1 Interpretazione bayesiana della probabilità
Introduzione
In questo capitolo adotteremo una prospettiva bayesiana sulla probabilità. Secondo questo approccio, la probabilità non è una proprietà intrinseca degli eventi, né una mera frequenza osservata, bensì un grado di credenza razionale che un agente assegna sulla base delle informazioni disponibili.
Questa visione, sviluppata da pensatori quali Thomas Bayes, Pierre‑Simon Laplace e Bruno de Finetti, fornisce una cornice concettuale particolarmente adatta alle scienze psicologiche, in cui spesso si è chiamati a ragionare in condizioni di informazione parziale, rumore sistematico e variabilità individuale strutturale.
Dal punto di vista bayesiano, gli assiomi della probabilità non descrivono proprietà oggettive dei fenomeni aleatori, ma costituiscono vincoli di coerenza logica per un sistema di credenze razionali. Essi specificano come le nostre valutazioni dell’incertezza devono relazionarsi tra loro per evitare contraddizioni. La violazione di questi vincoli renderebbe l’assegnazione di probabilità internamente incoerente, esponendo il soggetto a valutazioni paradossali e a scelte decisionali sistematicamente svantaggiose.
Nel corso del modulo faremo ampio uso di simulazioni al computer. Il loro scopo non è quello di definire in astratto “che cos’è” la probabilità, ma di illustrare concretamente come un sistema di credenze coerente si comporta quando entra in contatto con i dati empirici. Le simulazioni ci permetteranno di esplorare in modo intuitivo le conseguenze operative delle regole probabilistiche e di apprezzare perché l’approccio bayesiano costituisca uno strumento potente e flessibile per modellare il ragionamento scientifico e l’analisi dei dati in psicologia.
Perché la probabilità bayesiana in psicologia?
L’approccio bayesiano è particolarmente adatto alla ricerca psicologica per via di tre caratteristiche metodologiche fondamentali:
Integrazione di informazioni complementari. Molti studi operano con campioni di dimensioni modeste (\(n\) = 20–50), soprattutto in ambito clinico o sperimentale. In questi contesti, l’inferenza bayesiana compensa l’informazione limitata dai dati incorporando formalmente le conoscenze pregresse tramite la distribuzione a priori, sfruttando così tutta l’informazione disponibile in modo coerente.
Formalizzazione della conoscenza cumulativa. L’attività di ricerca raramente muove da uno stato di completa ignoranza, ma poggia invece su solide basi di letteratura e ipotesi strutturate. L’approccio bayesiano fornisce lo strumento matematico per quantificare e aggiornare tale patrimonio conoscitivo attraverso i prior, rendendo esplicito e trasparente il processo cumulativo della scienza.
Interpretabilità diretta dei risultati. L’inferenza bayesiana restituisce conclusioni formulate nel linguaggio intuitivo della probabilità. Ad esempio: “La probabilità che l’effetto sia compreso tra 0.2 e 0.8 è del 95%.” Questo approccio supera le ambiguità interpretative tipiche degli intervalli di confidenza frequentisti e facilita la traduzione dei risultati in decisioni cliniche, raccomandazioni pratiche e sviluppo teorico.
Scenario: uno psicologo clinico intende valutare l’efficacia di un nuovo protocollo per l’ansia attraverso uno studio pilota condotto su un campione ristretto (\(n\) = 15).
Approccio tradizionale: “La numerosità campionaria è insufficiente per garantire una potenza statistica adeguata. Non è possibile trarre conclusioni significative; l’unica soluzione è ampliare drasticamente il campione.”
Approccio bayesiano: “Posso integrare le evidenze della letteratura preesistente definendo un prior informativo, per poi aggiornarlo con i dati raccolti sui 15 pazienti. Ne deriverà una distribuzione a posteriori capace di quantificare con rigore sia l’effetto stimato sia l’incertezza residua, offrendo una base razionale per la decisione clinica anche in presenza di dati limitati.”
Panoramica del capitolo
- La probabilità come grado di credenza razionale.
- Incertezza epistemica e ontologica.
- Il decisore coerente di de Finetti e l’incertezza soggettiva.
- L’argomento della coerenza: il Dutch Book.
- Simulazioni come strumento di verifica (non di definizione).
- Introduzione all’aggiornamento bayesiano.
- Confronto con l’approccio frequentista.
Questo è il capitolo introduttivo del modulo. Non sono richiesti prerequisiti specifici oltre alle conoscenze di algebra elementare e statistica descrittiva indicate nell’introduzione generale.
Per consultazioni opzionali:
1.1 Casualità e incertezza: due prospettive a confronto
La vita è intrinsecamente incerta: non possiamo ricostruire il passato con precisione assoluta, né prevedere il futuro con certezza, e spesso fatichiamo a comprendere appieno la complessità del presente. Come osserva Spiegelhalter (2024), questa condizione ci invita a considerare la casualità non come una proprietà misteriosa degli eventi, ma come un modello operativo che, pur rinunciando a predizioni deterministiche, ci permette di individuare regolarità statistiche utili per interpretare la realtà e prendere decisioni informate.
Per analizzare sistematicamente l’incertezza, è utile distinguere due dimensioni fondamentali del nostro stato epistemico. Questa distinzione chiarisce quali aspetti dell’incertezza sembrano radicati nelle caratteristiche del mondo e quali, invece, derivano dai limiti della nostra conoscenza. Tale precisazione concettuale fornisce una solida base per comprendere il ruolo della probabilità nell’analisi del comportamento.
1.1.1 Incertezza epistemica
L’incertezza epistemica (dal greco ἐπιστήμη, “conoscenza”) deriva dalla mancanza di informazioni adeguate o dalla loro scarsa qualità. È un tipo di incertezza che, almeno in linea di principio, può essere ridotta: l’acquisizione di nuovi dati, l’adozione di disegni sperimentali più accurati o l’impiego di misurazioni più affidabili possono infatti diminuire il nostro margine di ignoranza.
In psicologia, l’incertezza epistemica si manifesta quotidianamente: nella limitata dimensione dei campioni, nella presenza di variabili non controllate, o nell’incompletezza delle informazioni cliniche o anamnestiche a disposizione.
1.1.2 Incertezza ontologica
L’incertezza ontologica (dal greco ὄντος, “essere”) riguarda invece l’imprevedibilità che sembra essere intrinseca ai fenomeni stessi. Questo tipo di incertezza non dipende dalle limitazioni del ricercatore e non scompare neppure quando le misurazioni sono estremamente precise.
In ambito psicologico, questa forma di incertezza include la variabilità comportamentale residua anche in condizioni sperimentali controllate, la natura probabilistica delle decisioni in situazioni ambigue e l’emergere spontaneo di fenomeni quali l’intuizione, la creatività e i cambiamenti improvvisi di strategia cognitiva.
1.1.3 La sintesi bayesiana: l’incertezza come stato epistemico
Nel framework bayesiano adottato in questo manuale, le due forme di incertezza, epistemica e ontologica, vengono trattate in modo unificato. Anche ciò che spesso viene descritto come “incertezza ontologica” viene formalizzato attraverso lo stesso strumento fondamentale: l’assegnazione di probabilità.
