![]()
39. Inferenza bayesiana su una media#
Esaminiamo ora in maggiore dettaglio un caso che abbiamo anticipato in precedenza, ovvero quello in cui disponiamo di un campione di dati a livello di scala a intervalli o rapporti e vogliamo fare inferenza sulla media della popolazione da cui il campione è stato estratto.
import arviz as az
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import pymc as pm
from scipy.stats import beta
from scipy.stats import norm
import statistics
import seaborn as sns
import scipy.stats as st
import warnings
warnings.filterwarnings("ignore")
warnings.simplefilter("ignore")
print(f"Running on PyMC v{pm.__version__}")
Running on PyMC v5.5.0
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
# Initialize random number generator
RANDOM_SEED = 8927
rng = np.random.default_rng(RANDOM_SEED)
plt.style.use("bmh")
plt.rcParams["figure.figsize"] = [10, 6]
plt.rcParams["figure.dpi"] = 100
plt.rcParams["figure.facecolor"] = "white"
sns.set_theme(palette="colorblind")
%load_ext autoreload
%autoreload 2
%config InlineBackend.figure_format = "svg"
39.1. Caso Normale-Normale con varianza nota#
Supponiamo che i dati \(y\) siano un campione casuale estratto da una popolazione che segue la legge Normale. Ciò significa che le osservazioni possono essere considerate come una sequenza di variabili casuali indipendenti e identicamente distribuite. Supponiamo che ciascuna v.c. segua la distribuzione Normale. Abbiamo dunque
Abbiamo visto in un capitolo precedente che, in tali circostanze, la verosimiglianza \(p(y \mid \mu, \sigma)\) è normale. Per fare inferenza sul parametro \(\mu\), assumiamo che \(\sigma\) sia noto e imponiamo una distribuzione a priori normale su \(\mu\). Questo definisce lo schema coniugato Normale-Normale. In questo caso, è possibile derivare analiticamente la distribuzione a posteriori \(p(\mu \mid y)\), ma la trattazione matematica è complessa e qui verrà solo accennata. Invece, impareremo ad applicare la soluzione ottenuta e mostreremo come fare inferenza su \(\mu\) usando i metodi MCMC.
39.2. Derivazione analitica della distribuzione a posteriori \(p(\mu \mid y)\)#
Per \(\sigma^2\) nota, la famiglia della distribuzione Normale è coniugata a sé stessa: se la funzione di verosimiglianza è Normale, la scelta di una distribuzione a priori Normale per \(\mu\) assicura che anche la distribuzione a posteriori \(p(\mu \mid y)\) sia Normale.
Poniamoci dunque il problema di trovare \(p(\mu \mid y)\) nel caso di un campione casuale \(Y_1, \dots, Y_n \stackrel{iid}{\sim} \mathcal{N}(\mu, \sigma)\), supponendo \(\sigma\) perfettamente nota e imponendo su \(\mu\) una distribuzione a priori Normale. Ricordiamo che la densità gaussiana è data da
Essendo le variabili i.i.d., possiamo scrivere la densità congiunta come il prodotto delle singole densità e quindi si ottiene
Una volta osservati i dati \(y\), la verosimiglianza diventa
Se la densità a priori \(p(\mu)\) è gaussiana, allora anche la densità a posteriori \(p(\mu \mid y)\) sarà gaussiana. Poniamo
ovvero imponiamo a \(\mu\) una distribuzione a priori gaussiana con media \(\mu_0\) e varianza \(\tau_0^2\). Ciò significa dire che, a priori, \(\mu_0\) rappresenta il valore più verosimile per \(\mu\), mentre \(\tau_0^2\) quantifica il grado della nostra incertezza rispetto a tale valore.
Svolgendo una serie di passaggi algebrici, si arriva alla distribuzione a posteriori gaussiana
dove
e
Ciò significa che, se la distribuzione a priori \(p(\mu)\) è gaussiana, allora anche la distribuzione a posteriori \(p(\mu \mid y)\) sarà gaussiana con valore atteso \(\mu_p\) e varianza \(\tau_p^2\) date dalle espressioni precedenti.
