here::here("code", "_common.R") |>
source()
# Load packages
if (!requireNamespace("pacman")) install.packages("pacman")
pacman::p_load(patchwork, ggforce, DiagrammeR)
# Riapplica il tema per sicurezza
apply_visual_theme()4 Probabilità condizionata come aggiornamento
Introduzione
Immaginate di essere uno psicologo clinico che ha appena ricevuto il risultato positivo di un test per un paziente. Prima del test, avevate stimato la probabilità di depressione sulla base della sua storia, dei sintomi e del contesto. Ora la prova è sul tavolo. Cosa è cambiato?
Tutto e niente. I fatti oggettivi non sono cambiati: il paziente era depresso o non lo era già prima dell’esito del test. Ciò che è cambiato radicalmente è il vostro stato di conoscenza. Avete incorporato un’informazione nuova che deve ristrutturare in modo coerente la vostra valutazione iniziale.
Questo processo dinamico di revisione razionale delle credenze di fronte all’evidenza è l’essenza stessa del pensiero bayesiano. La formula che lo incarna e lo rende operativo è la probabilità condizionata, il ponte matematico che collega sistematicamente il prima e il dopo.
4.1 Perché la probabilità condizionata è fondamentale
La probabilità condizionata non è un concetto tecnico fra i tanti. È il concetto che trasforma il calcolo delle probabilità in un ragionamento dinamico. Senza di essa, la probabilità sarebbe un sistema statico e inerte di fronte all’esperienza, incapace di apprendere.
In fondo, quasi ogni domanda rilevante nella ricerca e nella pratica psicologica esplicita una condizione:
- “Qual è la probabilità di ricaduta, dato che il paziente ha completato il trattamento?”
- “Qual è la probabilità che il bambino abbia l’ADHD, dato che il test è positivo?”
- “Qual è la probabilità di successo terapeutico, dato che conosciamo il profilo di personalità del paziente?”
Ogni volta che usiamo espressioni come “dato che”, “sapendo che” o “alla luce di”, stiamo implicitamente facendo riferimento alla probabilità condizionata. Essa formalizza l’idea intuitiva secondo cui ciò che sappiamo influenza ciò che possiamo ragionevolmente credere. È il ponte matematico tra un’evidenza osservata e un’ipotesi incerta, lo strumento che ci consente di aggiornare le nostre mappe mentali quando la realtà ci fornisce nuovi dati.
4.1.1 Un cambio di prospettiva epistemologico
C’è un punto filosofico importante da cogliere subito. Dal punto di vista bayesiano, ogni probabilità è sempre condizionata, anche quando non lo scriviamo esplicitamente.
Quando diciamo “\(P(A) = 0.3\)”, in realtà intendiamo “\(P(A \mid \mathcal{I}) = 0.3\)”, dove \(\mathcal{I}\) rappresenta tutto ciò che sappiamo: dati precedenti, teoria, contesto e assunzioni di modello. Non esistono probabilità assolute e prive di contesto; ogni assegnazione di probabilità è sempre condizionata implicitamente o esplicitamente a uno specifico sfondo informativo \(\mathcal{I}\).
Ciò significa che la notazione \(P(A)\) è un’abbreviazione comoda, non una descrizione di una proprietà intrinseca del mondo. La probabilità condizionata \(P(A \mid B)\) non è quindi un caso speciale, ma la forma generale. La probabilità “non condizionata” è semplicemente il caso in cui non esplicitiamo lo sfondo informativo.
4.1.2 Il percorso del capitolo
In questo capitolo esploreremo la probabilità condizionata da diverse angolazioni:
come meccanismo di aggiornamento: vedremo che apprendere “\(B\) è vero” significa restringere lo spazio delle possibilità e rinormalizzare le credenze;
come fondamento dell’indipendenza: capiremo che due eventi sono “indipendenti” quando l’informazione su uno non fornisce alcuna informazione sull’altro;
come strumento per costruire modelli complessi: il teorema del prodotto ci mostrerà come assemblare probabilità congiunte a partire da componenti più semplici;
come protezione dagli errori: il paradosso di Simpson illustrerà i pericoli dell’aggregazione incauta dei dati.
Questi concetti preparano direttamente il terreno per il teorema di Bayes che, nel prossimo capitolo, emergerà come la regola per “invertire” le probabilità condizionate, passando da ciò che i dati ci dicono sulle ipotesi a ciò che le ipotesi ci dicono sui dati.
ConsiglioPrerequisiti
Per seguire questo capitolo è necessario aver letto:
Conoscenze matematiche richieste:
- Appendice D - per operazioni su eventi (intersezione, unione);
- Appendice C - per la legge della probabilità totale.
Competenze pratiche:
- Familiarità con tabelle congiunte e rappresentazioni 2×2;
- Nozioni base di R per eseguire le simulazioni presentate.
Panoramica del capitolo
- Probabilità condizionata come riduzione dello spazio epistemico.
- Interpretazione epistemica dell’aggiornamento.
- Indipendenza come assenza di informazione reciproca.
- Teorema del prodotto e probabilità congiunta.
- Legge della probabilità totale.
- Paradosso di Simpson.
- Applicazioni a diagnostica clinica e test psicologici.
AttenzionePreparazione del Notebook
4.2 Definizione e interpretazione epistemica
Arriviamo ora alla definizione formale. Ma prima di presentarla, è utile capire cosa stiamo cercando di catturare.
Partiamo da una credenza iniziale in un evento \(A\). Poi apprendiamo che si è verificato un altro evento \(B\). Come dovrebbe cambiare la nostra credenza in \(A\)?
La risposta intuitiva è che dovremmo considerare solo le situazioni in cui \(B\) è vero e vedere quanto spesso \(A\) è vero in quelle situazioni. La formula seguente traduce esattamente questa intuizione in linguaggio matematico.
Definizione 4.1 (Probabilità condizionata) Se \(P(B) > 0\), la probabilità condizionata di \(A\) dato \(B\) è definita come:
\[ P(A \mid B) = \frac{P(A \cap B)}{P(B)}. \tag{4.1}\]
Interpretazione epistemica: \(P(A \mid B)\) quantifica il nostro grado di credenza in \(A\) dopo aver appreso che \(B\) è vero, tenendo conto del fatto che ora lo spazio delle possibilità si è ristretto a quelle compatibili con \(B\).
4.2.1 Perché questa formula e non un’altra?
La definizione potrebbe sembrare arbitraria: perché proprio quel rapporto? La risposta è che questa è l’unica formula coerente con i principi che abbiamo stabilito nei capitoli precedenti.
Immaginiamo di partire da una distribuzione di probabilità congiunta, ovvero la nostra “mappa” completa delle credenze su tutti gli scenari possibili. Apprendere che \(B\) è vero comporta due operazioni concettuali.
ImportanteIl meccanismo dell’aggiornamento
Riduzione e rinormalizzazione
L’acquisizione dell’informazione “\(B\) è vero” innesca un processo in due fasi:
1. Riduzione epistemica
Lo spazio delle possibilità \(\Omega\) viene ristretto al solo sottoinsieme \(B\). Tutte le configurazioni in cui \(B\) è falso vengono eliminate, non perché siano diventate “impossibili” in senso metafisico, ma perché sono diventate irrilevanti per il nostro ragionamento. Sappiamo che una di queste configurazioni non si è verificata.
2. Rinormalizzazione
Le probabilità delle configurazioni rimanenti (quelle in cui \(B\) è vero) vengono riscalate in modo che tornino a sommare a 1. Il fattore di scala è esattamente \(1/P(B)\).
Conseguenza importante: I rapporti relativi tra le probabilità delle configurazioni compatibili con \(B\) rimangono invariati. Se prima di apprendere \(B\) consideravamo la configurazione \(X\) due volte più probabile della configurazione \(Y\) (entrambe dentro \(B\)), dopo l’aggiornamento \(X\) rimane due volte più probabile di \(Y\).
Questa procedura garantisce coerenza: se avessimo modellato fin dall’inizio un mondo in cui \(B\) è l’unica possibilità, avremmo ottenuto esattamente le stesse probabilità relative che otteniamo condizionando.
