8 Proprietà delle variabili casuali
Introduzione
Immaginiamo uno scenario comune nella pratica clinica. Una psicologa deve decidere se raccomandare a un paziente affetto da depressione moderata un nuovo protocollo di intervento cognitivo-comportamentale. I dati disponibili indicano che, in media, i pazienti trattati mostrano un miglioramento di 8 punti nel BDI-II dopo 12 settimane. Ma quanto è informativo questo numero da solo?
Un miglioramento medio di 8 punti potrebbe derivare da situazioni molto diverse: potrebbe significare che quasi tutti i pazienti migliorano di circa 8 punti, oppure che la metà dei pazienti migliora di 16 punti, mentre l’altra metà non mostra alcun cambiamento. Nel primo caso, il trattamento è prevedibilmente efficace, mentre nel secondo l’esito per il singolo paziente è molto più incerto. Per poter prendere una decisione informata, la clinica ha bisogno di sapere non solo dove si colloca il centro della distribuzione degli esiti, ma anche quanto i singoli esiti si disperdono attorno a questo centro.
Questo capitolo introduce i due indicatori fondamentali che rispondono a queste domande: il valore atteso, che individua il “centro di gravità” della distribuzione, e la varianza, che ne quantifica la dispersione. Questi concetti non sono semplici convenzioni descrittive, ma possiedono un significato teorico profondo. In una prospettiva bayesiana, il valore atteso rappresenta la nostra aspettativa razionale data l’informazione disponibile, mentre la varianza quantifica l’incertezza residua, ovvero quanto ancora non sappiamo sul valore che osserveremo.
Per questo motivo, il valore atteso e la varianza occupano una posizione centrale non solo nella statistica descrittiva, ma anche nella teoria delle decisioni e nell’inferenza bayesiana. Comprenderne il significato e le proprietà è essenziale per interpretare correttamente le distribuzioni di probabilità e per poterle utilizzare come strumenti operativi nel ragionamento scientifico e clinico.
Panoramica del capitolo
- Il valore atteso come media ponderata e centro di massa probabilistico.
- Proprietà algebriche del valore atteso: linearità e additività.
- La varianza come misura della dispersione e dell’incertezza.
- Proprietà della varianza e formula computazionale alternativa.
- Deviazione standard e standardizzazione.
- Il teorema di Chebyshev e i momenti di una distribuzione.
Per seguire questo capitolo è necessario aver letto:
- Capitolo 6 — fondamentale.
- Capitolo 7 — fondamentale.
Questo capitolo introduce gli strumenti di sintesi numerica (valore atteso e varianza) per caratterizzare le distribuzioni di probabilità studiate nei capitoli precedenti.
Conoscenze matematiche richieste:
- Appendice C - per il calcolo del valore atteso discreto.
- Appendice F - per il calcolo del valore atteso continuo.
Competenze pratiche:
- Familiarità con R e operazioni vettoriali per verificare le proprietà attraverso simulazioni.
8.1 Il valore atteso come centro di gravità
Il valore atteso di una variabile casuale rappresenta il suo baricentro probabilistico, ovvero il punto attorno al quale la probabilità si bilancia. In una prospettiva frequentista, esso corrisponde al valore medio che ci si aspetta di osservare in una lunga serie di ripetizioni dell’esperimento. In una prospettiva bayesiana, invece, il valore atteso formalizza la nostra aspettativa razionale, ovvero la migliore previsione puntuale che possiamo fare alla luce dello stato informativo corrente.
Definizione 8.1 (Valore atteso (speranza matematica)) Il valore atteso (o media o speranza matematica) di una variabile casuale \(X\) è definito come segue.
Per variabili discrete con funzione di massa di probabilità \(p_X\):
\[ \mathbb{E}[X] = \sum_{x \in \mathcal{X}} x \cdot p_X(x). \]
Per variabili continue con funzione di densità di probabilità \(f_X\):
\[ \mathbb{E}[X] = \int_{-\infty}^{+\infty} x \cdot f_X(x)\,dx. \]
In entrambi i casi, il valore atteso è una media ponderata dei valori possibili della variabile, in cui i pesi sono dati dalle probabilità (nel caso discreto) o dalla densità di probabilità (nel caso continuo).
È importante sottolineare che il valore atteso non deve necessariamente coincidere con un valore osservabile della variabile. Questo punto è particolarmente rilevante in psicologia, dove molte scale forniscono solo valori interi.
Il valore atteso non è un esito
Consideriamo un singolo item di un test cognitivo. Definiamo la variabile casuale \(X\) tale che:
- \(X = 1\) se la risposta è corretta,
- \(X = 0\) se la risposta è errata.
Se la probabilità di risposta corretta è \(p = 0.7\) (ad esempio, per un item di difficoltà media), il valore atteso è: \[ \mathbb{E}[X] = 0 \cdot 0.3 + 1 \cdot 0.7 = 0.7. \]
Il valore 0.7 non è un esito possibile per questo item — la risposta sarà sempre 0 o 1. Tuttavia, 0.7 rappresenta correttamente il centro di gravità della distribuzione: se somministrassimo questo item a molti soggetti con la stessa probabilità di successo, la proporzione di risposte corrette tenderebbe a 0.7.
In termini bayesiani, 0.7 è la nostra aspettativa razionale: se dovessimo scommettere sul risultato prima di osservarlo, 0.7 rappresenterebbe la previsione ottimale in termini di minimizzazione dell’errore quadratico medio.
8.2 Il valore atteso come limite di frequenze
Un’interpretazione operativa del valore atteso è fornita dalla legge dei grandi numeri. Se ripetiamo un esperimento molte volte e calcoliamo la media aritmetica dei risultati, questa media tende al valore atteso teorico.
Formalmente, se \(X_1, X_2, \ldots, X_n\) sono realizzazioni indipendenti della stessa variabile casuale \(X\), allora:
\[ \bar{X}_n = \frac{X_1 + X_2 + \cdots + X_n}{n} \;\xrightarrow{n \to \infty}\; \mathbb{E}[X]. \]
Questa convergenza non definisce il valore atteso — che resta una media ponderata secondo la definizione formale — ma ne fornisce una giustificazione empirica. Il valore atteso è quindi il valore verso cui tende la media osservata quando il processo viene campionato ripetutamente.
Verifica della convergenza
Consideriamo un questionario composto da due sottoscale, ciascuna con punteggi da 1 a 6 (come in una scala Likert). Il punteggio totale \(X\) è la somma dei punteggi sulle due sottoscale e può variare da 2 a 12.
