26 Misura di Probabilità
Prerequisiti
- Leggi l’Appendice J.
Concetti e Competenze Chiave
26.1 Introduzione alle Probabilità: Origine e Definizione
Da dove derivano matematicamente i numeri che chiamiamo “probabilità”? Per rispondere, in questo capitolo faremo riferimento alla trattazione di Michael Betancourt. Questo capitolo offre una versione semplificata del suo lavoro, mantenendo la notazione e le figure originali.
26.2 Insiemi Finiti
Per semplificare, Betancourt introduce i fondamenti della teoria della probabilità utilizzando uno spazio campionario composto da un numero finito di elementi.
Un insieme finito è costituito da un numero finito di elementi distinti,
\[ X = \{x_1, ..., x_N\}. \]
Qui, l’indice numerico serve a distinguere gli \(N\) elementi individuali, senza implicare necessariamente un ordine particolare tra di essi. Per evitare qualsiasi presunzione di ordine, Betancourt utilizza il seguente insieme arbitrario di cinque elementi quale esempio:
\[ X = \{\Box, \clubsuit, \diamondsuit, \heartsuit, \spadesuit\}. \]
Nelle applicazioni pratiche della teoria della probabilità, gli elementi astratti \(x_{n}\) rappresentano oggetti concreti. Tuttavia, in questo capitolo, ci si concentrerà esclusivamente sui concetti matematici, evitando qualsiasi interpretazione particolare. Quando l’insieme \(X\) rappresenta tutti gli oggetti di interesse in una data applicazione, viene denominato spazio campionario. Una volta definito lo spazio campionario, possiamo organizzare e manipolare i suoi elementi in vari modi.
26.3 Sottoinsiemi
Un sottoinsieme di \(X\) è qualsiasi collezione di elementi in \(X\). Per evitare ambiguità, Betancourt usa le lettere romane minuscole \(x\) per indicare un elemento variabile nello spazio campionario \(X\) e le lettere minuscole sans serif \(\mathsf{x}\) per indicare un sottoinsieme variabile.
Ad esempio, \(\mathsf{x} = \{\Box, \diamondsuit, \heartsuit\}\) è un sottoinsieme di \(X = \{\Box, \clubsuit, \diamondsuit, \heartsuit, \spadesuit\}\). Importante notare che nel concetto di sottoinsieme non esiste la nozione di molteplicità, solo di appartenenza: un sottoinsieme può includere un elemento \(x_{n}\) ma non può includerlo più volte.
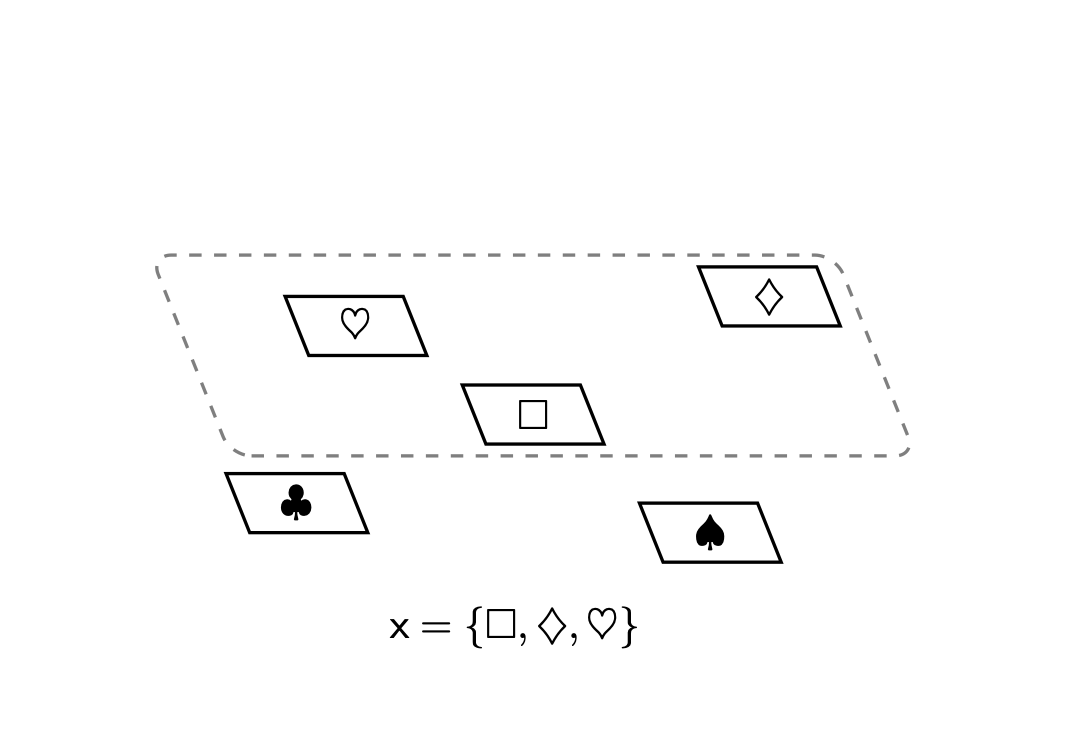
Se \(\mathsf{x}\) è un sottoinsieme dello spazio campionario \(X\) allora scriviamo \(\mathsf{x} \subset X\). Quando \(\mathsf{x}\) contiene tutti gli elementi di \(X\), ovvero \(\mathsf{x} = X\), allora scriviamo \(\mathsf{x} \subseteq X\).
Indipendentemente da quanti elementi un insieme finito \(X\) contiene, possiamo sempre costruire tre tipi speciali di sottoinsiemi. L’insieme vuoto \(\emptyset = \{\}\) non contiene alcun elemento. D’altra parte, l’intero insieme stesso può essere considerato un sottoinsieme contenente tutti gli elementi. Un sottoinsieme contenente un singolo elemento è denotato \(\{ x_{n} \}\) ed è chiamato insieme atomico.
Ci sono
\[ {N \choose n} = \frac{ N! }{ n! (N - n)!} \]
modi per selezionare \(n\) elementi da un insieme finito di \(N\) elementi totali, e quindi \({N \choose n}\) sottoinsiemi totali di dimensione \(n\). Ad esempio, esiste un solo sottoinsieme che non contiene alcun elemento,
\[ {N \choose 0} = \frac{ N! }{ 0! (N - 0)!} = \frac{ N! }{ N! } = 1, \]
ed è l’insieme vuoto. Allo stesso modo, esiste un solo sottoinsieme che contiene tutti gli elementi,
\[ {N \choose N} = \frac{ N! }{ N! (N - N)!} = \frac{ N! }{ N! } = 1, \]
ed è l’insieme completo stesso. D’altra parte, ci sono
\[ {N \choose 1} = \frac{ N! }{ 1! (N - 1)!} = N \]
insiemi atomici distinti che contengono un solo elemento, uno per ciascun elemento in \(X\).
Contando tutti i sottoinsiemi di tutte le dimensioni possibili si ottiene
\[ \sum_{n = 0}^{N} {N \choose n} = 2^{N} \]
sottoinsiemi possibili che possiamo costruire da un insieme finito con \(N\) elementi.
La collezione di tutti i sottoinsiemi è essa stessa un insieme finito con \(2^{N}\) elementi. Chiamiamo questo insieme insieme potenza di \(X\) e lo denotiamo \(2^{X}\).
26.4 Operazioni sui Sottoinsiemi
Possiamo sempre costruire sottoinsiemi elemento per elemento, ma possiamo anche costruirli manipolando sottoinsiemi esistenti.
Ad esempio, dato un sottoinsieme \(\mathsf{x} \subset X\) possiamo costruire il suo complemento raccogliendo tutti gli elementi in \(X\) che non sono già in \(\mathsf{x}\). L’insieme atomico \(\mathsf{x} = \{ \diamondsuit \}\) contiene l’unico elemento \(\diamondsuit\) e il suo complemento contiene i rimanenti elementi \[ \mathsf{x}^{c} = \{ \Box, \clubsuit, \heartsuit, \spadesuit \}. \] Per costruzione, il complemento dell’insieme vuoto è l’intero insieme, \(\emptyset^{c} = X\), e il complemento dell’insieme completo è l’insieme vuoto, \(X^{c} = \emptyset\).