4.2.2 Un’analogia utile: lo zoom fotografico
Pensate alla distribuzione di probabilità congiunta come a una fotografia di un paesaggio. La probabilità condizionata è come fare uno zoom su una porzione dell’immagine (la regione \(B\)).
Quando si effettua uno zoom:
- perdiamo di vista tutto ciò che sta fuori dalla regione inquadrata (riduzione);
- i dettagli della regione inquadrata riempiono ora tutto lo schermo (rinormalizzazione);
- i rapporti tra gli elementi all’interno della regione rimangono invariati.
# Visualizzazione grafica dell'aggiornamento
P_A <- 0.6
P_B <- 0.5
P_AB <- 0.35
P_A_given_B <- P_AB / P_B
P_Ac_given_B <- 1 - P_A_given_B
df <- data.frame(
Parte = c("A ∩ B", "A^c ∩ B"),
Valore = c(P_A_given_B, P_Ac_given_B)
)
ggplot(df, aes(x = "", y = Valore, fill = Parte)) +
geom_col(width = 0.6) +
coord_flip() +
geom_text(aes(label = sprintf("%.2f", Valore)),
position = position_stack(vjust = 0.5),
color = "white", size = 5) +
scale_fill_qualitative() +
labs(
title = "Probabilità condizionata: 'zoom' nello spazio B",
subtitle = sprintf("P(A|B) = %.2f/%.2f = %.2f", P_AB, P_B, P_A_given_B),
x = NULL, y = "Probabilità nel nuovo universo (B)"
) +
theme(axis.text.y = element_blank(),
panel.grid.major.y = element_blank(),
legend.position = "bottom")
Il grafico mostra come, dopo aver appreso \(B\), la massa probabilistica si ridistribuisce solo tra le configurazioni compatibili con \(B\). La proporzione tra \(A \cap B\) e \(A^c \cap B\) rimane quella originale, è solo la scala ad essere cambiata.
4.3 Proprietà della probabilità condizionata
Un risultato importante, che conferma la coerenza della definizione, è che le probabilità condizionate soddisfano tutti gli assiomi della probabilità. In altre parole, \(P(\cdot \mid B)\) è essa stessa una funzione di probabilità legittima, con \(B\) che funge da nuovo “universo”.
Teorema 4.1 (Proprietà della condizionata) Fissato un evento \(B\) con \(P(B) > 0\), la funzione \(P(\cdot \mid B)\) soddisfa tutti gli assiomi della probabilità.
Non-negatività: \(P(A \mid B) \geq 0\) per ogni evento \(A\).
Normalizzazione: \(P(B \mid B) = 1\) (certezza di \(B\) dato \(B\)).
Additività: se \(A_1, A_2\) sono eventi disgiunti, allora \[P(A_1 \cup A_2 \mid B) = P(A_1 \mid B) + P(A_2 \mid B).\]
Complemento: \(P(A^c \mid B) = 1 - P(A \mid B).\)
Regola della catena (o del prodotto): \[P(A \cap B \mid C) = P(A \mid B \cap C) \cdot P(B \mid C).\]
4.3.1 Cosa significa epistemicamente
Queste proprietà hanno un’interpretazione profonda: ci dicono che il ragionamento sotto informazione parziale obbedisce alle stesse regole del ragionamento generale. Non esistono “leggi speciali” per il condizionamento, ma solo l’applicazione coerente dei principi fondamentali a un universo ristretto.
La proprietà di normalizzazione, \(P(B \mid B) = 1\), merita attenzione: se sappiamo che \(B\) è vero, la nostra credenza in \(B\) deve essere assoluta. Può sembrare ovvio, ma è una conseguenza non banale della definizione. Qualsiasi altra regola di aggiornamento che non rispettasse questa proprietà sarebbe incoerente.
NotaEsempio clinico: test di screening per la depressione
Contesto
Uno psicologo utilizza un test di screening per il disturbo depressivo maggiore in un contesto di comunità. Questa situazione è paradigmatica: abbiamo informazioni sulla prevalenza del disturbo e sulle caratteristiche del test, e vogliamo capire cosa significhi un risultato positivo o negativo per un paziente specifico.
Informazioni epidemiologiche disponibili:
- prevalenza nella popolazione: \(P(D) = 0.08\) (l’8% degli individui presenta il disturbo);
- sensibilità del test: \(P(T^+ \mid D) = 0.85\) (l’85% dei depressi risulta positivo);
- specificità del test: \(P(T^- \mid D^c) = 0.90\) (il 90% dei non depressi risulta negativo).
Costruzione della distribuzione congiunta
Il primo passo è tradurre queste informazioni in una tabella di probabilità congiunta.
# Parametri epidemiologici
P_D <- 0.08
sens <- 0.85
spec <- 0.90
# Tassi di classificazione errata
fp_rate <- 1 - spec # P(T+ | D^c) = 0.10
# Probabilità congiunte
P_D_and_Tpos <- sens * P_D
P_D_and_Tneg <- (1 - sens) * P_D
P_Dc_and_Tpos <- fp_rate * (1 - P_D)
P_Dc_and_Tneg <- spec * (1 - P_D)
# Calcolo delle probabilità condizionate
P_Tpos <- P_D_and_Tpos + P_Dc_and_Tpos
P_Tneg <- P_D_and_Tneg + P_Dc_and_Tneg
P_D_given_Tpos <- P_D_and_Tpos / P_Tpos
P_D_given_Tneg <- P_D_and_Tneg / P_Tneg
# Rappresentazione tabellare
tab_diagnostic <- matrix(
c(P_D_and_Tpos, P_D_and_Tneg,
P_Dc_and_Tpos, P_Dc_and_Tneg),
nrow = 2, byrow = TRUE,
dimnames = list(
Stato = c("D", "D^c"),
Test = c("T+", "T-")
)
)Le domande cliniche cruciali
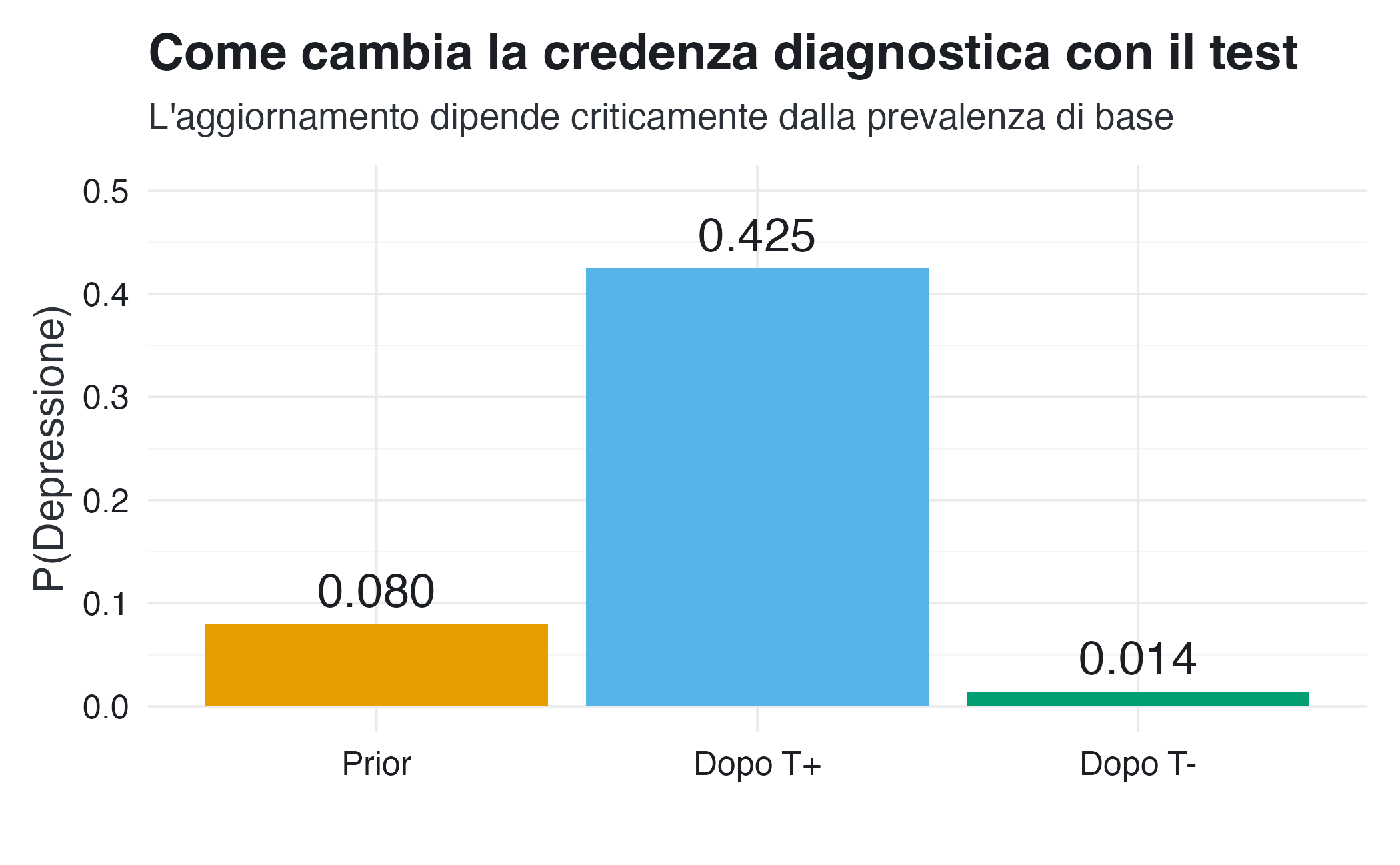
Il valore predittivo positivo risponde alla domanda: “Se il test è positivo, quanto è probabile che il paziente sia davvero depresso?”
