import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import arviz as az
import seaborn as sns
import matplotlib.patches as patches31 Il teorema di Bayes
It is, without exaggeration, perhaps the most important single equation in history.
Tom Chivers (2024)
Prerequisiti
- Leggere Everything is Predictable: How Bayesian Statistics Explain Our World (Chivers, 2024). Questo libro offre una descrizione chiara e accessibile dell’impatto che il teorema di Bayes ha avuto sulla vita moderna.
- Leggere Bayesian Models of Cognition di Thomas L. Griffiths, una voce della Open Encyclopedia of Cognitive Science.
Concetti e competenze chiave
- Capire in profondità il teorema di Bayes e la sua importanza.
- Utilizzare il teorema di Bayes per analizzare e interpretare i test diagnostici, tenendo in considerazione la prevalenza della malattia in questione.
- Affrontare e risolvere problemi di probabilità discreta che necessitano dell’applicazione del teorema di Bayes.
Preparazione del Notebook
seed: int = sum(map(ord, "bayes_theorem"))
rng: np.random.Generator = np.random.default_rng(seed=seed)
sns.set_theme(palette="colorblind")
az.style.use("arviz-darkgrid")
%config InlineBackend.figure_format = "retina"Introduzione
Il teorema di Bayes offre una soluzione ottimale ai problemi induttivi, che spaziano dall’identificazione della struttura tridimensionale del mondo basata su dati sensoriali limitati, all’inferenza dei pensieri altrui a partire dal loro comportamento. Questa regola si rivela particolarmente utile in situazioni in cui i dati osservati sono insufficienti per distinguere in modo definitivo tra diverse ipotesi.
Nonostante ciò, tutte le previsioni basate su questo metodo mantengono un certo grado di incertezza. Anche se l’universo fosse completamente deterministico, la nostra conoscenza di esso rimarrebbe imperfetta: non possiamo conoscere la posizione e lo stato di ogni singola particella che lo compone. Le informazioni a nostra disposizione sono inevitabilmente parziali e imprecise, ottenute attraverso i nostri sensi limitati.
La vita reale non è paragonabile a una partita di scacchi, un gioco con informazioni perfette che può essere “risolto” in linea di principio. Assomiglia piuttosto al poker, dove le decisioni vengono prese utilizzando le informazioni limitate a disposizione dei giocatori. Questo capitolo si concentra sull’equazione che ci permette di fare proprio questo: il teorema di Bayes. Esso descrive come modifichiamo le nostre convinzioni riguardo a un’ipotesi in una situazione in cui i dati disponibili non consentono una decisione certa.
Questo processo è noto come inferenza induttiva, che ci permette di trarre conclusioni generali da dati specifici e limitati. Il teorema di Bayes fornisce quindi un framework matematico per aggiornare le nostre credenze alla luce di nuove evidenze, permettendoci di prendere decisioni informate in un mondo caratterizzato dall’incertezza.
32 Una Rivoluzione nel Pensiero Probabilistico
Nel cuore del XVIII secolo, un ecclesiastico presbiteriano di nome Thomas Bayes gettò le basi per una delle più importanti rivoluzioni nel campo della statistica e del calcolo delle probabilità. Il suo contributo, noto oggi come teorema di Bayes, non solo ha trasformato il modo in cui comprendiamo e applichiamo la probabilità, ma continua a influenzare profondamente la scienza moderna e la tecnologia, inclusa l’intelligenza artificiale (Chivers, 2024).
Thomas Bayes nacque in una famiglia benestante e ricevette un’educazione di alto livello, studiando teologia a Edimburgo per prepararsi alla vita da ecclesiastico. Come nota il suo biografo Bellhouse, Bayes “non sembrava un accademico moderno. Era più un dilettante, un virtuoso. Lo faceva per il proprio piacere piuttosto che avere un’agenda di ricerca.”
Bayes pubblicò due opere principali durante la sua vita:
- Una di teologia, “Divine benevolence: Or, an attempt to prove that the principal end of the divine providence and government is the happiness of his creatures”, nel 1731.
- Una difesa del calcolo newtoniano, “An Introduction to the Doctrine of Fluxions”, in risposta a una critica del filosofo George Berkeley.
Tuttavia, fu il suo lavoro postumo, “An Essay towards Solving a Problem in the Doctrine of Chances”, pubblicato nel 1763 nella rivista Philosophical Transactions, a cambiare per sempre il corso della teoria della probabilità.
Bellhouse nota che l’interesse di Bayes per la matematica era tipico del suo tempo: “Nel XVIII secolo, i ricchi si dedicavano alla scienza. È un po’ come i ricchi di oggi che si dedicano agli sport.” Ma forse Bellhouse si riferiva solo al suo tempo: oggi i ricchi sembrano interessarsi solo ai social media.
Il contributo di Bayes non fu tanto matematico quanto filosofico. David Spiegelhalter, ex presidente della Royal Statistical Society, spiega che per Bayes “la probabilità è un’espressione della nostra mancanza di conoscenza sul mondo.” Questa visione introduce l’idea rivoluzionaria che la probabilità sia soggettiva, un’espressione della nostra conoscenza limitata e delle nostre supposizioni sulla verità, piuttosto che una proprietà oggettiva della realtà.
Per illustrare questo concetto, Bayes utilizzò l’esempio di un tavolo nascosto alla vista su cui vengono lanciate delle palle. Una palla bianca viene lanciata in modo tale che la sua posizione finale sia completamente casuale. Quando la palla bianca si ferma, viene rimossa e si traccia una linea sul tavolo nel punto in cui si trovava. La posizione della linea non è nota. Successivamente, un certo numero di palle rosse viene lanciato sul tavolo. Viene comunicato solo quante palle si trovano a sinistra della linea e quante a destra. Il compito è stimare la posizione della linea. La soluzione proposta da Bayes utilizza non solo i dati osservati (il numero di palle rosse a sinistra e a destra della linea), ma anche le convinzioni iniziali (il “prior”).
Richard Price (1723-1791), un altro ecclesiastico nonconformista, ebbe un ruolo cruciale nella diffusione del lavoro di Thomas Bayes. Molto più noto del suo amico, Price era ben inserito nei circoli intellettuali dell’epoca. Era in contatto con diversi Padri Fondatori della Rivoluzione Americana, tra cui Thomas Jefferson e Benjamin Franklin, così come John Adams, il secondo presidente degli Stati Uniti. Supportava attivamente la rivoluzione americana, pubblicando un influente opuscolo Observations on the Nature of Civil Liberty, the Principles of Government, and the Justice and Policy of the War with America nel 1776. Era amico di filosofi come David Hume e Adam Smith.