In conclusione, il risultato trovato indica che:
il valore atteso a posteriori è una media pesata fra il valore atteso a priori \(\mu_0\) e la media campionaria \(\bar{y}\); il peso della media campionaria è tanto maggiore tanto più è grande \(n\) (il numero di osservazioni) e \(\tau_0^2\) (l’incertezza iniziale);
l’incertezza (varianza) a posteriori \(\tau_p^2\) è sempre più piccola dell’incertezza a priori \(\tau_0^2\) e diminuisce al crescere di \(n\).
Per esaminare un esempio pratico, consideriamo i 30 valori BDI-II dei soggetti clinici di [ZBR19].
y = [
26.0,
35.0,
30,
25,
44,
30,
33,
43,
22,
43,
24,
19,
39,
31,
25,
28,
35,
30,
26,
31,
41,
36,
26,
35,
33,
28,
27,
34,
27,
22,
]
Supponiamo che la varianza \(\sigma^2\) della popolazione sia identica alla varianza del campione:
sigma = np.std(y)
sigma
6.495810615739622
Per fare un esempio, imponiamo su \(\mu\) una distribuzione a priori \(\mathcal{N}(25, 2)\). In tali circostanze, la distribuzione a posteriori del parametro \(\mu\) può essere determinata per via analitica e corrisponde ad una Normale di media e varianza definite dall’eq. eq-post-norm-mup e dall’eq. eq-post-norm-taup2. La figura seguente mostra un grafico della distribuzione a priori, della verosimiglianza e della distribuzione a posteriori di \(\mu\).
Iniziamo con la verosimiglianza.
def gaussian(y, m, s):
l = np.prod(norm.pdf(y, loc=m, scale=s))
return l
x_axis = np.arange(18, 38, 0.01)
s = np.std(y)
like = [gaussian(y, val, s) for val in x_axis]
l = like / np.sum(like) * 100
Usando l’eq. eq-post-norm-mup, definiamo una funzione che ritorna la media della distribuzione a posteriori di \(\mu\).
def mu_post(tau_0, mu_0, sigma, ybar, n):
return (1 / tau_0**2 * mu_0 + n / sigma**2 * ybar) / (
1 / tau_0**2 + n / sigma**2
)
Troviamo la media a posteriori.
mu_0 = 25 # media della distribuzione a priori per mu
tau_0 = 2 # sd della distribuzione a priori per mu
sigma = np.std(y) # sd del campione (assunta essere sigma)
ybar = np.mean(y) # media del campione
n = len(y)
mu_post(tau_0, mu_0, sigma, ybar, n)
29.389762700717927
Definiamo una funzione che ritorna la deviazione standard della distribuzione a posteriori di \(\mu\).
def tau_post(tau_0, sigma, n):
return np.sqrt(1 / (1 / tau_0**2 + n / sigma**2))
Troviamo la deviazione standard a posteriori.
tau_0 = 2 # sd della distribuzione a priori per mu
sigma = np.std(y) # sd del campione (assunta essere sigma)
n = len(y)
tau_post(tau_0, sigma, n)
1.0201026493673773
Possiamo ora disegnare la distribuzione a posteriori, insieme alla distribuzione a priori e alla verosimiglianza.
plt.plot(x_axis, norm.pdf(x_axis, 25, 2))
plt.plot(x_axis, l)
plt.plot(x_axis, norm.pdf(x_axis, 29.35073, 1.032919))
plt.show()

39.3. Il modello Normale con PyMC#
I priori coniugati Normali di una Normale non richiedono l’approssimazione numerica ottenuta mediante metodi MCMC. Tuttavia, per fare un esercizio e per verificare che i risultati con MCMC corrispondano a quelli trovati per via analitica, ripetiamo l’esercizio precedente usando PyMC.
