7 Distribuzioni di massa e di densità
Introduzione
Nel capitolo precedente (Capitolo 6) abbiamo introdotto le variabili casuali come funzioni che associano valori numerici agli esiti di un esperimento aleatorio. Abbiamo distinto tra variabili casuali discrete, che assumono un insieme finito o numerabile di valori, e variabili casuali continue, che possono assumere qualsiasi valore all’interno di un intervallo. Per ciascun caso, abbiamo definito formalmente la funzione di massa di probabilità (PMF) e la funzione di densità di probabilità (PDF) come strumenti fondamentali per descrivere l’incertezza sui valori assunti dalla variabile.
Questo capitolo ha lo scopo di approfondire la comprensione intuitiva, geometrica e operativa di tali concetti. Vedremo come la PMF assegni “pesi” discreti a singoli valori, mentre la PDF distribuisca la probabilità in modo continuo lungo la retta reale, rendendo necessario l’uso dell’integrazione per calcolare la probabilità associata a intervalli di valori. In questo contesto affronteremo anche il noto “paradosso” secondo cui, per una variabile casuale continua, la probabilità di osservare un valore esatto è sempre pari a zero, mostrando come questa proprietà non sia affatto paradossale, ma una conseguenza naturale della struttura matematica del continuo.
Un aspetto centrale della trattazione riguarda inoltre la distinzione interpretativa tra l’approccio frequentista e quello bayesiano alle distribuzioni di probabilità. Nel paradigma frequentista, la funzione di densità descrive il comportamento dei dati in ipotetiche ripetizioni dell’esperimento. Nell’approccio bayesiano, invece, la PDF rappresenta il grado di credenza assegnato ai possibili valori di una quantità incerta, come un parametro o una grandezza latente. Questa differenza concettuale, apparentemente sottile, ha implicazioni profonde per il modo in cui interpretiamo le distribuzioni, calcoliamo le probabilità e traiamo conclusioni inferenziali.
Per seguire questo capitolo è necessario aver letto:
- Capitolo 6 — fondamentale
Questo capitolo approfondisce i concetti di PMF e PDF introdotti nel Capitolo 6, fornendo una comprensione intuitiva, geometrica e operativa.
Conoscenze matematiche richieste:
- Appendice F - per comprendere l’integrale come area sotto una curva
- Familiarità con il concetto di limite per capire il passaggio da istogrammi a densità continue
Letture complementari consigliate:
- Blitzstein, J. K., & Hwang, J. (2019). Introduction to Probability (2nd ed.), capitolo “Random variables and their distributions” (Blitzstein & Hwang, 2019)
Panoramica del capitolo
- Distinzione operativa tra massa di probabilità e densità di probabilità.
- Dagli istogrammi alle funzioni di densità: il limite continuo.
- Il “paradosso” della probabilità zero per valori esatti.
- La funzione di distribuzione cumulativa come rappresentazione unificata.
- Interpretazioni bayesiana e frequentista delle distribuzioni.
7.1 Dalla massa alla densità di probabilità
La distinzione tra variabili casuali discrete e continue non è una differenza puramente tecnica, ma riflette due modi profondamente diversi in cui la probabilità può distribuirsi sui valori possibili. Nel caso discreto, è possibile assegnare una probabilità positiva a ciascun valore; nel caso continuo, la probabilità non è concentrata in singoli punti, ma si distribuisce su un continuum, rendendo significative solo le probabilità associate a intervalli.
Questa differenza concettuale è cruciale per comprendere correttamente il ruolo delle funzioni di massa e di densità di probabilità.
7.2 La funzione di massa di probabilità
Per una variabile casuale discreta \(X\) che assume valori nell’insieme \[ \mathcal{X} = {x_1, x_2, \ldots}, \] la funzione di massa di probabilità (PMF) associa a ciascun valore possibile la probabilità corrispondente: \[ p_X(x) = P(X = x). \]
Il termine massa evoca una metafora fisica appropriata: la probabilità può essere immaginata come una collezione di pesi discreti collocati sui valori possibili della variabile. Ogni valore \(x_i\) è associato a una quantità \(p_X(x_i)\) e la somma totale delle masse deve essere pari a 1. In questo contesto, è perfettamente lecito “concentrare” una parte rilevante della probabilità in pochi punti specifici.
Distribuzione tipica delle risposte
Consideriamo le risposte a un item sulla soddisfazione lavorativa, misurata su una scala Likert a 5 punti (1 = “molto insoddisfatto”, 5 = “molto soddisfatto”). In molte popolazioni lavorative, le risposte tendono a concentrarsi sui valori centrali e moderatamente positivi, con una distribuzione asimmetrica:
| Risposta | 1 (molto insod.) | 2 | 3 | 4 | 5 (molto sodd.) |
|---|---|---|---|---|---|
| \(p_X(x)\) | 0.05 | 0.10 | 0.25 | 0.40 | 0.20 |
Questa PMF riflette un pattern tipico: pochi lavoratori dichiarano una forte insoddisfazione, la maggior parte si colloca su livelli moderati o buoni, e una minoranza esprime una piena soddisfazione. La coerenza della distribuzione è immediatamente verificabile:
\[ \sum_{x=1}^{5} p_X(x) = 0.05 + 0.10 + 0.25 + 0.40 + 0.20 = 1. \]
