5 Il teorema di Bayes
Introduzione
Il teorema di Bayes rappresenta il punto di arrivo naturale del percorso concettuale sviluppato nei capitoli precedenti. Dopo aver interpretato la probabilità come grado di credenza razionale (Capitolo 1), chiarito il ruolo degli assiomi come vincoli di coerenza (Capitolo 2), riconosciuto l’equiprobabilità come caso particolare di simmetria epistemica (Capitolo 3) e identificato la probabilità condizionata come meccanismo generale di aggiornamento delle credenze (Capitolo 4), il teorema di Bayes emerge come la formalizzazione matematica dell’apprendimento dall’esperienza.
Prima di introdurne la formula, è tuttavia essenziale comprendere il problema concettuale che essa è chiamata a risolvere.
Il problema fondamentale della conoscenza
Immaginiamo di essere uno psicologo clinico. Un paziente si presenta con sintomi che potrebbero indicare depressione, ma che potrebbero anche essere spiegati da altre condizioni: stress lavorativo, disturbi del sonno o una fase di vita particolarmente difficile. Si decide di somministrare un test di screening e il risultato è positivo.
Che cosa sappiamo ora che non sapevamo prima?
La risposta intuitiva potrebbe essere: “Ora so che il paziente è probabilmente depresso.”
Ma questa conclusione è prematura. Il test, infatti, non fornisce direttamente questa informazione. Ci dice invece qualcosa di diverso: quanto è probabile osservare un risultato positivo se il paziente fosse depresso. Se la sensibilità del test è, ad esempio, dell’85%, ciò significa che l’85% delle persone depresse ottiene un risultato positivo.
Tuttavia, la domanda che realmente interessa il clinico è un’altra: quanto è probabile che questa persona specifica, che ha appena ottenuto un risultato positivo, sia effettivamente depressa?
Queste due domande, apparentemente simili, sono in realtà profondamente diverse.
L’asimmetria tra predizione e inferenza
L’esempio mette in luce una asimmetria fondamentale del ragionamento scientifico:
la predizione (dalla causa all’effetto): “Se il paziente è depresso, quanto è probabile che il test risulti positivo?”;
l’inferenza (dall’effetto alla causa): “Dato che il test è positivo, quanto è probabile che il paziente sia depresso?”.
I modelli scientifici sono quasi sempre costruiti nella direzione predittiva. Conosciamo il funzionamento dei test diagnostici: la loro sensibilità (capacità di individuare i casi positivi) e la loro specificità (capacità di escludere i casi negativi). Tuttavia, l’informazione che riceviamo dal mondo empirico procede nella direzione opposta: osserviamo esiti, non stati latenti.
Il teorema di Bayes è precisamente lo strumento che consente di collegare queste due direzioni. Esso permette di trasformare una conoscenza predittiva, ovvero quanto sarebbe probabile osservare questo risultato se un’ipotesi fosse vera, in una conoscenza inferenziale, ovvero quanto è probabile che l’ipotesi sia vera, dato il risultato osservato.
Perché questo è il cuore della scienza
Questa “inversione” non è un dettaglio tecnico. È l’essenza stessa del metodo scientifico.
Ogni esperimento produce dati. Ma i dati, da soli, non “parlano”. Non ci dicono direttamente quali ipotesi siano vere. Ci dicono soltanto quanto sarebbero attesi sotto diverse ipotesi. Il passaggio dai dati alle ipotesi, cioè l’inferenza, richiede un’operazione logica che il teorema di Bayes formalizza in modo preciso e coerente.
Nella ricerca psicologica questo problema si presenta continuamente:
- un questionario di personalità produce un certo punteggio: che cosa ci dice sul tratto latente sottostante?
- un esperimento mostra una differenza tra gruppi: quanto è plausibile che esista un effetto reale?
- un paziente risponde in un certo modo a un trattamento: in che misura possiamo generalizzare ad altri pazienti simili?
In ciascun caso, osserviamo dati e vogliamo trarre conclusioni su qualcosa che non osserviamo direttamente, ovvero parametri, ipotesi, stati latenti. Il teorema di Bayes fornisce una risposta a questa esigenza fondamentale: ci dice come integrare in modo razionalmente coerente le nuove informazioni con ciò che già sappiamo.
In questo senso, il teorema di Bayes non è soltanto una formula, ma una regola generale del ragionamento in condizioni di incertezza.
5.0.1 Il percorso del capitolo
In questo capitolo:
Deriveremo il teorema dalla simmetria della probabilità congiunta, mostrando che non è una nuova assunzione ma una conseguenza inevitabile di ciò che abbiamo già stabilito.
Interpreteremo ciascuna componente, ovvero prior, verosimiglianza, evidenza, posterior, dal punto di vista epistemico.
Esploreremo la forma in odds, particolarmente utile per applicazioni diagnostiche e per comprendere come le evidenze si accumulano.
Applicheremo il teorema a scenari clinici e di ricerca, mostrando sia il suo potere sia le insidie del ragionamento probabilistico.
Estenderemo l’aggiornamento bayesiano al caso di parametri continui, introducendo il modello Beta-Binomiale.
Per seguire questo capitolo è necessario aver letto:
- Capitolo 1
- Capitolo 2
- Capitolo 3
- Capitolo 4 — fondamentale
Conoscenze matematiche richieste:
- Appendice D - per operazioni su eventi;
- Appendice C - per legge della probabilità totale.
Letture complementari consigliate:
- Chivers, T. (2024). Everything is Predictable: How Bayesian Statistics Explain Our World (Chivers, 2024), per una prospettiva divulgativa sul ragionamento bayesiano
Panoramica del capitolo
- Derivazione del teorema dalla simmetria della probabilità congiunta.
- Interpretazione epistemica delle componenti: prior, likelihood, posterior.
- Probabilità inversa come problema fondamentale dell’inferenza.
- Forma in odds e rapporti di verosimiglianza per applicazioni cliniche.
- Applicazioni a test diagnostici e valutazione della comorbilità.
- Fallacia del tasso base e sue implicazioni per il ragionamento clinico.
- Aggiornamento bayesiano con distribuzioni Beta.
- Intervalli di credibilità e loro interpretazione epistemica.
5.1 La simmetria fondamentale della probabilità congiunta
Il teorema di Bayes non introduce nuovi principi probabilistici, ma emerge come una conseguenza algebrica inevitabile della definizione di probabilità condizionata. Questa derivazione mostra che l’aggiornamento bayesiano delle credenze non è una scelta arbitraria, bensì una necessità logica per chiunque accetti il quadro assiomatico della teoria della probabilità.
5.1.1 L’uguaglianza che genera tutto
Ricordiamo dal capitolo precedente che la probabilità congiunta può essere scritta in due modi equivalenti:
\[ P(A \cap B) = P(A \mid B) \cdot P(B) = P(B \mid A) \cdot P(A). \tag{5.1}\]
Questa uguaglianza esprime un fatto profondo: la probabilità congiunta è una struttura simmetrica. Non “appartiene” né ad \(A\) né a \(B\): è una proprietà della loro relazione. Possiamo “scomporla” partendo da \(A\) o partendo da \(B\), e otteniamo lo stesso risultato.
Ma se le due espressioni sono uguali, possiamo uguagliarle e risolvere per una delle probabilità condizionate:
\[ P(A \mid B) \cdot P(B) = P(B \mid A) \cdot P(A) \]
\[ P(A \mid B) = \frac{P(B \mid A) \cdot P(A)}{P(B)}. \]
Questo è il teorema di Bayes. Non abbiamo introdotto nulla di nuovo: abbiamo solo riorganizzato le stesse informazioni.
Teorema 5.1 (Teorema di Bayes (forma fondamentale)) Per eventi \(A\) e \(B\) con \(P(B) > 0\) vale:
\[ P(A \mid B) = \frac{P(B \mid A) \cdot P(A)}{P(B)}. \tag{5.2}\]
5.1.2 Perché questo è importante
La formula sembra semplice e lo è, dal punto di vista algebrico. Tuttavia, la sua importanza risiede in ciò che permette di fare: trasformare una probabilità condizionata in un’altra con l’ordine del condizionamento invertito.
Conosciamo \(P(B \mid A)\), ovvero la probabilità di osservare \(B\) se \(A\) è vero. Ora vogliamo conoscere \(P(A \mid B)\), ovvero quanto è probabile che \(A\) sia vero, dato che abbiamo osservato \(B\). Il teorema ci dice esattamente come effettuare questa trasformazione.
Questa inversione non è gratuita: richiede di specificare \(P(A)\) e \(P(B)\). Vedremo a breve cosa significano questi termini e perché sono essenziali.
5.1.3 Significato epistemico dei componenti
Ciascun termine del teorema di Bayes ha un’interpretazione precisa in termini di credenze e informazioni. Imparare a “leggere” la formula in questo modo è fondamentale per usarla correttamente.
La distribuzione a priori: \(P(A)\)
Rappresenta il grado di credenza nell’ipotesi \(A\) prima di osservare l’evidenza \(B\). Rappresenta tutto ciò che sapevamo (o credevamo) prima di raccogliere i nuovi dati: studi precedenti, esperienza clinica, prevalenze epidemiologiche, intuizioni teoriche.
Il prior non è un’invenzione arbitraria. È l’esplicitazione di conoscenze che comunque influenzano il nostro ragionamento, ma l’approccio bayesiano le rende visibili e criticabili.
La verosimiglianza: \(P(B \mid A)\)
Quantifica quanto l’evidenza osservata sia compatibile con l’ipotesi. Se \(A\) fosse vera, quanto sarebbe plausibile osservare \(B\)?