39.3.1. Versione 1 (\(\sigma\) nota)#
Come in precedenza, imponiamo su \(\mu\) una distribuzione a priori \(\mathcal{N}(25, 2)\) e consideriamo noto il parametro \(\sigma = 6.606858\).
Il modello diventa il seguente.
In base al modello così definito, la variabile casuale \(Y\) seguirà la distribuzione Normale di parametri \(\mu\) e \(\sigma\). Il parametro \(\mu\) è sconosciuto e abbiamo deciso di descrivere la nostra incertezza relativa ad esso mediante una distribuzione a priori Normale di media 25 e deviazione standard 2. Il parametro \(\sigma\) è invece assunto essere noto e uguale a 6.606858.
Definiamo questo modello usando la sintassi PyMC.
gauss_model = pm.Model()
with gauss_model:
# Priors
mu = pm.Normal("mu", mu=25, sigma=2)
# Likelihood (sampling distribution) of observations
Y_obs = pm.Normal("Y_obs", mu=mu, sigma=6.606858, observed=y)
Eseguiamo il campionamento MCMC.
with gauss_model:
idata = pm.sample()
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [mu]
---------------------------------------------------------------------------
KeyboardInterrupt Traceback (most recent call last)
Cell In[13], line 2
1 with gauss_model:
----> 2 idata = pm.sample()
File ~/mambaforge/envs/pymc_env/lib/python3.11/site-packages/pymc/sampling/mcmc.py:766, in sample(draws, tune, chains, cores, random_seed, progressbar, step, nuts_sampler, initvals, init, jitter_max_retries, n_init, trace, discard_tuned_samples, compute_convergence_checks, keep_warning_stat, return_inferencedata, idata_kwargs, nuts_sampler_kwargs, callback, mp_ctx, model, **kwargs)
764 _print_step_hierarchy(step)
765 try:
--> 766 _mp_sample(**sample_args, **parallel_args)
767 except pickle.PickleError:
768 _log.warning("Could not pickle model, sampling singlethreaded.")
File ~/mambaforge/envs/pymc_env/lib/python3.11/site-packages/pymc/sampling/mcmc.py:1141, in _mp_sample(draws, tune, step, chains, cores, random_seed, start, progressbar, traces, model, callback, mp_ctx, **kwargs)
1138 # We did draws += tune in pm.sample
1139 draws -= tune
-> 1141 sampler = ps.ParallelSampler(
1142 draws=draws,
1143 tune=tune,
1144 chains=chains,
1145 cores=cores,
1146 seeds=random_seed,
1147 start_points=start,
1148 step_method=step,
1149 progressbar=progressbar,
1150 mp_ctx=mp_ctx,
1151 )
1152 try:
1153 try:
File ~/mambaforge/envs/pymc_env/lib/python3.11/site-packages/pymc/sampling/parallel.py:402, in ParallelSampler.__init__(self, draws, tune, chains, cores, seeds, start_points, step_method, progressbar, mp_ctx)
399 if mp_ctx.get_start_method() != "fork":
400 step_method_pickled = cloudpickle.dumps(step_method, protocol=-1)
--> 402 self._samplers = [
403 ProcessAdapter(
404 draws,
405 tune,
406 step_method,
407 step_method_pickled,
408 chain,
409 seed,
410 start,
411 mp_ctx,
412 )
413 for chain, seed, start in zip(range(chains), seeds, start_points)
414 ]
416 self._inactive = self._samplers.copy()
417 self._finished: List[ProcessAdapter] = []
File ~/mambaforge/envs/pymc_env/lib/python3.11/site-packages/pymc/sampling/parallel.py:403, in <listcomp>(.0)
399 if mp_ctx.get_start_method() != "fork":
400 step_method_pickled = cloudpickle.dumps(step_method, protocol=-1)
402 self._samplers = [
--> 403 ProcessAdapter(
404 draws,
405 tune,
406 step_method,
407 step_method_pickled,
408 chain,
409 seed,
410 start,
411 mp_ctx,
412 )
413 for chain, seed, start in zip(range(chains), seeds, start_points)
414 ]
416 self._inactive = self._samplers.copy()
417 self._finished: List[ProcessAdapter] = []
File ~/mambaforge/envs/pymc_env/lib/python3.11/site-packages/pymc/sampling/parallel.py:259, in ProcessAdapter.__init__(self, draws, tune, step_method, step_method_pickled, chain, seed, start, mp_ctx)
242 step_method_send = step_method
244 self._process = mp_ctx.Process(
245 daemon=True,
246 name=process_name,
(...)
