2. L’analisi di regressione#
La padronanza dell’analisi di regressione è fondamentale per comprendere la teoria classica dei test, l’analisi fattoriale e i modelli di equazioni strutturali. Sebbene le tecniche di analisi di regressione si concentrino esclusivamente sulle variabili osservate, i principi della regressione costituiscono la base per tecniche più avanzate che incorporano anche le variabili latenti. Questo capitolo fornisce una sintesi dei concetti fondamentali.
2.1. Regressione bivariata#
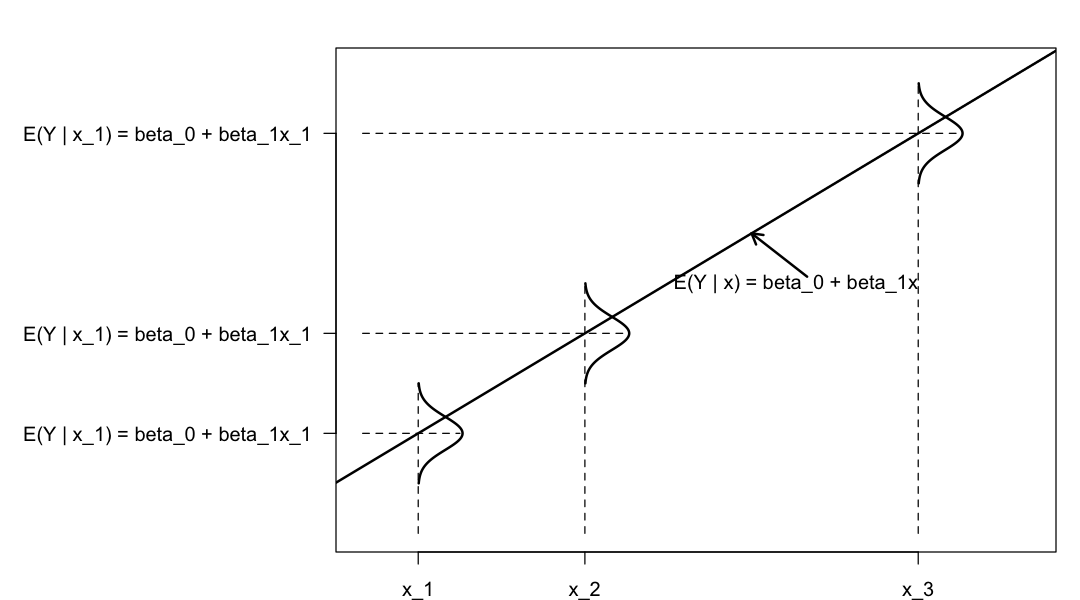
Il modello di regressione bivariata descrive l’associazione tra il valore atteso di \(Y \mid x_i\) e \(x\) nei termini di una relazione lineare:
dove i valori \(x_i\) sono considerati fissi per disegno. Nel modello “classico”, si assume che le distribuzioni \(Y \mid x_i\) siano Normali con deviazione standard \(\sigma_\varepsilon\).
Il significato dei coefficienti di regressione è semplice:
\(\alpha\) è il valore atteso di \(Y\) quando \(X = 0\);
\(\beta\) è l’incremento atteso nel valore atteso di \(Y\) quando \(X\) aumenta di un’unità.
Il modello statistico della regressione bivariata è rappresentato nella figura seguente.
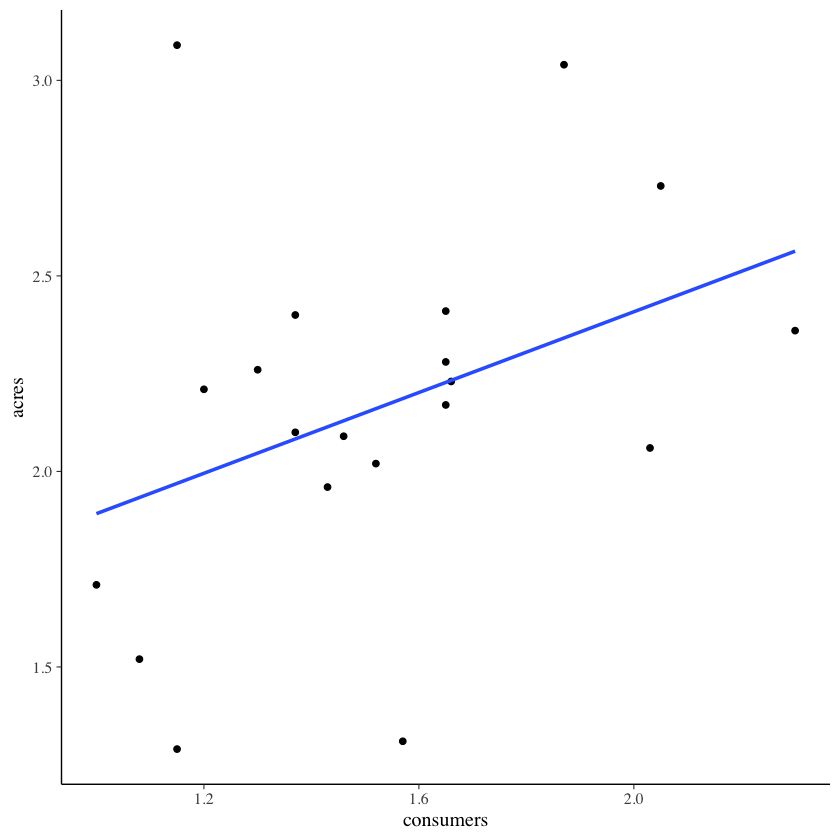
Per fare un esempio pratico, consideriamo i dati dell’antropologo Sahlins, il quale si è chiesto se esiste un’associazione tra l’ampiezza del clan (consumers) e l’area occupata da quel clan (acres) in una popolazione di cacciatori-raccoglitori. I dati sono i seguenti:
data(Sahlins)
head(Sahlins)
| consumers | acres | |
|---|---|---|
| <dbl> | <dbl> | |