Questa scelta si basa su una premessa epistemologica: l’accesso dell’osservatore allo stato del sistema è sempre parziale. Di conseguenza, la probabilità diventa lo strumento con cui quantifichiamo sistematicamente i limiti della nostra conoscenza, a prescindere dal fatto che questi derivino da informazioni incomplete o dalla complessità intrinseca del fenomeno studiato.
Laplace notò che, per un intelletto onnisciente in grado di conoscere tutte le forze della natura e la posizione di ogni particella, il futuro sarebbe determinato con la stessa certezza del passato. In un universo deterministico, dunque, l’impossibilità di formulare previsioni perfette non dipenderebbe dalla natura del mondo, ma esclusivamente dall’incompletezza della nostra conoscenza.
Da questa prospettiva, la probabilità non è una proprietà intrinseca del mondo, ma una conseguenza necessaria dei limiti cognitivi ed epistemici dell’osservatore. È il nostro stato informativo, non il mondo in sé, a generare l’incertezza.
Questa interpretazione epistemica della probabilità, intesa come misura del grado di credenza razionale, costituisce il fondamento concettuale e metodologico dell’approccio seguito nel manuale Inferenza bayesiana in psicologia: Ragionare con l’incertezza. Fondamenti, workflow e applicazioni.
1.2 Il decisore coerente di fronte all’incertezza
1.2.1 Il soggettivismo di de Finetti
Nel suo lavoro seminale, Bruno de Finetti ha adottato un approccio esplicitamente soggettivo al processo decisionale in condizioni di incertezza (Finetti, 1970). Le probabilità non sono proprietà intrinseche del mondo, ma valutazioni personali che esprimono quanto un agente ritiene plausibili i diversi stati possibili del sistema.
Di fronte alle stesse circostanze incerte, due decisori possono quindi divergere, talvolta in modo marcato, sia nella stima delle probabilità, sia nella desiderabilità degli esiti, sia nella valutazione dell’influenza delle proprie azioni sui risultati. Questa variabilità non rappresenta un difetto del ragionamento, ma una caratteristica inevitabile di qualsiasi processo decisionale reale.
Il paradigma bayesiano, tuttavia, non si limita a fornire una cornice soggettivista. Esso propone anche un ideale matematico di razionalità interna, specificando come dovrebbe comportarsi un decisore che, pur mantenendo le proprie valutazioni soggettive, rispetta un requisito fondamentale: la coerenza.
Essere coerenti significa che le proprie credenze e preferenze non devono entrare in contraddizione tra loro, in modo tale da esporre l’agente a perdite certe quando le sue valutazioni vengono tradotte in decisioni. Soddisfare questo requisito non è affatto banale. Il formalismo matematico che introdurremo non mira a descrivere fedelmente le credenze di ogni decisore in ogni situazione, ma fornisce famiglie di modelli sufficientemente flessibili da rappresentare almeno una versione coerente e operativa di tali credenze.
Nel quadro bayesiano, la coerenza è il massimo che possiamo ragionevolmente richiedere a un decisore. Non gli imponiamo di compiere scelte “giuste” secondo criteri esterni o oggettivi, ma solo di mantenere un sistema di credenze compatibile con le proprie valutazioni. In questa prospettiva, tutto è soggettivo, persino affermazioni apparentemente oggettive come “il vero valore del parametro è \(x\)”.
Formulazioni di questo tipo devono essere interpretate come abbreviazioni di frasi del tipo: “Sono convinto che il vero valore del parametro sia \(x\)”. Questa rilettura, lungi dall’essere un semplice dettaglio linguistico, ci permette di accettare le divergenze tra gli agenti senza rinunciare ai vincoli imposti dal requisito di coerenza (Heard, 2021).
1.2.2 L’incertezza soggettiva
Esistono molte fonti di incertezza che possono complicare il processo decisionale: eventi futuri non ancora verificati, circostanze passate di cui non si è avuta notizia, fatti che potrebbero essere scoperti in futuro, informazioni di cui altri sono a conoscenza ma che il decisore non possiede, o conoscenze dimenticate parzialmente o completamente.
Il paradigma bayesiano tratta tutte queste forme di incertezza in modo unitario. Qualsiasi aspetto rispetto al quale il decisore è incerto deve essere esplicitamente riconosciuto e incorporato nel processo decisionale razionale. Il framework considera esclusivamente lo stato attuale delle conoscenze del decisore, a prescindere da ciò che egli dovrebbe conoscere in linea di principio (Heard, 2021).
La gestione operativa di questa molteplicità di incertezze avviene attraverso uno strumento formale centrale: la probabilità interpretata come grado di credenza razionale. Questo apparato matematico permette di quantificare in modo coerente l’incertezza soggettiva alla luce delle informazioni disponibili.
Credenza categorica e grado di credenza
Nel linguaggio quotidiano, diciamo di credere o non credere in qualcosa: credo che domani pioverà, non credo che la Terra sia piatta. Questo è un atteggiamento categorico, ovvero “tutto o nulla”: si può credere, non credere, oppure sospendere il giudizio.
L’approccio bayesiano introduce invece i gradi di credenza (credence): non solo credo che pioverà, ma ho una fiducia del 70% in questa previsione. Questo approccio è graduato e ammette infinite sfumature tra la certezza assoluta e l’incredulità totale.
Come si relazionano questi due concetti? La questione è dibattuta in epistemologia (Jackson, 2020), ma ai nostri fini possiamo adottare una prospettiva pragmatica:
- nella vita di tutti i giorni, tendiamo a ragionare in termini categorici: decidiamo di prendere l’ombrello perché crediamo che pioverà, senza calcolare esplicitamente una probabilità;
- nel ragionamento bayesiano, quantifichiamo invece l’incertezza in modo esplicito, assegnando gradi di fiducia che rispettano gli assiomi della probabilità.
Una connessione intuitiva tra i due concetti è la cosiddetta tesi lockiana: crediamo (in senso categorico) a una proposizione quando il nostro grado di fiducia in essa supera una certa soglia, ad esempio quando ne siamo fiduciosi almeno al 70% o al 90%.
Questa connessione non è priva di paradossi (il paradosso della lotteria e il paradosso della prefazione mostrano tensioni tra credenze categoriche e gradi di credenza (Jackson, 2020)), ma per i nostri scopi è sufficiente riconoscere che i due concetti catturano aspetti complementari del ragionamento: le credenze categoriche semplificano le decisioni quotidiane, mentre i gradi di credenza permettono un’analisi più approfondita dell’incertezza, particolarmente utile nella ricerca scientifica e nella pratica clinica.
1.3 Probabilità come grado di credenza
1.3.1 La visione bayesiana soggettivista
Nel paradigma bayesiano, dare una forma misurabile all’incertezza soggettiva significa interpretare la probabilità come un grado di fiducia razionale nel verificarsi di un evento, sulla base di tutte le informazioni disponibili in un determinato momento.
La probabilità è il grado di credenza (plausibilità) assegnato a un’affermazione, in base a uno specifico stato dell’informazione.
Questa definizione si basa su quattro caratteristiche essenziali.
