10 Dal dato all’ipotesi: l’evidenza e l’aggiornamento delle credenze
Introduzione
Un psicologo clinico sta valutando se adottare un nuovo protocollo di intervento per la depressione nella propria struttura. I dati di uno studio pilota mostrano che il 36% dei pazienti trattati ha raggiunto la remissione completa dei sintomi. Ma cosa significa realmente questa stima? Può affidarsi a questo numero per prendere una decisione che riguarderà decine di pazienti futuri?
Il 36% osservato è una stima puntuale, ma non ci dice quanto potremmo essere lontani dal valore “vero”, cioè la proporzione di remissione che osserveremmo se potessimo trattare l’intera popolazione di pazienti con caratteristiche simili. Forse l’efficacia reale è del 45% e lo studio l’ha sottostimata casualmente. Oppure potrebbe essere solo del 25%, e lo studio l’ha invece sovrastimata. La differenza tra questi scenari ha implicazioni cliniche sostanziali.
La domanda cruciale diventa quindi: come possiamo quantificare l’incertezza sulle quantità di interesse a partire da dati limitati? In che modo possiamo esprimere, in termini probabilistici, il grado di fiducia che l’efficacia del trattamento rientri in un certo intervallo?
L’approccio che seguiremo in questo capitolo considera i parametri di un modello statistico, come proporzioni, medie e varianze, non come valori fissi, ma come quantità ignote su cui possediamo un’incertezza di tipo epistemico. Questa incertezza viene rappresentata tramite distribuzioni di probabilità. Prima di osservare i dati, formalizziamo le nostre conoscenze preliminari attraverso una distribuzione a priori. Dopo aver raccolto i dati, aggiorniamo tali credenze ottenendo una distribuzione a posteriori. Questo meccanismo di aggiornamento coerente delle credenze alla luce dell’evidenza empirica costituisce il nucleo dell’inferenza bayesiana.
Un esempio concreto: la stima della prevalenza dei sintomi depressivi
Immaginiamo di voler stimare la prevalenza di sintomi depressivi clinicamente rilevanti nella popolazione studentesca universitaria. Poiché non è possibile osservare l’intera popolazione, ci affidiamo a un campione e utilizziamo l’inferenza statistica per generalizzare i risultati.
Supponiamo di reclutare un campione casuale di 200 studenti universitari, rilevando che 72 di loro presentano sintomi depressivi clinicamente significativi (punteggio PHQ-9 ≥ 10). Il nostro obiettivo è stimare il parametro \(\theta\), che rappresenta la vera prevalenza di tali sintomi nella popolazione di riferimento, e quantificare l’incertezza associata a questa stima.
Nell’approccio bayesiano, il processo inferenziale inizia prima della raccolta dei dati. Le nostre conoscenze preliminari su \(\theta\) (ad esempio, da studi precedenti o considerazioni teoriche) vengono formalizzate in una distribuzione a priori. Dopo aver osservato i dati – 72 casi su 200 – queste credenze vengono aggiornate attraverso il teorema di Bayes, producendo una distribuzione a posteriori per il parametro \(\theta\).
A partire dalla distribuzione a posteriori possiamo ricavare diverse sintesi statistiche. Una delle più informative è l’intervallo di credibilità, che riassume l’incertezza sulla stima del parametro. Ad esempio, un intervallo di credibilità al 95% per \(\theta\) potrebbe essere [0.29; 0.43]. L’interpretazione è diretta: alla luce delle informazioni disponibili (prior e dati), riteniamo che vi sia una probabilità del 95% che il valore vero della prevalenza nella popolazione si trovi tra 0.29 e 0.43.
Questa interpretazione probabilistica dell’incertezza è non solo formalmente corretta, ma anche intuitiva per ricercatori e clinici, poiché riflette il modo naturale in cui esprimiamo la fiducia nelle nostre stime dopo aver osservato i dati.
Per seguire questo capitolo è necessario aver letto:
- Capitolo 5 — fondamentale.
- Capitolo 8 — per valore atteso, varianza, SE.
Questo capitolo segna il passaggio dalla teoria della probabilità all’inferenza statistica bayesiana, mostrando come quantificare l’incertezza sui parametri sconosciuti a partire dai dati campionari.
Letture complementari consigliate:
- Schervish, M. J. (2014). Theory of Statistics, capitolo “Sampling Distributions of Estimators” (Schervish & DeGroot, 2014).
Competenze pratiche:
- Familiarità con R per simulazioni e calcolo di distribuzioni campionarie.
Panoramica del capitolo
- Comprendere le proprietà statistiche della media campionaria (valore atteso, varianza, SE) e il loro significato inferenziale.
- Comprendere la distribuzione campionaria; come la sua forma determina la verosimiglianza che i dati impongono sui parametri.
- Legge dei Grandi Numeri: perché la media campionaria converge al valore vero e quali implicazioni ha per l’affidabilità delle stime.
- Teorema del Limite Centrale: quando e perché la distribuzione delle medie può essere approssimata con una distribuzione gaussiana e quali sono i limiti pratici di tale approssimazione.
- Come costruire prior, verosimiglianza e posterior; calcolo degli intervalli di credibilità e interpretazione probabilistica.
- Ruolo dell’errore standard come misura di informatività; definizione di precisione e regole di somma delle precisioni per sintetizzare studi indipendenti.
- Analisi di sensibilità per valutare l’effetto dei prior sulla posterior.
- Distinzione tra incertezza campionaria e distorsioni sistematiche e strategie metodologiche per mitigarle.
10.1 Dati, parametri e incertezza
10.1.1 Dati osservati e parametro di interesse
Riprendiamo l’esempio introdotto in precedenza, relativo alla stima della prevalenza \(\theta\) di studenti con sintomi depressivi clinicamente rilevanti. Dopo aver selezionato un campione rappresentativo di \(n\) studenti, registriamo per ciascun partecipante la presenza (1) o l’assenza (0) del sintomo.
Le osservazioni campionarie possono essere formalizzate come variabili casuali binarie \(X_1, X_2, \ldots, X_n\), dove:
\[ X_i = \begin{cases} 1 & \text{se lo studente } i \text{ presenta sintomi (PHQ-9} \geq 10\text{)}, \\[4pt] 0 & \text{altrimenti}. \end{cases} \]
Questa rappresentazione esplicita il collegamento tra i dati osservati e un modello probabilistico sottostante. In particolare, permette di descrivere formalmente l’incertezza associata alle osservazioni e di legarla direttamente al parametro di interesse \(\theta\), che rappresenta la vera proporzione del fenomeno nella popolazione di riferimento.
10.1.2 Dalla statistica descrittiva all’inferenza probabilistica
Una prima sintesi dei dati osservati è fornita dalla proporzione campionaria:
\[ \bar{X} = \frac{1}{n}\sum_{i=1}^n X_i = \frac{\text{numero di studenti con sintomo}}{n}. \]
Nel nostro esempio, \(\bar{X} = 72/200 = 0.36\). Questa quantità riassume l’informazione contenuta nel campione, ma ha un ruolo puramente descrittivo. Il nostro obiettivo non è semplicemente quello di descrivere i dati osservati, ma di utilizzare tali informazioni per trarre conclusioni sul parametro \(\theta\), che non è direttamente osservabile.
La questione centrale diventa quindi la seguente: in che modo il valore osservato di \(\bar{X}\) dovrebbe modificare la nostra incertezza riguardo a \(\theta\)? Per rispondere a questa domanda, è necessario andare oltre la statistica descrittiva e adottare un approccio inferenziale basato su un modello probabilistico.
10.1.3 Il modello probabilistico di riferimento
Per collegare i dati osservati al parametro di interesse, costruiamo un modello probabilistico che metta in relazione:
- le osservazioni empiriche \(X_1, \ldots, X_n\);
- il parametro \(\theta\), considerato come una quantità sconosciuta e soggetta a incertezza epistemica;
- le informazioni disponibili prima dell’osservazione dei dati.
Assumiamo che, condizionatamente al parametro \(\theta\), ciascuna osservazione segua una distribuzione di Bernoulli:
\[ X_i \mid \theta \sim \text{Bernoulli}(\theta). \]
Questa assunzione formalizza l’idea che, se il valore di \(\theta\) fosse noto, la probabilità che uno studente qualsiasi presenti il sintomo sarebbe pari a \(\theta\). Il modello specifica quindi come i dati sarebbero generati per ciascun valore possibile del parametro.
La notazione \(X_i \mid \theta\) indica che stiamo descrivendo la distribuzione della variabile casuale \(X_i\) a condizione che il parametro \(\theta\) sia fissato a un valore specifico. Questa formulazione non implica che il valore di \(\theta\) sia noto, ma serve a strutturare il ragionamento inferenziale: se \(\theta\) assumesse un certo valore, allora le osservazioni seguirebbero una determinata distribuzione.
10.2 Proprietà fondamentali della media campionaria
Nel Capitolo 8 abbiamo già derivato le proprietà algebriche di base della media campionaria come applicazioni dirette della linearità del valore atteso e dell’additività della varianza per variabili indipendenti. Abbiamo visto che \(\mathbb{E}[\bar{X}] = \mu\) e che \(\text{Var}(\bar{X}) = \sigma^2/n\).
In questa sezione, approfondiamo il significato inferenziale di questi risultati, esaminandoli in relazione all’incertezza sul parametro \(\theta\) e collegandoli esplicitamente alla struttura del processo di campionamento.