Questa è la componente che collega le ipotesi ai dati. In diagnostica, corrisponde alla sensibilità, in statistica, alla funzione di verosimiglianza e, in generale, alla capacità predittiva del nostro modello.
L’evidenza marginale: \(P(B)\)
Rappresenta la probabilità complessiva di osservare \(B\), indipendentemente dalla verità di \(A\). Viene calcolata considerando tutti i modi in cui \(B\) potrebbe verificarsi.
Questa quantità svolge un ruolo tecnico cruciale: garantisce che la probabilità a posteriori sia correttamente normalizzata, ovvero che la somma delle probabilità di tutte le ipotesi sia pari a 1.
La distribuzione a posteriori: \(P(A \mid B)\)
È la risposta alla nostra domanda inferenziale: quanto crediamo in \(A\) dopo aver osservato \(B\)? Rappresenta la sintesi razionale tra ciò che sapevamo prima e ciò che i dati ci dicono.
5.1.4 La forma proporzionale: ciò che conta davvero
Spesso è utile scrivere il teorema in forma proporzionale:
\[ P(A \mid B) \propto P(B \mid A) \cdot P(A). \]
Questa forma evidenzia un fatto importante: il posterior è proporzionale al prodotto di verosimiglianza e prior. Il denominatore \(P(B)\) serve solo a normalizzare, ovvero a garantire che le probabilità sommino a 1.
In pratica, questo significa che ciò che determina la forma del posterior è il prodotto verosimiglianza × prior. Il denominatore è lo stesso per tutte le ipotesi che stiamo confrontando e quindi non influenza i loro rapporti relativi.
5.1.5 Visualizzare Bayes attraverso le tabelle congiunte
Il significato del teorema diventa particolarmente chiaro se lo esaminiamo attraverso una tabella di probabilità congiunta:
| \(B\) | \(B^c\) | Marginali | |
|---|---|---|---|
| \(A\) | \(P(A \cap B)\) | \(P(A \cap B^c)\) | \(P(A)\) |
| \(A^c\) | \(P(A^c \cap B)\) | \(P(A^c \cap B^c)\) | \(P(A^c)\) |
| Marginali | \(P(B)\) | \(P(B^c)\) | \(1\) |
In questa rappresentazione:
- il prior \(P(A)\) è la marginale di riga—quanto crediamo in \(A\) prima di sapere qualcosa su \(B\);
- la verosimiglianza \(P(B \mid A) = P(A \cap B)/P(A)\) è la proporzione della riga \(A\) che cade nella colonna \(B\);
- il posterior \(P(A \mid B) = P(A \cap B)/P(B)\) è la proporzione della colonna \(B\) che appartiene alla riga \(A\).
Il teorema di Bayes realizza una rotazione della prospettiva: dal ragionamento “per righe” (condizionato sull’ipotesi) al ragionamento “per colonne” (condizionato sull’evidenza).
Consideriamo un test per la depressione con:
\[ P(D)=0.15,\quad P(T^+ \mid D)=0.85,\quad P(T^+ \mid D^c)=0.10. \]
Passo 1: Costruire la tabella congiunta degli eventi “stato clinico” ed “esito del test”:
P_D <- 0.15
sens <- 0.85
fp_rate <- 0.10
# Probabilità congiunte
P_D_and_Tpos <- sens * P_D
P_D_and_Tneg <- (1 - sens) * P_D
P_Dc_and_Tpos <- fp_rate * (1 - P_D)
P_Dc_and_Tneg <- (1 - fp_rate) * (1 - P_D)
tab <- matrix(
c(P_D_and_Tpos, P_D_and_Tneg,
P_Dc_and_Tpos, P_Dc_and_Tneg),
nrow = 2, byrow = TRUE,
dimnames = list(Stato = c("Depresso", "Non depresso"),
Test = c("T+", "T-"))
)
print(round(tab, 4))
#> Test
#> Stato T+ T-
#> Depresso 0.128 0.0225
#> Non depresso 0.085 0.7650Passo 2: Calcolare il posterior dalla tabella
Una volta che abbiamo la tabella, il teorema di Bayes emerge naturalmente:
Passo 3: Verificare con la formula di Bayes
Possiamo verificare che questo risultato coincide esattamente con l’applicazione diretta della formula di Bayes:
I due metodi danno lo stesso risultato, come deve essere, perché il teorema di Bayes non aggiunge informazioni, ma rende esplicita una relazione già contenuta nella distribuzione congiunta.
5.1.6 Forma estesa con legge della probabilità totale
Nelle applicazioni pratiche, spesso non conosciamo direttamente \(P(B)\), ma possiamo calcolarlo considerando tutti i modi in cui \(B\) può verificarsi:
\[ P(B) = P(B \mid A) \cdot P(A) + P(B \mid A^c) \cdot P(A^c) \]
Sostituendo nel teorema di Bayes otteniamo la forma estesa:
\[ P(A \mid B) = \frac{P(B \mid A) \cdot P(A)}{P(B \mid A) \cdot P(A) + P(B \mid A^c) \cdot P(A^c)} \tag{5.3}\]
Questa formulazione è particolarmente utile in diagnostica, dove conosciamo la sensibilità \(P(T^+ \mid D)\) e il tasso di falsi positivi \(P(T^+ \mid D^c)\), ma non conosciamo direttamente la probabilità marginale di un test positivo.
5.1.7 Forma estesa con legge della probabilità totale
Nelle applicazioni pratiche, spesso non conosciamo direttamente \(P(B)\), ma possiamo calcolarlo considerando tutti i modi in cui \(B\) può verificarsi:
\[ P(B) = P(B \mid A) \cdot P(A) + P(B \mid A^c) \cdot P(A^c) \]
Sostituendo nel teorema di Bayes otteniamo la forma estesa:
\[ P(A \mid B) = \frac{P(B \mid A) \cdot P(A)}{P(B \mid A) \cdot P(A) + P(B \mid A^c) \cdot P(A^c)} \tag{5.4}\]
Questa formulazione è particolarmente utile in diagnostica, dove conosciamo sensibilità \(P(T^+ \mid D)\) e tasso di falsi positivi \(P(T^+ \mid D^c)\), ma non direttamente la probabilità marginale di un test positivo.
5.2 Probabilità inversa: il fondamento dell’inferenza
Abbiamo visto la matematica del teorema di Bayes. Ora dobbiamo capire perché questa matematica è così importante, perché risolve un problema fondamentale per la conoscenza scientifica.
5.2.1 Il divario tra modelli e osservazioni
La scienza procede costruendo modelli, ovvero rappresentazioni semplificate del mondo che ci permettono di fare previsioni. Un modello ci dice: “Se le cose stanno così, dovremmo osservare questo.”
Ma il mondo ci presenta la situazione opposta: osserviamo qualcosa, e vogliamo sapere come stanno le cose. Questo è il problema della probabilità inversa: risalire dagli effetti alle cause, dalle osservazioni alle ipotesi.
Direzione predittiva (dal modello ai dati)
“Se l’ipotesi \(H\) fosse vera, quali dati \(D\) ci aspetteremmo?”
Matematicamente: \(P(D \mid H)\)
Questa è la direzione naturale dei modelli scientifici. Sappiamo come i meccanismi generano le osservazioni.
Direzione inferenziale (dai dati al modello)
“Dati i dati \(D\) che abbiamo osservato, quanto è plausibile l’ipotesi \(H\)?”
Matematicamente: \(P(H \mid D)\)
Questa è la direzione necessaria per la conoscenza. È ciò che vogliamo sapere.
Il teorema di Bayes è il ponte tra queste due direzioni. È la formula che traduce la conoscenza predittiva in conoscenza inferenziale.
5.2.2 L’errore più comune: confondere le direzioni
Una delle fonti più sistematiche di errore nel ragionamento probabilistico, documentata da decenni di ricerca psicologica sul giudizio umano, è la confusione tra \(P(D \mid H)\) e \(P(H \mid D)\).
Queste due quantità sembrano simili, ma sono profondamente diverse. Confonderle porta a errori gravi in ogni campo che richiede il ragionamento in condizioni di incertezza.
In diagnostica clinica
“Il test ha una sensibilità del 95%, quindi un risultato positivo indica che c’è il 95% di probabilità che il paziente sia malato.”
Questo ragionamento confonde \(P(T^+ \mid M)\) con \(P(M \mid T^+)\). Come vedremo, per una malattia rara con una prevalenza dello 0.1%, il valore predittivo positivo può essere inferiore al 5%, nonostante la sensibilità eccellente.
Nel contesto giuridico (la “fallacia del procuratore”)
“La probabilità che un innocente abbia questo profilo genetico è di 1 su 1 milione. Quindi, l’imputato è colpevole con una probabilità di 999.999 su 1 milione.”
Questo equivale a scambiare \(P(\text{DNA} \mid \text{innocente})\) con \(P(\text{innocente} \mid \text{DNA})\). In una città di 10 milioni di abitanti, ci si aspetterebbe di trovare circa 10 profili compatibili, il che renderebbe la “prova” molto meno definitiva.
Nella ricerca scientifica (l’interpretazione errata del valore-\(p\))
“Il valore-\(p\) è 0.05, quindi c’è solo il 5% di probabilità che l’ipotesi nulla sia vera.”
Questo confonde \(P(\text{dati così estremi} \mid H_0)\) con \(P(H_0 \mid \text{dati})\). Il valore-\(p\) non dice nulla sulla probabilità delle ipotesi, ma indica solo quanto sarebbero inusuali i dati se l’ipotesi nulla fosse vera.