La soggettività riconosce che individui diversi, dotati di conoscenze, esperienze e informazioni differenti, possano legittimamente attribuire probabilità diverse allo stesso evento. Tuttavia, tale soggettività non è arbitraria, ma è vincolata dalla razionalità che richiede il rispetto dei principi di coerenza logica formalizzati negli assiomi della probabilità.
Ogni valutazione probabilistica è inoltre intrinsecamente condizionata dall’insieme informativo disponibile al momento della stima: parlare di probabilità senza specificare “dato ciò che so” è, dal punto di vista bayesiano, concettualmente incompleto. Infine, il sistema è aggiornabile in modo sistematico: quando diventano disponibili nuove evidenze, le probabilità devono essere riviste in maniera coerente tramite il meccanismo dell’aggiornamento bayesiano.
Queste quattro caratteristiche rendono la probabilità uno strumento flessibile ma rigoroso per rappresentare e gestire l’incertezza nei contesti reali di decisione e di analisi dei dati.
Probabilità come credenza in psicologia clinica
Consideriamo, ad esempio, l’interpretazione di un test per la depressione. Lo stesso punteggio assume significati clinici profondamente diversi in due contesti diversi:
- se il soggetto è ricoverato in psichiatria, dove la prevalenza del disturbo è elevata;
- se proviene dalla popolazione generale, dove la prevalenza è bassa.
La probabilità che il soggetto sia effettivamente depresso non rappresenta una caratteristica intrinseca del risultato del test, ma piuttosto un grado di credenza razionale che sintetizza diverse fonti di informazione: le conoscenze pregresse (prevalenza del disturbo nel contesto, informazioni anamnestiche), l’evidenza empirica fornita dal test (sensibilità e specificità) e il ragionamento bayesiano che combina coerentemente questi elementi.
In questa prospettiva, la probabilità diventa una misura quantitativa della nostra conoscenza incerta riguardo alla condizione del paziente, piuttosto che una proprietà oggettiva e immutabile dell’evento stesso.
1.4 La coerenza: l’argomento della scommessa olandese
Se la probabilità viene interpretata come un grado di credenza soggettivo, come possiamo giustificare gli assiomi matematici che la governano? La risposta è fornita dal celebre argomento della scommessa olandese (Dutch Book), sviluppato da Frank Ramsey e Bruno de Finetti.
1.4.1 L’idea centrale
Supponiamo che un decisore sia talmente sicuro delle proprie valutazioni probabilistiche da essere disposto a scommettere denaro sulla loro correttezza. Cosa succede se queste credenze sono internamente incoerenti? L’argomento della scommessa olandese mostra che, in tal caso, esiste sempre una combinazione di puntate che il decisore giudica accettabili e che, se accettata, garantisce una perdita certa a prescindere dall’esito del fenomeno.
L’incoerenza non è quindi un problema puramente astratto o teorico, ma una forma di vulnerabilità strategica: un sistema di credenze incoerente può essere sfruttato sistematicamente a svantaggio dell’agente.
Consideriamo un caso semplice: il lancio di una moneta. Un decisore che assegna la stessa probabilità (2/3) sia a Testa sia a Croce ritiene equivalenti le seguenti scommesse:
- pagare 2 € per ricevere 3 € se esce Testa;
- pagare 2 € per ricevere 3 € se esce Croce.
Accettando entrambe le scommesse, il decisore paga complessivamente 4 €. Qualunque sia l’esito del lancio, incasserà solo 3 €, subendo una perdita certa di 1 €. L’avversario, simmetricamente, ottiene un guadagno garantito.
Questa è l’essenza della scommessa olandese: un agente incoerente può essere messo in condizione di perdere sempre. In questo esempio, l’incoerenza risiede nel fatto che le probabilità assegnate ai due esiti mutuamente esclusivi sommano a più di 1, violando le regole fondamentali della probabilità.
1.4.2 Gli assiomi di Kolmogorov
I lavori di Ramsey e De Finetti hanno dimostrato che per evitare tali perdite certe è necessario rispettare specifici vincoli di coerenza. Questi vincoli sono formalizzati nei tre assiomi della probabilità, introdotti assiomaticamente da Kolmogorov.
Una funzione di probabilità \(P\) definita su un insieme di eventi deve soddisfare:
Non negatività:
\[0 \leq P(A) \leq 1.\]
Il grado di credenza in un evento non può essere negativo né superare la certezza assoluta.Normalizzazione:
\[P(\Omega) = 1.\]
La probabilità dell’insieme di tutti gli eventi possibili è unitaria.Additività: per eventi mutuamente esclusivi (\(A \cap B = \emptyset\)):
\[P(A \cup B) = P(A) + P(B).\]
La probabilità dell’unione di eventi incompatibili è pari alla somma delle probabilità dei singoli eventi.
Questi assiomi non sono semplici convenzioni matematiche. Essi esprimono le condizioni minime che un sistema di credenze deve soddisfare per essere internamente coerente e per non esporre l’agente a perdite certe quando le proprie valutazioni vengono tradotte in decisioni.
1.4.3 Implicazioni per la psicologia
L’argomento della scommessa olandese mostra che le regole della probabilità hanno un significato pragmatico: non descrivono solo relazioni formali tra eventi, ma stabiliscono anche i vincoli che un sistema di credenze deve rispettare per poter guidare scelte razionali in condizioni di incertezza.
La psicologia cognitiva ha ampiamente documentato che gli individui mostrano deviazioni sistematiche da questi criteri di coerenza (Griffiths et al., 2024). L’argomento della scommessa olandese chiarisce la portata pratica di tali deviazioni: non si tratta soltanto di distorsioni cognitive astratte, ma di vulnerabilità decisionali che possono tradursi in esiti prevedibilmente sfavorevoli ogni volta che le credenze orientano il comportamento.
Una trattazione più formale dell’argomento del Dutch Book, insieme al Principio Principale di Lewis (che collega credenze soggettive e probabilità oggettive) e alle diverse misure quantitative dell’evidenza, si trova nel capitolo sui fondamenti-epistemologici del sito companion.
Le origini della teoria della probabilità risalgono al XVII secolo, quando Blaise Pascal e Pierre de Fermat iniziarono a studiare problemi legati ai giochi d’azzardo. Parallelamente a questa tradizione, fin dal Settecento si sviluppò un filone di pensiero che concepiva la probabilità come uno strumento per ragionare razionalmente in condizioni di incertezza: è in questo contesto che nacque l’approccio bayesiano.
Thomas Bayes (1701–1761) formulò il teorema che porta il suo nome, pubblicato postumo nel 1763. Il suo contributo fondamentale fu l’idea che il ragionamento probabilistico possa essere invertito: a partire dall’osservazione degli effetti, è possibile aggiornare razionalmente le proprie credenze sulle cause non osservate. Questo principio è alla base dell’inferenza bayesiana moderna.
Pierre-Simon Laplace (1749–1827) sviluppò e sistematizzò il lavoro di Bayes, applicando l’inferenza probabilistica a una vasta gamma di problemi scientifici. La sua celebre definizione della probabilità come “buon senso ridotto a calcolo” anticipa l’interpretazione epistemologica contemporanea. Come egli stesso osservò, “la probabilità è relativa in parte all’ignoranza e in parte alla conoscenza”, sottolineando che l’incertezza nasce dallo stato informativo dell’osservatore.
