import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import scipy.stats as stats
import arviz as az42 Pensare ad una proporzione in termini soggettivi
Prerequisiti
Leggere il settimo capitolo del libro di Albert & Hu (2019).
Concetti e Competenze Chiave
- Comprendere e applicare l’aggiornamento bayesiano per affinare le credenze preesistenti alla luce di nuovi dati.
- Rappresentare le convinzioni iniziali su un parametro tramite una distribuzione a priori, sia discreta che continua.
- Calcolare la verosimiglianza per dati binomiali e utilizzarla per aggiornare la distribuzione a priori.
- Derivare e interpretare la distribuzione a posteriori combinando la distribuzione a priori e la verosimiglianza dei dati osservati.
- Utilizzare il metodo basato su griglia per approssimare la distribuzione a posteriori di un parametro.
- Applicare il modello binomiale a un esempio concreto per stimare la probabilità di un evento specifico e quantificare l’incertezza associata.
- Calcolare quantità di interesse (media, moda, intervalli di credibilità) dalla distribuzione a posteriori e interpretare i risultati.
- Utilizzare una distribuzione a priori continua, come la Beta, per rappresentare un’ampia gamma di possibili valori del parametro.
Preparazione del Notebook
seed: int = sum(map(ord, "subj_prop"))
rng: np.random.Generator = np.random.default_rng(seed=seed)
sns.set_theme(palette="colorblind")
az.style.use("arviz-darkgrid")
%config InlineBackend.figure_format = "retina"Introduzione
L’unica cosa rilevante è l’incertezza – il grado della nostra conoscenza e ignoranza. Il fatto che gli eventi considerati siano in qualche modo determinati, o conosciuti da altre persone, non ha alcuna importanza.
(Bruno deFinetti)
L’inferenza bayesiana è un metodo di inferenza statistica che utilizza la probabilità per aggiornare le credenze sui parametri di un modello, sulla base di nuove evidenze o dati osservati. Essa fornisce un quadro concettuale per stimare variabili sconosciute, tenendo conto dell’incertezza. Attraverso un modello che descrive le dipendenze tra variabili aleatorie, la teoria della probabilità può essere impiegata per inferire tutte le quantità sconosciute. In questo approccio, tutte le incertezze, sia nelle osservazioni che nei parametri del modello, sono trattate come distribuzioni di probabilità.
In sintesi, l’inferenza bayesiana è il processo di deduzione delle proprietà di una distribuzione di probabilità a partire dai dati, utilizzando il teorema di Bayes. Questo processo incorpora l’idea che la probabilità rappresenti una misura della fiducia su una previsione o un risultato.
Questo capitolo ha lo scopo di esplorare in dettaglio il concetto di aggiornamento bayesiano, illustrandolo con un esempio concreto in un contesto semplificato. L’obiettivo è dimostrare come le credenze preesistenti sulla probabilità di un parametro \(\theta\) possano essere aggiornate attraverso l’osservazione di nuovi dati.
Il primo passo nell’inferenza bayesiana consiste nel rappresentare le credenze iniziali, formulate prima di raccogliere i dati, tramite una distribuzione a priori. La distribuzione a priori riflette le nostre conoscenze o ipotesi preesistenti su \(\theta\) e può variare in base al contesto o alle informazioni pregresse disponibili.
Una volta ottenuti nuovi dati, il passaggio successivo è l’aggiornamento delle credenze tramite la distribuzione a posteriori. Questo aggiornamento si ottiene moltiplicando la distribuzione a priori per la verosimiglianza dei dati osservati, il che riflette quanto i dati supportino un determinato valore di \(\theta\). Il prodotto di questi due termini fornisce una misura delle credenze aggiornate, che viene successivamente normalizzata per garantire che il risultato sia una distribuzione di probabilità valida (ovvero, che l’area sotto la curva sia pari a 1).
Il capitolo si concentra sul modello binomiale. Questo modello è utilizzato per stimare una proporzione sconosciuta basata su una serie di dati binari \(y_1, \ldots, y_n\), ciascuno dei quali può assumere valore 0 o 1.
Inizieremo esplorando un esempio in cui la distribuzione a priori di \(\theta\) è discreta, un caso in cui i valori possibili di \(\theta\) sono limitati a un insieme finito di opzioni. Successivamente, discuteremo scenari in cui la distribuzione a priori è continua, ampliando il modello per affrontare casi più complessi e realistici. Questo approccio progressivo consente di acquisire una comprensione graduale dei concetti centrali dell’inferenza bayesiana e del loro utilizzo pratico nel contesto di problemi statistici reali.
42.1 Verosimiglianza Binomiale
La distribuzione binomiale offre un modello naturale per dati che derivano da una sequenza di \(n\) prove indipendenti e identicamente distribuite, dove ciascuna prova dà origine a uno dei due possibili esiti, convenzionalmente etichettati come ‘successo’ e ‘fallimento’. Grazie al fatto che le prove sono iid, i dati possono essere riassunti dal numero totale di successi nelle \(n\) prove, che denotiamo con \(y\). Il parametro \(\theta\) rappresenta la proporzione di successi nella popolazione o, equivalentemente, la probabilità di successo in ciascuna prova. Il modello di campionamento binomiale è:
\[ p(y|\theta) = \text{Bin}(y|n, \theta) = \binom{n}{y} \theta^y (1 - \theta)^{n-y}, \]
dove nella parte sinistra dell’equazione non si indica la dipendenza da \(n\) perché viene considerato parte del disegno sperimentale e fissato; tutte le probabilità discusse per questo problema sono considerate condizionate su \(n\), cioè assumono che il numero totale di prove sia fissato e noto.
42.2 Applicazione Specifica del Modello Binomiale
In questo capitolo, esaminiamo un’applicazione specifica del modello binomiale per valutare la prestazione di un partecipante in un classico esperimento di psicologia, noto come Go/No-Go task (Shiffrin & Schneider, 1977). In questo tipo di compito, ai partecipanti viene richiesto di rispondere a determinati stimoli (prove Go) e di trattenere la risposta ad altri stimoli (prove No-Go). Ad esempio, i partecipanti possono vedere una serie di lettere presentate su uno schermo e devono premere un pulsante quando vedono qualsiasi lettera tranne una specifica lettera bersaglio (ad esempio, la lettera “X”). In questo esperimento, ogni prova rappresenta un evento di tipo bernoulliano con due possibili esiti: o il partecipante risponde correttamente o commette un errore. I ricercatori analizzano la percentuale di risposte corrette e di inibizioni, concentrandosi in particolare sulla capacità del partecipante di controllare l’impulso di rispondere durante le prove No-Go.
Consideriamo un piccolo numero di prove No-Go di un partecipante, dove i risultati sono: 1, 0, 1, 1, 1, 0, 1, 0, 1. Qui, il valore “1” indica che il partecipante è stato in grado di inibire la risposta, mentre “0” indica che non è riuscito a farlo. L’obiettivo dell’analisi è quantificare l’incertezza nella stima di \(\theta\), che rappresenta la proporzione di risposte corrette nel compito No-Go, ovvero la capacità inibitoria del partecipante.
Consideriamo questi dati come una sequenza di 9 prove bernoulliane indipendenti. Utilizzando il modello binomiale, stimiamo la probabilità \(\theta\) che il partecipante riesca a controllare il proprio impulso di rispondere durante le prove No-Go e quantifichiamo l’incertezza associata a questa stima.
42.2.1 Processo di Lavoro
McElreath (2020) descrive il flusso lavoro bayesiano nel modo seguente.
Definire un Modello Generativo per i Dati: Un modello generativo descrive il processo attraverso il quale i dati vengono prodotti. Nel contesto del compito No-Go, consideriamo ogni prova come un processo di Bernoulli con due possibili esiti: una prestazione corretta, ovvero l’inibizione della risposta (rappresentata da 1), oppure una prestazione errata, ovvero la mancata inibizione della risposta (rappresentata da 0). Definiamo \(\theta\) come la probabilità di ottenere una prestazione corretta nel compito No-Go. Il modello generativo per questi dati può essere formalizzato come:
\[ X_i \sim \text{Bernoulli}(\theta), \]
dove \(i = 1, 2, \dots, 9\) e \(X_i\) assume il valore 1 in caso di prestazione corretta e 0 in caso di prestazione errata nel compito No-Go.
