4 Probabilità condizionata
“Probability is always conditional.”
– Dennis V. Lindley, The Philosophy of Statistics (2000).
Introduzione
La probabilità condizionata esprime la probabilità di un evento in relazione al verificarsi di un altro evento. Questo concetto è fondamentale, in quanto riflette il modo in cui aggiorniamo le nostre credenze alla luce di nuove informazioni. Ad esempio, la probabilità che piova domani può variare in base alle condizioni atmosferiche odierne: osservare un cielo nuvoloso può influenzare la nostra valutazione della probabilità di pioggia. In questo senso, ogni nuova informazione può confermare, rafforzare o mettere in discussione le credenze preesistenti.
La probabilità condizionata riveste un ruolo centrale non solo nella teoria della probabilità, ma anche nelle applicazioni quotidiane e scientifiche. In molti contesti, le probabilità sono implicitamente condizionate da informazioni preesistenti, anche se non le esplicitiamo formalmente. Comprendere e quantificare questo processo di aggiornamento delle credenze ci permette di gestire l’incertezza in modo più efficace, trasformando la probabilità in uno strumento dinamico per la presa di decisioni e l’inferenza.
Panoramica del capitolo
- Concetti di probabilità congiunta, marginale e condizionata.
- Applicazione dei principi di indipendenza e probabilità condizionata.
- Il paradosso di Simpson;
- Il teorema del prodotto e della probabilità totale.
4.1 Indipendenza stocastica
In alcuni casi, l’aggiornamento delle probabilità diventa particolarmente semplice. Ciò si verifica quando due eventi non si influenzano a vicenda. In tali situazioni, la probabilità che essi si verifichino insieme può essere calcolata direttamente, grazie alla proprietà di indipendenza.
4.1.1 Indipendenza di due eventi
Definizione 4.1 Due eventi \(A\) e \(B\) si dicono indipendenti se la probabilità che si verifichino entrambi è pari al prodotto delle loro probabilità individuali:
\[ P(A \cap B) = P(A) \, P(B). \tag{4.1}\]
Ciò significa che conoscere l’esito di uno dei due eventi non fornisce alcuna informazione utile sull’altro. In simboli, si scrive \(A \perp B\) per indicare che \(A\) e \(B\) sono eventi indipendenti.
4.2 Indipendenza di un insieme di eventi
Il concetto di indipendenza non riguarda soltanto due eventi, ma può estendersi anche a un insieme più ampio. In generale, diciamo che \({A_i : i \in I}\) è un insieme di eventi indipendente se, per ogni sottoinsieme finito \(J \subseteq I\), la probabilità che si verifichino contemporaneamente tutti gli eventi di \(J\) è uguale al prodotto delle loro probabilità individuali:
\[ P \Bigl(\bigcap_{i \in J} A_i\Bigr) \;=\; \prod_{i \in J} P(A_i). \tag{4.2}\] In altre parole, nessun evento della collezione fornisce informazioni utili sugli altri: il verificarsi di uno non modifica la probabilità degli altri.
Nella pratica, questa condizione è molto forte. Per questo motivo, l’indipendenza di più eventi può avere due significati distinti:
- può essere un’ipotesi semplificante in un modello (per esempio, assumere che le risposte a diverse domande di un questionario siano indipendenti, cioè non influenzate tra loro);
- può essere una proprietà empirica dei dati, che deve però essere verificata con analisi specifiche.
4.2.1 Quando gli eventi non sono indipendenti
Se per due eventi \(A\) e \(B\) vale la disuguaglianza
\[
P(A \cap B) \neq P(A) \cdot P(B),
\] allora essi non sono indipendenti. In tal caso, la conoscenza dell’esito di uno dei due eventi fornisce informazioni rilevanti sulla probabilità del verificarsi dell’altro. Questa dipendenza deve essere esplicitamente considerata nei calcoli probabilistici, ad esempio ricorrendo al concetto di probabilità condizionata.
