In questo capitolo introdurremo il modello di regressione multipla mostrando come possa essere implementato in Stan. Ci concentreremo sull’interpretazione dei coefficienti parziali di regressione.
78.1 Regressione multipla
La regressione multipla rappresenta un’estensione del modello di regressione semplice, e permette di esplorare e quantificare le relazioni tra una variabile dipendente e più variabili indipendenti.
Un modello lineare univariato può essere descritto, in forma matriciale, come
dove \(\mathbf{y} \in \mathbb{R}^n\) è il vettore delle variabili di risposta, \(\mathbf{X} \in \mathbb{R}^{n \times p}\) è la matrice delle costanti note, \(\boldsymbol{\beta} \in \mathbb{R}^p\) è il vettore dei parametri sconosciuti, e \(\boldsymbol{\epsilon} \in \mathbb{R}^n\) è il vettore degli errori casuali non osservabili. Espanso in forma completa, il modello dell’Equazione 78.1 può essere espresso come
dove la prima colonna di \(\mathbf{X}\) è spesso un vettore di uno, denotato \(\mathbf{1}_n\). Il modello dell’Equazione 78.2 esprime ciascuna delle \(n\) osservazioni in \(\mathbf{y}\) come una combinazione lineare dei parametri sconosciuti in \(\boldsymbol{\beta}\) con coefficienti da \(\mathbf{X}\), cioè,
per \(i = 1, \ldots, n\), dove \(\mathbf{x}_i \in \mathbb{R}^p\) è l’ennesima riga di \(\mathbf{X}\).
78.2 Interpretazione
Passando dal modello semplice \(y = a + bx + \text{errore}\) al modello più generale \(y = \beta_0 + \beta_1x_1 + \beta_2x_2 + \cdots + \text{errore}\), emergono nuove complessità. Queste includono le decisioni su quali predittori \(x\) includere nel modello, l’interpretazione dei coefficienti e delle loro interazioni, e la costruzione di nuovi predittori a partire dalle variabili esistenti per catturare elementi di discrezionalità e non linearità.
I coefficienti di regressione, in un contesto di regressione multipla, sono tipicamente più complicati da interpretare rispetto a quelli di un modello con un solo predittore. L’interpretazione di un dato coefficiente, infatti, è parzialmente condizionata dalle altre variabili presenti nel modello. Il coefficiente \(\beta_k\) rappresenta la differenza media o attesa nella variabile risposta \(y\), confrontando due individui che differiscono di un’unità nel predittore \(x_k\) ma sono identici per quanto riguarda gli altri predittori. Questo concetto è talvolta sintetizzato con l’espressione “confrontare due osservazionni (o persone) che differiscono per \(x_k\) a parità delle altre variabili”.
Dal punto di vista dell’implementazione con Stan, l’estensione del modello per includere molteplici predittori dell’intelligenza del bambino è relativamente semplice. È necessario costruire una matrice \(X\) contenente le colonne che rappresentano i vari predittori che intendiamo analizzare. Per l’esempio specifico in questione, i predittori selezionati per l’intelligenza del bambino includono: la scolarità della madre (codificata come 0 o 1 a seconda che la madre abbia completato o meno le scuole superiori), l’intelligenza della madre e l’età della madre. Prima di procedere con l’analisi, è importante standardizzare tutte queste variabili per facilitare l’interpretazione dei risultati e migliorare la stabilità numerica del modello.
78.3 Un esempio pratico
Per fare un esempio pratico, analizzeremo nuovamente i dati sull’intelligenza di un gruppo di bambini. In questo caso, cercheremo di predire l’intelligenza media dei bambini considerando tre fattori: se le madri hanno completato la scuola superiore, l’intelligenza della madre e l’età della madre.