Price è importante in questa storia come colui che portò all’attenzione pubblica il lavoro di Bayes: mostrò il saggio al fisico John Canton nel 1761, dopo la morte di Bayes, e lo fece pubblicare nelle Philosophical Transactions della Royal Society due anni dopo. Parte del motivo per cui ci volle tanto tempo per pubblicarlo era che Price non si limitò a correggere refusi e virgole fuori posto. Price aveva una visione propria del lavoro: mentre Bayes scrisse la prima metà del saggio, la seconda metà, contenente tutte le possibili applicazioni pratiche del teorema, fu tutta opera di Price. Bayes non aveva interesse per le statistiche applicate: il suo lavoro, in questo e in tutti gli altri articoli, era “tutta teoria senza alcun accenno di applicazione.” Ma Price fu – come dice lo storico della statistica Stephen Stigler – “il primo bayesiano.”
Sebbene il lavoro di Bayes sia rimasto nell’ombra per decenni, con Pierre-Simon Laplace che giunse indipendentemente a conclusioni simili nel 1774 e le espanse nella sua “Théorie analytique des probabilités” del 1812, l’importanza del teorema di Bayes è oggi indiscutibile. Esso fornisce un meccanismo matematico per aggiornare le probabilità di un’ipotesi in base a nuove evidenze, riflettendo un approccio dinamico e iterativo alla conoscenza.
Nel panorama contemporaneo, il teorema di Bayes trova applicazioni in ogni campo della scienza e della tecnologia. È particolarmente rilevante nel campo dell’intelligenza artificiale, dove modelli linguistici avanzati come ChatGPT e Claude utilizzano principi bayesiani per fare previsioni e prendere decisioni.
In conclusione, il teorema di Bayes, nato dalle riflessioni di un ministro presbiteriano del XVIII secolo, ha trasformato il nostro modo di comprendere la probabilità e di aggiornare le nostre conoscenze. La sua rilevanza universale nella comprensione e previsione dei fenomeni è tale che, come afferma Brian Clegg nel suo libro “Everything is predictable: how bayesian statistics explain our world”, la statistica bayesiana è diventata uno strumento fondamentale per spiegare il nostro mondo (Chivers, 2024).
32.1 La Regola di Bayes
L’inferenza bayesiana si basa su una formula fondamentale nota come regola di Bayes. Sebbene possa sembrare un semplice risultato della teoria delle probabilità, la sua applicazione ha implicazioni profonde in molti campi, inclusa la scienza cognitiva e l’apprendimento automatico. Supponiamo di avere due variabili casuali, \(A\) e \(B\). Un principio della probabilità, chiamato regola della catena, ci consente di esprimere la probabilità congiunta di queste due variabili \(P(a, b)\) come il prodotto della probabilità condizionale di \(A\) dato \(B\), e la probabilità marginale di \(B\). In termini formali:
\[ P(a, b) = P(a \mid b) P(b). \tag{32.1}\]
Non vi è nulla di speciale nel trattare \(A\) prima di \(B\); possiamo infatti anche scrivere:
\[ P(a, b) = P(b \mid a) P(a). \tag{32.2}\]
Dalle due equazioni precedenti, possiamo derivare la regola di Bayes riorganizzando i termini:
\[ P(b \mid a) = \frac{P(a \mid b) P(b)}{P(a)}. \tag{32.3}\]
Questa espressione, nota come regola di Bayes, ci permette di calcolare la probabilità condizionale di \(b\) dato \(a\), usando la probabilità condizionale opposta \(P(a \mid b)\), la probabilità a priori \(P(b)\), e la probabilità marginale \(P(a)\).
32.1.1 Applicazioni della Regola di Bayes
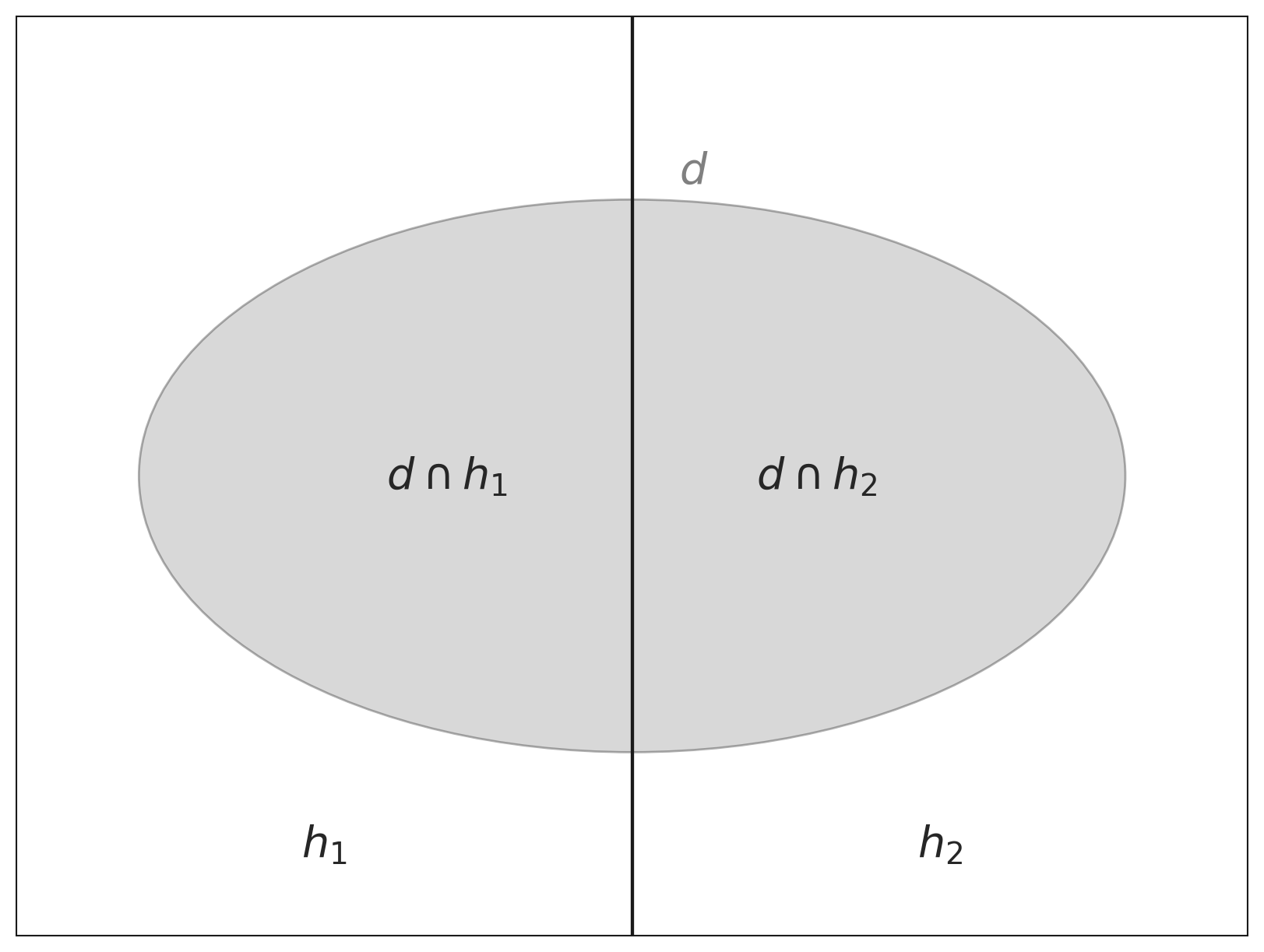
La forza della regola di Bayes si manifesta pienamente quando la applichiamo a un contesto di inferenza. Supponiamo di avere un agente che tenta di inferire quale processo ha generato alcuni dati \(d\). Lasciamo che \(h\) rappresenti un’ipotesi su tale processo. L’agente usa le probabilità per rappresentare il grado di credenza in \(h\) e in altre ipotesi alternative \(h'\), e indichiamo con \(P(h)\) la probabilità a priori dell’ipotesi \(h\), ovvero la credenza che l’agente attribuisce a \(h\) prima di osservare i dati.
