In questo capitolo esamineremo in dettaglio le distribuzioni predittive a priori e a posteriori. La distribuzione predittiva a priori rappresenta le aspettative sui dati prima di qualsiasi osservazione reale, riflettendo le conoscenze preesistenti e le ipotesi sui parametri del modello. Essa fornisce un’indicazione delle caratteristiche che i dati potrebbero assumere in base al modello. Confrontare queste previsioni con i dati effettivamente osservati consente di valutare la validità delle ipotesi incorporate nel modello.
La distribuzione predittiva è spesso di maggiore interesse rispetto alla distribuzione a posteriori. Mentre la distribuzione a posteriori descrive l’incertezza sui parametri (ad esempio, la proporzione di palline rosse in un’urna), la distribuzione predittiva descrive anche l’incertezza sugli eventi futuri (ad esempio, il colore della pallina che verrà estratta in futuro). Questa differenza è cruciale, soprattutto quando si tratta di prevedere gli effetti di un intervento, come la somministrazione di un trattamento a un paziente.
La distribuzione predittiva a posteriori è inoltre fondamentale per valutare quanto le previsioni del modello siano coerenti con i dati osservati. Se le previsioni del modello risultano allineate con i dati raccolti, il modello può essere considerato accurato nel rappresentare il processo generativo sottostante. Questo confronto è essenziale per convalidare il modello e assicurarsi che le ipotesi riflettano adeguatamente la realtà osservata.
56.1 La distribuzione predittiva a posteriori
La distribuzione predittiva a posteriori offre una valutazione critica della coerenza tra i dati reali e quelli simulati dal modello (Gelman & Shalizi, 2013). Confrontando direttamente i dati osservati con quelli generati dal modello, essa permette di identificare eventuali discrepanze che potrebbero segnalare problemi nella specificazione del modello. In pratica, la PPC (Posterior Predictive Check) funge da test diagnostico, consentendo di rilevare e correggere eventuali carenze nel modello, migliorandone così le capacità predittive.
Per comprendere meglio il concetto, consideriamo la distribuzione predittiva a posteriori in termini di un modello coniugato normale-normale. Supponiamo di voler predire la media di una distribuzione normale futura, basandoci sui dati osservati e sulle nostre conoscenze a priori. La PPD ci offre uno strumento per calcolare queste probabilità, combinando le informazioni provenienti dai dati osservati con quelle fornite dalla distribuzione a priori.
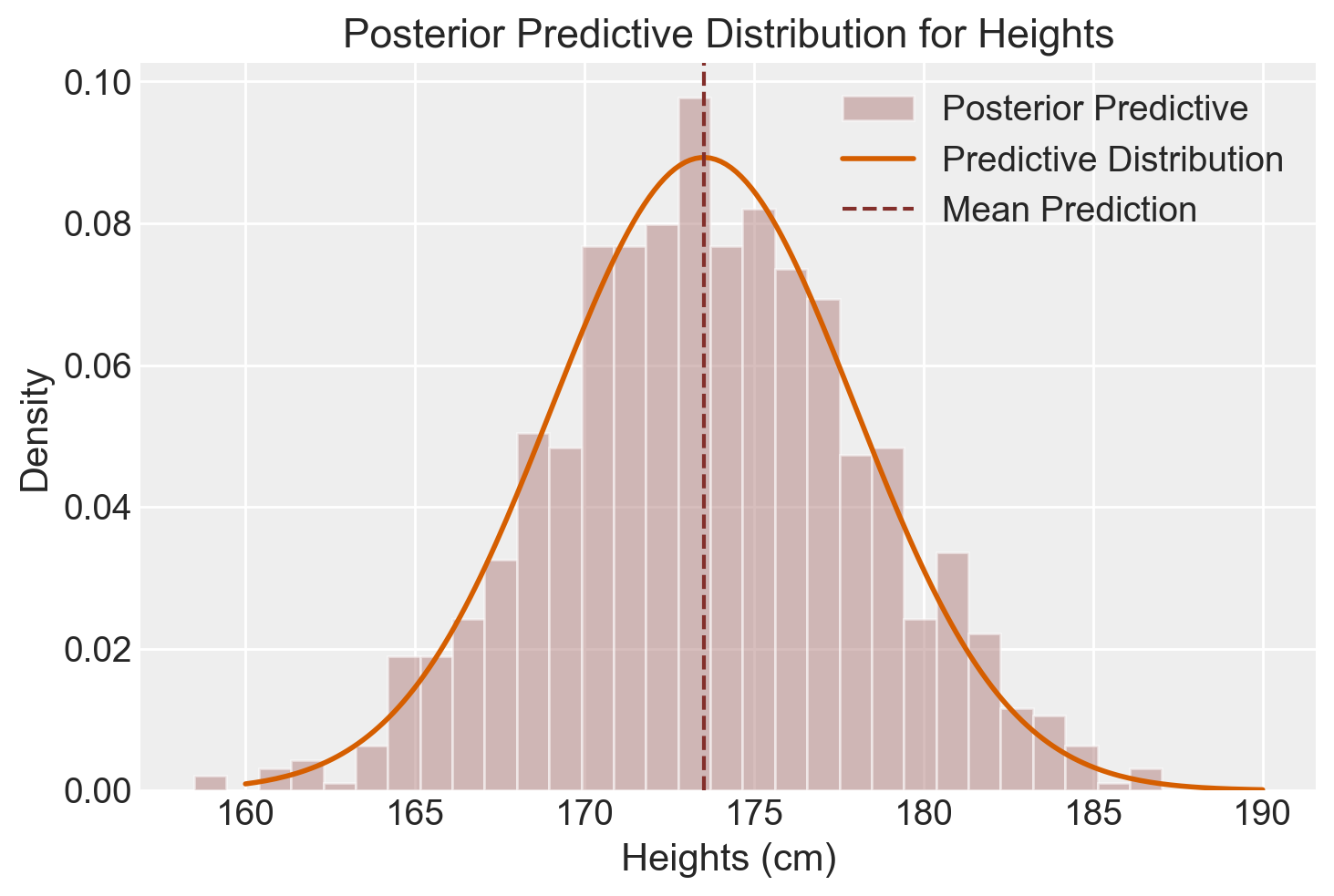
Ad esempio, immaginiamo di aver raccolto dati sulle altezze di 100 persone, ottenendo una media campionaria di 170 cm e una deviazione standard campionaria di 10 cm. Il nostro obiettivo è stimare la media delle altezze in un futuro campione di \(n=100\) persone. La nostra conoscenza a priori sulla media delle altezze è rappresentata da una distribuzione normale con media 175 cm e deviazione standard di 5 cm.