| 1 | 1.00 | 1.71 |
| 2 | 1.08 | 1.52 |
| 3 | 1.15 | 1.29 |
| 4 | 1.15 | 3.09 |
| 5 | 1.20 | 2.21 |
| 6 | 1.30 | 2.26 |
options(repr.plot.width = 4, repr.plot.height = 4)
Sahlins %>%
ggplot(aes(x = consumers, y = acres)) +
geom_point() +
geom_smooth(method=lm, se=FALSE)
`geom_smooth()` using formula = 'y ~ x'
fm <- lm(acres ~ consumers, data = Sahlins)
fm$coef
- (Intercept)
- 1.37564454847979
- consumers
- 0.516320060092059
Dalla figura notiamo che, se consumers aumenta di un’unità (da 1.2 a 2.2), allora la retta di regressione (ovvero, il valore atteso di \(Y\)) aumenta di circa 0.5 punti – esattamente, aumenta di 0.5163 punti, come indicato dalla stima del coefficiente \(\beta\). L’interpretazione del coefficiente \(\alpha\) è più problematica, perché non ha senso pensare ad un clan di ampiezza 0. Per affrontare questo problema, centriamo il predittore.
2.1.1. Regressori centrati#
Esprimiamo la variabile consumers nei termini degli scarti dalla media:
Sahlins <- Sahlins %>%
mutate(
xc = consumers - mean(consumers)
)
Svolgiamo nuovamente l’analisi di regressione con il nuovo predittore:
fm1 <- lm(acres ~ xc, data = Sahlins)
fm1$coef
- (Intercept)
- 2.162
- xc
- 0.51632006009206
Sahlins %>%
ggplot(aes(x = xc, y = acres)) +
geom_point() +
geom_smooth(method=lm, se=FALSE)
`geom_smooth()` using formula = 'y ~ x'
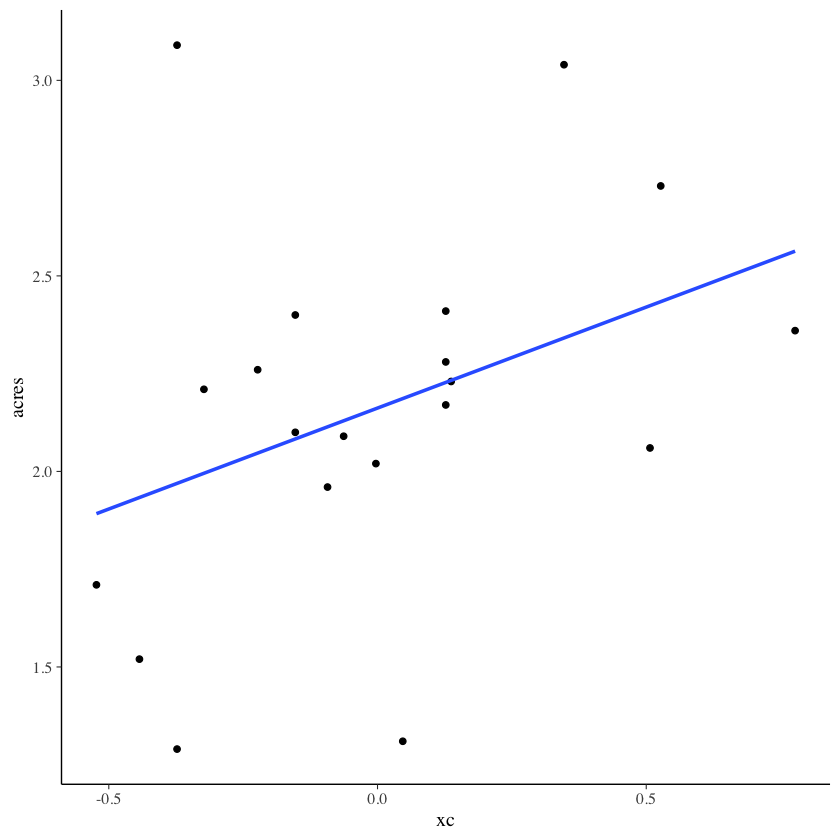
La stima di \(\beta\) è rimasta invariata ma ora possiamo attribuire un significato alla stima di \(\alpha\): questo coefficiente indica il valore atteso della \(Y\) quando \(X\) assume il suo valore medio.