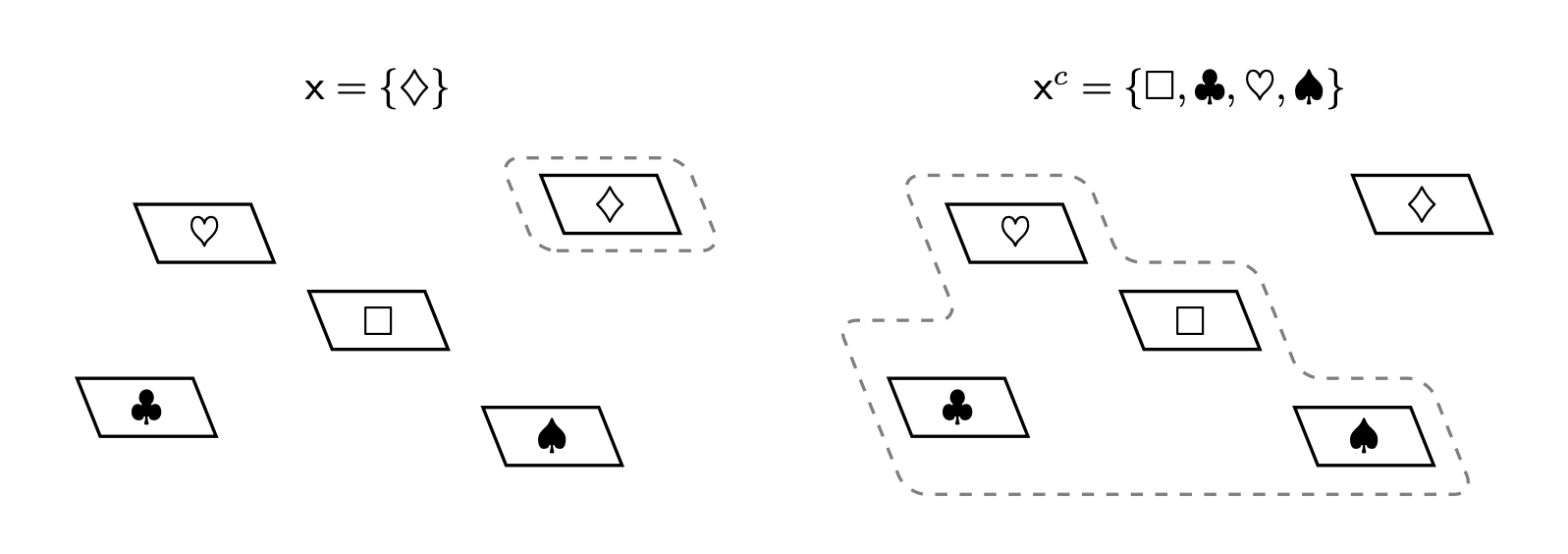
Ad esempio, applicando l’operatore di complemento al sottoinsieme \(\mathsf{x} = \{ \clubsuit, \spadesuit \}\) otteniamo \[ \mathsf{x}^{c} = \{ \clubsuit, \spadesuit \}^{c} = \{ \Box, \diamondsuit, \heartsuit \}. \]
Possiamo anche costruire sottoinsiemi da più di un sottoinsieme. Consideriamo, ad esempio, due sottoinsiemi \(\mathsf{x}_1 = \{ \Box, \heartsuit \}\) e \(\mathsf{x}_2 = \{ \Box, \spadesuit \}\). La collezione di tutti gli elementi che sono contenuti in uno qualsiasi dei due sottoinsiemi è essa stessa un sottoinsieme, \[ \{ \Box, \heartsuit, \spadesuit \} \subset X, \] così come la collezione di tutti gli elementi che sono contenuti in entrambi i sottoinsiemi, \[ \{ \Box \} \subset X. \] Questi sottoinsiemi derivati sono chiamati rispettivamente unione, \[ \mathsf{x}_1 \cup \mathsf{x}_2 = \{ \Box, \heartsuit \} \cup \{ \Box, \spadesuit \} = \{ \Box, \heartsuit, \spadesuit \}, \] e intersezione, \[ \mathsf{x}_1 \cap \mathsf{x}_2 = \{ \Box, \heartsuit \} \cap \{ \Box, \spadesuit \} = \{ \Box \}. \]
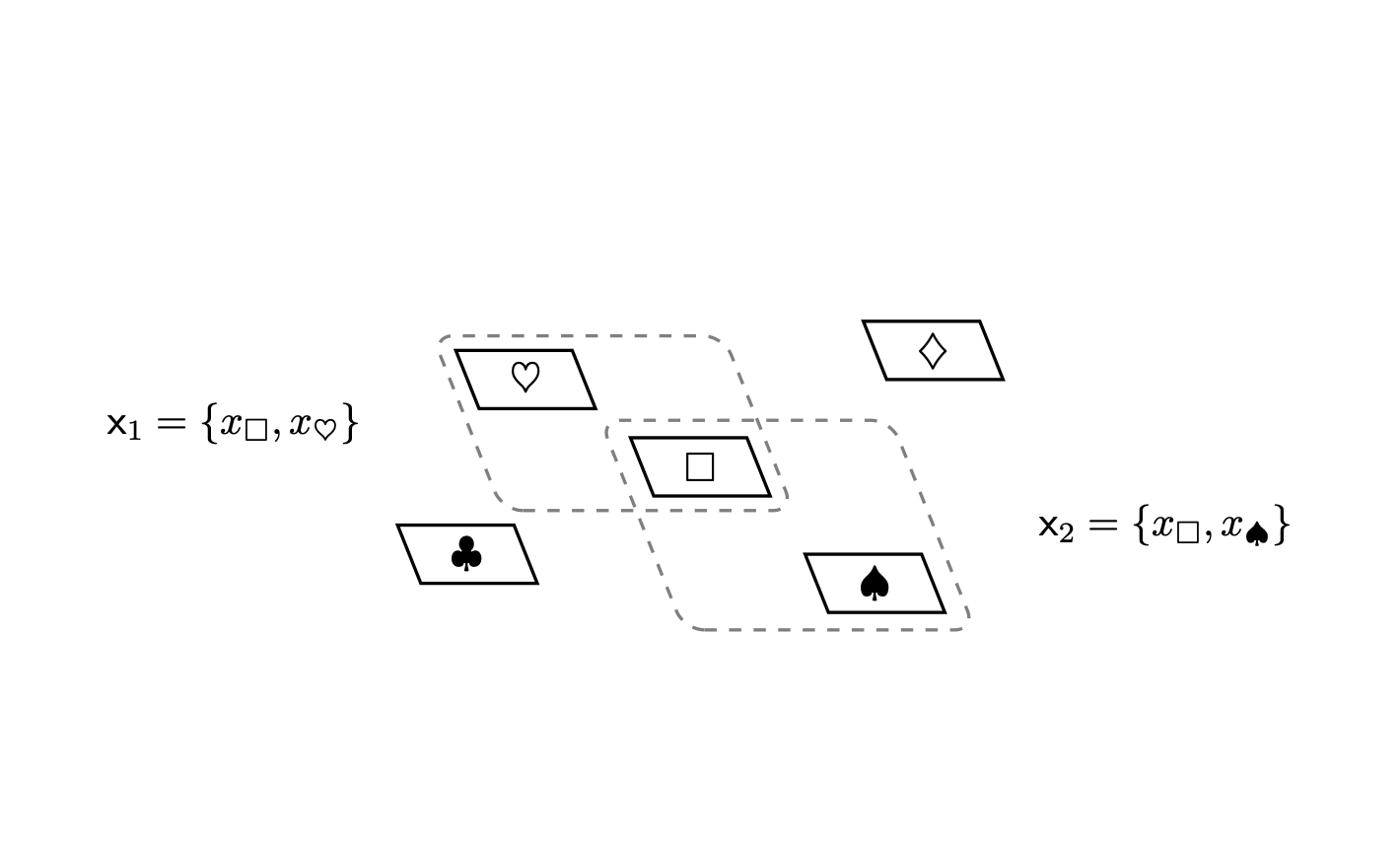
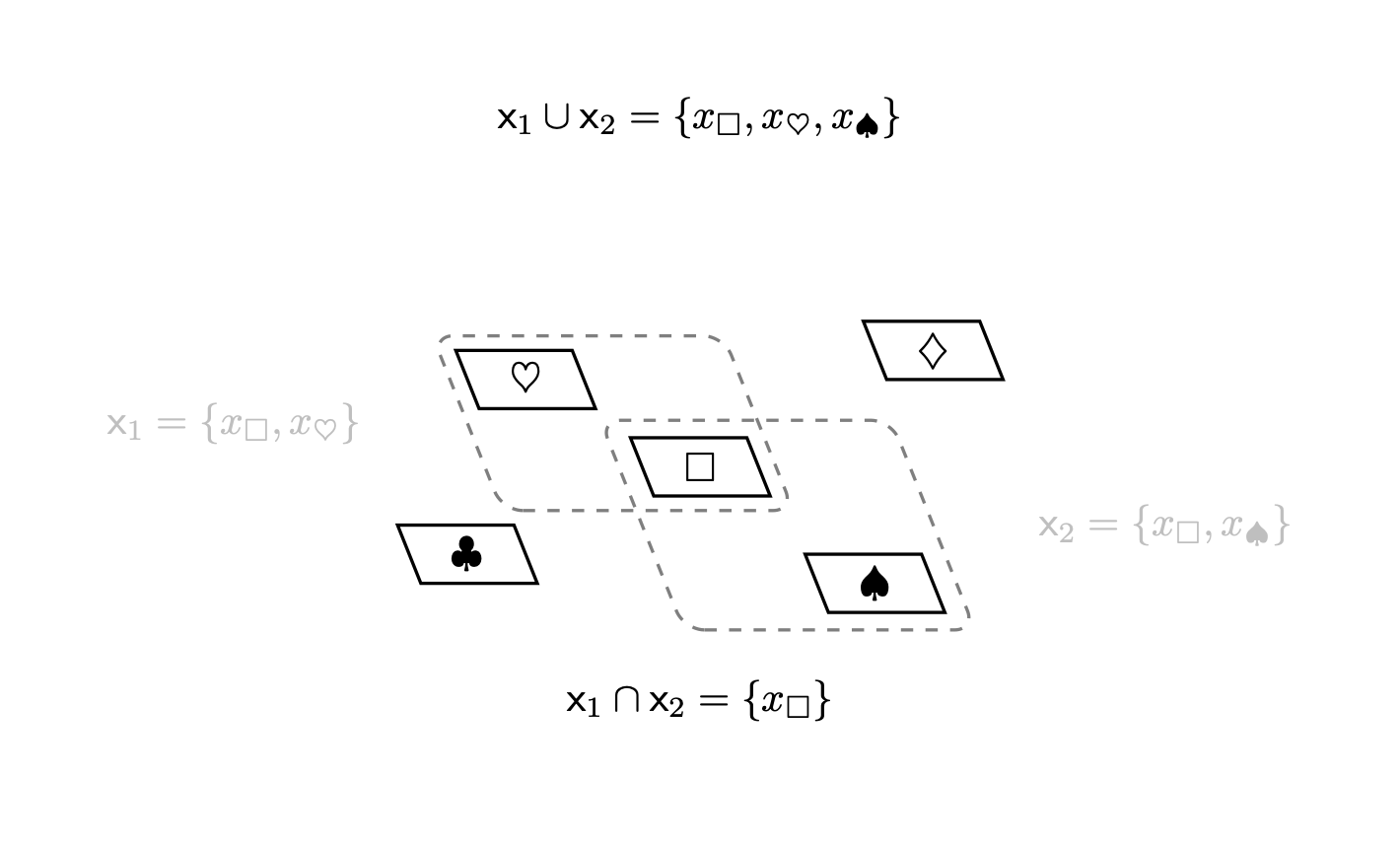
Due sottoinsiemi sono disgiunti se non condividono alcun elemento; in questo caso la loro intersezione è l’insieme vuoto, \[ \mathsf{x}_{1} \cap \mathsf{x}_{2} = \emptyset. \] L’unione e l’intersezione di un sottoinsieme con se stesso restituiscono quel sottoinsieme, \[ \mathsf{x} \cup \mathsf{x} = \mathsf{x} \cap \mathsf{x} = \mathsf{x}. \] Poiché l’insieme vuoto non contiene alcun elemento, la sua unione con qualsiasi sottoinsieme restituisce quel sottoinsieme, \[ \mathsf{x} \cup \emptyset = \emptyset \cup \mathsf{x} = \mathsf{x}, \] e la sua intersezione con qualsiasi sottoinsieme restituisce l’insieme vuoto, \[ \mathsf{x} \cap \emptyset = \emptyset \cap \mathsf{x} = \emptyset. \] Allo stesso modo, l’unione di un sottoinsieme con l’insieme completo restituisce l’insieme completo, \[ \mathsf{x} \cup X = X \cup \mathsf{x} = X, \] e l’intersezione di un sottoinsieme con l’insieme completo restituisce quel sottoinsieme, \[ \mathsf{x} \cap X = X \cap \mathsf{x} = \mathsf{x}. \]
