13 Distribuzioni di variabili casuali continue
Introduzione
Nel Capitolo 12 abbiamo esplorato le distribuzioni discrete come strumenti per rappresentare le credenze su fenomeni con esiti numerabili. In questo capitolo, estendiamo il framework alle distribuzioni continue che permettono di esprimere credenze su quantità che variano su scale numeriche continue, come i tempi, le distanze, le proporzioni, i tassi e i punteggi psicometrici. In questo contesto, la probabilità non viene assegnata a valori singoli, ma a intervalli tramite funzioni di densità.
Le distribuzioni continue rivestono, nel quadro bayesiano, un ruolo complementare a quello delle distribuzioni discrete. Esse vengono principalmente impiegate come modelli di verosimiglianza per dati continui, dove ogni famiglia di distribuzione riflette un diverso processo generativo: la normale descrive misure affette da errori simmetrici, l’esponenziale modella tempi di attesa, mentre la gamma è adatta a variabili positive di natura asimmetrica.
Le stesse distribuzioni, così come altre ancora, servono inoltre a formalizzare e aggiornare le credenze iniziali e finali, assumendo la funzione di prior e posterior per parametri continui. Ad esempio, la beta è usata per probabilità \(p \in (0,1)\), la gamma per tassi \(\lambda > 0\), la normale per medie \(\mu \in \mathbb{R}\), mentre la Cauchy e la \(t\) di Student sono spesso scelte come prior robusti, in grado di gestire code pesanti.
Una proprietà elegante dell’inferenza bayesiana è la dualità discreto-continuo espressa dalle famiglie coniugate: la distribuzione binomiale si abbina naturalmente alla beta, così come la Poisson alla gamma. Questa simmetria, già introdotta nel capitolo precedente, viene qui approfondita attraverso lo studio delle distribuzioni continue che agiscono come prior naturali per i parametri di modelli discreti.
Struttura del capitolo
L’esposizione procederà con una progressione graduale, dalle distribuzioni concettualmente più semplici a quelle con ruoli più specifici nell’inferenza bayesiana. Si inizierà con la distribuzione uniforme, che formalizza un’ignoranza locale e simmetrica all’interno di un intervallo finito. Si passerà quindi alla distribuzione esponenziale, fondamentale per modellare i tempi di attesa e i fenomeni privi di memoria, e alla distribuzione normale, pilastro del Teorema del Limite Centrale e modello di riferimento per le misurazioni affette da errori casuali simmetrici. Successivamente, si esamineranno la distribuzione chi-quadrato e la distribuzione t di Student, che derivano direttamente dalla normale e sono essenziali per l’inferenza su varianze e per la modellazione robusta con piccoli campioni. Si concluderà con le distribuzioni di massima rilevanza bayesiana: la beta come prior naturale per proporzioni e probabilità, la gamma per tassi e varianze, e la Cauchy come prior robusto a code pesanti, in grado di gestire valori anomali senza influenzare eccessivamente le stime.
Per ciascuna di queste distribuzioni, presenteremo la definizione matematica, l’interpretazione epistemica dei parametri, il ruolo nell’inferenza bayesiana e le applicazioni pratiche in R.
Per seguire questo capitolo è necessario aver letto:
- Capitolo 6
- Capitolo 7 — fondamentale per PDF
- Capitolo 8
- Capitolo 11
Questo capitolo studia in dettaglio le distribuzioni continue (Beta, Normale, Gamma, Esponenziale) essenziali per modellare parametri continui e costruire prior informativi.
Conoscenze matematiche richieste:
- Appendice F — fondamentale per calcolare probabilità tramite integrazione
13.1 Distribuzione uniforme continua
13.1.1 Definizione e interpretazione epistemica
La distribuzione uniforme continua modella una situazione di ignoranza simmetrica locale all’interno di un intervallo chiuso [a, b]. In assenza di evidenze o ragioni logiche che favoriscano un particolare valore dell’intervallo rispetto a un altro, essa esprime la massima incertezza: ogni valore in [a, b] ha la stessa densità di probabilità.
Definizione 13.1 Una variabile casuale X si distribuisce uniformemente sull’intervallo [a, b] se la sua funzione di densità di probabilità è costante:
\[ X \sim \text{Uniforme}(a, b), \quad f(x) = \frac{1}{b-a} \quad \text{per } x \in [a,b], \] e \(f(x) = 0\) al di fuori dell’intervallo.
Proprietà caratteristiche: \(\mathbb{E}(X) = \frac{a+b}{2}\), \(\mathbb{V}(X) = \frac{(b-a)^2}{12}\).
Interpretazione epistemica
Questa distribuzione implementa formalmente il principio di indifferenza (o principio di ragione insufficiente). Quando la conoscenza a priori non fornisce elementi per discriminare tra i possibili valori di un parametro all’interno di un certo dominio, si assegna credenza uguale a tutti i sottointervalli di uguale ampiezza. In questo senso, rappresenta l’analogo continuo della distribuzione uniforme discreta.
13.1.2 Ruolo nell’inferenza bayesiana
Nel quadro bayesiano, la distribuzione uniforme è tipicamente adottata come prior “vincolato non informativo” per parametri il cui supporto è un intervallo finito e noto. Un caso paradigmatico è l’uso della \(\text{Uniforme}(0, 1)\), matematicamente equivalente alla $(1, 1), come prior iniziale per una proporzione o una probabilità, per la quale non si possiede alcuna informazione specifica.
Limitazioni e criticità come prior
Nonostante la sua apparente neutralità, la scelta di un prior uniforme può veicolare informazioni involontarie e presenta svantaggi concettuali:
- Impone una probabilità zero assoluta a qualsiasi valore al di fuori dell’intervallo \([a, b]\), un’assunzione spesso troppo forte.
- La sua non-informatività non è invariante rispetto a trasformazioni del parametro. Un prior uniforme su un parametro \(\theta\) non implica un prior uniforme su una sua trasformazione non lineare (ad esempio, \(\log(\theta)\) o \(\theta^2\)), introducendo quindi un’arbitrarietà nella parametrizzazione scelta.
- Per intervalli semi-infiniti \([0, \infty]\) o infiniti \((-\infty, \infty)\), la distribuzione uniforme diventa impropria (il suo integrale non converge a 1), sebbene in alcuni casi possa comunque condurre a posteriori propri.
Per queste ragioni, in contesti che richiedono una reale non-informatività su scale illimitate o per parametri di scala, si ricorre spesso a prior impropri non informativi (come quello di Jeffreys) o a distribuzioni a code pesanti (ad esempio, Cauchy o t di Student) che, pur essendo proprie, non escludono in modo così netto valori estremi.
13.1.3 Calcolo delle probabilità
Per una variabile \(X \sim \text{Uniforme}(a, b)\), la probabilità che appartenga a un sottointervallo \([c, d] ⊆ [a, b]\) è semplicemente il rapporto tra la lunghezza del sottointervallo di interesse e la lunghezza totale dell’intervallo di definizione:
\[ P(c \leq X \leq d) = (d - c) / (b - a). \]
Questa proprietà rende il calcolo estremamente intuitivo.
13.1.4 Visualizzazione
Il seguente codice R genera un grafico che illustra la densità costante della distribuzione e evidenzia l’area corrispondente alla probabilità calcolata nell’esempio.
# Creazione della griglia di valori e calcolo della densità
x <- seq(-50, 410, length.out = 500)
density_uniform <- dunif(x, min = 0, max = 360)
df <- data.frame(x = x, y = density_uniform)
# Definizione dell'area da evidenziare
df_area <- subset(df, x >= 150 & x <= 250)
# Grafico
ggplot(df, aes(x = x, y = y)) +
geom_line(linewidth = 1.2) +
geom_area(data = df_area, aes(x = x, y = y), alpha = 0.4) +
scale_fill_qualitative() +
labs(
title = "Distribuzione Uniforme Continua su [0, 360]",
subtitle = "Area evidenziata: P(150 ≤ X ≤ 250) ≈ 0.278",
x = "Valore (x)",
y = "Densità f(x)"
) +
scale_x_continuous(breaks = seq(0, 360, by = 90))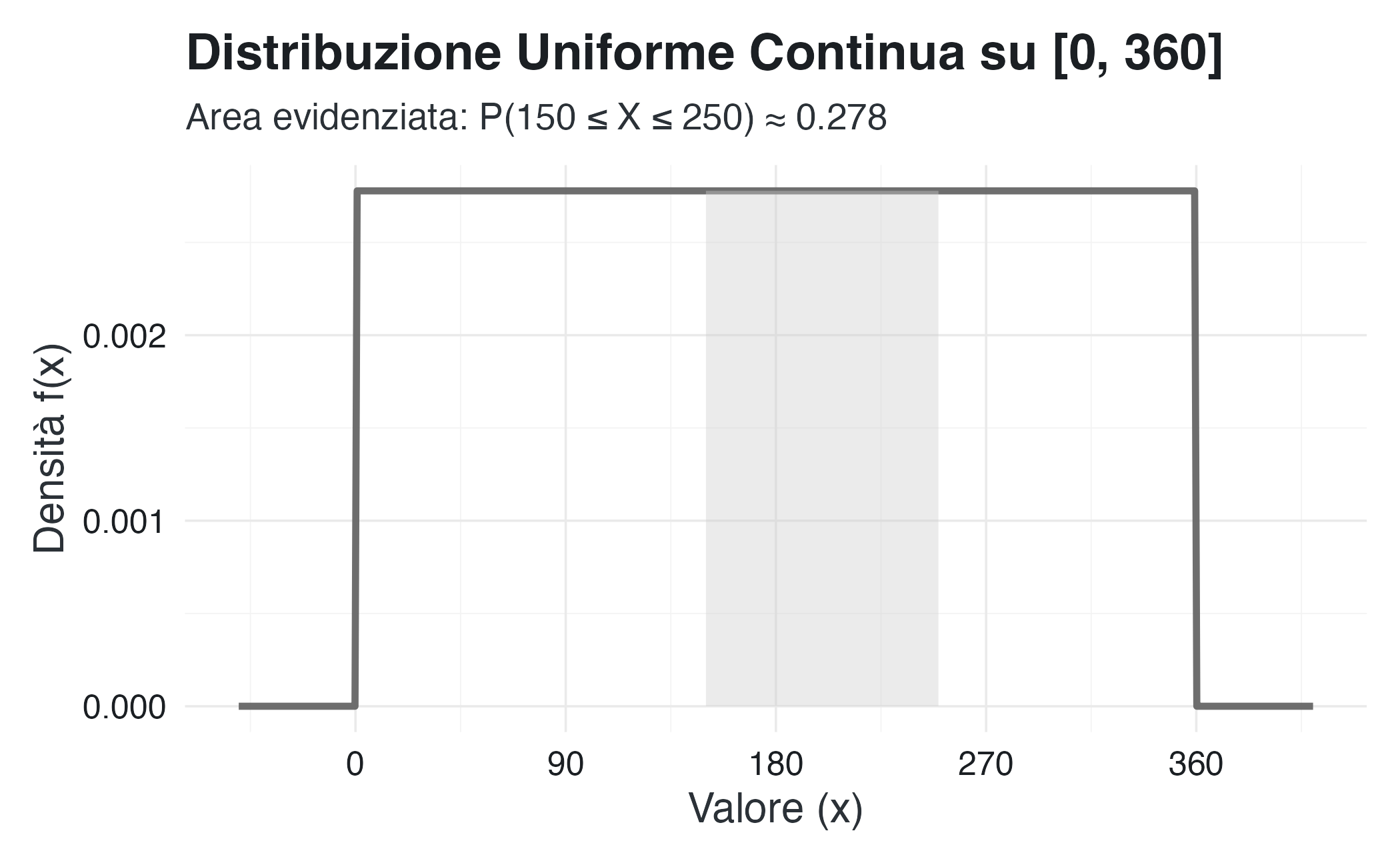
Legenda visiva: La linea continua rappresenta la funzione di densità costante f(x) = 1/360. L’area ombreggiata sotto la curva, delimitata tra x=150 e x=250, corrisponde alla probabilità dell’evento, visualizzando in modo diretto il principio “probabilità = area”.
13.2 Distribuzione esponenziale
13.2.1 Definizione e interpretazione epistemica
La distribuzione esponenziale modella il tempo di attesa fino al verificarsi di un evento, assumendo che il tasso di occorrenza sia costante nel tempo. Questa assunzione è cruciale e implica che la probabilità di osservare un evento non dipenda da quanto tempo si è già atteso.
Definizione 13.2 Una variabile casuale \(X\) segue una distribuzione esponenziale con parametro di tasso \(\lambda > 0\) se la sua funzione di densità di probabilità è:
\[ X \sim \text{Exp}(\lambda), \quad f(x) = \lambda e^{-\lambda x} \quad \text{per } x \geq 0. \]
Proprietà caratteristiche: \(\mathbb{E}(X) = \frac{1}{\lambda}\), \(\mathbb{V}(X) = \frac{1}{\lambda^2}\).