A questo punto, l’agente vuole aggiornare questa credenza alla luce dei nuovi dati \(d\), ottenendo la probabilità a posteriori \(P(h \mid d)\). Usando la regola di Bayes, possiamo calcolare questa probabilità nel seguente modo:
\[ P(h \mid d) = \frac{P(d \mid h) P(h)}{P(d)}. \tag{32.4}\]
Qui, \(P(d \mid h)\) rappresenta la verosimiglianza, ovvero la probabilità di osservare i dati \(d\) supponendo che l’ipotesi \(h\) sia vera. La verosimiglianza gioca un ruolo cruciale nell’aggiornamento delle nostre credenze: essa “ri-pesa” ogni ipotesi in base alla sua capacità di predire i dati osservati.
32.1.2 La Marginalizzazione
La teoria delle probabilità ci permette anche di calcolare la probabilità marginale associata a una singola variabile sommando o integrando su altre variabili in una distribuzione congiunta. Ad esempio, la probabilità marginale di \(b\) è data da:
\[ P(b) = \sum_a P(a, b). \]
Questo processo è chiamato marginalizzazione. Utilizzando questo principio, possiamo riscrivere la regola di Bayes in un formato che include esplicitamente la somma su tutte le ipotesi alternative \(h' \in H\) considerate dall’agente:
\[ P(h \mid d) = \frac{P(d \mid h) P(h)}{\sum_{h' \in H} P(d \mid h') P(h')}. \tag{32.5}\]
In questo caso, \(H\) rappresenta l’insieme di tutte le ipotesi possibili, a volte chiamato spazio delle ipotesi, e la somma al denominatore assicura che le probabilità a posteriori siano normalizzate, cioè che la loro somma sia pari a uno.
32.1.3 Estensione al Caso Continuo
Quando le ipotesi non sono discrete ma fanno parte di un continuum, la formula di Bayes assume una forma integrale:
\[ P(h_i \mid d) = \frac{P(d \mid h_i) \cdot P(h_i)}{\int P(d \mid H) \cdot P(H) \, dH}. \tag{32.6}\]
In questo caso, l’integrale nel denominatore somma tutte le ipotesi possibili, ponderandole per le loro probabilità a priori e verosimiglianze. Questo permette di aggiornare le credenze anche per ipotesi continue.
32.1.4 Componenti Chiave della Formula di Bayes
La formula di Bayes si basa su tre elementi principali:
Probabilità a Priori \(P(h_i)\): Questa rappresenta la credenza iniziale sull’ipotesi \(h_i\), prima di osservare i dati. È una stima preliminare basata su informazioni preesistenti.
Verosimiglianza \(P(d \mid h_i)\): Indica la probabilità di osservare i dati \(d\), dato che l’ipotesi \(h_i\) sia vera. Questa componente quantifica quanto l’ipotesi predice correttamente i dati osservati.
Probabilità a Posteriori \(P(h_i \mid d)\): Questa è la credenza aggiornata in \(h_i\), dopo aver considerato l’evidenza \(d\). È il prodotto della probabilità a priori e della verosimiglianza, normalizzato in modo che tutte le ipotesi abbiano probabilità totale pari a uno.
In conclusione, la regola di Bayes fornisce un quadro potente per aggiornare le credenze in modo coerente e sistematico man mano che si accumulano nuove informazioni, permettendo di affinare le nostre decisioni e previsioni.
Grazie alla regola di Bayes, possiamo aggiornare costantemente le nostre credenze man mano che nuove informazioni diventano disponibili. Questo processo dinamico di aggiornamento ci permette di affinare le nostre convinzioni e le nostre previsioni, rendendo il modello bayesiano particolarmente utile nelle situazioni in cui le informazioni sono incomplete o incerte. Questo approccio non solo ci consente di prendere decisioni più informate, ma ci permette anche di sviluppare modelli più accurati della realtà basati sulle evidenze.
32.1.5 Applicazioni dei modelli bayesiani
Come discusso da Griffiths et al. (2024), negli ultimi anni, i modelli bayesiani hanno acquisito un’importanza crescente in vari campi delle scienze cognitive. Questi modelli sono stati applicati allo studio dell’apprendimento animale (Courville, Daw, & Touretzky, 2006), dell’apprendimento induttivo umano e della generalizzazione (Tenenbaum, Griffiths, & Kemp, 2006), della percezione visiva (Yuille & Kersten, 2006), del controllo motorio (Kording & Wolpert, 2006), della memoria semantica (Steyvers, Griffiths, & Dennis, 2006), dell’acquisizione e del processamento del linguaggio (Chater & Manning, 2006; Xu & Tenenbaum, in press), del ragionamento simbolico (Oaksford & Chater, 2001), dell’apprendimento causale (Steyvers, Tenenbaum, Wagenmakers, & Blum, 2003; Griffiths & Tenenbaum, 2005, 2007a), e della cognizione sociale (Baker, Tenenbaum, & Saxe, 2007), tra molti altri argomenti.
Dietro questi diversi programmi di ricerca emerge una domanda centrale: come fa la mente umana ad andare oltre i dati dell’esperienza? In altre parole, come riesce la mente a costruire modelli complessi e astratti del mondo, partendo solo da dati sparsi e rumorosi, osservati attraverso i nostri sensi? La risposta proposta dall’approccio bayesiano è che la mente umana utilizza un processo di inferenza probabilistica per aggiornare le proprie credenze sulla base delle nuove evidenze, creando così modelli del mondo sempre più accurati e raffinati.
32.2 Alcuni esempi
Esempio 32.1 Il modo più comune per spiegare il teorema di Bayes è attraverso i test medici. Prendiamo come esempio il caso della mammografia e la diagnosi del cancro al seno che abbiamo già discusso in precedenza.
Supponiamo di avere un test di mammografia con una sensibilità del 90% e una specificità del 90%. Questo significa che:
- In presenza di cancro al seno, la probabilità che il test lo rilevi correttamente è del 90%.