4.3 Probabilità condizionata
La probabilità condizionata quantifica la probabilità che si verifichi un evento \(A\), dato che si è verificato un altro evento \(B\).
Definizione 4.2 Se \(P(B) > 0\), la probabilità condizionata di \(A\) dato \(B\) è definita come:
\[ P(A \mid B) = \frac{P(A \cap B)}{P(B)}. \tag{4.3}\]
Questa espressione può essere interpretata come un’operazione di confinamento probabilistico agli esiti in cui \(B\) si verifica, ricalibrando così la misura di probabilità sull’evento condizionante.
4.3.1 Interpretazione della probabilità condizionata
La probabilità condizionata rappresenta un meccanismo di aggiornamento delle nostre conoscenze. Inizialmente, si dispone di una probabilità \(P(A)\); dopo aver osservato il verificarsi di un evento correlato \(B\), si restringe lo spazio degli esiti possibili a quelli compatibili con \(B\), ricalibrando di conseguenza la probabilità di \(A\).
- Esempio intuitivo: Se una persona ha la febbre (\(B\)), la probabilità che abbia l’influenza (\(A\)) aumenta rispetto alla probabilità basata sulla sola popolazione generale.
Questa capacità di “aggiornare probabilisticamente” le credenze rende la probabilità condizionata uno strumento essenziale in:
-
diagnosi medica: per valutare la probabilità di una malattia (\(A\)) dato il risultato di un test (\(B\));
- previsioni meteorologiche, per stimare la probabilità di pioggia \(A\)) dato l’arrivo di un fronte nuvoloso (\(B\));
- modellizzazione delle dipendenze stocastiche, dove il verificarsi di un evento influisce sulla probabilità di un altro.
La formula \(P(A \mid B) = \frac{P(A \cap B)}{P(B)}\) quantifica proprio questo processo di revisione della probabilità alla luce di nuove informazioni.
Il problema di Monty Hall è un famoso quesito di teoria della probabilità che illustra in modo efficace il concetto di probabilità condizionata. Questo problema è diventato celebre grazie a una rubrica tenuta da Marilyn vos Savant nella rivista Parade, in cui rispose a una lettera pubblicata il 9 settembre 1990:
“Supponiamo di partecipare a un quiz televisivo e di dover scegliere tra tre porte. Dietro una di esse c’è un’auto, mentre dietro le altre due ci sono delle capre. Scegli una porta, ad esempio la numero 1, e il conduttore, che sa cosa c’è dietro ogni porta, ne apre un’altra, diciamo la numero 3, rivelando una capra. A questo punto, ti chiede se vuoi cambiare la tua scelta e passare alla porta numero 2. È vantaggioso cambiare porta?” Craig. F. Whitaker, Columbia, MD
La situazione descritta ricorda quella del popolare quiz televisivo degli anni ’70 Let’s Make a Deal, condotto da Monty Hall e Carol Merrill. Marilyn vos Savant rispose che il concorrente dovrebbe cambiare porta, poiché la probabilità di vincere l’auto raddoppia passando da 1/3 a 2/3. Tuttavia, la sua risposta suscitò un acceso dibattito, con molte persone, inclusi alcuni matematici, che sostenevano che cambiare porta non avrebbe offerto alcun vantaggio. Questo episodio ha reso il problema di Monty Hall uno dei più famosi esempi di come l’intuizione possa portare a conclusioni errate in ambito probabilistico.
Chiarire il Problema.
La lettera originale di Craig Whitaker è piuttosto vaga, quindi per analizzare il problema in modo rigoroso è necessario fare alcune ipotesi:
- Posizione dell’auto: L’auto è nascosta in modo casuale ed equiprobabile dietro una delle tre porte.
- Scelta iniziale del giocatore: Il giocatore sceglie una porta in modo casuale, indipendentemente dalla posizione dell’auto.
- Azione del conduttore: Dopo la scelta del giocatore, il conduttore apre una delle due porte rimanenti, rivelando una capra, e offre al giocatore la possibilità di cambiare porta.