257 ),
258 )
--> 259 self._process.start()
260 # Close the remote pipe, so that we get notified if the other
261 # end is closed.
262 remote_conn.close()
File ~/mambaforge/envs/pymc_env/lib/python3.11/multiprocessing/process.py:121, in BaseProcess.start(self)
118 assert not _current_process._config.get('daemon'), \
119 'daemonic processes are not allowed to have children'
120 _cleanup()
--> 121 self._popen = self._Popen(self)
122 self._sentinel = self._popen.sentinel
123 # Avoid a refcycle if the target function holds an indirect
124 # reference to the process object (see bpo-30775)
File ~/mambaforge/envs/pymc_env/lib/python3.11/multiprocessing/context.py:300, in ForkServerProcess._Popen(process_obj)
297 @staticmethod
298 def _Popen(process_obj):
299 from .popen_forkserver import Popen
--> 300 return Popen(process_obj)
File ~/mambaforge/envs/pymc_env/lib/python3.11/multiprocessing/popen_forkserver.py:35, in Popen.__init__(self, process_obj)
33 def __init__(self, process_obj):
34 self._fds = []
---> 35 super().__init__(process_obj)
File ~/mambaforge/envs/pymc_env/lib/python3.11/multiprocessing/popen_fork.py:19, in Popen.__init__(self, process_obj)
17 self.returncode = None
18 self.finalizer = None
---> 19 self._launch(process_obj)
File ~/mambaforge/envs/pymc_env/lib/python3.11/multiprocessing/popen_forkserver.py:58, in Popen._launch(self, process_obj)
55 self.finalizer = util.Finalize(self, util.close_fds,
56 (_parent_w, self.sentinel))
57 with open(w, 'wb', closefd=True) as f:
---> 58 f.write(buf.getbuffer())
59 self.pid = forkserver.read_signed(self.sentinel)
KeyboardInterrupt:
Una sintesi della distribuzione a posteriori dei parametri si ottiene nel modo seguente.
az.summary(idata, round_to=2)
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| mu | 29.36 | 1.04 | 27.41 | 31.3 | 0.03 | 0.02 | 1730.31 | 2643.65 | 1.0 |
Si noti che le stime ottenute corrispondono ai valori teorici attesi, ovvero \(\mu_p\) = 29.36 contro un valore teorico di 29.3898 e \(\tau_p\) = 1.04 contro un valore teorico di 1.0201.
Esaminiamo la traccia (cioè il vettore dei campioni del parametro \(\mu\) prodotti dalla procedura di campionamento MCMC) mediante un trace plot .
az.plot_trace(idata, combined=True)
plt.show()

Calcoliamo l’intervallo di credibilità a più alta densità a posteriori (HPD) al 95%.
az.hdi(idata, hdi_prob=0.95)
<xarray.Dataset>
Dimensions: (hdi: 2)
Coordinates:
* hdi (hdi) <U6 'lower' 'higher'
Data variables:
mu (hdi) float64 27.38 31.42Le stime così trovate sono molto simili ai quantili di ordine 0.025 e 0.975 della distribuzione a posteriori di \(\mu\) ottenuta per via analitica.
norm.ppf([0.025, 0.975], loc=29.35073, scale=1.032919)
array([27.32624596, 31.37521404])
39.3.2. Versione 2 (\(\sigma\) incognita)#
È facile estendere il caso precedente alla situazione in cui il parametro \(\sigma\) è incognito. Se non conosciamo \(\sigma\), è necessario imporre su tale parametro una distribuzione a priori. Supponiamo di ipotizzare per \(\sigma\) una distribuzione a priori \(Cauchy(0, 15)\).