- In assenza di cancro al seno, la probabilità che il test confermi correttamente l’assenza della malattia è del 90%.
In altri termini, il test ha un tasso di falsi negativi del 10% e un tasso di falsi positivi anch’esso del 10%.
Definiamo due ipotesi:
- \(M^+\): presenza della malattia
- \(M^-\): assenza della malattia
L’evidenza è rappresentata dal risultato positivo di un test di mammografia, che indichiamo con \(T^+\).
Applicando il teorema di Bayes, possiamo calcolare la probabilità di avere il cancro al seno dato un risultato positivo al test, come segue:
\[ P(M^+ \mid T^+) = \frac{P(T^+ \mid M^+) \cdot P(M^+)}{P(T^+ \mid M^+) \cdot P(M^+) + P(T^+ \mid M^-) \cdot P(M^-)}, \]
dove:
\(P(M^+ \mid T^+)\) è la probabilità di avere il cancro (\(M^+\)) dato un risultato positivo al test (\(T^+\)).
\(P(T^+ \mid M^+)\) rappresenta la sensibilità del test, ovvero la probabilità che il test risulti positivo in presenza effettiva del cancro. In questo caso, è pari a 0.90.
\(P(M^+)\) è la probabilità a priori che una persona abbia il cancro, ovvero la prevalenza della malattia nella popolazione.
\(P(T^+ \mid M^-)\) indica la probabilità di un falso positivo, cioè la probabilità che il test risulti positivo in assenza di cancro. Con una specificità del 90%, questa probabilità si calcola come:
\[ P(T^+ \mid M^-) = 1 - \text{Specificità} = 1 - 0.90 = 0.10 \]
Questo significa che c’è una probabilità del 10% che il test diagnostichi erroneamente la presenza del cancro in una persona sana.
\(P(M^-)\) è la probabilità a priori che una persona non sia affetta da cancro prima di effettuare il test.
Questa formulazione del teorema di Bayes ci permette di calcolare la probabilità effettiva di avere il cancro al seno, dato un risultato positivo al test di mammografia, tenendo conto sia della sensibilità e specificità del test, sia della prevalenza della malattia nella popolazione.
Inserendo nella formula i del problema, otteniamo:
\[ \begin{align} P(M^+ \mid T^+) &= \frac{0.9 \cdot 0.01}{0.9 \cdot 0.01 + 0.1 \cdot 0.99} \notag\\ &= \frac{9}{108} \notag\\ &\approx 0.083.\notag \end{align} \]
I calcoli effettuati evidenziano come, in presenza di una mammografia positiva ottenuta con un test avente sensibilità e specificità pari al 90%, la probabilità di effettiva positività al tumore al seno si attesta intorno all’8.3%. Tale risultato conferma quanto precedentemente ottenuto nel Capitolo 28, attraverso un metodo di calcolo alternativo.
32.2.1 Il Valore Predittivo di un Test di Laboratorio
Per semplicità, possiamo riscrivere il teorema di Bayes in due modi distinti per calcolare ciò che viene chiamato valore predittivo del test positivo e valore predittivo del test negativo.
La comprensione di tre elementi è fondamentale per questo calcolo: la prevalenza della malattia, la sensibilità e la specificità del test.
Prevalenza: Si riferisce alla percentuale di individui in una popolazione affetti da una certa malattia in un determinato momento. Viene espressa come percentuale o frazione della popolazione. Per esempio, una prevalenza dello 0,5% indica che su mille persone, cinque sono affette dalla malattia.
Sensibilità: Indica la capacità del test di identificare correttamente la malattia negli individui malati. Viene calcolata come la frazione di veri positivi (individui malati correttamente identificati) sul totale degli individui malati. La formula della sensibilità (\(Sens\)) è la seguente:
\[ \text{Sensibilità} = \frac{TP}{TP + FN}, \]
dove \(TP\) rappresenta i veri positivi e \(FN\) i falsi negativi. Pertanto, la sensibilità misura la probabilità che il test risulti positivo se la malattia è effettivamente presente.
Specificità: Misura la capacità del test di riconoscere gli individui sani, producendo un risultato negativo per chi non è affetto dalla malattia. Si calcola come la frazione di veri negativi (individui sani correttamente identificati) sul totale degli individui sani. La specificità (\(Spec\)) si definisce come:
\[ \text{Specificità} = \frac{TN}{TN + FP}, \]
dove \(TN\) sono i veri negativi e \(FP\) i falsi positivi. Così, la specificità rappresenta la probabilità che il test risulti negativo in assenza della malattia.
Questa tabella riassume la terminologia:
| \(T^+\) | \(T^-\) | Totale | |
|---|---|---|---|
| \(M^+\) | \(P(T^+ \cap M^+)\) (Sensibilità) |
\(P(T^- \cap M^+)\) (1 - Sensibilità) |
\(P(M^+)\) |
| \(M^-\) | \(P(T^+ \cap M^-)\) (1 - Specificità) |
\(P(T^- \cap M^-)\) (Specificità) |
\(P(M^-)\) |
| Totale | \(P(T^+)\) | \(P(T^-)\) | 1 |
dove \(T^+\) e \(T^-\) indicano rispettivamente un risultato positivo o negativo del test, mentre \(M^+\) e \(M^-\) la presenza o assenza effettiva della malattia. In questa tabella, i totali marginali rappresentano:
- Totale per \(M^+\) e \(M^-\) (ultima colonna): La probabilità totale di avere la malattia (\(P(M^+)\)) e la probabilità totale di non avere la malattia (\(P(M^-)\)), rispettivamente. Questi valori sono calcolati sommando le probabilità all’interno di ciascuna riga.
- Totale per \(T^+\) e \(T^-\) (ultima riga): La probabilità totale di un risultato positivo al test (\(P(T^+)\)) e la probabilità totale di un risultato negativo al test (\(P(T^-)\)), rispettivamente. Questi valori sono calcolati sommando le probabilità all’interno di ciascuna colonna.
- Totale generale (angolo in basso a destra): La somma di tutte le probabilità, che per definizione è 1, rappresentando l’intera popolazione o il set di casi considerati.
Mediante il teorema di Bayes, possiamo usare queste informazioni per stimare la probabilità post-test di avere o non avere la malattia basandoci sul risultato del test.