In termini di notazione, possiamo esprimere questa distribuzione come \(P(\tilde{y}|\theta=\theta_1)\), dove \(\tilde{y}\) rappresenta un nuovo dato che è diverso dai dati attuali \(y\), e \(\theta_1\) è la media a posteriori. Tuttavia, in statistica bayesiana, è fondamentale incorporare tutta l’incertezza nei risultati. Poiché \(\theta_1\) è solo uno dei possibili valori per \(\theta\), dovremmo includere ogni valore di \(\theta\) per la nostra previsione. Per ottenere la migliore previsione, possiamo “mediare” le previsioni attraverso i diversi valori di \(\theta\), ponderando ciascun valore secondo la sua probabilità a posteriori.
La distribuzione risultante è la distribuzione predittiva a posteriori, che in notazione matematica è data da:
In questo modo, la distribuzione predittiva a posteriori combina le informazioni dai dati osservati con la conoscenza a priori, fornendo una previsione che riflette l’incertezza associata a tutti i possibili valori dei parametri del modello.
56.2 Distribuzione predittiva a posteriori nel modello normale-normale
Nel modello coniugato normale-normale, se i dati osservati \(Y = \{y_1, y_2, ..., y_n\}\) sono modellati come provenienti da una distribuzione normale con media \(\mu\) e varianza \(\sigma^2\), e assumendo una distribuzione a priori normale per \(\mu\), la distribuzione a posteriori di \(\mu\) sarà anch’essa normale.
56.2.1 Formule della distribuzione predittiva a posteriori
Dato che:
I dati osservati \(y_i \sim \mathcal{N}(\mu, \sigma^2)\)
La prior per \(\mu\) è \(\mu \sim \mathcal{N}(\mu_0, \tau_0^2)\)
La distribuzione a posteriori per \(\mu\) sarà:
\[
\mu \mid Y \sim \mathcal{N}(\mu_n, \tau_n^2)
\]
Pertanto, la distribuzione a posteriori per \(\mu\) è:
\[
\mu \mid Y \sim \mathcal{N}(174, 4.47^2)
\]
Per la distribuzione predittiva a posteriori, dobbiamo considerare anche la varianza della distribuzione futura. Se stiamo predicendo per \(n_{\text{fut}}=100\) nuove osservazioni, la varianza della media predittiva sarà:
Quindi, la distribuzione predittiva a posteriori è:
\[
\tilde{Y} \sim \mathcal{N}(174, 4.58^2)
\]
56.3 Implementazione con cmdstanpy
Per illustrare come viene generata la distribuzione predittiva a posteriori nel contesto del modello normale-normale, possiamo utilizzare cmdstanpy per eseguire l’analisi. Il codice seguente mostra come configurare il modello e generare previsioni.
Questo codice produce un grafico che illustra visivamente la distribuzione predittiva a posteriori per le altezze nel nostro campione di 100 nuove osservazioni, tenendo conto sia dei dati osservati che delle nostre aspettative iniziali.
In sintesi, la distribuzione predittiva a posteriori è stata generata nel modo seguente:
Campioniamo un valore \(\mu\) dalla distribuzione a posteriori di \(\mu\).
Campioniamo un valore \(\sigma\) dalla distribuzione a posteriori di \(\sigma\).
Utilizziamo questi valori per generare un campione dalla distribuzione normale con parametri \(\mu\) e \(\sigma\).
Ripetiamo questo processo molte volte.
La distribuzione dei valori ottenuti da questi campionamenti costituisce la distribuzione predittiva a posteriori.
56.4 Metodo MCMC
Quando usiamo un PPL come Stan, la distribuzione predittiva viene stimata mediante il campionamento da una catena di Markov, che è particolarmente utile in scenari complessi dove l’analisi analitica potrebbe essere impraticabile. Attraverso i metodi MCMC, si stimano le potenziali osservazioni future \(p(\tilde{y} \mid y)\), indicate come \(p(y^{rep} \mid y)\), seguendo questi passaggi:
Si campiona \(\theta_i \sim p(\theta \mid y)\): Viene selezionato casualmente un valore del parametro (o dei parametri) dalla distribuzione a posteriori.
