3 Variabili e distribuzioni di frequenza
Le analisi esplorative dei dati e la statistica descrittiva costituiscono la prima fase dell’analisi dei dati psicologici. Consentono di capire come i dati sono distribuiti, ci aiutano ad individuare le osservazioni anomale e gli errori di tabulazione. Consentono di riassumere le distribuzioni dei dati mediante indici sintetici. Consentono di visualizzare e di studiare le relazioni tra le variabili. In questo Capitolo, dopo avere presentato gli obiettivi dell’analisi esplorative dei dati, discuteremo il problema della descrizione numerica e della rappresentazione grafica delle distribuzioni di frequenza.
3.1 Introduzione all’esplorazione dei dati
Le analisi esplorative dei dati sono indispensabili per condurre in modo corretto una qualsiasi analisi statistica, dal livello base a quello avanzato. Si parla di analisi descrittiva se l’obiettivo è quello di descrivere le caratteristiche di un campione. Si parla di analisi esplorativa dei dati (Exploratory Data Analysis o EDA) se l’obiettivo è quello di esplorare i dati alla ricerca di nuove informazioni e relazioni tra variabili. Questa distinzione, seppur importante a livello teorico, nella pratica è più fumosa perché spesso entrambe le situazioni si verificano contemporaneamente nella stessa indagine statistica e le metodologie di analisi che si utilizzano sono molto simili.
Né il calcolo delle statistiche descrittive né l’analisi esplorativa dei dati possono essere condotte senza utilizzare un software. Le descrizioni dei concetti di base della EDA saranno dunque fornite di pari passo alla spiegazione di come le quantità discusse possono essere calcolate in pratica utilizzando \(\mathsf{R}\).
3.2 Un excursus storico
Nel 1907 Francis Galton, cugino di Charles Darwin, matematico e statistico autodidatta, geografo, esploratore, teorico della dattiloscopia (ovvero, dell’uso delle impronte digitali a fini identificativi) e dell’eugenetica, scrisse una lettera alla rivista scientifica Nature sulla sua visita alla Fat Stock and Poultry Exhibition di Plymouth. Lì vide alcuni membri del pubblico partecipare ad un gioco il cui scopo era quello di indovinare il peso della carcassa di un grande bue che era appena stato scuoiato. Galton si procurò i 787 dei biglietti che erano stati compilati dal pubblico e considerò il valore medio di 547 kg come la “scelta democratica” dei partecipanti, in quanto “ogni altra stima era stata giudicata troppo alta o troppo bassa dalla maggioranza dei votanti”. Il punto interessante è che il peso corretto di 543 kg si dimostrò essere molto simile alla “scelta democratica” basata sulle stime dei 787 partecipanti. Galton intitolò la sua lettera a Nature Vox Populi (voce del popolo), ma questo processo decisionale è ora meglio conosciuto come la “saggezza delle folle” (wisdom of crowds). Possiamo dire che, nel suo articolo del 1907, Galton effettuò quello che ora chiamiamo un riepilogo dei dati, ovvero calcolò un indice sintetico a partire da un insieme di dati. In questo capitolo esamineremo le tecniche che sono state sviluppate nel secolo successivo per riassumere le grandi masse di dati con cui sempre più spesso ci dobbiamo confrontare. Vedremo come calcolare e interpretare gli indici di posizione e di dispersione, discuteremo le distribuzioni di frequenze e le relazioni tra variabili. Vedremo inoltre quali sono le tecniche di visualizzazione che ci consentono di rappresentare questi sommari dei dati mediante dei grafici. Ma prima di entrare nei dettagli, prendiamoci un momento per capire perché abbiamo bisogno della statistica e, per ciò che stiamo discutendo qui, della statistica descrittiva.
In generale, che cos’è la statistica? Ci sono molte definizioni. Fondamentalmente, la statistica è un insieme di tecniche che ci consentono di dare un senso al mondo attraverso i dati. Ciò avviene tramite il processo di analisi statistica. L’analisi statistica traduce le domande che abbiamo a proposito del mondo in modelli matematici, utilizza i dati per scegliere i modelli matematici che sono apppropriati per descrivere il mondo e, infine, applica tali modelli per trovare una risposta alle domande che ci siamo posti. La statistica consente quindi di collegare le nostre domande a proposito del mondo ai dati, di utilizzare i dati per trovare le risposte alle domande che ci siamo posti e di valutare l’impatto delle risposte che abbiamo trovato.
3.3 Riassumere i dati
Iniziamo a porci una domanda. Quando riassumiamo i dati, necessariamente buttiamo via delle informazioni; ma è una buona idea procedere in questo modo? Non sarebbe meglio conservare le informazioni specifiche di ciascun soggetto che partecipa ad un esperimento psicologico, al di là di ciò che viene trasmesso dagli indici riassuntivi della statistica descrittiva? Che dire delle informazioni che descrivono come sono stati raccolti i dati, come l’ora del giorno o l’umore del partecipante? Tutte queste informazioni vengono perdute quando riassumiamo i dati. La risposta alla domanda che ci siamo posti è che, in generale, non è una buona idea conservare tutti i dettagli di ciò che sappiamo. È molto più utile riassumere le informazioni perché la semplificazione risultante consente i processi di generalizzazione.
In un contesto letterario, l’importanza della generalizzazione è stata sottolineata da Jorge Luis Borges nel suo racconto “Funes o della memoria”, che descrive un individuo che perde la capacità di dimenticare. Borges si concentra sulla relazione tra generalizzazione e pensiero:
Pensare è dimenticare una differenza, generalizzare, astrarre. Nel mondo troppo pieno di Funes, c’erano solo dettagli.
Come possiamo ben capire, la vita di Funes non è facile. Se facciamo riferimento alla psicologia possiamo dire che gli psicologi hanno studiato a lungo l’utilità della generalizzazione per il pensiero. Un esempio è fornito dal fenomeno della formazione dei concetti e lo psicologo che viene in mente a questo proposito è sicuramente Eleanor Rosch, la quale ha studiato i principi di base della categorizzazione. I concetti ci forniscono uno strumento potente per organizzare le conoscenze. Noi siamo in grado di riconoscere facilmente i diversi esemplare di un concetto – per esempio, “gli uccelli” – anche se i singoli esemplari che fanno parte di una categoria sono molto diversi tra loro (l’aquila, il gabbiano, il pettirosso). L’uso dei concetti, cioè la generalizzazione, è utile perché ci consente di fare previsioni sulle proprietà dei singoli esemplari che appartengono ad una categoria, anche se non abbiamo mai avuto esperienza diretta con essi – per esempio, possiamo fare la predizione che tutti gli uccelli possono volare e mangiare vermi, ma non possono guidare un’automobile o parlare in inglese. Queste previsioni non sono sempre corrette, ma sono utili.