Interpretazione epistemica Il parametro \(\lambda\) rappresenta il tasso atteso di occorrenza (eventi per unità di tempo). Un valore elevato di \(\lambda\) indica eventi frequenti e attese brevi, mentre un valore piccolo corrisponde a eventi rari e attese lunghe. Il suo inverso, \(\frac{1}{\lambda}\), ha un’interpretazione concreta: è il tempo medio di attesa. Questa distribuzione è dunque l’espressione probabilistica di un unico, semplice presupposto: il processo di attesa in esame è “sempre come nuovo”.
13.2.2 Proprietà di assenza di memoria
La caratteristica distintiva della distribuzione esponenziale è la proprietà di assenza di memoria: la probabilità che un evento si verifichi in un intervallo futuro è indipendente dal tempo già trascorso. Formalmente, per ogni \(s, t > 0\):
\[ P(X > s + t \mid X > s) = P(X > t). \]
Questa uguaglianza significa che, sapendo che l’evento non si è verificato fino al tempo \(s\), la distribuzione del tempo di attesa aggiuntivo \(t\) è identica alla distribuzione del tempo di attesa dall’inizio. Se si aspetta un autobus la cui frequenza segue un processo esponenziale, la probabilità di dover aspettare altri 5 minuti è sempre la stessa, indipendentemente dal fatto che si sia già atteso 1 minuto o 10 minuti. L’esponenziale è l’unica distribuzione continua con questa proprietà, che rende appropriato il suo utilizzo per modellare durate di eventi senza “usura” o “invecchiamento”.
13.2.3 Ruolo nell’inferenza bayesiana
Nell’inferenza bayesiana, la distribuzione esponenziale riveste un duplice ruolo, fondamentale per modellare processi psicologici o comportamentali caratterizzati da attese, tempi di risposta o intervalli tra eventi.
-
Come funzione di verosimiglianza: è il modello naturale per dati continui e positivi che rappresentano durate, in contesti dove si assume un tasso costante di occorrenza (proprietà di assenza di memoria). Per esempio:
- modellare il tempo che intercorre tra uno stimolo (es., un suono) e la risposta motoria di un partecipante in un compito di tempi di reazione semplice, dove il processo cognitivo sottostante non cambia nel tempo.
- modellare la durata di un episodio di concentrazione focalizzata prima di un’interruzione (es., distrazione da notifica), assumendo che la probabilità di interrompersi sia costante in ogni istante.
-
Nel contesto dell’aggiornamento bayesiano: formalmente, la distribuzione esponenziale è un caso particolare della distribuzione Gamma, con \(\exp(\lambda) = Gamma(1, 1/\lambda)\) (nella comune parametrizzazione a tasso). Di conseguenza, la distribuzione Gamma funge da prior coniugato per il parametro di tasso \(\lambda\) di un modello di verosimiglianza esponenziale.
Questo permette un aggiornamento bayesiano analitico e intuitivo. Supponiamo di voler inferire il tasso latente \(\lambda\) di un processo psicologico (es., il tasso con cui emergono pensieri intrusivi). Si specifica una credenza a priori come \(\lambda \sim Gamma(\alpha_0, \beta_0)\), dove:
- \(\alpha_0\) (parametro di forma) può essere interpretato come un numero pseudo-osservato di eventi attesi.
- \(\beta_0\) (parametro di velocità/inverso scala) può essere interpretato come la durata pseudo-osservata totale di riferimento.
Dopo aver osservato \(n\) intervalli di tempo indipendenti \(x_\, \dots, x_N\) tra gli eventi (con \(x_i \sim \exp(\lambda)\)), la distribuzione a posteriori per \(\lambda\) è ancora una Gamma, i cui parametri si aggiornano semplicemente aggiungendo le osservazioni alle pseudo-osservazioni del prior:
\[ \lambda \mid \mathbf{x} \sim \text{Gamma}(\alpha_n, \beta_n), \] \[ \alpha_n = \alpha_0 + n, \quad \beta_n = \beta_0 + \sum_{i=1}^{n} x_i. \]
Interpretazione epistemica: il parametro di forma \(\alpha\) accumula il conteggio degli eventi (reali e pseudo-osservati), mentre il parametro di velocità \(\beta\) accumula il tempo totale osservato (reale e pseudo-osservato). La media a posteriori \(E[\lambda \mid x] = \alpha_n / \beta\) è dunque una media pesata tra il tasso medio a priori (\(\alpha_0 / \beta_0\)) e il tasso osservato nei dati (\(n / \sum x_i\)).
13.2.4 Esempio: tempi di attesa
# Tempo medio di attesa: 4 giorni (lambda = 0.25)
lambda <- 0.25
# Probabilità di attesa ≤ 1.5 giorni
cat("P(X ≤ 1.5) =", round(pexp(1.5, rate = lambda), 3), "\n")
#> P(X ≤ 1.5) = 0.313
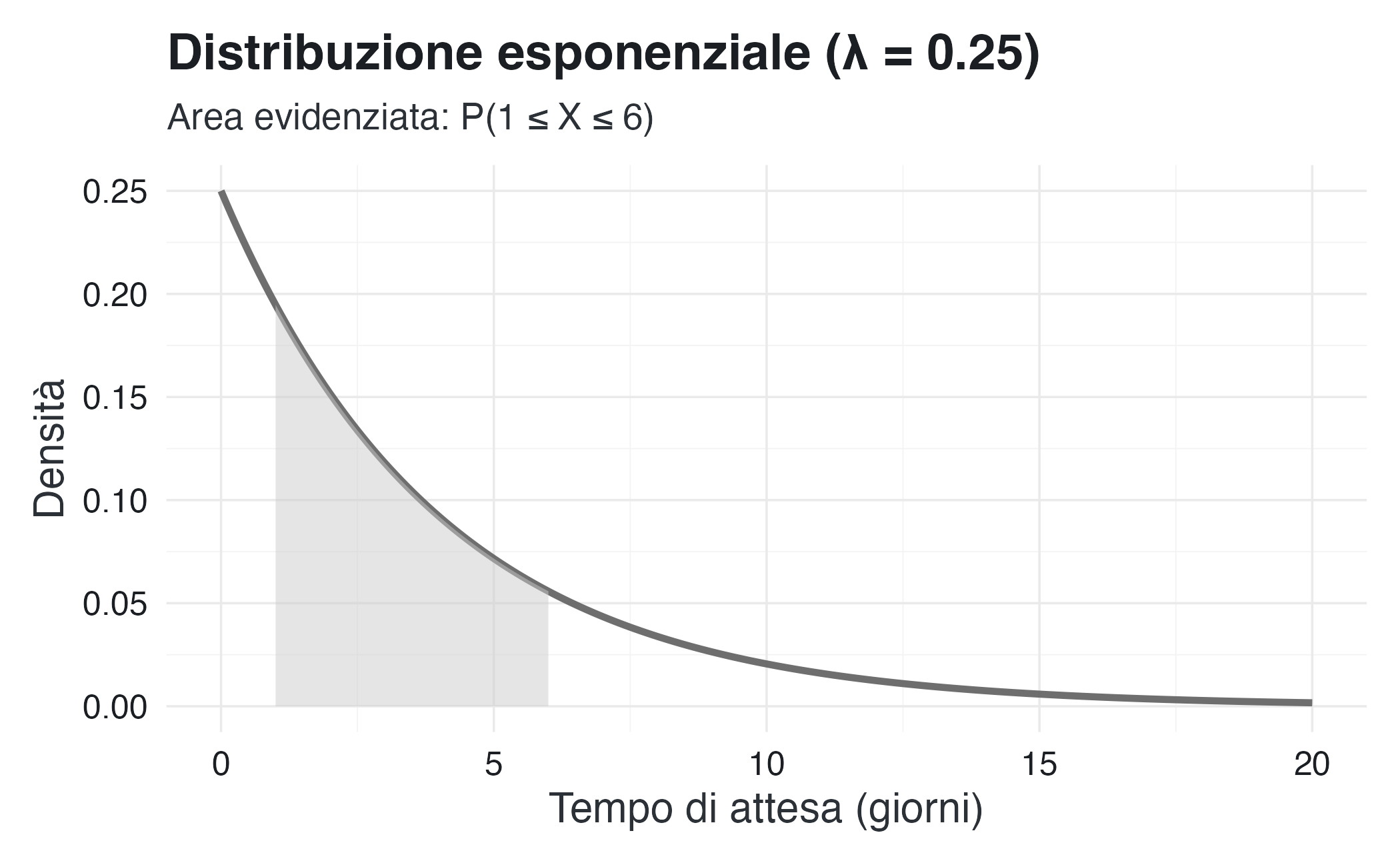
# Probabilità di attesa tra 1 e 6 giorni
cat("P(1 ≤ X ≤ 6) =", round(pexp(6, rate = lambda) - pexp(1, rate = lambda), 3), "\n")
#> P(1 ≤ X ≤ 6) = 0.556x <- seq(0, 20, by = 0.1)
pdf <- dexp(x, rate = lambda)
ggplot(data.frame(x = x, y = pdf), aes(x = x, y = y)) +
geom_line(linewidth = 1.2) +
geom_area(
data = subset(data.frame(x, y = pdf), x >= 1 & x <= 6),
alpha = 0.5
) +
scale_fill_qualitative() +
labs(
title = "Distribuzione esponenziale (λ = 0.25)",
subtitle = "Area evidenziata: P(1 ≤ X ≤ 6)",
x = "Tempo di attesa (giorni)", y = "Densità"
) 
13.3 Distribuzione normale
13.3.1 Definizione e interpretazione epistemica
La distribuzione normale (o gaussiana) emerge naturalmente come risultato della somma di molti effetti casuali indipendenti, un principio formalizzato dal Teorema del Limite Centrale. Questa proprietà la rende centrale nella modellazione di fenomeni psicologici influenzati da molteplici fattori. È importante sottolineare che la distribuzione normale non va interpretata come una descrizione letterale della realtà, bensì come un modello ideale che emerge quando molte fonti di variabilità indipendenti contribuiscono in modo additivo. In questo senso, la normale rappresenta spesso una approssimazione epistemicamente giustificata, più che una legge naturale dei fenomeni.
Definizione 13.3 Una variabile casuale \(Y\) segue una distribuzione normale con media \(\mu\) e deviazione standard \(\sigma\) se:
\[ Y \sim \mathcal{N}(\mu, \sigma^2), \quad f(y) = \frac{1}{\sigma\sqrt{2\pi}} \exp\left(-\frac{(y - \mu)^2}{2\sigma^2}\right). \]
Proprietà caratteristiche: \(\mathbb{E}(Y) = \mu\), \(\mathbb{V}(Y) = \sigma^2\).
Interpretazione epistemica dei parametri:
- il parametro \(\mu\) rappresenta il valore atteso, costituendo il “centro di massa” attorno al quale si concentrano le nostre credenze;
- il parametro \(\sigma\) quantifica il grado di incertezza associato a tali credenze, indicando quanto riteniamo plausibile che i valori veri possano discostarsi dal valore centrale \(\mu\).
13.3.2 Ruolo nell’inferenza bayesiana
La distribuzione normale occupa una posizione centrale nell’inferenza bayesiana e si rivela utile in molti contesti applicativi. In qualità di verosimiglianza, viene comunemente impiegata per modellare una vasta gamma di fenomeni continui, quali gli errori di misurazione, i punteggi psicometrici e le variabili di natura biologica. Quando viene utilizzata come distribuzione a priori per i parametri di posizione, nella forma \(\mu \sim \mathcal{N}(\mu_0, \sigma_0^2)\), essa permette di esprimere formalmente le credenze iniziali riguardo alla posizione del parametro di interesse. Un’ulteriore proprietà che ne accresce l’utilità pratica è la coniugazione: se la varianza \(\sigma^2\) è nota, la distribuzione normale si configura come prior coniugata per il parametro \(\mu\), garantendo che la distribuzione a posteriori appartenga alla stessa famiglia distributiva.
Un ulteriore motivo della centralità della distribuzione normale nell’inferenza bayesiana è che essa emerge frequentemente come approssimazione della distribuzione a posteriori, anche quando il modello di partenza non è normale. In virtù del Teorema del Limite Centrale e delle approssimazioni di tipo laplaciano, posteriori complesse tendono ad assumere una forma approssimativamente normale in prossimità del loro massimo, soprattutto in presenza di campioni numerosi.
In psicologia, numerose variabili osservate violano l’assunzione di normalità:
- Tempi di reazione: sono sempre positivi e presentano una tipica asimmetria positiva → modelli come Gamma o Log-normale sono spesso più appropriati.
- Scale Likert con pochi item: sono variabili discrete e possono mostrare effetti di floor o ceiling.