Il valore predittivo positivo (VPP) del test, cioè la probabilità post-test che un individuo sia malato dato un risultato positivo del test, è calcolato come:
\[ P(M^+ \mid T^+) = \frac{P(T^+ \mid M^+) \cdot P(M^+)}{P(T^+ \mid M^+) \cdot P(M^+) + P(T^+ \mid M^-) \cdot P(M^-)}. \]
ovvero,
\[ VPP = \frac{(\text{Sensibilità} \times \text{Prevalenza})}{(\text{Sensibilità} \times \text{Prevalenza}) + (1 - \text{Specificità}) \times (1 - \text{Prevalenza})} \]
Analogamente, il valore predittivo negativo (VPN), che è la probabilità che un individuo non sia malato dato un risultato negativo del test, si calcola come:
\[ P(M^- \mid T^-) = \frac{P(T^- \mid M^-) \cdot (1 - P(M^+))}{P(T^- \mid M^-) \cdot (1 - P(M^+)) + P(T^- \mid M^+) \cdot P(M^+)}. \]
ovvero,
\[ NPV = \frac{\text{Specificità} \cdot (1 - \text{Prevalenza})}{\text{Specificità} \cdot (1 - \text{Prevalenza}) + (1 - \text{Sensibilità}) \cdot \text{Prevalenza}}. \]
Esempio 32.2 Implementiamo le formule del valore predittivo positivo e del valore predittivo negativo del test in Python e usiamo gli stessi dati dell’esercizio precedente.
def positive_predictive_value_of_diagnostic_test(sens, spec, prev):
return (sens * prev) / (sens * prev + (1 - spec) * (1 - prev))def negative_predictive_value_of_diagnostic_test(sens, spec, prev):
return (spec * (1 - prev)) / (spec * (1 - prev) + (1 - sens) * prev)Inseriamo i dati del problema.
sens = 0.9 # sensibilità
spec = 0.9 # specificità
prev = 0.01 # prevalenzaIl valore predittivo del test positivo è:
res_pos = positive_predictive_value_of_diagnostic_test(sens, spec, prev)
print(f"P(M+ | T+) = {round(res_pos, 3)}")P(M+ | T+) = 0.083Il valore predittivo del test negativo è:
res_neg = negative_predictive_value_of_diagnostic_test(sens, spec, prev)
print(f"P(M- | T-) = {round(res_neg, 3)}")P(M- | T-) = 0.999Esempio 32.3 La simulazione seguente ha lo scopo di aiutare a visualizzare il teorema di Bayes, utilizzando come esempio gli stessi dati della mammografia che abbiamo analizzato in precedenza.
# Parametri
sensitivity = 0.90 # Sensibilità del test (P(T+ | M+))
specificity = 0.90 # Specificità del test (P(T- | M-))
prev_cancer = 0.01 # Prevalenza (P(M+))
# La simulazione considera una popolazione di 100_000 persone.
N_mammography = 100_000
# Si genera un campione casuale di 100.000 persone, dove ogni persona viene
# etichettata come "Cancer" (cancro) o "Healthy" (sana), sulla base della
# prevalenza definita (1% per il cancro, 99% per i sani).
# np.random.choice sceglie tra le due opzioni ("Cancer", "Healthy") per ogni persona,
# con una probabilità di 0.01 per il cancro e 0.99 per essere sani.
outcome_mammography = np.random.choice(
["Cancer", "Healthy"], N_mammography, p=[prev_cancer, 1 - prev_cancer]
)
# Conteggio delle persone con e senza cancro.
# N_C: numero di persone con cancro nella simulazione.
# N_H: numero di persone sane nella simulazione.
N_C = np.sum(outcome_mammography == "Cancer")
N_H = np.sum(outcome_mammography == "Healthy")
# Si inizializza un array vuoto per memorizzare i risultati del test
# (positivo "+" o negativo "-").
test_mammography = np.empty(N_mammography, dtype=str)
# Per le persone con cancro, il risultato del test viene simulato utilizzando la
# sensibilità del test (90% positivo se hanno il cancro).
test_mammography[outcome_mammography == "Cancer"] = np.random.choice(
["+", "-"], N_C, p=[sensitivity, 1 - sensitivity]
)
# Per le persone sane, il risultato del test viene simulato utilizzando la
# specificità del test (90% negativo se sono sane).
test_mammography[outcome_mammography == "Healthy"] = np.random.choice(
["-", "+"], N_H, p=[specificity, 1 - specificity]
)
# Creazione di un DataFrame per memorizzare i risultati.
df_mammography = pd.DataFrame(
{"outcome": outcome_mammography, "test": test_mammography}
)
# Creazione di una tabella di contingenza. La tabella di contingenza mostra
# il numero di persone in ogni combinazione di esito (cancro o sano) e risultato
# del test (positivo o negativo). Questa tabella fornisce il conteggio dei veri
# positivi, falsi positivi, falsi negativi e veri negativi.
contingency_table_mammography = pd.crosstab(
df_mammography["outcome"], df_mammography["test"]
)
contingency_table_mammography| test | + | - |
|---|---|---|
| outcome | ||
| Cancer | 863 | 89 |
| Healthy | 9879 | 89169 |
# I risultati nella tabella di contingenza vengono usati per calcolare
# le probabilità sulla base della simulazione.
# Veri positivi (cancro e risultato positivo al test)
true_positives = contingency_table_mammography.loc["Cancer", "+"]
# Falsi positivi (sani e risultato positivo al test)
false_positives = contingency_table_mammography.loc["Healthy", "+"]
# Frequenza totale dei risultati positivi
total_positives = true_positives + false_positives
# Applicazione del teorema di Bayes sui dati simulati
P_M_given_T = true_positives / total_positives
P_M_given_T0.08033885682368275Utilizzando i dati della simulazione, la probabilità che una persona abbia il cancro al seno dato un risultato positivo al test è molto vicina al valore teorico calcolato in precedenza (circa 8.3%). Se eseguissimo la simulazione nuovamente, il valore ottenuto potrebbe variare leggermente a causa della casualità intrinseca nel campionamento. Tuttavia, ripetendo la simulazione molte volte, i risultati tenderanno a convergere verso il valore teorico, grazie alla legge dei grandi numeri. Questo conferma che il modello teorico è coerente con i risultati simulati.
Esempio 32.4 Poniamoci il problema di capire quanto sia affidabile un test per l’HIV. Per fare questo, utilizzeremo le seguenti informazioni (Petersen, 2024):
- Tasso di base dell’HIV (P(HIV)): 0.3% (0.003). Questa è la probabilità che una persona nella popolazione generale abbia l’HIV.
- Sensibilità del test (P(Test+ HIV)): 95% (0.95). Questa è la probabilità che il test risulti positivo se la persona ha effettivamente l’HIV.
- Specificità del test (P(Test- ¬HIV)): 99.28% (0.9928). Questa è la probabilità che il test risulti negativo se la persona non ha l’HIV.
Calcolo della probabilità di HIV dato un test positivo.
Per calcolare la probabilità di avere l’HIV dato un test positivo (P(HIV Test+)), utilizziamo il teorema di Bayes:
\[ P(HIV \mid Test+) = \frac{P(Test+ \mid HIV) \times P(HIV)}{P(Test+)}. \]
Abbiamo bisogno di calcolare il denominatore, ovvero la probabilità complessiva di ottenere un test positivo (P(Test+)). Questo valore include sia i veri positivi che i falsi positivi:
\[ P(Test+) = P(Test+ \mid HIV) \times P(HIV) + P(Test+ \mid \neg HIV) \times P(\neg HIV), \]
dove:
- \(P(Test+ \mid \neg HIV) = 1 - P(Test- \mid \neg HIV) = 1 - 0.9928 = 0.0072\) (tasso di falsi positivi),
- \(P(\neg HIV) = 1 - P(HIV) = 1 - 0.003 = 0.997\).
