here::here("code", "_common.R") |>
source()
# Load packages
if (!requireNamespace("pacman")) install.packages("pacman")
pacman::p_load(viridis)
# Riapplica il tema per sicurezza
apply_visual_theme()2 Assiomi e coerenza delle credenze
Introduzione
Nel capitolo precedente abbiamo visto che, nell’interpretazione bayesiana, la probabilità non descrive frequenze oggettive, ma gradi di credenza razionale. Questa idea, apparentemente semplice, solleva immediatamente una domanda cruciale: cosa significa, esattamente, che una credenza sia “razionale”?
Non basta avere opinioni: tutti ne abbiamo. Non basta nemmeno avere opinioni informate o ragionevoli. Il punto è più sottile e profondo: le nostre credenze devono essere internamente coerenti tra loro. Se, per esempio, credo che pioverà con probabilità 0.7 e che non pioverà con probabilità 0.5, sto commettendo un errore logico, a prescindere da quanto siano informate le mie valutazioni meteorologiche. La somma delle mie credenze su eventi mutuamente esclusivi ed esaustivi deve essere 1, non per una convenzione arbitraria, ma perché altrimenti il mio sistema di credenze si contraddice.
Questo capitolo sviluppa il quadro matematico che rende espliciti e controllabili questi vincoli di coerenza. Ma attenzione: non si tratta di aggiungere un livello puramente formale alla discussione. La matematica che introdurremo non è un semplice ornamento tecnico, ma il linguaggio attraverso cui possiamo esprimere con precisione il significato di un ragionamento coerente in condizioni di incertezza.
Perché questo è importante per la psicologia
Lo psicologo potrebbe chiedersi: “Perché dovrei preoccuparmi di assiomi e vincoli formali?” La risposta tocca il cuore stesso della disciplina.
La psicologia studia il modo in cui le persone ragionano, decidono e valutano rischi e incertezze. Decenni di ricerca, a partire da Kahneman e Tversky, hanno documentato sistematicamente le violazioni della razionalità normativa nel giudizio umano (Kahneman & Tversky, 1979). Ma per identificare una violazione, dobbiamo prima sapere cosa dovrebbe essere. Gli assiomi di coerenza che studieremo in questo capitolo definiscono precisamente questo standard normativo.
Inoltre, quando costruiamo modelli statistici per analizzare i dati psicologici, stiamo implicitamente assumendo che le nostre specificazioni probabilistiche siano coerenti. Un modello con assunzioni incoerenti non è semplicemente “sbagliato”, ma è logicamente impossibile, come un triangolo con quattro lati. Comprendere i vincoli di coerenza ci rende ricercatori più consapevoli.
Infine, nella pratica clinica, i professionisti formulano continuamente giudizi probabilistici: quanto è probabile che questo paziente soffra di depressione? Quanto è probabile che risponda a un certo trattamento? La capacità di formulare questi giudizi in modo coerente e di riconoscere quando non lo sono è una competenza professionale fondamentale.
ConsiglioPrerequisiti
Per seguire questo capitolo è necessario aver letto:
Conoscenze matematiche richieste:
- Appendice C - per comprendere le proprietà additive
- Appendice D - per operazioni su eventi (unione, intersezione, complemento)
Panoramica del capitolo
Il percorso che seguiremo è questo:
Reinterpreteremo lo spazio campionario non come l’insieme degli esiti fisicamente possibili, ma come l’insieme delle possibilità che noi consideriamo date le nostre informazioni.
Vedremo come gli eventi diventino proposizioni sul mondo a cui assegniamo gradi di credenza.
Introdurremo gli assiomi di Kolmogorov non come regole arbitrarie, ma come vincoli necessari per evitare auto-contraddizioni.
Impareremo a diagnosticare incoerenze nelle assegnazioni probabilistiche.
Costruiremo tabelle di probabilità congiunta, lo strumento operativo fondamentale per rappresentare sistemi di credenze complessi.
Mostreremo come tutte le probabilità di interesse (marginali, condizionate) derivino dalla distribuzione congiunta.
AttenzionePreparazione del Notebook
2.1 Spazio campionario come possibilità epistemiche
Prima di addentrarci nelle definizioni formali, fermiamoci a riflettere su cosa stiamo cercando di catturare.
Quando uno psicologo clinico valuta un paziente, non sta osservando un “esperimento casuale” nel senso fisico del termine. Non c’è un dado che rotola, né una moneta che viene lanciata. Eppure, il clinico si trova in una condizione di incertezza genuina: sulla base delle informazioni raccolte (anamnesi, colloquio, test), deve formarsi un’opinione su quale sia la condizione del paziente tra diverse possibilità.
Questa situazione, ovvero avere informazioni incomplete e dover ragionare su possibilità alternative, è esattamente ciò che la teoria della probabilità, nell’interpretazione bayesiana, è progettata per gestire. Il primo passo è definire le possibilità che stiamo prendendo in considerazione.
Definizione 2.1 (Spazio campionario) Lo spazio campionario \(\Omega\) rappresenta l’insieme delle possibilità epistemiche compatibili con lo stato informativo corrente. Esso non descrive necessariamente tutto ciò che può accadere fisicamente, ma piuttosto ciò che, dati i limiti della nostra conoscenza, consideriamo logicamente possibile.
2.1.1 Un cambio di prospettiva fondamentale
Questa definizione merita attenzione. Nella visione frequentista tradizionale, lo spazio campionario è qualcosa di “oggettivo”: l’insieme di tutti gli esiti che un esperimento può produrre, indipendentemente da chi lo osserva. Nell’approccio bayesiano, invece, lo spazio campionario diventa epistemico: dipende da ciò che noi sappiamo e dalle distinzioni che noi riteniamo rilevanti.
Questo cambiamento non è un dettaglio tecnico, ma un cambio di prospettiva filosofica con conseguenze pratiche profonde. Ciò significa che:
ricercatori diversi possono legittimamente usare spazi campionari diversi per lo stesso fenomeno, se hanno informazioni diverse o interessi diversi;
lo spazio campionario può cambiare quando si acquisiscono nuove informazioni. Prima di un test diagnostico, consideriamo come possibili sia il risultato “positivo” che quello “negativo”; dopo aver osservato il risultato, lo spazio delle possibilità rilevanti si restringe.
la scelta dello spazio campionario è una decisione di modellazione, non una scoperta empirica; richiede un giudizio su quale livello di dettaglio sia appropriato per il problema in esame.
2.1.2 Caratteristiche dello spazio campionario epistemico
La composizione dello spazio campionario riflette dunque la natura informazionale e soggettiva della probabilità bayesiana. Non esiste “lo” spazio campionario corretto in senso assoluto, ma esiste quello appropriato, date le nostre informazioni e i nostri obiettivi.
NotaEsempio psicologico: livelli di granularità nella valutazione clinica
Consideriamo la valutazione di un paziente per una possibile depressione. Lo spazio campionario può essere definito a diversi livelli, a seconda delle informazioni disponibili e degli obiettivi clinici:
Livello 1 (binario):
\[\Omega_1 = \{\text{Depresso}, \text{Non depresso}\}.\]
Questo è il livello appropriato per una decisione sì/no: il paziente necessita di trattamento per depressione?
Livello 2 (severità):
\[\Omega_2 = \{\text{Nessuna}, \text{Lieve}, \text{Moderata}, \text{Severa}\}.\]
Qui distinguiamo gradi di severità, che sono importanti quando dobbiamo decidere quale tipo di trattamento proporre.
Livello 3 (combinazioni diagnostiche):
\[\Omega_3 = \{\text{Depressione}, \text{Ansia}, \text{Comorbidità}, \text{Nessuna}\}.\]
Questo livello considera la possibilità di diagnosi multiple o alternative.
Nessuno di questi spazi campionari è “più corretto” degli altri in senso assoluto. La scelta dipende da:
- le informazioni disponibili (uno screening rapido vs. una valutazione approfondita);
- l’obiettivo dell’analisi (screening di popolazione vs. diagnosi differenziale);
- le decisioni da prendere (inviare a uno specialista o pianificare un trattamento specifico).
La consapevolezza che lo spazio campionario è una scelta di modellazione e non un dato di fatto è il primo passo verso un uso maturo della probabilità.