- Scelta del conduttore: Se il conduttore ha la possibilità di scegliere tra due porte (entrambe con capre), ne apre una in modo casuale.
Con queste assunzioni, possiamo rispondere alla domanda: Qual è la probabilità che il giocatore vinca l’auto se decide di cambiare porta?
Di seguito, esploreremo tre metodi per risolvere il problema di Monty Hall: il diagramma ad albero, l’analisi delle probabilità e una simulazione.
Metodo 1: diagramma ad albero.
Il diagramma ad albero è uno strumento utile per visualizzare tutti i possibili esiti di un esperimento probabilistico. Nel caso del problema di Monty Hall, possiamo suddividere il processo in tre fasi:
- Posizione dell’auto: L’auto può trovarsi dietro una delle tre porte (A, B o C), ciascuna con probabilità 1/3.
- Scelta del giocatore: Il giocatore sceglie una porta in modo casuale, indipendentemente dalla posizione dell’auto.
- Azione del conduttore: Il conduttore apre una delle due porte rimanenti, rivelando una capra.
Il diagramma ad albero mostra tutte le possibili combinazioni di questi eventi. Ad esempio, se l’auto è dietro la porta A e il giocatore sceglie la porta B, il conduttore aprirà la porta C (l’unica porta rimanente con una capra).
Passo 1: Identificare lo spazio campionario
Lo spazio campionario è composto da 12 esiti possibili, rappresentati dalle combinazioni di:
- Posizione dell’auto (A, B, C).
- Scelta iniziale del giocatore (A, B, C).
- Porta aperta dal conduttore (una delle due rimanenti con una capra).
Ecco un diagramma ad albero che rappresenta questa situazione:
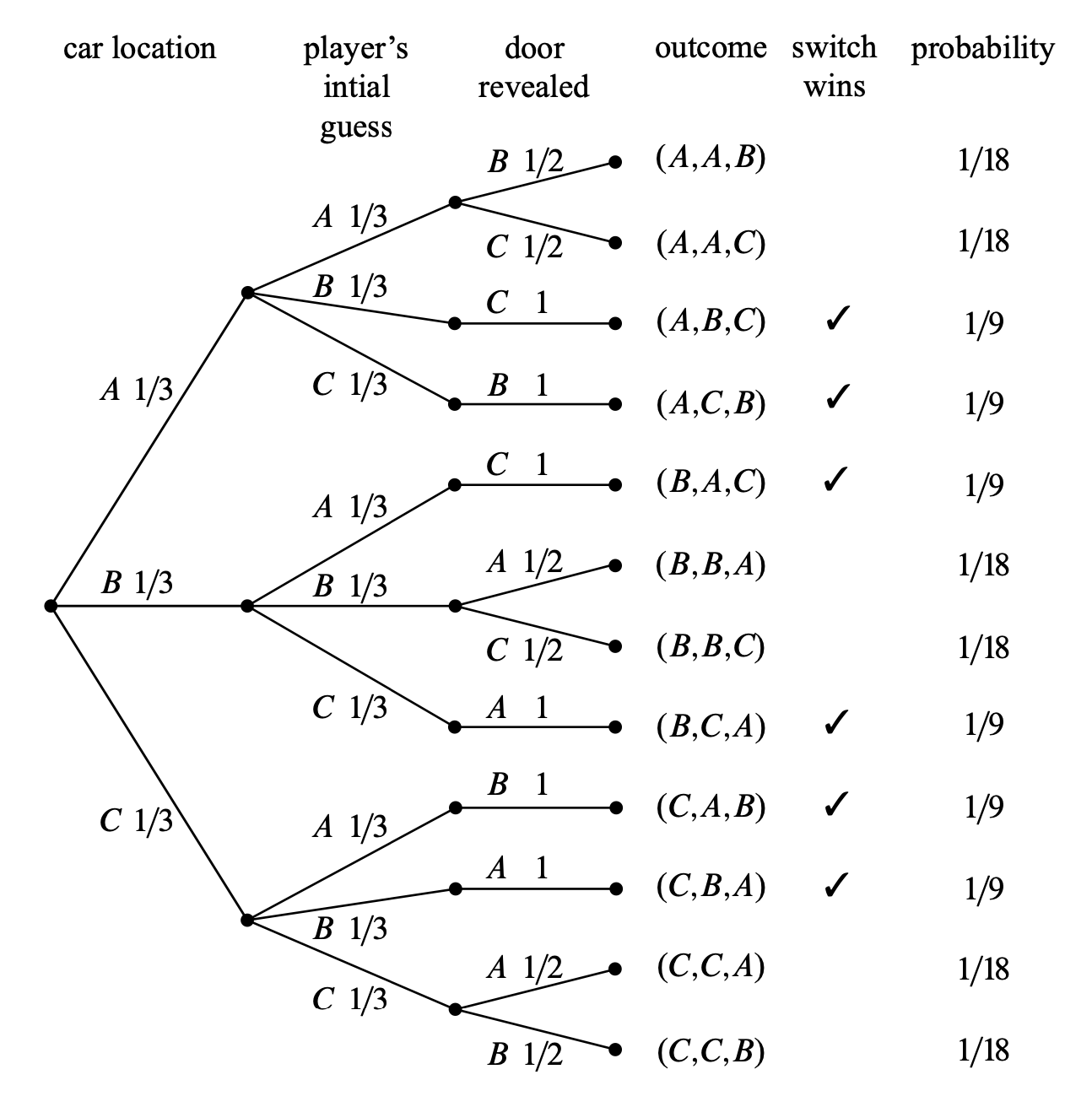
Passo 2: Definire l’evento di interesse
L’evento di interesse è “il giocatore vince cambiando porta”. Questo si verifica quando la porta inizialmente scelta dal giocatore non nasconde l’auto, e il giocatore decide di cambiare porta.
Gli esiti che soddisfano questa condizione sono:
(Auto A, Scelta B, Apertura C)(Auto A, Scelta C, Apertura B)(Auto B, Scelta A, Apertura C)(Auto B, Scelta C, Apertura A)(Auto C, Scelta A, Apertura B)(Auto C, Scelta B, Apertura A)
Questi esiti sono in totale 6.
Passo 3: Calcolare le probabilità degli esiti
Ogni esito ha una probabilità specifica, calcolata moltiplicando le probabilità lungo il percorso nel diagramma ad albero.
Esempio di calcolo per l’esito (Auto A, Scelta B, Apertura C):
- La probabilità che l’auto sia dietro la porta A è \(\frac{1}{3}\).
- La probabilità che il giocatore scelga la porta B è \(\frac{1}{3}\).
- La probabilità che il conduttore apra la porta C (che contiene una capra) è \(1\) (poiché il conduttore deve aprire una porta con una capra, e la porta C è l’unica possibile).
La probabilità totale per questo esito è:
\[ P(\text{Auto A, Scelta B, Apertura C}) = \frac{1}{3} \times \frac{1}{3} \times 1 = \frac{1}{9}. \]
Procedendo in modo simile per tutti gli altri esiti, otteniamo le probabilità per tutti i 12 esiti.
Passo 4: Calcolare la probabilità dell’evento
La probabilità di vincere cambiando porta è la somma delle probabilità degli esiti favorevoli.
\[ \begin{aligned} P&(\text{vincere cambiando porta}) = \notag \\ &\quad P(\text{Auto A, Scelta B, Apertura C}) + P(\text{Auto A, Scelta C, Apertura B}) + \notag\\ &\quad P(\text{Auto B, Scelta A, Apertura C}) + \dots \notag \end{aligned} \]
\[ = \frac{1}{9} + \frac{1}{9} + \frac{1}{9} + \frac{1}{9} + \frac{1}{9} + \frac{1}{9} = \frac{6}{9} = \frac{2}{3}. \]
La probabilità di vincere mantenendo la scelta originale è il complemento:
\[ P(\text{vincere mantenendo la scelta}) = 1 - P(\text{vincere cambiando porta}) = 1 - \frac{2}{3} = \frac{1}{3}. \]
La conclusione è che il giocatore ha una probabilità di vincere pari a \(\frac{2}{3}\) se cambia porta, contro una probabilità di \(\frac{1}{3}\) se mantiene la sua scelta iniziale. Cambiare porta è quindi la strategia vincente.