data {
int<lower=1> N; // Numero di osservazioni
int<lower=1> K; // Numero di variabili indipendenti, intercetta inclusa
vector[N] x1; // Prima variabile indipendente
vector[N] x2; // Seconda variabile indipendente
vector[N] x3; // Seconda variabile indipendente
// Aggiungi altri vettori se ci sono più variabili indipendenti
vector[N] y; // Vettore della variabile dipendente
}
parameters {
real alpha; // Intercetta
real beta1; // Coefficiente per la prima variabile indipendente
real beta2; // Coefficiente per la seconda variabile indipendente
real beta3; // Coefficiente per la terza variabile indipendente
// Definisci altri real per ulteriori coefficienti
real<lower=0> sigma; // Errore del modello
}
model {
// Prior
alpha ~ student_t(3, 0, 2.5);
beta1 ~ student_t(3, 0, 2.5);
beta2 ~ student_t(3, 0, 2.5);
beta3 ~ student_t(3, 0, 2.5);
// Definisci prior per altri coefficienti
sigma ~ exponential(1);
// Likelihood
for (n in 1:N) {
y[n] ~ normal(alpha + beta1 * x1[n] + beta2 * x2[n] + + beta3 * x3[n], sigma);
// Aggiungi termini per altri coefficienti se necessario
}
}
generated quantities {
vector[N] log_lik; // Log-likelihood per ogni osservazione
vector[N] y_rep; // Predizioni posteriori per ogni osservazione
for (n in 1:N) {
log_lik[n] = normal_lpdf(y[n] | alpha + beta1 * x1[n] + beta2 * x2[n] + + beta3 * x3[n], sigma);
// Aggiungi termini per altri coefficienti se necessario
y_rep[n] = normal_rng(alpha + beta1 * x1[n] + beta2 * x2[n] + beta3 * x3[n], sigma);
// Aggiungi termini per altri coefficienti se necessario
}
}
df = pd.DataFrame({"one": [1] *len(x1), # Crea una lista di 1 della stessa lunghezza di x1"x1": x1,"x2": x2,"x3": x3})df.head()
one
x1
x2
x3
0
1
0.522233
1.409460
1.562029
1
1
0.522233
-0.710026
0.820727
2
1
0.522233
1.030732
1.562029
3
1
0.522233
-0.036733
0.820727
4
1
0.522233
-0.484177
1.562029
# Convert scaled DataFrame to numpy matrixX = df.to_numpy()
# Verificare le dimensioni di Xprint("Dimensioni di X:", X.shape)
Dimensioni di X: (434, 4)
Creiamo un dizionario con i dati nel formato atteso da Stan:
stan_data = {"N": X.shape[0],"K": X.shape[1], # Nota: questa include anche la colonna dell'intercetta"x1": df["x1"],"x2": df["x2"],"x3": df["x3"],"y": stats.zscore( kidiq["kid_score"] )}
Eseguiamo il campionamento MCMC:
fit = model.sample( data=stan_data, iter_warmup=1_000, iter_sampling=2_000, seed=123, show_progress=False, show_console=False)
21:00:45 - cmdstanpy - INFO - CmdStan start processing
21:00:45 - cmdstanpy - INFO - Chain [1] start processing
21:00:45 - cmdstanpy - INFO - Chain [2] start processing
21:00:45 - cmdstanpy - INFO - Chain [3] start processing
21:00:45 - cmdstanpy - INFO - Chain [4] start processing
21:00:46 - cmdstanpy - INFO - Chain [2] done processing
21:00:46 - cmdstanpy - INFO - Chain [1] done processing
21:00:46 - cmdstanpy - INFO - Chain [4] done processing
21:00:46 - cmdstanpy - INFO - Chain [3] done processing
Anche nel caso della regressione multipla, i risultati ottenuti con l’approccio bayesiano sono molto simili a quelli prodotti dall’approccio basato sulla massima verosimiglianza.
