6 Variabili casuali
Introduzione
Immaginiamo uno scenario comune nella pratica clinica. Una psicologa sta valutando l’efficacia di un intervento cognitivo-comportamentale per l’ansia sociale. Ha somministrato la Liebowitz Social Anxiety Scale (LSAS) a 50 pazienti prima e dopo un ciclo di 12 sedute. I punteggi variano da 0 a 144 e valori più alti indicano una maggiore gravità.
La domanda clinica non si limita a chiedere se un intervento funzioni, un quesito binario che potrebbe essere affrontato con gli strumenti probabilistici visti finora. Piuttosto, la domanda è più complessa: quanto ci aspettiamo che i pazienti migliorino? Qual è la distribuzione dei possibili miglioramenti? E quale grado di incertezza accompagna queste stime? Per rispondere a queste domande è necessario compiere un salto concettuale: passare dall’assegnare probabilità a eventi discreti all’assegnare probabilità a quantità numeriche.
Questo passaggio è reso possibile dalle variabili casuali che costituiscono il ponte tra la teoria della probabilità, intesa come sistema di credenze coerenti, e i modelli statistici utilizzati nell’inferenza bayesiana. Senza questo concetto, non potremmo porre domande come: “Qual è la probabilità che il miglioramento medio sia superiore a 20 punti?” o “In quale intervallo cadrà il punteggio post-trattamento con probabilità del 95%?”.
Per seguire questo capitolo è necessario aver letto:
Conoscenze matematiche richieste:
- Appendice F — fondamentale per comprendere le PDF e le variabili continue.
- Appendice C - per marginalizzazione di variabili discrete.
Competenze pratiche:
- Familiarità con R e operazioni vettoriali di base per eseguire le simulazioni.
Panoramica del capitolo
- Definizione formale di variabile casuale come funzione dallo spazio campionario ai numeri reali.
- Distinzione tra variabili casuali discrete e continue.
- Funzione di massa di probabilità (PMF) per variabili discrete.
- Funzione di densità di probabilità (PDF) per variabili continue.
- Funzione di distribuzione cumulativa (CDF) come rappresentazione unificata.
- Variabili casuali multiple e nozione di indipendenza.
6.1 Dalla probabilità degli eventi ai valori numerici
Nel framework bayesiano sviluppato nei capitoli precedenti, abbiamo assegnato delle probabilità a degli eventi, ovvero a dei sottoinsiemi dello spazio campionario che rappresentano delle proposizioni sul mondo. Quando un clinico afferma \(P(\text{Depressione maggiore}) = 0.3\), sta quantificando la propria credenza in una proposizione binaria: il paziente soddisfa o non soddisfa i criteri diagnostici.
Questa struttura è potente per molte domande cliniche, come la diagnosi differenziale, la valutazione del rischio e la previsione di esiti categoriali, ma risulta insufficiente quando l’oggetto dell’incertezza non è un evento sì/no, bensì un valore numerico. Consideriamo alcune domande tipiche della ricerca psicologica:
- Quale sarà il punteggio di questo paziente al BDI-II tra sei mesi?
- Quanto tempo impiegherà un partecipante a rispondere in questo compito di decisione lessicale?
- Quanti sintomi depressivi riporterà il paziente nella prossima settimana?
- Quale livello di cortisolo mostrerà lo studente prima dell’esame?
In tutti i casi, l’incertezza non riguarda il verificarsi di un evento, ma l’ampiezza, la durata o l’intensità di un fenomeno. Per modellare questo tipo di incertezza, dobbiamo passare dagli eventi alle variabili casuali.
6.1.1 L’idea fondamentale
Il passaggio concettuale consiste nel riconoscere che molti esperimenti producono naturalmente risultati numerici. Un test psicometrico restituisce un punteggio, una misurazione fisiologica produce un valore continuo e un compito cognitivo genera un tempo di reazione. Anche quando gli esiti originari non sono numerici, è sempre possibile codificarli come tali, assegnando 1 al successo e 0 al fallimento in un singolo item o utilizzando codifiche ordinali per le categorie diagnostiche.
La traduzione sistematica degli esiti in numeri è realizzata tramite una variabile casuale. La “casualità” non risiede nella funzione in sé, che è perfettamente deterministica, ma nell’incertezza relativa all’esito che si verificherà nello spazio campionario. Una volta che l’esito è stato determinato, il valore numerico associato viene automaticamente calcolato.
6.2 Definizione formale di variabile casuale
Definizione 6.1 (Variabile casuale) Sia \(\Omega\) uno spazio campionario. Una variabile casuale è una funzione
\[ X : \Omega \longrightarrow \mathbb{R} \] che associa a ogni esito \(\omega \in \Omega\) un unico numero reale \(X(\omega)\).
Questa definizione va interpretata con attenzione. Lo spazio campionario \(\Omega\) rappresenta, nella nostra prospettiva epistemica, l’insieme di tutte le possibilità compatibili con le informazioni a nostra disposizione. La variabile casuale \(X\) traduce ciascuna di queste possibilità in un numero, rendendo possibile l’applicazione dell’analisi matematica allo studio dell’incertezza.
Il termine “casuale” è quindi in parte fuorviante: la funzione \(X\) non è affatto aleatoria, ma completamente deterministica. L’incertezza deriva esclusivamente dal fatto che non sappiamo quale elemento di \(\Omega\) si realizzerà.
Per convenzione, le variabili casuali come funzioni sono indicate con lettere maiuscole (\(X\), \(Y\), \(Z\)), mentre i valori numerici che possono assumere sono indicati con lettere minuscole (\(x\), \(y\), \(z\)). Questa distinzione permette di scrivere espressioni come \(P(X = x)\) o \(P(X \leq x)\), separando chiaramente l’oggetto aleatorio dai suoi possibili valori.
Il punteggio come variabile casuale
Consideriamo un breve test di memoria di lavoro composto da 5 item. Ogni item può essere risolto correttamente (C) o erroneamente (E). Lo spazio campionario è costituito da tutte le possibili sequenze di risposte:
\[ \Omega = \{CCCCC, CCCCE, CCCEC, \ldots, EEEEE\}. \]
Poiché ogni item ha due esiti possibili e gli item sono 5, lo spazio campionario contiene \(2^5 = 32\) elementi.
Definiamo la variabile casuale \(X\) che associa a ogni sequenza di risposte il numero totale di risposte corrette:
\[ X(\omega) = \text{numero di C in } \omega. \]
Per l’esito \(\omega = CCECE\), ad esempio, il valore della variabile casuale è \(X(CCECE) = 3\). La funzione \(X\) è perfettamente deterministica: data la sequenza di risposte, il punteggio è univocamente determinato. L’incertezza riguarda solo quale sequenza di risposte verrà osservata.
