Codice
library("bayesrules")
plot_beta(alpha = 4, beta = 4, mean = TRUE, mode = TRUE)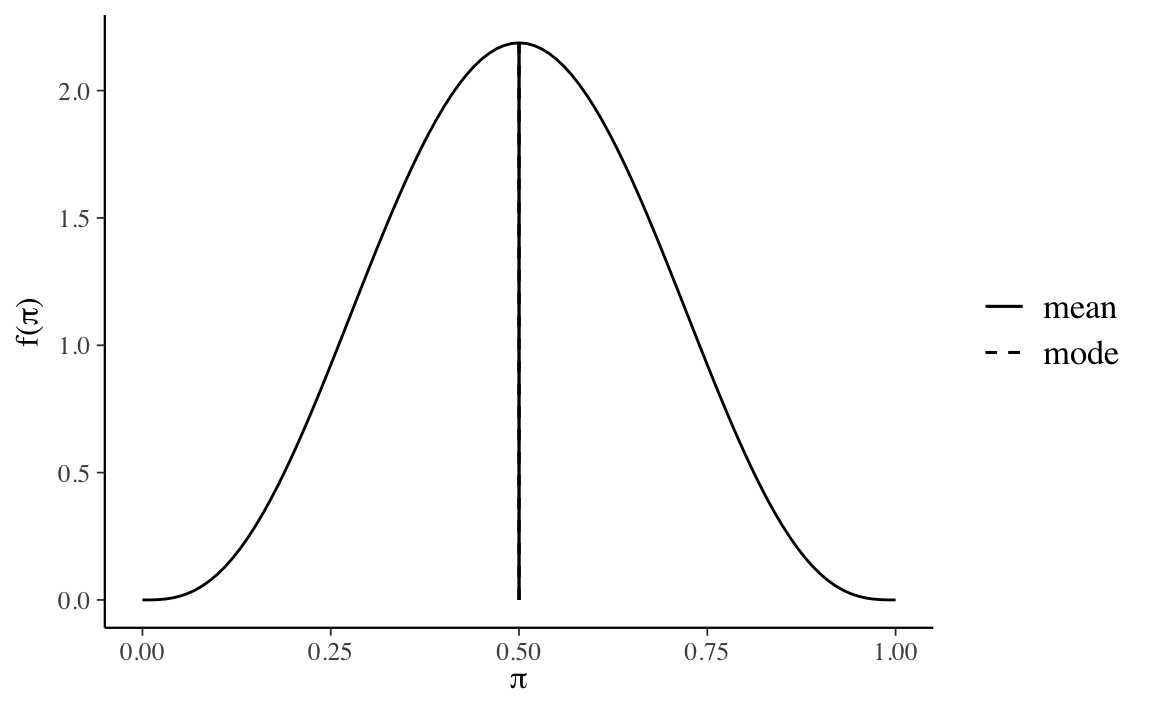
Obiettivo di questo Capitolo è fornire un esempio di derivazione della distribuzione a posteriori scegliendo quale distribuzione a priori una distribuzione coniugata. Esamineremo qui il lo schema beta-binomiale.
Esiste una particolare classe di distribuzioni a priori, dette distribuzioni a priori coniugate al modello, che godono di un’importante proprietà: se la distribuzione iniziale appartiene a tale classe, anche la distribuzione finale vi appartiene, cioé ha la stessa forma funzionale, e l’aggiornamento della fiducia si riduce alla modifica dei parametri della distribuzione a priori. Ad esempio, se la distribuzione a priori è una Beta e la verosimiglianza è binomiale, allora la distribuzione a posteriori sarà anch’essa una distribuzione Beta.
Da un punto di vista matematico, le distribuzioni a priori coniugate sono la scelta più conveniente in quanto consentono di calcolare analiticamente la distribuzione a posteriori con “carta e penna”, senza la necessità di ricorrere a calcoli complessi. Da una prospettiva computazionale moderna, però, le distribuzioni a priori coniugate generalmente non sono migliori delle alternative, dato che i moderni metodi computazionali consentono di eseguire l’inferenza praticamente con qualsiasi scelta delle distribuzioni a priori, e non solo con le distribuzioni a priori che risultano matematicamente convenienti. Tuttavia, le famiglie coniugate offronto un utile ausilio didattico nello studio dell’inferenza bayesiana. Questo è il motivo per cui le esamineremo qui. Nello specifico, esamineremo quello che viene chiamato lo schema beta-binomiale.
Per fare un esempio concreto, consideriamo nuovamente i dati di Zetsche et al. (2019): nel campione di 30 partecipanti clinici le aspettative future di 23 partecipanti risultano negativamente distorte mentre quelle di 7 partecipanti risultano positivamente distorte. Nel seguito, indicheremo con \(\theta\) la probabilità che le aspettative di un paziente clinico siano distorte negativamente. Ci poniamo il problema di ottenere una stima a posteriori di \(\theta\) avendo osservato 23 “successi” in 30 prove. I dati osservati (\(y = 23\)) possono essere considerati la manifestazione di una variabile casuale Bernoulliana, dunque la verosimiglianza è binomiale. In tali circostanze, se viene scelta una distribuzione a priori Beta, allora anche la distribuzione a posteriori sarà una Beta.