Simulando 10,000 risposte secondo questa distribuzione e confrontando le frequenze empiriche con la PMF teorica, osserviamo una chiara convergenza:
set.seed(123)
prob_teoriche <- c(0.05, 0.10, 0.25, 0.40, 0.20)
n_risposte <- 10000
risposte <- sample(1:5, size = n_risposte, replace = TRUE, prob = prob_teoriche)
freq_rel <- table(risposte) / n_risposte
df <- data.frame(
valore = 1:5,
empirica = as.numeric(freq_rel),
teorica = prob_teoriche
)
ggplot(df, aes(x = factor(valore))) +
geom_col(aes(y = empirica), alpha = 0.7, width = 0.6) +
geom_point(aes(y = teorica), size = 4) +
scale_fill_binary() +
labs(
x = "Livello di soddisfazione",
y = "Probabilità / Frequenza relativa",
title = "PMF della soddisfazione lavorativa (scala Likert 1-5)"
) 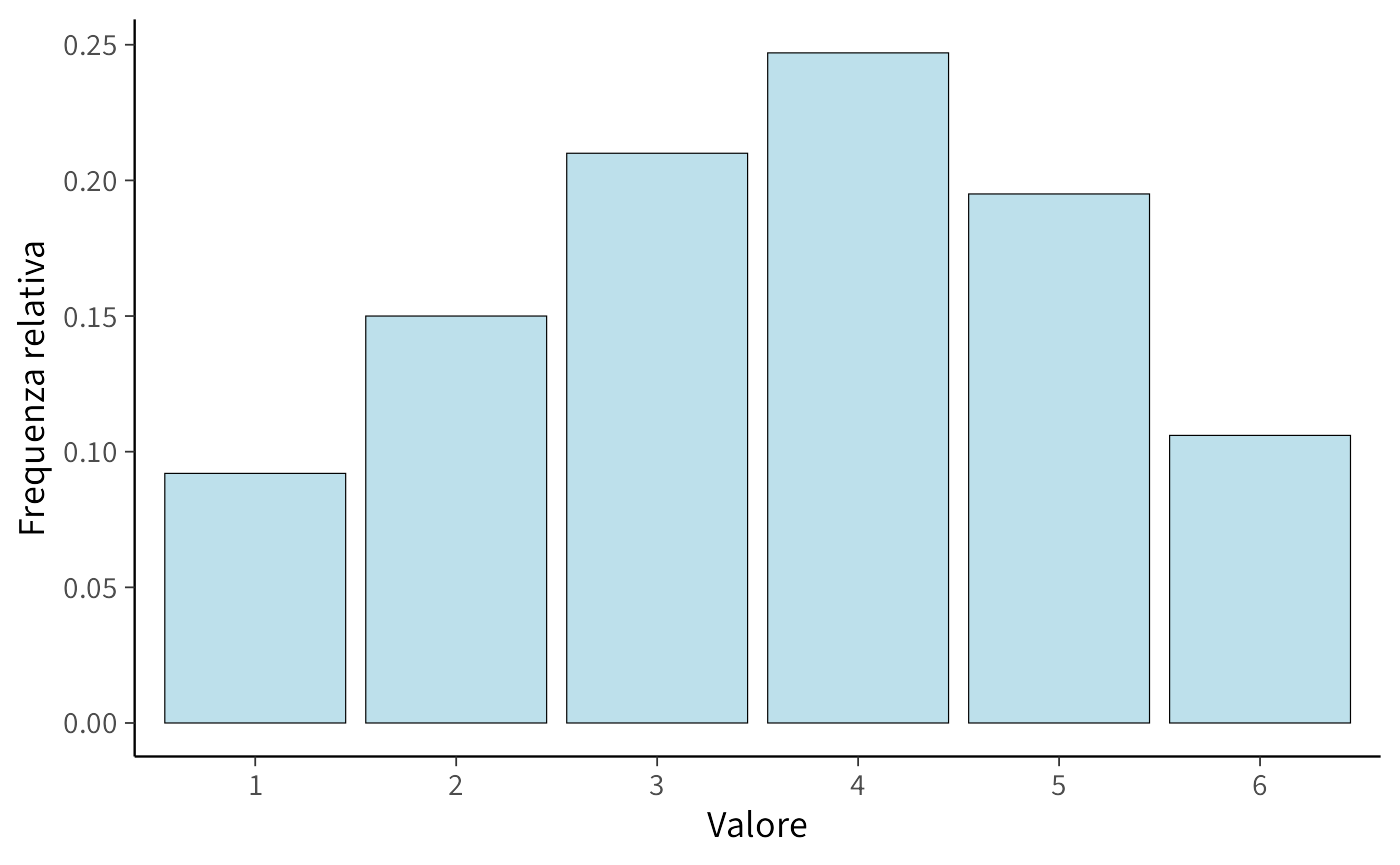
Da questa distribuzione possiamo calcolare probabilità di interesse pratico. Ad esempio, la probabilità che un lavoratore riporti almeno un livello di soddisfazione “buono” (4 o 5) è:
\[ P(X \geq 4) = p_X(4) + p_X(5) = 0.40 + 0.20 = 0.60. \]
La probabilità di insoddisfazione (1 o 2) è invece: \[ P(X \leq 2) = p_X(1) + p_X(2) = 0.05 + 0.10 = 0.15. \]
Questa convergenza tra frequenze empiriche e probabilità teoriche non definisce le probabilità, ma ne verifica la coerenza: un sistema di credenze coerente produce il comportamento empirico atteso quando viene sottoposto a prove ripetute.
7.3 La funzione di densità di probabilità
Nel caso delle variabili casuali continue, questo approccio non è più possibile. Non è possibile assegnare probabilità positive ai singoli valori, in quanto i punti sono infiniti e la somma delle probabilità divergerebbe. La soluzione concettuale consiste nel passare dalla “massa” alla “densità”.
Invece di chiederci quanta probabilità c’è in un punto, ci chiediamo quanta probabilità c’è attorno a un punto per unità di lunghezza.
Definizione 7.3 (Funzione di densità di probabilità) Una funzione
\[
f_X : \mathbb{R} \to [0, +\infty)
\]
è una funzione di densità di probabilità (PDF) per una variabile casuale continua \(X\) se, per ogni intervallo \([a,b] \subseteq \mathbb{R}\),
\[ P(a \leq X \leq b) = \int_a^b f_X(x)\,dx, \] e se soddisfa la condizione di normalizzazione
\[ \int_{-\infty}^{+\infty} f_X(x)\,dx = 1. \]
La densità \(f_X(x)\) misura la concentrazione locale della probabilità in prossimità del punto \(x\). Un valore elevato di \(f_X(x)\) indica che, in un intorno molto piccolo di \(x\), si concentra una probabilità relativamente maggiore rispetto alle regioni con densità inferiore.
È importante notare che la densità non rappresenta una probabilità puntuale: per una variabile continua la probabilità che \(X\) assuma esattamente un singolo valore è sempre zero, \(P(X = x) = 0\). La probabilità è un’area sotto la curva della PDF, non un’altezza.
7.4 Dagli istogrammi alle densità
Un modo particolarmente intuitivo per comprendere la PDF consiste nel considerarla come il limite ideale di un istogramma: all’aumentare delle osservazioni e al ridursi della larghezza delle classi, il profilo dell’istogramma delle frequenze relative tende a una curva liscia che approssima la funzione di densità teorica.
Per illustrare questo concetto, consideriamo la distribuzione del quoziente intellettivo (QI) nella popolazione generale. Il QI è convenzionalmente definito con una media \(\mu = 100\) e una deviazione standard \(\sigma = 15\), e segue approssimativamente una distribuzione normale. Osserviamo come l’istogramma tenda alla PDF teorica all’aumentare della dimensione campionaria:
set.seed(42)
mu <- 100
sigma <- 15
n_piccolo <- 50
n_grande <- 20000
x_piccolo <- rnorm(n_piccolo, mean = mu, sd = sigma)
x_grande <- rnorm(n_grande, mean = mu, sd = sigma)
x_seq <- seq(40, 160, length.out = 200)
y_teorica <- dnorm(x_seq, mean = mu, sd = sigma)
df_teorica <- data.frame(x = x_seq, y = y_teorica)
p1 <- ggplot(data.frame(x = x_piccolo), aes(x = x)) +
geom_histogram(aes(y = after_stat(density)), bins = 15,
color = "white", alpha = 0.7) +
geom_line(data = df_teorica, aes(x = x, y = y),
linewidth = 1) +
labs(title = paste("n =", n_piccolo, "individui"),
x = "QI", y = "Densità")
p2 <- ggplot(data.frame(x = x_grande), aes(x = x)) +
geom_histogram(aes(y = after_stat(density)), bins = 50,
color = "white", alpha = 0.7) +
geom_line(data = df_teorica, aes(x = x, y = y),
linewidth = 1) +
labs(
title = paste("n =", format(n_grande, big.mark = ","), "individui"),
x = "QI", y = "Densità")
gridExtra::grid.arrange(p1, p2, ncol = 2)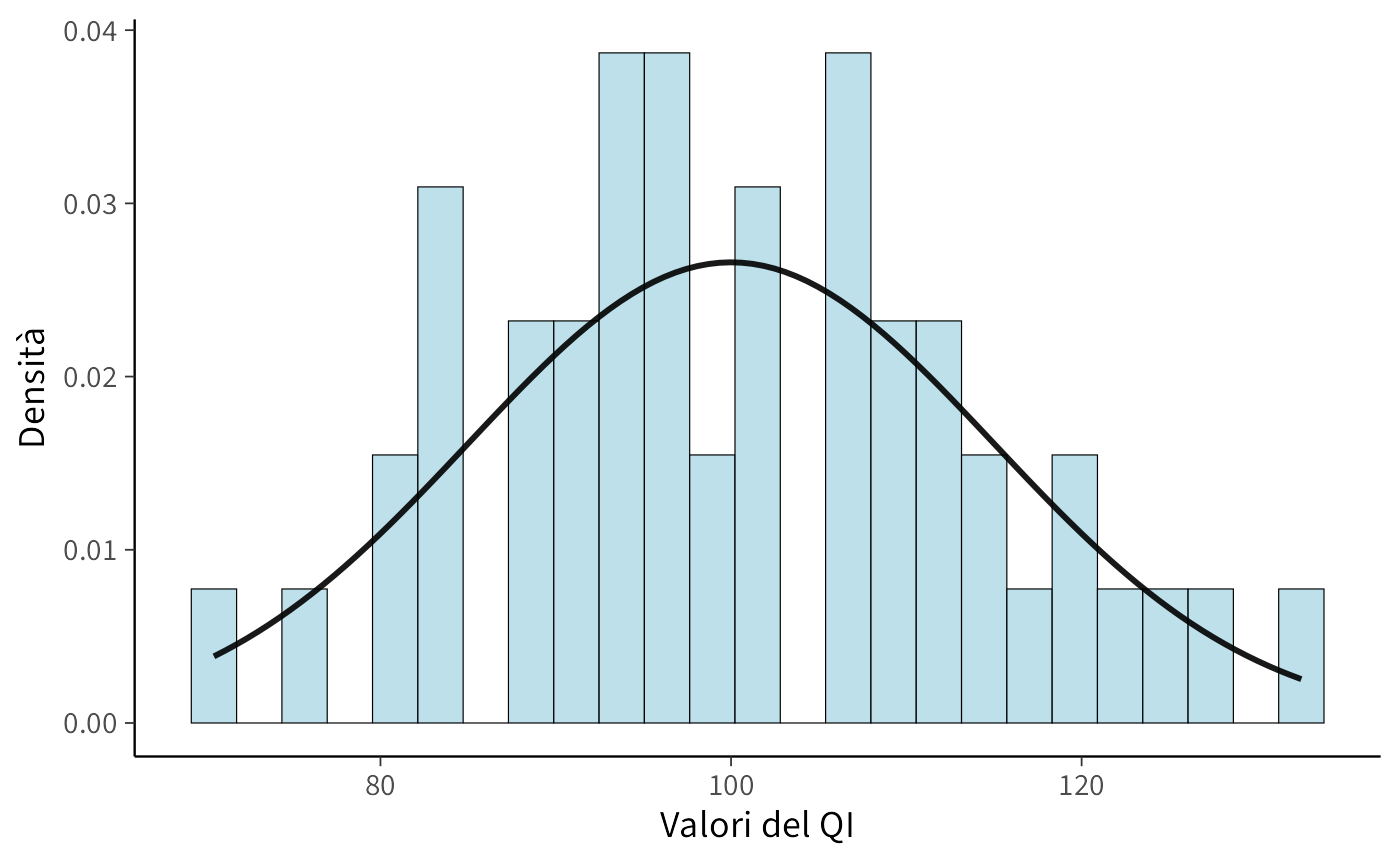
Con soli 50 individui (pannello di sinistra), l’istogramma mostra delle irregolarità dovute alla variabilità campionaria. Con 20.000 individui (pannello di destra), l’istogramma aderisce quasi perfettamente alla curva normale teorica. Questo passaggio dal discreto al continuo mostra visivamente come la PDF emerga come modello ideale della distribuzione dei dati nella popolazione.
La PDF non descrive i dettagli di ogni singola osservazione, ma il pattern probabilistico sottostante che emerge quando si aggrega un gran numero di dati. Essa rappresenta quindi un modello idealizzato della popolazione che, sacrificando il rumore individuale, permette di ottenere un maggiore potere descrittivo, predittivo e inferenziale.
