![]()
37. La predizione bayesiana#
import arviz as az
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import scipy as sc
import statistics
import seaborn as sns
from scipy.stats import betabinom, beta, binom
import pymc as pm
import xarray as xr
import warnings
warnings.filterwarnings("ignore")
warnings.simplefilter("ignore")
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
# Initialize random number generator
RANDOM_SEED = 8927
rng = np.random.default_rng(RANDOM_SEED)
plt.style.use("bmh")
plt.rcParams["figure.figsize"] = [10, 6]
plt.rcParams["figure.dpi"] = 100
plt.rcParams["figure.facecolor"] = "white"
sns.set_theme(palette="colorblind")
%load_ext autoreload
%autoreload 2
%config InlineBackend.figure_format = "svg"
L’analisi bayesiana si pone diversi obiettivi, tra cui la sintesi della distribuzione a posteriori dei parametri, la verifica di ipotesi e la predizione di nuovi dati futuri. Dopo aver osservato i dati di un campione e aver ottenuto le distribuzioni a posteriori dei parametri, è possibile fare delle previsioni sulle proprietà di dati futuri. Una delle applicazioni più immediate di questa stima è la verifica del modello, poiché il modo più diretto per testare un modello è quello di utilizzare il modello corrente per fare previsioni sui possibili dati futuri e poi confrontare questi dati predetti con i dati effettivamente osservati nel campione corrente. Questo processo è chiamato controllo predittivo a posteriori.
In questo capitolo ci concentreremo sul problema della predizione bayesiana, partendo dal caso più semplice, ovvero lo schema beta-binomiale, per poi estendere la discussione al caso generale. In sostanza, l’obiettivo è di utilizzare l’informazione a priori e a posteriori sui parametri del modello per fare previsioni sulle proprietà dei dati futuri, fornendo così un metodo utile per la verifica del modello e per il supporto alle decisioni.
37.1. La distribuzione predittiva a posteriori#
Dopo aver costruito la distribuzione a posteriori dei parametri sconosciuti, un’analisi inferenziale bayesiana può essere utilizzata per fare previsioni sui possibili risultati futuri, dando origine all’analisi predittiva. Nel caso specifico del modello beta-binomiale, la distribuzione a priori del parametro \(\theta\) (probabilità di successo) è una distribuzione Beta, la verosimiglianza è binomiale e i dati consistono nel numero \(y\) di successi in \(n\) prove Bernoulliane indipendenti.
Nell’esempio che andremo a esaminare, utilizzeremo ancora i dati del campione di pazienti clinici depressi di Zetsche et al. [ZBR19]. Immaginiamo di voler esaminare in futuro un altro gruppo di \(m\) pazienti clinici e ci chiediamo quanti di essi potrebbero manifestare una depressione grave. Supponiamo di voler fare previsioni sui risultati di nuovi campioni di \(m=30\) osservazioni. Indichiamo con \(\tilde{Y}\) la variabile casuale che rappresenta il numero di pazienti con depressione grave in un nuovo campione di \(m\) pazienti clinici. Quindi, in un nuovo campione, \(\tilde{Y}\) potrebbe assumere un valore \(\tilde{y}_1\) (ad esempio 12), un altro campione potrebbe produrre un valore \(\tilde{y}_2\) (ad esempio 23) e così via. Vogliamo calcolare le probabilità di osservare ciascuno dei valori \(\tilde{Y}\) compresi tra \(0\) e \(30\) inclusi. Questa distribuzione di massa di probabilità è chiamata distribuzione predittiva a posteriori, \(p(\tilde{Y} = \tilde{y} \mid Y = y)\). Essa rappresenta la probabilità assegnata a ciascuno dei possibili valori \(\tilde{Y}\) (\(0, 1, 2, \dots, 29, 30\)) nei possibili campioni futuri di \(m\) pazienti clinici.
In questo capitolo ci concentreremo sull’individuazione della distribuzione predittiva a posteriori nel contesto del modello beta-binomiale. Esploreremo tre diverse metodologie per raggiungere questo obiettivo:
L’approccio analitico, che prevede la risoluzione della distribuzione in modo matematico.
L’utilizzo della simulazione.
L’impiego della tecnica del campionamento MCMC per stimare la distribuzione predittiva a posteriori.
I tre metodi sono equivalenti e producono gli stessi risultati. Tuttavia, in seguito utilizzeremo il metodo MCMC perché ci permette di ottenere la soluzione desiderata in modo semplice, anche quando non è disponibile una soluzione analitica.
