Codice
theta = seq(0.1, 1, length.out = 10)
theta
#> [1] 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0Obiettivo di questo Capitolo è introdurre l’inferenza bayesiana considerando il modello binomiale. Esamineremo prima il caso di una distribuzione a priori discreta; esamineremo poi il caso di una distribuzione a priori continua. Il materiale qui presentato segue molto da vicino il capitolo 7 del testo di Albert & Hu (2019).
Nei problemi tradizionali di teoria delle probabilità ci sono molti esempi che riguardano l’estrazione di palline colorate da un’urna. In questi esempi ci viene fornito il numero di palline di vari colori presenti nell’urna e ci viene chiesto di calcolare le probabilità di vari eventi. Ad esempio, in un’urna ci sono 40 palline bianche e 20 rosse. Se estrai due palline a caso, qual è la probabilità che entrambe siano bianche?
L’approccio bayesiano considera uno scenario diverso, ovvero quello in cui non conosciamo le proporzioni delle palline colorate presenti nell’urna. Cioè, nell’esempio precedente, sappiamo solo che nell’urna ci sono due tipi di palline colorate, ma non sappiamo che 40 sono bianche (proporzione di bianco = \(2/3\)) e 20 sono rosse (proporzione di rosso = \(1/3\)). Ci poniamo la seguente domanda: è possibile inferire le proporzioni di palline nell’urna estraendo un campione di palline dall’urna e osservando i colori delle palline estratte? Espresso in questo modo, questo diventa un problema di inferenza statistica, perché stiamo cercando di inferire la proporzione \(\theta\) della popolazione sulla base di un campione casuale. Per continuare con l’esempio precedente, quello che vogliamo fare è inferire \(\theta\), ad esempio, la proporzione di palline rosse nell’urna, alla luce del numero di palline rosse e bianche nel campione.
Le proporzioni assomigliano alle probabilità. Ricordiamo che sono state proposte tre diverse interpretazioni del concetto di probabilità.
La visione classica non sembra potere funzionare qui, perché sappiamo solo che ci sono due tipi di palline colorate e che il numero totale di palline è 60. Anche se estraiamo un campione di 10 palline, possiamo solo osservare la proporzione di palline rosse nel campione. Non c’è modo per potere stabilire che, nello spazio campione, ogni risultato è ugualmente probabile.
La visione frequentista potrebbe funzionare nel caso presente. Possiamo considerare il processo del campionamento (cioè l’estrazione di un campione casuale di 10 palline dall’urna) come un esperimento casuale che produce una proporzione campionaria \(p\). Potremmo quindi pensare di ripetere l’esperimento casuale molte volte nelle stesse condizioni, ottenere una serie di proporzioni campionarie \(p\) e infine riassumere in qualche modo questa distribuzione di statistiche campionarie. Ripetendo l’esperimento casuale tante volte è possibile ottenere una stima abbastanza accurata della proporzione \(\theta\) di palline rosse nell’urna. Questo processo è fattibile, ma però è noioso, dispendioso in termini di tempo e soggetto ad errori.
La visione soggettivista concepisce invece la probabilità sconosciuta \(\theta\) come un’opinione soggettiva di cui possiamo essere più o meno certi. Questa opinione soggettiva dipende da due tipi di evidenze: le nostre credenze iniziali e le nuove informazioni fornite dai dati che abbiamo osservato. Vedremo in questo capitolo come sia possibile combinare le credenze iniziali rispetto al possibile valore \(\theta\) con le evidenze fornite dai dati per giungere ad una nuova credenza a posteriori su \(\theta\). In particolare, vedremo come si possa pensare in termini soggetti a delle quantità sconosciute (in questo caso, \(\theta\)) usando le distribuzioni di probabilità.
Essendo una proporzione, \(\theta\) può assumere valori compresi tra 0 e 1. È possibile pensare che \(\theta\) sia uguale, ad esempio, a 0.5. Ciò significa assegnare all’evento \(\theta = 0.5\) la probabilità 1; in altri termini, significa dire che siamo assolutamente certi che la quantità sconosciuta \(\theta\) abbia il valore di 0.5. Questa posizione, però, è troppo estrema: non possiamo essere assolutamente certi che una quantità sconosciuta abbia uno specifico valore; altrimenti non sarebbe una quantità sconosciuta. Invece, sembra più sensato pensare che \(\theta\) può, in linea di principio, assumere diversi valori e attribuire a tali valori livelli diversi di certezza soggettiva.