10.2.1 Valore atteso della media campionaria
Supponiamo di avere osservazioni \(X_1, X_2, \ldots, X_n\) indipendenti e identicamente distribuite (i.i.d.), ciascuna con valore atteso \[ \mathbb{E}[X_i \mid \theta] = \theta. \]
Teorema 10.1 Il valore atteso della media campionaria è: \[ \mathbb{E}[\bar{X} \mid \theta] = \theta. \]
Dimostrazione. Per definizione, la media campionaria è: \[ \bar{X} = \frac{1}{n}\sum_{i=1}^n X_i. \]
Applicando l’operatore di valore atteso: \[ \mathbb{E}[\bar{X} \mid \theta] = \mathbb{E}\left[\frac{1}{n}\sum_{i=1}^n X_i \,\bigg|\, \theta\right]. \]
Per la linearità del valore atteso: \[ = \frac{1}{n}\sum_{i=1}^n \mathbb{E}[X_i \mid \theta]. \]
Poiché tutte le variabili sono identicamente distribuite con valore atteso pari a \(\theta\): \[ = \frac{1}{n}\cdot n\theta = \theta. \]
Interpretazione: questo risultato mostra che la media campionaria è centrata sul valore del parametro \(\theta\). In assenza di errori sistematici, \(\bar{X}\) non tende né a sovrastimare né a sottostimare la prevalenza reale nella popolazione. Questa proprietà giustifica l’uso della media campionaria come base per l’inferenza.
10.2.2 Varianza della media campionaria
La seconda proprietà fondamentale riguarda la variabilità della media campionaria.
Teorema 10.2 Se le osservazioni sono indipendenti e ciascuna ha varianza \[ \text{Var}(X_i \mid \theta) = \sigma^2, \] allora: \[ \text{Var}(\bar{X} \mid \theta) = \frac{\sigma^2}{n}. \]
Dimostrazione. Per definizione: \[ \text{Var}(\bar{X} \mid \theta) = \text{Var}\left(\frac{1}{n}\sum_{i=1}^n X_i \,\bigg|\, \theta\right). \]
Usando la proprietà \(\text{Var}(aY) = a^2 \text{Var}(Y)\): \[ = \frac{1}{n^2}\text{Var}\left(\sum_{i=1}^n X_i \,\bigg|\, \theta\right). \]
Poiché le osservazioni sono indipendenti, la varianza della somma è la somma delle varianze: \[ = \frac{1}{n^2}\sum_{i=1}^n \text{Var}(X_i \mid \theta) = \frac{1}{n^2}\cdot n\sigma^2 = \frac{\sigma^2}{n}. \]
Interpretazione: la variabilità della media campionaria diminuisce all’aumentare della dimensione del campione. In particolare:
- la varianza di \(\bar{X}\) decresce proporzionalmente a \(1/n\);
- per ridurre della metà la deviazione standard della media è necessario quadruplicare il numero di osservazioni.
10.2.3 Il caso delle variabili Bernoulliane
Nel contesto considerato, ciascuna osservazione \(X_i\) è una variabile aleatoria binaria. La varianza di una variabile Bernoulliana è: \[ \text{Var}(X_i \mid \theta) = \theta(1-\theta). \]
La varianza della media campionaria (proporzione osservata) è quindi: \[ \text{Var}(\bar{X} \mid \theta) = \frac{\theta(1-\theta)}{n}. \]
L’errore standard (SE) è la radice quadrata della varianza: \[ \text{SE}(\bar{X}) = \sqrt{\frac{\theta(1-\theta)}{n}}. \]
L’errore standard quantifica la variabilità attesa della proporzione osservata da un campione all’altro. In termini bayesiani, fornisce un’indicazione diretta del contenuto informativo dei dati: un errore standard ridotto segnala che le osservazioni sono altamente informative e conducono a una distribuzione a posteriori concentrata.
10.2.4 Ponte applicativo: cosa significano queste proprietà per il ricercatore
Queste proprietà matematiche hanno conseguenze pratiche immediate:
La proporzione campionaria è una buona stima: poiché \(\mathbb{E}[\bar{X}] = \theta\), osservare 72/200 = 0.36 ci dice che la nostra migliore stima puntuale della prevalenza è 36%.
L’incertezza è quantificabile: con \(\theta \approx 0.36\) e \(n = 200\), l’errore standard è circa \(\sqrt{0.36 \times 0.64 / 200} \approx 0.034\), ovvero circa 3.4 punti percentuali.
Campioni più grandi forniscono stime più precise: se avessimo \(n = 800\) studenti invece di 200, l’errore standard si dimezzerebbe.
La regola del 4×: per dimezzare l’incertezza è necessario quadruplicare il campione. Questa regola pratica è utile per la pianificazione degli studi.
10.3 Comprendere la variabilità dei dati
10.3.1 Il concetto di distribuzione campionaria
Immaginiamo di poter osservare molti campioni diversi, tutti della stessa dimensione \(n\), estratti dalla stessa popolazione. Per ciascun campione potremmo calcolare la media campionaria \(\bar{X}\), ottenendo ogni volta un valore potenzialmente diverso a causa della variabilità casuale del campionamento.
La distribuzione campionaria della media descrive come questi valori di \(\bar{X}\) si distribuiscono al variare del campione. Essa non si riferisce a un singolo insieme di dati osservati, ma un esperimento ipotetico ripetuto molte volte nelle stesse condizioni.
Questo concetto teorico è fondamentale per comprendere il ruolo dei dati nell’inferenza statistica. La distribuzione campionaria costituisce la base della funzione di verosimiglianza, che quantifica quanto ciascun possibile valore del parametro \(\theta\) sia compatibile con i dati osservati.
10.3.2 Esempio concreto: risposte a un item Likert
Per rendere il concetto più tangibile, consideriamo un esempio con dati psicologicamente riconoscibili. Supponiamo di avere una piccola popolazione di 4 partecipanti che hanno risposto a un item sulla soddisfazione di vita su una scala da 1 a 5:
# Risposte dei 4 partecipanti all'item "Sono soddisfatto della mia vita"
risposte <- c(2, 4, 4, 5)
risposte
#> [1] 2 4 4 5Calcoliamo la media e la varianza della popolazione:
Supponiamo ora di estrarre tutti i possibili campioni di dimensione \(n = 2\) con reinserimento (come faremmo campionando da una popolazione molto grande). Ciò genera \(4^2 = 16\) campioni possibili.
# Generiamo tutte le coppie possibili
campioni <- expand.grid(risposte, risposte)
colnames(campioni) <- c("Partecipante_1", "Partecipante_2")
# Calcoliamo la media di ciascun campione
medie_campionarie <- rowMeans(campioni)
# Mostriamo alcuni campioni con le loro medie
df_campioni <- data.frame(
Campione = paste(campioni[,1], campioni[,2], sep = ", "),
Media = medie_campionarie
)
head(df_campioni, 8)
#> Campione Media
#> 1 2, 2 2.0
#> 2 4, 2 3.0
#> 3 4, 2 3.0
#> 4 5, 2 3.5
#> 5 2, 4 3.0
#> 6 4, 4 4.0
#> 7 4, 4 4.0
#> 8 5, 4 4.5Visualizziamo la distribuzione delle medie campionarie:
ggplot(data.frame(media = medie_campionarie), aes(x = media)) +
geom_histogram(aes(y = after_stat(density)),
binwidth = 0.5, boundary = 0) +
geom_vline(xintercept = media_pop, linetype = "dashed",
linewidth = 1.2, color = "red") +
labs(
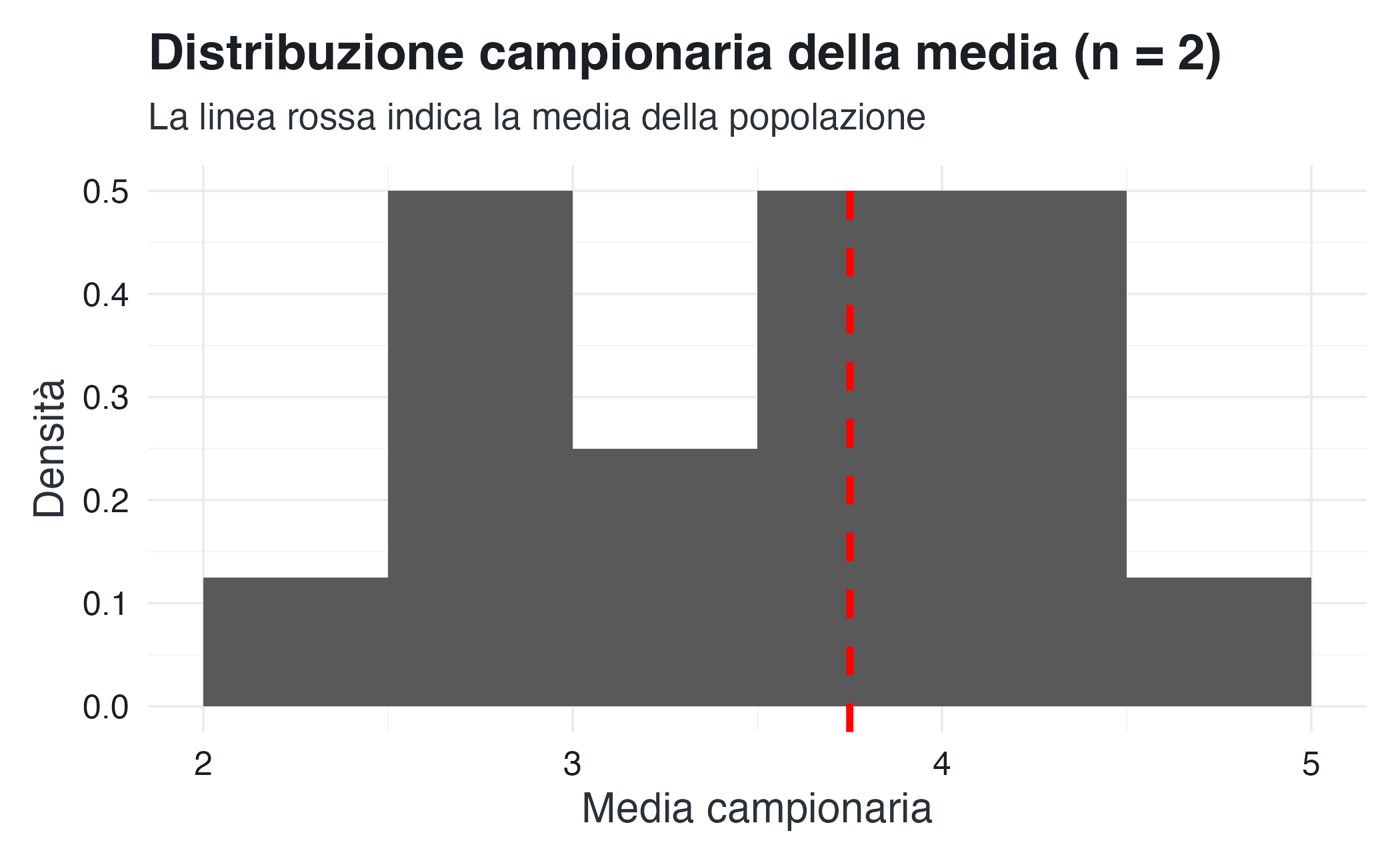
title = "Distribuzione campionaria della media (n = 2)",
subtitle = "La linea rossa indica la media della popolazione",
x = "Media campionaria",
y = "Densità"
)
Verifichiamo le proprietà teoriche:
cat("Media delle medie campionarie:", mean(medie_campionarie), "\n")
#> Media delle medie campionarie: 3.75
cat("Media della popolazione:", media_pop, "\n")
#> Media della popolazione: 3.75
cat("\n")
cat("Varianza delle medie campionarie:",
round(var(medie_campionarie) * 15/16, 3), "\n")
#> Varianza delle medie campionarie: 0.594
cat("Varianza teorica (σ²/n):", round(var_pop / 2, 3), "\n")
#> Varianza teorica (σ²/n): 0.594I risultati confermano le proprietà teoriche: la media delle medie campionarie coincide con la media della popolazione, e la varianza delle medie campionarie è circa la metà della varianza della popolazione (perché \(n = 2\)).
