Nella loro ricerca, Zetsche et al. (2019) hanno misurato il livello di depressione dei soggetti utilizzando due scale psicometriche: il Beck Depression Inventory II (BDI-II) e la Center for Epidemiologic Studies Depression Scale (CES-D). Il BDI-II è uno strumento self-report che valutare la presenza e l’intensità di sintomi depressivi in pazienti adulti e adolescenti di almeno 13 anni di età con diagnosi psichiatrica mentre la CES-D è una scala self-report progettata per misurare i sintomi depressivi che sono stati vissuti nella settimana precedente nella popolazione generale, specialmente quella degli adolescenti/giovani adulti. Una domanda ovvia che ci può venire in mente è: quanto sono simili le misure ottenute mediante queste due scale?
È chiaro che i numeri prodotti dalle scale BDI-II e CES-D non possono essere identici, e questo per due motivi: (1) la presenza degli errori di misurazione e (2) l’unità di misura delle due variabili. L’errore di misurazione corrompe sempre, almeno in parte, qualunque operazione di misurazione. E questo è vero specialmente in psicologia dove l’attendibilità degli strumenti di misurazione è minore che in altre discipline (quali la fisica, ad esempio). Il secondo motivo per cui i valori delle scale BDI-II e CES-D non possono essere uguali è che l’unità di misura delle due scale è arbitraria. Infatti, qual è l’unità di misura della depressione? Chi può dirlo! Ma, al di là delle differenze derivanti dall’errore di misurazione e dalla differente unità di misura, ci aspettiamo che, se le due scale misurano entrambe lo stesso costrutto, allora i valori prodotti dalle due scale dovranno essere tra loro linearmente associati. Per capire cosa si intende con “associazione lineare” iniziamo a guardare i dati. Per fare questo utilizziamo una rappresentazione grafica che va sotto il nome di diagramma a dispersione.
5.1 Diagramma a dispersione
Il diagramma di dispersione è la rappresentazione grafica delle coppie di punti individuati da due variabili \(X\) e \(Y\).
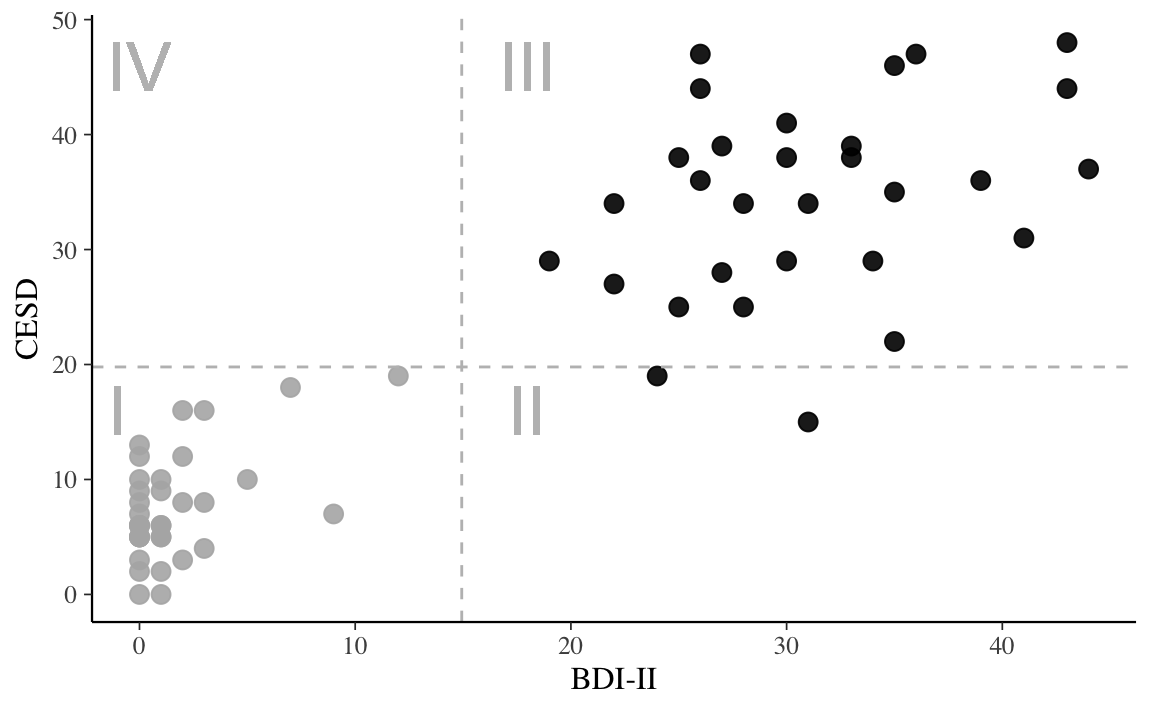
Per fare un esempio concreto, consideriamo le variabili BDI-II e CES-D di Zetsche et al. (2019). Il diagramma di dispersione per tali variabili si ottiene ponendo, ad esempio, i valori BDI-II sull’asse delle ascisse e quelli del CES-D sull’asse delle ordinate. In tale grafico, fornito dalla Figura 5.1, cascun punto corrisponde ad un individuo del quale, nel caso presente, conosciamo il livello di depressione misurato dalle due scale psicometriche.