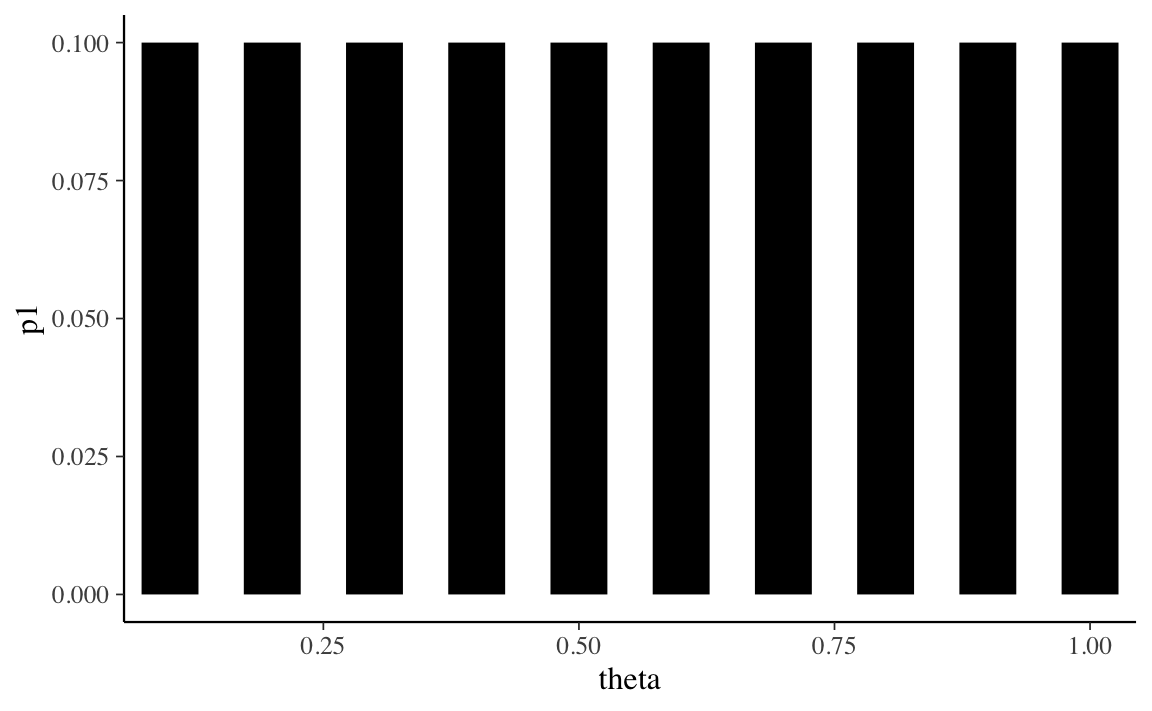
Consideriamo, ad esempio, 10 possibili valori \(\theta\).
theta = seq(0.1, 1, length.out = 10)
theta
#> [1] 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0Se non abbiamo alcun motivo di pensare diversamente, possiamo assegnare a ciascun valore \(\theta\) la stessa credibilità.
p1 <- rep(0.1, 10)
p1
#> [1] 0.1 0.1 0.1 0.1 0.1 0.1 0.1 0.1 0.1 0.1tibble(theta, p1) %>%
ggplot(aes(theta, p1)) +
geom_segment(
aes(xend = theta, yend = 0), size = 10, lineend = "butt"
)
Oppure, per qualche ragione, potremmo pensare che i valori centrali della distribuzione di \(\theta\) siamo più credibili dei valori estremi. Tale opinione soggettiva può essere descritta dalla seguente distribuzione di massa di probabilità.