L’evento \(\{X = 3\}\) rappresenta l’insieme di tutti gli esiti che producono esattamente 3 risposte corrette:
\[ \{X = 3\} = \{CCCEE, CCECE, CCEEC, CECCE, \ldots\}. \]
Questo insieme contiene \(\binom{5}{3} = 10\) elementi. Se assumiamo che ciascuna risposta sia corretta con probabilità \(p = 0.6\) indipendentemente dalle altre, la probabilità di ottenere esattamente 3 risposte corrette è:
\[ P(X = 3) = \binom{5}{3} (0.6)^3 (0.4)^2 = 10 \times 0.216 \times 0.16 = 0.3456. \]
6.2.1 Perché questo passaggio è cruciale per l’inferenza bayesiana
L’introduzione delle variabili casuali non è un mero tecnicismo, ma un prerequisito concettuale per tutto ciò che seguirà. Nell’inferenza bayesiana, i parametri dei modelli, come la probabilità di successo \(\theta\) in un modello binomiale, o la media \(\mu\) di una distribuzione normale, sono trattati essi stessi come variabili casuali. La distribuzione a priori \(p(\theta)\) esprime l’incertezza iniziale sul valore del parametro, mentre la distribuzione a posteriori \(p(\theta \mid \text{dati})\) esprime l’incertezza aggiornata dopo l’osservazione dei dati.
Senza il concetto di variabile casuale, non sarebbe nemmeno possibile formulare domande del tipo: “Qual è la probabilità che l’efficacia del trattamento superi a una certa soglia clinicamente rilevante?” — domande che sono, al contrario, fondamentali per la pratica bayesiana.
6.3 Variabili casuali discrete
La distinzione più fondamentale tra le variabili casuali riguarda la natura dell’insieme dei valori che possono assumere. Una variabile casuale è detta discreta quando l’insieme dei suoi valori possibili è finito o numerabile, ovvero quando tali valori possono essere elencati in una sequenza (eventualmente infinita).
Definizione 6.2 (Variabile casuale discreta) Una variabile casuale \(X\) è discreta se esiste un insieme finito o numerabile
\[ \mathcal{X} = \{x_1, x_2, \ldots\} \] tale che
\[ P(X \in \mathcal{X}) = 1. \]
In altre parole, \(X\) assume con certezza uno dei valori appartenenti all’insieme \(\mathcal{X}\).
6.3.1 Esempi in psicologia
Le variabili casuali discrete compaiono in numerosi contesti della ricerca e della pratica psicologica:
- Punteggi grezzi nei test: il numero di risposte corrette in un test cognitivo (valori da 0 a \(n\), dove \(n\) è il numero di item).
- Scale Likert: i punteggi su singoli item o su scale composite con valori discreti (ad esempio, da 1 a 5 o da 1 a 7).
- Conteggi di comportamenti: il numero di episodi di abbuffata in una settimana, il numero di risvegli notturni, il numero di interazioni sociali.
- Categorie diagnostiche codificate: quando si assegnano codici numerici a categorie (0 = assente, 1 = lieve, 2 = moderato, 3 = grave).
- Numero di criteri soddisfatti: in una valutazione diagnostica, quanti criteri del DSM-5 sono soddisfatti per una certa condizione.
La caratteristica distintiva delle variabili discrete è che tra due valori consecutivi non esistono valori intermedi: non è possibile osservare, per esempio, 2.7 risposte corrette su 5, né un punteggio Likert di 3.5 su una scala da 1 a 5.
6.4 Funzione di massa di probabilità
Per descrivere completamente una variabile casuale discreta è sufficiente specificare la probabilità associata a ciascun valore possibile. Questa specificazione prende il nome di funzione di massa di probabilità.
Definizione 6.3 (Funzione di massa di probabilità (PMF)) La funzione di massa di probabilità di una variabile casuale discreta \(X\) è la funzione
\[ p_X : \mathcal{X} \to [0,1] \] definita da
\[ p_X(x) = P(X = x) \] per ogni \(x \in \mathcal{X}\).
La PMF deve soddisfare due condizioni fondamentali, che discendono direttamente dagli assiomi di coerenza della probabilità:
Non-negatività \[ p_X(x) \geq 0 \quad \text{per ogni } x \in \mathcal{X}. \]
Normalizzazione \[ \sum_{x \in \mathcal{X}} p_X(x) = 1. \]
Una volta nota la funzione di massa di probabilità, è possibile calcolare la probabilità di qualunque evento relativo alla variabile \(X\). Per un sottoinsieme \(B \subseteq \mathcal{X}\) vale infatti: \[ P(X \in B) = \sum_{x \in B} p_X(x). \]
6.4.1 Ponte applicativo: la PMF nella pratica clinica
Quando uno psicologo riporta che, su una scala di esito del trattamento, “il 15% dei pazienti mostra remissione completa (4), il 35% miglioramento sostanziale (3), il 30% miglioramento parziale (2), il 15% nessun cambiamento (1) e il 5% peggioramento (0)”, sta implicitamente descrivendo una PMF:
| \(x\) (esito) | 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|---|
| \(p_X(x)\) | 0.05 | 0.15 | 0.30 | 0.35 | 0.15 |
Questa tabella soddisfa entrambe le proprietà richieste: tutti i valori sono non-negativi e la loro somma è 1. Da questa PMF possiamo calcolare, ad esempio, la probabilità di un esito positivo (miglioramento parziale o superiore):
\[ P(X \geq 2) = p_X(2) + p_X(3) + p_X(4) = 0.30 + 0.35 + 0.15 = 0.80. \]
Derivazione completa della distribuzione
Riprendiamo il test di memoria di lavoro a 5 item. Supponiamo che ogni risposta sia corretta con probabilità \(p = 0.7\), indipendentemente dalle altre. La variabile casuale \(X\) (numero di risposte corrette) può assumere valori compresi tra 0 e 5.
Per ogni valore \(x\), il numero di sequenze con esattamente \(x\) risposte corrette è \(\binom{5}{x}\), e ciascuna di queste sequenze ha probabilità \((0.7)^x (0.3)^{5-x}\). Pertanto:
\[ p_X(x) = \binom{5}{x} (0.7)^x (0.3)^{5-x}. \]
La distribuzione completa risulta:
| \(x\) | 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|---|
| \(p_X(x)\) | 0.0024 | 0.0284 | 0.1323 | 0.3087 | 0.3601 | 0.1681 |
Si osservi che la distribuzione è asimmetrica, con la moda (valore più probabile) a \(x = 4\). La probabilità di ottenere almeno 3 risposte corrette è:
\[ P(X \geq 3) = 0.3087 + 0.3601 + 0.1681 = 0.8369. \]
Questa è esattamente la struttura della distribuzione binomiale, che studieremo in dettaglio nel capitolo sulle famiglie di distribuzioni.
6.4.2 Connessione con il percorso bayesiano
La PMF che abbiamo appena costruito, ovvero quella relativa al numero di successi in \(n\) prove con probabilità \(p\), è una delle funzione di verosimiglianza più importanti nei modelli bayesiani. Quando osserviamo \(k\) successi su \(n\) prove e vogliamo stimare la probabilità di successo \(\theta\), la verosimiglianza è proprio:
\[ L(\theta | k) = \binom{n}{k} \theta^k (1-\theta)^{n-k}. \]
Comprendere la PMF significa quindi comprendere una delle due componenti essenziali dell’inferenza bayesiana (l’altra è la distribuzione a priori).