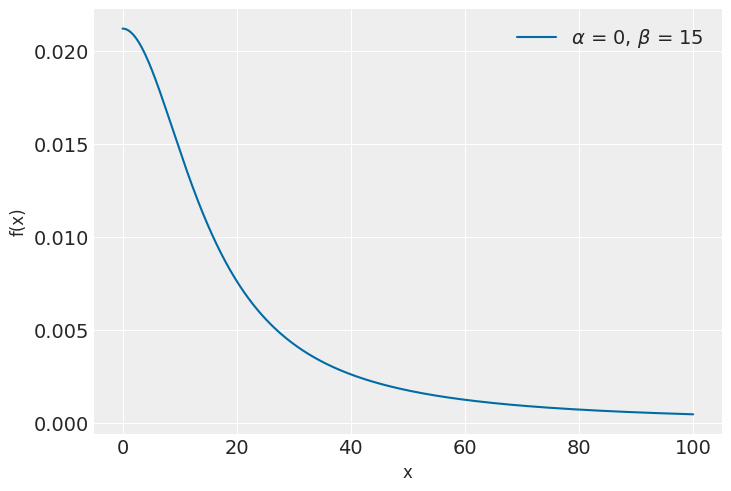
Mediante una Cauchy(0, 15) descriviamo il grado di credibilità soggettiva che attribuiamo ai possibili valori (> 0) del parametro \(\sigma\). Ai valori prossimi allo 0 attribuiamo la credibilità maggiore; la credibilità dei valori \(\sigma > 0\) diminuisce progressivamente quando ci si allontana dallo 0, come indicato dalla curva della figura seguente. Riteniamo poco credibili i valori \(\sigma\) maggiori di 40, anche se non escludiamo completamente che \(\sigma\) possa assumere un valore in questo intervallo.
La Cauchy(0, 15) è rappresentata nella figura seguente.
x = np.linspace(0, 100, 500)
alpha = 0
beta = 15
pdf = st.cauchy.pdf(x, loc=alpha, scale=beta)
plt.plot(x, pdf, label=r"$\alpha$ = {}, $\beta$ = {}".format(alpha, beta))
plt.xlabel("x", fontsize=12)
plt.ylabel("f(x)", fontsize=12)
plt.legend(loc=1)
plt.show()
In questo secondo caso, più realistico, il modello diventa il seguente.
Il modello precedente è simile a quello esaminato in precedenza, eccetto che abbiamo quantificato la nostra incertezza relativa a \(\sigma\) (che è ignota) mediante una distribuzione a priori Cauchy(0, 15).
Il campionamento MCMC utilizzato di default da PyMC è basata sull’algoritmo NUTS che è una variante del metodo Hybrid/Hamiltonian Monte Carlo. Tale algoritmo ha il vantaggio di massimizzare l’accettanza e di non richiedere l’uso di distribuzioni a priori coniugate. Pertanto è possibile scegliere per i parametri una qualunque distribuzione a priori. Nel caso presente, sul parametro \(\sigma\) abbiamo imposto una Cauchy(0, 15). Per un tale caso non è possibile ottenere la derivazione analitica della distribuzione a posteriori di \(\mu\). È dunque necessario procedere con il campionamento MCMC.
Scriviamo il modello in PyMC.
gauss2_model = pm.Model()
with gauss2_model:
# Priors
mu = pm.Normal("mu", mu=25, sigma=2)
sigma = pm.Cauchy("sigma", alpha=0, beta=15)
# Likelihood (sampling distribution) of observations
Y_obs = pm.Normal("Y_obs", mu=mu, sigma=sigma, observed=y)
Eseguiamo il campionamento.
with gauss2_model:
idata = pm.sample()
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [mu, sigma]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 18 seconds.