p2 <- c(
0.05, 0.05, 0.05, 0.175, 0.175, 0.175, 0.175, 0.05, 0.05, 0.05
)
p2
#> [1] 0.050 0.050 0.050 0.175 0.175 0.175 0.175 0.050 0.050 0.050tibble(theta, p2) %>%
ggplot(aes(theta, p2)) +
geom_segment(
aes(xend = theta, yend = 0), size = 10, lineend = "butt"
)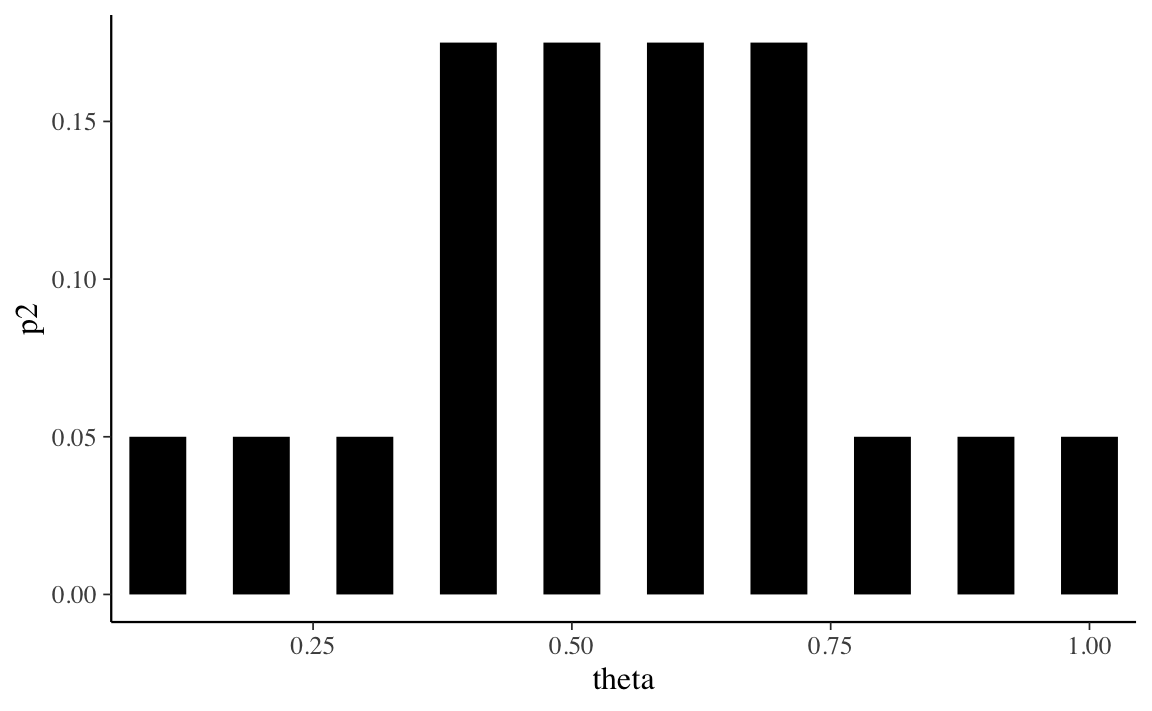
La prima distribuzione di probabilità è chiamata distribuzione discreta uniforme perché attribuisce la stessa probabilità (ovvero, 1/10) ad ogni elemento dell’insieme discreto su cui è definita (ovvero, \(0.1, 0.2, \dots, 1.0\)). Anche la seconda distribuzione è discreta, ma non è uniforme: riteniamo più credibile che \(\theta\) assuma un valore nell’insieme \(\{0.4, 0.5, 0.6, 0.7\}\) piuttosto che nell’insieme \(\{0.1, 0.2, 0.3, 0.8, 0.9, 1.0\}\).
Le credenze relative alla credibilità dei possibili valori che \(\theta\) possono assumere forme diverse e corrispondono a quella che viene chiamata la distribuzione a priori, ovvero descrivono le credenze iniziali relative alla quantità sconosciuta di interesse.
La procedura di inferenza bayesiana “aggiorna” tali credenze a priori utilizzando le informazioni fornite da un campione di dati. Usando il teorema di Bayes, le informazioni fornite dai dati vengono combinate con le nostre credenze precedenti relative alla quantità sconosciuta \(\theta\) per giungere ad una credenza detta “a posteriori”.
Supponendo che i dati corrispondano all’osservazione di 12 palline rosse in 20 estrazioni con rimessa dall’urna, usiamo ora la seconda delle distribuzioni a priori descritte sopra per ottenere la distribuzione a posteriori.