Dalla Figura 5.1 possiamo vedere che i dati mostrano una tendenza a disporsi attorno ad una retta – nel gergo statistico, questo fatto viene espresso dicendo che i punteggi CES-D tendono ad essere linearmente associati ai punteggi BDI-II. È ovvio, tuttavia, che tale relazione lineare è lungi dall’essere perfetta – se fosse perfetta, tutti i punti del diagramma a dispersione si disporrebbero esattamente lungo una retta.
Codice
df<-rio::import(here("data", "data.mood.csv"), header =TRUE)bysubj<-df%>%group_by(esm_id, group)%>%summarise( bdi =mean(bdi), cesd =mean(cesd_sum))%>%na.omit()%>%ungroup()m_cesd<-bysubj%>%dplyr::pull(cesd)%>%mean()m_bdi<-bysubj%>%dplyr::pull(bdi)%>%mean()FONT_SIZE<-9bysubj%>%ggplot(aes(x =bdi, y =cesd, color =group))+geom_point(size =3, alpha =.9)+geom_hline(yintercept =m_cesd, linetype ="dashed", color ="gray")+geom_vline(xintercept =m_bdi, linetype ="dashed", color ="gray")+geom_text(x =-1, y =16, label ="I", color ="gray", size =FONT_SIZE)+geom_text(x =0, y =46, label ="IV", color ="gray", size =FONT_SIZE)+geom_text(x =18, y =46, label ="III", color ="gray", size =FONT_SIZE)+geom_text(x =18, y =16, label ="II", color ="gray", size =FONT_SIZE)+labs( x ="BDI-II", y ="CESD")+theme(legend.position ="none")+scale_colour_grey(start =0.7, end =0)
Figura 5.1: Associazione tra le variabili BDI-II e CES-D nello studio di Zetsche et al. (2019). In grigio sono rappresentate le osservazioni del gruppo di controllo; in nero quelle dei pazienti.
5.2 Covarianza
Il problema che ci poniamo ora è quello di trovare un indice numerico che descrive di quanto la nube di punti si discosta da una perfetta relazione lineare tra le due variabili, ovvero che descrive la direzione e la forza della relazione lineare tra le due variabili. Ci sono vari indici statistici che possono essere utilizzati a questo scopo.
Iniziamo a considerare il più importante di tali indici, chiamato covarianza. In realtà la definizione di questo indice non ci sorprenderà più di tanto in quanto, in una forma solo apparentemente diversa, l’abbiamo già incontrato in precedenza. Ci ricordiamo infatti che la varianza di una generica variabile \(X\) è definita come la media degli scarti quadratici di ciascuna osservazione dalla media:
Infatti, la varianza viene talvolta descritta come la “covarianza di una variabile con sé stessa”.
Adesso facciamo un passo ulteriore. Invece di valutare la dispersione di una sola variabile, chiediamoci come due variabili \(X\) e \(Y\) “variano insieme” (co-variano). È facile capire come una risposta a tale domanda possa essere fornita da una semplice trasformazione della formula precedente che diventa:
L’equazione precedente ci fornisce dunque la definizione della covarianza.
