone: Europe/Rome
#> tzcode source: internal
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] ragg_1.5.0 tinytable_0.15.2 withr_3.0.2
#> [4] systemfonts_1.3.1 patchwork_1.3.2 ggdist_3.3.3
#> [7] tidybayes_3.0.7 bayesplot_1.15.0 ggplot2_4.0.1
#> [10] reliabilitydiag_0.2.1 priorsense_1.2.0 posterior_1.6.1
#> [13] loo_2.9.0 rstan_2.32.7 StanHeaders_2.32.10
#> [16] brms_2.23.0 Rcpp_1.1.1 sessioninfo_1.2.3
#> [19] conflicted_1.2.0 janitor_2.2.1 matrixStats_1.5.0
#> [22] modelr_0.1.11 tibble_3.3.1 dplyr_1.1.4
#> [25] tidyr_1.3.2 rio_1.2.4 here_1.0.2
#>
#> loaded via a namespace (and not attached):
#> [1] svUnit_1.0.8 tidyselect_1.2.1 farver_2.1.2
#> [4] S7_0.2.1 fastmap_1.2.0 TH.data_1.1-5
#> [7] tensorA_0.36.2.1 digest_0.6.39 timechange_0.3.0
#> [10] estimability_1.5.1 lifecycle_1.0.5 survival_3.8-3
#> [13] magrittr_2.0.4 compiler_4.5.2 rlang_1.1.7
#> [16] tools_4.5.2 yaml_2.3.12 knitr_1.51
#> [19] labeling_0.4.3 bridgesampling_1.2-1 htmlwidgets_1.6.4
#> [22] curl_7.0.0 pkgbuild_1.4.8 RColorBrewer_1.1-3
#> [25] abind_1.4-8 multcomp_1.4-29 purrr_1.2.1
#> [28] grid_4.5.2 stats4_4.5.2 colorspace_2.1-2
#> [31] xtable_1.8-4 inline_0.3.21 emmeans_2.0.1
#> [34] scales_1.4.0 MASS_7.3-65 cli_3.6.5
#> [37] mvtnorm_1.3-3 rmarkdown_2.30 generics_0.1.4
#> [40] otel_0.2.0 RcppParallel_5.1.11-1 cachem_1.1.0
#> [43] stringr_1.6.0 splines_4.5.2 parallel_4.5.2
#> [46] vctrs_0.6.5 V8_8.0.1 Matrix_1.7-4
#> [49] sandwich_3.1-1 jsonlite_2.0.0 arrayhelpers_1.1-0
#> [52] glue_1.8.0 codetools_0.2-20 distributional_0.6.0
#> [55] lubridate_1.9.4 stringi_1.8.7 gtable_0.3.6
#> [58] QuickJSR_1.8.1 pillar_1.11.1 htmltools_0.5.9
#> [61] Brobdingnag_1.2-9 R6_2.6.1 textshaping_1.0.4
#> [64] rprojroot_2.1.1 evaluate_1.0.5 lattice_0.22-7
#> [67] backports_1.5.0 memoise_2.0.1 broom_1.0.11
#> [70] snakecase_0.11.1 rstantools_2.6.0 gridExtra_2.3
#> [73] coda_0.19-4.1 nlme_3.1-168 checkmate_2.3.3
#> [76] xfun_0.55 zoo_1.8-15 pkgconfig_2.0.3