Questa simulazione illustra perché l’osservazione di un valore specifico di \(\bar{X}\) fornisce informazioni sul parametro sottostante. I valori della media campionaria tendono a concentrarsi intorno al valore effettivo del parametro. Se nel nostro campione osserviamo \(\bar{X} = 4.0\), è ragionevole credere che la media della popolazione sia vicina a 4.
In termini bayesiani, la distribuzione a posteriori di \(\theta\) sarà centrata in prossimità del valore osservato, con una dispersione che riflette l’incertezza residua.
10.4 Legge dei Grandi Numeri
La Legge dei Grandi Numeri (LGN) è uno dei risultati fondamentali della teoria della probabilità e fornisce una giustificazione matematica cruciale per l’inferenza statistica.
10.4.1 Enunciato intuitivo
In forma intuitiva, la LGN afferma che, all’aumentare del numero di osservazioni \(n\), la media campionaria \(\bar{X}_n\) tende ad avvicinarsi al valore atteso della variabile casuale:
\[ \bar{X}_n \xrightarrow{n \to \infty} \theta. \]
Questa convergenza può essere formalizzata in due modi:
Legge dei Grandi Numeri Debole: per ogni \(\varepsilon > 0\): \[ \Pr\bigl(|\bar{X}_n - \theta| > \varepsilon \mid \theta\bigr) \to 0 \quad \text{quando } n \to \infty. \]
Legge dei Grandi Numeri Forte: la media campionaria converge quasi certamente: \[ \Pr\left(\lim_{n \to \infty} \bar{X}_n = \theta \,\bigg|\, \theta\right) = 1. \]
Entrambe le formulazioni esprimono l’idea che, con un numero sufficientemente elevato di osservazioni, la media campionaria fornisce una rappresentazione sempre più accurata del parametro.
10.4.2 Implicazioni per l’inferenza bayesiana
Nel contesto bayesiano, la LGN ha una conseguenza fondamentale: al crescere della dimensione campionaria, l’informazione contenuta nei dati prevale progressivamente su quella contenuta nella distribuzione a priori. La distribuzione a posteriori tende a concentrarsi sempre più attorno al valore vero del parametro.
Più precisamente: con un numero sufficiente di osservazioni, i ricercatori che partono da credenze iniziali diverse giungeranno a conclusioni sostanzialmente coincidenti.
10.4.3 Simulazione della convergenza
Per osservare empiricamente la LGN, consideriamo uno scenario in cui il valore vero della prevalenza è \(\theta = 0.45\). Simuliamo una sequenza di osservazioni e calcoliamo la media cumulativa:
set.seed(42)
theta_true <- 0.45
n_max <- 1000
# Generazione delle osservazioni (presenza/assenza sintomo)
osservazioni <- rbinom(n_max, size = 1, prob = theta_true)
# Calcolo delle medie cumulative
medie_cumulative <- cumsum(osservazioni) / seq_along(osservazioni)
# Preparazione dei dati per la visualizzazione
data_plot <- data.frame(
n = 1:n_max,
media = medie_cumulative
)
ggplot(data_plot, aes(x = n, y = media)) +
geom_line(linewidth = 0.8, alpha = 0.8) +
geom_hline(yintercept = theta_true,
linetype = "dashed",
linewidth = 1.2, color = "red") +
geom_ribbon(aes(ymin = media - 1.96 * sqrt(media * (1 - media) / n),
ymax = media + 1.96 * sqrt(media * (1 - media) / n)),
alpha = 0.2) +
labs(
title = "Convergenza della proporzione campionaria",
subtitle = "La linea tratteggiata indica il valore vero θ = 0.45",
x = "Numero di partecipanti (n)",
y = "Proporzione con sintomi depressivi"
) +
ylim(0.2, 0.7) +
annotate("text", x = 800, y = theta_true + 0.03,
label = paste("θ =", theta_true),
size = 4.5)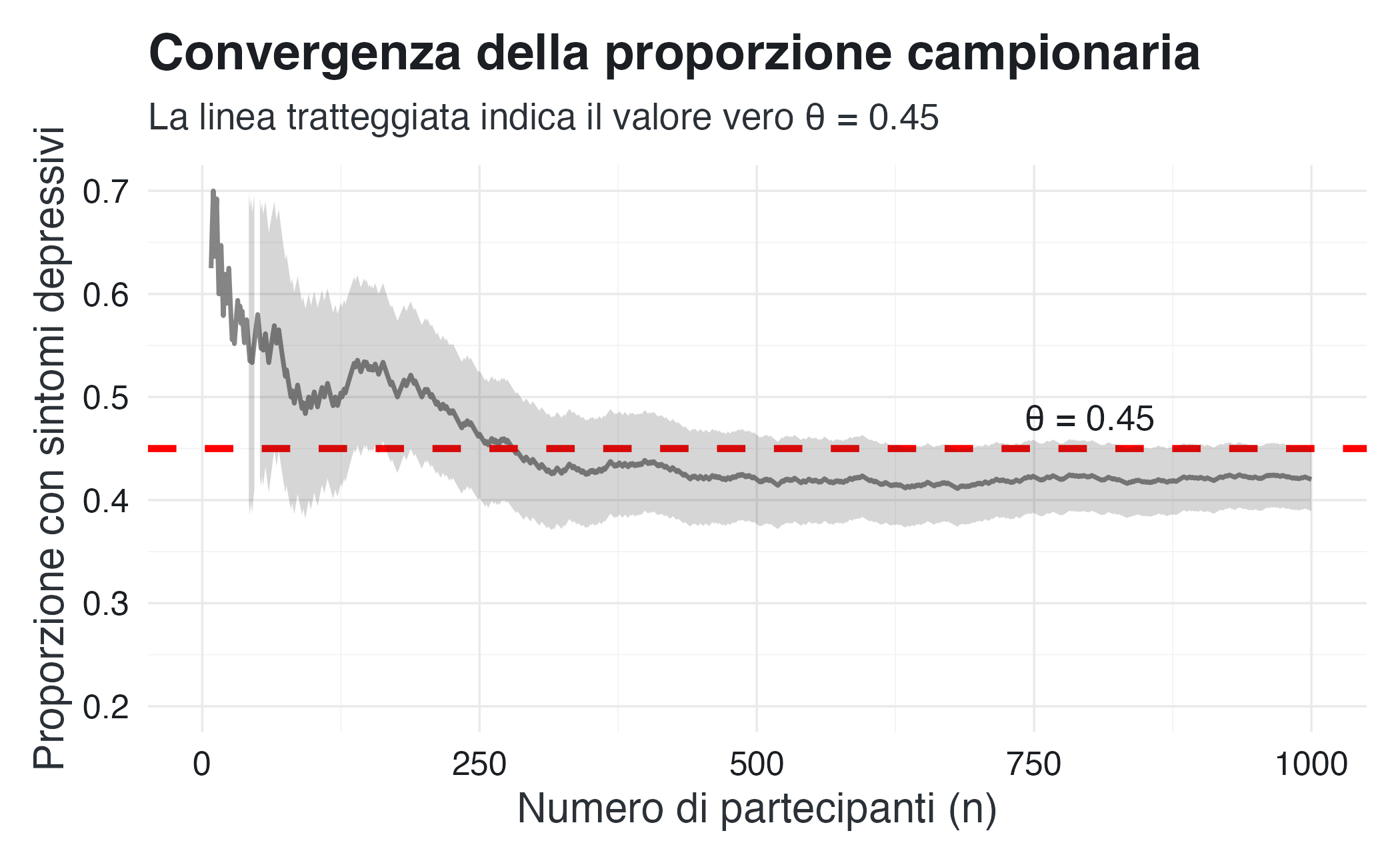
Osservazioni: nelle fasi iniziali, la proporzione osservata mostra ampie fluttuazioni. Man mano che \(n\) aumenta, le oscillazioni diminuiscono e la stima si stabilizza intorno al valore vero.