Metodo 2: analisi delle probabilità.
Il problema di Monty Hall può essere chiarito analizzando i tre scenari possibili, immaginando di essere osservatori esterni che sanno cosa si nasconde dietro ogni porta:
-
Primo scenario:
- Il giocatore sceglie inizialmente la porta con una capra (chiamiamola “capra 1”).
- Il conduttore apre l’altra porta con la “capra 2”.
- Se il giocatore cambia porta, vince l’automobile.
- Il giocatore sceglie inizialmente la porta con una capra (chiamiamola “capra 1”).
-
Secondo scenario:
- Il giocatore sceglie inizialmente la porta con l’altra capra (“capra 2”).
- Il conduttore apre la porta con la “capra 1”.
- Se il giocatore cambia porta, vince l’automobile.
- Il giocatore sceglie inizialmente la porta con l’altra capra (“capra 2”).
-
Terzo scenario:
- Il giocatore sceglie inizialmente la porta con l’automobile.
- Il conduttore apre una delle due porte con una capra (non importa quale).
- Se il giocatore cambia porta, perde l’automobile.
- Il giocatore sceglie inizialmente la porta con l’automobile.
All’inizio del gioco, il giocatore ha:
-
1/3 di probabilità di scegliere l’automobile.
- 2/3 di probabilità di scegliere una capra.
Dopo la scelta iniziale, il conduttore apre una porta con una capra, ma questa azione non altera le probabilità iniziali. Il giocatore si trova quindi con due porte chiuse: quella scelta inizialmente e una rimanente.
- Se il giocatore ha scelto l’automobile inizialmente (1/3 di probabilità), cambiando porta perde.
- Se il giocatore ha scelto una capra inizialmente (2/3 di probabilità), cambiando porta vince l’automobile.
In sintesi, cambiando porta, il giocatore ha 2/3 di probabilità di vincere l’automobile, mentre mantenendo la scelta iniziale ha solo 1/3 di probabilità. Pertanto, la strategia migliore è cambiare porta per massimizzare le possibilità di vittoria.
Metodo 3: simulazione.
Per confermare il risultato, possiamo eseguire una simulazione. Ripetendo il gioco migliaia di volte, possiamo confrontare la frequenza con cui il giocatore vince cambiando porta rispetto a quando mantiene la scelta iniziale.
Ecco un esempio di codice in R per la simulazione:
# Numero di simulazioni da effettuare.
# Più è grande B, più precisa sarà la stima.
B <- 10000
# Definiamo una funzione "monty_hall" che
# a) simula un gioco
# b) restituisce TRUE/FALSE a seconda che il giocatore vinca l'auto o no.
monty_hall <- function(strategy){
# 1. Dichiariamo le porte possibili, in forma di stringhe.
doors <- c("1", "2", "3")
# 2. Stabiliamo dove si trova il premio (auto) e le capre.
# "prize" sarà un vettore con dentro "car" per la porta con l’auto
# e "goat" per quelle con la capra.
# La funzione sample() crea una distribuzione casuale di "car" e "goat".
prize <- sample(c("car", "goat", "goat"))
# 3. Troviamo qual è la porta che ha la macchina.
prize_door <- doors[ prize == "car" ]
# 4. Il giocatore fa la sua prima scelta, pescando a caso fra le 3 porte.
my_pick <- sample(doors, 1)
