![]()
25. Generazione di numeri casuali#
In questo insegnamento introdurremo molti concetti tramite la simulazione. Pertanto deve essere ben chiaro come sia possibile generare numeri casuali da varie distribuzioni di probabilità. In questo capitolo esamineremo NumPy dato che questo modulo offre generatori di numeri casuali per tutte le principali distribuzioni di probabilità.
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
import seaborn as sns
import arviz as az
from scipy.constants import golden
import scipy.stats as st
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
# Initialize random number generator
RANDOM_SEED = 8927
rng = np.random.default_rng(RANDOM_SEED)
sns.set(color_codes=True)
az.style.use("arviz-darkgrid")
sns.set_theme(
context="paper",
palette="colorblind",
)
Tutto ciò che succede sul nostro computer è generato da un algoritmo. L’algoritmo che genera i numeri “casuali” su computer è necessariamente deterministico. Questo diventa chiaro quando notiamo che otteniamo sempre lo stesso insieme di numeri casuali quando usiamo lo stesso seme (punto di partenza), su qualsiasi macchina o per diverse ripetizioni sulla stessa macchina. Per generare un numero veramente casuale sui nostri computer è necessario ottenere dei dati casuali da una fonte esterna; questa fonte esterna può essere la nostra sequenza di tasti, i movimenti del mouse, i dati sulla rete, ecc. La necessità di ottenere dei numeri veramente casuali nasce solo in contesti specifici, per esempio nei contesti legati alla sicurezza (crittografia, ecc.). Per gli scopi della data science, invece, sono sufficienti i numeri pseudo-casuali generati dal computer. In Python, il principale generatore di numeri (pseudo)casuali è NumPy.
Il generatore rng può usare una serie di metodi per generare numeri casuali estratti da una varietà di distribuzioni di probabilità. Oltre agli argomenti specifici della distribuzione, ogni metodo prende un argomento size il cui valore predefinito è None. Se size è None, viene generato e restituito un singolo valore. Se size è un numero intero, viene restituito un array 1-D riempito con i valori generati.