10.4.4 Ponte applicativo: implicazioni per la ricerca psicologica
La LGN ha conseguenze pratiche dirette:
Studi pilota: con campioni piccoli (n = 20-30), le stime sono inevitabilmente instabili. È normale che uno studio pilota osservi una prevalenza del 50% e che una replica osservi il 30%. Questo non indica necessariamente un errore, ma semplicemente la variabilità campionaria attesa con campioni ridotti.
Meta-analisi: combinare i risultati di molti studi indipendenti equivale, in un certo senso, ad aumentare la dimensione del campione complessivo. La LGN spiega perché le meta-analisi producono stime più stabili rispetto ai singoli studi.
Disegni longitudinali che prevedono l’osservazione ripetuta degli stessi individui nel tempo, permettono di accumulare informazioni progressivamente più dettagliate sui parametri di interesse. La LGN garantisce che questa informazione converga verso i valori reali.
Quando ricercatori diversi partono da distribuzioni a priori differenti, ma nessuna esclude il valore vero del parametro, l’osservazione degli stessi dati conduce a distribuzioni a posteriori sempre più simili. L’evidenza empirica “corregge” progressivamente le credenze iniziali.
Questo carattere autocorrettivo conferisce all’approccio bayesiano una notevole solidità: le conclusioni non dipendono in modo arbitrario dalle ipotesi iniziali, ma sono guidate dall’evidenza osservata.
10.5 Teorema del Limite Centrale
Il Teorema del Limite Centrale (TLC) è uno dei risultati più profondi della teoria della probabilità e riveste un ruolo centrale nell’inferenza statistica.
10.5.1 Enunciato formale
Teorema 10.3 Siano \(X_1, X_2, \ldots, X_n\) variabili aleatorie indipendenti e identicamente distribuite, con valore atteso \(\mu\) e varianza finita \(\sigma^2\). Allora, al crescere di \(n\), la distribuzione della media campionaria converge verso una distribuzione normale:
\[ \bar{X}_n \;\dot\sim\; \mathcal{N}\!\left(\mu, \frac{\sigma^2}{n}\right), \]
dove la notazione \(\dot\sim\) indica che la distribuzione è approssimativamente normale per valori di \(n\) sufficientemente grandi.
10.5.2 Portata concettuale
La proprietà più sorprendente del TLC è che la distribuzione della media campionaria tende alla normalità indipendentemente dalla forma della distribuzione delle variabili originarie, purché queste abbiano varianza finita.
Ciò significa che le variabili provenienti da distribuzioni uniformi, esponenziali, binarie o fortemente asimmetriche, una volta mediate su un numero sufficientemente elevato di osservazioni, producono una distribuzione approssimativamente normale. Questa regolarità emergente spiega il ruolo onnipresente della distribuzione normale in statistica.
10.5.3 Visualizzazione del TLC
Consideriamo una popolazione con distribuzione uniforme (chiaramente non normale):
set.seed(42)
popolazione <- runif(5000, min = 0, max = 1)
ggplot(data.frame(x = popolazione), aes(x = x)) +
geom_histogram(aes(y = after_stat(density)), bins = 30) +
labs(
title = "Distribuzione della popolazione (uniforme)",
subtitle = "Questa distribuzione NON è normale",
x = "Valore",
y = "Densità"
)
Estraiamo 300 campioni di dimensione \(n = 30\) e calcoliamo le medie:
n_campione <- 30
n_ripetizioni <- 300
medie <- replicate(n_ripetizioni, {
campione <- sample(popolazione, size = n_campione, replace = TRUE)
mean(campione)
})
x_bar <- mean(medie)
std <- sd(medie)
cat("Media delle medie campionarie:", round(x_bar, 4), "\n")
#> Media delle medie campionarie: 0.501
cat("Deviazione standard delle medie:", round(std, 4), "\n")
#> Deviazione standard delle medie: 0.0524
cat("Valore teorico (σ/√n):", round(sd(popolazione) / sqrt(n_campione), 4), "\n")
#> Valore teorico (σ/√n): 0.0531ggplot(data.frame(media = medie), aes(x = media)) +
geom_histogram(aes(y = after_stat(density)), bins = 30) +
stat_function(fun = dnorm, args = list(mean = x_bar, sd = std),
linewidth = 1.2, color = "red") +
labs(
title = "Distribuzione delle medie campionarie (n = 30)",
subtitle = "La curva rossa è la normale teorica — l'approssimazione è eccellente",
x = "Media campionaria",
y = "Densità"
)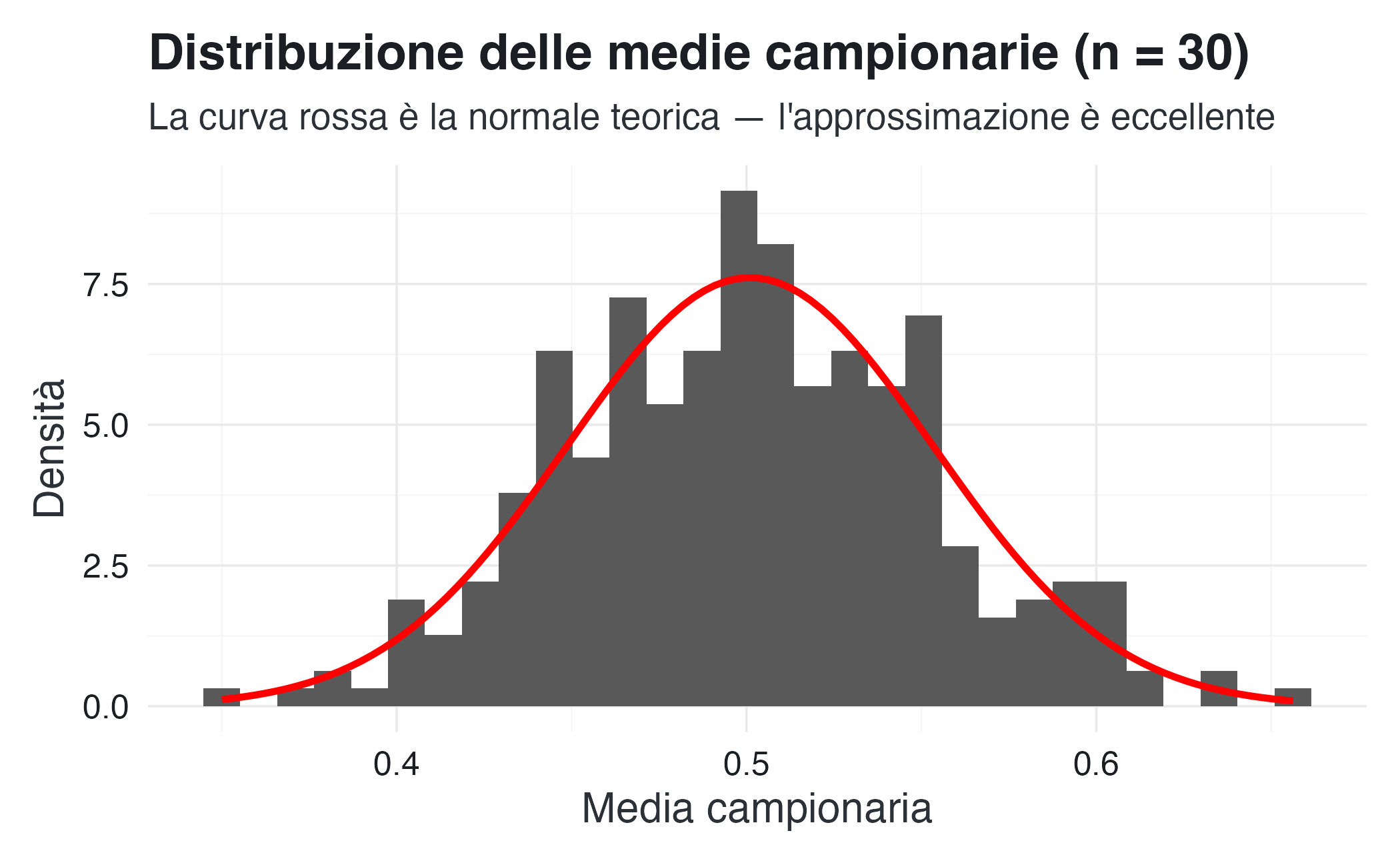
Nonostante la popolazione sia uniforme, le medie campionarie seguono una distribuzione approssimativamente normale.
10.5.4 Ponte applicativo: quando funziona la regola “n ≥ 30”?
La regola pratica secondo cui “con n ≥ 30 l’approssimazione normale è adeguata” è utile ma non universale. Dipende dalla forma della distribuzione originaria:
| Situazione | n necessario | Esempio in psicologia |
|---|---|---|
| Distribuzione simmetrica | n ≥ 15-20 | Punteggi QI, scale ben bilanciate |
| Distribuzione moderatamente asimmetrica | n ≥ 30-50 | Tempi di reazione, molte scale Likert |
| Distribuzione fortemente asimmetrica | n ≥ 100+ | Conteggi di eventi rari (es. tentativi di suicidio) |
| Distribuzione bimodale | Dipende | Popolazioni eterogenee, effetti misti |
Esempio critico: se stiamo stimando la proporzione di eventi rari (es. \(\theta = 0.02\)), anche con \(n = 100\) abbiamo solo circa 2 casi attesi. L’approssimazione normale sarà inadeguata, e conviene usare metodi esatti o simulazioni.