2.2 Eventi come proposizioni sul mondo
Una volta definito lo spazio delle possibilità, il passo successivo è considerare le affermazioni su queste possibilità. Qui avviene un’altra importante traduzione concettuale.
Nella teoria degli insiemi, un “evento” è semplicemente un sottoinsieme dello spazio campionario. Tuttavia, nell’interpretazione epistemica, un evento acquista un significato più ricco: diventa una proposizione, un’affermazione sul mondo che può essere vera o falsa.
Definizione 2.2 (Evento) Un evento \(A \subseteq \Omega\) è una proposizione alla quale possiamo assegnare un grado di credenza \(P(A)\), condizionato allo stato informativo corrente.
2.2.1 La logica delle proposizioni incerte
Questa interpretazione collega la teoria della probabilità alla logica proposizionale. Le operazioni insiemistiche diventano operazioni logiche:
- L’unione \(A \cup B\) corrisponde alla disgiunzione logica: “\(A\) oppure \(B\) è vera” (o entrambe).
- L’intersezione \(A \cap B\) corrisponde alla congiunzione logica: “\(A\) e \(B\) sono entrambe vere”.
- Il complemento \(A^c\) corrisponde alla negazione: “\(A\) è falsa”.
Questa corrispondenza non è casuale. La teoria della probabilità può essere considerata come un’estensione della logica classica al caso dell’incertezza. Mentre la logica classica assegna solo valori “vero” (1) o “falso” (0) alle proposizioni, la probabilità assegna valori intermedi che rappresentano gradi di credenza.
L’insieme vuoto \(\varnothing\) corrisponde a una proposizione logicamente contraddittoria, qualcosa che non può essere vero in nessuna delle possibilità che prendiamo in considerazione. Al contrario, lo spazio campionario \(\Omega\) corrisponde a una tautologia, qualcosa che è necessariamente vero, dato che una delle possibilità deve realizzarsi.
NotaEsempio: Eventi in un test psicometrico
La Satisfaction with Life Scale (SWLS) produce punteggi compresi tra 5 e 35. Definiamo:
- \(\Omega = \{5, 6, 7, \ldots, 35\}\) (punteggi possibili);
- \(A =\) “Punteggio ≥ 25” (alta soddisfazione) \(= \{25, 26, \ldots, 35\}\);
- \(B =\) “Punteggio ≤ 15” (bassa soddisfazione) \(= \{5, 6, \ldots, 15\}\);
- \(C =\) “Punteggio tra 16 e 24” (soddisfazione moderata) \(= \{16, 17, \ldots, 24\}\).
Alcune operazioni sugli eventi e il loro significato:
- \(A \cup B\): “La persona ha soddisfazione alta oppure bassa” (estremi).
- \(A \cap B = \varnothing\): “Alta e bassa soddisfazione insieme”—impossibile per definizione.
- \(A^c = B \cup C\): “Non alta soddisfazione” = “soddisfazione bassa o moderata”.
- \(A \cup B \cup C = \Omega\): le tre categorie esauriscono tutte le possibilità.
Quando assegniamo \(P(A) = 0.30\), stiamo dicendo: “Dato ciò che so della popolazione di riferimento e del contesto di valutazione, ritengo plausibile che un individuo selezionato presenti un’alta soddisfazione di vita con una probabilità del 30%”
Questa è un’affermazione epistemica, non una frequenza oggettiva. Due ricercatori con informazioni diverse potrebbero legittimamente assegnare valori diversi.
2.3 Gli assiomi di Kolmogorov come vincoli di coerenza
Arriviamo ora al cuore concettuale del capitolo. Abbiamo visto che le probabilità sono gradi di credenza su proposizioni. Ma quali valori possiamo assegnare? Siamo liberi di scegliere qualsiasi numero ci piaccia?
La risposta è no, e capire perché è fondamentale.
2.3.1 Il problema della coerenza
Immaginiamo un clinico che, valutando un paziente, assegna le seguenti probabilità a tre diagnosi mutualmente esclusive:
- \(P(\text{Schizofrenia}) = 0.6\)
- \(P(\text{Disturbo Bipolare}) = 0.5\)
- \(P(\text{Nessun disturbo psicotico}) = 0.2\)
La somma è 1.3. Cosa significa? Significa che il clinico sta assegnando più certezza di quanta ne abbia a disposizione. È come se il clinico dicesse: “Sono sicuro al 130% che una di queste tre cose sia vera”, il che non ha senso.
Questo non è un errore di valutazione clinica (il clinico potrebbe avere ottime ragioni per ciascuna stima individuale). Si tratta di un errore logico: le credenze sono in contraddizione tra loro. Come abbiamo visto nel capitolo precedente, un sistema di credenze incoerente espone a perdite certe (l’argomento della scommessa olandese).
Gli assiomi che introduciamo ora sono precisamente i vincoli che impediscono questo tipo di auto-contraddizioni.
Definizione 2.3 (Funzione di probabilità) Una funzione di probabilità è una funzione \[ P: \mathcal{F} \to [0,1], \] che assegna a ogni evento \(A\) appartenente a una famiglia di eventi \(\mathcal{F}\) il numero \(P(A)\), interpretabile come il grado di credenza nell’affermazione \(A\), dato lo stato informativo corrente.
Per essere coerente, la funzione \(P\) deve soddisfare i seguenti assiomi di coerenza:
Non negatività
\[P(A) \geq 0 \quad \text{per ogni evento } A.\]Normalizzazione
\[P(\Omega) = 1.\]Additività finita
Se \(A\) e \(B\) sono eventi mutuamente esclusivi (\(A \cap B = \varnothing\)), allora \[P(A \cup B) = P(A) + P(B).\]Additività numerabile (per spazi infiniti)
Se \(A_1, A_2, \ldots\) è una sequenza di eventi mutuamente esclusivi, allora \[P\!\left(\bigcup_{i=1}^{\infty} A_i\right) = \sum_{i=1}^{\infty} P(A_i).\]
2.3.2 Perché questi assiomi e non altri?
Una domanda legittima è: perché proprio questi tre (o quattro) vincoli? La risposta profonda a questa domanda viene dalla teoria della decisione e dall’argomento della scommessa olandese, che abbiamo trattato nel capitolo precedente. Tuttavia, è possibile fornire un’interpretazione intuitiva di ciascun assioma.
La non negatività riflette un fatto semplice: non esiste un grado di credenza “meno che impossibile”. Zero significa “sono certo che non accadrà”; non c’è nulla al di sotto dello zero. Se qualcuno vi dicesse: “Credo che pioverà con probabilità -0.3”, non sapreste nemmeno cosa intende.
La normalizzazione esprime la convinzione che qualcosa debba accadere. Per costruzione, lo spazio campionario contiene tutte le possibilità che prendiamo in considerazione. Una di queste deve realizzarsi. Assegnare \(P(\Omega) < 1\) significherebbe ammettere la possibilità che nessuna delle alternative si verifichi, ma in tal caso avremmo dimenticato qualche alternativa nel nostro spazio campionario.
L’additività è forse il vincolo più importante, e merita una riflessione più approfondita. Dice che, se \(A\) e \(B\) non possono verificarsi insieme, allora la mia credenza che “si verifichi \(A\) oppure \(B\)” deve essere esattamente la somma delle mie credenze separate in \(A\) e in \(B\).
Perché? Qualsiasi altra assegnazione sarebbe incoerente. Se assegnassi \(P(A \cup B) < P(A) + P(B)\), direi che credo “meno” nella disgiunzione rispetto alle due opzioni prese separatamente, ma la disgiunzione include entrambe le opzioni! Viceversa, se assegnassi \(P(A \cup B) > P(A) + P(B)\), starei “contando due volte” qualcosa.
L’additività numerabile estende questo ragionamento a sequenze infinite di eventi, necessarie per trattare variabili continue, ma il principio è lo stesso.
2.3.3 Conseguenze immediate degli assiomi
Una volta accettati questi vincoli fondamentali, molte altre proprietà ne derivano come conseguenze logiche necessarie. Non si tratta di regole aggiuntive da memorizzare, ma di teoremi che derivano dagli assiomi.