È possibile esprimere diverse credenze iniziali rispetto a \(\theta\) mediante la distribuzione Beta. Ad esempio, la scelta di una \(\mbox{Beta}(\alpha = 4, \beta = 4)\) quale distribuzione a priori per il parametro \(\theta\) corrisponde alla credenza a priori che associa all’evento “presenza di una aspettativa futura distorta negativamente” una grande incertezza: il valore 0.5 è il valore di \(\theta\) più plausibile, ma anche gli altri valori del parametro (tranne gli estremi) sono ritenuti piuttosto plausibili. Questa distribuzione a priori esprime la credenza che sia egualmente probabile per un’aspettativa futura essere distorta negativamente o positivamente.
library("bayesrules")
plot_beta(alpha = 4, beta = 4, mean = TRUE, mode = TRUE)
Possiamo quantificare la nostra incertezza calcolando, con un grado di fiducia del 95%, la regione nella quale, in base a tale credenza a priori, si trova il valore del parametro. Per ottenere tale intervallo di credibilità a priori, usiamo la funzione qbeta() di \(\mathsf{R}\). Nella funzione qbeta() i parametri \(\alpha\) e \(\beta\) sono chiamati shape1 e shape2.
Se poniamo \(\alpha=10\) e \(\beta=10\), anche questa scelta descrive una credenza a priori per la quale è egualmente probabile osservare un’aspettativa futura distorta negativamente o positivamente.
plot_beta(alpha = 10, beta = 10, mean = TRUE, mode = TRUE)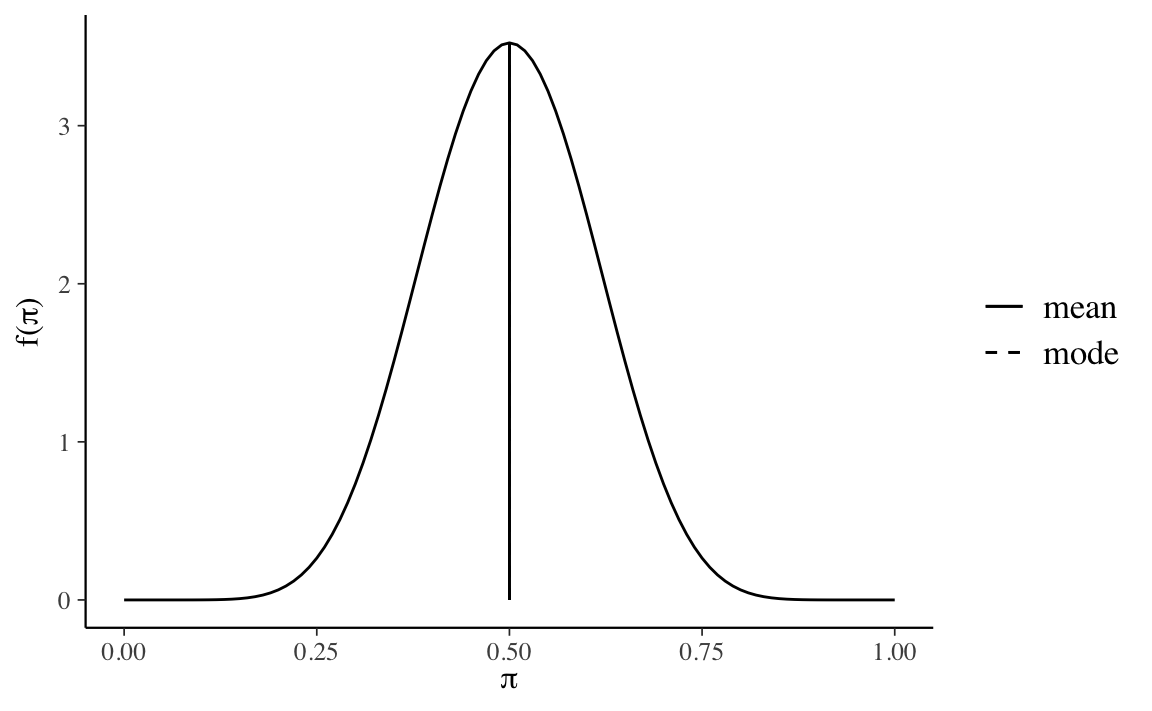
Tuttavia, in questo caso la nostra certezza a priori sul valore del parametro è maggiore, come indicato dall’intervallo di ordine 0.95.
Quale distribuzione a priori dobbiamo scegliere? In un problema concreto di analisi dei dati, la scelta della distribuzione a priori dipende dalle credenze a priori che vogliamo includere nell’analisi dei dati. Se non abbiamo alcuna informazione a priori, allora è possibile usare \(\alpha=1\) e \(\beta=1\), che corrisponde ad una distribuzione a priori uniforme. Ma l’uso di distribuzioni a priori uniformi è sconsigliato per vari motivi, inclusa l’instabilità numerica della stima dei parametri. In tali circostanze sarebbe preferibile usare una distribuzione a priori debolmente informativa, come una \(\mbox{Beta}(2, 2)\).