Calcoliamo una sintesi delle distribuzioni a posteriori dei parametri:
Nel contesto della regressione multipla, l’interpretazione dei coefficienti parziali differisce da quella della regressione bivariata. Una differenza chiave rispetto al modello di regressione bivariato è nell’interpretazione dei coefficienti. Nel caso bivariato, il coefficiente \(\beta_1\) viene interpretato come il cambiamento atteso in \(Y\) al variare di una unità in \(X_1\). Tuttavia, nel modello di regressione multipla, l’interpretazione di \(\beta_1\) cambia. In questo caso, \(\beta_1\) rappresenta il cambiamento atteso in \(Y\) al variare di una unità in \(X_1\), mantenendo costanti gli effetti di tutte le altre variabili \(X_2, X_3, \ldots, X_p\). In altre parole, \(\beta_1\) ci dice come varia in media \(Y\) quando \(X_1\) cambia, ma considera che altre variabili possono variare insieme a \(X_1\), e \(\beta_1\) tiene conto di queste variazioni.
Nel nostro caso, il coefficiente associato all’intelligenza della madre, indicato come \(\beta\) = 0.41, assume il seguente significato: prevediamo che l’intelligenza del bambino aumenti di 0.41 deviazioni standard in media per ogni deviazione standard aggiuntiva nell’intelligenza della madre, mantenendo costanti gli effetti del livello di istruzione e dell’età della madre. Questo implica che stiamo considerando l’impatto dell’intelligenza della madre sull’intelligenza del bambino all’interno di una popolazione di madri che sono omogenee per quanto riguarda il livello di istruzione e l’età.
Cosa significa mantenere costante l’effetto di altre variabili? Consideriamo l’esempio della correlazione tra il numero di scarpe e le abilità matematiche. Esiste una marcata correlazione positiva tra queste due variabili. Tuttavia, è evidente che i bambini, avendo in genere numeri di scarpe più piccoli rispetto agli adulti, mostrano anche, presumibilmente, minori capacità matematiche. Questo esempio illustra che, se controlliamo per l’età, ossia se consideriamo solo soggetti della stessa età, la correlazione tra il numero di scarpe e le abilità matematiche scompare. Pertanto, nell’analisi della relazione tra abilità matematiche (Y) e numero di scarpe (X), l’età (Z) agisce come variabile confondente. Controllare per Z significa esaminare la relazione tra Y e X limitandosi a individui della stessa età.
