57 Flusso di lavoro bayesiano
Prerequisiti
Concetti e Competenze Chiave
- Workflow bayesiano: Approccio iterativo che include formulazione, implementazione, verifica e miglioramento continuo dei modelli.
- Ciclo di Box: Processo iterativo di modellizzazione statistica, basato su inferenza, valutazione e revisione continua del modello.
- Verifiche predittive: Simulazioni dei dati a priori e a posteriori per testare la coerenza del modello con i dati osservati.
- Iterazione e miglioramento: Il processo di costruzione dei modelli procede per successivi raffinamenti, partendo da modelli semplici a soluzioni più complesse e precise.
- Analisi multiverso: Un framework per la considerazione congiunta e trasparente di diversi modelli candidati (Steegen et al., 2016).
57.1 Introduzione
L’applicazione dell’inferenza bayesiana nella risoluzione di problemi reali richiede un approccio strutturato e multidisciplinare, noto come workflow bayesiano. Questo processo iterativo e complesso va ben oltre la semplice applicazione della regola di Bayes, che pur costituendo il fondamento teorico dell’inferenza bayesiana, rappresenta solo il punto di partenza di un percorso analitico più articolato.
Il workflow bayesiano richiede al ricercatore una combinazione di competenze che spaziano dalla statistica alla conoscenza approfondita del dominio applicativo, dalle abilità di programmazione alla comprensione dei processi decisionali nell’analisi dei dati. Questo approccio comprende diverse fasi interconnesse: la costruzione iterativa di modelli, la loro verifica e validazione, la risoluzione di problemi computazionali, l’interpretazione dei risultati e il confronto tra modelli alternativi.
L’applicazione pratica del workflow bayesiano emerge, per esempio, in contesti come la valutazione dell’effetto di un intervento psicologico. In questo scenario, il ricercatore si trova di fronte a molteplici decisioni: la scelta delle covariate, la definizione di componenti gerarchiche del modello, la selezione delle distribuzioni per le osservazioni e le priori marginali. Queste scelte non sono definitive, ma parte di un processo iterativo che può richiedere revisioni e aggiustamenti in base ai risultati ottenuti.
La complessità del workflow bayesiano si manifesta anche nella gestione di possibili problemi computazionali, che possono compromettere la qualità dei campioni dalla distribuzione a posteriori. In questi casi, il ricercatore deve essere pronto a riformulare il modello o a modificare l’approccio computazionale. Inoltre, l’analisi non si limita alla stima dei parametri di interesse, ma include anche la valutazione delle capacità predittive del modello e il confronto con modelli alternativi.
Un aspetto cruciale del workflow bayesiano è la necessità di bilanciare la complessità dell’analisi con la rilevanza pratica dei risultati. Mentre l’uso di un singolo modello può portare a stime distorte dell’effetto del trattamento, l’esplorazione di numerosi modelli alternativi può generare una mole di informazioni difficile da gestire e interpretare. Il ricercatore deve quindi essere in grado di identificare i modelli più rilevanti per la valutazione dell’effetto del trattamento, considerando che modelli diversi possono portare a conclusioni differenti.
In sintesi, il workflow bayesiano si configura come una procedura strutturata per gestire le molteplici decisioni relative alla costruzione, revisione e miglioramento dei modelli statistici. Questo approccio, pur basandosi sui principi dell’inferenza bayesiana, va oltre la semplice applicazione della regola di Bayes, offrendo un quadro metodologico completo per affrontare le sfide dell’analisi dei dati in contesti reali e complessi.
57.2 Principi del workflow bayesiano
I workflow esistono in una varietà di discipline dove definiscono cosa costituisce una “buona pratica”.
57.3 Il Ciclo di Box
George Box, figura di spicco nel campo della statistica, ha introdotto negli anni ’60 un approccio ciclico alla modellizzazione statistica, noto come Ciclo di Box. Questo paradigma ha profondamente influenzato il modo in cui i ricercatori affrontano la costruzione e la valutazione dei modelli, in particolare nell’ambito dell’inferenza bayesiana.