# 5. Il conduttore deve aprire una porta che:
# - non sia la mia (my_pick)
# - non abbia la macchina (prize_door)
# Così facendo, rivela una porta con la capra.
# Se ci sono due porte con capra, ne sceglie una a caso.
show <- sample(doors[!doors %in% c(my_pick, prize_door)], 1)
# 6. La strategia "stick" significa: RESTARE sulla scelta iniziale (my_pick).
# La strategia "switch" significa: CAMBIARE porta, passando a quella
# rimasta tra le due che NON sono state aperte.
stick <- my_pick
switch <- doors[!doors %in% c(my_pick, show)]
# 7. Se la strategia scelta (in input) è "stick", la mia scelta finale è "stick".
# Altrimenti, è "switch".
final_choice <- ifelse(strategy == "stick", stick, switch)
# 8. La funzione restituisce TRUE se la scelta finale coincide con la porta premiata,
# altrimenti FALSE.
return(final_choice == prize_door)
}Nel codice qui sopra:
-
my_pickè la porta che il giocatore sceglie subito. -
showè la porta che il conduttore mostra, rivelando la capra. -
stickrimane la scelta iniziale (quindi è my_pick). -
switchè la porta che rimane fra le non aperte e non scelte inizialmente.
Al termine, la funzione monty_hall() stabilisce se, con la strategia considerata, si vince (TRUE) o si perde (FALSE).
- La media di un vettore di
TRUE/FALSEin R è pari alla frazione diTRUE. - In questo modo,
mean(stick_results)ci dice la probabilità di vincere restando sulla scelta iniziale. -
mean(switch_results)ci dice la probabilità di vincere se si cambia sempre porta dopo l’intervento del conduttore.
Risultati attesi:
- Mantenere la Scelta Iniziale: La frequenza di vittoria dovrebbe essere circa 1/3 (33.3%).
- Cambiare Porta: La frequenza di vittoria dovrebbe essere circa 2/3 (66.6%).
La simulazione conferma che cambiare porta aumenta la probabilità di vincere da 1/3 a 2/3, dimostrando che la strategia ottimale nel problema di Monty Hall è quella di cambiare porta dopo che il conduttore ha rivelato una capra.
In sintesi, il problema di Monty Hall mette in luce come l’intuizione possa trarci in inganno quando ci confrontiamo con scenari probabilistici. Attraverso l’uso del diagramma ad albero, un’analisi delle probabilità e l’esecuzione di simulazioni, abbiamo dimostrato che cambiare porta raddoppia le possibilità di vincita, facendole passare da 1/3 a 2/3. Questo risultato, in apparente contrasto con ciò che potrebbe sembrare intuitivo, costituisce un esempio emblematico dell’importanza di adottare un approccio formale nella valutazione delle probabilità, anziché affidarsi esclusivamente a impressioni iniziali che spesso si rivelano fuorvianti.
4.4 Indipendenza e probabilità condizionata
Il concetto di indipendenza tra due eventi \(A\) e \(B\) può essere caratterizzato in modo intuitivo attraverso la lente della probabilità condizionata. Due eventi sono indipendenti se il verificarsi di uno non altera la probabilità del verificarsi dell’altro. In altre parole, la conoscenza dell’esito di \(B\) non fornisce alcuna informazione utile su \(A\), e viceversa.
Formalmente, questa condizione si esprime attraverso le relazioni:
\[ P(A \mid B) = \frac{P(A \cap B)}{P(B)} = P(A), \] \[ P(B \mid A) = \frac{P(A \cap B)}{P(A)} = P(B). \] Di conseguenza, \(A\) e \(B\) sono indipendenti se e solo se vale una delle seguenti condizioni equivalenti:
- \(P(A \mid B) = P(A)\),
- \(P(B \mid A) = P(B)\),
- \(P(A \cap B) = P(A) \cdot P(B)\). Questo implica che la probabilità di \(A\) rimane invariata sia che \(B\) si sia verificato o meno, e analogamente per \(B\). L’indipendenza stocastica rappresenta dunque l’assenza completa di influenza reciproca tra i due eventi.