Calcoliamo \(P(Test+)\):
\[ P(Test+) = (0.95 \times 0.003) + (0.0072 \times 0.997) \approx 0.010027. \]
Ora possiamo calcolare \(P(HIV \mid Test+)\):
\[ P(HIV \mid Test+) = \frac{0.95 \times 0.003}{0.010027} \approx 0.2844 \text{ o 28.44\%}. \]
Quindi, se il test risulta positivo, la probabilità di avere l’HIV è circa il 28.44%.
Calcolo della probabilità di un secondo test positivo.
Dopo un primo test positivo, la probabilità di avere l’HIV è aumentata al 28.44%. Ora calcoleremo la probabilità che un secondo test risulti positivo e la conseguente probabilità di avere l’HIV dopo due test positivi consecutivi.
Per calcolare \(P(\text{Secondo Test+})\), consideriamo due scenari:
- La persona ha effettivamente l’HIV:
- Probabilità: \(P(HIV \mid Test+) = 0.2844\).
- Probabilità di un test positivo: \(P(\text{Test+} \mid HIV) = 0.95\) (sensibilità del test).
- La persona non ha l’HIV:
- Probabilità: \(P(\neg HIV \mid Test+) = 1 - P(HIV \mid Test+) = 0.7156\).
- Probabilità di un test positivo: \(P(\text{Test+} \mid \neg HIV) = 0.0072\) (tasso di falsi positivi).
Utilizziamo la formula della probabilità totale:
\[ \begin{aligned} P(\text{Secondo Test+}) &= P(\text{Test+} \mid HIV) \times P(HIV \mid Test+) + \\ &\quad P(\text{Test+} \mid \neg HIV) \times P(\neg HIV \mid Test+). \end{aligned} \]
Sostituendo i valori:
\[ P(\text{Secondo Test+}) = (0.95 \times 0.2844) + (0.0072 \times 0.7156) \approx 0.2753. \]
Applichiamo nuovamente il teorema di Bayes per calcolare la probabilità di avere l’HIV dopo un secondo test positivo:
\[ P(HIV \mid \text{Secondo Test+}) = \frac{P(\text{Secondo Test+} \mid HIV) \times P(HIV \mid Test+)}{P(\text{Secondo Test+})}. \]
Sostituendo i valori:
\[ P(HIV \mid \text{Secondo Test+}) = \frac{0.95 \times 0.2844}{0.2753} \approx 0.981. \]
Dopo un secondo test positivo, la probabilità di avere l’HIV aumenta significativamente, passando dal 28.44% al 98.1%. Questo aumento drastico dimostra l’importanza di:
- Considerare il tasso di base (prevalenza) nella popolazione.
- Aggiornare progressivamente le probabilità con nuove evidenze.
- Interpretare i risultati di test diagnostici multipli in modo bayesiano.
L’analisi evidenzia come l’accumulo di evidenze attraverso test ripetuti, in linea con i principi del teorema di Bayes, possa portare a una stima molto più accurata della probabilità di avere una condizione medica, riducendo significativamente l’incertezza iniziale.
Esempio 32.5 Consideriamo ora un altro esempio relativo ai test medici e analizziamo i risultati del test antigenico rapido per il virus SARS-CoV-2 alla luce del teorema di Bayes. Questo test può essere eseguito mediante tampone nasale, tampone naso-orofaringeo o campione di saliva. L’Istituto Superiore di Sanità, nel documento pubblicato il 5 novembre 2020, sottolinea che, fino a quel momento, i dati disponibili sui vari test erano quelli forniti dai produttori: la sensibilità varia tra il 70% e l’86%, mentre la specificità si attesta tra il 95% e il 97%.
Prendiamo un esempio specifico: nella settimana tra il 17 e il 23 marzo 2023, in Italia, il numero di individui positivi al virus è stato stimato essere di 138.599 (fonte: Il Sole 24 Ore). Questo dato corrisponde a una prevalenza di circa lo 0,2% su una popolazione totale di circa 59 milioni di persone.
prev = 138599 / 59000000
prev0.002349135593220339L’obiettivo è determinare la probabilità di essere effettivamente affetti da Covid-19, dato un risultato positivo al test antigenico rapido, ossia \(P(M^+ \mid T^+)\). Per raggiungere questo scopo, useremo la formula relativa al valore predittivo positivo del test.
sens = (0.7 + 0.86) / 2 # sensibilità
spec = (0.95 + 0.97) / 2 # specificità
res_pos = positive_predictive_value_of_diagnostic_test(sens, spec, prev)
print(f"P(M+ | T+) = {round(res_pos, 3)}")P(M+ | T+) = 0.044Pertanto, se il risultato del tampone è positivo, la probabilità di essere effettivamente affetti da Covid-19 è solo del 4.4%.
Se la prevalenza fosse 100 volte superiore (cioè, pari al 23.5%), la probabilità di avere il Covid-19, dato un risultato positivo del tampone, aumenterebbe notevolmente e sarebbe pari a circa l’86%.
prev = 138599 / 59000000 * 100
res_pos = positive_predictive_value_of_diagnostic_test(sens, spec, prev)
print(f"P(M+ | T+) = {round(res_pos, 3)}")P(M+ | T+) = 0.857Se il risultato del test fosse negativo, considerando la prevalenza stimata del Covid-19 nella settimana dal 17 al 23 marzo 2023, la probabilità di non essere infetto sarebbe del 99.9%.
sens = (0.7 + 0.86) / 2 # sensibilità
spec = (0.95 + 0.97) / 2 # specificità
prev = 138599 / 59000000 # prevalenza
res_neg = negative_predictive_value_of_diagnostic_test(sens, spec, prev)
print(f"P(M- | T-) = {round(res_neg, 3)}")P(M- | T-) = 0.999Tuttavia, un’esito del genere non dovrebbe sorprenderci, considerando che la prevalenza della malattia è molto bassa; in altre parole, il risultato negativo conferma una situazione già presunta prima di sottoporsi al test. Il vero ostacolo, specialmente nel caso di malattie rare come il Covid-19 in quel periodo specifico, non risiede tanto nell’asserire l’assenza della malattia quanto piuttosto nel confermarne la presenza.
Esempio 32.6 Consideriamo le persone in attesa di un figlio. Il teorema di Bayes gioca un ruolo cruciale nell’interpretazione dei test prenatali non invasivi (NIPT), un esame del sangue materno usato per rilevare anomalie cromosomiche fetali. Sebbene il NIPT sia spesso pubblicizzato con un’accuratezza del 99%, la sua affidabilità varia significativamente a seconda della condizione testata e della popolazione esaminata.