Questi non sono errori di persone poco istruite. Si tratta di errori sistematici commessi da professionisti come medici, avvocati e scienziati che non hanno interiorizzato la distinzione tra le due direzioni del condizionamento.
5.2.3 La soluzione: rendere esplicita l’inversione
Il teorema di Bayes non elimina la difficoltà intrinseca dell’inferenza, ma la rende esplicita, formale e quindi gestibile. Ci costringe a specificare con precisione:
- ciò che sapevamo prima dell’osservazione dei dati (prior), ossia le nostre conoscenze o assunzioni iniziali;
- quanto i dati osservati siano compatibili con ciascuna ipotesi (verosimiglianza), sulla base di un modello esplicito del processo generatore;
- come queste informazioni vengono integrate (attraverso la formula di Bayes) per ottenere credenze aggiornate (posterior).
Questa esplicitazione ha un valore epistemologico cruciale. Rendendo separabili i diversi contributi al ragionamento inferenziale, il teorema di Bayes trasforma l’analisi da un processo opaco a uno trasparente e criticabile. Se due persone giungono a conclusioni differenti, non è necessario attribuire il disaccordo a un generico “errore”: è possibile individuare con precisione il punto di divergenza — nelle assunzioni iniziali, nel modello dei dati o nella loro combinazione.
Rispetto al ragionamento intuitivo, che tende a fondere informazioni pregresse ed evidenza empirica in modo indistinto, questo rappresenta un progresso sostanziale. L’inferenza bayesiana non elimina il giudizio, ma lo struttura, rendendolo esplicito, discutibile e, soprattutto, migliorabile.
5.3 Teorema di Bayes in forma di odds
In molte applicazioni, in particolare in ambito diagnostico e decisionale, il teorema di Bayes può essere espresso in una forma particolarmente elegante e intuitiva: la forma in odds (quote). Questa formulazione rende l’aggiornamento bayesiano immediatamente interpretabile come un processo di rafforzamento o indebolimento progressivo di un’ipotesi alla luce dell’evidenza.
5.3.1 Dalle probabilità agli odds
Le odds associate a un’ipotesi \(H\) rappresentano il rapporto tra la probabilità che l’ipotesi sia vera e la probabilità che sia falsa:
\[ \text{Odds}(H) = \frac{P(H)}{1 - P(H)} = \frac{P(H)}{P(H^c)}. \]
Ad esempio, se \(P(H) = 0.20\), gli odds sono:
\[ \frac{0.20}{0.80} = 0.25, \] che si leggono comunemente come “una possibilità favorevole contro quattro contrarie” (1:4). Gli odds offrono quindi una rappresentazione alternativa della probabilità, spesso più naturale quando si ragiona in termini comparativi.
5.3.2 L’aggiornamento diventa moltiplicativo
Espresso in termini di odds, il teorema di Bayes assume una forma estremamente semplice:
\[ \text{Odds}(H \mid E) = \text{Odds}(H) \times \text{LR}, \] dove \(\text{LR}\) è il rapporto di verosimiglianza (Likelihood Ratio):
\[ \text{LR} = \frac{P(E \mid H)}{P(E \mid H^c)}. \]
L’aggiornamento bayesiano si riduce così a una moltiplicazione: gli odds a posteriori sono gli odds a priori moltiplicati per quanto l’evidenza favorisce (o sfavorisce) l’ipotesi rispetto alla sua negazione.
Questa forma rende evidente che l’inferenza bayesiana non “riparte da zero” a ogni nuova osservazione, ma aggiorna progressivamente una credenza iniziale.
5.3.3 Il significato del rapporto di verosimiglianza
Il rapporto di verosimiglianza possiede un’interpretazione diretta e potente: esso misura quanto l’evidenza osservata sia più compatibile con l’ipotesi \(H\) rispetto alla sua negazione \(H^c\).
- Se \(\text{LR} > 1\): l’evidenza è più probabile sotto \(H\) che sotto \(H^c\) → favorisce \(H\);
- Se \(\text{LR} < 1\): l’evidenza è più probabile sotto \(H^c\) → sfavorisce \(H\);
- Se \(\text{LR} = 1\): l’evidenza è ugualmente probabile sotto entrambe → non è informativa.
In altre parole, il rapporto di verosimiglianza quantifica il peso informativo di un’osservazione, indipendentemente dalle credenze iniziali.
5.3.4 La forma logaritmica: l’evidenza si somma
Passando alla scala logaritmica, l’aggiornamento bayesiano diventa additivo:
\[ \log \text{Odds}(H \mid E) = \log \text{Odds}(H) + \log \text{LR}. \]
Questa rappresentazione è particolarmente utile perché rende trasparente l’accumulo dell’evidenza: ogni nuova osservazione aggiunge (o sottrae) un contributo ai log-odds. L’inferenza può così essere vista come un processo cumulativo, in cui le evidenze si sommano progressivamente nel tempo.
5.3.5 Rapporti di verosimiglianza in diagnostica
In ambito diagnostico, si distinguono due rapporti di verosimiglianza fondamentali.
Rapporto di verosimiglianza positivo (\(\text{LR}^+\)) Misura quanto un test positivo aumenti le odds di malattia:
\[ \text{LR}^+ = \frac{P(T^+ \mid M)}{P(T^+ \mid M^c)} = \frac{\text{Sensibilità}}{1 - \text{Specificità}}. \]
Rapporto di verosimiglianza negativo (\(\text{LR}^-\)) Misura quanto un test negativo riduca le odds di malattia:
\[ \text{LR}^- = \frac{P(T^- \mid M)}{P(T^- \mid M^c)} = \frac{1 - \text{Sensibilità}}{\text{Specificità}}. \]
Un test diagnostico ideale presenta:
- una \(\text{LR}^+\) molto elevata (un risultato positivo è forte evidenza di malattia);
- una \(\text{LR}^-\) molto piccola (un risultato negativo è forte evidenza di assenza).
5.3.6 Sintesi concettuale
La forma in odds del teorema di Bayes mostra chiaramente che l’inferenza bayesiana consiste nell’aggiornare proporzionalmente le credenze in base all’evidenza. Non ci sono soglie arbitrarie né decisioni dicotomiche: ogni osservazione contribuisce in modo graduale e quantificabile a rafforzare o indebolire un’ipotesi. In questo senso, la formulazione in odds rappresenta una delle espressioni più trasparenti e operative del ragionamento bayesiano.
Linee guida comunemente usate in medicina:
| \(\text{LR}^+\) | \(\text{LR}^-\) | Impatto diagnostico |
|---|---|---|
| > 10 | < 0.1 | Forte, spesso conclusivo |
| 5-10 | 0.1-0.2 | Moderato |
| 2-5 | 0.2-0.5 | Debole |
| 1-2 | 0.5-1 | Trascurabile |
Un test con \(\text{LR}^+ = 8.5\) significa che un risultato positivo è 8.5 volte più probabile in un paziente malato che in uno sano. Questo è un test ragionevolmente informativo.
Consideriamo un test con sensibilità 85% e specificità 90%, applicato a una popolazione con prevalenza del 10%.
Conversione in odds
Scenario 1: test positivo
Le odds aumentano di un fattore 8.5, passando da circa 0.11 a circa 0.94. In termini di probabilità, passiamo dal 10% al 49%.
Scenario 2: test negativo
Le odds diminuiscono di un fattore circa 6 (vengono moltiplicate per 0.17), passando da 0.11 a 0.018. La probabilità scende dal 10% a meno del 2%.
Sintesi: il test è asimmetrico nel suo potere informativo
data.frame(
Scenario = c("Prima del test", "Dopo test positivo", "Dopo test negativo"),
Probabilità = paste0(round(c(prior_prob, post_prob_pos, post_prob_neg) * 100, 1), "%"),
Odds = round(c(prior_odds, post_odds_pos, post_odds_neg), 3)
)
#> Scenario Probabilità Odds
#> 1 Prima del test 10% 0.111
#> 2 Dopo test positivo 48.6% 0.944
#> 3 Dopo test negativo 1.8% 0.019Il test è più utile per escludere la condizione (un risultato negativo la rende molto improbabile) che per confermarla (un risultato positivo lascia ancora un’incertezza sostanziale).
5.4 La fallacia del tasso base
Una delle applicazioni più importanti del teorema di Bayes è la comprensione di un errore cognitivo sistematico: la fallacia del tasso base. Questo errore, documentato da decenni di ricerca psicologica, consiste nel sottovalutare l’importanza della prevalenza (il “tasso base”) nell’interpretazione dei test diagnostici.
5.4.1 Il problema
Immaginate questo scenario: un test per una malattia rara ha una sensibilità e una specificità del 99%. Sembra un test quasi perfetto. Un paziente risulta positivo. Qual è la probabilità che sia realmente malato?
La risposta intuitiva di molte persone, inclusi molti medici, è “circa il 99%”. Ma questa risposta è gravemente errata se la malattia è rara.
5.4.2 L’aritmetica della prevalenza
Svolgiamo i calcoli in maniera esplicita. Supponiamo che la malattia abbia una prevalenza dello 0.1% (1 persona su 1000).
prevalenza <- 0.001
sens <- 0.99
spec <- 0.99
# Applicazione del teorema di Bayes
P_Tpos <- sens * prevalenza + (1 - spec) * (1 - prevalenza)
VPP <- (sens * prevalenza) / P_Tpos
cat("Prevalenza:", prevalenza * 100, "%\n")
#> Prevalenza: 0.1 %
cat("Sensibilità:", sens * 100, "%\n")
#> Sensibilità: 99 %
cat("Specificità:", spec * 100, "%\n")
#> Specificità: 99 %
cat("Valore predittivo positivo:", round(VPP * 100, 1), "%\n")
#> Valore predittivo positivo: 9 %Il valore predittivo positivo è solo del 9%! Nonostante la sensibilità e la specificità eccellenti, la maggior parte dei risultati positivi è falsa.