Per capire il significato di tale equazione, supponiamo di dividere il grafico della Figura 5.1 in quattro quadranti definiti da una retta verticale passante per la media dei valori BDI-II e da una retta orizzontale passante per la media dei valori CES-D. Numeriamo i quadranti partendo da quello in basso a sinistra e muovendoci in senso antiorario.
Se prevalgono punti nel I e III quadrante, allora la nuvola di punti avrà un andamento crescente (per cui a valori bassi di \(X\) tendono ad associarsi valori bassi di \(Y\) e a valori elevati di \(X\) tendono ad associarsi valori elevati di \(Y\)) e la covarianza segno positivo. Mentre se prevalgono punti nel II e IV quadrante la nuvola di punti avrà un andamento decrescente (per cui a valori bassi di \(X\) tendono ad associarsi valori elevati di \(Y\) e a valori elevati di \(X\) tendono ad associarsi valori bassi di \(Y\)) e la covarianza segno negativo. Dunque, il segno della covarianza ci informa sulla direzione della relazione lineare tra due variabili: l’associazione lineare si dice positiva se la covarianza è positiva, negativa se la covarianza è negativa.
Il segno della covarianza ci informa sulla direzione della relazione, ma invece il valore assoluto della covarianza ci dice ben poco. Esso, infatti, dipende dall’unità di misura delle variabili. Nel caso presente questo concetto è difficile da comprendere, dato che le due variabili in esame non hanno un’unità di misura (ovvero, hanno un’unità di misura arbitraria e priva di significato). Ma quest’idea diventa chiara se pensiamo alla relazione lineare tra l’altezza e il peso delle persone, ad esempio. La covarianza tra queste due quantità è certamente positiva, ma il valore assoluto della covarianza diventa più grande se l’altezza viene misurata in millimetri e il peso in grammi, e diventa più piccolo l’altezza viene misurata in metri e il peso in chilogrammi. Dunque, il valore della covarianza cambia al mutare dell’unità di misura delle variabili anche se l’associazione tra le variabili resta costante.
5.3 Correlazione
Dato che il valore assoluto della covarianza è di difficile interpretazione – in pratica, non viene mai interpretato – è necessario trasformare la covarianza in modo tale da renderla immune alle trasformazioni dell’unità di misura delle variabili. Questa operazione si dice standardizzazione e corrisponde alla divisione della covarianza per le deviazioni standard (\(s_X\), \(s_Y\)) delle due variabili:
\[
r_{XY} = \frac{S_{XY}}{s_X s_Y}.
\]
La quantità che si ottiene in questo modo viene chiamata correlazione di Bravais-Pearson (dal nome degli autori che, indipendentemente l’uno dall’altro, la hanno introdotta).
Il coefficiente di correlazione ha le seguenti proprietà:
ha lo stesso segno della covarianza, dato che si ottiene dividendo la covarianza per due numeri positivi;
è un numero puro, cioè non dipende dall’unità di misura delle variabili;
assume valori compresi tra -1 e +1.
Ad esso possiamo assegnare la seguente interpretazione:
\(r_{XY} = -1\)\(\rightarrow\) perfetta relazione negativa: tutti i punti si trovano esattamente su una retta con pendenza negativa (dal quadrante in alto a sinistra al quadrante in basso a destra);
\(r_{XY} = +1\)\(\rightarrow\) perfetta relazione positiva: tutti i punti si trovano esattamente su una retta con pendenza positiva (dal quadrante in basso a sinistra al quadrante in alto a destra);
\(-1 < r_{XY} < +1\)\(\rightarrow\) presenza di una relazione lineare di intensità diversa;
\(r_{XY} = 0\)\(\rightarrow\) assenza di relazione lineare tra \(X\) e \(Y\).
Per i dati della Figura 5.1, la covarianza è 207.426. Il segno positivo della covarianza ci dice che tra le due variabili c’è un’associazione lineare positiva. Per capire qual è l’intensità della relazione lineare tra le due variabili calcoliamo la correlazione. Essendo le deviazioni standard del BDI-II e del CES-D rispettavamente uguali a 15.37 e 14.93, la correlazione diventa uguale a \(\frac{207.426}{15.38 \cdot 14.93} = 0.904.\) Tale valore è prossimo a 1.0, il che vuol dire che i punti del diagramma a dispersione non si discostano troppo da una retta con una pendenza positiva.