Il teorema di Bayes specifica la distribuzione a posteriori come il prodotto della verosimiglianza e della distribuzione a priori, diviso per una costante di normalizzazione:
\[ p(\theta \mid y) = \frac{p(y \mid \theta)p(\theta)}{p(y)}. \]
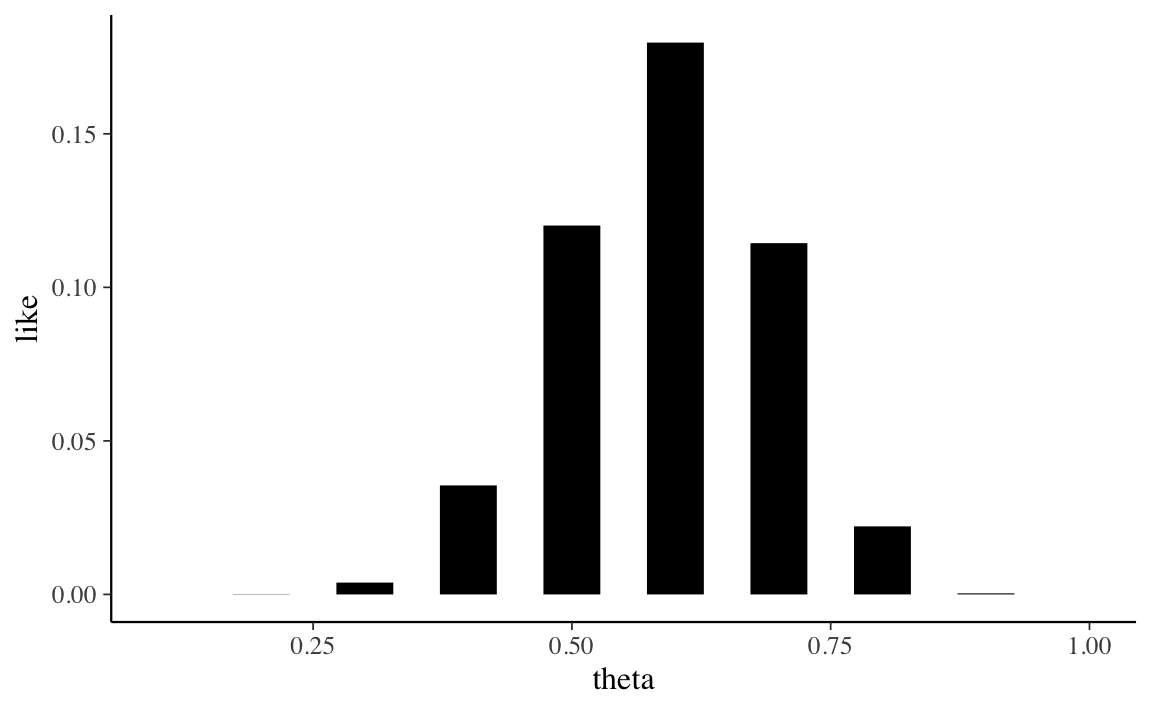
Per trovare la funzione di verosimiglianza, \(p(y \mid \theta)\), è necessario pensare a come sono stati ottenuti i dati. I dati corrispondono ai risultati di 20 estrazioni con rimessa da un’urna. Se l’estrazione è casuale con reinserimento, allora i dati (12 successi in 20 prove) possono essere intesi come il risultato di un esperimento casuale binomiale. Usando \(\textsf{R}\), la funzione di verosimiglianza può essere generata mediante la funzione dbinom().
like <- dbinom(12, 20, theta)
like
#> [1] 5.422595e-08 8.656592e-05 3.859282e-03 3.549744e-02 1.201344e-01
#> [6] 1.797058e-01 1.143967e-01 2.216088e-02 3.557765e-04 0.000000e+00Per i 10 valori \(\theta\) considerati, la funzione di verosimiglianza assume la forma indicata dalla Figura 16.3 .
tibble(theta, like) %>%
ggplot(aes(theta, like)) +
geom_segment(
aes(xend = theta, yend = 0), size = 10, lineend = "butt"
)
Per calcolare la distribuzione a posteriori dobbiamo fare il prodotto (elemento per elemento) del vettore che contiene i valori della distribuzione a priori e del vettore che contiene i valori della funzione di verosimiglianza. Tale prodotto andrà poi diviso per una costante di normalizzazione, \(p(y)\).
Per la legge della probabilità totale, il denominatore corrisponde alla probabilità marginale dei dati \(y\) ed è uguale alla somma dei prodotti tra la distribuzione a priori e la funzione di verosimiglianza. Nel caso discreto qui considerato, la probabilità marginale dei dati ci calcola come sum(p2 * like).
sum(p2 * like)
#> [1] 0.08002663La distribuzione a posteriori di \(\theta\) sarà dunque uguale a (p2 * like) / sum(p2 * like).
post <- (p2 * like) / sum(p2 * like)
post
#> [1] 3.387994e-08 5.408570e-05 2.411248e-03 7.762481e-02 2.627064e-01
#> [6] 3.929756e-01 2.501596e-01 1.384594e-02 2.222863e-04 0.000000e+00Una rappresentazione grafica della distribuzione a posteriori di \(\theta\) è fornita dalla Figura 16.4.