Le statistiche descrittive, in un certo senso, ci fornisco l’analogo dei “prototipi” che, secondo Eleanor Rosch, stanno alla base del processo psicologico di creazione dei concetti. Un prototipo è l’esemplare più rappresentativo di una categoria. In maniera simile, una statistica descrittiva come la media, ad esempio, potrebbe essere intesa come l’osservazione “tipica”.
La statistica descrittiva ci fornisce gli strumenti per riassumere i dati che abbiamo a disposizione in una forma visiva o numerica. Le rappresentazioni grafiche più usate della statistica descrittiva sono gli istogrammi, i diagrammi a dispersione o i box-plot, e gli indici sintetici più comuni sono la media, la mediana, la varianza e la deviazione standard.
3.4 I dati grezzi
Per introdurre i principali strumenti della statistica descrittiva considereremo qui i dati raccolti da Zetsche et al. (2019). Questi ricercatori hanno studiato le aspettative negative quale meccanismo chiave nel mantenimento e nella reiterazione della depressione. Nello studio, Zetsche et al. (2019) si sono chiesti se individui depressi maturino delle aspettative accurate sul loro umore futuro, oppure se tali aspettative sono distorte negativamente.1. In uno studio viene esaminato un campione costituito da 30 soggetti con almeno un episodio depressivo maggiore e da 37 controlli sani. Gli autori hanno misurato il livello depressivo con il Beck Depression Inventory (BDI-II). Questi sono i dati che considereremo qui.
Esercizio 3.1 Qual è la la gravità della depressione riportata dai soggetti nel campione esaminato da Zetsche et al. (2019)?
Soluzione. Per rispondere alla domanda del problema, iniziamo a leggere in \(\mathsf{R}\) i dati, assumendo che il file data.mood.csv si trovi nella cartella data contenuta nella working directory.
C’è un solo valore BDI-II per ciascun soggetto ma tale valore viene ripetuto tante volte quante volte sono le righe del data.frame associate ad ogni soggetto (ciascuna riga corrispondente ad una prova diversa). È dunque necessario trasformare il data.frame in modo tale da avere un’unica riga per ciascun soggetto, ovvero un unico valore BDI-II per soggetto.
Ci sono dunque 66 soggetti i quali hanno ottenuto i valori sulla scala del BDI-II stampati di seguito. Per semplicità, li presentiamo ordinati dal più piccolo al più grande.
Codice
sort(bysubj$bdi)
#> [1] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1
#> [26] 2 2 2 2 3 3 3 5 7 9 12 19 22 22 24 25 25 26 26 26 27 27 28 28 30
#> [51] 30 30 31 31 33 33 34 35 35 35 36 39 41 43 43 443.5 Distribuzioni di frequenze
È chiaro che i dati grezzi sono di difficile lettura. Poniamoci dunque il problema di creare una rappresentazione sintetica e comprensibile di questo insieme di valori. Uno dei modi che ci consentono di effettuare una sintesi dei dati è quello di generare una distribuzione di frequenze.
Definizione 3.1 Una distribuzione di frequenze è un riepilogo del conteggio della frequenza con cui le modalità osservate in un insieme di dati si verificano in un intervallo di valori.
In altre parole, la distribuzione di frequenze della variabile \(X\) corrisponde all’insieme delle frequenze assegnate a ciascun possibile valore di \(X\).
Per creare una distribuzione di frequenze possiamo procedere effettuando una partizione delle modalità della variabile di interesse in \(m\) classi (denotate con \(\Delta_i\)) tra loro disgiunte. In tale partizione, la classe \(i\)-esima coincide con un intervallo di valori aperto a destra \([a_i, b_i)\) o aperto a sinistra \((a_i, b_i]\). Ad ogni classe \(\Delta_i\) avente \(a_i\) e \(b_i\) come limite inferiore e superiore associamo l’ampiezza \(b_i - a_i\) (non necessariamente uguale per ogni classe) e il valore centrale \(\bar{x}_i\). La scelta delle classi è arbitraria, ma è buona norma non definire classi con un numero troppo piccolo (\(< 5\)) di osservazioni. Poiché ogni elemento dell’insieme \(\{x_i\}_{i=1}^n\) appartiene ad una ed una sola classe \(\Delta_i\), possiamo calcolare le quantità elencate di seguito.
-
La frequenza assoluta \(n_i\) di ciascuna classe, ovvero il numero di osservazioni che ricadono nella classe \(\Delta_i\).
- Proprietà: \(n_1 + n_2 + \dots + n_m = n\).
-
La frequenza relativa \(f_i = n_i/n\) di ciascuna classe.
- Proprietà: \(f_1+f_2+\dots+f_m =1\).
La frequenza cumulata \(N_i\), ovvero il numero totale delle osservazioni che ricadono nelle classi fino alla \(i\)-esima compresa: \(N_i = \sum_{i=1}^m n_i.\)
La frequenza cumulata relativa \(F_i\), ovvero \(F_i = f_1+f_2+\dots+f_m = \frac{N_i}{n} = \frac{1}{n} \sum_{i=1}^m f_i.\)
Esercizio 3.2 Si calcoli la distribuzione di frequenza assoluta e la distribuzione di frequenza relativa per i valori del BDI-II del campione clinico di Zetsche et al. (2019).
Soluzione. Per costruire una distribuzione di frequenza è innanzitutto necessario scegliere gli intervalli delle classi. Facendo riferimento ai cut-off usati per l’interpretazione del BDI-II, definiamo i seguenti intervalli aperti a destra:
- depressione minima: [0, 13.5),
- depressione lieve: [13.5, 19.5),
- depressione moderata: [19.5, 28.5),
- depressione severa: [28.5, 63).