37.2. Soluzione analitica#
Nel caso dell’esempio in discussione, la distribuzione di \(\tilde{Y}\) dipende da \(\theta\) e ciò che sappiamo di \(\theta\) è sintetizzato nella distribuzione a posteriori \(p(\theta \mid y)\). Usando la regola della catena, possiamo scrivere la distribuzione congiunta di \(\tilde{y}\) e \(\theta\) nel modo seguente
Assumendo che le osservazioni future \(\tilde{y}\) e passate \(y\) siano condizionalmente indipendenti dato \(\theta\), l’espressione precedente può essere scritta come
La distribuzione predittiva a posteriori viene ottenuta dalla distribuzione congiunta di \(\tilde{y}\) e \(\theta\) integrando rispetto a \(\theta\):
Nel caso dello schema beta-binomiale, la funzione \(p(\tilde{y} \mid \theta)\) è binomiale di parametri \(m\) e \(\theta\), e la distribuzione a posteriori \(p(\theta \mid y)\) è una \(Beta(\alpha + y, \beta + n - y)\). Risolvendo l’integrale otteniamo:
In conclusione, per lo schema beta-binomiale, la distribuzione predittiva a posteriori corrisponde ad una distribuzione di probabilità discreta chiamata distribuzione beta-binomiale di parametri \(m\), \(\alpha+y\) e \(\beta+n-y\).
Nell’esempio relativo allo studio di Zetsche et al. [ZBR19], la verosimiglianza è binomiale, i dati sono costituiti da 23 successi su 30 prove e la distribuzione a priori su \(\theta\) è una Beta(2, 10). Di conseguenza, la distribuzione a posteriori è una Beta(25, 17). Vogliamo calcolare la distribuzione predittiva a posteriori per un nuovo campione, poniamo, di \(m = 30\) osservazioni (ma, in generale, \(m\) può essere diverso da \(n\)).
In base all’eq. (37.3) sappiamo che la distribuzione predittiva a posteriori è una distribuzione beta-binomiale di parametri \(m\), \(\alpha+y\) e \(\beta+n-y\), dove \(m\) è il numero di prove nel nuovo campione, \(\alpha\) e \(\beta\) sono i parametri della distribuzione a priori, e \(y\) e \(n\) sono le proprietà del campione corrente. Nel caso dell’esempio in discussione, \(m = 30\), \(\alpha = 2 + 23 = 25\), \(\beta = 10 + 30 - 23 = 17\).
Utilizziamo Python per rappresentare la distribuzione predittiva a posteriori che abbiamo definito mediante la funzione betabinom.pmf.
n = 30
a = 25
b = 17
x = np.arange(0, 30)
plt.plot(x, betabinom.pmf(x, n, a, b), "bo", ms=8, label="betabinom pmf")
_ = plt.vlines(x, 0, betabinom.pmf(x, n, a, b), colors="b", lw=5, alpha=0.5)

La distribuzione predittiva a posteriori illustrata nella figura precedente ci dice qual è la credibilità relativa di osservare \(0, 1, \dots, 30\) successi su \(m = 30\) prove in un futuro campione di osservazioni, alla luce dei dati che abbiamo osservato nel campione corrente (23 successi in 30 prove) e tenuto conto delle nostre opinioni a priori sulla plausibilità dei possibili valori \(\theta\) (ovvero, Beta(2, 10)).
Esaminando la distribuzione predittiva notiamo che, nei possibili campioni futuri di 30 osservazioni, il valore \(\tilde{y}\) più plausibile è 18. Tuttavia, \(\tilde{y}\) può assumere anche altri valori e la distribuzione predittiva ci informa sulla credibilità relativa di ciascuno dei possibili valori futuri \(\tilde{y}\) – nel presente esempio, \(\tilde{y}\) corrisponde al numero di pazienti clinici (su 30) che manifestano una depressione grave.
È desiderabile costruire un intervallo che contiene le realizzazioni \(\tilde{y}\) ad un livello specificato di probabilità. Supponiamo che il livello di probabilità richiesto sia 0.89. L’intervallo si costruisce aggiungendo valori \(\tilde{y}\) all’intervallo (partendo da quello con la probabilità maggiore) fino a che il contenuto di probabilità dell’insieme eccede la soglia richiesta, nel caso presente di 0.89.
Sulla base delle informazioni disponibili, possiamo dunque prevedere, con un livello di certezza soggettiva che eccede la soglia di 0.91, che in un futuro campione di 30 soggetti clinici depressi, il numero di pazienti con depressione grave sarà compreso tra 12 e 23.
x_set = np.arange(12, 24)
betabinom.pmf(x_set, n, a, b).sum()
0.9152884954868495
In conclusione, per il caso beta-binomiale, possiamo concludere che la predizione bayesiana di una nuova osservazione futura è la realizzazione di una distribuzione beta-binomiale di parametri \(m\), \(\alpha + y\), e \(\beta + n - y\), dove \(m\) è il numero di prove nel nuovo campione, \(\alpha\) e \(\beta\) sono i parametri della distribuzione a priori, e \(y\) e \(n\) sono le caratteristiche del campione.