7.4.1 Punto chiave da ricordare
- La PMF assegna probabilità a punti.
- La PDF assegna densità a regioni.
- Solo intervalli hanno probabilità non nulla nel continuo.
- Le densità sono modelli di credenza, non frequenze puntuali.
7.5 Il paradosso della probabilità nulla
Una delle proprietà più controintuitive delle variabili casuali continue è che la probabilità di osservare esattamente un valore specifico è sempre nulla:
\[ P(X = x_0) = 0 \quad \text{per ogni } x_0 \in \mathbb{R}. \]
A prima vista ciò sembra generare un paradosso epistemologico: se ogni valore puntuale ha probabilità zero, com’è possibile osservare empiricamente un valore qualunque? Quando misuriamo un’altezza di 170 cm, non stiamo forse registrando un evento che, secondo la teoria, avrebbe una probabilità nulla?
7.5.1 Fondamento matematico della probabilità puntuale nulla
La chiave interpretativa risiede nel significato geometrico dell’integrazione. Per una variabile continua, la probabilità si ottiene come area sottostante la densità su un intervallo. Un singolo punto corrisponde a un intervallo di ampiezza nulla e, quindi, a un’area nulla:
\[ P(X = x_0) = \int_{x_0}^{x_0} f_X(x) \, dx = 0. \]
Questa non è una lacuna della teoria, bensì una proprietà logica del continuo matematico: qualsiasi area calcolata su un intervallo di lunghezza zero è necessariamente pari a zero.
Se ciò sembra controintuitivo, si consideri la condizione di normalizzazione:
\[ \int_{-\infty}^{+\infty} f_X(x) \, dx = 1. \] Se a ogni punto singolo fosse assegnata una probabilità positiva \(\varepsilon > 0\), l’accumulo su un insieme non numerabile di punti violerebbe la condizione di normalizzazione. Pertanto, l’unico modo per mantenere coerenza tra densità e probabilità totale è assegnare probabilità zero a ogni punto, affidando tutta la massa di probabilità a insiemi con estensione (misura) positiva.
7.5.2 Perché allora osserviamo un valore?
L’apparente paradosso si dissolve ricordando che una misura empirica non fornisce mai un punto matematico “perfetto”, ma un valore con una risoluzione finita. Dire “170 cm” significa, in pratica, “un valore in un piccolo intervallo attorno a 170”, determinato dalla precisione dello strumento e dal processo di arrotondamento. La teoria continua descrive proprio questo: le probabilità su intervalli, non su singoli punti.
7.5.3 La prospettiva degli infinitesimi
Un modo alternativo, più “intuitivo” ma non necessario per la teoria standard, consiste nel richiamare la prospettiva degli infinitesimi della teoria dei numeri iperreali, proposta da Abraham Robinson negli anni ’60. Senza entrare nei dettagli formali, l’idea è che a ogni singolo punto si possa associare una quantità infinitesimale, più piccola di qualsiasi numero reale positivo, ma non esattamente pari a zero (Keisler, 2012).
In questa lettura:
- a un punto \(x_0\) si potrebbe associare una probabilità infinitesimale;
- un intervallo \([a,b]\) ha probabilità finita perché “somma” un numero enorme di contributi infinitesimali;
- il limite di queste somme è precisamente l’integrale.
Questa prospettiva non modifica i risultati della teoria classica, ma può aiutare a conciliare l’intuizione con il fatto che nel continuo la probabilità si manifesta come area e non come massa puntuale.
Un’analogia classica
Il paradosso della probabilità puntuale nulla ricorda il celebre paradosso di Zenone della freccia: in ogni istante la freccia occupa una posizione determinata e quindi, in quell’istante, sembra “immobile” in quell’istante; ma se è immobile in ogni istante, come può muoversi?
La risoluzione moderna riconosce che il movimento non è la somma di posizioni statiche, ma un fenomeno che può essere descritto correttamente nel continuo attraverso limiti e integrazione. Allo stesso modo, la probabilità continua non è la “somma” di probabilità puntuali (tutte nulle), ma l’integrale della densità su intervalli.
In entrambi i casi, il paradosso nasce dall’applicazione di intuizioni discrete a un contesto continuo.
7.5.4 Implicazioni pratiche
Per le variabili continue non ha senso chiedersi: “Qual è la probabilità che il tempo di reazione sia esattamente 250 ms?”. La domanda operativa corretta è: “Qual è la probabilità che il tempo di reazione sia compreso tra 245 e 255 ms?”. Le probabilità si calcolano sempre su intervalli, mai su punti singoli.
Un corollario importante è che, per le variabili continue, includere o escludere gli estremi di un intervallo non modifica la probabilità.
\[ P(a < X < b) = P(a \leq X < b) = P(a < X \leq b) = P(a \leq X \leq b). \] Questo perché i singoli punti \(a\) e \(b\) hanno probabilità zero.
7.5.5 Ponte applicativo: conseguenze per la valutazione psicologica
Questa proprietà matematica ha conseguenze dirette sull’interpretazione dei punteggi nei test psicologici. Consideriamo, ad esempio, la valutazione del QI: non ha senso chiedersi “qual è la probabilità che il QI di questo bambino sia esattamente 115?”. La risposta sarebbe sempre zero, a prescindere dal bambino.
Le domande clinicamente significative riguardano invece gli intervalli:
- “Qual è la probabilità che il QI rientri nell’intervallo 110-120?” (nella media superiore).