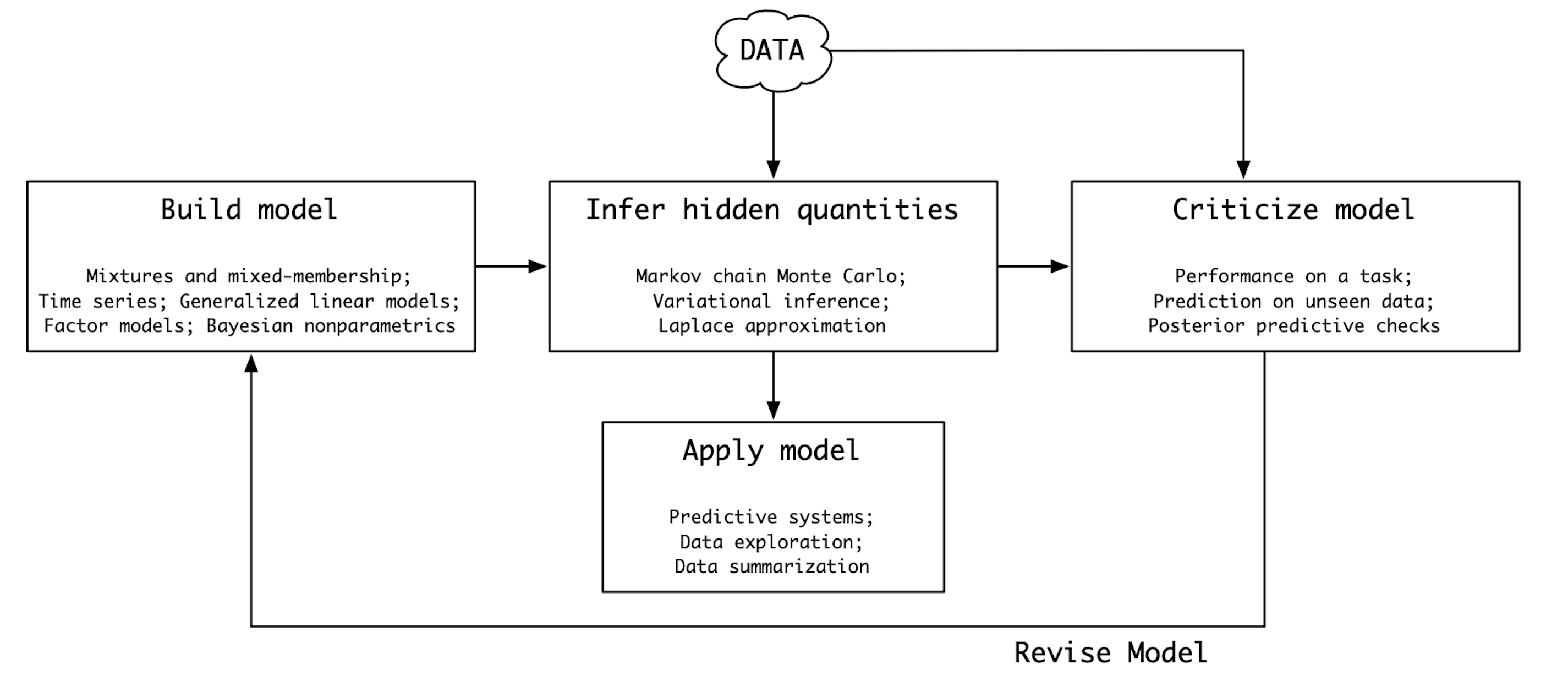
Il Ciclo di Box si articola in una serie di fasi iterative:
- Formulazione del modello: Sulla base delle conoscenze a priori e dei dati disponibili, si costruisce un modello statistico che cattura le caratteristiche essenziali del fenomeno in esame.
- Inferenza: Attraverso l’applicazione di tecniche inferenziali, si stimano i parametri del modello e si valutano le incertezze associate alle stime stesse.
- Valutazione del modello: Il modello viene confrontato con i dati osservati al fine di verificarne l’adeguatezza e individuare eventuali discrepanze.
- Revisione del modello: In caso di inadeguatezza, il modello viene modificato e si ritorna alla fase di inferenza. Questo processo iterativo continua fino a quando il modello non fornisce una descrizione soddisfacente dei dati.