Ma ovviamente questo controllo empirico non è sempre possibile. Nel modello di regressione, esso viene “approssimato” con una procedura statistica.
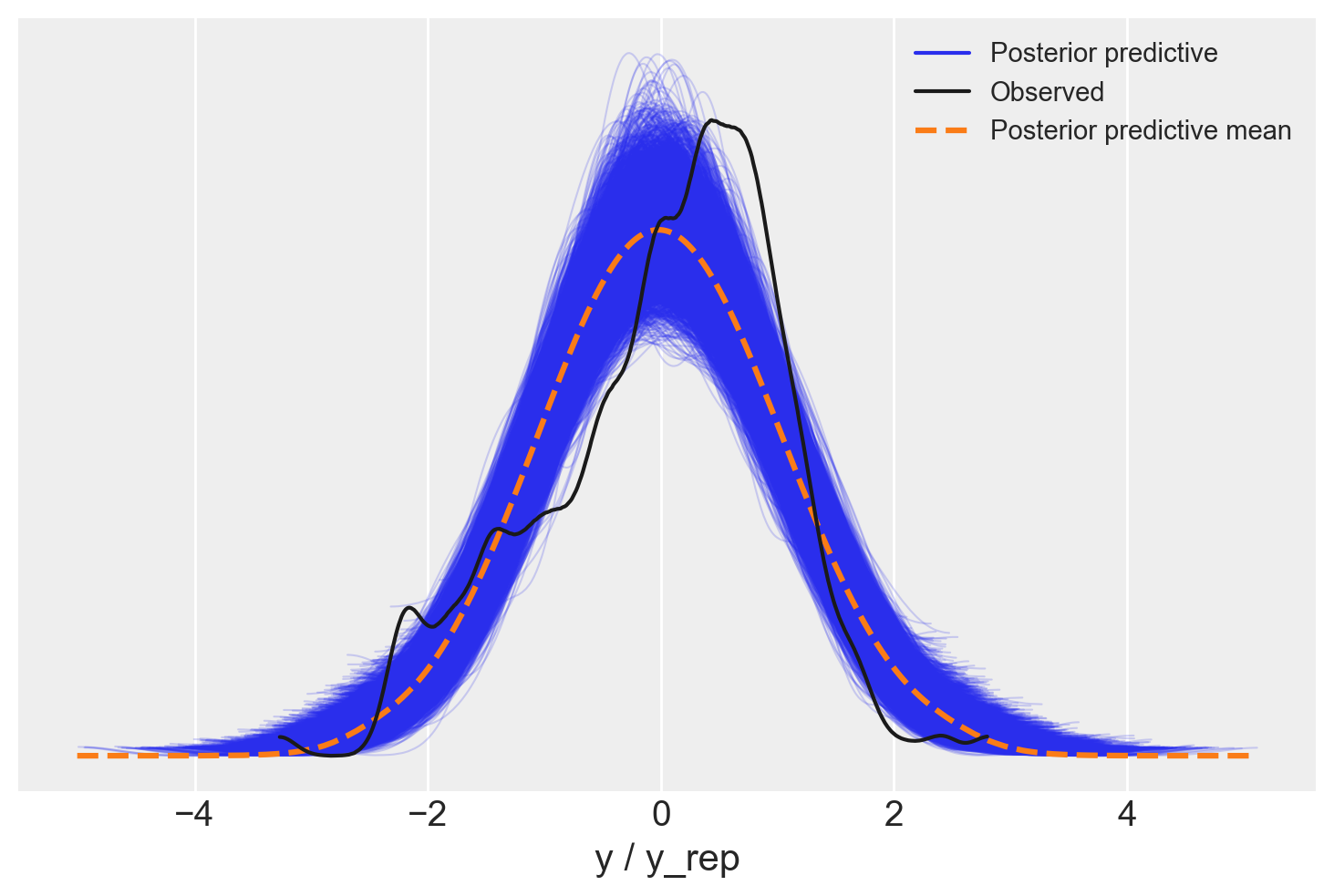
78.5 Distribuzione predittiva a posteriori
Calcoliamo la distribuzione predittiva a posteriori e generiamo il PPC plot:
Nella seguente simulazione illustreremo la procedura statistica utilizzata per isolare l’effetto di una variabile controllando per un’altra.
# Creiamo dei dati di esempionp.random.seed(0)N =100X1 = np.random.normal(0, 1, N)X2 = X1 + np.random.normal(0, 0.5, N)Y =1+2* X1 +3* X2 + np.random.normal(0, 1, N)# Modello completo Y ~ X1 + X2model_full = sm.OLS(Y, sm.add_constant(np.column_stack((X1, X2))))results_full = model_full.fit()# Regressione di Y su X2model_Y_on_X2 = sm.OLS(Y, sm.add_constant(X2))residuals_Y = model_Y_on_X2.fit().resid# Regressione di X1 su X2model_X1_on_X2 = sm.OLS(X1, sm.add_constant(X2))residuals_X1 = model_X1_on_X2.fit().resid# Regressione dei residui di Y sui residui di X1model_residuals = sm.OLS(residuals_Y, sm.add_constant(residuals_X1))results_residuals = model_residuals.fit()# Stampiamo i risultatiprint("Coefficient from full model for X1: {:.4f}".format(results_full.params[1]))print("Coefficient from regression of residuals: {:.4f}".format( results_residuals.params[1] ))
Coefficient from full model for X1: 1.9782
Coefficient from regression of residuals: 1.9782
Questo esempio illustra il concetto di coefficiente parziale di regressione. Questo coefficiente quantifica l’effetto della variabile esplicativa \(X_j\) sulla variabile dipendente \(Y\), depurando l’effetto di \(X_j\) dall’influenza degli altri predittori nel modello. In sostanza, il coefficiente parziale di regressione valuta l’impiego di \(X_j\) su \(Y\) quando \(X_j\) è considerata linearmente indipendente rispetto agli altri predittori \(X\). L’effetto misurato è quindi quello della sola componente di \(X_j\) che non è spiegata linearmente dai restanti predittori \(X\) sulla parte di \(Y\) che è anch’essa indipendente dai medesimi predittori.