2.1.2. Minimi quadrati#
La stima dei coefficienti del modello di regressione può essere effettuata in modi diversi: massima verosimiglianza o metodi bayesiani. Se ci limitiamo qui alla massima verosimiglianza possiamo semplificare il problema assumento che le distribuzioni condizionate \(Y \mid x\) siano Normali. In tali circostanze, la stima dei coefficienti del modello di regressione può essere trovata con il metodo dei minimi quadrati.
In pratica, questo significa trovare i coefficienti \(a\) e \(b\) che minimizzano
con \(\hat{y}_i = a + b x_i\).
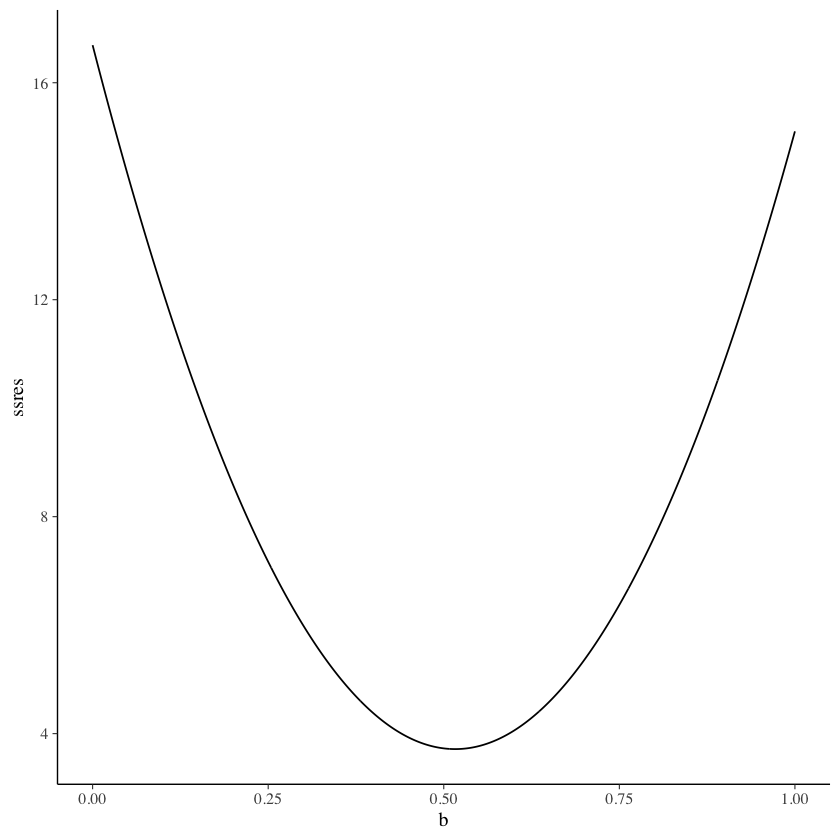
Per fornire un’idea di come questo viene fatto, usiamo una simulazione. Per semplicità, supponiamo di conoscere \(a = 1.3756445\) e di volere stimare \(b\).
x <- Sahlins$consumers
y <- Sahlins$acres
a <- 1.3756445
nrep <- 1e3
b <- seq(0, 1, length.out = nrep)
ssres <- rep(NA, nrep)
for (i in 1:nrep) {
yhat <- a + b[i] * x
ssres[i] <- sum((y - yhat)^2)
}
Un grafico di \(SS_{\text{res}}\) in funzione di \(b\) mostra che il valore \(b\) che minimizza \(SS_{\text{res}}\) corrisponde, appunto, a 0.5163.
tibble(b, ssres) %>%
ggplot(aes(x = b, y = ssres)) +
geom_line()
2.1.3. Relazione tra \(b\) e \(r\)#
Un altro modo per interpretare \(b\) è quello di considerare la relazione tra la pendenza della retta di regressione e il coefficiente di correlazione:
L’equazione precedente rende chiaro che, se i dati sono standardizzati, \(b = r\).
Verifichiamo:
Sahlins %>%
dplyr::select(acres, consumers) %>%
cor()
| acres | consumers | |
|---|---|---|
| acres | 1.0000000 | 0.3756561 |
| consumers | 0.3756561 | 1.0000000 |
fm2 <- lm(scale(acres) ~ scale(consumers), data = Sahlins)
fm2$coef
- (Intercept)
- 9.91710589115135e-17
- scale(consumers)
- 0.375656119968214
2.1.4. Attenuazione#
Il fenomeno dell’attenuazione si verifica quando \(X\) viene misurato con una componente di errore. Esaminiamo la seguente simulazione.
set.seed(1234)
n <- 100
x <- rnorm(n, 10, 1.5)
y <- 1.5 * x + rnorm(n, 0, 2)
tibble(x, y) %>%
ggplot(aes(x, y)) +
geom_point()
sim_dat <- tibble(x, y)
fm <- lm(y ~ x, sim_dat)
fm$coef
- (Intercept)
- 0.422107439446964
- x
- 1.46522006762439
Questi sono i coefficienti di regressione quando \(X\) è misurata senza errori.
sim_dat <- sim_dat %>%
mutate(
x1 = x + rnorm(n, 0, 2)
)
fm1 <- lm(y ~ x1, sim_dat)
fm1$coef
- (Intercept)
- 8.38721756937908
- x1
- 0.629592427655326
Aggiungendo una componente d’errore su \(X\), la grandezza del coefficiente \(b\) diminuisce.