Definire uno Stimatore per il Parametro di Interesse: Uno stimatore è una regola o una formula che utilizza i dati campionari per fornire una stima del parametro di interesse. Nel nostro caso, lo stimatore di interesse è la probabilità \(\theta\) di inibire correttamente la risposta durante le prove No-Go. L’obiettivo è non solo calcolare questa probabilità, ma anche quantificare l’incertezza associata alla stima di \(\theta\), basandoci sui dati raccolti.
Sviluppare un Metodo Statistico per la Stima del Parametro di Interesse: Per stimare \(\theta\), utilizziamo l’approccio bayesiano. In statistica bayesiana, si parte da una distribuzione a priori che rappresenta le nostre convinzioni iniziali su \(\theta\), e poi si aggiorna questa distribuzione alla luce dei dati osservati per ottenere una distribuzione a posteriori. Nel contesto di un modello Bernoulli/Binomiale, una scelta comune per la distribuzione a priori è la distribuzione Beta. In questo caso, iniziamo con una distribuzione a priori non informativa, \(\text{Beta}(1, 1)\), che corrisponde a una distribuzione uniforme su \(\theta\).
La verosimiglianza dei nostri dati (6 “successi”, 3 “insuccessi”) è data dalla distribuzione binomiale:
\[ L(p) = {9 \choose 6} \theta^{6} (1-\theta)^{3}. \]
Utilizziamo il teorema di Bayes per combinare priori e verosimiglianza e ottenere la distribuzione a posteriori:
\[ \text{Posteriore} \propto \text{Verosimiglianza} \times \text{Priori} \]
Validazione del Modello tramite Simulazioni:
Prima di analizzare i dati reali, eseguiamo una simulazione predittiva a priori per verificare se il modello è in grado di generare dati plausibili. Successivamente, dopo aver adattato il modello ai dati osservati, conduciamo una simulazione predittiva a posteriori per valutare la capacità del modello di riprodurre dati simili a quelli effettivamente osservati.Analisi e Sintesi dei Risultati:
Infine, analizziamo i dati reali calcolando la distribuzione a posteriori, tipicamente tramite metodi computazionali come il Monte Carlo a catene di Markov (MCMC). Riassumiamo questa distribuzione per fare inferenze su \(\theta\), utilizzando statistiche descrittive come la media, la mediana e gli intervalli di credibilità.
Nel corso di questo capitolo, illustreremo come generare numericamente la distribuzione a posteriori, mentre nei capitoli successivi approfondiremo ulteriormente le varie fasi del flusso di lavoro proposto da McElreath (2020).
42.3 Metodo Basato su Griglia nell’Aggiornamento Bayesiano
Dopo aver discusso l’aggiornamento bayesiano e come permette di raffinare le nostre convinzioni preesistenti alla luce di nuove evidenze, esploreremo ora una tecnica specifica per realizzare questo aggiornamento: il metodo basato su griglia.
Il metodo basato su griglia è un approccio semplice e intuitivo per stimare la distribuzione a posteriori, particolarmente utile quando non sono disponibili soluzioni analitiche esatte o si desidera evitare l’uso di algoritmi computazionali complessi. La procedura si articola nei seguenti passi:
- Selezione di un intervallo per il parametro: Basandosi sulle convinzioni a priori, si definisce un intervallo ragionevole per il parametro di interesse.
- Creazione di una griglia di punti: Su questo intervallo, si distribuiscono una serie di punti, di solito equidistanti tra loro.
- Calcolo della posteriori per ogni punto: Per ogni punto della griglia, si moltiplica la verosimiglianza per il prior corrispondente.
- Normalizzazione dei risultati: Per garantire che la somma delle probabilità sia pari a 1, si normalizzano i valori ottenuti dividendo ciascun punto per l’area totale sottesa dalla curva della distribuzione a posteriori.
Attraverso questo metodo, si ottiene una rappresentazione approssimativa ma illustrativa della distribuzione a posteriori. Questo approccio offre un modo accessibile per visualizzare e comprendere il processo di aggiornamento bayesiano.
42.4 Aggiornamento Bayesiano con una Distribuzione a Priori Discreta
42.4.1 Distribuzione a priori
Quando non disponiamo di informazioni specifiche preliminari su \(\theta\), potremmo inizialmente assegnare un valore di 0.5, suggerendo una probabilità a priori uniforme tra le due alternative (la capacità di inibire la risposta e la mancanza di questa capacità in una prova del compito Go/No-Go). Tuttavia, questo valore non rappresenta adeguatamente l’intero spettro della nostra incertezza iniziale.
Per riflettere meglio questa incertezza, utilizziamo una distribuzione a priori discreta, che assegna una probabilità distinta a ciascun valore plausibile di \(\theta\). Questo approccio ci permette di quantificare le nostre convinzioni preliminari sulla distribuzione di questi valori.
Supponiamo di considerare undici possibili valori per \(\theta\), che variano da 0 a 1 con incrementi di 0.1. Possiamo attribuire a ciascun valore una probabilità a priori uguale, creando così una distribuzione uniforme, oppure scegliere una distribuzione non uniforme che meglio rifletta le nostre aspettative sui valori di \(\theta\) più probabili.
Dopo aver osservato i dati — nel nostro caso, 6 successi in 9 prove — applichiamo il teorema di Bayes per trasformare la distribuzione a priori in una distribuzione a posteriori. Questo processo consiste nel combinare la probabilità a priori di \(\theta\) con la verosimiglianza dei dati per produrre una probabilità a posteriori aggiornata per \(\theta\).
La distribuzione a posteriori integra quindi le nostre conoscenze pregresse con le nuove informazioni ottenute dalle osservazioni, offrendoci una visione aggiornata e quantitativamente informata del parametro \(\theta\). Attraverso questo esempio, possiamo osservare un approccio sistematico ed efficace per affinare le nostre credenze alla luce di nuove prove.
theta = np.linspace(0, 1, 11)
print(theta)[0. 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1. ]Nel caso in cui non vi siano motivi fondati per assegnare probabilità diverse ai vari valori di \(\theta\), è possibile attribuire la stessa probabilità a ciascun valore, creando così una distribuzione uniforme. È importante prestare attenzione alla seconda riga di codice, che esegue una standardizzazione. Poiché unif_discr_pdf è un vettore composto da un numero finito di elementi, questi elementi devono essere considerati come probabilità, e tali probabilità devono obbligatoriamente sommarsi a uno.
unif_prior = stats.uniform.pdf(theta)
unif_prior = unif_prior / np.sum(unif_prior)
print(unif_prior)[0.09090909 0.09090909 0.09090909 0.09090909 0.09090909 0.09090909
0.09090909 0.09090909 0.09090909 0.09090909 0.09090909]np.sum(unif_prior)1.0Una rappresentazione visiva di questa distribuzione di massa di probabilità si ottiene nel modo seguente.