\[P(D \mid T^+) = 0.43\]
Questo risultato è spesso sorprendente. Il test ha una sensibilità dell’85%: sembra ottimo! Eppure, un test positivo indica la presenza di depressione solo nel 42% dei casi. Perché?
La ragione è la bassa prevalenza. Nella popolazione generale, infatti, il 92% delle persone non è depresso. Anche con un tasso di falsi positivi “basso” del 10%, questo produce un numero assoluto di falsi positivi che è paragonabile a quello dei veri positivi.
Il valore predittivo negativo risponde alla domanda opposta:
\[P(D^c \mid T^-) = 1 - P(D \mid T^-) = 0.986\]
In questo contesto, un test negativo è molto più informativo: riduce la probabilità di depressione a circa l’1%. Il test è più utile per escludere la diagnosi che per confermarla.
Visualizzazione dell’aggiornamento
La lezione epistemica
Questo esempio illustra un principio fondamentale: l’informazione fornita da un test dipende non solo dalle sue caratteristiche intrinseche (sensibilità e specificità), ma anche dal contesto in cui viene applicato (prevalenza). Lo stesso test, con le stesse proprietà, può essere molto informativo in un contesto ad alta prevalenza e quasi inutile in uno a bassa prevalenza.
Ciò è una diretta conseguenza della struttura della probabilità condizionata, in quanto l’aggiornamento dipende sia dal numeratore (la probabilità congiunta) sia dal denominatore (la probabilità marginale del condizionante).
Verifica con simulazione
set.seed(123)
N <- 100000
# Simulare stato reale e risultato test
stato <- rbinom(N, 1, P_D) # 1 = Depresso, 0 = Non depresso
test_result <- ifelse(stato == 1,
rbinom(N, 1, sens), # Se depresso, test+ con prob sens
rbinom(N, 1, fp_rate)) # Se non depresso, test+ con prob fp_rate
# Calcolare condizionate empiriche
P_D_given_Tpos_sim <- mean(stato[test_result == 1] == 1)
P_D_given_Tneg_sim <- mean(stato[test_result == 0] == 1)Le simulazioni confermano i calcoli: \(P(D \mid T^+)_{sim} = 0.418\) (teorico: 0.425).
4.4 Indipendenza stocastica
Abbiamo visto che la probabilità condizionata descrive l’impatto dell’informazione su un evento sulle credenze riguardo a un altro evento. Ma cosa succede quando l’informazione non modifica nulla?
Questa situazione limite, l’indipendenza, è tanto importante quanto il caso generale. Descrive le situazioni in cui due aspetti del mondo sono, dal punto di vista informativo, completamente separati.
Definizione 4.2 (Indipendenza (definizione epistemica)) Due eventi \(A\) e \(B\) sono detti indipendenti (notazione: \(A \perp B\)) se l’informazione che uno dei due eventi si è verificato non modifica la credenza relativa all’altro:
\[ P(A \mid B) = P(A), \] e, in modo equivalente,
\[ P(B \mid A) = P(B). \]
4.4.1 Cosa significa davvero l’indipendenza
L’indipendenza è un concetto epistemico, non causale. Affermare che \(A\) e \(B\) sono indipendenti non significa che non abbiano relazioni causali, ma che, date le informazioni in nostro possesso, sapere che uno si è verificato non ci dice nulla sull’altro.
Un esempio classico è il lancio di due monete. Sapere che la prima è uscita testa non ci dice nulla sulla seconda. Tuttavia, questo non è un fatto “della natura”, ma una conseguenza del modo in cui modifichiamo la situazione, assumendo che i lanci siano fisicamente isolati e che non ci siano informazioni nascoste che li colleghino.
4.4.2 La fattorizzazione come conseguenza
Dalla definizione segue immediatamente una proprietà algebrica fondamentale:
\[ P(A \cap B) = P(A) \cdot P(B). \]
Questa relazione è spesso presentata come definizione di indipendenza, ma è più illuminante considerarla come conseguenza della definizione epistemica. La fattorizzazione dice che la probabilità congiunta “si scompone” nel prodotto delle marginali: non c’è nulla nella distribuzione congiunta che non sia già catturato dalle marginali separate.
4.4.3 Test di indipendenza nella pratica
Quando abbiamo una tabella di probabilità congiunta, possiamo verificare l’indipendenza confrontando:
- la probabilità congiunta osservata \(P(A \cap B)\);
- il prodotto delle marginali \(P(A) \cdot P(B)\).
Se coincidono, gli eventi sono indipendenti; altrimenti, c’è informazione reciproca.
# Esempio con il test diagnostico
P_A <- rowSums(tab_diagnostic)[1] # P(D)
P_B <- colSums(tab_diagnostic)[1] # P(T+)
P_AB_obs <- tab_diagnostic[1, 1] # P(D ∩ T+)
P_AB_indep <- P_A * P_B # Se fossero indipendenti
cat("P(D) × P(T+) =", round(P_AB_indep, 4), "\n")
#> P(D) × P(T+) = 0.0128
cat("P(D ∩ T+) osservato =", round(P_AB_obs, 4), "\n")
#> P(D ∩ T+) osservato = 0.068
cat("Differenza:", round(P_AB_obs - P_AB_indep, 4), "\n")
#> Differenza: 0.0552Nel caso del test diagnostico, la differenza è sostanziale: test e stato sono (fortunatamente!) dipendenti. Un test diagnostico deve essere dipendente dalla condizione che cerca di rilevare, altrimenti sarebbe inutile.
AvvisoUn errore comune: confondere disgiunzione e indipendenza
Due eventi disgiunti (mutualmente esclusivi) non possono essere indipendenti, a meno che uno dei due abbia probabilità zero.
Questo è controintuitivo per molti studenti, che pensano: “Se non possono verificarsi insieme, devono essere ‘separati’, quindi indipendenti.” Ma è proprio il contrario!
Perché?
Se \(A \cap B = \varnothing\) e \(P(A) > 0\), \(P(B) > 0\), allora:
\[ P(A \cap B) = 0, \quad\text{mentre}\quad P(A) \cdot P(B) > 0. \]
La fattorizzazione fallisce clamorosamente.
Interpretazione epistemica
Gli eventi disgiunti sono massimamente dipendenti: l’informazione che uno si è verificato implica con certezza che l’altro non si è verificato. Non esiste informazione più forte di questa! L’indipendenza, al contrario, è l’assenza totale di informazione reciproca.