Supponiamo che ciascuna sottoscala abbia la seguente distribuzione (leggermente asimmetrica verso valori alti, tipica di scale di soddisfazione):
| Punteggio | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| Probabilità | 0.05 | 0.10 | 0.15 | 0.25 | 0.30 | 0.15 |
Il valore atteso di ciascuna sottoscala è: \[ \mathbb{E}[S] = 1(0.05) + 2(0.10) + 3(0.15) + 4(0.25) + 5(0.30) + 6(0.15) = 4.10. \]
Per la somma delle due sottoscale (assumendo indipendenza): \[ \mathbb{E}[X] = \mathbb{E}[S_1] + \mathbb{E}[S_2] = 4.10 + 4.10 = 8.20. \]
Una simulazione mostra che la media empirica converge a questo valore:
set.seed(123)
# Distribuzione di ciascuna subscala
valori_subscala <- 1:6
prob_subscala <- c(0.05, 0.10, 0.15, 0.25, 0.30, 0.15)
E_subscala <- sum(valori_subscala * prob_subscala)
# Simulazione
n_sim <- 100000
subscala1 <- sample(valori_subscala, n_sim, replace = TRUE, prob = prob_subscala)
subscala2 <- sample(valori_subscala, n_sim, replace = TRUE, prob = prob_subscala)
punteggio_totale <- subscala1 + subscala2
E_teorico <- 2 * E_subscala
E_empirico <- mean(punteggio_totale)
cat("Valore atteso teorico:", E_teorico, "\n")
#> Valore atteso teorico: 8.2
cat("Media empirica:", round(E_empirico, 3), "\n")
#> Media empirica: 8.2La convergenza della media empirica al valore teorico illustra concretamente la legge dei grandi numeri.
8.2.1 Ponte applicativo: il punteggio atteso di una scala
Il risultato appena visto ha un’implicazione pratica immediata: il punteggio atteso di una scala psicometrica equivale alla somma dei valori attesi dei suoi singoli item. Ad esempio, se una scala è composta da 20 item, ciascuno con un valore atteso di 3.5 (su una scala da 1 a 5), il punteggio totale atteso sarà semplicemente \(20 \times 3.5 = 70\).
Questa proprietà, che formalizzeremo in seguito come linearità del valore atteso, semplifica notevolmente i calcoli e permette di ragionare sulle proprietà aggregate di scale composite senza dover ricostruire tutta la complessa distribuzione congiunta degli item.
8.3 La linearità del valore atteso
Il valore atteso possiede una proprietà algebrica di importanza cruciale: la linearità. Per qualunque coppia di variabili casuali \(X\) e \(Y\) e per qualunque costante \(a\) vale: \[ \mathbb{E}[X + Y] = \mathbb{E}[X] + \mathbb{E}[Y], \qquad \mathbb{E}[aX] = a\,\mathbb{E}[X]. \]
Questa proprietà non richiede alcuna assunzione di indipendenza: vale sempre, anche quando le variabili sono correlate.
Teorema 8.1 (Linearità) Per qualsiasi variabile casuale \(X\) e per qualunque costanti \(a,b \in \mathbb{R}\) vale: \[ \mathbb{E}[aX + b] = a\,\mathbb{E}[X] + b. \]
La linearità afferma che traslazioni e riscalamenti dei valori di una variabile si riflettono in modo diretto sul valore atteso. Se moltiplichiamo tutti i valori per una costante \(a\), la media viene moltiplicata per \(a\); se aggiungiamo una costante \(b\) a tutti i valori, la media aumenta di \(b\).
Teorema 8.2 (Additività) Per qualsiasi coppia di variabili casuali \(X\) e \(Y\) vale:
\[ \mathbb{E}[X + Y] = \mathbb{E}[X] + \mathbb{E}[Y]. \] Questa proprietà è valida sempre, indipendentemente dal fatto che \(X\) e \(Y\) siano indipendenti o dipendenti.
Per una somma di \(n\) variabili casuali \(X_1, \ldots, X_n\) si ottiene:
\[ \mathbb{E}\left[\sum_{i=1}^{n} X_i\right] = \sum_{i=1}^{n} \mathbb{E}[X_i]. \]
Applicazione della linearità in un contesto clinico
Si consideri una valutazione psicometrica che combina due scale:
- punteggio di ansia \(A\) (scala 0–21, es. GAD-7);
- punteggio di depressione \(D\) (scala 0–27, es. PHQ-9).
Nella popolazione clinica di riferimento si supponga che:
- \(\mathbb{E}[A] = 12\) (ansia moderata);
- \(\mathbb{E}[D] = 14\) (depressione moderata).
Un possibile indice composito di distress psicologico può essere definito come: \[ \text{Distress} = A + D. \]
Per la proprietà di linearità del valore atteso, otteniamo immediatamente: \[ \mathbb{E}[\text{Distress}] = \mathbb{E}[A] + \mathbb{E}[D] = 12 + 14 = 26. \]
Nota importante: il calcolo rimane valido anche se ansia e depressione sono correlate, come accade tipicamente per comorbidità clinica. La linearità non richiede l’indipendenza tra le variabili.
Se volessimo costruire un indice ponderato che attribuisce maggiore peso alla depressione: \[ \text{Distress}_w = 0.4 \cdot A + 0.6 \cdot D, \] il suo valore atteso sarebbe: \[ \mathbb{E}[\text{Distress}_w] = 0.4 \cdot 12 + 0.6 \cdot 14 = 4.8 + 8.4 = 13.2. \]
# Verifica con simulazione (ipotesi: correlazione moderata tra A e D)
set.seed(42)
library(MASS)
# Generiamo dati correlati (correlazione r = 0.6, realistico in clinica)
n <- 10000
Sigma <- matrix(c(25, 18, 18, 36), 2, 2) # Var(A)=25, Var(D)=36, Cov=18
dati <- mvrnorm(n, mu = c(12, 14), Sigma = Sigma)
A <- pmax(0, pmin(21, round(dati[,1]))) # adattiamo al range della scala
D <- pmax(0, pmin(27, round(dati[,2])))
distress <- A + D
distress_w <- 0.4 * A + 0.6 * D
cat("Valore atteso teorico di Distress: 26")
#> Valore atteso teorico di Distress: 26
cat(" | Valore atteso empirico:", round(mean(distress), 2), "\n")
#> | Valore atteso empirico: 25.8
cat("Valore atteso teorico di Distress_w: 13.2")
#> Valore atteso teorico di Distress_w: 13.2
cat(" | Valore atteso empirico:", round(mean(distress_w), 2), "\n")
#> | Valore atteso empirico: 13.1
cat("Correlazione osservata tra A e D:", round(cor(A, D), 2), "\n")
#> Correlazione osservata tra A e D: 0.59Come si vede, nonostante la correlazione tra le due scale, il valore atteso del punteggio composito coincide con il calcolo analitico, confermando la robustezza della proprietà di linearità.