Il Ciclo di Box rappresenta un approccio pragmatico alla modellizzazione statistica. Il processo di modellazione è concepito come un percorso evolutivo, in cui il modello viene continuamente raffinato alla luce delle nuove evidenze. Il paradigma bayesiano si sposa perfettamente con il Ciclo di Box. L’inferenza bayesiana permette di aggiornare le credenze a priori alla luce dei dati osservati, fornendo una base solida per la revisione iterativa dei modelli. Più recentemente, Gelman et al. (2020) hanno proposto un’estensione più dettagliata del Ciclo di Box, offrendo una guida pratica per l’implementazione di un workflow bayesiano completo.
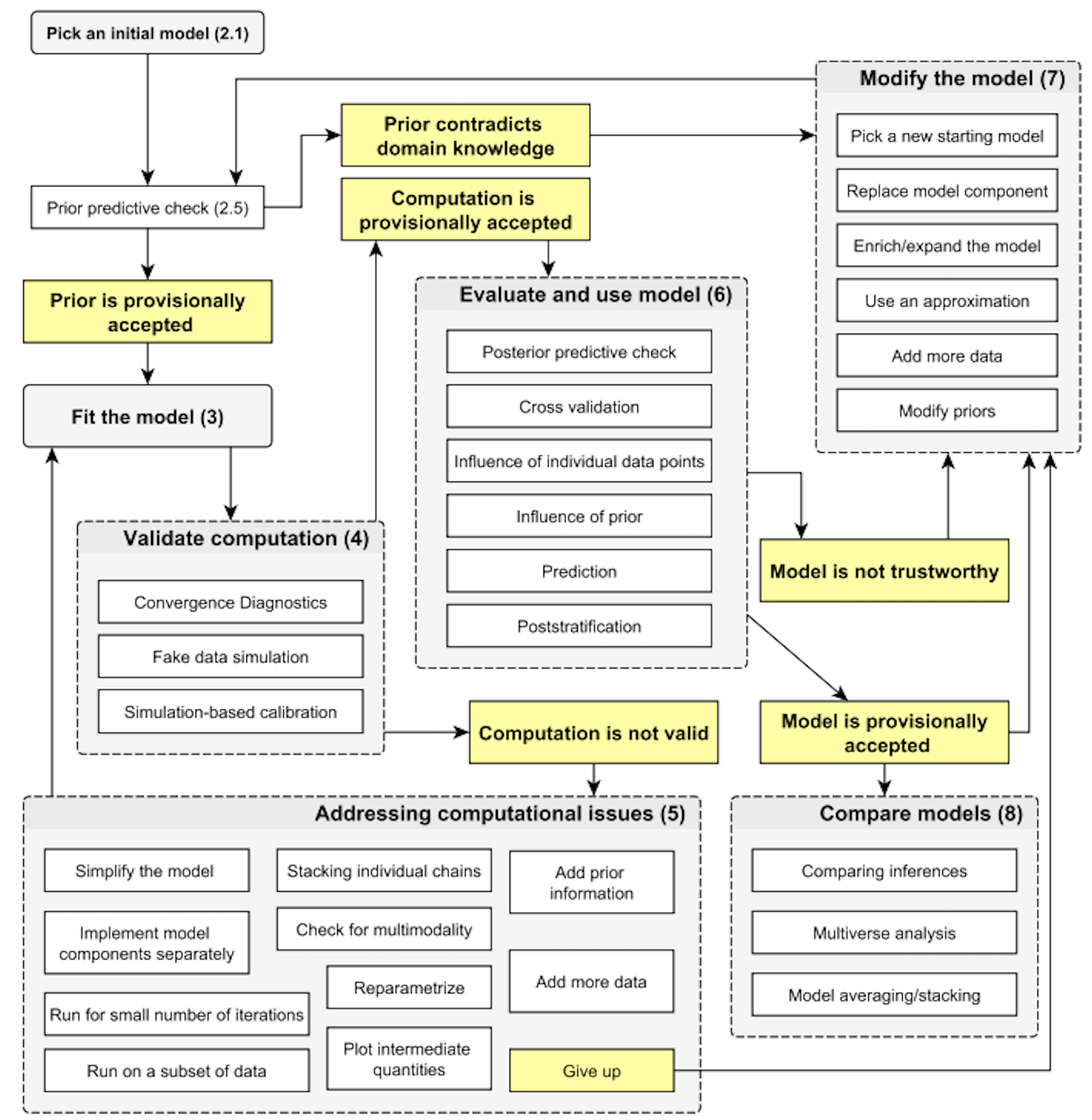
57.4 Costruzione iterativa del modello
In pratica, un possibile ciclo del workflow bayesiano può essere descritto nei seguenti termini:
Comprendere il fenomeno di interesse e formulare chiaramente il problema da risolvere. Come verrà discusso in modo approfondito nelle sezioni dedicate all’inferenza causale, limitarsi a descrivere le associazioni tra variabili offre una comprensione limitata del fenomeno di interesse. È molto più utile partire da un’ipotesi sul meccanismo generatore dei dati, cioè sul funzionamento causale del fenomeno, per poi testarla attraverso la modellizzazione bayesiana.