Un esempio classico per consolidare l’intuizione
Consideriamo il lancio di due dadi equilibrati, un esempio classico che, pur essendo distante dalla pratica psicologica, illustra con particolare chiarezza la struttura combinatoria alla base della PMF.
Lo spazio campionario è costituito dalle 36 coppie ordinate:
\[ \Omega = \{(1,1), (1,2), \ldots, (6,5), (6,6)\}. \]
Definiamo la variabile casuale \(X\) che associa a ogni coppia \((i,j)\) la somma dei valori:
\[ X(i,j) = i + j. \]
La somma può assumere valori da 2 a 12. Per ciascun valore, contiamo quante coppie lo producono:
| \(x\) | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Casi | 1 | 2 | 3 | 4 | 5 | 6 | 5 | 4 | 3 | 2 | 1 |
| \(p_X(x)\) | \(\tfrac{1}{36}\) | \(\tfrac{2}{36}\) | \(\tfrac{3}{36}\) | \(\tfrac{4}{36}\) | \(\tfrac{5}{36}\) | \(\tfrac{6}{36}\) | \(\tfrac{5}{36}\) | \(\tfrac{4}{36}\) | \(\tfrac{3}{36}\) | \(\tfrac{2}{36}\) | \(\tfrac{1}{36}\) |
La simmetria della distribuzione attorno al valore 7 riflette la struttura combinatoria del problema. Questa forma “triangolare” è un primo esempio di come la struttura del processo generativo (in questo caso, la somma di due quantità uniformi) determini la forma della distribuzione.
Un’analogia psicometrica: se un punteggio composito è la somma di due subscale ciascuna uniformemente distribuita su 1-6, allora la distribuzione del punteggio totale avrà esattamente questa forma triangolare.
6.5 Verifica computazionale della PMF
Le simulazioni al computer costituiscono uno strumento efficace per verificare empiricamente le proprietà teoriche di una funzione di massa di probabilità. Generando un gran numero di realizzazioni della variabile casuale, è possibile osservare come le frequenze relative tendano a convergere verso le probabilità teoriche.
set.seed(42)
# Simulazione del test a 5 item con p = 0.7
n_sim <- 100000
n_item <- 5
p_corretto <- 0.7
# Generiamo le risposte per tutti i partecipanti simulati
punteggi <- rbinom(n_sim, size = n_item, prob = p_corretto)
# Frequenze empiriche
freq_emp <- table(factor(punteggi, levels = 0:5)) / n_sim
# Probabilità teoriche (distribuzione binomiale)
valori <- 0:5
prob_teor <- dbinom(valori, size = n_item, prob = p_corretto)
# Confronto
df_confronto <- data.frame(
x = valori,
empirica = as.numeric(freq_emp),
teorica = prob_teor
)
ggplot(df_confronto, aes(x = x)) +
geom_col(aes(y = empirica), alpha = 0.7, width = 0.6) +
geom_point(aes(y = teorica), size = 3) +
geom_line(aes(y = teorica), linewidth = 1) +
scale_x_continuous(breaks = 0:5) +
labs(
x = "Numero di risposte corrette",
y = "Probabilità",
title = "PMF del punteggio in un test a 5 item (p = 0.7)"
)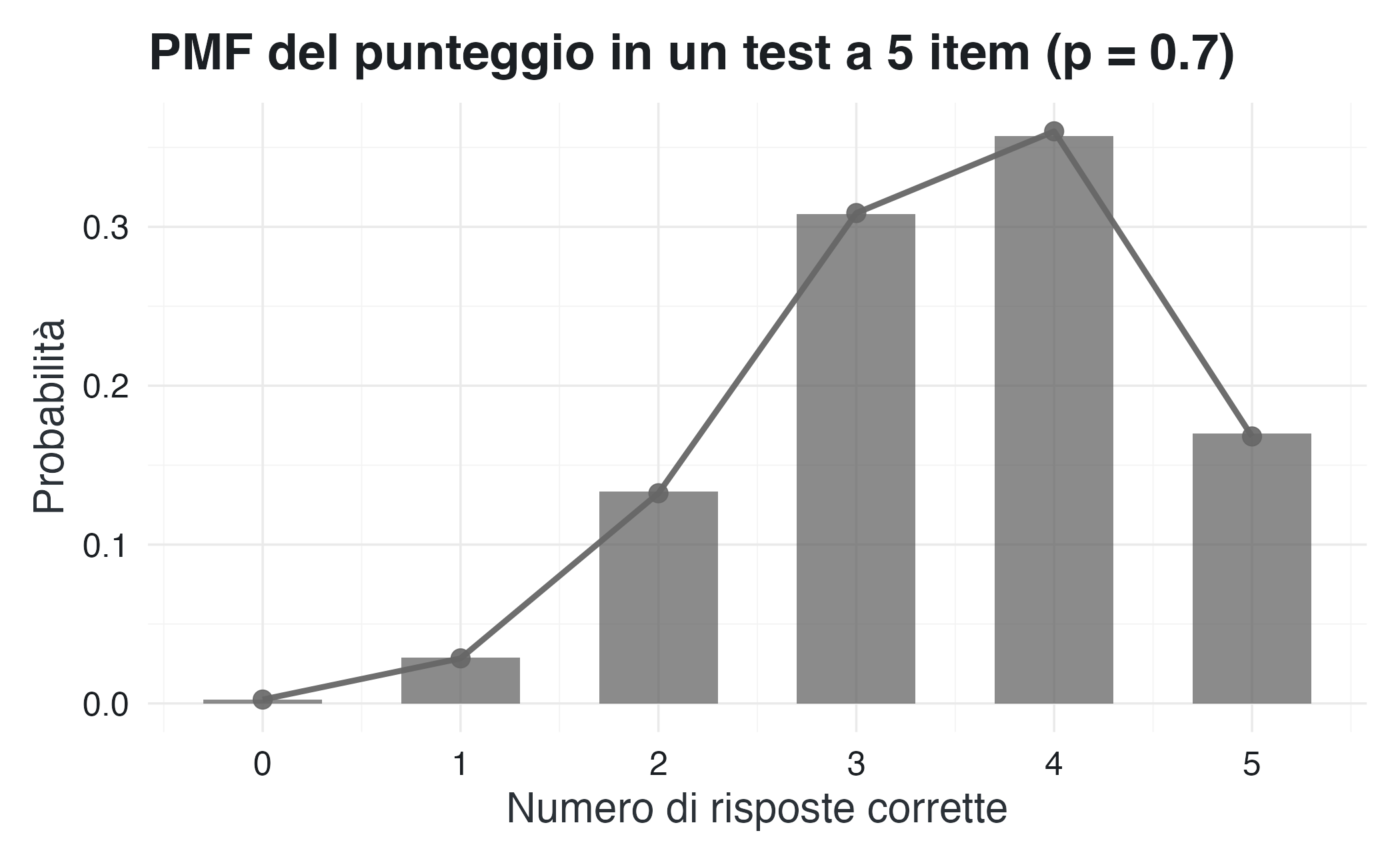
La convergenza delle frequenze empiriche verso le probabilità teoriche non definisce la distribuzione di probabilità, ma ne verifica la coerenza interna. La simulazione mostra che un sistema di credenze coerente genera il comportamento atteso quando viene sottoposto a ripetute osservazioni.