Nella discussione presente, quale distribuzione a priori useremo una \(\mbox{Beta}(2, 10)\).
\[ p(\theta) = \frac{\Gamma(12)}{\Gamma(2)\Gamma(10)}\theta^{2-1} (1-\theta)^{10-1}. \]
plot_beta(alpha = 2, beta = 10, mean = TRUE, mode = TRUE)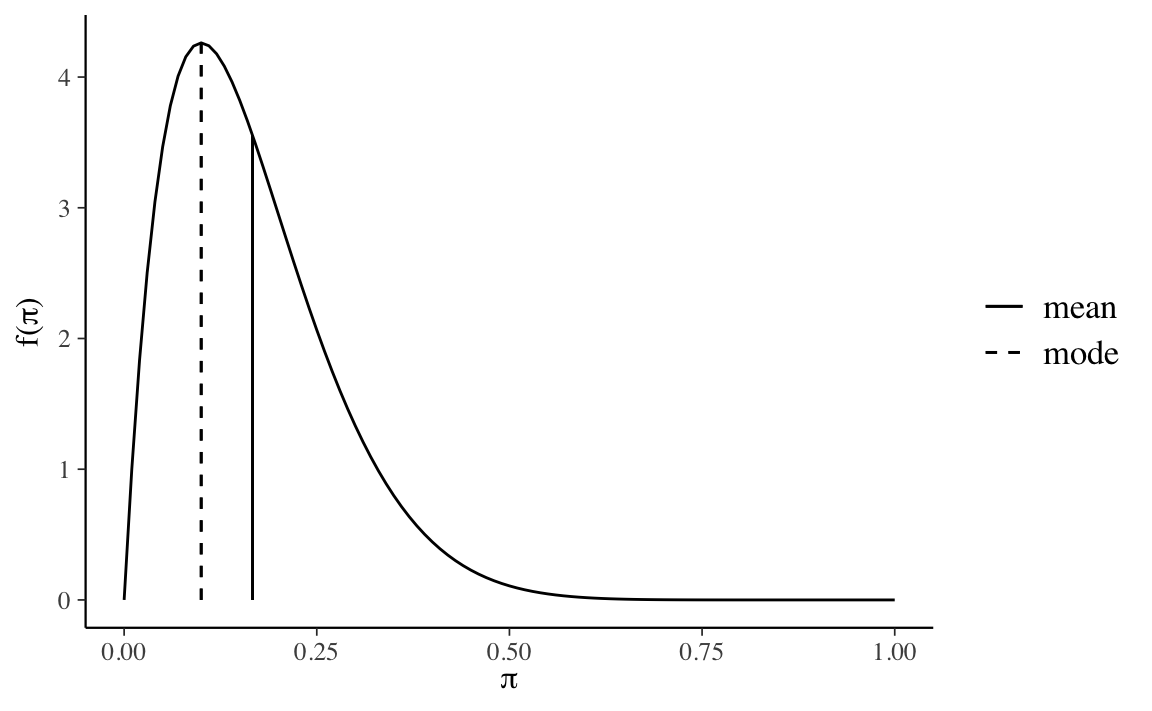
Tale distribuzione a priori è del tutto inappropriata per i dati di Zetsche et al. (2019). La \(\mbox{Beta}(2, 10)\) esprime la credenza che \(\theta < 0.5\), con il valore più plausibile pari a cicrca 0.1. Ma non c’è motivo di pensare, a priori, che, per questa popolazione, vi sia una bassa probabilità di un’aspettativa futura distorta negativamente – piuttosto è vero il contrario. La \(\mbox{Beta}(2, 10)\) verrà usata qui solo per mostrare l’effetto che ha una tale scelta sulla distribuzione a posteriori.
Una volta scelta una distribuzione a priori di tipo Beta, i cui parametri rispecchiano le nostre credenze iniziali su \(\theta\), la distribuzione a posteriori viene specificata dalla formula di Bayes:
\[ \text{distribuzione a posteriori} = \frac{\text{verosimiglianza}\cdot\text{distribuzione a priori}}{\text{verosimiglianza marginale}}. \]
Per i dati presenti la verosimiglianza è binomiale per cui abbiamo
\[ p(\theta \mid n=30, y=23) = \frac{\Big[\binom{30}{23}\theta^{23}(1-\theta)^{30-23}\Big]\Big[\frac{\Gamma(12)}{\Gamma(2)\Gamma(10)}\theta^{2-1} (1-\theta)^{10-1}\Big]}{p(y = 23)}, \]
laddove \(p(y = 23)\), ovvero la verosimiglianza marginale, è una costante di normalizzazione.