5.4 Correlazione e causazione
Facendo riferimento nuovamente alla Figura 5.1, possiamo dire che, in molte applicazioni (ma non nel caso presente!) l’asse \(x\) rappresenta una quantità nota come variabile indipendente e l’interesse si concentra sulla sua influenza sulla variabile dipendente tracciata sull’asse \(y\). Ciò presuppone però che sia nota la direzione in cui l’influenza causale potrebbe risiedere. È importante tenere bene a mente che la correlazione è soltanto un indice descrittivo della relazione lineare tra due variabili e in nessun caso può essere usata per inferire alcunché sulle relazioni causali che legano le variabili. È ben nota l’espressione: “correlazione non significa causazione”.
Di opinione diversa era invece Karl Pearson (1911), il quale ha affermato:
Quanto spesso, quando è stato osservato un nuovo fenomeno, sentiamo che viene posta la domanda: ‘qual è la sua causa?’. Questa è una domanda a cui potrebbe essere assolutamente impossibile rispondere. Invece, può essere più facile rispondere alla domanda: ‘in che misura altri fenomeni sono associati con esso?’. Dalla risposta a questa seconda domanda possono risultare molte preziose conoscenze.
Che alla seconda domanda posta da Pearson sia facile rispondere è indubbio. Che la nostra comprensione di un fenomeno possa aumentare sulla base delle informazioni fornite unicamente dalle correlazioni, invece, è molto dubbio e quasi certamente falso.
5.5 Usi della correlazione
Anche se non può essere usata per studiare le relazioni causali, la correlazione viene usata per molti altri scopi tra i quali, per esempio, quello di misurare la validità concorrente di un test psiologico. Se un test psicologico misura effettivamente ciò che ci si aspetta che misuri (nel caso dell’esempio presente, la depressione), allora dovremo aspettarci che fornisca una correlazione alta con risultati di altri test che misurano lo stesso costrutto – come nel caso dei dati di (Zetsche et al., 2019). Un’altra proprietà desiderabile di un test psicometrico è la validità divergente: i risultati di test psicometrici che misurano costrutti diversi dovrebbero essere poco associati tra loro. In altre parole, in questo secondo caso dovremmo aspettarci che la correlazione sia bassa.
5.6 Correlazione di Spearman
Una misura alternativa della relazione lineare tra due variabili è fornita dal coefficiente di correlazione di Spearman e dipende soltanto dalla relazione d’ordine dei dati, non dagli specifici valori dei dati. Tale misura di associazione è appropriata quando, del fenomeno in esame, gli psicologi sono stati in grado di misurare soltanto le relazioni d’ordine tra le diverse modalità della risposta dei soggetti, non l’intensità della risposta. Le variabili psicologiche che hanno questa proprietà si dicono ordinali. Nel caso di variabili ordinali, non è possibile sintetizzare i dati mediante le statistiche descrittive che abbiamo introdotto in questo capitolo, quali ad esempio la media e la varianza, ma è invece solo possibile riassumere i dati mediante una distribuzione di frequenze per le varie modalità della risposta.
5.7 Correlazione nulla
Un ultimo aspetto da mettere in evidenza a proposito della correlazione riguarda il fatto che la correlazione descrive la direzione e l’intensità della relazione lineare tra due variabili. Relazioni non lineari tra le variabili, anche se sono molto forti, non vengono catturate dalla correlazione. È importante rendersi conto che una correlazione pari a zero non significa che non c’è relazione tra le due variabili, ma solo che tra esse non c’è una relazione lineare.
La Figura 5.2 fornisce un esempio di correlazione nulla in presenza di una chiara relazione (non lineare) tra due variabili.
Figura 5.2: Due insiemi di dati (fittizi) per i quali i coefficienti di correlazione di Pearson sono entrambi 0. Ma questo non significa che non vi sia alcuna relazione tra le variabili.