Pensateci in questo modo: se so che è uscito un numero pari, so con certezza che non è uscito un numero dispari. Questa è dipendenza totale, non indipendenza.
4.5 Teorema del prodotto (regola della catena)
Il teorema del prodotto ci permette di costruire probabilità congiunte a partire da componenti più semplici. Non introduce nuove assunzioni, ma è una riformulazione diretta della definizione di probabilità condizionata e fornisce uno strumento operativo potente.
Teorema 4.2 (Teorema del prodotto) Per due eventi \(A\) e \(B\) con \(P(B) > 0\):
\[ P(A \cap B) = P(A \mid B) \cdot P(B). \]
Per simmetria (scambiando i ruoli di \(A\) e \(B\)):
\[ P(A \cap B) = P(B \mid A) \cdot P(A). \]
4.5.1 Interpretazione: costruire credenze complesse da credenze semplici
Il teorema del prodotto ci dice che possiamo considerare la probabilità congiunta come a un processo sequenziale:
- prima valutiamo la probabilità che \(B\) sia vero: \(P(B)\).
- poi valutiamo la probabilità che \(A\) sia vero dato che \(B\) è vero: \(P(A \mid B)\);
- la probabilità che entrambi siano veri è il prodotto.
Questa scomposizione non è solo un trucco di calcolo. Riflette un modo naturale di costruire modelli complessi, in cui si specifica come gli eventi si influenzano sequenzialmente piuttosto che cercare di specificare direttamente tutte le probabilità congiunte.
4.5.2 La regola della catena: generalizzazione a molti eventi
Il teorema si estende naturalmente a sequenze di eventi:
\[ P(A_1 \cap A_2 \cap \cdots \cap A_n) = P(A_1) \cdot P(A_2 \mid A_1) \cdot P(A_3 \mid A_1 \cap A_2) \cdots P(A_n \mid A_1 \cap \cdots \cap A_{n-1}). \]
Ogni fattore condiziona su tutto ciò che “viene prima”. Questo è esattamente il modo in cui funziona l’aggiornamento sequenziale delle credenze: partiamo da una credenza iniziale, poi incorporiamo informazioni una alla volta, aggiornando a ogni passo.
NotaEsempio: test diagnostici multipli
Scenario clinico
Un paziente con sospetto disturbo d’ansia si sottopone a due test: un questionario autosomministrato (\(T_1\)) e un colloquio clinico strutturato (\(T_2\)).
Informazioni disponibili:
- prevalenza: \(P(\text{Ansia}) = 0.20\);
- questionario: sensibilità 0.80, falsi positivi 0.15;
- colloquio: sensibilità 0.85, falsi positivi 0.10.
Assunzione chiave: i due test sono condizionatamente indipendenti dato lo stato del paziente. Ciò significa che, una volta noto se il paziente soffre o meno del disturbo, il risultato di un test non fornisce alcuna informazione sul risultato dell’altro.
Questa assunzione è cruciale, ma non sempre realistica (ad esempio, se entrambi i test misurano gli stessi sintomi, potrebbero essere correlati anche in presenza di uno stato noto). Tuttavia, rappresenta un punto di partenza ragionevole.
Calcolo della probabilità congiunta
La probabilità che il paziente sia ansioso e che risulti positivo a entrambi i test è:
\[ P(\text{Ansia} \cap T_1^+ \cap T_2^+) = P(T_2^+ \mid \text{Ansia}) \cdot P(T_1^+ \mid \text{Ansia}) \cdot P(\text{Ansia}) \]
\[ = 0.85 \times 0.80 \times 0.20 = 0.136 \]
Interpretazione
Il 13.6% della popolazione risulterà positivo a entrambi i test e sarà effettivamente ansioso. Questo valore combina coerentemente:
- la probabilità a priori del disturbo;
- le caratteristiche dei due strumenti;
- l’assunzione di indipendenza condizionale.
Il teorema del prodotto rende esplicita la combinazione di queste componenti, consentendo di controllare le assunzioni e di modificarle, se necessario.
4.6 Legge della probabilità totale
La legge della probabilità totale è una diretta conseguenza del teorema del prodotto, ma merita un’attenzione a sé stante, in quanto risponde a una domanda frequente: come calcolare la probabilità di un evento che può verificarsi attraverso scenari alternativi?
Teorema 4.3 (Legge della probabilità totale) Sia \({B_1, B_2, \ldots, B_n}\) una partizione dello spazio campionario \(\Omega\), ossia un insieme di eventi che soddisfa le seguenti proprietà:
\[ B_i \cap B_j = \varnothing \quad \text{per } i \neq j, \qquad \bigcup_{i=1}^n B_i = \Omega. \]
In altre parole, gli eventi \(B_i\) sono mutuamente esclusivi e collettivamente esaustivi: ogni possibile esito appartiene a uno e un solo elemento della partizione.
In queste condizioni, la probabilità di un evento (A) può essere espressa come:
\[ P(A) = \sum_{i=1}^{n} P(A \mid B_i), P(B_i). \]
In parole semplici: si sommano i contributi che ogni scenario \(B_i\) fornisce ad \(A\), ponderando ciascuno per la probabilità che tale scenario si verifichi.
4.6.1 Interpretazione: il principio dello “scenario per scenario”
La formula racchiude un principio di ragionamento universale: la probabilità totale si ottiene considerando tutti i modi alternativi in cui l’evento può verificarsi.
- \(P(A \mid B_i)\) risponde a: “Se ci troviamo nello scenario \(B_i\), quanto è probabile \(A\)?”;
- \(P(B_i)\) risponde a: “Qual è la probabilità che ci si trovi proprio nello scenario \(B_i\)?”.
La legge formalizza l’idea di calcolare la media di queste possibilità, assegnando a ciascuna di esse un peso proporzionale alla sua plausibilità. È il modo matematicamente corretto di “fare un passo indietro” quando la risposta diretta alla domanda “Quanto è probabile \(A\)?” è “Dipende dal contesto”.
4.6.2 L’importanza epistemologica e il legame con Bayes
Questa legge non è un semplice trucco algebrico, ma un pilastro del ragionamento probabilistico per due ragioni fondamentali:
- Ponte verso Bayes: è il passaggio cruciale per calcolare il denominatore nel teorema di Bayes (\(P(E)\)). Senza di essa, non potremmo combinare in modo coerente l’evidenza osservata (\(E\)) con le nostre ipotesi (\(H_i\)) per ottenere credenze aggiornate.
- Modello di pensiero strutturato: fornisce una strategia sistematica per gestire l’incertezza complessa. Invece di affrontare un problema incerto in blocco, lo si scompone in scenari più semplici e condizionati, che poi vengono ricomposti. È l’essenza del pensiero analitico.
Esempio lampante: riprendendo il caso del test diagnostico, la probabilità di un risultato positivo \(P(T^+)\) si calcola proprio applicando questa legge, ovvero sommando la probabilità di un risultato positivo tra i malati (\(P(T^+ \mid D)P(D)\)) e quella tra i sani (\(P(T^+ \mid \neg D)P(\neg D)\)). È la procedura che, nel nostro esempio precedente, ha rivelato che la maggior parte dei risultati positivi erano in realtà falsi.
4.6.3 Applicazione: trattare popolazioni eterogenee (clinica specializzata vs. popolazione generale)
In contesti reali, i pazienti provengono spesso da sottopopolazioni con rischi di base molto diversi. Immaginiamo uno scenario clinico in cui un nuovo test per la depressione viene somministrato a due gruppi distinti:
| Fonte del Paziente | Proporzione della Popolazione | Prevalenza della Depressione |
|---|---|---|
| Clinica Specialistica | 30% | 40% |
| Popolazione Generale | 70% | 5% |
Il test presenta una sensibilità \(P(T+ \mid D)\) di 0.85 e una specificità \(P(T^- \mid \neg D)\) di 0.90. Con questi dati, qual è la probabilità complessiva di un test positivo?
4.6.3.1 Calcolo passo-passo
Passo 1: calcolare i tassi di positività in ogni sottogruppo. Per ciascun gruppo, il tasso di positività combina veri positivi e falsi positivi, tenendo conto del loro rischio di base.