8.3.1 Prodotto di variabili casuali
Teorema 8.3 (Prodotto di variabili indipendenti) Se \(X\) e \(Y\) sono variabili casuali indipendenti, allora vale:
\[ \mathbb{E}[XY] = \mathbb{E}[X]\cdot \mathbb{E}[Y]. \]
A differenza dell’additività, questa proprietà richiede l’indipendenza. In generale, per variabili dipendenti il valore atteso del prodotto non è uguale al prodotto dei valori attesi. Questa distinzione sarà cruciale quando introdurremo concetti come covarianza e correlazione.
8.3.2 Valore atteso della media campionaria
Una conseguenza fondamentale della linearità riguarda la media aritmetica di più osservazioni. Se \(X_1, \ldots, X_n\) sono variabili casuali indipendenti e identicamente distribuite (i.i.d.) con valore atteso \(\mathbb{E}[X_i] = \mu\), la media campionaria:
\[ \bar{X} = \frac{1}{n}\sum_{i=1}^{n} X_i \]
ha valore atteso:
\[ \mathbb{E}[\bar{X}] = \frac{1}{n}\sum_{i=1}^{n} \mathbb{E}[X_i] = \frac{1}{n} \cdot n \cdot \mu = \mu. \]
Questo risultato mostra che la media campionaria è uno stimatore non distorto del valore atteso della popolazione: in media, la media campionaria coincide con il parametro che intende stimare.
8.3.3 Ponte applicativo: perché la media campionaria è uno stimatore coerente
Questo risultato ha implicazioni dirette per la pratica della ricerca in psicologia. Quando calcoliamo la media dei punteggi BDI-II in un campione di pazienti, stiamo utilizzando la media campionaria come stimatore del valore atteso (media) della popolazione. La proprietà \(\mathbb{E}[\bar{X}] = \mu\), nota come non distorsione, ci garantisce che, in media su infiniti campioni possibili, questa procedura di stima “centra il bersaglio”.
Tuttavia, ciò non significa che la stima ottenuta da un singolo campione sia perfettamente accurata: la media campionaria è soggetta a una variabilità intrinseca, poiché dipende dai soggetti selezionati. Per quantificare quanto possa oscillare questa stima da campione a campione, è necessario introdurre il concetto di varianza (e di errore standard, che da essa deriva).
8.4 La varianza come misura di dispersione e incertezza
Il valore atteso identifica il centro di una distribuzione, ma da solo non informa su quanto i valori reali tendano a discostarsene. Riprendiamo l’esempio clinico: sapere che il miglioramento medio nel BDI-II è di 8 punti non ci dice se questo cambiamento sia relativamente uniforme tra i pazienti o estremamente variabile.
Dal punto di vista epistemico, la varianza quantifica la nostra incertezza residua su una quantità, anche dopo averne stimato il valore centrale. Un’elevata varianza indica che, pur conoscendo la media, rimaniamo ampiamente incerti sul risultato specifico che osserveremo; una varianza bassa suggerisce invece che la media costituisce una guida affidabile per prevedere le singole realizzazioni.
8.4.1 Perché non usare la media degli scarti?
Per misurare la dispersione di una variabile attorno alla sua media, l’idea naturale è considerare gli scarti dalla media, ovvero \(X - \mathbb{E}[X]\). Tuttavia, per la stessa definizione di valore atteso, si ha: \[ \mathbb{E}[X - \mathbb{E}[X]] = \mathbb{E}[X] - \mathbb{E}[X] = 0. \] La media degli scarti è sempre zero: gli scarti positivi e quelli negativi si bilanciano esattamente, rendendo questa quantità inefficace come indice di variabilità.
Per ottenere una misura che sia sempre non negativa e che rifletta l’entità delle deviazioni, si utilizza il quadrato degli scarti. Elevando al quadrato si eliminano i segni negativi e, allo stesso tempo, si dà un peso maggiore agli scostamenti più ampi rispetto alla media.
Definizione 8.2 (Varianza) La varianza di una variabile casuale \(X\) è definita come il valore atteso del quadrato degli scarti dalla media: \[ \operatorname{Var}(X) = \mathbb{E}\!\left[(X - \mathbb{E}[X])^2\right]. \]
Denotando con \(\mu = \mathbb{E}[X]\), la definizione si esprime operativamente come:
Caso discreto \[ \operatorname{Var}(X) = \sum_i (x_i - \mu)^2 \; p_X(x_i), \] dove \(p_X\) è la funzione di massa di probabilità.
Caso continuo \[ \operatorname{Var}(X) = \int_{-\infty}^{+\infty} (x - \mu)^2 \; f_X(x) \, dx, \] dove \(f_X\) è la funzione di densità.
La varianza è una quantità non negativa: \(\operatorname{Var}(X) \geq 0\). Vale \(\operatorname{Var}(X)=0\) se e solo se \(X\) assume un unico valore con probabilità 1 — cioè quando non c’è alcuna variabilità. ### Interpretazione epistemica
La varianza può essere letta come la perdita attesa quando utilizziamo il valore atteso \(\mu\) come previsione puntuale e misuriamo l’errore con una funzione di perdita quadratica. Se formuliamo sempre \(\mu\) come previsione, l’errore quadratico medio associato è: \[ \mathbb{E}\big[(X - \mu)^2\big] = \operatorname{Var}(X). \]
In quest’ottica, la varianza quantifica quanto, in media, la nostra previsione si discosta dal valore effettivo che osserveremo. Rappresenta quindi una misura dell’incertezza residua intrinseca alla variabile, anche una volta adottata la migliore stima puntuale possibile.