37.3. La distribuzione predittiva a posteriori mediante simulazione#
In situazioni in cui non è possibile ottenere l’esatta distribuzione predittiva a posteriori, è comunque possibile ottenere un campione casuale di valori dalla distribuzione mediante simulazione. Nel caso che stiamo discutendo, supponiamo di volere ottenere un campione casuale di \(n\) osservazioni dalla distribuzione predittiva a posteriori. Per fare ciò, possiamo svolgere la simulazione in due fasi:
estraiamo \(n\) valori casuali del parametro \(\theta\) dalla distribuzione a posteriori \(p(\theta \mid y)\);
usiamo i valori del parametro \(\theta\) estratti per generare \(n\) valori casuali \(\tilde{y}\), utilizzando il modello binomiale con i parametri \(m\) e \(\theta_i\) (con \(i = 1, \dots, n\)).
In questo modo otteniamo \(n\) realizzazioni casuali di \(n\) distribuzioni binomiali, ciascuna con i parametri specificati sopra, che rappresentano un campione casuale di valori della distribuzione predittiva a posteriori.
Vediamo come questo risultato possa essere ottenuto in pratica. Per l’esempio che stiamo discutendo, la distribuzione a posteriori di \(\theta\) è una Beta(25, 17). Estraiamo 100,000 valori a caso da tale distribuzione e ne stampiamo i primi 10:
nrep = 100000
theta = beta.rvs(a, b, size=nrep)
print(*theta[0:10])
0.6208447755308778 0.5495287577513954 0.6502923899391857 0.5879026411368966 0.5090012336446235 0.5629230408323764 0.49387622962585737 0.6466416524065831 0.45972709662809796 0.5935627687211145
Per ciascuno di questi 100,000 valori \(\theta\) estraggo a caso un valore dalla distribuzione binomiale di parametri \(n = 30\) e probabilità \(\theta\). Stampo qui di seguito i primi 10 valori così trovati.
pred_y_sim = [binom.rvs(n=30, p=th, size=1) for th in theta]
pred_y_sim = np.concatenate(pred_y_sim)
print(*pred_y_sim[0:10])
18 19 21 21 14 17 16 16 17 17
L’insieme dei valori pred_y_sim costituisce un campione casuale dalla distribuzione predittiva a posteriori. Qui di seguito è mostrata una figura che riporta i risultati della simulazione (l’istogramma dei valori pred_y_sim). All’istogramma sono sovrapposti i punti della corretta distribuzione a posteriori corrispondente ad una distribuzione Beta-Binomiale di parametri n = 30, a = 25, b = 17. Si noti la corrispondenza tra i valori ottenuti mediante la simulazione e i valori teorici.
counts = plt.hist(pred_y_sim, bins=np.arange(0, 31), density=True)
_ = plt.plot(x, betabinom.pmf(x, n, a, b), "bx", ms=4, label="betabinom pmf")

37.4. La distribuzione predittiva a posteriori mediante MCMC#
Il metodo basato su simulazione che abbiamo discusso sopra si basa sulla stessa logica che i metodi MCMC usano per ottenere un’approssimazione della distribuzione predittiva a posteriori. Mediante i metodi MCMC, le stime delle possibili osservazioni future \(p(\tilde{y} \mid y)\), chiamate \(p(y^{rep} \mid y)\), si ottengono nel modo seguente:
campionare \(\theta_i \sim p(\theta \mid y)\), ovvero scegliere un valore a caso del parametro dalla distribuzione a posteriori;
campionare \(y^{rep} \sim p(y^{rep} \mid \theta_i)\), ovvero scegliere un’osservazione a caso dalla funzione di verosimiglianza condizionata al valore del parametro definito nel passo precedente.
Se i due passaggi descritti sopra vengono ripetuti un numero sufficiente di volte, l’istogramma risultante approssimerà la distribuzione predittiva a posteriori che, in alcuni casi, può essere ottenuta per via analitica (come nell’esempio presente).
Eseguiamo il campionamento MCMC per i dati dell’esempio.
ntrials = 30
y = 23
alpha_prior = 2
beta_prior = 10
with pm.Model() as model:
theta = pm.Beta("theta", alpha=alpha_prior, beta=beta_prior)
obs = pm.Binomial("obs", p=theta, n=ntrials, observed=y)
idata = pm.sample(2000)
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [theta]
---------------------------------------------------------------------------
KeyboardInterrupt Traceback (most recent call last)
Cell In[8], line 10
8 theta = pm.Beta("theta", alpha=alpha_prior, beta=beta_prior)
9 obs = pm.Binomial("obs", p=theta, n=ntrials, observed=y)
---> 10 idata = pm.sample(2000)
File ~/mambaforge/envs/pymc_env/lib/python3.11/site-packages/pymc/sampling/mcmc.py:766, in sample(draws, tune, chains, cores, random_seed, progressbar, step, nuts_sampler, initvals, init, jitter_max_retries, n_init, trace, discard_tuned_samples, compute_convergence_checks, keep_warning_stat, return_inferencedata, idata_kwargs, nuts_sampler_kwargs, callback, mp_ctx, model, **kwargs)
764 _print_step_hierarchy(step)
765 try:
--> 766 _mp_sample(**sample_args, **parallel_args)
767 except pickle.PickleError:
768 _log.warning("Could not pickle model, sampling singlethreaded.")