26.5 Misura e Probabilità sugli Elementi
Da un punto di vista matematico, la teoria della misura riguarda l’allocazione coerente di una qualche quantità astratta attraverso lo spazio campionario. Consideriamo un serbatoio (il termine standard in questo contesto sarebbe “misura totale” o “massa totale”) di una qualche quantità positiva, continua e conservata, \(M \in [0, \infty]\). Poiché \(M\) è conservato, qualsiasi quantità \(m_{n}\) che viene allocata all’elemento \(x_{n} \in X\) deve essere detratta dal serbatoio, lasciando meno da allocare agli altri elementi.
Un caso particolare si verifica quando il contenuto totale del serbatoio \(M\) è infinito. In questo scenario, possiamo allocare una quantità infinita dal serbatoio pur avendo ancora una quantità infinita rimanente. Allo stesso tempo, allocare una quantità infinita può esaurire completamente il serbatoio o lasciare qualsiasi quantità finita residua. L’infinito è un concetto matematicamente complesso da trattare.
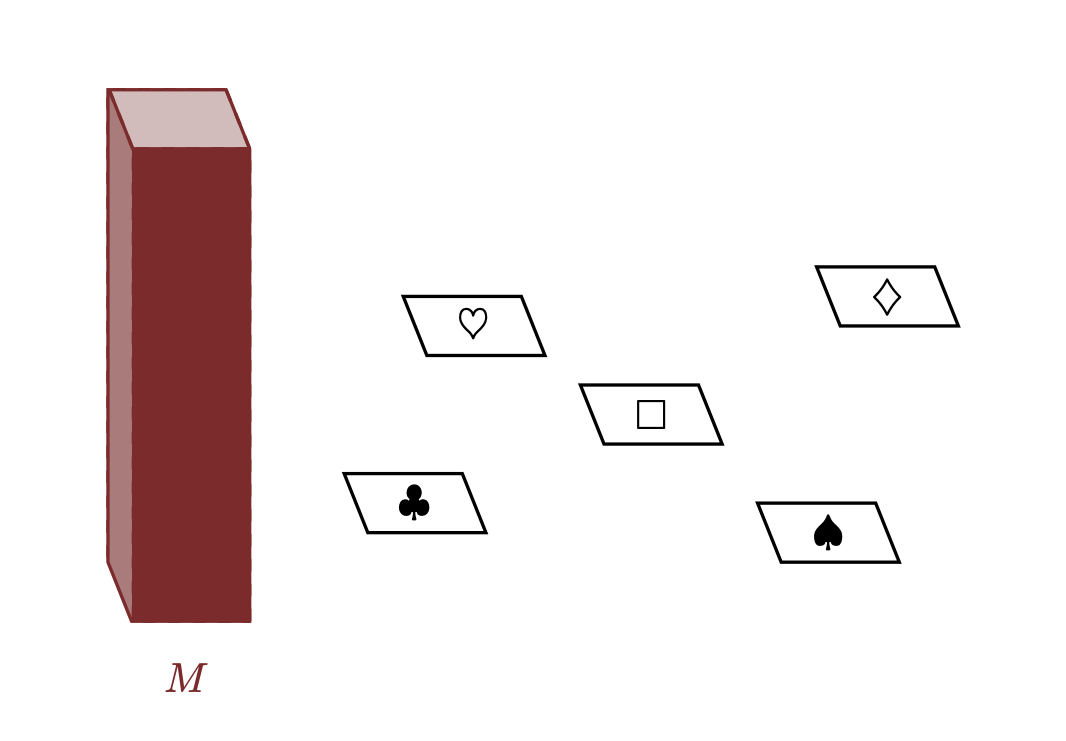
Un’allocazione esaustiva di \(M\) su tutto lo spazio campionario assicura che il serbatoio sia completamente svuotato. In altre parole, l’intero valore di \(M\) deve essere distribuito tra gli elementi \(x_{n} \in X\).
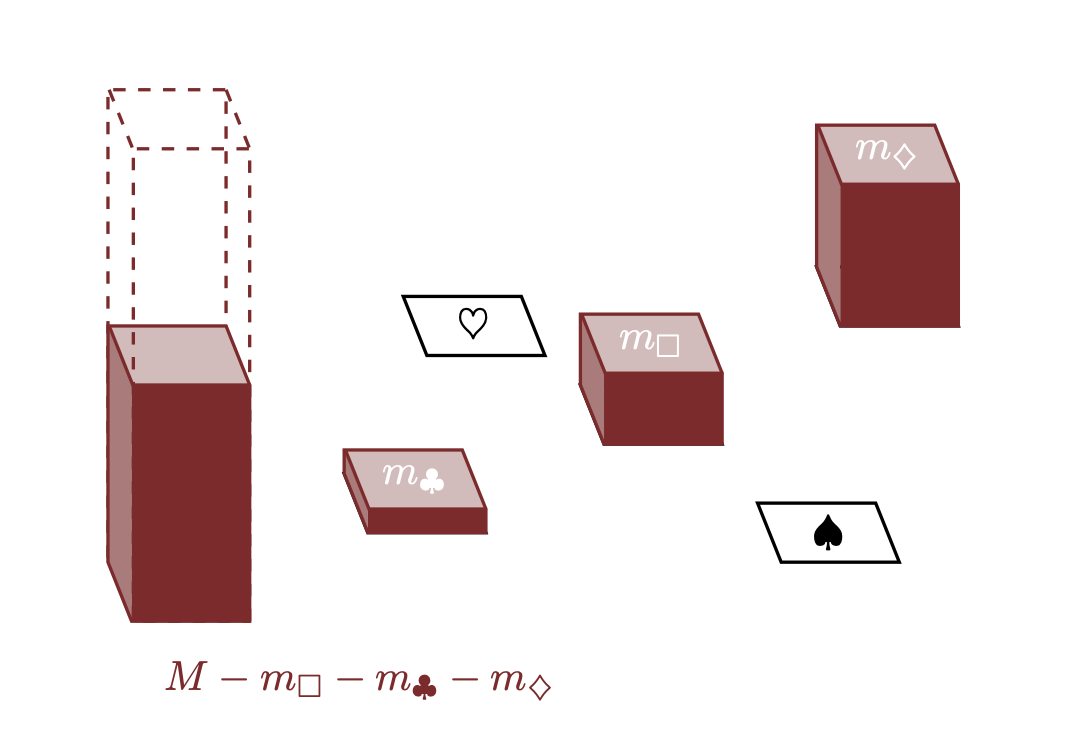
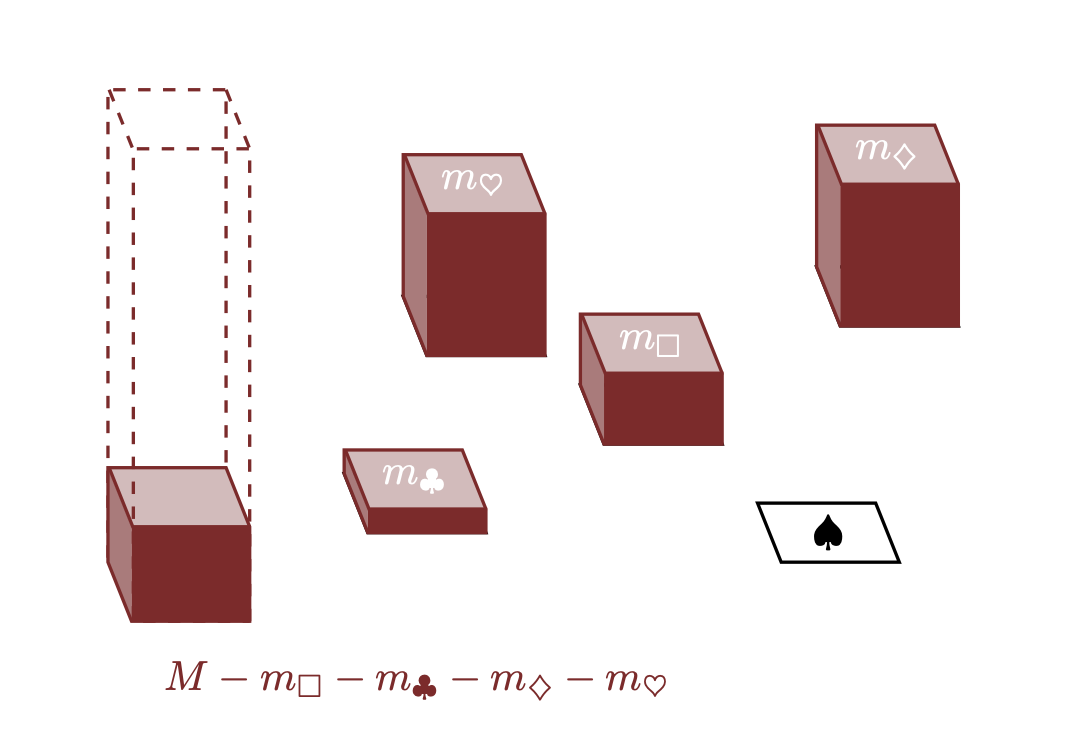
Per illustrare questo concetto, consideriamo il nostro spazio campionario dimostrativo \(X = \{\Box, \clubsuit, \diamondsuit, \heartsuit, \spadesuit \}\). Il processo di allocazione può essere descritto come segue:
- Allocchiamo \(m_\Box\) a \(\Box\), lasciando \(M - m_\Box\) nel serbatoio.