Riscriviamo l’equazione precedente in termini più generali:
\[ p(\theta \mid n, y) = \frac{\Big[\binom{n}{y}\theta^{y}(1-\theta)^{n-y}\Big]\Big[\frac{\Gamma(a+b)}{\Gamma(a)\Gamma(b)}\theta^{a-1} (1-\theta)^{b-1}\Big]}{p(y)}. \]
Raccogliendo tutte le costanti otteniamo:
\[ p(\theta \mid n, y) =\left[\frac{\binom{n}{y}\frac{\Gamma(a+b)}{\Gamma(a)\Gamma(b)}}{p(y)}\right] \theta^{y}(1-\theta)^{n-y}\theta^{a-1} (1-\theta)^{b-1}. \]
Se ignoriamo il termine costante all’interno della parentesi quadra il termine di destra dell’equazione precedente identifica il kernel della distribuzione a posteriori e corrisponde ad una Beta non normalizzata di parametri \(a + y\) e \(b + n - y\):
\[ \begin{align} p(\theta \mid n, y) &\propto \theta^{y}(1-\theta)^{n-y}\theta^{a-1} (1-\theta)^{b-1},\notag\\ &\propto \theta^{a+y-1}(1-\theta)^{b+n-y-1}. \end{align} \]
Per ottenere una distribuzione di densità, dobbiamo aggiungere una costante di normalizzazione al kernel della distribuzione a posteriori. In base alla definizione della distribuzione Beta, ed essendo \(a' = a+y\) e \(b' = b+n-y\), tale costante di normalizzazione è uguale a
\[ \frac{\Gamma(a'+b')}{\Gamma(a')\Gamma(b')} = \frac{\Gamma(a+b+n)}{\Gamma(a+y)\Gamma(b+n-y)}. \]
Possiamo dunque concludere, nel caso dello schema beta-binomiale, che la distribuzione a posteriori è una \(\mbox{Beta}(a+y, b+n-y)\):
\[ \mbox{Beta}(a+y, b+n-y) = \frac{\Gamma(a+b+n)}{\Gamma(a+y)\Gamma(b+n-y)} \theta^{a+y-1}(1-\theta)^{b+n-y-1}. \]
In sintesi, per i dati in discussione, moltiplicando verosimiglianza \(\mbox{Bin}(n = 30, y = 23 \mid \theta)\) per la la distribuzione a priori \(\theta \sim \mbox{Beta}(2, 10)\) e dividendo per la costante di normalizzazione, si ottiene la distribuzione a posteriori \(p(\theta \mid n, y) \sim \mbox{Beta}(25, 17)\).
Questo è un esempio di analisi coniugata. La presente combinazione di verosimiglianza e distribuzione a priori è chiamata caso coniugato beta-binomiale ed è descritta dal seguente teorema.
Teorema 17.1 Sia data la funzione di verosimiglianza \(\mbox{Bin}(n, y \mid \theta)\) e sia \(\mbox{Beta}(\alpha, \beta)\) una distribuzione a priori. In tali circostanze, la distribuzione a posteriori del parametro \(\theta\) sarà una distribuzione \(\mbox{Beta}(\alpha + y, \beta + n - y)\).
È facile calcolare il valore atteso a posteriori di \(\theta\). Essendo \(\mathbb{E}[\mbox{Beta}(\alpha, \beta)] = \frac{\alpha}{\alpha + \beta}\), il risultato cercato diventa
\[ \mathbb{E}_{\text{post}} [\mathrm{Beta}(\alpha + y, \beta + n - y)] = \frac{\alpha + y}{\alpha + \beta +n}. \tag{17.1}\]
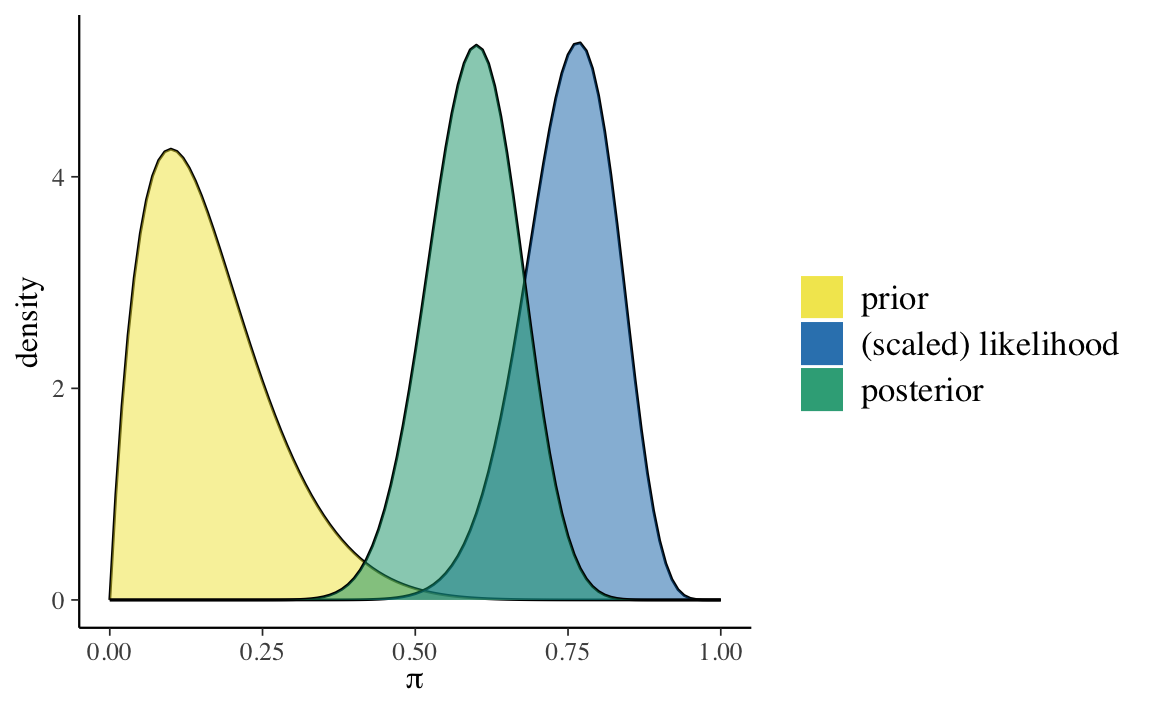
Esercizio 17.1 Si rappresenti in maniera grafica e si descriva in forma numerica l’aggiornamento bayesiano beta-binomiale per i dati di Zetsche et al. (2019). Si assuma una distribuzione a priori \(\mbox{Beta}(2, 10)\).