- Conteggi di sintomi: sono discreto e spesso caratterizzati da un eccesso di zeri → si adattano meglio a modelli come Poisson o a varianti Zero-inflated.
- Proporzioni o punteggi standardizzati: vincolati nell’intervallo \([0,1]\) → la distribuzione Beta offre una modellazione più naturale.
La distribuzione normale rimane una scelta appropriata per punteggi compositi derivati da scale psicometriche ben validate (ad esempio, QI, fattori del NEO-PI-R) e come approssimazione robusta quando il Teorema del Limite Centrale garantisce che la media campionaria si distribuisca approssimativamente in modo normale.
13.3.3 La regola 68-95-99.7
La distribuzione normale possiede una proprietà universale che rimane invariata indipendentemente dai valori specifici dei parametri \(\mu\) e \(\sigma\). In particolare, si può affermare che approssimativamente il 68.3% della massa probabilistica è concentrato entro un intervallo di più o meno una deviazione standard dalla media, percentuale che sale al 95.4% quando si considera un intervallo di due deviazioni standard e raggiunge il 99.7% per uno scarto di tre deviazioni standard.
Questa caratteristica fondamentale conferisce alla deviazione standard il ruolo di unità di misura naturale per quantificare la “distanza dalla media” in termini probabilistici, trasformandola da semplice misura di dispersione a strumento per l’interpretazione probabilistica della distribuzione.
Questa concentrazione rapida della massa probabilistica attorno alla media riflette la presenza di code leggere, una caratteristica che rende la distribuzione normale sensibile a osservazioni estreme. Nei contesti in cui tali osservazioni sono plausibili o frequenti, può risultare opportuno ricorrere a distribuzioni alternative con code più pesanti, come la \(t\) di Student o la Cauchy.
13.3.4 Il Teorema del Limite Centrale in azione: una simulazione psicologica
Il Teorema del Limite Centrale (TLC) spiega l’onnipresenza della distribuzione normale in statistica: la somma (o media) di molte variabili casuali indipendenti e identicamente distribuite tende a una distribuzione normale, indipendentemente dalla forma della distribuzione originaria. Questo fenomeno non è solo teorico ma emerge costantemente in processi complessi.
Visualizziamo questo principio attraverso una metafora psicologica: il processo decisionale come somma di piccole influenze. Immaginiamo che un giudizio finale (es., la valutazione di un prodotto) sia il risultato della somma di numerose micro-considerazioni (n = 16), ciascuna delle quali può spingere leggermente l’opinione in una direzione positiva o negativa. Ogni micro-considerazione è modellata come una variabile uniforme tra -1 e +1, rappresentando un piccolo “passo” casuale nell’atteggiamento.
set.seed(123) # Per riproducibilità
n_soggetti <- 1000 # Numero di giudizi simulati
n_influenze <- 16 # Numero di micro-considerazioni per giudizio
# Simula le micro-influenze per ogni soggetto
micro_influenze <- matrix(
runif(n_soggetti * n_influenze, min = -1, max = 1),
ncol = n_influenze
)
# Il giudizio finale è la somma di tutte le micro-influenze
giudizio_finale <- rowSums(micro_influenze)
# Visualizzazione
df_giudizi <- data.frame(Giudizio = giudizio_finale)
ggplot(df_giudizi, aes(x = Giudizio)) +
geom_histogram(
aes(y = after_stat(density)),
bins = 30,
alpha = 0.6
) +
# Sovrapponi la curva normale teorica
stat_function(
fun = dnorm,
args = list(
mean = mean(giudizio_finale),
sd = sd(giudizio_finale)
),
linewidth = 1.2
) +
scale_fill_qualitative() +
labs(
title = "Il Teorema del Limite Centrale nella Cognizione",
subtitle = sprintf(
"Distribuzione del giudizio finale (somma di %d influenze uniformi)",
n_influenze
),
x = "Valore del giudizio finale",
y = "Densità"
) 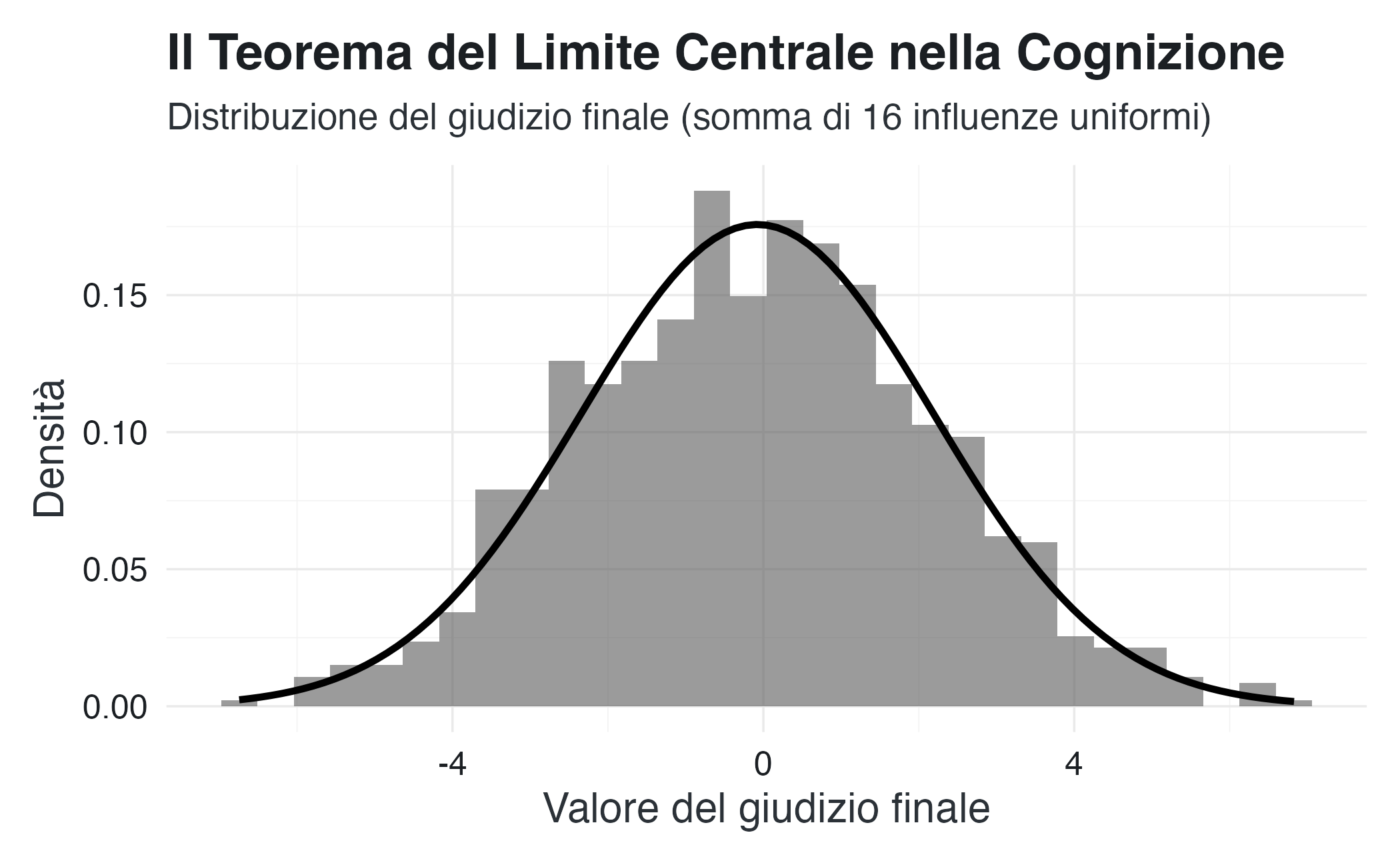
Interpretazione del risultato: Nonostante ogni singola “micro-influenza” segua una distribuzione uniforme (tutti i suoi valori sono ugualmente probabili), la distribuzione del giudizio finale (la loro somma) assume una forma a campana caratteristica della distribuzione normale. Questa simulazione mostra empiricamente come processi complessi — come la formazione di un’opinione — possano produrre distribuzioni normali anche quando i loro componenti elementari non lo sono, fornendo una giustificazione fondamentale per l’uso ubiquitario della normale nella modellazione psicologica e statistica.
13.3.5 Visualizzazione degli intervalli di credibilità (o probabilità)
Un’altra proprietà cruciale della distribuzione normale è che una proporzione precisa della sua massa di probabilità è contenuta entro intervalli definiti in termini di deviazioni standard (\(\pm \sigma\)) dalla media (\(\mu\)). L’intervallo \(μ \pm 1.96 \sigma\) contiene esattamente il 95% della probabilità, rendendolo l’intervallo di credibilità (o confidenza) standard per questa distribuzione.
Il seguente grafico illustra questa proprietà per una distribuzione \(\mathcal{N}(\mu=100, \sigma=15)\), tipica dei punteggi di QI.
mu <- 100 # Media
sigma <- 15 # Deviazione standard
# Crea una sequenza di valori x attorno alla media
x <- seq(mu - 4*sigma, mu + 4*sigma, length.out = 1000)
# Calcola la densità di probabilità normale
pdf <- dnorm(x, mean = mu, sd = sigma)
df <- data.frame(x = x, densita = pdf)
# Definisci i limiti dell'intervallo al 95%
lim_inf <- mu - 1.96 * sigma
lim_sup <- mu + 1.96 * sigma
# Crea il dataframe per l'area evidenziata (intervallo al 95%)
df_area <- subset(df, x >= lim_inf & x <= lim_sup)
ggplot(df, aes(x = x, y = densita)) +
# Traccia la linea della curva normale
geom_line(linewidth = 1) +
# Evidenzia l'area dell'intervallo al 95%
geom_area(data = df_area, aes(x = x, y = densita), alpha = 0.7) +
# Aggiunge linee verticali per i limiti dell'intervallo
geom_vline(xintercept = c(lim_inf, lim_sup), linetype = "dashed") +
# Aggiunge etichette testuali
annotate("text", x = mu, y = 0.005, label = "95%", size = 5, fontface = "bold") +
annotate("text", x = lim_inf, y = 0.002, label = round(lim_inf,1), hjust = 1.1) +
annotate("text", x = lim_sup, y = 0.002, label = round(lim_sup,1), hjust = -0.1) +
scale_fill_qualitative() +
labs(
title = "Distribuzione Normale e\nIntervallo di Credibilità al 95%",
subtitle = sprintf("N(μ = %.0f, σ = %.0f)", mu, sigma),
x = "Valore (es., punteggio QI)",
y = "Densità di probabilità f(x)"
) 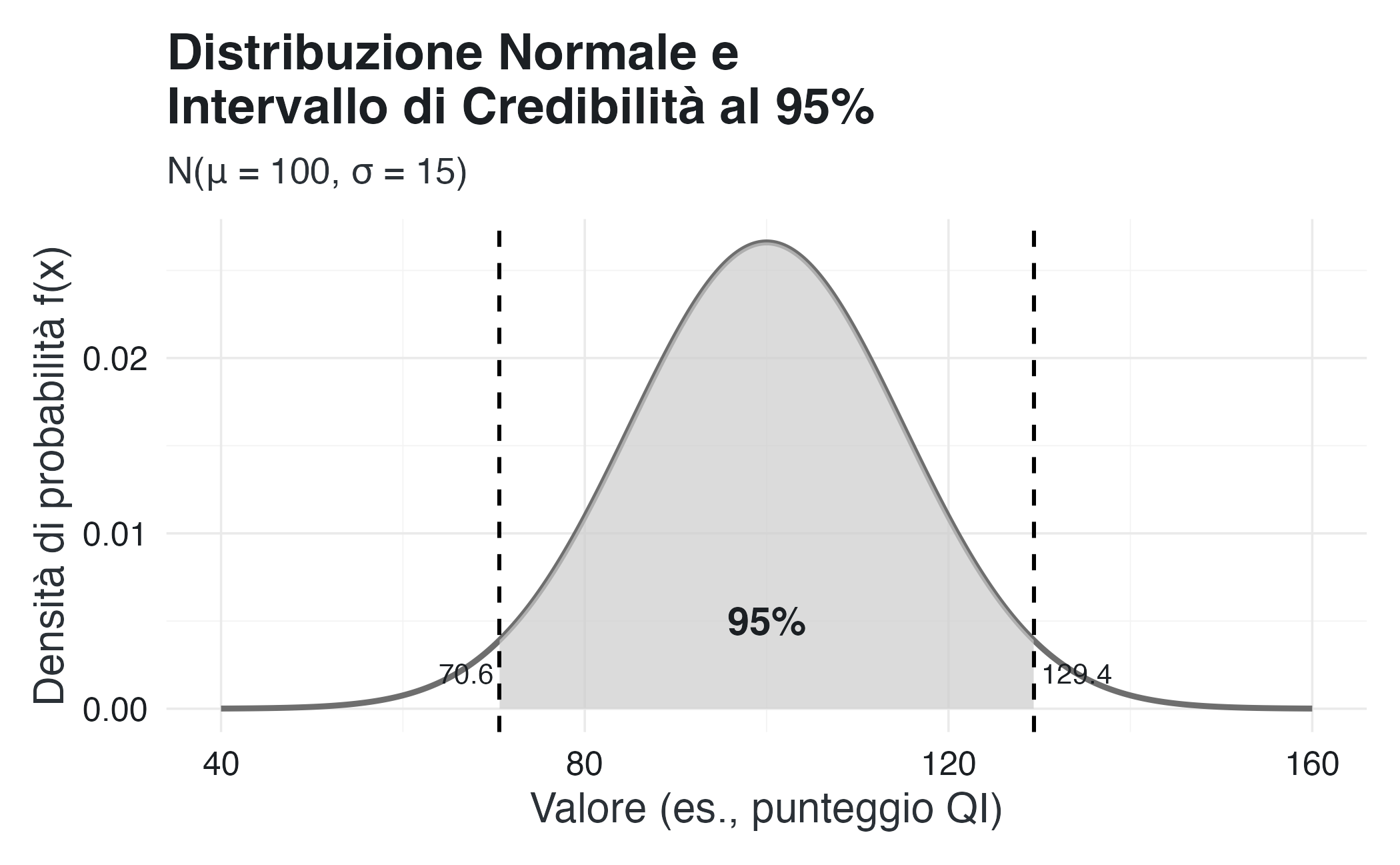
Interpretazione del grafico: la curva nera rappresenta la densità della normale. L’area verde evidenziata mostra la porzione centrale della distribuzione che contiene il 95% della probabilità totale. I trattini verticali verdi indicano i limiti esatti di questo intervallo (\(\mu \pm 1.96 \sigma = 100 \pm 29.4\)), che qui vanno da circa 70.6 a 129.4. Questa visualizzazione rende immediatamente evidente come la distribuzione normale concentri la maggior parte della sua probabilità in una regione simmetrica attorno alla media, una proprietà fondamentale per la costruzione di intervalli di credibilità in inferenza bayesiana e di confidenza in statistica frequentista.