- Assegniamo \(m_\clubsuit\) a \(\clubsuit\), riducendo ulteriormente il contenuto del serbatoio a \(M - m_\Box - m_\clubsuit\).
- Continuiamo questo processo per \(\diamondsuit\) e \(\heartsuit\).
- Infine, per svuotare completamente il serbatoio, dobbiamo allocare tutto ciò che rimane a \(\spadesuit\).
Matematicamente, l’ammontare finale allocato a \(\spadesuit\) sarà:
\[ M - m_{\Box} - m_{\clubsuit} - m_{\diamondsuit} - m_{\heartsuit}. \]
Questa allocazione finale assicura che la somma di tutte le quantità distribuite sia esattamente uguale a \(M\), svuotando così completamente il serbatoio.
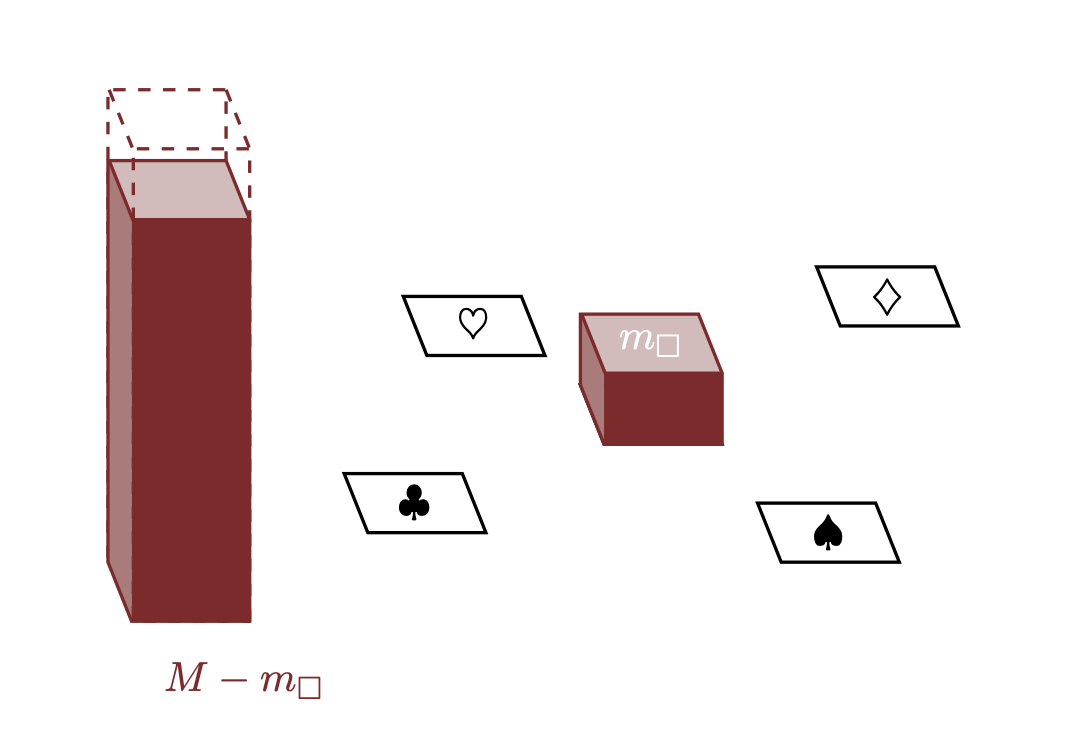
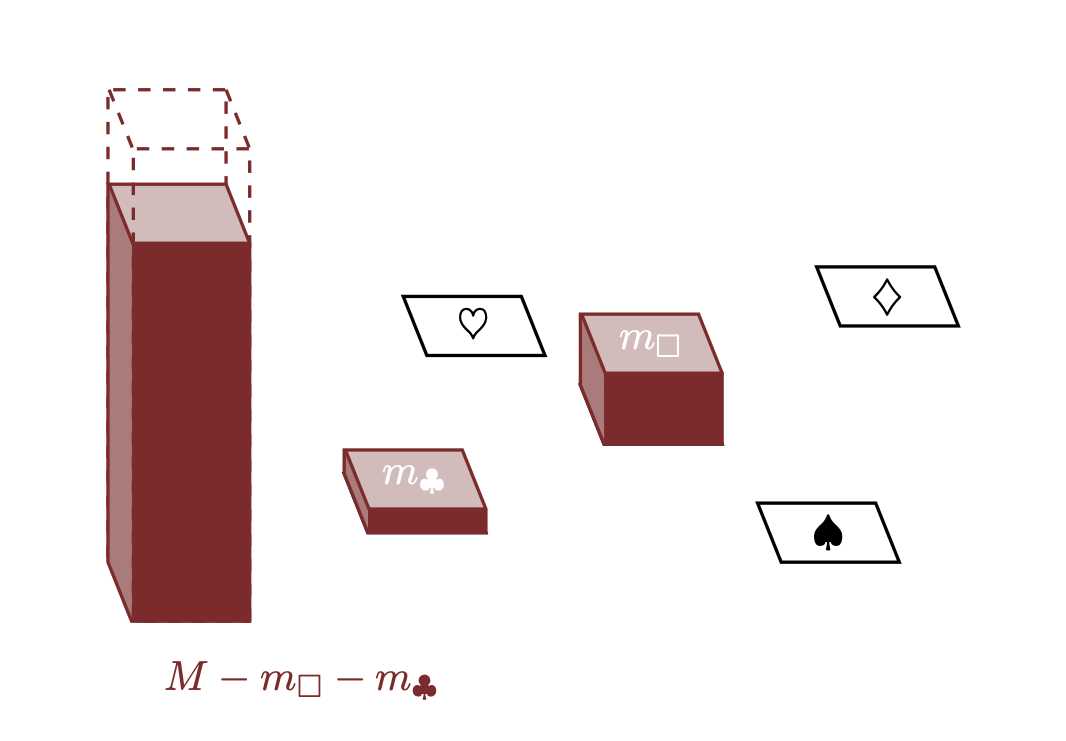

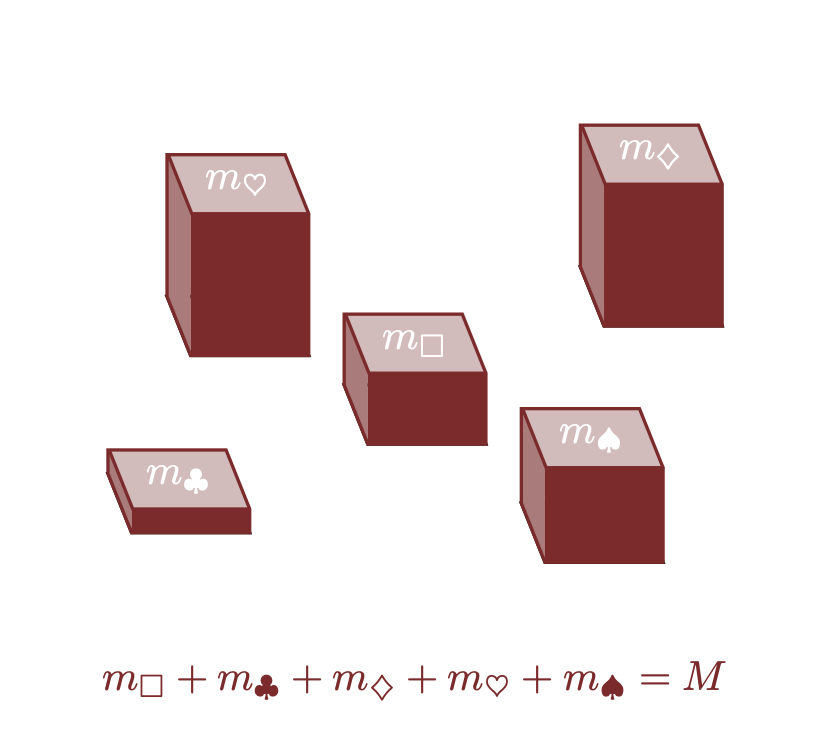
Una misura è qualsiasi allocazione coerente della quantità \(M\) agli elementi di uno spazio campionario. Matematicamente, qualsiasi misura su un insieme finito può essere caratterizzata da \(N\) numeri \[ \mu = \{ m_{1}, \ldots, m_{N} \} \] che soddisfano \[ 0 \le m_{n} \] e \[ \sum_{n = 1}^{N} m_{n} = M. \] Ad esempio, qualsiasi misura sui cinque elementi dell’insieme \(X = \{\Box, \clubsuit, \diamondsuit, \heartsuit, \spadesuit\}\) è specificata da cinque numeri positivi \(\{ m_\Box, m_\clubsuit, m_\diamondsuit, m_\heartsuit, m_\spadesuit \}\) che soddisfano \[ m_\Box + m_\clubsuit + m_\diamondsuit + m_\heartsuit + m_\spadesuit = M. \]
Più grande è \(m_{n}\), più di \(M\) viene allocato all’elemento \(x_{n}\). Seguendo questa terminologia, chiameremo anche \(M\) come la misura totale e \(m_{n}\) come la misura allocata a \(x_{n}\).