5.4.3 Perché succede questo?
Il meccanismo è semplice ma controintuitivo. Consideriamo 100.000 persone:
-
100 sono malate (0.1% di 100.000):
- di queste, 99 risultano positive (sensibilità 99%);
- 1 risulta negativa (falso negativo).
-
99.900 sono sane (99.9% di 100.000):
- di queste, 98.901 risultano negative (specificità 99%);
- 999 risultano positive (falsi positivi).
Totale positivi: 99 veri positivi + 999 falsi positivi = 1.098.
Proporzione di veri positivi tra tutti i positivi: 99/1.098 ≈ 9%.
Il problema è che anche un tasso di errore piccolo (1% di falsi positivi), applicato a un gruppo molto grande (99.900 persone sane), produce un numero assoluto di falsi positivi che supera il numero di veri positivi.
5.4.4 Visualizzazione dell’effetto della prevalenza
VPP <- function(prev, sens, spec) {
fp <- 1 - spec
P_Tpos <- sens * prev + fp * (1 - prev)
(sens * prev) / P_Tpos
}
sens <- 0.85
spec <- 0.90
prevalences <- seq(0.01, 0.50, by = 0.01)
vpps <- VPP(prevalences, sens, spec)
# Punti di riferimento
vpp_bassa <- VPP(0.08, sens, spec) # Medicina generale
vpp_alta <- VPP(0.30, sens, spec) # Ambulatorio specialistico
df_baseRate <- data.frame(
Prevalenza = prevalences,
VPP = vpps
)
ggplot(df_baseRate, aes(x = Prevalenza, y = VPP)) +
geom_line(linewidth = 1.2) +
geom_hline(yintercept = 0.5, linetype = "dashed", alpha = 0.7) +
geom_vline(xintercept = c(0.08, 0.30), linetype = "dotted", alpha = 0.5) +
geom_point(aes(x = 0.08, y = vpp_bassa), size = 3) +
geom_point(aes(x = 0.30, y = vpp_alta), size = 3) +
annotate("text", x = 0.10, y = vpp_bassa - 0.08,
label = "Medicina\ngenerale (8%)", hjust = 0, size = 3.5) +
annotate("text", x = 0.32, y = vpp_alta,
label = "Ambulatorio\nspecialistico (30%)", hjust = 0, size = 3.5) +
scale_x_continuous(labels = scales::percent) +
scale_y_continuous(labels = scales::percent) +
labs(
title = "L'effetto del tasso base sul significato di un test positivo",
subtitle = paste0("Test: sensibilità ", sens*100, "%, specificità ", spec*100, "%"),
x = "Prevalenza del disturbo",
y = "Valore Predittivo Positivo"
)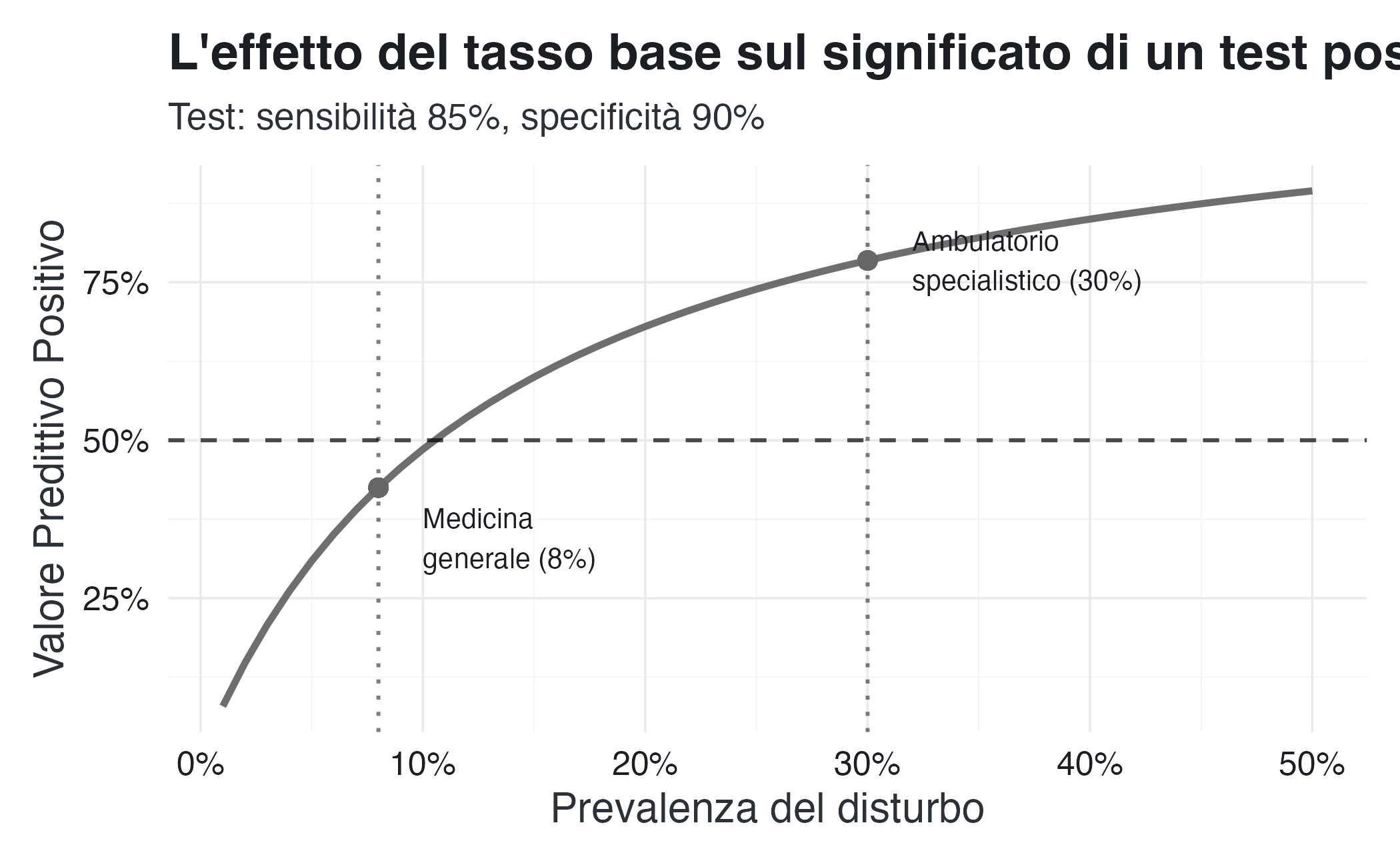
5.4.5 La lezione per la pratica clinica
Questo grafico illustra un principio fondamentale: lo stesso test può avere significati diversi in contesti diversi.
- In medicina generale (prevalenza ~8%): un test positivo indica solo il ~43% di probabilità di malattia.
- In un ambulatorio specialistico (prevalenza ~30%): lo stesso test positivo indica una probabilità del ~78%.
La differenza non sta nel test, ma nel contesto. Il teorema di Bayes ci obbliga a considerare esplicitamente questo contesto, mentre l’intuizione tende a ignorarlo.
5.4.6 Implicazioni per lo screening di popolazione
Questa analisi ha importanti conseguenze pratiche:
lo screening di massa è problematico per le condizioni rare: anche i test eccellenti producono troppi falsi positivi;
il valore principale di molti test è escludere la malattia: un risultato negativo è spesso più informativo di un risultato positivo;
la pre-selezione migliora l’utilità diagnostica: testare le persone con sintomi aumenta la prevalenza “effettiva” e quindi il VPP;
comunicare i risultati richiede attenzione: dire “il test è positivo” senza spiegare cosa significa può generare ansia ingiustificata.
5.5 Applicazioni al ragionamento clinico
Il teorema di Bayes non è solo uno strumento di calcolo, ma un modo di pensare al ragionamento clinico. Vediamo alcune applicazioni che illustrano questo concetto.
Il ragionamento clinico raramente si basa su una singola fonte di informazione. Il teorema di Bayes fornisce il quadro naturale per integrare evidenze multiple.
Scenario: valutazione di un bambino per possibile ADHD utilizzando due strumenti complementari.