Esaminando i dati, possiamo notare che 36 soggetti cadono nella prima classe, uno nella seconda classe, e così via. La distribuzione di frequenza della variabile bdi2 è riportata nella tabella seguente. Questa distribuzione di frequenza ci aiuta a capire meglio cosa sta succedendo. Se consideriamo la frequenza relativa, ad esempio, possiamo notare che ci sono due valori maggiormente ricorrenti e tali valori corrispondono alle due classi più estreme. Questo ha senso nel caso presente, in quanto il campione esaminato da Zetsche et al. (2019) includeva due gruppi di soggetti: soggetti sani (con valori BDI-II bassi) e soggetti depressi (con valori BDI-II alti).2 In una distribuzione di frequenza tali valori tipici vanno sotto il nome di mode della distribuzione.
| Lim. classi | Fr. ass. | Fr. rel. | Fr. ass. cum. | Fr. rel. cum. |
|---|---|---|---|---|
| \([0, 13.5)\) | 36 | 36/66 | 36 | 36/66 |
| \([13.5, 19.5)\) | 1 | 1/66 | 37 | 37/66 |
| \([19.5, 28.5)\) | 12 | 12/66 | 49 | 49/66 |
| \([28.5, 63)\) | 17 | 17/66 | 66 | 66/66 |
Poniamoci ora il problema di costruire la tabella precedente utilizzando \(\mathsf{R}\). Usando la funzione cut(), dividiamo il campo di variazione (ovvero, la differenza tra il valore massimo di una distribuzione ed il valore minimo) di una variabile continua x in intervalli e codifica ciascun valore x nei termini dell’intervallo a cui appartiene. Così facendo otteniamo:
Codice
bysubj$bdi_level <- cut(
bysubj$bdi,
breaks = c(0, 13.5, 19.5, 28.5, 63),
include.lowest = TRUE,
labels = c(
"minimal", "mild", "moderate", "severe"
)
)
bysubj$bdi_level
#> [1] moderate severe severe moderate severe severe severe severe
#> [9] moderate severe moderate mild severe minimal minimal minimal
#> [17] severe moderate minimal minimal minimal minimal minimal moderate
#> [25] minimal minimal minimal minimal minimal minimal minimal severe
#> [33] minimal minimal severe minimal moderate minimal minimal minimal
#> [41] severe minimal minimal severe severe moderate severe severe
#> [49] minimal moderate minimal moderate severe moderate moderate minimal
#> [57] minimal minimal minimal minimal minimal minimal minimal minimal
#> [65] minimal minimal
#> Levels: minimal mild moderate severePossiamo ora usare la funzione table() la quale ritorna un elenco che associa la frequenza assoluta a ciascuna modalità della variabile – ovvero, ritorna la distribuzione di frequenza assoluta.
Codice
table(bysubj$bdi_level)
#>
#> minimal mild moderate severe
#> 36 1 12 17La distribuzione di frequenza relativa si ottiene dividendo ciascuna frequenza assoluta per il numero totale di osservazioni:
| Limiti delle classi | Frequenza assoluta | Frequenza relativa |
|---|---|---|
| [0, 13.5) | 36 | 36/66 |
| [13.5, 19.5) | 1 | 1/66 |
| [19.5, 28.5) | 12 | 12/66 |
| [28.5, 63] | 17 | 17/66 |
Insiemi di variabili possono anche avere distribuzioni di frequenze, dette distribuzioni congiunte. La distribuzione congiunta di un insieme di variabili \(V\) è l’insieme delle frequenze di ogni possibile combinazione di valori delle variabili in \(V\). Ad esempio, se \(V\) è un insieme di due variabili, \(X\) e \(Y\), ciascuna delle quali può assumere due valori, 1 e 2, allora una possibile distribuzione congiunta di frequenze relative per \(V\) è \(f(X = 1, Y = 1) = 0.2\), \(f(X = 1, Y = 2) = 0.1\), \(f(X = 2, Y = 1) = 0.5\), \(f(X = 2, Y = 2) = 0.2\). Proprio come con le distribuzioni di frequenze relative di una singola variabile, le frequenze relative di una distribuzione congiunta devono sommare a 1.
3.6 Istogramma
I dati che sono stati sintetizzati in una distribuzione di frequenze possono essere rappresentati graficamente in un istogramma. Un istogramma si costruisce riportando sulle ascisse i limiti delle classi \(\Delta_i\) e sulle ordinate i valori della funzione costante a tratti
\[ \varphi_n(x)= \frac{f_i}{b_i-a_i}, \quad x\in \Delta_i,\, i=1, \dots, m \]
che misura la densità della frequenza relativa della variabile \(X\) nella classe \(\Delta_i\), ovvero il rapporto fra la frequenza relativa \(f_i\) e l’ampiezza (\(b_i - a_i\)) della classe. In questo modo il rettangolo dell’istogramma associato alla classe \(\Delta_i\) avrà un’area proporzionale alla frequenza relativa \(f_i\). Si noti che l’area totale dell’istogramma delle frequenze relative è data della somma delle aree dei singoli rettangoli e quindi vale 1.0.
Esercizio 3.3 Si utilizzi \(\mathsf{R}\) per costruire un istogramma per i valori BDI-II riportati da Zetsche et al. (2019).
Soluzione. Con i quattro intervalli individuati dai cut-off del BDI-II otteniamo la rappresentazione riportata nella Figura 3.1. Per chiarezza, precisiamo che ggplot() utilizza intervalli aperti a destra. Nel caso della prima barra dell’istogramma, l’ampiezza dell’intervallo è pari a 13.5 e l’area della barra (ovvero, la frequenza relativa) è uguale a 36/66. Dunque l’altezza della barra è uguale a \((36 / 66) / 13.5 = 0.040\). Lo stesso procedimento si applica per il calcolo dell’altezza degli altri rettangoli.