L’approssimazione normale può fallire quando:
- Il parametro è vicino ai limiti (es. proporzioni vicine a 0 o 1)
- La distribuzione originaria ha code molto pesanti
- Ci sono outlier estremi nel campione
- La dimensione campionaria è piccola E la distribuzione è asimmetrica
In questi casi, è preferibile usare metodi bayesiani esatti (con prior coniugate) o metodi computazionali (MCMC, bootstrap).
10.5.5 Implicazioni per l’inferenza bayesiana
Il TLC ha conseguenze rilevanti anche nel contesto bayesiano. In presenza di campioni di grandi dimensioni, la distribuzione a posteriori tende a assumere una forma approssimativamente gaussiana. Questa “normalità asintotica” contribuisce alla robustezza dell’approccio bayesiano: l’influenza delle scelte specifiche del prior si attenua con l’aumentare dell’evidenza empirica.
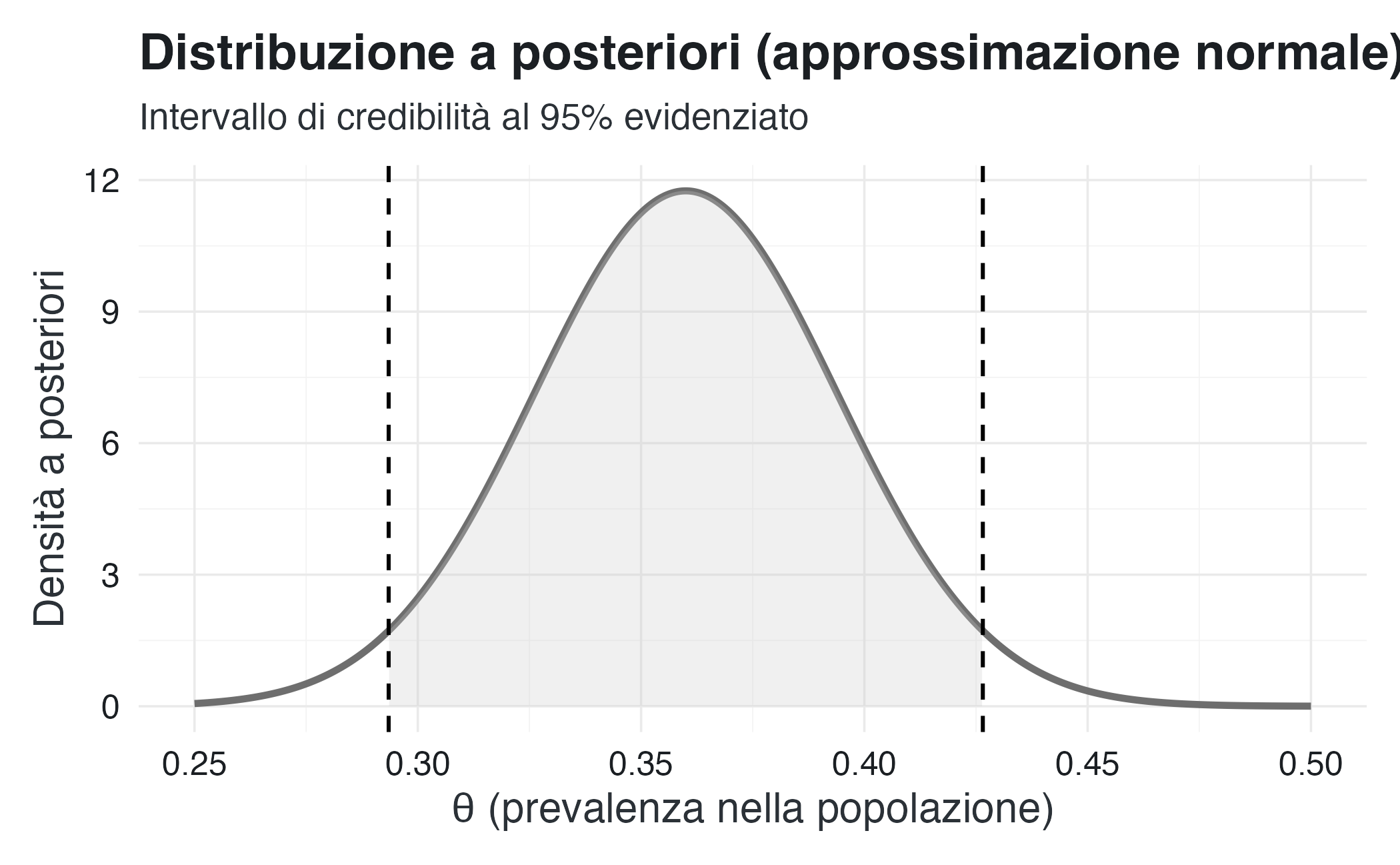
10.5.6 Esempio: intervallo di credibilità con approssimazione normale
Consideriamo lo studio sui sintomi depressivi: \(n = 200\) studenti, di cui \(y = 72\) con sintomi. Con un prior uniforme, la distribuzione a posteriori può essere approssimata nel modo seguente:
\[ \theta \mid y \;\dot\sim\; \mathcal{N}\!\left(\frac{72}{200}, \frac{0.36 \times 0.64}{200}\right) \]
n <- 200
y <- 72
p_hat <- y / n
# Approssimazione normale
media_post <- p_hat
sd_post <- sqrt(p_hat * (1 - p_hat) / n)
cat("Media a posteriori:", media_post, "\n")
#> Media a posteriori: 0.36
cat("Deviazione standard a posteriori:", round(sd_post, 4), "\n")
#> Deviazione standard a posteriori: 0.0339
# Intervallo di credibilità al 95%
lower <- qnorm(0.025, mean = media_post, sd = sd_post)
upper <- qnorm(0.975, mean = media_post, sd = sd_post)
cat("\nIntervallo di credibilità 95%: [",
round(lower, 3), ",", round(upper, 3), "]\n")
#>
#> Intervallo di credibilità 95%: [ 0.293 , 0.427 ]theta_grid <- seq(0.25, 0.50, length.out = 500)
densita <- dnorm(theta_grid, mean = media_post, sd = sd_post)
ggplot(data.frame(theta = theta_grid, densita = densita),
aes(x = theta, y = densita)) +
geom_line(linewidth = 1.2) +
geom_area(data = subset(data.frame(theta = theta_grid, densita = densita),
theta >= lower & theta <= upper),
aes(x = theta, y = densita), alpha = 0.3) +
geom_vline(xintercept = c(lower, upper), linetype = "dashed") +
labs(
title = "Distribuzione a posteriori (approssimazione normale)",
subtitle = "Intervallo di credibilità al 95% evidenziato",
x = "θ (prevalenza nella popolazione)",
y = "Densità a posteriori"
)
10.5.7 Ponte applicativo: come comunicare l’intervallo di credibilità
L’intervallo [0.29, 0.43] ha un’interpretazione diretta che possiamo comunicare al committente dello studio:
“Sulla base dei dati raccolti, stimiamo che la prevalenza di sintomi depressivi clinicamente rilevanti nella popolazione studentesca sia compresa tra il 29% e il 43%, con una probabilità del 95%. La nostra stima puntuale migliore è del 36%.”
Questa comunicazione è:
- probabilistica: esprime direttamente l’incertezza sul parametro;
- informativa: fornisce un range plausibile, non solo una stima puntuale;
- interpretabile: il committente capisce cosa significa “95% di probabilità”.
10.6 Precisione, informazione ed errore standard
10.6.1 L’errore standard come misura di informatività
L’errore standard di una statistica è definito come la deviazione standard della sua distribuzione campionaria:
\[ \text{SE}(\bar{X}) = \sqrt{\frac{\sigma^2}{n}}. \]
Un errore standard ridotto indica che i dati forniscono un’evidenza precisa del valore di \(\theta\). In termini bayesiani, ciò si traduce in una distribuzione a posteriori stretta e ben localizzata.
10.6.2 Precisione come inverso della varianza
Nell’inferenza bayesiana è spesso utile esprimere l’incertezza attraverso la nozione di precisione:
\[ \text{Precisione} = \frac{1}{\text{Varianza}} = \frac{1}{\text{SE}^2}. \]
Per la media campionaria: \[ \text{Precisione}(\bar{X}) = \frac{n}{\sigma^2}. \]
La precisione cresce linearmente con la dimensione campionaria \(n\), rendendo questa parametrizzazione particolarmente intuitiva: ogni osservazione aggiuntiva aumenta la precisione di una quantità costante.
10.6.3 Combinazione di informazioni: prior e dati
Uno degli aspetti più eleganti dell’approccio bayesiano è la sua capacità di integrare formalmente diverse fonti di informazione. Nel modello normale–normale, la precisione a posteriori è la somma delle precisioni:
\[ \tau_{\text{post}} = \tau_{\text{prior}} + \frac{n}{\sigma^2}. \]
Questa relazione mostra che ogni nuova osservazione contribuisce ad aumentare la precisione complessiva. Il peso relativo attribuito alla conoscenza pregressa e ai nuovi dati è determinato dalle rispettive precisioni.