Si campiona \(y^{rep} \sim p(y^{rep} \mid \theta_i)\): Viene scelta casualmente un’osservazione dalla funzione di verosimiglianza, condizionata al valore del parametro (o dei parametri)ottenuto nel passo precedente.
Ripetendo questi due passaggi un numero sufficiente di volte, l’istogramma risultante approssimerà la distribuzione predittiva a posteriori.
Esaminiamo ora come ottenere la distribuzione predittiva a posteriori con Stan per i dati dell’esempio precedente. Iniziamo creando le distribuzioni a posteriori di \(\mu\) e \(\sigma\).
data {
int<lower=0> N; // number of observations
vector[N] y; // observed data
real mu_prior; // prior mean for mu
real<lower=0> sigma_prior; // prior standard deviation for mu
real<lower=0> sigma_prior_mean; // prior mean for sigma
real<lower=0> sigma_prior_sd; // prior standard deviation for sigma
}
parameters {
real mu; // parameter of interest
real<lower=0> sigma; // parameter for the standard deviation
}
model {
mu ~ normal(mu_prior, sigma_prior); // prior for mu
sigma ~ normal(sigma_prior_mean, sigma_prior_sd); // prior for sigma
y ~ normal(mu, sigma); // likelihood
}
generated quantities {
array[N] real y_rep;
for (n in 1 : N) {
y_rep[n] = normal_rng(mu, sigma);
}
}
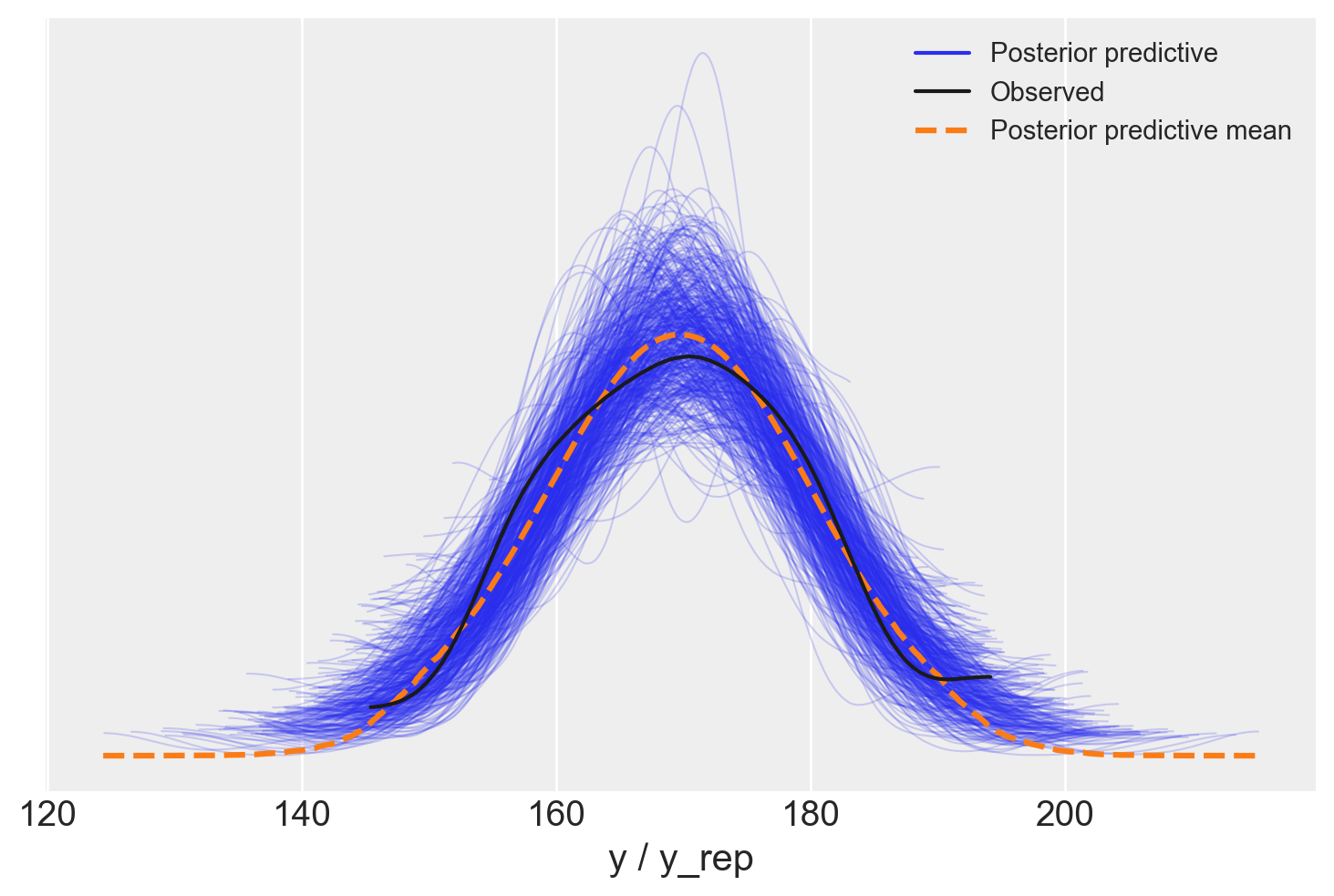
La distribuzione predittiva a posteriori è utilizzata per eseguire i controlli predittivi a posteriori (PPC), noti come Posterior Predictive Checks. I PPC consistono in un confronto grafico tra \(p(y^{rep} \mid y)\), ossia la distribuzione delle osservazioni future previste, e i dati osservati \(y\). Questo confronto visivo permette di valutare se il modello utilizzato è adeguato per descrivere le proprietà dei dati osservati.