Stessa media, varianza diversa
Consideriamo due trattamenti per la depressione. Entrambi producono un miglioramento medio di 8 punti al BDI-II, ma con distribuzioni diverse:
Trattamento A (esiti prevedibili): | Miglioramento | 6 | 7 | 8 | 9 | 10 | |:————-:|:-:|:-:|:-:|:-:|:–:| | Probabilità | 0.10 | 0.25 | 0.30 | 0.25 | 0.10 |
Trattamento B (esiti variabili): | Miglioramento | 0 | 4 | 8 | 12 | 16 | |:————-:|:-:|:-:|:-:|:–:|:–:| | Probabilità | 0.10 | 0.25 | 0.30 | 0.25 | 0.10 |
# Trattamento A
valori_A <- c(6, 7, 8, 9, 10)
prob_A <- c(0.10, 0.25, 0.30, 0.25, 0.10)
E_A <- sum(valori_A * prob_A)
Var_A <- sum((valori_A - E_A)^2 * prob_A)
# Trattamento B
valori_B <- c(0, 4, 8, 12, 16)
prob_B <- c(0.10, 0.25, 0.30, 0.25, 0.10)
E_B <- sum(valori_B * prob_B)
Var_B <- sum((valori_B - E_B)^2 * prob_B)
cat("Trattamento A: E[X] =", E_A, ", Var(X) =", Var_A, "\n")
#> Trattamento A: E[X] = 8 , Var(X) = 1.3
cat("Trattamento B: E[X] =", E_B, ", Var(X) =", Var_B, "\n")
#> Trattamento B: E[X] = 8 , Var(X) = 20.8Entrambi i trattamenti hanno lo stesso valore atteso (8 punti), ma la varianza del Trattamento B è 16 volte maggiore! Con il Trattamento A, possiamo dire al paziente con ragionevole confidenza che migliorerà di circa 8 punti. Con il Trattamento B, invece, alcuni pazienti non miglioreranno affatto mentre altri miglioreranno moltissimo.
La scelta tra i due trattamenti dipende dalle preferenze del paziente e del clinico riguardo al rischio: un paziente avverso al rischio potrebbe preferire il Trattamento A, mentre uno disposto a “scommettere” su un miglioramento maggiore potrebbe preferire il Trattamento B.
8.5 Formula alternativa della varianza
Spesso, dal punto di vista computazionale, è più conveniente utilizzare una forma equivalente della varianza.
Teorema 8.4 (Formula alternativa) \[ \text{Var}(X) = \mathbb{E}[X^2] - \bigl(\mathbb{E}[X]\bigr)^2. \]
8.5.1 Dimostrazione
Dimostrazione. Sia \(\mu = \mathbb{E}[X]\). Partendo dalla definizione: \[\begin{align*} \text{Var}(X) &= \mathbb{E}[(X - \mu)^2] \\ &= \mathbb{E}[X^2 - 2\mu X + \mu^2] \\ &= \mathbb{E}[X^2] - 2\mu\,\mathbb{E}[X] + \mu^2 \\ &= \mathbb{E}[X^2] - 2\mu^2 + \mu^2 \\ &= \mathbb{E}[X^2] - \mu^2. \end{align*}\]
Questa formulazione mostra che la varianza dipende esclusivamente da due momenti della distribuzione: il valore atteso \(\mathbb{E}[X]\) e il valore atteso del quadrato \(\mathbb{E}[X^2]\).
Calcolo con entrambe le formule
Riprendiamo l’esempio delle due scale con distribuzione:
| Punteggio | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| Probabilità | 0.05 | 0.10 | 0.15 | 0.25 | 0.30 | 0.15 |
Varianza di una singola scala:
valori <- 1:6
prob <- c(0.05, 0.10, 0.15, 0.25, 0.30, 0.15)
E_S <- sum(valori * prob)
E_S2 <- sum(valori^2 * prob)
# Formula diretta
Var_diretta <- sum((valori - E_S)^2 * prob)
# Formula alternativa
Var_alternativa <- E_S2 - E_S^2
cat("E[S] =", E_S, "\n")
#> E[S] = 4.1
cat("E[S²] =", E_S2, "\n")
#> E[S²] = 18.7
cat("Varianza (formula diretta):", round(Var_diretta, 4), "\n")
#> Varianza (formula diretta): 1.89
cat("Varianza (formula alternativa):", round(Var_alternativa, 4), "\n")
#> Varianza (formula alternativa): 1.89Le due formule producono lo stesso risultato, come atteso.
Varianza della somma di due scale indipendenti:
# Per variabili indipendenti: Var(S1 + S2) = Var(S1) + Var(S2)
Var_somma_teorica <- 2 * Var_diretta
# Verifica con simulazione
set.seed(123)
n_sim <- 100000
S1 <- sample(valori, n_sim, replace = TRUE, prob = prob)
S2 <- sample(valori, n_sim, replace = TRUE, prob = prob)
somma <- S1 + S2
cat("\nVarianza della somma (teorica):", round(Var_somma_teorica, 4), "\n")
#>
#> Varianza della somma (teorica): 3.78
cat("Varianza della somma (empirica):", round(var(somma) * (n_sim-1)/n_sim, 4), "\n")
#> Varianza della somma (empirica): 3.768.6 Proprietà algebriche della varianza
La varianza presenta proprietà algebriche simili a quelle del valore atteso, ma con differenze cruciali che hanno importanti implicazioni per la pratica statistica.
8.6.1 Trasformazioni lineari
Per qualsiasi variabile casuale \(X\) e per costanti \(a\) e \(b\):
\[ \text{Var}(aX + b) = a^2 \text{Var}(X). \]
Dimostrazione. Sia \(\mu = \mathbb{E}[X]\). Allora \(\mathbb{E}[aX + b] = a\mu + b\) e quindi: \[\begin{align*} \text{Var}(aX + b) &= \mathbb{E}[(aX + b - a\mu - b)^2] \\ &= \mathbb{E}[a^2(X - \mu)^2] \\ &= a^2 \mathbb{E}[(X - \mu)^2] \\ &= a^2 \text{Var}(X). \end{align*}\]
Osservazione cruciale: una traslazione (l’addizione di una costante \(b\)) non modifica la varianza. Questo ha senso: spostare tutti i valori di una costante non cambia quanto sono dispersi tra loro. La moltiplicazione per una costante \(a\), invece, amplifica o riduce la varianza proporzionalmente a \(a^2\).
8.6.2 Ponte applicativo: conversione tra scale
Questa proprietà risulta particolarmente utile nella trasformazione di scale psicometriche. Ad esempio, convertendo un punteggio grezzo \(X\) in un punteggio standardizzato del tipo \(T = 10X + 50\) (come avviene per i T-score), la varianza si trasforma come: \[ \operatorname{Var}(T) = 10^2 \cdot \operatorname{Var}(X) = 100 \cdot \operatorname{Var}(X). \]
Si noti che il termine additivo (50) non ha alcun effetto sulla dispersione: solo il coefficiente moltiplicativo (10) amplifica la varianza secondo il suo quadrato.