Codice
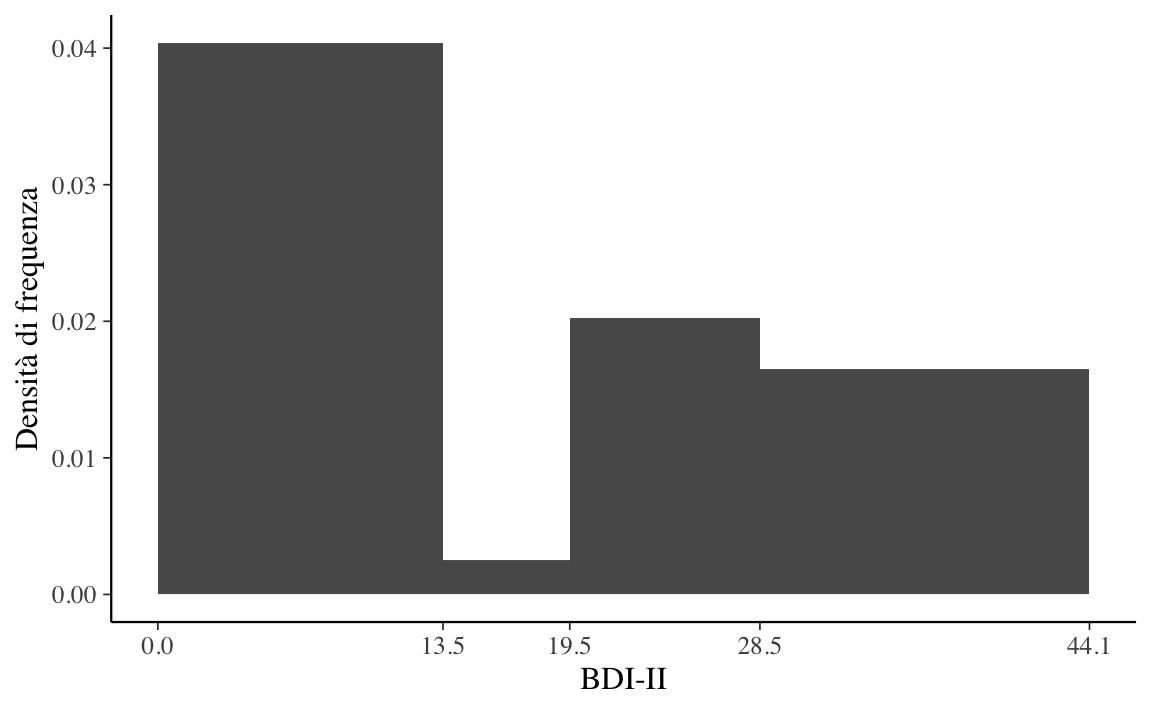
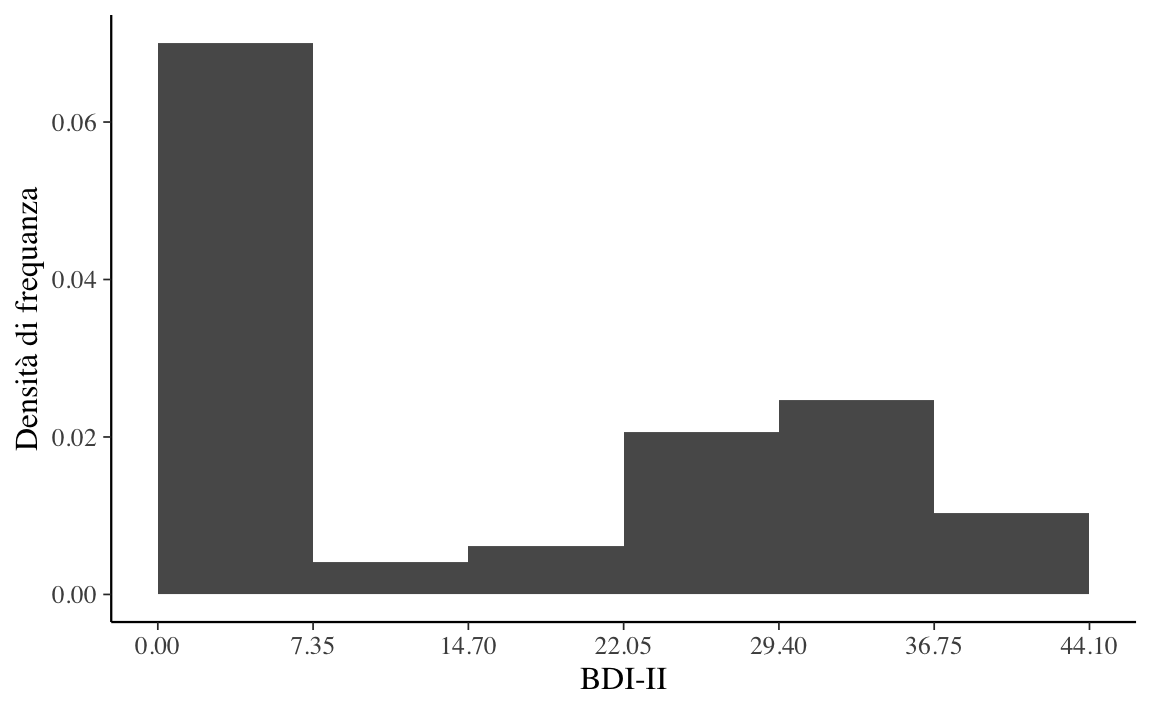
Anche se nel caso presente è sensato usare ampiezze diverse per gli intervalli delle classi, in generale gli istogrammi si costruiscono utilizzando intervalli riportati sulle ascisse con un’ampiezza uguale. Questo è il caso dell’istogramma della Figura 3.2.
Codice
3.7 Kernel density plot
Il confronto tra la Figura 3.1 e la Figura 3.2 rende chiaro il limite dell’istogramma: il profilo dell’istogramma è arbitrario, in quanto dipende dal numero e dall’ampiezza delle classi. Questo rende difficile l’interpretazione.
Il problema precedente può essere alleviato utilizzando una rappresentazione alternativa della distribuzione di frequenza, ovvero la stima della densità della frequenza dei dati (detta anche stima kernel di densità). Un modo semplice per pensare a tale rappresentazione, che in inglese va sotto il nome di kernel density plot (cioè i grafici basati sulla stima kernel di densità), è quello di immaginare un grande campione di dati, in modo che diventi possibile definire un enorme numero di classi di equivalenza di ampiezza molto piccola, le quali non risultino vuote. In tali circostanze, la funzione di densità empirica non è altro che il profilo lisciato dell’istogramma. La stessa idea si applica anche quando il campione è piccolo. In tali circostanze, invece di raccogliere le osservazioni in barre come negli istogrammi, lo stimatore di densità kernel colloca una piccola “gobba” (bump), determinata da un fattore \(K\) (kernel) e da un parametro \(h\) di smussamento detto ampiezza di banda (bandwidth), in corrispondenza di ogni osservazione, quindi somma le gobbe risultanti generando una curva smussata.
L’interpretazione che possiamo attribuire al kernel density plot è simile a quella che viene assegnata agli istogrammi: l’area sottesa al kernel density plot in un certo intervallo rappresenta la proporzione di casi della distribuzione che hanno valori compresi in quell’intervallo.