Oltre al confronto grafico tra le distribuzioni \(p(y)\) e \(p(y^{rep})\), è possibile effettuare un confronto tra le distribuzioni di varie statistiche descrittive calcolate su diversi campioni \(y^{rep}\) e le corrispondenti statistiche calcolate sui dati osservati. Tipicamente, vengono considerate statistiche descrittive come la media, la varianza, la deviazione standard, il minimo o il massimo, ma è possibile confrontare qualsiasi altra statistica rilevante.
I controlli predittivi a posteriori offrono un valido strumento per un’analisi critica delle prestazioni del modello e, se necessario, per apportare eventuali modifiche o considerare modelli alternativi più adatti ai dati in esame.
Possiamo ora usare ArviZ per generare il posterior-predictive plot:
Le verifiche predittive a priori generano dati utilizzando unicamente le distribuzioni a priori, ignorando i dati osservati, al fine di valutare se tali distribuzioni a priori sono appropriate. La distribuzione predittiva a priori è quindi simile alla distribuzione predittiva a posteriori, ma senza dati osservati, rappresentando il caso limite di una verifica predittiva a posteriori senza dati.
Questo processo può essere realizzato facilmente simulando i parametri secondo le distribuzioni a priori e poi simulando i dati in base al modello dati i parametri simulati. Il risultato è una simulazione dalla distribuzione predittiva a priori.
Questa procedura è fondamentale per verificare se le ipotesi a priori sono realistiche e adeguate prima di raccogliere o utilizzare i dati osservati. Se i dati simulati dalla distribuzione predittiva a priori non risultano plausibili, potrebbe essere necessario rivedere le scelte delle distribuzioni a priori.
Un prior predictive check è codificato come un posterior predictive check. Se disponiamo già del codice per un posterior predictive check ed è possibile impostare i dati come vuoti, allora non è necessario alcun codice ulteriore. I prior predictive checks possono essere codificati interamente all’interno del blocco generated quantities utilizzando la generazione di numeri casuali. I draw risultanti saranno indipendenti.
Esempio 56.2 Consideriamo un primo esempio pratico utilizzando il modello beta-binomiale. Il modello iniziale, che include il blocco model, serve per stimare i parametri del modello sulla base dei dati osservati.
data {int<lower=0> N;array[N] int<lower=0, upper=1> y;int<lower=0> alpha_prior;int<lower=0> beta_prior;}parameters {real<lower=0, upper=1> theta;}model { theta ~ beta(alpha_prior, beta_prior); y ~ bernoulli(theta);}
Per ottenere un campione dalla distribuzione a priori (cioè prima di osservare i dati), possiamo modificare il modello come segue:
data {int<lower=0> N; // Numero di osservazioniint<lower=0> alpha_prior; // Parametro di forma della distribuzione beta a prioriint<lower=0> beta_prior; // Parametro di forma della distribuzione beta a priori}generated quantities {array[N] int y_sim; // Dati simulatireal<lower=0, upper=1> theta_prior; // Valore di theta estratto dalla distribuzione a priori// Estraiamo un valore per theta dalla distribuzione beta a priori theta_prior = beta_rng(alpha_prior, beta_prior);// Simuliamo N osservazioni dalla distribuzione binomiale// utilizzando il valore di theta estratto e il numero totale di osservazioni Nfor (n in1:N) y_sim[n] = binomial_rng(N, theta_prior);}
In questo secondo script abbiamo
eliminato il blocco model: Questo blocco serve per l’inferenza Bayesiana, ma non è necessario per generare dati a priori.
aggiunto il blocco generated quantities: In questo blocco generiamo quantità di interesse, come i dati simulati y_sim e il valore di theta estratto dalla distribuzione a priori.
utilizzato la funzione beta_rng per estrarre un valore per theta dalla distribuzione \(\mathcal{Beta}\) definita dai parametri alpha_prior e beta_prior. Questo valore rappresenta una possibile realizzazione del parametro prima di osservare i dati.
utilizzato la funzione binomial_rng per simulare N osservazioni dalla distribuzione binomiale. Il parametro di successo theta è fissato al valore estratto theta_prior.
In sostanza, questo codice ci permette di generare un dataset simulato che potrebbe essere osservato se il processo stocastico fosse governato unicamente dai parametri specificati nella distribuzione a priori. In questo modo, possiamo valutare le proprietà del modello e la sua capacità di generare dati simili a quelli reali, prima ancora di avere a disposizione i dati osservati.