Per la Clinica Specialistica (Alta Prevalenza): \[ P(T^+ \mid \text{Clinica}) = (0.85 \times 0.40) + ((1 - 0.90) \times (1 - 0.40)) = 0.34 + 0.06 = 0.40. \]
Per la Popolazione Generale (Bassa Prevalenza): \[ P(T^+ \mid \text{Pop.Gen.}) = (0.85 \times 0.05) + ((1 - 0.90) \times (1 - 0.05)) = 0.0425 + 0.095 = 0.1375 \]
Passo 2: calcolare il tasso di positività complessivo (applicando la legge della probabilità totale). La legge della probabilità totale ci dice di calcolare la media ponderata dei tassi dei sottogruppi, utilizzando la proporzione dei pazienti come peso:
\[ P(T^+) = (0.40 \times 0.30) + (0.1375 \times 0.70) = 0.12 + 0.09625 \approx 0.216. \]
Risultato: la probabilità complessiva di un test positivo in questa popolazione mista è di circa il 21.6%.
4.6.3.2 Implicazioni cliniche e concettuali
Questo semplice calcolo rivela un principio fondamentale per la pratica e la ricerca:
Il “numero aggregato” maschera la realtà: il tasso complessivo del 21.6% è un valore medio che nasconde una profonda eterogeneità. Un test positivo in una clinica specialistica (dove il tasso è del 40%) ha un significato predittivo molto diverso rispetto a un test positivo nella popolazione generale (dove il tasso è solo del 13.75%).
La prevalenza è parte integrante del risultato: la probabilità di un test positivo non dipende solo dall’affidabilità del test, ma dalla popolazione a cui viene applicato. Ignorare questa eterogeneità (utilizzando, ad esempio, un unico “valore di cutoff” per tutti) porta inevitabilmente a interpretazioni errate e a decisioni cliniche potenzialmente inappropriate.
La legge è uno strumento di disaggregazione: la legge della probabilità totale fornisce il metodo formale per gestire questa complessità. Consente di scomporre un problema aggregato in scenari omogenei più semplici, calcolare le probabilità in ciascuno di essi e poi ricomporli correttamente per ottenere un quadro realistico.
In sintesi, questo esempio mostra come la legge della probabilità totale non sia una mera curiosità matematica, ma una necessità pratica per qualsiasi valutazione diagnostica o decisione in contesti eterogenei.
4.7 Paradosso di Simpson
Il paradosso di Simpson è uno degli esempi più istruttivi, e più insidiosi, di come un’aggregazione ingenua dei dati possa condurre a conclusioni diametralmente opposte rispetto a quelle valide a livello disaggregato. Più che un paradosso logico, esso rappresenta un avvertimento metodologico cruciale: i dati non “parlano da soli”. L’interpretazione corretta dipende in modo cruciale dal particolare contesto informativo che si assume come condizione per l’analisi.
4.7.1 Il fenomeno
Il paradosso di Simpson si manifesta quando una relazione statistica osservata tra due variabili si inverte una volta che i dati vengono analizzati separatamente all’interno di sottogruppi rilevanti. In altre parole, una tendenza apparente nell’analisi aggregata può contraddire sistematicamente le tendenze presenti in ogni sottogruppo.
Ciò si verifica in presenza di una variabile confondente che influenza sia l’esposizione (ad esempio, il trattamento ricevuto) sia l’esito (ad esempio, la guarigione). Ignorare tale variabile equivale a confrontare grandezze non omogenee, producendo inferenze spurie.
NotaEsempio: efficacia di un trattamento per la depressione
Il caso
Due cliniche, la A e la B, stanno valutando l’efficacia di un nuovo trattamento per la depressione. La clinica A si occupa principalmente di casi lievi, mentre la clinica B si occupa principalmente di casi gravi.
# Clinica A (casi lievi)
n_A_trattati <- 90
n_A_guariti_trattati <- 81 # 90% successo
n_A_controllo <- 10
n_A_guariti_controllo <- 9 # 90% successo
# Clinica B (casi gravi)
n_B_trattati <- 10
n_B_guariti_trattati <- 2 # 20% successo
n_B_controllo <- 90
n_B_guariti_controllo <- 27 # 30% successo
# Proporzioni per clinica
prop_A_trattati <- n_A_guariti_trattati / n_A_trattati
prop_A_controllo <- n_A_guariti_controllo / n_A_controllo
prop_B_trattati <- n_B_guariti_trattati / n_B_trattati
prop_B_controllo <- n_B_guariti_controllo / n_B_controllo
# Aggregato
n_tot_trattati <- n_A_trattati + n_B_trattati
n_tot_guariti_trattati <- n_A_guariti_trattati + n_B_guariti_trattati
n_tot_controllo <- n_A_controllo + n_B_controllo
n_tot_guariti_controllo <- n_A_guariti_controllo + n_B_guariti_controllo
prop_tot_trattati <- n_tot_guariti_trattati / n_tot_trattati
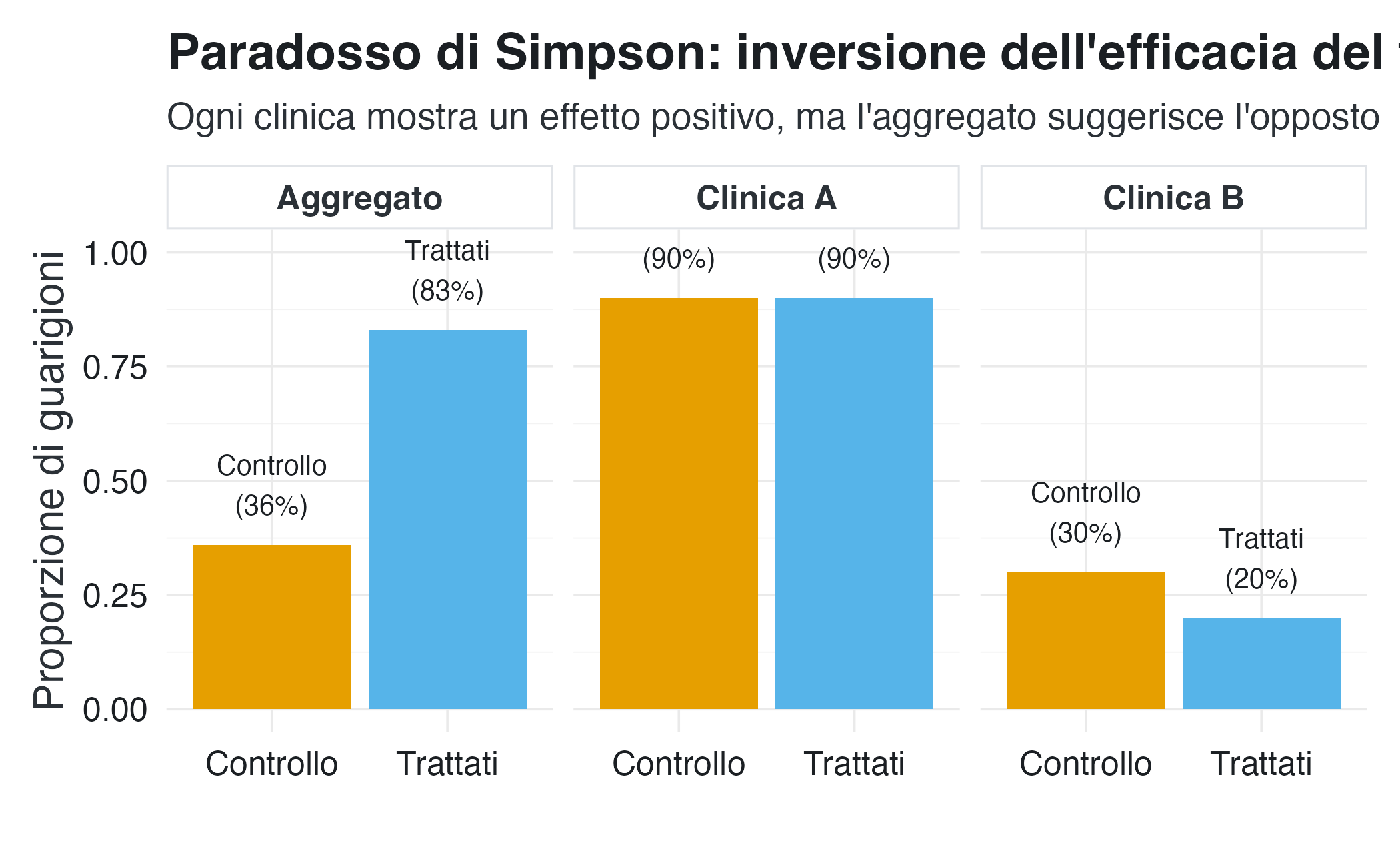
prop_tot_controllo <- n_tot_guariti_controllo / n_tot_controlloRisultati per sottogruppo
- Clinica A (casi lievi): Trattati 90%, Controllo 90% → nessuna differenza.