Teorema 2.1 (Proprietà derivate della probabilità)
Probabilità del complemento
\[P(A^c) = 1 - P(A).\]Probabilità dell’insieme vuoto
\[P(\varnothing) = 0.\]Monotonia
Se \(A \subseteq B\), allora \[P(A) \leq P(B).\]Regola dell’unione (eventi non disgiunti)
\[P(A \cup B) = P(A) + P(B) - P(A \cap B).\]Principio di inclusione–esclusione (caso generale)
\[P(A_1 \cup A_2 \cup A_3) = \sum P(A_i) - \sum P(A_i \cap A_j) + P(A_1 \cap A_2 \cap A_3).\]
La prima proprietà è particolarmente importante e vale la pena di comprenderla bene: se credo che pioverà con probabilità 0.7, devo credere che non pioverà con probabilità 0.3. Non ho scelta. È una conseguenza logica degli assiomi.
La quarta proprietà (regola dell’unione generale) merita attenzione, in quanto mostra cosa accade quando gli eventi non sono disgiunti. La sottrazione di \(P(A \cap B)\) corregge il “doppio conteggio” che si verificherebbe sommando semplicemente le due probabilità.
NotaUn’analogia utile: le aree
Le proprietà della probabilità sono analoghe a quelle delle aree. Se due regioni non si sovrappongono, la loro area totale è la somma delle due aree. Se le regioni si sovrappongono, devo sottrarre l’area di sovrapposizione per evitare di contarla due volte. L’area totale disponibile (normalizzata a 1) non può essere superata. Nessuna regione ha un’area negativa.
Questa analogia non è casuale: matematicamente, la probabilità è una “misura” e le misure generalizzano il concetto di area/volume. Tuttavia, l’interpretazione è diversa: non stiamo misurando estensioni spaziali, ma gradi di credenza.
2.4 Diagnosi di incoerenze: casi tipici
La teoria è utile solo se ci permette di individuare e correggere gli errori nella pratica. Vediamo alcuni pattern comuni di incoerenza e come riconoscerli.
2.4.1 Incoerenza 1: violazione dell’additività
Questo è l’errore più comune e l’abbiamo già visto nell’esempio iniziale. Quando abbiamo eventi mutuamente esclusivi che insieme esauriscono tutte le possibilità, le loro probabilità devono sommare a 1.
AvvisoEsempio di incoerenza clinica
Sovrastima delle probabilità
Un clinico valuta un paziente con sintomi psicotici e assegna i seguenti gradi di credenza a tre diagnosi mutualmente esclusive:
- \(P(\text{Schizofrenia}) = 0.6\);
-
\(P(\text{Disturbo Bipolare}) = 0.5\);
- \(P(\text{Nessun disturbo psicotico}) = 0.2\).
La somma \(0.6 + 0.5 + 0.2 = 1.3\) eccede il valore massimo consentito di 1.
Diagnosi del problema: il clinico ha probabilmente valutato ciascuna ipotesi separatamente, chiedendosi “quanto è plausibile questa diagnosi?” senza considerare il vincolo secondo cui le tre ipotesi devono spartirsi il 100% della credenza disponibile.
Correzione: il clinico deve riconsiderare le sue valutazioni come un sistema. Una possibilità è normalizzare i valori (dividere ogni valore per 1.3), ma è meglio rivalutare criticamente quale diagnosi sia stata sovrastimata. Forse la sicurezza sulla schizofrenia (0.6) e sul disturbo bipolare (0.5) è eccessiva, data l’evidenza disponibile.
2.4.2 Incoerenza 2: violazione dei vincoli di Fréchet per eventi congiunti
Un tipo più sottile di incoerenza emerge quando consideriamo la probabilità che due eventi si verifichino insieme. Anche qui esistono vincoli logici che non possono essere violati.
Consideriamo un esempio. Sappiamo che il 60% dei pazienti di un determinato ambulatorio soffre di depressione e il 50% di ansia. Qual è la probabilità che un paziente soffra di entrambe le condizioni?
La risposta non è libera. Non possiamo dire “10%” perché la matematica ci impone un valore minimo più alto. Non possiamo neanche dire “55%” perché supererebbe la probabilità dell’evento meno probabile.
Teorema 2.2 (Vincoli di Fréchet) Per qualsiasi coppia di eventi \(A\) e \(B\) vale la disuguaglianza:
\[ \max\{0,\, P(A) + P(B) - 1\} \;\leq\; P(A \cap B) \;\leq\; \min\{P(A), P(B)\}. \]
Interpretazione intuitiva
Il limite superiore dice qualcosa di ovvio una volta che ci si pensa: la probabilità che accadano sia A che B non può essere maggiore della probabilità che accada solo A (né di quella che accada solo B). Se credo al 50% che pioverà, non posso credere che pioverà e farà freddo con una probabilità del 60%.
Il limite inferiore è meno ovvio ma altrettanto importante: se \(P(A) + P(B) > 1\), i due eventi devono sovrapporsi almeno in parte. Se il 60% dei pazienti soffre di depressione e il 50% di ansia, allora almeno il 10% deve soffrire di entrambe le patologie, semplicemente perché altrimenti avremmo più del 100% di pazienti!
NotaApplicazione alla comorbidità psicologica
Definizione dello scenario
Torniamo all’esempio con \(P(\text{Depressione}) = 0.6\) e \(P(\text{Ansia}) = 0.5\).
I vincoli di Fréchet determinano l’intervallo ammissibile per la comorbidità:
- limite inferiore: \(\max(0, 0.6 + 0.5 - 1) = 0.1\);
- limite superiore: \(\min(0.6, 0.5) = 0.5\).
Quindi la probabilità di comorbidità deve essere compresa tra il 10% e il 50%.
Implicazioni pratiche: se un collega vi dicesse: “Nella mia esperienza, solo il 5% dei pazienti presenta entrambe le condizioni”, potreste rispondergli che questa stima è logicamente impossibile, date le prevalenze di depressione e ansia riportate. O ha sbagliato le prevalenze, o ha sbagliato la stima della comorbidità. Non c’è una terza possibilità.
Viceversa, qualsiasi valore compreso tra il 10% e il 50% è logicamente ammissibile, il che non significa che sia corretto, ma solo che non contraddice le altre assunzioni.
Mappa dei valori ammissibili.