Commenti e considerazioni finali
La prima fase dell’analisi dei dati riassume i dati mediante gli strumenti della statistica descrittiva. Le tipiche domande che vengono affrontate in questa fase sono: qual è la distribuzione delle variabili di interesse? Quali relazioni a coppie si possono osservare nel campione? Ci sono delle osservazioni ‘anomale’, ovvero estremamente discrepanti rispetto alle altre, sia quando si esaminano le statistiche descrittive univariate (ovvero, quelle che riguardano le caratteristiche di una variabile presa singolarmente), sia quando vengono esaminate le statistiche bivariate (ovvero, le statistiche che descrivono l’associazione tra le variabili)? È importante avere ben chiare le idee su questi punti prima di procedere con qualsiasi procedura statistica di tipo inferenziale. Per rispondere alle domande che abbiamo elencato sopra, ed ad altre simili, è molto utile procedere con delle rappresentazioni grafiche dei dati. È chiaro che, quando disponiamo di grandi moli di dati (come è sempre il caso in psicologia), l’analisi descrittiva dei dati deve essere svolta mediante un software statistico.
Zetsche, U., Bürkner, P.-C., & Renneberg, B. (2019). Future expectations in clinical depression: Biased or realistic? Journal of Abnormal Psychology, 128(7), 678–688.
Source Code
# Le relazioni tra variabili {#sec-corr}```{r, include = FALSE}source("_common.R")```Nella loro ricerca, @zetschefuture2019 hanno misurato il livello di depressione dei soggetti utilizzando due scale psicometriche: il Beck Depression Inventory II (BDI-II) e la Center for Epidemiologic Studies Depression Scale (CES-D). Il BDI-II è uno strumento self-report che valutare la presenza e l'intensità di sintomi depressivi in pazienti adulti e adolescenti di almeno 13 anni di età con diagnosi psichiatrica mentre la CES-D è una scala self-report progettata per misurare i sintomi depressivi che sono stati vissuti nella settimana precedente nella popolazione generale, specialmente quella degli adolescenti/giovani adulti. Una domanda ovvia che ci può venire in mente è: quanto sono simili le misure ottenute mediante queste due scale?È chiaro che i numeri prodotti dalle scale BDI-II e CES-D non possono essere identici, e questo per due motivi: (1) la presenza degli errori di misurazione e (2) l'unità di misura delle due variabili. L'errore di misurazione corrompe sempre, almeno in parte, qualunque operazione di misurazione. E questo è vero specialmente in psicologia dove l'*attendibilità* degli strumenti di misurazione è minore che in altre discipline (quali la fisica, ad esempio). Il secondo motivo per cui i valori delle scale BDI-II e CES-D non possono essere uguali è che l'unità di misura delle due scale è arbitraria. Infatti, qual è l'unità di misura della depressione? Chi può dirlo! Ma, al di là delle differenze derivanti dall'errore di misurazione e dalla differente unità di misura, ci aspettiamo che, se le due scale misurano entrambe lo stesso costrutto, allora i valori prodotti dalle due scale dovranno essere tra loro *linearmente associati*. Per capire cosa si intende con "associazione lineare" iniziamo a guardare i dati. Per fare questo utilizziamo una rappresentazione grafica che va sotto il nome di diagramma a dispersione.## Diagramma a dispersioneIl diagramma di dispersione è la rappresentazione grafica delle coppie di punti individuati da due variabili $X$ e $Y$.Per fare un esempio concreto, consideriamo le variabili BDI-II e CES-D di @zetschefuture2019. Il diagramma di dispersione per tali variabili si ottiene ponendo, ad esempio, i valori BDI-II sull'asse delle ascisse e quelli del CES-D sull'asse delle ordinate. In tale grafico, fornito dalla @fig-zetsche-scatter, cascun punto corrisponde ad un individuo del quale, nel caso presente, conosciamo il livello di depressione misurato dalle due scale psicometriche.Dalla @fig-zetsche-scatter possiamo vedere che i dati mostrano una tendenza a disporsi attorno ad una retta -- nel gergo statistico, questo fatto viene espresso dicendo che i punteggi CES-D tendono ad essere linearmente associati ai punteggi BDI-II. È ovvio, tuttavia, che tale relazione lineare è lungi dall'essere perfetta -- se fosse perfetta, tutti i punti del diagramma a dispersione si disporrebbero esattamente lungo una retta.