File ~/mambaforge/envs/pymc_env/lib/python3.11/site-packages/pymc/sampling/mcmc.py:1141, in _mp_sample(draws, tune, step, chains, cores, random_seed, start, progressbar, traces, model, callback, mp_ctx, **kwargs)
1138 # We did draws += tune in pm.sample
1139 draws -= tune
-> 1141 sampler = ps.ParallelSampler(
1142 draws=draws,
1143 tune=tune,
1144 chains=chains,
1145 cores=cores,
1146 seeds=random_seed,
1147 start_points=start,
1148 step_method=step,
1149 progressbar=progressbar,
1150 mp_ctx=mp_ctx,
1151 )
1152 try:
1153 try:
File ~/mambaforge/envs/pymc_env/lib/python3.11/site-packages/pymc/sampling/parallel.py:402, in ParallelSampler.__init__(self, draws, tune, chains, cores, seeds, start_points, step_method, progressbar, mp_ctx)
399 if mp_ctx.get_start_method() != "fork":
400 step_method_pickled = cloudpickle.dumps(step_method, protocol=-1)
--> 402 self._samplers = [
403 ProcessAdapter(
404 draws,
405 tune,
406 step_method,
407 step_method_pickled,
408 chain,
409 seed,
410 start,
411 mp_ctx,
412 )
413 for chain, seed, start in zip(range(chains), seeds, start_points)
414 ]
416 self._inactive = self._samplers.copy()
417 self._finished: List[ProcessAdapter] = []
File ~/mambaforge/envs/pymc_env/lib/python3.11/site-packages/pymc/sampling/parallel.py:403, in <listcomp>(.0)
399 if mp_ctx.get_start_method() != "fork":
400 step_method_pickled = cloudpickle.dumps(step_method, protocol=-1)
402 self._samplers = [
--> 403 ProcessAdapter(
404 draws,
405 tune,
406 step_method,
407 step_method_pickled,
408 chain,
409 seed,
410 start,
411 mp_ctx,
412 )
413 for chain, seed, start in zip(range(chains), seeds, start_points)
414 ]
416 self._inactive = self._samplers.copy()
417 self._finished: List[ProcessAdapter] = []
File ~/mambaforge/envs/pymc_env/lib/python3.11/site-packages/pymc/sampling/parallel.py:259, in ProcessAdapter.__init__(self, draws, tune, step_method, step_method_pickled, chain, seed, start, mp_ctx)
242 step_method_send = step_method
244 self._process = mp_ctx.Process(