# Creare griglia di valori
grid <- expand.grid(
P_A = seq(0, 1, by = 0.02),
P_B = seq(0, 1, by = 0.02)
)
# Calcolare vincoli per ogni coppia
grid$limite_inferiore <- pmax(0, grid$P_A + grid$P_B - 1)
grid$limite_superiore <- pmin(grid$P_A, grid$P_B)
grid$ampiezza_lecita <- grid$limite_superiore - grid$limite_inferiore
# Visualizzazione
ggplot(grid, aes(x = P_A, y = P_B, fill = ampiezza_lecita)) +
geom_tile() +
scale_fill_viridis_c(
name = "Ampiezza dell'intervallo\nammissibile",
option = "plasma",
limits = c(0, 1)
) +
labs(
title = "Vincoli di Fréchet:\nintervalli ammissibili per P(A ∩ B)",
subtitle = "Per ogni coppia (P(A), P(B)), l'area colorata mostra\nquanti valori di P(A ∩ B) sono logicamente possibili",
x = "P(A)",
y = "P(B)",
caption = "Colori più chiari = maggiore libertà nella scelta di P(A ∩ B)"
) +
coord_fixed()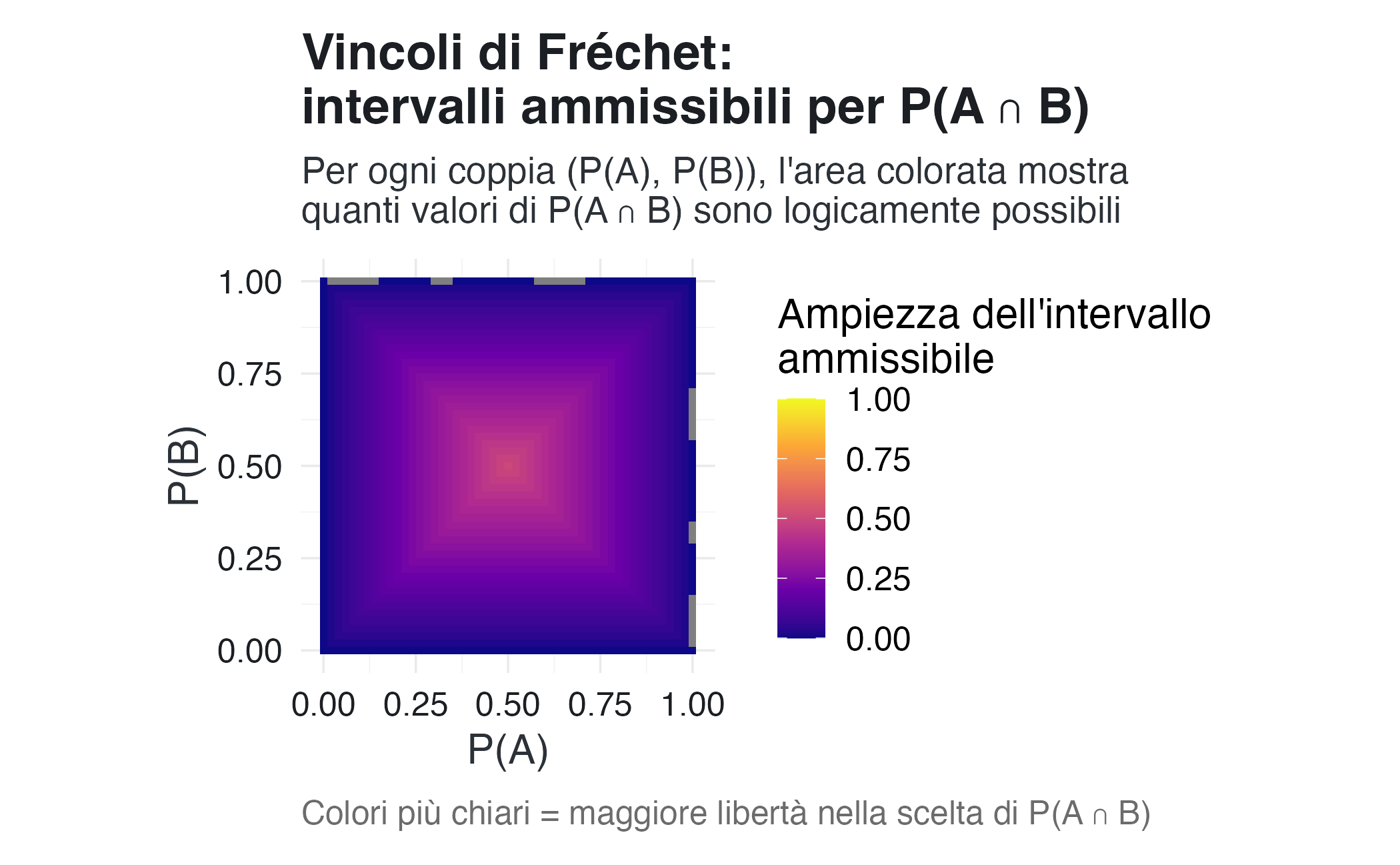
La mappa rivela pattern interessanti. Negli angoli, corrispondenti agli eventi rari o quasi certi, i vincoli sono stringenti e c’è poca libertà nella scelta della probabilità congiunta. Al centro, dove le probabilità sono intermedie, c’è più libertà.
La regione in alto a destra, in cui \(P(A) + P(B) > 1\), impone una sovrapposizione minima obbligatoria. La regione in basso a sinistra permette una sovrapposizione nulla.
2.5 Tabelle di probabilità congiunta
Passiamo ora dallo studio dei vincoli teorici alla costruzione di rappresentazioni operative. Le tabelle di probabilità congiunta sono lo strumento fondamentale per questo scopo.
2.5.1 L’idea centrale: la distribuzione congiunta è la “fonte”
Prima di addentrarci nei dettagli tecnici, è importante comprendere il principio guida. Quando abbiamo due o più variabili (o eventi), possiamo chiederci:
- Qual è la probabilità di ciascun valore della prima variabile? (marginale)
- Qual è la probabilità di ciascun valore della seconda variabile? (marginale)
- Qual è la probabilità di ciascuna combinazione di valori? (congiunta)
- Se conosco il valore della prima variabile, qual è la probabilità dei valori della seconda? (condizionata)
Tutte queste domande hanno risposte diverse. Ma ecco il punto cruciale: non si tratta di domande indipendenti. Se conosco la distribuzione congiunta, ovvero le probabilità di tutte le combinazioni, posso derivare tutte le altre.
La distribuzione congiunta è come il DNA del sistema: contiene tutte le informazioni. Le distribuzioni marginali e condizionate sono come le caratteristiche fenotipiche che emergono da quel DNA.
2.5.2 Struttura di una tabella 2×2
Consideriamo il caso più semplice: due eventi dicotomici \(A\) e \(B\). La loro distribuzione congiunta può essere rappresentata in una tabella:
| \(B\) | \(B^c\) | Marginale | |
|---|---|---|---|
| \(A\) | \(P(A \cap B)\) | \(P(A \cap B^c)\) | \(P(A)\) |
| \(A^c\) | \(P(A^c \cap B)\) | \(P(A^c \cap B^c)\) | \(P(A^c)\) |
| Marginale | \(P(B)\) | \(P(B^c)\) | \(1\) |
Le quattro celle interne contengono le probabilità congiunte, ovvero quanto crediamo in ciascuna delle quattro possibili combinazioni.
I margini (i bordi) contengono le probabilità marginali, ottenute sommando le righe o le colonne: \[P(A) = P(A \cap B) + P(A \cap B^c)\] \[P(B) = P(A \cap B) + P(A^c \cap B)\]
L’angolo in basso a destra deve valere 1: la somma di tutte le celle interne (e di tutte le marginali su ciascun asse) deve dare 1.
NotaEsempio completo: test diagnostico per la depressione
Costruzione passo-passo
Consideriamo un test diagnostico per la depressione. Ci sono due variabili:
- stato reale: \(D\) (depresso) o \(D^c\) (non depresso);
- esito del test: \(T^+\) (positivo) o \(T^-\) (negativo).
Supponiamo di conoscere:
- prevalenza: \(P(D) = 0.15\) (il 15% della popolazione clinica è depresso);
- sensibilità: \(P(T^+ \mid D) = 0.85\) (l’85% dei depressi risulta positivo);
- tasso di falsi positivi: \(P(T^+ \mid D^c) = 0.20\) (il 20% dei non depressi risulta positivo).
Come costruiamo la tabella congiunta? Usiamo la regola del prodotto:
\[ P(D \cap T^+) = P(T^+ \mid D) \cdot P(D) = 0.85 \times 0.15 = 0.1275. \]
Procediamo sistematicamente:
# Parametri di base
prevalenza <- 0.15
sensibilita <- 0.85
tasso_falsi_positivi <- 0.20
# Calcolo delle probabilità congiunte
p_depresso_positivo <- sensibilita * prevalenza
p_depresso_negativo <- (1 - sensibilita) * prevalenza
p_non_depresso_positivo <- tasso_falsi_positivi * (1 - prevalenza)
p_non_depresso_negativo <- (1 - tasso_falsi_positivi) * (1 - prevalenza)
# Creazione della tabella
tabella_congiunta <- matrix(
c(p_depresso_positivo, p_depresso_negativo,
p_non_depresso_positivo, p_non_depresso_negativo),
nrow = 2,
byrow = TRUE,
dimnames = list(
"Stato reale" = c("Depresso", "Non depresso"),
"Risultato test" = c("Positivo", "Negativo")
)
)
print(round(tabella_congiunta, 4))
#> Risultato test
#> Stato reale Positivo Negativo
#> Depresso 0.128 0.0225
#> Non depresso 0.170 0.6800Interpretazione delle celle:
- 0.1275: probabilità di essere depresso e risultare positivo (vero positivo);
- 0.0225: probabilità di essere depresso e risultare negativo (falso negativo);
- 0.1700: probabilità di non essere depresso e risultare positivo (falso positivo);
- 0.6800: probabilità di non essere depresso e risultare negativo (vero negativo).
Verifica di coerenza: \(0.1275 + 0.0225 + 0.1700 + 0.6800 = 1.0000\) ✓
2.5.3 Calcolo di probabilità marginali e condizionate
Una volta costruita la tabella congiunta, tutte le altre probabilità di interesse si ottengono con semplici operazioni algebriche.