tibble(theta, post) %>%
ggplot(aes(theta, post)) +
geom_segment(
aes(xend = theta, yend = 0), size = 10, lineend = "butt"
)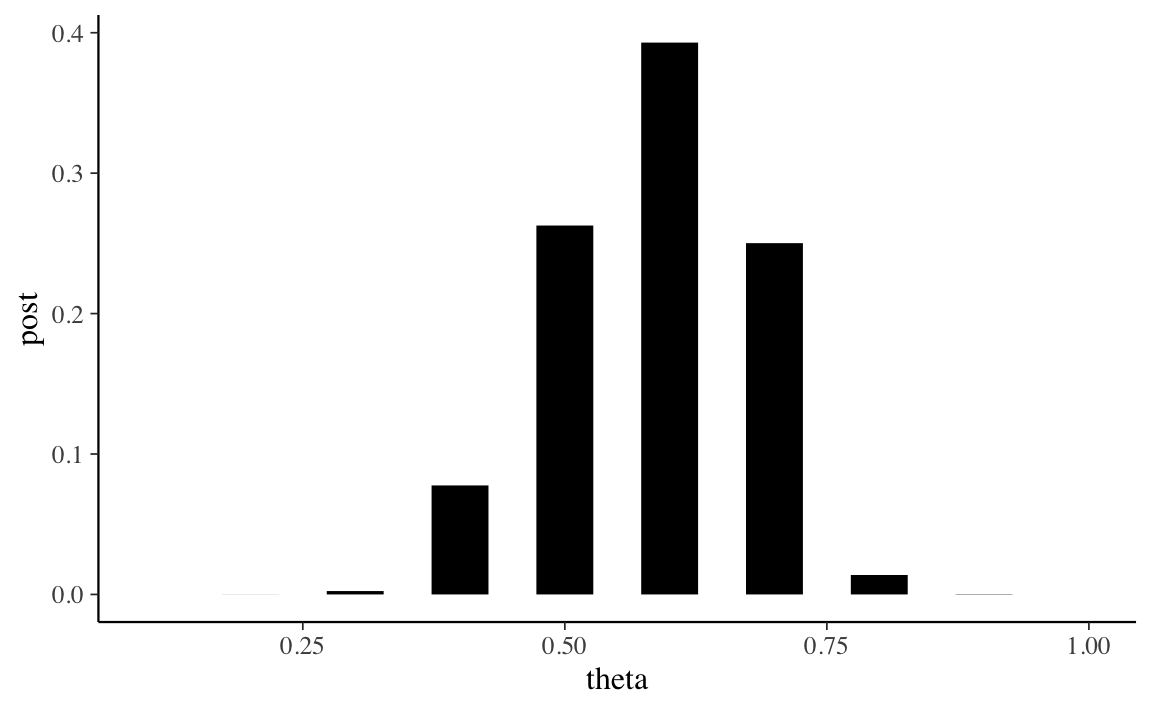
Conoscendo la distribuzione a posteriori di \(\theta\) diventa possibile calcolare altre quantità di interesse. Per esempio, la moda a posteriori di \(\theta\) si ricava direttamente dal grafico precedente, e corrisponde a 0.6. La media a posteriori si trova con la formula del valore atteso delle v.c..
sum(theta * post)
#> [1] 0.5853112Lo stesso si può dire della varianza della distribuzione a posteriori.
Nel caso di una distribuzione a priori discreta, il calcolo della distribuzione a posteriori è implementata nella funzione bayesian_crank() del pacchetto ProbBayes. Dato che ProbBayes non è su CRAN, può essere installato nel modo seguente.
library("devtools")
install_github("bayesball/ProbBayes")Una volta installato, il pacchetto può essere caricato come facciamo normalmente.
Per usare bayesian_crank() procediamo come indicato di seguito:
d <- tibble(p = theta, Prior = p2)
y <- 12
n <- 20
d$Likelihood <- dbinom(y, prob = d$p, size = n)
df <- bayesian_crank(d)
df %>% as.data.frame()
#> p Prior Likelihood Product Posterior
#> 1 0.1 0.050 5.422595e-08 2.711298e-09 3.387994e-08
#> 2 0.2 0.050 8.656592e-05 4.328296e-06 5.408570e-05
#> 3 0.3 0.050 3.859282e-03 1.929641e-04 2.411248e-03
#> 4 0.4 0.175 3.549744e-02 6.212052e-03 7.762481e-02
#> 5 0.5 0.175 1.201344e-01 2.102351e-02 2.627064e-01
#> 6 0.6 0.175 1.797058e-01 3.144851e-02 3.929756e-01
#> 7 0.7 0.175 1.143967e-01 2.001943e-02 2.501596e-01
#> 8 0.8 0.050 2.216088e-02 1.108044e-03 1.384594e-02
#> 9 0.9 0.050 3.557765e-04 1.778882e-05 2.222863e-04
#> 10 1.0 0.050 0.000000e+00 0.000000e+00 0.000000e+00Verifichiamo il risultato trovato calcolando, ad esempio, la media a posteriori (come abbiamo fatto sopra):
sum(theta * df$Posterior)
#> [1] 0.5853112Usando questo metodo possiamo trovare la distribuzione a posteriori di \(\theta\) nel caso di qualunque distribuzione a priori discreta.