2.1.5. Coefficiente di determinazione#
Tecnicamente, il coefficiente di determinazione è dato da:
Al denominatore abbiamo la devianza totale, ovvero una misura della dispersione di \(y_i\) rispetto alla media \(\bar{y}\). Al numeratore abbiamo una misura della dispersione del valore atteso della \(Y\) rispetto alla sua media. Il rapporto, dunque, ci dice qual è la quota della variabilità totale di \(Y\) che può essere predetta in base al modello lineare.
Per i dati di Sahlins abbiamo:
mod <- lm(acres ~ consumers, data = Sahlins)
a <- mod$coef[1]
b <- mod$coef[2]
yhat <- a + b * Sahlins$consumers
ss_tot <- sum((Sahlins$acres - mean(Sahlins$acres))^2)
ss_reg <- sum((yhat - mean(Sahlins$acres))^2)
r2 <- ss_reg / ss_tot
r2
Verifichiamo:
print(summary(mod))
Call:
lm(formula = acres ~ consumers, data = Sahlins)
Residuals:
Min 1Q Median 3Q Max
-0.8763 -0.1873 -0.0211 0.2135 1.1206
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.3756 0.4684 2.937 0.00881 **
consumers 0.5163 0.3002 1.720 0.10263
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.4543 on 18 degrees of freedom
Multiple R-squared: 0.1411, Adjusted R-squared: 0.0934
F-statistic: 2.957 on 1 and 18 DF, p-value: 0.1026
Da cui deriva che \(R^2\) è uguale al quadrato del coefficiente di correlazione:
cor(Sahlins$acres, Sahlins$consumers)^2
2.1.6. Errore standard della regressione#
L’errore standard della regressione è una stima della dispersione di \(y \mid x_i\) nella popolazione. Non è altro che la deviazione standard dei residui
che, al denominatore, riporta \(n-2\). La ragione è che, per calcolare \(\hat{y}\), vengono “perduti” due gradi di libertà – il calcolo di \(\hat{y}\) è basato sulla stima di due coefficienti: \(a\) e \(b\).
e <- yhat - Sahlins$acres
(sum(e^2) / (length(Sahlins$acres) - 2)) %>%
sqrt()
Il valore trovato corrisponde a quello riportato nell’output di lm().
2.2. Regressione multipla#
Nella regressione multipla vengono utilizzati \(k > 1\) predittori:
L’interpretazione geometrica è simile a quella del modello bivariato. Nel caso di due predittori, il valore atteso della \(y\) può essere rappresentato da un piano; nel caso di \(k > 2\) predittori, da un iper-piano. Nel caso di \(k=2\), tale piano è posto in uno spazio di dimensioni \(x_1\), \(x_2\) (che possiamo immaginare definire un piano orizzontale) e \(y\) (ortogonale a tale piano). La superficie piana che rappresenta \(\mathbb{E}(y)\) è inclinata in maniera tale che l’angolo tra il piano e l’asse \(x_1\) corrisponde a \(\beta_1\) e l’angolo tra il piano e l’asse \(x_2\) corrisponde a \(\beta_2\).
2.2.1. Significato dei coefficienti parziali di regressione#
Ai coefficienti parziali del modello di regressione multipla possiamo assegnare la seguente interpretazione:
Il coefficiente parziale di regressione \(\beta_j\) rappresenta l’incremento atteso della \(y\) se \(x_j\) viene incrementata di un’unità, tenendo costante il valore delle altre variabili indipendenti.
Un modo per interpretare la locuzione “al netto dell’effetto delle altre variabili indipendenti” è quello di esaminare la relazione tra la \(y\) parzializzata e la \(x_j\) parzializzata. In questo contesto, parzializzare significa decomporre una variabile di due componenti: una componente che è linearmente predicibile da una o più altre variabili e una componente che è linearmente incorrelata con tali varibili “terze”.
Se eseguiamo questa “depurazione” dell’effetto delle variabili “terze” sia sulla \(y\) sia su \(x_j\), possiamo poi esaminare la relazione bivariata che intercorre tra la componente della \(y\) linearmente indipendente dalle variabili “terze” e la componente della \(x_j\) linearmente indipendente dalle variabili “terze”. Il coefficiente di regressione bivariato così ottenuto sarà identico al coefficiente parziale di regressione nel modello di regressione multipla. Questa procedura ci consente di assegnare un’interpretazione “intuitiva” al coefficiente parziale di regressione \(\beta_j\).