Per chiarire ulteriormente, questo approccio statistico si focalizza sull’analizzare l’effetto di \(X_j\) eliminando l’influenza lineare degli altri predittori \(X\). È simile a valutare la relazione tra \(Y\) e \(X_j\) in un contesto ideale dove tutti gli individui presentano livelli identici per le altre variabili \(X\). Tale metodo non eguaglia gli effetti non lineari che possono essere presenti tra le variabili, limitandosi a correggere solo per le associazioni lineari. In questo modo, il controllo statistico tenta di approssimare una condizione di omogeneità tra i soggetti rispetto alle altre variabili \(X\), consentendo di isolare e valutare più precisamente l’effetto puro di \(X_j\) su \(Y\).
78.7 Quali Predittori Includere nel Modello?
L’uso del modello di regressione multipla ha principalmente due scopi. In primo luogo, è impiegato per la predizione, ovvero per ottenere la migliore stima possibile di \(Y\) utilizzando una combinazione lineare delle variabili \(X_1, X_2, \ldots, X_p\). In questo contesto, i coefficienti \(\beta_i\) sono interpretati come pesi che ottimizzano la previsione di \(Y\) in base ai valori delle variabili indipendenti.
In secondo luogo, il modello di regressione multipla viene spesso utilizzato per descrivere le relazioni tra variabili. Tuttavia, è cruciale comprendere che il modello non è stato originariamente creato per stabilire relazioni causali. Pertanto, bisogna essere cauti nell’attribuire interpretazioni causali dirette ai coefficienti \(\beta_i\). Il modello stima correttamente i coefficienti parziali di regressione solo quando tutte le variabili che influenzano \(Y\) sono incluse nel modello. Nella pratica, spesso non conosciamo tutte le variabili rilevanti, il che può portare a errori di specificazione.
Il modello di regressione multipla è uno strumento potente per predire e analizzare le relazioni tra variabili, ma è fondamentale riconoscerne le limitazioni, soprattutto quando si cercano interpretazioni causali. In campi come la psicologia, dove è cruciale comprendere le dinamiche causali, diventa essenziale una scelta accurata delle variabili da includere nel modello per prevenire distorsioni nelle stime dei coefficienti di regressione.
Tradizionalmente, si riteneva vantaggioso includere nel modello il maggior numero possibile di variabili per ottenere un livello di “controllo” statistico più elevato. Tuttavia, come sottolineato da McElreath (2020), questo approccio può portare a una “insalata causale”. Questo termine descrive una situazione in cui la mancanza di attenzione alla struttura causale tra le variabili porta all’inclusione di variabili di controllo inappropriate, causando distorsioni nelle stime.
In alcuni casi, l’inserimento di determinate variabili di controllo è indispensabile per evitare distorsioni, mentre in altri casi, l’inclusione di variabili non pertinenti può portare a risultati fuorvianti. Questo sottolinea l’importanza di formulare ipotesi chiare e ben ponderate sulla struttura causale tra le variabili in esame.
L’efficacia e la validità dei risultati ottenuti tramite regressione dipendono strettamente dalla correttezza delle ipotesi causali formulate, sia esplicitamente che implicitamente, dal ricercatore. Per superare i limiti dell’approccio dell’“insalata causale”, è cruciale che la costruzione del modello di regressione rifletta attentamente queste ipotesi causali.
78.8 Interpretazione dei Coefficienti Parziali di Regressione
La regressione lineare è un metodo statistico utilizzato per adattare una linea (o un iperpiano in spazi multidimensionali) che descrive la relazione tra una variabile dipendente e una o più variabili indipendenti. L’obiettivo principale di questo metodo è spiegare la variazione della variabile dipendente in base alle variazioni delle variabili indipendenti. È importante sottolineare che il modello di regressione, di per sé, non implica alcun tipo di relazione causale tra le variabili. Nonostante ciò, è comune, e spesso errato, attribuire ai coefficienti del modello un’interpretazione causale.