In questa discussione, ci occuperemo solo di misure finite, dove la misura totale \(M\) è un numero positivo e finito (\(0 \leq M \leq \infty\)). Non tratteremo il caso di misure infinite (\(M = \infty\)), poiché richiede considerazioni più complesse che vanno oltre lo scopo di questa trattazione.
Una misura \(\mu\) su uno spazio campionario \(X\) può essere vista come una funzione che assegna un valore numerico non negativo (la misura) a ogni elemento dello spazio:
\[ \begin{alignat*}{6} \mu :\; & X & &\rightarrow& \; & [0, \infty] & \\ & x_{n} & &\mapsto& & m_{n} = \mu(x_{n}) &, \end{alignat*} \] dove:
- \(X\) è lo spazio campionario,
- \(x_n\) è un elemento di \(X\),
- \(m_n\) è la misura assegnata a \(x_n\).
Questo approccio funzionale ci permette di considerare ogni elemento dello spazio campionario separatamente, valutando \(\mu(x_{n})\) per ciascun \(x_{n}\), invece di dover gestire tutte le allocazioni contemporaneamente.
È importante notare che esistono molti modi diversi per distribuire una misura totale \(M\) tra gli elementi di un insieme finito. L’insieme di tutte le possibili misure su \(X\) si indica con \(\mathcal{M}(X)\).
All’interno di questa collezione ci sono alcuni esempi notevoli. Ad esempio, una misura singolare alloca la misura totale \(M\) a un singolo elemento, lasciando il resto con niente. D’altra parte, una misura uniforme alloca la stessa misura \(M / N\) a ciascun elemento. Su insiemi finiti ci sono \(N\) misure singolari distinte, una per ciascun elemento distinto, e una misura uniforme unica.
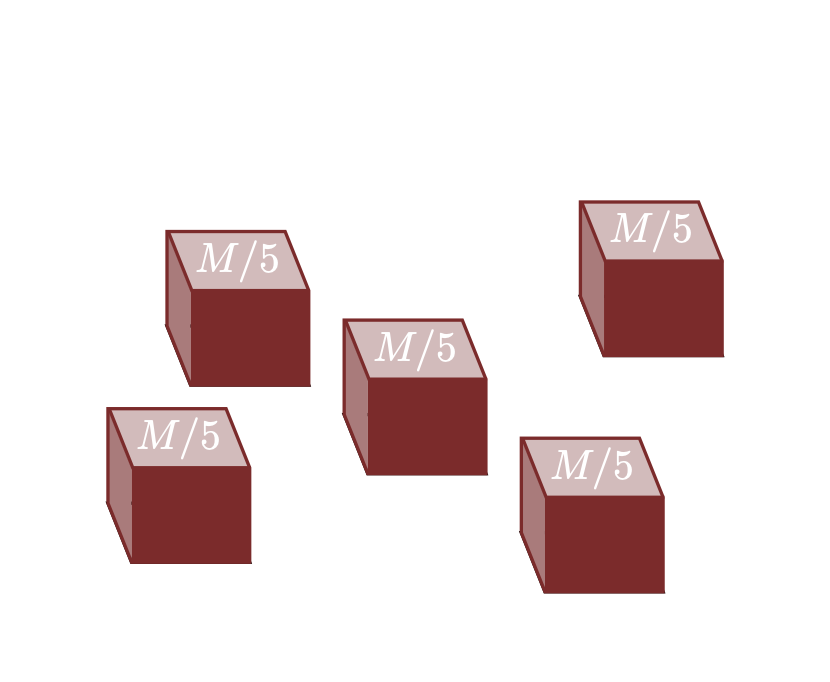
Le misure finite sono una categoria particolarmente importante nel campo della teoria della misura. Una misura si definisce finita quando la sua misura totale \(M\) è un numero positivo e limitato, ovvero \(0 < M < \infty\).
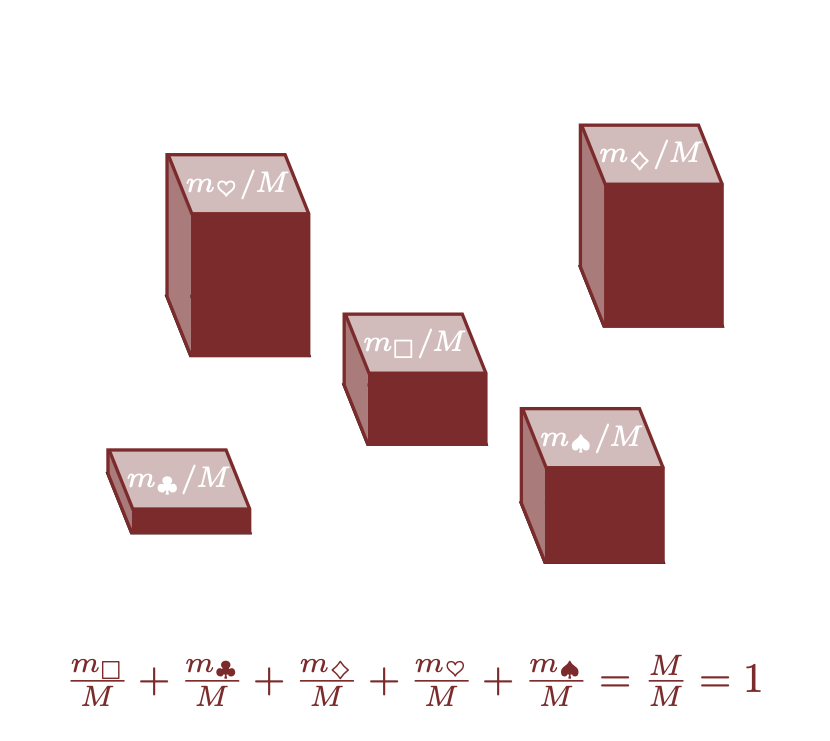
L’importanza delle misure finite risiede nella possibilità di esprimere le allocazioni in termini relativi anziché assoluti. Questo significa che possiamo rappresentare la misura di ciascun elemento come una frazione o una percentuale della misura totale, invece di usare il valore assoluto. Invece di considerare la misura assoluta allocata a ciascun elemento \(m_{n}\), possiamo considerare la proporzione della misura totale allocata a ciascun elemento \[ p_{n} = m_{n} / M. \] Per costruzione, le proporzioni sono confinate all’intervallo unitario \([0, 1]\). Come per qualsiasi quantità che assume valori in \([0, 1]\), possiamo rappresentare le proporzioni altrettanto bene con decimali, ad esempio \(p_{n} = 0.2\), e percentuali, \(p_{n} = 20\%\).
Questo approccio relativo offre diversi vantaggi: permette di confrontare facilmente l’importanza relativa di diversi elementi, facilita la comprensione della distribuzione della misura sull’intero spazio campionario e consente di normalizzare misure diverse, rendendo più semplice il confronto tra sistemi diversi. In sintesi, le misure finite ci permettono di passare da una visione “assoluta” a una “relativa” della distribuzione della misura, offrendo una prospettiva più intuitiva e utile per l’analisi.
In altre parole, una misura proporzionale definisce la funzione \[ \begin{alignat*}{6} \pi :\; & X & &\rightarrow& \; & [0, 1] & \\ & x_{n} & &\mapsto& & p_{n} = \pi(x_{n}) & \end{alignat*} \] con \[ 0 \le p_{n} \le 1 \] e \[ \sum_{n = 1}^{N} p_{n} = 1. \] Una collezione di variabili \(\{ p_{1}, \ldots, p_{N} \}\) che soddisfano queste proprietà è chiamata simplex.