245 daemon=True,
246 name=process_name,
(...)
257 ),
258 )
--> 259 self._process.start()
260 # Close the remote pipe, so that we get notified if the other
261 # end is closed.
262 remote_conn.close()
File ~/mambaforge/envs/pymc_env/lib/python3.11/multiprocessing/process.py:121, in BaseProcess.start(self)
118 assert not _current_process._config.get('daemon'), \
119 'daemonic processes are not allowed to have children'
120 _cleanup()
--> 121 self._popen = self._Popen(self)
122 self._sentinel = self._popen.sentinel
123 # Avoid a refcycle if the target function holds an indirect
124 # reference to the process object (see bpo-30775)
File ~/mambaforge/envs/pymc_env/lib/python3.11/multiprocessing/context.py:300, in ForkServerProcess._Popen(process_obj)
297 @staticmethod
298 def _Popen(process_obj):
299 from .popen_forkserver import Popen
--> 300 return Popen(process_obj)
File ~/mambaforge/envs/pymc_env/lib/python3.11/multiprocessing/popen_forkserver.py:35, in Popen.__init__(self, process_obj)
33 def __init__(self, process_obj):
34 self._fds = []
---> 35 super().__init__(process_obj)
File ~/mambaforge/envs/pymc_env/lib/python3.11/multiprocessing/popen_fork.py:19, in Popen.__init__(self, process_obj)
17 self.returncode = None
18 self.finalizer = None
---> 19 self._launch(process_obj)
File ~/mambaforge/envs/pymc_env/lib/python3.11/multiprocessing/popen_forkserver.py:58, in Popen._launch(self, process_obj)
55 self.finalizer = util.Finalize(self, util.close_fds,
56 (_parent_w, self.sentinel))
57 with open(w, 'wb', closefd=True) as f:
---> 58 f.write(buf.getbuffer())
59 self.pid = forkserver.read_signed(self.sentinel)
KeyboardInterrupt:
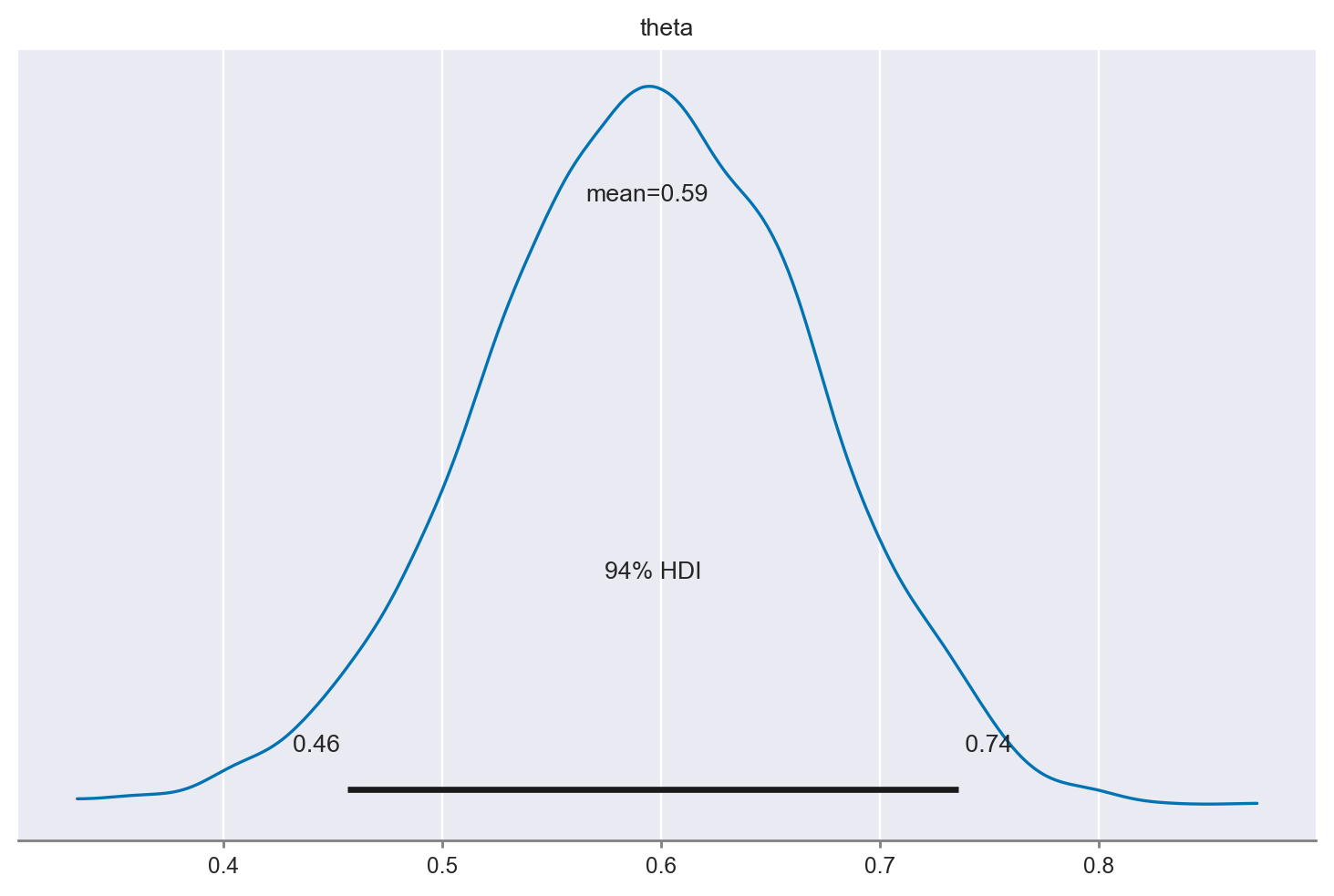
Esaminiamo la distribuzione a posteriori.
_ = az.plot_posterior(idata.posterior.theta)
Creiamo un campione di osservazioni predittive a posteriori, \(y^{rep} \sim p(y^{rep} \mid \theta_i)\).
with model:
post_pred = pm.sample_posterior_predictive(idata)
Sampling: [obs]
Esaminiamo i dati ottenuti.