- “Qual è la probabilità che il QI sia inferiore a 70?” (soglia per la disabilità intellettiva).
- “Qual è la probabilità che il QI superi 130?” (soglia per alto potenziale).
Questo principio si applica a tutte le misurazioni continue in psicologia: punteggi di ansia, tempi di reazione, livelli di cortisolo e indici di benessere. La teoria delle variabili continue ci insegna a formulare le domande nel modo corretto, sempre in termini di intervalli e mai di valori puntuali.
7.6 La funzione di distribuzione cumulativa
La funzione di distribuzione cumulativa (CDF) fornisce una rappresentazione unificata delle distribuzioni di probabilità, valida sia per le variabili discrete che per quelle continue.
Definizione 7.1 (Funzione di distribuzione cumulativa) La funzione di distribuzione cumulativa di una variabile casuale \(X\) è definita come
\[ F_X(x) = P(X \leq x). \]
Questa definizione è universale: la CDF “accumula” probabilità da \(-\infty\) fino al valore \(x\), e quantifica la credenza che la variabile non superi la soglia \(x\).
7.6.1 Proprietà fondamentali della CDF
Ogni CDF soddisfa tre proprietà strutturali.
Teorema 7.1 (Proprietà della CDF) Per qualsiasi variabile casuale \(X\), la CDF \(F_X\) soddisfa:
- Monotonia non decrescente: se \(a < b\), allora \(F_X(a) \leq F_X(b)\).
- Limiti agli estremi: \(\lim_{x \to -\infty} F_X(x) = 0\) e \(\lim_{x \to +\infty} F_X(x) = 1\).
- Continuità a destra: \(\lim_{h \to 0^+} F_X(x+h) = F_X(x)\) per ogni \(x\).
La monotonia riflette l’ovvio: ampliando l’intervallo \((-\infty,x]\) non si può perdere probabilità. I limiti garantiscono la normalizzazione globale. La continuità a destra è una convenzione tecnica necessaria soprattutto per le variabili discrete, in cui la CDF presenta salti.
7.6.2 CDF per variabili discrete e continue
Per variabili discrete, la CDF è una funzione a gradini: è costante tra due valori possibili e cresce a salti. L’altezza del salto nel punto \(x_i\) è esattamente \(p_X(x_i)\).
Per le variabili continue, invece, la CDF è continua e spesso derivabile. In questo caso, la densità si ottiene come derivata: \[ f_X(x) = \frac{d}{dx} F_X(x), \] e reciprocamente la CDF si ottiene integrando la densità: \[ F_X(x) = \int_{-\infty}^{x} f_X(t)\,dt. \]
# CDF discreta (soddisfazione lavorativa 1-5)
valori_disc <- 1:5
prob_disc <- c(0.05, 0.10, 0.25, 0.40, 0.20)
cdf_disc <- cumsum(prob_disc)
df_disc <- data.frame(
x_start = c(0, valori_disc),
x_end = c(valori_disc, 6),
y = c(0, cdf_disc)
)
p1 <- ggplot() +
geom_segment(data = df_disc, aes(x = x_start, xend = x_end, y = y, yend = y),
linewidth = 1) +
geom_point(data = data.frame(x = valori_disc, y = cdf_disc),
aes(x = x, y = y), size = 3) +
geom_point(data = data.frame(x = valori_disc, y = c(0, cdf_disc[-5])),
aes(x = x, y = y), size = 3, shape = 1) +
scale_x_continuous(breaks = 0:6, limits = c(0, 6)) +
scale_y_continuous(breaks = seq(0, 1, 0.2)) +
scale_fill_qualitative() +
labs(title = "CDF discreta (soddisfazione lavorativa)",
x = "Livello di soddisfazione", y = expression(F[X](x)))
# CDF continua (QI, normale con mu=100, sigma=15)
x_cont <- seq(40, 160, length.out = 200)
cdf_cont <- pnorm(x_cont, mean = 100, sd = 15)
p2 <- ggplot(data.frame(x = x_cont, y = cdf_cont), aes(x = x, y = y)) +
geom_line(linewidth = 1) +
scale_y_continuous(breaks = seq(0, 1, 0.2)) +
scale_fill_qualitative() +
labs(title = "CDF continua (QI)",
x = "QI", y = expression(F[X](x)))
gridExtra::grid.arrange(p1, p2, ncol = 2)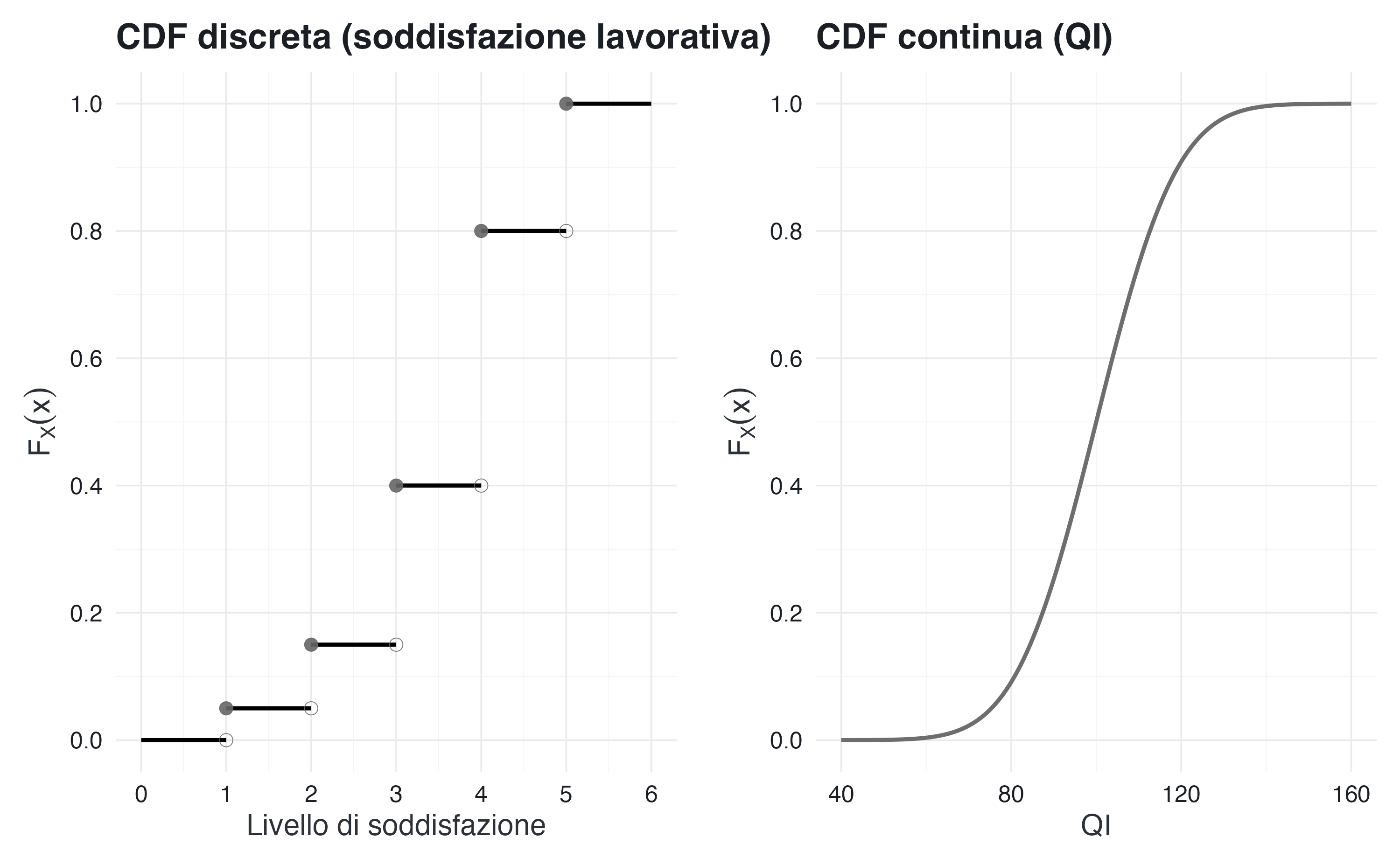
7.6.3 Calcolo di probabilità mediante la CDF
Uno dei principali vantaggi principali della CDF è che permette di calcolare la probabilità di qualsiasi intervallo come differenza di due valori: \[ P(a < X \leq b) = F_X(b) - F_X(a). \] Questa relazione è valida sia per le variabili discrete che per quelle continue ed è uno strumento computazionale fondamentale in statistica.