Una sintesi della distribuzione a posteriori dei parametri si ottiene nel modo seguente.
az.summary(idata, round_to=2)
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| mu | 29.21 | 1.17 | 27.06 | 31.40 | 0.03 | 0.02 | 2044.34 | 2356.70 | 1.0 |
| sigma | 7.06 | 1.01 | 5.31 | 8.96 | 0.02 | 0.02 | 2397.96 | 2083.34 | 1.0 |
Troviamo l’intervallo di credibilità a più alta densità a posteriori (HPD) al 95%.
az.hdi(idata, hdi_prob=0.95)
<xarray.Dataset>
Dimensions: (hdi: 2)
Coordinates:
* hdi (hdi) <U6 'lower' 'higher'
Data variables:
mu (hdi) float64 26.87 31.4
sigma (hdi) float64 5.291 9.108Esaminiamo la traccia con un trace plot .
az.plot_trace(idata, combined=True)
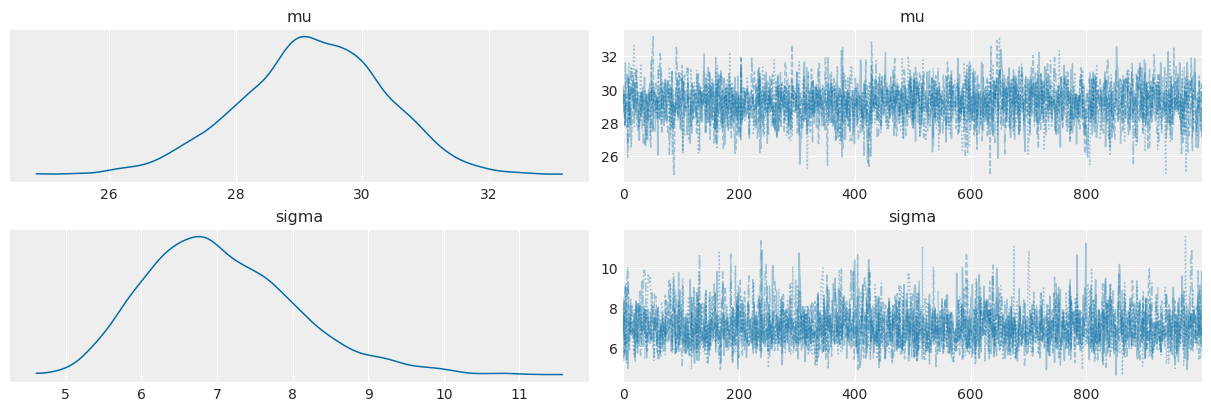
Considerati i dati osservati e le nostre ipotesi a priori sui parametri, possiamo concludere, con un grado di certezza soggettiva del 95%, che la media della popolazione dei punteggi BDI-II dei pazienti clinici depressi è compresa nell’intervallo [27.04, 31.33].
39.4. Commenti e considerazioni finali#
In questo capitolo abbiamo visto come calcolare l’intervallo di credibilità per la media di una v.c. Normale. La domanda più ovvia di analisi dei dati, dopo avere visto come trovare l’intervallo di credibilità per la media di un solo gruppo, riguarda il confronto tra le medie di due gruppi. Questo sarà l’argomento discusso nei prossimi capitoli.
39.5. Watermark#
%load_ext watermark
%watermark -n -u -v -iv -w -p pytensor
Last updated: Mon Dec 26 2022
Python implementation: CPython
Python version : 3.8.15
IPython version : 8.7.0
pytensor: 2.8.10
sys : 3.8.15 (default, Nov 24 2022, 09:04:07)
[Clang 14.0.6 ]
scipy : 1.9.3
pymc : 5.0.0
numpy : 1.24.0
matplotlib: 3.6.2
arviz : 0.14.0
pandas : 1.5.2
Watermark: 2.3.1