6.6 Variabili casuali continue
Molte grandezze psicologiche non possono essere rappresentate adeguatamente da variabili discrete. Il tempo di reazione in un compito cognitivo, il livello di cortisolo in una misurazione fisiologica, la latenza di una risposta comportamentale, o anche i punteggi su scale psicometriche quando vengono trattati come misure continue di un costrutto latente — tutte queste quantità possono assumere, almeno in linea di principio, qualsiasi valore all’interno di un intervallo continuo.
Definizione 6.4 (Variabile casuale continua) Una variabile casuale \(X\) è continua se esiste una funzione non negativa
\[ f_X : \mathbb{R} \to [0, +\infty), \] detta funzione di densità di probabilità (PDF), tale che per ogni intervallo \([a,b]\) valga:
\[ P(a \leq X \leq b) = \int_a^b f_X(x)\,dx. \]
Questa definizione esprime un cambiamento concettuale importante rispetto al caso discreto: la probabilità non è più assegnata a singoli valori, ma a intervalli della retta reale.
6.6.1 Esempi in psicologia
Le variabili casuali continue sono ampiamente utilizzate nella ricerca psicologica:
- Tempi di reazione: la latenza di risposta in compiti cognitivi, tipicamente misurata in millisecondi.
- Misure fisiologiche: livelli di cortisolo, frequenza cardiaca, conduttanza cutanea.
- Punteggi standardizzati: quando i punteggi grezzi vengono trasformati in scale continue (z-score, T-score, percentili).
- Variabili latenti: i costrutti psicologici non osservabili direttamente (come l’intelligenza, l’ansia di tratto e l’apertura mentale) sono solitamente modellati come variabili continue.
- Effetti stimati: le dimensioni dell’effetto, i coefficienti di regressione, le differenze tra le medie.
6.7 Funzione di densità di probabilità
La funzione di densità di probabilità svolge per le variabili continue un ruolo analogo a quello della PMF per le variabili discrete, ma con una differenza cruciale. Il valore \(f_X(x)\) non rappresenta la probabilità che la variabile assuma esattamente il valore \(x\).
Infatti, per una variabile casuale continua vale sempre:
\[ P(X = x_0) = \int_{x_0}^{x_0} f_X(x)\,dx = 0. \]
Questo risultato, che può apparire controintuitivo, riflette la struttura del continuo: esistono infiniti valori possibili, e non è possibile assegnare a ciascun punto una probabilità positiva mantenendo la normalizzazione. La probabilità non è concentrata nei punti, ma distribuita sugli intervalli.
6.7.1 Come interpretare la densità
La densità \(f_X(x)\) può essere interpretata come una misura della concentrazione della probabilità. Valori elevati di \(f_X(x)\) indicano le regioni della retta reale in cui la variabile è più probabile che assuma un determinato valore, nel senso che gli intervalli di piccole dimensioni attorno a quei punti hanno una probabilità relativamente maggiore.
Un’analogia utile: se la probabilità fosse acqua e la retta reale fosse un contenitore, la densità \(f_X(x)\) indicherebbe l’altezza dell’acqua nel punto \(x\). La quantità totale di acqua (ovvero la probabilità totale) è sempre pari a 1, ma può essere distribuita in modo più o meno concentrato in diverse regioni.
Teorema 6.1 (Proprietà delle funzioni di densità di probabilità) Una funzione \(f_X(x)\) è una valida funzione di densità di probabilità se e solo se soddisfa le seguenti condizioni:
Non-negatività \[ f_X(x) \geq 0 \quad \text{per ogni } x \in \mathbb{R}. \]
Normalizzazione \[ \int_{-\infty}^{+\infty} f_X(x)\,dx = 1. \]
È importante notare che il valore della densità \(f_X(x)\) può superare 1: ciò non viola alcun principio, in quanto \(f_X(x)\) non rappresenta una probabilità. Solo l’integrale della densità su un intervallo restituisce una probabilità. In termini geometrici, la probabilità \(P(a \leq X \leq b)\) corrisponde all’area all’area sottesa dalla curva di \(f_X(x)\) tra \(a\) e \(b\).
6.7.2 Ponte applicativo: la PDF nella valutazione clinica
Quando un clinico afferma che “i punteggi del BDI-II nella popolazione generale seguono approssimativamente una distribuzione normale con media 10 e deviazione standard 8”, sta implicitamente specificando una PDF. Da questa distribuzione è possibile calcolare, ad esempio:
- La probabilità che un individuo estratto casualmente abbia un punteggio superiore a 20 (soglia per depressione lieve).
- L’intervallo entro cui cade il 95% centrale della popolazione.
- La probabilità di osservare un punteggio estremo come quello di un particolare paziente.
Questi calcoli sono fondamentali per interpretare i punteggi individuali nel contesto della variabilità normale.
Probabilità come area sotto la curva
Consideriamo una variabile casuale continua \(T\) che rappresenta il tempo di reazione (in millisecondi) in un compito di decisione lessicale. I tempi di reazione sono solitamente modellati con distribuzioni asimmetriche positive; una scelta comune è la distribuzione log-normale.
Supponiamo che la variabile \(T\) segua una distribuzione log-normale con parametri \(\mu = 5.7\) e \(\sigma = 0.3\). Ciò significa che il logaritmo naturale del tempo di reazione segue una distribuzione normale: \(\ln(T) \sim N(5.7, 0.3^2)\).
La funzione di densità di probabilità è:
\[ f_T(t) = \frac{1}{t \sigma \sqrt{2\pi}} \exp\left(-\frac{(\ln(t) - \mu)^2}{2\sigma^2}\right) \quad \text{per } t > 0 \] e \(f_T(t) = 0\) per \(t \leq 0\).
#> Mediana del tempo di reazione: 299 ms
#> Media del tempo di reazione: 313 msLa mediana (298 ms) è inferiore alla media (312 ms) perché la distribuzione è asimmetrica a destra, una caratteristica tipica dei tempi di reazione.
La probabilità che il tempo di reazione cada in un certo intervallo si ottiene integrando la densità:
\[ P(300 \leq T \leq 400) = \int_{300}^{400} f_T(t) \, dt \]
#> P(300 ≤ T ≤ 400): 0.329Questa probabilità (circa 47%) rappresenta l’area sotto la curva di densità compresa tra 300 e 400 ms.