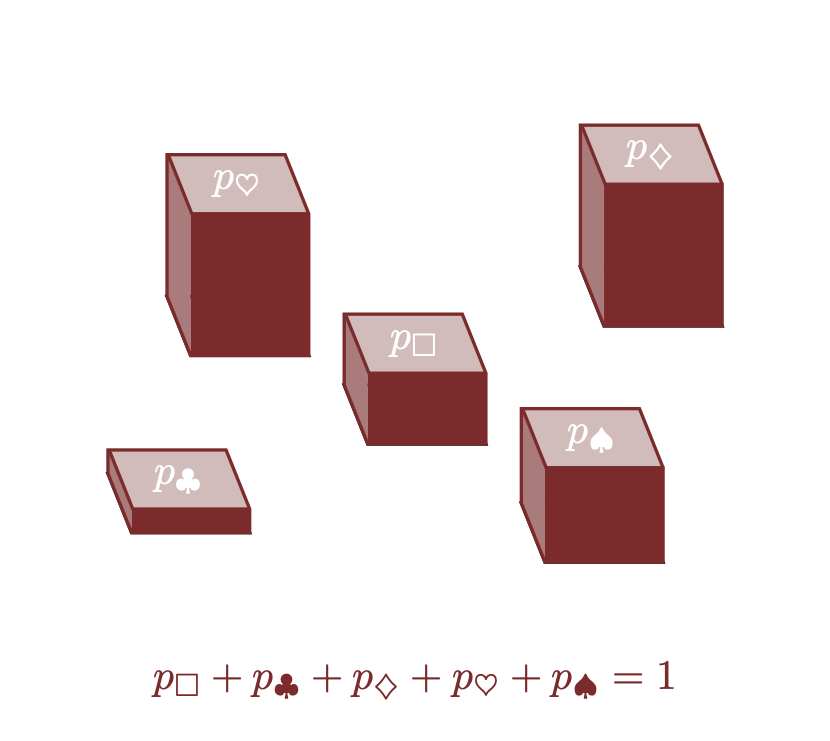
Più importante, una misura proporzionale \(\pi\) è anche conosciuta come distribuzione di probabilità, e le allocazioni proporzionali \(p_{n}\) sono chiamate probabilità. Sebbene il termine “probabilità” sia spesso carico di significati interpretativi e filosofici, la sua struttura matematica è piuttosto semplice: su un insieme finito, una probabilità rappresenta semplicemente la proporzione di una quantità finita assegnata a ciascun elemento individuale.
26.6 Misura e Probabilità sui Sottoinsiemi
Sugli insiemi finiti, qualsiasi allocazione, sia assoluta che proporzionale, agli elementi individuali \(x \in X\) determina anche un’allocazione per i sottoinsiemi \(\mathsf{x} \in 2^{X}\). La misura assegnata a un sottoinsieme è semplicemente la somma delle misure assegnate agli elementi che lo compongono. Ad esempio, la misura assegnata al sottoinsieme \(\mathsf{x} = \{ \Box, \clubsuit, \heartsuit \}\) è \(m_{\Box} + m_{\clubsuit} + m_{\heartsuit}\).
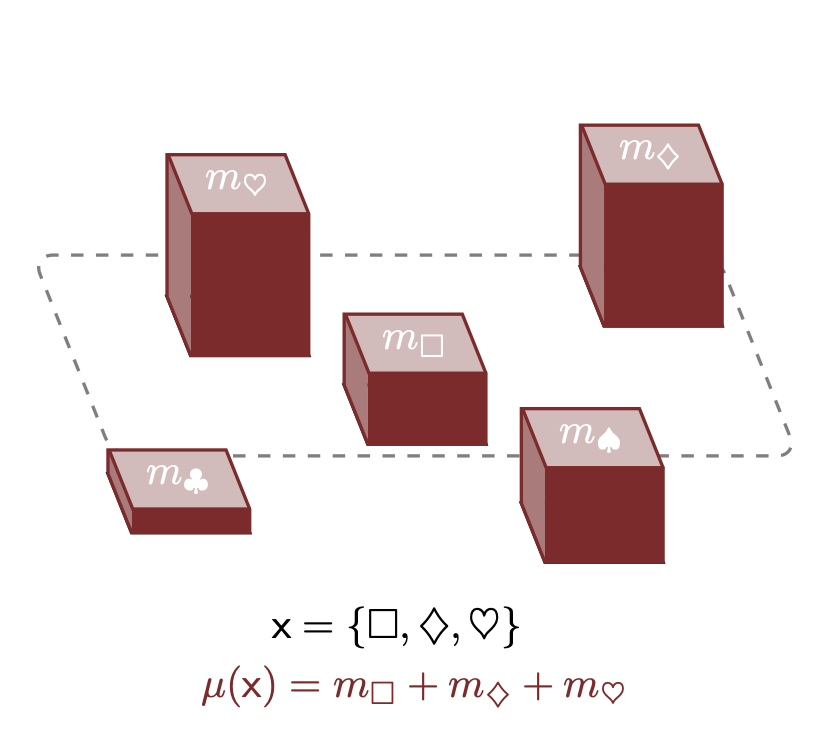
Per costruzione, qualsiasi misura sui sottoinsiemi e distribuzione di probabilità soddisfano una serie di proprietà utili. Ad esempio, per qualsiasi misura \[ \mu( \emptyset ) = 0 \] e \[ \mu( X ) = \sum_{n = 1}^{N} \mu(x_{n}) = M, \] mentre per qualsiasi distribuzione di probabilità abbiamo \(\pi( \emptyset ) = 0\) e \(\pi( X ) = 1\).
Le allocazioni sui sottoinsiemi si combinano in modo naturale con le operazioni sui sottoinsiemi. Consideriamo, ad esempio, i due sottoinsiemi disgiunti \(\mathsf{x}_{1} = \{ \Box, \diamondsuit \}\) e \(\mathsf{x}_{2} = \{ \clubsuit, \spadesuit \}\). Poiché i due sottoinsiemi sono disgiunti, la loro unione include semplicemente tutti i loro elementi:
\[ \mathsf{x}_{1} \cup \mathsf{x}_{2} = \{ \Box, \diamondsuit \} \cup \{ \clubsuit, \spadesuit \} = \{ \Box, \clubsuit, \diamondsuit, \spadesuit \}, \]
e la misura di questa unione è solo la somma delle misure dei due sottoinsiemi:
\[ \begin{align*} \mu ( \mathsf{x}_{1} \cup \mathsf{x}_{2} ) &= \mu ( \{ \Box, \clubsuit, \diamondsuit, \spadesuit \} ) \\ &= m_{\Box} + m_{\clubsuit} + m_{\diamondsuit} + m_{\spadesuit} \\ &= ( m_{\Box} + m_{\diamondsuit} ) + ( m_{\clubsuit} + m_{\spadesuit} ) \\ &= \mu( \mathsf{x}_{1} ) + \mu( \mathsf{x}_{2} ). \end{align*} \]
Più in generale, per qualsiasi collezione di sottoinsiemi
\[ \mathsf{x}_{1}, \ldots, \mathsf{x}_{K} \]
che sono reciprocamente disgiunti,
\[ \mathsf{x}_{k} \cap \mathsf{x}_{k'} = \emptyset \quad \text{per} \quad k \ne k', \]
abbiamo
\[ \mu ( \cup_{k = 1}^{K} \mathsf{x}_{k} ) = \sum_{k = 1}^{K} \mu ( \mathsf{x}_{k} ). \]
In altre parole, se possiamo scomporre un sottoinsieme in una collezione di sottoinsiemi più piccoli e disgiunti, possiamo anche scomporre la misura allocata a quel sottoinsieme iniziale nelle misure allocate ai sottoinsiemi componenti. Questa proprietà di coerenza è chiamata additività.