Il caso di una distribuzione a priori discreta è stato discusso solo per scopi didattici. In generale, l’uso di una distribuzione a priori discreta non è una buona scelta per rappresentare le nostre credenze a priori sul parametro sconosciuto. Infatti, per definizione, una distribuzione a priori discreta può rappresentare solo alcuni dei possibili valori del parametro – nel caso discusso sopra, ad esempio, non abbiamo considerato il valore 0.55. Sembra dunque più sensato descrivere le nostre credenze a priori sul parametro utilizzando una distribuzione continua.
Cerchiamo una funzione di densità con supporto in \([0, 1]\). Il candidato naturale è fornito dalla funzione Beta (si veda il Capitolo 13). Come per le altre funzioni di densità, abbiamo a disposizione quattro funzioni \(\textsf{R}\) che ci consentono di manipolare facilmente questa densità.
Ad esempio, possiamo valutare la funzione di densità \(\mbox{Beta}(1, 1)\) in corrispondenza dei valori \(p = 0.5\) e \(p = 0.8\), che dovrebbe essere entrambi uguali a 1, e in corrispondenza di \(p = 1.2\), che dovrebbe essere ugualea 0 poiché questo valore è al di fuori dell’intervallo \([ 0, 1]\).
Oppure possiamo valutare la funzione distribuzione \(\mbox{Beta}(1, 1)\) in corrispondenza dei punti 0.5 e 0.8:
Oppure possiamo calcolare la probabilità \(P(0.5 < p < 0.8)\)
Possiamo trovare i quantili della distribuzione \(\mbox{Beta}(1, 1)\) di ordine 0.5 e 0.8:
Infine, è possibile simulare dei valori casuali dalla distribuzione \(\mbox{Beta}(1, 1)\). Se vogliamo 5 valori, scriviamo:
rbeta(5, 1, 1)
#> [1] 0.2523117 0.5492791 0.2174402 0.4063601 0.2128675Se vogliamo 5 valori da una \(\mbox{Beta}(2, 10)\), scriviamo:
rbeta(5, 2, 10)