Formulare matematicamente il modello. La formulazione matematica del modello è facilitata dall’uso di linguaggi probabilistici (PPL), come Stan, che permettono di tradurre le ipotesi sul processo generativo dei dati in modelli probabilistici concreti.
Implementare il modello. Il modello matematico può essere implementato utilizzando diverse interfacce per Stan, come R, Python o Julia. Queste interfacce forniscono strumenti potenti per definire e adattare modelli complessi, consentendo un’integrazione agevole con i flussi di lavoro esistenti.
Eseguire verifiche predittive a priori. Le verifiche predittive a priori consistono nel simulare dati a partire dai valori di parametri estratti dalle distribuzioni a priori. Questo processo permette di visualizzare l’intervallo di dati che il modello ritiene plausibile prima di osservare i dati effettivi, fornendo un modo intuitivo per valutare l’adeguatezza dei priori scelti. È spesso più semplice ottenere una conoscenza esperta su quantità osservabili piuttosto che su parametri astratti, per cui queste simulazioni aiutano a calibrare i modelli in base alle aspettative ragionevoli.
Adattare il modello. Una volta definito il modello, esso viene adattato ai dati attraverso l’esecuzione del campionamento, utilizzando la sintassi specifica dell’interfaccia scelta (ad esempio,
cmdstanrocmdstanpy).Valutare le diagnostiche di convergenza. Una volta completato il campionamento, è fondamentale verificare che la catena MCMC sia convergente e stabile. Diagnostiche come il
R-hat, l’efficienza della campionatura, e il controllo della varianza tra le catene sono essenziali per confermare che il modello sia stato adattato correttamente e che le inferenze siano affidabili.Eseguire verifiche predittive a posteriori. Le verifiche predittive a posteriori prevedono la simulazione di nuovi dati utilizzando la distribuzione predittiva posteriore. In altre parole, dopo aver stimato i parametri del modello basandoci sui dati osservati, generiamo nuovi dataset che potrebbero essere stati osservati. Il confronto tra questi dati simulati e i dati reali è cruciale per valutare la capacità del modello di riprodurre il fenomeno osservato. Se emergono discrepanze significative, potrebbe essere necessario rivedere le assunzioni del modello. Inoltre, le verifiche a posteriori forniscono un’indicazione dell’incertezza nelle previsioni, permettendoci di calcolare intervalli di credibilità per le nuove osservazioni.
Migliorare iterativamente il modello. Il processo di costruzione del modello è spesso iterativo: si parte da modelli semplici, che vengono progressivamente raffinati e resi più complessi o efficienti dal punto di vista computazionale. Questa iterazione è guidata dalle verifiche predittive, dalle diagnostiche e dal confronto tra i dati osservati e quelli simulati, fino a raggiungere un modello che descriva adeguatamente il fenomeno di interesse e fornisca previsioni robuste.
Questo processo ciclico permette di costruire modelli sempre più accurati, rendendo il workflow bayesiano una strategia flessibile ed efficace per affrontare problemi complessi.
57.5 Analisi Multiverso
Il concetto di workflow bayesiano è stato recentemente arricchito dall’introduzione della multiverse analysis, come proposto da Riha et al. (2024). Questo approccio innovativo supera la tradizionale focalizzazione su un singolo modello, abbracciando invece l’analisi simultanea di molteplici modelli plausibili. Il risultato è la creazione di un “multiverso” di modelli, dove ciascuno rappresenta una combinazione unica di scelte modellistiche, dalle covariate selezionate alle distribuzioni per osservazioni e priori.