8.6.3 Additività della varianza per variabili indipendenti
Se \(X\) e \(Y\) sono variabili casuali indipendenti, allora:
\[ \text{Var}(X + Y) = \text{Var}(X) + \text{Var}(Y). \]
Questa è una differenza fondamentale rispetto al valore atteso: l’additività della varianza richiede l’indipendenza. In presenza di correlazione, la varianza della somma può essere maggiore o minore della somma delle varianze, a seconda del segno della covarianza.
Varianza con e senza indipendenza
Riprendiamo l’esempio di ansia (\(A\)) e depressione (\(D\)) con \(\text{Var}(A) = 25\) e \(\text{Var}(D) = 36\).
Se fossero indipendenti: \[ \text{Var}(A + D) = 25 + 36 = 61. \]
Con correlazione positiva (\(\rho = 0.6\), tipica per comorbidità): \[ \text{Var}(A + D) = \text{Var}(A) + \text{Var}(D) + 2\text{Cov}(A, D). \]
La covarianza è \(\text{Cov}(A, D) = \rho \cdot \sigma_A \cdot \sigma_D = 0.6 \cdot 5 \cdot 6 = 18\), quindi: \[ \text{Var}(A + D) = 25 + 36 + 2(18) = 97. \]
# Verifica con i dati simulati precedentemente
cat("Var(A) teorica: 25, empirica:", round(var(A), 1), "\n")
#> Var(A) teorica: 25, empirica: 23.5
cat("Var(D) teorica: 36, empirica:", round(var(D), 1), "\n")
#> Var(D) teorica: 36, empirica: 34.9
cat("Var(A+D) se indipendenti: 61\n")
#> Var(A+D) se indipendenti: 61
cat("Var(A+D) con correlazione teorica: 97\n")
#> Var(A+D) con correlazione teorica: 97
cat("Var(A+D) empirica:", round(var(A + D), 1), "\n")
#> Var(A+D) empirica: 92.3La correlazione positiva aumenta la varianza della somma: quando una variabile è alta, l’altra tende a essere alta, amplificando la dispersione complessiva.
8.6.4 Varianza della media campionaria
Un risultato di diretta rilevanza per l’inferenza statistica riguarda la varianza della media campionaria. Siano \(X_1, X_2, \ldots, X_n\) variabili casuali indipendenti e identicamente distribuite (i.i.d.) con
\[ \mathbb{E}[X_i] = \mu, \qquad \text{Var}(X_i) = \sigma^2. \]
La media campionaria è definita come
\[ \bar{X} = \frac{1}{n}\sum_{i=1}^{n} X_i. \]
Applicando le proprietà della varianza:
\[ \text{Var}(\bar{X}) = \text{Var}\left(\frac{1}{n}\sum_{i=1}^{n} X_i\right) = \frac{1}{n^2}\,\text{Var}\left(\sum_{i=1}^{n} X_i\right). \]
Poiché le variabili sono indipendenti, la varianza della somma è la somma delle varianze:
\[ \text{Var}\left(\sum_{i=1}^{n} X_i\right) = \sum_{i=1}^{n} \text{Var}(X_i) = n \sigma^2. \]
Sostituendo:
\[ \text{Var}(\bar{X}) = \frac{\sigma^2}{n}. \]
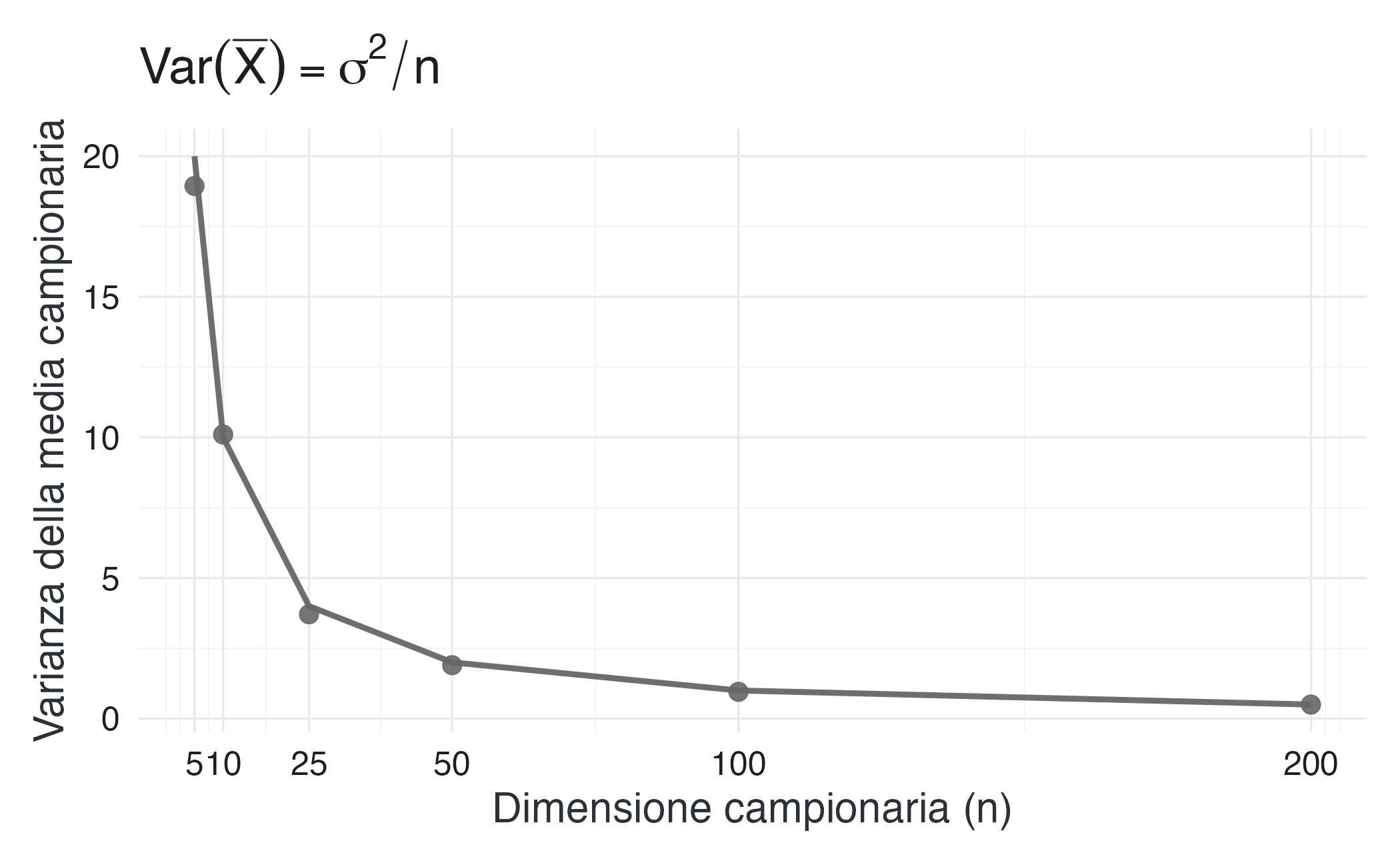
8.6.5 Ponte applicativo: perché campioni più grandi danno stime più precise
Questo risultato costituisce il fondamento matematico del principio per cui “più dati portano a stime più precise”. La varianza della media campionaria decresce linearmente con l’inverso della numerosità campionaria:
- con \(n = 25\) pazienti, \(\operatorname{Var}(\bar{X}) = \sigma^2/25\);
- con \(n = 100\) pazienti, \(\operatorname{Var}(\bar{X}) = \sigma^2/100\).