25.1. Distribuzione uniforme#
Consideriamo la distribuzione uniforme: uniform([low, high, size]). Genero un singolo valore:
rng.uniform(0, 1)
0.6796309437437675
Lo genero una seconda volta:
rng.uniform(0, 1)
0.7274366452916092
Genero 20 valori:
rng.uniform(0, 1, size=20)
array([0.53653002, 0.28676371, 0.70024186, 0.7385279 , 0.77247024,
0.72982057, 0.65634736, 0.12702644, 0.90376911, 0.13566858,
0.84483562, 0.17637326, 0.47232729, 0.33718846, 0.95885522,
0.01879581, 0.72651356, 0.10591038, 0.19344365, 0.95198006])
Creo un istogramma.
_ = plt.hist(rng.uniform(0, 1, size=100000), bins=50, density=True)
25.2. Distribuzione normale#
Estraiamo ora dei campioni casuali dalla distribuzione Gaussiana, normal([loc, scale, size]). Inizio con un solo valore valore estratto dalla distribuzione del QI, ovvero, \(\mathcal{N}(\mu = 100, \sigma = 15)\):
x = rng.normal(loc=100, scale=15, size=1)
print(x)
[61.43062126]
x = rng.normal(loc=100, scale=15, size=1)
print(x)
[98.0411494]
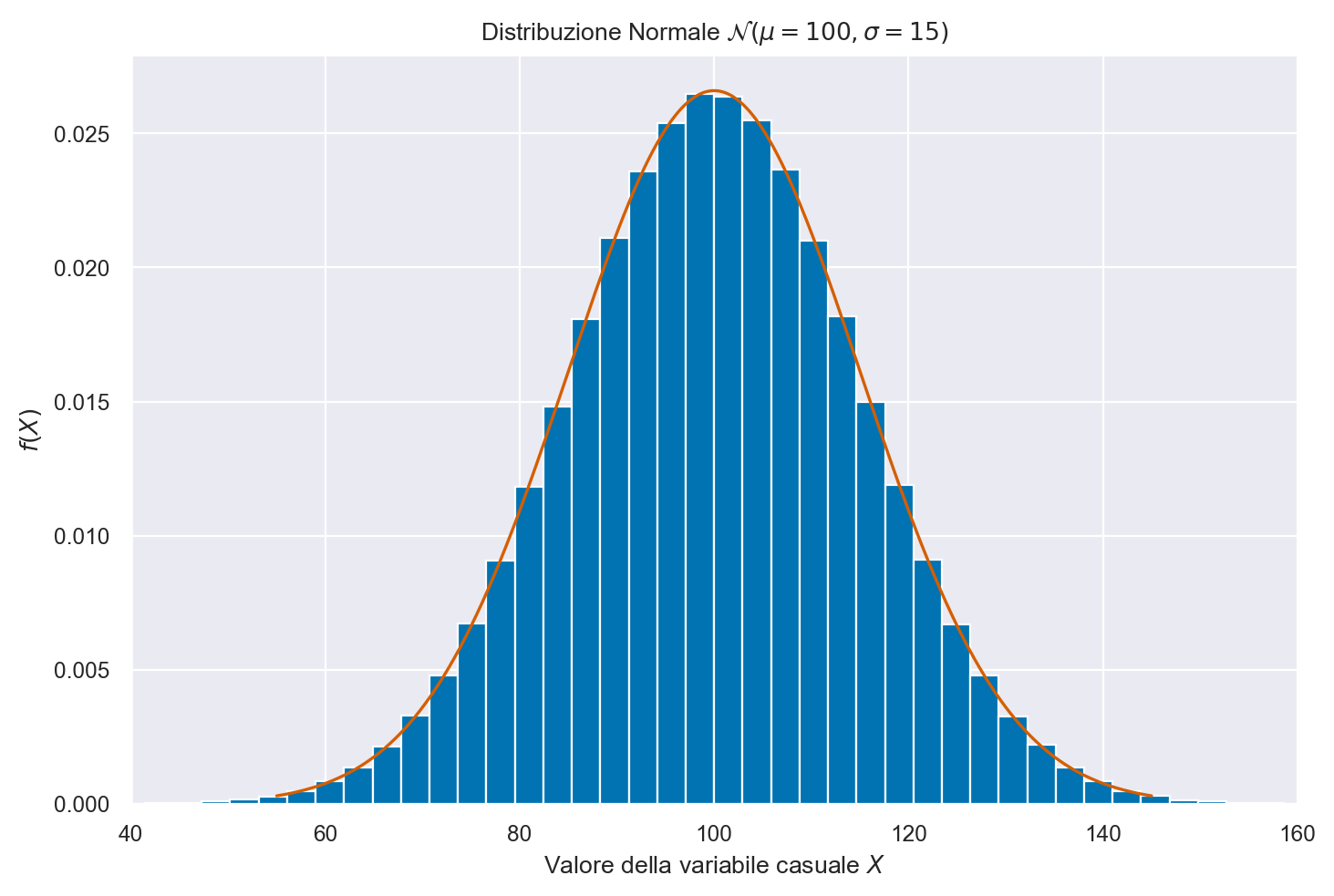
Ora genero un grande numero (1000000) di valori casuali dalla \(\mathcal{N}(\mu = 100, \sigma = 15)\). Con questi valori creo un istogramma e a tale istogramma sovrappongo la funzione di densità \(\mathcal{N}(\mu = 100, \sigma = 15)\). In questo modo posso accertarmi che i numeri casuali che ho ottenuto si riferiscano veramente alla densità desiderata.
Per trovare la densità della distribuzione normale, uso norm.pdf da scipy.stats.
Si noti rng.normal() per la generazione dei numeri casuali.
n = 1000000
mu = 100
sigma = 15
# create x's
xs = np.linspace(55, 145, 100001)
y_pdf = st.norm.pdf(xs, mu, sigma)
# create random samples
samps = rng.normal(loc=mu, scale=sigma, size=n)
# plot them
plt.plot(xs, y_pdf, color="r")
plt.hist(samps, bins=50, density=True)
plt.title("Distribuzione Normale $\mathcal{N}(\mu=100, \sigma=15)$")
plt.ylabel("$f(X)$")
plt.xlabel("Valore della variabile casuale $X$")
plt.xlim(40, 160)
(40.0, 160.0)
La stessa procedura può essere usata per tutte le distribuzioni implementate da NumPy. Presento alcuni esempi qui sotto.