L’integrazione della multiverse analysis nel workflow bayesiano offre numerosi vantaggi:
- Trasparenza: Esplicita tutte le scelte di modellazione, chiarendo quali modelli sono stati considerati e perché.
- Esplorazione completa: Permette un’indagine parallela di diverse ipotesi, riducendo il rischio di trascurare modelli validi. Risponde a domande quali: “In che modo i risultati differiscono tra i vari modelli esplorati?”, “Quali sono le principali differenze e somiglianze?”
- Valutazione comparativa: Facilita il confronto diretto tra modelli, consentendo una valutazione più robusta delle conclusioni. Risponde a domande quali: “In base a quali criteri sono stati selezionati i modelli più adatti?”, “Lo spazio dei modelli possibili è stato esplorato in modo esaustivo?”, “Sono state considerate tutte le alternative plausibili?”, “In che modo i risultati differiscono tra i vari modelli esplorati?”, “Quali sono le principali differenze e somiglianze?”
- Iterazione efficiente: Consente di perfezionare simultaneamente più modelli, anziché di perfezionare sequenzialmente un singolo modello.
- Replicabilità: Fornisce informazioni dettagliate per riprodurre l’analisi e i risultati.
Questo approccio incorpora anche verifiche computazionali e analisi di sensibilità. Le prime identificano i modelli che necessitano di ulteriori verifiche per garantire l’affidabilità dei risultati, mentre le seconde esaminano la robustezza delle conclusioni rispetto alle diverse scelte di modellazione e all’influenza delle priori sulle stime posteriori.