post_pred.posterior_predictive.obs
<xarray.DataArray 'obs' (chain: 4, draw: 2000)>
array([[12, 21, 13, ..., 11, 15, 17],
[24, 21, 17, ..., 17, 19, 15],
[22, 20, 18, ..., 21, 15, 20],
[12, 16, 12, ..., 21, 16, 21]])
Coordinates:
* chain (chain) int64 0 1 2 3
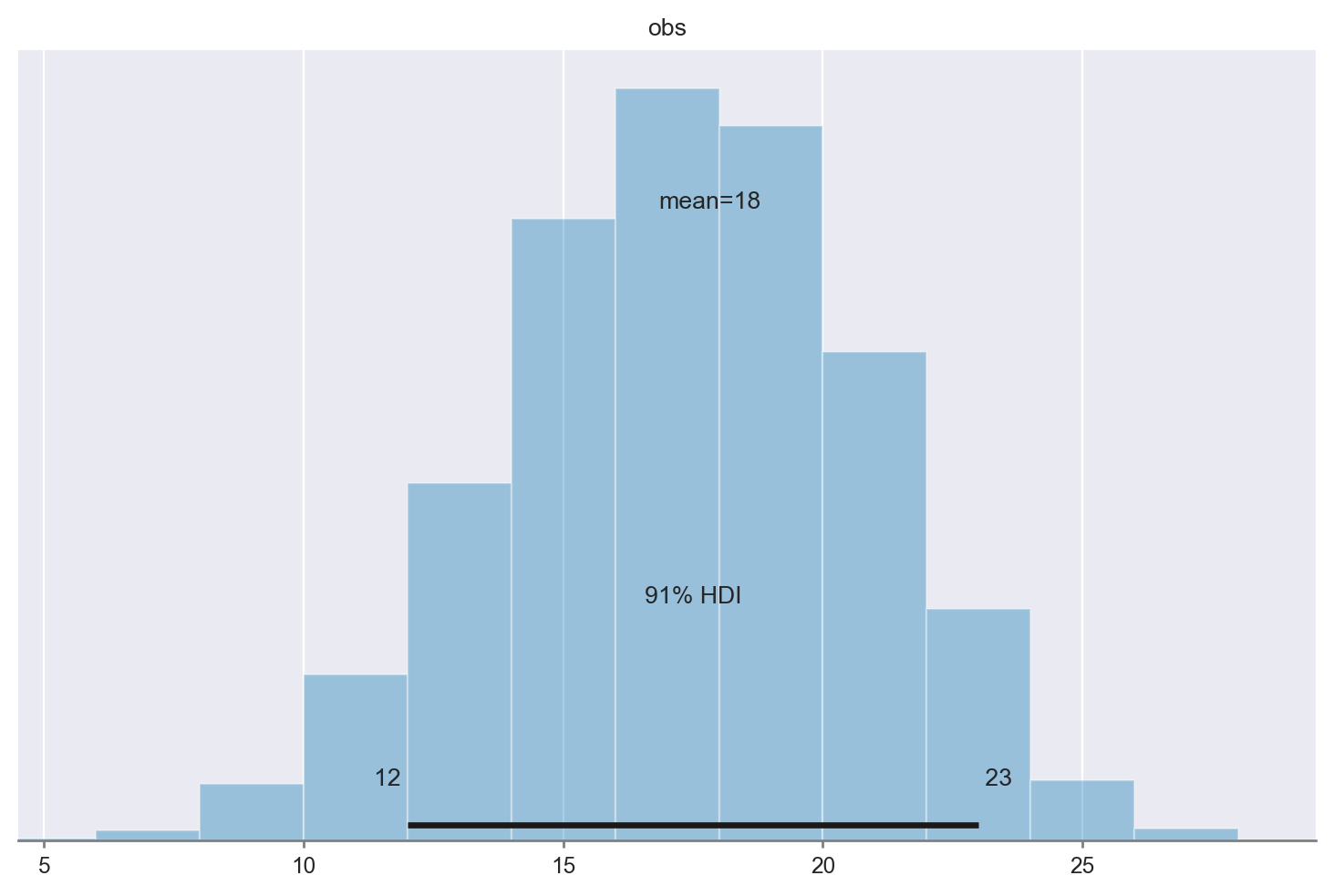
* draw (draw) int64 0 1 2 3 4 5 6 7 ... 1993 1994 1995 1996 1997 1998 1999Creiamo un istogramma con i dati \(y^{rep}\). Si noti che il risultato riproduce ciò che abbiamo ottenuto in precedenza per via analitica e tramite simulazione. L’intervallo di credibilità del 91% è, anche in questo caso, pari a [12, 23].
az.plot_posterior(post_pred.posterior_predictive.obs, hdi_prob=0.91)
<Axes: title={'center': 'obs'}>
37.4.1. Posterior predictive checks#
La distribuzione predittiva a posteriori viene utilizzata per eseguire i cosiddetti controlli predittivi a posteriori (Posterior Predictive Checks, PPC). I PPC eseguono un confronto grafico tra \(p(y^{rep} \mid y)\) e i dati osservati \(y\): confrontando visivamente gli aspetti chiave dei dati previsti futuri \(y^{rep}\) e dei dati osservati \(y\) è possibile determinare se il modello è adeguato.