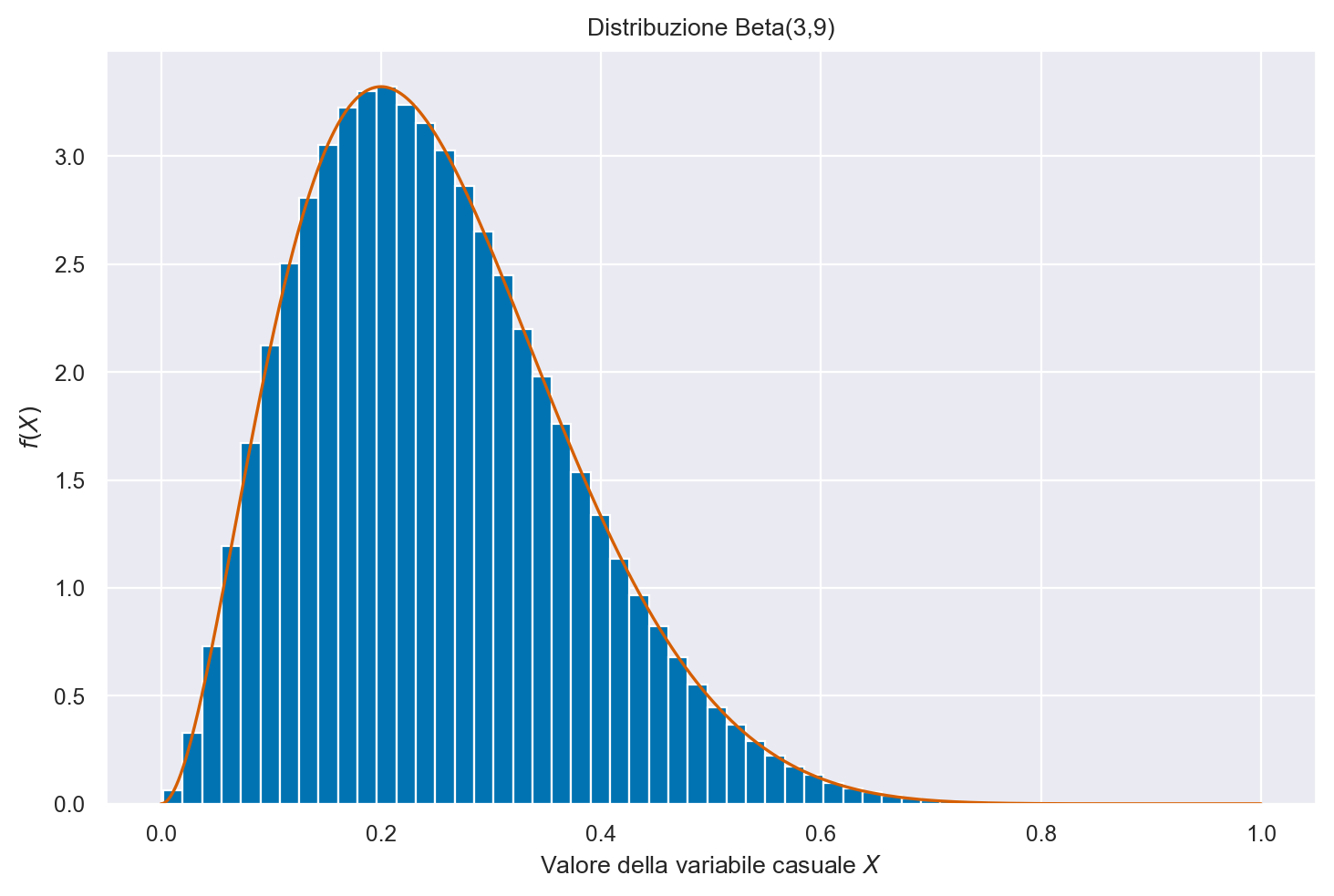
25.3. Distribuzione Beta#
Per estrarre dei campioni casuali dalla distribuzione Beta uso il generatore rng con beta(a, b[, size]); per la densità Beta uso beta.pdf da scipy.stats.