Soluzione. Per i dati in questione, l’aggiornamento bayesiano può essere rappresentato in forma grafica usando la funzione plot_beta_binomial() del pacchetto bayesrules:
bayesrules::plot_beta_binomial(
alpha = 2, beta = 10, y = 23, n = 30
) 
Un sommario delle distribuzioni a priori e a posteriori può essere ottenuto, ad esempio, usando la funzione summarize_beta_binomial() del pacchetto bayesrules:
bayesrules:::summarize_beta_binomial(
alpha = 2, beta = 10, y = 23, n = 30
)
#> model alpha beta mean mode var sd
#> 1 prior 2 10 0.1666667 0.1 0.010683761 0.1033623
#> 2 posterior 25 17 0.5952381 0.6 0.005603016 0.0748533Esercizio 17.2 Per i dati di Zetsche et al. (2019), si trovino la media, la moda, la deviazione standard della distribuzione a posteriori di \(\theta\). Si trovi inoltre l’intervallo di credibilità a posteriori del 95% per il parametro \(\theta\).
Soluzione. L’intervallo di credibilità a posteriori del 95% per il parametro \(\theta\) si trova usando il Teorema Teorema 17.1.
La media della distribuzione a posteriori si trova con l’Equazione 17.1.
25 / (25 + 17)
#> [1] 0.5952381La moda della distribuzione a posteriori si trova usando le proprietà della distribuzione Beta.
(25 - 1) / (25 + 17 - 2)
#> [1] 0.6La deviazione standard della distribuzione a posteriori si trova usando le proprietà della distribuzione Beta.
sqrt((25 * 17) / ((25 + 17)^2 * (25 + 17 + 1)))
#> [1] 0.0748533Esercizio 17.3 Si trovino i parametri e le proprietà della distribuzione a posteriori del parametro \(\theta\) per i dati dell’esempio relativo alla ricerca di Stanley Milgram discussa da Johnson et al. (2022).
Nel 1963, Stanley Milgram presentò una ricerca sulla propensione delle persone a obbedire agli ordini di figure di autorità, anche quando tali ordini possono danneggiare altre persone (Milgram, 1963). Nell’articolo, Milgram descrive lo studio come
consist[ing] of ordering a naive subject to administer electric shock to a victim. A simulated shock generator is used, with 30 clearly marked voltage levels that range from IS to 450 volts. The instrument bears verbal designations that range from Slight Shock to Danger: Severe Shock. The responses of the victim, who is a trained confederate of the experimenter, are standardized. The orders to administer shocks are given to the naive subject in the context of a “learning experiment” ostensibly set up to study the effects of punishment on memory. As the experiment proceeds the naive subject is commanded to administer increasingly more intense shocks to the victim, even to the point of reaching the level marked Danger: Severe Shock.
All’insaputa del partecipante, gli shock elettrici erano falsi e l’attore stava solo fingendo di provare il dolore dello shock.