13.4 Distribuzione chi-quadrato
13.4.1 Definizione e interpretazione epistemica
La distribuzione chi-quadrato emerge naturalmente dalla somma dei quadrati di variabili normali standard indipendenti. Essa quantifica quindi la magnitudine complessiva delle deviazioni rispetto a un valore centrale, indipendentemente dal segno.
Definizione 13.4 Se \(Z_1, \ldots, Z_k\) sono variabili casuali i.i.d. con distribuzione \(\mathcal{N}(0, 1)\), allora:
\[ X = Z_1^2 + Z_2^2 + \cdots + Z_k^2 \sim \chi^2_k, \]
dove \(k\) rappresenta il numero di gradi di libertà.
Proprietà: \(\mathbb{E}(X) = k\), \(\mathbb{V}(X) = 2k\).
Interpretazione epistemica La distribuzione chi-quadrato misura la dispersione quadratica di un insieme di variabili normali. Elevando al quadrato le deviazioni si elimina l’informazione sul segno e si attribuisce maggiore peso agli scostamenti più ampi. I gradi di libertà \(k\) indicano quante fonti indipendenti di variabilità contribuiscono alla dispersione complessiva.
13.4.2 Ruolo nell’inferenza bayesiana
La distribuzione chi-quadrato è un caso particolare della distribuzione gamma ed è formalmente equivalente a:
\[ \chi^2_k = \text{Gamma}\left(\frac{k}{2}, \frac{1}{2}\right). \]
Nel contesto dell’inferenza bayesiana, essa riveste un ruolo fondamentale nella modellazione dell’incertezza associata alla variabilità dei dati. In particolare, la somma dei quadrati delle deviazioni standardizzate di osservazioni normali segue una distribuzione chi-quadrato, fornendo una base teorica per la distribuzione della varianza campionaria.
La trasformazione inversa di questa distribuzione, nota come chi-quadrato inversa, costituisce la prior coniugata per il parametro di varianza \(\sigma^2\) nel modello normale con media nota. In molte formulazioni bayesiane si preferisce modellare la precisione \(\tau = 1/\sigma^2\), grandezza positiva per la quale la famiglia gamma (e quindi la chi-quadrato) risulta particolarmente naturale.
La distribuzione chi-quadrato compare inoltre implicitamente in modelli gerarchici e multilevel, dove consente di rappresentare formalmente l’incertezza sulla scala della variabilità.
13.4.3 Visualizzazione
x <- seq(0, 40, by = 0.1)
nus <- c(2, 4, 8, 16)
data <- do.call(rbind, lapply(nus, function(nu) {
data.frame(x = x, f_x = dchisq(x, df = nu), nu = as.factor(nu))
}))
ggplot(data, aes(x = x, y = f_x, color = nu)) +
geom_line(linewidth = 1) +
scale_fill_qualitative() +
labs(
title = "Distribuzione chi-quadrato",
subtitle = "La distribuzione diventa più simmetrica all’aumentare dei gradi di libertà",
x = "x", y = "f(x)", color = "ν"
) 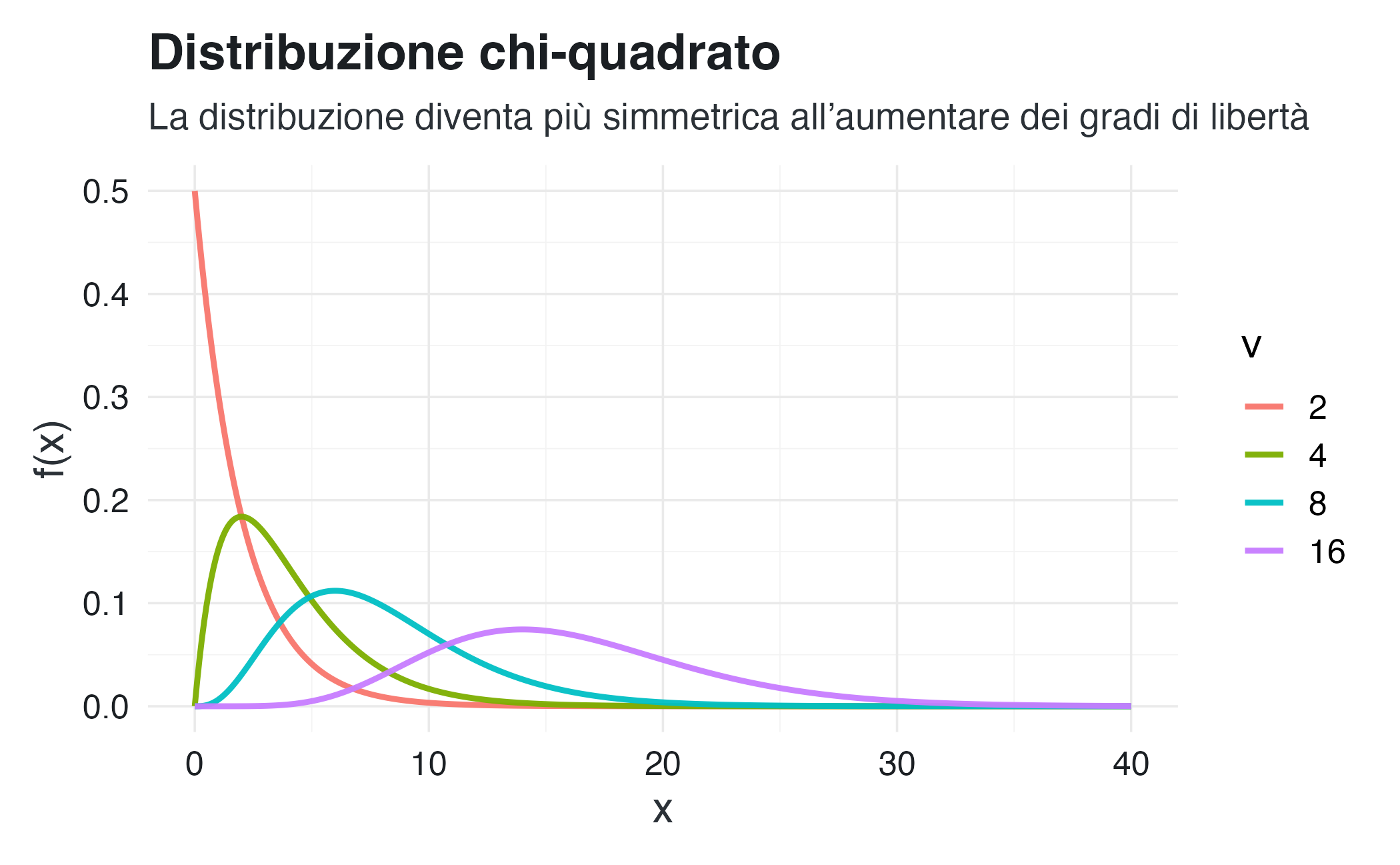
(Nota: al crescere dei gradi di libertà, la distribuzione chi-quadrato tende ad assumere una forma sempre più simmetrica, avvicinandosi a una distribuzione normale.)
13.5 Distribuzione \(t\) di Student
13.5.1 Definizione e interpretazione epistemica
La distribuzione \(t\) di Student emerge quando una variabile aleatoria normale viene standardizzata utilizzando una stima incerta della sua varianza, tipicamente derivata da un campione finito. In questo senso, la distribuzione \(t\) può essere interpretata come una distribuzione normale la cui scala non è nota con certezza.
Definizione 13.5 Date due variabili aleatorie indipendenti \(Z \sim \mathcal{N}(0, 1)\) e \(W \sim \chi^2_\nu\), la variabile risultante dalla trasformazione:
\[ T = \frac{Z}{\sqrt{W/\nu}} \sim t_\nu \]
segue una distribuzione \(t\) di Student con \(\nu\) gradi di libertà.
Proprietà: \(\mathbb{E}(T) = 0\) per \(\nu > 1\); \(\mathbb{V}(T) = \frac{\nu}{\nu - 2}\) per \(\nu > 2\).
Interpretazione epistemica La distribuzione \(t\) di Student presenta code più pesanti rispetto alla normale, riflettendo l’incertezza aggiuntiva associata alla stima della varianza. I gradi di libertà \(\nu\) possono essere interpretati come una misura indiretta della quantità di informazione disponibile sulla scala del fenomeno: per valori piccoli di \(\nu\) l’incertezza è elevata, mentre all’aumentare di \(\nu\) la distribuzione \(t\) converge progressivamente alla distribuzione normale.
13.5.2 Ruolo nell’inferenza bayesiana
La distribuzione \(t\) di Student riveste un ruolo di particolare rilievo nell’inferenza bayesiana per almeno tre motivi fondamentali.
In primo luogo, essa funge da prior robusta per parametri di posizione. L’uso di una distribuzione \(t_\nu(\mu_0, \sigma_0)\) come prior per una media assegna una maggiore plausibilità ai valori estremi rispetto a una distribuzione normale, rendendo il modello meno sensibile a osservazioni anomale o inattese.
In secondo luogo, la distribuzione \(t\) emerge naturalmente come distribuzione predittiva quando si tiene conto dell’incertezza congiunta sia sulla media sia sulla varianza in un modello normale. In tali condizioni, la distribuzione predittiva marginale per nuove osservazioni assume una forma t di Student, a differenza del caso in cui la varianza sia nota, dove la predittiva rimane normale.
Infine, la distribuzione \(t\) si presta efficacemente come prior debolmente informativa. Specificando un numero ridotto di gradi di libertà, come \(\nu = 3\), o nel caso limite \(\nu = 1\), che corrisponde alla distribuzione di Cauchy, è possibile costruire prior che esercitano una regolarizzazione moderata senza dominare l’evidenza fornita dai dati, anche in presenza di campioni di piccole dimensioni.