2.5.3.1 Probabilità marginali
Le probabilità marginali si ottengono sommando lungo righe o colonne:
\[P(A) = P(A \cap B) + P(A \cap B^c)\] \[P(B) = P(A \cap B) + P(A^c \cap B)\]
Il nome “marginale” deriva dal fatto che questi valori compaiono sui margini della tabella.
NotaEsempio: marginali dal test diagnostico
#> Probabilità marginali derivate:
#> P(D) = 0.15 (prevalenza depressione)
#> P(D^c) = 0.85 (assenza depressione)
#> P(T+) = 0.297 (test positivo)
#> P(T-) = 0.703 (test negativo)Notiamo che la probabilità di un test positivo (≈0.30) è molto più alta della prevalenza della depressione (0.15). Ciò è dovuto al fatto che include sia i veri positivi che i falsi positivi.
2.5.3.2 Probabilità condizionate
Le probabilità condizionate si ottengono come rapporto tra la probabilità congiunta e quella marginale:
\[P(A \mid B) = \frac{P(A \cap B)}{P(B)}\]
Interpretazione epistemica: condizionare significa restringere lo spazio delle possibilità a quelle compatibili con l’informazione acquisita. Se si sa che \(B\) si è verificato, le uniche configurazioni rilevanti sono quelle in cui \(B\) è vero. La probabilità condizionata ri-normalizza le probabilità congiunte su questo spazio ristretto.
NotaEsempio: condizionate dal test diagnostico
La domanda clinica più importante è: “Se il test è positivo, qual è la probabilità che il paziente soffra di depressione?”
#> Probabilità condizionate derivate:
#> P(D | T+) = 0.429 (Valore predittivo positivo)
#> P(D | T-) = 0.032 (Probabilità residua dopo test negativo)Questo risultato è spesso sorprendente: nonostante una sensibilità dell’85%, un test positivo indica la presenza di depressione solo nel 43% dei casi! La ragione è la bassa prevalenza: la maggior parte dei risultati positivi è falsa.
Questo fenomeno, noto come “paradosso dei test diagnostici”, è stato introdotto nel Capitolo 1 e sarà approfondito nel Capitolo 5. Per ora, il punto importante è che questa probabilità è stata derivata dalla tabella congiunta, non è stata assunta.
ImportanteMessaggio chiave: le condizionate non sono numeri a parte
Un errore comune è quello di considerare le probabilità condizionate come assegnazioni indipendenti. Non lo sono. Una volta specificata la tabella congiunta, le probabilità condizionate sono determinate e non c’è libertà di scelta.
Ciò garantisce la coerenza interna del sistema. Se provassimo a specificare arbitrariamente sia \(P(A \mid B)\), sia \(P(B \mid A)\), sia \(P(A \cap B)\), quasi certamente introdurremmo delle contraddizioni.
La regola è: specificare la distribuzione congiunta e derivare tutto il resto.
2.5.4 Verifica empirica: le simulazioni come test di coerenza
Un modo potente per verificare la coerenza di un sistema di credenze è simulare dati secondo quella distribuzione e controllare che le frequenze osservate convergano alle probabilità teoriche.
Se la distribuzione congiunta è coerente, le simulazioni produrranno dati con le proprietà attese. Se c’è un errore (di calcolo o concettuale), le simulazioni lo evidenzieranno.
NotaVerifica mediante simulazione Monte Carlo
set.seed(123)
N <- 100000
# Simulare secondo la distribuzione congiunta
probs_vector <- c(p_depresso_positivo, p_depresso_negativo,
p_non_depresso_positivo, p_non_depresso_negativo)
outcomes <- sample(1:4, size = N, replace = TRUE, prob = probs_vector)
# Contare frequenze empiriche
freq_empiriche <- table(outcomes) / N
# Confronto
df_verifica <- data.frame(
Configurazione = c("D∩T+", "D∩T-", "D^c∩T+", "D^c∩T-"),
Teorica = probs_vector,
Empirica = as.numeric(freq_empiriche)
)
df_verifica$Teorica <- round(df_verifica$Teorica, 4)
df_verifica$Empirica <- round(df_verifica$Empirica, 4)
print(df_verifica)
#> Configurazione Teorica Empirica
#> 1 D∩T+ 0.1275 0.1266
#> 2 D∩T- 0.0225 0.0226
#> 3 D^c∩T+ 0.1700 0.1699
#> 4 D^c∩T- 0.6800 0.6809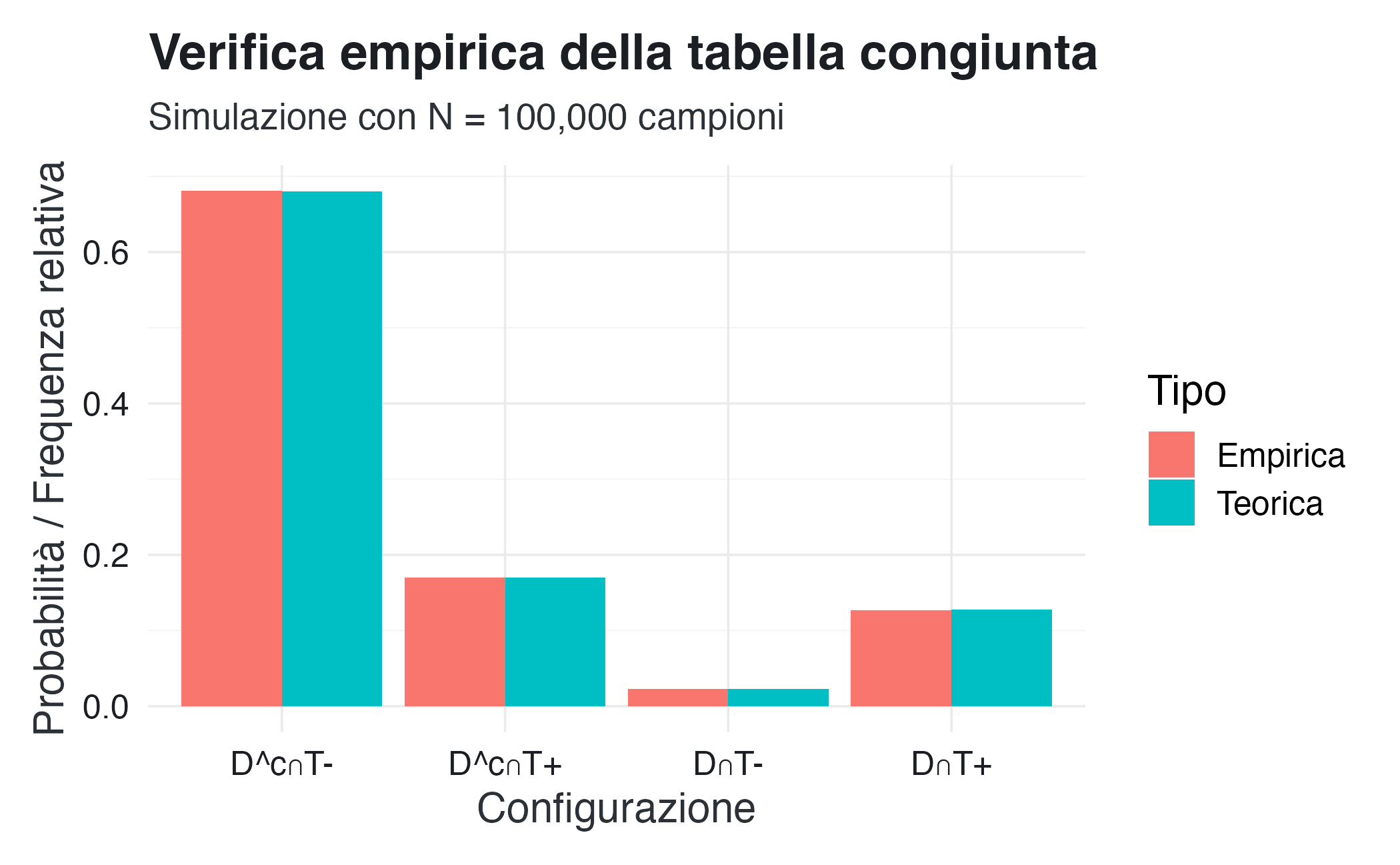
La convergenza delle frequenze empiriche verso le probabilità teoriche conferma che la distribuzione congiunta è un sistema coerente in grado di generare dati con le proprietà attese.