10.6.4 Ponte applicativo: sintesi di studi multipli (meta-analisi bayesiana)
Consideriamo uno scenario tipico: due studi indipendenti hanno indagato la stessa domanda, ovvero l’efficacia di un intervento CBT per la depressione.
- Studio A (studio pilota): \(n_A = 50\), proporzione di remissione \(\hat{p}_A = 0.42\), \(\text{SE}_A = 0.07\);
- Studio B (RCT multicentrico): \(n_B = 200\), proporzione di remissione \(\hat{p}_B = 0.38\), \(\text{SE}_B = 0.035\).
Come possiamo combinare queste evidenze?
# Parametri degli studi
n_A <- 50; p_hat_A <- 0.42; se_A <- 0.07
n_B <- 200; p_hat_B <- 0.38; se_B <- 0.035
# Calcolo delle precisioni
precisione_A <- 1 / se_A^2
precisione_B <- 1 / se_B^2
cat("Precisione Studio A:", round(precisione_A, 1), "\n")
#> Precisione Studio A: 204
cat("Precisione Studio B:", round(precisione_B, 1), "\n")
#> Precisione Studio B: 816
cat("Lo Studio B è", round(precisione_B / precisione_A, 1),
"volte più informativo\n")
#> Lo Studio B è 4 volte più informativo# Sintesi bayesiana
precisione_combinata <- precisione_A + precisione_B
media_combinata <- (precisione_A * p_hat_A + precisione_B * p_hat_B) / precisione_combinata
se_combinata <- sqrt(1 / precisione_combinata)
cat("\nStima combinata:", round(media_combinata, 3), "\n")
#>
#> Stima combinata: 0.388
cat("Errore standard combinato:", round(se_combinata, 4), "\n")
#> Errore standard combinato: 0.0313
cat("\nIntervallo di credibilità 95%:\n")
#>
#> Intervallo di credibilità 95%:
cat("[", round(media_combinata - 1.96 * se_combinata, 3), ",",
round(media_combinata + 1.96 * se_combinata, 3), "]\n")
#> [ 0.327 , 0.449 ]Interpretazione: la stima combinata (38,8%) è più vicina allo studio B, perché quest’ultimo è circa quattro volte più informativo. L’intervallo di credibilità combinato è più stretto rispetto a quello di entrambi gli studi singoli, riflettendo l’accumulo di evidenze.
Questo è esattamente ciò che fa una meta-analisi bayesiana: combina le evidenze di studi diversi, assegnando a ciascuno un peso in base alla sua precisione e producendo una sintesi ottimale dell’informazione disponibile.
10.7 Convergenza bayesiana: da credenze diverse a conclusioni condivise
10.7.1 Il teorema di convergenza bayesiana
Un risultato teorico centrale riguarda il comportamento asintotico della distribuzione a posteriori.
Teorema 10.4 (Consistenza bayesiana) Sotto opportune condizioni di regolarità, se la prior assegna una densità positiva al valore vero del parametro \(\theta_0\), allora, al crescere del numero di osservazioni:
la distribuzione a posteriori converge verso il valore vero: \[ p(\theta \mid \mathbf{X}_n) \xrightarrow{n \to \infty} \delta(\theta - \theta_0); \]
la media a posteriori converge: \[ \mathbb{E}[\theta \mid \mathbf{X}_n] \xrightarrow{n \to \infty} \theta_0; \]
la varianza a posteriori tende a zero: \[ \text{Var}(\theta \mid \mathbf{X}_n) \xrightarrow{n \to \infty} 0. \]
10.7.2 Illustrazione: convergenza con prior differenti
Consideriamo tre ricercatori con credenze iniziali molto diverse sulla prevalenza dei sintomi depressivi:
- Ricercatore A: prior Beta(2, 8) — crede che la prevalenza sia bassa (circa 20%).
- Ricercatore B: prior Beta(8, 2) — crede che la prevalenza sia alta (circa 80%).
- Ricercatore C: prior Beta(1, 1) — non ha opinioni forti (prior uniforme).
Il valore vero è \(\theta_0 = 0.45\). Osserviamo come le loro credenze convergono:
theta_true <- 0.45
n_osservazioni <- c(10, 50, 200, 1000)
# Prior dei tre ricercatori
prior_A <- c(2, 8) # pessimista
prior_B <- c(8, 2) # ottimista
prior_C <- c(1, 1) # agnostico
# Funzione per calcolare la posterior (Beta-Binomiale)
calcola_posterior <- function(prior, n, theta) {
y <- rbinom(1, n, theta) # successi osservati
c(prior[1] + y, prior[2] + n - y)
}
set.seed(42)
posteriors <- list()
for (n in n_osservazioni) {
theta_grid <- seq(0.1, 0.9, length.out = 200)
post_A <- calcola_posterior(prior_A, n, theta_true)
post_B <- calcola_posterior(prior_B, n, theta_true)
post_C <- calcola_posterior(prior_C, n, theta_true)
posteriors[[as.character(n)]] <- data.frame(
theta = rep(theta_grid, 3),
density = c(
dbeta(theta_grid, post_A[1], post_A[2]),
dbeta(theta_grid, post_B[1], post_B[2]),
dbeta(theta_grid, post_C[1], post_C[2])
),
ricercatore = rep(c("A (prior pessimista)",
"B (prior ottimista)",
"C (prior agnostico)"),
each = length(theta_grid)),
n = n
)
}
all_posteriors <- do.call(rbind, posteriors)
all_posteriors$n <- factor(all_posteriors$n,
levels = n_osservazioni,
labels = paste("n =", n_osservazioni))
ggplot(all_posteriors,
aes(x = theta, y = density,
color = ricercatore, linetype = ricercatore)) +
geom_line(linewidth = 1.2) +
geom_vline(xintercept = theta_true,
linetype = "dashed",
linewidth = 1.2) +
facet_wrap(~ n, ncol = 2, scales = "free_y") +
labs(
title = "Convergenza bayesiana: da credenze diverse a conclusioni condivise",
subtitle = "La linea verticale indica il valore vero θ = 0.45",
x = "Parametro θ",
y = "Densità a posteriori",
color = "Ricercatore",
linetype = "Ricercatore"
) +
theme(legend.position = "bottom")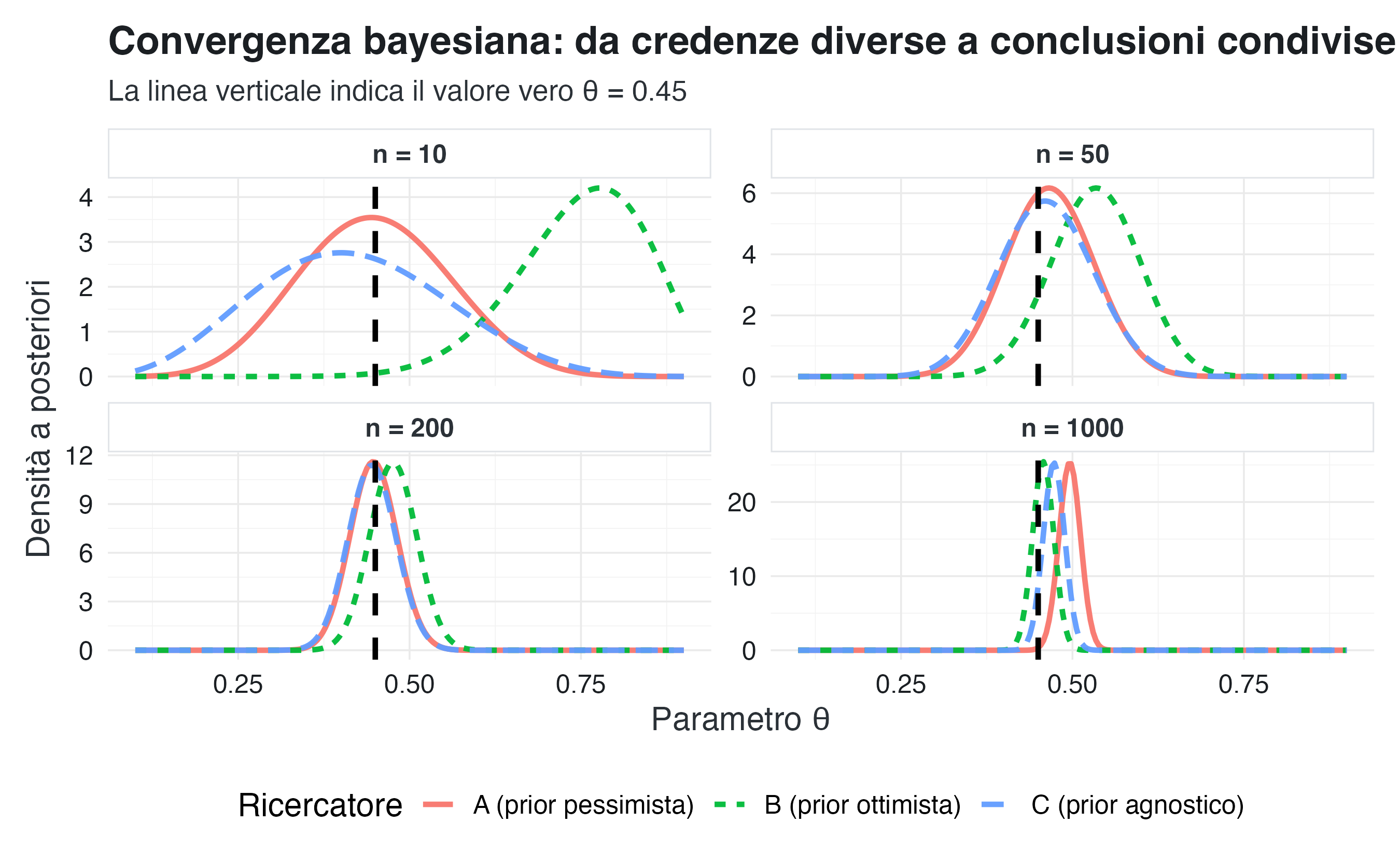
Osservazioni:
- Con \(n = 10\): le posterior riflettono fortemente le prior diverse.