plt.stem(theta, unif_prior, markerfmt=" ")
plt.title("Distribuzione a priori")
plt.xlabel("$\\theta$")
plt.ylabel("Probabilità");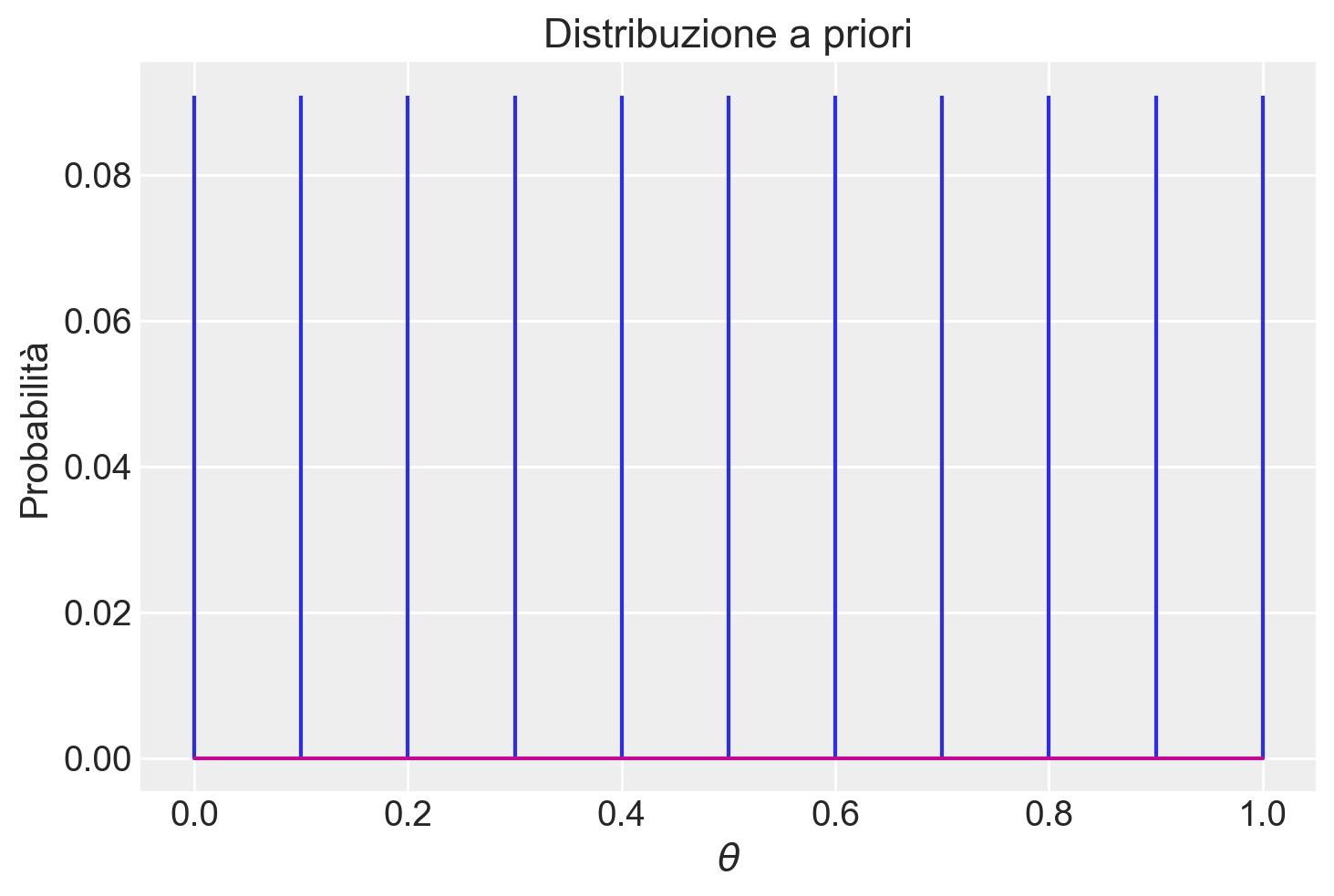
Se, al contrario, riteniamo che i valori centrali nella distribuzione di \(\theta\) siano più credibili rispetto a quelli situati agli estremi, potremmo esprimere questa opinione soggettiva mediante la seguente distribuzione di massa di probabilità.
not_unif_prior = [0, 0.05, 0.05, 0.05, 0.175, 0.175, 0.175, 0.175, 0.05, 0.05, 0.05]
plt.stem(theta, not_unif_prior, markerfmt=" ")
plt.title("Distribuzione a priori")
plt.xlabel("$\\theta$")
plt.ylabel("Probabilità");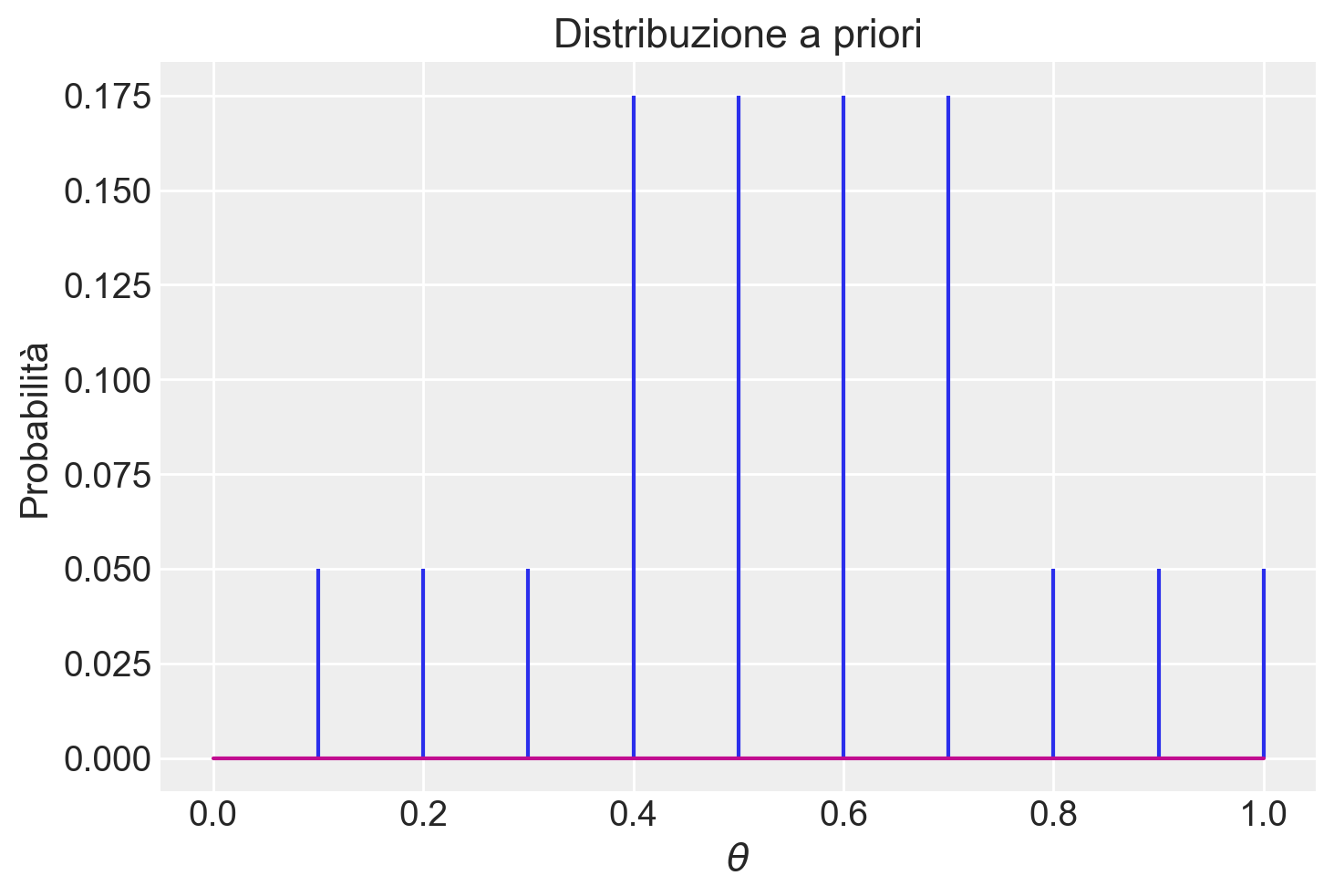
La prima distribuzione di probabilità è una distribuzione discreta uniforme, in quanto assegna la stessa probabilità a ciascun elemento dell’insieme discreto su cui è definita, ossia i valori \(\{0, 0.1, 0.2, \dots, 1.0\}\). La seconda distribuzione di probabilità, pur essendo discreta, segue un andamento non uniforme: si presume che \(\theta\) abbia una probabilità maggiore di assumere un valore nell’insieme \(\{0.4, 0.5, 0.6, 0.7\}\) rispetto all’insieme \(\{0.1, 0.2, 0.3, 0.8, 0.9, 1.0\}\).