13.5.3 Confronto con la normale
x <- seq(-4, 4, length.out = 1000)
gradi_liberta <- c(1, 3, 10)
dati_plot <- data.frame(
x = rep(x, length(gradi_liberta) + 1),
densita = c(
dnorm(x),
dt(x, df = gradi_liberta[1]),
dt(x, df = gradi_liberta[2]),
dt(x, df = gradi_liberta[3])
),
distribuzione = rep(
c("Normale", paste0("t (ν = ", gradi_liberta, ")")),
each = length(x)
)
)
ggplot(dati_plot, aes(x = x, y = densita, color = distribuzione)) +
geom_line(linewidth = 1) +
scale_fill_qualitative() +
labs(
title = "Confronto t di Student e Normale",
subtitle = "Code più pesanti per ν piccoli; convergenza alla normale per ν → ∞",
x = "Valore", y = "Densità", color = "Distribuzione"
) 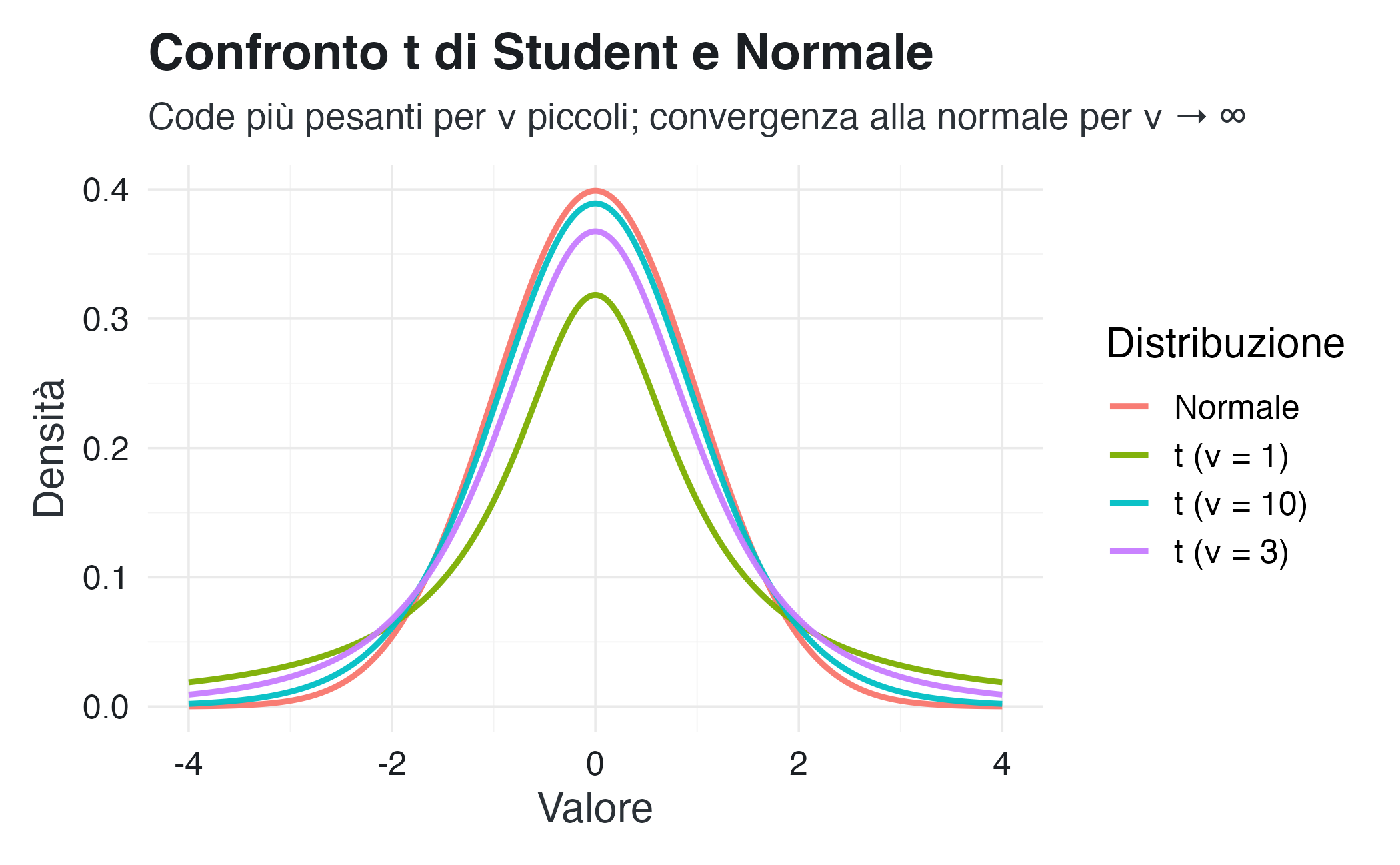
Il grafico mostra chiaramente come, per valori piccoli di \(\nu\), la distribuzione \(t\) presenti code più pesanti rispetto alla normale, mentre al crescere dei gradi di libertà le due distribuzioni diventino praticamente indistinguibili.
13.6 Distribuzione di Cauchy
13.6.1 Definizione e interpretazione epistemica
La distribuzione di Cauchy costituisce un caso particolare della distribuzione \(t\) di Student, corrispondente a un singolo grado di libertà (\(t_1\)). La sua caratteristica distintiva è la presenza di code estremamente pesanti, che decadono molto più lentamente rispetto a quelle della distribuzione normale.
Definizione 13.6 Una variabile casuale \(X\) segue una distribuzione di Cauchy con parametro di posizione \(\alpha\) e parametro di scala \(\beta > 0\) se la sua funzione di densità è data da:
\[ X \sim \text{Cauchy}(\alpha, \beta), \quad f(x) = \frac{1}{\pi\beta\left[1 + \left(\frac{x-\alpha}{\beta}\right)^2\right]}. \]
Proprietà distintive A differenza di molte distribuzioni parametriche comuni, la distribuzione di Cauchy non possiede momenti primi e secondi definiti. Sebbene il parametro \(\alpha\) rappresenti una posizione centrale (mediana e moda), gli integrali che definiscono la media e la varianza non convergono, a causa del decadimento estremamente lento delle code.
Interpretazione epistemica La distribuzione di Cauchy esprime un grado elevato di incertezza, assegnando una plausibilità non trascurabile anche a valori molto distanti dal parametro di posizione. Essa risulta particolarmente appropriata nei contesti inferenziali in cui non si intende escludere a priori la possibilità di osservare valori estremi, adottando un atteggiamento epistemico di massima prudenza nei confronti delle potenziali osservazioni anomale.
13.6.2 Ruolo nell’inferenza bayesiana
La distribuzione di Cauchy trova ampia applicazione come prior debolmente informativa e robusta nell’inferenza bayesiana. Viene frequentemente utilizzata come prior per parametri di posizione: ad esempio, una Cauchy(0, 2.5) è una scelta comune per i coefficienti di regressione standardizzati, poiché consente valori estremi pur mantenendo una concentrazione significativa di massa probabilistica attorno allo zero.
Per i parametri di scala, la half-Cauchy, ottenuta troncando la distribuzione ai valori positivi, è spesso raccomandata come prior per le deviazioni standard nei modelli gerarchici. In questi contesti, la Cauchy svolge un ruolo cruciale: non impone una scala caratteristica rigida, lasciando che siano i dati a informare l’ampiezza della variabilità, pur esercitando una regolarizzazione debole.
13.6.3 Confronto con altre distribuzioni
x <- seq(-5, 5, length.out = 500)
df <- data.frame(
x = rep(x, 3),
density = c(dnorm(x), dt(x, df = 3), dcauchy(x)),
distribuzione = rep(c("Normale(0,1)", "t (ν = 3)", "Cauchy(0,1)"), each = length(x))
)
ggplot(df, aes(x = x, y = density, color = distribuzione)) +
geom_line(linewidth = 1) +
scale_fill_qualitative() +
labs(
title = "Confronto delle code",
subtitle = "La Cauchy ha le code più pesanti, seguita dalla t",
x = "x", y = "Densità"
) 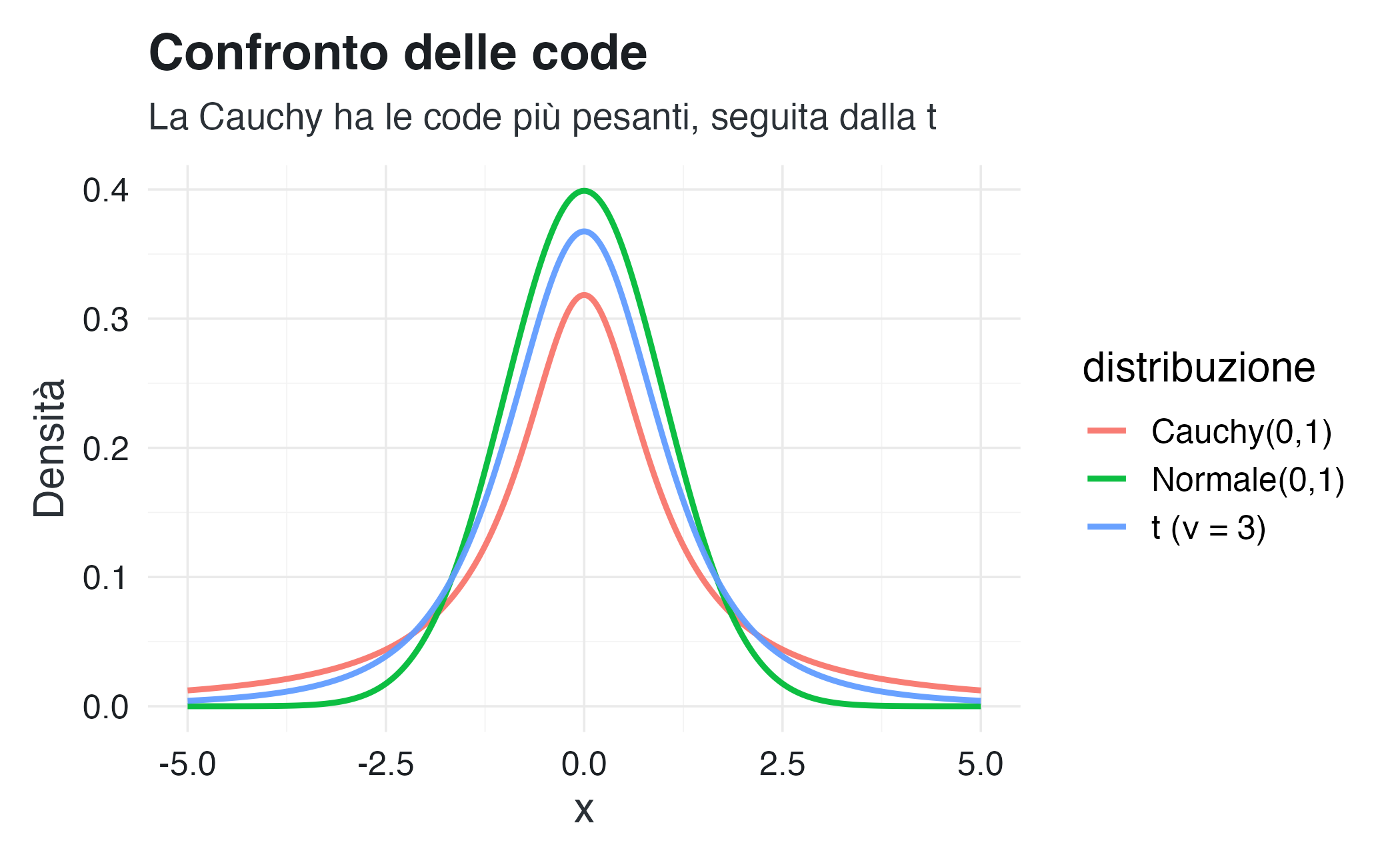
Il confronto evidenzia come la distribuzione di Cauchy presenti le code più pesanti, seguita dalla distribuzione \(t\) di Student, mentre la normale concentra la massa probabilistica in modo più marcato attorno al valore centrale.
13.6.4 Chiusura concettuale
Nel complesso, la distribuzione di Cauchy rappresenta il punto estremo di un continuum che va dalla distribuzione normale alla \(t\) di Student: al crescere dell’incertezza sulla scala del fenomeno, il modello probabilistico adotta code sempre più pesanti, riflettendo un atteggiamento epistemico progressivamente più prudente. In questo senso, la Cauchy non costituisce un’anomalia, ma una scelta coerente quando si desidera minimizzare le assunzioni a priori sulla variabilità dei dati.
13.7 Distribuzione beta
13.7.1 Definizione e interpretazione epistemica
La distribuzione beta è la scelta naturale per rappresentare credenze su proporzioni o probabilità, ovvero quantità vincolate all’intervallo \((0, 1)\). È importante sottolineare che la distribuzione beta non descrive la variabilità dei dati osservati, bensì lo stato di conoscenza (o di incertezza) riguardo al valore del parametro \(p\), che rimane non osservabile.
Definizione 13.7 Una variabile casuale \(\theta\) segue una distribuzione beta con parametri \(\alpha > 0\) e \(\beta > 0\) se:
\[ \theta \sim \text{Beta}(\alpha, \beta), \quad f(\theta) = \frac{\theta^{\alpha-1}(1-\theta)^{\beta-1}}{B(\alpha, \beta)}, \] dove \(B(\alpha, \beta)\) è la funzione beta di Eulero.
Proprietà:
- \(\mathbb{E}(\theta) = \frac{\alpha}{\alpha + \beta}\);
- \(\mathbb{V}(\theta) = \frac{\alpha\beta}{(\alpha + \beta)^2(\alpha + \beta + 1)}\);
- Moda (per \(\alpha, \beta > 1\)): \(\frac{\alpha - 1}{\alpha + \beta - 2}\).