Probabilità per la distribuzione del QI
Consideriamo il quoziente intellettivo (QI) come variabile normale con media \(\mu = 100\) e deviazione standard \(\sigma = 15\). Calcoliamo alcune probabilità di interesse clinico.
mu <- 100
sigma <- 15
# P(QI > 130) - QI molto elevato (gifted)
p_alto <- 1 - pnorm(130, mean = mu, sd = sigma)
cat("P(QI > 130) =", round(p_alto, 4), "\n")
#> P(QI > 130) = 0.0228
# P(85 < QI < 115) - QI nella norma (±1 SD)
p_norma <- pnorm(115, mean = mu, sd = sigma) - pnorm(85, mean = mu, sd = sigma)
cat("P(85 < QI < 115) =", round(p_norma, 4), "\n")
#> P(85 < QI < 115) = 0.683
# P(QI < 70) - disabilità intellettiva
p_basso <- pnorm(70, mean = mu, sd = sigma)
cat("P(QI < 70) =", round(p_basso, 4), "\n")
#> P(QI < 70) = 0.0228
# Percentile 95
q95 <- qnorm(0.95, mean = mu, sd = sigma)
cat("95° percentile:", round(q95, 1), "\n")
#> 95° percentile: 125Questi calcoli mostrano come la CDF (implementata in R da pnorm) consenta di tradurre le domande cliniche in operazioni matematiche dirette:
- solo circa il 2.3% della popolazione ha un QI superiore a 130 (comunemente utilizzato per definire un “alto potenziale cognitivo”);
- circa il 68% della popolazione ha un QI compreso tra 85 e 115 (all’interno di una deviazione standard dalla media);
- circa il 2.3% ha un QI inferiore a 70 (soglia tradizionale per la disabilità intellettiva);
- il 95° percentile corrisponde a un QI di circa 125.
7.7 Interpretazioni bayesiana e frequentista
Le distribuzioni di probabilità assumono significati diversi nei due principali paradigmi dell’inferenza statistica. Questa distinzione non è soltanto filosofica, ma ha un impatto diretto sul modo in cui interpretiamo i risultati, formuliamo i modelli e comunichiamo l’incertezza.
7.7.1 L’interpretazione frequentista
Eccola rivista per migliorare la struttura logica, la precisione terminologica e il flusso del discorso.
Nel paradigma frequentista, la probabilità è definita come frequenza relativa limite in una lunga serie ideale di ripetizioni indipendenti dello stesso esperimento, eseguite in condizioni identiche. Per un evento del tipo \(a \leq X \leq b\), questa interpretazione implica:
\[ P(a \leq X \leq b) = \lim_{n \to \infty} \frac{\#\{X_i \in [a,b]\}}{n}, \] dove \(X_1, X_2, \ldots, X_n\) sono realizzazioni indipendenti dello stesso processo stocastico.
In questa prospettiva, la funzione di densità (PDF) non è una misura di credenza soggettiva, ma una descrizione del meccanismo generativo dei dati: essa rappresenta la forma limite alla quale converge l’istogramma delle osservazioni man mano che il campione si espande e gli intervalli di classizzazione diventano arbitrariamente fini. La variabile casuale \(X\) modella l’esito di un esperimento ripetibile, e la sua PDF descrive la variabilità osservabile tra le diverse ripetizioni.
Un esempio classico è la distribuzione dell’altezza nella popolazione adulta. Un modello normale con media \(\mu = 170\) cm e deviazione standard \(\sigma = 10\) cm descrive quale proporzione di individui ci aspetteremmo di osservare in ogni intervallo di altezza, se potessimo campionare ripetutamente e a caso da una popolazione di riferimento molto ampia e stabile.
7.7.2 L’interpretazione bayesiana
Nel paradigma bayesiano, la probabilità quantifica un grado di credenza razionale, ovvero una misura della plausibilità assegnata a diverse possibilità alla luce delle informazioni disponibili. Non è necessario immaginare delle ripetizioni ipotetiche: la probabilità è una proprietà dello stato informativo dell’osservatore.
Definizione 7.2 (Interpretazione bayesiana della PDF) Dal punto di vista bayesiano, la funzione di densità \(f_X(x)\) rappresenta la distribuzione della nostra incertezza sul valore di una quantità \(X\), che è considerata fissa ma ignota. L’integrale \(\int_a^b f_X(x)\,dx\) non misura una frequenza, ma il grado di credenza che il valore effettivo di \(X\) appartenga all’intervallo \([a,b]\).
Ne deriva un’implicazione cruciale: il paradigma bayesiano permette di descrivere con distribuzioni di probabilità non solo i dati osservabili, ma anche quelle quantità che nel frequentismo sono considerate parametri fissi, come l’effetto medio di un trattamento, la prevalenza di una malattia o la probabilità soggettiva di risposta alla terapia.
In questa logica, una funzione di densità bayesiana rappresenta una mappa di plausibilità: le regioni con densità più alta corrispondono a valori che riteniamo più credibili, mentre quelle con densità bassa riflettono ipotesi meno plausibili. La forma stessa della distribuzione, la sua simmetria o asimmetria, l’estensione delle code e il grado di concentrazione esprimono esplicitamente ciò che sappiamo e, soprattutto, ciò che ignoriamo sulla quantità di interesse.
7.7.3 Confronto tra le due prospettive
Le differenze metodologiche emergono in modo netto in un esempio elementare. Supponiamo di voler stimare l’altezza media di una popolazione, denotata con \(\theta\).
Nel paradigma frequentista, \(\theta\) è un parametro fisso ma sconosciuto. La probabilità si applica alle statistiche calcolate dai campioni, come la media campionaria \(\bar{X}\). La PDF di \(\bar{X}\) descrive come quest’ultima varierebbe se ripetessimo infinite volte il campionamento dalla stessa popolazione. Di conseguenza, un intervallo di confidenza al 95% non afferma che il valore di \(\theta\) abbia una probabilità dello 0.95 di cadere in quell’intervallo (dal momento che \(\theta\) non è una variabile casuale), ma piuttosto che il metodo utilizzato per costruire l’intervallo lo conterrebbe nel 95% delle ripetizioni sperimentali.
Nel paradigma bayesiano, invece, è possibile assegnare direttamente una distribuzione di probabilità a \(\theta\), quantificando la nostra incertezza su di esso. La distribuzione a priori formalizza le conoscenze iniziali, mentre quella a posteriori aggiorna tali conoscenze con le informazioni provenienti dai dati. Pertanto, un intervallo di credibilità al 95% dichiara esattamente ciò che suggerisce: alla luce dei dati osservati e della prior, la probabilità soggettiva che il valore di \(\theta\) si trovi in quell’intervallo è 0.95.