La distribuzione a priori rappresenta la nostra conoscenza o credenza sul valore del parametro theta prima di osservare i dati. Scegliendo diversi valori per alpha_prior e beta_prior, possiamo specificare diverse distribuzioni a priori e quindi esplorare come queste influenzano i risultati della simulazione.
data {
int<lower=0> N;
real<lower=0> alpha_prior;
real<lower=0> beta_prior;
}
parameters {
real<lower=0, upper=1> theta;
}
model {
// Definizione del priore Beta
theta ~ beta(alpha_prior, beta_prior);
}
generated quantities {
// Generazione della distribuzione predittiva a priori
array[N] int<lower=0, upper=1> y_sim;
for (n in 1 : N) {
y_sim[n] = bernoulli_rng(theta);
}
}
Creiamo il dizionario Stan per il caso dell’esempio in discussione.
N =100y =14# Create an integer array of zerosy_vec = np.zeros(N, dtype=np.int32)# Assign 1 to the first y elementsy_vec[:y] =1alpha_prior =4beta_prior =6stan_data = {"N": N,"y": y_vec,"alpha_prior": alpha_prior,"beta_prior": beta_prior,}
Eseguiamo il campionamento.
pp_samples = model_beta_binomial_prior.sample( data=stan_data, iter_sampling=1000, iter_warmup=0, # Un numero adeguato di iterazioni di warmup adapt_engaged=False, # Disabilita l'adattamento chains=1, show_progress=False, show_console=False,)
Calcoliamo le statistiche descrittive per i valori y_sim che abbiamo ottenuto.
y_rep_mean = np.mean(y_sim_flattened)y_rep_std = np.std(y_sim_flattened)print(f"Mean of y_rep: {y_rep_mean}")print(f"Standard Deviation of y_rep: {y_rep_std}")
Mean of y_rep: 0.40553
Standard Deviation of y_rep: 0.49099431676955296
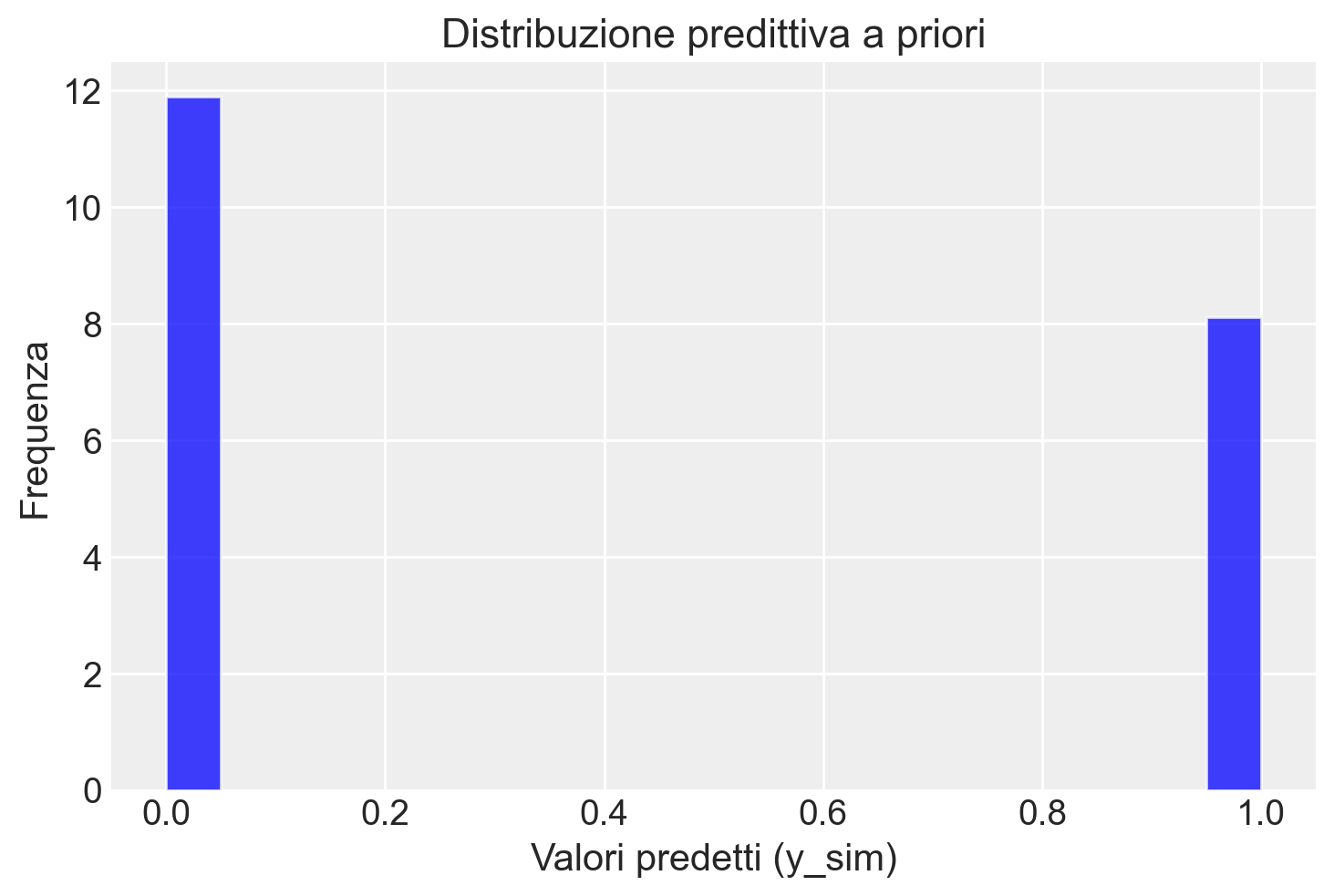
Generiamo una rappresentazione grafica della distribuzione di y_sim.