Esaminiamo un caso concreto.
d <- rio::import("data/kidiq.dta")
glimpse(d)
Rows: 434
Columns: 5
$ kid_score <dbl> 65, 98, 85, 83, 115, 98, 69, 106, 102, 95, 91, 58, 84, 78, 1…
$ mom_hs <dbl> 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 0, …
$ mom_iq <dbl> 121.11753, 89.36188, 115.44316, 99.44964, 92.74571, 107.9018…
$ mom_work <dbl> 4, 4, 4, 3, 4, 1, 4, 3, 1, 1, 1, 4, 4, 4, 2, 1, 3, 3, 4, 3, …
$ mom_age <dbl> 27, 25, 27, 25, 27, 18, 20, 23, 24, 19, 23, 24, 27, 26, 24, …
fm <- lm(
kid_score ~ mom_iq + mom_work + mom_age + mom_hs, data = d
)
fm$coef
- (Intercept)
- 20.8226117032724
- mom_iq
- 0.562081421559238
- mom_work
- 0.133728709291299
- mom_age
- 0.219859856510774
- mom_hs
- 5.56117805423644
Eseguiamo la parzializzazione di \(y\) in funzione delle variabili mom_work, mom_age e mom_hs:
fm_y <- lm(kid_score ~ mom_work + mom_age + mom_hs, data = d)
Lo stesso per mom_iq:
fm_x <- lm(mom_iq ~ mom_work + mom_age + mom_hs, data = d)
Esaminiamo ora la regressione bivariata tra le componenti parzializzate della \(y\) e di \(x_j\):
mod <- lm(fm_y$residuals ~ fm_x$residuals)
mod$coef
- (Intercept)
- -1.65185057983985e-15
- fm_x$residuals
- 0.562081421559238
Si vede come il coefficiente di regressione bivariato risulta identico al corrispondente coefficiente parziale di regressione.
2.2.2. Relazioni causali#
Un altro modo per interpretare i coefficienti parziali di regressione è nell’ambito dei quelli che vengono chiamati i path diagrams. I diagrammi di percorso, che tratteremo in seguito e qui solo anticipiamo, descrivono le relazioni “causali” tra variabili: le variabili a monte del diagramma di percorso rappresentano le “cause” esogene e le variabili a valle indicano gli effetti, ovvero le variabili endogene. I coefficienti di percorso vengono rappresentati graficamente come frecce orientate e corrispondono all’effetto diretto sulla variabile verso cui punta la freccia della variabile a monte della freccia. In tale rappresentazione grafica, i coefficienti di percorso non sono altro che i coefficienti parziali di regressione del modello di regressione multipla. In questo contesto, indicano l’effetto diretto atteso sulla variabile endogena in conseguenza dell’incremento di un’unità della variabile esogena, lasciano immutate tutte le altre relazioni strutturali del modello.
Usiamo la funzione sem() del pacchetto lavaan per definire il modello rappresentato nel successivo diagramma di percorso:
model <- "
kid_score ~ mom_hs + mom_iq + mom_work + mom_age
"
Adattiamo il modello ai dati
fit <- sem(model, data = d)
Il diagramma di percorso si ottiene con le seguenti istruzioni:
options(repr.plot.width = 5, repr.plot.height = 3)
semPaths(
fit, "est",
posCol = c("black"),
edge.label.cex = 0.9,
sizeMan = 7,
what = "path"
)
Error in eval(expr, envir, enclos): object 'fit' not found
Traceback:
1. semPaths(fit, "est", posCol = c("black"), edge.label.cex = 0.9,
. sizeMan = 7, what = "path")
2. "semPlotModel" %in% class(object)
Come indicato nel diagramma, l’effetto diretto di mom_iq su kid_score è identico al corrispondente coefficiente parziale di regressione.
Il problema di capire se sia appropriato utilizzare un modello di regressione per descrivere le relazioni causali tra le variabili è affrontato nel prossimo paragrafo in riferimento all’errore di specificazione.
2.2.3. Errore di specificazione#
Spiritosamente chiamato “heartbreak of L.O.V.E.” [Left-Out Variable Error; @mauro1990understanding], l’errore di specificazione è una caratteristica fondamentale dei modelli di regressione che deve sempre essere tenuta a mente quando interpretiamo i risultati di questa tecnica di analisi statistica.
L’errore di specificazione si verifica quando escludiamo dal modello di regressione una variabile che ha due caratteristiche:
è associata con altre variabili inserite nel modello,
ha un effetto diretto sulla \(y\).
Come conseguenza dell’errore di specificazione, l’intensità e il segno dei coefficienti parziali di regressione risultano sistematicamente distorti.