Tuttavia, la generazione di numerosi modelli può complicare la gestione e l’interpretazione dei risultati. Per affrontare questa sfida, Riha et al. (2024) propongono un metodo di “iterative filtering” che comprende:
- Creazione di un multiverso iniziale di modelli.
- Valutazione delle capacità predittive attraverso controlli predittivi posteriori (PPC) e calcolo dell’expected log point-wise predictive density (elpd).
- Verifica della qualità computazionale, esaminando convergenza ed efficienza del campionamento MCMC.
- Filtraggio iterativo basato su criteri di qualità predefiniti.
- Possibilità di estendere il multiverso e ripetere il processo.
Questo approccio mantiene i vantaggi della multiverse analysis riducendo al contempo la complessità attraverso un filtraggio sistematico. Il risultato è un workflow bayesiano più robusto e informativo, che bilancia la necessità di considerare molteplici ipotesi modellistiche con l’esigenza pratica di focalizzarsi sui modelli più promettenti per il problema in esame.
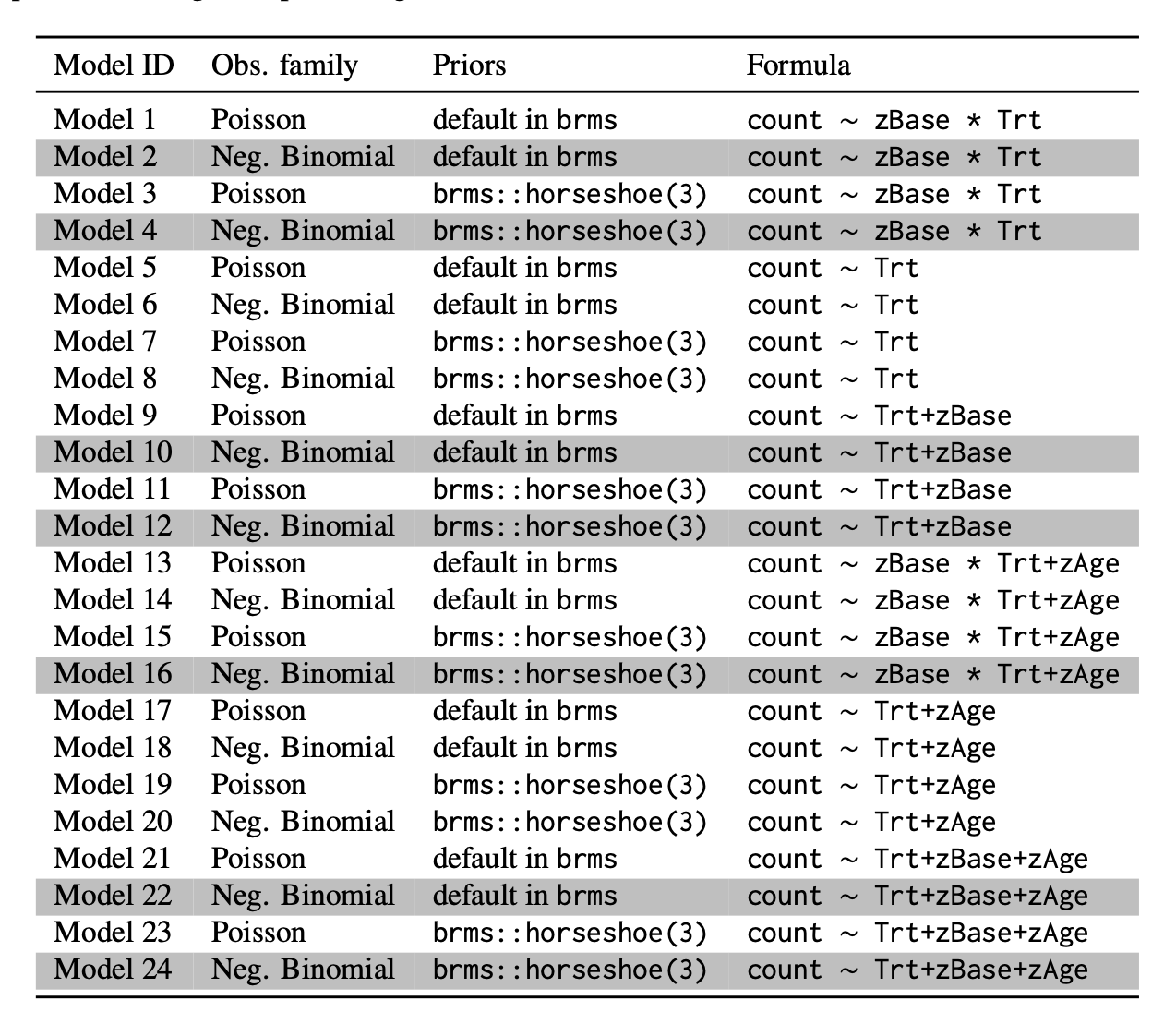
Uno dei casi di studio esaminati da Riha et al. (2024) riguarda l’analisi del numero di crisi epilettiche in relazione a diverse variabili (covariate) e scelte di modellazione. I dati utilizzati provengono dallo studio di Leppik et al. (1987) e sono disponibili nel pacchetto R brms.