Le credenze iniziali riguardo ai possibili valori di \(\theta\) costituiscono la “distribuzione a priori”. L’inferenza bayesiana aggiorna queste credenze iniziali utilizzando le informazioni ottenute dai dati. Queste informazioni vengono combinate con le credenze iniziali su \(\theta\) attraverso l’applicazione del teorema di Bayes, allo scopo di ottenere la “distribuzione a posteriori”. Quest’ultima rappresenta le nostre credenze aggiornate sui possibili valori di \(\theta\) dopo l’osservazione dei dati.
Abbiamo osservato 6 successi in 9 prove. Per calcolare la distribuzione a posteriori, utilizzeremo la seconda delle due distribuzioni a priori precedentemente descritte. In base al teorema di Bayes, la distribuzione a posteriori si ottiene moltiplicando la verosimiglianza per la distribuzione a priori e quindi dividendo per una costante di normalizzazione (la verosimiglianza marginale):
\[ p(\theta \mid y) = \frac{p(y \mid \theta)p(\theta)}{p(y)}. \]
42.4.2 Verosimiglianza
Per calcolare la funzione di verosimiglianza, \(p(y \mid \theta)\), è essenziale comprendere il processo attraverso il quale i dati sono stati generati. Nel nostro caso, i dati rappresentano i risultati di 9 ripetizioni di un esperimento casuale, in cui ciascuna prova può avere solo due esiti possibili: risposta corretta (inibizione della risposta nelle prove No-Go) o risposta scorretta (mancata inibizione della risposta nelle prove No-Go). Inoltre, assumiamo che le 9 prove siano indipendenti tra loro, cioè che la prestazione in una prova non influenzi quella nelle prove successive. Date queste condizioni, possiamo modellare il processo generativo dei dati utilizzando un modello binomiale con una probabilità sconosciuta \(\theta\).
Utilizzando Python, è possibile calcolare la funzione di verosimiglianza tramite la funzione binom.pmf().
like = stats.binom.pmf(6, 9, theta)
like = like / np.sum(like)
likearray([0.00000000e+00, 6.11961968e-05, 2.75072287e-03, 2.09902955e-02,
7.42695176e-02, 1.63955860e-01, 2.50659622e-01, 2.66654495e-01,
1.76046264e-01, 4.46120274e-02, 0.00000000e+00])Per i 10 valori \(\theta\) considerati, la funzione di verosimiglianza (normalizzata) assume la forma indicata dalla figura seguente.
plt.stem(theta, like, markerfmt=" ")
plt.title("Funzione di verosimiglianza")
plt.xlabel("$\\theta$")
plt.ylabel("$L(\\theta)$");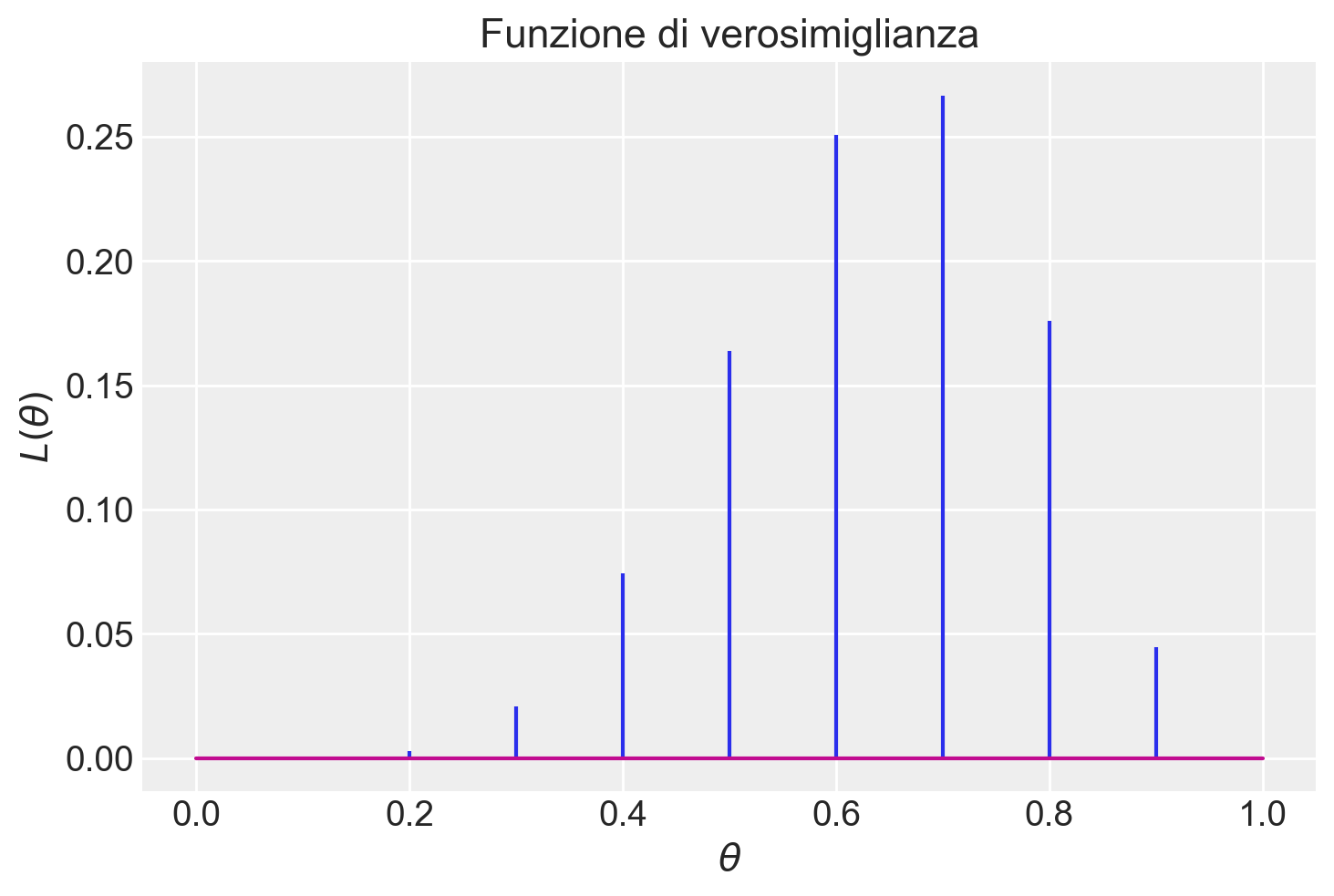
Per calcolare la distribuzione a posteriori, eseguiamo una moltiplicazione elemento per elemento tra il vettore contenente i valori della distribuzione a priori e il vettore contenente i valori della funzione di verosimiglianza. Usando Python, il risultato si trova nel modo seguente.
not_unif_prior * likearray([0.00000000e+00, 3.05980984e-06, 1.37536144e-04, 1.04951477e-03,
1.29971656e-02, 2.86922755e-02, 4.38654338e-02, 4.66645366e-02,
8.80231320e-03, 2.23060137e-03, 0.00000000e+00])Per illustrare con un esempio, il valore dell’ottavo elemento della distribuzione a posteriori si calcola come segue (tenendo presente che in Python gli indici partono da 0):
not_unif_prior[7] * like[7]0.04666453655213576Dopo questa moltiplicazione, otteniamo una distribuzione che rappresenta le probabilità condizionate dei possibili valori di \(\theta\) alla luce dei dati osservati. Tuttavia, questa distribuzione potrebbe non è normalizzata, il che significa che la somma di tutte le probabilità condizionate non è uguale a 1.
Per ottenere una distribuzione di probabilità correttamente normalizzata, dobbiamo dividere ciascun valore ottenuto precedentemente per la probabilità marginale dei dati \(y\). La probabilità marginale dei dati \(y\) è una costante di normalizzazione e può essere calcolata utilizzando la legge della probabilità totale (si veda l’eq. {eq}eq-prob-tot).