# Visualizzazione
t_vals <- seq(150, 600, length.out = 500)
df_rt <- data.frame(
t = t_vals,
densita = dlnorm(t_vals, meanlog = mu, sdlog = sigma)
)
# Area da evidenziare
df_area <- df_rt[df_rt$t >= 300 & df_rt$t <= 400, ]
ggplot(df_rt, aes(x = t, y = densita)) +
geom_area(data = df_area, aes(x = t, y = densita),
alpha = 0.4) +
geom_line(linewidth = 1) +
geom_vline(xintercept = c(300, 400), linetype = "dashed", alpha = 0.5) +
labs(
x = "Tempo di reazione (ms)",
y = "Densità di probabilità",
title = "Distribuzione dei tempi di reazione"
) +
annotate("text", x = 350, y = 0.002,
label = paste0("P = ", round(prob_300_400, 3)))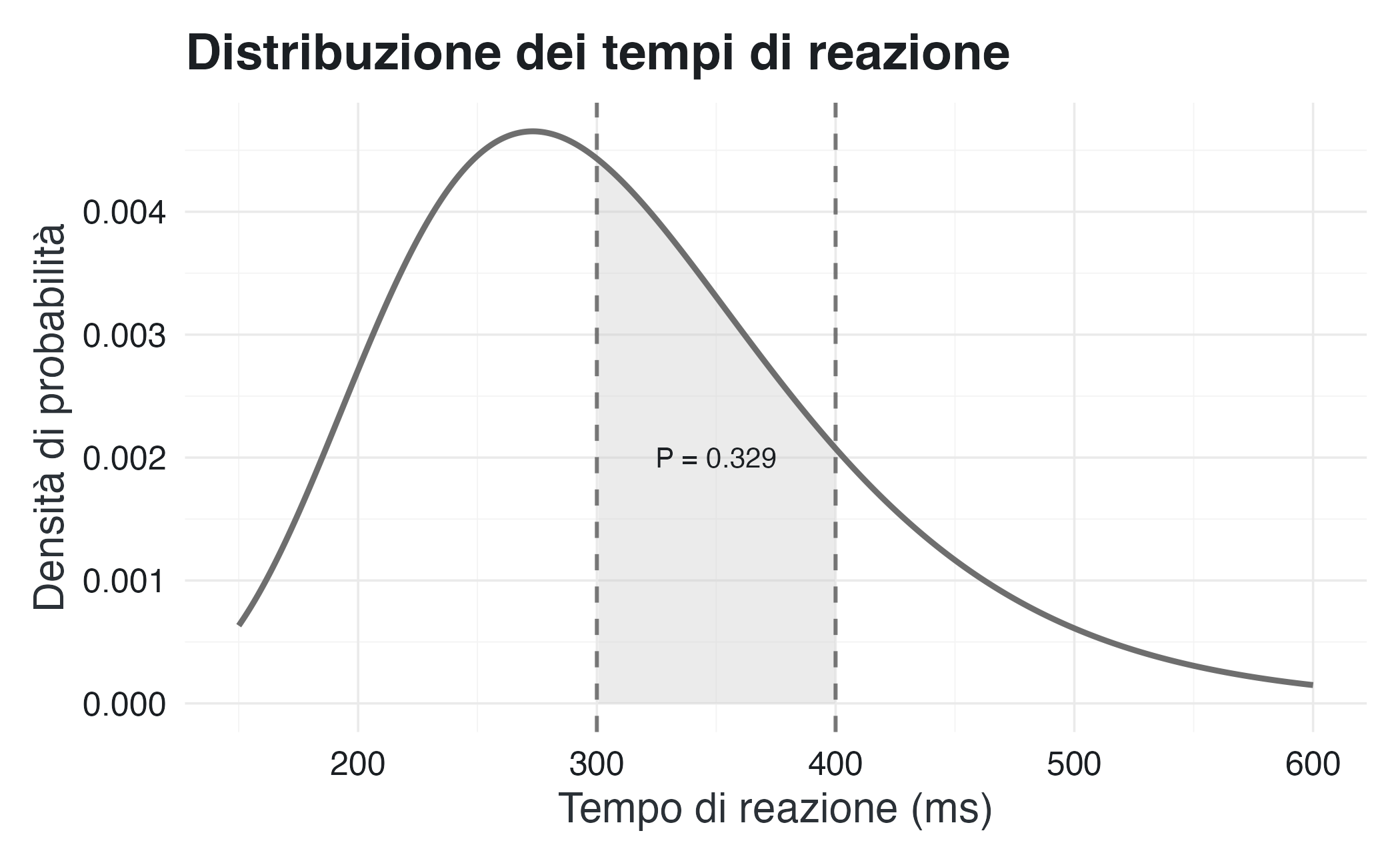
L’area ombreggiata rappresenta la probabilità che il tempo di reazione cada tra 300 e 400 ms.
Nelle funzioni di densità di probabilità, il valore della funzione può talvolta superare 1. Ciò non rappresenta un problema o un errore, poiché la densità stessa non è una probabilità, ma una misura di concentrazione.
6.7.3 Connessione con il percorso bayesiano
La distinzione tra PMF e PDF diventa centrale quando specifichiamo le distribuzioni nel modello bayesiano. Per un parametro come una proporzione (che può assumere qualsiasi valore compreso tra 0 e 1), useremo una densità continua — tipicamente la distribuzione Beta. Per il numero di successi osservati (assumere solo i valori 0, 1, 2, …, \(n\)), useremo invece una distribuzione discreta, ovvero la distribuzione binomiale.
La distribuzione a priori \(p(\theta)\) su un parametro continuo è sempre una PDF; la verosimiglianza \(p(\text{dati} \mid \theta)\) per dati discreti è una PMF rispetto ai dati possibili, ma una funzione continua di \(\theta\).
6.8 Funzione di distribuzione cumulativa
Esiste una descrizione della distribuzione di probabilità che vale sia per le variabili discrete che per quelle continue e che specifica direttamente la probabilità che la variabile assuma valori inferiori o uguali a una determinata soglia. Questa descrizione è fornita dalla funzione di distribuzione cumulativa.
Definizione 6.5 (Funzione di distribuzione cumulativa (CDF)) La funzione di distribuzione cumulativa di una variabile casuale \(X\) è la funzione
\[ F_X : \mathbb{R} \to [0,1] \] definita da
\[ F_X(x) = P(X \leq x). \]
Dal punto di vista epistemico, \(F_X(x)\) rappresenta il grado di credenza che il valore della variabile casuale \(X\) non superi la soglia \(x\). Questa interpretazione rende la CDF particolarmente utile per rispondere a domande come: “Qual è la probabilità che il punteggio sia inferiore a questa soglia clinica?”.
6.8.1 Relazione con PMF e PDF
La funzione di distribuzione cumulativa caratterizza completamente la distribuzione di probabilità. Da essa è possibile ricavare:
- la funzione di massa di probabilità nel caso discreto;
- la funzione di densità di probabilità nel caso continuo.