set.seed(123)
# Frequentista: distribuzione dei dati
x_freq <- rnorm(1000, mean = 170, sd = 10)
x_seq <- seq(140, 200, length.out = 200)
y_teorica <- dnorm(x_seq, mean = 170, sd = 10)
p1 <- ggplot() +
geom_histogram(data = data.frame(x = x_freq), aes(x = x, y = after_stat(density)),
bins = 30, alpha = 0.5, color = "white") +
geom_line(data = data.frame(x = x_seq, y = y_teorica),
aes(x = x, y = y), linewidth = 1.2) +
scale_fill_qualitative() +
labs(title = "Frequentista:\ndistribuzione dei dati",
subtitle = "PDF come istogramma limite di ripetizioni",
x = "Altezza (cm)", y = "Densità")
# Bayesiano: distribuzione della credenza su un parametro
theta_seq <- seq(165, 175, length.out = 200)
prior <- dnorm(theta_seq, mean = 170, sd = 2)
p2 <- ggplot() +
geom_ribbon(data = data.frame(x = theta_seq, y = prior),
aes(x = x, ymin = 0, ymax = y),
alpha = 0.3) +
geom_line(data = data.frame(x = theta_seq, y = prior),
aes(x = x, y = y), linewidth = 1.2) +
geom_point(aes(x = 170, y = 0), size = 3, color = "black") +
annotate("text", x = 170, y = -0.02, label = "θ (valore vero ignoto)", size = 3) +
scale_fill_qualitative() +
labs(title = "Bayesiano:\ndistribuzione della credenza",
subtitle = "PDF come mappa di plausibilità sul parametro",
x = expression(theta ~ "(altezza media)"), y = "Densità")
gridExtra::grid.arrange(p1, p2, ncol = 2)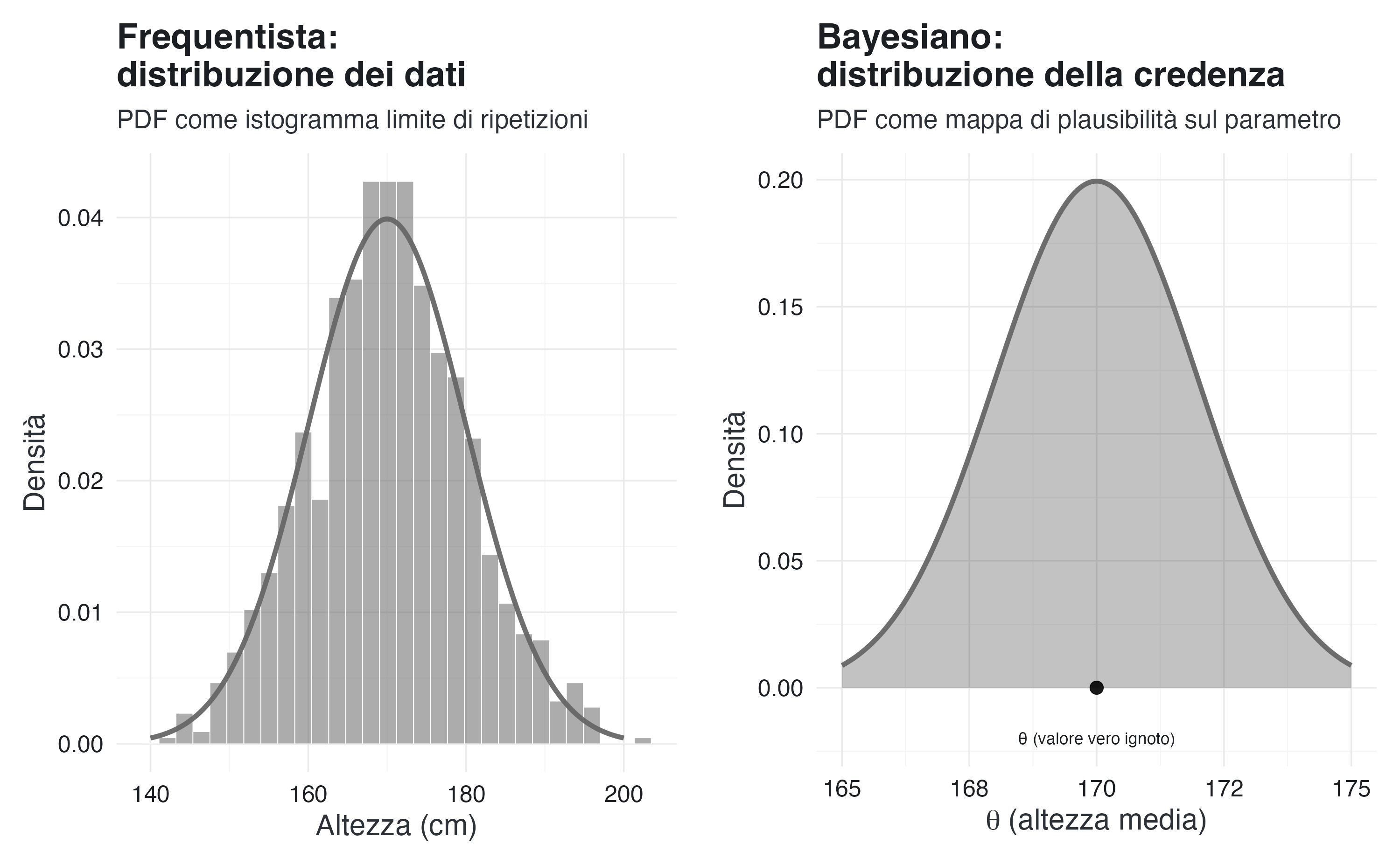
La CDF rimane in entrambi i paradigmi lo strumento fondamentale per calcolare le probabilità degli intervalli. A cambiare è il significato che attribuiamo a queste probabilità: nel paradigma frequentista essa rappresenta una frequenza limite di un evento su ripetizioni ideali dell’esperimento; nel paradigma bayesiana, essa esprime il grado di credenza soggettiva che una proposizione sia vera, sulla base delle informazioni disponibili.
Riflessioni conclusive
La distinzione tra massa e densità di probabilità evidenzia una differenza strutturale fondamentale tra variabili casuali discrete e continue. Per le variabili casuali discrete, la probabilità è concentrata in punti isolati, mentre per quelle continue è distribuita in modo continuo e misurabile solo integrando su intervalli di valori.
Il cosiddetto “paradosso” della probabilità nulla per punti esatti nelle distribuzioni continue si dissolve quando si riconosce che, in questo ambito, la probabilità è intrinsecamente una proprietà degli intervalli, non dei punti. Ogni singolo valore contribuisce con probabilità nulla, ma l’integrazione su un continuum di valori produce quantità probabilisticamente significative. Per lo psicologo, ciò si traduce in una prassi operativa: formulare domande come “Qual è la probabilità che il punteggio cada in questo intervallo?”, anziché chiedersi “Qual è la probabilità di ottenere esattamente questo punteggio?”.
In questo contesto, la funzione di distribuzione cumulativa (CDF) si rivela uno strumento unificante. Essa offre una rappresentazione coerente delle distribuzioni sia per variabili discrete che continue, consente il calcolo diretto delle probabilità su intervalli arbitrari e chiarisce sistematicamente il legame tra la funzione di massa, la funzione di densità e le probabilità osservabili.
Infine, la differenza tra l’interpretazione frequentista e bayesiana delle distribuzioni non è un dibattito puramente filosofico, ma implica scelte metodologiche concrete nella costruzione e nell’interpretazione dei modelli statistici. Poiché l’obiettivo di questo corso è l’inferenza in condizioni di incertezza, ci concentreremo sul paradigma bayesiano, il cui formalismo è appositamente concepito per rappresentare, e aggiornare in modo logicamente coerente, lo stato delle nostre conoscenze alla luce dell’evidenza empirica.
Punti chiave da ricordare
Concetti essenziali di questo capitolo:
-
Massa vs densità: due modi profondamente diversi di distribuire probabilità
- Massa (PMF): probabilità concentrata in punti discreti, come “pesi” su una bilancia.
- Densità (PDF): probabilità distribuita su un continuum, come massa in un fluido.
- La distinzione non è solo tecnica ma riflette strutture matematiche diverse (somme vs integrali).
-
La PMF assegna probabilità dirette a valori specifici
- \(p_X(x) = P(X = x)\) è la probabilità del punto \(x\).
- Diagramma a barre: l’altezza rappresenta direttamente la probabilità.
- Somma delle probabilità: \(\sum_x p_X(x) = 1\).
-
La PDF misura concentrazione locale, non probabilità diretta
- \(f_X(x)\) indica “quanta probabilità c’è per unità di lunghezza” attorno a \(x\).
- \(f_X(x)\) può essere maggiore di 1 (non è una probabilità!).
- Probabilità tramite integrazione: \(P(a \leq X \leq b) = \int_a^b f_X(x) \, dx\).