4.4.1 Indipendenza di tre eventi
La definizione di indipendenza si generalizza a tre eventi \(A\), \(B\) e \(C\) richiedendo condizioni più stringenti rispetto al caso bivariato. Tre eventi si definiscono completamente indipendenti se:
Indipendenza a coppie: \[ \begin{aligned} P(A \cap B) &= P(A) P(B), \\ P(A \cap C) &= P(A) P(C), \\ P(B \cap C) &= P(B) P(C). \end{aligned} \]
Indipendenza dell’intersezione tripla: \[ P(A \cap B \cap C) = P(A) P(B) P(C). \]
Le prime tre condizioni garantiscono l’indipendenza tra ogni coppia di eventi, mentre la quarta condizione assicura che l’indipendenza sia valida anche per l’interazione simultanea dei tre eventi. È cruciale osservare che l’indipendenza a coppie non implica l’indipendenza completa: possono esistere esempi in cui le coppie sono indipendenti ma l’intersezione tripla non factorizza nel prodotto delle probabilità marginali.
In sintesi, l’indipendenza completa richiede che il verificarsi di qualsiasi sottoinsieme degli eventi non influenzi la probabilità degli altri. Questa proprietà semplifica notevolmente il calcolo delle probabilità congiunte ed è alla base di molti modelli probabilistici e statistici.
4.5 Teorema del prodotto
A partire dalla definizione di probabilità condizionata, si deriva il Teorema del Prodotto (noto anche come regola della catena o regola moltiplicativa). Questo teorema consente di esprimere la probabilità congiunta di due o più eventi come prodotto di probabilità condizionate.
4.5.1 Caso di due eventi
Per due eventi \(A\) e \(B\), il Teorema del Prodotto afferma che:
\[ P(A \cap B) = P(B) \cdot P(A \mid B) = P(A) \cdot P(B \mid A). \tag{4.4}\] In altre parole, la probabilità che \(A\) e \(B\) si verifichino simultaneamente può essere calcolata in due modi equivalenti:
- moltiplicando la probabilità di \(B\) per la probabilità di \(A\) dato \(B\);
- moltiplicando la probabilità di \(A\) per la probabilità di \(B\) dato \(A\).
La scelta dell’ordine dipende dalla disponibilità delle probabilità condizionate o dalla struttura del problema.
4.5.2 Generalizzazione a \(n\) eventi
Il teorema si estende a \(n\) eventi \(A_1, A_2, \dots, A_n\), assumendo che \(P(A_1 \cap A_2 \cap \cdots \cap A_{n-1}) > 0\). In tal caso:
\[ \begin{aligned} P(A_1 \cap A_2 \cap \cdots \cap A_n) = & \, P(A_1) \\ & \cdot P(A_2 \mid A_1) \\ & \cdot P(A_3 \mid A_1 \cap A_2) \\ & \, \vdots \\ & \cdot P(A_n \mid A_1 \cap A_2 \cap \cdots \cap A_{n-1}). \end{aligned} \tag{4.5}\] Ogni fattore rappresenta la probabilità di un evento condizionata al verificarsi di tutti gli eventi precedenti. Questa forma è particolarmente utile per modellare processi sequenziali o dipendenze condizionate.
4.5.2.1 Procedura di applicazione
- Inizia con la probabilità marginale del primo evento: \(P(A_1)\);
- Moltiplica progressivamente per le probabilità condizionate successive;
- Includi l’ultimo termine: \(P(A_n \mid A_1 \cap \cdots \cap A_{n-1})\).
In sintesi, il Teorema del Prodotto riveste un ruolo fondamentale in molteplici contesti applicativi e teorici. In particolare, esso costituisce uno strumento essenziale nella modellazione di processi stocastici sequenziali, dove consente di calcolare la probabilità congiunta di eventi concatenati esprimendola come prodotto di probabilità condizionate lungo la sequenza. Inoltre, il teorema permette la scomposizione di problemi complessi in fasi condizionate, facilitando così l’analisi di scenari multivariati attraverso un approccio graduale e gerarchico. Infine, trova un’applicazione cruciale nella costruzione di reti bayesiane e nell’inferenza probabilistica, dove viene utilizzato per rappresentare e calcolare efficientemente le dipendenze condizionali tra variabili aleatorie, fornendo una base formale per l’aggiornamento delle credenze alla luce di nuove evidenze.