Questo collegamento tra probabilità teoriche e dati simulati è un tema centrale dell’approccio bayesiano: le probabilità non sono “solo numeri”, ma specificano un modello generativo del mondo.
2.6 Estensione a tabelle multidimensionali
Il framework delle tabelle congiunte si estende naturalmente a situazioni più complesse con più variabili e più categorie. Il principio rimane lo stesso: specificare le probabilità di tutte le combinazioni, da cui derivare tutto il resto.
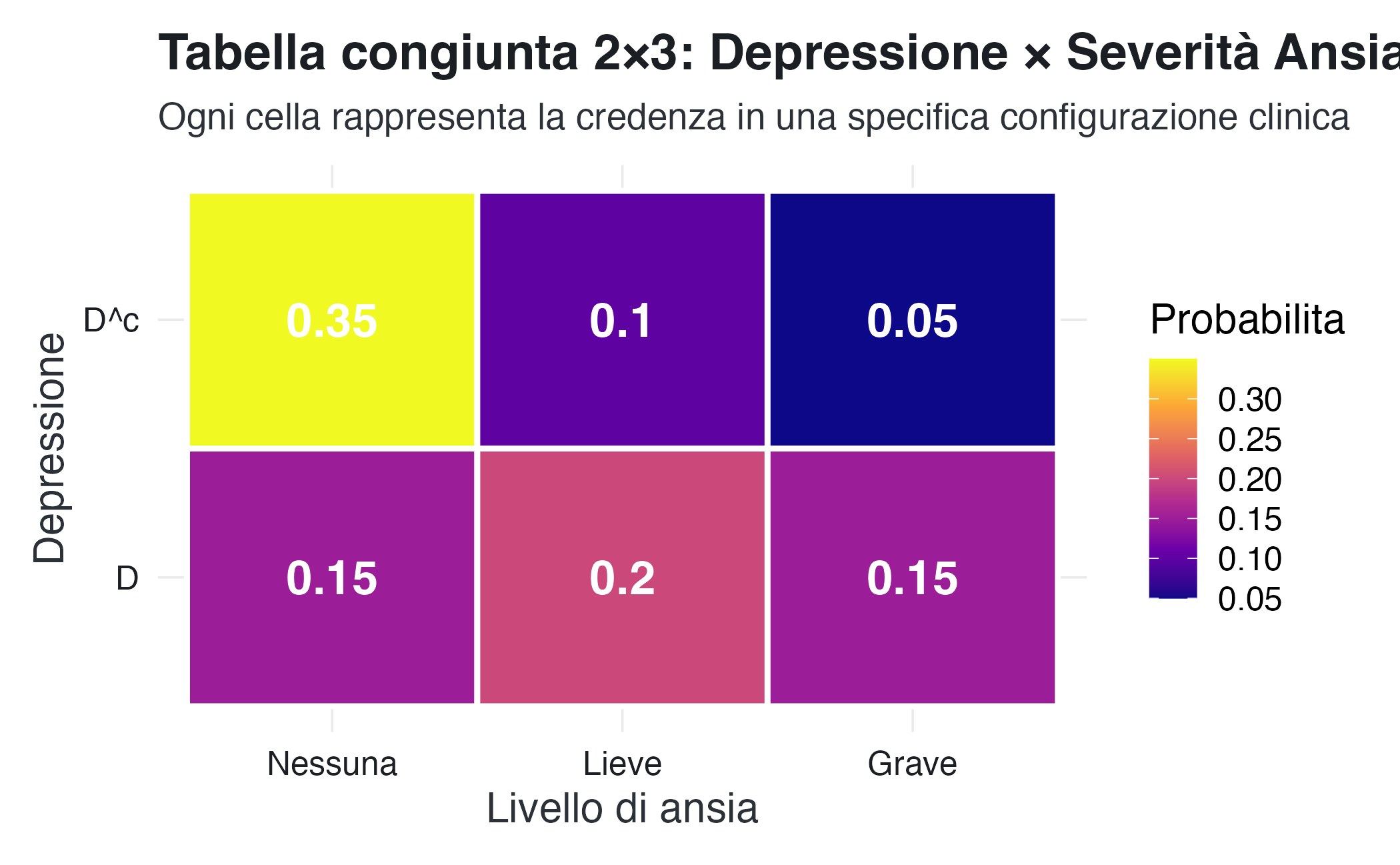
NotaEsempio: depressione × livelli di ansia (tabella 2×3)
Consideriamo due dimensioni:
- depressione: presente o assente (2 livelli);
- severità dell’ansia: nessuna, lieve, grave (3 livelli).
tab_2x3 <- matrix(
c(0.15, 0.20, 0.15, # Depresso: Ansia Nessuna/Lieve/Grave
0.35, 0.10, 0.05), # Non depresso: Ansia Nessuna/Lieve/Grave
nrow = 2, byrow = TRUE,
dimnames = list(
Depressione = c("D", "D^c"),
Ansia = c("Nessuna", "Lieve", "Grave")
)
)
cat("Tabella 2×3:\n")
#> Tabella 2×3:
print(tab_2x3)
#> Ansia
#> Depressione Nessuna Lieve Grave
#> D 0.15 0.2 0.15
#> D^c 0.35 0.1 0.05
cat("\nMarginali:\n")
#>
#> Marginali:
cat("Depressione:", rowSums(tab_2x3), "\n")
#> Depressione: 0.5 0.5
cat("Ansia:", colSums(tab_2x3), "\n")
#> Ansia: 0.5 0.3 0.2
cat("Totale:", sum(tab_2x3), "\n")
#> Totale: 1La struttura rivela pattern clinicamente interessanti. Ad esempio:
- i pazienti depressi mostrano più frequentemente ansia lieve o grave;
- tra i non depressi, la maggior parte non soffre di ansia;
- la comorbidità depressione + ansia grave riguarda il 15% della popolazione.
Riflessioni conclusive
Siamo partiti da una domanda apparentemente astratta: cosa significa che le credenze siano “coerenti”? e siamo arrivati a strumenti concreti per rappresentare e manipolare sistemi di credenze complessi.
Il percorso ha rivelato che la matematica della probabilità non è un formalismo arbitrario, ma la struttura logica necessaria per ragionare in modo coerente in situazioni di incertezza. Gli assiomi di Kolmogorov non sono delle semplici convenzioni, ma dei vincoli che dobbiamo rispettare se vogliamo evitare contraddizioni.
2.6.1 Cosa abbiamo guadagnato
Per lo psicologo, questo framework offre diversi vantaggi:
Uno standard normativo: ora sappiamo cosa significa che un giudizio probabilistico sia “corretto” dal punto di vista logico, anche se può essere sbagliato dal punto di vista empirico.
Strumenti diagnostici: possiamo identificare incoerenze nei ragionamenti (nostri e altrui) utilizzando criteri precisi, come i vincoli di Fréchet.
Una rappresentazione unificata: le tabelle di probabilità congiunta condensano in un’unica struttura tutte le informazioni probabilistiche rilevanti su un sistema.
Un ponte verso i dati: la connessione tra probabilità teoriche e simulazioni mostra come le nostre credenze si traducano in aspettative sui dati osservabili.
2.6.2 Cosa manca ancora
Questo capitolo ha gettato le basi, ma restano ancora delle domande senza risposta:
- Come assegnare le probabilità iniziali quando non abbiamo dati? (Tema dell’equiprobabilità).
- Come aggiorniamo le nostre credenze quando osserviamo nuove evidenze? (Teorema di Bayes).
- Come trattiamo variabili continue che non rientrano in tabelle discrete? (Distribuzioni di probabilità).
Questi temi verranno sviluppati nei capitoli successivi. Tuttavia, la struttura di coerenza che abbiamo costruito rimarrà la cornice di riferimento.
2.6.3 Un invito alla riflessione
Prima di procedere, è opportuno soffermarsi a considerare un punto filosofico più profondo. Abbiamo visto che la coerenza è necessaria per evitare contraddizioni. Ma è sufficiente per ragionare bene?
La risposta è no. Un sistema di credenze può essere perfettamente coerente ma completamente errato. Posso credere con certezza matematica che domani pioveranno pesci dal cielo, e queste credenze possono essere internamente coerenti, ma saranno smentite dalla realtà.