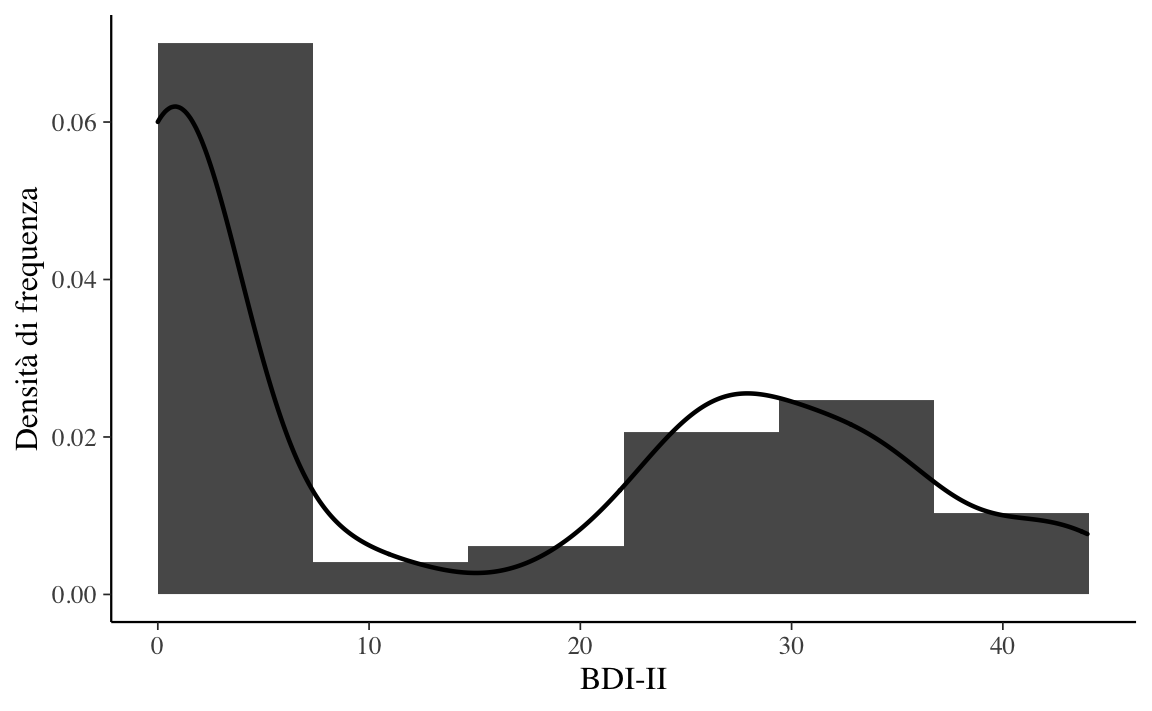
Esercizio 3.4 All’istogramma dei valori BDI-II di Zetsche et al. (2019) si sovrapponga un kernel density plot.
Codice
bysubj %>%
ggplot(aes(x = bdi)) +
geom_histogram(
aes(y = ..density..),
breaks = seq(0, 44.1, length.out = 7)
) +
geom_density(
aes(x = bdi),
adjust = 0.5,
size = 0.8,
#fill = colors[2],
alpha = 0.5
) +
labs(
x = "BDI-II",
y = "Densità di frequenza"
)
3.8 Forma di una distribuzione
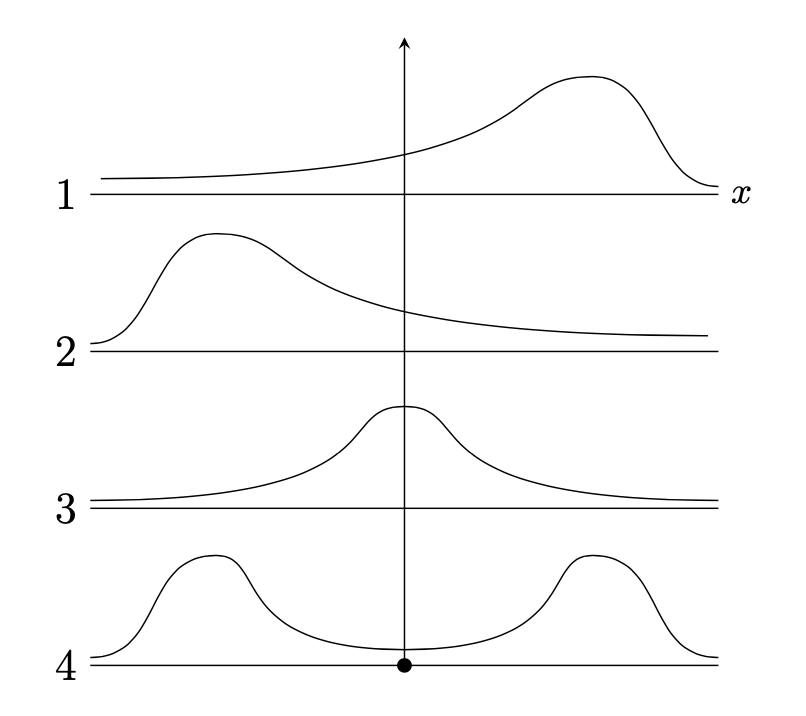
In generale, la forma di una distribuzione descrive come i dati si distribuiscono intorno ai valori centrali. Distinguiamo tra distribuzioni simmetriche e asimmetriche, e tra distribuzioni unimodali o multimodali. Un’illustrazione grafica è fornita nella ?fig-distrib-shapes. Nel pannello 1 la distribuzione è unimodale con asimmetria negativa; nel pannello 2 la distribuzione è unimodale con asimmetria positiva; nel pannello 3 la distribuzione è simmetrica e unimodale; nel pannello 4 la distribuzione è bimodale.
Esercizio 3.5 Il kernel density plot della Figura 3.3 indica che la distribuzione dei valori del BDI-II nel campione di Zetsche et al. (2019) è bimodale. Ciò indica che le osservazioni della distribuzione si addensano in due cluster ben distinti: un gruppo di osservazioni tende ad avere valori BDI-II bassi, mentre l’altro gruppo tende ad avere BDI-II alti. Questi due cluster di osservazioni corrispondono al gruppo di controllo e al gruppo clinico nel campione di dati esaminato da Zetsche et al. (2019).