Ad esempio, si dice spesso che il coefficiente parziale \(\beta_j\) rappresenta l’incremento atteso della variabile dipendente \(Y\) per una variazione unitaria della variabile indipendente \(X_j\), mantenendo costanti gli effetti lineari degli altri predittori inclusi nel modello. Questa interpretazione suggerisce implicitamente una relazione causale: se \(X_j\) cambia di un’unità, allora, tenendo conto dell’effetto lineare delle altre variabili, la media di \(Y\) cambierà necessariamente di una quantità pari a \(\beta_j\)(Westreich & Greenland, 2013).
Tuttavia, questa interpretazione è valida solo sotto condizioni specifiche che sono raramente soddisfatte nella pratica. Nella maggior parte dei casi, il coefficiente \(\beta_j\) riflette semplicemente una descrizione di ciò che accade nel campione di dati analizzato. La sua validità al di fuori del campione, cioè nella popolazione generale, dipende dal fatto che il modello di regressione rappresenti accuratamente il processo generativo dei dati nella popolazione. Se il modello è mal specificato o se esistono variabili confondenti non incluse nel modello, l’interpretazione causale dei coefficienti diventa invalida.
In altre parole, i risultati di un’analisi di regressione lineare su un campione di dati non possono essere utilizzati direttamente per inferire nessi causali. L’inferenza causale richiede una conoscenza approfondita del dominio e l’uso di metodi appropriati, come esperimenti controllati o modelli di equazioni strutturali, che permettono di identificare relazioni causali. Solo una volta stabiliti i nessi causali, la regressione lineare può essere impiegata per quantificare la forza di queste relazioni. Pertanto, non è possibile procedere nel modo opposto, ovvero dedurre relazioni causali direttamente dai coefficienti di regressione — si vedano le sezioni relative all’errore di specificazione del modello e all’inferenza causale nei modelli di regressione per maggiori dettagli.
78.9 Considerazioni Conclusive
Nel suo libro Statistical Rethinking, McElreath (2020) introduce una metafora per i modelli statistici, paragonandoli ai Golem, creature della mitologia antica, prive di volontà propria e animate solo dall’intento di chi le crea. Questi esseri, dotati di grande forza ma privi di giudizio autonomo, possono diventare pericolosi se non vengono guidati con saggezza. Allo stesso modo, i modelli statistici sono strumenti potenti che, se utilizzati senza una comprensione adeguata del contesto e delle loro limitazioni, possono portare a conclusioni errate o fuorvianti.
McElreath (2020) suggerisce che, nella costruzione di modelli matematici, gli scienziati creano moderni equivalenti di questi Golem. Sebbene tali modelli influenzino il mondo reale attraverso le previsioni che generano e le intuizioni che offrono, non dovrebbero essere considerati come rappresentazioni assolute della verità. I modelli statistici, infatti, sono strumenti costruiti per uno scopo specifico: essi eseguono calcoli con grande precisione, ma mancano della capacità di comprendere o interpretare il contesto più ampio in cui vengono applicati.
Il modello di regressione, in particolare, è un esempio di come questi strumenti possano produrre risultati numerici concreti, ma siano limitati nella loro capacità di affrontare questioni che richiedono un approccio più creativo e comprensivo. McElreath (2020) sottolinea che nessun modello statistico, da solo, è sufficiente per risolvere il complesso problema dell’inferenza causale a partire da dati empirici. Il modello di regressione, per quanto utile nel descrivere relazioni tra variabili, non è dotato di una reale comprensione delle dinamiche di causa ed effetto. Senza un’interpretazione critica e un uso consapevole da parte degli studiosi, questo strumento, progettato per scopi specifici, può risultare non solo inefficace, ma anche potenzialmente dannoso.
Carlin & Moreno-Betancur (2023) sottolineano che il modello di regressione può essere usato per tre scopi diversi:
Descrizione delle associazioni: ad esempio, descrivere la prevalenza di una certa condizione in diverse sottopopolazioni;
Predizione: utilizzare un insieme di predittori per prevedere in modo attendibile il valore di (Y) per gli individui per i quali sono disponibili le misure di (X);
Analisi delle relazioni causali: determinare in che misura un esito dipende da un particolare intervento.