Oltre al confronto visivo tra le distribuzioni \(p(y)\) e \(p(y^{rep})\) è anche possibile un confronto tra la distribuzione di varie statistiche descrittive, i cui valori sono calcolati su diversi campioni \(y^{rep}\), e le corrispondenti statistiche calcolate sui dati osservati. Vengono solitamente considerate statistiche descrittive quali la media, la varianza, la deviazione standard, il minimo o il massimo, ma sono possibili confronti di questo tipo per qualunque altra statistica.
37.5. Distribuzione predittiva a priori#
Nella sezione precedente abbiamo visto come la distribuzione predittiva viene usata per generare nuovi dati previsti futuri. Più precisamente, mediante l’eq. (37.1) abbiamo descritto la nostra incertezza sulla distribuzione di future osservazioni di dati, data la distribuzione a posteriori di \(\theta\), ovvero tenendo conto della scelta del modello e della stima dei parametri mediante i dati osservati:
Si noti che, nell’eq. (37.1), \(\tilde{y}\) è condizionato da \(y\) ma non da ciò che è incognito, ovvero \(\theta\): la distribuzione predittiva a posteriori è ottenuta mediante marginalizzazione sopra i parametri incogniti \(\theta\).
In un modello bayesiano dove \(\theta\) ha una distribuzione a priori \(p(\theta)\) e per \(y\) possiamo definire la funzione di verosimiglianza \(p(y \mid \theta)\), è possibile scrivere la distribuzione congiunta \(p(y, \theta)\) come il prodotto della verosimiglianza e della distribuzione a priori:
Una rappresentazione alternativa della distribuzione congiunta \(p(y, \theta)\) è
Il primo termine in questo prodotto, la densità \(p(\theta \mid y)\), è la densità a posteriori di \(\theta\) date le osservazioni \(y\). Il secondo termine in questo prodotto, \(p(y)\), è la distribuzione predittiva a priori che rappresenta la distribuzione dei dati futuri previsti dal modello prima di avere osservato il campione \(y\). Se risulta che i dati osservati \(y\) non sono coerenti con la distribuzione predittiva a priori, ciò significa che il modello bayesiano non è specificato correttamente. In altre parole, questo ci dice che, in base al modello bayesiano che abbiamo formulato, è improbabile che si verifichino i dati che sono stati effettivamente osservati. Ovviamente, questo vuol dire che il modello è inadeguato.
La distribuzione predittiva a priori può essere ricavata facilmente se l’inferenza bayesiana viene svolta mediante i metodi MCMC e viene usata per verificare l’adeguatezza della formulazione del modello.