- Clinica B (casi gravi): Trattati 20%, Controllo 30% → trattamento peggiore.
In nessun sottogruppo il trattamento risulta superiore al controllo.
Risultato aggregato
- Trattati: 83%.
- Controllo: 36%.
Nell’analisi aggregata, il trattamento appare invece nettamente migliore del controllo.
Cosa sta succedendo?
La chiave interpretativa risiede nella distribuzione diseguale dei casi:
- la clinica B (casi gravi, bassa probabilità di guarigione) contribuisce in misura maggiore al gruppo trattato;
- la clinica A (casi lievi, alta probabilità di guarigione) contribuisce in misura maggiore al gruppo di controllo.
La variabile gravità agisce da confondente: influisce sia sulla probabilità di ricevere il trattamento sia sull’esito. L’aggregazione ignora questa struttura e produce una media ponderata che non rappresenta correttamente nessuno dei contesti reali.
La lezione epistemica
Dal punto di vista della probabilità condizionata, l’errore consiste nel rispondere alla domanda sbagliata. Non stiamo realmente stimando
\[ P(\text{Guarigione} \mid \text{Trattamento}), \] bensì una combinazione implicita di probabilità condizionate diverse. La domanda corretta è invece:
\[ P(\text{Guarigione} \mid \text{Trattamento}, \text{Gravità}). \]
Se non si considera la variabile rilevante, si mescolano popolazioni eterogenee. L’aggregazione applica implicitamente la legge della probabilità totale, ma lo fa nascondendo la partizione epistemicamente cruciale.
4.7.2 Quando è legittimo aggregare?
Il paradosso di Simpson non implica che l’aggregazione sia sempre scorretta. Essa è metodologicamente giustificata quando:
- non esistono confondenti rilevanti,
- i confondenti sono distribuiti in modo uniforme tra i gruppi,
- l’obiettivo dell’analisi è esplicitamente marginale, e non condizionato.
Tuttavia, in presenza di confondenti non controllati, l’aggregazione può non solo attenuare, ma anche invertire completamente le conclusioni inferenziali.
La regola d’oro è quindi epistemica prima ancora che statistica: prima di aggregare, rendi esplicite — e giustifica — le tue assunzioni di omogeneità.
Riflessioni conclusive
Siamo partiti da una domanda apparentemente semplice—come cambiano le nostre credenze quando apprendiamo qualcosa di nuovo?—e abbiamo scoperto che la risposta richiede un intero apparato concettuale.
Cosa abbiamo imparato
La probabilità condizionata non è un dettaglio tecnico. È il meccanismo fondamentale attraverso cui l’informazione si trasforma in conoscenza. Ogni volta che aggiorniamo le nostre credenze, in ambito clinico, nella ricerca o nella vita quotidiana, stiamo implicitamente applicando le regole che abbiamo studiato.
L’indipendenza rappresenta il caso limite in cui l’informazione non fluisce: sapere una cosa non dice nulla sull’altra. Riconoscere quando questa condizione è soddisfatta (e quando non lo è) è cruciale per costruire modelli corretti.
Il teorema del prodotto ci ha mostrato come costruire credenze complesse a partire da componenti più semplici, scomponendo la probabilità congiunta in una sequenza di aggiornamenti. Questo non è solo un trucco di calcolo, ma riflette il modo in cui ragioniamo naturalmente su eventi interconnessi.
La legge della probabilità totale ci ha insegnato a ragionare su scenari alternativi combinando le probabilità di ciascuno di essi in una media ponderata. Il paradosso di Simpson, invece, ci ha messo in guardia sui pericoli dell’aggregazione incauta, mostrando come conclusioni apparentemente solide possano essere ribaltate quando si svela la struttura nascosta dei dati.
Verso il teorema di Bayes
Tutti questi strumenti preparano il terreno per il passo successivo. Abbiamo visto come calcolare \(P(A \mid B)\), ovvero la probabilità di \(A\) sapendo che si verifica \(B\). Spesso, però, la domanda che ci interessa è l’inversa: abbiamo osservato un effetto e vogliamo risalire alla causa.
Nel prossimo capitolo, il teorema di Bayes emergerà come la regola per questa “inversione”. Ci permetterà di passare da \(P(\text{Dati} \mid \text{Ipotesi})\) a \(P(\text{Ipotesi} \mid \text{Dati})\), il cuore dell’inferenza scientifica.
Tuttavia, il teorema di Bayes non è magia. Si tratta semplicemente di un’applicazione intelligente della probabilità condizionata e del teorema del prodotto. Tutto ciò che abbiamo imparato in questo capitolo è il fondamento necessario per comprenderlo profondamente.
Un invito alla riflessione
Prima di procedere, è opportuno soffermarsi su un punto di natura filosofica. La probabilità condizionata non descrive come il mondo è, ma come le nostre credenze dovrebbero cambiare quando riceviamo informazioni. Si tratta di una teoria della razionalità in condizioni di incertezza, non di una teoria della realtà.
Questo ha una conseguenza liberatoria: non dobbiamo chiederci se le probabilità che assegniamo siano “vere” in senso assoluto. Dobbiamo chiederci se sono coerenti con le informazioni in nostro possesso e se si aggiornano correttamente quando le informazioni cambiano. La probabilità condizionata fornisce la risposta a questa seconda domanda.
Punti chiave da ricordare
Importante
Concetti essenziali di questo capitolo:
-
Probabilità condizionata come aggiornamento epistemico
- \(P(A \mid B)\) quantifica la credenza in \(A\) dopo aver appreso che \(B\) è vero;
- Meccanismo: riduzione dello spazio epistemico + rinormalizzazione;
- Ogni probabilità è sempre relativa a uno sfondo informativo: \(P(A) = P(A \mid \mathcal{I})\).
-
Indipendenza come assenza di informazione reciproca
- \(A \perp B\) se e solo se \(P(A \mid B) = P(A)\);
- Equivalentemente: \(P(A \cap B) = P(A) \cdot P(B)\);
- Eventi disgiunti NON sono indipendenti (hanno informazione reciproca massima).
-
Teorema del prodotto per costruire probabilità congiunte
- \(P(A \cap B) = P(A \mid B) \cdot P(B) = P(B \mid A) \cdot P(A)\);
- Generalizzazione: regola della catena per sequenze di eventi.
-
Legge della probabilità totale
- \(P(A) = \sum_{i} P(A \mid B_i) P(B_i)\) per partizione \(\{B_i\}\);
- Fondamentale per ragionare su scenari alternativi.
-
Paradosso di Simpson
- Trend aggregati possono invertirsi rispetto a trend stratificati;
- Non è un paradosso ma un avvertimento: condiziona sui confondenti!
Formule da ricordare:
\[ P(A \mid B) = \frac{P(A \cap B)}{P(B)} \quad \text{(definizione)} \]
\[ P(A \cap B) = P(A \mid B) \cdot P(B) = P(B \mid A) \cdot P(A) \quad \text{(teorema del prodotto)} \]
\[ P(A) = \sum_{i=1}^{n} P(A \mid B_i) P(B_i) \quad \text{(legge probabilità totale)} \]
Per il prossimo capitolo:
Nel Capitolo 5 vedremo come il teorema di Bayes permetta di invertire le probabilità condizionate, passando da \(P(\text{Dati} \mid \text{Ipotesi})\) a \(P(\text{Ipotesi} \mid \text{Dati})\).