- Con \(n = 50\): si osserva un chiaro avvicinamento.
- Con \(n = 200\): le posterior sono ampiamente sovrapposte.
- Con \(n = 1000\): le differenze sono praticamente impercettibili.
10.7.3 Ponte applicativo: analisi di sensibilità nella pratica
L’analisi di sensibilità consiste nel verificare se le conclusioni cambiano sostanzialmente con prior diversi. In pratica:
- specificare 2-3 prior alternative che rappresentano credenze ragionevolmente diverse;
- calcolare le posterior per ciascuna prior;
- confrontare gli intervalli di credibilità.
Se gli intervalli si sovrappongono ampiamente, le conclusioni sono robuste rispetto alla scelta del prior. Se invece differiscono in modo sostanziale, il prior è influente e richiede una giustificazione.
# Analisi di sensibilità per lo studio n=200
n <- 200
y <- 90 # supponiamo 90 casi su 200
# Tre prior alternative
priors <- list(
"Informativo pessimista" = c(2, 8),
"Non informativo" = c(1, 1),
"Informativo ottimista" = c(8, 2)
)
cat("Analisi di sensibilità (n=200, y=90)\n")
#> Analisi di sensibilità (n=200, y=90)
cat("=====================================\n\n")
#> =====================================
for (nome in names(priors)) {
prior <- priors[[nome]]
post_alpha <- prior[1] + y
post_beta <- prior[2] + n - y
media <- post_alpha / (post_alpha + post_beta)
ic_lower <- qbeta(0.025, post_alpha, post_beta)
ic_upper <- qbeta(0.975, post_alpha, post_beta)
cat(nome, ":\n")
cat(" Media posteriori:", round(media, 3), "\n")
cat(" IC 95%: [", round(ic_lower, 3), ",", round(ic_upper, 3), "]\n\n")
}
#> Informativo pessimista :
#> Media posteriori: 0.438
#> IC 95%: [ 0.372 , 0.506 ]
#>
#> Non informativo :
#> Media posteriori: 0.45
#> IC 95%: [ 0.383 , 0.519 ]
#>
#> Informativo ottimista :
#> Media posteriori: 0.467
#> IC 95%: [ 0.4 , 0.534 ]In questo esempio, gli intervalli si sovrappongono ampiamente, il che indica che le conclusioni sono robuste rispetto alla scelta del prior. Con \(n = 200\) osservazioni, i dati prevalgono sulle credenze iniziali.
10.8 Incertezza, distorsione sistematica e limiti dell’inferenza
10.8.1 L’errore standard quantifica solo l’incertezza campionaria
È essenziale chiarire che l’errore standard e la dispersione della distribuzione a posteriori misurano esclusivamente l’incertezza dovuta alla variabilità campionaria. Tale misura non fornisce alcuna informazione sulla presenza di errori sistematici nel disegno della ricerca.
Di conseguenza, una stima può essere estremamente precisa dal punto di vista statistico e, al tempo stesso, sostanzialmente errata dal punto di vista scientifico.
10.8.2 Fonti di distorsione che persistono
Alcune fonti di distorsione non vengono attenuate dall’aumento della dimensione campionaria:
Distorsione da selezione: se stimiamo la prevalenza della depressione attraverso un campione di volontari che rispondono a un annuncio online, potremmo sovrarappresentare individui con sintomi (che cercano informazioni) o sottorappresentarli (se evitano l’argomento). Anche con \(n = 10{,}000\), la stima risulterà distorta.
Distorsione da risposta: nello studio di costrutti auto-riferiti come la frequenza di pensieri suicidari, la desiderabilità sociale può indurre risposte attenuate. Otterremo quindi una stima precisa di una quantità sistematicamente sottostimata.
Errori di misurazione: se il PHQ-9 non coglie adeguatamente la depressione in una specifica popolazione (ad esempio, gli anziani o le persone di culture diverse), l’aumento del campione produce stime più precise di una quantità mal definita.
10.8.3 Rappresentazione visiva: precisione versus accuratezza
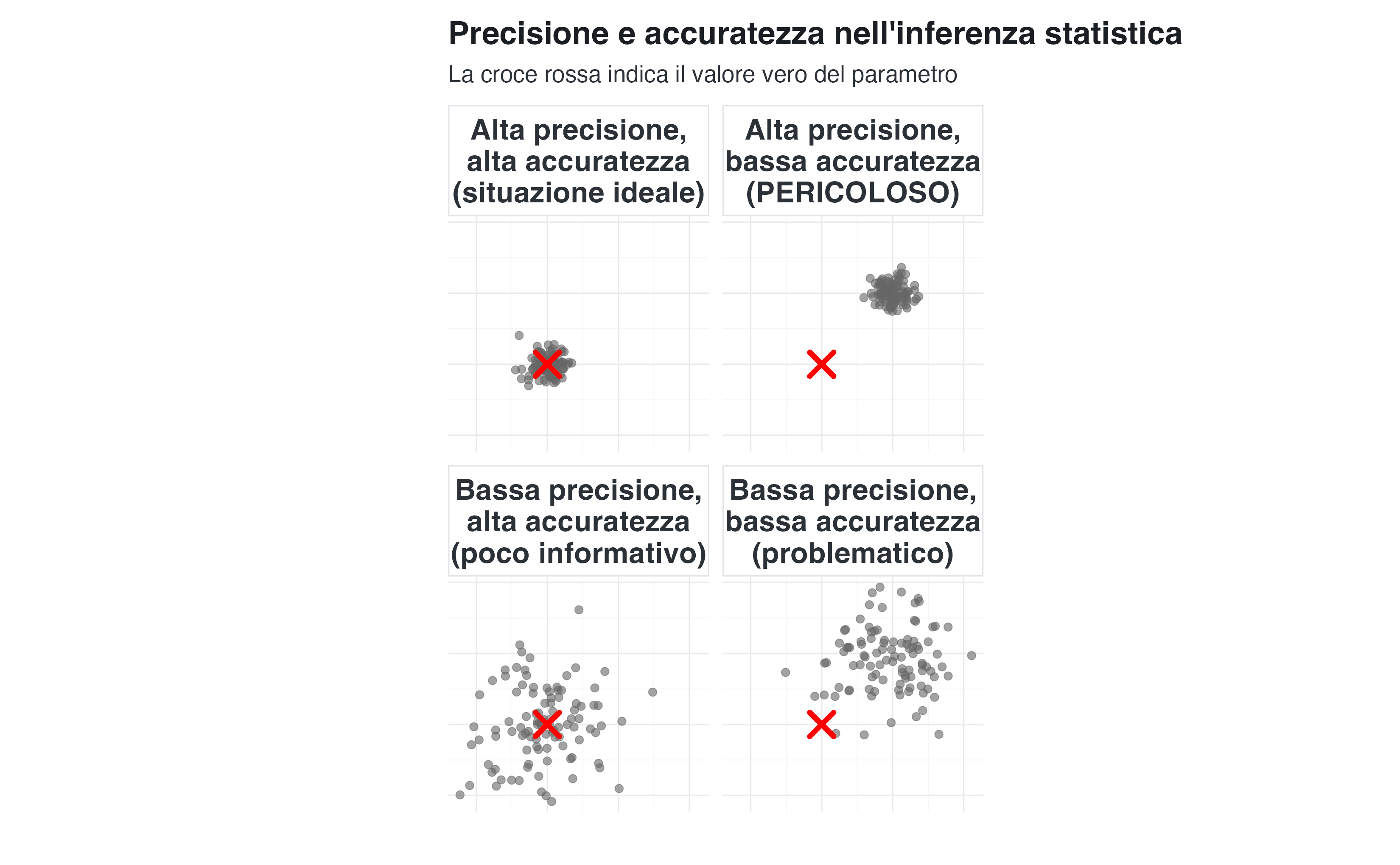
Il caso più pericoloso è quello in alto a destra: alta precisione con bassa accuratezza. I metodi statistici producono intervalli di credibilità stretti attorno a un valore errato, creando una falsa sensazione di certezza.
Un intervallo di credibilità stretto può indurre l’illusione di una conoscenza accurata. Tuttavia, tale intervallo quantifica esclusivamente l’incertezza campionaria.
In presenza di bias sistematici, il valore vero potrebbe collocarsi ben al di fuori dell’intervallo calcolato. La precisione statistica non deve mai essere confusa con la validità scientifica.
Un esempio concreto: uno studio online con \(n = 5{,}000\) partecipanti auto-selezionati potrebbe produrre un intervallo di credibilità [0.32, 0.34] per la prevalenza della depressione. Tuttavia, se il campione è distorto (per esempio, se sovrarappresenta le persone interessate alla salute mentale), il valore vero nella popolazione potrebbe essere 0.20, completamente fuori dall’intervallo “preciso”.
10.8.4 Strategie di mitigazione
Progettazione metodologica solida: campionamento probabilistico, protocolli standardizzati, strumenti validati.
Analisi di sensibilità: valutare la robustezza delle conclusioni rispetto a diverse assunzioni.
Modellazione esplicita del bias: quando possibile, includere nel modello le potenziali fonti di distorsione.
Trasparenza epistemica: riconoscere esplicitamente i limiti metodologici come parte integrante dell’inferenza.