Un sottoinsieme \(\mathsf{x}\) e il suo complemento \(\mathsf{x}^{c}\) sono sempre disgiunti, ovvero \(\mathsf{x} \cap \mathsf{x}^{c} = \emptyset\). Allo stesso tempo, la loro unione copre l’intero insieme: \(\mathsf{x} \cup \mathsf{x}^{c} = X\). Di conseguenza, l’additività implica che:
\[ \begin{align*} M &= \mu (X) \\ &= \mu ( \mathsf{x} \cup \mathsf{x}^{c} ) \\ &= \mu ( \mathsf{x} ) + \mu ( \mathsf{x}^{c} ), \end{align*} \]
da cui segue che:
\[ \mu ( \mathsf{x}^{c} ) = M - \mu ( \mathsf{x} ). \]
In altre parole, la misura assegnata al complemento di un sottoinsieme è la misura totale meno la misura assegnata a quel sottoinsieme. Per le distribuzioni di probabilità, questo concetto è ancora più evidente:
\[ \pi ( \mathsf{x}^{c} ) = 1 - \pi ( \mathsf{x} ). \]
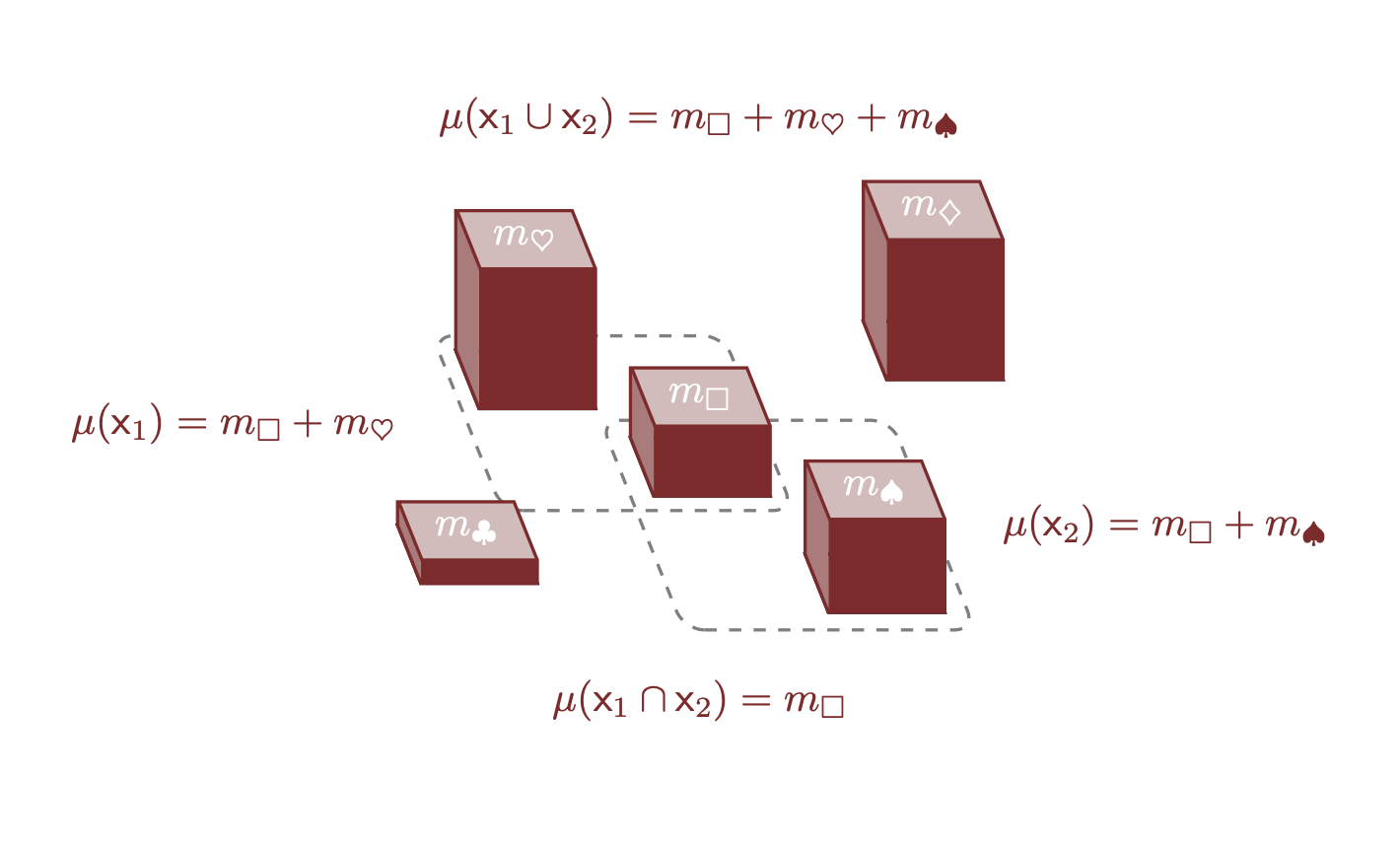
Quando due sottoinsiemi si sovrappongono, dobbiamo considerare che la somma delle loro misure \(\mu (\mathsf{x}_{1} ) + \mu ( \mathsf{x}_{2} )\) conta due volte la misura degli elementi condivisi tra di essi. Ad esempio, se \(\mathsf{x}_{1} = \{ \Box, \heartsuit \}\) e \(\mathsf{x}_{2} = \{ \Box, \spadesuit \}\), allora l’unione include l’elemento sovrapposto \(\Box\) solo una volta:
\[ \mathsf{x}_{1} \cup \mathsf{x}_{2} = \{ \Box, \heartsuit \} \cup \{ \Box, \spadesuit \} = \{ \Box, \heartsuit, \spadesuit \}. \]
Di conseguenza:
\[ \begin{align*} \mu( \mathsf{x}_{1} \cup \mathsf{x}_{2} ) &= \mu( \{ \Box, \heartsuit, \spadesuit \} ) \\ &= m_{\Box} + m_{\heartsuit} + m_{\spadesuit}. \end{align*} \]
Sommando le misure allocate ai due sottoinsiemi individualmente, tuttavia, otteniamo:
\[ \begin{align*} \mu( \mathsf{x}_{1} ) + \mu ( \mathsf{x}_{2} ) &= (m_{\Box} + m_{\heartsuit} ) + ( m_{\Box} + m_{\spadesuit} ) \\ &= m_{\Box} + m_{\Box} + m_{\heartsuit} + m_{\spadesuit} \\ &= m_{\Box} + \mu( \mathsf{x}_{1} \cup \mathsf{x}_{2} ). \end{align*} \]
L’elemento che viene contato due volte è esattamente l’unico elemento nell’intersezione dei due sottoinsiemi:
\[ m_{\Box} = \mu( \{ \Box \} ) = \mu( \mathsf{x}_{1} \cap \mathsf{x}_{2} ). \]
In altre parole, possiamo scrivere:
\[ \mu( \mathsf{x}_{1} ) + \mu ( \mathsf{x}_{2} ) = \mu( \mathsf{x}_{1} \cup \mathsf{x}_{2} ) + \mu( \mathsf{x}_{1} \cap \mathsf{x}_{2} ). \]
Questa relazione vale per qualsiasi due sottoinsiemi, indipendentemente dalla loro sovrapposizione.
Queste proprietà dei sottoinsiemi ci permettono di costruire una misura in molti modi diversi, ciascuno dei quali può essere utile in circostanze diverse. Questa flessibilità è molto comoda quando si applica la teoria della misura e la teoria della probabilità nella pratica.
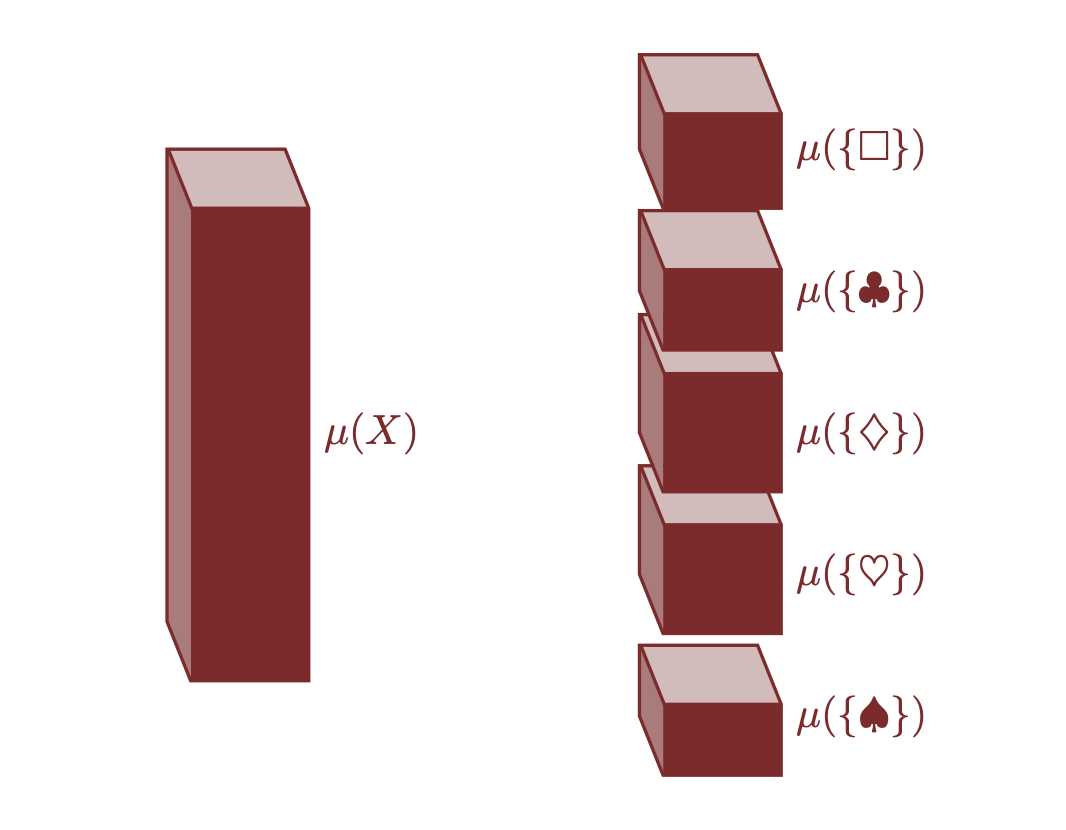
Ad esempio, possiamo specificare una misura in due modi principali:
- Allocazione globale: possiamo assegnare le misure a tutti gli elementi individuali contemporaneamente. Questo metodo considera l’intero insieme fin dall’inizio e assegna una misura a ciascun elemento.
- Allocazione locale: possiamo assegnare la misura a ciascun elemento uno alla volta. Questo metodo permette di concentrarsi su un elemento alla volta, aggiungendo gradualmente le misure agli altri elementi.