Consideriamo un esempio con dati simulati nei quali immaginiamo che la prestazione sia positivamente associata alla motivazione e negativamente associata all’ansia. Immaginiamo inoltre che vi sia una correlazione positiva tra ansia a motivazione. Ci chiediamo cosa succede al coefficiente parziale della variabile “motivazione” se la variabile “ansia” viene esclusa dal modello di regressione.
set.seed(123)
n <- 400
anxiety <- rnorm(n, 10, 1.5)
motivation <- 4.0 * anxiety + rnorm(n, 0, 3.5)
cor(anxiety, motivation)
Creo la variabile performance come una combinazione lineare di motivazione e ansia nella quale la motivazione ha un effetto piccolo, ma positivo, sulla prestazione, e l’ansia ha un grande effetto negativo sulla prestazione:
performance <- 0.5 * motivation - 5.0 * anxiety + rnorm(n, 0, 3)
Salvo i dati in un DataFrame:
sim_dat2 <- tibble(performance, motivation, anxiety)
Eseguo l’analisi di regressione specificando in maniera corretta il modello, ovvero usando come predittori sia l’ansia che la depressione:
fm1 <- lm(performance ~ motivation + anxiety, sim_dat2)
Le stime dei coefficienti parziali di regressione recuperano correttamente l’intensità e il segno dei coefficienti utilizzati nel modello generatore dei dati:
coef(fm1)
- (Intercept)
- 1.37119646932022
- motivation
- 0.495388553436189
- anxiety
- -5.10521755591756
Eseguo ora l’analisi di regressione ignorando il predittore anxiety che ha le due caratteristiche di essere associato a motivation e di avere un effetto diretto sulla prestazione:
fm2 <- lm(performance ~ motivation, sim_dat2)
summary(fm2)
Call:
lm(formula = performance ~ motivation, data = sim_dat2)
Residuals:
Min 1Q Median 3Q Max
-13.501 -3.409 0.005 3.311 12.616
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -12.39720 1.44591 -8.574 2.24e-16 ***
motivation -0.43717 0.03553 -12.305 < 2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 4.866 on 398 degrees of freedom
Multiple R-squared: 0.2756, Adjusted R-squared: 0.2738
F-statistic: 151.4 on 1 and 398 DF, p-value: < 2.2e-16
Si noti che, al di là della “significatività statistica” (si vedano le considerazioni fornite nel paragrafo sulla stepwise regression), il risultato prodotto dal modello di regressione è totalmente sbagliato: come conseguenza dell’errore di specificazione, il segno del coefficiente parziale di regressione della variabile “motivazione” è negativo, anche se nel modello generatore dei dati tale coefficiente aveva il segno opposto.
Quindi, se interpretiamo il coefficiente parziale ottenuto in termini casuali, siamo portati a concludere che la motivazione fa diminuire la prestazione. Ma in realtà è vero l’opposto.
È facile vedere perché si verifica l’errore di specificazione. Supponiamo che il vero modello sia
il quale verrebbe stimato da
Supponiamo però che il ricercatore creda invece che
e quindi stimi
omettendo \(X_2\) dal modello.
Per capire che relazione intercorre tra \(b_1^\prime\) e \(b_1\), iniziamo a scrivere la formula per \(b_1^\prime\):
Sviluppando, otteniamo
Quindi, se erroneamente omettiamo \(X_2\) dal modello, abbiamo che
Verifichiamo tale conclusione per i dati dell’esempio che stiamo discutendo. Nel caso presente, \(X_1\) è motivation e \(X_2\) è anxiety. Applicando l’eq. (2.1) otteniamo lo stesso valore per il coefficiente di regressione associato a motivation che era stato ottenuto adattando ai dati il modello performance ~ motivation:
fm1$coef[2] + fm1$coef[3] *
cov(sim_dat2$motivation, sim_dat2$anxiety) /
var(sim_dat2$motivation)
Possiamo dunque concludere che \(b_1^\prime\) è uno stimatore distorto di \(\beta_1\). Si noti che questa distorsione non scompare all’aumentare della numerosità campionaria, il che (in termini statistici) significa che un tale stimatore è inconsistente. Quello che succede in pratica è che alla variabile \(X_1\) vengono attribuiti gli effetti delle variabili che sono state omesse dal modello. Si noti che una tale distorsione sistematica di \(b_1^\prime\) può essere evitata solo se si verificano due condizioni:
\(\beta_2 = 0\). Questo è ovvio, dato che, se \(\beta_2 = 0\), ciò significa che il modello non è specificato in modo errato, cioè \(X_2\) non appartiene al modello perché non ha un effetto diretto sulla \(Y\).
\(\sigma_{12} = 0\). Cioè, se \(X_1\) e \(X_2\) sono incorrelate, allora l’omissione di una delle due variabili non comporta stime distorte dell’effetto dell’altra.
2.2.4. Soppressione#
Le conseguenze dell’errore di specificazione sono chiamate “soppressione” (suppression). In generale, si ha soppressione quando (1) il valore assoluto del peso beta di un predittore è maggiore di quello della sua correlazione bivariata con il criterio o (2) i due hanno segni opposti.
L’esempio descritto sopra è un caso di soppressione negativa, dove il predittore ha correlazioni bivariate positive con il criterio, ma si riceve un peso beta negativo nell’analisi di regressione multipla.
Un secondo tipo di soppressione è la soppressione classica, in cui un predittore non è correlato al criterio ma riceve un peso beta diverso da zero.
C’è anche la soppressione reciproca che può verificarsi quando due variabili sono correlate positivamente con il criterio ma negativamente tra loro.