Per chiarire, ricordiamo che, nel capitolo {ref}cond-prob-notebook abbiamo considerato il caso di una partizione dello spazio campione in due eventi mutualmente esclusivi ed esaustivi, \(H_1\) e \(H_2\). All’interno dello spazio campione abbiamo definito un evento \(E\) non nullo e abbiamo visto che \(P(E) = P(E \cap H_1) + P(E \cap H_2)\), ovvero \(P(E) = P(E \mid H_1) P(H_1) + P(E \mid H_2) P(H_2)\). Usando la terminologia che stiamo usando qui, \(P(E \mid H_i)\) corrisponde alla funzione di verosimiglianza e \(P(H_i)\) corrisponde alla funzione a priori. Nel caso discreto, come quello che stiamo considerando ora, il teorema della probabilità totale ci dice dunque che dobbiamo fare la somma dei prodotti tra i valori della funzione di verosimiglianza e i corrispondenti valori della distribuzione a priori.
np.sum(not_unif_prior * like)0.14444243675028887Otteniamo dunque il seguente risultato.
post = (not_unif_prior * like) / np.sum(not_unif_prior * like)
print(post)[0.00000000e+00 2.11835933e-05 9.52186538e-04 7.26597251e-03
8.99816278e-02 1.98641591e-01 3.03687994e-01 3.23066667e-01
6.09399384e-02 1.54428395e-02 0.00000000e+00]Verifichiamo di avere ottenuto una distribuzione di massa di probabilità:
np.sum(post)0.9999999999999999Esaminiamo la distribuzione a posteriori di \(\theta\) con un grafico.
plt.stem(theta, post, markerfmt=" ")
plt.title("Distribuzione a posteriori")
plt.xlabel("$\\theta$")
plt.ylabel(r"$f(\theta)$");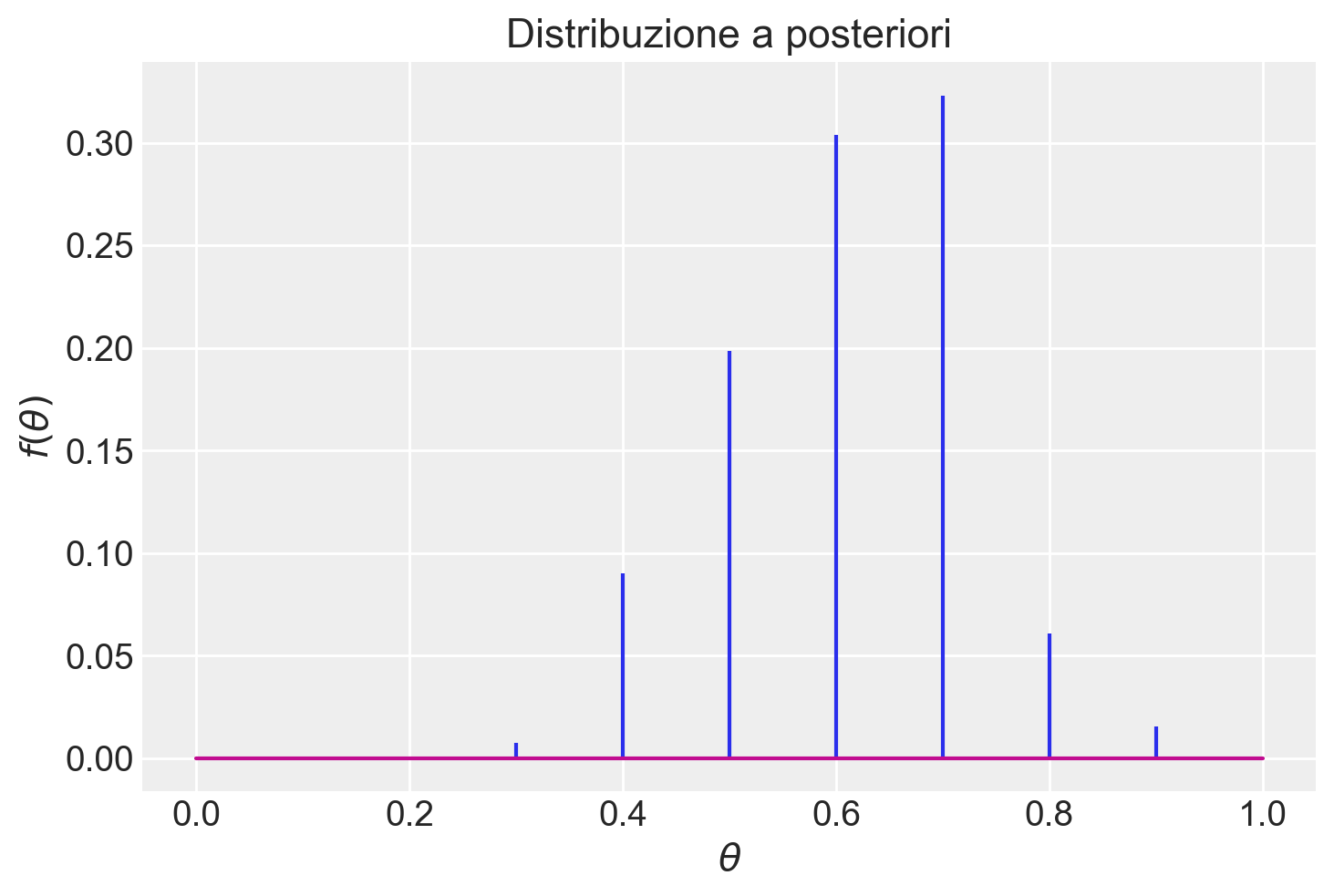
Una volta trovata la distribuzione a posteriori di \(\theta\), possiamo calcolare altre quantità di interesse. Ad esempio, la moda a posteriori di \(\theta\) può essere individuata direttamente dal grafico precedente e risulta pari a 0.5. Per calcolare invece la media a posteriori, ci avvaliamo della formula del valore atteso delle variabili casuali.
np.sum(theta * post)0.6086957633539818La varianza della distribuzione a posteriori è
np.sum(theta**2 * post) - (np.sum(theta * post)) ** 20.013379767754025107Con questo metodo, possiamo calcolare la distribuzione a posteriori di \(\theta\) per qualsiasi distribuzione a priori discreta.
42.5 Aggiornamento bayesiano con una distribuzione a priori continua
A fini didattici, abbiamo esaminato il caso di una distribuzione a priori discreta. Tuttavia, è importante notare che l’impiego di una distribuzione a priori continua, come la distribuzione Beta, risulta più appropriato in quanto permette di rappresentare un’ampia gamma di possibili valori per il parametro non noto \(\theta\), senza essere vincolati a un insieme discreto di valori. Inoltre, la distribuzione Beta presenta l’ulteriore vantaggio di avere un dominio definito nell’intervallo [0, 1], che corrisponde alla gamma dei possibili valori per la proporzione \(\theta\).
Per esempio, consideriamo la distribuzione Beta(2, 2), caratterizzata da una simmetria nella sua forma. Per valutare la distribuzione Beta in corrispondenza di punti specifici, come ad esempio 0.5, 0.8 e 1.2, possiamo fare affidamento sulla funzione beta.pdf. A titolo illustrativo, la densità di probabilità della distribuzione Beta(2, 2) nel caso del valore 0.5 risulta essere 1.5, suggerendo che i valori di \(\theta\) vicini a 0.5 appaiono più plausibili rispetto a quelli intorno a 0.8, dove la funzione assume un valore di 0.96. È importante sottolineare che la densità di probabilità della distribuzione Beta(2, 2) relativa al valore 1.2 è pari a 0, poiché tale valore esula dall’intervallo di definizione della distribuzione (0 e 1). La distribuzione Beta(2, 2) è illustrata nella figura qui di seguito.