Quadruplicando la dimensione del campione, la varianza si riduce a un quarto. In termini di deviazione standard, ovvero l’errore standard della media, si ha: \[ \operatorname{SE}(\bar{X}) = \frac{\sigma}{\sqrt{n}}. \]
Per dimezzare l’errore standard è necessario quadruplicare il campione. Questo legame inversamente proporzionale tra precisione e numerosità spiega perché gli studi clinici con campioni più ampi tendono a fornire stime dell’efficacia del trattamento più affidabili e meno influenzate dalla variabilità individuale.
# Simulazione della varianza della media per diversi n
set.seed(123)
sigma2 <- 100 # Varianza della popolazione
n_values <- c(5, 10, 25, 50, 100, 200)
n_rep <- 1000
risultati <- data.frame(
n = integer(),
var_media = numeric()
)
for (n in n_values) {
medie <- replicate(n_rep, mean(rnorm(n, mean = 50, sd = sqrt(sigma2))))
risultati <- rbind(risultati, data.frame(
n = n,
var_media = var(medie),
var_teorica = sigma2 / n
))
}
ggplot(risultati, aes(x = n)) +
geom_point(aes(y = var_media), size = 3) +
geom_line(aes(y = var_teorica), linewidth = 1) +
scale_x_continuous(breaks = n_values) +
labs(
x = "Dimensione campionaria (n)",
y = "Varianza della media campionaria",
title = expression(Var(bar(X)) == sigma^2 / n)
)
Le proprietà della media campionaria che abbiamo derivato hanno conseguenze profonde per l’inferenza statistica. Nel Capitolo 10 esploreremo in dettaglio come questi risultati si concretizzino operativamente nell’aggiornamento delle credenze e nella quantificazione dell’incertezza, introducendo strumenti centrali come la distribuzione campionaria, la funzione di verosimiglianza e l’errore standard.
8.7 Deviazione standard e standardizzazione
La varianza è definita come il valore atteso degli scarti al quadrato dalla media, il che implica che la sua unità di misura è il quadrato di quella della variabile originale. Se, ad esempio, misuriamo il miglioramento in punti al BDI-II, la varianza sarà espressa in “punti al quadrato”, un’unità priva di interpretazione clinica diretta.
Per ottenere una misura di dispersione che sia nella stessa scala dei dati osservati, si introduce la deviazione standard.
Definizione 8.3 (Deviazione standard) La deviazione standard di una variabile casuale \(X\) è definita come \[ \sigma_X = \text{SD}(X) = \sqrt{\text{Var}(X)}. \]
La deviazione standard misura la dispersione in unità direttamente confrontabili con i valori osservati. In termini intuitivi, essa rappresenta una “distanza tipica” dei valori dalla media.
8.7.1 Standardizzazione
Un ulteriore passo concettualmente importante consiste nel trasformare una variabile casuale in una forma standardizzata, eliminando l’effetto della scala e della posizione.
Definizione 8.4 (Variabile standardizzata) Data una variabile casuale \(X\) con valore atteso \(\mathbb{E}[X] = \mu\) e deviazione standard \(\text{SD}(X) = \sigma\), la variabile standardizzata è definita come
\[ Z = \frac{X - \mu}{\sigma}. \]
La variabile standardizzata \(Z\) ha sempre:
\[ \mathbb{E}[Z] = 0, \qquad \text{Var}(Z) = 1, \] indipendentemente dalla distribuzione originaria di \(X\). La standardizzazione esprime ogni osservazione in termini di quante deviazioni standard essa si discosta dalla media.
Standardizzazione per confrontare misure eterogenee
Immaginiamo che una psicologa clinica voglia confrontare la gravità dei sintomi di due pazienti valutati con strumenti diversi:
- Paziente A: punteggio BDI-II = 28 (scala 0–63, con media \(\mu = 14\) e deviazione standard \(\sigma = 10\) nella popolazione di riferimento).
- Paziente B: punteggio PHQ-9 = 18 (scala 0–27, con media \(\mu = 10\) e deviazione standard \(\sigma = 6\) nella stessa popolazione).
Senza la standardizzazione, i punteggi grezzi non sono direttamente confrontabili, poiché le due scale differiscono per intervallo, unità di misura e distribuzione dei punteggi nella popolazione.
# Standardizzazione
z_A <- (28 - 14) / 10
z_B <- (18 - 10) / 6
cat("Paziente A (BDI-II = 28):\n")
#> Paziente A (BDI-II = 28):
cat(" z =", z_A, "deviazioni standard sopra la media\n\n")
#> z = 1.4 deviazioni standard sopra la media
cat("Paziente B (PHQ-9 = 18):\n")
#> Paziente B (PHQ-9 = 18):
cat(" z =", round(z_B, 2), "deviazioni standard sopra la media\n\n")
#> z = 1.33 deviazioni standard sopra la media
cat("Interpretazione: Il Paziente A mostra sintomi più gravi in termini relativi,\n")
#> Interpretazione: Il Paziente A mostra sintomi più gravi in termini relativi,
cat("essendo più lontano dalla media della sua distribuzione di riferimento.\n")
#> essendo più lontano dalla media della sua distribuzione di riferimento.La standardizzazione rivela che il Paziente A, pur avendo un punteggio grezzo che sembra “moderato” sulla scala BDI-II, in realtà si colloca più in alto nella distribuzione rispetto al Paziente B sulla scala PHQ-9.