Parametri chiave del NIPT:
Sensibilità:
- Sindrome di Down: 99%
- Sindrome di Edwards: 97%
- Sindrome di Patau: 91%
Specificità: circa 99.9% per tutte le condizioni citate
Prevalenza nelle nascite:
- Sindrome di Down: 1 su 700 (0.14%)
- Sindrome di Edwards: 1 su 5,000 (0.02%)
- Sindrome di Patau: 1 su 10,000 (0.01%)
Nonostante l’alta sensibilità e specificità, il VPP può essere sorprendentemente basso, soprattutto nella popolazione generale. Questo implica che molti risultati positivi potrebbero essere falsi positivi, in particolare per le condizioni più rare.
Per calcolare il VPP, utilizziamo il teorema di Bayes:
\[ VPP = \frac{(\text{Sensibilità} \times \text{Prevalenza})}{(\text{Sensibilità} \times \text{Prevalenza}) + (1 - \text{Specificità}) \times (1 - \text{Prevalenza})} \]
Applicando questa formula alla popolazione generale:
Sindrome di Down: \[ VPP = \frac{(0.99 \times 0.0014)}{(0.99 \times 0.0014) + (1 - 0.999) \times (1 - 0.0014)} \approx 58\% \]
Sindrome di Edwards: \[ VPP = \frac{(0.97 \times 0.0002)}{(0.97 \times 0.0002) + (1 - 0.999) \times (1 - 0.0002)} \approx 16.2\% \]
Sindrome di Patau: \[ VPP = \frac{(0.91 \times 0.0001)}{(0.91 \times 0.0001) + (1 - 0.999) \times (1 - 0.0001)} \approx 8.3\% \]
Questi calcoli rivelano VPP molto bassi, specialmente per condizioni molto rare come la sindrome di Patau. Anche in questo caso, dunque, il teorema di Bayes ci mostra che la probabilità che un risultato positivo sia effettivamente corretto dipende non solo dall’accuratezza del test, ma anche dalla prevalenza della condizione nella popolazione testata. Per questo motivo, il NIPT risulta più affidabile nelle categorie ad alto rischio.
In conclusione, mentre il NIPT è uno strumento prezioso per lo screening prenatale, è fondamentale interpretare i risultati con cautela, considerando il contesto specifico di ogni paziente e la prevalenza della condizione nella popolazione di riferimento.
Esempio 32.7 Il teorema di Bayes non è rilevante solo in medicina. In ambito legale è presente un fenomeno noto come la Fallacia del Procuratore. La “fallacia del procuratore” è un errore logico che si verifica quando si confonde la probabilità di un evento dato un certo risultato con la probabilità di quel risultato dato l’evento. In ambito legale, si tratta spesso di confondere la probabilità di ottenere un risultato di un test (ad esempio, una corrispondenza del DNA) se una persona è innocente, con la probabilità che una persona sia innocente dato che il test ha mostrato una corrispondenza.
Supponiamo di avere i seguenti parametri per un test del DNA:
- Sensibilità: 99% (probabilità di identificare correttamente il colpevole).
- Specificità: 99.99997% (probabilità di identificare correttamente un innocente).
- Prevalenza: 1 su 65 milioni (probabilità a priori che una persona qualsiasi sia il colpevole, data una popolazione di 65 milioni).
Immaginiamo che ci sia stato un crimine e che un campione di DNA sia stato trovato sulla scena del crimine. Il campione è confrontato con il DNA di una persona nel database.
Svolgiamo i calcoli:
Probabilità a Priori (Prevalenza):
- La prevalenza \(P(C)\) che una persona casuale sia il colpevole è \(\frac{1}{65.000.000}\).
Sensibilità e Specificità:
- Sensibilità \(P(T+|C) = 0.99\).
- Specificità \(P(T-|I) = 0.9999997\).
Probabilità del Test Positivo:
- Probabilità di ottenere un test positivo \(P(T+)\) è la somma della probabilità di ottenere un positivo dai veri colpevoli e dai falsi positivi:
\[ P(T+) = P(T+|C) \cdot P(C) + P(T+|I) \cdot P(I), \]
- dove \(P(T+|I)\) è \(1 - \text{Specificità}\) e \(P(I)\) è la probabilità di essere innocente (\(1 - P(C)\)).
\[ P(T+) = 0.99 \cdot \frac{1}{65.000.000} + (1 - 0.9999997) \cdot \frac{64.999.999}{65.000.000} \]
\[ P(T+) \approx 0.99 \cdot 1.5385 \times 10^{-8} + 0.0000003 \cdot 0.9999999 \]
\[ P(T+) \approx 1.5231 \times 10^{-8} + 2.9999997 \times 10^{-7} \]
\[ P(T+) \approx 3.1523 \times 10^{-7} \]
- Probabilità Condizionale che il Sospetto sia Colpevole Dato un Test Positivo:
- Utilizzando il teorema di Bayes:
\[ P(C|T+) = \frac{P(T+|C) \cdot P(C)}{P(T+)} \]
\[ P(C|T+) = \frac{0.99 \cdot \frac{1}{65.000.000}}{3.1523 \times 10^{-7}} \]
\[ P(C|T+) = \frac{0.99 \times 1.5385 \times 10^{-8}}{3.1523 \times 10^{-7}} \]
\[ P(C|T+) \approx 0.0483 \]
Quindi, la probabilità che il sospetto sia effettivamente il colpevole, dato che il test del DNA è positivo, è circa 4.83%, nonostante l’alta specificità del test.
In sintesi, quando si afferma che c’è solo una probabilità su 3 milioni che il sospetto sia innocente (ovvero la specificità), si commette la fallacia del procuratore. In realtà, la probabilità che il sospetto sia colpevole, data una corrispondenza del DNA, è molto inferiore, come dimostrato nell’esempio numerico (circa 4.83%).
Questa fallacia può portare a errori giudiziari perché non si considera la bassa prevalenza del colpevole nella popolazione generale e si confonde la specificità del test con la probabilità condizionale di colpevolezza. In altre parole, non si riconosce che le due domande ‘Quanto è probabile che il DNA di una persona corrisponda al campione, se è innocente?’ e ‘Quanto è probabile che qualcuno sia innocente, dato che il suo DNA corrisponde al campione?’ non sono equivalenti. È come confondere ‘Quanto è probabile che un determinato essere umano sia il papa?’ con ‘Quanto è probabile che il papa sia un essere umano?’.
Esempio 32.8 Due dadi equi vengono lanciati e ti viene detto che la somma dei loro punteggi è 9. Qual è la distribuzione a posteriori dei punteggi di ciascun dado? (Questo esempio è tratto da Taylan Cemgil ed è discusso da Barber (2012)).