Secondo Carlin & Moreno-Betancur (2023) è importante che i ricercatori chiariscano l’obiettivo specifico per cui utilizzano il modello di regressione. Purtroppo, questa fondamentale classificazione delle domande di ricerca non è ancora penetrata a fondo nell’insegnamento e nella pratica della statistica, soprattutto per quanto riguarda i metodi di regressione. In molti campi, inclusa la psicologia, si continua a insegnare e a utilizzare i modelli di regressione come un toolkit universale, applicato senza un’adeguata considerazione dello scopo reale. Un approccio diffuso è quello di “trovare il miglior modello per i dati” e successivamente sviluppare un’interpretazione del modello adattato.
Invece, Carlin & Moreno-Betancur (2023) raccomandano che l’insegnamento del modello di regressione sia guidato da una prospettiva basata sull’obiettivo specifico della ricerca. Suggeriscono di utilizzare la classificazione delle tre tipologie di domande di ricerca per orientare l’apprendimento, introducendo gli aspetti tecnici dei modelli di regressione e di altri metodi solo quando sono direttamente rilevanti per il particolare scopo della ricerca. Questo approccio permette di focalizzarsi sull’uso appropriato dei modelli in base al contesto e all’obiettivo specifico, evitando l’applicazione indiscriminata e la conseguente possibilità di fraintendimenti.
In conclusione, come afferma McElreath (2020), è fondamentale che i ricercatori utilizzino i modelli statistici con piena consapevolezza delle loro limitazioni e con una considerazione attenta del contesto in cui vengono applicati. I modelli sono strumenti potenti, ma la loro efficacia dipende dalla saggezza e dall’intenzione di chi li utilizza. Solo adottando un approccio critico e informato possiamo evitare di trasformare questi potenti strumenti in Golem senza controllo, assicurando che essi contribuiscano realmente alla comprensione del mondo che ci circonda.
78.10 Esercizi
Esercizio 78.1 Considera il seguente modello lineare univariato in forma matriciale:
Questa formula minimizza la somma dei quadrati degli errori tra i valori osservati e quelli previsti dal modello. In altre parole, cerca di trovare i valori di \(\beta\) che riducono al minimo le discrepanze tra i dati osservati e quelli stimati dal modello lineare.
Aggiungi una colonna di 1 alla matrice \(\mathbf{X}\) per includere l’intercetta.
Scrivi la matrice \(\mathbf{X}\) e il vettore \(\mathbf{y}\) utilizzando i dati forniti.
Calcola i coefficienti \(\beta\) utilizzando la formula dei minimi quadrati. Implementa la formula in Python e calcola i valori di \(\beta\). Controlla i risultati usando pingouin.
Informazioni sull’Ambiente di Sviluppo
%load_ext watermark%watermark -n -u -v -iv -w -m
Last updated: Wed Jul 17 2024
Python implementation: CPython
Python version : 3.12.4
IPython version : 8.26.0
Compiler : Clang 16.0.6
OS : Darwin
Release : 23.5.0
Machine : arm64
Processor : arm
CPU cores : 8
Architecture: 64bit
pandas : 2.2.2
arviz : 0.18.0
matplotlib : 3.9.1
cmdstanpy : 1.2.4
pingouin : 0.5.4
scipy : 1.14.0
statsmodels: 0.14.2
numpy : 1.26.4
logging : 0.5.1.2
Watermark: 2.4.3
Carlin, J. B., & Moreno-Betancur, M. (2023). On the uses and abuses of regression models: a call for reform of statistical practice and teaching. arXiv preprint arXiv:2309.06668.
Gelman, A., Hill, J., & Vehtari, A. (2020). Regression and Other Stories. Cambridge University Press.
McElreath, R. (2020). Statistical rethinking: ABayesian course with examples in R and Stan (2nd Edition). CRC Press.
Westreich, D., & Greenland, S. (2013). The table 2 fallacy: presenting and interpreting confounder and modifier coefficients. American Journal of Epidemiology, 177(4), 292–298.