Bruno de Finetti (1906–1985) fornì una fondazione filosofica rigorosa alla probabilità bayesiana soggettivista. La sua affermazione provocatoria secondo cui “la probabilità non esiste” va intesa nel senso che la probabilità non è una proprietà intrinseca del mondo fisico, ma uno strumento formale per quantificare l’incertezza soggettiva. De Finetti sviluppò l’argomento della scommessa olandese e il concetto di scambiabilità, mostrando che risultati classici come la legge dei grandi numeri possono essere derivati senza postulare l’esistenza di probabilità oggettive.
Harold Jeffreys (1891–1989), nel suo influente Theory of Probability (1939), elaborò un approccio bayesiano spesso definito “oggettivo”, basato sull’uso di prior non informativi e su principi di invarianza. La sua opera dimostrò l’efficacia pratica dell’inferenza bayesiana nell’analisi dei dati scientifici, contribuendo a renderla uno strumento metodologico utilizzabile in contesti applicativi reali.
Dopo un periodo di relativa eclissi, dovuto al predominio della statistica frequentista di Fisher, Neyman e Pearson, l’approccio bayesiano ha conosciuto una significativa rinascita a partire dagli anni Novanta del XX secolo. Questa rinascita è stata resa possibile dallo sviluppo di tecniche computazionali avanzate, come i metodi Monte Carlo via catena di Markov (MCMC), dalla pubblicazione di nuovi testi didattici e divulgativi (Gelman et al., 2013; Johnson et al., 2022; Kruschke, 2014; McElreath, 2020), e dalla crescente applicazione dell’inferenza bayesiana nel machine learning e nell’intelligenza artificiale.
1.5 Il ruolo delle simulazioni: illustrazione, non definizione
Una differenza fondamentale tra l’approccio bayesiano e quello frequentista classico riguarda l’interpretazione del ruolo delle simulazioni e della legge dei grandi numeri. In particolare, le due prospettive divergono sul significato delle frequenze empiriche e sul modo in cui queste si relazionano al concetto di probabilità.
1.5.1 La prospettiva frequentista
Secondo la prospettiva frequentista, la probabilità di un evento è definita come il limite della sua frequenza relativa in una sequenza ideale infinita di prove identiche:
\[ P(A) = \lim_{n \to \infty} \frac{\text{frequenza di occorrenza di } A}{n}. \]
Questa definizione implica alcune assunzioni chiave: la probabilità è concepita come una proprietà oggettiva del fenomeno, esiste indipendentemente dall’osservatore ed è, almeno in linea di principio, stimabile tramite esperimenti ripetuti o simulazioni. In questo contesto, la probabilità concettualmente coincide con il comportamento a lungo termine delle frequenze osservate.
Quando viene applicato a decisioni concrete, tuttavia, questo approccio presenta diverse difficoltà:
Eventi singolari o non ripetibili
Non è chiaro come attribuire una probabilità a eventi unici, come “domani pioverà a Firenze”, poiché non è possibile osservare una sequenza infinita di repliche dello stesso evento.Limite ideale e irraggiungibile: una definizione basata su un’astrazione non osservabile La definizione si fonda su un concetto teorico, il limite di una sequenza infinita di prove identiche, che non può essere realizzato empiricamente. Nella pratica, è necessario fermarsi a un numero finito di osservazioni \(n\), ottenendo una frequenza relativa \(\hat{p}\) che è solo una stima della probabilità \(P(A)\). La probabilità vera rimane quindi un’entità ideale e inosservabile, e non esiste un criterio puramente frequentista per stabilire quando una stima finita sia “abbastanza buona”.
Mancanza di una quantificazione dell’incertezza per la singola decisione (il “problema del singolo caso”) Anche quando un evento è ripetibile e disponiamo di una stima frequentista robusta (ad esempio: “Il 55% dei pazienti trattati con questa psicoterapia ha mostrato una riduzione clinicamente rilevante dei sintomi”), tale probabilità descrive il comportamento di un collettivo (l’intera popolazione del campione studiato). Tuttavia, per un individuo (un singolo paziente o uno psicologo che deve prendere una decisione per lui) o per una singola istanza futura, l’approccio frequentista non fornisce uno strumento matematico diretto per quantificare l’incertezza soggettiva o la credenza razionale riguardo al verificarsi o meno dell’evento in quel caso specifico.
In altre parole, la probabilità frequentista risponde alla domanda: “Che cosa accade in generale?”, ma non risponde formalmente alla domanda cruciale nella pratica: “Date le informazioni che ho su questo specifico caso, quanto è ragionevole credere che la terapia avrà successo?”. La risposta del frequentista rimanda necessariamente al livello della frequenza di gruppo, lasciando al decisore il compito di tradurre soggettivamente quel dato collettivo in un giudizio sul caso singolo.
In sintesi, la prospettiva frequentista è particolarmente adatta alla descrizione di fenomeni ripetibili su grandi campioni, ma risulta meno naturale quando l’obiettivo è ragionare e prendere decisioni in contesti singoli o non replicabili.
1.5.2 La prospettiva bayesiana
La prospettiva bayesiana propone un’interpretazione diversa: la probabilità è intesa come un grado di credenza razionale riguardo al verificarsi di un evento, sulla base delle informazioni disponibili. Le assegnazioni probabilistiche riflettono quindi lo stato informativo dell’agente prima dell’osservazione dei dati.
In questo contesto, le simulazioni non servono a definire che cosa sia la probabilità, ma a verificare che un sistema di credenze coerente produca comportamenti empirici compatibili con le aspettative. La Legge dei Grandi Numeri spiega perché, se le credenze iniziali sono coerenti, le frequenze osservate tenderanno a rifletterle nel lungo periodo. Tuttavia, questa convergenza non costituisce la definizione ontologica della probabilità, ma una conseguenza delle sue regole di coerenza.
Prospettiva frequentista
«La probabilità è pari a 0.5 perché, in una sequenza infinita di lanci, la frequenza relativa dell’esito “testa” convergerà asintoticamente al 50%.» (la probabilità è definita come proprietà del comportamento osservabile nel lungo periodo)
Prospettiva bayesiana
«Attribuisco una probabilità di 0.5 in virtù di un principio di simmetria epistemica: in assenza di informazioni che favoriscano un esito rispetto a un altro, questa rappresenta la mia misura razionale di incertezza. La legge dei grandi numeri garantisce che le frequenze empiriche tenderanno, nel lungo periodo, a riflettere tale assegnazione iniziale.» (la probabilità esprime uno stato di conoscenza che guida aspettative razionali sui fenomeni osservabili)
La distinzione è sostanziale. Nel paradigma frequentista, la probabilità di un evento è definita attraverso la regolarità empirica che emerge dalla ripetizione ideale di un esperimento. Nel paradigma bayesiano, invece, la probabilità rappresenta uno stato di conoscenza: un modello interno coerente che quantifica l’incertezza e consente di formulare previsioni razionali sui fenomeni che possono essere successivamente confrontate con l’evidenza empirica.