a = 3
b = 9
# create x's
xs = np.linspace(0, 1, 100001)
y_pdf = st.beta.pdf(xs, a, b)
# create random samples
samps = rng.beta(a=a, b=b, size=n)
# plot them
plt.plot(xs, y_pdf, color='r')
plt.hist(samps, bins=50, density=True)
plt.title('Distribuzione Beta(3,9)')
plt.ylabel('$f(X)$')
plt.xlabel('Valore della variabile casuale $X$')
Text(0.5, 0, 'Valore della variabile casuale $X$')
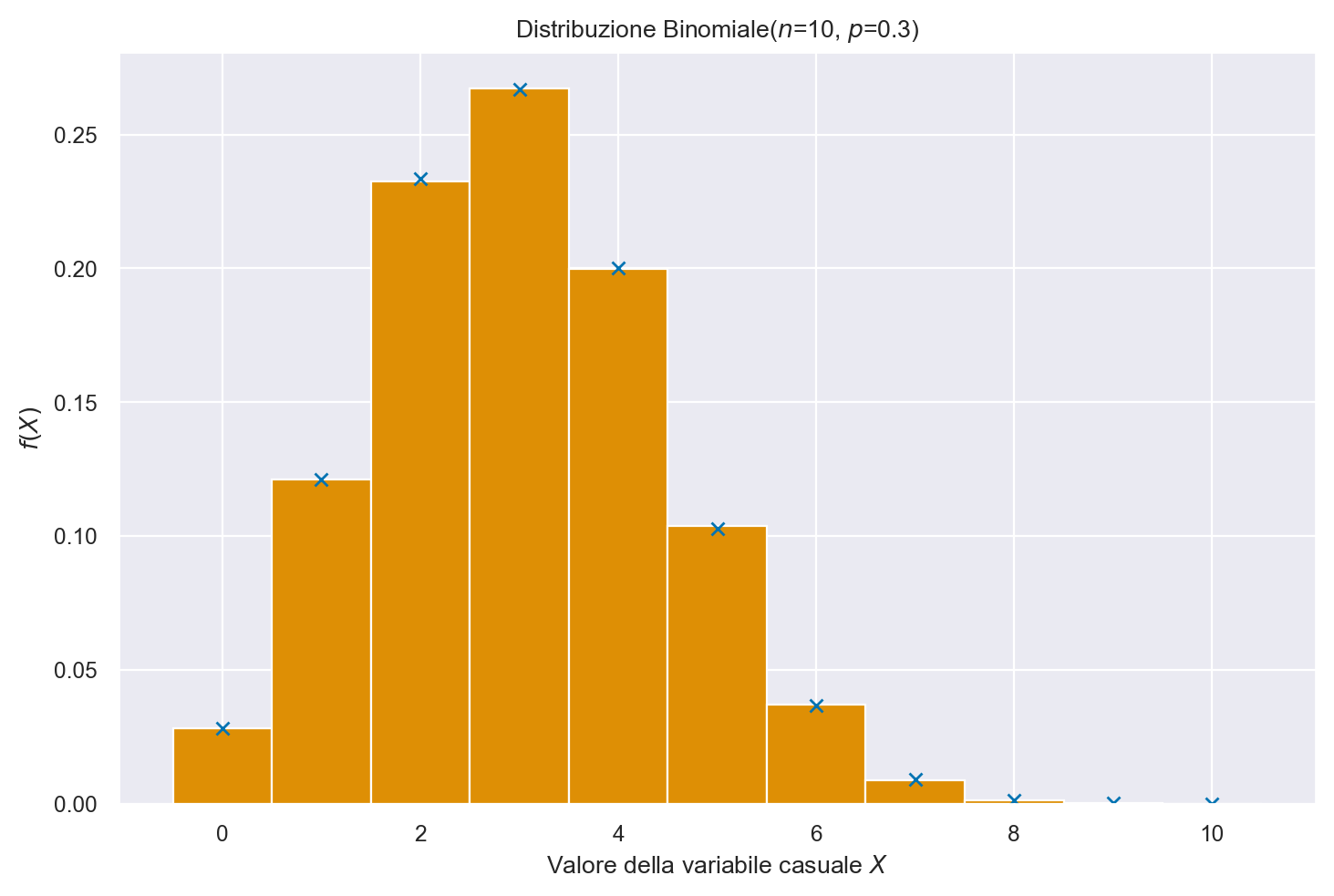
25.4. Distribuzione binomiale#
Per estrarre dei campioni casuali dalla distribuzione Binomiale uso il generatore rng con binomial(n, p[, size]); per la distribuzione di massa Binomiale uso binom.pmf da scipy.stats.
