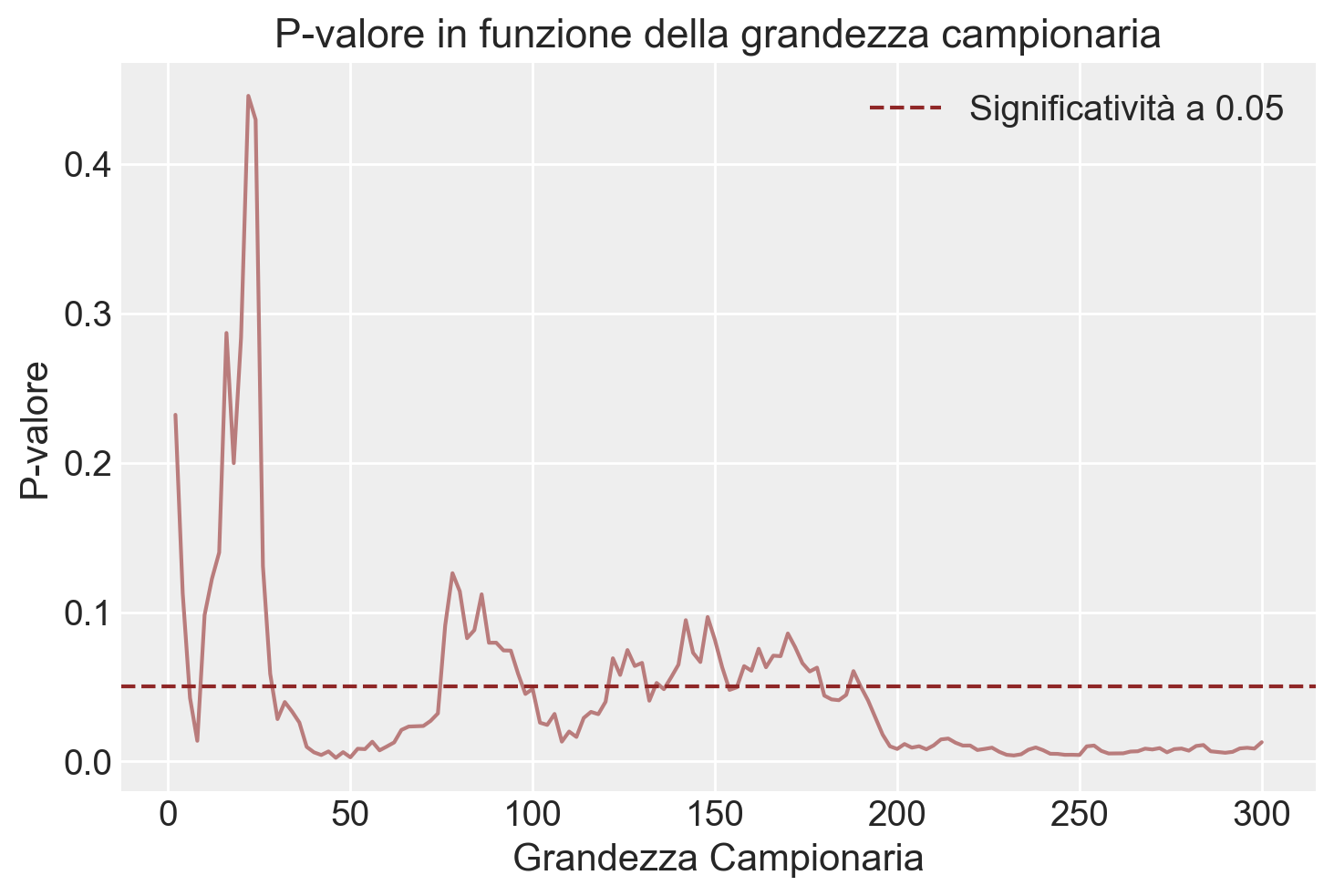
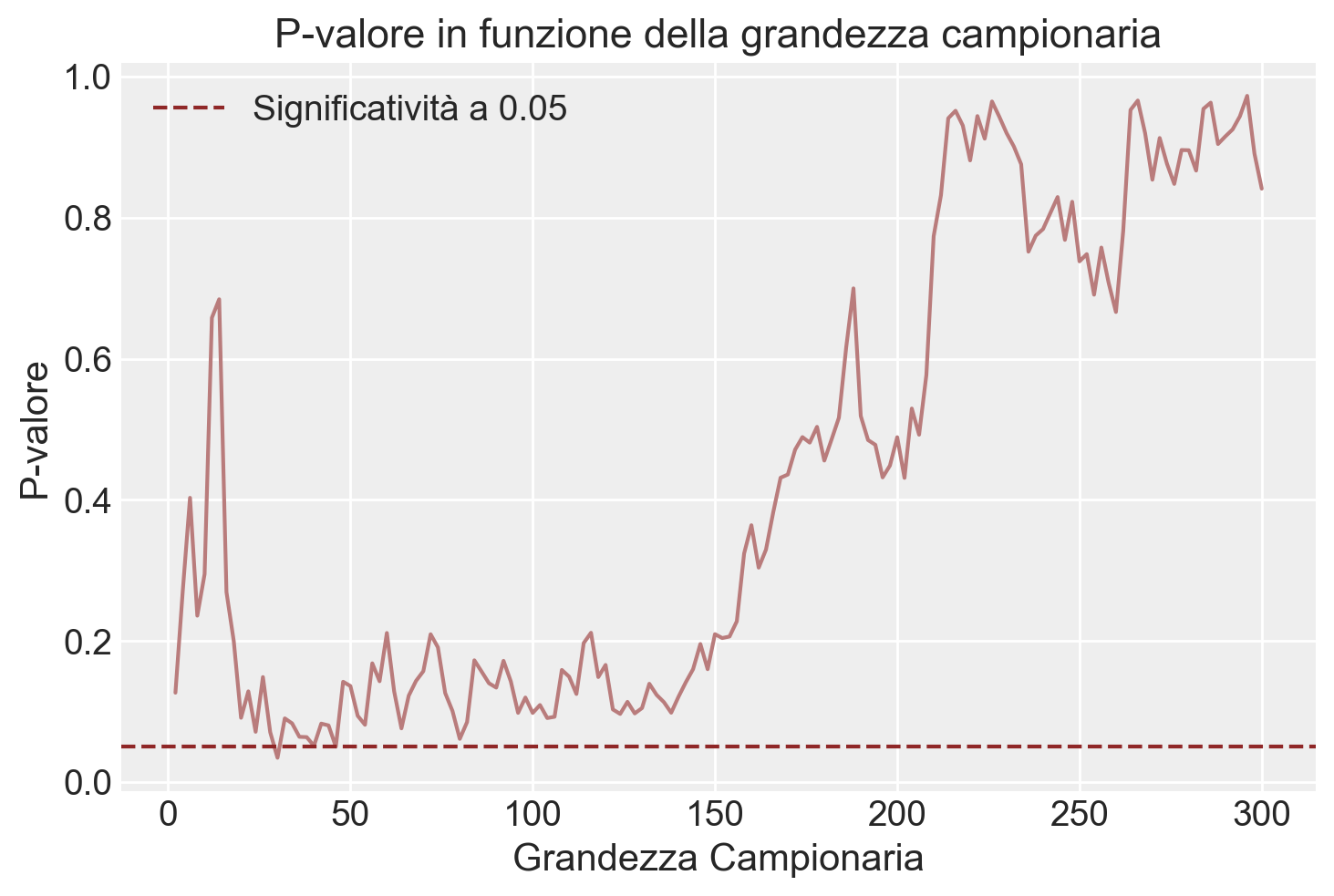
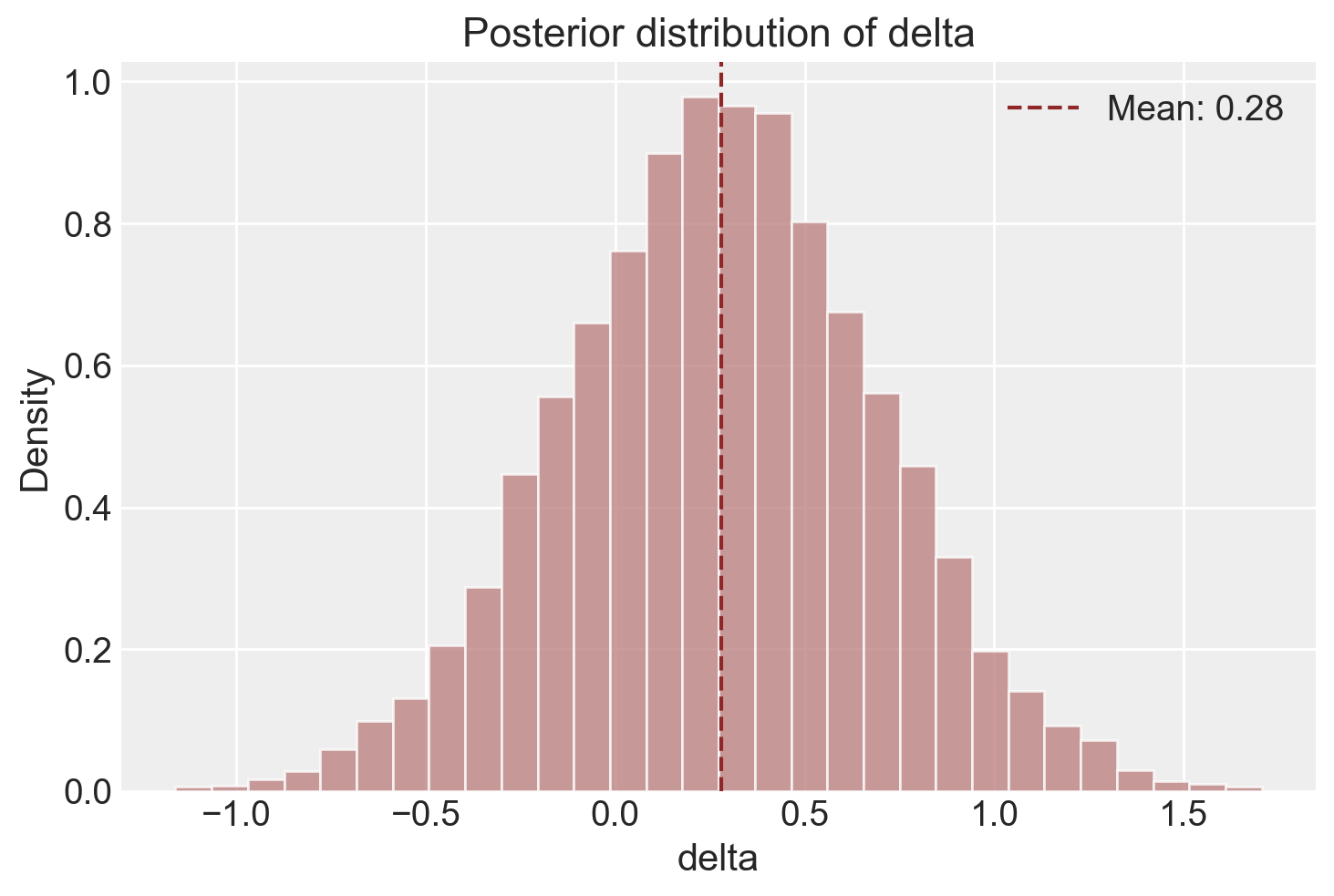
Aungle, P., & Langer, E. (2023). Physical healing as a function of perceived time. Scientific Reports, 13(1), 22432.
Bargh, J. A., Chen, M., & Burrows, L. (1996). Automaticity of social behavior: Direct effects of trait construct and stereotype activation on action. Journal of personality and social psychology, 71(2), 230–244.