-
Il “paradosso” P(X = x) = 0 per variabili continue
- Non è un paradosso: un singolo punto ha “misura zero” nel continuo.
- Come la “massa di un punto” in un filo: zero, ma il punto esiste.
- Differenza cruciale: probabilità zero ≠ impossibilità logica.
- Solo intervalli (anche infinitesimi) hanno probabilità positiva.
-
Dagli istogrammi alle densità: il limite continuo
- All’aumentare di \(n\) e al diminuire della larghezza dei bin, gli istogrammi convergono alla PDF.
- La PDF è il limite ideale quando bin → 0 e \(n\) → ∞.
- Illustra visivamente come la densità emerga naturalmente dai dati.
-
CDF come rappresentazione unificata
- \(F_X(x) = P(X \leq x)\) vale sia per discrete che per continue.
- Discrete: funzione a gradini con salti in corrispondenza dei valori possibili.
- Continue: funzione liscia e crescente.
- Proprietà universali: monotona non decrescente, \(F(-\infty) = 0\), \(F(+\infty) = 1\).
-
Interpretazioni bayesiana vs frequentista delle distribuzioni
- Frequentista: la PDF descrive il comportamento dei dati in ripetizioni ipotetiche.
- Bayesiano: la PDF rappresenta il grado di credenza sui possibili valori (anche parametri!).
- Stessa forma matematica, interpretazione epistemica profondamente diversa.
- Per il bayesiano, distribuzioni di parametri sono naturali; per il frequentista no.
Formule da ricordare:
PMF (discrete): \[ p_X(x) = P(X = x), \quad \sum_{x} p_X(x) = 1 \]
PDF (continue): \[ P(a \leq X \leq b) = \int_a^b f_X(x) \, dx, \quad \int_{-\infty}^{+\infty} f_X(x) \, dx = 1 \]
CDF (universale): \[ F_X(x) = P(X \leq x) = \begin{cases} \sum_{x_i \leq x} p_X(x_i) & \text{(discreta)} \\ \int_{-\infty}^x f_X(t) \, dt & \text{(continua)} \end{cases} \]
Relazione PDF-CDF per variabili continue: \[ f_X(x) = \frac{d}{dx} F_X(x) \quad \text{(la densità è la derivata della CDF)} \]
Calcolo di probabilità da CDF: \[ P(a \leq X \leq b) = F_X(b) - F_X(a) \]
Proprietà chiave:
- Discrete: \(P(X = x) = p_X(x) > 0\) è possibile.
- Continue: \(P(X = x) = 0\) sempre (ma \(f_X(x)\) può essere > 0).
- PDF può essere > 1: non è una probabilità ma una densità!
- CDF sempre ∈ [0,1]: rappresenta una probabilità cumulativa.
Per il prossimo capitolo:
Nel Capitolo 8 le proprietà delle variabili casuali: valore atteso (centro di gravità probabilistico), varianza (dispersione), e le loro proprietà algebriche. Questi strumenti di sintesi ci permetteranno di caratterizzare distribuzioni complesse con pochi numeri e di propagare l’incertezza attraverso trasformazioni matematiche, preparando il terreno per l’inferenza bayesiana parametrica.
Esercizi concettuali
Spiega perché il termine “massa” è appropriato per le distribuzioni discrete e “densità” per quelle continue. Quale proprietà fisica richiamano queste metafore?
Un collega afferma: “Se \(P(X = 170) = 0\), allora è impossibile osservare \(X = 170\).” Correggi questo fraintendimento e spiega la distinzione tra “probabilità zero” e “impossibilità”.
Nel paradigma bayesiano, ha senso assegnare una distribuzione di probabilità a una costante fisica come la velocità della luce? Perché sì o perché no?
Esercizi sulla PMF
-
Un test psicometrico produce punteggi interi da 1 a 5 secondo la distribuzione:
Punteggio 1 2 3 4 5 \(p_X(x)\) 0.10 0.20 0.35 0.25 0.10 - Calcola \(P(X \geq 3)\).
- Calcola \(P(2 \leq X \leq 4)\).
- Calcola il valore atteso \(\mathbb{E}[X]\).
- Costruisci la CDF e rappresentala graficamente.
-
Nella scala LSNS-6 (Lubben Social Network Scale), il numero di amici intimi segue approssimativamente questa distribuzione:
Amici 0 1 2 3 4 5+ \(p_X(x)\) 0.05 0.15 0.25 0.30 0.15 0.10 - Qual è la probabilità di avere almeno 3 amici intimi?
- Qual è la probabilità di avere meno di 2 amici intimi?
- Calcola valore atteso e varianza.
Esercizi sulla PDF e CDF
-
Il punteggio alla Satisfaction with Life Scale (SWLS) può essere approssimato da una distribuzione normale con \(\mu = 20\) e \(\sigma = 5\).
- Qual è la probabilità di un punteggio superiore a 25?
- Qual è la probabilità di un punteggio tra 15 e 25?
- Quale punteggio delimita il 10% superiore della distribuzione?
- Verifica i calcoli con le funzioni R
pnormeqnorm.
-
Il tempo di reazione in un compito cognitivo segue una distribuzione normale con \(\mu = 350\) ms e \(\sigma = 50\) ms.
- Qual è la probabilità che un tempo di reazione sia inferiore a 300 ms?
- Entro quale intervallo simmetrico attorno alla media cade il 95% dei tempi?
- Un tempo di 450 ms è “anomalo”? Calcola la probabilità di osservare un tempo così estremo o più.
Esercizi sulle interpretazioni
Legge della probabilità totale: Il 60% degli studenti ha un forte supporto sociale, il 40% ha un supporto limitato. La probabilità di SWLS > 20 è 0.75 per chi ha forte supporto e 0.50 per chi ha supporto limitato. Calcola \(P(\text{SWLS} > 20)\) per uno studente scelto a caso.
Teorema di Bayes: Usando i dati dell’esercizio 8, calcola la probabilità che uno studente abbia forte supporto sociale dato che il suo punteggio SWLS è superiore a 20.
Un frequentista e un bayesiano osservano lo stesso dataset e calcolano la stessa PDF normale come modello per i dati. In che senso le loro interpretazioni differiscono, pur concordando sulla forma matematica?
Esercizi computazionali
Scrivi una funzione R che, data una PMF (vettori di valori e probabilità), generi un grafico con la PMF (diagramma a barre) e la CDF (funzione a gradini) affiancati.
-
Simula 10,000 osservazioni da una distribuzione normale con \(\mu = 100\) e \(\sigma = 15\). Confronta:
- Media e varianza empiriche con quelle teoriche.
- Proporzione di valori in \([\mu - \sigma, \mu + \sigma]\) con la proporzione teorica (≈ 68.3%).
- Proporzione di valori in \([\mu - 2\sigma, \mu + 2\sigma]\) con la proporzione teorica (≈ 95.4%).
Soluzioni esercizi concettuali
“Massa” evoca l’idea di pesi discreti concentrati in punti specifici, come pesi su una bilancia. “Densità” richiama la distribuzione continua di materia nello spazio: non chiediamo “quanta massa c’è in questo punto” (sarebbe zero), ma “quanta massa c’è per unità di volume attorno a questo punto”. Analogamente, la PDF misura la “concentrazione” della probabilità per unità di lunghezza.
“Probabilità zero” significa che l’evento ha misura nulla nell’insieme delle possibilità, non che sia logicamente escluso. È come chiedere la massa di un singolo punto in un filo: la risposta è zero, ma il punto esiste. L’impossibilità logica (come ottenere 7 con un dado) è diversa dalla probabilità zero (come \(X = 170\) esatto in una distribuzione continua).
Dal punto di vista bayesiano, sì: la distribuzione rappresenta la nostra incertezza sul valore, non una variabilità intrinseca. Prima delle misurazioni di Michelson-Morley, un bayesiano avrebbe assegnato una distribuzione che rifletteva l’ignoranza sul valore esatto. Oggi, con misure estremamente precise, la distribuzione sarebbe concentratissima attorno al valore noto, ma tecnicamente ancora una distribuzione.