plt.hist(y_sim_flattened, bins=20, density=True, alpha=0.75, color="blue")plt.title("Distribuzione predittiva a priori")plt.xlabel("Valori predetti (y_sim)")plt.ylabel("Frequenza")plt.show()
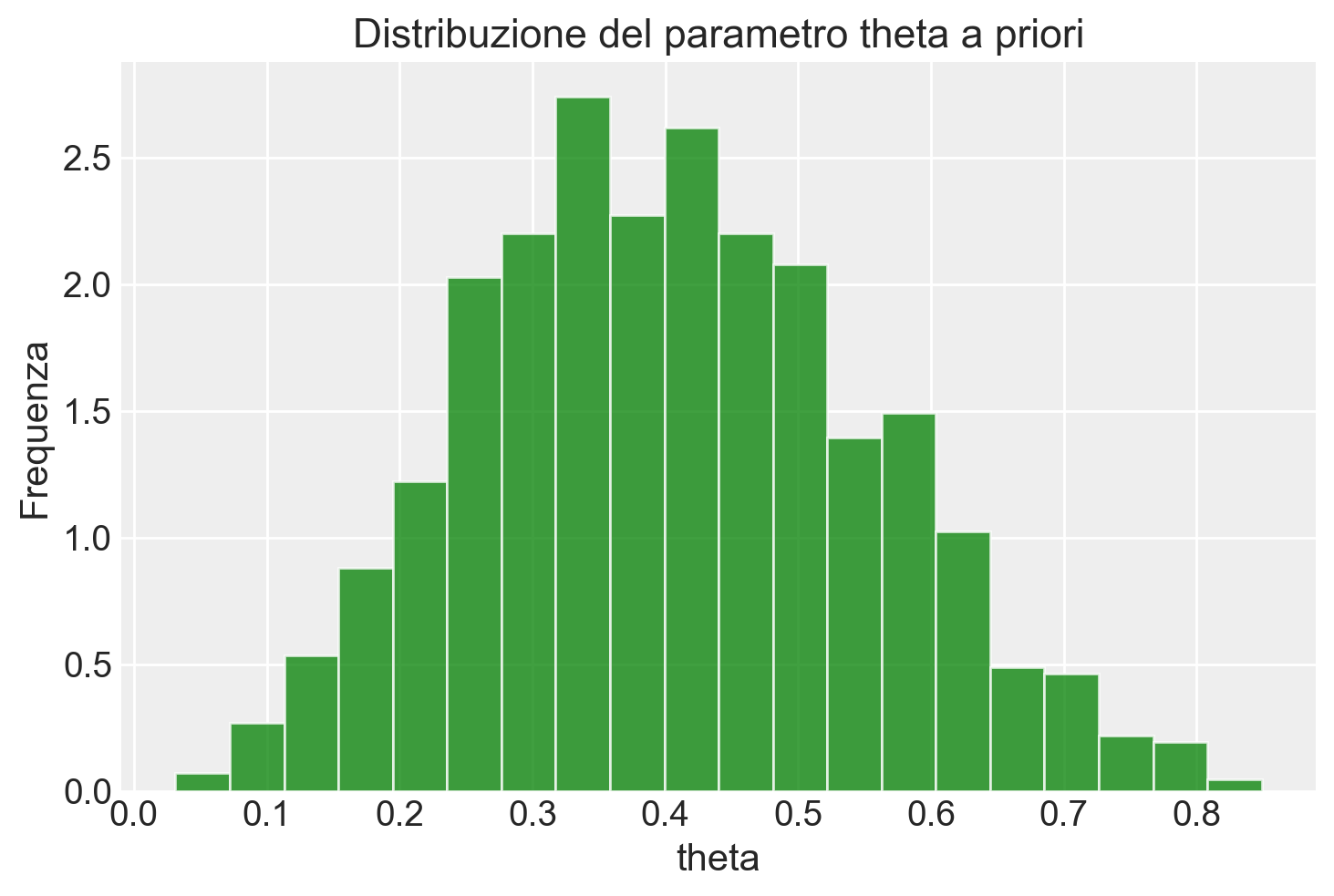
Estraiamo i valori theta e generiamo un istogramma.
theta_samples = pp_samples.stan_variable("theta")plt.hist(theta_samples, bins=20, density=True, alpha=0.75, color="green")plt.title("Distribuzione del parametro theta a priori")plt.xlabel("theta")plt.ylabel("Frequenza")plt.show()
Possiamo interpretare i risulati ottenuti nel modo seguente. In questo modello, stiamo utilizzando un prior \(\mathcal{Beta}(4, 6)\) per il parametro \(\theta\), che rappresenta la probabilità di successo in una distribuzione Bernoulliana. Questo prior riflette una convinzione a priori secondo la quale \(\theta\) ha una media di \(\frac{4}{4+6} = 0.4\), con una deviazione standard piuttosto ampia. Il risultato del prior predictive check mostra che la distribuzione simulata di successi ha una media di circa 0.405, con una deviazione standard di 0.491.