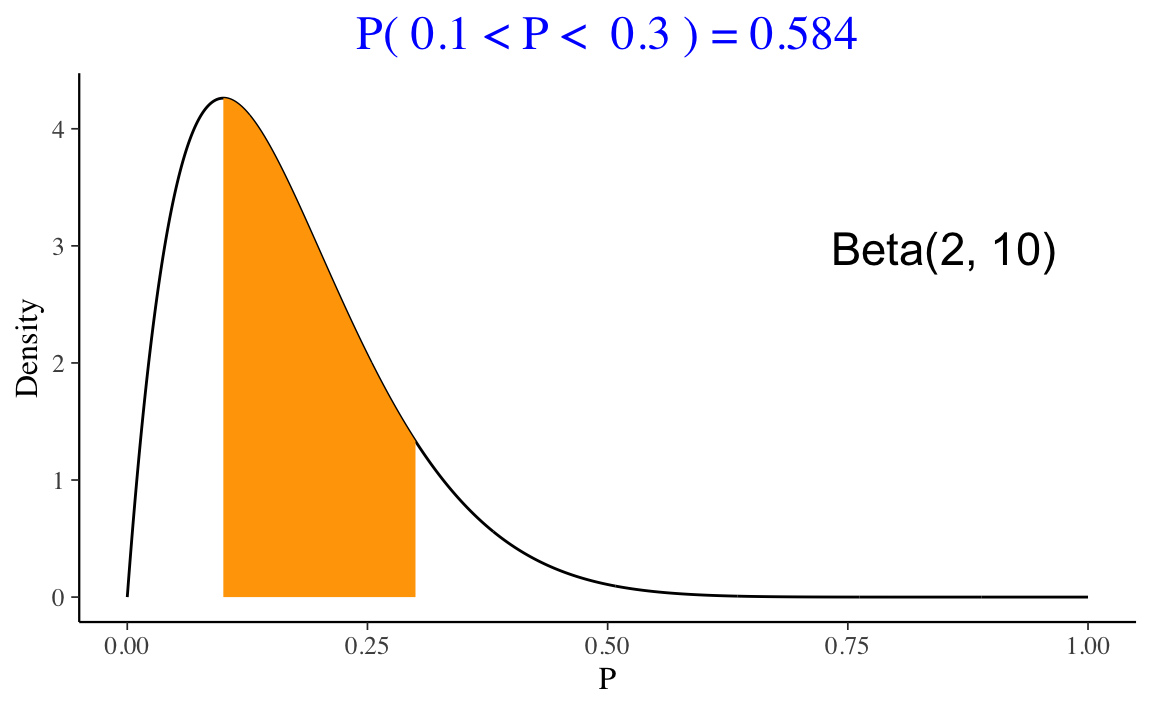
#> [1] 0.17364773 0.21332530 0.24430864 0.15817644 0.04897118Il pacchetto ProbBayes offre la funzione beta_area() per visualizzare la probabilità di una distribuzione Beta in un certo intrvallo di valori. Per esempio, se vogliamo la probabilità dell’evento per cui la variabile casuale \(p\) è contenuta nell’intervallo \([0.1, 0.3]\) nel caso di una \(\mbox{Beta}(2, 10)\), scriviamo:
Se usiamo una distribuzione Beta per rappresentare le nostre credenze a priori sul parametro \(\theta\) (probabilità di successo), allora dobbiamo porci il problema di scegliere i parametri che definiscono la distribuzione Beta che meglio rappresenta le nostre opinioni a priori. Il modo più ovvio per ottenere questo risultato è per prove ed errori. Oppure, possiamo individuare i parametri \(\alpha\) e \(\beta\) della distribuzione interpretando \(\alpha\) come la nostra stima a priori del numero di “successi”, \(\beta\) come a nostra stima a priori del numero di “insuccessi” e \(\alpha + \beta\) come il numero di prove del campione. Ad esempio, se pensiamo che, su 30 prove, verranno osservati 10 successi, otteniamo una \(\mbox{Beta}(10, 20)\).
bayesrules::plot_beta(10, 20, mean = TRUE, mode = TRUE)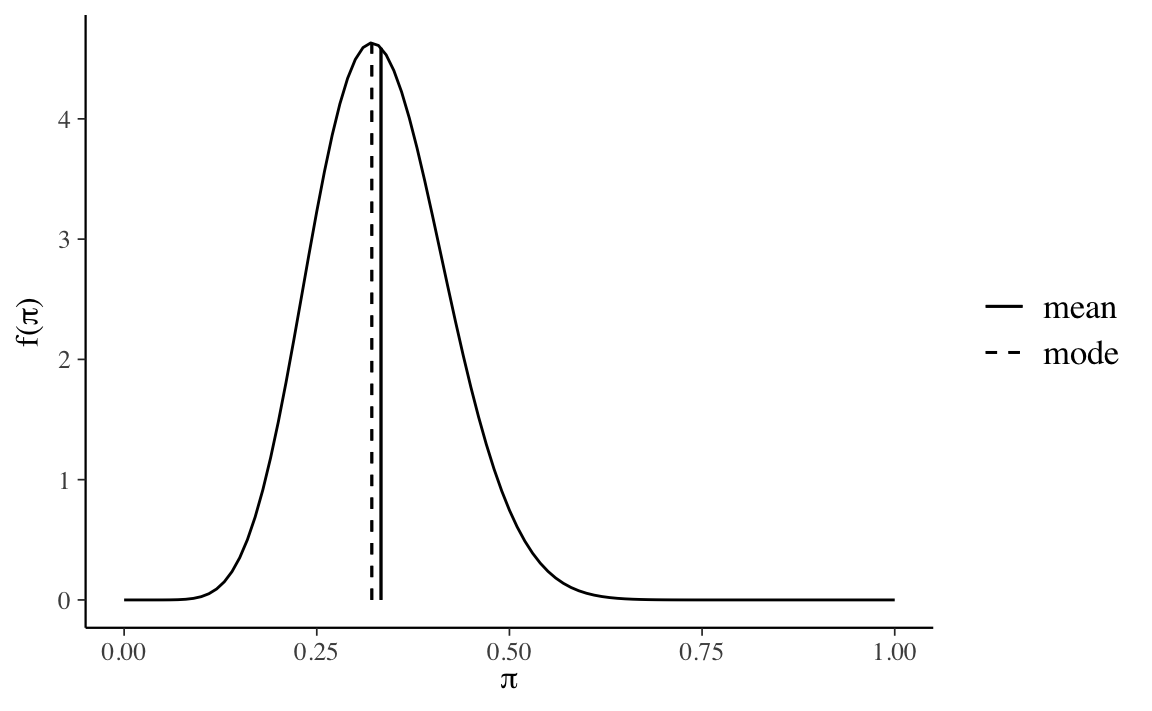
In alternativa, potremmo specificare la distribuzione a priori definendo la mediana e un quantile della distribuzione. Per esempio, le nostre opinioni a priori sul parametro potrebbero essere tali per cui pensiamo che la mediana della distribuzione sia 0.25 e il quantile della distribuzione di ordine 0.9 sia 0.5. Usando la Shiny App ProbBayes::ChooseBeta() troviamo i parametri \(\alpha = 1.84\) e \(\beta = 4.89\).