# Parametri iniziali
P_ADHD <- 0.05 # Prevalenza nella popolazione scolastica
sens_T1 <- 0.80 # Questionario genitori
spec_T1 <- 0.85
sens_T2 <- 0.75 # Osservazione in classe
spec_T2 <- 0.88
# Rapporti di verosimiglianza
LR_pos_T1 <- sens_T1 / (1 - spec_T1)
LR_pos_T2 <- sens_T2 / (1 - spec_T2)
cat("LR+ questionario:", round(LR_pos_T1, 1), "\n")
#> LR+ questionario: 5.3
cat("LR+ osservazione:", round(LR_pos_T2, 1), "\n")
#> LR+ osservazione: 6.2Aggiornamento sequenziale
Partiamo dalla prevalenza e aggiorniamo dopo ogni test positivo:
# Fase 1: Prior
prior_odds <- P_ADHD / (1 - P_ADHD)
# Fase 2: Dopo questionario positivo
post_odds_T1 <- prior_odds * LR_pos_T1
post_prob_T1 <- post_odds_T1 / (1 + post_odds_T1)
# Fase 3: Dopo anche osservazione positiva
post_odds_both <- post_odds_T1 * LR_pos_T2
post_prob_both <- post_odds_both / (1 + post_odds_both)
# Sintesi
evoluzione <- data.frame(
Fase = c("Prevalenza iniziale",
"Dopo questionario (+)",
"Dopo osservazione (+)"),
Probabilità = paste0(round(c(P_ADHD, post_prob_T1, post_prob_both) * 100, 1), "%")
)
print(evoluzione)
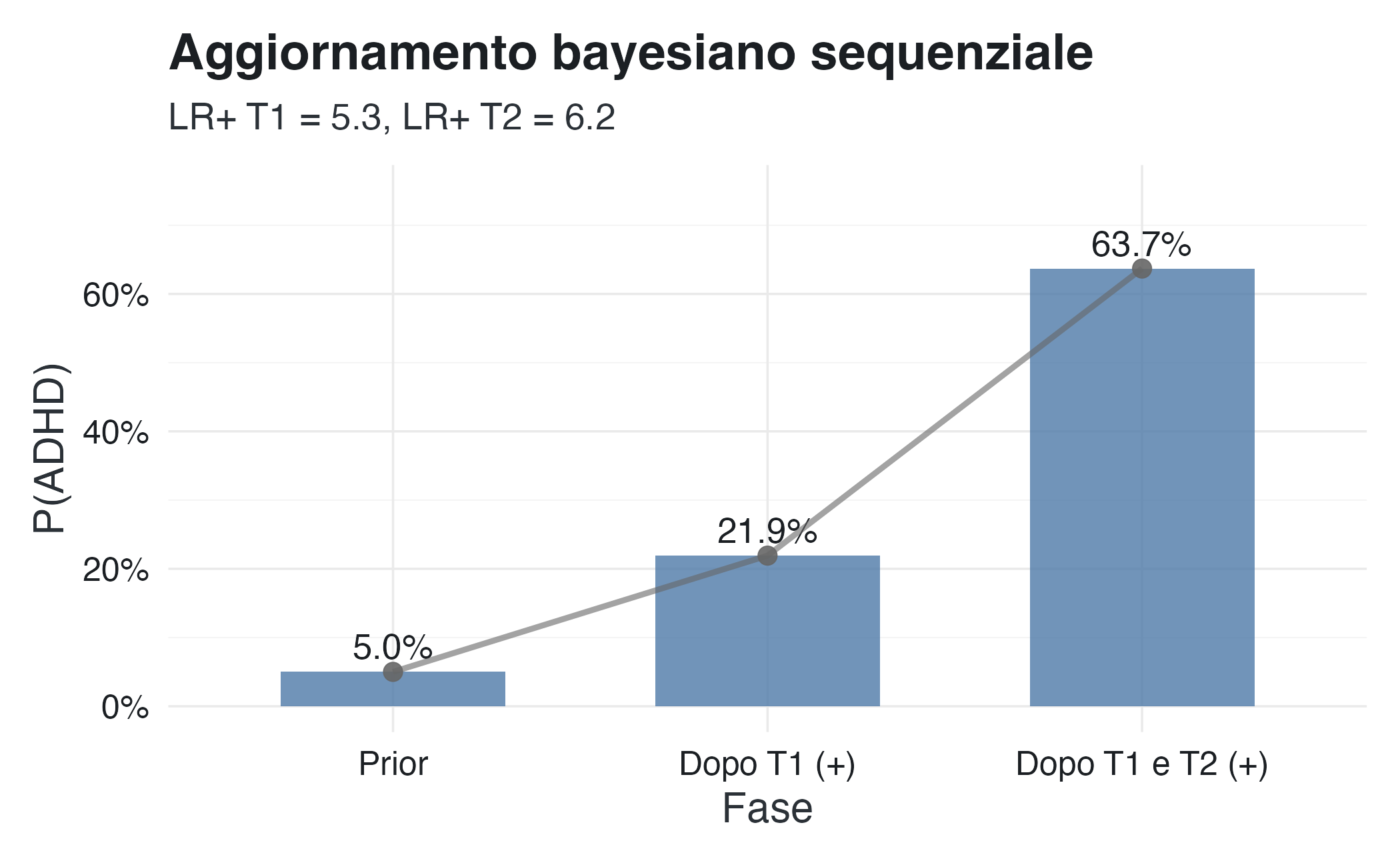
#> Fase Probabilità
#> 1 Prevalenza iniziale 5%
#> 2 Dopo questionario (+) 21.9%
#> 3 Dopo osservazione (+) 63.7%Visualizzazione dell’accumulo di evidenze
df_seq <- data.frame(
Fase = factor(c("Prior", "Dopo T1 (+)", "Dopo T1 e T2 (+)"),
levels = c("Prior", "Dopo T1 (+)", "Dopo T1 e T2 (+)")),
Probabilità = c(P_ADHD, post_prob_T1, post_prob_both)
)
ggplot(df_seq, aes(x = Fase, y = Probabilità)) +
geom_col(fill = "#4E79A7", alpha = 0.8, width = 0.6) +
geom_text(aes(label = sprintf("%.1f%%", Probabilità * 100)),
vjust = -0.5, size = 4.5) +
geom_line(aes(group = 1), linewidth = 1, alpha = 0.6) +
geom_point(size = 3) +
scale_y_continuous(labels = scales::percent, limits = c(0, 0.75)) +
labs(
title = "Aggiornamento bayesiano sequenziale",
subtitle = paste0("LR+ T1 = ", round(LR_pos_T1, 1),
", LR+ T2 = ", round(LR_pos_T2, 1)),
y = "P(ADHD)"
)
Interpretazione clinica
Il processo illustra diversi principi importanti.
L’evidenza si accumula: partendo dal 5%, arriviamo al 64% dopo due test positivi concordanti.
L’assunzione di indipendenza condizionale: abbiamo assunto che i due test forniscano informazioni indipendenti dato lo stato del bambino. Questo è plausibile perché misurano contesti diversi (casa vs scuola).
I rapporti di verosimiglianza si moltiplicano: l’effetto combinato (LR totale ≈ 33) è il prodotto dei singoli LR.
Il prior conta: se la prevalenza fosse 20% invece che 5%, lo stesso pattern di test produrrebbe una probabilità finale molto più alta.
Il ragionamento bayesiano si applica naturalmente anche alla valutazione della comorbilità.
Scenario: in un contesto clinico, sappiamo che depressione e ansia sono frequentemente co-occorrenti. Come cambia la nostra valutazione della depressione quando osserviamo ansia?
# Parametri dalla letteratura
P_D <- 0.40 # Prevalenza depressione in contesto clinico
P_A_given_D <- 0.60 # P(Ansia | Depressione)
P_A <- 0.35 # Prevalenza generale ansia
# Teorema di Bayes per calcolare P(D | A)
P_D_given_A <- (P_A_given_D * P_D) / P_A
# E se l'ansia fosse assente?
P_D_and_A <- P_A_given_D * P_D
P_D_and_not_A <- P_D - P_D_and_A
P_not_A <- 1 - P_A
P_D_given_not_A <- P_D_and_not_A / P_not_A
cat("P(Depressione) = ", P_D * 100, "%\n")
#> P(Depressione) = 40 %
cat("P(Depressione | Ansia presente) =", round(P_D_given_A * 100, 1), "%\n")
#> P(Depressione | Ansia presente) = 68.6 %
cat("P(Depressione | Ansia assente) =", round(P_D_given_not_A * 100, 1), "%\n")
#> P(Depressione | Ansia assente) = 24.6 %Interpretazione
La presenza di ansia quasi raddoppia la probabilità di depressione (dal 40% al 69%), mentre l’assenza di ansia la riduce sostanzialmente (al 25%).
Questo esempio illustra come le informazioni cliniche si influenzino a vicenda. Un clinico esperto sa intuitivamente che ansia e depressione spesso coesistono. Il teorema di Bayes quantifica precisamente questa intuizione e la rende comunicabile.
5.6 Come interpretare il risultato di un test psicologico
Abbiamo discusso il teorema di Bayes attraverso esempi diagnostici. Ma cosa significa tutto questo concretamente per uno psicologo che somministra un test a un paziente specifico? Questa domanda merita una risposta esplicita, in quanto tocca il cuore della pratica professionale.
5.6.1 Lo scenario
Immaginate di aver somministrato il Beck Depression Inventory (BDI-II) a un paziente. Il punteggio ottenuto è 22, che supera il cut-off clinico di 20, comunemente utilizzato per indicare una depressione moderata. Cosa potete concludere?
La risposta non è: “Il paziente è depresso.” E nemmeno: “C’è il 90% di probabilità che il paziente sia depresso” (o qualsiasi altra percentuale derivata dalle proprietà psicometriche del test).
5.6.2 L’errore da evitare
L’errore più comune, e anche il più grave, è interpretare il risultato del test come se fornisse direttamente la probabilità della condizione. “Il test ha una sensibilità dell’85%, quindi, se risulta positivo, c’è l’85% di probabilità che il paziente sia depresso”.
Come abbiamo visto, questo ragionamento confonde \(P(T^+ \mid D)\) con \(P(D \mid T^+)\). La sensibilità ci dice quanto è probabile che il test dia esito positivo se il paziente è depresso. Ma noi vogliamo sapere quanto è probabile che il paziente sia depresso dato che il test è positivo. Sono domande diverse, con risposte diverse.
5.6.3 L’interpretazione corretta: un processo bayesiano
Per una corretta interpretazione, è necessario pensare in termini bayesiani, anche se non è necessario effettuare calcoli espliciti. Il processo ha tre componenti.
1. La probabilità pre-test (il prior)
Prima di somministrare il test, avevate già delle informazioni sul paziente? Perché si è rivolto a voi? Quali sintomi ha riferito? Qual è la sua storia? In quale contesto lavorate?