Conversione in T-score (media 50, SD 10):
I T-score permettono un confronto immediato su una scala comune.
8.7.2 Ponte applicativo: la standardizzazione nella pratica clinica
La trasformazione in punti z (o in punteggi standardizzati analoghi) è uno strumento essenziale in psicometria e nella valutazione clinica, poiché consente di:
- Confrontare punteggi provenienti da scale diverse – come nell’esempio del BDI-II e del PHQ-9 – neutralizzando le differenze di media e dispersione.
- Interpretare la posizione di un individuo all’interno della distribuzione del gruppo di riferimento, indipendentemente dalla scala originale.
- Identificare punteghi clinicamente rilevanti o estremi: convenzionalmente, valori con \(|z| > 2\) sono considerati atipici, mentre con \(|z| > 3\) sono molto rari nella popolazione di riferimento.
- Costruire indicatori compositi integrando misure che hanno unità e scale di misura differenti.
Una domanda che sorge naturalmente quando si interpretano deviazioni standard è: quanta probabilità si concentra entro un certo numero di deviazioni standard dalla media?
Il teorema di Chebyshev fornisce una risposta universale, applicabile a qualsiasi distribuzione con media e varianza finite, a prescindere dalla sua forma.
Teorema 8.5 Teorema di Chebyshev
Sia \(X\) una variabile casuale con media \(\mu\) e deviazione standard \(\sigma\). Per ogni \(k > 0\) vale:
\[ P(|X - \mu| \geq k\sigma) \leq \frac{1}{k^2}. \]
Formulato in modo equivalente:
\[ P(|X - \mu| < k\sigma) \geq 1 - \frac{1}{k^2}. \]
Il teorema offre un limite inferiore universale alla probabilità che una qualsiasi osservazione cada entro \(k\) deviazioni standard dalla media:
| \(k\) | \(P(|X - \mu| < k\sigma) \geq\) |
|---|---|
| 1 | 0% (limite banale) |
| 2 | 75% |
| 3 | 88.9% (~89%) |
| 4 | 93.75% (~94%) |
Questi limiti sono molto conservativi. Per una distribuzione normale, le probabilità effettive sono notevolmente più alte: 68.3%, 95.4% e 99.7% rispettivamente per \(k = 1, 2, 3\) — significativamente superiori a quanto garantito da Chebyshev.
Applicazione clinica
Immaginiamo che un test cognitivo abbia una media di 100 e una deviazione standard di 15 nella popolazione di riferimento, ma che nulla sia noto sulla forma della sua distribuzione. Grazie a Chebyshev possiamo comunque affermare che almeno il 75% dei punteghi si trova nell’intervallo \([70, 130]\), indipendentemente da come i punteggi siano distribuiti.
Questa proprietà è utile quando:
- la distribuzione è sconosciuta o non gaussiana;
- si desiderano conclusioni robuste con minime assunzioni;
- si lavora con scale nuove o non ancora completamente validate.
Momenti di una distribuzione
Il valore atteso e la varianza possono essere visti come i primi due momenti di una distribuzione — una famiglia di quantità che descrivono sistematicamente la forma della distribuzione.
Definizione 8.5 Momenti
Il momento di ordine \(r\) di una variabile casuale \(X\) è definito come: \[ \mathbb{E}[X^r] = \begin{cases} \sum_i x_i^r \cdot p_X(x_i) & \text{(caso discreto)} \\ \int_{-\infty}^{+\infty} x^r \cdot f_X(x)\,dx & \text{(caso continuo)} \end{cases} \]
Il momento centrale di ordine \(r\) è invece: \[ \mathbb{E}[(X - \mu)^r], \] dove \(\mu = \mathbb{E}[X]\).
- Il momento di ordine 1 è il valore atteso (centro).
- Il momento centrale di ordine 2 è la varianza (dispersione).
- Il momento centrale di ordine 3 (normalizzato) è la skewness — misura l’asimmetria.
- Il momento centrale di ordine 4 (normalizzato) è la kurtosis — misura quanto le code sono “pesanti”.
Questi concetti diventano rilevanti nella validazione di scale psicometriche (dove la normalità è spesso assunta) e nella scelta di modelli statistici appropriati.
Riflessioni conclusive
Il valore atteso e la varianza rappresentano i due strumenti fondamentali per sintetizzare una distribuzione di probabilità. Il primo identifica il centro della distribuzione, ovvero il suo baricentro probabilistico, mentre il secondo misura la dispersione dei valori attorno a questo centro, quantificando l’incertezza residua associata alla variabile.
Per lo psicologo clinico, questi concetti non sono mere astrazioni teoriche, ma strumenti operativi quotidiani. Quando comunichiamo a un paziente che “il miglioramento atteso è di circa 8 punti”, stiamo facendo riferimento al valore atteso. Se aggiungiamo che “la maggior parte dei pazienti mostra un miglioramento compreso tra 4 e 12 punti”, stiamo implicitamente descrivendo la varianza. Entrambi gli elementi sono essenziali per una comunicazione clinica completa e informativa.
Le proprietà algebriche di queste grandezze spiegano la loro importanza pratica. La linearità del valore atteso permette di calcolare in modo semplice le medie di somme e combinazioni lineari di variabili casuali: ecco perché il punteggio atteso di una scala psicometrica è semplicemente la somma dei punteggi attesi dei suoi item. Il comportamento della varianza, invece, sottolinea il ruolo cruciale dell’indipendenza: soltanto in assenza di dipendenza la varianza di una somma coincide con la somma delle varianze.
Il risultato secondo cui la varianza della media campionaria decresce come \(1/n\) fornisce il fondamento matematico della precisione statistica: maggiore è il numero di osservazioni, minore sarà l’incertezza associata alla stima. Questo principio guida la progettazione degli studi clinici, determinando le dimensioni campionarie necessarie, e spiega come l’accumulo di evidenza empirica riduca progressivamente l’incertezza nelle nostre conclusioni.
Nel quadro bayesiano, questi concetti assumono una valenza pienamente inferenziale. Nei capitoli successivi, il valore atteso della distribuzione a posteriori fungerà da stima puntuale razionale del parametro di interesse, mentre la sua varianza misurerà l’incertezza residua dopo aver osservato i dati. In questo senso, valore atteso e varianza costituiscono il punto d’incontro tra probabilità, decisione e apprendimento: sintetizzano ciò che sappiamo, guidano le previsioni ottimali e rendono esplicito quanto ancora ignoriamo.
Punti chiave da ricordare
Concetti essenziali di questo capitolo:
-
Valore atteso come centro di gravità probabilistico
- Media ponderata dei valori possibili, con pesi dati dalle probabilità.