alpha = 2
beta = 2
x = np.linspace(0, 1, 1000)
pdf = stats.beta.pdf(x, alpha, beta)
plt.plot(x, pdf)
plt.xlabel('x')
plt.ylabel('Probability Density')
_ = plt.title('Probability Density Function of Beta Distribution')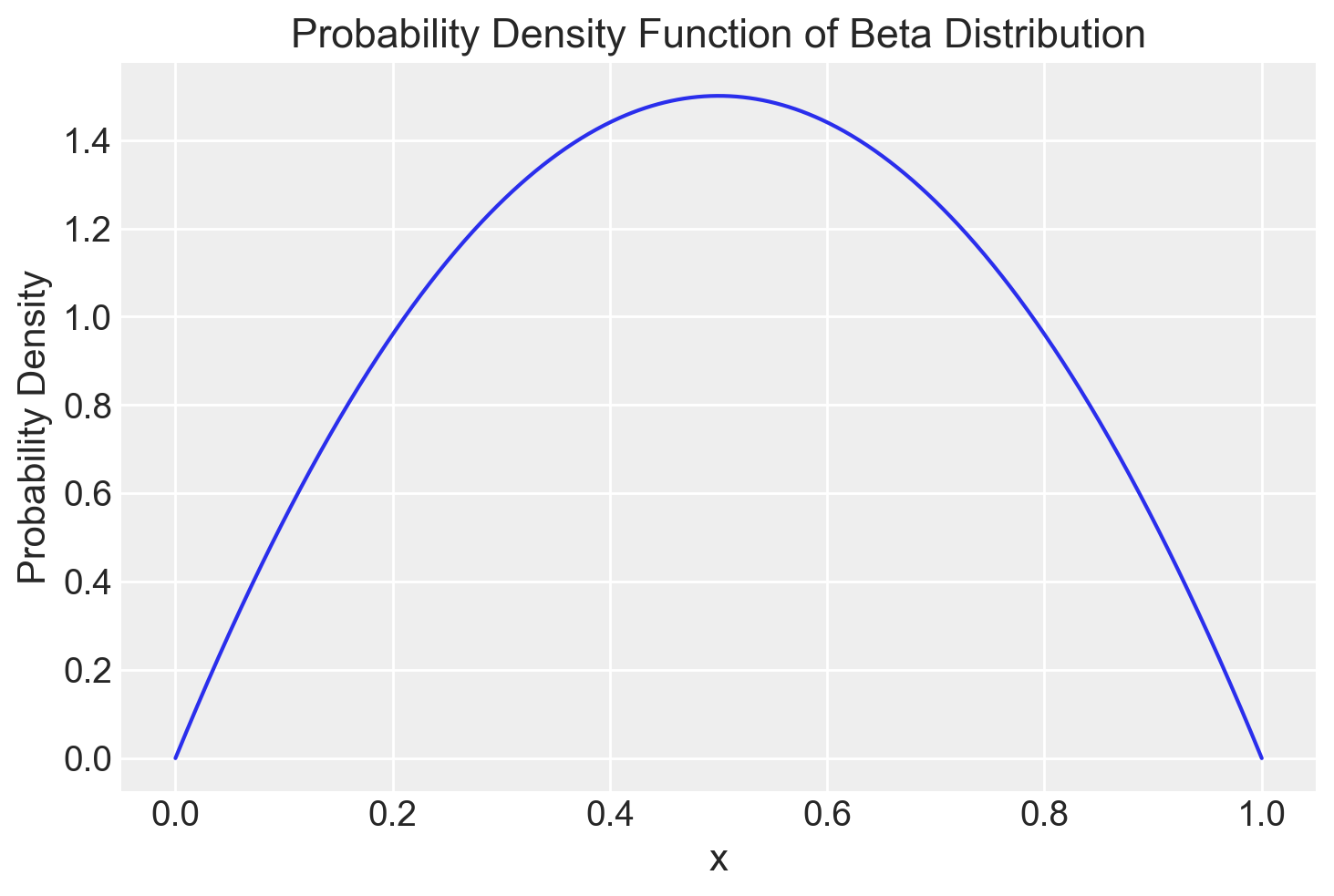
Supponiamo – solo allo scopo di illustrare la procedura – che le nostre credenze a priori siano rappresentate da una Beta(2, 5).
alpha = 2
beta = 5
x = np.linspace(0, 1, 1000)
pdf = stats.beta.pdf(x, alpha, beta)
plt.plot(x, pdf)
plt.xlabel('x')
plt.ylabel('Probability Density')
_ = plt.title('Probability Density Function of Beta Distribution')
Nel seguente esempio, useremo la funzione beta.pdf() per generare una distribuzione a priori discretizzata.
print(stats.beta.pdf(theta, 2, 5))[0. 1.9683 2.4576 2.1609 1.5552 0.9375 0.4608 0.1701 0.0384 0.0027
0. ]_ = plt.plot(theta, stats.beta.pdf(theta, 2, 5))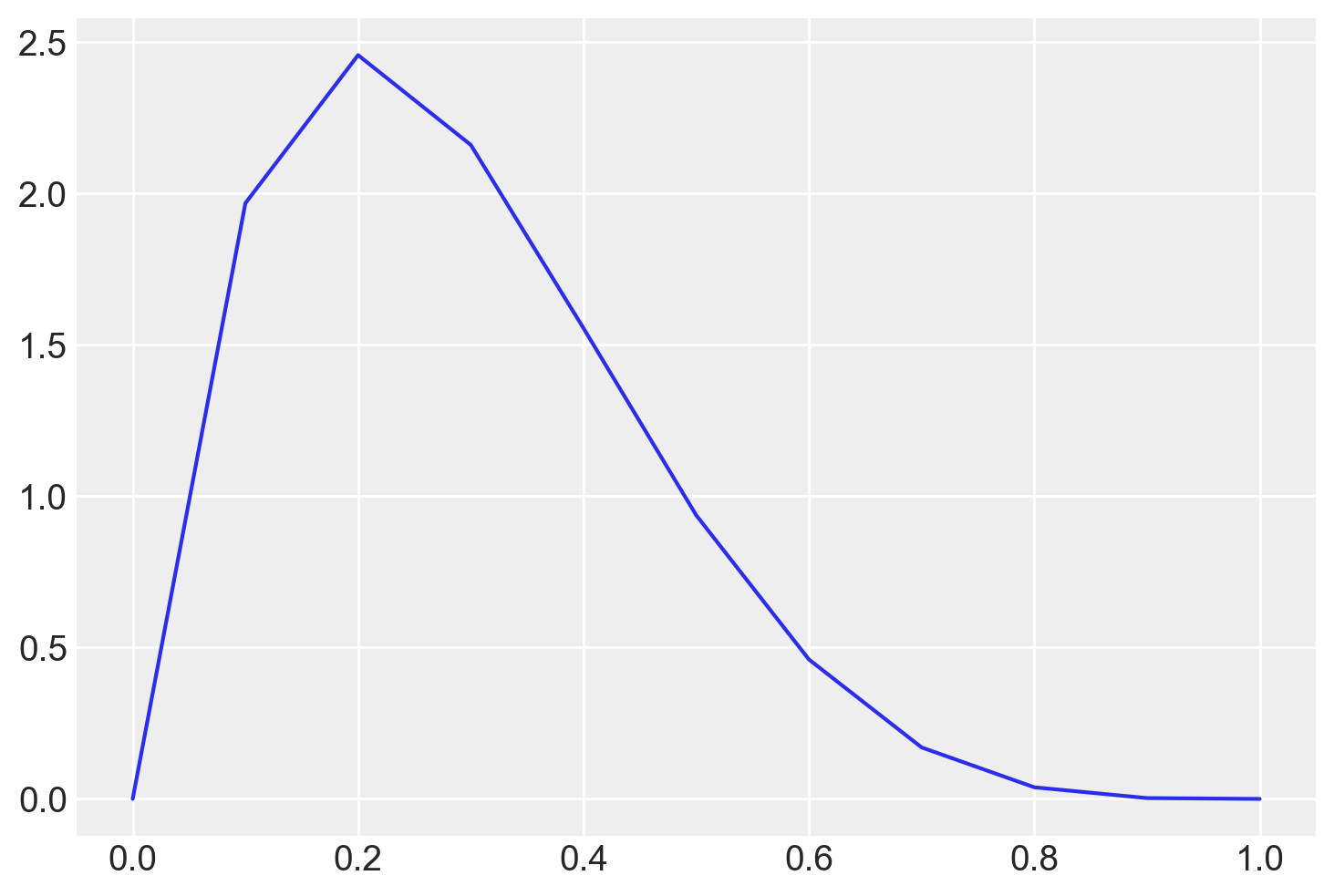
Ora però usiamo un numero maggiore di valori \(\theta\).