n = 10
p = 0.3
n_samples = 100001
# create r values
r_values = list(range(n + 1))
# pmf
y_pmf = [st.binom.pmf(r, n, p) for r in r_values]
# create random samples
r_samps = rng.binomial(n=n, p=p, size=n_samples)
plt.plot(r_values, y_pmf, 'x')
plt.hist(r_samps, bins=np.arange(-.5, 11.5, 1), density=True)
plt.title('Distribuzione Binomiale($n$=10, $p$=0.3)')
plt.ylabel('$f(X)$')
plt.xlabel('Valore della variabile casuale $X$')
Text(0.5, 0, 'Valore della variabile casuale $X$')
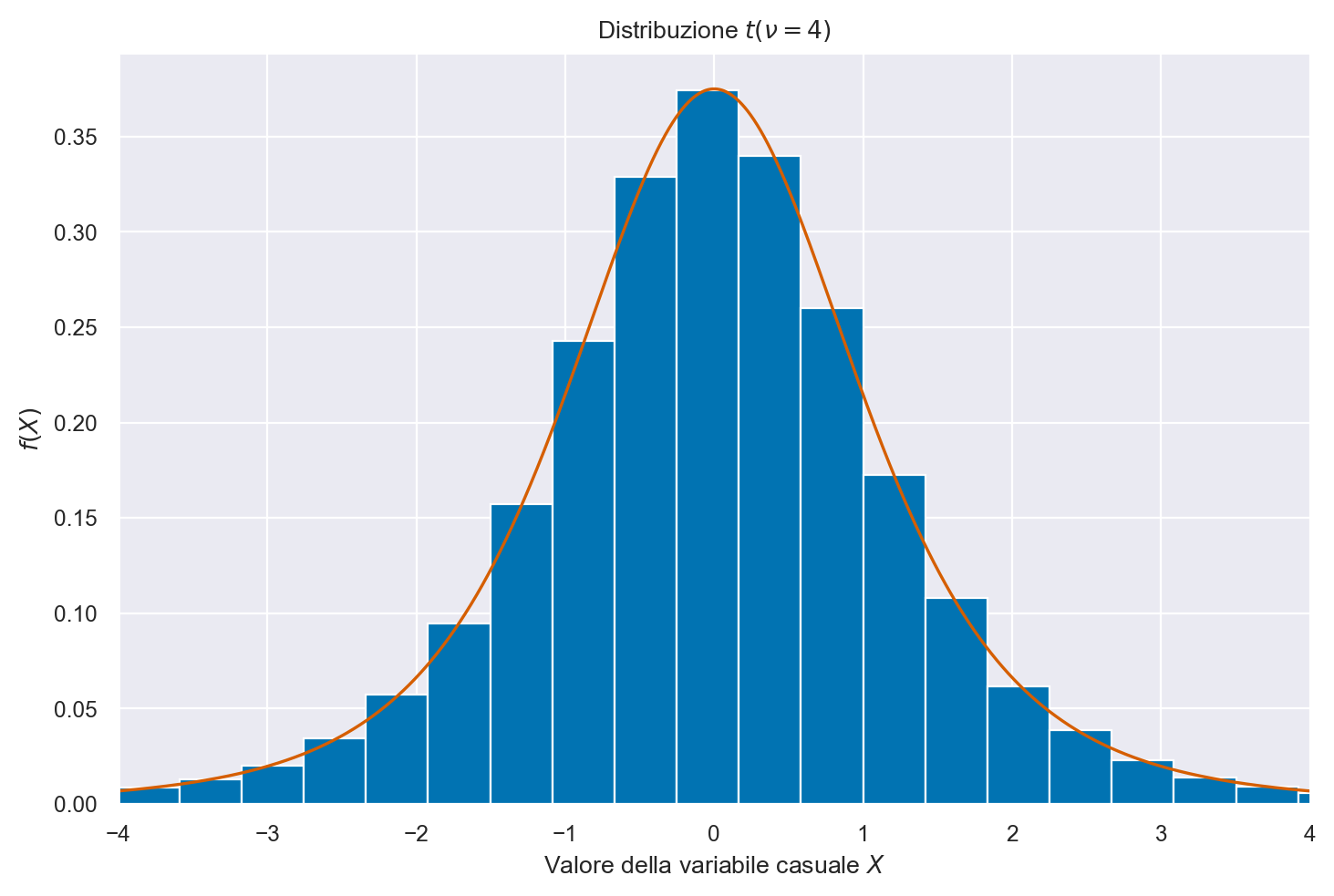
25.5. Distribuzione \(t\) di Student#
Per estrarre dei campioni casuali dalla distribuzione \(t\) di Student uso il generatore rng con standard_t(df, size=None); per la densità \(t\) di Student uso t.pdf da scipy.stats.