Per le variabili casuali continue vale la relazione fondamentale: \[ F_X(x) = \int_{-\infty}^{x} f_X(t)\,dt, \qquad f_X(x) = \frac{d}{dx} F_X(x), \] ovvero la CDF è l’integrale cumulativo della densità e, viceversa, la densità è la derivata della CDF.
Nel caso discreto, la CDF cresce per salti, ciascuno dei quali ha un’ampiezza pari alla probabilità del valore corrispondente: \[ F_X(x) = \sum_{x_i \leq x} p_X(x_i). \]
Teorema 6.2 (Proprietà della funzione di distribuzione cumulativa) Ogni funzione di distribuzione cumulativa soddisfa le seguenti proprietà:
Monotonia non decrescente: per ogni \(a < b\), \[ F_X(a) \leq F_X(b). \]
Comportamento asintotico: \[ \lim_{x \to -\infty} F_X(x) = 0, \qquad \lim_{x \to +\infty} F_X(x) = 1. \]
Continuità da destra: per ogni \(x \in \mathbb{R}\), \[ \lim_{h \to 0^+} F_X(x + h) = F_X(x). \]
6.8.2 Ponte applicativo: uso della CDF per i cut-off clinici
La CDF è lo strumento naturale per calcolare la proporzione di individui che cadono sotto (o sopra) una certa soglia. Se il punteggio \(X\) al PHQ-9 nella popolazione clinica segue una certa distribuzione, allora:
- \(F_X(9)\) = probabilità che un paziente abbia un punteggio ≤ 9 (depressione minima)
- \(1 - F_X(19)\) = probabilità di depressione grave (punteggio > 19)
- \(F_X(14) - F_X(9)\) = probabilità di depressione moderata (10-14)
Queste probabilità sono fondamentali per interpretare le proprietà delle scale di screening.
# CDF per il test a 5 item con p = 0.7
valori <- 0:5
prob <- dbinom(valori, size = 5, prob = 0.7)
cdf <- pbinom(valori, size = 5, prob = 0.7)
# Dati per il grafico a gradini
df_cdf <- data.frame(
x_start = c(-0.5, valori),
x_end = c(valori, 5.5),
y = c(0, cdf)
)
ggplot() +
geom_segment(
data = df_cdf,
aes(x = x_start, xend = x_end, y = y, yend = y),
linewidth = 1
) +
geom_point(
data = data.frame(x = valori, y = cdf),
aes(x = x, y = y),
size = 3
) +
scale_x_continuous(breaks = 0:5, limits = c(-0.5, 5.5)) +
scale_y_continuous(breaks = seq(0, 1, 0.2)) +
labs(
x = "x (numero di risposte corrette)",
y = expression(F[X](x) == P(X <= x)),
title = "CDF del punteggio nel test a 5 item"
)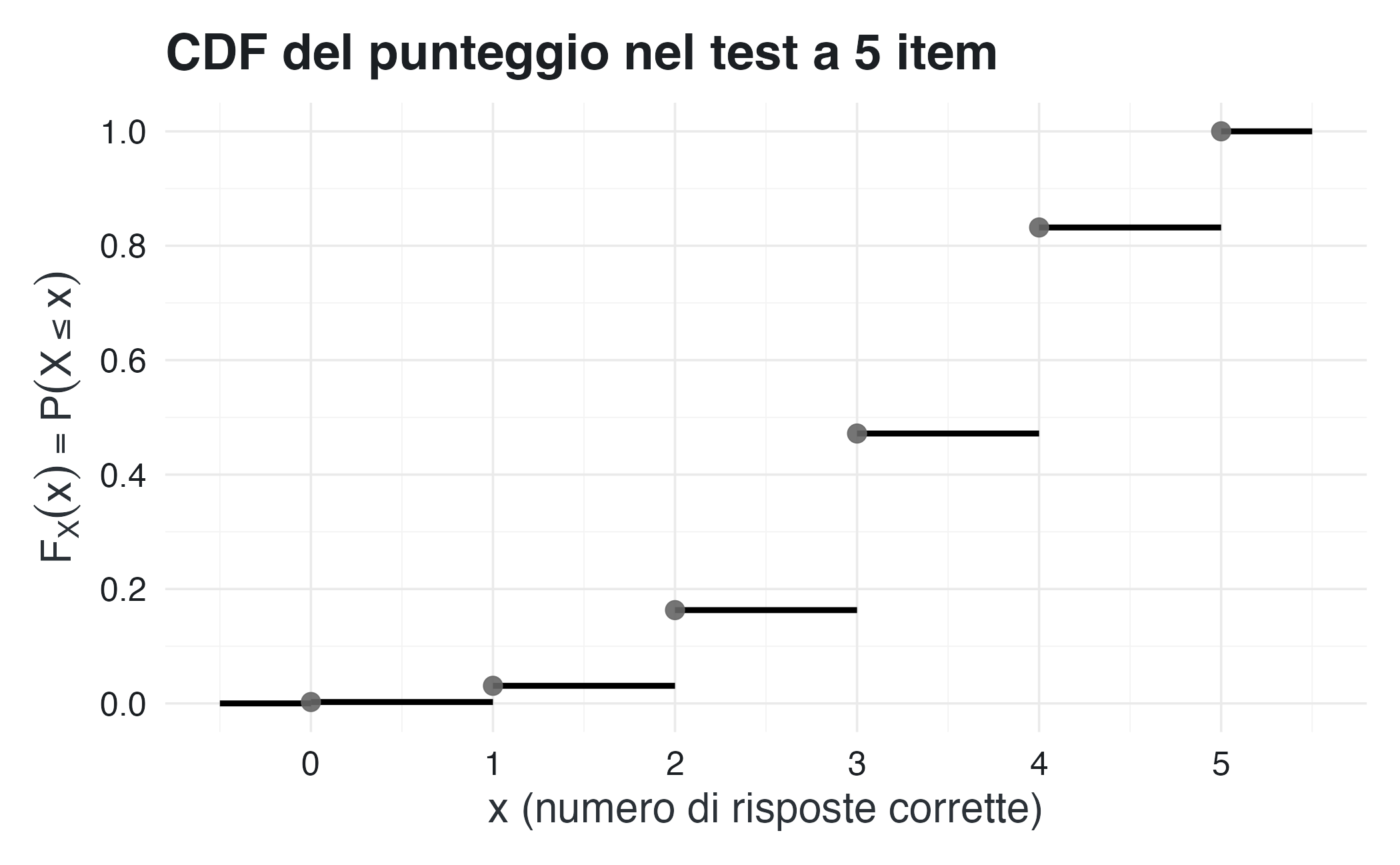
Nel grafico, ogni salto della funzione corrisponde a un possibile valore del punteggio. L’altezza del salto in \(x\) è pari alla probabilità \(P(X = x)\). Ad esempio, il salto da \(F_X(3)\) a \(F_X(4)\) ha ampiezza 0.36, che corrisponde esattamente a \(p_X(4)\).