theta = np.linspace(0, 1, 1001)
print(theta)[0. 0.001 0.002 ... 0.998 0.999 1. ]Calcoliamo la distribuzione a priori normalizzata.
prior = stats.beta.pdf(theta, 2, 5)
prior = prior / np.sum(prior)
print(prior)[0.00000000e+00 2.98802546e-05 5.95215869e-05 ... 4.79041198e-13
2.99700749e-14 0.00000000e+00]sum(prior)1.0000000000000002Per calcolare la verosimiglianza, seguiamo la medesima procedura illustrata nel capitolo {ref}cap-likelihood. In aggiunta, effettuiamo la normalizzazione dei valori discretizzati della verosimiglianza, come precedentemente descritto.
like = stats.binom.pmf(6, 9, theta)
like = like / np.sum(like)
print(like)[0.00000000e+00 8.37482519e-19 5.34380847e-17 ... 6.63976213e-09
8.34972583e-10 0.00000000e+00]Infine, otteniamo la distribuzione a posteriori moltiplicando la distribuzione a priori per la verosimiglianza e dividendo per la costante di normalizzazione.
post = (prior * like) / np.sum(prior * like)np.sum(post)1.0plt.plot(theta, prior, linestyle="solid", color="C0", label="Prior")
plt.plot(theta, like, linestyle="solid", color="C1", label="Likelihood")
plt.plot(theta, post, linestyle="solid", color="C4", label="Posterior")
plt.xlabel(r"$\theta$")
plt.ylabel(r"$f(\theta)$")
_ = plt.legend()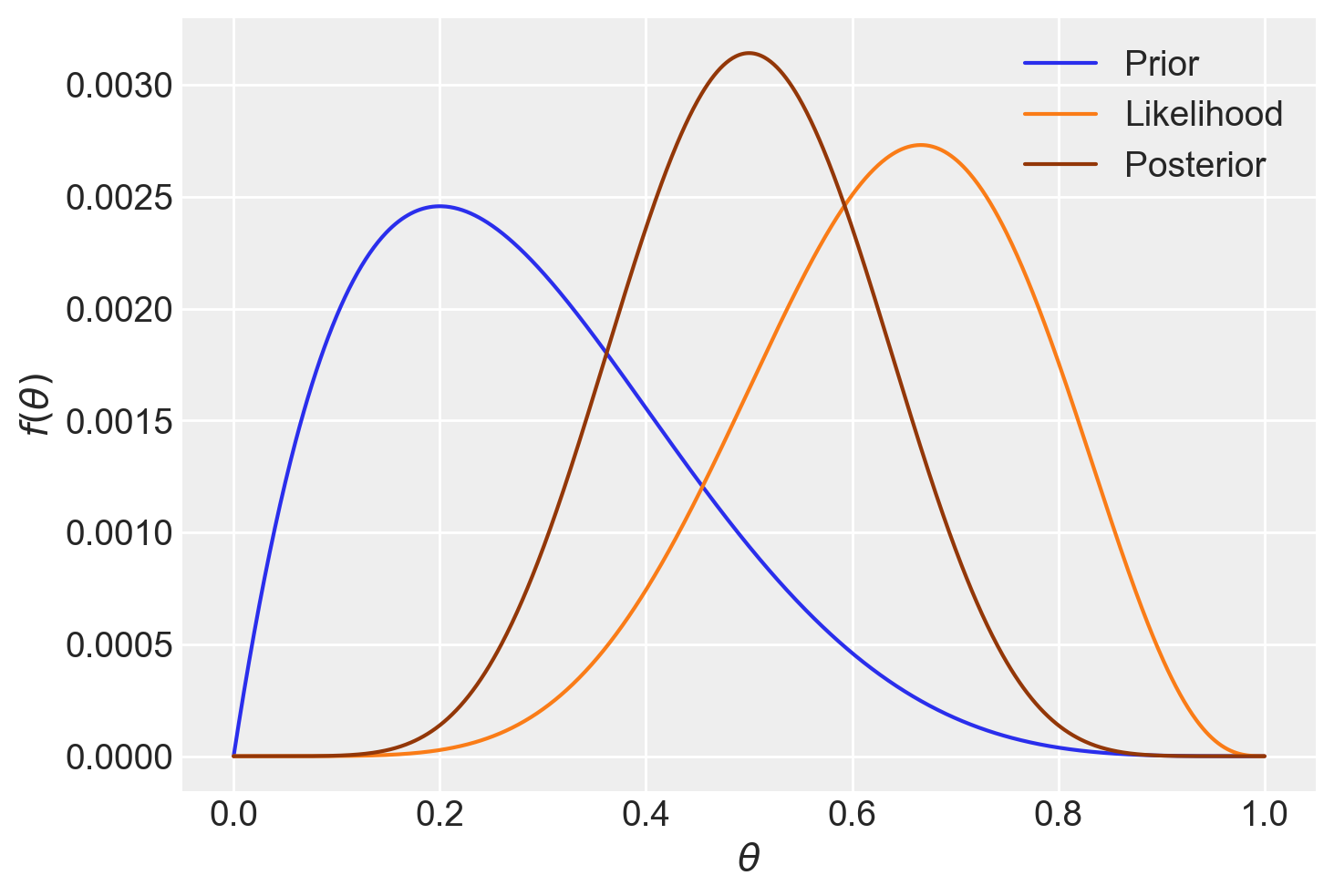
Possiamo calcolare la media e la deviazione standard della distribuzione a posteriori come abbiamo fatto in precedenza.
# media
np.sum(theta * post)0.5000000000000001# deviazione standard
np.sqrt(np.sum(theta**2 * post) - (np.sum(theta * post)) ** 2)0.1212678125181662842.6 Sintesi ed elaborazioni inferenziali sulla distribuzione a posteriori
Una volta ottenuta la distribuzione a posteriori, è possibile generare un campione casuale da questa distribuzione. A titolo di esempio, possiamo estrarre un campione di 10000 punti dalla distribuzione a posteriori di \(\theta\) che abbiamo calcolato.
samples = np.random.choice(theta, p=post, size=int(1e4), replace=True)L’istruzione precedente genera un array denominato samples contenente 10000 punti campionati dalla distribuzione a posteriori calcolata. La funzione np.random.choice viene impiegata per selezionare casualmente i valori theta basandosi sulle probabilità definite da post.
fig, axs = plt.subplots(1, 2, figsize=(12, 6))
# Primo subplot: Scatter plot
axs[0].plot(samples, "o", alpha=0.2, color="rebeccapurple")
axs[0].set_xlabel("Numero di campione")
axs[0].set_ylabel(r"$\theta$")
axs[0].set_title("Scatter Plot dei Campioni")
# Secondo subplot: KDE plot
az.plot_kde(samples, ax=axs[1], plot_kwargs={"color": "rebeccapurple"})
axs[1].set_xlabel(r"$\theta$")
axs[1].set_ylabel("Densità")
axs[1].set_title("KDE Plot dei Campioni")
plt.tight_layout()
plt.show()/var/folders/s7/z86r4t9j6yx376cm120nln6w0000gn/T/ipykernel_59892/1469964889.py:15: UserWarning: The figure layout has changed to tight
plt.tight_layout()
Sfruttando il campione estratto dalla distribuzione a posteriori, è possibile calcolare diverse quantità di interesse. Ad esempio, la stima della media a posteriori di \(\theta\) si ottiene semplicemente calcolando la media dei valori così ottenuti.
np.mean(samples)0.49900239999999996In maniera analoga possiamo calcolare la deviazione standard della distribuzione a posteriori di \(\theta\).
np.std(samples)0.120342000956607La moda a posteriori si può calcolare nel modo seguente.
print(theta[post == max(post)])[0.5]Oppure, usando il campione estratto dalla distribuzione a posteriori di \(\theta\), otteniamo
stats.mode(samples)[0]0.481Usando il campione estratto dalla distribuzione a posteriori, è immediato trovare la mediana a posteriori di \(\theta\).