1.5.3 Simulazione come verifica di coerenza
Nel quadro bayesiano, le simulazioni svolgono un ruolo di verifica e di illustrazione. Esse mostrano come un sistema di credenze coerente generi regolarità empiriche compatibili con le aspettative teoriche.
Le simulazioni permettono di illustrare concetti quali la convergenza statistica e la variabilità campionaria, di confrontare le previsioni di un modello probabilistico con i dati osservati e di esplorare il comportamento dei modelli in condizioni controllate. È importante sottolineare che le simulazioni non stabiliscono cosa sia la probabilità, ma rendono visibili le conseguenze operative delle assegnazioni probabilistiche.
1.5.4 Esempio: lancio di moneta rivisitato
set.seed(42)
# Assegno credenza P(Testa) = 0.5 per simmetria epistemica
p_testa_credenza <- 0.5
# Simulazione: verifico che questa credenza è coerente
n_lanci <- 10000
risultati <- rbinom(n_lanci, 1, p_testa_credenza)
# Frequenza cumulativa
freq_cumulativa <- cumsum(risultati) / seq_along(risultati)
# Grafico
df <- data.frame(
lancio = seq_along(risultati),
freq = freq_cumulativa
)
ggplot(df, aes(x = lancio, y = freq)) +
geom_line(alpha = 0.7) +
geom_hline(yintercept = p_testa_credenza,
linetype = "dashed", color = "red", size = 1) +
scale_fill_qualitative() +
labs(
title = "Frequenza cumulativa converge alla credenza",
subtitle = "La credenza P(Testa)=0.5 predice la convergenza osservata",
x = "Numero di lanci",
y = "Frequenza cumulativa di Teste"
) +
ylim(0.3, 0.7)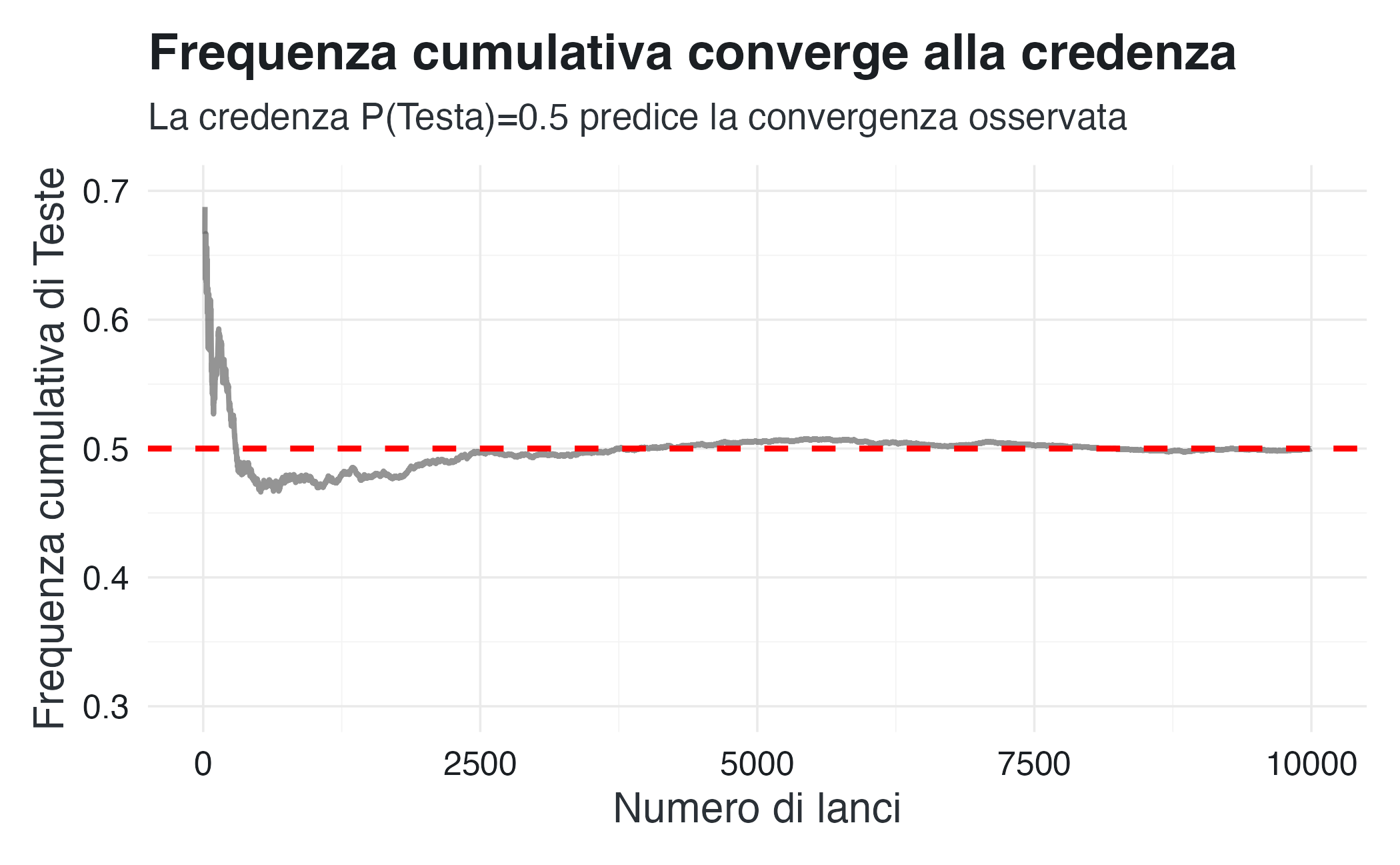
L’interpretazione bayesiana di questa simulazione evidenzia che l’assegnazione di \(P(\text{Testa}) = 0.5\) deriva da un principio di simmetria epistemica, in assenza di informazioni che privilegino un esito rispetto all’altro. La simulazione verifica la coerenza di questa credenza con il comportamento empirico atteso. È importante notare che la probabilità 0.5 non è definita dalla convergenza empirica, ma rappresenta un’assegnazione a priori che la legge dei grandi numeri successivamente conferma.
1.6 Introduzione all’aggiornamento bayesiano
Uno dei principi centrali dell’epistemologia bayesiana è che un agente razionale possiede credenze di diversa intensità che devono rispettare i vincoli di coerenza imposti dagli assiomi della probabilità. Sia lo stato attuale di una credenza sia la sua evoluzione in seguito all’acquisizione di nuove informazioni possono essere rappresentati tramite distribuzioni di probabilità.
1.6.1 Il principio di condizionamento
Il Principio di Condizionamento stabilisce come un agente razionale debba aggiornare le proprie credenze di fronte a nuove evidenze. Esso traduce il concetto di probabilità condizionata in una regola operativa: la probabilità iniziale (o a priori) di un’ipotesi \(H\) viene trasformata nella sua probabilità finale (o a posteriori), una volta osservato un dato \(E\) rilevante.