4.6 Teorema della probabilità totale
Il Teorema della Probabilità Totale (noto anche come legge della probabilità totale) consente di calcolare la probabilità di un evento \(A\) scomponendolo rispetto a una partizione dello spazio campionario. Questo approccio è particolarmente utile quando si considerano scenari multipli, categorie distinte o gruppi che formano una suddivisione esaustiva di \(\Omega\).
4.6.1 Enunciato formale
Definizione 4.3 Sia \(\{B_1, B_2, \dots, B_n\}\) una partizione di \(\Omega\), cioè una collezione di eventi tali che:
- Mutua esclusività: \(B_i \cap B_j = \emptyset\) per ogni \(i \neq j\);
- Copertura completa: \(\bigcup_{i=1}^n B_i = \Omega\).
Allora, per qualsiasi evento \(A \subseteq \Omega\), vale:
\[ P(A) = \sum_{i=1}^n P(A \cap B_i) = \sum_{i=1}^n P(A \mid B_i) \cdot P(B_i). \tag{4.6}\] In pratica, \(P(A)\) è una media ponderata delle probabilità condizionate \(P(A \mid B_i)\), con pesi dati dalle probabilità \(P(B_i)\).
4.6.2 Caso particolare: partizione binaria
Quando la partizione è composta da due eventi complementari \(B\) e \(B^c\), la formula assume la forma semplificata:
\[ P(A) = P(A \mid B) \cdot P(B) + P(A \mid B^c) \cdot P(B^c). \tag{4.7}\]
4.6.3 Applicazioni
Analisi stratificata:
Utile quando la popolazione è suddivisa in sottogruppi (es. fasce d’età, regioni geografiche). La probabilità di \(A\) si calcola aggregando i contributi di ciascun gruppo.Teorema di Bayes:
Il denominatore nella formula di Bayes è un’applicazione diretta di questo teorema, dove le ipotesi \(H_1, \dots, H_n\) formano una partizione dello spazio delle ipotesi.Processi decisionali:
Consente di valutare la probabilità di un evento considerando tutti i possibili scenari o stati del mondo.
In sintesi, il teorema della probabilità totale permette di frammentare un problema complesso in componenti più gestibili, condizionate a elementi di una partizione, per poi ricombinarle in una soluzione completa.
Riflessioni conclusive
La probabilità condizionata è uno dei concetti più importanti in statistica, poiché fornisce il quadro teorico per:
- comprendere e formalizzare l’indipendenza tra eventi o variabili (assenza di ogni tipo di relazione);
- espandere e generalizzare il calcolo delle probabilità (ad esempio, la legge della probabilità totale, che scompone in modo sistematico eventi complessi);
- alimentare metodi inferenziali avanzati, come il Teorema di Bayes.
In particolare, il Teorema di Bayes rappresenta uno strumento cardine dell’inferenza statistica: grazie alla probabilità condizionata, è possibile “aggiornare” in modo continuo le credenze sulle ipotesi (o sui parametri di un modello) alla luce di nuove osservazioni. Tale caratteristica di “apprendimento” graduale rende l’inferenza bayesiana flessibile e potente, ideale per affrontare situazioni in cui vengono resi disponibili dati aggiuntivi o in cui le condizioni iniziali possono cambiare.
In definitiva, la probabilità condizionata non solo chiarisce la nozione di indipendenza e getta le fondamenta di metodi inferenziali evoluti, ma soprattutto rappresenta il “motore” di modelli che si adattano dinamicamente alle nuove informazioni. Questa prospettiva “attiva” nell’aggiornamento delle probabilità è ciò che rende l’analisi statistica uno strumento versatile per descrivere e interpretare il mondo reale.