```{r, fig-zetsche-scatter, fig.cap = "Associazione tra le variabili BDI-II e CES-D nello studio di Zetsche et al. (2019). In grigio sono rappresentate le osservazioni del gruppo di controllo; in nero quelle dei pazienti."}df <- rio::import(here("data", "data.mood.csv"),header =TRUE)bysubj <- df %>%group_by(esm_id, group) %>%summarise(bdi =mean(bdi),cesd =mean(cesd_sum) ) %>%na.omit() %>%ungroup()m_cesd <- bysubj %>% dplyr::pull(cesd) %>%mean()m_bdi <- bysubj %>% dplyr::pull(bdi) %>%mean()FONT_SIZE <-9bysubj %>%ggplot(aes(x = bdi, y = cesd, color = group) ) +geom_point(size =3, alpha = .9) +geom_hline(yintercept = m_cesd, linetype ="dashed", color ="gray") +geom_vline(xintercept = m_bdi, linetype ="dashed", color ="gray") +geom_text(x =-1, y =16, label ="I", color ="gray", size = FONT_SIZE) +geom_text(x =0, y =46, label ="IV", color ="gray", size = FONT_SIZE) +geom_text(x =18, y =46, label ="III", color ="gray", size = FONT_SIZE) +geom_text(x =18, y =16, label ="II", color ="gray", size = FONT_SIZE) +labs(x ="BDI-II",y ="CESD" ) +theme(legend.position ="none") +scale_colour_grey(start =0.7, end =0)```## CovarianzaIl problema che ci poniamo ora è quello di trovare un indice numerico che descrive di quanto la nube di punti si discosta da una perfetta relazione lineare tra le due variabili, ovvero che descrive la direzione e la forza della relazione lineare tra le due variabili. Ci sono vari indici statistici che possono essere utilizzati a questo scopo.Iniziamo a considerare il più importante di tali indici, chiamato *covarianza*. In realtà la definizione di questo indice non ci sorprenderà più di tanto in quanto, in una forma solo apparentemente diversa, l'abbiamo già incontrato in precedenza. Ci ricordiamo infatti che la varianza di una generica variabile $X$ è definita come la media degli scarti quadratici di ciascuna osservazione dalla media:$$S_{XX} = \frac{1}{n} \sum_{i=1}^n(X_i - \bar{X}) (X_i - \bar{X}). $$Infatti, la varianza viene talvolta descritta come la "covarianza di una variabile con sé stessa".Adesso facciamo un passo ulteriore. Invece di valutare la dispersione di una sola variabile, chiediamoci come due variabili $X$ e $Y$ "variano insieme" (co-variano). È facile capire come una risposta a tale domanda possa essere fornita da una semplice trasformazione della formula precedente che diventa:$$S_{XY} = \frac{1}{n} \sum_{i=1}^n(X_i - \bar{X}) (Y_i - \bar{Y}).$$L'equazione precedente ci fornisce dunque la definizione della covarianza.Per capire il significato di tale equazione, supponiamo di dividere il grafico della @fig-zetsche-scatter in quattro quadranti definiti da una retta verticale passante per la media dei valori BDI-II e da una retta orizzontale passante per la media dei valori CES-D. Numeriamo i quadranti partendo da quello in basso a sinistra e muovendoci in senso antiorario.Se prevalgono punti nel I e III quadrante, allora la nuvola di punti avrà un andamento crescente (per cui a valori bassi di $X$ tendono ad associarsi valori bassi di $Y$ e a valori elevati di $X$ tendono ad associarsi valori elevati di $Y$) e la covarianza segno positivo. Mentre se prevalgono punti nel II e IV quadrante la nuvola di punti avrà un andamento decrescente (per cui a valori bassi di $X$ tendono ad associarsi valori elevati di $Y$ e a valori elevati di $X$ tendono ad associarsi valori bassi di $Y$) e la covarianza segno negativo. Dunque, il segno della covarianza ci informa sulla direzione della relazione lineare tra due variabili: l'associazione lineare si dice positiva se la covarianza è positiva, negativa se la covarianza è negativa.Il segno della covarianza ci informa sulla direzione della relazione, ma invece il valore assoluto della covarianza ci dice ben poco. Esso, infatti, dipende dall'unità di misura delle variabili. Nel caso presente questo concetto è difficile da comprendere, dato che le due variabili in esame non hanno un'unità di misura (ovvero, hanno un'unità di misura arbitraria e priva di significato). Ma quest'idea diventa chiara se pensiamo alla relazione lineare tra l'altezza e il peso delle persone, ad esempio. La covarianza tra queste due quantità è certamente positiva, ma il valore assoluto della covarianza diventa più grande se l'altezza viene misurata in millimetri e il peso in grammi, e diventa più piccolo l'altezza viene misurata in metri e il peso in chilogrammi. Dunque, il valore della covarianza cambia al mutare dell'unità di misura delle variabili anche se l'associazione tra le variabili resta costante.