Interpretazione epistemica dei parametri: i parametri \(\alpha\) e \(\beta\) della distribuzione beta ammettono un’interpretazione epistemica particolarmente intuitiva in termini di “pseudo-osservazioni”. In questa prospettiva, \(\alpha - 1\) rappresenta il numero ipotetico di successi precedentemente osservati, mentre \(\beta - 1\) corrisponde al numero analogo di insuccessi. Questa caratteristica consente di incorporare in modo trasparente l’informazione a priori nel modello. Il caso particolare \(\alpha = \beta = 1\) assume un significato speciale, in quanto produce una distribuzione uniforme che rappresenta formalmente uno stato di massima ignoranza riguardo al parametro di interesse.
In questa interpretazione, la quantità \(\alpha + \beta\) può essere vista come la dimensione di un campione virtuale che quantifica la forza informativa della prior. Valori piccoli di \(\alpha + \beta\) corrispondono a credenze deboli e facilmente aggiornabili dai dati, mentre valori grandi indicano credenze più rigide che richiedono un’evidenza empirica consistente per essere modificate.
13.7.2 Ruolo nell’inferenza bayesiana
La beta è la prior coniugata per il parametro \(p\) della distribuzione binomiale:
\[ \text{Prior: } p \sim \text{Beta}(\alpha, \beta), \quad \text{Dati: } k \text{ successi su } n \text{ prove}. \]
\[ \text{Posterior: } p \mid k \sim \text{Beta}(\alpha + k, \beta + n - k). \] Questa proprietà rende l’aggiornamento bayesiano analiticamente trattabile: i parametri della distribuzione a posteriori si ottengono semplicemente sommando i conteggi osservati agli pseudo-conteggi della distribuzione a priori.
La media della distribuzione a posteriori può essere interpretata come una media ponderata tra la proporzione implicita nella prior e la proporzione osservata nei dati, con pesi determinati rispettivamente dalla forza della prior e dalla dimensione del campione osservato. In questo senso, l’aggiornamento bayesiano realizza un compromesso quantitativo tra credenze iniziali ed evidenza empirica.
La coniugazione tra distribuzione beta e modello binomiale non rappresenta soltanto una semplificazione computazionale, ma riflette una profonda coerenza epistemica: le informazioni a priori e quelle fornite dai dati sono espresse nella stessa unità concettuale, ovvero conteggi di successi e insuccessi, rendendo l’aggiornamento trasparente e interpretabile.
13.7.3 Flessibilità della forma
La distribuzione beta può assumere forme molto diverse a seconda dei parametri:
x <- seq(0, 1, length.out = 200)
params <- list(
c(0.5, 0.5), c(1, 1), c(2, 2), c(2, 5), c(5, 2)
)
df <- do.call(rbind, lapply(params, function(p) {
data.frame(
x = x,
density = dbeta(x, p[1], p[2]),
label = paste0("α = ", p[1], ", β = ", p[2])
)
}))
ggplot(df, aes(x = x, y = density, color = label)) +
geom_line(linewidth = 1) +
scale_fill_qualitative() +
labs(
title = "Flessibilità della distribuzione Beta",
subtitle = "Diverse combinazioni di parametri producono forme radicalmente diverse",
x = "θ", y = "f(θ)"
)
theme(legend.title = element_blank())
#> <theme> List of 1
#> $ legend.title: <ggplot2::element_blank>
#> @ complete: logi FALSE
#> @ validate: logi TRUE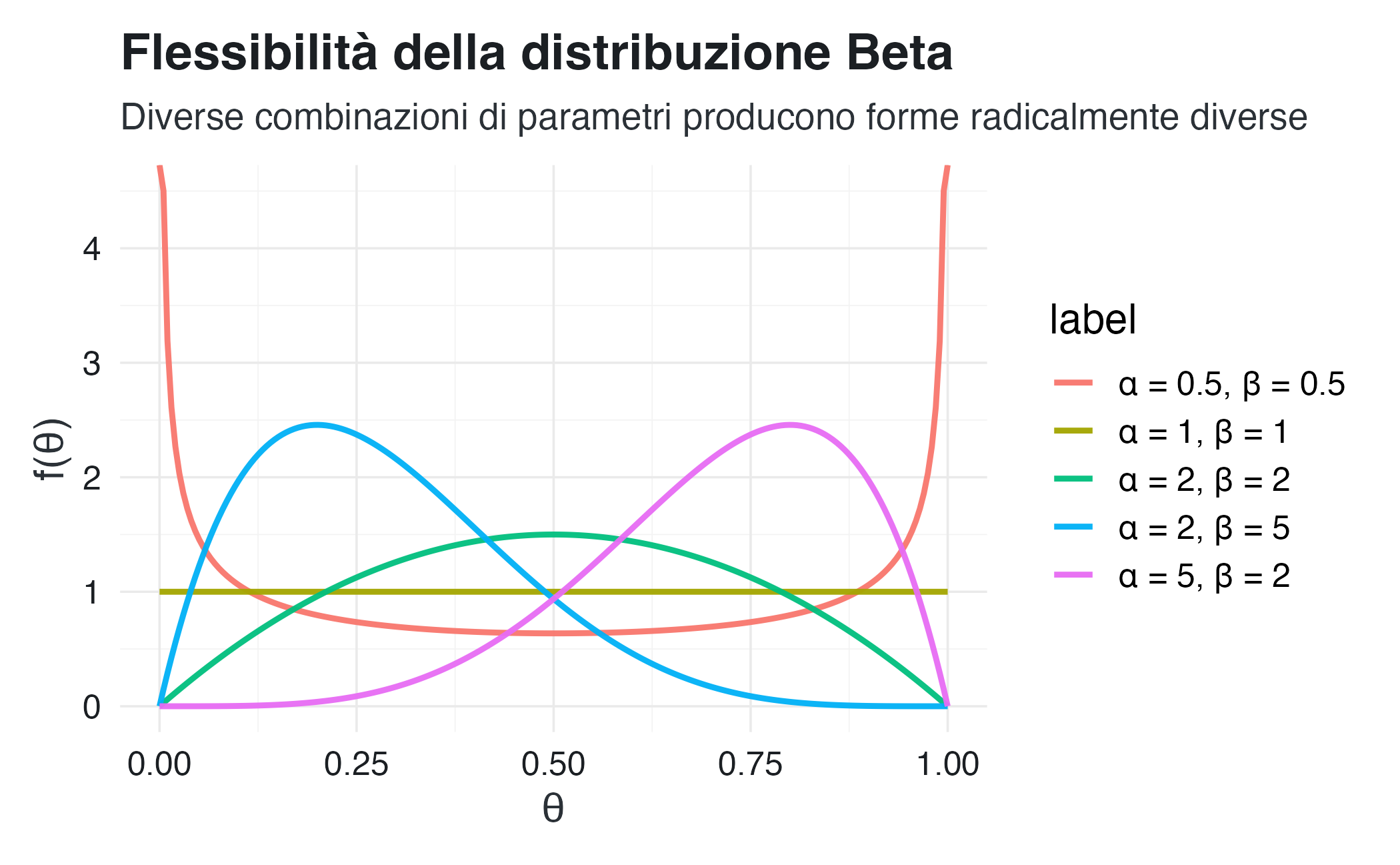
13.7.4 Esempio: aggiornamento bayesiano
# Prior: Beta(2, 2) - credenza iniziale moderatamente incerta
alpha_prior <- 2
beta_prior <- 2
# Dati osservati: 7 successi su 10 prove
successi <- 7
prove <- 10
# Posterior: Beta(2+7, 2+3) = Beta(9, 5)
alpha_post <- alpha_prior + successi
beta_post <- beta_prior + (prove - successi)
# Visualizzazione
x <- seq(0, 1, length.out = 200)
df <- data.frame(
x = rep(x, 2),
density = c(dbeta(x, alpha_prior, beta_prior), dbeta(x, alpha_post, beta_post)),
tipo = rep(c("Prior Beta(2,2)", "Posterior Beta(9,5)"), each = length(x))
)
ggplot(df, aes(x = x, y = density, color = tipo)) +
geom_line(linewidth = 1.2) +
scale_fill_qualitative() +
labs(
title = "Aggiornamento Bayesiano: Beta-Binomiale",
subtitle = "7 successi su 10 prove aggiornano la prior",
x = "p", y = "Densità"
)
cat("Media prior:", round(alpha_prior/(alpha_prior + beta_prior), 3), "\n")
#> Media prior: 0.5
cat("Media posterior:", round(alpha_post/(alpha_post + beta_post), 3), "\n")
#> Media posterior: 0.643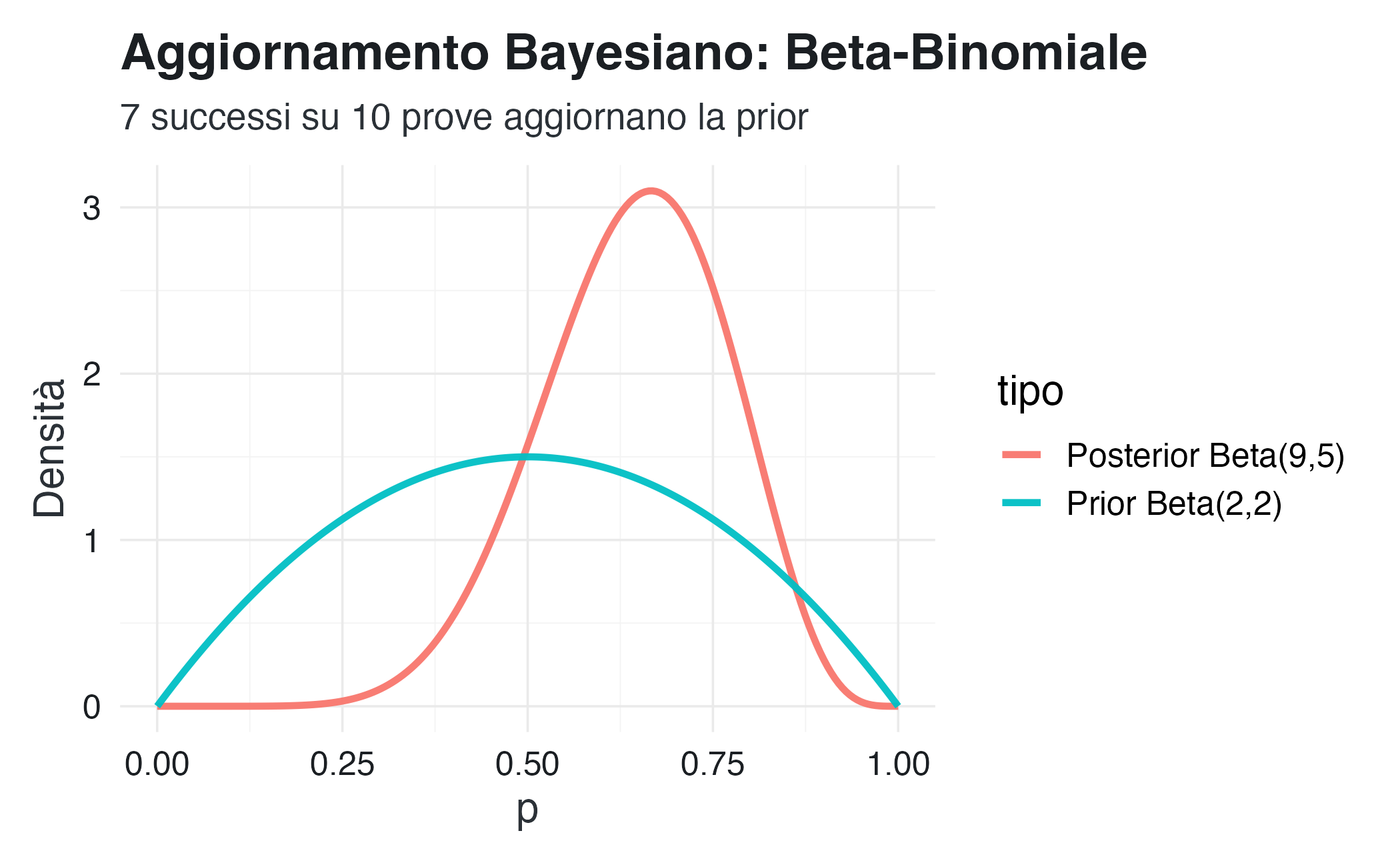
13.7.5 Distribuzione gamma
13.7.5.1 Definizione e interpretazione epistemica
La distribuzione gamma rappresenta una famiglia di distribuzioni per variabili casuali strettamente positive, che svolge un ruolo fondamentale come distribuzione a priori coniugata per il parametro di tasso nella distribuzione di Poisson. Dal punto di vista epistemico, la distribuzione gamma rappresenta l’analogo continuo della distribuzione beta: mentre la beta modella credenze su proporzioni, la gamma modella credenze su tassi di occorrenza o quantità positive associate a conteggi di eventi.