bayesrules::plot_beta(1.84, 4.89, mean = TRUE, mode = TRUE)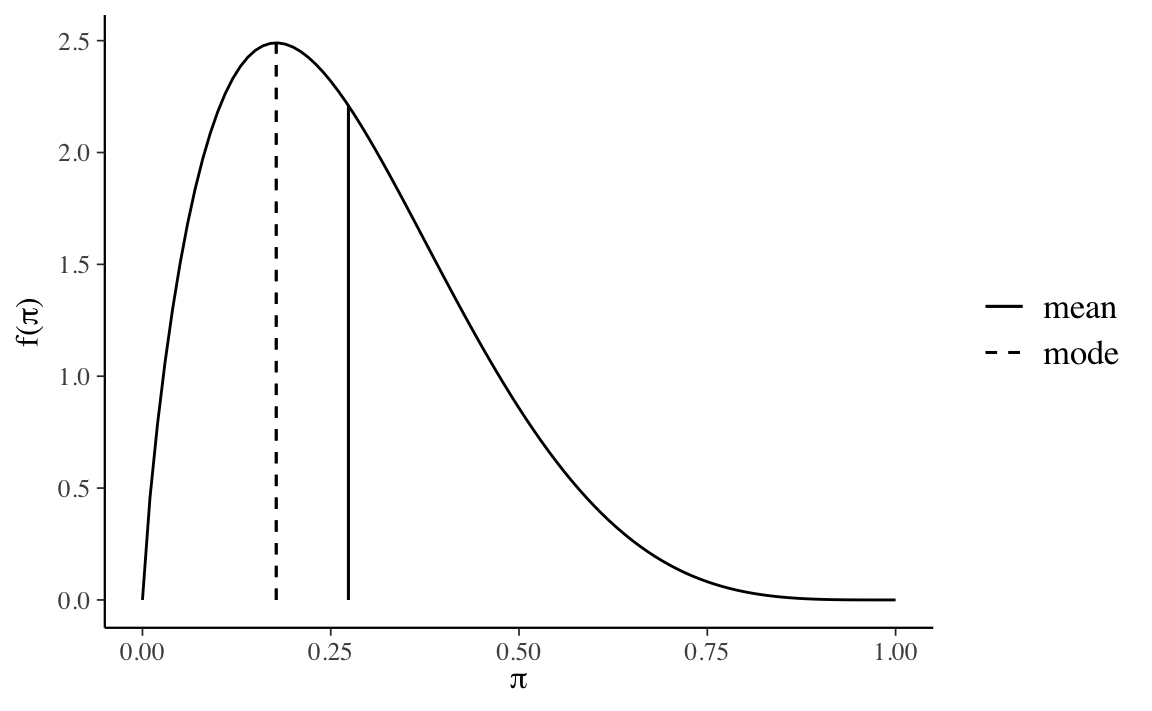
Abbiamo qui introdotto la procedura dell’aggiornamento bayesiano nel caso in cui la distribuzione a priori sia discreta. Abbiamo anche fornito alcune informazioni che sono utili per affrontare il problema nel caso in cui viene utilizzata una distribuzione a priori continua. Se viene utilizzata una distribuzione a priori continua, al denominatore del rapporto di Bayes troviamo un integrale che, in generale, non si può risolvere per via analitica. Il caso dell’inferenza su una proporzione, in cui la distribuzione a priori è una distribuzione Beta e la verosimiglianza è binoniale, rappresenta però un’eccezione, ovvero consente di derivare le proprietà della distribuzione a posteriori per via analitica. Il prossimo capitolo ha lo scopo di illustrare questo argomento.