Più che un assioma, il principio è una prescrizione di coerenza dinamica: impone che il nuovo grado di credenza in \(H\) coincida con la probabilità che ad esso si attribuiva inizialmente, dato che si è verificato \(E\). Formalmente, se al tempo \(t\) si assegna \(P_t(H)\) e al tempo \(t' > t\) si osserva l’evidenza \(E\), allora la credenza aggiornata deve essere
\[ P_{t'}(H) = P_t(H \mid E). \]
In questo modo, l’informazione nuova viene incorporata in modo sistematico e non arbitrario, garantendo che la revisione delle credenze rimanga coerente con lo stato di conoscenza precedente.
1.6.2 Il teorema di Bayes
Il teorema di Bayes è la regola matematica che realizza il principio di condizionamento. Esso fornisce il calcolo esplicito della probabilità a posteriori:
\[ P(H \mid E) = \frac{P(E \mid H)\, P(H)}{P(E)}. \]
Il teorema scompone la credenza aggiornata in tre componenti fondamentali:
- Probabilità a priori \(P(H)\): il grado di credenza iniziale nell’ipotesi, prima dell’osservazione.
- Verosimiglianza \(P(E \mid H)\): quanto sia probabile osservare l’evidenza \(E\) nell’ipotesi che \(H\) sia vera. Essa misura la compatibilità del dato con l’ipotesi.
- Probabilità marginale dell’evidenza \(P(E)\): un fattore di normalizzazione che garantisce la coerenza e che è pari alla probabilità totale di osservare \(E\) sotto tutte le possibili ipotesi.
In sintesi, il teorema formalizza in modo inequivocabile come una credenza iniziale \(P(H)\) venga modulata dalla forza dell’evidenza \(P(E \mid H)\) per produrre una credenza finale \(P(H \mid E)\). Questo processo rappresenta il nucleo matematico dell’apprendimento da esperienza: l’aggiornamento sistematico e coerente delle opinioni alla luce di nuovi dati.
1.6.2.1 Applicazione ai test diagnostici
Un esempio paradigmatico di aggiornamento bayesiano è l’interpretazione dei risultati di un test diagnostico. In questo contesto, l’ipotesi \(H\) corrisponde tipicamente alla presenza di una malattia \(D\), mentre l’evidenza \(E\) è un risultato positivo del test (\(+\)).
La probabilità a priori \(P(D)\) riflette la prevalenza della malattia nella popolazione di riferimento. La verosimiglianza \(P(+ \mid D)\) coincide con la sensibilità del test, ovvero la probabilità di ottenere un risultato positivo in un soggetto effettivamente malato, mentre \(P(+ \mid \neg D)\) rappresenta il tasso di falsi positivi (ovvero, l’evento complementare della specificità).
Il teorema di Bayes consente di combinare queste informazioni per ottenere la probabilità a posteriori di malattia in presenza di un risultato positivo:
\[ P(D \mid +) = \frac{P(+ \mid D)\, P(D)} {P(+ \mid D)\, P(D) + P(+ \mid \neg D)\, P(\neg D)}. \]
In questo modo, l’aggiornamento bayesiano integra in modo coerente le caratteristiche del test (sensibilità e specificità) con il contesto epidemiologico (prevalenza), fornendo una stima quantitativa della probabilità che un individuo sia effettivamente malato dopo aver ottenuto un risultato positivo.
1.6.2.1.1 Implementazione numerica
Per fare un esempio, consideriamo uno scenario diagnostico con prevalenza \(P(D) = 0.10\), sensibilità \(P(+ \mid D) = 0.80\) e specificità \(P(- \mid \neg D) = 0.90\) (da cui un tasso di falsi positivi \(P(+ \mid \neg D) = 0.10\)).
# Parametri del test
p_D <- 0.10 # Prevalenza = prior P(D)
sens <- 0.80 # Sensibilità = P(+ | D)
spec <- 0.90 # Specificità = P(- | ~D)
p_pos_given_notD <- 1 - spec # Falsi positivi P(+ | ~D)
# Probabilità complessiva di test positivo
p_pos <- sens * p_D + p_pos_given_notD * (1 - p_D)
# Teorema di Bayes: posterior
p_D_given_pos <- (sens * p_D) / p_pos
cat("P(D) =", p_D, "\n")
#> P(D) = 0.1
cat("P(D | +) =", round(p_D_given_pos, 3), "\n")
#> P(D | +) = 0.471L’aggiornamento delle conoscenze rivela che, nonostante il risultato positivo del test, la probabilità a posteriori di essere malati è solo del 47%. Questo risultato controintuitivo si spiega con la bassa prevalenza della malattia nella popolazione: il numero di falsi positivi è così elevato da superare quello dei veri positivi.
1.6.2.1.2 Analisi tramite tabella di contingenza
La rappresentazione tramite tabella di contingenza per una popolazione di 1000 individui chiarisce visivamente il risultato:
# Costruzione della tabella di contingenza
N <- 1000
malati <- N * p_D
sani <- N * (1 - p_D)
veri_positivi <- malati * sens
falsi_negativi <- malati * (1 - sens)
falsi_positivi <- sani * p_pos_given_notD
veri_negativi <- sani * spec
tabella_contingenza <- data.frame(
Stato_reale = c("Malato (D)", "Sano (¬D)", "Totale"),
Positivo = c(veri_positivi, falsi_positivi, veri_positivi + falsi_positivi),
Negativo = c(falsi_negativi, veri_negativi, falsi_negativi + veri_negativi),
Totale = c(malati, sani, N)
)
tabella_contingenza
#> Stato_reale Positivo Negativo Totale
#> 1 Malato (D) 80 20 100
#> 2 Sano (¬D) 90 810 900
#> 3 Totale 170 830 1000La tabella mostra che su 170 test positivi totali, solo 80 (il 47%) provengono da persone malate. I rimanenti 90 (il 53%) sono falsi positivi di persone sane.
1.6.2.2 Sintesi concettuale
Il processo di aggiornamento bayesiano può essere riassunto in forma schematica come una trasformazione razionale delle credenze alla luce dell’evidenza empirica:
\[ \underbrace{P(D)}_{\text{prior}} \;\xrightarrow[\text{osservazione dei dati}]{\text{aggiornamento bayesiano}}\; \underbrace{P(D \mid +)}_{\text{posterior}}. \]
Questa rappresentazione mette in evidenza un principio centrale dell’inferenza bayesiana: l’interpretazione dell’evidenza è sempre relativa allo stato informativo di partenza. Anche un’informazione altamente diagnostica, come un test caratterizzato da elevata sensibilità e specificità, può condurre a una probabilità a posteriori modesta se l’ipotesi considerata era inizialmente poco plausibile.
Dal punto di vista psicologico, ciò chiarisce perché le persone, inclusi spesso i professionisti, tendano a sovrastimare \(P(D \mid +)\) in presenza di un risultato positivo, trascurando la prevalenza di base del fenomeno (fallacia del tasso base). Il teorema di Bayes fornisce quindi non solo una regola di calcolo, ma anche un correttivo normativo a una delle più robuste distorsioni del ragionamento umano in condizioni di incertezza.