10.9 Verso la verosimiglianza: come i dati informano le credenze
In questo capitolo abbiamo esaminato le proprietà matematiche fondamentali che governano il comportamento della media campionaria:
- è centrata sul parametro: \(\mathbb{E}[\bar{X}] = \theta\);
- la sua variabilità diminuisce con \(n\): \(\text{Var}(\bar{X}) = \sigma^2/n\);
- converge al valore vero: Legge dei Grandi Numeri;
- la sua distribuzione tende alla normale: Teorema del Limite Centrale.
Resta ora da chiarire come queste proprietà si traducano operativamente nell’aggiornamento delle credenze bayesiane. La risposta risiede nella funzione di verosimiglianza, che formalizza il modo in cui i dati informano le credenze: per ogni possibile valore del parametro \(\theta\), essa quantifica quanto tale valore renda plausibili le osservazioni raccolte.
È attraverso la verosimiglianza che le informazioni contenute nei dati vengono combinate con la distribuzione a priori, generando la distribuzione a posteriori. Le proprietà analizzate in questo capitolo, ovvero centratura, precisione crescente e convergenza, trovano nella funzione di verosimiglianza la loro espressione formale.
Riflessioni conclusive
In questo capitolo abbiamo esaminato come quantificare sistematicamente l’incertezza quando si traggono conclusioni da evidenze limitate. Per lo psicologo e il ricercatore clinico, questi concetti non sono mere astrazioni matematiche, ma strumenti operativi che guidano scelte concrete:
- Pianificare studi: sapere che l’errore standard decresce come \(1/\sqrt{n}\) permette di calcolare dimensioni campionarie adeguate alla precisione desiderata.
- Interpretare risultati: gli intervalli di credibilità comunicano l’incertezza in modo probabilisticamente rigoroso e clinicamente significativo.
- Combinare evidenze: la regola di aggregazione delle precisioni (somma delle informazioni) costituisce la base formale della meta-analisi bayesiana.
- Valutare la robustezza: l’analisi di sensibilità verifica se le conclusioni dipendono criticamente dalle assunzioni a priori o dal modello scelto.
L’inferenza bayesiana si conferma come un framework coerente per rappresentare e aggiornare l’incertezza epistemica. Le credenze iniziali (prior) vengono integrate in modo logico con i nuovi dati, producendo una distribuzione a posteriori che rappresenta lo stato più informato delle nostre conoscenze. Con evidenza sufficiente, credenze iniziali anche molto diverse tendono a convergere verso stime condivise, garantendo oggettività nel lungo termine.
Tuttavia, è essenziale riconoscere i limiti di questa logica: le procedure inferenziali quantificano l’incertezza campionaria, ma non correggono errori sistematici (bias). Un campione ampio ma distorto può portare a stime molto precise, ma altrettanto erronee. La validità del disegno di ricerca e la qualità della misurazione rimangono presupposti irrinunciabili, che nessuna sofisticazione statistica può sostituire.
Punti chiave da ricordare
Concetti essenziali di questo capitolo:
-
Distribuzione campionaria della media
- \(\mathbb{E}[\bar{X}] = \mu\) (stimatore non distorto)
- \(\text{Var}(\bar{X}) = \frac{\sigma^2}{n}\) (decresce con la dimensione campionaria)
- SE\((\bar{X}) = \frac{\sigma}{\sqrt{n}}\) misura la precisione della stima
-
Legge dei Grandi Numeri (LGN)
- La media campionaria converge al valore vero al crescere di \(n\)
- Giustifica l’uso della media come stimatore consistente
- Spiega perché meta-analisi e studi grandi sono più affidabili
-
Teorema del Limite Centrale (TLC)
- Per \(n\) grande, la media campionaria è approssimativamente normale
- Vale indipendentemente dalla distribuzione di \(X\)
- Regola pratica: \(n \geq 30\) spesso sufficiente, ma dipende dalla simmetria
-
Prior, verosimiglianza e posterior
- Prior: \(p(\theta)\) codifica credenze iniziali
- Verosimiglianza: \(p(D \mid \theta)\) descrive compatibilità dati-parametro
- Posterior: \(p(\theta \mid D) \propto p(D \mid \theta) \cdot p(\theta)\)
-
Intervalli di credibilità bayesiani
- IC al 95%: “C’è probabilità 95% che \(\theta\) sia in questo intervallo”
- Interpretazione diretta sul parametro (diverso da IC frequentista)
-
Precisione e meta-analisi
- Precisione: \(\tau = 1/\text{SE}^2\) (cresce linearmente con \(n\))
- Studi indipendenti: le precisioni si sommano
- Fondamento della sintesi bayesiana delle evidenze
-
Analisi di sensibilità
- Verifica se le conclusioni dipendono dal prior
- Se prior diversi → posterior simili: conclusioni robuste
- Se posterior cambiano molto: prior influente
-
Incertezza campionaria vs distorsioni sistematiche
- L’errore standard quantifica SOLO la variabilità campionaria
- Bias di selezione, risposta, misurazione NON si risolvono con \(n\) grande
- Alta precisione + bassa accuratezza = pericolo di false certezze
Formule da ricordare:
\[ \mathbb{E}[\bar{X}] = \mu, \quad \text{Var}(\bar{X}) = \frac{\sigma^2}{n}, \quad \text{SE}(\bar{X}) = \frac{\sigma}{\sqrt{n}} \]
\[ p(\theta \mid D) \propto p(D \mid \theta) \cdot p(\theta) \]
\[ \tau_{\text{combinata}} = \tau_1 + \tau_2 + \cdots + \tau_k \]
Per il prossimo capitolo:
Nel Capitolo 11 inizieremo lo studio sistematico delle famiglie parametriche di distribuzioni (Beta, Binomiale, Normale, Poisson, Gamma), che costituiscono il vocabolario standard per specificare prior, verosimiglianze e posterior nell’inferenza bayesiana.
Esercizi sulla distribuzione campionaria e sull’inferenza sono disponibili sulla seguente pagina web.
sessionInfo()
#> R version 4.5.2 (2025-10-31)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Tahoe 26.2
#>
#> Matrix products: default
#> BLAS: /System/Library/Frameworks/Accelerate.framework/Versions/A/Frameworks/vecLib.framework/Versions/A/libBLAS.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
#>
#> locale:
#> [1] C.UTF-8/UTF-8/C.UTF-8/C/C.UTF-8/C.UTF-8
#>
#> time zone: Europe/Rome
#> tzcode source: internal
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] ragg_1.5.0 tinytable_0.15.2 withr_3.0.2
#> [4] systemfonts_1.3.1 patchwork_1.3.2 ggdist_3.3.3
#> [7] tidybayes_3.0.7 bayesplot_1.15.0 ggplot2_4.0.1
#> [10] reliabilitydiag_0.2.1 priorsense_1.2.0 posterior_1.6.1
#> [13] loo_2.9.0 rstan_2.32.7 StanHeaders_2.32.10
#> [16] brms_2.23.0 Rcpp_1.1.1 sessioninfo_1.2.3
#> [19] conflicted_1.2.0 janitor_2.2.1 matrixStats_1.5.0
#> [22] modelr_0.1.11 tibble_3.3.1 dplyr_1.1.4
#> [25] tidyr_1.3.2 rio_1.2.4 here_1.0.2
#>
#> loaded via a namespace (and not attached):
#> [1] svUnit_1.0.8 tidyselect_1.2.1 farver_2.1.2
#> [4] S7_0.2.1 fastmap_1.2.0 TH.data_1.1-5
#> [7] tensorA_0.36.2.1 digest_0.6.39 timechange_0.3.0
#> [10] estimability_1.5.1 lifecycle_1.0.5 survival_3.8-3
#> [13] magrittr_2.0.4 compiler_4.5.2 rlang_1.1.7
#> [16] tools_4.5.2 yaml_2.3.12 knitr_1.51
#> [19] labeling_0.4.3 bridgesampling_1.2-1 htmlwidgets_1.6.4
#> [22] curl_7.0.0 pkgbuild_1.4.8 RColorBrewer_1.1-3
#> [25] abind_1.4-8 multcomp_1.4-29 purrr_1.2.1
#> [28] grid_4.5.2 stats4_4.5.2 colorspace_2.1-2
#> [31] xtable_1.8-4 inline_0.3.21 emmeans_2.0.1
#> [34] scales_1.4.0 MASS_7.3-65 cli_3.6.5
#> [37] mvtnorm_1.3-3 rmarkdown_2.30 generics_0.1.4
#> [40] otel_0.2.0 RcppParallel_5.1.11-1 cachem_1.1.0
#> [43] stringr_1.6.0 splines_4.5.2 parallel_4.5.2
#> [46] vctrs_0.6.5 V8_8.0.1 Matrix_1.7-4
#> [49] sandwich_3.1-1 jsonlite_2.0.0 arrayhelpers_1.1-0
#> [52] glue_1.8.0 codetools_0.2-20 distributional_0.6.0
#> [55] lubridate_1.9.4 stringi_1.8.7 gtable_0.3.6
#> [58] QuickJSR_1.8.1 pillar_1.11.1 htmltools_0.5.9
#> [61] Brobdingnag_1.2-9 R6_2.6.1 textshaping_1.0.4
#> [64] rprojroot_2.1.1 evaluate_1.0.5 lattice_0.22-7
#> [67] backports_1.5.0 memoise_2.0.1 broom_1.0.11
#> [70] snakecase_0.11.1 rstantools_2.6.0 gridExtra_2.3
#> [73] coda_0.19-4.1 nlme_3.1-168 checkmate_2.3.3
#> [76] xfun_0.55 zoo_1.8-15 pkgconfig_2.0.3