3.9 Indici di posizione
3.9.1 Quantili
La descrizione della distribuzione dei valori BDI-II di Zetsche et al. (2019) può essere facilitata dalla determinazione di alcuni valori caratteristici che sintetizzano le informazioni contenute nella distribuzione di frequenze. Si dicono quantili (o frattili) quei valori caratteristici che hanno le seguenti proprietà. I quartili sono quei valori che ripartiscono i dati \(x_i\) in quattro parti ugualmente numerose (pari ciascuna al 25% del totale). Il primo quartile, \(q_1\), lascia alla sua sinistra il 25% del campione pensato come una fila ordinata (a destra quindi il 75%). Il secondo quartile \(q_2\) lascia a sinistra il 50% del campione (a destra quindi il 50%). Esso viene anche chiamato mediana. Il terzo quartile lascia a sinistrail 75% del campione (a destra quindi il 25%). Secondo lo stesso criterio, si dicono decili i quantili di ordine \(p\) multiplo di 0.10 e percentili i quantili di ordine \(p\) multiplo di 0.01.
Come si calcolano i quantili? Consideriamo la definizione di quantile non interpolato di ordine \(p\) \((0 < p < 1)\). Si procede innanzitutto ordinando i dati in ordine crescente, \(\{x_1, x_2, \dots, x_n\}\). Ci sono poi due possibilità. Se il valore \(np\) non è intero, sia \(k\) l’intero tale che \(k < np < k + 1\) – ovvero, la parte intera di \(np\). Allora \(q_p = x_{k+1}.\) Se \(np = k\) con \(k\) intero, allora \(q_p = \frac{1}{2}(x_{k} + x_{k+1}).\) Se vogliamo calcolare il primo quartile \(q_1\), ad esempio, utilizziamo \(p = 0.25\). Dovendo calcolare gli altri quantili basta sostituire a \(p\) il valore appropriato.
Gli indici di posizione, tra le altre cose, hanno un ruolo importante, ovvero vengono utilizzati per creare una rappresentazione grafica di una distribuzione di valori che è molto popolare e può essere usata in alternativa ad un istogramma (in realtà vedremo poi come possa essere combinata con un istogramma). Tale rappresentazione va sotto il nome di box-plot.
Esercizio 3.6 Per fare un esempio, consideriamo i nove soggetti del campione clinico di Zetsche et al. (2019) che hanno riportato un unico episodio di depressione maggiore. Per tali soggetti i valori ordinati del BDI-II (per semplicità li chiameremo \(x\)) sono i seguenti: 19, 26, 27, 28, 28, 33, 33, 41, 43. Per il calcolo del secondo quartile (non interpolato), ovvero per il calcolo della mediana, dobbiamo considerare la quantità \(np = 9 \cdot 0.5 = 4.5\), non intero. Quindi, \(q_1 = x_{4 + 1} = 27\). Per il calcolo del quantile (non interpolato) di ordine \(p = 2/3\) dobbiamo considerare la quantità \(np = 9 \cdot 2/3 = 6\), intero. Quindi, \(q_{\frac{2}{3}} = \frac{1}{2} (x_{6} + x_{7}) = \frac{1}{2} (33 + 33) = 33\).
3.9.2 Diagramma a scatola
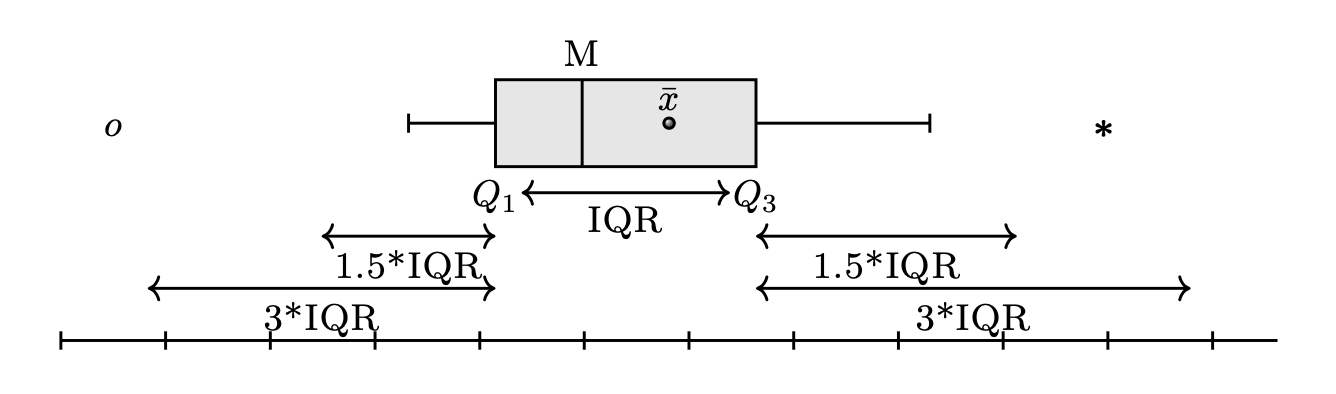
Il diagramma a scatola (o box plot) è uno strumento grafico utile al fine di ottenere informazioni circa la dispersione e l’eventuale simmetria o asimmetria di una distribuzione. Per costruire un box-plot si rappresenta sul piano cartesiano un rettangolo (cioè la “scatola”) di altezza arbitraria la cui base corrisponde alla dist intanza interquartile (IQR = \(q_{0.75} - q_{0.25}\)). La linea interna alla scatola rappresenta la mediana \(q_{0.5}\). Si tracciano poi ai lati della scatola due segmenti di retta i cui estremi sono detti “valore adiacente” inferiore e superiore. Il valore adiacente inferiore è il valore più piccolo tra le osservazioni che risulta maggiore o uguale al primo quartile meno la distanza corrispondente a 1.5 volte la distanza interquartile. Il valore adiacente superiore è il valore più grande tra le osservazioni che risulta minore o uguale a \(Q_3+1.5\) IQR. I valori esterni ai valori adiacenti (chiamati valori anomali) vengono rappresentati individualmente nel box-plot per meglio evidenziarne la presenza e la posizione.
Esercizio 3.7 Per i dati di Zetsche et al. (2019), si utilizzi un box-plot per rappresentare graficamente la distribuzione dei punteggi BDI-II nel gruppo dei pazienti e nel gruppo di controllo.
Nella Figura 3.6 sinistra sono rappresentati i dati grezzi. La linea curva che circonda (simmetricamente) le osservazioni è l’istogramma lisciato (kernel density plot) che abbiamo descritto in precedenza. Nella Figura 3.6 destra sono rappresentanti gli stessi dati: il kernel density plot è lo stesso di prima, ma al suo interno è stato collocato un box-plot. Entrambe le rappresentazioni suggeriscono che la distribuzione dei dati è all’incirca simmetrica nel gruppo clinico. Il gruppo di controllo mostra invece un’asimmetria positiva.