Sono stati confrontati 24 modelli statistici, ciascuno con una specifica formulazione matematica (illustrata nella Tabella seguente). La scelta dei modelli ha riguardato diverse combinazioni di covariate e di distribuzioni di probabilità per descrivere il fenomeno in esame.
Per valutare la capacità predittiva dei modelli, è stato utilizzato il criterio ELPD (Expected Log-Predictive Density). I risultati sono riportati nel grafico seguente.
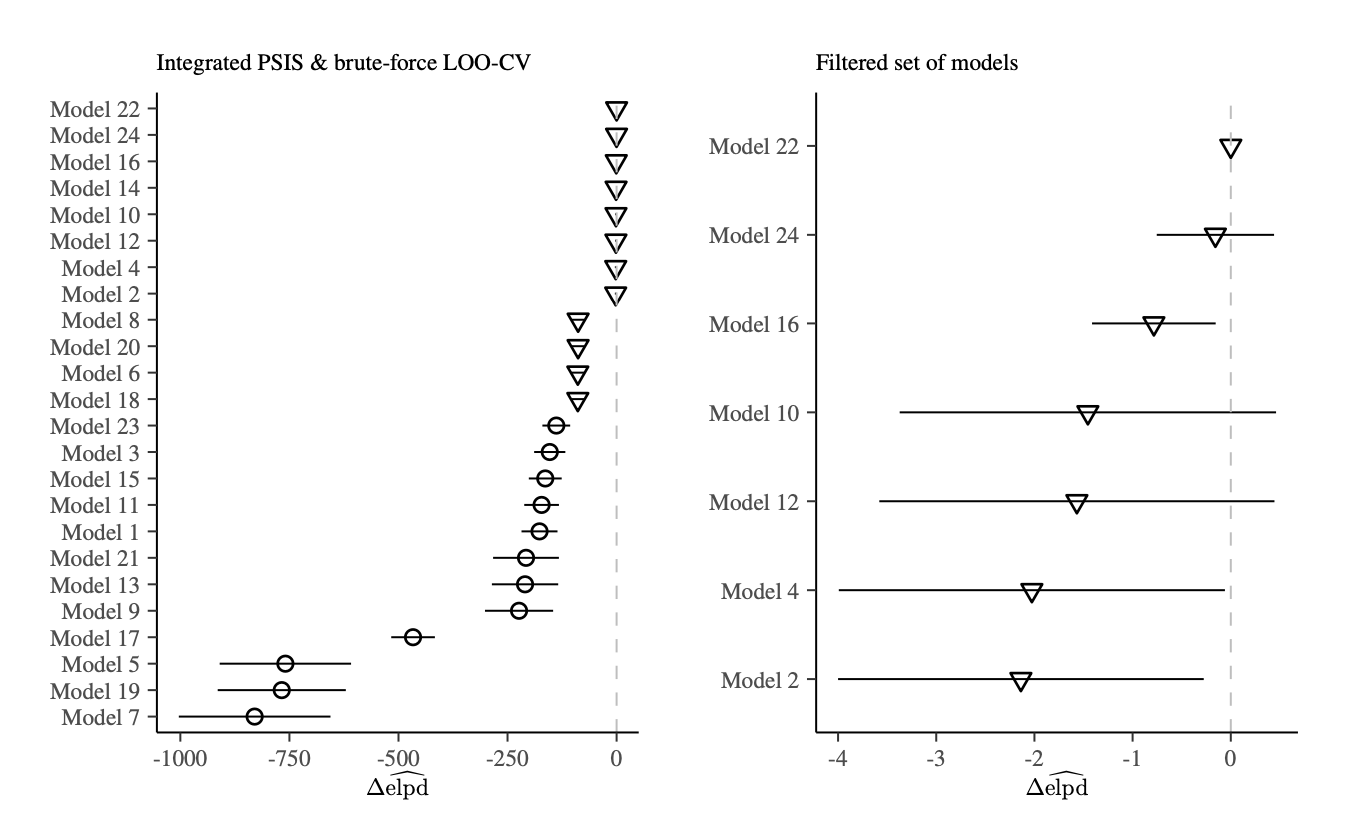
Come si può osservare, i modelli presentano performance predittive differenti.
Oltre all’ELPD, sono stati condotti controlli predittivi posteriori (PPC) per valutare la plausibilità dei modelli rispetto ai dati osservati. I risultati dei PPC sono visualizzati nella figura seguente.
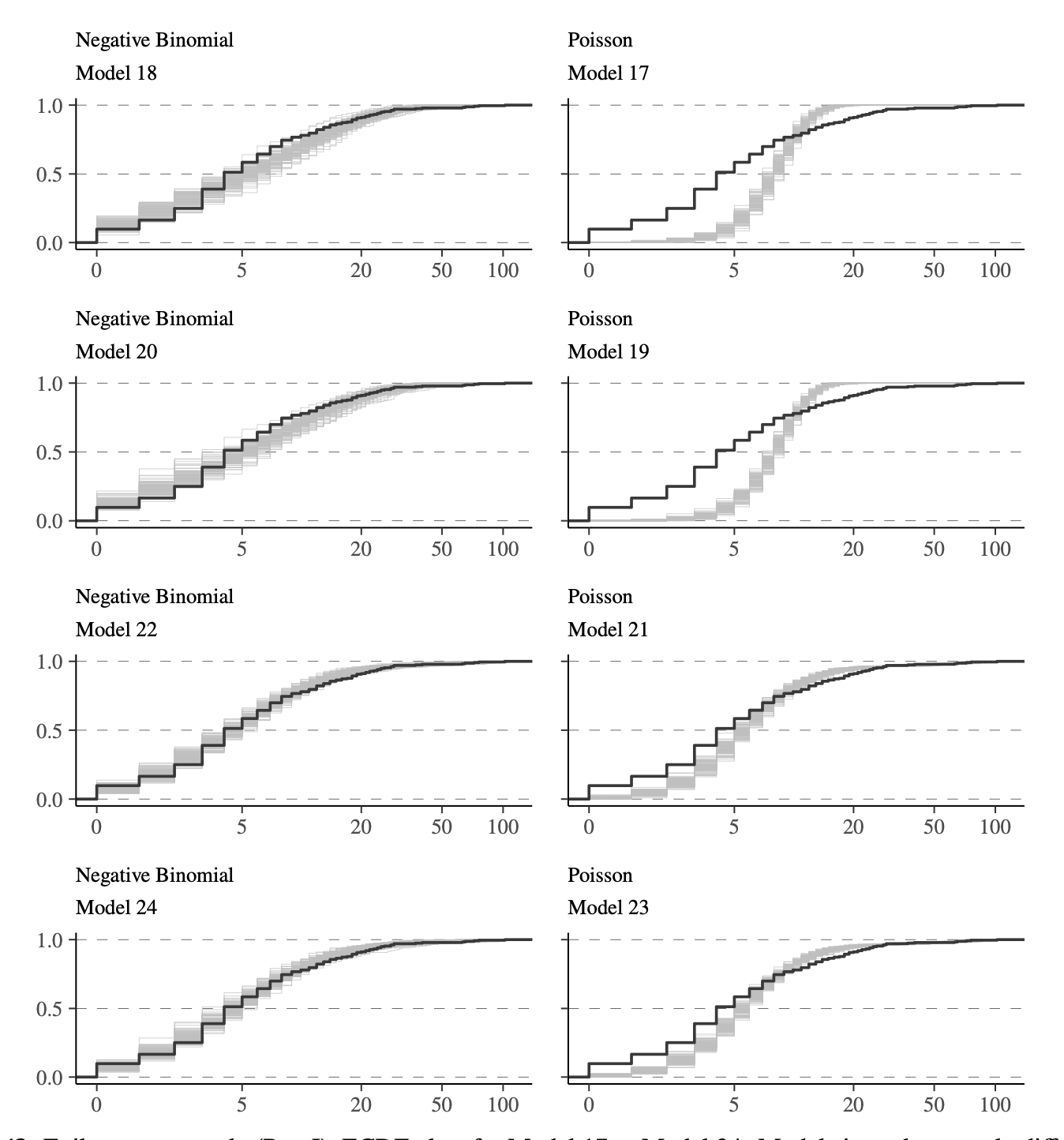
Il modello selezionato è quello che ha mostrato il miglior valore di ELPD, evidenziando una buona capacità predittiva. Inoltre, i controlli PPC hanno confermato la plausibilità del modello rispetto ai dati osservati. Infine, il modello selezionato non ha presentato problemi computazionali durante la stima dei parametri.
57.6 Considerazioni Conclusive