np.median(samples)0.497Possiamo calcolare la probabilità di varie ipotesi relative a \(\theta\) nella distribuzione a posteriori. Per esempio, calcoliamo la probabilità \(P(\theta < 0.5)\).
sum(post[theta < 0.5])0.49842895507812507Alternativamente, utilizzando il campione estratto dalla distribuzione a posteriori di \(\theta\), otteniamo un risultato analogo, sebbene soggetto a variazioni dovute all’approssimazione numerica.
sum(samples < 0.5) / 1e40.5078Possiamo trovare la probabilità a posteriori che \(\theta\) sia compresa in un dato intervallo. Per esempio, troviamo \(P(0.5 < \theta < 0.75)\).
sum((samples > 0.6) & (samples < 0.8)) / 1e40.2056Utilizzando il campionamento effettuato dalla distribuzione a posteriori di \(\theta\), è possibile risolvere il problema inverso, ovvero determinare l’intervallo che contiene \(\theta\) con una specifica probabilità. Ad esempio, si può calcolare l’intervallo che ha una probabilità pari a 0.94 di contenere \(\theta\), basandosi sulla distribuzione a posteriori campionata.
np.percentile(samples, [2, 98])array([0.25798, 0.744 ])L’intervallo specificato è noto come intervallo di credibilità e rappresenta una quantificazione statistica dell’incertezza associata alla stima del parametro \(\theta\). In termini probabilistici, si può affermare con il 94% di credibilità che il valore “vero” di \(\theta\) è contenuto nell’intervallo [0.26, 0.74].
Se vogliamo trovare l’intervallo di credibilità a più alta densità a posteriori (HPD), usiamo la funzione ArviZ hdi() (si veda il capitolo {ref}sintesi-distr-post-notebook).
az.hdi(samples, hdi_prob=0.94)array([0.276, 0.722])Nel contesto attuale, la distribuzione a posteriori è simmetrica. Di conseguenza, l’intervallo di credibilità calcolato attraverso i quantili e l’intervallo di credibilità a più alta densità a posteriori (HPDI) sono molto simili.
42.7 Qual è il modo migliore per stimare il parametro \(\theta\)?
Nonostante abbiamo discusso in precedenza dei diversi metodi di stima puntuale e intervallare per riassumere la distribuzione a posteriori di \(\theta\), la migliore stima del parametro che stiamo cercando di inferire è rappresentata dall’intera distribuzione a posteriori. Per citare le parole di McElreath (2020):
That an arbitrary interval contains an arbitrary value is not meaningful. Use the whole distribution.
42.8 Metodo basato su griglia
Il metodo utilizzato in questo capitolo per generare la distribuzione a posteriori è noto come metodo basato su griglia. Questo metodo numerico esatto si basa sul calcolo della distribuzione a posteriori mediante una griglia di punti uniformemente spaziati. Nonostante la maggior parte dei parametri sia continua, l’approssimazione della distribuzione a posteriori può essere ottenuta considerando soltanto una griglia finita di valori dei parametri. Il metodo segue quattro fasi:
- Fissare una griglia discreta di possibili valori dei parametri.
- Valutare la distribuzione a priori e la funzione di verosimiglianza per ciascun valore della griglia.
- Calcolare l’approssimazione della densità a posteriori, ottenuta moltiplicando la distribuzione a priori per la funzione di verosimiglianza per ciascun valore della griglia e normalizzando i prodotti in modo che la loro somma sia uguale a 1.
- Selezionare \(n\) valori casuali dalla griglia per ottenere un campione casuale della densità a posteriori normalizzata.
Questo metodo può essere potenziato aumentando il numero di punti nella griglia, ma il limite principale risiede nel fatto che all’aumentare della dimensionalità dello spazio dei parametri, il numero di punti necessari per una stima accurata cresce in modo esponenziale, rendendo il metodo impraticabile per problemi complessi.
In sintesi, l’approccio basato sulla griglia è intuitivo e non richiede competenze di programmazione avanzate per l’implementazione. Inoltre, fornisce un risultato che può essere considerato, per tutti gli scopi pratici, come un campione casuale estratto dalla distribuzione di probabilità a posteriori condizionata ai dati. Tuttavia, questo metodo è limitato a causa della maledizione della dimensionalità1, il che significa che può essere applicato soltanto a modelli statistici semplici con non più di due parametri. Di conseguenza, in pratica, è spesso sostituito da altre tecniche più efficienti, poiché i modelli impiegati in psicologia richiedono frequentemente la stima di centinaia o anche migliaia di parametri.
42.9 Riflessioni Conclusive
In questo capitolo, abbiamo esplorato l’aggiornamento bayesiano utilizzando una distribuzione a priori discreta, accennando brevemente al caso delle distribuzioni a priori continue. Quando si affrontano scenari con distribuzioni a priori continue, l’elaborazione della distribuzione a posteriori generalmente richiede la risoluzione di un integrale che, nella maggior parte dei casi, non ammette una soluzione analitica. Tuttavia, ci sono eccezioni notevoli, come nell’inferenza relativa alle proporzioni, dove la distribuzione a priori è modellata come una distribuzione Beta e la funzione di verosimiglianza segue una distribuzione binomiale. In queste circostanze particolari, è possibile derivare analiticamente la distribuzione a posteriori. L’analisi dettagliata di questo caso sarà trattata nel capitolo successivo.
42.10 Esercizi
Esercizio 42.1 Viene chieso di calcolare la distribuzione a posteriori della probabilità che uno studio condivida i materiali di ricerca utilizzando il metodo basato su griglia. Si utilizzeranno dati reali per motivare e costruire una distribuzione a priori discretizzata.
In uno studio sull’analisi delle pratiche di trasparenza e riproducibilità nella ricerca in psicologia, Hardwicke et al. (2022) hanno riportato che la condivisione dei materiali di ricerca è stata rilevata nel 14% dei casi (26 su 183 studi), con un intervallo di confidenza al 95% pari a [10%, 19%]. Questo suggerisce che la condivisione di materiali è rara.
Ispirandoti ai risultati di questo studio, costruisci una distribuzione a priori per la probabilità \(\theta\) che uno studio condivida i materiali di ricerca. Per semplicità, discretizza \(\theta\) in 10 livelli equispaziati: \(0.05, 0.15, 0.25, 0.35, 0.45, 0.55, 0.65, 0.75, 0.85, 0.95\).
Attribuisci le seguenti probabilità a priori ai 10 livelli, basandoti sull’informazione che la condivisione dei materiali è un evento raro ma non trascurabile: \(0.05, 0.20, 0.30, 0.15, 0.10, 0.08, 0.05, 0.03, 0.02, 0.02\).
Supponiamo che siano stati osservati 20 studi su 100 che hanno condiviso i materiali di ricerca. Calcola la distribuzione a posteriori utilizzando il metodo basato su griglia. Calcola la media della distribuzione a posteriori e l’intervallo di credibilità al 89%.
Informazioni sull’Ambiente di Sviluppo
%load_ext watermark
%watermark -n -u -v -iv -w -mLast updated: Wed Jul 17 2024
Python implementation: CPython
Python version : 3.12.4
IPython version : 8.26.0
Compiler : Clang 16.0.6
OS : Darwin
Release : 23.5.0
Machine : arm64
Processor : arm
CPU cores : 8
Architecture: 64bit
pandas : 2.2.2
scipy : 1.14.0
seaborn : 0.13.2
arviz : 0.18.0
matplotlib: 3.9.1
numpy : 1.26.4
Watermark: 2.4.3
Per comprendere la maledizione della dimensionalità, possiamo considerare l’esempio di una griglia di 100 punti equispaziati. Nel caso di un solo parametro, sarebbe necessario calcolare solo 100 valori. Tuttavia, se abbiamo due parametri, il numero di valori da calcolare diventa \(100^2\). Se invece abbiamo 10 parametri, il numero di valori da calcolare sarebbe di \(10^{10}\). È evidente che la quantità di calcoli richiesta diventa troppo grande persino per un computer molto potente. Pertanto, per modelli che richiedono la stima di un numero significativo di parametri, è necessario utilizzare un approccio diverso.↩︎