Se il paziente si è presentato spontaneamente lamentando umore depresso, perdita di interesse e disturbi del sonno da tre mesi, la probabilità pre-test di depressione era già alta, forse 60-70%. Se invece il test è stato somministrato come screening di routine a un dipendente aziendale senza particolari segnali di malessere, la probabilità pre-test era molto più bassa, forse del 5-10%.
Questa probabilità non è arbitraria, ma riflette tutto ciò che si sa sul paziente e sulla popolazione di riferimento. È il punto di partenza.
2. L’evidenza fornita dal test (la verosimiglianza)
Il test positivo modifica la vostra credenza iniziale. Di quanto? Dipende dalle proprietà psicometriche del test, ovvero dalla sua capacità di discriminare chi ha la condizione da chi non ce l’ha.
Un test con alta sensibilità e alta specificità fornisce un’evidenza forte: un risultato positivo aumenta molto la probabilità della condizione, mentre un risultato negativo la diminuisce notevolmente. Un test con proprietà più modeste fornisce un’evidenza più debole.
Ma, e questo è il punto cruciale, l’entità dell’aggiornamento dipende anche dalla probabilità pre-test. Lo stesso test positivo ha un significato diverso per il paziente che si è presentato con sintomi evidenti (dove conferma un sospetto già forte) e per il dipendente sottoposto a screening (dove deve “vincere” contro una bassa probabilità di base).
3. La probabilità post-test (il posterior)
Il risultato finale, ovvero la vostra credenza aggiornata sulla condizione del paziente, è la sintesi bayesiana di prior ed evidenza.
Per il paziente sintomatico, se partivate da una probabilità del 65% e il test è positivo, potreste arrivare a una probabilità dell’85-90%. Il test ha confermato e rafforzato un sospetto già forte.
Per il dipendente sottoposto a screening: se partivate da un valore del 8% e il test è risultato positivo, potreste arrivare a un valore compreso tra il 40% e il 50%. Il test ha aumentato in modo significativo la probabilità, ma non l’ha resa elevata. Quel risultato positivo richiede un approfondimento, non una diagnosi.
5.6.4 Implicazioni pratiche
Questa analisi ha conseguenze concrete per la pratica clinica:
Un test positivo non è una diagnosi. È un’informazione che aggiorna le vostre credenze. L’entità dell’aggiornamento dipende dal punto di partenza. Se la probabilità di partenza era bassa, anche dopo un test positivo, potreste non avere la certezza sufficiente per una diagnosi.
Il contesto clinico è parte integrante dell’interpretazione. Lo stesso punteggio BDI di 22 può avere significati diversi per pazienti diversi. Non si tratta di un difetto del test, ma di una conseguenza inevitabile della logica probabilistica.
I test sono più utili in alcune situazioni che in altre. In generale, sono più utili per escludere condizioni (un risultato negativo in un contesto ad alta probabilità pre-test è molto informativo) che per confermarle (un risultato positivo in un contesto a bassa probabilità pre-test lascia molta incertezza).
La comunicazione al paziente richiede attenzione. Dire “il test è positivo per depressione” può essere fuorviante se non si fornisce il contesto adeguato. È meglio dire: “Il test suggerisce la possibilità di depressione. Insieme alle altre informazioni che abbiamo raccolto, questo mi porta a pensare che [valutazione integrata].”
5.6.5 Un esempio numerico
Rendiamo concreto il ragionamento. Supponiamo che il BDI-II abbia una sensibilità dello 0.85 e una specificità di 0.80 per la depressione maggiore.
# Proprietà del test
sens <- 0.85
spec <- 0.80
LR_pos <- sens / (1 - spec) # = 4.25
# Due scenari
prior_sintomatico <- 0.65
prior_screening <- 0.08
# Funzione per calcolare posterior
calcola_posterior <- function(prior, LR) {
odds_prior <- prior / (1 - prior)
odds_post <- odds_prior * LR
odds_post / (1 + odds_post)
}
post_sintomatico <- calcola_posterior(prior_sintomatico, LR_pos)
post_screening <- calcola_posterior(prior_screening, LR_pos)
cat("Paziente sintomatico:\n")
#> Paziente sintomatico:
cat(" Prior:", prior_sintomatico * 100, "%\n")
#> Prior: 65 %
cat(" Posterior dopo test +:", round(post_sintomatico * 100, 1), "%\n\n")
#> Posterior dopo test +: 88.8 %
cat("Screening aziendale:\n")
#> Screening aziendale:
cat(" Prior:", prior_screening * 100, "%\n")
#> Prior: 8 %
cat(" Posterior dopo test +:", round(post_screening * 100, 1), "%\n")
#> Posterior dopo test +: 27 %Lo stesso test positivo porta a conclusioni molto diverse: l’88% di probabilità di depressione per il paziente sintomatico e solo il 27% per il dipendente sottoposto a screening. Nel primo caso, una diagnosi provvisoria è ragionevole, mentre nel secondo è necessario un approfondimento prima di poter trarre qualsiasi conclusione.
5.6.6 Il messaggio per la pratica
Il teorema di Bayes non è solo matematica astratta, ma la formalizzazione di ciò che un clinico esperto fa intuitivamente. Quando affermate “Questo test positivo è rilevante, dato il quadro clinico” o “Non mi fido di questo risultato, non è coerente con tutto il resto”, state ragionando in modo bayesiano.
La differenza è che il ragionamento esplicito vi protegge dagli errori sistematici, come la tendenza a sovrastimare il significato di un test positivo, a ignorare il contesto o a considerare il risultato come la risposta definitiva, invece che come un elemento da integrare.
In sintesi: un test non vi dice se il paziente ha una determinata condizione. Vi dice quanto dovreste aggiornare la vostra credenza sulla condizione, sulla base della vostra valutazione iniziale. Questa distinzione può sembrare sottile, ma ha conseguenze profonde per la qualità del ragionamento clinico.
5.7 Aggiornamento bayesiano con distribuzioni continue
Finora abbiamo applicato il teorema di Bayes a ipotesi discrete: il paziente è depresso o non lo è, la moneta è bilanciata o non lo è. Tuttavia, in molte situazioni, il parametro di interesse è continuo: non vogliamo sapere se un effetto esiste, ma quanto è grande; non se uno studente conosce la risposta, ma qual è la sua abilità.
In questi casi, l’aggiornamento bayesiano opera su distribuzioni di probabilità piuttosto che su singoli valori.
5.7.1 Il modello Beta-Binomiale
Quando il parametro di interesse è una probabilità \(\theta \in [0,1]\) e i dati sono binari (successi e fallimenti), la distribuzione Beta offre un framework particolarmente elegante.
- Prior: \(\theta \sim \text{Beta}(\alpha, \beta)\).
- Dati: \(k\) successi su \(n\) prove.
- Posterior: \(\theta \mid k \sim \text{Beta}(\alpha + k, \beta + n - k)\).
I parametri \(\alpha\) e \(\beta\) possono essere interpretati come “pseudo-osservazioni” precedenti: \(\alpha - 1\) successi virtuali e \(\beta - 1\) fallimenti virtuali. L’aggiornamento consiste semplicemente nell’aggiungere i nuovi dati a questi conteggi.
Questa proprietà di coniugazione, ovvero il fatto che prior e posterior appartengano alla stessa famiglia di distribuzioni, rende l’aggiornamento bayesiano computazionalmente semplice e concettualmente trasparente.
5.7.2 Esempio: valutazione di uno studente
Consideriamo un test a scelta multipla con 4 opzioni per domanda. Il nostro prior riflette l’ipotesi che lo studente stia rispondendo a caso (probabilità 1/4 = 0.25).