## CorrelazioneDato che il valore assoluto della covarianza è di difficile interpretazione -- in pratica, non viene mai interpretato -- è necessario trasformare la covarianza in modo tale da renderla immune alle trasformazioni dell'unità di misura delle variabili. Questa operazione si dice *standardizzazione* e corrisponde alla divisione della covarianza per le deviazioni standard ($s_X$, $s_Y$) delle due variabili:$$ r_{XY} = \frac{S_{XY}}{s_X s_Y}. $$La quantità che si ottiene in questo modo viene chiamata *correlazione* di Bravais-Pearson (dal nome degli autori che, indipendentemente l'uno dall'altro, la hanno introdotta).Il coefficiente di correlazione ha le seguenti proprietà:- ha lo stesso segno della covarianza, dato che si ottiene dividendo la covarianza per due numeri positivi;- è un numero puro, cioè non dipende dall'unità di misura delle variabili;- assume valori compresi tra -1 e +1.Ad esso possiamo assegnare la seguente interpretazione:1. $r_{XY} = -1$ $\rightarrow$ perfetta relazione negativa: tutti i punti si trovano esattamente su una retta con pendenza negativa (dal quadrante in alto a sinistra al quadrante in basso a destra);2. $r_{XY} = +1$ $\rightarrow$ perfetta relazione positiva: tutti i punti si trovano esattamente su una retta con pendenza positiva (dal quadrante in basso a sinistra al quadrante in alto a destra);3. $-1 < r_{XY} < +1$ $\rightarrow$ presenza di una relazione lineare di intensità diversa;4. $r_{XY} = 0$ $\rightarrow$ assenza di relazione lineare tra $X$ e $Y$.::: exercisePer i dati della @fig-zetsche-scatter, la covarianza è 207.426. Il segno positivo della covarianza ci dice che tra le due variabili c'è un'associazione lineare positiva. Per capire qual è l'intensità della relazione lineare tra le due variabili calcoliamo la correlazione. Essendo le deviazioni standard del BDI-II e del CES-D rispettavamente uguali a 15.37 e 14.93, la correlazione diventa uguale a $\frac{207.426}{15.38 \cdot 14.93} = 0.904.$ Tale valore è prossimo a 1.0, il che vuol dire che i punti del diagramma a dispersione non si discostano troppo da una retta con una pendenza positiva.:::## Correlazione e causazioneFacendo riferimento nuovamente alla @fig-zetsche-scatter, possiamo dire che, in molte applicazioni (ma non nel caso presente!) l'asse $x$ rappresenta una quantità nota come *variabile indipendente* e l'interesse si concentra sulla sua influenza sulla *variabile dipendente* tracciata sull'asse $y$. Ciò presuppone però che sia nota la direzione in cui l'influenza causale potrebbe risiedere. È importante tenere bene a mente che la correlazione è soltanto un indice descrittivo della relazione lineare tra due variabili e in nessun caso può essere usata per inferire alcunché sulle relazioni *causali* che legano le variabili. È ben nota l'espressione: "correlazione non significa causazione".Di opinione diversa era invece Karl Pearson (1911), il quale ha affermato:> Quanto spesso, quando è stato osservato un nuovo fenomeno, sentiamo che viene posta la domanda: 'qual è la sua causa?'. Questa è una domanda a cui potrebbe essere assolutamente impossibile rispondere. Invece, può essere più facile rispondere alla domanda: 'in che misura altri fenomeni sono associati con esso?'. Dalla risposta a questa seconda domanda possono risultare molte preziose conoscenze.Che alla seconda domanda posta da Pearson sia facile rispondere è indubbio. Che la nostra comprensione di un fenomeno possa aumentare sulla base delle informazioni fornite unicamente dalle correlazioni, invece, è molto dubbio e quasi certamente falso.