Più in generale, l’inferenza bayesiana fornisce un modello formale del ragionamento inferenziale mostrando come le nuove informazioni debbano essere integrate in modo coerente con le conoscenze pregresse, evitando sia di ignorare i dati sia di sopravvalutarli. In questo senso, il teorema di Bayes non è solo uno strumento matematico, ma una guida razionale per pensare e decidere in condizioni di incertezza.
1.7 Il ruolo della probabilità nello studio dei fenomeni psicologici
La teoria bayesiana della probabilità si rivela particolarmente adatta allo studio dei fenomeni psicologici, in quanto fornisce strumenti concettuali e metodologici in grado di affrontare in modo esplicito e coerente l’incertezza che caratterizza sia la ricerca empirica sia la pratica clinica.
1.7.1 Quantificare l’incertezza diagnostica
La pratica clinica si svolge raramente in condizioni di certezza assoluta. Il processo diagnostico richiede l’integrazione di molteplici fonti informative, quali l’anamnesi, l’osservazione comportamentale e i test psicometrici, ciascuna delle quali presenta un proprio grado di affidabilità e incertezza.
Il framework bayesiano fornisce strumenti formali per quantificare l’incertezza diagnostica e per aggiornare in modo sistematico le credenze del clinico alla luce di ogni nuova evidenza. Un aspetto particolarmente rilevante è la possibilità di incorporare esplicitamente la prevalenza dei disturbi nella popolazione di riferimento, riducendo il rischio di errori diagnostici dovuti alla negligenza dei tassi di base.
1.7.2 Modellare i processi cognitivi
Un filone di ricerca sempre più influente propone che molti aspetti del funzionamento cognitivo umano possano essere descritti come approssimazioni di un ragionamento bayesiano ideale (Griffiths et al., 2024). In ambito percettivo, ad esempio, numerosi modelli suggeriscono che il cervello integri sistematicamente le aspettative pregresse con le informazioni sensoriali correnti.
Questa prospettiva permette di spiegare fenomeni come le illusioni percettive, in cui aspettative forti possono prevalere su segnali sensoriali ambigui. Allo stesso modo, l’apprendimento può essere interpretato come un processo di aggiornamento bayesiano delle credenze in risposta all’esperienza, mentre molti bias cognitivi documentati in letteratura possono essere visti come deviazioni sistematiche dall’ottimalità bayesiana.
1.7.3 Analisi dei dati sperimentali
Dal punto di vista metodologico, l’inferenza bayesiana offre diversi vantaggi nell’analisi dei dati psicologici. Consente, infatti, di incorporare formalmente le conoscenze pregresse attraverso distribuzioni a priori, di quantificare direttamente l’evidenza a favore di ipotesi specifiche (superando alcune limitazioni del valore-\(p\)), di gestire in modo naturale i campioni di piccole dimensioni e di propagare l’incertezza in modo coerente attraverso tutti i livelli dei modelli statistici complessi.
Queste caratteristiche rendono l’approccio bayesiano particolarmente adatto alla complessità e alla variabilità tipiche dei dati psicologici.
1.7.4 Decisioni cliniche
In ambito terapeutico, l’approccio bayesiano supporta il processo decisionale clinico mediante l’aggiornamento sequenziale delle stime di efficacia degli interventi. Le informazioni derivanti da studi condotti su popolazioni generali possono essere progressivamente integrate con le risposte specifiche del singolo paziente.
Questo processo iterativo consente di adattare i protocolli terapeutici alla luce di nuove evidenze e fornisce strumenti analitici per bilanciare probabilità ed esiti attesi nelle scelte cliniche, promuovendo una pratica informata, flessibile e coerente con l’incertezza intrinseca del contesto clinico. ## Confronto con l’approccio frequentista
Per comprendere appieno la prospettiva bayesiana, è utile confrontarla con l’approccio frequentista, mettendo in luce le differenze fondamentali già a livello di definizione della probabilità. Nel frequentismo, la probabilità è interpretata come il limite della frequenza relativa di un evento in una serie infinita ideale di prove ripetute. Nell’approccio bayesiano, invece, la probabilità è intesa come un grado di credenza razionale, soggettivo ma formalmente coerente, assegnato a eventi o ipotesi in condizioni di incertezza.
Nel paradigma frequentista, i parametri di interesse sono considerati quantità fisse ma ignote: non è lecito attribuire loro una probabilità. L’inferenza si concentra quindi sulle proprietà delle procedure di stima nel lungo periodo, valutando il loro comportamento in un numero teoricamente infinito di replicazioni dello stesso esperimento. Al contrario, l’approccio bayesiano tratta i parametri come variabili aleatorie dotate di distribuzioni di probabilità che rappresentano l’incertezza dell’osservatore Questo consente di formulare direttamente affermazioni probabilistiche, come ad esempio: “La probabilità che l’effetto del trattamento sia positivo è pari a 0.85”.
Una differenza particolarmente rilevante riguarda gli intervalli di stima. Nel frequentismo, un intervallo di confidenza al 95% viene costruito in modo tale che, in una sequenza ideale di repliche dello stesso esperimento, il 95% degli intervalli così ottenuti contenga il valore effettivo del parametro. Tuttavia, questa interpretazione non consente di attribuire una probabilità a un intervallo specifico una volta osservati i dati.
Gli intervalli di credibilità bayesiani, invece, ammettono un’interpretazione probabilistica diretta: dati i dati osservati e il modello adottato, possiamo affermare, ad esempio, che esiste una probabilità del 95% che il parametro cada all’interno dell’intervallo. Questa caratteristica rende l’inferenza bayesiana particolarmente adatta a supportare decisioni concrete in contesti applicativi.
Un’ulteriore differenza riguarda il ruolo delle conoscenze pregresse. Il framework frequentista non fornisce un meccanismo formale per integrarle nell’analisi, mentre l’approccio bayesiano le incorpora esplicitamente attraverso la distribuzione a priori, rendendo trasparente il modo in cui le informazioni precedenti contribuiscono alle inferenze finali.
Infine, l’approccio frequentista fa ampio uso dei valori-\(p\), che rispondono alla domanda: “Quanto sarebbero sorprendenti i dati osservati se l’ipotesi nulla fosse vera?”. Tuttavia, questa quantità non corrisponde direttamente alla domanda scientifica che spesso interessa il ricercatore, ovvero la plausibilità dell’ipotesi alla luce dei dati osservati. L’approccio bayesiano, invece, consente di rispondere direttamente a questa domanda centrale, calcolando le probabilità a posteriori delle ipotesi e fornendo una misura quantitativa della loro credibilità razionale.
❌ FALSO: «La probabilità bayesiana è un’opinione soggettiva arbitraria»
✅ VERO: La probabilità bayesiana rispetta pienamente gli assiomi della probabilità. I prior vengono aggiornati in modo rigoroso e oggettivo dai dati tramite il teorema di Bayes.
❌ FALSO: «Per un’inferenza valida serve sempre un campione molto grande»
✅ VERO: Con prior informativi, anche campioni piccoli possono produrre inferenze utili. L’aspetto cruciale è quantificare correttamente l’incertezza.