Esercizi
ImportanteProblemi
Esercizi concettuali
Spiega perché “ogni probabilità è condizionata” da una prospettiva bayesiana. Cosa significa \(P(A)\) implicitamente?
La formula \(P(A \mid B) = P(A \cap B) / P(B)\) può sembrare circolare. Spiega perché non lo è, e in quale ordine concettuale pensiamo queste quantità.
Quando due eventi sono disgiunti, possono essere indipendenti? Perché o perché no?
Il teorema del prodotto dice \(P(A \cap B) = P(A \mid B) P(B)\). Questo è simmetrico? Cioè, posso scrivere \(P(A \cap B) = P(B \mid A) P(A)\)? Cosa implica questa simmetria?
Il paradosso di Simpson dimostra che l’aggregazione è sempre sbagliata? Quando è legittimo aggregare dati?
Esercizi su probabilità condizionata
-
Data una tabella congiunta: | | \(B\) | \(B^c\) | |——-|——|——-| | \(A\) | 0.20 | 0.30 | | \(A^c\) | 0.15 | 0.35 |
Calcola:
- \(P(A \mid B)\)
- \(P(B \mid A)\)
- \(P(A \mid B^c)\)
- Gli eventi sono indipendenti?
-
\(P(A) = 0.6\), \(P(B) = 0.5\), \(P(A \mid B) = 0.7\). Calcola:
- \(P(A \cap B)\)
- \(P(B \mid A)\)
- \(P(A \cup B)\)
-
Test diagnostico: \(P(M) = 0.01\), sens = 0.95, spec = 0.98.
- Costruisci tabella congiunta
- Calcola VPP e VPN
- Quanto deve essere alta la sensibilità per avere VPP > 0.9?
Esercizi sull’indipendenza
- Un dado viene lanciato. Siano:
- \(A\) = “Esce numero pari”
- \(B\) = “Esce numero ≤ 3”
- \(A\) e \(B\) sono indipendenti?
- Calcola \(P(A \mid B)\) e confronta con \(P(A)\)
- Due monete equilibrate vengono lanciate. Siano:
- \(A\) = “Prima moneta è testa”
- \(B\) = “Almeno una testa”
- Costruisci tabella congiunta
- Calcola \(P(A \mid B)\)
- \(A\) e \(B\) sono indipendenti?
- In una popolazione, \(P(\text{Depressione}) = 0.15\) e \(P(\text{Insonnia}) = 0.25\). Se fossero indipendenti, quanto sarebbe \(P(\text{Depressione} \cap \text{Insonnia})\)? È plausibile l’indipendenza?
Esercizi sul teorema del prodotto
\(P(A) = 0.5\), \(P(B \mid A) = 0.6\), \(P(C \mid A \cap B) = 0.7\). Calcola \(P(A \cap B \cap C)\).
Tre test sequenziali per ansia, ciascuno con sens = 0.80 (indipendenti dato stato). \(P(\text{Ansia}) = 0.20\). Calcola \(P(\text{Ansia} \cap T_1^+ \cap T_2^+ \cap T_3^+)\).
Usa la regola del prodotto per dimostrare che se \(A\) e \(B\) sono indipendenti, allora \(A\) e \(B^c\) sono indipendenti.
Esercizi sulla probabilità totale
-
Una clinica riceve pazienti da due fonti:
- 60% da medico di base (prevalenza depressione = 10%)
- 40% da pronto soccorso (prevalenza depressione = 30%)
Qual è la prevalenza complessiva nella clinica?
-
Un questionario ha due versioni (A e B), distribuite casualmente (50% ciascuna). La versione A è più facile:
- \(P(\text{punteggio} > 20 \mid \text{Versione A}) = 0.7\)
- \(P(\text{punteggio} > 20 \mid \text{Versione B}) = 0.4\)
Qual è \(P(\text{punteggio} > 20)\) complessivamente?
Dimostra che \(P(A) = P(A \mid B) P(B) + P(A \mid B^c) P(B^c)\) usando la legge della probabilità totale con partizione \(\{B, B^c\}\).
Esercizi sul Paradosso di Simpson
-
Considera questi dati su un farmaco antidepressivo:
Pazienti giovani (N=200):
- Farmaco: 70/100 migliorati (70%)
- Placebo: 50/100 migliorati (50%)
Pazienti anziani (N=200):
- Farmaco: 60/100 migliorati (60%)
- Placebo: 40/100 migliorati (40%)
- In ciascun gruppo, il farmaco è migliore?
- Calcola le proporzioni aggregate (tutti i pazienti insieme)
- Costruisci uno scenario dove l’aggregato inverte la tendenza
Spiega in termini epistemici perché il paradosso di Simpson non è veramente un “paradosso” ma un avvertimento sull’importanza di condizionare correttamente.
Esercizi applicati
-
Test per disturbo d’ansia sociale:
- Prevalenza in popolazione universitaria: 5%
- Sensibilità: 85%
- Specificità: 92%
- Costruisci tabella congiunta completa
- Uno studente risulta positivo. Qual è la probabilità che abbia davvero il disturbo?
- Quale prevalenza minima serve per avere VPP > 0.5?
-
Comorbidità PTSD e Depressione:
- In un campione clinico: \(P(\text{PTSD}) = 0.30\), \(P(\text{Depressione}) = 0.45\)
- Osservi che \(P(\text{Depressione} \mid \text{PTSD}) = 0.70\)
- Calcola \(P(\text{PTSD} \cap \text{Depressione})\)
- Calcola \(P(\text{PTSD} \mid \text{Depressione})\)
- Sono indipendenti? Commenta il risultato clinicamente
-
Due test per ADHD in un bambino:
- Prior: \(P(\text{ADHD}) = 0.08\) (popolazione generale)
- Test comportamentale: positivo (sens=0.80, spec=0.90)
- Test cognitivo: positivo (sens=0.75, spec=0.85)
- Assumendo indipendenza condizionale:
- Calcola \(P(\text{ADHD} \mid T_1^+)\) dopo primo test
- Calcola \(P(\text{ADHD} \mid T_1^+, T_2^+)\) dopo entrambi i test
- Visualizza l’aggiornamento sequenziale delle credenze
Esercizi computazionali
- Scrivi una funzione R che:
- Input: tabella congiunta 2×2
- Output: tutte le probabilità condizionate possibili e test di indipendenza
- Simula il paradosso di Simpson:
- Genera dati per due gruppi con trend positivo in ciascuno
- Aggrega i dati mostrando inversione del trend
- Visualizza con ggplot
- Crea una visualizzazione interattiva (o animazione) che mostra come \(P(A \mid B)\) varia al variare della “forza” dell’associazione tra \(A\) e \(B\) (da indipendenza a dipendenza totale).
ConsiglioSoluzioni selezionate
Soluzioni degli esercizi concettuali
Da prospettiva bayesiana, ogni probabilità riflette uno stato di informazione. Scrivere \(P(A)\) è abbreviazione per \(P(A \mid \mathcal{I})\) dove \(\mathcal{I}\) è “tutto ciò che sappiamo”. Non esistono probabilità “incondizionate”—solo probabilità condizionate allo sfondo informativo corrente.
Non è circolare perché concettualmente partiamo dalla tabella congiunta \(P(A \cap B)\) (rappresentazione completa del nostro stato di credenza), poi deriviamo le condizionate come rapporti. La formula ci dice come calcolare condizionate da congiunte, non come definire le congiunte.
No (a meno che uno abbia probabilità zero). Eventi disgiunti hanno informazione reciproca massima: sapere che uno è vero implica certezza che l’altro è falso. Indipendenza richiede assenza di informazione.
Sì, è simmetrico: \(P(A \cap B) = P(A \mid B) P(B) = P(B \mid A) P(A)\). Questa simmetria è il cuore del teorema di Bayes! Mostra che la congiunta può essere costruita in due modi equivalenti.