Nella discussione dell’analisi dei dati di [ZBR19], la \(Beta(2, 10)\) è stata utilizzata quale distribuzione a priori solo per evidenziare le proprietà dell’aggiornamento bayesiano (ovvero, la differenza tra distribuzione a priori e distribuzione a posteriori). Calcolando la distribuzione predittiva a priori è facile rendersi conto che la \(Beta(2, 10)\) non è una buona scelta per i dati considerati.
Per svolgere l’analisi predittiva a priori, usiamo la funzione pm.sample_prior_predictive().
ntrials = 16
y = 14
alpha_prior = 2
beta_prior = 10
with pm.Model() as model:
theta = pm.Beta("theta", alpha=alpha_prior, beta=beta_prior)
obs = pm.Binomial("obs", p=theta, n=ntrials, observed=y)
idata = pm.sample_prior_predictive(samples=2000, random_seed=rng)
Sampling: [obs, theta]
idata
-
<xarray.Dataset> Dimensions: (chain: 1, draw: 2000) Coordinates: * chain (chain) int64 0 * draw (draw) int64 0 1 2 3 4 5 6 7 ... 1993 1994 1995 1996 1997 1998 1999 Data variables: theta (chain, draw) float64 0.3556 0.07959 0.04808 ... 0.3395 0.1366 Attributes: created_at: 2023-05-06T06:23:43.774396 arviz_version: 0.15.1 inference_library: pymc inference_library_version: 5.3.0 -
<xarray.Dataset> Dimensions: (chain: 1, draw: 2000) Coordinates: * chain (chain) int64 0 * draw (draw) int64 0 1 2 3 4 5 6 7 ... 1993 1994 1995 1996 1997 1998 1999 Data variables: obs (chain, draw) int64 5 3 1 4 2 4 0 1 0 4 1 ... 5 7 1 1 5 5 0 0 2 6 1 Attributes: created_at: 2023-05-06T06:23:43.776375 arviz_version: 0.15.1 inference_library: pymc inference_library_version: 5.3.0 -
<xarray.Dataset> Dimensions: (obs_dim_0: 1) Coordinates: * obs_dim_0 (obs_dim_0) int64 0 Data variables: obs (obs_dim_0) int64 14 Attributes: created_at: 2023-05-06T06:23:43.777234 arviz_version: 0.15.1 inference_library: pymc inference_library_version: 5.3.0
I dati (sulla scala delle osservazioni \(y\)) sono contenuti in idata.prior_predictive.obs. Uso arviz per generare un istogramma:
az.plot_posterior(idata.prior_predictive.obs)
<Axes: title={'center': 'obs'}>
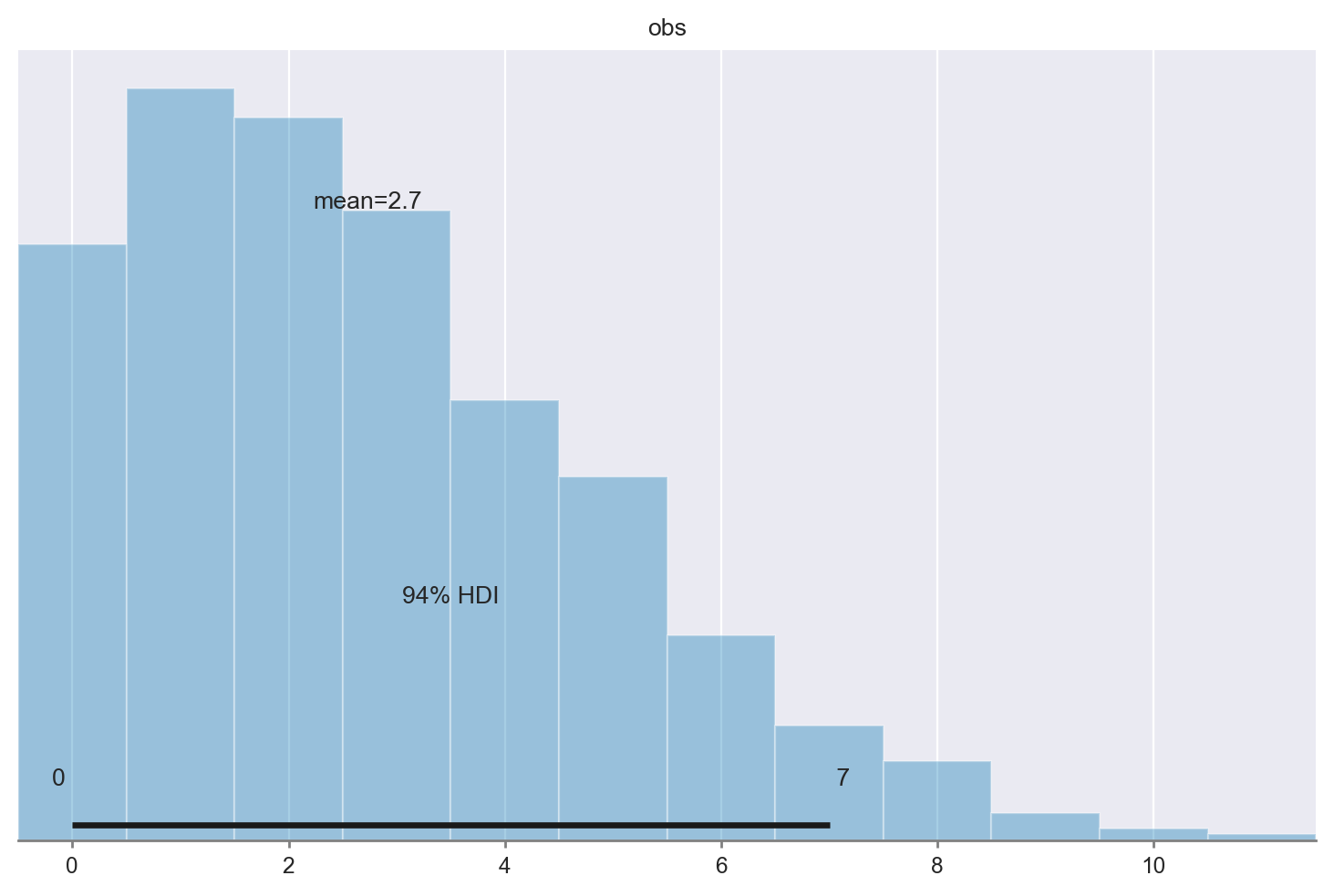
La regione HDI al 94% è [0, 6]. Ma noi abbiamo osservato \(y\) = 23. Questo ci dice che Beta(2, 10) non è una distribuzione a priori adeguata per i nostri dati.
37.6. Watermark#
%load_ext watermark
%watermark -n -u -v -iv -w
Last updated: Sat May 06 2023
Python implementation: CPython
Python version : 3.11.3
IPython version : 8.13.2
pymc : 5.3.0
numpy : 1.23.5
seaborn : 0.12.2
scipy : 1.10.1
xarray : 2023.4.2
matplotlib: 3.7.1
pandas : 1.5.3
arviz : 0.15.1
Watermark: 2.3.1