❌ FALSO: «L’approccio bayesiano è solo per esperti di matematica»
✅ VERO: I software moderni (come brms e rstanarm) rendono l’approccio bayesiano accessibile. Questo modulo fornirà le basi necessarie per utilizzarlo in modo consapevole.
Riflessioni conclusive
In questo capitolo abbiamo abbandonato l’interpretazione della probabilità come frequenza relativa, per abbracciare una visione più ampia: la probabilità come grado di credenza razionale. Questa prospettiva, che affonda le sue radici nella tradizione di Bayes, Laplace e De Finetti, non costituisce un mero tecnicismo matematico, ma rappresenta una vera e propria lente interpretativa attraverso cui analizzare il ragionamento umano in condizioni di incertezza.
In questa prospettiva, gli assiomi della probabilità assumono un nuovo significato: non sono semplici regole matematiche, ma principi di coerenza logica che vincolano le nostre credenze. Essi rappresentano i requisiti minimi di razionalità la cui violazione porterebbe inevitabilmente a contraddizioni interne e a scelte decisionali sistematicamente svantaggiose.
L’approccio bayesiano offre quindi un grande vantaggio epistemologico: permette di quantificare l’incertezza anche riguardo a eventi singoli e non ripetibili, come la prognosi di un paziente specifico o l’esito di un’elezione politica, senza dover ricorrere alla finzione concettuale di esperimenti infinitamente replicabili. L’incertezza non è più una proprietà del “mondo esterno” che emerge solo in lunghe sequenze di prove, ma diventa una misura della nostra conoscenza imperfetta riguardo a ogni singolo evento.
Questo quadro teorico garantisce un’elevata trasparenza epistemica: ogni assunzione iniziale viene resa esplicita attraverso la scelta del prior, mentre il processo di apprendimento dai dati viene formalizzato con rigore matematico attraverso il teorema di Bayes. L’aggiornamento delle credenze non è così affidato all’intuizione soggettiva, ma segue regole di coerenza interna precise e verificabili.
Nei prossimi capitoli svilupperemo gli strumenti formali di questo approccio. Scopriremo che concetti spesso considerati oggettivi, come l’equiprobabilità, non sono proprietà intrinseche del mondo, ma riflettono simmetrie nel nostro stato informativo. La probabilità bayesiana non elimina l’incertezza, ma fornisce un linguaggio matematico per quantificarla, comunicarla e gestirla in modo razionale.
Questo costituisce forse il suo contributo più prezioso allo studio dei fenomeni psicologici: un ambito in cui l’incertezza non è un’eccezione da eliminare, ma una condizione strutturale con cui ogni ricercatore e professionista deve costantemente confrontarsi.
Punti chiave da ricordare
Concetti essenziali di questo capitolo:
-
Interpretazione soggettivista della probabilità
- La probabilità misura il grado di credenza razionale di un agente riguardo a un evento incerto
- È personale ma non arbitraria: deve rispettare regole di coerenza
-
Differenza con l’approccio frequentista
- Frequentista: probabilità come limite di frequenze relative (ripetibilità)
- Bayesiano: probabilità come quantificazione dell’incertezza epistemica
-
Applicabilità universale
- L’approccio bayesiano si applica a eventi non ripetibili (es. probabilità che piova domani, che un’ipotesi scientifica sia vera)
Per il prossimo capitolo:
Nel Capitolo 2 vedremo come le regole di coerenza delle credenze si formalizzano negli assiomi della probabilità, garantendo che i nostri gradi di credenza siano internamente consistenti.
sessionInfo()
#> R version 4.5.2 (2025-10-31)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Tahoe 26.2
#>
#> Matrix products: default
#> BLAS: /System/Library/Frameworks/Accelerate.framework/Versions/A/Frameworks/vecLib.framework/Versions/A/libBLAS.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
#>
#> locale:
#> [1] C.UTF-8/UTF-8/C.UTF-8/C/C.UTF-8/C.UTF-8
#>
#> time zone: Europe/Rome
#> tzcode source: internal
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] ragg_1.5.0 tinytable_0.15.2 withr_3.0.2
#> [4] systemfonts_1.3.1 patchwork_1.3.2 ggdist_3.3.3
#> [7] tidybayes_3.0.7 bayesplot_1.15.0 ggplot2_4.0.1
#> [10] reliabilitydiag_0.2.1 priorsense_1.2.0 posterior_1.6.1
#> [13] loo_2.9.0 rstan_2.32.7 StanHeaders_2.32.10
#> [16] brms_2.23.0 Rcpp_1.1.1 sessioninfo_1.2.3
#> [19] conflicted_1.2.0 janitor_2.2.1 matrixStats_1.5.0
#> [22] modelr_0.1.11 tibble_3.3.1 dplyr_1.1.4
#> [25] tidyr_1.3.2 rio_1.2.4 here_1.0.2
#>
#> loaded via a namespace (and not attached):
#> [1] svUnit_1.0.8 tidyselect_1.2.1 farver_2.1.2
#> [4] S7_0.2.1 fastmap_1.2.0 TH.data_1.1-5
#> [7] tensorA_0.36.2.1 digest_0.6.39 timechange_0.3.0
#> [10] estimability_1.5.1 lifecycle_1.0.5 survival_3.8-3
#> [13] magrittr_2.0.4 compiler_4.5.2 rlang_1.1.7
#> [16] tools_4.5.2 yaml_2.3.12 knitr_1.51
#> [19] labeling_0.4.3 bridgesampling_1.2-1 htmlwidgets_1.6.4
#> [22] curl_7.0.0 pkgbuild_1.4.8 RColorBrewer_1.1-3
#> [25] abind_1.4-8 multcomp_1.4-29 purrr_1.2.1
#> [28] grid_4.5.2 stats4_4.5.2 colorspace_2.1-2
#> [31] xtable_1.8-4 inline_0.3.21 emmeans_2.0.1
#> [34] scales_1.4.0 MASS_7.3-65 cli_3.6.5
#> [37] mvtnorm_1.3-3 rmarkdown_2.30 generics_0.1.4
#> [40] otel_0.2.0 RcppParallel_5.1.11-1 cachem_1.1.0
#> [43] stringr_1.6.0 splines_4.5.2 parallel_4.5.2
#> [46] vctrs_0.6.5 V8_8.0.1 Matrix_1.7-4
#> [49] sandwich_3.1-1 jsonlite_2.0.0 arrayhelpers_1.1-0
#> [52] glue_1.8.0 codetools_0.2-20 distributional_0.6.0
#> [55] lubridate_1.9.4 stringi_1.8.7 gtable_0.3.6
#> [58] QuickJSR_1.8.1 pillar_1.11.1 htmltools_0.5.9
#> [61] Brobdingnag_1.2-9 R6_2.6.1 textshaping_1.0.4
#> [64] rprojroot_2.1.1 evaluate_1.0.5 lattice_0.22-7
#> [67] backports_1.5.0 memoise_2.0.1 broom_1.0.11
#> [70] snakecase_0.11.1 rstantools_2.6.0 gridExtra_2.3
#> [73] coda_0.19-4.1 nlme_3.1-168 checkmate_2.3.3
#> [76] xfun_0.55 zoo_1.8-15 pkgconfig_2.0.3