Indichiamo il punteggio del dado \(a\) con \(s_a\), dove \(\text{dom}(s_a) = \{1,2,3,4,5,6\}\), e in modo simile per \(s_b\). Le tre variabili coinvolte sono quindi \(s_a\), \(s_b\) e la somma totale, \(t = s_a + s_b\). Un modello per queste tre variabili assume la forma:
\[ p(t, s_a, s_b) = p(t | s_a, s_b) p(s_a, s_b), \]
dove:
- Likelihood: \(p(t | s_a, s_b)\) rappresenta la probabilità che la somma dei dadi sia \(t\) dato \(s_a\) e \(s_b\).
- Prior: \(p(s_a, s_b)\) è la probabilità congiunta dei punteggi \(s_a\) e \(s_b\) senza conoscere la somma \(t\).
Assumiamo che i dadi siano equi e indipendenti, quindi la probabilità congiunta \(p(s_a, s_b)\) è il prodotto delle distribuzioni uniformi di \(s_a\) e \(s_b\):
\[ p(s_a, s_b) = p(s_a) p(s_b) = \frac{1}{6} \times \frac{1}{6} = \frac{1}{36}. \]
Il termine di likelihood è dato da:
\[ p(t | s_a, s_b) = I[t = s_a + s_b], \]
dove \(I[A]\) è la funzione indicatrice che vale 1 se la condizione \(A\) è vera e 0 altrimenti.
Abbiamo che \(p(t = 9 | s_a, s_b)\) è 1 se la somma di \(s_a\) e \(s_b\) è 9, altrimenti è 0. Quindi la likelihood è data dalla seguente tabella:
| \(s_b\) \ | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| \(s_a\) | ||||||
| 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 | 0 | 0 | 1 |
| 4 | 0 | 0 | 0 | 0 | 1 | 0 |
| 5 | 0 | 0 | 0 | 1 | 0 | 0 |
| 6 | 0 | 0 | 1 | 0 | 0 | 0 |
Le combinazioni possibili sono quindi \((3,6), (4,5), (5,4), (6,3)\).
La distribuzione a posteriori dei punteggi dei dadi, data la somma \(t = 9\), si calcola con:
\[ p(s_a, s_b | t = 9) = \frac{p(t = 9 | s_a, s_b) p(s_a) p(s_b)}{p(t = 9)}. \]
Il denominatore \(p(t = 9)\) è la somma dei termini non nulli del numeratore:
\[ p(t = 9) = \sum_{s_a, s_b} p(t = 9 | s_a, s_b) p(s_a) p(s_b) = 4 \times \frac{1}{36} = \frac{1}{9}. \]
Quindi, la distribuzione a posteriori è:
| \(s_b\) \ | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| \(s_a\) | ||||||
| 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 | 0 | 0 | 1/4 |
| 4 | 0 | 0 | 0 | 0 | 1/4 | 0 |
| 5 | 0 | 0 | 0 | 1/4 | 0 | 0 |
| 6 | 0 | 0 | 1/4 | 0 | 0 | 0 |
In questo caso, le uniche combinazioni con probabilità non nulla sono quelle in cui la somma è 9, e ciascuna di queste ha probabilità \(1/4\).
32.3 Probabilità Inversa
Gli esempi precedenti evidenziano la differenza tra due domande fondamentali. La prima è: “Qual è la probabilità di osservare un determinato risultato, supponendo che una certa ipotesi sia vera?” La seconda, invece, è: “Qual è la probabilità che un’ipotesi sia vera, dato il risultato osservato?”
Un esempio che risponde alla prima domanda potrebbe essere questo: supponiamo che la probabilità di ottenere testa nel lancio di una moneta sia 0,5 (ipotesi). Qual è la probabilità di ottenere 0 teste in cinque lanci?
Per la seconda domanda, un esempio potrebbe essere: supponiamo di aver ottenuto 0 teste in 5 lanci di una moneta (evidenza). Qual è la probabilità che la moneta sia effettivamente bilanciata, alla luce di questa osservazione?
Per molto tempo, lo studio della probabilità si è concentrato principalmente sulla prima domanda. Tuttavia, nel XVIII secolo, il reverendo Thomas Bayes iniziò a riflettere sulla seconda domanda, dando origine a quello che oggi chiamiamo probabilità inversa.
Questo approccio ha generato numerose controversie nella storia della statistica, in gran parte perché influenza molti ambiti. Ad esempio, possiamo chiederci: quanto è probabile che un’ipotesi scientifica sia vera, dato il risultato di un esperimento? Per stimare questa probabilità — un compito che molti scienziati ritengono essenziale per la statistica moderna — è necessario fare uso del teorema di Bayes e delle probabilità a priori.
32.4 Riflessioni Conclusive
In questo capitolo abbiamo esplorato vari esempi, principalmente nel campo medico e forense, per illustrare come il teorema di Bayes permetta di combinare le informazioni derivate dalle osservazioni con le conoscenze precedenti (priori), aggiornando così il nostro grado di convinzione rispetto a un’ipotesi. Il teorema di Bayes fornisce un meccanismo razionale, noto come “aggiornamento bayesiano”, che ci consente di ricalibrare le nostre convinzioni iniziali alla luce di nuove evidenze.
Una lezione fondamentale che il teorema di Bayes ci insegna, sia nella ricerca scientifica che nella vita quotidiana, è che spesso non ci interessa tanto conoscere la probabilità che qualcosa accada assumendo vera un’ipotesi, quanto piuttosto la probabilità che un’ipotesi sia vera, dato che abbiamo osservato una certa evidenza. In altre parole, la forza del teorema di Bayes sta nella sua capacità di affrontare direttamente il problema inverso, cioè come dedurre la verità di un’ipotesi a partire dalle osservazioni.
Il framework bayesiano per l’inferenza probabilistica offre un approccio generale per comprendere come i problemi di induzione possano essere risolti in linea di principio e, forse, anche come possano essere affrontati dalla mente umana.
In questo capitolo ci siamo concentrati sull’applicazione del teorema di Bayes utilizzando probabilità puntuali. Tuttavia, il teorema esprime pienamente il suo potenziale quando sia l’evidenza che i gradi di certezza a priori delle ipotesi sono rappresentati attraverso distribuzioni di probabilità continue. Questo sarà l’argomento centrale nel Capitolo 40, dove approfondiremo il flusso di lavoro bayesiano e l’uso di distribuzioni continue nell’aggiornamento bayesiano.
32.5 Informazioni sull’Ambiente di Sviluppo
%load_ext watermark
%watermark -n -u -v -iv -w -mLast updated: Sat Mar 16 2024
Python implementation: CPython
Python version : 3.11.8
IPython version : 8.22.2
Compiler : Clang 16.0.6
OS : Darwin
Release : 23.4.0
Machine : arm64
Processor : arm
CPU cores : 8
Architecture: 64bit
seaborn : 0.13.2
pandas : 2.2.1
matplotlib: 3.8.3
numpy : 1.26.4
arviz : 0.17.0
Watermark: 2.4.3