2.2.5. Stepwise regression#
Un’implicazione della soppressione è che i predittori non dovrebbero essere selezionati in base ai valori delle correlazioni bivariate con il criterio. Queste associazioni, dette di ordine zero, non controllano gli effetti degli altri predittori, quindi i loro valori possono essere fuorvianti rispetto ai coefficienti di regressione parziale per le stesse variabili. Per lo stesso motivo, il fatto che le correlazioni bivariate con il criterio siano statisticamente significative o meno è irrilevante per quanto riguarda la selezione dei predittori. Sebbene le procedure informatiche di regressione rendano facile i processi di selezione dei predittori in base a tali criteri, tali procedure sono da evitare. Il rischio è che anche piccole, ma non rilevate, non-linearità o effetti indiretti tra i predittori possano seriamente distocere i coefficienti di regressione parziale. È meglio selezionare giudiziosamente il minor numero di predittori sulla base di ragioni teoriche o dei risultati di ricerche precedenti. In altri termini, le procedure di stepwise regression non dovrebbero mai essere usate.
Una volta che sono stati selezionati, i predittori possono essere inseriti nell’equazione di regressione in due modi diversi:
tutti i predittori possono essere inseriti nel modello contemporaneamente;
i predittori possono essere inseriti nel modello sequenzialmente, mediante una serie di passaggi.
L’ordine di ingresso può essere determinato in base a standard: teorici (razionali) o empirici (statistici). Lo standard razionale corrisponde alla regressione gerarchica, in cui si comunica al computer un ordine fisso per inserire i predittori. Ad esempio, a volte le variabili demografiche vengono inserite nel primo passaggio, quindi nel secondo passaggio viene inserita una variabile psicologica di interesse. Questo ordine non solo controlla le variabili demografiche ma permette anche di valutare il potere predittivo della variabile psicologica, al di là di quello delle semplici variabili demografiche. Quest’ultimo può essere stimato come l’aumento della correlazione multipla al quadrato, o \(\Delta R^2\), da quella della fase 1 con solo predittori demografici a quella della fase 2 con tutti i predittori nell’equazione di regressione.
Un esempio di standard statistico è la regressione stepwise, in cui il computer seleziona l’inserimento dei predittori in base esclusivamente alla significatività statistica; cioè, viene chiesto: quale predittore, se inserito nell’equazione, avrebbe il valore_\(p\) più piccolo per il test del suo coefficiente di regressione parziale? Dopo la selezione, i predittori in una fase successiva possono essere rimossi dall’equazione di regressione in base ai loro valori-\(p\) (ad esempio, se \(p \geq\) .05). Il processo stepwise si interrompe quando, aggiungendo più predittori, \(\Delta R^2\) non migliora. Varianti della regressione stepwise includono forward inclusion, in cui i predittori selezionati non vengono successivamente rimossi dal modello, e backward elimination, che inizia con tutti i predittori nel modello per poi rimuoverne alcuni in passi successivi. Per le ragioni descritte nel paragrafo sull’errore di specificazione, i metodi basati sulle procedure di stepwise regression non dovrebbero mai essere usati. Infatti, i problemi relativi a tale procedura sono così gravi che varie riviste non accettano studi che fanno uso di una tale tecnica statistica. I risultati ottenuti con tali metodi, infatti, sono quasi certamente non replicabili in campioni diversi.
Una considerazione finale riguarda l’idea di rimuovere i predittori “non significativi” dal modello di regressione. Questa è una cattiva idea. Il ricercatore non deve sentirsi in dovere di trascurare quei predittore che non risultano “statisticamente significativi”. In campioni piccoli, la potenza dei test di significatività è bassa e la rimozione di un predittore non significativo può alterare sostanzialmente la soluzione. Se c’è una buona ragione per includere un predittore, allora è meglio lasciarlo nel modello, fino a prova contraria. In termini generali, qualsiasi considerazione basata sulla “significatività statistia” è fuorviante.
2.3. Proprietà degli stimatori dei minimi quadrati#
Consideriamo il problema dell’inferenza statistica nel caso più semplice, quello della regressione bivariata. Il caso generale della regressione multipla segue lo stesso approccio, anche se le formule sono più complesse in quanto vengono formulate nei termini dell’albebra matriciale.
Per il caso bivariato, si può dire che il coefficiente dei minimi quadrati \(b\) è una combinazione lineare delle osservazioni \(y_i\). Tale proprietà è importante perché consente di derivare la distribuzione di \(b\) dalla distribuzione delle \(y_i\). Può essere dimostrato che la formula per il calcolo di \(b\) si può scrivere nel modo seguente:
dove \(m_i \triangleq (x_i-\bar{x}) / \sum (x_j-\bar{x})^2\) è il peso associato a ciascun valore \(y_i\). Dato che i valori \(x_i\) sono fissi e \(m_i\) dipende solo da \(x_i\), anche i pesi \(m_i\) sono fissi.