Definizione 13.8 Una variabile casuale \(X\) segue una distribuzione gamma con parametro di forma \(\alpha > 0\) e parametro di tasso \(\beta > 0\) quando la sua funzione di densità è data da:
\[ X \sim \text{Gamma}(\alpha, \beta), \quad f(x) = \frac{\beta^\alpha x^{\alpha-1} e^{-\beta x}}{\Gamma(\alpha)} \quad \text{per } x > 0 \]
Proprietà fondamentali: \(\mathbb{E}(X) = \frac{\alpha}{\beta}\), \(\mathbb{V}(X) = \frac{\alpha}{\beta^2}\).
Interpretazione epistemica dei parametri: Il parametro di forma \(\alpha\) determina la configurazione morfologica della distribuzione: quando \(\alpha < 1\) la densità risulta monotona decrescente, per \(\alpha = 1\) si ottiene la distribuzione esponenziale, mentre per \(\alpha > 1\) la distribuzione presenta una forma unimodale. Il parametro di tasso \(\beta\) governa invece la scala della distribuzione, per cui valori più elevati tendono a concentrare la massa probabilistica in prossimità dello zero.
In un’interpretazione bayesiana, i parametri \(\alpha\) e \(\beta\) possono essere letti come pseudo-conteggi: \(\alpha\) rappresenta un numero equivalente di eventi precedentemente osservati, mentre \(\beta\) corrisponde a una quantità equivalente di esposizione (tempo, area, numero di unità osservate). Questa lettura rende l’aggiornamento bayesiano particolarmente trasparente.
13.7.5.2 Ruolo nell’inferenza bayesiana
La distribuzione gamma riveste un ruolo di primo piano nell’inferenza bayesiana grazie alle sue molteplici applicazioni. In primo luogo, funge da distribuzione a priori coniugata per il parametro \(\lambda\) nel modello di Poisson:
\[ \text{Prior: } \lambda \sim \text{Gamma}(\alpha, \beta), \quad \text{Dati: } y_1, \ldots, y_n \sim \text{Poisson}(\lambda) \]
\[ \text{Posterior: } \lambda \mid \mathbf{y} \sim \text{Gamma}\left(\alpha + \sum y_i, \beta + n\right) \] L’aggiornamento bayesiano assume quindi una forma estremamente intuitiva: gli eventi osservati si sommano agli eventi “attesi” a priori, mentre l’esposizione empirica si aggiunge a quella implicita nella prior. La media della distribuzione a posteriori, \(\mathbb{E}(\lambda \mid \mathbf{y}) = \frac{\alpha + \sum y_i}{\beta + n}\), rappresenta così un compromesso ponderato tra credenze iniziali ed evidenza empirica.
In secondo luogo, la distribuzione gamma è comunemente utilizzata come distribuzione a priori per il parametro di precisione (definito come l’inverso della varianza) nei modelli normali. Infine, essa fornisce un modello flessibile per la rappresentazione dei tempi di attesa, generalizzando la distribuzione esponenziale al caso in cui si considera l’attesa per il verificarsi di \(\alpha\) eventi successivi.
In questo senso, la distribuzione gamma generalizza la distribuzione esponenziale: mentre quest’ultima descrive il tempo di attesa fino al primo evento, la gamma consente di modellare il tempo necessario al verificarsi di un numero arbitrario di eventi, mantenendo la stessa struttura probabilistica di base.
13.7.6 Esempio: inferenza su un tasso Poisson
# Prior: Gamma(2, 1) - credenza che λ sia intorno a 2
alpha_prior <- 2
beta_prior <- 1
# Dati: 5 osservazioni con totale 18 eventi
n_obs <- 5
totale_eventi <- 18
# Posterior: Gamma(2 + 18, 1 + 5) = Gamma(20, 6)
alpha_post <- alpha_prior + totale_eventi
beta_post <- beta_prior + n_obs
# Visualizzazione
x <- seq(0, 8, length.out = 200)
df <- data.frame(
x = rep(x, 2),
density = c(dgamma(x, alpha_prior, beta_prior), dgamma(x, alpha_post, beta_post)),
tipo = rep(c("Prior Gamma(2,1)", "Posterior Gamma(20,6)"), each = length(x))
)
ggplot(df, aes(x = x, y = density, color = tipo)) +
geom_line(linewidth = 1.2) +
scale_fill_qualitative() +
labs(
title = "Aggiornamento Bayesiano: Gamma-Poisson",
subtitle = "18 eventi in 5 osservazioni aggiornano la prior",
x = "λ", y = "Densità"
)
cat("Media prior:", round(alpha_prior/beta_prior, 3), "\n")
#> Media prior: 2
cat("Media posterior:", round(alpha_post/beta_post, 3), "\n")
#> Media posterior: 3.33
cat("IC 95%: [", round(qgamma(0.025, alpha_post, beta_post), 2), ", ",
round(qgamma(0.975, alpha_post, beta_post), 2), "]\n", sep = "")
#> IC 95%: [2.04, 4.95]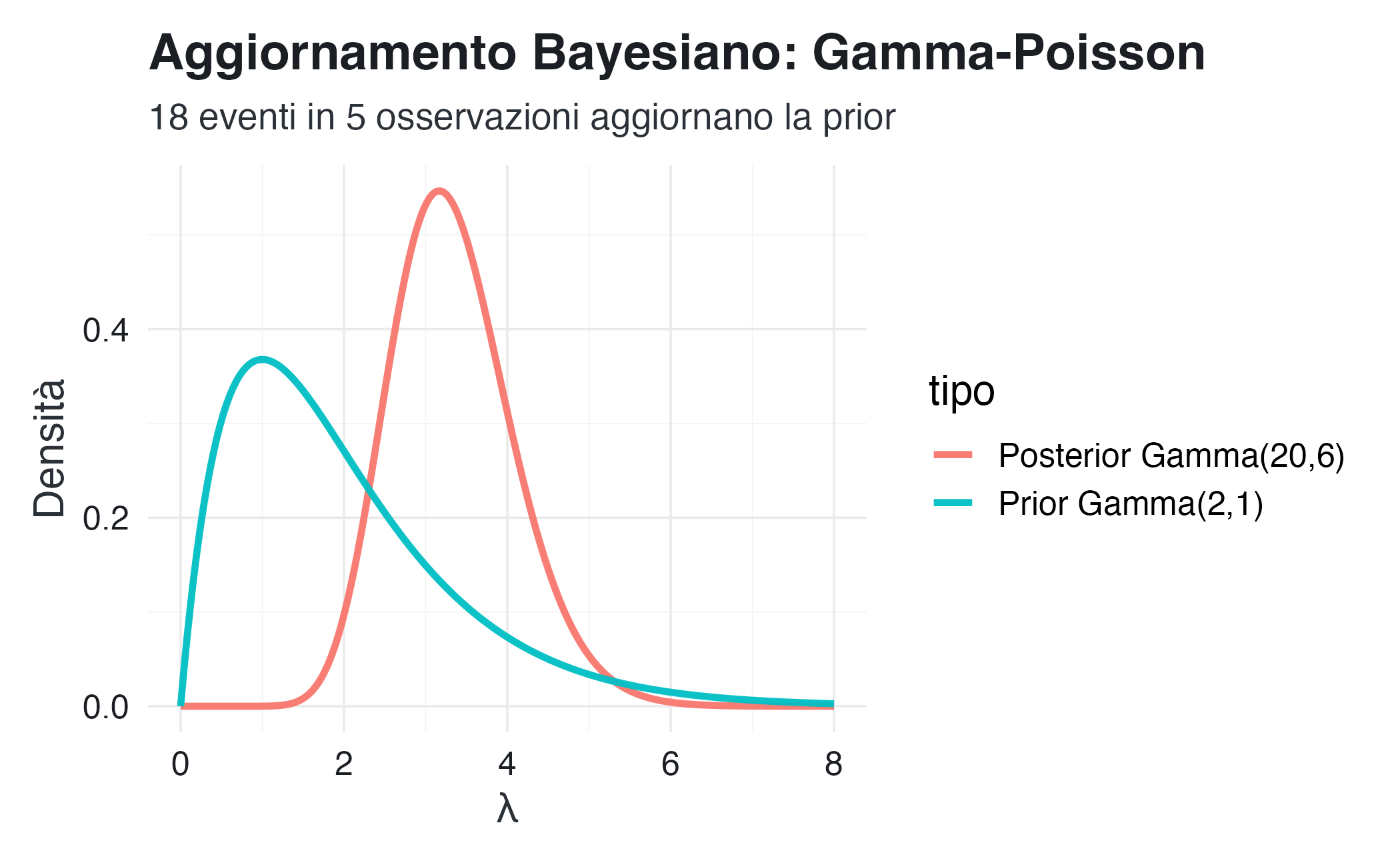
13.7.7 Visualizzazione della flessibilità
x <- seq(0, 10, length.out = 200)
params <- list(c(1, 0.5), c(2, 0.5), c(3, 1), c(5, 1), c(9, 2))
df <- do.call(rbind, lapply(params, function(p) {
data.frame(
x = x,
density = dgamma(x, shape = p[1], rate = p[2]),
label = paste0("α = ", p[1], ", β = ", p[2])
)
}))
ggplot(df, aes(x = x, y = density, color = label)) +
geom_line(linewidth = 1) +
scale_fill_qualitative() +
labs(
title = "Flessibilità della distribuzione Gamma",
x = "x", y = "f(x)"
) +
theme(legend.title = element_blank())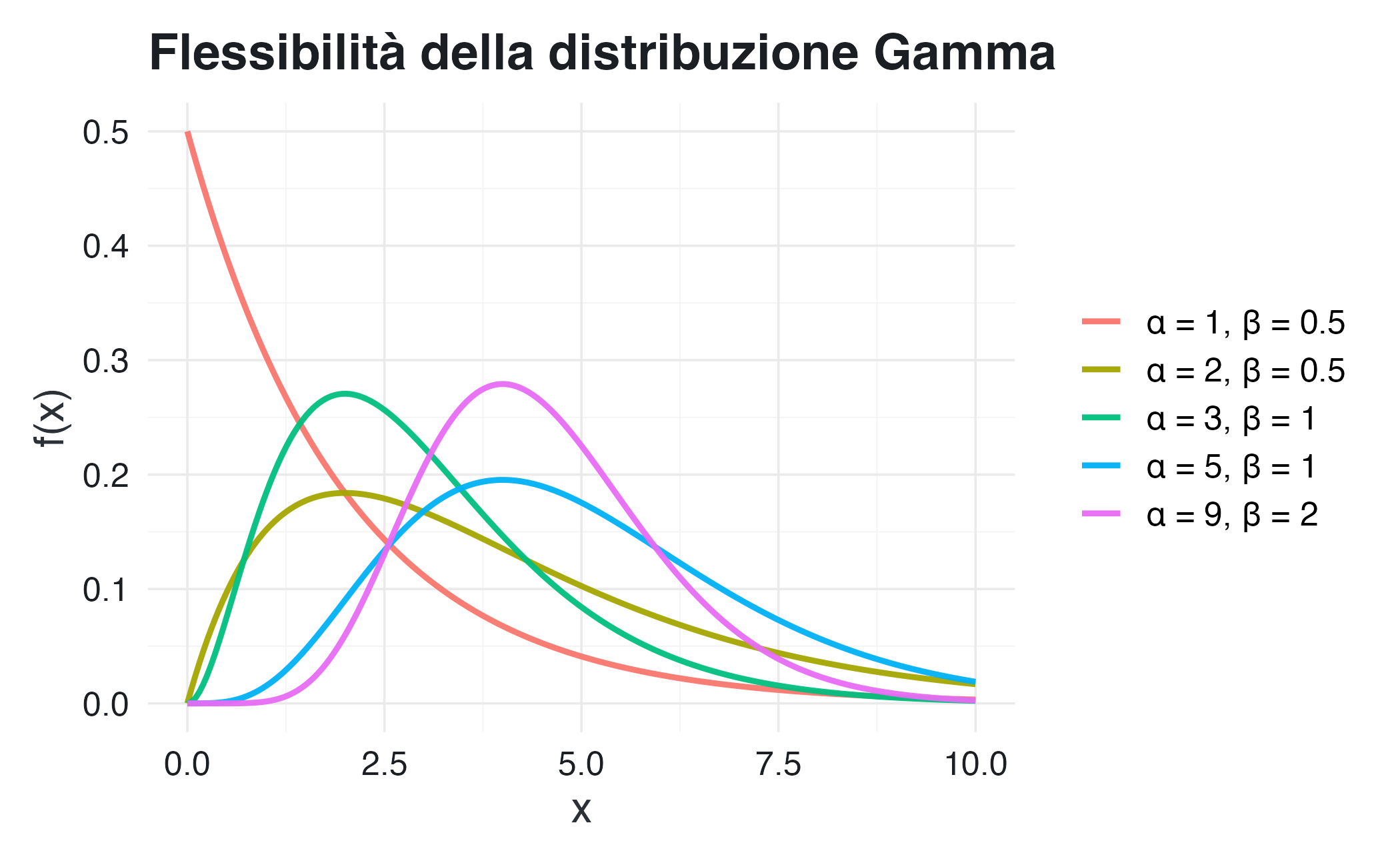
Riflessioni conclusive
Le distribuzioni continue esplorate in questo capitolo costituiscono il vocabolario fondamentale per esprimere credenze su quantità numeriche nell’inferenza bayesiana. Ogni famiglia presenta caratteristiche distintive che la rendono adatta a ruoli specifici all’interno del processo inferenziale.