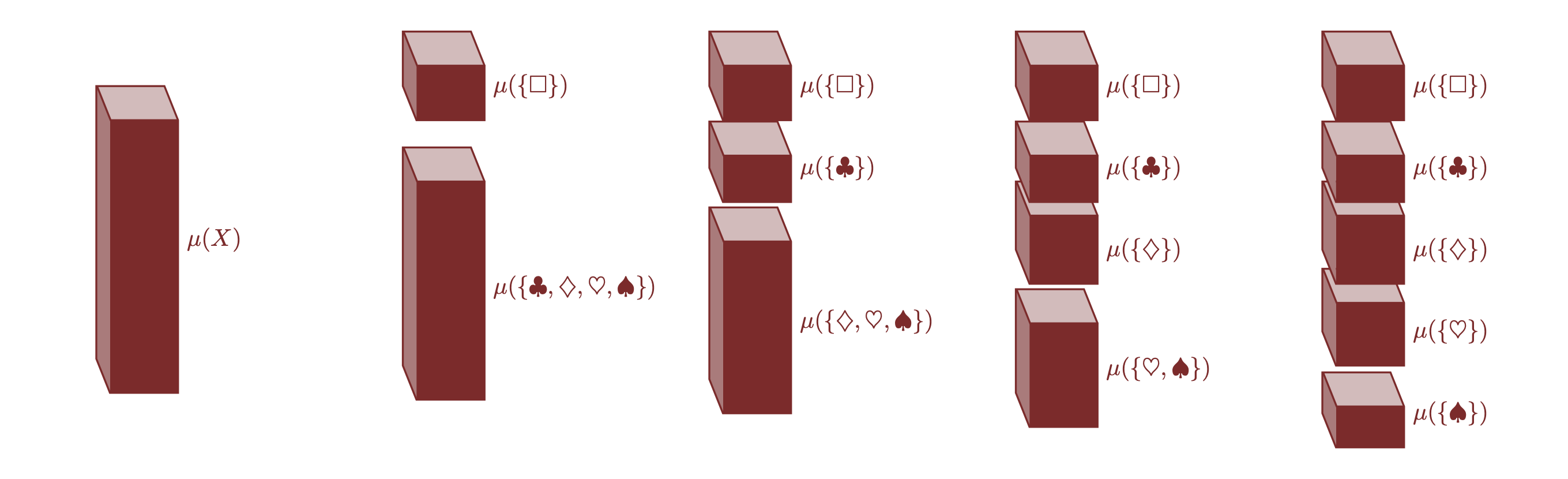
Inoltre, non è sempre necessario partire dalle allocazioni individuali. Un altro metodo consiste nel:
- Allocazione iterativa: possiamo iniziare allocando la misura totale a sottoinsiemi disgiunti e poi affinare iterativamente questa allocazione suddividendo i sottoinsiemi in parti sempre più piccole fino a raggiungere gli elementi individuali.
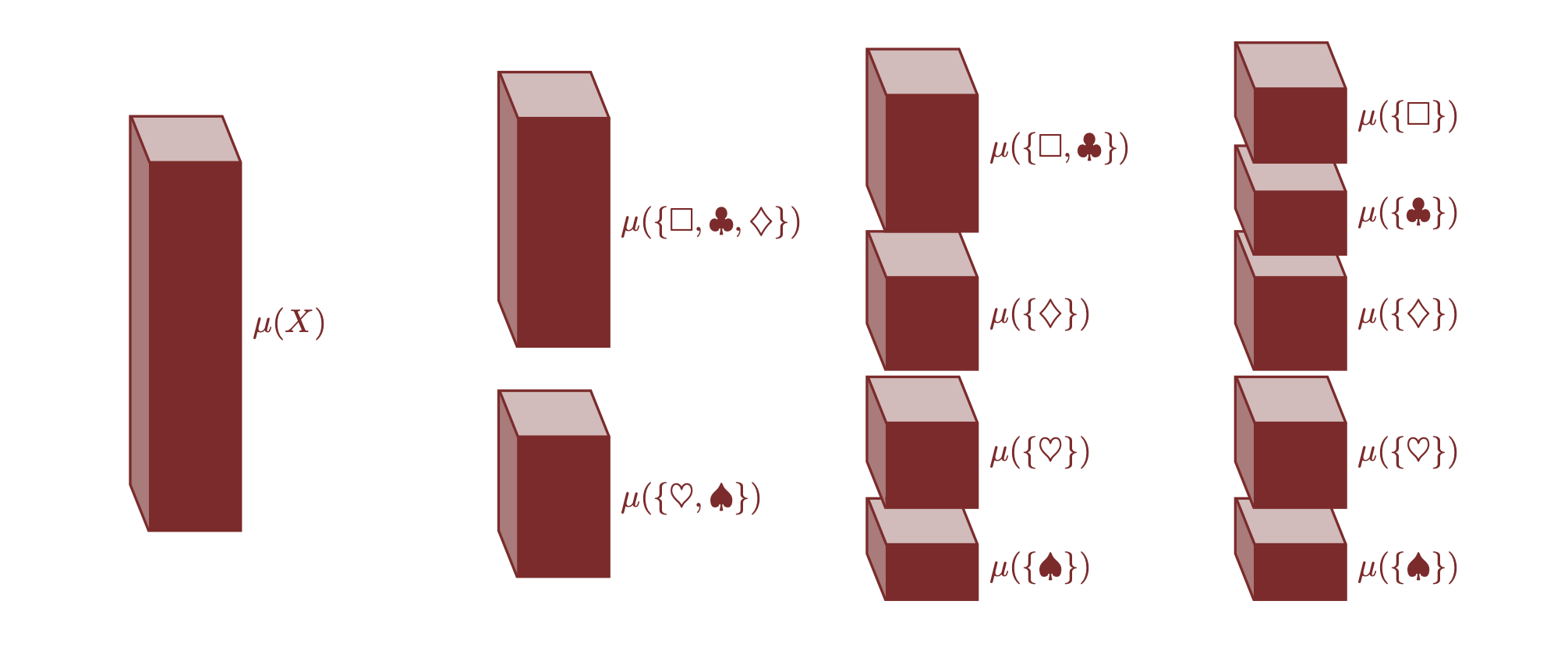
Questa flessibilità nelle modalità di costruzione delle misure è particolarmente utile perché permette di adattare l’approccio alle specifiche necessità del problema in questione. Ad esempio, nella pratica, potremmo trovare più semplice allocare inizialmente misure a grandi gruppi di elementi e poi suddividere questi gruppi, oppure potremmo voler assegnare le misure a ciascun elemento uno per uno a seconda delle esigenze del contesto.
Infine, la definizione di misura sui sottoinsiemi \(\mu : 2^{X} \rightarrow [0, \infty]\) è cruciale per estendere la teoria della misura oltre gli insiemi finiti. Questa estensione è necessaria per definire misure in modo coerente su insiemi matematicamente più complessi, come la retta reale.
26.7 Riflessioni Conclusive
Il significato applicativo delle nozioni di misura e distribuzione di probabilità è centrale per comprendere come utilizzare questi concetti nella pratica, in particolare nella statistica bayesiana. Il punto cruciale è capire cosa rappresenta \(M\), la “misura totale”. Nelle applicazioni bayesiane, \(M\) rappresenta la nostra certezza complessiva.
Quando si lavora con distribuzioni di probabilità, stiamo effettivamente allocando questa certezza complessiva tra diversi eventi possibili. Una distribuzione (di massa) di probabilità è quindi l’allocazione relativa della nostra certezza tra un insieme di eventi disgiunti. Ogni probabilità individuale, \(p_n\), rappresenta la proporzione della nostra certezza totale che assegniamo a un particolare evento.
Nella teoria bayesiana, la “misura totale” \(M\) è interpretata come la somma totale delle probabilità, che è sempre uguale a 1. Questo riflette il fatto che la somma delle nostre certezze relative per tutti gli eventi possibili deve essere completa: siamo completamente certi che uno degli eventi nel nostro spazio campionario si verificherà.
Quando creiamo una distribuzione di probabilità, stiamo dividendo questa certezza totale tra i vari eventi possibili nel nostro spazio campionario. Ad esempio, se stiamo analizzando un problema con cinque possibili esiti distinti, dobbiamo allocare l’intera certezza (pari a 1) tra questi esiti. Ogni valore di probabilità \(p_n\) rappresenta la frazione della nostra certezza totale che attribuiamo a un particolare esito.
Le nozioni di misura e distribuzione di probabilità trovano numerose applicazioni pratiche. Ad esempio:
- Inferenza bayesiana: Utilizziamo distribuzioni di probabilità per rappresentare le nostre incertezze sui parametri di interesse. Dopo aver osservato i dati, aggiorniamo queste distribuzioni tramite il teorema di Bayes.
- Modellizzazione probabilistica: Costruiamo modelli che descrivono il comportamento di sistemi complessi assegnando probabilità agli eventi possibili. Questo ci permette di fare previsioni e prendere decisioni informate basate sulle probabilità assegnate.
In conclusione, le nozioni di misura e distribuzione di probabilità sono strumenti potenti per allocare e manipolare la nostra certezza tra diversi eventi possibili. Comprendere questi concetti è fondamentale per comprendere le applicazioni della teoria della probabilità e della statistica bayesiana. La “misura totale” \(M\) rappresenta la nostra certezza complessiva, e le distribuzioni di probabilità ci permettono di distribuire questa certezza in modo coerente e informato tra gli eventi possibili.