# Prior: centrato su risposta casuale
alpha_prior <- 1
beta_prior <- 3 # Media = 1/(1+3) = 0.25
# Dati: 12 risposte corrette su 30
n_obs <- 30
k_success <- 12
# Posterior
alpha_post <- alpha_prior + k_success
beta_post <- beta_prior + (n_obs - k_success)
# Griglia per visualizzazione
theta_seq <- seq(0, 1, length.out = 500)
prior_dens <- dbeta(theta_seq, alpha_prior, beta_prior)
posterior_dens <- dbeta(theta_seq, alpha_post, beta_post)
# Verosimiglianza (normalizzata per visualizzazione)
lik_dens <- dbinom(k_success, n_obs, theta_seq)
lik_dens <- lik_dens / max(lik_dens) * max(posterior_dens)
df_beta <- data.frame(
theta = rep(theta_seq, 3),
Densità = c(prior_dens, lik_dens, posterior_dens),
Componente = rep(c("Prior", "Verosimiglianza", "Posterior"), each = 500)
)
ggplot(df_beta, aes(x = theta, y = Densità, color = Componente, linetype = Componente)) +
geom_line(linewidth = 1.2) +
geom_vline(xintercept = 0.25, linetype = "dotted", alpha = 0.5) +
geom_vline(xintercept = k_success/n_obs, linetype = "dotted", alpha = 0.5) +
annotate("text", x = 0.27, y = max(posterior_dens) * 0.95,
label = "Prior\n(caso)", hjust = 0, size = 3) +
annotate("text", x = k_success/n_obs + 0.02, y = max(posterior_dens) * 0.7,
label = "MLE", hjust = 0, size = 3) +
scale_linetype_manual(values = c("Prior" = "dashed",
"Verosimiglianza" = "dotted",
"Posterior" = "solid")) +
labs(
title = "Aggiornamento bayesiano: 12 corrette su 30 domande",
x = expression(theta ~ "(probabilità di risposta corretta)"),
y = "Densità"
)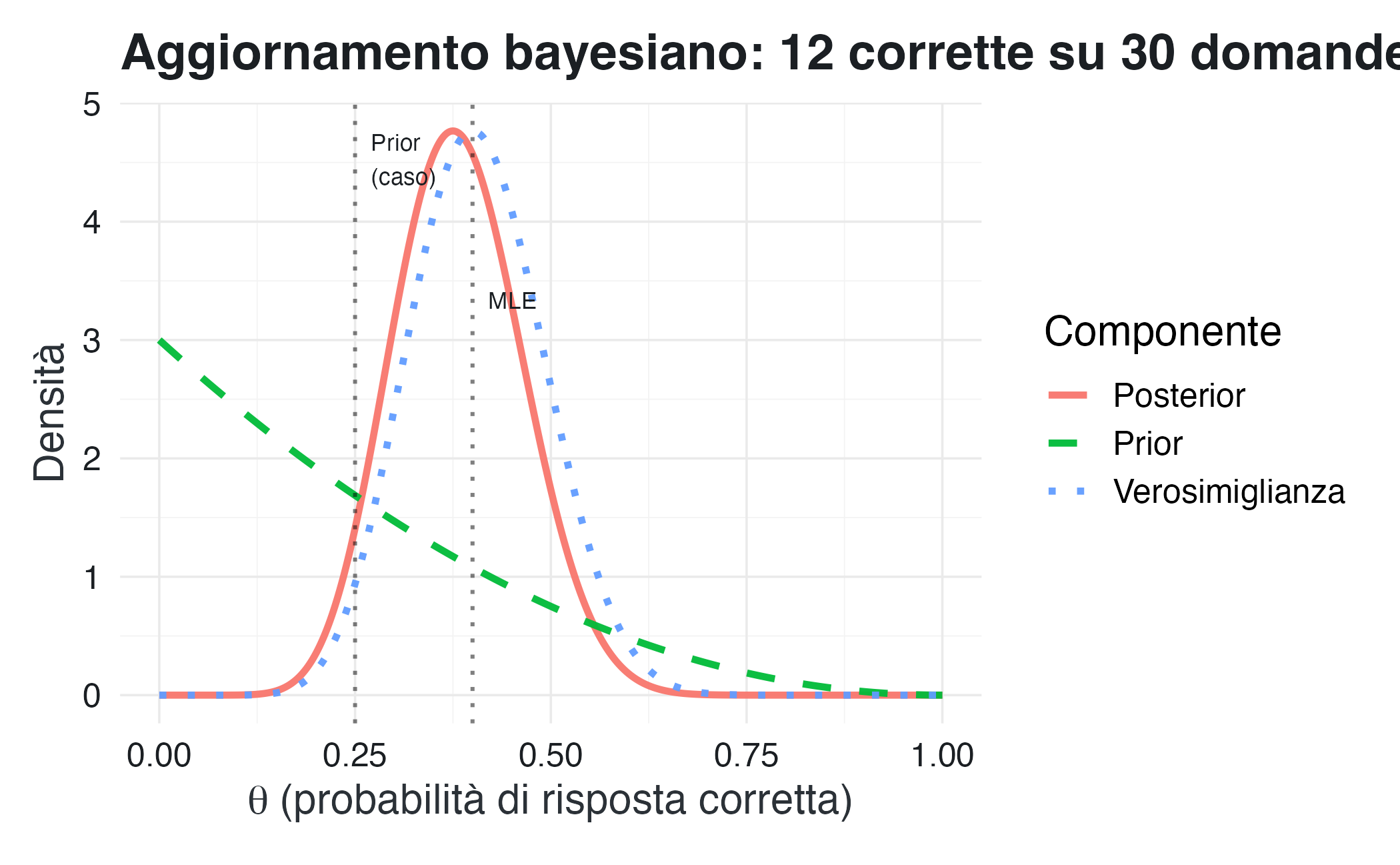
Cosa mostra il grafico:
- il prior (tratteggiato) è centrato su 0.25, l’ipotesi di risposta casuale;
- la verosimiglianza (punteggiato) indica che i dati (12/30 = 0.40) favoriscono valori più alti;
- il posterior (continuo) è un compromesso: spostato verso i dati rispetto al prior, ma non coincide con la stima di massima verosimiglianza.
# Confronto numerico
prior_mean <- alpha_prior / (alpha_prior + beta_prior)
mle <- k_success / n_obs
post_mean <- alpha_post / (alpha_post + beta_post)
data.frame(
Stima = c("Media a priori", "Massima verosimiglianza", "Media a posteriori"),
Valore = round(c(prior_mean, mle, post_mean), 3)
)
#> Stima Valore
#> 1 Media a priori 0.250
#> 2 Massima verosimiglianza 0.400
#> 3 Media a posteriori 0.382La media a posteriori (0.382) si colloca tra il prior (0.25) e i dati (0.40). Questo “shrinkage” verso il prior riflette il fatto che non abbiamo ancora abbastanza dati per abbandonare completamente le nostre credenze iniziali.
5.7.3 Intervalli di credibilità: quantificare l’incertezza
A differenza degli intervalli di confidenza frequentisti, che descrivono le proprietà di una procedura, gli intervalli di credibilità bayesiani forniscono affermazioni dirette sulla probabilità che il parametro cada in un certo intervallo.
# Intervallo di credibilità 95%
ci_lower <- qbeta(0.025, alpha_post, beta_post)
ci_upper <- qbeta(0.975, alpha_post, beta_post)
df_post <- data.frame(theta = theta_seq, densità = posterior_dens)
ggplot(df_post, aes(x = theta, y = densità)) +
geom_line(linewidth = 1.2) +
geom_area(data = df_post %>% filter(theta >= ci_lower & theta <= ci_upper),
alpha = 0.3) +
geom_vline(xintercept = c(ci_lower, ci_upper), linetype = "dashed") +
geom_vline(xintercept = post_mean, linewidth = 1) +
annotate("text", x = post_mean + 0.02, y = max(posterior_dens) * 0.8,
label = paste0("Media: ", round(post_mean, 3)), hjust = 0) +
annotate("text", x = (ci_lower + ci_upper)/2, y = max(posterior_dens) * 0.4,
label = paste0("IC 95%\n[", round(ci_lower, 2), ", ", round(ci_upper, 2), "]")) +
labs(
title = "Quantificazione dell'incertezza su θ",
x = expression(theta),
y = "Densità a posteriori"
)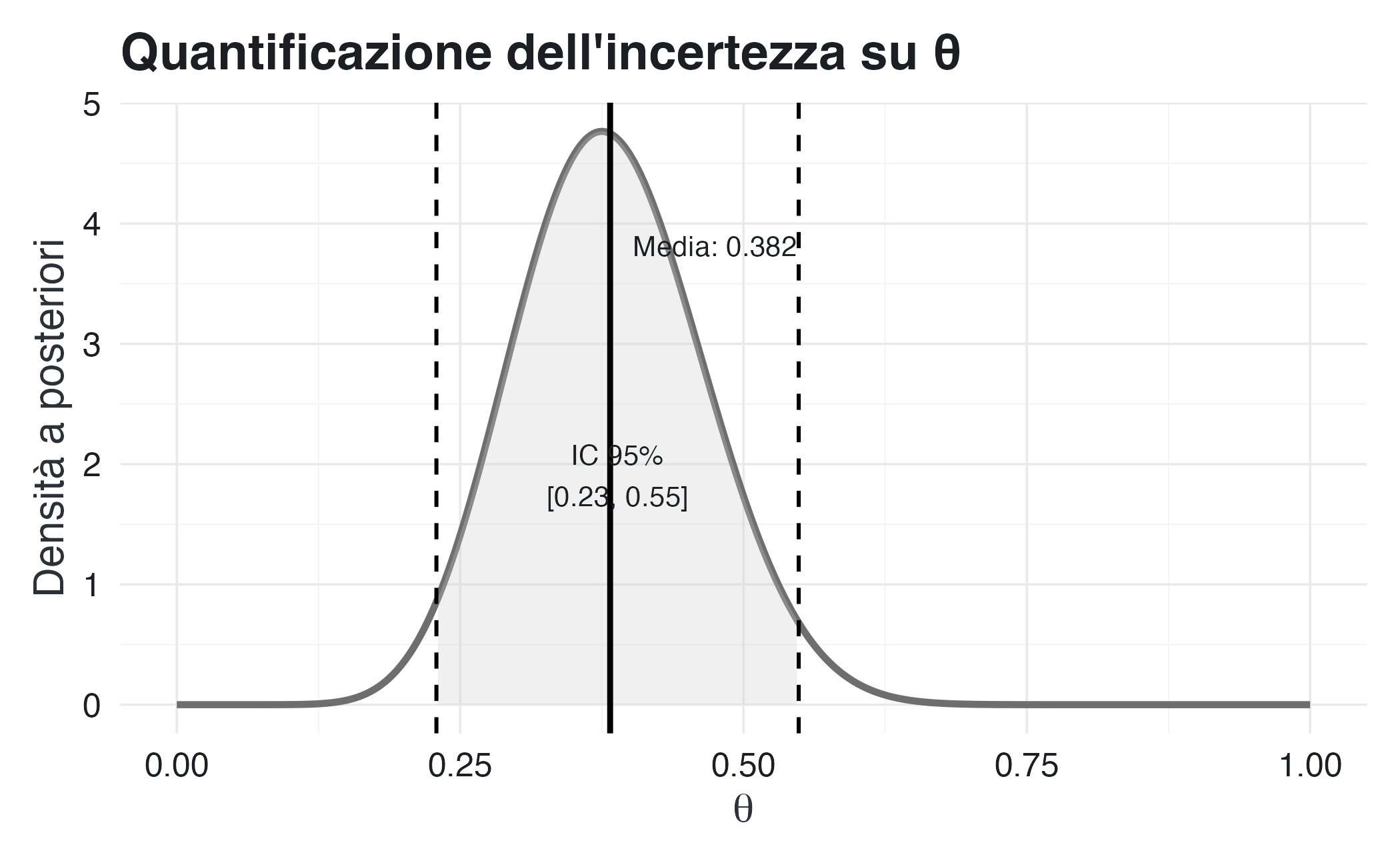
Intervallo di credibilità bayesiano (95%):
“C’è una probabilità del 95% che il vero valore del parametro sia compreso tra 0.23 e 0.55, date le nostre informazioni.”