df = 4
size = 100001
# create x's
xs = np.linspace(-4, 4, 100001)
y_pdf = st.t.pdf(xs, df=df)
# create random samples
samps = rng.standard_t(df=df, size=size)
# plot them
fig, ax = plt.subplots()
plt.plot(xs, y_pdf, color='r')
plt.hist(samps, bins=150, density=True)
plt.title('Distribuzione $t(\\nu=4)$')
plt.ylabel('$f(X)$')
plt.xlabel('Valore della variabile casuale $X$')
plt.xlim(-4, 4)
(-4.0, 4.0)
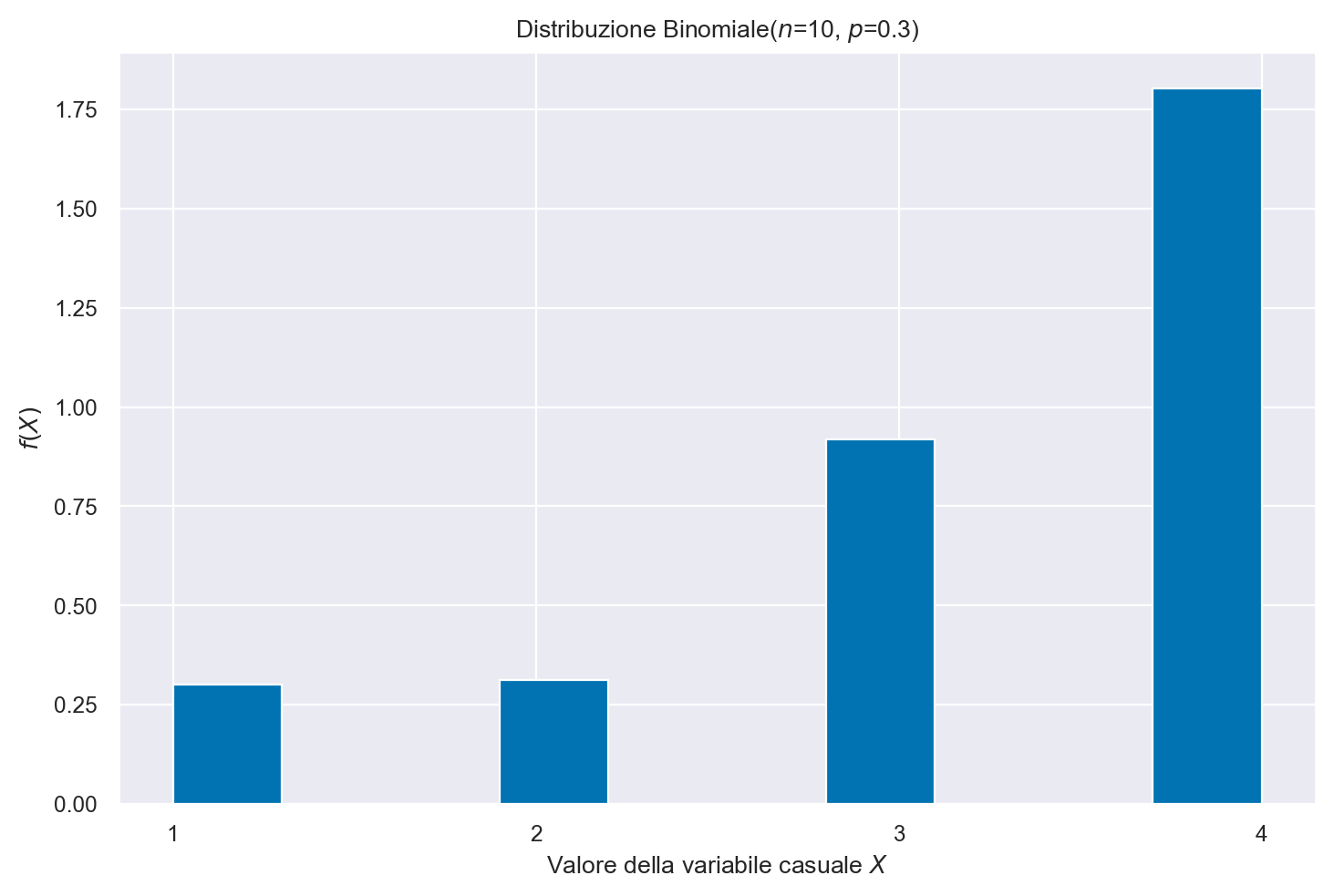
25.6. Distribuzione arbitraria di una variabile casuale distreta#
Con la funzione random.choices è possible specificare i valori di una variabile casuale discreta.