Codice
bysubj <- df %>%
group_by(esm_id, group) %>%
summarise(
bdi = mean(bdi),
nr_of_episodes = mean(nr_of_episodes, na.rm = TRUE)
) %>%
na.omit() %>%
ungroup()
bysubj$group <- forcats::fct_recode(
bysubj$group,
"Controlli\n sani" = "ctl",
"Depressione\n maggiore" = "mdd"
)
p1 <- bysubj %>%
ggplot(aes(x = group, y = bdi)) +
geom_violin(trim = FALSE) +
geom_dotplot(binaxis = "y", stackdir = "center", dotsize = 0.7) +
labs(
x = "",
y = "BDI-II"
)
p2 <- bysubj %>%
ggplot(aes(x = group, y = bdi)) +
geom_violin(trim = FALSE) +
geom_boxplot(width = 0.05) +
labs(
x = "",
y = "BDI-II"
)
p1 + p2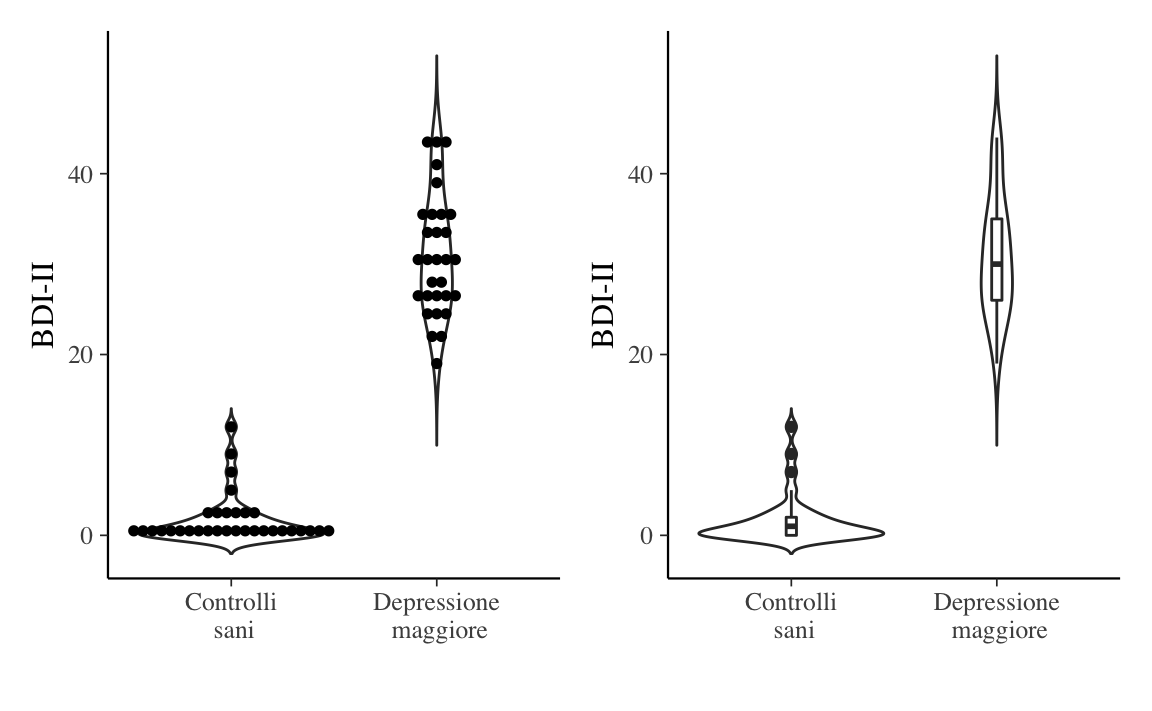
3.9.3 Sina plot
Si noti che i box plot non sono necessariamente la rappresentazione migliore della distribuzione di una variabile. Infatti, richiedono la comprensione di concetti complessi (quali i quantili e la differenza interquantile) che non sono necessari se vogliamo presentare in maniera grafica la distribuzione della variabile e, in generale, non sono compresi da un pubblico di non specialisti. Inoltre, i box plot nascondono informazioni che di solito sono importanti. È dunque preferibile presentare direttamente i dati.
Nella Figura 3.7 viene presentato un cosiddetto “sina plot”. In tale rappresentazione grafica vengono mostrate le singole osservazioni divise in classi. Ai punti viene aggiunto un jitter, così da evitare sovrapposizioni. L’ampiezza del jitter lungo l’asse \(x\) è determinata dalla distribuzione della densità dei dati all’interno di ciascuna classe; quindi il grafico mostra lo stesso contorno di un violin plot, ma trasmette informazioni sia sul numero di punti dati, sia sulla distribuzione della densità, sui valori anomali e sulla distribuzione dei dati in un formato molto semplice, comprensibile e sintetico. Per un esempio in una recente pubblicazione, possiamo considerare le figure 3 e 6 di Lazic et al. (2020).
Esercizio 3.8 Si generi un sina plot per i dati della Figura 3.6. Si aggiunga alla figura una rappresentazione della mediana.