Da questo grafico si può leggere direttamente che:
- \(P(X \leq 2) = F_X(2) \approx 0.16\);
- \(P(X \leq 3) = F_X(3) \approx 0.47\);
- \(P(X \geq 4) = 1 - F_X(3) \approx 0.53\).
6.8.3 Connessione con il percorso bayesiano
La CDF è lo strumento fondamentale per calcolare gli intervalli di credibilità nell’inferenza bayesiana. Se il parametro \(\theta\) ha una distribuzione a posteriori \(p(\theta \mid \text{dati})\) e una CDF \(F_\theta(t)\), allora:
- il quantile \(q_\alpha\) tale che \(F_\theta(q_\alpha) = \alpha\) indica il valore sotto il quale cade una proporzione \(\alpha\) della massa a posteriori;
- l’intervallo di credibilità al 95% è tipicamente \([q_{0.025}, q_{0.975}]\);
- la probabilità a posteriori che il valore di \(\theta\) superi una soglia \(\theta_0\) è data da \(1 - F_\theta(\theta_0)\).
Queste operazioni sono al centro dell’inferenza bayesiana e richiedono una buona padronanza della CDF.
6.9 Variabili casuali multiple
In molti contesti sperimentali e clinici è necessario modellare più fenomeni aleatori simultaneamente. In uno studio sulla comorbilità tra ansia e depressione, ad esempio, è necessario rappresentare congiuntamente i punteggi su entrambe le scale. Nello studio della memoria, ad esempio, potremmo voler modellare insieme accuratezza e tempo di risposta. Nell’analisi delle misure ripetute, l’incertezza riguarda i valori osservati in momenti diversi.
Il framework probabilistico si estende naturalmente a questi contesti multivariati: invece di descrivere l’incertezza relativa a una singola variabile casuale, si descrive l’incertezza relativa alla combinazione dei valori assunti da più variabili.
6.9.1 Distribuzione congiunta
Definizione 6.6 (Distribuzione congiunta) Siano \(X\) e \(Y\) due variabili casuali discrete. La funzione di massa di probabilità congiunta è definita come \[ p_{X,Y}(x,y) = P(X = x, Y = y). \]
Essa assegna una probabilità a ciascuna possibile coppia di valori \((x,y)\) assunta congiuntamente dalle due variabili.
La distribuzione congiunta fornisce la descrizione più completa dello stato di credenza riguardo alle variabili considerate: tutte le altre quantità probabilistiche possono essere derivate da essa.
6.9.2 Esempio: ansia e depressione
Supponiamo di classificare i pazienti in base a tre livelli di ansia (bassa, media, alta) e tre livelli di depressione (bassa, media, alta). La distribuzione congiunta potrebbe essere la seguente:
| Depr. bassa | Depr. media | Depr. alta | |
|---|---|---|---|
| Ansia bassa | 0.25 | 0.10 | 0.05 |
| Ansia media | 0.08 | 0.15 | 0.07 |
| Ansia alta | 0.02 | 0.08 | 0.20 |
La somma di tutte le celle è 1. La probabilità di osservare un paziente con ansia alta e depressione alte è \(p_{X,Y}(\text{alta}, \text{alta}) = 0.20\).
6.9.3 Distribuzioni marginali
Le distribuzioni marginali si ottengono eliminando una variabile dalla distribuzione congiunta e sommando i valori della variabile da eliminare.
\[ p_X(x) = \sum_y p_{X,Y}(x,y), \qquad p_Y(y) = \sum_x p_{X,Y}(x,y). \]
Nell’esempio precedente:
- \(p_X(\text{ansia alta}) = 0.02 + 0.08 + 0.20 = 0.30\);
- \(p_Y(\text{depr. alta}) = 0.05 + 0.07 + 0.20 = 0.32\).
Dal punto di vista epistemico, la marginalizzazione corrisponde all’ignorare una delle variabili, concentrandosi esclusivamente sull’incertezza relativa all’altra.
6.9.4 Indipendenza stocastica
Le variabili casuali \(X\) e \(Y\) si dicono stocasticamente indipendenti se e solo se la loro distribuzione congiunta si scompone nel prodotto delle distribuzioni marginali:
\[ p_{X,Y}(x,y) = p_X(x) \cdot p_Y(y) \quad \text{per ogni } (x,y). \]
Questa condizione esprime l’assenza di qualsiasi relazione informativa: conoscere il valore assunto da una variabile non modifica la distribuzione dell’altra.
Nella tabella di esempio, ansia e depressione non sono indipendenti. Se lo fossero, dovremmo avere:
\[ p_{X,Y}(\text{alta}, \text{alta}) = p_X(\text{alta}) \cdot p_Y(\text{alta}) = 0.30 \times 0.32 = 0.096. \]
Ma il valore osservato è 0.20, molto superiore: le due condizioni tendono a co-occorrere più di quanto ci si aspetterebbe in caso di indipendenza. Questa è la struttura della comorbidità.
6.9.5 Ponte applicativo: perché le variabili multiple sono cruciali
Nella pratica clinica, raramente ci interessa una singola variabile presa in isolamento. Le relazioni tra ansia e depressione, tra sintomi e funzionamento, tra processi cognitivi e comportamento manifesto richiedono tutte di modellare distribuzioni congiunte.
Nell’inferenza bayesiana, le variabili multiple sono costantemente presenti. Quando abbiamo più parametri nel modello, come la media e la varianza o gli effetti fissi e casuali, la distribuzione a posteriori è una distribuzione congiunta su tutti i parametri. Comprendere come le distribuzioni congiunte si scompongono in marginali e come l’indipendenza semplifica i calcoli è essenziale per poter utilizzare questi modelli.
6.9.6 Connessione con il percorso bayesiano
La struttura delle variabili casuali multiple è il fondamento per comprendere concetti avanzati che incontreremo:
- Gerarchie di parametri: nei modelli multilivello, i parametri di livello inferiore (ad esempio, gli effetti individuali) hanno una distribuzione condizionata ai parametri di livello superiore (ad esempio, i parametri di gruppo).
- Modelli grafici: le reti bayesiane rappresentano le relazioni di dipendenza condizionata tra variabili attraverso grafi.
- Marginalizzazione: il calcolo della distribuzione a posteriori marginale di un singolo parametro richiede l’integrazione (o marginalizzazione) rispetto agli altri parametri.
Riflessioni conclusive
Il concetto di variabile casuale costituisce il ponte fondamentale tra la teoria della probabilità, intesa come sistema di credenze coerenti, e l’analisi quantitativa dei fenomeni psicologici. Grazie a questa formalizzazione, qualsiasi risultato, che si tratti di un punteggio, di un tempo o di un conteggio, può essere tradotto in un oggetto matematico sul quale è possibile applicare gli strumenti del calcolo delle probabilità.
Le due principali classi di variabili casuali, discrete e continue, richiedono formalizzazioni tecniche differenti (somme vs integrali), ma si basano sullo stesso principio: descrivere la distribuzione della credenza nello spazio dei possibili valori. La funzione di massa di probabilità (PMF) per variabili discrete e la funzione di densità di probabilità (PDF) per le variabili continue svolgono ruoli analoghi, mentre la funzione di distribuzione cumulativa (CDF) fornisce una rappresentazione unificante.