import random
x_rv = [1, 2, 3, 4]
x_sample = random.choices(x_rv, k=10)
print(x_sample)
[2, 1, 4, 3, 1, 3, 1, 1, 3, 2]
Se aggiungiamo l’argomento k possiamo definire i pesi (indirettamente, le probabilità) dei diversi valori della variabile casuale che sono stati specificati. Nell’esempio, i pesi [1, 1, 3, 6] indicano che, nella distribuzione, il valore 4 è presente con una frequenza di sei volte maggiore dei valori 1 e 2.
x = random.choices(x_rv, weights=[1, 1, 3, 6], k=10)
print(x)
[4, 3, 4, 4, 4, 2, 4, 3, 4, 2]
x = random.choices(x_rv, weights=[1, 1, 3, 6], k=100000)
bins = plt.hist(x, density=True)
plt.title('Distribuzione Binomiale($n$=10, $p$=0.3)')
plt.ylabel('$f(X)$')
plt.xlabel('Valore della variabile casuale $X$')
plt.xticks(x_rv)
([<matplotlib.axis.XTick at 0x121cba550>,
<matplotlib.axis.XTick at 0x121b99dd0>,
<matplotlib.axis.XTick at 0x121b9b910>,
<matplotlib.axis.XTick at 0x121d04fd0>],
[Text(1, 0, '1'), Text(2, 0, '2'), Text(3, 0, '3'), Text(4, 0, '4')])
Consideriamo il campione di valori casuali che abbiamo ottenuto, Se dividiamo la frequenza relativa del valore 4 e quella del valore 1 otteniamo il rappporto che ci aspettiamo:
print(bins)
(array([0.30016667, 0. , 0. , 0.3109 , 0. ,
0. , 0.91836667, 0. , 0. , 1.8039 ]), array([1. , 1.3, 1.6, 1.9, 2.2, 2.5, 2.8, 3.1, 3.4, 3.7, 4. ]), <BarContainer object of 10 artists>)
1.8221 / 0.30036667
6.0662522909083085
25.7. Commenti e considerazioni finali#
Dalla libreria scipy.stats utilizzo
.pdfper ottenere i valori della funzione di densità di probabilità oppure.pmfper ottenere i valori della distribuzione di massa di probabilità;.ppfper ottenere i quantili della distribuzione;.cdfper ottenere la probabilità – nel caso di una variabile casuale continua, il valore della funzione di ripartizione, ovvero l’area sottesa alla curva di densità nella coda di sinistra; nel caso di una variabile casuale discreta, la somma delle probabilità della distribuzione di massa di probabilità dal valore minimo fino al valore indicato (incluso).
Dalla libreria numpy utilizzo
.randomper ottenere un campione di numeri casuali da una distribuzione.
25.8. Watermark#
%load_ext watermark
%watermark -n -u -v -iv -w -p pytensor
Last updated: Sat Jun 17 2023
Python implementation: CPython
Python version : 3.11.3
IPython version : 8.12.0
pytensor: 2.12.2
pandas : 1.5.3
seaborn : 0.12.2
matplotlib: 3.7.1
arviz : 0.15.1
scipy : 1.10.1
numpy : 1.24.3
Watermark: 2.3.1