Soluzioni esercizi PMF
\(P(X \geq 3) = 0.35 + 0.25 + 0.10 = 0.70\)
\(P(2 \leq X \leq 4) = 0.20 + 0.35 + 0.25 = 0.80\)
\(\mathbb{E}[X] = 1(0.10) + 2(0.20) + 3(0.35) + 4(0.25) + 5(0.10) = 3.05\)
CDF: \(F(1) = 0.10\), \(F(2) = 0.30\), \(F(3) = 0.65\), \(F(4) = 0.90\), \(F(5) = 1.00\)
\(P(X \geq 3) = 0.30 + 0.15 + 0.10 = 0.55\)
\(P(X < 2) = 0.05 + 0.15 = 0.20\)
-
\(\mathbb{E}[X] = 0(0.05) + 1(0.15) + 2(0.25) + 3(0.30) + 4(0.15) + 5(0.10) = 2.65\)
\(\mathbb{E}[X^2] = 0 + 0.15 + 1.00 + 2.70 + 2.40 + 2.50 = 8.75\)
\(\text{Var}(X) = 8.75 - 2.65^2 = 1.7275\)
Soluzioni esercizi PDF e CDF
-
\(P(X > 25) = 1 - \Phi\left(\frac{25-20}{5}\right) = 1 - \Phi(1) = 1 - 0.8413 = 0.1587\)
\(P(15 < X < 25) = \Phi(1) - \Phi(-1) = 0.8413 - 0.1587 = 0.6826\)
\(z_{0.90} = 1.28\), quindi \(x = 20 + 1.28 \times 5 = 26.4\)
Verifica R:
\(P(X < 300) = \Phi\left(\frac{300-350}{50}\right) = \Phi(-1) = 0.1587\)
Intervallo al 95%: \(350 \pm 1.96 \times 50 = [252, 448]\) ms
\(P(X > 450) = 1 - \Phi(2) = 0.0228\). Bilaterale: \(P(|X - 350| > 100) = 2 \times 0.0228 = 0.0456\). È inusuale (circa 5% di probabilità).
Soluzioni esercizi interpretazioni
Per la legge della probabilità totale: \[P(\text{SWLS} > 20) = 0.75 \times 0.60 + 0.50 \times 0.40 = 0.45 + 0.20 = 0.65\]
Per il teorema di Bayes: \[P(\text{Forte} \mid \text{SWLS} > 20) = \frac{0.75 \times 0.60}{0.65} = \frac{0.45}{0.65} = 0.692\]
Entrambi descrivono la stessa PDF, ma il frequentista la interpreta come la distribuzione dei dati in ripetizioni ipotetiche dell’esperimento, mentre il bayesiano la vede come una distribuzione predittiva che incorpora le sue credenze sui parametri. Se la PDF è usata per descrivere l’incertezza su un parametro, il frequentista rifiuterebbe questa interpretazione (i parametri sono fissi, non casuali), mentre il bayesiano la considererebbe naturale.
Soluzioni esercizi computazionali
plot_pmf_cdf <- function(valori, prob) { df <- data.frame(x = valori, pmf = prob, cdf = cumsum(prob)) p1 <- ggplot(df, aes(x = factor(x), y = pmf)) + geom_col(fill = "steelblue") + labs(x = "x", y = "P(X = x)", title = "PMF") # CDF a gradini df_cdf <- data.frame( x_start = c(min(valori) - 1, valori), x_end = c(valori, max(valori) + 1), y = c(0, cumsum(prob)) ) p2 <- ggplot() + geom_segment(data = df_cdf, aes(x = x_start, xend = x_end, y = y, yend = y)) + labs(x = "x", y = "F(x)", title = "CDF") gridExtra::grid.arrange(p1, p2, ncol = 2) }set.seed(42) x <- rnorm(10000, mean = 100, sd = 15) # a) Media e varianza cat("Media empirica:", mean(x), "(teorica: 100)\n") cat("Varianza empirica:", var(x), "(teorica: 225)\n") # b) ±1 SD prop_1sd <- mean(x >= 85 & x <= 115) cat("Proporzione in [μ-σ, μ+σ]:", prop_1sd, "(teorica: 0.683)\n") # c) ±2 SD prop_2sd <- mean(x >= 70 & x <= 130) cat("Proporzione in [μ-2σ, μ+2σ]:", prop_2sd, "(teorica: 0.954)\n")
sessionInfo()
#> R version 4.5.2 (2025-10-31)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Tahoe 26.2
#>
#> Matrix products: default
#> BLAS: /System/Library/Frameworks/Accelerate.framework/Versions/A/Frameworks/vecLib.framework/Versions/A/libBLAS.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
#>
#> locale:
#> [1] C.UTF-8/UTF-8/C.UTF-8/C/C.UTF-8/C.UTF-8
#>
#> time zone: Europe/Rome
#> tzcode source: internal
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] ragg_1.5.0 tinytable_0.15.2 withr_3.0.2
#> [4] systemfonts_1.3.1 patchwork_1.3.2 ggdist_3.3.3
#> [7] tidybayes_3.0.7 bayesplot_1.15.0 ggplot2_4.0.1
#> [10] reliabilitydiag_0.2.1 priorsense_1.2.0 posterior_1.6.1
#> [13] loo_2.9.0 rstan_2.32.7 StanHeaders_2.32.10
#> [16] brms_2.23.0 Rcpp_1.1.1 sessioninfo_1.2.3
#> [19] conflicted_1.2.0 janitor_2.2.1 matrixStats_1.5.0
#> [22] modelr_0.1.11 tibble_3.3.1 dplyr_1.1.4
#> [25] tidyr_1.3.2 rio_1.2.4 here_1.0.2
#>
#> loaded via a namespace (and not attached):
#> [1] svUnit_1.0.8 tidyselect_1.2.1 farver_2.1.2
#> [4] S7_0.2.1 fastmap_1.2.0 TH.data_1.1-5
#> [7] tensorA_0.36.2.1 digest_0.6.39 timechange_0.3.0
#> [10] estimability_1.5.1 lifecycle_1.0.5 survival_3.8-3
#> [13] magrittr_2.0.4 compiler_4.5.2 rlang_1.1.7
#> [16] tools_4.5.2 yaml_2.3.12 knitr_1.51
#> [19] labeling_0.4.3 bridgesampling_1.2-1 htmlwidgets_1.6.4
#> [22] curl_7.0.0 pkgbuild_1.4.8 RColorBrewer_1.1-3
#> [25] abind_1.4-8 multcomp_1.4-29 purrr_1.2.1
#> [28] grid_4.5.2 stats4_4.5.2 colorspace_2.1-2
#> [31] xtable_1.8-4 inline_0.3.21 emmeans_2.0.1
#> [34] scales_1.4.0 MASS_7.3-65 cli_3.6.5
#> [37] mvtnorm_1.3-3 rmarkdown_2.30 generics_0.1.4
#> [40] otel_0.2.0 RcppParallel_5.1.11-1 cachem_1.1.0
#> [43] stringr_1.6.0 splines_4.5.2 parallel_4.5.2
#> [46] vctrs_0.6.5 V8_8.0.1 Matrix_1.7-4
#> [49] sandwich_3.1-1 jsonlite_2.0.0 arrayhelpers_1.1-0
#> [52] glue_1.8.0 codetools_0.2-20 distributional_0.6.0
#> [55] lubridate_1.9.4 stringi_1.8.7 gtable_0.3.6
#> [58] QuickJSR_1.8.1 pillar_1.11.1 htmltools_0.5.9
#> [61] Brobdingnag_1.2-9 R6_2.6.1 textshaping_1.0.4
#> [64] rprojroot_2.1.1 evaluate_1.0.5 lattice_0.22-7
#> [67] backports_1.5.0 memoise_2.0.1 broom_1.0.11
#> [70] snakecase_0.11.1 rstantools_2.6.0 gridExtra_2.3
#> [73] coda_0.19-4.1 nlme_3.1-168 checkmate_2.3.3
#> [76] xfun_0.55 zoo_1.8-15 pkgconfig_2.0.3