Dato che nei dati reali abbiamo osservato 14 successi su 100 prove, corrispondenti a una proporzione di 0.14, il prior \(\mathcal{Beta}(4, 6)\) risulta essere piuttosto largo e centrato su un valore di probabilità di successo notevolmente più alto rispetto ai dati osservati.
In conclusione,
Se abbiamo ragioni forti per imporre il prior \(\mathcal{Beta}(4, 6)\), ad esempio, una conoscenza precedente o una letteratura consolidata che suggerisce che la probabilità di successo dovrebbe aggirarsi attorno a 0.4, allora il prior predictive check conferma che il modello predittivo a priori si comporta come ci aspettiamo: il prior è informativo e impone un certo grado di convinzione sulla probabilità di successo. Questo significa che la nostra conoscenza a priori influenza fortemente il modello.
Se invece vogliamo imporre un prior debolmente informativo, che permetta ai dati di avere un peso maggiore nell’inferenza, questo prior non è ideale. In questo caso, il prior \(\mathcal{Beta}(4, 6)\) è troppo informativo, portando a una distribuzione predittiva a priori che è troppo concentrata intorno a 0.4 e non riflette adeguatamente la possibilità di avere proporzioni di successo più basse come quella osservata nei dati (0.14). Per un prior debolmente informativo, potremmo considerare un prior meno concentrato, come un \(\mathcal{Beta}(2, 2)\), che lascia più spazio all’influenza dei dati osservati.
Esempio 56.3 Consideriamo un secondo esempio, ovvero il caso discusso in precedenza di un campione di dati gaussiani e di un modello gaussiano in cui le distribuzioni a priori per μ e σ sono gaussiane.
data {
int<lower=0> N; // number of observations
real mu_prior; // prior mean for mu
real<lower=0> sigma_prior; // prior standard deviation for mu
real<lower=0> sigma_prior_mean; // prior mean for sigma
real<lower=0> sigma_prior_sd; // prior standard deviation for sigma
}
generated quantities {
real mu = normal_rng(mu_prior, sigma_prior); // prior draw for mu
real<lower=0> sigma = normal_rng(sigma_prior_mean, sigma_prior_sd); // prior draw for sigma
array[N] real y_rep;
for (n in 1 : N) {
y_rep[n] = normal_rng(mu, sigma);
}
}
Il codice precedente
for (n in1:N) { y_rep[n] = normal_rng(mu, sigma); }
illustra come generare campioni predittivi a priori nel blocco generated quantities. In questo esempio, mu e sigma sono generati dalle loro rispettive distribuzioni a priori e usati per generare campioni di dati simulati y_rep.
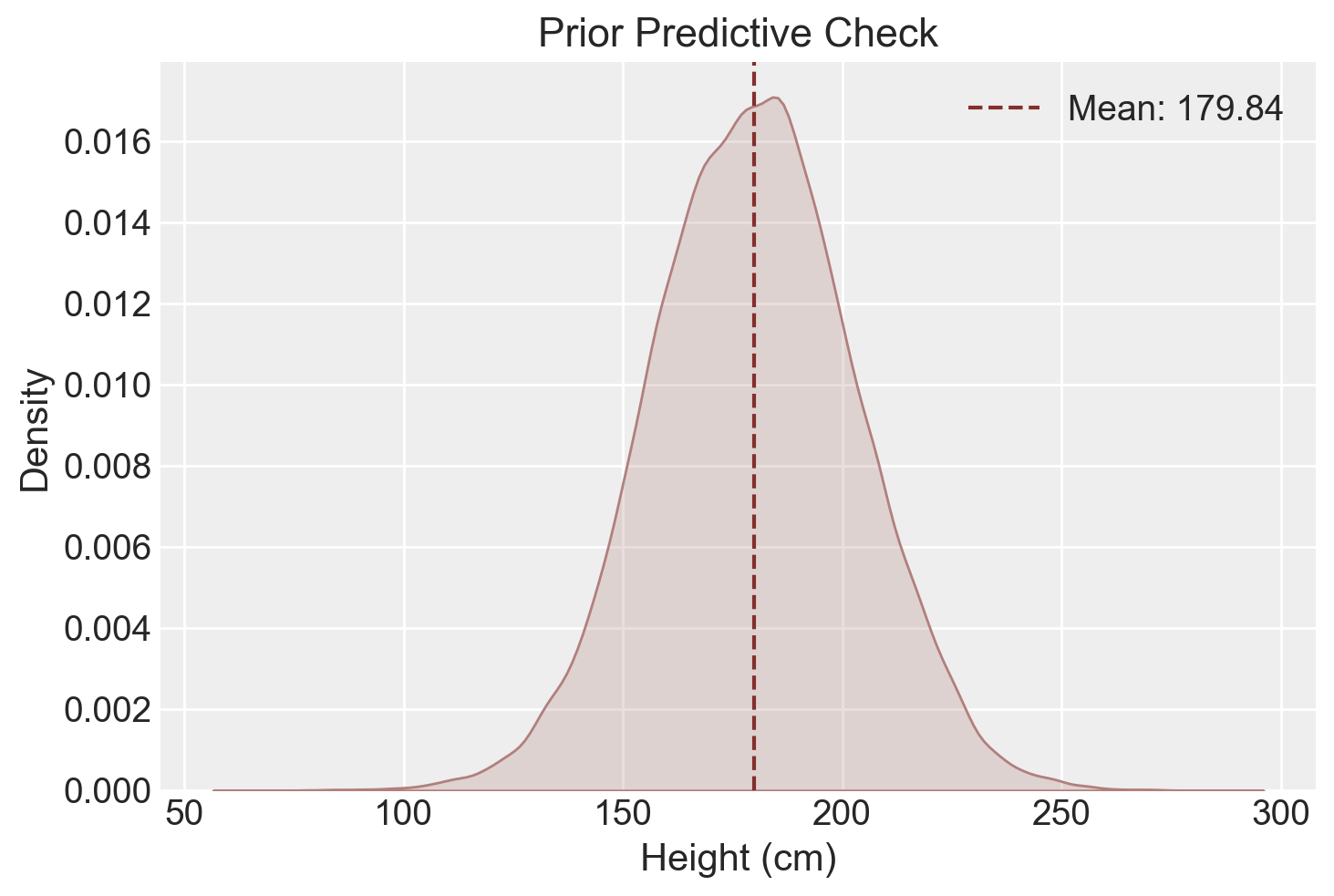
Il grafico della distribuzione predittiva a priori ci mostra che i prior utilizzati nel codice Stan implicano una distribuzione della variabile di interesse y che è approssimativamente normale con media di 180.25 e deviazione standard di 22.23. Questo prior predictive check garantisce che le distribuzioni a priori dei parametri mu e sigma siano realistiche e adeguate per l’analisi dei dati considerati. Questo passaggio consente di identificare e correggere eventuali ipotesi errate prima di procedere con l’analisi dei dati osservati, migliorando così la validità dei risultati ottenuti.
56.6 Considerazioni Conclusive