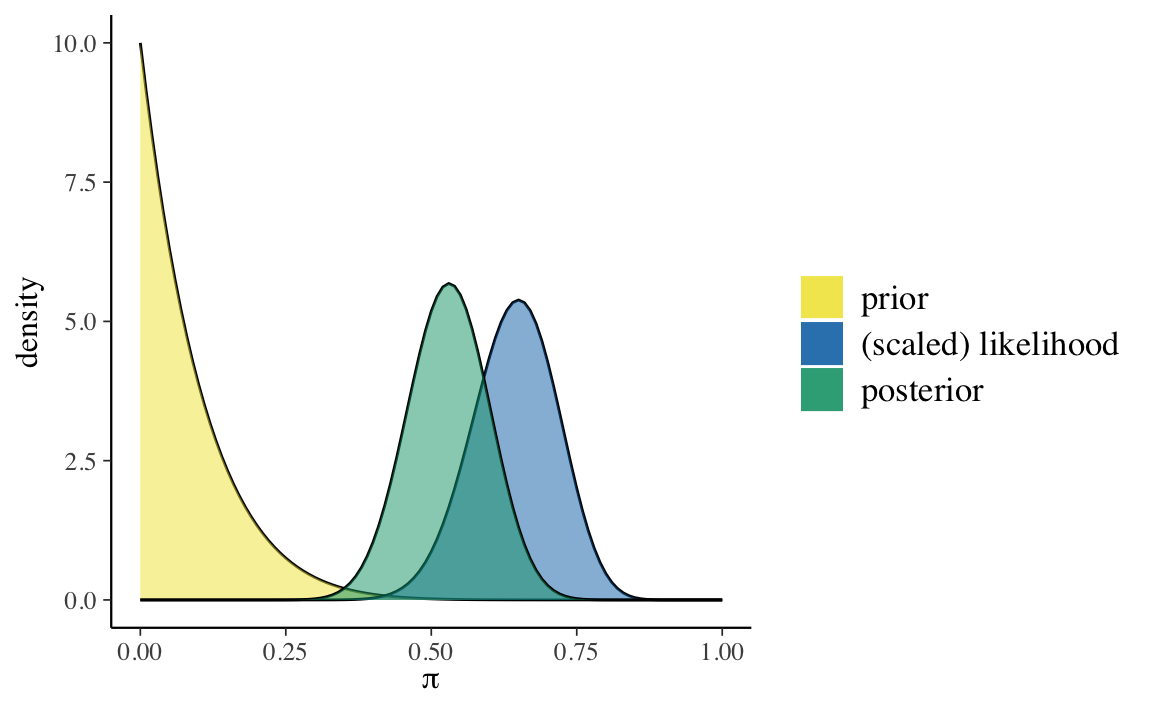
Soluzione. Johnson et al. (2022) fanno inferenza sui risultati dello studio di Milgram mediante il modello Beta-Binomiale. Il parametro di interesse è \(\theta\), la probabiltà che una persona obbedisca all’autorità (in questo caso, somministrando lo shock più severo), anche se ciò significa recare danno ad altri. Johnson et al. (2022) ipotizzano che, prima di raccogliere dati, le credenze di Milgram relative a \(\theta\) possano essere rappresentate mediante una \(\mbox{Beta}(1, 10)\). Sia \(y = 26\) il numero di soggetti che, sui 40 partecipanti allo studio, aveva accettato di infliggere lo shock più severo. Assumendo che ogni partecipante si comporti indipendentemente dagli altri, possiamo modellare la dipendenza di \(y\) da \(\theta\) usando la distribuzione binomiale. Giungiamo dunque al seguente modello bayesiano Beta-Binomiale:
\[ \begin{align} y \mid \theta & \sim \mbox{Bin}(n = 40, \theta) \notag\\ \theta & \sim \text{Beta}(1, 10) \; . \notag \end{align} \]
Usando le funzioni di bayesrules possiamo facilmente calcolare i parametri e le proprietà della distribuzione a posteriori.
bayesrules::summarize_beta_binomial(
alpha = 1, beta = 10, y = 26, n = 40
)
#> model alpha beta mean mode var sd
#> 1 prior 1 10 0.09090909 0.0000000 0.006887052 0.08298827
#> 2 posterior 27 24 0.52941176 0.5306122 0.004791057 0.06921746Il processo di aggiornamento bayesiano è descritto dalla figura ottenuta con la funzione bayesrules::plot_beta_binomial().
bayesrules::plot_beta_binomial(
alpha = 1, beta = 10, y = 26, n = 40
) 
L’inferenza bayesiane sulla proporzione \(\theta\) si basa su vari riepiloghi della distribuzione a posteriori Beta. Il riepilogo che si calcola dalla distribuzione a posteriori dipende dal tipo di inferenza. Consideriamo qui su due tipi di inferenza:
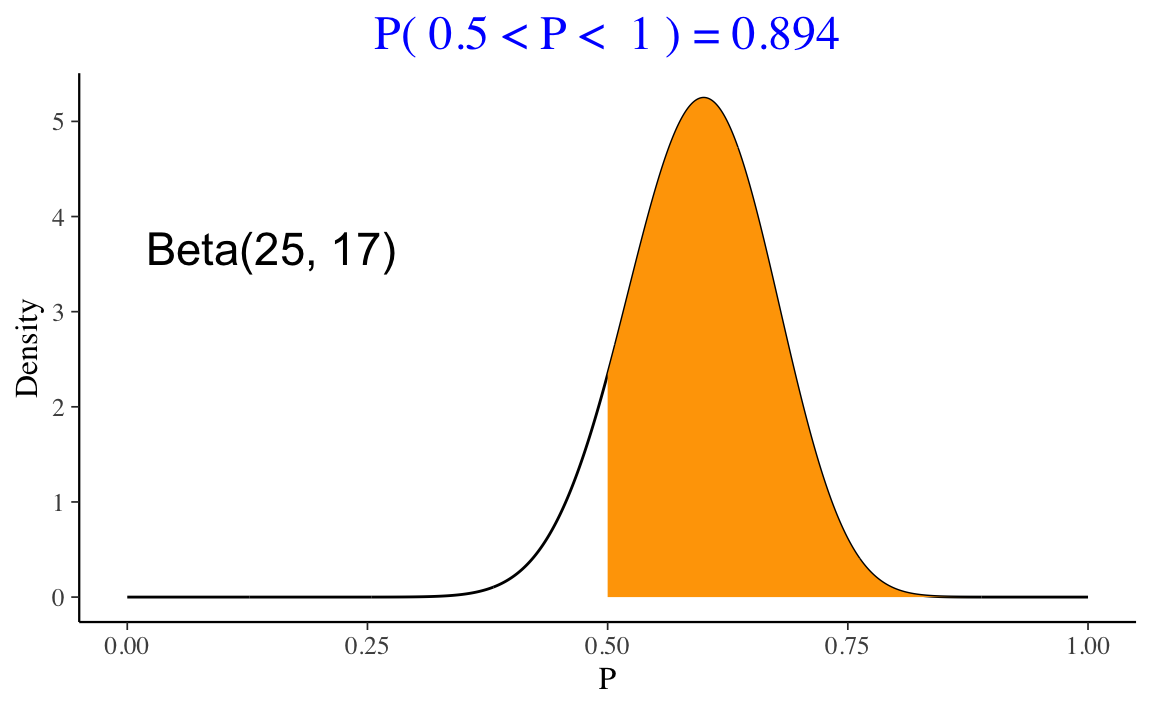
Nell’esempio in discussione sui dati di Zetsche et al. (2019), la nostra credenza a posteriori relativa a \(\theta\) (ovvero, la probabilità che l’aspettativa dell’umore futuro sia distorta negativamente) è descritta da una distribuzione Beta(25,17). Una volta definita la distribuzione a posteriori, ci possiamo porre altre domande. Per esempio: qual è la probabilità che \(\theta\) sia maggiore di 0.5?
Una risposta a questa domanda si può trovare usando la funzione pbeta().
1 - pbeta(0.5, 25, 17)
#> [1] 0.8944882Oppure, in maniera equivalente, con la funzione ProbBayes::beta_area().
Questo calcolo può anche essere svolto mediante simulazione. Dato che conosciamo la distribuzione target, è possibile ricavare un campione casuale di osservazioni da una tale distribuzione per poi riassumere il campione in modo tale da trovare \(\theta > 0.5\).
Il risultato della simulazione è molto simile a quello ottenuto in precedenza.
Un secondo tipo di inferenza bayesiana è quella che ci porta a costruire gli intervalli di credibilità. Un intervallo di credibilità di ordine \(a \in [0, 1]\) è l’intervallo di valori che contiene una proporzione della distribuzione a posteriori pari ad \(a\).
La funzione ProbBayes::beta_interval() consente di calcolare l’intervallo di credibilità che lascia la stessa probabilità nelle due code. Per esempio, l’intervallo di credibilità all’89% per la distribuzione a posteriori dell’esempio relativo ai dati di Zetsche et al. (2019) è il seguente.
ProbBayes::beta_interval(0.89, c(25, 17))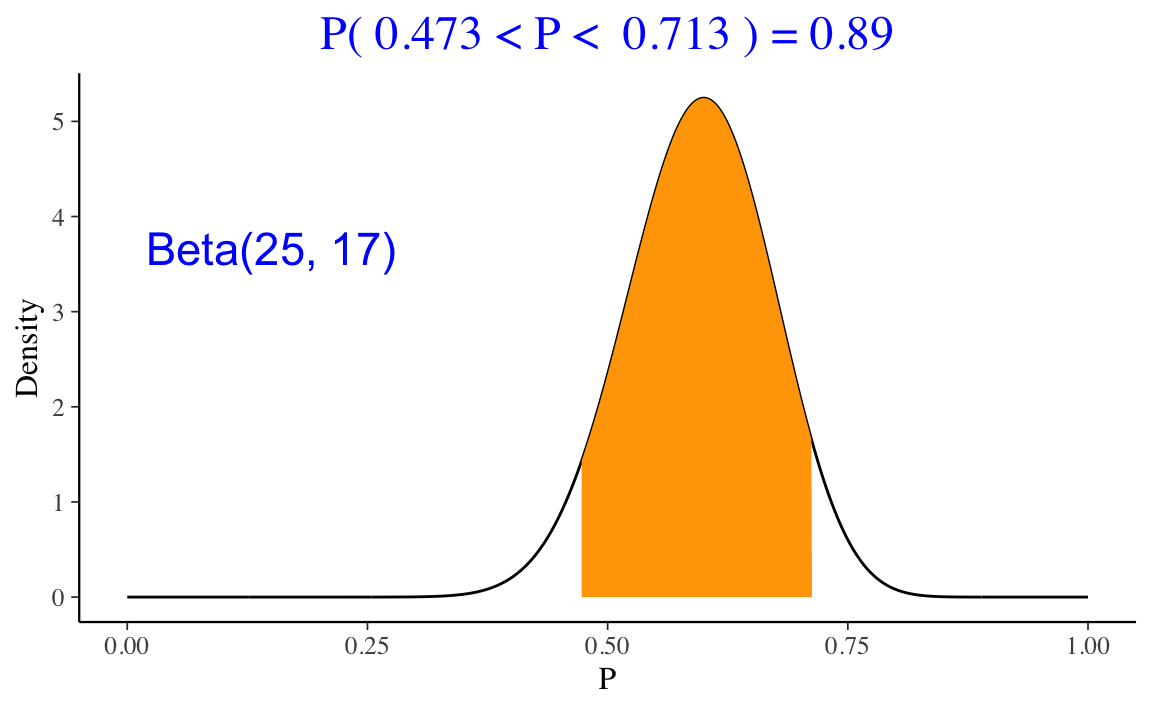
Per i dati di Zetsche et al. (2019), l’intervallo di credibilità all’50% è il seguente.