No, l’aggregazione è legittima quando non c’è confondente rilevante, o quando la confondente è distribuita uniformemente. Il paradosso avverte: esplicita le tue assunzioni di omogeneità prima di aggregare.
Soluzioni degli esercizi sulla probabilità condizionata
- \(P(A \mid B) = 0.20 / (0.20 + 0.15) = 0.571\)
- \(P(B \mid A) = 0.20 / (0.20 + 0.30) = 0.400\)
- \(P(A \mid B^c) = 0.30 / (0.30 + 0.35) = 0.462\)
- Test: \(P(A) = 0.50\), \(P(B) = 0.35\), \(P(A) P(B) = 0.175 \neq P(A \cap B) = 0.20\). NON indipendenti.
- \(P(A \cap B) = P(A \mid B) P(B) = 0.7 \times 0.5 = 0.35\)
- \(P(B \mid A) = P(A \cap B) / P(A) = 0.35 / 0.6 \approx 0.583\)
- \(P(A \cup B) = 0.6 + 0.5 - 0.35 = 0.75\)
- Tabella: \(P(M \cap T^+) = 0.0095\), \(P(M \cap T^-) = 0.0005\), etc.
- VPP = \(0.0095 / (0.0095 + 0.0198) \approx 0.324\); VPN \(\approx 0.9995\)
- Per VPP > 0.9: serve sens \(\approx 0.998\) (quasi perfetta con prevalenza così bassa!)
Soluzioni degli esercizi sull’indipendenza
- \(P(A) = 1/2\), \(P(B) = 1/2\), \(P(A \cap B) = P(\{2\}) = 1/6\) \(P(A) P(B) = 1/4 \neq 1/6\). NON indipendenti.
- \(P(A \mid B) = (1/6) / (1/2) = 1/3 \neq 1/2 = P(A)\)
- Spazio: {TT, TC, CT, CC}, equiprobabili.
- Tabella con \(A\) = {TT, TC}, \(B\) = {TT, TC, CT}
- \(P(A \mid B) = P(\{TT, TC\}) / P(B) = (1/2) / (3/4) = 2/3\)
- \(P(A) = 1/2 \neq 2/3 = P(A \mid B)\). NON indipendenti.
- Se indipendenti: \(P(D \cap I) = 0.15 \times 0.25 = 0.0375\). Ma clinicamente sappiamo che depressione e insonnia sono altamente correlate, quindi l’indipendenza è implausibile.
Soluzioni degli esercizi sul teorema del prodotto
\(P(A \cap B \cap C) = P(C \mid A \cap B) \cdot P(B \mid A) \cdot P(A) = 0.7 \times 0.6 \times 0.5 = 0.21\)
\(P(\text{Ansia} \cap \text{tutti +}) = 0.80^3 \times 0.20 = 0.512 \times 0.20 = 0.1024\)
Dimostrazione:
P(A ∩ B^c) = P(A) - P(A ∩ B) [additività] = P(A) - P(A)P(B) [indipendenza A,B] = P(A)(1 - P(B)) = P(A)P(B^c) [quindi A ⊥ B^c]
Soluzioni degli esercizi sulla probabilità totale
\(P(D) = 0.10 \times 0.60 + 0.30 \times 0.40 = 0.06 + 0.12 = 0.18\) (18%)
\(P(>20) = 0.7 \times 0.5 + 0.4 \times 0.5 = 0.35 + 0.20 = 0.55\)
Soluzioni degli esercizi sulle applicazioni psicologiche
- \(P(A \cap T^+) = 0.85 \times 0.05 = 0.0425\), etc.
- VPP = \(0.0425 / (0.0425 + 0.076) = 0.359\) (solo 36%!)
- Per VPP > 0.5, serve prev \(\geq 0.10\) (10%)
- \(P(P \cap D) = P(D \mid P) \times P(P) = 0.70 \times 0.30 = 0.21\)
- \(P(P \mid D) = 0.21 / 0.45 \approx 0.467\)
- Se indipendenti: \(P(P) P(D) = 0.30 \times 0.45 = 0.135 \neq 0.21\). DIPENDENTI (comorbidità alta, clinicamente attesa)
NotaInformazioni sull’ambiente di sviluppo
sessionInfo()
#> R version 4.5.2 (2025-10-31)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Tahoe 26.2
#>
#> Matrix products: default
#> BLAS: /System/Library/Frameworks/Accelerate.framework/Versions/A/Frameworks/vecLib.framework/Versions/A/libBLAS.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
#>
#> locale:
#> [1] C.UTF-8/UTF-8/C.UTF-8/C/C.UTF-8/C.UTF-8
#>
#> time zone: Europe/Rome
#> tzcode source: internal
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] DiagrammeR_1.0.11 ggforce_0.5.0 ragg_1.5.0
#> [4] tinytable_0.15.2 withr_3.0.2 systemfonts_1.3.1
#> [7] patchwork_1.3.2 ggdist_3.3.3 tidybayes_3.0.7
#> [10] bayesplot_1.15.0 ggplot2_4.0.1 reliabilitydiag_0.2.1
#> [13] priorsense_1.2.0 posterior_1.6.1 loo_2.9.0
#> [16] rstan_2.32.7 StanHeaders_2.32.10 brms_2.23.0
#> [19] Rcpp_1.1.1 sessioninfo_1.2.3 conflicted_1.2.0
#> [22] janitor_2.2.1 matrixStats_1.5.0 modelr_0.1.11
#> [25] tibble_3.3.1 dplyr_1.1.4 tidyr_1.3.2
#> [28] rio_1.2.4 here_1.0.2
#>
#> loaded via a namespace (and not attached):
#> [1] gridExtra_2.3 inline_0.3.21 sandwich_3.1-1
#> [4] rlang_1.1.7 magrittr_2.0.4 multcomp_1.4-29
#> [7] snakecase_0.11.1 otel_0.2.0 compiler_4.5.2
#> [10] vctrs_0.6.5 stringr_1.6.0 pkgconfig_2.0.3
#> [13] arrayhelpers_1.1-0 fastmap_1.2.0 backports_1.5.0
#> [16] labeling_0.4.3 rmarkdown_2.30 purrr_1.2.1
#> [19] xfun_0.55 cachem_1.1.0 jsonlite_2.0.0
#> [22] tweenr_2.0.3 broom_1.0.11 parallel_4.5.2
#> [25] R6_2.6.1 stringi_1.8.7 RColorBrewer_1.1-3
#> [28] lubridate_1.9.4 estimability_1.5.1 knitr_1.51
#> [31] zoo_1.8-15 pacman_0.5.1 Matrix_1.7-4
#> [34] splines_4.5.2 timechange_0.3.0 tidyselect_1.2.1
#> [37] abind_1.4-8 yaml_2.3.12 codetools_0.2-20
#> [40] curl_7.0.0 pkgbuild_1.4.8 lattice_0.22-7
#> [43] bridgesampling_1.2-1 S7_0.2.1 coda_0.19-4.1
#> [46] evaluate_1.0.5 survival_3.8-3 polyclip_1.10-7
#> [49] RcppParallel_5.1.11-1 pillar_1.11.1 tensorA_0.36.2.1
#> [52] checkmate_2.3.3 stats4_4.5.2 distributional_0.6.0
#> [55] generics_0.1.4 rprojroot_2.1.1 rstantools_2.6.0
#> [58] scales_1.4.0 xtable_1.8-4 glue_1.8.0
#> [61] emmeans_2.0.1 tools_4.5.2 visNetwork_2.1.4
#> [64] mvtnorm_1.3-3 grid_4.5.2 QuickJSR_1.8.1
#> [67] colorspace_2.1-2 nlme_3.1-168 cli_3.6.5
#> [70] textshaping_1.0.4 svUnit_1.0.8 Brobdingnag_1.2-9
#> [73] V8_8.0.1 gtable_0.3.6 digest_0.6.39
#> [76] TH.data_1.1-5 htmlwidgets_1.6.4 farver_2.1.2
#> [79] memoise_2.0.1 htmltools_0.5.9 lifecycle_1.0.5
#> [82] MASS_7.3-65