Le distribuzioni predittive a priori e a posteriori, pur essendo generate in modo simile, differiscono per la fonte di informazione utilizzata nella loro costruzione.
Distribuzione Predittiva a Priori: Questa distribuzione rappresenta le nostre aspettative sui dati prima che qualsiasi osservazione effettiva sia disponibile. Per costruirla, prendiamo i valori dei parametri dalla distribuzione a priori e li utilizziamo nella funzione di verosimiglianza per generare dati simulati. La distribuzione risultante di questi dati generati è la distribuzione predittiva a priori, che riflette le nostre conoscenze e incertezze iniziali, prima di osservare i dati reali.
Distribuzione Predittiva a Posteriori: Dopo aver osservato i dati, aggiorniamo le nostre credenze sui parametri utilizzando il teorema di Bayes, ottenendo così la distribuzione a posteriori dei parametri. La distribuzione predittiva a posteriori viene quindi generata prendendo valori dei parametri dalla distribuzione a posteriori, che ora incorpora l’informazione ottenuta dai dati osservati, e utilizzandoli nella funzione di verosimiglianza per generare nuovi dati simulati. Questa distribuzione riflette le nostre previsioni sui dati futuri o non osservati, dopo aver tenuto conto dei dati già raccolti.
La differenza principale tra queste due distribuzioni predittive risiede nella distribuzione dei parametri utilizzata: nella distribuzione predittiva a priori si utilizzano i parametri estratti dal prior, mentre nella distribuzione predittiva a posteriori si utilizzano i parametri estratti dal posterior. La distribuzione predittiva a posteriori è generalmente più informativa poiché integra i dati osservati, migliorando le previsioni future.
È cruciale per l’integrità del modello che la distribuzione predittiva a posteriori sia coerente con la distribuzione dei dati osservati. Per verificare questa coerenza, si utilizzano le verifiche predittive a posteriori, confrontando la distribuzione predittiva con i dati empirici tramite tecniche come le stime di densità kernel (KDE). Questo confronto permette di valutare quanto bene il modello riesca ad approssimare la struttura reale dei dati e la sua capacità di fornire previsioni affidabili.
Ad esempio, consideriamo un modello gaussiano con varianza \(\sigma^2\) nota:
dove \(\sigma^2/n\) rappresenta l’incertezza epistemica legata a \(\theta\). La distribuzione predittiva a posteriori per un nuovo valore \(\tilde{y}\) sarà:
In questo caso, l’incertezza totale è data dalla somma dell’incertezza epistemica (\(\sigma^2/n\)) e dell’incertezza aleatoria (\(\sigma^2\)).
Informazioni sull’Ambiente di Sviluppo
%load_ext watermark%watermark -n -u -v -iv -w -m
Last updated: Sun Aug 04 2024
Python implementation: CPython
Python version : 3.12.4
IPython version : 8.26.0
Compiler : Clang 16.0.6
OS : Darwin
Release : 23.6.0
Machine : arm64
Processor : arm
CPU cores : 8
Architecture: 64bit
numpy : 1.26.4
arviz : 0.18.0
scipy : 1.14.0
pandas : 2.2.2
seaborn : 0.13.2
matplotlib: 3.9.1
Watermark: 2.4.3
Gelman, A., & Shalizi, C. R. (2013). Philosophy and the practice of Bayesian statistics. British Journal of Mathematical and Statistical Psychology, 66(1), 8–38.