L’inferenza bayesiana offre un potente framework per la modellizzazione dei dati complessi, fornendo una metodologia che non si limita alla stima dei parametri, ma permette di rappresentare e aggiornare le incertezze sulle ipotesi in modo iterativo. Come abbiamo visto, il workflow bayesiano, ispirato dal Ciclo di Box e dai contributi più recenti, si articola in una serie di fasi che vanno dalla comprensione del fenomeno alla costruzione, implementazione e verifica dei modelli. Ogni passaggio è essenziale per garantire che il modello rispecchi non solo i dati, ma anche la nostra conoscenza del processo generativo sottostante.
L’approccio iterativo consente una continua revisione e ottimizzazione del modello, tenendo conto delle evidenze empiriche e delle nostre credenze a priori. Le verifiche predittive, sia a priori che a posteriori, sono strumenti fondamentali per valutare la qualità del modello e per affrontare le eventuali discrepanze tra i dati osservati e quelli simulati. Questo processo ciclico ci permette di costruire modelli sempre più precisi ed efficaci, rappresentando una strategia dinamica e flessibile per affrontare le sfide dell’inferenza in contesti reali. Inoltre, l’analisi multiverso permette di confrontare numerosi modelli plausibili, variando ipotesi su covariate, meccanismo generativo e prior.
Infine, l’integrazione del workflow bayesiano con linguaggi probabilistici come Stan o PyMC facilita l’applicazione di queste metodologie, consentendo ai ricercatori di affrontare problemi complessi in modo strutturato ed efficiente.