Bem, D. J. (2011). Feeling the future: experimental evidence for anomalous retroactive influences on cognition and affect. Journal of Personality and Social Psychology, 100(3), 407–425.
Bruton, S. V., Medlin, M., Brown, M., & Sacco, D. F. (2020). Personal motivations and systemic incentives: Scientists on questionable research practices. Science and Engineering Ethics, 26(3), 1531–1547.
Caudek, C., Lorenzino, M., & Liperoti, R. (2017). Delta plots do not reveal response inhibition in lying. Consciousness and Cognition, 55, 232–244.
Chivers, T. (2024). Everything is Predictable: How Bayesian Statistics Explain Our World. Simon; Schuster.
Collaboration, O. S. (2015). Estimating the reproducibility of psychological science. Science, 349(6251), aac4716.
Ferguson, C. J., & Heene, M. (2012). A vast graveyard of undead theories: Publication bias and psychological science’s aversion to the null. Perspectives on Psychological Science, 7(6), 555–561.
Gelman, A., & Brown, N. J. (2024). How statistical challenges and misreadings of the literature combine to produce unreplicable science: An example from psychology.
Gelman, A., & Loken, E. (2013). The garden of forking paths: Why multiple comparisons can be a problem, even when there is no «fishing expedition» or «p-hacking» and the research hypothesis was posited ahead of time. Department of Statistics, Columbia University, 348(1-17), 3.
Gelman, A., & Loken, E. (2014). The statistical crisis in science. American scientist, 102(6), 460–465.
Gopalakrishna, G., Ter Riet, G., Vink, G., Stoop, I., Wicherts, J. M., & Bouter, L. M. (2022). Prevalence of questionable research practices, research misconduct and their potential explanatory factors: A survey among academic researchers in The Netherlands. PloS one, 17(2), e0263023.
Grimes, D. R., Bauch, C. T., & Ioannidis, J. P. (2018). Modelling science trustworthiness under publish or perish pressure. Royal Society open science, 5(1), 171511.
Ioannidis, J. P. (2005). Why most published research findings are false. PLoS medicine, 2(8), e124.
Karataş, M., & Cutright, K. M. (2023). Thinking about God increases acceptance of artificial intelligence in decision-making. Proceedings of the National Academy of Sciences, 120(33), e2218961120.
Lakens, D. (2015). On the challenges of drawing conclusions from p-values just below 0.05. PeerJ, 3, e1142.
Loken, E., & Gelman, A. (2017). Measurement Error and the Replication Crisis. Science, 355(6325), 584–585.
Meehl, P. E. (2012). Why summaries of research on psychological theories are often uninterpretable. In Improving inquiry in social science (pp. 13–59). Routledge.
Moore, D. A., Schroeder, J., Bailey, E. R., Gershon, R., Moore, J. E., & Simmons, J. P. (2024). Does thinking about God increase acceptance of artificial intelligence in decision-making? Proceedings of the National Academy of Sciences, 121(31), e2402315121.
Nelson, L. D., Simmons, J., & Simonsohn, U. (2018). Psychology’s renaissance. Annual review of psychology, 69(1), 511–534.
Nosek, B. A., Spies, J. R., & Motyl, M. (2012). Scientific utopia: II. Restructuring incentives and practices to promote truth over publishability. Perspectives on Psychological Science, 7(6), 615–631.
Ritchie, S. J., Wiseman, R., & French, C. C. (2012). Failing the future: Three unsuccessful attempts to replicate Bem’s ‘Retroactive Facilitation of Recall’Effect. PloS one, 7(3), e33423.
Ware, J. J., & Munafò, M. R. (2015). Significance chasing in research practice: causes, consequences and possible solutions. Addiction, 110(1), 4–8.
Youyou, W., Yang, Y., & Uzzi, B. (2023). A discipline-wide investigation of the replicability of Psychology papers over the past two decades. Proceedings of the National Academy of Sciences, 120(6), e2208863120.