Questa interpretazione è diretta e intuitiva: è esattamente ciò che le persone si aspettano da un intervallo di confidenza, ma che l’interpretazione frequentista non permette.
Intervallo di confidenza frequentista (95%):
“Se ripetessimo questo esperimento infinite volte e calcolassimo l’intervallo ogni volta, il 95% di questi intervalli conterrebbe il vero parametro.”
Questa interpretazione riguarda le proprietà della procedura, non del parametro specifico che ci interessa.
La differenza non è solo filosofica, ma ha anche conseguenze pratiche. L’interpretazione bayesiana consente affermazioni come “è molto improbabile che \(\theta > 0.6\)”, cosa che l’interpretazione frequentista, tecnicamente, non permette.
Riflessioni conclusive
Siamo arrivati al termine del percorso che ha costruito le fondamenta del ragionamento bayesiano. Il teorema di Bayes non è stato presentato come una formula da memorizzare, ma come l’espressione matematica di un principio epistemologico profondo: l’apprendimento razionale dall’esperienza.
Cosa abbiamo compreso
La derivazione del teorema dalla simmetria della probabilità congiunta ha mostrato che l’aggiornamento bayesiano non è una scelta metodologica arbitraria. È una necessità logica per chiunque accetti i vincoli di coerenza della teoria della probabilità. Non c’è alternativa coerente: se le nostre credenze devono rispettare gli assiomi, devono aggiornarsi secondo Bayes.
L’interpretazione epistemica dei componenti—prior, verosimiglianza, evidenza, posterior—ha rivelato una struttura del ragionamento che è al tempo stesso rigorosa e intuitiva. Il prior esplicita ciò che sapevamo prima; la verosimiglianza misura la compatibilità tra dati e ipotesi; il posterior sintetizza tutto in una credenza aggiornata.
Le applicazioni diagnostiche hanno illustrato sia il potere del teorema sia i pericoli dell’intuizione non guidata. La fallacia del tasso base—l’errore sistematico di ignorare la prevalenza—è una delle scoperte più robuste della psicologia del giudizio. Il teorema di Bayes non solo spiega perché commettiamo questo errore, ma ci fornisce lo strumento per evitarlo.
Il messaggio fondamentale
Se dovessimo condensare tutto in un’unica idea, sarebbe questa: la razionalità è coerenza, e la coerenza richiede Bayes.
Questo non significa che l’approccio bayesiano sia l’unico valido, o che non abbia limiti. Significa che, una volta accettata l’interpretazione della probabilità come grado di credenza, l’aggiornamento bayesiano segue come conseguenza inevitabile. Le alternative—ignorare il prior, confondere le direzioni del condizionamento, non aggiornare le credenze—non sono semplicemente “scelte diverse”. Sono incoerenze.
Verso il futuro
Questo capitolo conclude la trattazione dei fondamenti. I concetti stabiliti, ovvero, prior, verosimiglianza, posterior, aggiornamento sequenziale e quantificazione dell’incertezza, costituiranno la base per tutto ciò che seguirà: modelli più complessi, metodi computazionali e applicazioni avanzate.
Tuttavia, la logica sottostante rimarrà invariata. Come scrisse Pierre-Simon Laplace oltre due secoli fa, il calcolo delle probabilità non è altro che “il buon senso ridotto a calcolo”. Il teorema di Bayes è il motore che rende possibile questa riduzione.
Punti chiave da ricordare
Concetti essenziali di questo capitolo:
-
Il teorema di Bayes come inversione probabilistica
- deriva dalla simmetria della probabilità congiunta;
- permette di passare da \(P(E \mid H)\) a \(P(H \mid E)\);
- non è un’assunzione aggiuntiva, ma una conseguenza degli assiomi.
-
Interpretazione epistemica dei componenti
- prior \(P(H)\): credenza prima dei dati;
- verosimiglianza \(P(E \mid H)\): compatibilità dati-ipotesi;
- evidenza \(P(E)\): normalizzazione;
- posterior \(P(H \mid E)\): credenza aggiornata.
-
Forma in odds
- odds posteriori = LR × Odds a priori;
- il rapporto di verosimiglianza quantifica la forza dell’evidenza;
- aggiornamenti sequenziali: i LR si moltiplicano.
-
La fallacia del tasso base
- ignorare la prevalenza porta a sovrastimare il VPP;
- lo stesso test ha significati diversi in contesti diversi;
- il teorema di Bayes costringe a considerare il contesto.
-
Aggiornamento con distribuzioni continue
- Beta-Binomiale: \(\text{Beta}(\alpha, \beta) \to \text{Beta}(\alpha+k, \beta+n-k)\);
- intervalli di credibilità: interpretazione probabilistica diretta.
Formule da ricordare:
\[P(H \mid E) = \frac{P(E \mid H) \cdot P(H)}{P(E)}\]
\[\text{Odds}(H \mid E) = \text{LR} \times \text{Odds}(H)\]
\[\text{LR}^+ = \frac{\text{Sensibilità}}{1 - \text{Specificità}}\]
Per il prossimo capitolo:
Nel Capitolo 6 inizieremo lo studio delle variabili casuali, formalizzando il passaggio da eventi discreti a quantità numeriche e preparando il terreno per modelli statistici più sofisticati.
sessionInfo()
#> R version 4.5.2 (2025-10-31)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Tahoe 26.2
#>
#> Matrix products: default
#> BLAS: /System/Library/Frameworks/Accelerate.framework/Versions/A/Frameworks/vecLib.framework/Versions/A/libBLAS.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
#>
#> locale:
#> [1] C.UTF-8/UTF-8/C.UTF-8/C/C.UTF-8/C.UTF-8
#>
#> time zone: Europe/Rome
#> tzcode source: internal
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] ragg_1.5.0 tinytable_0.15.2 withr_3.0.2
#> [4] systemfonts_1.3.1 patchwork_1.3.2 ggdist_3.3.3
#> [7] tidybayes_3.0.7 bayesplot_1.15.0 ggplot2_4.0.1
#> [10] reliabilitydiag_0.2.1 priorsense_1.2.0 posterior_1.6.1
#> [13] loo_2.9.0 rstan_2.32.7 StanHeaders_2.32.10
#> [16] brms_2.23.0 Rcpp_1.1.1 sessioninfo_1.2.3
#> [19] conflicted_1.2.0 janitor_2.2.1 matrixStats_1.5.0
#> [22] modelr_0.1.11 tibble_3.3.1 dplyr_1.1.4
#> [25] tidyr_1.3.2 rio_1.2.4 here_1.0.2
#>
#> loaded via a namespace (and not attached):
#> [1] svUnit_1.0.8 tidyselect_1.2.1 farver_2.1.2
#> [4] S7_0.2.1 fastmap_1.2.0 TH.data_1.1-5
#> [7] tensorA_0.36.2.1 digest_0.6.39 timechange_0.3.0
#> [10] estimability_1.5.1 lifecycle_1.0.5 survival_3.8-3
#> [13] magrittr_2.0.4 compiler_4.5.2 rlang_1.1.7
#> [16] tools_4.5.2 yaml_2.3.12 knitr_1.51
#> [19] labeling_0.4.3 bridgesampling_1.2-1 htmlwidgets_1.6.4
#> [22] curl_7.0.0 pkgbuild_1.4.8 RColorBrewer_1.1-3
#> [25] abind_1.4-8 multcomp_1.4-29 purrr_1.2.1
#> [28] grid_4.5.2 stats4_4.5.2 colorspace_2.1-2
#> [31] xtable_1.8-4 inline_0.3.21 emmeans_2.0.1
#> [34] scales_1.4.0 MASS_7.3-65 cli_3.6.5
#> [37] mvtnorm_1.3-3 rmarkdown_2.30 generics_0.1.4
#> [40] otel_0.2.0 RcppParallel_5.1.11-1 cachem_1.1.0
#> [43] stringr_1.6.0 splines_4.5.2 parallel_4.5.2
#> [46] vctrs_0.6.5 V8_8.0.1 Matrix_1.7-4
#> [49] sandwich_3.1-1 jsonlite_2.0.0 arrayhelpers_1.1-0
#> [52] glue_1.8.0 codetools_0.2-20 distributional_0.6.0
#> [55] lubridate_1.9.4 stringi_1.8.7 gtable_0.3.6
#> [58] QuickJSR_1.8.1 pillar_1.11.1 htmltools_0.5.9
#> [61] Brobdingnag_1.2-9 R6_2.6.1 textshaping_1.0.4
#> [64] rprojroot_2.1.1 evaluate_1.0.5 lattice_0.22-7
#> [67] backports_1.5.0 memoise_2.0.1 broom_1.0.11
#> [70] snakecase_0.11.1 rstantools_2.6.0 gridExtra_2.3
#> [73] coda_0.19-4.1 nlme_3.1-168 checkmate_2.3.3
#> [76] xfun_0.55 zoo_1.8-15 pkgconfig_2.0.3