ProbBayes::beta_interval(0.5, c(25, 17))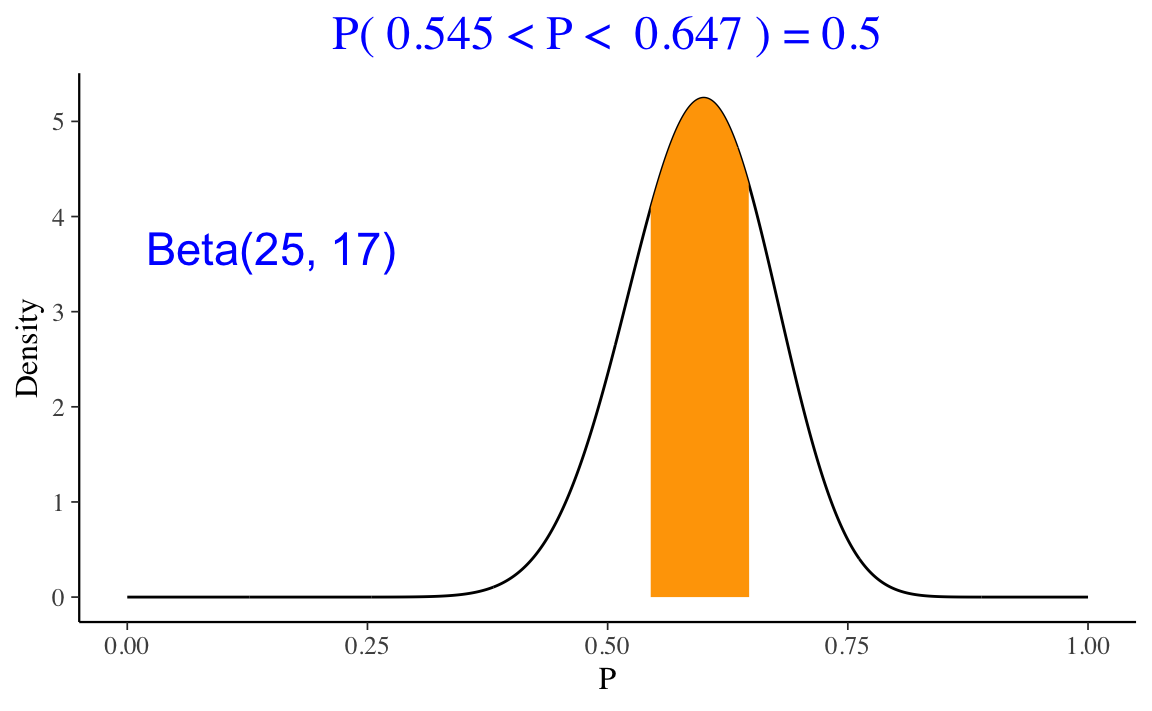
Esistono altre combinazioni di verosimiglianza e distribuzione a priori le quali producono una distribuzione a posteriori che ha la stessa densità della distribuzione a priori. Sono elencate qui sotto le più note coniugazioni tra modelli statistici e distribuzioni a priori.
Lo scopo di questo Capitolo è stato quello di mostrare come sia possibile integrare le conoscenze a priori (espresse nei termini di una distribuzione a priori) con le evidenze fornite dai dati (espresse nei termini della funzione di verosimiglianza), così da determinare, mediante il teorema di Bayes, una distribuzione a posteriori, la quale condensa l’incertezza che abbiamo sul parametro sconosciuto \(\theta\). Per illustrare tale problema, abbiamo considerato una situazione nella quale \(\theta\) corrisponde alla probabilità di successo in una sequenza di prove Bernoulliane. In tali circostanze è ragionevole esprimere le credenze a priori mediante la densità Beta, con opportuni parametri. L’inferenza rispetto a \(\theta\) può essere dunque svolta utilizzando una distribuzione a priori Beta e una verosimiglianza binomiale. In tali circostanze, la distribuzione a posteriori diventa essa stessa una distribuzione Beta. Questo è il cosiddetto schema beta-binomiale. Dato che utilizza una distribuzione a priori coniugata, lo schema beta-binomiale rende possibile la determinazione analitica dei parametri della distribuzione a posteriori.