## Usi della correlazioneAnche se non può essere usata per studiare le relazioni causali, la correlazione viene usata per molti altri scopi tra i quali, per esempio, quello di misurare la *validità concorrente* di un test psiologico. Se un test psicologico misura effettivamente ciò che ci si aspetta che misuri (nel caso dell'esempio presente, la depressione), allora dovremo aspettarci che fornisca una correlazione alta con risultati di altri test che misurano lo stesso costrutto -- come nel caso dei dati di [@zetschefuture2019]. Un'altra proprietà desiderabile di un test psicometrico è la *validità divergente*: i risultati di test psicometrici che misurano costrutti diversi dovrebbero essere poco associati tra loro. In altre parole, in questo secondo caso dovremmo aspettarci che la correlazione sia bassa.## Correlazione di SpearmanUna misura alternativa della relazione lineare tra due variabili è fornita dal coefficiente di correlazione di Spearman e dipende soltanto dalla relazione d'ordine dei dati, non dagli specifici valori dei dati. Tale misura di associazione è appropriata quando, del fenomeno in esame, gli psicologi sono stati in grado di misurare soltanto le relazioni d'ordine tra le diverse modalità della risposta dei soggetti, non l'intensità della risposta. Le variabili psicologiche che hanno questa proprietà si dicono *ordinali*. Nel caso di variabili ordinali, non è possibile sintetizzare i dati mediante le statistiche descrittive che abbiamo introdotto in questo capitolo, quali ad esempio la media e la varianza, ma è invece solo possibile riassumere i dati mediante una distribuzione di frequenze per le varie modalità della risposta.## Correlazione nullaUn ultimo aspetto da mettere in evidenza a proposito della correlazione riguarda il fatto che la correlazione descrive la direzione e l'intensità della relazione lineare tra due variabili. Relazioni non lineari tra le variabili, anche se sono molto forti, non vengono catturate dalla correlazione. È importante rendersi conto che una correlazione pari a zero non significa che non c'è relazione tra le due variabili, ma solo che tra esse non c'è una relazione *lineare*.::: exerciseLa @fig-zerocorr fornisce un esempio di correlazione nulla in presenza di una chiara relazione (non lineare) tra due variabili.```{r fig-zerocorr, echo=FALSE, fig.cap = "Due insiemi di dati (fittizi) per i quali i coefficienti di correlazione di Pearson sono entrambi 0. Ma questo non significa che non vi sia alcuna relazione tra le variabili."}library("datasauRus")slant <-ggplot( datasaurus_dozen_wide,aes(x = slant_down_x, y = slant_down_y),colour = dataset)slant <- slant +geom_point()slant <- slant +theme_void()slant <- slant +theme(legend.position ="none",panel.border =element_rect(colour ="black", fill =NA, size =1),plot.margin =margin(0, 2, 0, 2), aspect.ratio =1 )dino <-ggplot( datasaurus_dozen_wide,aes(x = dino_x, y = dino_y),colour = dataset) +geom_point()dino <- dino +theme_void()dino <- dino +theme(legend.position ="none",panel.border =element_rect(colour ="black", fill =NA, size =1),plot.margin =margin(0, 2, 0, 2), aspect.ratio =1 )slant + dino```:::## Commenti e considerazioni finali {.unnumbered}La prima fase dell'analisi dei dati riassume i dati mediante gli strumenti della statistica descrittiva. Le tipiche domande che vengono affrontate in questa fase sono: qual è la distribuzione delle variabili di interesse? Quali relazioni a coppie si possono osservare nel campione? Ci sono delle osservazioni 'anomale', ovvero estremamente discrepanti rispetto alle altre, sia quando si esaminano le statistiche descrittive univariate (ovvero, quelle che riguardano le caratteristiche di una variabile presa singolarmente), sia quando vengono esaminate le statistiche bivariate (ovvero, le statistiche che descrivono l'associazione tra le variabili)? È importante avere ben chiare le idee su questi punti prima di procedere con qualsiasi procedura statistica di tipo inferenziale. Per rispondere alle domande che abbiamo elencato sopra, ed ad altre simili, è molto utile procedere con delle rappresentazioni grafiche dei dati. È chiaro che, quando disponiamo di grandi moli di dati (come è sempre il caso in psicologia), l'analisi descrittiva dei dati deve essere svolta mediante un software statistico.