La coerenza è una condizione minima, non una garanzia di verità. Ci protegge dagli errori logici, ma non da quelli empirici. Per avvicinarci alla verità, dobbiamo anche confrontare le nostre credenze con i dati, e questo sarà il tema dell’inferenza bayesiana.
Punti chiave da ricordare
Importante
Concetti essenziali di questo capitolo:
-
I tre assiomi di Kolmogorov
- Non-negatività: \(P(A) \geq 0\) per ogni evento \(A\).
- Normalizzazione: \(P(\Omega) = 1\) (certezza per l’intero spazio campionario).
- Additività: \(P(A \cup B) = P(A) + P(B)\) se \(A\) e \(B\) sono disgiunti.
-
Principio di coerenza
- Le credenze probabilistiche devono essere internamente consistenti.
- Un sistema di credenze incoerente porta a perdite certe (Dutch book argument).
- Gli assiomi garantiscono la coerenza razionale delle nostre valutazioni.
-
Conseguenze degli assiomi
- Probabilità del complemento: \(P(A^c) = 1 - P(A)\).
- Evento impossibile: \(P(\emptyset) = 0\).
- Regola dell’unione generale: \(P(A \cup B) = P(A) + P(B) - P(A \cap B)\).
-
Tabelle di probabilità congiunta
- Contengono l’informazione completa sul sistema.
- Marginali = somme di righe/colonne.
- Condizionate = rapporti (congiunta / marginale).
- Tutto deriva dalla distribuzione congiunta.
Formule da ricordare:
\[P(A^c) = 1 - P(A)\]
\[P(A \cup B) = P(A) + P(B) - P(A \cap B)\]
\[P(A \mid B) = \frac{P(A \cap B)}{P(B)}\]
Per il prossimo capitolo:
Nel Capitolo 3 vedremo come applicare questi assiomi a situazioni di equiprobabilità, introducendo il calcolo combinatorio per contare i casi favorevoli e possibili.
Esercizi
ImportanteProblemi
2.6.4 Esercizi sulla coerenza
-
Verifica se le seguenti assegnazioni per eventi mutuamente esclusivi sono coerenti:
- \(P(A) = 0.3, P(B) = 0.4, P(C) = 0.3\)
- \(P(A) = 0.5, P(B) = 0.4, P(C) = 0.2\)
- \(P(A) = 0.25, P(B) = 0.25, P(C) = 0.25, P(D) = 0.25\)
Un ricercatore assegna \(P(A) = 0.7\) e \(P(A^c) = 0.4\). Identifica l’incoerenza e spiega perché viola gli assiomi.
Per eventi disgiunti \(A\) e \(B\) con \(P(A) = 0.6\) e \(P(B) = 0.3\), qualcuno afferma \(P(A \cup B) = 0.8\). È coerente? Se no, qual è il valore corretto?
2.6.5 Esercizi sui vincoli di Fréchet
-
Dati \(P(A) = 0.4\) e \(P(B) = 0.7\):
- Calcola i vincoli di Fréchet per \(P(A \cap B)\)
- Quali dei seguenti valori sono coerenti: 0.05, 0.1, 0.3, 0.5?
- Visualizza graficamente la regione ammissibile
-
In uno studio su depressione e insonnia:
- \(P(\text{Depressione}) = 0.30\)
- \(P(\text{Insonnia}) = 0.45\)
Determina l’intervallo di valori plausibili per \(P(\text{Depressione} \cap \text{Insonnia})\).
Scrivi una funzione R che, dati \(P(A)\) e \(P(B)\), verifichi se un proposto \(P(A \cap B)\) rispetta i vincoli di Fréchet.
2.6.6 Esercizi su tabelle congiunte
-
Completa la seguente tabella congiunta (alcune celle sono mancanti):
\(B\) \(B^c\) Marg. \(A\) 0.25 ? 0.40 \(A^c\) ? 0.45 ? Marg. ? ? 1 -
Costruisci una tabella congiunta 2×2 per:
- Test COVID: \(P(+) = 0.08\)
- Malattia: \(P(\text{COVID}) = 0.05\)
- Sensibilità: \(P(+ \mid \text{COVID}) = 0.90\)
Calcola poi:
- \(P(\text{COVID} \mid +)\) (valore predittivo positivo)
- \(P(\text{COVID} \mid -)\) (probabilità dopo test negativo)
- Specificità del test
Verifica con simulazione Monte Carlo (N=100,000) che la tabella dell’esercizio 8 è coerente confrontando frequenze empiriche con probabilità teoriche.
2.6.7 Esercizi applicati (psicologia)
-
Comorbidità: In un campione clinico:
- \(P(\text{Depressione}) = 0.55\)
- \(P(\text{PTSD}) = 0.30\)
- \(P(\text{PTSD} \mid \text{Depressione}) = 0.45\)
- Costruisci la tabella congiunta completa
- Calcola \(P(\text{Depressione} \mid \text{PTSD})\)
- Le due condizioni sono indipendenti?
- Qual è la probabilità di avere almeno una delle due condizioni?
-
Test psicometrico: Un test di ansia ha:
- Sensibilità: 0.80
- Specificità: 0.85
- Prevalenza nell’ambulatorio: 0.25
- Costruisci la tabella 2×2 per (Ansia × Test)
- Un paziente ha test positivo. Quanto è probabile che sia ansioso?
- Se il test è negativo, quanto è probabile l’assenza di ansia?
-
Tre diagnosi: Un paziente può avere Depressione (D), Ansia (A), o Nessuna condizione (N). Assegnazioni:
- \(P(D) = 0.40\)
- \(P(A) = 0.35\)
- \(P(N) = 0.30\)
Identifica e correggi l’incoerenza.
2.6.8 Esercizi di pensiero critico
Spiega perché, nell’approccio bayesiano, specificare una tabella congiunta coerente è “più fondamentale” che specificare separatamente marginali e condizionate.
Un frequentista obietta: “Le tabelle congiunte funzionano solo per spazi finiti. Come gestite il caso continuo?” Rispondi dall’ottica bayesiana.
Due clinici costruiscono tabelle congiunte diverse per Depressione × Test, partendo da prior diversi ma usando la stessa sensibilità/specificità. È un problema? Cosa succederebbe con molti dati?
2.6.9 Esercizi computazionali
-
Scrivi una funzione R che:
- Input: vettore di probabilità per eventi mutuamente esclusivi
- Output: TRUE se coerente, FALSE con messaggio di errore se incoerente
- Bonus: Se incoerente, proponi correzione per normalizzazione
Crea una visualizzazione interattiva (Shiny app o plot animato) che mostri come variano i vincoli di Fréchet al variare di \(P(A)\) e \(P(B)\).
-
Simula 10,000 pazienti secondo la tabella dell’esercizio 10, poi:
- Calcola frequenze empiriche delle 4 configurazioni
- Confronta con probabilità teoriche
- Visualizza convergenza all’aumentare di N
ConsiglioSoluzioni
2.6.10 Soluzioni esercizi sulla coerenza
-
\(0.3 + 0.4 + 0.3 = 1.0\) ✓ Coerente
-
\(0.5 + 0.4 + 0.2 = 1.1\) ✗ Incoerente (somma > 1)
- \(4 \times 0.25 = 1.0\) ✓ Coerente
-
\(0.3 + 0.4 + 0.3 = 1.0\) ✓ Coerente
Per l’assioma del complemento: \(P(A) + P(A^c) = 1\). Ma \(0.7 + 0.4 = 1.1 \neq 1\). Incoerente. Correzione: deve essere \(P(A^c) = 0.3\).
Per eventi disgiunti: \(P(A \cup B) = P(A) + P(B) = 0.6 + 0.3 = 0.9\). Il valore 0.8 è incoerente (troppo basso).