Codice
zetsche_summary <- bysubj %>%
group_by(group) %>%
summarize(
bdi_mean = mean(bdi),
bdi_sd = sd(bdi),
bdi_median = median(bdi)
) %>%
ungroup()
bysubj %>%
ggplot(
aes(x = group, y = bdi, color = group)
) +
ggforce::geom_sina(aes(color = group, size = 1, alpha = .5)) +
geom_errorbar(
aes(y = bdi_median, ymin = bdi_median, ymax = bdi_median),
data = zetsche_summary, width = 0.3, size = 1
) +
labs(
x = "",
y = "BDI-II",
color = "Gruppo"
) +
theme(legend.position = "none") +
scale_colour_grey(start = 0.7, end = 0)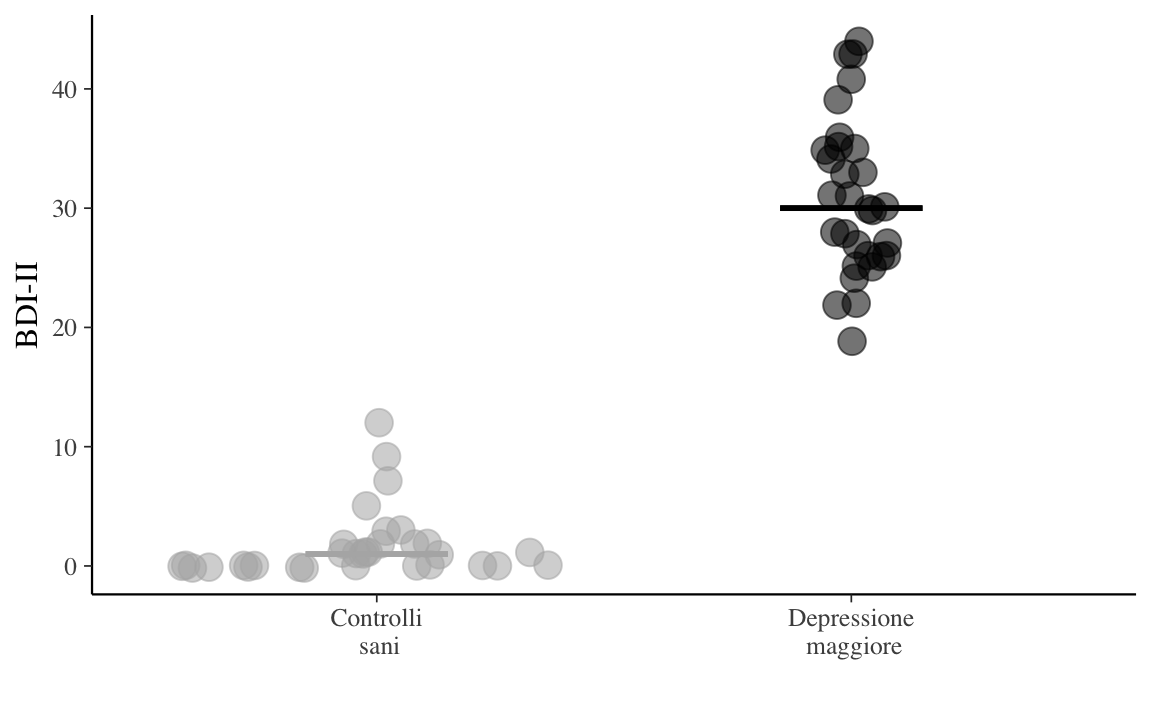
3.9.4 L’eccellenza grafica
Non c’è un unico modo “corretto” per la rappresentazione grafica dei dati. Ciascuno dei grafici che abbiamo discusso in precedenza ha i suoi pregi e i suoi difetti. Un ricercatore che ha molto influenzato il modo in cui viene realizzata la visualizzazione dei dati scientifici è Edward Tufte, soprannominato dal New York Times il “Leonardo da Vinci dei dati.” Secondo Tufte, “l’eccellenza nella grafica consiste nel comunicare idee complesse in modo chiaro, preciso ed efficiente”. Nella visualizzazione delle informazioni, l’“eccellenza grafica” ha l’obiettivo di comunicare al lettore il maggior numero di idee nella maniera più diretta e semplice possibile. Secondo Tufte (2001), le rappresentazioni grafiche dovrebbero:
- mostrare i dati;
- indurre l’osservatore a riflettere sulla sostanza piuttosto che sulla progettazione grafica, o qualcos’altro;
- evitare di distorcere quanto i dati stanno comunicando (“integrità grafica”);
- presentare molte informazioni in forma succinta;
- rivelare la coerenza tra le molte dimensioni dei dati;
- incoraggiare l’osservatore a confrontare differenti sottoinsiemi di dati;
- rivelare i dati a diversi livelli di dettaglio, da una visione ampia alla struttura di base;
- servire ad uno scopo preciso (descrizione, esplorazione, o la risposta a qualche domanda);
- essere fortemente integrate con le descrizioni statistiche e verbali dei dati fornite nel testo.
In base a questi principi, la Figura 3.7 sembra fornire la rappresentazione migliore dei dati di Zetsche et al. (2019). Il seguente link fornisce alcune illustrazioni dei principi elencati sopra.
Commenti e considerazioni finali
Una distribuzione è una rappresentazione del modo in cui le diverse modalità di una variabile si distribuiscono nelle unità statistiche che compongono il campione o la popolazione oggetto di studio. Il modo più diretto per trasmettere descrivere le proprietà della distribuzione di una variabile discreta è quello di fornire una rappresentazione grafica della distribuzione di frequenza. In seguito vedremo la corrispondente rappresentazione che viene usata nel caso delle variabili continue.
Si veda l’Appendice @ref(es-pratico-zetsche).↩︎
In una sezione successiva di questo capitolo discuteremo i principi che, secondo Edward Tufte, devono guidare la Data Science. Parlando delle rappresentazioni grafiche dei dati, Edward Tufte ci dice che la prima cosa da fare è “mostrare i dati”. Questa può sembrare una tautologia, considerato che questo è lo scopo della statistica descrittiva: trasformare i dati attraverso vari indici riassuntivi o rappresentazioni grafiche, in modo tale da renderli comprensibili. Tuttavia, spesso le tecniche statistiche vengono usate per nascondere e non per mostrare i dati. L’uso delle frequenze relative offre un chiaro esempio di questo. Di questi tempi capita spesso di incontrare, sulla stampa, notizie a proposito un nuovo farmaco che, in una prova clinica, ha mostrato risultati incoraggianti che suggeriscono la sua efficacia come possibile trattamento del COVID-19. Alle volte i risultati della sperimentazione clinica sono riportati nei termini di una frequenza relativa. Ad esempio, potremmo leggere che l’uso del farmaco ha portato ad una riduzione del 21% dei ricoveri o dei decessi. Sembra tanto. Ma è necessario guardare i dati! Ovvero, molto spesso, quello che non viene riportato dai comunicati stampa. Infatti, una riduzione del 21% può corrispondere ad un cambiamento dal 5% al 4%. E una riduzione del 44% può corrispondere ad una differenza di 10 contro 18, o di 5 contro 9, o di 15 contro 27. In altri termini, una proporzione, anche grande, può corrispondere ad una differenza assoluta piuttosto piccola: un piccolo passo in avanti, ma non ad un balzo! Per questa ragione, per capire cosa i dati significano, è necessario guardare i dati da diversi punti di vista, utilizzando diverse statistiche descrittive, senza limitarci alla statistica descrittiva che racconta la storia che piace di più. Perché la scelta della statistica descrittiva da utilizzare per riassumere i dati dipende dagli scopi di chi esegue l’analisi statisica: il nostro scopo è quello di capire se il farmaco funziona; lo scopo delle compagnie farmaceutiche è quello di vendere il farmaco. Sono obiettivi molto diversi.↩︎