Per lo psicologo che si avvicina all’inferenza bayesiana, questi concetti non sono astrazioni matematiche fini a sé stesse, ma il vocabolario necessario per:
- specificare le distribuzioni a priori sui parametri di interesse;
- comprendere la funzione di verosimiglianza che connette parametri e dati;
- interpretare le distribuzioni a posteriori e gli intervalli di credibilità;
- formulare domande probabilistiche sui fenomeni psicologici.
Nei capitoli successivi studieremo le famiglie parametriche di distribuzioni, come la distribuzione Beta, la distribuzione Normale, la distribuzione Binomiale, la distribuzione di Poisson e altre, che costituiscono i mattoni elementari della modellazione bayesiana. Ogni distribuzione codifica specifiche assunzioni sul processo generativo dei dati; comprendere le variabili casuali significa essere pronti a scegliere e interpretare queste distribuzioni in modo consapevole.
Punti chiave da ricordare
Concetti essenziali:
-
Variabile casuale come funzione
- \(X: \Omega \to \mathbb{R}\) associa a ogni esito un valore numerico;
- la funzione è deterministica; l’incertezza riguarda quale esito si realizzerà;
- permette di passare da eventi qualitativi a quantità analizzabili.
-
Discrete vs Continue
- discrete: valori numerabili (punteggi, conteggi);
- continue: valori in intervalli (tempi, misure fisiologiche);
- richiedono strumenti diversi: somme vs integrali.
-
PMF per variabili discrete
- \(p_X(x) = P(X = x)\) è una probabilità vera e propria;
- \(\sum_x p_X(x) = 1\).
-
PDF per variabili continue
- \(f_X(x)\) è una densità, non una probabilità;
- \(P(a \leq X \leq b) = \int_a^b f_X(x) \, dx\);
- \(P(X = x) = 0\) per ogni \(x\) specifico.
-
CDF come rappresentazione unificata
- \(F_X(x) = P(X \leq x)\) funziona per entrambi i tipi;
- fondamentale per quantili e intervalli di credibilità.
-
Variabili multiple
- la distribuzione congiunta descrive l’incertezza su combinazioni di valori;
- marginalizzazione: eliminare una variabile sommando/integrando;
- indipendenza: \(p_{X,Y}(x,y) = p_X(x) \cdot p_Y(y)\).
Formule essenziali:
\[ \text{PMF: } p_X(x) = P(X = x), \quad \sum_x p_X(x) = 1 \]
\[ \text{PDF: } P(a \leq X \leq b) = \int_a^b f_X(x) \, dx, \quad \int_{-\infty}^{+\infty} f_X(x) \, dx = 1 \]
\[ \text{CDF: } F_X(x) = P(X \leq x) \]
\[ \text{Marginale: } p_X(x) = \sum_y p_{X,Y}(x,y) \]
Per il prossimi capitoli:
Studieremo le famiglie di distribuzioni parametriche (Bernoulli, Binomiale, Normale, Beta…) che costituiscono il vocabolario della modellazione bayesiana. Ogni distribuzione codifica assunzioni specifiche sul processo generativo dei dati.
sessionInfo()
#> R version 4.5.2 (2025-10-31)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Tahoe 26.2
#>
#> Matrix products: default
#> BLAS: /System/Library/Frameworks/Accelerate.framework/Versions/A/Frameworks/vecLib.framework/Versions/A/libBLAS.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
#>
#> locale:
#> [1] C.UTF-8/UTF-8/C.UTF-8/C/C.UTF-8/C.UTF-8
#>
#> time zone: Europe/Rome
#> tzcode source: internal
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] ragg_1.5.0 tinytable_0.15.2 withr_3.0.2
#> [4] systemfonts_1.3.1 patchwork_1.3.2 ggdist_3.3.3
#> [7] tidybayes_3.0.7 bayesplot_1.15.0 ggplot2_4.0.1
#> [10] reliabilitydiag_0.2.1 priorsense_1.2.0 posterior_1.6.1
#> [13] loo_2.9.0 rstan_2.32.7 StanHeaders_2.32.10
#> [16] brms_2.23.0 Rcpp_1.1.1 sessioninfo_1.2.3
#> [19] conflicted_1.2.0 janitor_2.2.1 matrixStats_1.5.0
#> [22] modelr_0.1.11 tibble_3.3.1 dplyr_1.1.4
#> [25] tidyr_1.3.2 rio_1.2.4 here_1.0.2
#>
#> loaded via a namespace (and not attached):
#> [1] svUnit_1.0.8 tidyselect_1.2.1 farver_2.1.2
#> [4] S7_0.2.1 fastmap_1.2.0 TH.data_1.1-5
#> [7] tensorA_0.36.2.1 digest_0.6.39 timechange_0.3.0
#> [10] estimability_1.5.1 lifecycle_1.0.5 survival_3.8-3
#> [13] magrittr_2.0.4 compiler_4.5.2 rlang_1.1.7
#> [16] tools_4.5.2 yaml_2.3.12 knitr_1.51
#> [19] labeling_0.4.3 bridgesampling_1.2-1 htmlwidgets_1.6.4
#> [22] curl_7.0.0 pkgbuild_1.4.8 RColorBrewer_1.1-3
#> [25] abind_1.4-8 multcomp_1.4-29 purrr_1.2.1
#> [28] grid_4.5.2 stats4_4.5.2 colorspace_2.1-2
#> [31] xtable_1.8-4 inline_0.3.21 emmeans_2.0.1
#> [34] scales_1.4.0 MASS_7.3-65 cli_3.6.5
#> [37] mvtnorm_1.3-3 rmarkdown_2.30 generics_0.1.4
#> [40] otel_0.2.0 RcppParallel_5.1.11-1 cachem_1.1.0
#> [43] stringr_1.6.0 splines_4.5.2 parallel_4.5.2
#> [46] vctrs_0.6.5 V8_8.0.1 Matrix_1.7-4
#> [49] sandwich_3.1-1 jsonlite_2.0.0 arrayhelpers_1.1-0
#> [52] glue_1.8.0 codetools_0.2-20 distributional_0.6.0
#> [55] lubridate_1.9.4 stringi_1.8.7 gtable_0.3.6
#> [58] QuickJSR_1.8.1 pillar_1.11.1 htmltools_0.5.9
#> [61] Brobdingnag_1.2-9 R6_2.6.1 textshaping_1.0.4
#> [64] rprojroot_2.1.1 evaluate_1.0.5 lattice_0.22-7
#> [67] backports_1.5.0 memoise_2.0.1 broom_1.0.11
#> [70] snakecase_0.11.1 rstantools_2.6.0 gridExtra_2.3
#> [73] coda_0.19-4.1 nlme_3.1-168 checkmate_2.3.3
#> [76] xfun_0.55 zoo_1.8-15 pkgconfig_2.0.3