Il valore atteso di \(b\) è uguale a
Il coefficiente dei minimi quadrati \(b\) è dunque uno stimatore corretto di \(\beta\). In maniera equivalente si può dimostrare che \(E(a) = \alpha\).
Sotto le ipotesi di omoschedasticità \(\big[ var(y_i) = var(\varepsilon_i)=\sigma^2_{\varepsilon}\big]\) e indipendenza, la varianza di \(b\) è
In maniera simile si dimostra che la varianza di \(a\) è
Dato che sia \(a\) che \(b\) sono funzioni lineari di \(y_i\), se i valori \(y_i\) seguono la distribuzione gaussiana, allora anche \(a\) e \(b\) saranno distribuiti secondo una distribuzione normale. In conclusione,
2.3.1. Ipotesi statistiche e statistica test#
Una volta definite le proprietà delle distribuzioni degli stimatori dei minimi quadrati è possibile procedere con l’inferenza sui parametri del modello di regressione. L’inferenza statistica si articola nella formulazione degli intervalli di confidenza per i parametri di interesse e nei test di significatività statistica.
Un’ipotesi che viene frequentemente sottoposta a verifica è quella di significatività, cioè l’ipotesi che alla variabile esplicativa sia associato un coefficiente nullo. In tal caso, l’ipotesi nulla è
e l’ipotesi alternativa è
Sotto l’ipotesi nulla \(H_0: \beta = 0\) la statistica
si distribuisce come una variabile aleatoria \(t\) di Student con \(n-2\) gradi di libert{`a}.
Di fronte al problema di decidere se il valore stimato \(\hat{\beta}\) sia sufficientemente “distante” da zero, in modo da respingere l’ipotesi nulla che il vero valore \(\beta\) sia nullo, non è sufficiente basarsi soltanto sul valore numerico assunto da \(\hat{\beta}\), ma occorre tener conto della variabilità campionaria. La statistica ottenuta dividendo \(\hat{\beta}\) per la stima del suo errore standard, \(s_{\hat{\beta}}\), ci permette di utilizzare la distribuzione \(t\) di Student come metrica per stabilire se la stima trovata si debba considerare “diversa” da quanto ipotizzato sotto \(H_0\).
L’ipotesi nulla viene rifiutata quando il valore assoluto del rapporto è esterno alla regione di accettazione, i cui limiti sono definiti dai valori critici della distribuzione \(t\) di Student con \(n - 2\) gradi di libertà per il livello di significatività \(\alpha\) prescelto. Se l’ipotesi nulla viene rifiutata si dice che il coefficiente \(\hat{\beta}\) è \enquote{statisticamente significativo} ammettendo così la possibilità di descrivere con un modello lineare la relazione esistente tra le variabili \(X\) e \(Y\). Quando non si può rifiutare l’ipotesi nulla nel modello di regressione, si conclude che il coefficiente angolare della retta non risulta significativamente diverso da zero, individuando così nella popolazione una retta parallela all’asse delle
2.3.2. Riportare i risultati#
È consuetudine riportare i risultati dell’analisi di regressione in modo che insieme alle stime dei coefficienti vengano riportati i rispettivi errori standard stimati. Il valore-\(p\) esprime la probabilità di ottenere un valore del test uguale o superiore a quello ottenuto nel campione esaminato, utilizzando la distribuzione campionaria del test sotto l’ipotesi nulla. Se \(t_{\hat{\beta}}\) è il valore osservato del rapporto \(t\) per il coefficiente angolare della retta di regressione, allora il { \(p\)-valore} è dato da
dove \(t\) è il valore di una variabile aleatoria \(t\) di Student con \((n-2)\) gradi di libertà.
2.3.2.1. Regola di decisione#
Ogni volta che il \(p\)-valore del test è inferiore al livello di significatività che si è scelto per \(H_0\), il test porta al rifiuto dell’ipotesi nulla. Solitamente si sceglie un livello \(\alpha\) pari a 0.05 o 0.01.
I test di significatività possono essere eseguiti con R, utilizzando la funzione \texttt{summary()} applicata all’oggetto creato dal \texttt{lm()}.
Il test statistico sul parametro \(\beta\) del modello di regressione verifica l’ipotesi nulla di indipendenza, ovvero l’ipotesi che, nella popolazione, la pendenza della retta di regressione sia uguale a zero. Pi{`u} informativo del test statistico \(H_0: \beta=0\) è l’intervallo di confidenza per il parametro \(\beta\):
2.3.3. Considerazioni conclusive#
Il modello di regressione lineare semplice è un metodo per studiare la relazione tra due variabili e per prevedere il valore della variabile dipendente in base alla variabile indipendente. Tuttavia, questo modello è limitato poiché si concentra solo sulla relazione tra una singola variabile indipendente e la variabile dipendente. Quando ci sono più variabili indipendenti, il modello di regressione diventa più complesso e richiede l’uso dell’algebra matriciale. Questo modello può includere variabili indipendenti sia quantitative che qualitative e può essere utilizzato anche per l’analisi della varianza. Il modello lineare è alla base dell’analisi fattoriale, una tecnica ampiamente utilizzata per la costruzione e la validazione dei test psicometrici.