Riepilogo dei ruoli nell’inferenza bayesiana
| Distribuzione | Dominio | Ruolo principale | Prior coniugata per |
|---|---|---|---|
| Uniforme | \([a, b]\) | Prior “non informativa” | — |
| Esponenziale | \((0, \infty)\) | Verosimiglianza per tempi di attesa | — |
| Normale | \(\mathbb{R}\) | Prior/verosimiglianza per parametri di posizione | \(\mu\) nella normale |
| Chi-quadrato | \((0, \infty)\) | Modellazione della variabilità | — |
| \(t\) di Student | \(\mathbb{R}\) | Prior robusta, distribuzione predittiva | — |
| Beta | \((0, 1)\) | Prior per proporzioni | \(p\) nella binomiale |
| Cauchy | \(\mathbb{R}\) | Prior robusta debolmente informativa | — |
| Gamma | \((0, \infty)\) | Prior per tassi e precisioni | \(\lambda\) nella Poisson |
Principi guida per la scelta
La scelta della distribuzione appropriata dipende da tre considerazioni fondamentali.
Il dominio del parametro costituisce il primo vincolo: la distribuzione beta è naturale per le proporzioni, la distribuzione gamma per i tassi positivi, la distribuzione normale o la distribuzione \(t\) per parametri non vincolati.
L’informazione a priori determina i valori dei parametri della distribuzione: prior vaghe producono distribuzioni disperse, mentre prior informative concentrano la massa probabilistica attorno a valori ritenuti plausibili.
Infine, la robustezza desiderata guida la scelta tra distribuzioni con comportamento delle code differente: la Cauchy e la \(t\) con pochi gradi di libertà offrono una maggiore protezione contro l’influenza di osservazioni estreme rispetto alla distribuzione normale.
La prospettiva unificante
Tutte le distribuzioni discusse condividono lo stesso ruolo epistemico: sono strumenti per rappresentare formalmente i nostri gradi di credenza. Queste distribuzioni non descrivono “come sono realmente le cose”, ma codificano “quanto riteniamo plausibile ciascun valore” alla luce delle informazioni disponibili. Questa interpretazione soggettivista costituisce il filo conduttore che unisce le diverse famiglie in un framework coerente per il ragionamento sotto incertezza.
Le proprietà matematiche, come la coniugazione, l’esistenza dei momenti o il comportamento delle code, non sono fini a sé stesse, ma hanno conseguenze epistemiche concrete: determinano come le credenze vengono aggiornate, quanta incertezza residua permane e quali previsioni possono essere formulate riguardo alle osservazioni future. Nei capitoli successivi, questi strumenti verranno combinati e messi in opera all’interno di modelli bayesiani sempre più articolati.
Come scelgo la distribuzione giusta?
Domande chiave per i dati:
- “Sono misure simmetriche senza vincoli?” → Normale (o t se outlier)
- “Sono solo valori positivi?” → Gamma, Log-normale, Esponenziale
- “Sono tempi di attesa con tasso costante?” → Esponenziale
- “Sono proporzioni tra 0 e 1?” → Beta (come dato, non come prior)
Domande chiave per i parametri:
- “È una probabilità p ∈ (0,1)?” → Beta come prior
- “È un tasso λ > 0?” → Gamma come prior
- “È una media μ senza vincoli?” → Normale come prior
- “Voglio essere robusto a outlier?” → t di Student o Cauchy
Coniugazioni da ricordare:
- Beta ↔︎ Binomiale/Bernoulli
- Gamma ↔︎ Poisson
- Normale ↔︎ Normale (su μ)
Punti chiave da ricordare
Concetti essenziali di questo capitolo:
-
Distribuzione Beta
- Supporto: \([0,1]\) (perfetta per proporzioni e probabilità)
- Parametri: \(\alpha, \beta > 0\) (shape parameters)
- \(\mathbb{E}[\theta] = \frac{\alpha}{\alpha+\beta}\), Moda \(= \frac{\alpha-1}{\alpha+\beta-2}\) (se \(\alpha,\beta > 1\))
- Coniugata con Binomiale: essenziale per inferenza bayesiana su proporzioni
- Interpretazione: \(\alpha-1\) = “successi pregressi”, \(\beta-1\) = “fallimenti pregressi”
-
Distribuzione Normale (Gaussiana)
- Supporto: \(\mathbb{R}\) (intera retta reale)
- Parametri: \(\mu \in \mathbb{R}\) (media), \(\sigma^2 > 0\) (varianza)
- \(\mathbb{E}[X] = \mu\), \(\text{Var}(X) = \sigma^2\)
- Simmetrica, unimodale, code esponenziali
- Emerge dal TLC: distribuzione naturale per somme di variabili
- Circa 68% entro \(\mu \pm \sigma\), 95% entro \(\mu \pm 1.96\sigma\)
-
Distribuzione Gamma
- Supporto: \(\mathbb{R}^+\) (numeri positivi)
- Parametri: shape \(\alpha > 0\), rate \(\beta > 0\) (o scale \(\theta = 1/\beta\))
- \(\mathbb{E}[X] = \alpha/\beta\), \(\text{Var}(X) = \alpha/\beta^2\)
- Flessibile per modellare tempi di attesa, variabilità
- Coniugata con Poisson e Normale (per precisione)
-
Distribuzione Esponenziale
- Caso speciale di Gamma con \(\alpha=1\)
- Modella tempo fino al primo evento in processo Poisson
- \(\mathbb{E}[X] = 1/\lambda\), \(\text{Var}(X) = 1/\lambda^2\)
- Proprietà di assenza di memoria: \(P(X > s+t \mid X > s) = P(X > t)\)
- Usata per tempi di reazione, durate, intervalli tra eventi
-
Distribuzione Uniforme
- Supporto: \([a,b]\)
- Massima entropia data solo l’informazione sui limiti
- \(\mathbb{E}[X] = (a+b)/2\), \(\text{Var}(X) = (b-a)^2/12\)
- Prior non informativo per parametri limitati
-
Relazioni tra distribuzioni
- Esponenziale è Gamma con \(\alpha=1\)
- Beta(1,1) è Uniforme(0,1)
- Normale emerge dal TLC
- Gamma modella somme di Esponenziali
-
Applicazioni psicologiche
- Beta: prior su proporzioni (prevalenza disturbi, accuratezza)
- Normale: punteggi psicometrici, QI, misure standardizzate
- Gamma: tempi di reazione, durate di episodi
- Esponenziale: tempi tra sintomi, latenze
Formule da ricordare:
Beta(\(\alpha, \beta\)): \[ f(\theta) = \frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta)}\theta^{\alpha-1}(1-\theta)^{\beta-1}, \quad \theta \in [0,1] \] \[ \mathbb{E}[\theta] = \frac{\alpha}{\alpha+\beta}, \quad \text{Var}(\theta) = \frac{\alpha\beta}{(\alpha+\beta)^2(\alpha+\beta+1)} \]
Normale(\(\mu, \sigma^2\)): \[ f(x) = \frac{1}{\sqrt{2\pi\sigma^2}}\exp\left(-\frac{(x-\mu)^2}{2\sigma^2}\right), \quad x \in \mathbb{R} \] \[ \mathbb{E}[X] = \mu, \quad \text{Var}(X) = \sigma^2 \]
Gamma(\(\alpha, \beta\)): \[ f(x) = \frac{\beta^\alpha}{\Gamma(\alpha)}x^{\alpha-1}e^{-\beta x}, \quad x > 0 \] \[ \mathbb{E}[X] = \frac{\alpha}{\beta}, \quad \text{Var}(X) = \frac{\alpha}{\beta^2} \]
Esponenziale(\(\lambda\)): \[ f(x) = \lambda e^{-\lambda x}, \quad x > 0 \] \[ \mathbb{E}[X] = \frac{1}{\lambda}, \quad \text{Var}(X) = \frac{1}{\lambda^2} \]
Proprietà critiche:
- Beta è coniugata con Binomiale (aggiornamento: \(\text{Beta}(\alpha, \beta) \to \text{Beta}(\alpha+k, \beta+n-k)\))
- Normale è coniugata con sé stessa (per la media)
- Gamma è coniugata con Poisson e Normale (per precisione)
- Circa 95% della massa normale sta entro \(\mu \pm 1.96\sigma\)
Per il prossimo capitolo:
Nel Capitolo 14 studieremo formalmente la funzione di verosimiglianza, che quantifica quanto i dati osservati sono compatibili con ciascun valore del parametro. Vedremo come la verosimiglianza costituisca il ponte tra il modello probabilistico (le distribuzioni appena studiate) e l’inferenza bayesiana, permettendo di aggiornare le credenze sui parametri alla luce dell’evidenza empirica.
sessionInfo()
#> R version 4.5.2 (2025-10-31)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Tahoe 26.2
#>
#> Matrix products: default
#> BLAS: /System/Library/Frameworks/Accelerate.framework/Versions/A/Frameworks/vecLib.framework/Versions/A/libBLAS.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
#>
#> locale:
#> [1] C.UTF-8/UTF-8/C.UTF-8/C/C.UTF-8/C.UTF-8
#>
#> time zone: Europe/Rome
#> tzcode source: internal
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] ragg_1.5.0 tinytable_0.15.2 withr_3.0.2
#> [4] systemfonts_1.3.1 patchwork_1.3.2 ggdist_3.3.3
#> [7] tidybayes_3.0.7 bayesplot_1.15.0 ggplot2_4.0.1
#> [10] reliabilitydiag_0.2.1 priorsense_1.2.0 posterior_1.6.1
#> [13] loo_2.9.0 rstan_2.32.7 StanHeaders_2.32.10
#> [16] brms_2.23.0 Rcpp_1.1.1 sessioninfo_1.2.3
#> [19] conflicted_1.2.0 janitor_2.2.1 matrixStats_1.5.0
#> [22] modelr_0.1.11 tibble_3.3.1 dplyr_1.1.4
#> [25] tidyr_1.3.2 rio_1.2.4 here_1.0.2
#>
#> loaded via a namespace (and not attached):
#> [1] svUnit_1.0.8 tidyselect_1.2.1 farver_2.1.2
#> [4] S7_0.2.1 fastmap_1.2.0 TH.data_1.1-5
#> [7] tensorA_0.36.2.1 digest_0.6.39 timechange_0.3.0
#> [10] estimability_1.5.1 lifecycle_1.0.5 survival_3.8-3
#> [13] magrittr_2.0.4 compiler_4.5.2 rlang_1.1.7
#> [16] tools_4.5.2 knitr_1.51 labeling_0.4.3
#> [19] bridgesampling_1.2-1 htmlwidgets_1.6.4 curl_7.0.0
#> [22] pkgbuild_1.4.8 RColorBrewer_1.1-3 abind_1.4-8
#> [25] multcomp_1.4-29 purrr_1.2.1 grid_4.5.2
#> [28] stats4_4.5.2 colorspace_2.1-2 xtable_1.8-4
#> [31] inline_0.3.21 emmeans_2.0.1 scales_1.4.0
#> [34] MASS_7.3-65 cli_3.6.5 mvtnorm_1.3-3
#> [37] rmarkdown_2.30 generics_0.1.4 otel_0.2.0
#> [40] RcppParallel_5.1.11-1 cachem_1.1.0 stringr_1.6.0
#> [43] splines_4.5.2 parallel_4.5.2 vctrs_0.6.5
#> [46] V8_8.0.1 Matrix_1.7-4 sandwich_3.1-1
#> [49] jsonlite_2.0.0 arrayhelpers_1.1-0 glue_1.8.0
#> [52] codetools_0.2-20 distributional_0.6.0 lubridate_1.9.4
#> [55] stringi_1.8.7 gtable_0.3.6 QuickJSR_1.8.1
#> [58] pillar_1.11.1 htmltools_0.5.9 Brobdingnag_1.2-9
#> [61] R6_2.6.1 textshaping_1.0.4 rprojroot_2.1.1
#> [64] evaluate_1.0.5 lattice_0.22-7 backports_1.5.0
#> [67] memoise_2.0.1 broom_1.0.11 snakecase_0.11.1
#> [70] rstantools_2.6.0 gridExtra_2.3 coda_0.19-4.1
#> [73] nlme_3.1-168 checkmate_2.3.3 xfun_0.55
#> [76] zoo_1.8-15 pkgconfig_2.0.3