- Rappresenta l’aspettativa razionale — la migliore previsione puntuale.
- Non deve necessariamente coincidere con un valore osservabile.
- Legge dei grandi numeri: la media campionaria converge al valore atteso.
-
Linearità del valore atteso (proprietà cruciale)
- \(\mathbb{E}[X + Y] = \mathbb{E}[X] + \mathbb{E}[Y]\) sempre (anche con dipendenza!).
- \(\mathbb{E}[aX + b] = a\mathbb{E}[X] + b\) per costanti \(a, b\).
- Applicazione: il punteggio atteso di una scala è la somma dei valori attesi degli item.
-
Varianza come misura di dispersione e incertezza
- \(\text{Var}(X) = \mathbb{E}[(X - \mu)^2]\) quantifica quanto i valori si discostano dalla media.
- Interpretazione epistemica: perdita attesa usando il valore atteso come previsione.
- Formula computazionale: \(\text{Var}(X) = \mathbb{E}[X^2] - (\mathbb{E}[X])^2\).
-
Proprietà della varianza
- \(\text{Var}(aX + b) = a^2 \text{Var}(X)\) (traslazioni non cambiano dispersione).
- \(\text{Var}(X + Y) = \text{Var}(X) + \text{Var}(Y)\) solo se \(X \perp Y\).
- Varianza della media campionaria: \(\text{Var}(\bar{X}) = \sigma^2/n\) (fondamento della precisione statistica).
-
Deviazione standard e standardizzazione
- \(\sigma = \sqrt{\text{Var}(X)}\) riporta la dispersione nelle unità originali.
- \(Z = (X - \mu)/\sigma\) crea variabile con media 0 e varianza 1.
- Permette confronti tra scale diverse (es. BDI-II vs PHQ-9).
Formule da ricordare:
\[ \mathbb{E}[X] = \sum_x x \cdot p_X(x) \quad \text{o} \quad \int x \cdot f_X(x)\,dx \]
\[ \text{Var}(X) = \mathbb{E}[X^2] - (\mathbb{E}[X])^2 \]
\[ \text{Var}(\bar{X}_n) = \frac{\sigma^2}{n} \]
Proprietà critiche:
- Linearità del valore atteso vale sempre (anche con dipendenza).
- Additività della varianza richiede indipendenza.
- La varianza della media decresce con \(n\) (più dati → meno incertezza).
Per il prossimo capitolo:
Nel Capitolo 9 studieremo come quantificare la dipendenza stocastica tra due variabili attraverso la covarianza e la correlazione, concetti essenziali per comprendere quando e perché l’additività della varianza fallisce e per costruire modelli in grado di catturare le relazioni tra le variabili psicologiche.
sessionInfo()
#> R version 4.5.2 (2025-10-31)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Tahoe 26.2
#>
#> Matrix products: default
#> BLAS: /System/Library/Frameworks/Accelerate.framework/Versions/A/Frameworks/vecLib.framework/Versions/A/libBLAS.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
#>
#> locale:
#> [1] C.UTF-8/UTF-8/C.UTF-8/C/C.UTF-8/C.UTF-8
#>
#> time zone: Europe/Rome
#> tzcode source: internal
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] MASS_7.3-65 ragg_1.5.0 tinytable_0.15.2
#> [4] withr_3.0.2 systemfonts_1.3.1 patchwork_1.3.2
#> [7] ggdist_3.3.3 tidybayes_3.0.7 bayesplot_1.15.0
#> [10] ggplot2_4.0.1 reliabilitydiag_0.2.1 priorsense_1.2.0
#> [13] posterior_1.6.1 loo_2.9.0 rstan_2.32.7
#> [16] StanHeaders_2.32.10 brms_2.23.0 Rcpp_1.1.1
#> [19] sessioninfo_1.2.3 conflicted_1.2.0 janitor_2.2.1
#> [22] matrixStats_1.5.0 modelr_0.1.11 tibble_3.3.1
#> [25] dplyr_1.1.4 tidyr_1.3.2 rio_1.2.4
#> [28] here_1.0.2
#>
#> loaded via a namespace (and not attached):
#> [1] svUnit_1.0.8 tidyselect_1.2.1 farver_2.1.2
#> [4] S7_0.2.1 fastmap_1.2.0 TH.data_1.1-5
#> [7] tensorA_0.36.2.1 digest_0.6.39 timechange_0.3.0
#> [10] estimability_1.5.1 lifecycle_1.0.5 survival_3.8-3
#> [13] magrittr_2.0.4 compiler_4.5.2 rlang_1.1.7
#> [16] tools_4.5.2 yaml_2.3.12 knitr_1.51
#> [19] labeling_0.4.3 bridgesampling_1.2-1 htmlwidgets_1.6.4
#> [22] curl_7.0.0 pkgbuild_1.4.8 RColorBrewer_1.1-3
#> [25] abind_1.4-8 multcomp_1.4-29 purrr_1.2.1
#> [28] grid_4.5.2 stats4_4.5.2 colorspace_2.1-2
#> [31] xtable_1.8-4 inline_0.3.21 emmeans_2.0.1
#> [34] scales_1.4.0 cli_3.6.5 mvtnorm_1.3-3
#> [37] rmarkdown_2.30 generics_0.1.4 otel_0.2.0
#> [40] RcppParallel_5.1.11-1 cachem_1.1.0 stringr_1.6.0
#> [43] splines_4.5.2 parallel_4.5.2 vctrs_0.6.5
#> [46] V8_8.0.1 Matrix_1.7-4 sandwich_3.1-1
#> [49] jsonlite_2.0.0 arrayhelpers_1.1-0 glue_1.8.0
#> [52] codetools_0.2-20 distributional_0.6.0 lubridate_1.9.4
#> [55] stringi_1.8.7 gtable_0.3.6 QuickJSR_1.8.1
#> [58] pillar_1.11.1 htmltools_0.5.9 Brobdingnag_1.2-9
#> [61] R6_2.6.1 textshaping_1.0.4 rprojroot_2.1.1
#> [64] evaluate_1.0.5 lattice_0.22-7 backports_1.5.0
#> [67] memoise_2.0.1 broom_1.0.11 snakecase_0.11.1
#> [70] rstantools_2.6.0 gridExtra_2.3 coda_0.19-4.1
#> [73] nlme_3.1-168 checkmate_2.3.3 xfun_0.55
#> [76] zoo_1.8-15 pkgconfig_2.0.3