2.6.11 Soluzioni vincoli di Fréchet
Lower: \(\max(0, 0.4 + 0.7 - 1) = 0.1\); Upper: \(\min(0.4, 0.7) = 0.4\)
Intervallo: \([0.1, 0.4]\)Coerenti: 0.1 (al limite), 0.3 (interno), 0.5 (FUORI, troppo alto)
Non coerente: 0.05 (troppo basso)
Lower: \(\max(0, 0.30 + 0.45 - 1) = 0\); Upper: \(\min(0.30, 0.45) = 0.30\)
Intervallo plausibile: \([0, 0.30]\)check_frechet <- function(P_A, P_B, P_AB) { lower <- max(0, P_A + P_B - 1) upper <- min(P_A, P_B) if (P_AB >= lower && P_AB <= upper) { cat("✓ Coerente: P(A∩B) ∈ [", lower, ",", upper, "]\n") return(TRUE) } else { cat("✗ Incoerente: P(A∩B) =", P_AB, "ma deve essere in [", lower, ",", upper, "]\n") return(FALSE) } }
2.6.12 Soluzioni tabelle congiunte
- Tabella completata:
- \(P(A \cap B^c) = 0.40 - 0.25 = 0.15\)
- \(P(A^c \cap B) = P(B) - 0.25\) (serve calcolare \(P(B)\) da altre info)
- \(P(A^c) = 1 - 0.40 = 0.60\)
- \(P(A^c \cap B) = 0.60 - 0.45 = 0.15\)
- \(P(B) = 0.25 + 0.15 = 0.40\)
- \(P(B^c) = 0.15 + 0.45 = 0.60\)
\(B\) \(B^c\) Marg. \(A\) 0.25 0.15 0.40 \(A^c\) 0.15 0.45 0.60 Marg. 0.40 0.60 1.00 P_C <- 0.05 P_pos <- 0.08 sens <- 0.90 # Congiunta P_C_and_pos <- sens * P_C # = 0.045 P_C_and_neg <- P_C - P_C_and_pos # = 0.005 P_notC_and_pos <- P_pos - P_C_and_pos # = 0.035 P_notC_and_neg <- 1 - (P_C_and_pos + P_C_and_neg + P_notC_and_pos) # = 0.915 # a) P(C | +) = 0.045 / 0.08 = 0.5625 # b) P(C | -) = 0.005 / 0.92 ≈ 0.0054 # c) Specificità = P(- | C^c) = 0.915 / 0.95 ≈ 0.963
2.6.13 Soluzioni esercizi applicati
P_D <- 0.55 P_P <- 0.30 P_P_given_D <- 0.45 # a) Tabella P_D_and_P <- P_P_given_D * P_D # = 0.2475 P_D_and_notP <- P_D - P_D_and_P # = 0.3025 P_notD_and_P <- P_P - P_D_and_P # = 0.0525 P_notD_and_notP <- 1 - (P_D_and_P + P_D_and_notP + P_notD_and_P) # = 0.3975 # b) P(D | P) = 0.2475 / 0.30 = 0.825 # c) Test indipendenza: P(D) × P(P) = 0.55 × 0.30 = 0.165 # P(D ∩ P) = 0.2475 ≠ 0.165 → DIPENDENTI # d) P(D ∪ P) = 0.55 + 0.30 - 0.2475 = 0.6025# Vedi soluzione 8, adattata con prevalenza 0.25 # a) Tabella costruita con sens=0.80, spec=0.85, prev=0.25 # b) P(A | +) = [0.80 × 0.25] / [0.80 × 0.25 + 0.15 × 0.75] ≈ 0.640 # c) P(A^c | -) = [0.85 × 0.75] / [0.20 × 0.25 + 0.85 × 0.75] ≈ 0.927- Somma = 1.05 > 1. Incoerente. Correzione (normalizzazione):
- \(P(D) = 0.40 / 1.05 ≈ 0.381\)
- \(P(A) = 0.35 / 1.05 ≈ 0.333\)
- \(P(N) = 0.30 / 1.05 ≈ 0.286\)
2.6.14 Soluzioni pensiero critico
La tabella congiunta è più fondamentale perché rappresenta lo stato di credenza completo sul sistema. Da essa derivano automaticamente (e coerentemente) tutte le marginali e condizionate. Specificare marginali e condizionate separatamente rischia incoerenze (es. \(P(A \mid B) P(B) \neq P(B \mid A) P(A)\)).
Nel continuo si usano densità di probabilità congiunta \(f(x, y)\). Il principio è identico: la densità congiunta determina tutto (marginali tramite integrazione, condizionate tramite rapporti di densità). La struttura di coerenza è preservata.
Non è un problema—riflette informazioni diverse. Con molti dati, la verosimiglianza dominerà e i posterior convergeranno, riducendo l’influenza dei prior diversi. È una caratteristica, non un bug: la soggettività è nelle assunzioni iniziali esplicite.
NotaInformazioni sull’ambiente di sviluppo
sessionInfo()
#> R version 4.5.2 (2025-10-31)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Tahoe 26.2
#>
#> Matrix products: default
#> BLAS: /System/Library/Frameworks/Accelerate.framework/Versions/A/Frameworks/vecLib.framework/Versions/A/libBLAS.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
#>
#> locale:
#> [1] C.UTF-8/UTF-8/C.UTF-8/C/C.UTF-8/C.UTF-8
#>
#> time zone: Europe/Rome
#> tzcode source: internal
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] viridis_0.6.5 viridisLite_0.4.2 ragg_1.5.0
#> [4] tinytable_0.15.2 withr_3.0.2 systemfonts_1.3.1
#> [7] patchwork_1.3.2 ggdist_3.3.3 tidybayes_3.0.7
#> [10] bayesplot_1.15.0 ggplot2_4.0.1 reliabilitydiag_0.2.1
#> [13] priorsense_1.2.0 posterior_1.6.1 loo_2.9.0
#> [16] rstan_2.32.7 StanHeaders_2.32.10 brms_2.23.0
#> [19] Rcpp_1.1.1 sessioninfo_1.2.3 conflicted_1.2.0
#> [22] janitor_2.2.1 matrixStats_1.5.0 modelr_0.1.11
#> [25] tibble_3.3.1 dplyr_1.1.4 tidyr_1.3.2
#> [28] rio_1.2.4 here_1.0.2
#>
#> loaded via a namespace (and not attached):
#> [1] gridExtra_2.3 inline_0.3.21 sandwich_3.1-1
#> [4] rlang_1.1.7 magrittr_2.0.4 multcomp_1.4-29
#> [7] snakecase_0.11.1 otel_0.2.0 compiler_4.5.2
#> [10] vctrs_0.6.5 stringr_1.6.0 pkgconfig_2.0.3
#> [13] arrayhelpers_1.1-0 fastmap_1.2.0 backports_1.5.0
#> [16] labeling_0.4.3 rmarkdown_2.30 purrr_1.2.1
#> [19] xfun_0.55 cachem_1.1.0 jsonlite_2.0.0
#> [22] broom_1.0.11 parallel_4.5.2 R6_2.6.1
#> [25] stringi_1.8.7 RColorBrewer_1.1-3 lubridate_1.9.4
#> [28] estimability_1.5.1 knitr_1.51 zoo_1.8-15
#> [31] pacman_0.5.1 Matrix_1.7-4 splines_4.5.2
#> [34] timechange_0.3.0 tidyselect_1.2.1 abind_1.4-8
#> [37] yaml_2.3.12 codetools_0.2-20 curl_7.0.0
#> [40] pkgbuild_1.4.8 lattice_0.22-7 bridgesampling_1.2-1
#> [43] S7_0.2.1 coda_0.19-4.1 evaluate_1.0.5
#> [46] survival_3.8-3 RcppParallel_5.1.11-1 pillar_1.11.1
#> [49] tensorA_0.36.2.1 checkmate_2.3.3 stats4_4.5.2
#> [52] distributional_0.6.0 generics_0.1.4 rprojroot_2.1.1
#> [55] rstantools_2.6.0 scales_1.4.0 xtable_1.8-4
#> [58] glue_1.8.0 emmeans_2.0.1 tools_4.5.2
#> [61] mvtnorm_1.3-3 grid_4.5.2 QuickJSR_1.8.1
#> [64] colorspace_2.1-2 nlme_3.1-168 cli_3.6.5
#> [67] textshaping_1.0.4 svUnit_1.0.8 Brobdingnag_1.2-9
#> [70] V8_8.0.1 gtable_0.3.6 digest_0.6.39
#> [73] TH.data_1.1-5 htmlwidgets_1.6.4 farver_2.1.2
#> [76] memoise_2.0.1 htmltools_0.5.9 lifecycle_1.0.5
#> [79] MASS_7.3-65Bibliografia
Kahneman, D., & Tversky, A. (1979). Prospect Theory: An Analysis of Decision under Risk. Econometrica, 47(2), 263–291. https://doi.org/10.2307/1914185